1. Introduction
Visual object tracking is a typical problem in computer vision. It has been studied for many years and applied in the fields of security monitoring, telemedicine, smart city, and so on [
1,
2,
3,
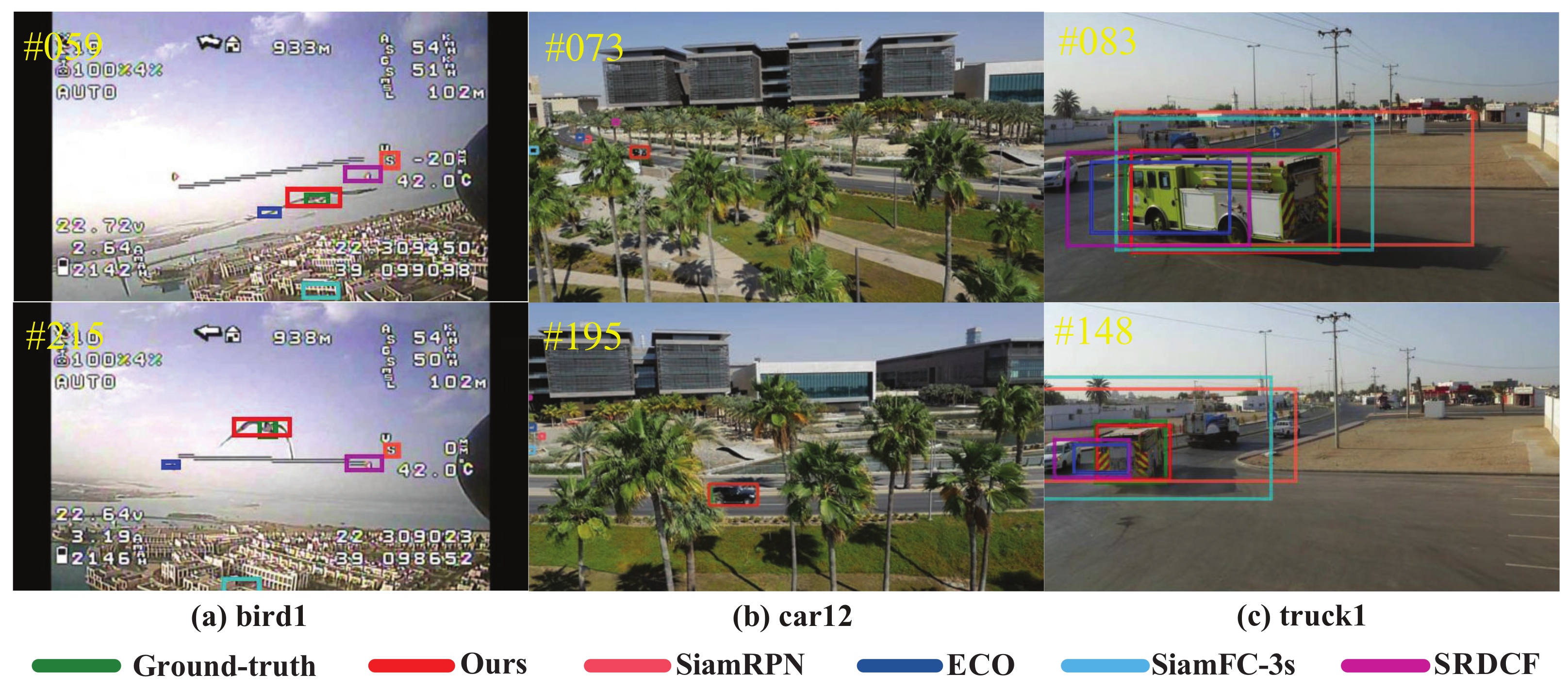
4]. Different from traditional video sequences, the object in the video shot by UAV has distinct characteristics: (1) smaller object size and more complex background, as shown in
Figure 1a; (2) targets often disappear because of occlusion, illustrated in
Figure 1b; (3) broader perspective and changeable appearance, shown in
Figure 1c. Due to these problems, visual object tracking in videos shot by UAV is still challenging [
5,
6,
7].
Most of the visual object tracking methods for UAV are divided into two categories: one is based on correlation filter, another is based on deep learning. The trackers [
8,
9,
10] based on correlation filter calculate a filter to maximize their response to the region of the target. Due to their excellent speed performance, they have gradually become a popular research topic in the field of visual object tracking. Recently, the trackers based on deep learning have received extensive attention because of their superior performance [
11,
12,
13]. The deep features are more robust than handcrafted features, leading to a considerably improved tracking accuracy. However, due to the large computation of backpropagation, even though many trackers train the network offline and fine-tune it in the tracking phase, their tracking speed is still far from meeting the requirements of working in real time.
Figure 1.
Comparison of proposed tracker with other existed methods (SiamRPN [
14], ECO [
15], SiamFC-3s [
16], SRDCF [
17]) on the bird1, car12 and truck1 from UAV123 [
18].
Figure 1.
Comparison of proposed tracker with other existed methods (SiamRPN [
14], ECO [
15], SiamFC-3s [
16], SRDCF [
17]) on the bird1, car12 and truck1 from UAV123 [
18].
Fortunately, the visual object tracking algorithms [
14,
16,
19,
20,
21,
22,
23] based on Siamese networks can well balance the accuracy and speed simultaneously, which has gradually attracted people’s attention. The concise Y-shaped structure simplifies visual object tracking into the template matching process. They train the network parameters in the offline stage and fix the parameters in the inference stage. Therefore, the performance of these template-based trackers depends mainly on the quality of the template. However, since the appearance of the target in the video captured by UAV often changes, a fixed template is obviously not enough to ensure the tracking stability of the whole video sequence. To solve this problem, many efforts have been made. Bertinetto et al. proposed the SiamFC [
16] using a multiscale strategy to improve robustness. Li et al. combined the region proposal network with the Siamese network to remove the multiscale test and improve the tracking speed greatly [
14]. Although significant success has been achieved, the performance of visual object tracking for UAV is still not satisfactory. As shown in
Figure 1, the performance of SiamFC and SiamRPN will become worse in the case of complex background, occlusions, and appearance changes commonly seen in the field of view of UAV.
In view of this, this paper proposes a template-driven Siamese network (TDSiam) which is more suitable for UAV aerial video. The TDSiam can be divided into three main parts: feature extraction subnetwork, feature fusion subnetwork and bounding box estimation subnetwork. Additionally, the feature-aligned (FA) module is the key of the feature fusion subnetwork. The FA module can more effectively fuse features from multiple templates and the bounding box estimation subnetwork can more accurately regress the parameters of the bounding box. In addition, the average peak-to-correlation energy (APCE) [
24] is applied to avoid distractors from polluting the template in the inference stage. The experimental results show that the proposed method has competitive performance. In addition, when AlexNet [
25] is selected as the backbone, it reaches 180 fps, and when ResNet [
26] is selected as the backbone, it reaches 35 fps, both exceeding the real-time requirements (speed > 20 fps). The main contributions of this work are as follows:
This paper proposes a template-driven Siamese network, which is more suitable for the tracking task under the UAV’s vision. Compared with existing approaches, the proposed template-driven Siamese network has concise forms and favorable properties;
A template library structure is proposed, which can effectively improve the tracking performance combined with the new template updating strategy. In addition, a feature alignment module is proposed to fuse template features more efficiently;
Detailed experiments show that the proposed method has competitive performance, not only in accuracy but also in speed.
The structure of this paper is as follows: other works related to ours have been reviewed in
Section 2. A description of the framework of TDSiam has been given in
Section 3. Tracking results obtained by applying the proposed method on UAV video benchmarks are presented in
Section 4. Along with a discussion on these results, conclusions from this work are presented in
Section 5.
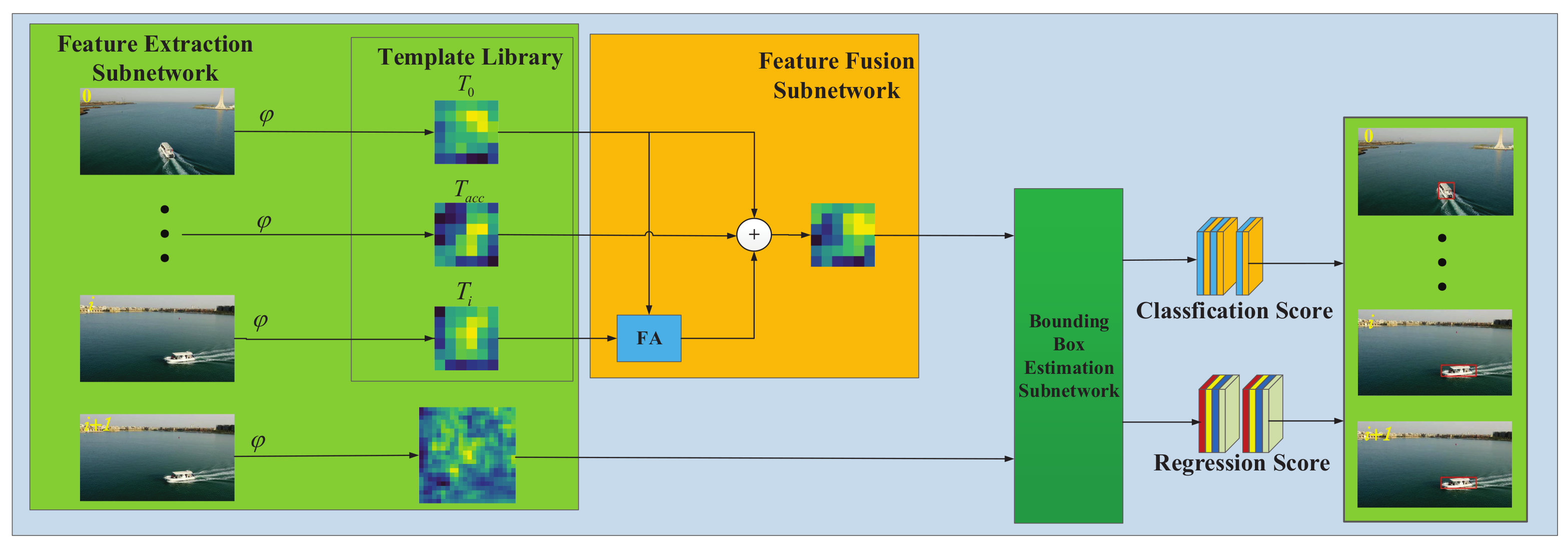
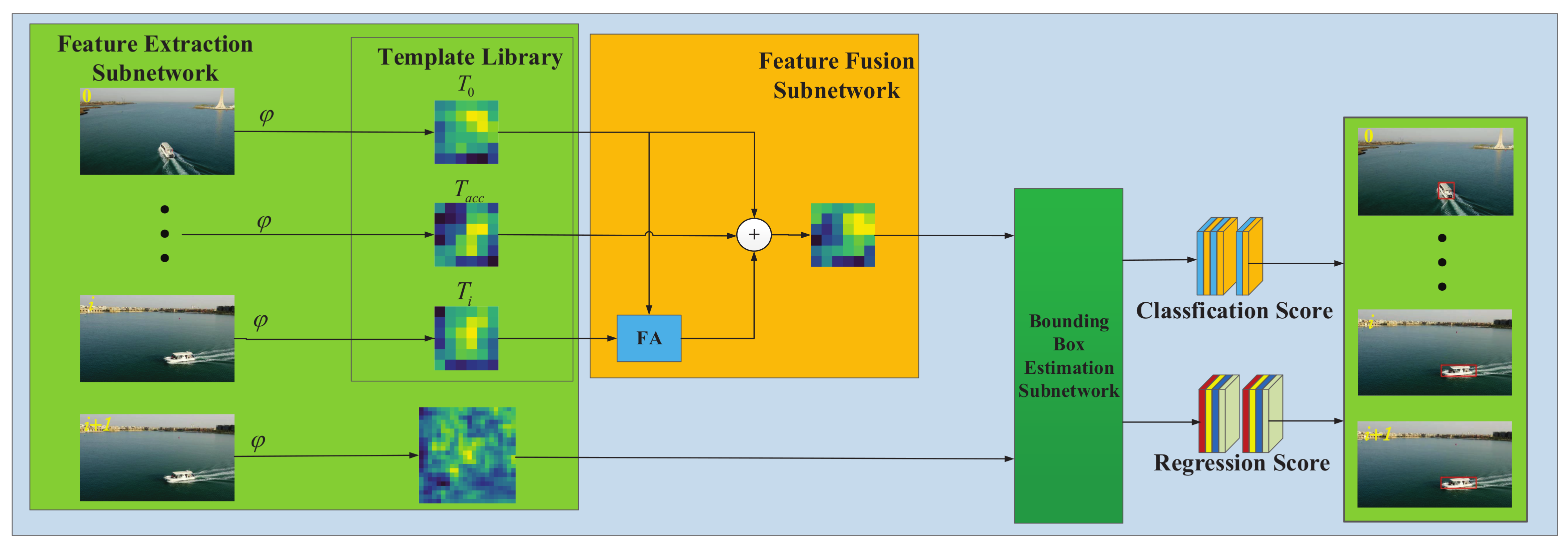
3. Template-Driven Siamese Network
Figure 2 illustrates the framework of TDSiam—it consists of three main parts: feature extraction subnetwork, feature fusion subnetwork and bounding box estimation subnetwork. The feature extraction subnetwork is divided into two main branches: template library branch and searching branch. For more useful information, the template library contains strong template
, weak template
and
. The feature fusion subnetwork is responsible for merging information from the template library. In particular, the FA module is the core of the template feature fusion subnetwork, which is responsible for template feature alignment. The bounding box estimation subnetwork adopts the RPN network proposed in Faster RCNN [
36], which decomposes the tracking into two tasks: classification and regression. Based on the success of target and background classification, the bounding box is regressed more finely.
Next, the proposed TDSiam will be introduced in detail. Firstly, we will illustrate the feature extraction subnetwork in
Section 3.1. Secondly, the feature fusion subnetwork is proposed in
Section 3.2. Finally, we will introduce the bounding box estimation subnetwork in
Section 3.3 and the inference stage in
Section 3.4, respectively.
3.1. The Feature Extraction Subnetwork
In order to obtain diversified target appearance information, we designed the template library (TL) structure in Siamese network with reference to Updatenet [
30]. The template library contains three templates:
,
and
, where
is the strong template cropped according to the ground-truth from the first frame,
is obtained from the prediction result of the current frame, and
represents the last accumulated template.
where
is the initial ground-truth template and contains highly reliable information.
is used to adapt to the changes of the target appearance during the tracking phase. Moreover, by integrating the historical appearance information of the object under consideration, the last accumulated template
can increase the robustness against model drift.
The feature extraction is accomplished by a deep convolutional neural network. The AlexNet [
25] and ResNet [
26] are chosen as the backbone of TDSiam in the experiment. The former is more concise, which can make the tracking speed faster. The latter can stack the network deeper and obtain higher tracking accuracy. The tracking process is transformed into two tasks: classification and regression. The classification task is responsible for identifying whether the candidate area contains targets, and the regression task is in charge of refining the classification results. The detailed optimization process will be described in
Section 3.3.
3.2. The Feature Fusion Subnetwork
The weighted sum is a simple but efficient way of fusing these templates. However, the object might not always be at the center of the template
because of tracking error. The direct fusion of the misaligned features will result in the aliasing effect [
37]. Therefore, a feature-aligned (FA) module has been proposed to obtain the central-aligned features.
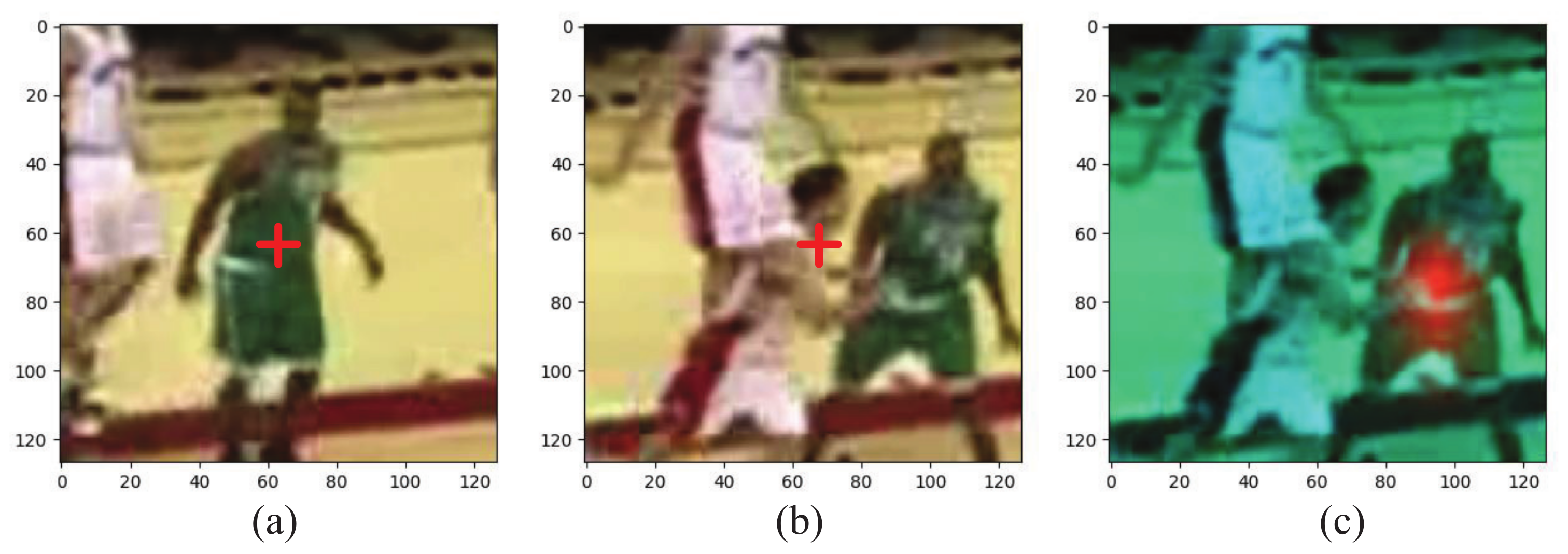
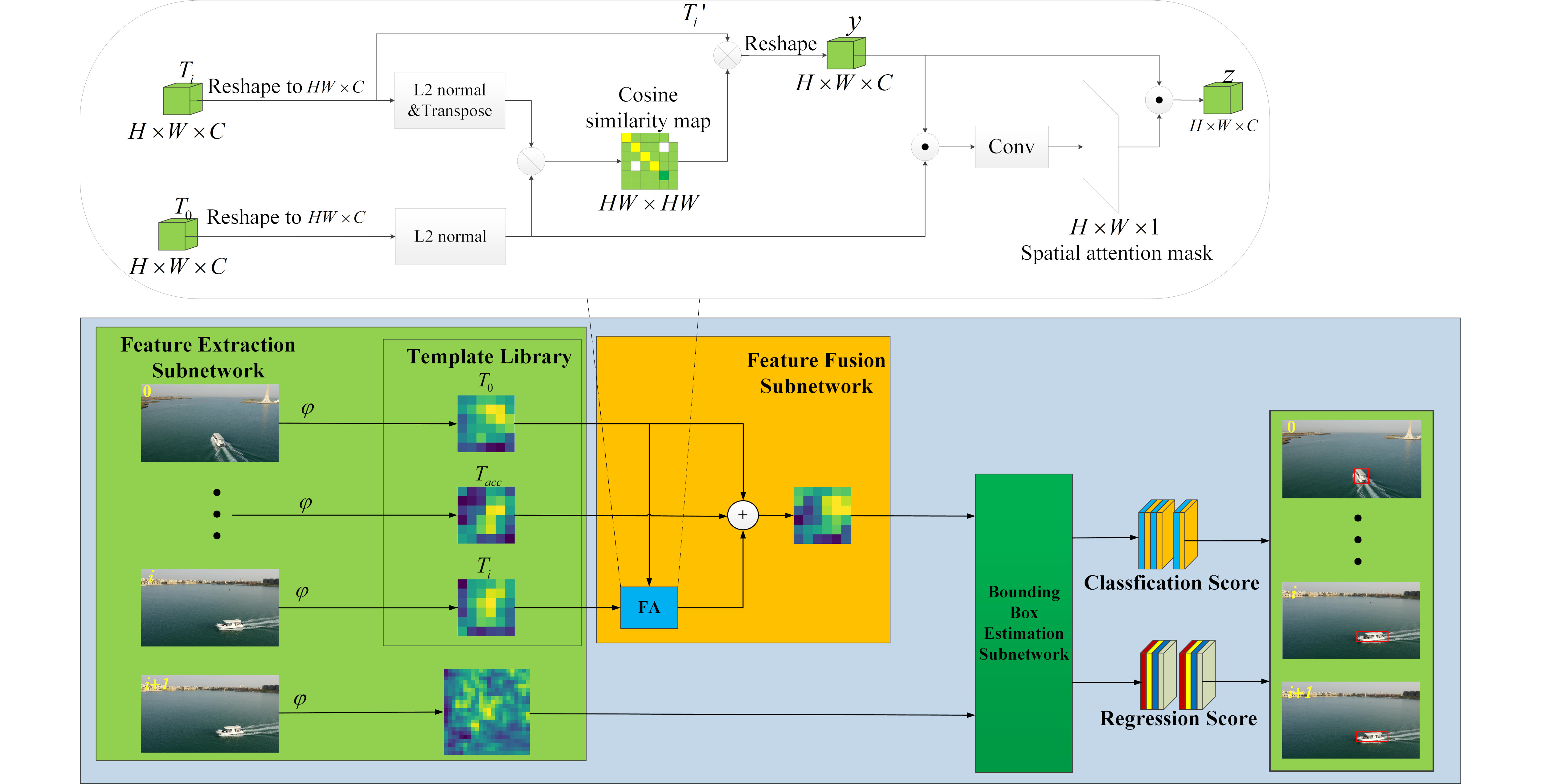
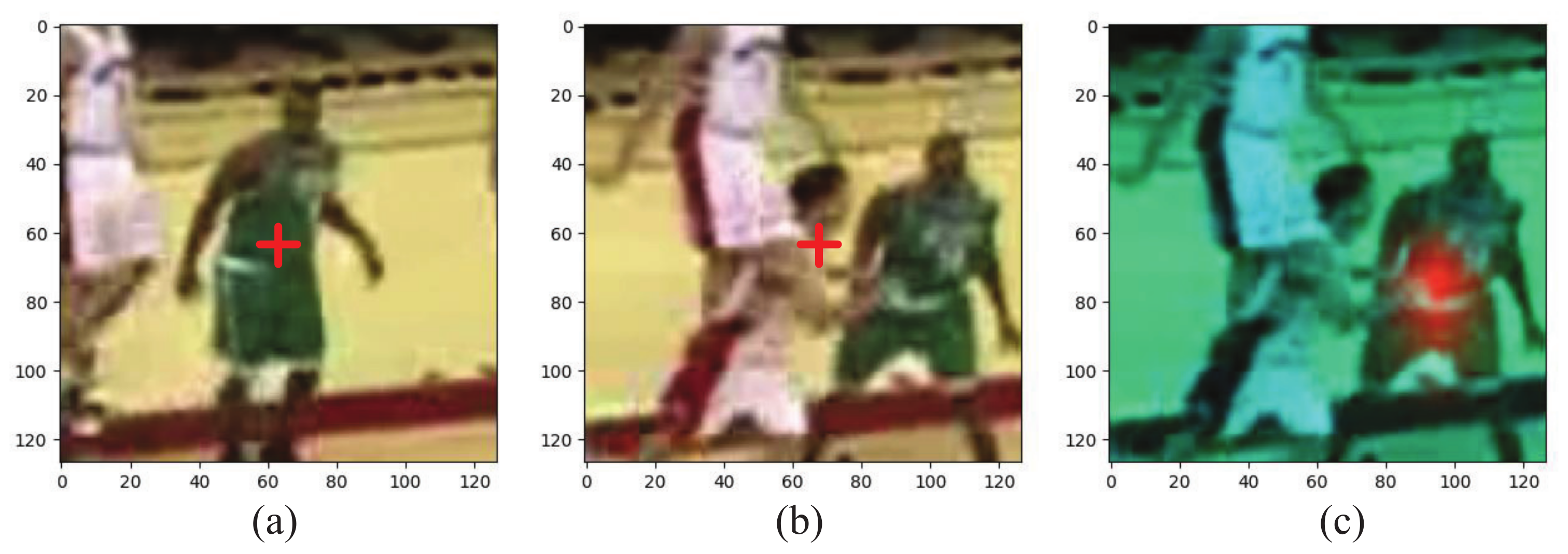
Figure 3a,b present the templates cropped from the predicted results during the tracking process. The red cross indicates the center of the image, but they belong to different targets. If we fuse them according to their linear weights, interference will be introduced into the template. Fortunately, we notice that features with the same appearance have high cosine similarity, as seen in
Figure 3c, where the red region indicates a high value. Thus, we have proposed an FA module to reconstruct the misaligned template features based on their cosine similarity.
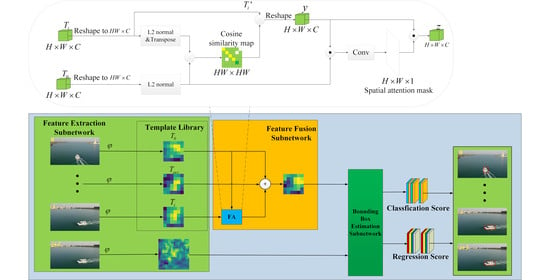
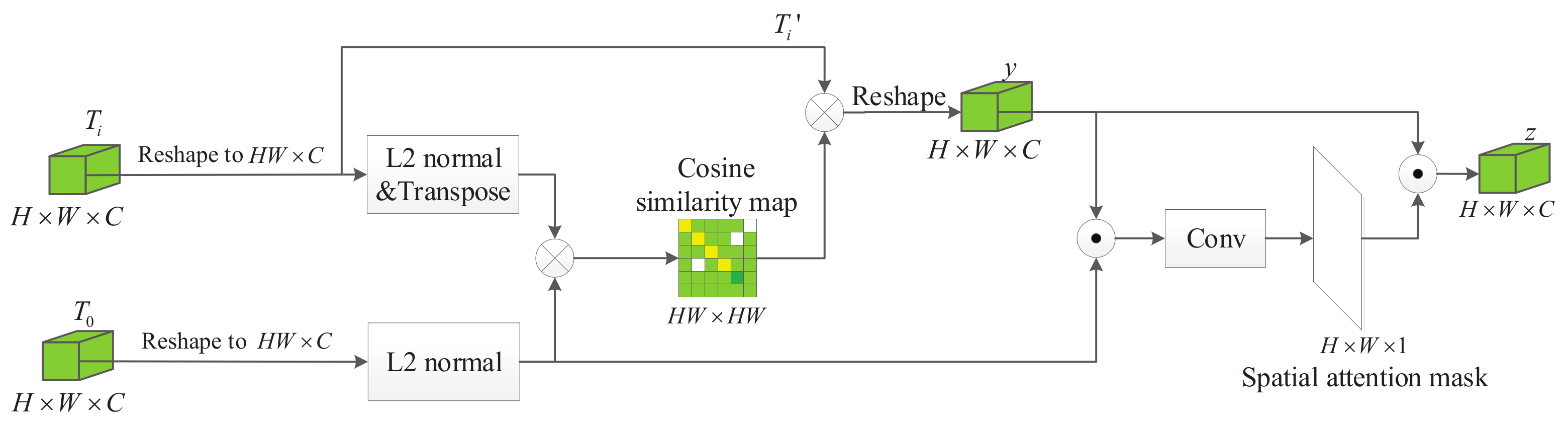
The goal of the FA module is to ensure that the same spatial position on the reconstructed feature map belongs to the same part by reconstructing each misaligned feature map. It can be considered as a matching task between two feature maps. The detailed construction of the FA module is shown in
Figure 4. The
and
indicate the feature map extracted from the initial ground-truth and the predicted results, respectively, both their dimensions are
. The cosine similarity (CS) between each position of
and
can be calculated as follows:
where
is the position in the feature map. Then, the whole cosine similarity map can be calculated as follows:
The Equation (
3) can be simplified as follows:
where the
indicates the normalization process and the symbol · represents the dot product. The shape of the cosine similarity map is
, each of its rows corresponds to the cosine similarity between each feature in
and all features in
.
Since the scales of the same object in a video sequence can be different, one position in the template
can have several corresponding pixels in the template
and vice versa. Therefore, we cannot simply shift the features to the corresponding position, all pixels that have the same appearance should be included. Therefore, we obtain new features
by weighted summation of features with similar appearance, which can be formulated as follows:
where
H and
W are the size of the feature map, and the
function maps the weight parameters to a range of 0 to 1.
The object might become incomplete during the tracking process, in which case the feature map
cannot align well with
. Thus, in order to avoid errors caused in such a case, we use a spatial attention mask to determine the correctness of matching as shown in
Figure 4. The
is implemented by a
convolution and ⊙ is the element-wise multiplication. The mask produced by
indicates the semantic similarity between
and the reconstructed feature.
3.3. The Bounding Box Estimation Subnetwork
The main part of the bounding box prediction subnetwork is the RPN network, which is composed of a classification and regression subnetwork. Firstly, a few anchors with different scales are defined. Inspired by SiamRPN [
14], the number of anchors is set to 5. Since the target does not scale considerably between adjacent frames, we only adopt one scale with different ratios
. After feature extraction, we can obtain
and
, which denote the template library branch feature and searching branch feature, respectively. The classification and regression scores can be calculated as follows:
where the
and
are applied to the classification subnetwork, which are from the template image and the search area, respectively. Similarly, the results of cross-correlation operation between
and
are used to regress the finer bounding box, and ∗ denotes the cross-correction operation.
After cross-correlation operation, we can obtain and . The represents the confidence score of target and background classification of each candidate box, and represents the refined parameters of each candidate box. For classification subnetwork, a function is applied to monitor the classification loss.
IOU is used as an indicator to distinguish positive and negative samples. Positive samples indicate that the IOU between anchor boxes and their ground truth is greater than 0.6, and the negative samples indicate that the IOU is less than 0.3. Therefore, for a single sample, the loss function is defined as:
where
y represents the label and
v represents the classification score of network prediction. For a set of anchors,
y and
v will be vectors. Thus, the corresponding loss function is
where
D denotes a sample space,
u is the sample serial number and
is the size of sample space. The process of training the network is constantly searching for the appropriate
to minimize the classification loss:
For the regression task, the parameters of the bounding box need to be refined by the regression network. In order to obtain a more stable regression training process, the regression parameters are standardized:
where
,
,
and
represent the central coordinates
, width and height of bounding box predicted by the current frame, respectively. Similarly,
,
,
and
represent the central coordinates
, width and height of annotation of the current frame, respectively.
The regression branch is supervised by the loss function
, which can be formulated as follows:
The
can be written as:
The overall loss function is:
where the
is the coefficient, it can be used to balance the loss of classification and regression.
3.4. Inference Phase: Template Updating
During the tracking phase, updating the template too frequently can not only lead to error accumulation, but also affect the tracking speed. Partial- and full-occlusion phenomena also occur sometimes. When the target in the template is blocked, adding it to the template library will introduce a lot of adverse noise. To address the problem that the target might be occluded during the tracking process, the APCE index was used to measure the tracking result. Following the SiamFC [
16], the response map
R was calculated by performing a cross-correction operation.
here,
z and
x represent the template image and the search area, respectively. The ∗ denotes the cross-correction operation.
As shown in
Figure 5, when the target is not occluded, there is only a particularly high peak in the response graph, and the response value is several times greater than that in other places. Otherwise, the response map will fluctuate intensely when the target is occluded. Inspired by the LMCF algorithm [
24], the APCE index is used to evaluate the occlusion degree of the target, which can be calculated as follows:
where
,
represent the maximum and minimum values in the response map, respectively.
is the corresponding value at
. The numerator part reflects the peak value in the response map and represents the reliability of the current response map, whereas the denominator represents the average degree of fluctuation of the response map. Once the target is occluded, the APCE will become smaller immediately, compared with its previous level.
In this paper, the historical average of APCE, i.e.,
, is used as the criterion to judge whether the target is occluded or not, i.e.,
where the
represents the APCE value of the
ith frame image, the
m is the number of frames that have been tracked. where the
represents the APCE value of the
ith frame image,
m is the number of frames that have been tracked. When APCE is less than the
, the target is considered as occluded and the tracker should stop updating the template. The detailed tracking process is shown as Algorithm 1.
| Algorithm 1: The proposed TDSiam algorithm |
![Remotesensing 14 01584 i001]() |
4. Experiments
We selected three UAV video benchmarks, UAV123, UAV20L [
18] and UAVDT, for qualitative and quantitative experiments. The UAV123 consists of 123 shorter UAV aerial videos, and UAV20L consists of 20 longer video sequences. Compared with UAV123, UAV20L has more changes in appearance due to its long-time series, and there are many scenes in which the target completely disappears or reappears.
Success plot and precision plot both are important indicators used in the evaluation of this experiment. The success plot mainly reflects the overlap rate, that is, the proportion of the overlap area between the bounding box predicted by the tracker and the ground truth in the total area. When the overlap ratio exceeds this threshold, the tracking can be considered successful. We count the proportion of successful tracking frames to the total frames and draw the curve with this proportion as the ordinate. The precision plot is responsible for measuring the distance between the prediction result and the center of ground truth. When the distance between the center coordinate of the prediction result and the real position is less than this threshold, the tracking can be considered successful.
The evaluation is divided into two parts: overall evaluation and attribute-based evaluation. Attribute-based evaluation is responsible for evaluating the performance of the algorithm under different attributes, including aspect ratio change (ARC), background cluster (BC), camera motion (CM), fast motion (FM), full occlusion (FOC), illumination variation (IV), low resolution (LR), out of view (OV), partial occlusion (POC), similar object (SOB), scale variation (SV), and viewpoint change (VC).
The UAVDT [
38] dataset was proposed by Du et al. in 2018 for UAV video object detection and tracking, in which 50 video sequences are used for single-object tracking. There are eight attributes in UAVDT that are different from UAV123, including Camera Rotation (CR), Large Occlusion (LO), Small Object (SMO), Object Motion (OM), Background Clutter (BC), Scale Variations (SV), Illumination Variations (IV) and Object Blur (OB). The evaluation methods and indicators are consistent with those of UAV123.
4.1. Implementation Details
Our tracker was implemented with the Pytorch toolkit, which runs on the hardware environment with Intel(R) Xeon(R) Sliver 4110 2.1 GHz CPU and a single NVIDIA RTX2080 GPU.
In the training phase, we adopted a two-stage training method. In the first stage, we only trained the Siamese tracker without the FA module and the template library. The sample pairs were picked from ImageNet VID [
39], GOT10K [
40] and YouTube-BB datasets [
41]. We chose the template patch and search region from the same video with an interval of less than 100. The template was cropped to a size of
centered on the target, and the search region was cropped to a size of
in the same manner. In addition, the affine transformation was also adopted. In this stage, the Siamese tracker was trained using the Adam [
42] optimization algorithm with a batch size of 32 pairs in 20 epochs. The parameters of the feature extraction network were pretrained on ImageNet, and the first three convolution layers were fixed. The initial learning rate was set to 0.01, and there was no fine-tuning. In the second stage, the FA module and the template library were integrated into the Siamese tracker and an end-to-end training process was adopted. In this stage, pairs of input triplets
from the same video sequence were required. The
and
can be obtained directly from the same video sequence. For
, the ground truth was too accurate to reflect the predicted location in practice. Therefore, we added a random shift to the object so that it is not exactly at the center of the image.
could be obtained by a standard linear update, three historical frames before
were selected for feature extraction and fusion. This can be formulated as follows:
In addition, we use two backbones, AlexNet and ResNet, to obtain more fair results. The backbones in the feature extraction networks of TDSiam_Res50 and TDSiam_Alex are ResNet and AlexNet, respectively.
4.2. Experiments on the UAV123 Benchmark
We compared our method with SiamRPN [
14], SiamRPN++ [
28], DaSiamRPN [
23], SiamFC-3s [
12] and a few methods provided on the UAV123 benchmark, which include SRDCF [
17], MEEM [
43] and SAMF [
44].
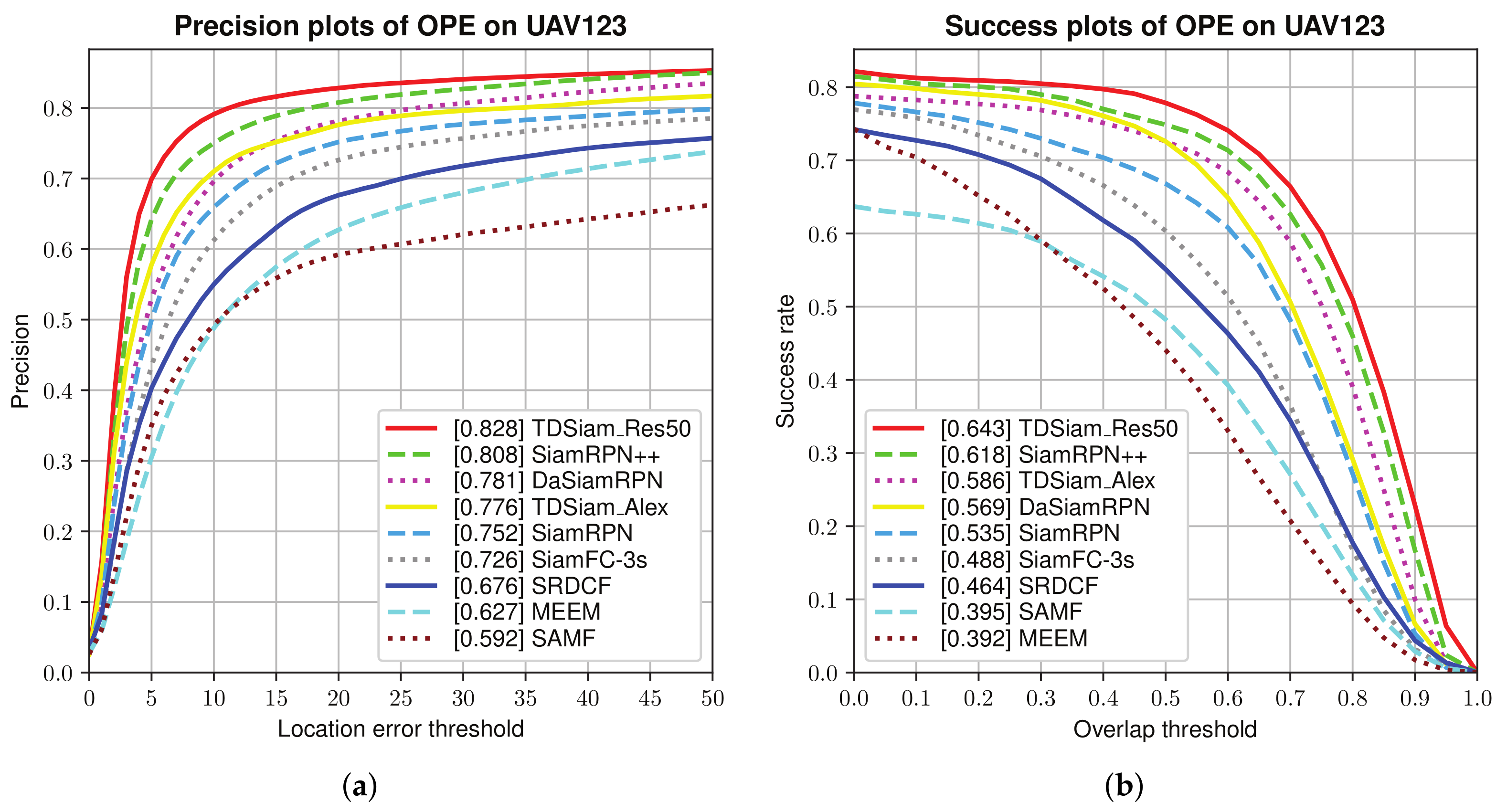
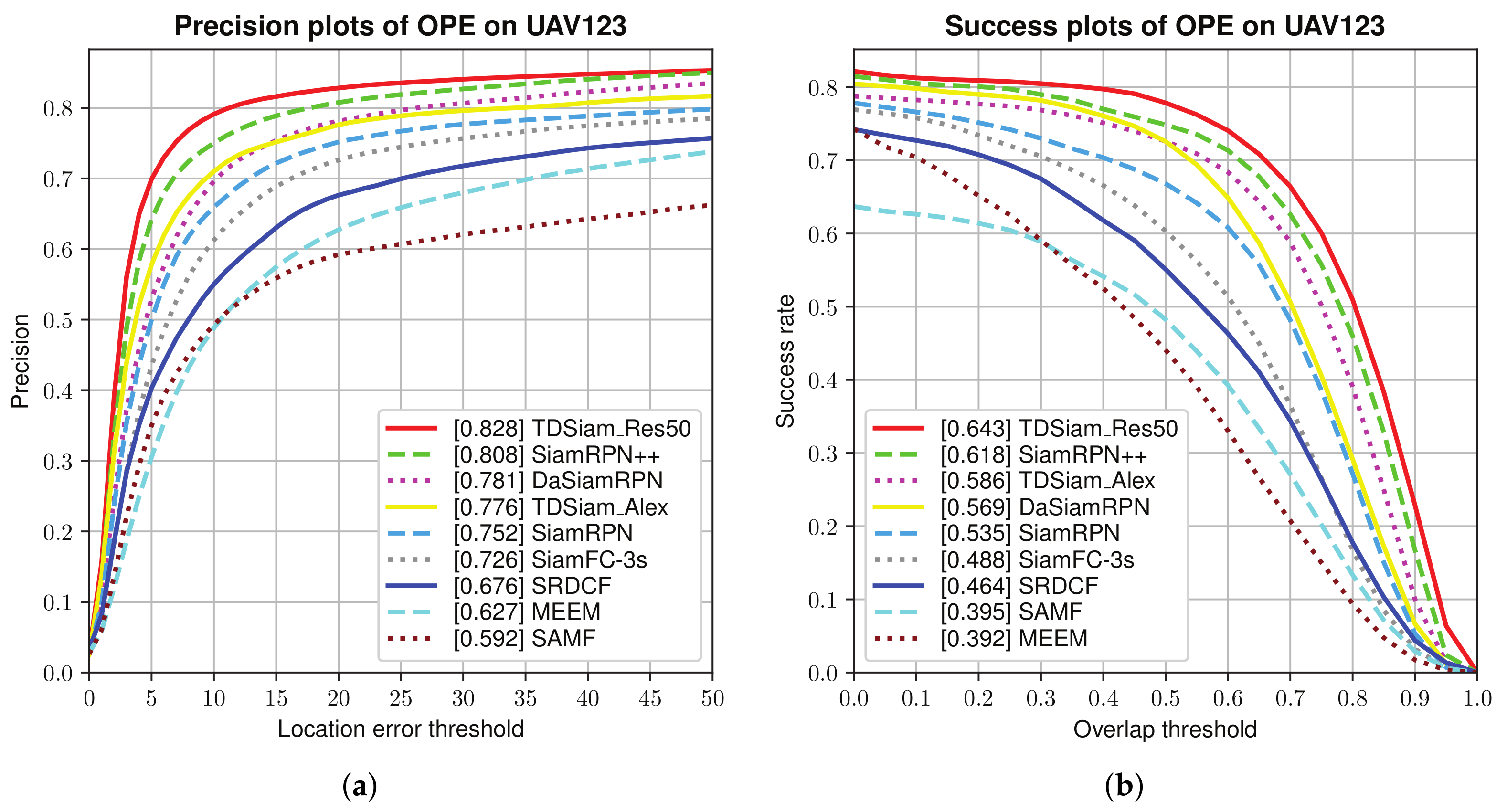
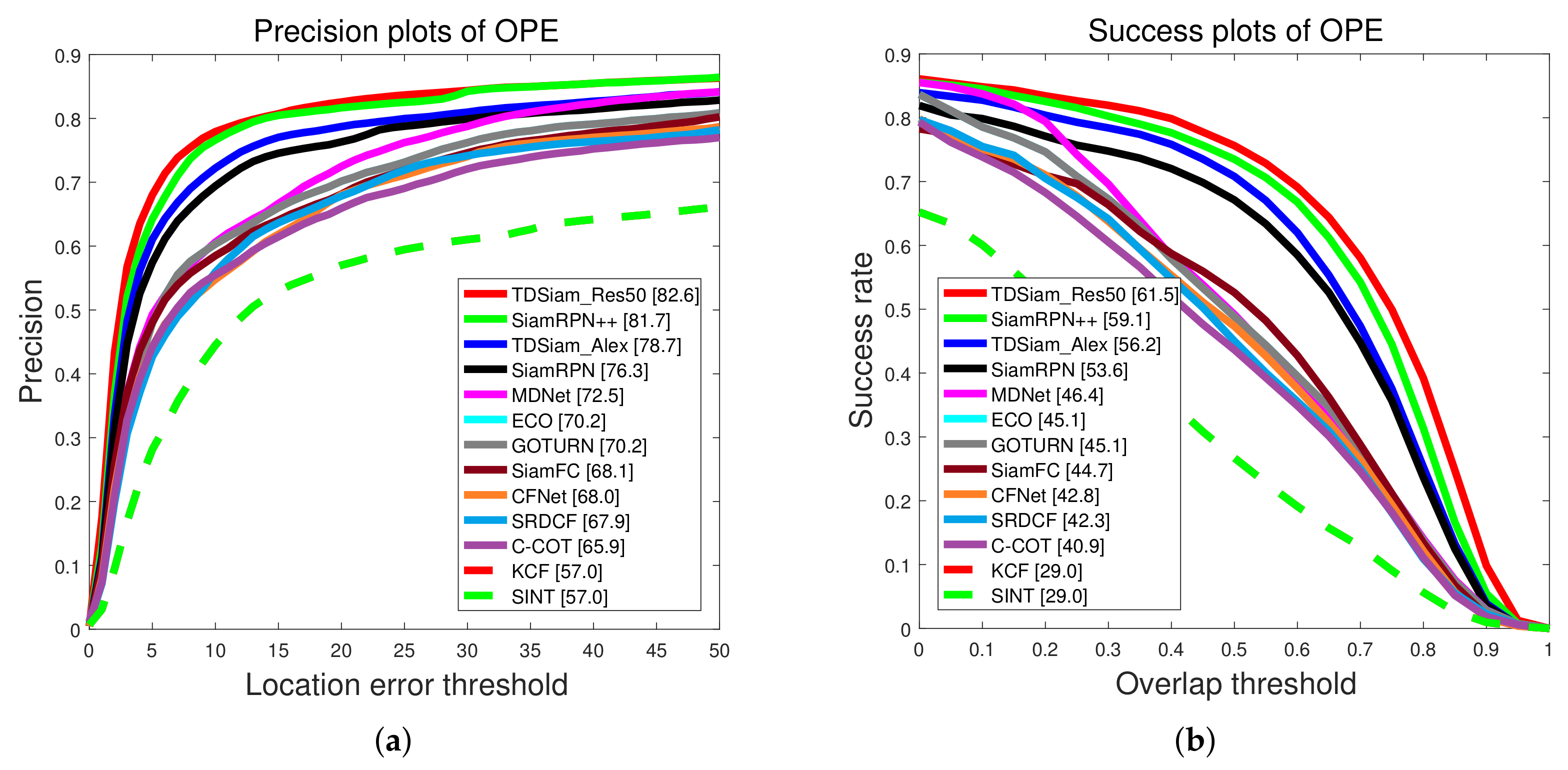
Overall Evaluation: The success plots and precision plots of the one-pass evaluation (OPE) are shown in
Figure 6. TDSiam_Alex is observed to achieve a success score of 0.586 and a precision score of 0.776. Compared to the SiamRPN, TDSiam_Alex significantly outperforms in terms of the success score as well as precision score. In addition, we replaced the backbone of TDSiam with ResNet for performance comparison with SiamRPN++. The TDSiam_Res50 outperforms SiamRPN++ in terms of both metrics, TDSiam_Res50 achieves a substantial gain of 4% in terms of the success score.
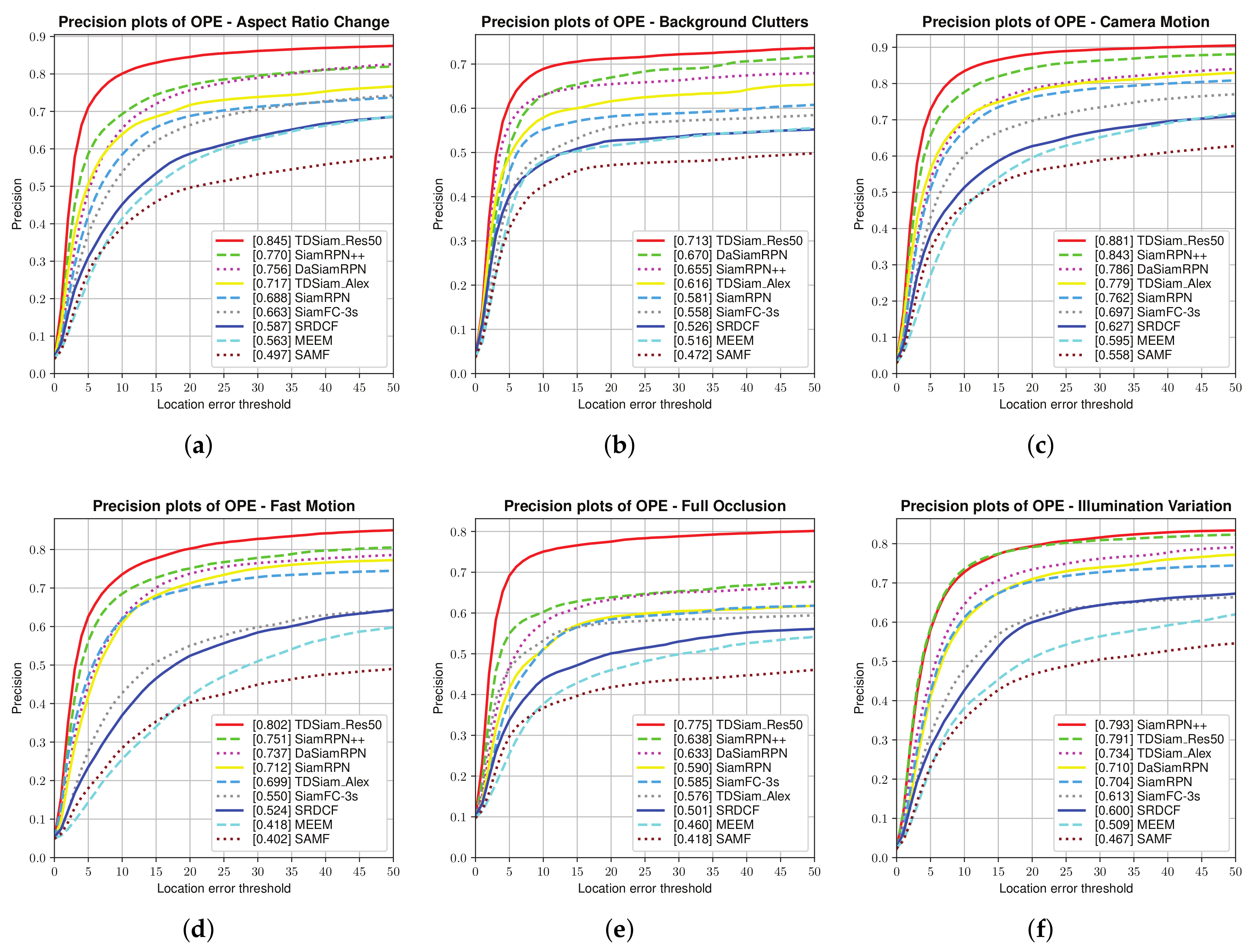
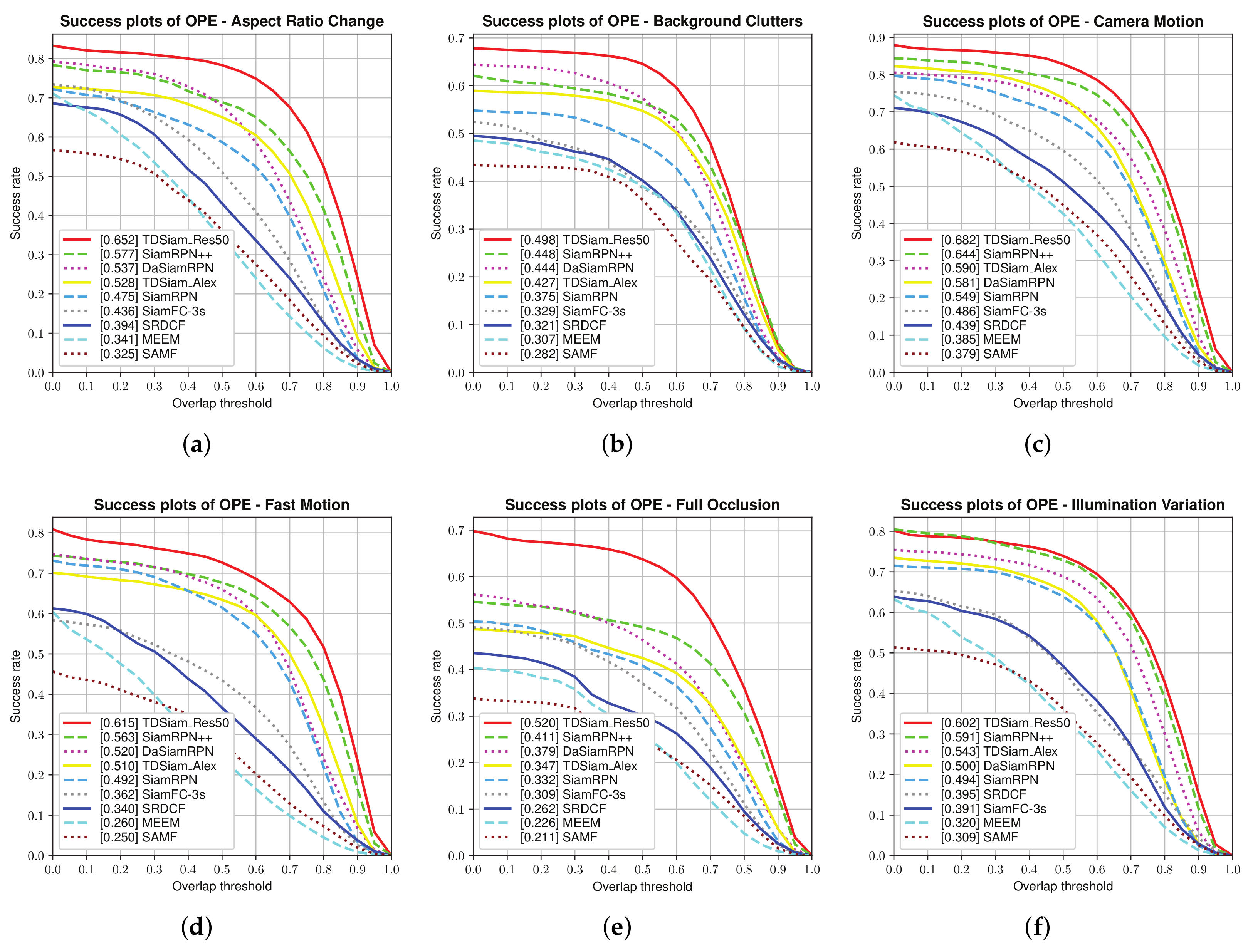
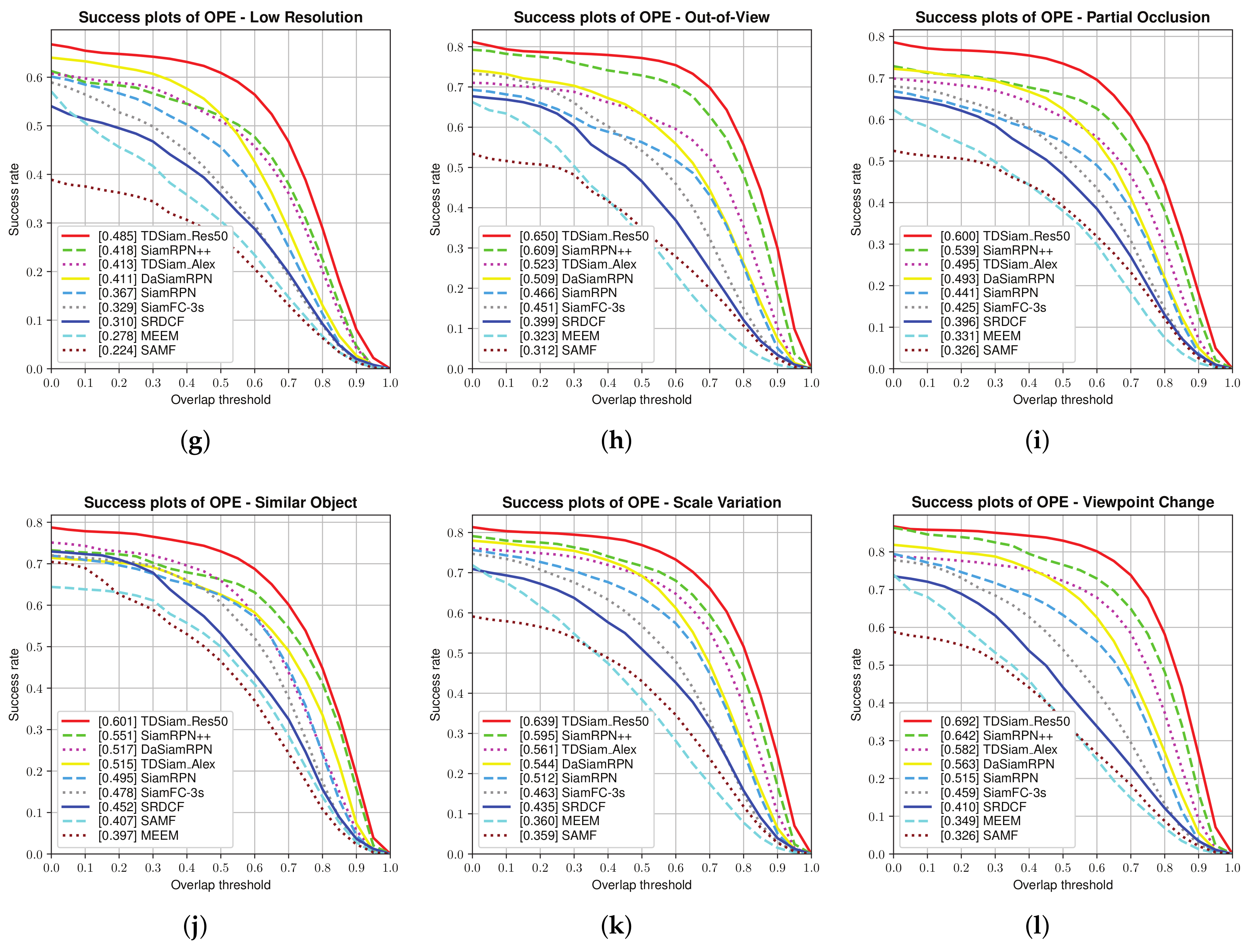
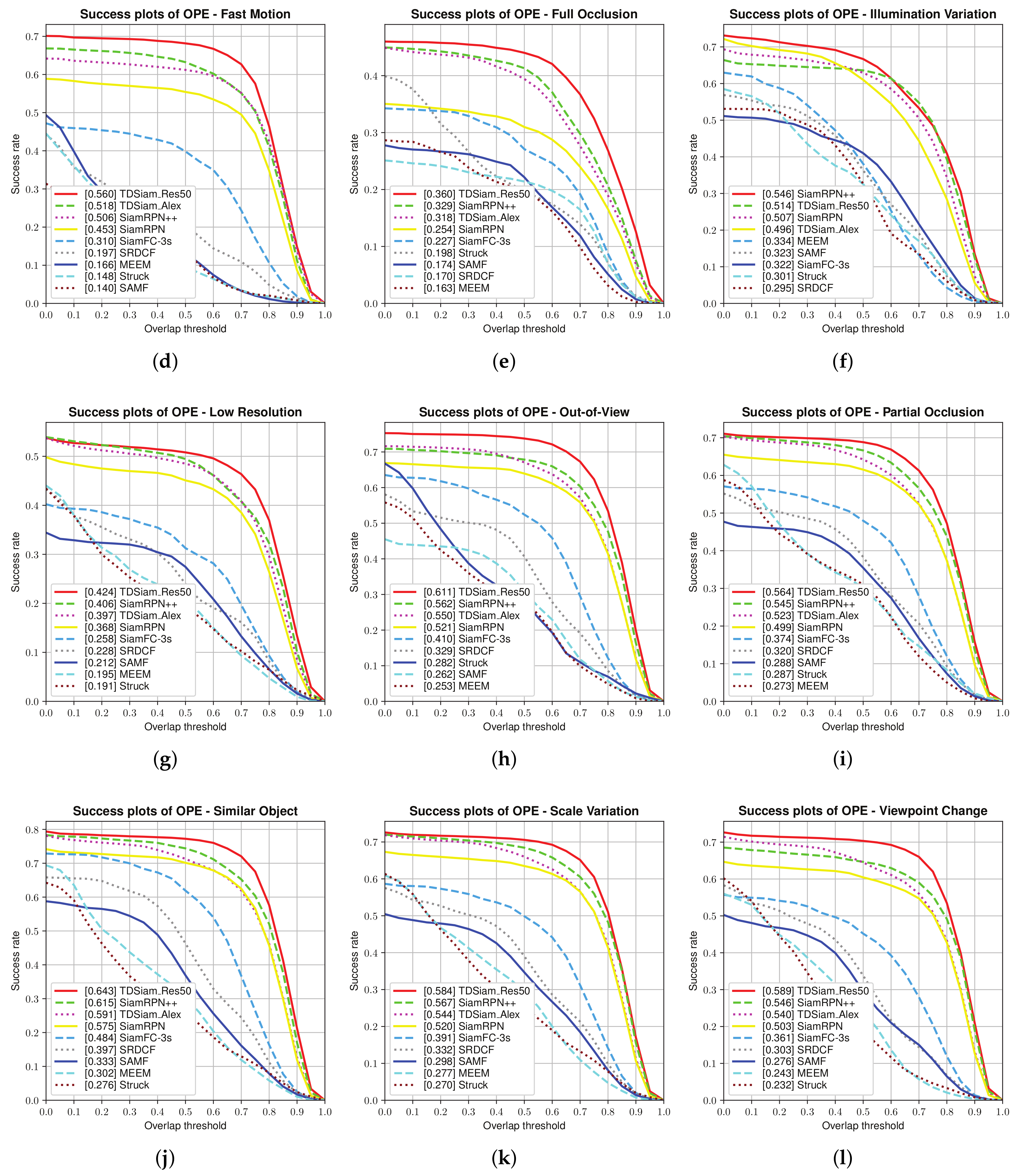
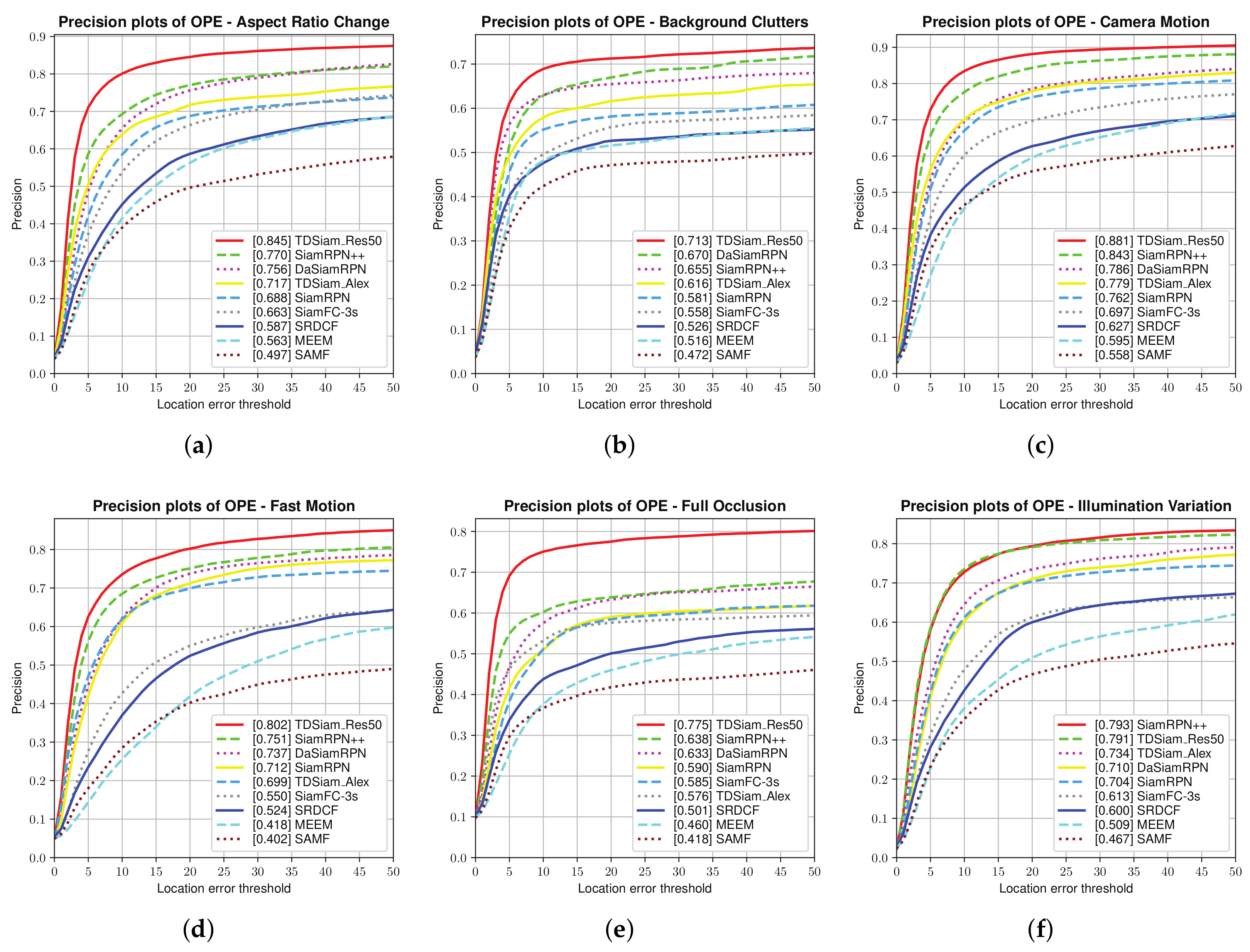
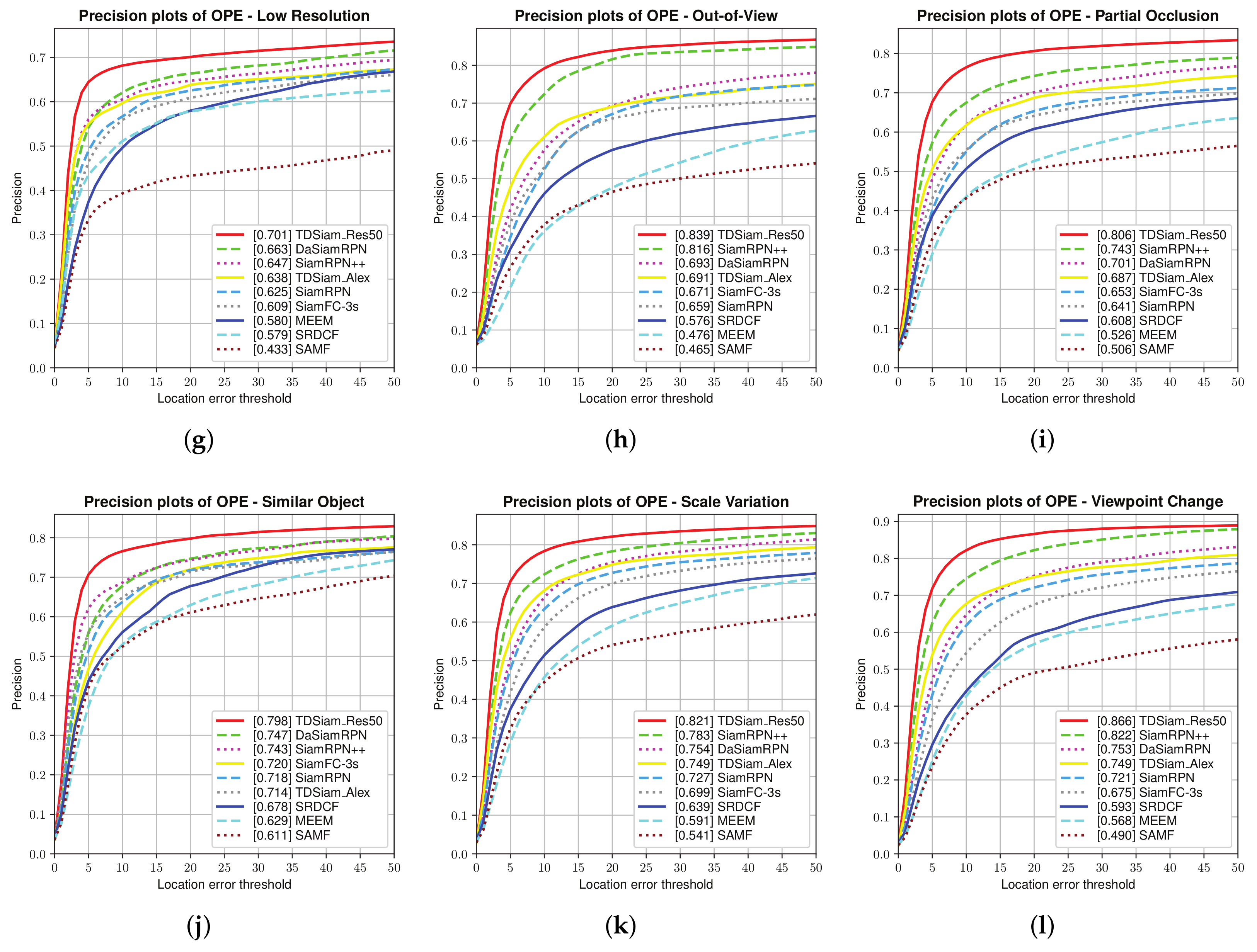
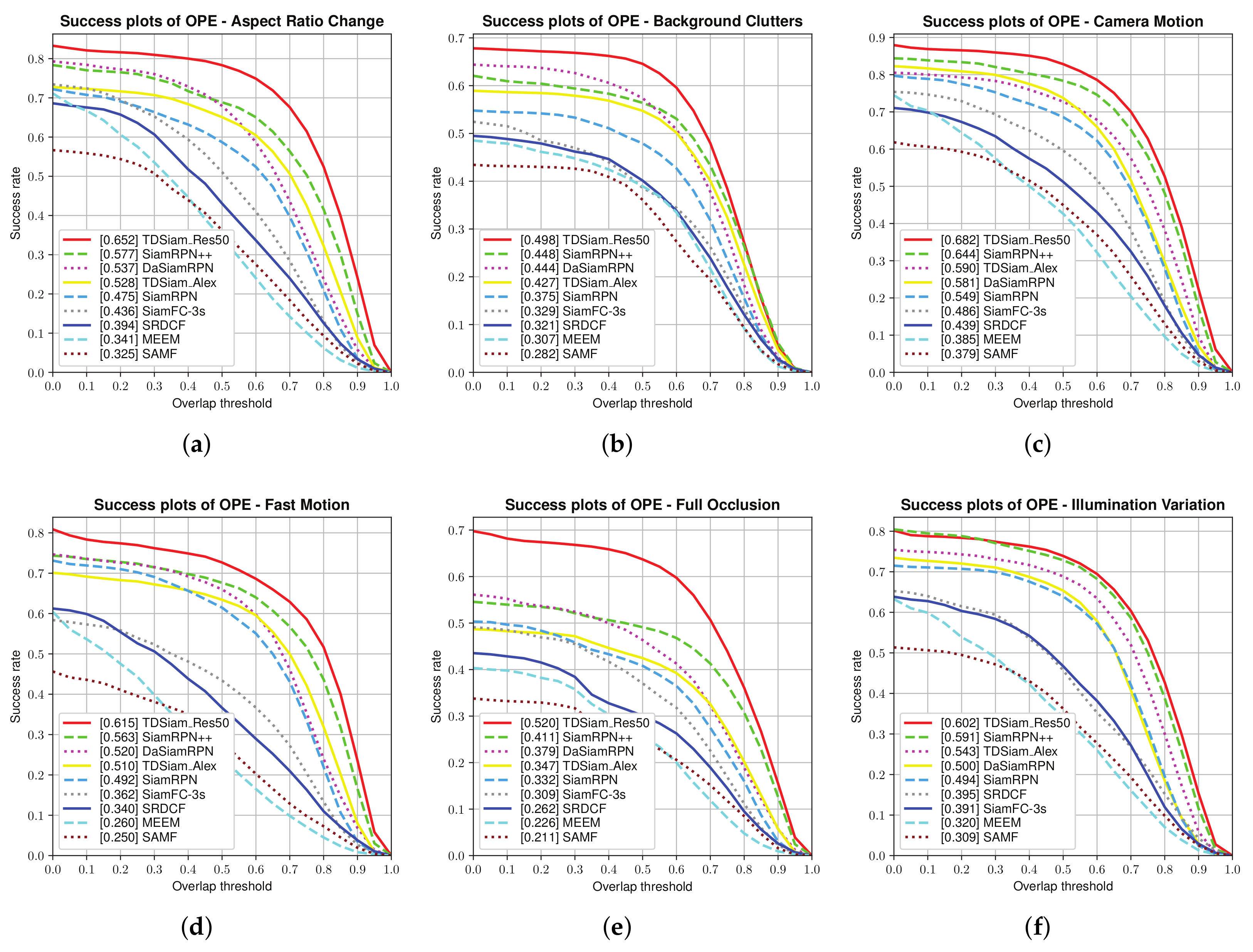
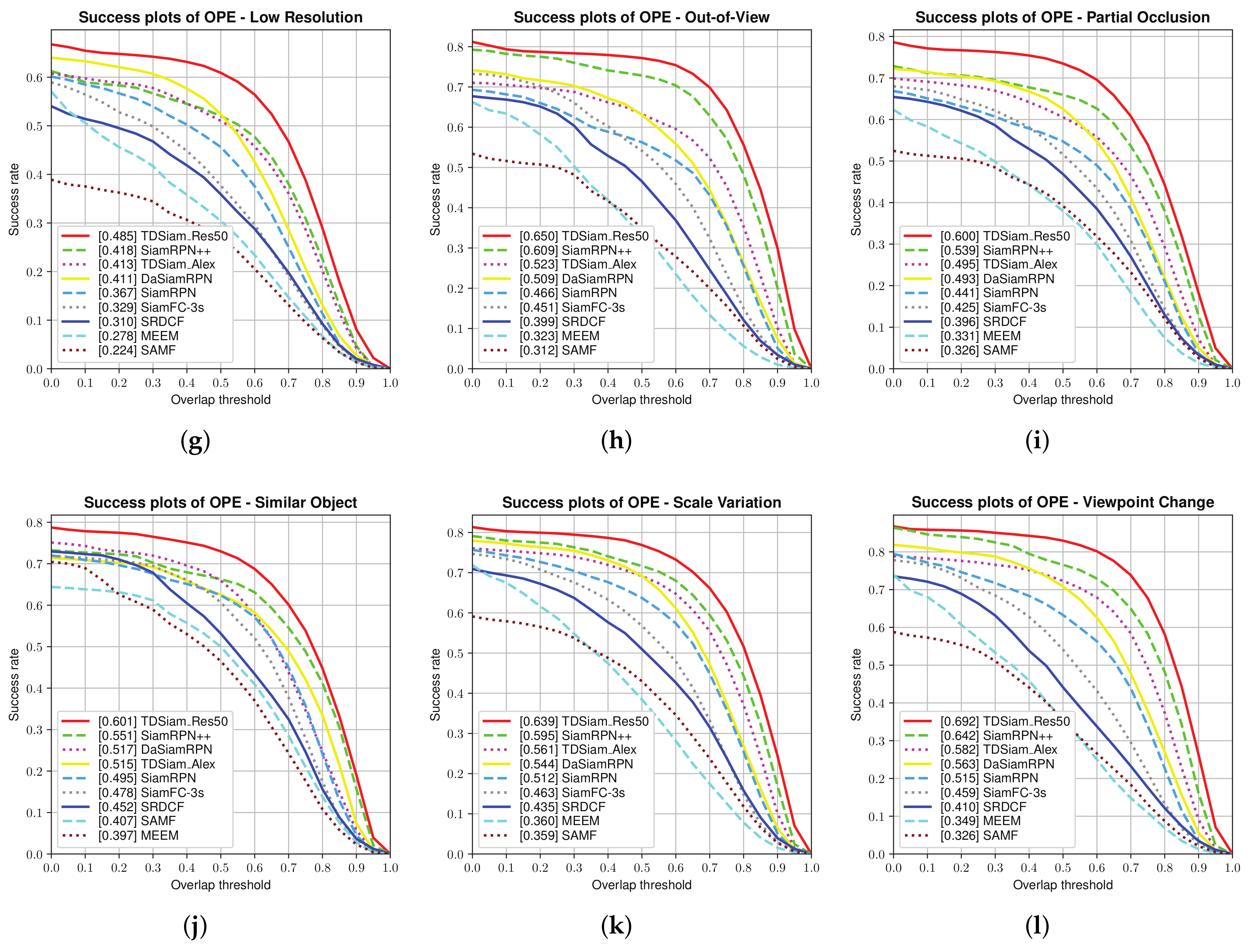
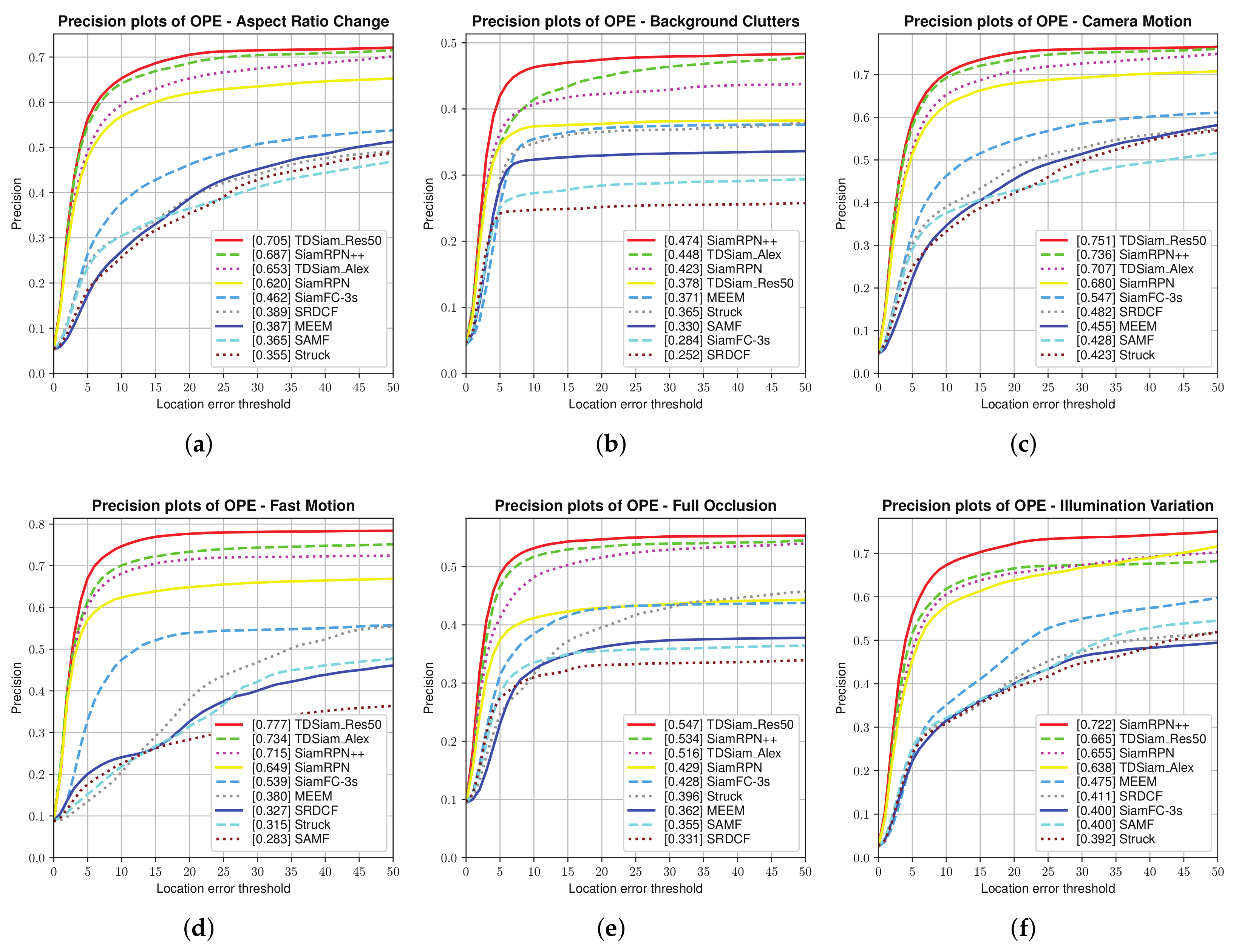
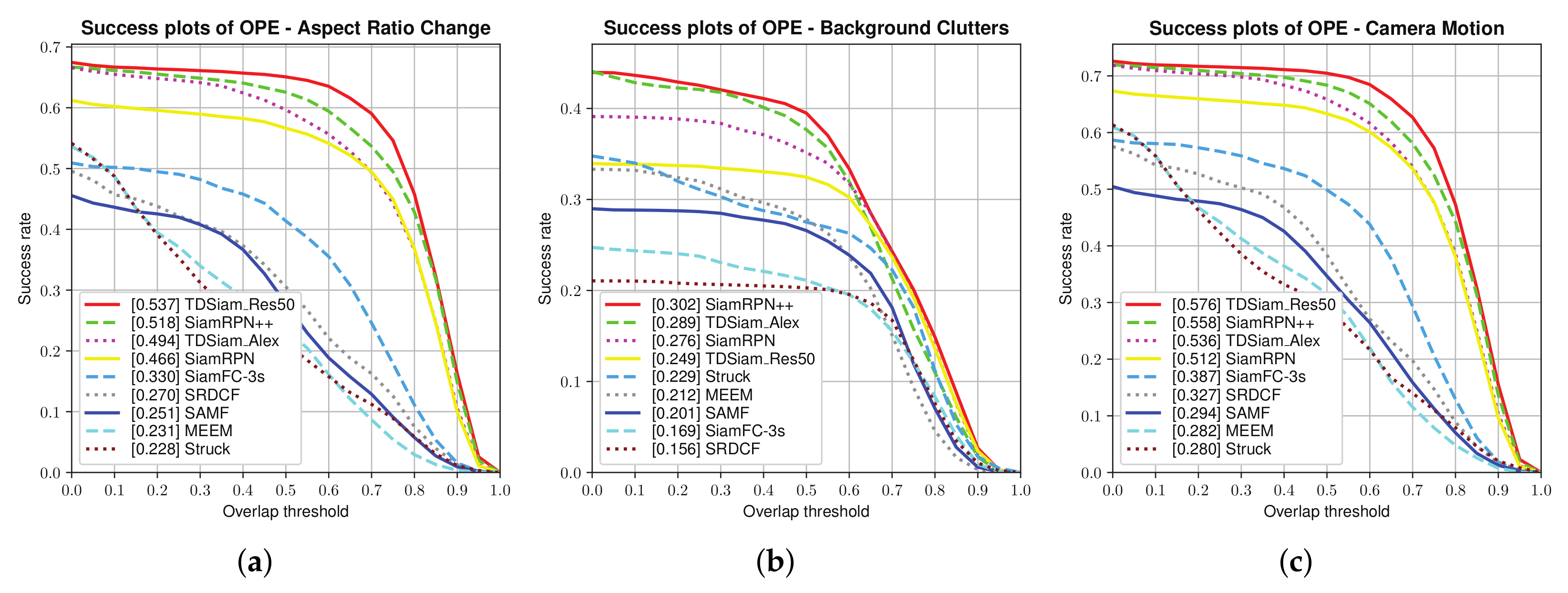
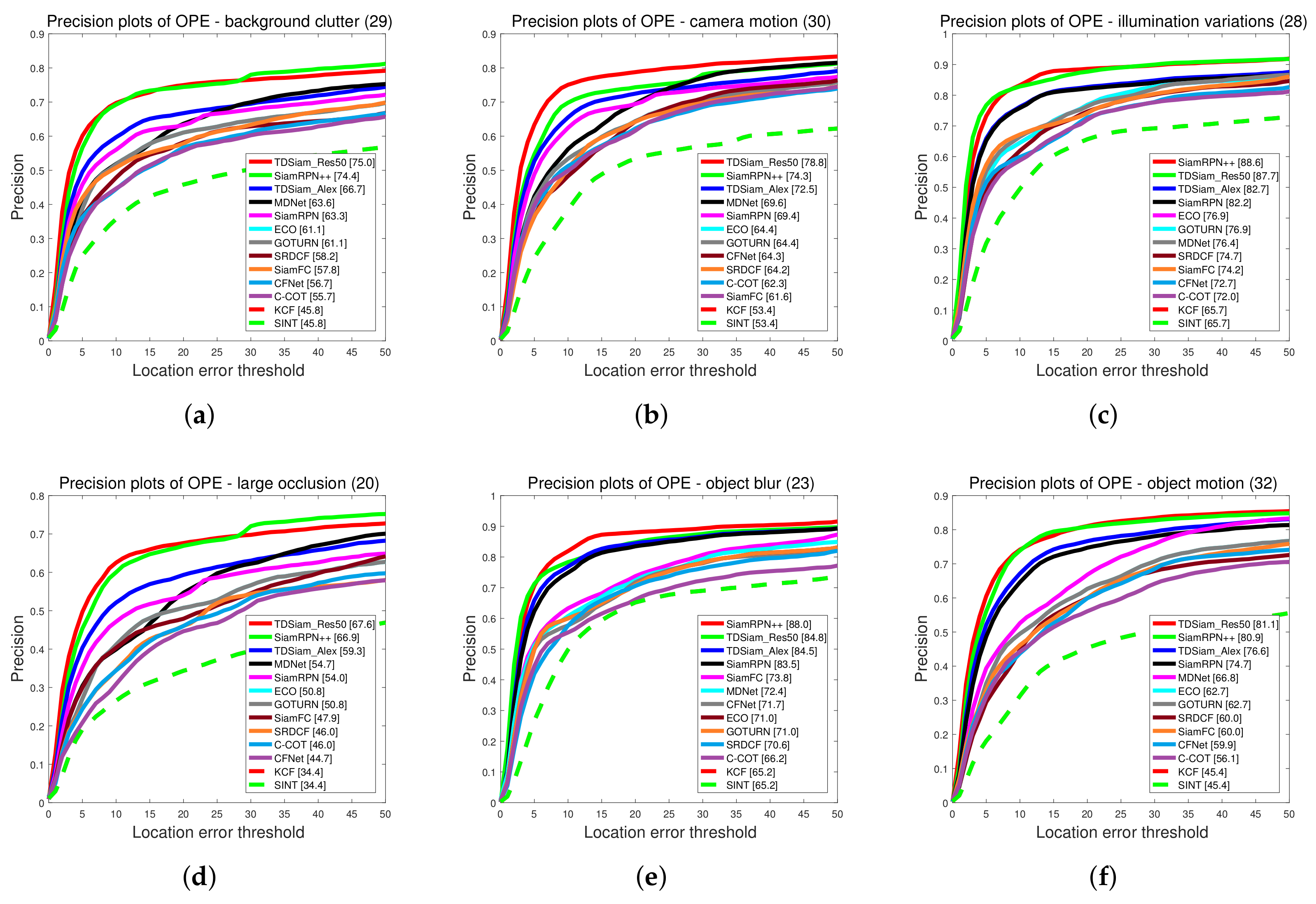
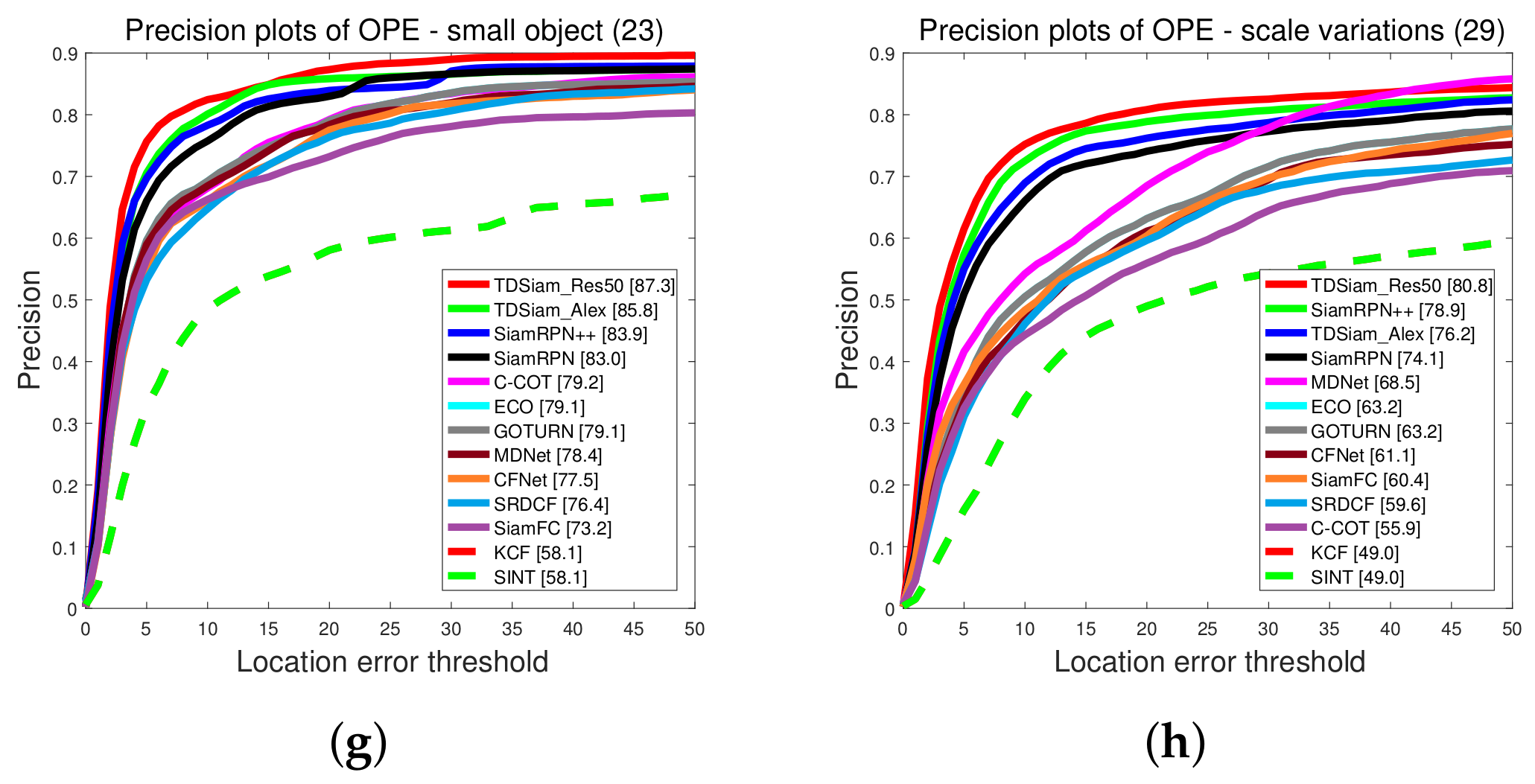
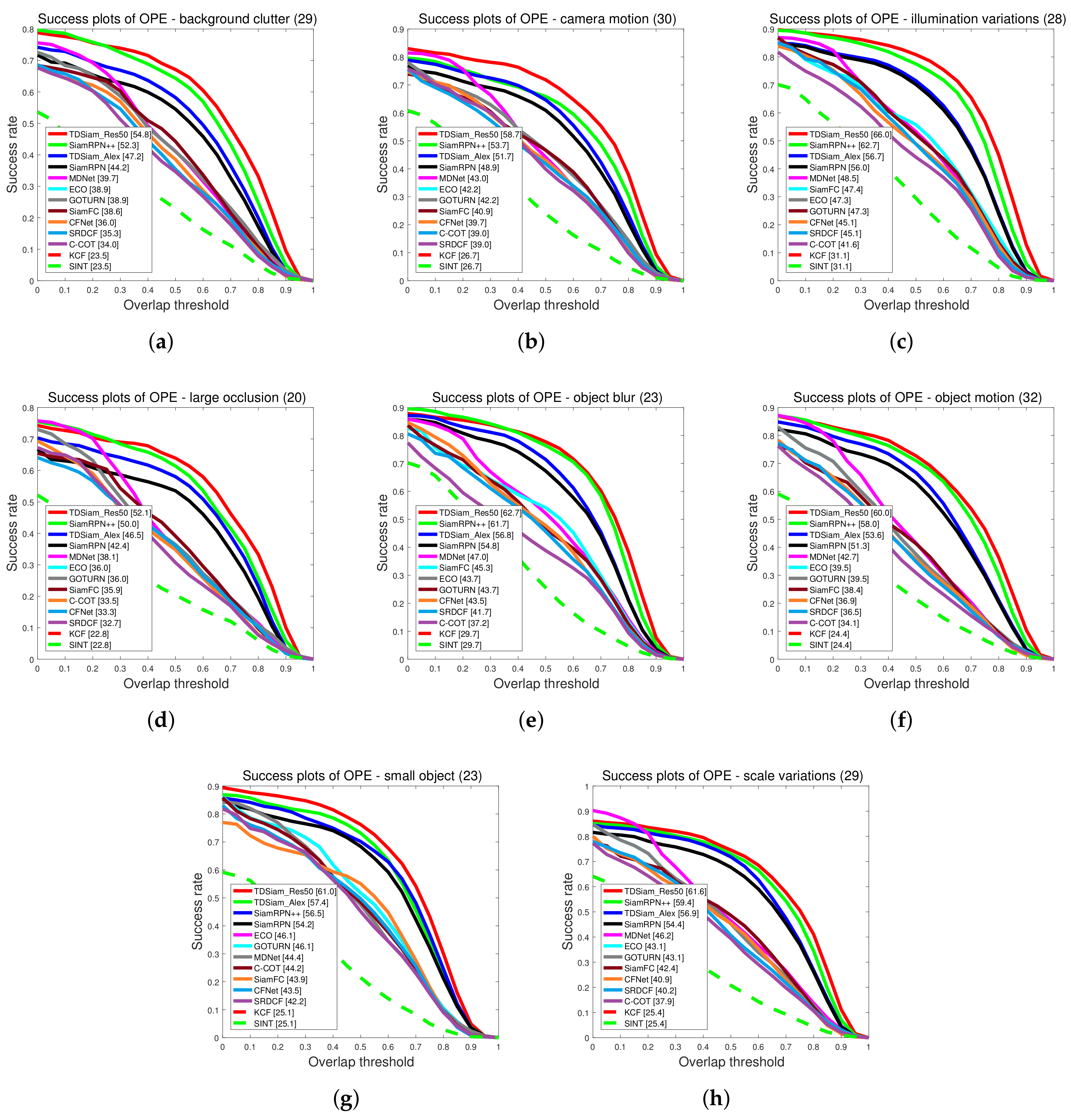
Attribute-Based Evaluation: The performance in the 12 attributes is shown in
Figure 7 and
Figure 8, from which it can be seen that TDSiam_Res50 achieves superior performance. On the one hand, as for the precision score, our method achieves better results, including ARC (0.845), BC (0.713), CM (0.881), FM (0.802), FO (0.775), LR (0.701), OV (0.839), PO (0.806), SO (0.798), SV (0.821), VC (0.865). On the other hand, as for the success rate, our method also yields the best performance, including ARC (0.652), BC (0.498), CM (0.682), FM (0.615), FO (0.520), IV (0.602), LR (0.485), OV (0.650), PO (0.600), SO (0.601), SV (0.639), VC (0.692). In particular, in several scenarios, ARC, CM and VC, our method achieved more significant performance gain, with 9.7%, 4.5%, 5.3% in precision score and 13%, 5.9%, 7.8% in success rate. To sum up, the attribute-based evaluation proves that the proposed method can significantly improve the performance in the scene where the appearance of the target changes.
4.3. Experiments on the UAV20L Benchmark
The UAV20L [
18] dataset consists of 20 long-term challenging video sequences. There are more appearance changes in the whole video sequence, especially the accumulation of appearance changes for a long time. In the experiment, we compared our proposed method with SiamRPN++ [
28], SiamRPN [
14], SiamFC-3s [
12], SRDCF [
17], MEEM [
43], SAMF [
44] and Struck [
45]. The indicators used in the evaluation are the same as those of UAV123.
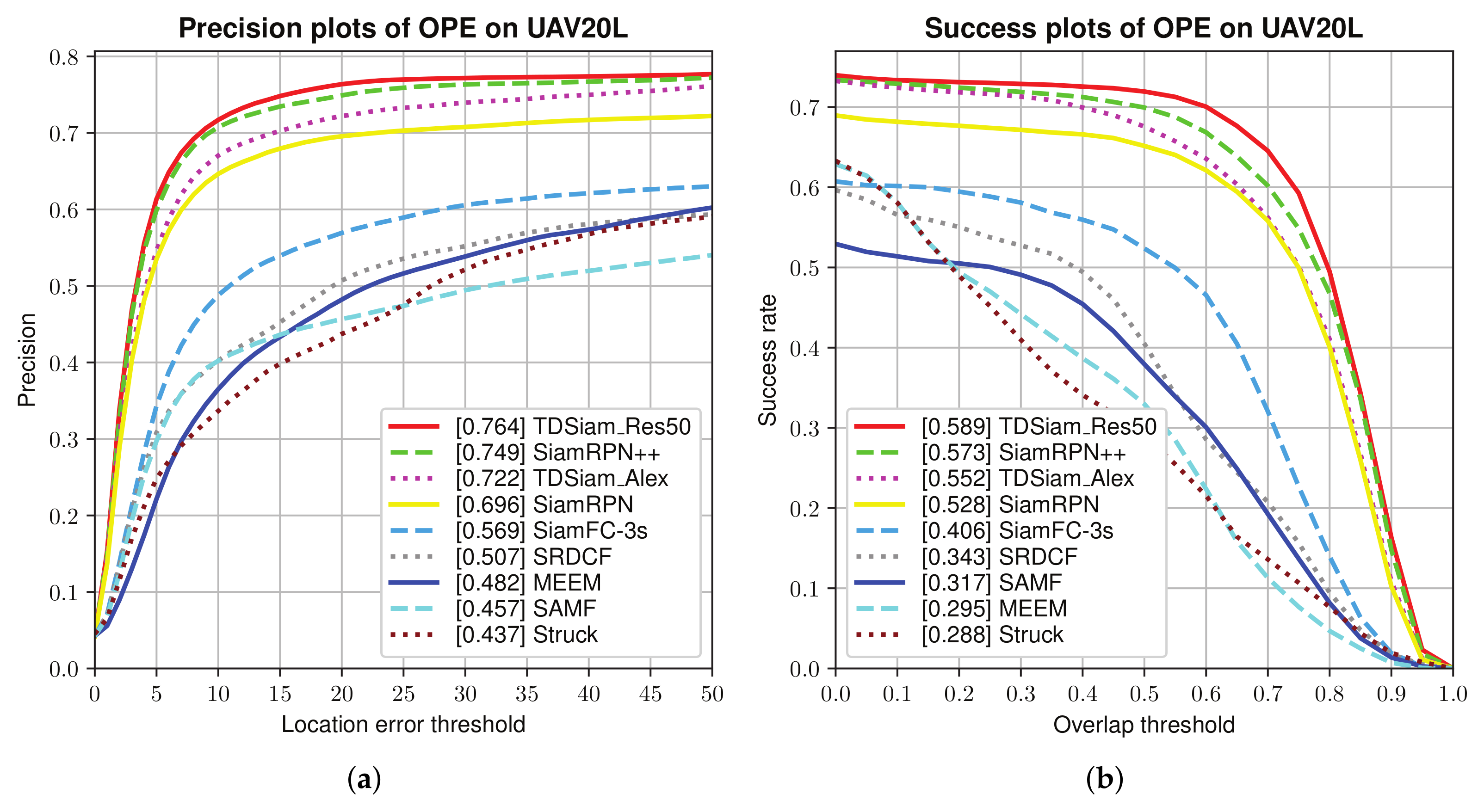
Overall Evaluation: As can be seen from
Figure 9, the TDSiam_Res50 achieves the best performance in terms of precision score and success rate, which are 0.764 and 0.589. In particular, compared to the SiamRPN, our proposed method TDSiam_Alex achieves a substantial gain of 4.5% in terms of the success score.
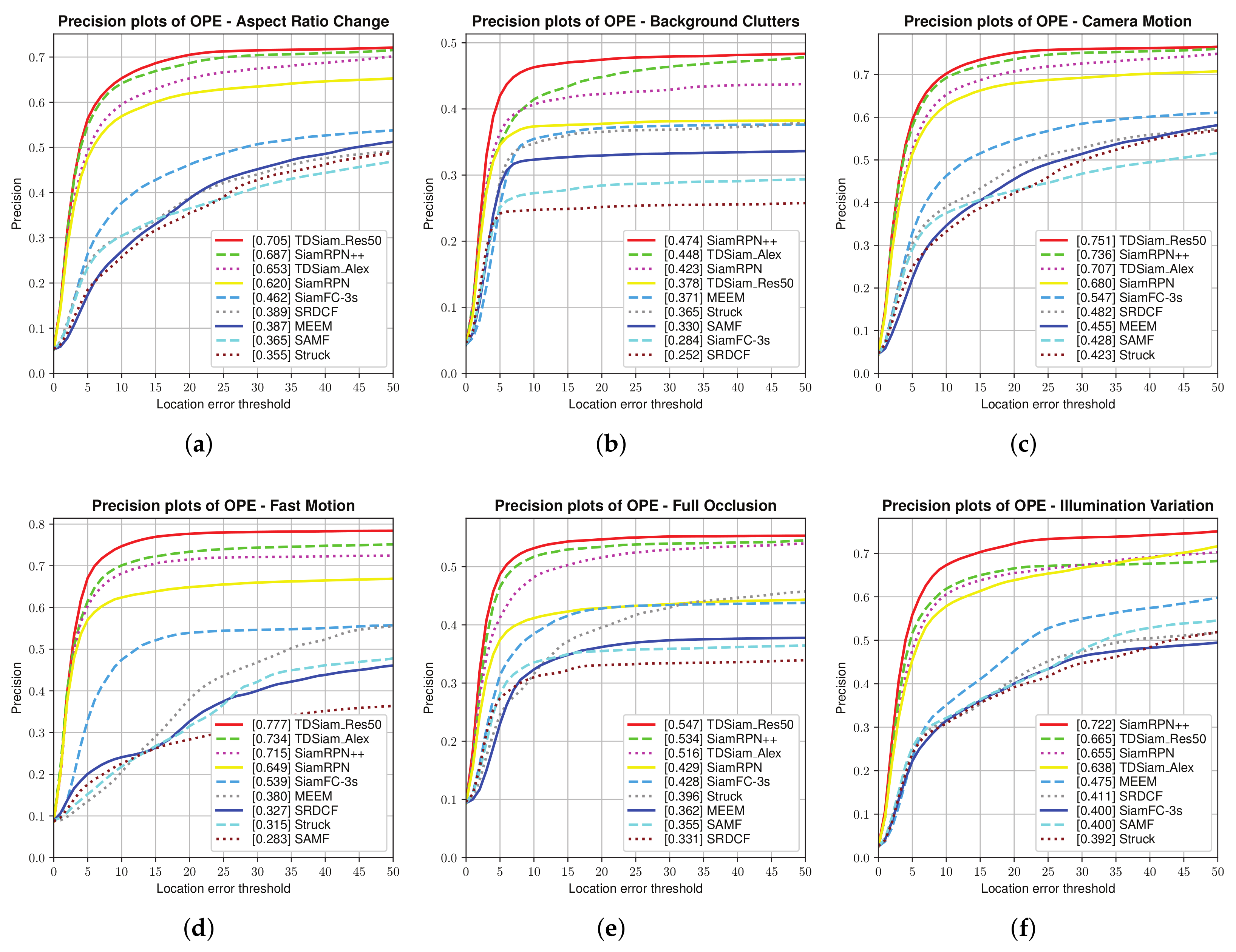
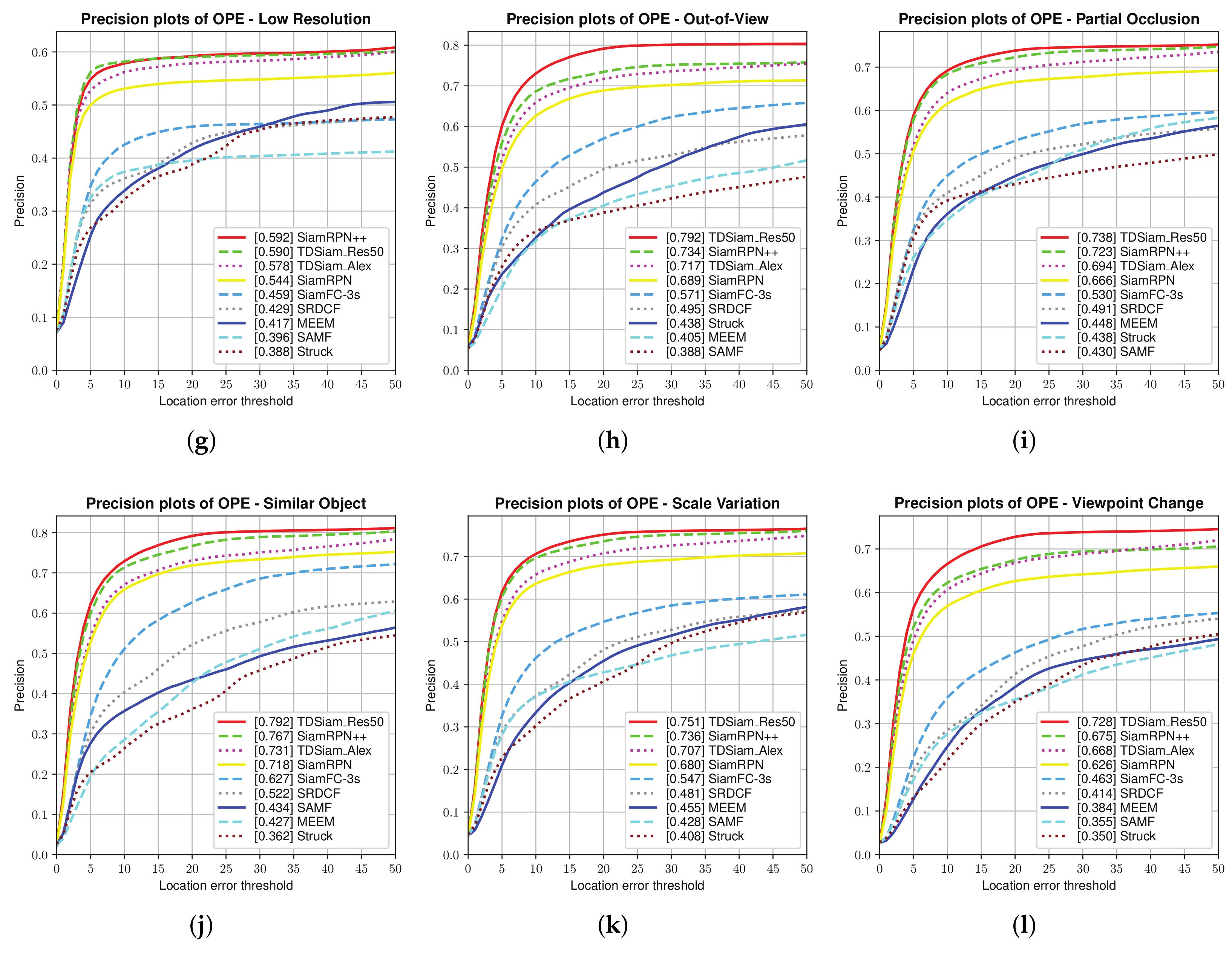
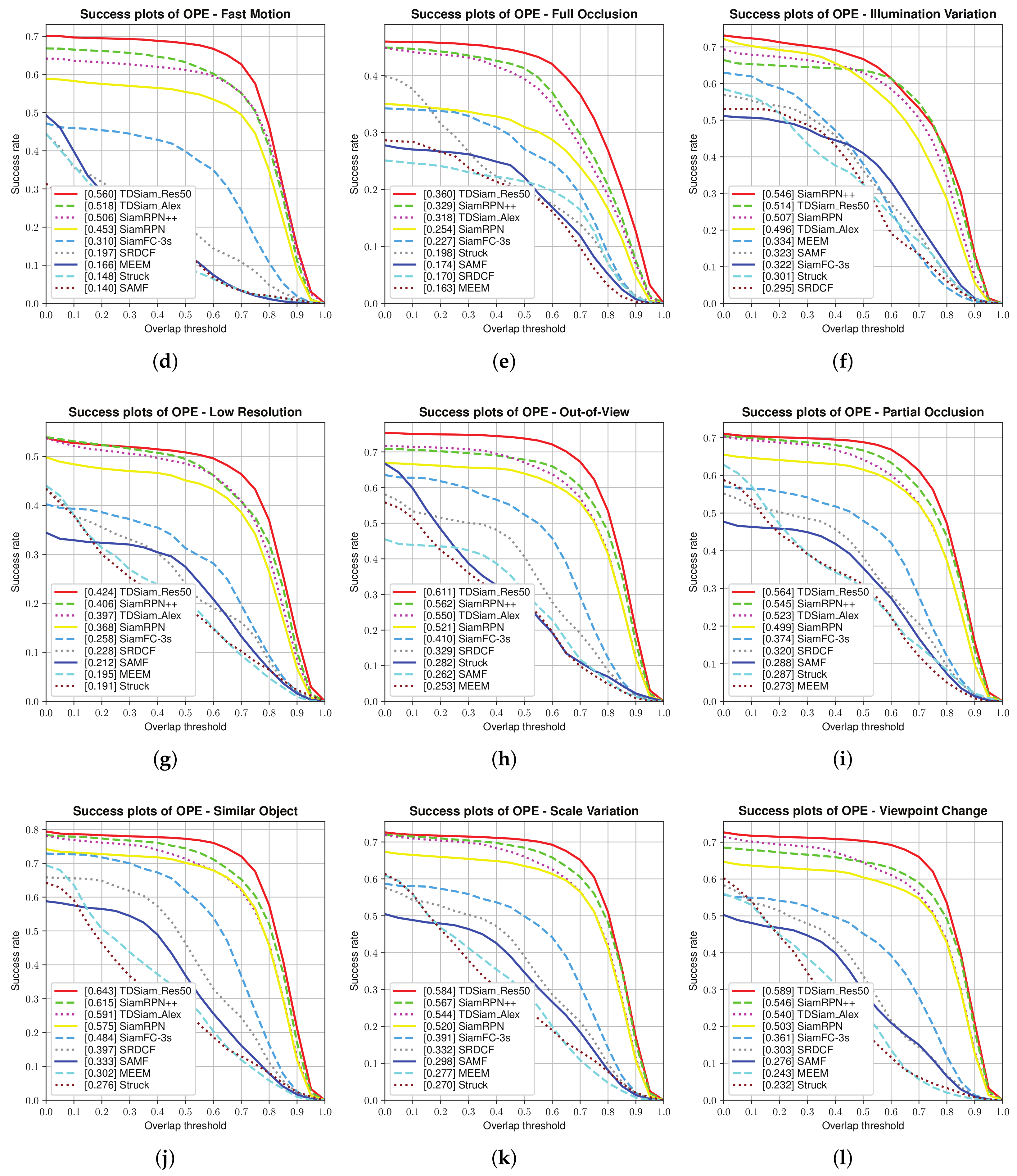
Attribute-Based Evaluation: As shown in
Figure 10 and
Figure 11, our proposed method TDSiam can performs better than other recent methods in some typical scenarios under aerial version. As for the precision score, our method TDSiam_Res50 also achieves better results, including ARC (0.705), CM (0.751), FM (0.777), FO (0.547), LR (0.590), OV (0.792), PO (0.738), SO (0.792), SV (0.751), VC (0.728). As for the success rate, our method also yields the best performance, including ARC (0.537), CM (0.576), FM (0.650), FO (0.360), LR (0.424), OV (0.611), PO (0.564), SO (0.643), SV (0.584), VC (0.589). However, in both scenarios, BV and IV, the performance of our method is still unsatisfactory. The reason for this may be that the template-matching methods such as SiamRPN++, SiamRPN and SiamFC do not have good tracking performance in complex backgrounds.
4.4. Experiments on the UAVDT Benchmark
In the experiment, the algorithms involved in the comparisons are SiamRPN [
14], SiamRPN++ [
28], SiamFC [
12], and some methods provided by the UAVDT benchmark, including MDNet [
13], ECO, GOTURN [
20], CFNet [
21], SRDCF [
46], C-COT [
47], KCF and SINT [
19].
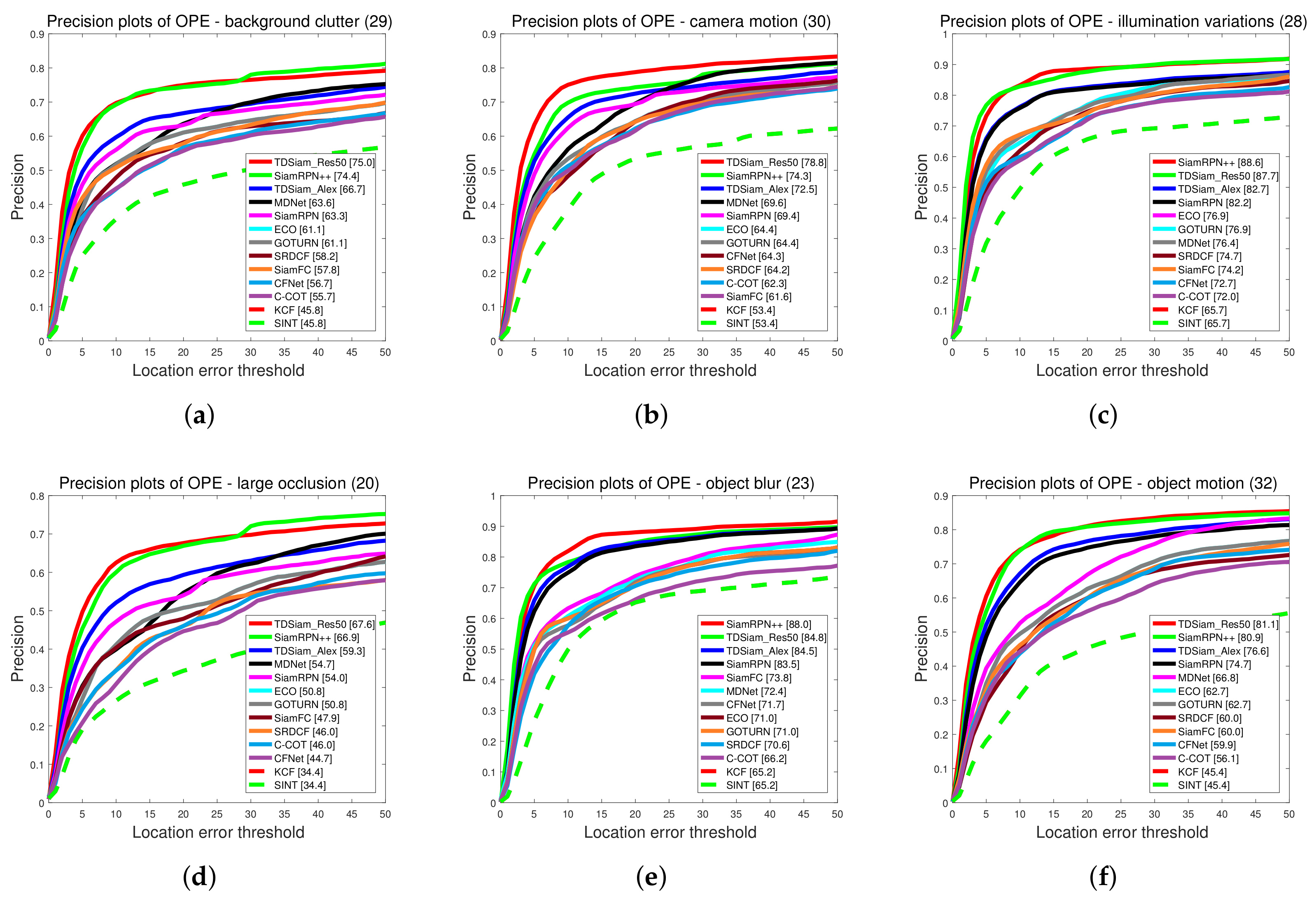
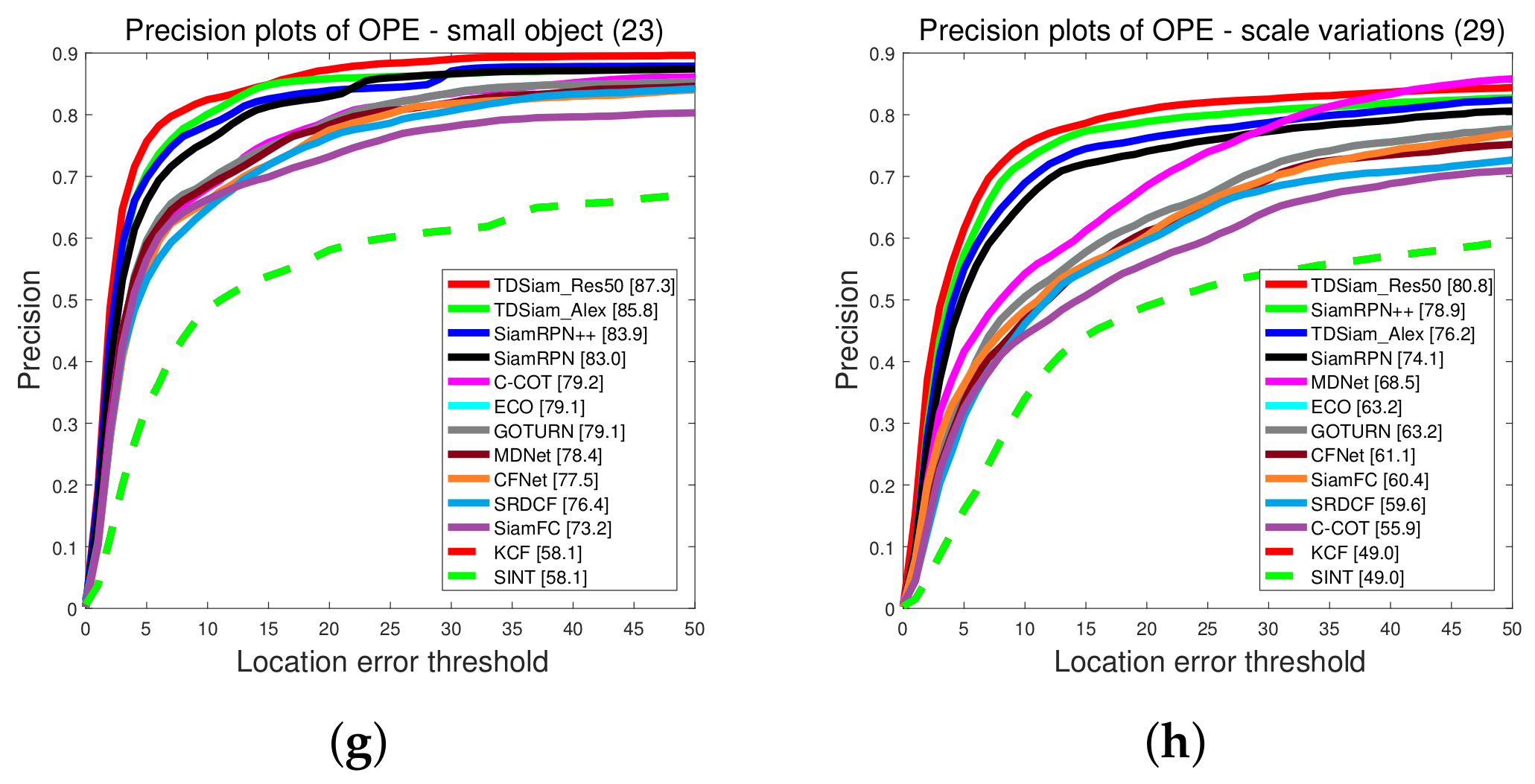
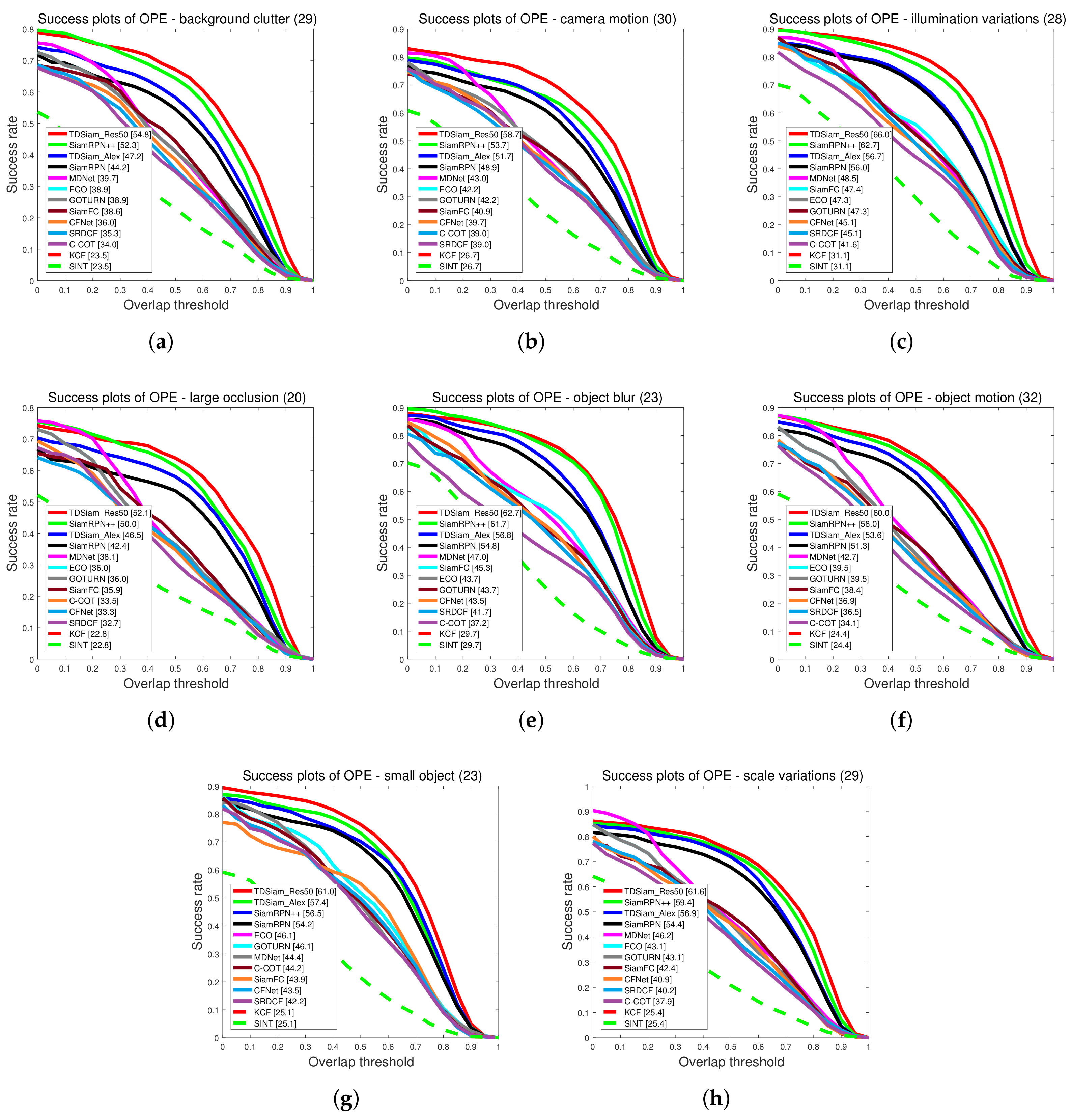
Overall Evaluation: The precision plots and Success plots are shown in
Figure 12. Our proposed method TDSiam achieved better performance under both the AlexNet and ResNet backbones. The TDSiam_Alex achieved a success rate of 0.562 and a precision score of 0.787. Compared with the SiamRPN, the success rate is improved by 4.9% and the precision score is improved by 3.1%. In addition, TDSiam_Res50 also achieved the best results. The success rate and precision score exceeded SiamRPN++, reaching 0.615 and 0.826, respectively.
Attribute-Based Evaluation: The performance is evaluated under eight attributes and the comparison results are shown in
Figure 13 and
Figure 14. In terms of success rate, the TDSiam_Res50 achieved the best performance under all the attributes, which were BC (0.548), CM (0.587), IV (0.66), LO (0.521), OB (0.627), OM (0.600), SMO (0.610), SV (0.616). In particular, compared with SiamRPN++, the success rate under CM, SMO and IV was increased by 9.3%, 6.3% and 5.3%, respectively. In addition, compared with the baseline tracker SiamRPN, the TDSiam_Alex also achieved better performance under all the attributes. As for precision score, the TDSiam_Res50 achieved the best performance under six attributes, which were BC (0.750), CM (0.788), LO (0.676), OM (0.811), SMO (0.879), SV (0.808), respectively. In addition, compared with the baseline tracker SiamRPN, TDSiam_Alex achieved better performance under all the attributes.
4.5. Qualitative Evaluation
In order to present the tracking performance more intuitively, we carried out qualitative experiments with the other algorithms, including SiamRPN++ [
28], DaSiamRPN [
23], SiamRPN [
14] and SiamFC-3s [
12], in the UAV123 dataset. We selected five typical video sequences in UAV123 for analysis, as shown in
Figure 15, including VC, CM, IV, SV and other common attributes.
boat3: The boat3 video sequence contains a typical view-changing scene. At the 114th frame, the performance gap of all tracking algorithms is not obvious. From the 331st to the 871st frame, the appearance and the scale of the target change slowly, our proposed method TDSiam_Res50 can still track the target stably, while the tracking performance of other methods has declined.
car2_s: This video sequence is a process of continuous rotation and rolling of a vehicle, and the appearance of the target changes dramatically due to the change of illumination in the scene. In the first 48 frames, the appearance of the target has not changed significantly, and all methods can track continuously. However, in the 176th and 275th frames, other algorithms have failed to trace completely due to rotation and illumination changes, but our method can still locate the target effectively.
car4: The car4 sequence shows the whole process of a car being blocked and then reappearing. In the 404th frame, all trackers lost their target due to occlusion and the DaSiamRPN even drifted to another car. In the rest of the video sequence, only our method TDSiam_Res50 can find the target again and track it continuously.
car12: In this video sequence, a car passes through a straight road, which is blocked by many trees. In the whole video sequence, only our method can continuously complete the tracking, and other algorithms cannot track after losing the target. In the 174th frame, the DaSiamRPN finds the target again, but the scale estimation is not accurate.
truck2: The scale of the target in the truck2 sequence is small, and the scene also contains many similar buildings. From the 112nd frame, the tracking performance of other algorithms is no longer stable, especially after the occlusion of the 189th frame, the other algorithms even lose the target. Fortunately, our method TDSiam_Res50 can recover the tracking performance more quickly.
4.6. Ablation Study
To further verify the effectiveness of the each module, we conducted an ablation study using the UAV123 dataset. It aims to show which module contributes to the overall performance of the tracker. As shown in
Table 2, the symbol represents that a particular module has been used, whereas the symbol × indicates that the module has not been used.
As shown in the second row of
Table 2, the performance of the proposed template-driven Siamese network is worse than that of baseline because the interference is easy to introduce once the target is occluded. In other words, the template-driven Siamese network using the polluted template may harm the tracking performance. To solve this problem, we propose an effective template updating strategy in this paper. By adding the APCE index, the template-driven Siamese network can recognize whether the target is occluded or not. When the target is not occluded, the template library can bring performance gains to the tracker by updating the template. This strategy is indispensable for the template-driven Siamese network and guarantees that the introduced template is not polluted. On the contrary, the tracking performance will be worse than the baseline if the template library does not use the template updating strategy with the APCE index.
APCE boosts the performance significantly with a score of 0.630 in terms of success rate, exceeding baseline by 1.3%. As shown in the last row of the table, on incorporating the FA module, our proposed method achieves a success score of 0.643 and a precision score of 0.828, which leads to a performance improvement of 4% and 2.5%, respectively. Experimental results show that template library (TL), feature aligned module (FA) and average peak-to-correlation energy (APCE) all play an important role in the algorithm.
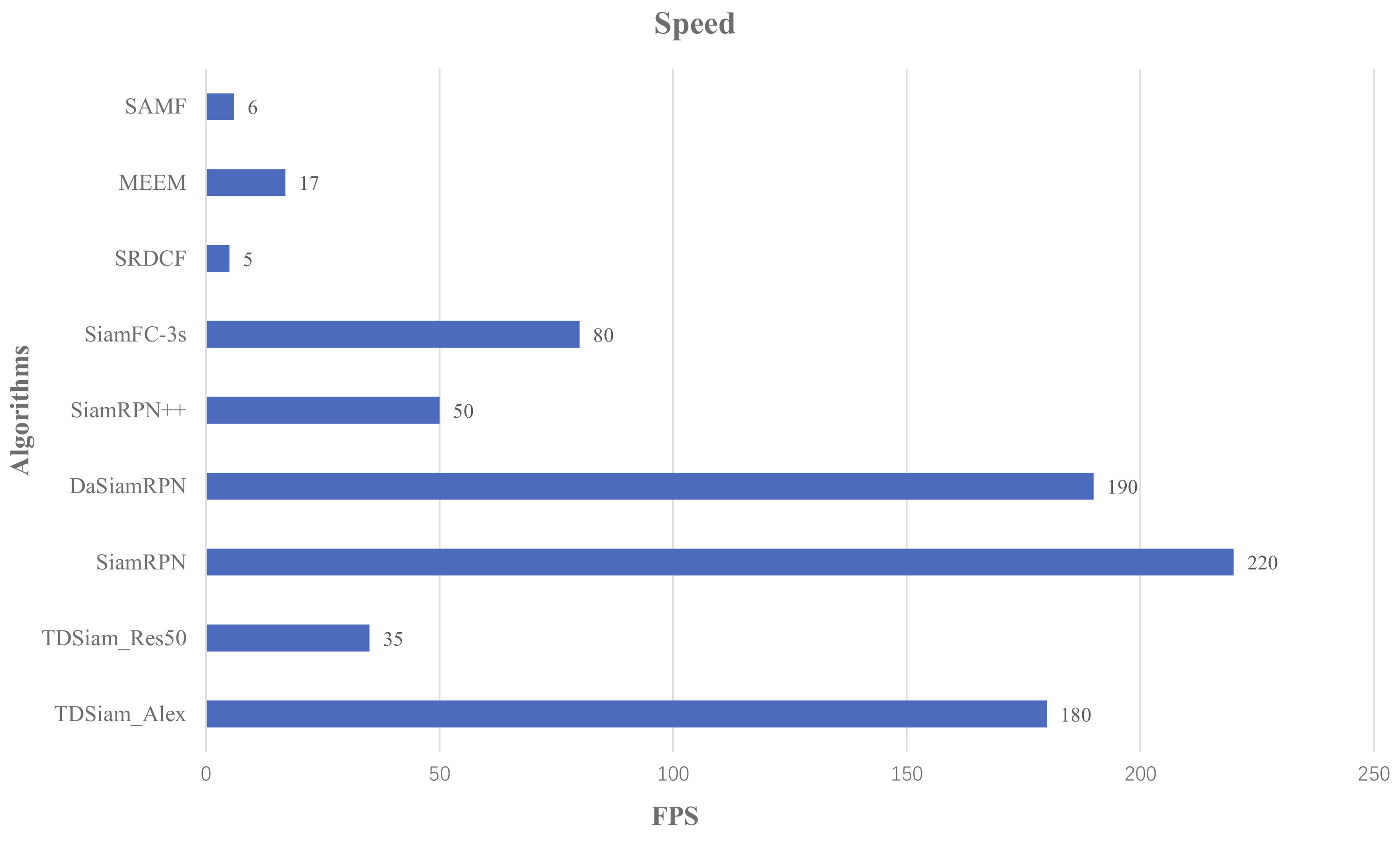
4.7. Speed Performance
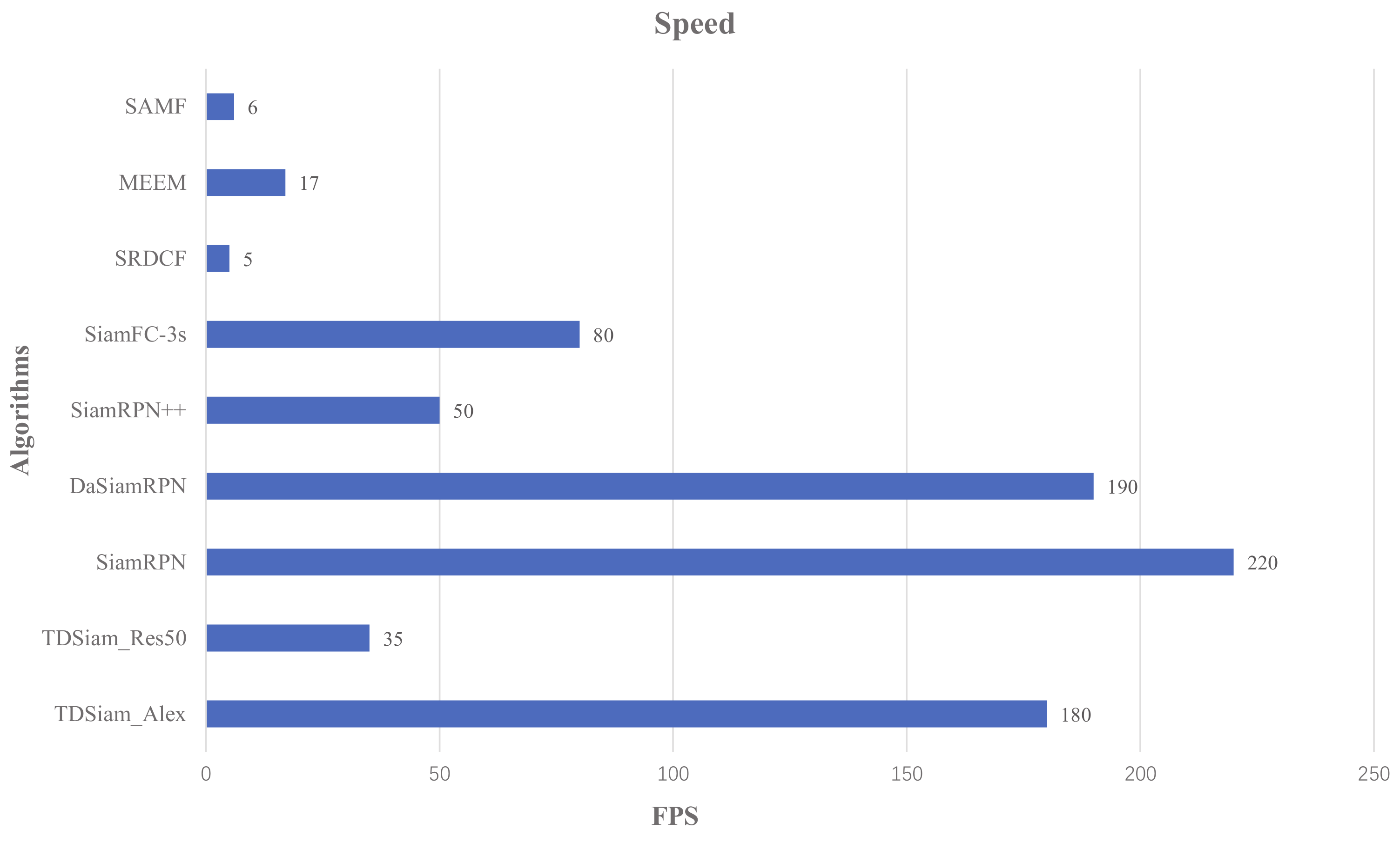
Figure 16 shows the speed performance of different methods, including SiamRPN++ [
28], DaSiamRPN [
23], SiamRPN [
14], SiamFC-3s [
12], SRDCF [
17], MEEM [
43] and SAMF [
44]. Due to the addition of template library, the tracking speed of our proposed method decreases slightly compared with the SiamRPN++ and SiamRPN. Although our method TDSiam_Res50 is not the fastest, it can still meet the real-time requirements and reach 35 fps.
5. Conclusions
To improve the performance of the visual object tracking in unmanned aerial vehicle videos, this paper has proposed a template-driven Siamese network (TDSiam), in which a template library has been integrated into the Siamese network for solving the problem that the appearance of the target in UAV videos often changes. A feature alignment module is proposed to fuse the features from the template library more efficiently. Moreover, we have designed a template updating strategy to guarantee the effectiveness of templates in the inference stage. Performance comparisons on three challenging UAV video benchmarks, including UAV123, UAV20L and UAVDT, have demonstrated that the proposed approach can bring significant performance improvement. It also provides help for the application of UAVs in practical tracking scenarios. However, there are some problems, such as the long-term tracking performance degradation, which still need to be solved. To summarize, the proposed approach has room for development and improvement, and future research should focus on exploring the trajectory prediction and redetection strategy for UAV tracking.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}