In this section, we propose two building extraction methods that combine orthorectified remote sensing images and the corresponding LiDAR point-clouds. We assume that the LiDAR data and image data have been precisely co-registered. We focus on how to combine the height information of the LiDAR data and the vegetation information recognised from the remote sensing images to improve the automation level and accuracy of building extraction from remotely sensed data, and how to utilise the image features to refine the initial building mask automatically. In addition, we focus on processing relatively flat terrains, which apply to most cities worldwide and many rural areas.
2.2. Building Mask Refinement Based on Image Feature Consistency Constraints
Although building-mask refinement methods have been developed, they have limitations. Some methods adopt the features of LiDAR point clouds when refining building masks [
30,
35]. Thus, they inevitably incorporate inaccurate boundaries derived from the LiDAR data. Some methods attempt to project the initial building boundaries generated from LiDAR data onto the corresponding images and then use the boundaries or segments extracted from images to replace the initial coarse building boundaries [
3,
62,
69]. This idea works theoretically but is difficult in practice. This idea requires precise matching between boundaries or between segments, but the correspondence between the boundaries of the initial building mask and the boundaries extracted from the images may not be good, making matching difficult. In addition, existing unsupervised boundary detection and segment detection methods are not sufficiently mature to obtain optimal results automatically, which leads to a dilemma: if strict parameters are used for the boundary detection or segment detection algorithm, the necessary boundaries or segments may not be retained; if loose parameters are used, too many boundaries or segments may be detected, which will increase the difficulty of matching boundaries or segments.
We also adopt the strategy of using image-derived boundaries to replace LiDAR-derived boundaries, but through region matching instead of boundary matching. Region matching is much less difficult than boundary matching and hence much more stable; thus, accurate results may be obtained automatically. Furthermore, it is easy to combine multiple matching results to further improve the refinement result if the strategy of region matching is adopted.
Specifically, the fundamental underpinning our method can be described as follows: the image features (including the spectral features and the texture features) of one building or one building part should be internally consistent, and through image segmentation we can obtain these regions with consistent image features. Because these segmentation regions have high overlap (matching degree) with the initial building regions, by computing the union of these segmentation regions with high matching degrees, we can replace the LiDAR-derived boundaries with the image-derived boundaries; that is, obtain the building mask with accurate boundaries. If the threshold for the matching degree is not very high, our method can also recover incorrectly removed building points. Because the adopted vegetation detection methods are highly accurate, each of the connected vegetated regions remaining in the initial building mask is only a small portion of the real connected vegetation region; thus, our method can also remove the remaining vegetation regions with large size, regardless of whether they are close to the real buildings.
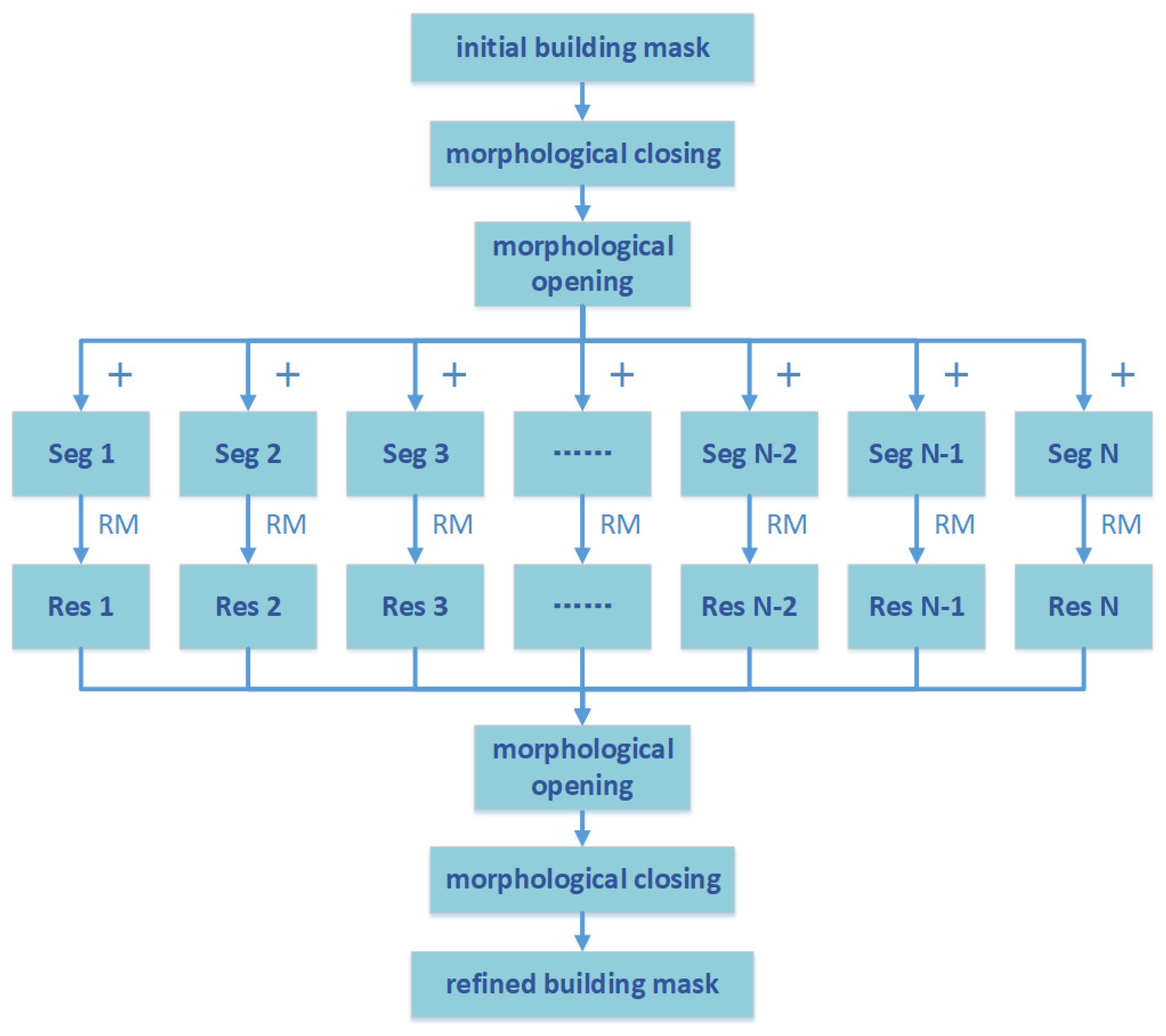
The workflow of our building-mask refinement method is shown in
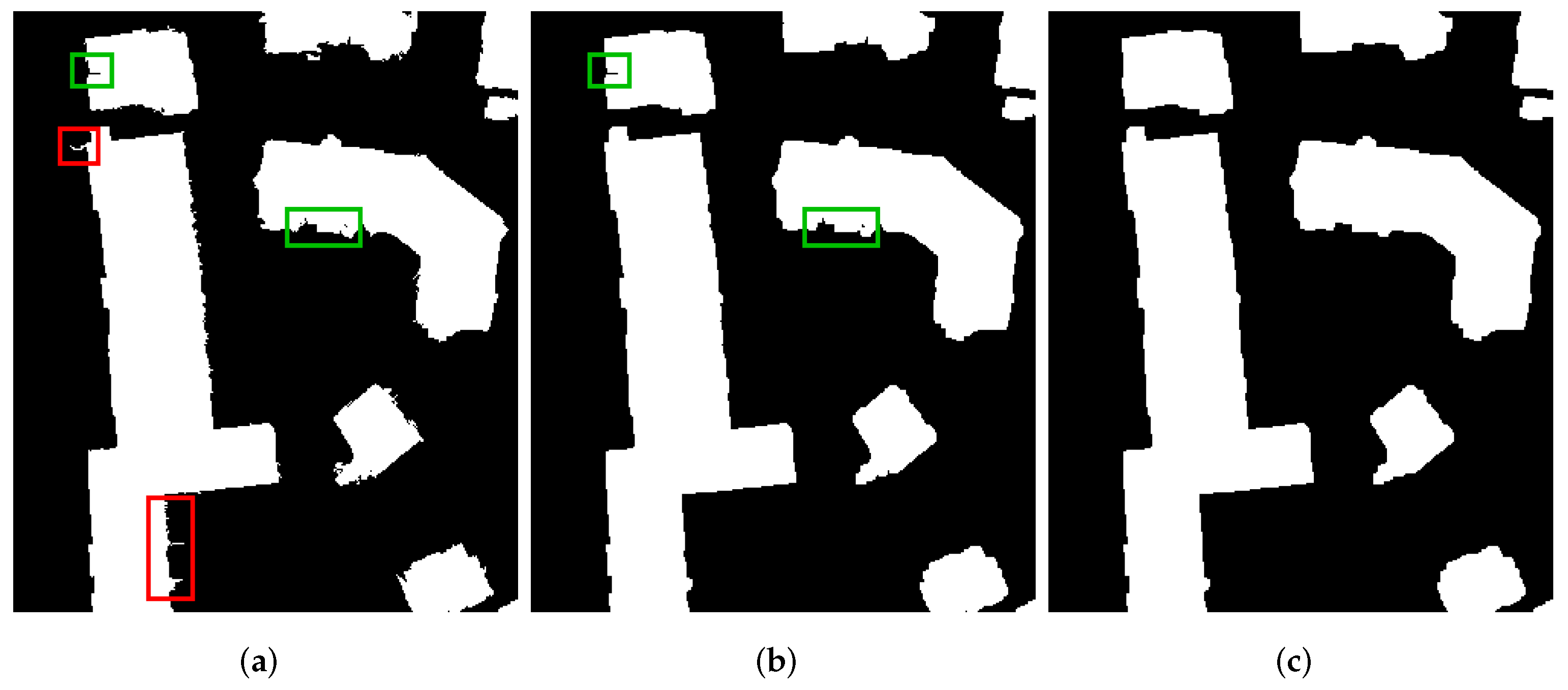
Figure 2. To better recover the missing building points (in
Figure 3a, some examples are marked by green rectangles), before region matching, the morphological closing operation is performed on the initial building mask. However, this operation may also recover some non-building points (mostly vegetation points; in
Figure 3b, some examples are marked by red rectangles). To counteract this side effect, the morphological opening operation is also performed, which can also remove the small-area non-building regions remaining in the initial building mask (
Figure 3c is much clearer than
Figure 3a,b). The first-closing-then-opening operation can mainly recover the missing building points as expected, as shown in
Figure 3. However, the above preprocessing steps may introduce some unwanted points (see the region marked by the second red rectangle in
Figure 3b,c), and some large non-building regions are still not removed (see the regions marked by the first and third red rectangles in
Figure 3c).
Next, for region matching, three superpixel segmentation methods are adopted: the graph-based image segmentation (GS) algorithm [
80], the simple linear iterative clustering (SLIC) algorithm [
81], and the entropy rate superpixel segmentation (ERS) algorithm [
82]. The GS algorithm [
80] is an adaptive graph-based region growing method, which can lower the threshold for merging pixels in low-contrast regions and raise it in high-contrast regions. The SLIC algorithm [
81] is essentially a K-means method that searches for pixels belonging to a cluster in a local space to reduce the computational cost. The ERS algorithm [
82] is also a graph-based method, trying to maximise an objective function composed of two parts: the entropy rate of a random walk that encourages the superpixels to have compact shapes, and a balancing term that encourages the superpixels to have equal size. The input to the three segmentation algorithms is only the remote sensing image. All three segmentation algorithms have certain parameters to be set. However, we only need over-segmentations of the image, not the optimal segmentations. Therefore, the parameters are easy to set, and we can consider the three segmentation algorithms to be automatic methods. Notably, the SLIC and ERS algorithms both have the parameter of the number of superpixels, which may vary greatly for images with different resolutions or sizes. To make these two algorithms work automatically, we set this parameter to the superpixel number of the GS algorithm.
It should be pointed out that there are two segmentation types in this paper: semantic segmentation and non-semantic segmentation. Semantic segmentation methods assign a semantic label to each pixel/point in the image/LiDAR data. The building extraction, vegetation detection, shadow detection, and DEM extraction involved in this paper can all be regarded as semantic segmentation tasks. However, the GS, SLIC and ERS algorithms used for region matching are non-semantic segmentation methods. They are used to generate disjointed homogeneous regions (superpixels), each corresponding to an object or a part of it, but we do not know the semantic label of each superpixel. Generally, the non-semantic segmentation methods do not need to be trained, i.e., they are unsupervised methods. In contrast, most state-of-the-art semantic segmentation methods are supervised deep learning methods.
The thresholds of the matching degrees for the GS and ERS algorithms are both set to 0.85; thus, a segmentation region (superpixel) is considered a building or building part only when the portion of initial building pixels in it exceeds 85%. The threshold of the matching degrees for the SLIC algorithm is set to 0.90, because the maximum colour distance in the SLIC algorithm may vary significantly from image to image, but the authors of SLIC simply fixed it to a constant value; we conceive that such a setting will make the SLIC algorithm unable to adhere well to the boundaries for some images and that raising the region-matching threshold can help prevent the less accurate segmentation regions generated by the SLIC algorithm from appearing in the final building mask.
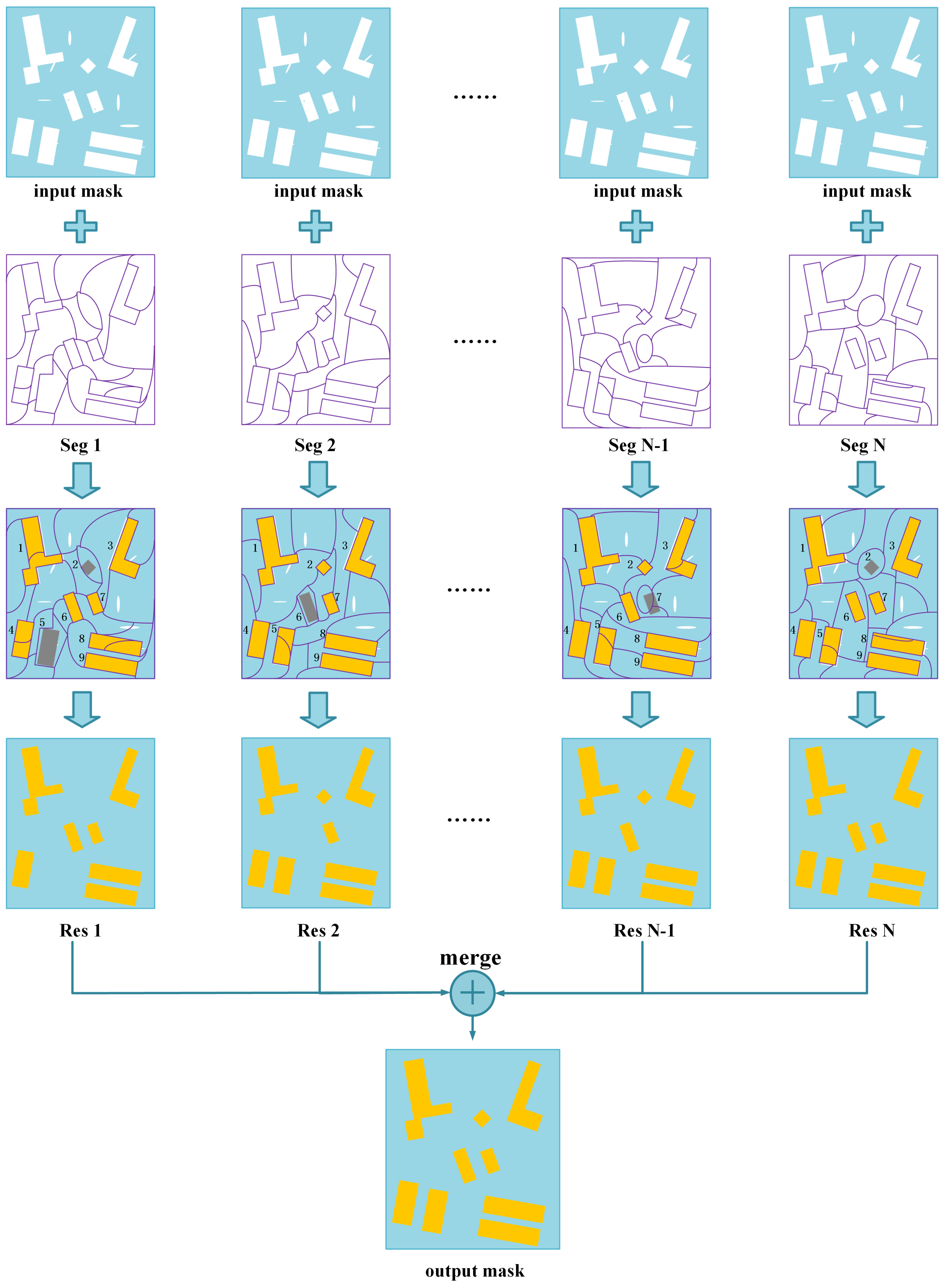
The workflow of the region-matching part of our method is presented in
Figure 4 to explain the fundamental clearly. In the input building mask (see the first row of
Figure 4), the buildings are marked by the colour white, while the background is marked by a light blue colour. N non-semantic segmentation algorithms are used for the region matching, where the boundaries of the segmentation regions are marked by a purple colour (see the second row of
Figure 4) and each four-connected region enclosed by purple boundaries is a segmentation region. Then, each of the non-semantic segmentation results is superimposed on the input building mask, respectively, to compute the matching degrees (see the third row of
Figure 4). Segmentation regions with high matching degrees are marked by a yellow color, while segmentation regions with not-high matching degrees are still marked by the original light blue colour. For example, for the first non-semantic segmentation algorithm (see the third row and the first column of
Figure 4), the segmentation regions corresponding to the first, third, fourth, and sixth to ninth buildings have high matching degrees and are marked with a yellow colour, while the segmentation regions corresponding to the the second and the fifth buildings have low matching degrees and are marked by a light blue colour. Segmentation regions with high matching degrees are regarded as buildings (see the fourth row of
Figure 4). However, none of the existing non-semantic segmentation algorithms are perfect and some of the segmentation regions will not match the corresponding buildings in the input building mask well (see the segmentation regions corresponding to the grey buildings in the third row of
Figure 4). Therefore, each single region-matching result will probably miss some buildings or building parts (see the fourth row of
Figure 4). So, we compute the union of the all the region matching results to get a complete building mask (see the last row of
Figure 4).
To retain the real buildings, the segmentation regions corresponding to them should be optimally segmented or oversegmented. For example, in the third row and the first column of
Figure 4, segmentation regions corresponding to the third, sixth, seventh, and ninth buildings are optimally segmented, with each segmentation region matching a real building well; while the segmentation regions corresponding to the first, fourth, and eighth buildings are oversegmented, with each segmentation region matching only a building part. In both cases, the real buildings can be retained. However, if one segmentation region is undersegmented, i.e., it corresponds to a building (or a building part) plus many other object pixels (see the segmentation regions corresponding to the grey buildings in the third row of
Figure 4), the corresponding building will be missing in the region-matching result. In fact, optimal segmentation result is very challenging to generate automatically, but oversegmentation results are very easy to obtain and their generation can be regarded as an automatic process. Therefore, to obtain a satisfactory region matching result, we use oversegmentation instead of the optimal segmentation. Note that we use segmentation regions instead of superpixels when depicting the workflow of the region matching because, generally, superpixels mean oversegmented regions [
83], but we are not assuming regions are oversegmented before we reach the above conclusion.
The number N in
Figure 2 and
Figure 4 does not have to be set to three, which means that we do not have to use three non-semantic segmentation algorithms. More segmentation algorithms can be used to obtain better refinement results, which, however, means a higher computational cost is required. We utilise only three segmentation algorithms to guarantee the accuracy of the refinement and simultaneously guarantee the processing efficiency. The segmentation algorithms also do not have to be the three algorithms that we adopt. However, we should note that the segmentation results can influence the refinement accuracy. The segmentation algorithms used should be sensitive to the details in the images to differentiate the building parts and non-building parts in shadowed areas or other areas with low contrast. Both the GS and ERS algorithms fulfil the requirement. The SLIC algorithm may fail in some cases, and we use a higher matching threshold to address these adverse situations.
If a segmentation algorithm can generate the optimal segmentation result, then we can use only this algorithm instead of three or more algorithms to perform region matching, and the refinement method becomes the popular object-based method [
84,
85]. However, none of the existing non-semantic segmentation algorithms are perfect so far. Hence, the segmentation regions of one algorithm cannot correspond to all the real building regions well. Thus, the region-matching result will miss some building parts when the threshold for the matching degree is high. Lowering the threshold can overcome the problem of missing detection (underdetection), but this will probably introduce some unrelated points to the building mask and thus cannot realise the goal of refinement. The thresholds for the matching degree of our method are high, and thus it can effectively avoid incorporating unrelated points, and computing the union of the matching results of multiple segmentation algorithms can also overcome the problem of missing detection.
Notably, although we only need each non-semantic segmentation of the remote sensing image to be an oversegmentation, the segmentation regions of this oversegmentation cannot be too small, otherwise the refinement functionality of the region matching would be weakened. In extreme cases, assuming that each segmentation region contains only one pixel, the refined mask will be just the initial building mask regardless of the tuning of the threshold for the region matching (still in the range of (0, 1]).
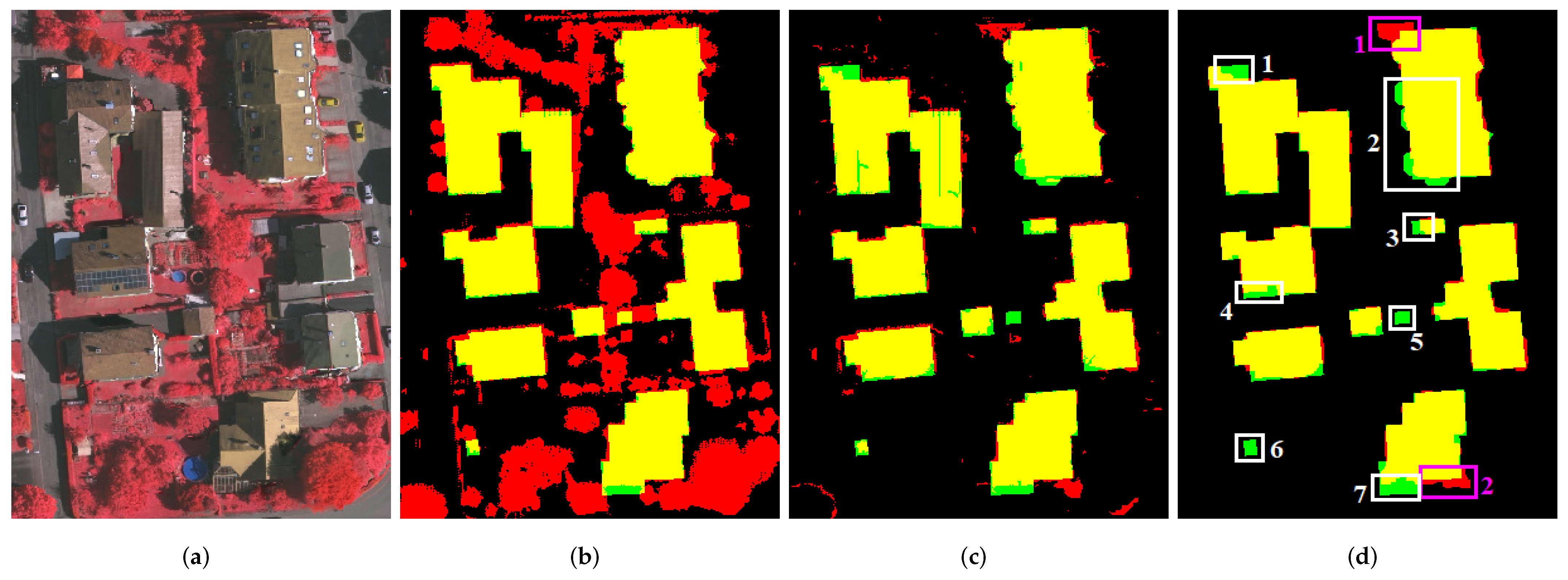
The morphological closing operation performed before the region matching may have caused the final building mask to incorporate some unrelated points near the boundaries. The imperfect non-semantic segmentation algorithm we used may also lead to some small-area elongated false building regions (some examples are marked by the red rectangles in
Figure 5a), and some underdetection (some examples are marked by the green rectangles in
Figure 5a). To eliminate these non-building points, morphological opening operation is performed after the region matching. However, this opening operation may worsen the underdetection problem (some examples are marked by the green rectangles in
Figure 5b). To counteract this side effect, a morphological closing operation is performed after it. After this first-opening-then-closing postprocessing, the building mask looks much better.
After all the aforementioned steps, the remaining non-building points become disconnected and fragmentary, which can be easily removed through region size filtering. In this study, connected regions smaller than 2.5 are regarded as non-building points and thus removed.
Figure 6 presents an illustration of our building-mask refinement method on the first test area of the Vaihingen dataset, for which the initial building mask is generated using our biSH method (see
Figure 1d). We can see that the matching result of each non-semantic segmentation algorithm has accurate boundaries, and most of the remaining vegetated regions have been successfully removed, but each single matching result misses some real building parts. However, the union of the three matching results has relatively complete building regions and accurate boundaries, and most of the vegetated regions remaining in the initial building mask have also successfully been removed.
We call our building-mask refinement method the IFCC method, in which IFCC denotes the image feature consistency constraint, and we call our building extraction methods (including the initial building mask generation stage and the building-mask refinement stage) the beSH+IFCC method and the biSH+IFCC method. The premise of our IFCC method is that the initial building mask has high accuracy. Therefore, in addition to the proposed beSH and biSH methods, it can be combined with other accurate building extraction methods.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}