1. Introduction
A prominent instrument to acquire spectral data from orbit to determine mineralogical properties of specific areas is the CRISM [
1] hyperspectral imaging spectrometer onboard NASA’s Mars Reconnaissance Orbiter (MRO). In particular, the area of Nili Fossea including Jezero Crater has been extensively covered. The data indicate mineralogical structures formed in ancient wet environments and therefore supports the 2020 Perserverance rover mission goals.
The planetary geologic mapping process itself relies on basic geometric and stratigraphic principles, historically limited by the availability of image and topographic data. Such process has been greatly aided in the last two decades by the availability of digital data [
2] and geospatial qualitative and quantitative applications [
3].
The availability of compositional data in the last decades allowed the inclusion of different kind of methods, varying from heuristical methods to statistical approaches [
4,
5,
6,
7]. Our work here relies on unsupervised classification, which is an important standard procedure in geospatial analysis [
8]. Such unsupervised techniques are established methods in data analysis of hyperspectral data, particularly in planetary data analysis where there is insufficient calibration in-field data. Clusters of similar spectral signatures can be generated with these methods which in turn can be used to derive the composition of the surface. Such an approach has a direct impact on geologic mapping activities, such as the analysis of Oxia Planum by Fawdon et al. or Zambon et al. on Mercury [
9,
10]. On the other hand, many of these methods are learning procedures that are sensitive to initial conditions, data preprocessing, and other influences such as atmospheric effects. Also the results depend on the model, the choice of parameters and the number of clusters. Therefore, it is critical to develop a robust methodology. The combination of band information and spatial distributions is formed into a data structure, in this paper called Spectral Cluster Maps (SCMs). High-dimensional data are transferred to a low latent variable representation by directly applying advanced methods on the full spectrum itself and these clusters can be related to underlying geochemical composition [
11].
It is essential to find suitable unsupervised dimensionality reduction techniques to produce accurate SCMs before applying various clustering algorithms on the feature space. The principal component analysis (PCA) [
12] is the most commonly used technique applied to spectral data (e.g., [
13,
14]) and therefore we use this here to benchmark against more elaborate algorithms. In recent studies of Machine Learning Networks, approaches such as t-SNE [
15] have achieved promising results. Distinct grouping has been obtained by focussing on more local structures and mapping the feature space into a low-dimensional representation. Further studies in this direction include, amongst others, [
16,
17].
In this category, the self-organizing maps technique, developed by Kohonen [
18], has already been proposed for generating spectral databases. Specifically for Mars, a recently proposed algorithm for spectral application is the autoencoder technique which is mentioned by Gao et al. [
11].
The application of the UMAP technique to spectral data is relatively rare at present. Groups tackling this issue include Picollo et al. [
19] and Wander et al. [
20]. Publications using UMAP are more abundant in the biology research field [
21,
22]. In a previous work Fernandes et al. [
23] made a detailed comparison of these techniques on datasets of Capri Chasmata within the VISNIR range. They reached promising results by applying UMAP as the dimensionality reduction technique and showed superior performance of this technique. Taking into account their findings, this study intends to examine the properties of UMAP in the relevant NIR range. Due to its non-linear processing the use of UMAP in combination with unsupervised clustering can increase the ability to identify clusters in certain cases [
24].
The rest of this paper is structured as follows:
Section 2 describes the data and the data pipeline used. The examined UMAP reduction technique applied in this study is also presented. In
Section 3, the obtained results are illustrated and discussed intensely.
Section 4 proceeds with a new proposed method for quantitative geological mapping of the generated spectral cluster maps based on the summary browse products. The paper finishes with a brief discussion and conclusion (
Section 6).
2. Materials and Methods
This section is devoted to the UMAP algorithm and data pipeline considered in this study. The data and their origin are also described.
2.1. Data and Location
CRISM is a high spectral resolution visible and infrared mapping spectrometer currently in orbit around Mars onboard NASA’s Mars Reconnaissance Orbiter (MRO) [
1]. For this analysis we selected data as described in
Appendix B. The CRISM MTRDR products are sophisticated empirical and statistically corrected sets to remove spikes, rectify for imaging geometry and gimbal motion, and remove atmospheric contamination to obtain approximate surface reflectance [
11].
It provides 2D spatially resolved spectra over a wavelength range of 362 nm to 3920 nm at 6.55 nm/channel. The spatial resolution is typically around 18 m/px. Pelkey et al. [
25] and Viviano et al. [
26] generated a feature set of “image products” from CRISM spectra, which are strongly related to the geochemical composition of the Martian surface.
The area under investigation exhibits significant color diversity at visible wavelengths and is of major interest in studies of the history of liquid water on Mars. Jezero (e.g., [
27,
28,
29]) is a 45 km wide crater in the vicinity of Nili Fossae, that experienced fluvio-lacustrine activity during the Noachian-Hesperian (e.g., [
30,
31,
32]).
While not all channel systems are associated to clear fluvial deposits on Mars [
33], the use of hyperspectral data can help identifying water-altered material both in well-characterised settings [
34], as well as after eventual erosion and transport outside of the original basin and context.
The crater contains well-preserved and well-exposed delta deposits at its western edge, and the area displays a rich and varied surface mineralogy [
35,
36,
37,
38,
39,
40].
The entire Jezero area, especially the delta at its western border, has been well observed by several experiments, with a series of overlapping MRO CRISM cubes (
Figure 1).
Recent detailed orbital geologic mapping of the landing site area is available [
32,
41], as well as geomorphologic algorithm-aided mapping [
42]. Jezero Crater was selected as landing site for the Perserverance mission in 2020 [
43].
Figure 1.
Location map of used cubes in the present work. (
A) HRSC MC-13 quadrant color basemap [
44]: of Nili Fossae and surrounding areas, including Jezero, in the highlighted subset. (
B) Jezero Crater CTX mosaic [
45,
46] with indicated CRISM observation HRL000040FF, highlighed in white of overlapping CRISM MTRDR data covering its delta. (
C) IR enhanced color composite (FAL) using as RGB R2529, R1506, R1080 [
26] for CRISM observation HRL000040FF.
Figure 1.
Location map of used cubes in the present work. (
A) HRSC MC-13 quadrant color basemap [
44]: of Nili Fossae and surrounding areas, including Jezero, in the highlighted subset. (
B) Jezero Crater CTX mosaic [
45,
46] with indicated CRISM observation HRL000040FF, highlighed in white of overlapping CRISM MTRDR data covering its delta. (
C) IR enhanced color composite (FAL) using as RGB R2529, R1506, R1080 [
26] for CRISM observation HRL000040FF.
For reason of comparison we include datasets from the Capri Chasma area which were selected in our previous publication and summarize briefly the results in the
Appendix A.
2.2. Dimensionality Reduction
In 2018, McInnes and Healy [
47] presented the Uniform Manifold Approximation and Projection (UMAP) as a method for dimensionality reduction and data visualization. The idea and computation resembles the one for t-SNE [
48] to a large extent. A concise overview of the algorithm is given by Allaoui et al. [
49]. UMAP aims to represent the dataset
X in a fuzzy topological structure. In order to build such a structure, the data points are represented in a high-dimensional weighted graph. Each edge weight depicts the probability that two points are connected and is defined by
where
depicts the distance between the
i-th and
j-th data points,
is the distance between
i-th data points and its first nearest neighbor and
is the scale parameter.
Subsequently, a lower-dimensional representation
Y has to be determined which properly reproduces the relations of the data points in the high-dimensional graph. The projections,
and
, have to be mapped in the way that they correctly rebuild the similarities between the high-dimensional data points implying that the conditional probabilities
and
are equal. To model these low-dimensional similarities, UMAP uses a distribution similar to the Student t-distribution
In the default UMAP implementation
and
are used but setting
and
results in the Student t-distribution applied in t-SNE [
47].
For optimization of the embedding
Y, the low-dimensional representation UMAP uses binary cross-entropy as a cost function. It is also necessary to specify the number of nearest neighbors. As outlined by Vermeulen et al. [
50], this parameter controls how UMAP handles local versus global structure in the data. A small value affects concentration on very local structure, while a larger value forces UMAP to search for larger neighborhoods.
The UMAP algorithm has achieved promising results by processing MTRDR CRISM datasets, as shown in Fernandes et al. [
23]. They report superior performance of UMAP in comparison to other feature extraction techniques based on multiple scores. However, it is important to note that their work is limited to the visible and near-infrared wavelength range.
Nevertheless, we follow their parameter setup and reduce the original spectral dimension to two-dimensional data. Furthermore, we set the number of nearest neighbors to 100.
2.3. Data Pipeline
The intention of this paper is to establish a new method for spectral clustering of CRISM datasets. To include already published approaches in this research field and to exploit this existing knowledge we follow the approach of Gao et al. [
11] and implement their data pipeline. This pipeline is an easy to understand procedure and consists of three main parts: preprocessing, feature extraction and clustering algorithm. Another reason for this choice is to create an equivalent basis of comparison for our new approach.
The preprocessing is an iterative process of several steps including removing nonphysical outliers and a ”per pixel” normalization. We select the same wavelength under investigation (1050 to 2550 nm) and apply also a mask to cut out the region of interest. The spectra are divided by the mean of spectra from a nearby bland area over many pixels in order to reduce systematic errors and minimize physical biases [
1,
51,
52]. For a more detailed description, we refer to Gao et al. [
11].
We extend the implementation by adding a new method for dimensionality reduction. As outlined in
Section 2.2, we follow the approach of Fernandes et al. [
23] and pick up the UMAP algorithm.
The autoencoder model by Gao et al. [
11] is unchanged. The only modification is the insertion of the size of the latent feature space, determined by HySime [
53], to a minimum value of 5.
For benchmarking the proposed techniques, we continue to use the standard statistical principal component analysis (PCA) and the t-distributed Stochastic Neighbor Embedding (t-SNE) in our data pipeline. The number of extracted principal components is also fixed at 5 as this number of components explains about 95% of the variance in the data and the increase of ratio of explained variance is very small by increasing components.
Finally, the clustering is performed by k-Means and GMM. Contrary to Gao et al. [
11] we decide not to operate with a predefined number of clusters, but to explore a certain parameter space and then specify the most adequate number of clusters based on some appropriate metrics. Previous work, [
11,
23] suggests that a good a priori estimator is probably located between 5 and 20 clusters.
Overall, multiple different methods for generating SCMs were introduced and implemented, but we focus on the evaluation of the UMAP+k-Means approach.
2.4. Quantitative Metrics
To assess the clustering performance in a quantitative manner, we computed multiple unsupervised cluster-separation metrics for evaluation. To start with, the Calinski-Harabasz index (CH) [
54] for a set of data
E with
pixels and split into
k clusters is defined as the ratio of the dispersion between and within clusters.
where
with
denoting the set of points in cluster
q,
the center of cluster
q,
the center of
E and
the number of points in cluster
q. The measure indicates a higher score when clusters are dense and well separated.
The Davies-Bouldin index (DB) [
55] is based on the average similarity between each cluster
i and its most similar one
j and is given by
where
is the cluster similarity measure.
is the cluster diameter and
is the distance between cluster centroids
i and
j. A lower score refers to a higher cluster validity.
As a final measure, the span of the Silhouette Coefficient (SC) is limited between −1 for incorrect clustering and +1 for highly dense clustering whereby scores around zero indicate overlapping clusters. Thus, a significant advantage of this metric is that it allows direct conclusions about the efficiency and goodness of the clustering algorithm. The SC [
56] for a single sample can be written as
The measure is based on the mean distance a between a point and all other points in the same group and the mean distance b between the point and all samples in the next nearest cluster. The value of SC for a generated SCM is depicted by the average of the coefficient for each pixel.
3. Results
The presentation of results is split into two different segments. First we will report the metrics for the examined methods in order to identify the best quantitative fit for the cluster number and perform a quantitative evaluation. On the basis of these findings, we can operate with the generated SCM of the highest level of validity on the subsequent qualitative and visual analysis and have not to deal with assumptions and an arbitrary chosen number of clusters.
3.1. Quantitative Analysis
We start by calculating the metrics, introduced in
Section 2.4, over the defined range of clusters. The CH and DB coefficient are fast to compute, thus they will be shown as a base line. Furthermore, these scores are used to filter the best method. As outlined by Milligan and Cooper [
57], the CH score is a powerful criterion for evaluating the validity of clustering.
By inspecting the computed values we face the same issue as reported by Fernandes et al. [
23] and observe also strong fluctuation in the scores. Therefore, it is difficult to draw an evidence-based conclusion about method and clusters. To treat this problem we proceed in a similar way and compute the mean over the full range of investigated clusters for each method and score. We list the results for the HRL000040FF dataset in
Table 1.
According to the CH score both UMAP approaches outperform the benchmark methods and UMAP in combination with the k-Means clustering has the highest score. The PCA and autoencoder models exhibit the lowest CH value. In the case of DB, there is a similar ranking. The models using t-SNE as dimensionalirty reduction perform the best but the differences among UMAP and t-SNE are marginal. It should be emphasized again that UMAP and t-SNE are based on a related concept to cut down multidimensional data [
47,
48].
In order not to confine the results to a particular CRISM dataset, we include several MTRDR products in our analysis additionally. The values of both metrics for the FRT0000c564, FRT000b776 and FRT0001c71b dataset can be found in
Appendix A.1. Apart from a few exceptions, there is also a consistent pattern between the CH and DB metric when establishing rank statistics of the individual scores for each dataset where a higher rank invokes denser clusters. To summarize, the UMAP+k-Means approach is able to exceed the benchmarks.
These results correspond with previous studies [
23]. Fernandes et al. [
23] also used the Capri Chasma set FRT0001c71b, so we confirm their findings for a different wavelength range. In summary, we provide another evidence of UMAP’s capabilities as a dimensionality reduction technique in dealing with spectral data.
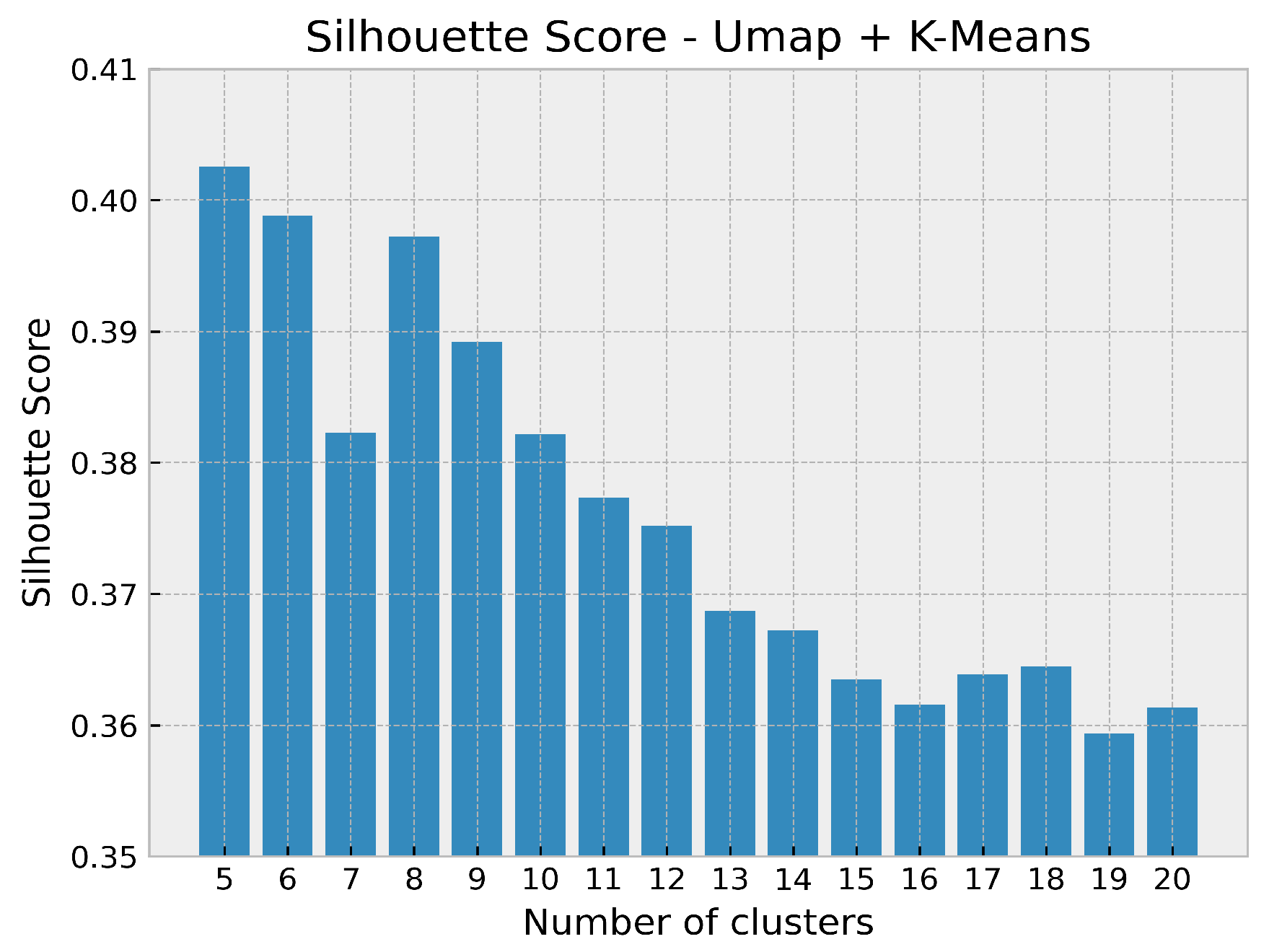
So far, we examined a predefined range of possible number of clusters without knowing the ground truth labels of the pixels. In the next step, we apply the SC due to its interpretability for selecting the best convenient total number of labels. Within the scope of this examination, we restrict ourselves to the UMAP+k-Means method because of its best performance.
Hence, we plot the SC index against number of clusters for the Jezero Crater dataset. Apart from a little sharp bend at seven clusters
Figure 2 shows an almost continuously declining graph by an increasing number of clusters. Thus, there is a strong evidence that the true number of clusters is at the lower end of the range under investigation.
In general, the values vary from below 0.36 (19 clusters) to about 0.40 (5 and 6 clusters) resulting in a moderate clustering ability for the model within this scope.
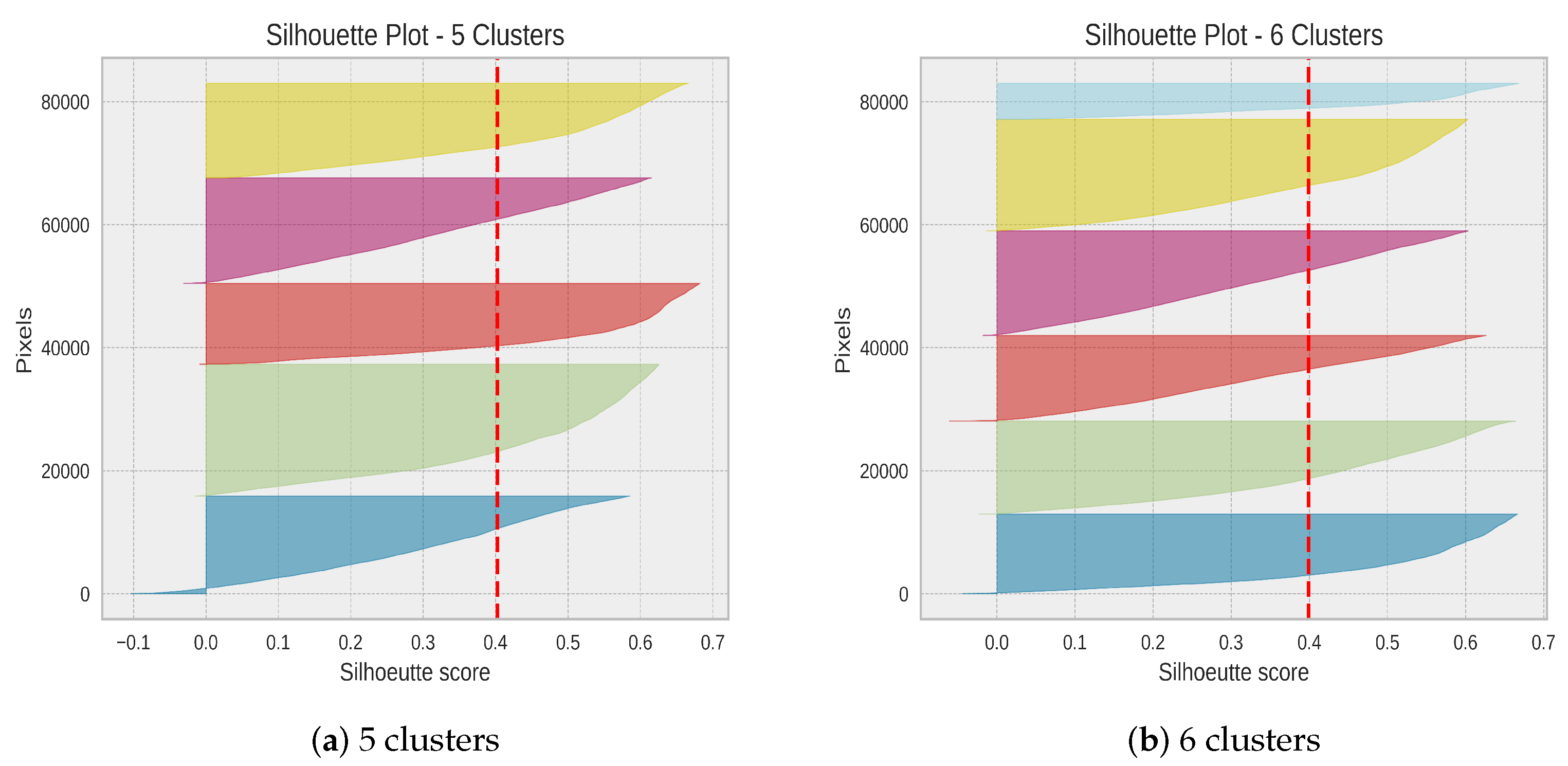
To ensure an accurate decision as possible, we illustrate the Silhouette plot for the two cluster values with the highest score in
Figure 3. The Silhouette plot depicts the SC index for each single pixel grouped by class label. Moreover the dashed vertical line corresponds to the average score across all pixels. We conclude that for both numbers of classes all clusters are located above the mean score. To make a choice we have to extend the analysis.
At first, it is clearly visible that 5 clusters in
Figure 3a have a more uniform thickness whereas the small class breaks this structure at 6 clusters. In spite of this fact we tend rather to 6 clusters for the following reasons: By observing the fluctuations between all clusters within one cluster environment we note a slightly higher variation for 5 clusters in comparison to 6 ones. High variation usually indicates a sub-optimal number of clusters.
Furthermore, we detect in
Figure 3b several pixels with a relative negative score around 0.10. By adding one extra class this “hitch” can be rectified and the high negative scores are eliminated. Finally, we reduce the fluctuations between the clusters. Consequently, we fix this number and proceed with a UMAP+k-Means generated SCM of 6 classes.
3.2. Qualitative Analysis
To perform qualitative evaluation we resort to the partial expert classification map used by Gao et al. [
11]. This is a 6-class partially classified image of the Jezero Crater whereas five classes are directly mapped with some mineralogy and one class exists as unclassified area.
At first sight, it is evident that the expert map (
Figure 4a) and the UMAP SCM (
Figure 4b) exhibit strong similarity in the form and characteristics of the located clusters. The shapes of the individual clusters of both images resemble each other closely.
In order to ensure a consistent assessment, we start evaluation with the three most dominant classes: olivine, Fe/Mg smectite and carbonate; colored yellow, blue and green in expert map.
The presented SCM distinctly identifies all three regions and all areas of these classes are correctly clustered. One single difference is that, in the upper left half of expert map, the carbonate class is omnipresent while the UMAP created SCM indicates a mix of the Fe/Mg smectite and carbonate classes.
The pyroxene, orange color in
Figure 4a, is likewise reliably detected by the proposed method. Besides the pyroxene deposit below the Fe/Mg smectite and partly inside this class area, it seems that the algorithm assigns some unclassified areas to pyroxene mineralogy as well.
To continue with the unlabeled fraction of the expert map, we discovered a new class, including a large part of this territory. On the left side of the SCM in an area not covered by the expert map, the applied approach provides another novel group (cf.
Figure 5). In order to label these areas we introduce a quantitative UMAP-based approach for automated class to mineralogy mapping in
Section 4.
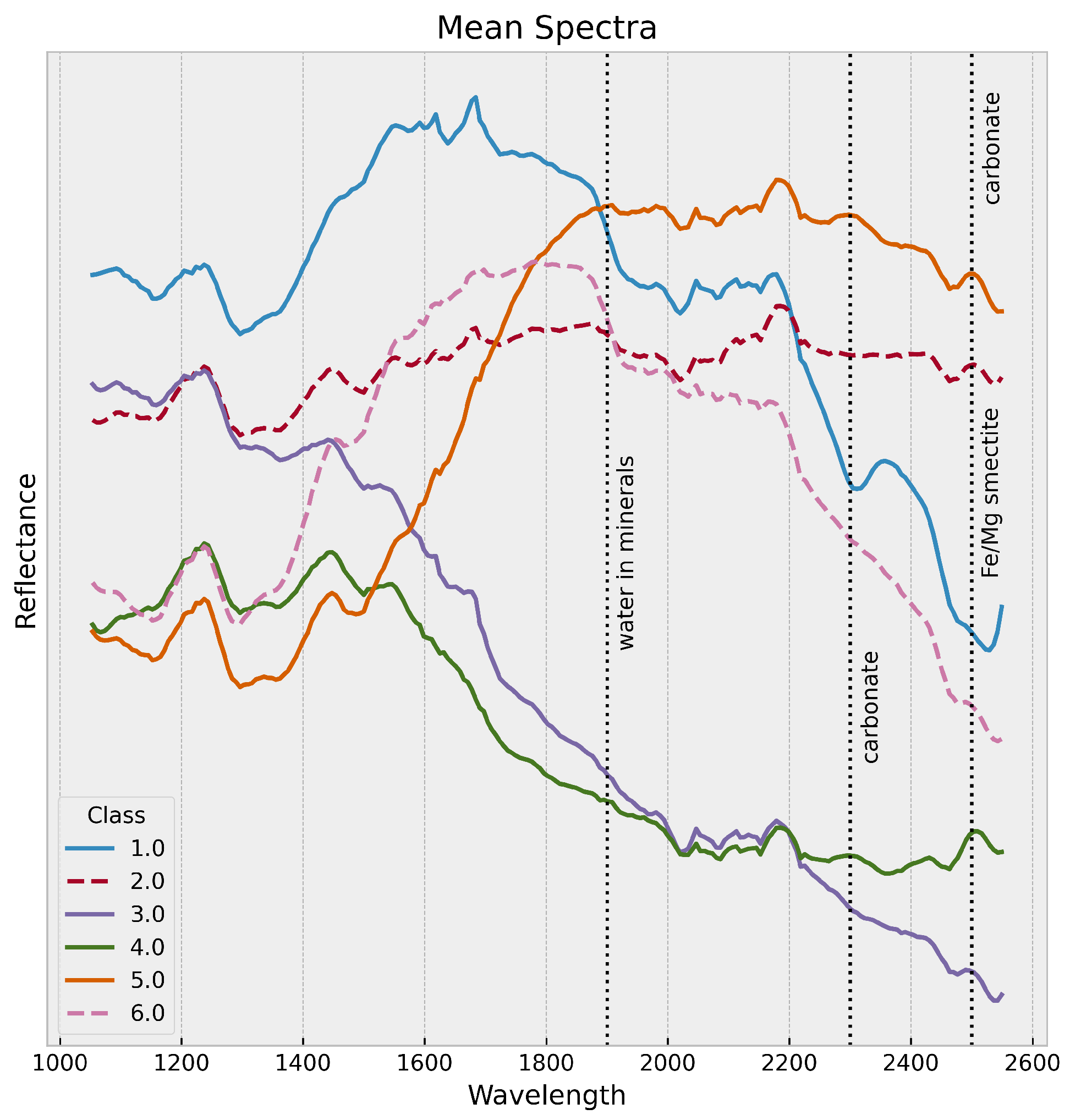
To complete the visual analysis we also inspect the spectra of the generated clusters since the remaining expert silica class is not seen in the produced cluster map. The correlation with the mineralogical findings is supported by calculating mean spectra per cluster.
In
Figure 6, we can observe the broad discriminative character of these spectra. For the dispersion of each band of the computed mean spectra for each cluster we observe values of about 5 percent. A broad absorption from 1050 nm to 1800 nm (olivine) for class 5 and a broad absorption from 1300 nm to 2300 nm (pyroxene) can be identified in case of class 4. We can see especially the key absorption of carbonates at 2500 nm (class 1). For a detailed comparison we refer to Gao et al. [
11].
The benefit of using k-Means clustering is that instead of mean spectra, which are mixtures of different mineralogical fingerprints also the k-Means cluster center spectra, can be selected and analyzed, which in this case does not fundamentally differ from the mean spectra.
4. Quantitative Geological Mapping
After the visual assessment of the UMAP+k-Means spectral cluster map, we demonstrate the geological relevance of the different classes in a quantitative way. In addition, the goal is to classify mineralogically the so far unmapped area (cf.
Figure 4a and
Figure 5).
To connect the clusters with geo-morphological properties we use the summary products of the HRL000040FF dataset. Summary products can be applied to draw conclusions about the mineralogy and related surface types [
58].
We define X as the summary products matrix with p pixels and N products. For consistency purposes we exclude several products in our investigation, mainly because the wavelength to which they respond are not within the examined range. In total, we have 29 products.
Considering a particular cluster c, where and C denotes the set of clusters, we select all pixels from X corresponding to c. Then, we pick up the first component of the UMAP feature embedding space and also mask out all unwanted pixels which are not clustered to c. Subsequent, we fit a Random Forest Regressor model M where the summary products are the input samples and the extracted latent variables of the first UMAP component are the target values y. Each forest consists of 100 trees.
After the estimator is fit, we compute permutation importance to filter the most important features
G in the model. The permutation feature importance is defined to be the decline in a model score when a single feature value is randomly shuffled [
59]. The idea is to establish a link between class and mineralogy based on the extracted summary products. The summarized methodology is given in Algorithm 1.
| Algorithm 1: Quantitative geological mapping |
 |
We repeated this procedure for each class
c and report the results of our investigation for
in
Table 2. Results with fewer products are also included.
The fitted Random Forest estimators have a
score of about 0.94 or higher for every
c. So a high predictive power of the individual models is observable. The geology information indicated with the selected products is based on Viviano et al. [
26]. All further remarks on mapping between summary products and the mineralogy refer to this work.
For all labeled classes (apart form the silica area) in expert map, the algorithm is capable of properly linking the UMAP feature embedding space to mineralogical properties. The summary browse product HCPINDEX2 is an indicator for silicate minerals and contributes significantly to the model for each cluster.
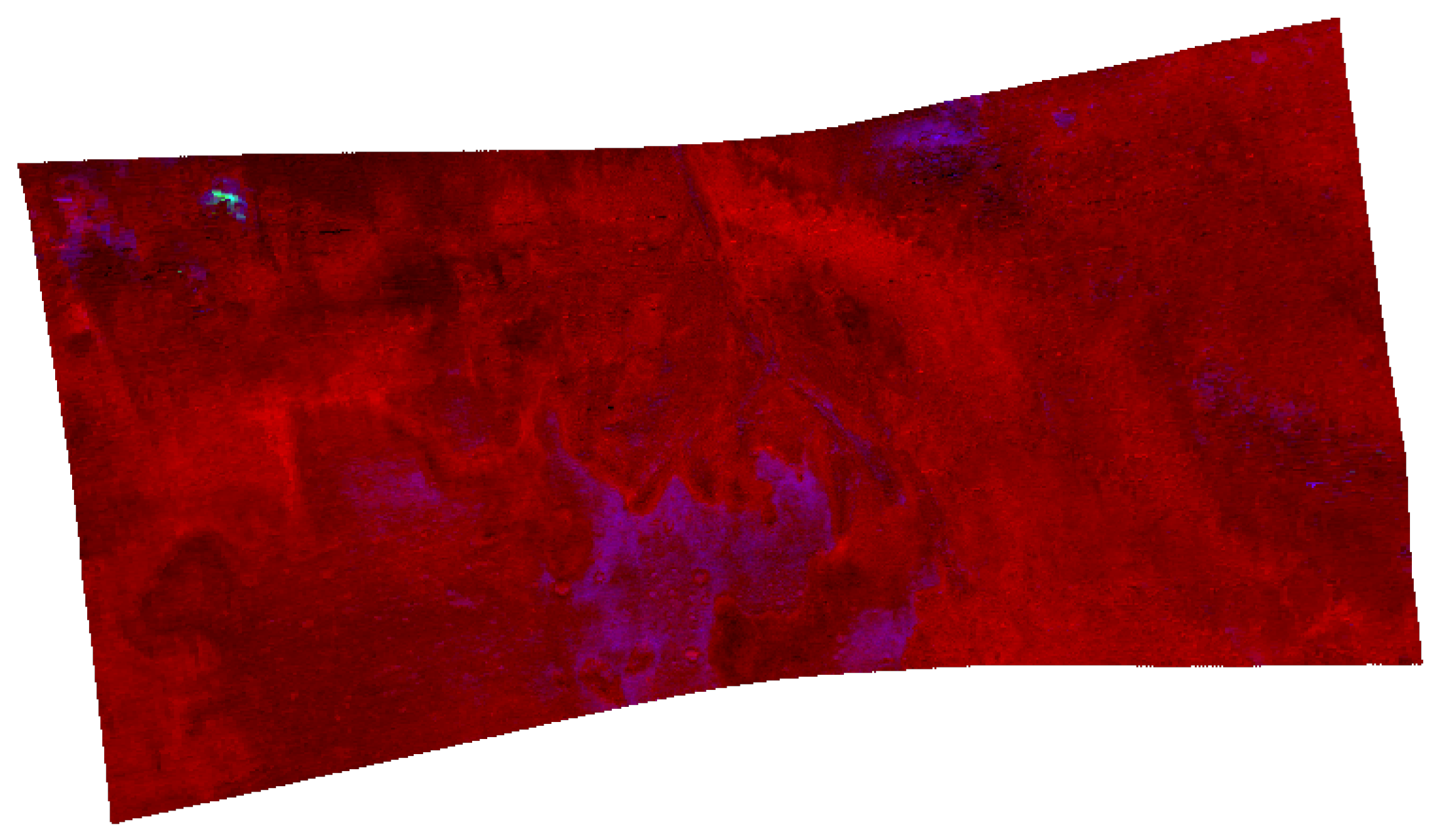
The MAF browse product (cf.
Figure 7) combining OLINDEX3, LCPINDEX2 and HCPINDEX2 in its RGB channels visualizes the mafic mineralogy and highlights the presence of olivine and Fe-phyllosilicate in red.
Of particular interest are the non by expert classified regions in
Figure 4a and the new clustered area on the left-side of the UMAP+k-Means SCM (cf.
Figure 5). We illustrate these two classes in
Figure 8. Besides the presence of HCPINDEX2, we detected the areas seen in summary product BD1750_2 and the OLINDEX3 in cluster 6. According to Viviano et al. [
26] this finding indicate occurrences of aluminum clays and carbonates.This is in agreement with Horgan et al. [
38], who visualized a mixture of aluminium clays and carbonates in distinct regions for Jezero crater. In general, the identified clusters characterize compositional mixtures and represent the mineralogy diversity given in [
38].
5. Discussion
Based on the results of all metrics (CH and DB) the UMAP combined with the k-Means cluster procedure shows the best scores (cf.
Table 1 and
Appendix A.1). Consequently, this method was selected and was optimized with respect to the cluster size. The same metrics can be used and figure shows that a cluster size of 6 is proposed for the individual dataset investigated in this study.
Our analysis shows that summary browse products can be linked to each cluster in a quantitative manner. It confirms the composition given in the expert map and found by Gao et al. [
11] supporting regions of carbonates, smectites and hydrated minerals. Moreover, for the 2 newly assigned clusters we could identify for cluster 1 and for cluster 6 mixtures of Al-clays and carbonates.
6. Conclusions
In this paper, a simple fast method is proposed to derive spectral clusters from hyperspectral data in the near-infrared wavelength range. The analyses show that the UMAP algorithm in combination with the k-Means clustering method, on the one hand, provides results quickly and, based on common cluster metrics, yields comparable or even better results than other proposed methods.
The evaluation of the presented cluster metrics suggests an optimal cluster number of six. The optimized cluster map for Jezero Crater shows a strong similarity to the given expert map.
Another important finding is that the method could identify two more regions, which for other methods were hard to distinguish. Spectral signatures of each cluster could clearly be related to the mineralogy (e.g., pyroxene, carbonates and Fe) found in Jezero. As the algorithm by its design executes its calculations very fast, it is useful for the evaluation and combination of large hyperspectral datasets in planetary applications.
It must be emphasized that the results can depend strongly on the data selection, the preprocessing and the signal-to-noise ratio. Thus, this procedure should rather be implemented in an iterative process with semi-manual approaches. Therefore, further iterative optimization of the procedure regarding robustness is required.
Research is still needed to quantify how the use of UMAP can address common challenges of unsupervised clustering, such as sensitivity to initial conditions, choice of parameters and data preprocessing.
To test the algorithm, we are planning an expanded analysis of the entire Jezero Crater area and to make it available to the broad community of different research groups.

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






