
Semi-Supervised Adversarial Semantic Segmentation Network Using Transformer and Multiscale Convolution for High-Resolution Remote Sensing Imagery


 and
and
Abstract
:
1. Introduction
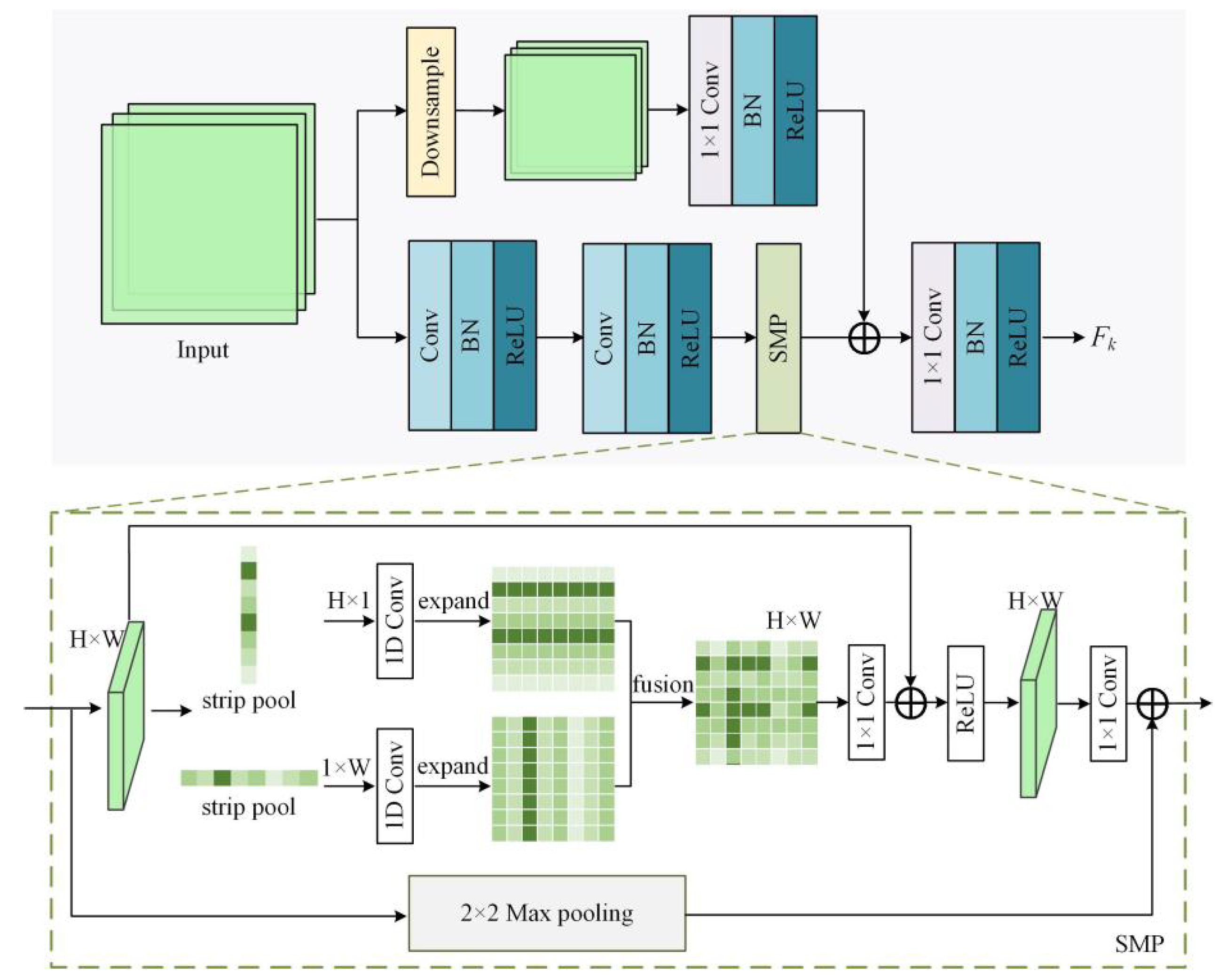
- A multiscale input convolution module (MICM) and an improved strip-max pooling (SMP) structure are provided. The MICM adopts multiscale downsampling and skip connections to capture information of different input scales, while maintaining the spatial details of objects in complex remote sensing scenes. The SMP preserves both the global and horizontal/vertical information during feature extraction, thereby reducing the information loss when the resolutions of the feature maps are gradually reduced.
- TRANet is developed with two subnetworks. The segmentation network is characterized by a double-branch encoder, which integrates the Transformer module (TM) and the MICM. The discriminator network is designed by using a parallel convolution architecture with different kernel sizes. Two subnetworks are trained under the SSAL framework. TRANet can extract local features and long-range contextual information simultaneously and improve generalization capability with the assistance of unlabeled data.
- Taking building extraction as a case study, experiments on the WHU Building Dataset (WBD) [35], Massachusetts Building Dataset (MBD) [36] and GID [10] are carried out to validate TRANet. DeepLabv2, PSPNet, UNet and TransUNet are used as segmentation networks for a performance comparison under the same SSAL scheme. The results demonstrate that TRANet improves segmentation accuracy compared to other approaches when only a few labeled samples are available.
2. Related Work
2.1. Semi-Supervised Semantic Segmentation
2.2. Convolution Neural Network and Variants
2.3. Transformer
3. Methodology
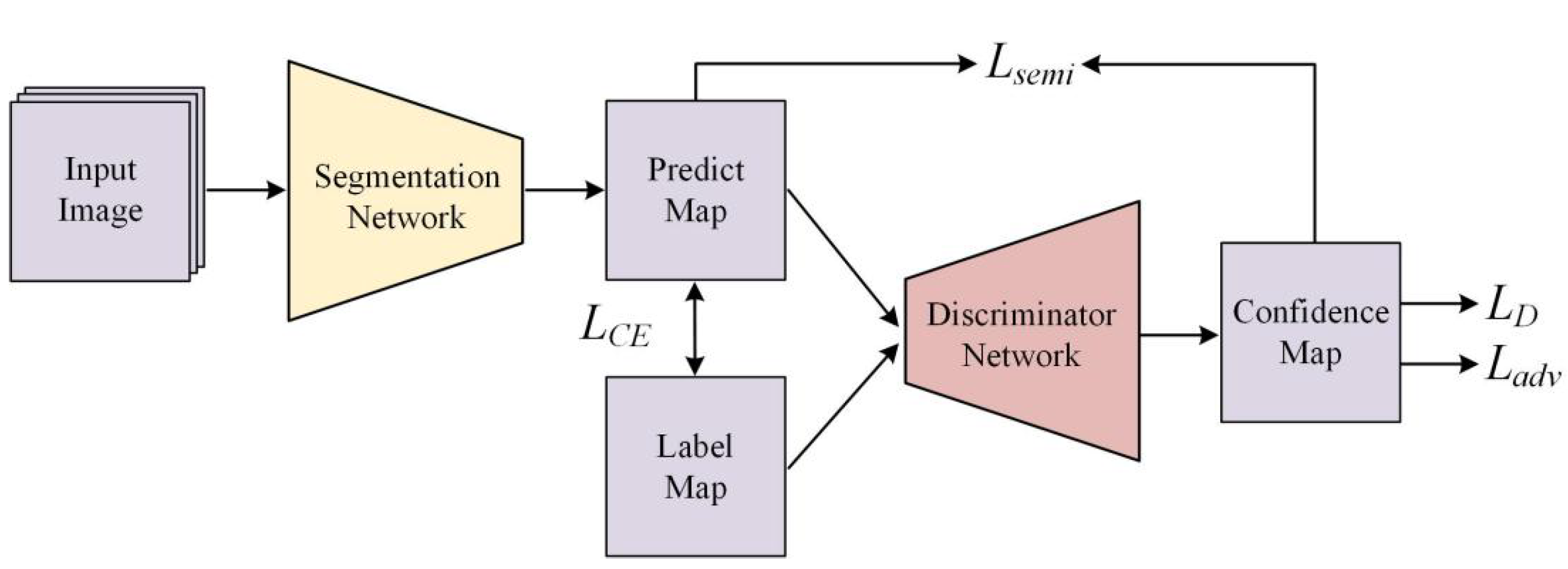
3.1. Algorithm Overview
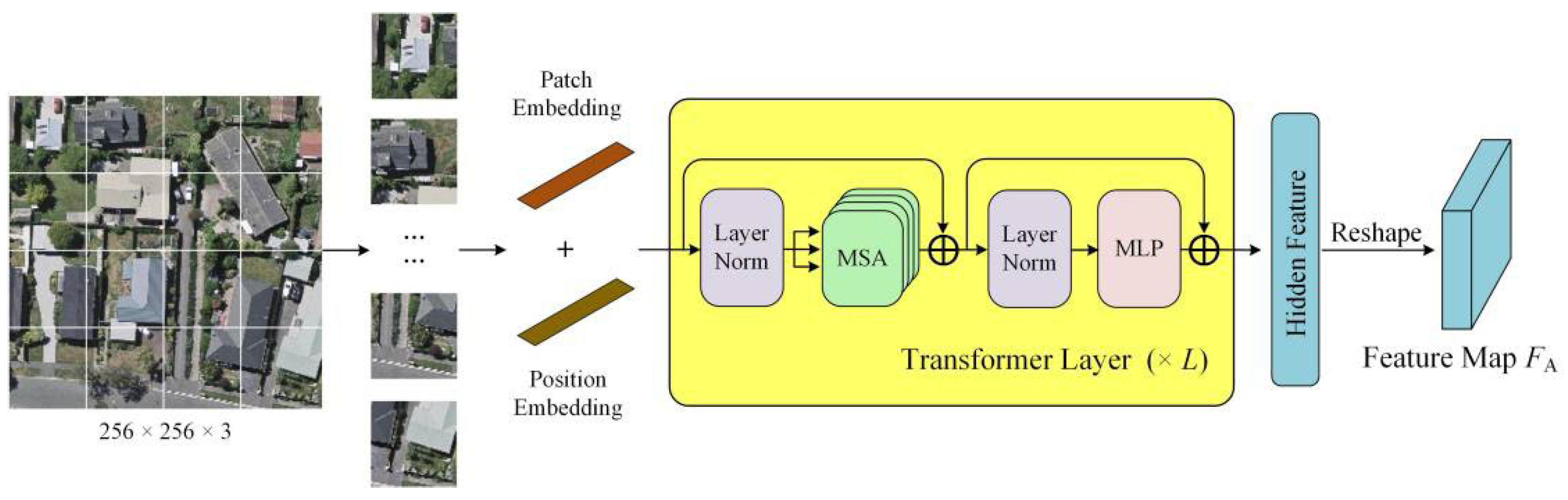
3.2. Segmentation Network
3.2.1. Transformer Module
3.2.2. Multiscale Input Convolution Module
3.2.3. Decoder
3.3. Discriminator Network
3.4. Loss Function
4. Results
4.1. Datasets
- WBD: This building dataset consists of 8189 aerial image tiles and contains 187,000 buildings with diverse usages, sizes and colors in Christchurch, New Zealand. The spatial resolution is 0.3 m. After cropping without overlap, 15,256 image patches were selected and randomly split into 14,256 patches for training and 1000 patches for testing.
- MBD: The MBD is a large dataset for building segmentation that consists of 151 aerial images of the Boston area with 1500 × 1500 pixels. The spatial resolution is 1 m. A total of 11,384 image patches containing buildings with 256 × 256 pixels were chosen after cropping. These patches were further randomly divided into 10,384 patches for training and 1000 patches for testing.
- GID: This land-use dataset contains 5 land-use categories and 150 Gaofen-2 satellite images, obtained from more than 60 different cities in China. The spatial resolution is 4 m. We extracted the building class and constructed a dataset containing 13,671 image patches for our experiments, among which 12,175 patches were used for training and 1496 were used for testing.
4.2. Experimental Procedure
4.2.1. Method Implementation
4.2.2. Method Evaluation Measures
4.3. Experimental Results and Analysis
4.3.1. Quantitative Analyses
4.3.2. Qualitative Analyses
5. Discussion
5.1. Comparison between Single/Double-Branch Encoder Structures
5.2. Comparison among Different Pooling Modules
5.3. Comparison among Different Multiscale Modules
5.4. Comparison among Different Discriminator Networks
5.5. Model Parameter Discussions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kang, J.; Wang, Z.; Zhu, R.; Sun, X.; Fernandez-Beltran, R.; Plaza, A. PiCoCo: Pixelwise Contrast and Consistency Learning for Semisupervised Building Footprint Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10548–10559. [Google Scholar] [CrossRef]
- Su, Y.; Cheng, J.; Bai, H.; Liu, H.; He, C. Semantic Segmentation of Very-High-Resolution Remote Sensing Images via Deep Multi-Feature Learning. Remote Sens. 2022, 14, 533. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar] [CrossRef]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Mura, M.D. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Li, Y.; Lu, H.; Liu, Q.; Zhang, Y.; Liu, X. SSDBN: A Single-Side Dual-Branch Network with Encoder–Decoder for Building Extraction. Remote Sens. 2022, 14, 768. [Google Scholar] [CrossRef]
- Kang, J.; Guan, H.; Peng, D.; Chen, Z. Multi-scale context extractor network for water-body extraction from high-resolution optical remotely sensed images. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102499. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, NY, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar] [CrossRef] [Green Version]
- Tong, X.; Xia, G.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-Cover Classification with High-Resolution Remote Sensing Images Using Transferable Deep Models. arXiv 2019, arXiv:1807.05713. Available online: https://arxiv.org/abs/1807.05713 (accessed on 20 November 2019). [CrossRef] [Green Version]
- Zhang, M.; Hu, X.; Zhao, L.; Lv, Y.; Luo, M. Learning dual multi-scale manifold ranking for semantic segmentation of high-resolution images. Remote Sens. 2017, 9, 500. [Google Scholar] [CrossRef] [Green Version]
- Gerke, M.; Rottensteiner, F.; Wegner, J.D.; Sohn, G. ISPRS Semantic Labeling Contest. 2014. Available online: https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-sem-label-potsdam.aspx (accessed on 7 September 2014).
- Kemker, R.; Luu, R.; Kanan, C. Low-shot learning for the semantic segmentation of remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6214–6223. [Google Scholar] [CrossRef] [Green Version]
- Wambugu, N.; Chen, Y.; Xiao, Z.; Tan, K.; Wei, M.; Liu, X.; Li, J. Hyperspectral image classification on insufficient-sample and feature learning using deep neural networks: A review. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102603. [Google Scholar] [CrossRef]
- Lee, D.H. Pseudo-Label: The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Qiao, S.; Shen, W.; Zhang, Z.; Wang, B.; Yuille, A. Deep Co-Training for Semi-Supervised Image Recognition. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 142–159. [Google Scholar] [CrossRef] [Green Version]
- Laine, S.; Aila, T. Temporal ensembling for semisupervised learning. arXiv 2017, arXiv:1610.02242. Available online: https://arxiv.org/abs/1610.02242 (accessed on 15 March 2017).
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semisupervised deep learning results. arXiv 2017, arXiv:1703.01780. Available online: https://arxiv.org/abs/1703.01780 (accessed on 6 March 2017).
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Oliver, A.; Papernot, N.; Raffel, C. MixMatch: A holistic approach to semi-supervised learning. arXiv 2019, arXiv:1905.02249. Available online: https://arxiv.org/abs/1905.02249 (accessed on 23 October 2019).
- Sohn, K.; Berthelot, D.; Li, C.; Zhang, Z.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Zhang, H.; Raffel, C. FixMatch: Simplifying semi-supervised learning with consistency and confidence. arXiv 2020, arXiv:2001.07685v2. Available online: https://arxiv.org/abs/2001.07685v2 (accessed on 25 November 2020).
- Odena, A. Semi-supervised learning with generative adversarial networks. arXiv 2016, arXiv:1606.01583. [Google Scholar]
- Wang, L.; Sun, Y.; Wang, Z. CCS-GAN: A semi-supervised generative adversarial network for image classification. Vis. Comput. 2021, 4, 1–13. [Google Scholar] [CrossRef]
- Luc, P.; Couprie, C.; Chintala, S.; Verbeek, J. Semantic segmentation using adversarial networks. arXiv 2016, arXiv:1611.08408. Available online: https://arxiv.org/abs/1611.08408 (accessed on 25 November 2016).
- Hung, W.C.; Tsai, Y.H.; Liou, Y.T.; Lin, Y.Y.; Yang, M.H. Adversarial learning for semi-supervised semantic segmentation. arXiv 2018, arXiv:1802.07934. Available online: https://arxiv.org/abs/1802.07934 (accessed on 24 July 2018).
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Zhang, L. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. arXiv 2020, arXiv:2012.15840. Available online: https://arxiv.org/abs/2012.15840 (accessed on 31 December 2020).
- Chen, Z.; Wang, C.; Li, J.; Fan, W.; Du, J.; Zhong, B. Adaboost-like End-to-End multiple lightweight U-nets for road extraction from optical remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2021, 100, 2341. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical vision transformer using shifted windows. arXiv 2021, arXiv:2103.14030. [Google Scholar] [CrossRef]
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning texture transformer network for image super-resolution. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Seattle, DC, USA, 13–19 June 2020; pp. 5790–5799. [Google Scholar] [CrossRef]
- Wang, Z.; Zhao, J.; Zhang, R.; Li, Z.; Lin, Q.; Wang, X. UATNet: U-Shape Attention-Based Transformer Net for Meteorological Satellite Cloud Recognition. Remote Sens. 2022, 14, 104. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, NY, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, H.; Hu, Q. TransFuse: Fusing transformers and cnns for medical image segmentation. arXiv 2021, arXiv:2102.08005. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multi-source building extraction from an open aerial and satellite imagery dataset. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Dissertation, Department Computer Science, Toronto University, Toronto, ON, Canada, 2013. [Google Scholar]
- Mittal, S.; Tatarchenko, M.; Brox, T. Semi-supervised semantic segmentation with high- and low-level consistency. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1369–1379. [Google Scholar] [CrossRef] [Green Version]
- He, Y.; Wang, J.; Liao, C.; Shan, B.; Zhou, X. ClassHyPer: ClassMix-Based Hybrid Perturbations for Deep Semi-Supervised Semantic Segmentation of Remote Sensing Imagery. Remote Sens. 2022, 14, 879. [Google Scholar] [CrossRef]
- Souly, N.; Spampinato, C.; Shah, M. Semi Supervised Semantic Segmentation Using Generative Adversarial Network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5689–5697. [Google Scholar] [CrossRef]
- Zhang, J.; Li, Z.; Zhang, C.; Ma, H. Robust Adversarial Learning for Semi-Supervised Semantic Segmentation. In Proceedings of the IEEE International Conference on Image Processing, Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 728–732. [Google Scholar] [CrossRef]
- Sun, X.; Shi, A.; Huang, H.; Mayer, H. BAS4Net: Boundary-aware semi-supervised semantic segmentation network for very high resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5398–5413. [Google Scholar] [CrossRef]
- Luo, H.; Chen, C.; Fang, L.; Zhu, X.; Lu, L. High-resolution aerial images semantic segmentation using deep fully convolutional network with channel attention mechanism. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3492–3507. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, X.; Sun, Y.; Xin, Q. Attention-guided label refinement network for semantic segmentation of very high resolution aerial orthoimages. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4490–4503. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, L.A.; Zhou, Y. TransUNet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Hou, Q.; Zhang, L.; Cheng, M.; Feng, J. Strip Pooling: Rethinking Spatial Pooling for Scene Parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4002–4011. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. Available online: https://arxiv.org/abs/1412.6980 (accessed on 22 December 2014).
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, NY, USA, 15–20 June 2019; pp. 510–519. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Labeled Data Amount | |||
|---|---|---|---|---|
| 1/8 | 1/4 | 1/2 | Full | |
| WBD | 1782 | 3564 | 7128 | 14,256 |
| MBD | 1298 | 2596 | 5192 | 10,384 |
| GID | 1522 | 3044 | 6088 | 12,671 |
| Method | Labeled Data Amount | |||||||
|---|---|---|---|---|---|---|---|---|
| 1/8 | 1/4 | |||||||
| Recall | Precision | F1 | mIoU | Recall | Precision | F1 | mIoU | |
| DeepLabv2 | 0.8965 | 0.8713 | 0.8837 | 0.8714 | 0.9187 | 0.8586 | 0.8876 | 0.8759 |
| PSPNet | 0.8834 | 0.8267 | 0.8541 | 0.8429 | 0.8886 | 0.8301 | 0.8583 | 0.8470 |
| UNet | 0.9293 | 0.9284 | 0.9288 | 0.9182 | 0.9421 | 0.9352 | 0.9387 | 0.9290 |
| TransUNet | 0.9193 | 0.9202 | 0.9197 | 0.9084 | 0.9362 | 0.9282 | 0.9322 | 0.9219 |
| TRANet | 0.9364 | 0.9301 | 0.9332 | 0.9230 | 0.9495 | 0.9346 | 0.9420 | 0.9327 |
| Method | 1/2 | Full | ||||||
| Recall | Precision | F1 | mIoU | Recall | Precision | F1 | mIoU | |
| DeepLabv2 | 0.8973 | 0.8924 | 0.8949 | 0.8824 | 0.9204 | 0.8831 | 0.9013 | 0.8895 |
| PSPNet | 0.9002 | 0.8220 | 0.8593 | 0.8483 | 0.9020 | 0.8294 | 0.8642 | 0.8529 |
| UNet | 0.9512 | 0.9394 | 0.9453 | 0.9364 | 0.9554 | 0.9408 | 0.9480 | 0.9394 |
| TransUNet | 0.9457 | 0.9317 | 0.9387 | 0.9290 | 0.9496 | 0.9337 | 0.9416 | 0.9323 |
| TRANet | 0.9547 | 0.9402 | 0.9474 | 0.9387 | 0.9571 | 0.9421 | 0.9495 | 0.9411 |
| Method | Labeled Data Amount | |||||||
|---|---|---|---|---|---|---|---|---|
| 1/8 | 1/4 | |||||||
| Recall | Precision | F1 | mIoU | Recall | Precision | F1 | mIoU | |
| DeepLabv2 | 0.7706 | 0.4964 | 0.6038 | 0.6704 | 0.7032 | 0.5799 | 0.6356 | 0.6856 |
| PSPNet | 0.7296 | 0.5224 | 0.6088 | 0.6714 | 0.7576 | 0.4923 | 0.5968 | 0.6659 |
| UNet | 0.7490 | 0.6819 | 0.7139 | 0.7380 | 0.7752 | 0.6943 | 0.7325 | 0.7523 |
| TransUNet | 0.7252 | 0.6437 | 0.6820 | 0.7156 | 0.7630 | 0.6852 | 0.7220 | 0.7443 |
| TRANet | 0.7839 | 0.6693 | 0.7221 | 0.7454 | 0.7785 | 0.7178 | 0.7469 | 0.7627 |
| Method | 1/2 | Full | ||||||
| Recall | Precision | F1 | mIoU | Recall | Precision | F1 | mIoU | |
| DeepLabv2 | 0.7398 | 0.5526 | 0.6326 | 0.6858 | 0.7292 | 0.6312 | 0.6766 | 0.7124 |
| PSPNet | 0.7590 | 0.5062 | 0.6073 | 0.6720 | 0.7623 | 0.5060 | 0.6083 | 0.6726 |
| UNet | 0.7988 | 0.7225 | 0.7588 | 0.7723 | 0.8127 | 0.7402 | 0.7748 | 0.7848 |
| TransUNet | 0.7926 | 0.7001 | 0.7435 | 0.7608 | 0.8047 | 0.7180 | 0.7589 | 0.7726 |
| TRANet | 0.7987 | 0.7355 | 0.7658 | 0.7775 | 0.8160 | 0.7482 | 0.7806 | 0.7894 |
| Method | Labeled Data Amount | |||||||
|---|---|---|---|---|---|---|---|---|
| 1/8 | 1/4 | |||||||
| Recall | Precision | F1 | mIoU | Recall | Precision | F1 | mIoU | |
| DeepLabv2 | 0.8560 | 0.6946 | 0.7669 | 0.7679 | 0.8281 | 0.7381 | 0.7805 | 0.7773 |
| PSPNet | 0.8003 | 0.6553 | 0.7205 | 0.7302 | 0.8064 | 0.6701 | 0.7320 | 0.7388 |
| UNet | 0.7647 | 0.7460 | 0.7552 | 0.7535 | 0.7731 | 0.7442 | 0.7583 | 0.7565 |
| TransUNet | 0.7904 | 0.7534 | 0.7715 | 0.7679 | 0.7538 | 0.7711 | 0.7624 | 0.7582 |
| TRANet | 0.7659 | 0.7939 | 0.7797 | 0.7728 | 0.7765 | 0.8052 | 0.7905 | 0.7823 |
| Method | 1/2 | Full | ||||||
| Recall | Precision | F1 | mIoU | Recall | Precision | F1 | mIoU | |
| DeepLabv2 | 0.8288 | 0.7533 | 0.7893 | 0.7844 | 0.8358 | 0.7507 | 0.7910 | 0.7862 |
| PSPNet | 0.7850 | 0.7122 | 0.7468 | 0.7486 | 0.8268 | 0.6851 | 0.7493 | 0.7530 |
| UNet | 0.8154 | 0.7326 | 0.7718 | 0.7697 | 0.8326 | 0.7532 | 0.7909 | 0.7860 |
| TransUNet | 0.8368 | 0.7519 | 0.7921 | 0.7872 | 0.8240 | 0.7687 | 0.7954 | 0.7892 |
| TRANet | 0.8406 | 0.7597 | 0.7981 | 0.7923 | 0.8433 | 0.7720 | 0.8061 | 0.7991 |
| Dataset | Encoder | Labeled Data Amount | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1/8 | 1/4 | 1/2 | |||||||||||
| Recall | Precision | F1 | mIoU | Recall | Precision | F1 | mIoU | Recall | Precision | F1 | mIoU | ||
| WBD | TM | 0.8258 | 0.8205 | 0.8231 | 0.8125 | 0.8599 | 0.8465 | 0.8532 | 0.8411 | 0.8801 | 0.8505 | 0.8650 | 0.8529 |
| MICM | 0.9355 | 0.9293 | 0.9324 | 0.9221 | 0.9364 | 0.9396 | 0.9380 | 0.9282 | 0.9562 | 0.9361 | 0.9461 | 0.9373 | |
| TM+MICM | 0.9364 | 0.9301 | 0.9332 | 0.9230 | 0.9495 | 0.9346 | 0.9420 | 0.9327 | 0.9547 | 0.9402 | 0.9474 | 0.9387 | |
| MBD | TM | 0.5461 | 0.5187 | 0.5321 | 0.6169 | 0.6161 | 0.4859 | 0.5433 | 0.6291 | 0.6579 | 0.5050 | 0.5714 | 0.6466 |
| MICM | 0.7477 | 0.6688 | 0.7060 | 0.7327 | 0.7809 | 0.7103 | 0.7439 | 0.7607 | 0.7892 | 0.7348 | 0.761 | 0.7735 | |
| TM+MICM | 0.7839 | 0.6693 | 0.7221 | 0.7454 | 0.7785 | 0.7178 | 0.7469 | 0.7627 | 0.7987 | 0.7355 | 0.7658 | 0.7775 | |
| GID | TM | 0.7228 | 0.5878 | 0.6483 | 0.6762 | 0.7534 | 0.6269 | 0.6843 | 0.7019 | 0.7630 | 0.6299 | 0.6901 | 0.7065 |
| MICM | 0.7584 | 0.7734 | 0.7658 | 0.7613 | 0.7815 | 0.7702 | 0.7758 | 0.7708 | 0.8039 | 0.7787 | 0.7911 | 0.7846 | |
| TM+MICM | 0.7659 | 0.7939 | 0.7797 | 0.7728 | 0.7765 | 0.8052 | 0.7905 | 0.7823 | 0.8406 | 0.7597 | 0.7981 | 0.7923 | |
| Method | Recall | Precision | F1 | mIoU |
|---|---|---|---|---|
| CNN_MP | 0.9476 | 0.9360 | 0.9418 | 0.9325 |
| CNN_SP | 0.9502 | 0.9346 | 0.9424 | 0.9332 |
| CNN_SMP | 0.9532 | 0.9391 | 0.9461 | 0.9373 |
| TM+CNN_MP | 0.9518 | 0.9398 | 0.9458 | 0.9369 |
| TM+CNN_SP | 0.9453 | 0.9366 | 0.9409 | 0.9315 |
| TM+CNN_SMP | 0.9547 | 0.9402 | 0.9474 | 0.9387 |
| Method | Recall | Precision | F1 | mIoU |
|---|---|---|---|---|
| CNN | 0.9476 | 0.9360 | 0.9418 | 0.9325 |
| CNN+ASPP | 0.9515 | 0.9357 | 0.9435 | 0.9344 |
| CNN+SK | 0.9546 | 0.9379 | 0.9462 | 0.9374 |
| CNN+MICM | 0.9559 | 0.9379 | 0.9468 | 0.9381 |
| TM+CNN | 0.9518 | 0.9398 | 0.9458 | 0.9369 |
| TM+CNN+ASPP | 0.9540 | 0.9377 | 0.9458 | 0.9370 |
| TM+CNN+SK | 0.9539 | 0.9391 | 0.9464 | 0.9377 |
| TM+CNN+MICM | 0.9547 | 0.9402 | 0.9474 | 0.9387 |
| Method | Recall | Precision | F1 | mIoU | Method | Recall | Precision | F1 | mIoU |
|---|---|---|---|---|---|---|---|---|---|
| DeepLabv2 | 0.9042 | 0.8564 | 0.8797 | 0.8677 | DeepLabv2 * | 0.8973 | 0.8924 | 0.8949 | 0.8824 |
| PSPNet | 0.8738 | 0.8283 | 0.8504 | 0.8391 | PSPNet * | 0.9002 | 0.8220 | 0.8593 | 0.8483 |
| UNet | 0.9415 | 0.9329 | 0.9372 | 0.9274 | UNet * | 0.9512 | 0.9394 | 0.9453 | 0.9364 |
| TransUNet | 0.9451 | 0.9302 | 0.9376 | 0.9279 | TransUNet * | 0.9457 | 0.9317 | 0.9387 | 0.9290 |
| TRANet | 0.9504 | 0.9386 | 0.9445 | 0.9354 | TRANet * | 0.9547 | 0.9402 | 0.9474 | 0.9387 |
| layer_num | Recall | Precision | F1 | mIoU |
|---|---|---|---|---|
| 4 | 0.9477 | 0.9236 | 0.9355 | 0.9257 |
| 8 | 0.9502 | 0.9282 | 0.9391 | 0.9296 |
| 12 | 0.9547 | 0.9402 | 0.9474 | 0.9387 |
| 16 | 0.9443 | 0.9361 | 0.9402 | 0.9307 |
| 20 | 0.9453 | 0.9278 | 0.9365 | 0.9267 |
| head_num | Recall | Precision | F1 | mIoU |
|---|---|---|---|---|
| 2 | 0.9461 | 0.9336 | 0.9398 | 0.9303 |
| 4 | 0.9467 | 0.9347 | 0.9407 | 0.9313 |
| 8 | 0.9547 | 0.9402 | 0.9474 | 0.9387 |
| 12 | 0.9456 | 0.9327 | 0.9391 | 0.9295 |
| 16 | 0.9328 | 0.9407 | 0.9367 | 0.9268 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Y.; Yang, M.; Wang, M.; Qian, X.; Yang, R.; Zhang, X.; Dong, W. Semi-Supervised Adversarial Semantic Segmentation Network Using Transformer and Multiscale Convolution for High-Resolution Remote Sensing Imagery. Remote Sens. 2022, 14, 1786. https://doi.org/10.3390/rs14081786
Zheng Y, Yang M, Wang M, Qian X, Yang R, Zhang X, Dong W. Semi-Supervised Adversarial Semantic Segmentation Network Using Transformer and Multiscale Convolution for High-Resolution Remote Sensing Imagery. Remote Sensing. 2022; 14(8):1786. https://doi.org/10.3390/rs14081786
Chicago/Turabian StyleZheng, Yalan, Mengyuan Yang, Min Wang, Xiaojun Qian, Rui Yang, Xin Zhang, and Wen Dong. 2022. "Semi-Supervised Adversarial Semantic Segmentation Network Using Transformer and Multiscale Convolution for High-Resolution Remote Sensing Imagery" Remote Sensing 14, no. 8: 1786. https://doi.org/10.3390/rs14081786
APA StyleZheng, Y., Yang, M., Wang, M., Qian, X., Yang, R., Zhang, X., & Dong, W. (2022). Semi-Supervised Adversarial Semantic Segmentation Network Using Transformer and Multiscale Convolution for High-Resolution Remote Sensing Imagery. Remote Sensing, 14(8), 1786. https://doi.org/10.3390/rs14081786