1. Introduction
Hyperspectral imaging collects the spectral response of the Earth’s surface from the visible to the infrared spectrum with a high spectral resolution, which enables the discrimination of different materials using the acquired rich spectral information. In particular, hyperspectral image (HSI) classification is used to assign a category label to each pixel for understanding the land cover and even its conditions. As a result, HSIs have been successfully applied in many application fields, such as urban planning [
1], land use mapping [
2], and natural resource monitoring [
3].
In the past few decades, many approaches have been developed for the classification of HSIs, based mainly on the spectral information, such as the support vector machine (SVM) [
4], multinomial logistic regression [
5], and artificial neural network (ANN) [
6], etc. However, noise is inevitably present in these methods, mainly due to the fact that they ignore the high spatial consistency of land cover [
7]. Many attempts have been made recently to incorporate spatial information to promote the classification of HSIs [
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19]. Typical methods include the Gabor filter [
9], extended random walker [
10], morphological attribute profiles [
11,
12], edge preserving filters (EPF) [
13,
14,
20], and the two-dimensional version of singular spectrum analysis (SSA) [
15,
16,
19]. Moreover, to deal with the two typical problems of HSIs, i.e., the curse of dimensionality and small sample problems, a series of methods for dimensionality reduction and representation/useful feature learning have been developed [
21,
22,
23,
24,
25]. These methods each have their own advantages.
More recently, researchers have introduced deep learning algorithms such as convolutional neural networks to HIS classification, which extract spatial information through local receptive fields [
17,
26]. Furthermore, several deeper networks and 2/3D CNN models have been investigated in HSI classification [
18,
27]. The deep learning-based classification methods have achieved superior classification accuracy, but they are usually time-consuming and require large amounts of training samples [
28].
In recent years, sparse representation (SR) has attracted increasing attention in the field of face recognition [
29] and signal processing [
30,
31], where a signal can be linearly represented or reconstructed by using a few determined elemental atoms in a low-dimensional subspace. By applying SR to HSI, sparsity can be adopted from the highly redundant spectral dimension for SR classification (SRC) of HSIs [
32,
33,
34,
35,
36]. Due to the effect of noise, conventional pixelwise SRC has limitations when only spectral information is used for the classification of land cover. Therefore, joint sparse representation classification (JSRC) is proposed to combine both spatial and spectral information for more robust SRC in HSI [
35]. JSRC performs classification by extending each pixel to a block of pixels centered at the given pixel, usually with a fixed size, and assuming that all pixels within the block belong to the same class. However, the fixed size of image blocks popularly adopted by JSRC-based methods is problematic, which has two main drawbacks. One is the inability to sufficiently exploit the structure diversity of land cover, and the other is the inclusion of noisy and heterogeneous pixels within the block, especially at the boundary of different classes.
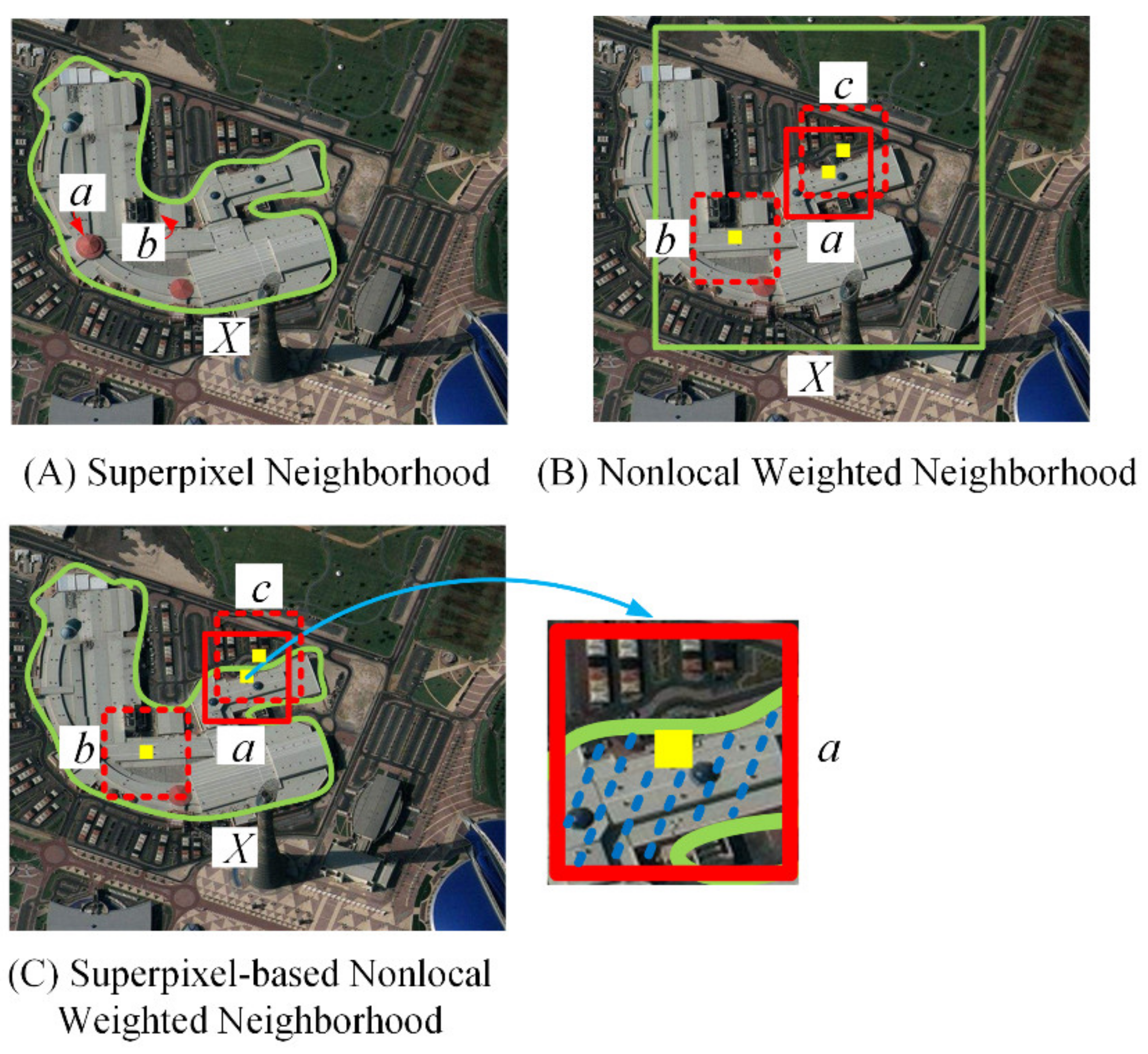
Superpixel segmentation is a widely applied method for tackling the structure diversity of land cover, with typical segmentation methods including simple linear iterative clustering (SLIC) [
37], graph-based image segmentation [
38,
39,
40,
41], and entropy rate superpixel (ERS) [
42]. From the plentiful applications, it is concluded that SLIC focuses more on seeking the structural equilibrium of the segmented units [
43]. Graph-based methods cannot accurately reflect the object boundary when the boundary is weak or with complex noise [
39]. By contrast, ERS shows a better ability to delineate the boundary of targets. For the sparse-representation-based methods, Fang et al. [
32] proposed a multiscale JSRC method with an adaptive sparsity strategy. It can achieve good performance only when proper scales are selected. Some researchers introduced superpixels to HSI classification, which are adaptively formed from over-segmented images for the effective description of land cover structures [
33,
44,
45]. There is also a shape adaptive method [
34] proposed to determine a polygon to represent spatial information, based on the similarity between the pixels in different directions and the center pixel. However, in practice, superpixels or adaptive shapes have to face internal heterogeneity and outliers [
45] due to inherent noise in the image.
As the spatial information of fixed-sized blocks is degraded by heterogeneous and noisy pixels, some methods are employed to increase the contribution of the central pixel whilst decreasing the influence of noisy pixels in a block. For instance, Tu et al. [
46] used correlation coefficients between the central pixel and samples to enhance classification decisions. A weighted joint nearest-neighbor method is applied to improve the reliability of the classification performance [
47]. These methods, however, are highly dependent on the training samples. Additionally, a neighborhood weighting strategy is also used for the suppression of heterogeneous pixels within the fixed-sized block. For example, Qiao et al. [
48] proposed a weighting scheme based on spectral similarity, where the weights are based on an implicit assumption that the center pixels of blocks are noise-free, which is hardly satisfied. Zhang et al. [
49] proposed a nonlocal weighting scheme (NLW) based on the local self-similarity of images. NLW can preserve pixels with local self-similarity in a smooth region.
In summary, neither the adaptive neighborhood nor weighting-based methods can fully solve the aforementioned two drawbacks in JSRC, i.e., the structure diversity of land cover and noisy pixels. To this end, in this paper, we propose a superpixel-based nonlocal weighted JSRC (SNLW-JSRC) for HSI classification. By combining nonlocal weighting and the adaptive neighborhood together, the two drawbacks faced by JSRC can be solved simultaneously. Specifically, the superpixel-based weighting scheme (SNLW) is conducted to select pixels within superpixels according to their associated structural and spectral similarity measurements.
The major purposes of this paper can be concluded as follows:
- (1)
To simultaneously and adaptively extract land cover structures while removing the effects of noise and outliers;
- (2)
To fully explore the advantages of the superpixel and nonlocal weighting scheme for spectral–spatial feature extraction in HSI;
- (3)
To outperform several classical SRC approaches and achieve improved data classification results of HSI.
The remainder of this paper is organized as follows.
Section 2 introduces the traditional SRC and nonlocal weighted SRC. In
Section 3, the detailed introduction of the proposed SNLW-JSRC is presented. The experimental results and analysis are given in
Section 4. Finally,
Section 5 provides some concluding remarks.
2. Nonlocal Weighted Sparse Representation for HSI Classification
For an HSI image, pixels from the same category lie in a low-dimensional subspace; thus, these pixels can be represented linearly by a small number of pixels from the same class [
35]. This has formed the theoretical basis for SR classification (SRC) of HSI. Denote a pixel of HSI as a vector
, where
B is the number of spectral bands, and in total, the pixels are in
C classes. We select
training samples from the
i-th class to form an overcomplete dictionary
, and the pixel
of the
i-th class can be reconstructed by [
35]:
where
represents the sparsity coefficient of
with respect to
.
As the class of
is unknown before classification, we need to build a dictionary
that contains all the classes, i.e.,
, where
,
i = 1, 2,...,
C. Accordingly,
can be reconstructed by [
35]:
where
is the sparse coefficient of
with respect to
. In order to obtain a sparse enough solution of
, we need to solve the following optimization problem [
35]:
where
represents the number of non-zero elements of
. This is an NP-hard problem and can be solved by using the orthogonal matching pursuit (OMP) [
50]. After determining
, the class of
can be determined as follows [
35]:
Since the SRC is based on the spectral characteristics of a single pixel, the spatial information of the pixel is ignored. As a result, it may lead to limited accuracy or sensitivity to noise [
51]. To tackle this problem, joint sparse representation classification (JSRC) considering the spatial information of the pixel has been used to incorporate spectral–spatial information [
35]. For a pixel
, its spatial neighborhood is denoted as
, where
K denotes the number of pixels in
. The JSRC of
in relation to
can be derived as [
47]:
where
represents the sparse coefficient of
with respect to
, and
denotes the sparse coefficient of
with respect to
. Specifically, each column in
shares the same sparse elements; hence, the spatial information of the land cover can be jointly utilized. In order to derive a solution of
, we need to solve the following objective function [
47]:
where
represents the number of non-zero rows. Similarly, the optimization of Equation (6) is an NP-hard problem, which can be approximated by a variant of OMP called simultaneous OMP (SOMP) [
52]. After obtaining
, the class of
can be determined by [
47]:
However, spectral–spatial information extracted by JSRC is easily affected by heterogeneous pixels in the defined neighborhood region
. In [
49], a nonlocal weighting scheme (NLW) is developed to solve this problem. For a given test sample
, a fixed-sized block
is obtained, centering on
. The weight of a neighboring pixel
within
is determined as follows [
49]:
where
is a joint neighborhood definition function, and
and
refer to
-centric and
-centric HSI neighborhood blocks, respectively.
represents the spectral–spatial difference between the two blocks, and
T is the number of neighboring pixels.
denotes a Tukey weight function [
49] to weigh the spectral–spatial differences.
With the determined weights, a weighted region
centered on
can be obtained as below [
49]:
where
is a vector of the weights for neighboring pixels in
. Finally, JSRC is performed on
, using Equations (6) and (7) to obtain the labeled value of
. However, the weighted results of NLW cannot completely suppress the effects of noise and heterogeneous pixels, especially at the edges of land cover. Therefore, this paper proposes the SNLW scheme, which will be introduced in the following section.
4. Experimental Results and Discussion
In the experimental part, the performance of the proposed SNLW-JSRC approach is evaluated using four publicly available HSI datasets: Indian Pines, Pavia University (PaviaU), Salinas, and 2013 GRSS Data Fusion Contest (DFC2013) [
55]. The proposed method was benchmarked with several classical HSI classification approaches, including pixel-wise sparse representation classification (SRC) [
29], joint sparse representation classification (JSRC) [
35], nonlocal weighted joint sparse representation (NLW-JSRC) [
49], superpixel-based joint sparse representation (SP-JSRC), its single-scale version in [
33], and SVM [
4]. In these methods, SRC and SVM are typical pixel-wise classifiers; others are spectral–spatial-based classifiers. The NLW-JSRC method uses the same weighting scheme as ours, yet it is based on local self-similarity, i.e., spectral–spatial information. The SP-JSRC is a superpixel-level spectral–spatial classifier. The quantitative metrics used in this study include the overall accuracy (OA), the average accuracy (AA), and the Kappa coefficient (Kappa) [
32].
4.1. Datasets
The Indian Pines dataset was acquired by the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) sensor in Northwestern Indiana, USA. The spectral range is from 400 to 2450 nm. We removed 20 water absorption bands and used the remaining 200 bands for experiments. The imaged scene had 145 × 145 pixels with a 20 m spatial resolution, among which 10,249 pixels are labeled. The total number of classes in this dataset is 16.
The PaviaU dataset was acquired in Pavia University, Italy, by the Reflective Optics System Imaging Spectrometer. The spatial resolution of the dataset is 1.3 m, while the spectral range is from 430 nm to 860 nm. After removing 12 water absorption bands, we keep 103 bands from the original 115 bands for the experiment. The imaged scene has 610 × 340 pixels, among which 42,776 pixels are labeled. The number of classes is 9.
The Salinas scene dataset was also collected by the AVIRIS sensor in Salinas Valley, California, which has a continuous spectral coverage from 400 nm to 2450 nm. The spatial resolution of the dataset is 3.7 m. There are 512 × 217 pixels, among which 54,129 pixels were labeled and used for the experiment. After removing the water absorption bands, we keep the remaining 204 bands in the experiments. The number of classes is 16.
The DFC2013 dataset is a part of the outcome of the 2013 GRSS Data Fusion Contest, and it was acquired by the NSF-funded Center for Airborne Laser Mapping over the University of Houston campus and its neighboring area in the summer of 2012. This dataset has 144 bands in the 380–1050 nm spectral region. The spatial resolution of the dataset is 2.5 m. There are 349 × 1905 pixels, and 15029 of them were labeled as training and testing pixels. The number of classes is 15.
4.2. Comparison of Classification Results
For SVM, we use the RBF kernel, where a fivefold cross-validation is used. The parameters of SRC were tuned to the best. For all the SRC-based methods, the sparse level was set to 3, as used in [
18]. Additionally, the scale of local blocks is 5 × 5 for JSRC and 11 × 11 for NLW-JSRC. For SP-JSRC and SNLW-JSRC, the size of superpixels was chosen from a sequence, which is 400, 500, 600, 700, 800, 900, 1000, 1100, and 1200, and we chose 500 for Indian Pines, 1100 for PaviaU, 400 for Salinas, and 1000 for DFC2013. The parameter
α in Equation (14) is set to 3 in this paper.
The first experiment was on the Indian Pines, where 2.5% of samples in each class were randomly selected for training, and the remaining (97.5%) for testing. The specific numbers of training and testing samples for each class are summarized in
Table 1. The quantitative results for our approach and the benchmarking ones are given in
Table 2 for comparison, where the best results are highlighted in bold. Note that to reduce the impact of randomness, all the experiments were repeated for 10 runs, where the averaged results are reported.
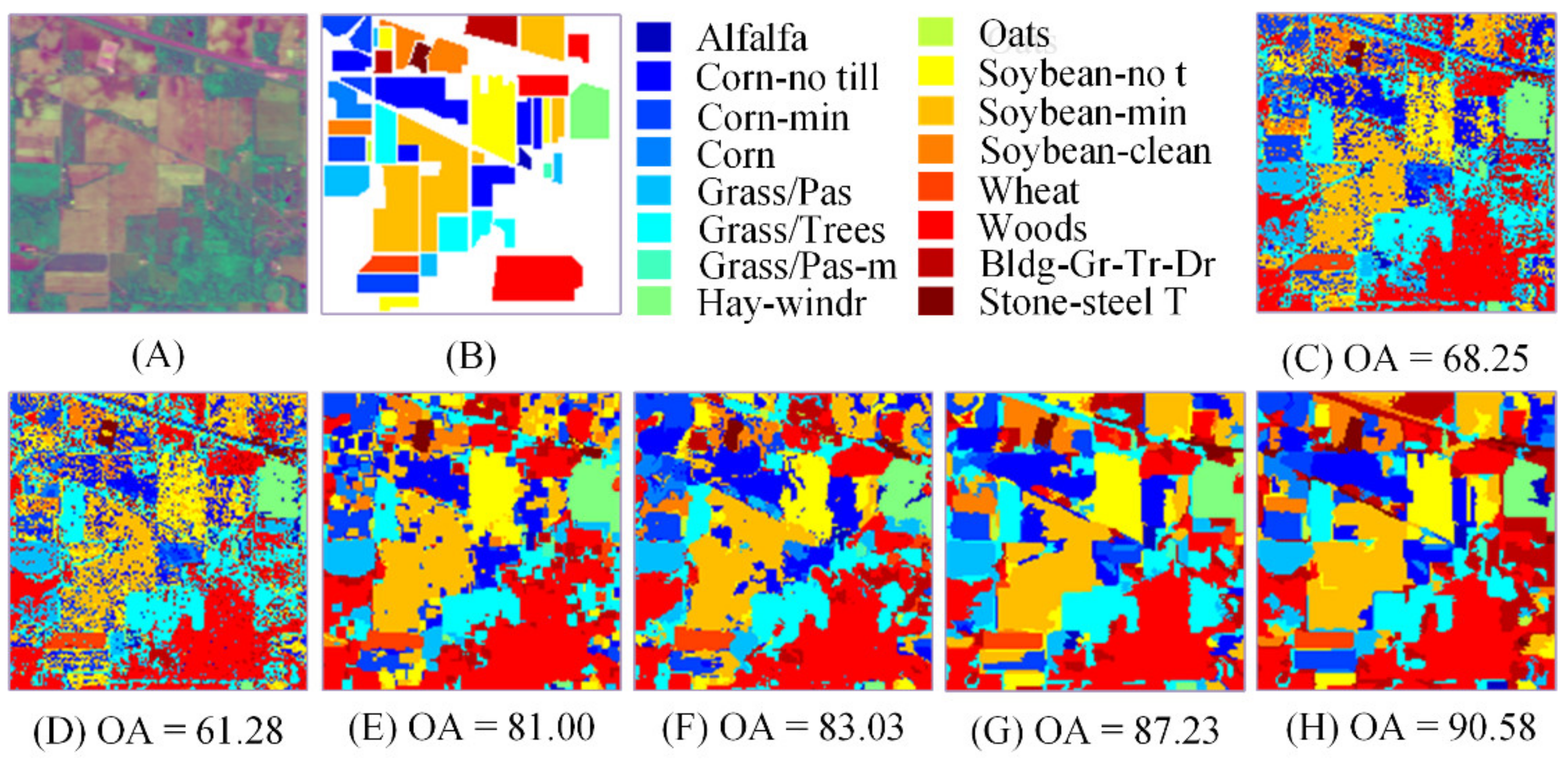
Figure 4 shows the classification maps of the last run.
According to the visualization results of
Figure 4, the classification map of pixel-wise SRC has serious noise, while the classification results based on the spectral–spatial information classifier are obviously superior in both quantitative and qualitative terms. Although the classification result of JSRC suppresses the influence of noise, there is obvious misclassification. For NLW-JSRC, partial misclassification of JSRC is solved, but because NLW-JSRC cannot make good use of spectral–spatial information in the weighting process, the improvement is limited. In SP-JSRC, due to the use of superpixels, good boundaries of the classification map and higher accuracy were obtained, but the noise and outliers within several superpixels brought misclassifications. For the SNLW-JSRC, the quantitative result in
Table 2 is the best among the comparison methods. In terms of qualitative results, the classification map is almost immune to noise, has good boundaries, and overcomes the problem of superpixel internal noise.
The second experiment was conducted on the PaviaU dataset. For each class of this dataset, 50 samples were randomly selected as training samples, and the rest of the samples were taken as testing samples. The specific numbers of training and testing samples are shown in
Table 3. The quantitative results for comparison methods and the proposed method are tabulated in
Table 4, in which the best results are in bold. As with Indian Pines, all the results were averaged in 10 runs with different training sets. The obtained estimation maps of the last run are given in
Figure 5.
As shown in
Figure 5, compared to pixel-wise classifiers and block-based classifiers, superpixel-based methods achieve better noise suppression and boundary division. However, the superpixel information used by the SP-JSRC method may contain noise and outliers, thus causing misclassifications in the superpixel level. In SNLW-JSRC, these misclassifications were well solved due to the SNLW strategy. The quantitative results listed in
Table 4 also confirm the superiority of SNLW-JSRC. In addition, the advantages of SNLW-JSRC on PaviaU are more obvious than those on Indian Pines. This may be because of the higher spatial resolution of the PaviaU dataset.
For the experiment of Salinas, we randomly selected 0.25% of the samples in each category as training samples, and the rest (99.75%) were taken as testing samples. The specific numbers of training and testing samples for each class are available in
Table 5. The quantitative and qualitative results for comparison methods and the proposed method are tabulated in
Table 6 and
Figure 6, respectively. In
Table 6, the best results of each row are in bold. The results shown in
Table 6 were also averaged in 10 runs with different training sets, and the classification map was obtained from the last run.
As shown in
Figure 6, all the four SRC variants integrated with spatial information have less salt and pepper noise compared to the spectral-reliant SVM and SRC. Moreover, the misclassification of the proposed SNLW-JSRC is the lowest. This is also confirmed by the quantitative results tabulated in
Table 6. In addition, it is shown that although the SNLW-JSRC still produced the best OA and Kappa, its advantages on the Salinas dataset are not so remarkable as on the PaviaU dataset. This comes from the simple scene and lower spatial resolution of Salinas, which make its spatial heterogeneity lower. From
Table 6, we can see that the performance of SP-JSRC and SNLW-JSRC is similar. This also indicates that SNLW-JSRC has a better effect on the HSI with higher heterogeneity.
The last experiment was conducted on the DFC2013 dataset. In this paper, a central part of the Houston University campus containing 336 × 420 pixels belonging to 11 classes of targets is selected as the experimental area. For each class of this dataset, we selected 1% of samples as training samples, and the rest (99%) were taken as testing samples. The specific numbers of training and testing samples for each class are shown in
Table 7. The quantitative and qualitative results for comparison methods and the proposed method are tabulated in
Table 8 and
Figure 7, respectively. The results shown in
Table 8 were also averaged in 10 runs with different training sets, in which the best results are in bold. The classification map displayed in
Figure 7 was obtained from the last run.
From
Table 8, we can conclude that for the more complicated DFC2013 dataset, the SNLW-JSRC performs with obvious superiority, with OA and Kappa equal to 86.83% and 0.85, respectively. Similar to the PaviaU dataset, the spatial resolution and heterogeneity of DFC2013 are higher; this also reveals that the SNLW-JSRC can not only provide adaptive neighborhood information following the irregular morphological characteristics of targets but also eliminates the outliers and noise in the neighborhood. Especially for the targets with confusing spectral characteristics, such as soil, residential areas, and parking lot areas, the SNLW-JSRC shows better classification performance, as highlighted in
Figure 7C–H by the red circles.
To further test the computational efficiency of the proposed SNLW-JSRC, we calculated the running time of each experiment. These experiments were conducted on a PC with an Intel (R) Pentium (R) CPU 2.9 GHz and 6 GB RAM, and Matlab R2017b. The CPU times (in seconds) of the compared methods are listed in
Table 9.
As shown, due to the first four algorithms paying more and more attention to the use of spatial neighboring information, their CPU time increases. By contrast, the CPU time of SP-JSRC is much lower since it performs superpixel-level sparse decomposition. Compared to the SP-JSRC, the proposed SNLW-JSRC adds a more time-consuming SNLW-based weighting procedure. Thus, the SNLW-JSRC consumes more computing time than the SP-JSRC. Nevertheless, the SNLW-JSRC is clearly more efficient than the NLW-JSRC. Overall, comprehensively considering its superior classification performance and efficiency, the proposed SNLW-JSRC is a more preferable algorithm. Even so, mixed programming with C language and Matlab, as well as the use of GPU, will further speed up the calculation process, and SNLW-JSRC is still optional.
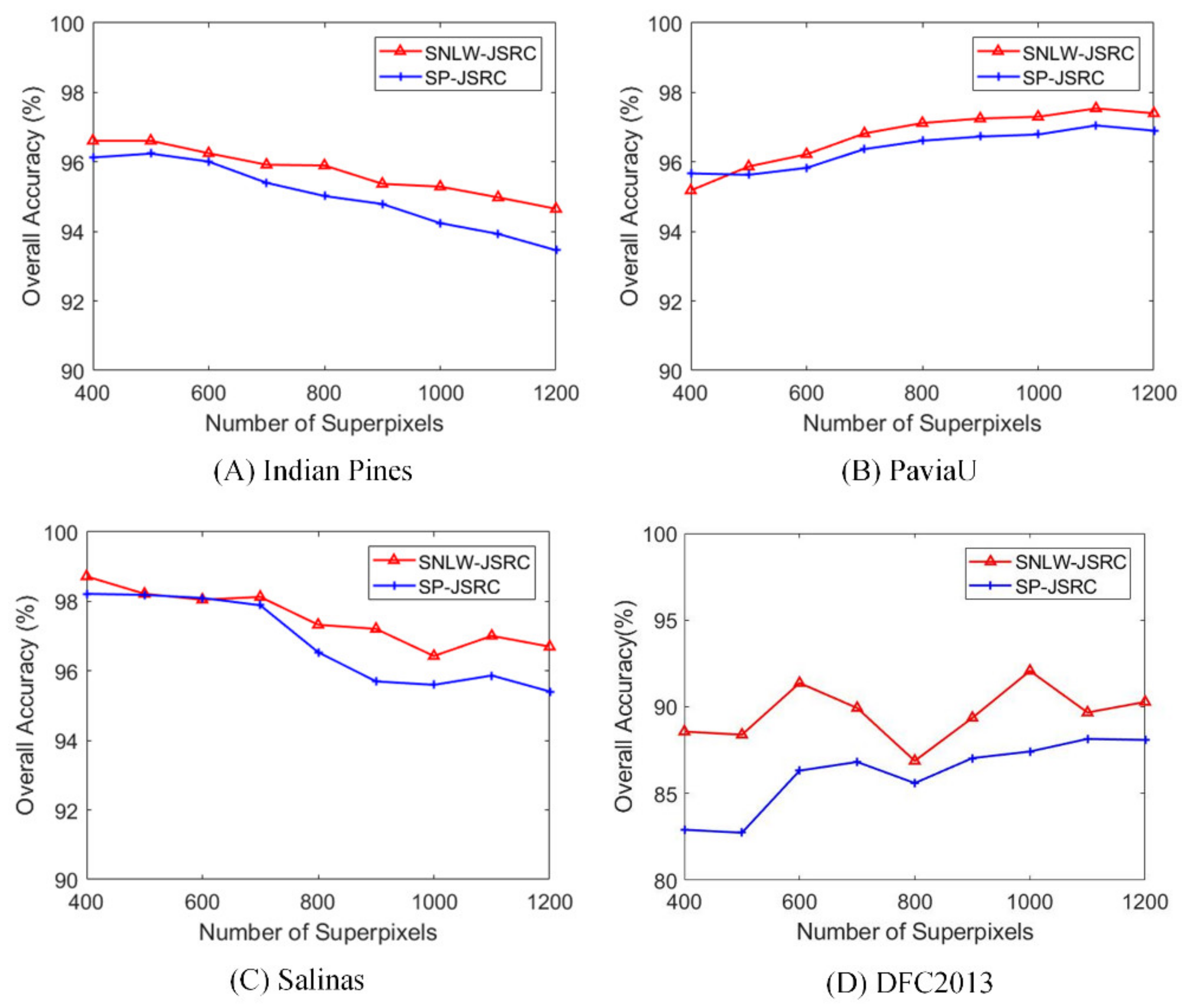
4.3. Effect of Superpixel Numbers
The number of superpixels affects the size of the superpixel. Generally, the larger the superpixel number, the smaller the superpixel size, and vice versa. Therefore, the number of superpixels has a great influence on the quality of superpixel segmentation. Here, we set up a sequence of superpixel numbers—400, 500, 600, 700, 800, 900, 1000, 1100, and 1200—to explore the impact on SNLW-JSRC and SP-JSRC. In the experiment, the number of training samples was 10%, 200, 1%, and 2% of each class for Indian Pines, PaviaU, Salinas, and DFC2013, respectively. The remaining parameters were the same as those in
Section 4.2. The effect of the superpixel number on the Indian Pines, PaviaU Salinas, and DFC 2013 datasets is shown in
Figure 8. As can be observed, for almost all the numbers of superpixels, SNLW-JSRC has an obvious improvement over SP-JSRC due to better noise suppression achieved by SNLW-JSRC. In addition, after an upward trend of accuracy, a downward trend is presented. As the number of superpixels becomes larger and larger, the superpixel scale becomes smaller and smaller, resulting in failure to provide sufficient spatial information for proper classification. However, the decline in the accuracy of SNLW-JSRC is slower than that of SP-JSRC, indicating that noise suppression promotes the robustness of classification.
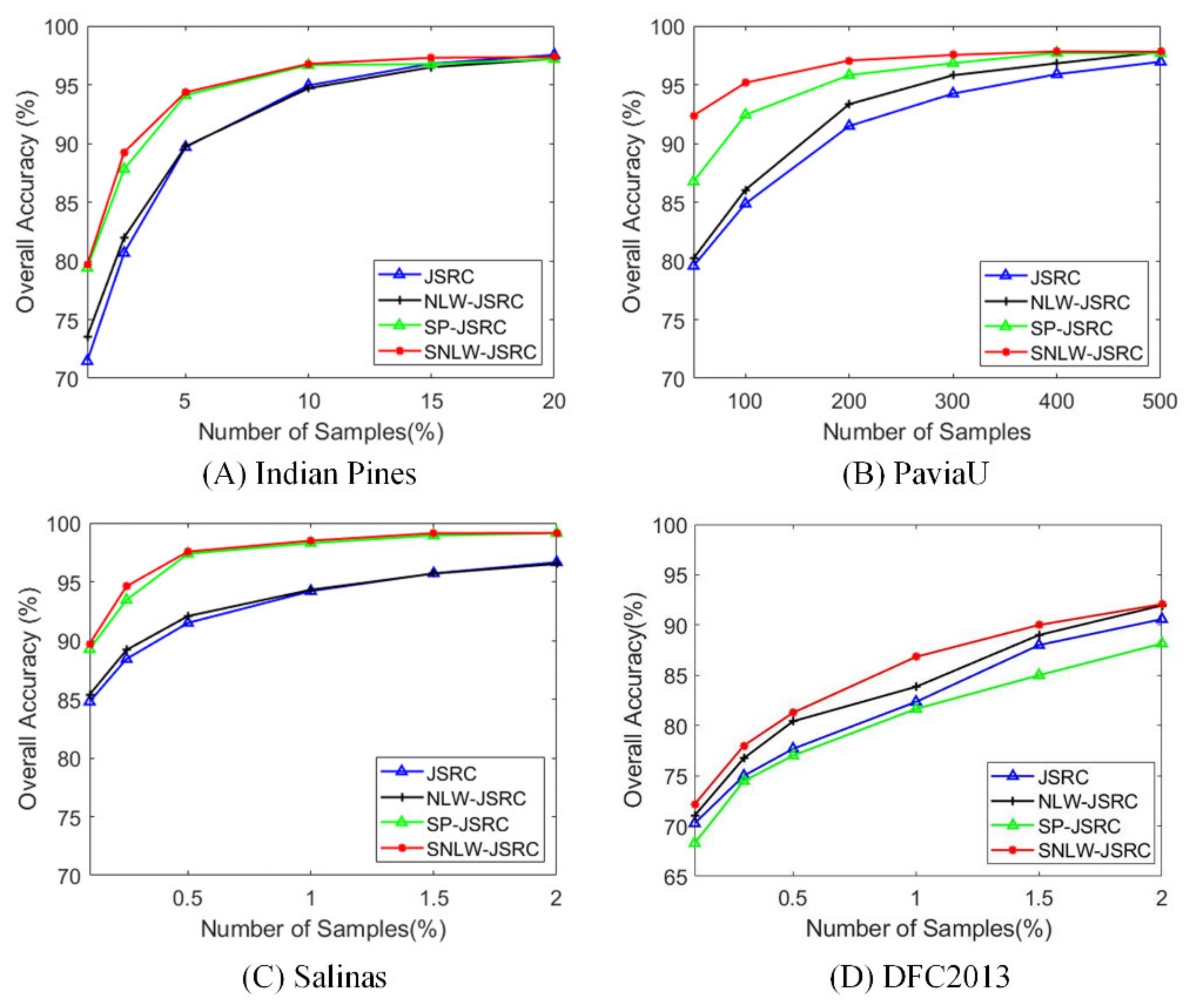
4.4. Effect of the Number of Training Samples
Here, we explore the impact of the number of training samples on different methods, including JSRC, NLW-JSRC, SP-JSRC, and SNLW-JSRC, on four datasets. We set the percentage of training samples as 1%, 2.5%, 5%, 10%, 15%, and 20% of each class for Indian Pines, select 50, 100, 200, 300, 400, and 500 samples of each class for PaiviaU, and set the percentage as 0.1%, 0.25%, 0.5%, 1%, 1.5%, and 2% of each class for Salinas and DFC2013. The remaining parameters are the same as those in
Section 4.2. The results are shown in
Figure 9. The overall trend is that the more training samples included, the higher the classification accuracy of each method. When the sample percentage is 10% for Indian Pines, 200 for PaviaU, 1% for Salinas, and 2% for DFC 2013, the growth trend becomes slower. In particular, SNLW-JSRC is basically superior to other methods, especially for the more complex PaviaU data, indicating that the proposed method is good at handling complex data. When the training sample is small, SNLW-JSRC can achieve a better improvement since SNLW-JSRC achieves good noise suppression and makes the classification more robust to samples.




 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}