
Remote Sensing Image Denoising Based on Deep and Shallow Feature Fusion and Attention Mechanism


Abstract
1. Introduction
- Because remote sensing images have complex feature characteristics, inspired by the inception network architecture [20], we use a multi-scale feature extraction block in the first layer of the model to extract as many features and detailed textures as possible from the original noisy images, effectively improving the model’s ability to maintain details and the model’s generalization ability. The learning difficulties of the network can be alleviated without the loss of information.
- We designed a network structure for deep and shallow feature fusion by analyzing the signal transfer in the network and fused the deep and shallow information of the model into the main feature mapping part through skip connections in the subsequent network structure to facilitate the subsequent reconstruction process. The shallow information focuses on local information in the image such as edges, while the deep information focuses on global information in the image such as texture and high-level semantic information, thus improving the expressiveness of the denoising model to obtain satisfactory noise feature maps for global feature fusion and noise map reconstruction.
- The main component of the model, the enhanced attention block (EAB), has been specifically designed to process remote sensing images with complex information. The module is significantly useful for processing complex noisy images by being able to mine the noise information hidden in the complex background from a given noisy image.
- In this paper, a variety of evaluation indicators are proposed for the evaluation of the denoising effect of remote sensing images. The evaluation metrics include pixel-level evaluation and visual effect evaluation metrics. Our proposed denoising algorithm achieves superior results than other traditional methods and deep learning methods on both synthetic noisy images and real noisy images.
2. Related Work
2.1. Traditional Methods of Remote Sensing Image Denoising
2.2. Deep Learning Methods of Remote Sensing Image Denoising
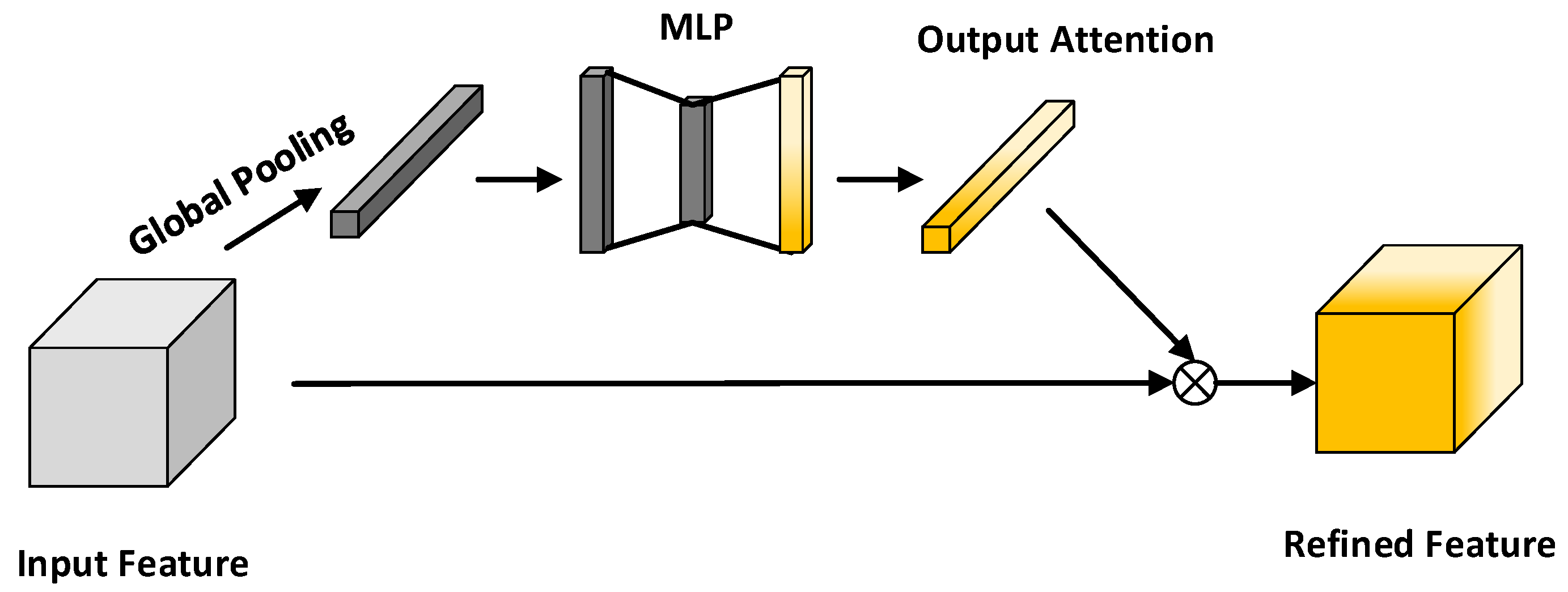
2.3. Attentional Mechanism
2.4. Residual Structure
3. Proposed Method
3.1. Network Architecture
3.2. Role of Multi-Scale Feature Extraction Module
3.3. Loss Function
4. Experiments
4.1. Datasets
4.2. Implementation Details and Hyperparameter Settings
4.2.1. Implementation Settings
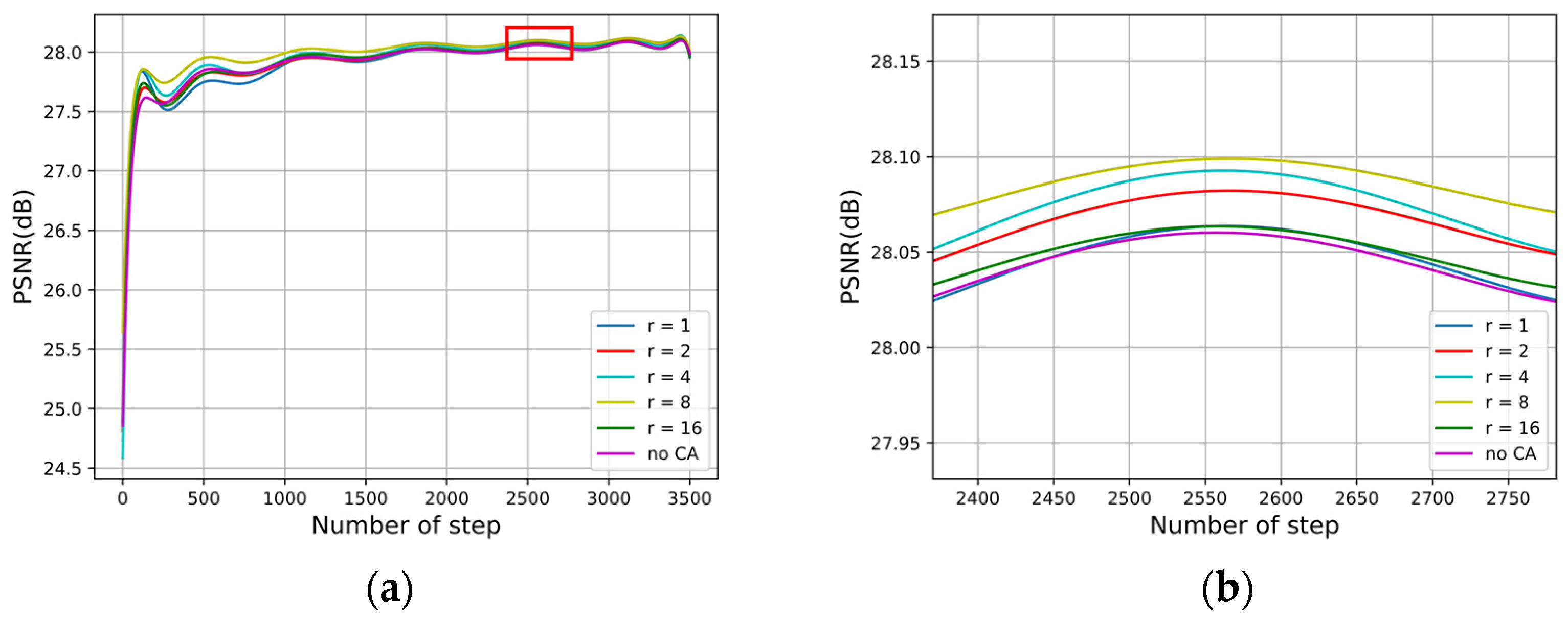
4.2.2. Network Hyperparameters
4.2.3. Implementation Process
4.3. Compare with Advanced Algorithms
4.3.1. Gray and Color Synthetic Noisy Remote Sensing Image
4.3.2. Real Noisy Remote Sensing Images
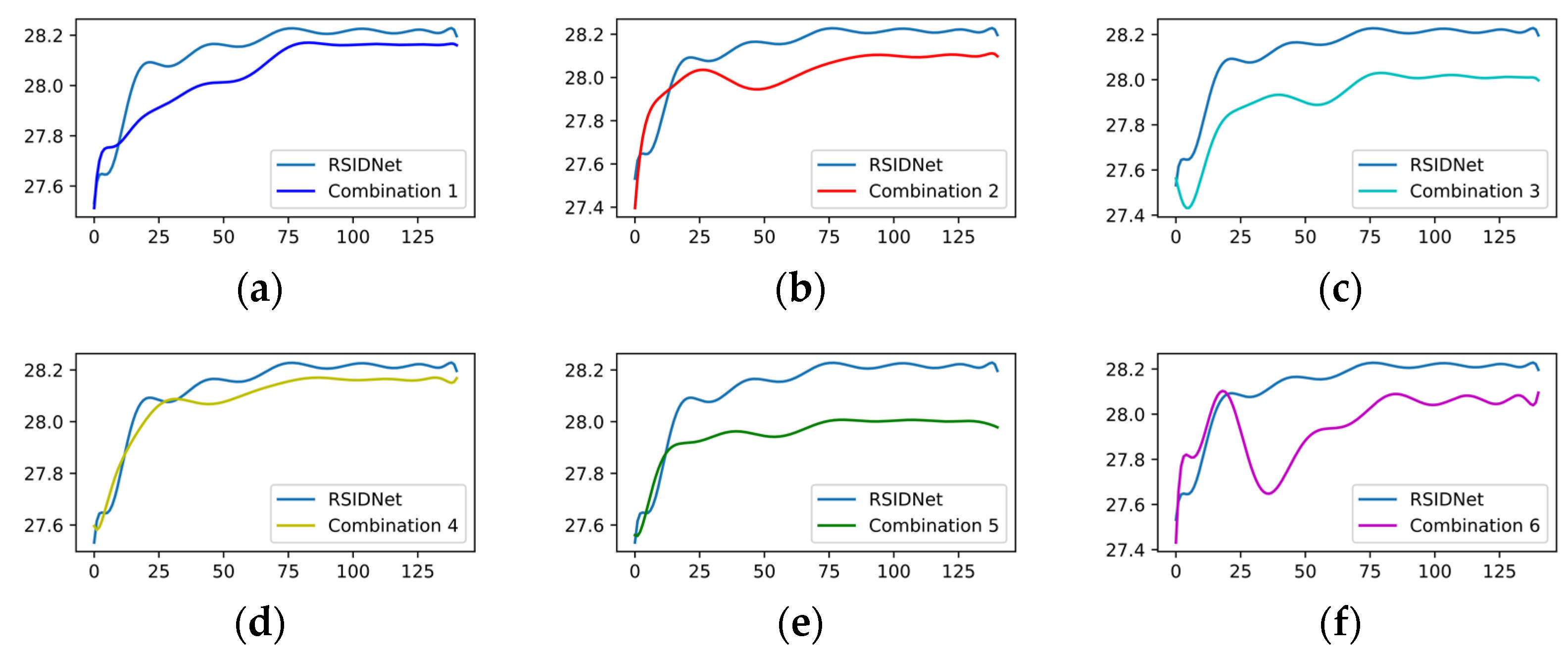
4.4. Ablation Experiment
5. Summary and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Feng, X.B.; Zhang, W.X.; Su, X.Q.; Xu, Z.P. Optical Remote Sensing Image Denoising and Super-Resolution Reconstructing Using Optimized Generative Network in Wavelet Transform Domain. Remote Sens. 2021, 13, 1858. [Google Scholar] [CrossRef]
- Zhu, Y.H.; Yang, G.J.; Yang, H.; Zhao, F.; Han, S.Y.; Chen, R.Q.; Zhang, C.J.; Yang, X.D.; Liu, M.; Cheng, J.P.; et al. Estimation of Apple Flowering Frost Loss for Fruit Yield Based on Gridded Meteorological and Remote Sensing Data in Luochuan, Shaanxi Province, China. Remote Sens. 2021, 13, 1630. [Google Scholar] [CrossRef]
- Qi, J.H.; Wan, P.C.; Gong, Z.Q.; Xue, W.; Yao, A.H.; Liu, X.Y.; Zhong, P. A Self-Improving Framework for Joint Depth Estimation and Underwater Target Detection from Hyperspectral Imagery. Remote Sens. 2021, 13, 1721. [Google Scholar] [CrossRef]
- Zhang, J.Y.; Zhang, X.R.; Tang, X.; Huang, Z.J.; Jiao, L.C. Vehicle Detection and Tracking in Remote Sensing Satellite Vidio Based on Dynamic Association. In Proceedings of the 10th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Shanghai, China, 5–7 August 2019. [Google Scholar]
- Xia, J.Q.; Wang, Y.Z.; Zhou, M.R.; Deng, S.S.; Li, Z.W.; Wang, Z.H. Variations in Channel Centerline Migration Rate and Intensity of a Braided Reach in the Lower Yellow River. Remote Sens. 2021, 13, 1680. [Google Scholar] [CrossRef]
- Yuan, Q.Q.; Zhang, Q.; Li, J.; Shen, H.F.; Zhang, L.P. Hyperspectral Image Denoising Employing a Spatial-Spectral Deep Residual Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1205–1218. [Google Scholar] [CrossRef]
- Gao, F.; Huang, T.; Sun, J.P.; Wang, J.; Hussain, A.; Yang, E.F. A New Algorithm for SAR Image Target Recognition Based on an Improved Deep Convolutional Neural Network. Cogn. Comput. 2019, 11, 809–824. [Google Scholar] [CrossRef]
- Landgrebe, D.A.; Malaret, E. Noise in Remote-Sensing Systems—The Effect on Classification Error. IEEE Trans. Geosci. Remote Sens. 1986, 24, 294–300. [Google Scholar] [CrossRef]
- Tian, C.W.; Fei, L.K.; Zheng, W.X.; Xu, Y.; Zuo, W.M.; Lin, C.W. Deep learning on image denoising: An overview. Neural Netw. 2020, 131, 251–275. [Google Scholar] [CrossRef]
- Anwar, S.; Barnes, N. Real Image Denoising with Feature Attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 3155–3164. [Google Scholar]
- Xue, S.K.; Qiu, W.Y.; Liu, F.; Jin, X.Y. Wavelet-based residual attention network for image super-resolution. Neurocomputing 2020, 382, 116–126. [Google Scholar] [CrossRef]
- Goyal, B.; Dogra, A.; Agrawal, S.; Sohi, B.S.; Sharma, A. Image denoising review: From classical to state-of-the-art approaches. Inf. Fusion 2020, 55, 220–244. [Google Scholar] [CrossRef]
- Singh, L.; Janghel, R. Image Denoising Techniques: A Brief Survey. In Proceedings of the 4th International Conference on Harmony Search, Soft Computing and Applications (ICHSA), BML Munjal Univ, Sidhrawali, India, 7–9 February 2018; pp. 731–740. [Google Scholar]
- Foi, A.; Trimeche, M.; Katkovnik, V.; Egiazarian, K. Practical Poissonian-Gaussian noise modeling and fitting for single-image raw-data. IEEE Trans. Image Process. 2008, 17, 1737–1754. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.H.; Zhang, F.Q.; Liu, Q.G.; Wang, S.S. VST-Net: Variance-stabilizing transformation inspired network for Poisson denoising. J. Vis. Commun. Image Represent. 2019, 62, 12–22. [Google Scholar] [CrossRef]
- Chen, J.W.; Chen, J.W.; Chao, H.Y.; Yang, M. Image Blind Denoising with Generative Adversarial Network Based Noise Modeling. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3155–3164. [Google Scholar]
- Cha, S.; Park, T.; Kim, B.; Baek, J.; Moon, T.J. GAN2GAN: Generative Noise Learning for Blind Denoising with Single Noisy Images. arXiv 2019, arXiv:1905.10488. [Google Scholar]
- Huang, T.; Li, S.; Jia, X.; Lu, H.; Liu, J.J. Neighbor2Neighbor: Self-Supervised Denoising from Single Noisy Images. arXiv 2021, arXiv:2101.02824. [Google Scholar]
- Pang, T.; Zheng, H.; Quan, Y.; Ji, H. Recorrupted-to-Recorrupted: Unsupervised Deep Learning for Image Denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2043–2052. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear Total Variation Based Noise Removal Algorithms. Physica D 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Yihu, C.; Zhenglin, Y.E. Improved anisotropic diffusion image denoising method. Comput. Eng. Appl. 2008, 44, 170–172. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.M. Nonlocal image and movie denoising. Int. J. Comput. Vis. 2008, 76, 123–139. [Google Scholar] [CrossRef]
- Gu, S.H.; Zhang, L.; Zuo, W.M.; Feng, X.C. Weighted Nuclear Norm Minimization with Application to Image Denoising. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 2862–2869. [Google Scholar]
- Donoho, D.L.; Johnstone, I.M. Ideal Spatial Adaptation by Wavelet Shrinkage. Biometrika 1994, 81, 425–455. [Google Scholar] [CrossRef]
- Gai, S.; Bao, Z.Y.; Zhang, K.G. Vector extension of quaternion wavelet transform and its application to colour image denoising. IET Signal Process. 2019, 13, 133–140. [Google Scholar] [CrossRef]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef]
- Lewicki, G.; Marino, G. Approximation by superpositions of a sigmoidal function. Z. Anal. Ihre. Anwend. 2003, 22, 463–470. [Google Scholar] [CrossRef]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Zhao, H.H.; Luo, J.; Huang, Z.H.; Nagumo, T.; Murayama, J.; Zhang, L.Q. Statistically Adaptive Image Denoising Based on Overcomplete Topographic Sparse Coding. Neural Process. Lett. 2015, 41, 357–369. [Google Scholar] [CrossRef]
- Burger, H.C.; Schuler, C.J.; Harmeling, S. Image denoising: Can plain neural networks compete with BM3D? In Proceedings of the 2012 IEEE conference on computer vision and pattern recognition(CVPR), Providence, RI, USA, 16-21 June 2012; pp. 2392–2399. [Google Scholar]
- Chen, Y.J.; Yu, W.; Pock, T. On learning optimized reaction diffusion processes for effective image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5261–5269. [Google Scholar]
- Jain, V.; Seung, S.J.A. Natural image denoising with convolutional networks. In Proceedings of the 21st International Conference on Neural Information Processing Systems (NIPS), Vancouver, Canada, 8–10 December 2008; pp. 769–776. [Google Scholar]
- Zhang, K.; Zuo, W.M.; Chen, Y.J.; Meng, D.Y.; Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Zhang, K.; Zuo, W.M.; Zhang, L. FFDNet: Toward a Fast and Flexible Solution for CNN-Based Image Denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef]
- Divakar, N.; Babu, R.V. Image Denoising via CNNs: An Adversarial Approach. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1076–1083. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Varga, D. Multi-pooled Inception Features for No-reference Video Quality Assessment. In Proceedings of the 15th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP)/15th International Conference on Computer Vision Theory and Applications (VISAPP), Valletta, Malta, 27–29 February 2020; pp. 338–347. [Google Scholar]
- Yuan, B.H.; Li, S.J.; Li, N. Multiscale deep features learning for land-use scene recognition. J. Appl. Remote Sens. 2018, 12, 12. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.W.; Lu, X.Q. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Zoran, D.; Weiss, Y. From Learning Models of Natural Image Patches to Whole Image Restoration. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 479–486. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1026–1034. [Google Scholar]
- Kingma, D.P.; Ba, J.J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.M.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Tian, C.W.; Xu, Y.; Li, Z.Y.; Zuo, W.M.; Fei, L.K.; Liu, H. Attention-guided CNN for image denoising. Neural Netw. 2020, 124, 117–129. [Google Scholar] [CrossRef]
- Tian, C.W.; Xu, Y.; Fei, L.K.; Wang, J.Q.; Wen, J.; Luo, N. Enhanced CNN for image denoising. CAAI T. Intell. Technol. 2019, 4, 17–23. [Google Scholar] [CrossRef]
- Liu, L.X.; Liu, B.; Huang, H.; Bovik, A.C. No-reference image quality assessment based on spatial and spectral entropies. Signal Process. Image Commun. 2014, 29, 856–863. [Google Scholar] [CrossRef]
- Saad, M.A.; Bovik, A.C.; Charrier, C. Blind Image Quality Assessment: A Natural Scene Statistics Approach in the DCT Domain. IEEE Trans. Image Process. 2012, 21, 3339–3352. [Google Scholar] [CrossRef] [PubMed]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-Reference Image Quality Assessment in the Spatial Domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.Y.; Guo, Y.W.; Wang, Y.L.; Wang, D.; Peng, C.; He, G.P. Denoising of Hyperspectral Images Using Nonconvex Low Rank Matrix Approximation. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5366–5380. [Google Scholar] [CrossRef]
- Bigdeli, B.; Samadzadegan, F.; Reinartz, P. A Multiple SVM System for Classification of Hyperspectral Remote Sensing Data. J. Indian Soc. Remote Sens. 2013, 41, 763–776. [Google Scholar] [CrossRef][Green Version]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Methods | σ = 15 PSNR/SSIM | σ = 25 PSNR/SSIM | σ = 35 PSNR/SSIM | σ = 50 PSNR/SSIM |
|---|---|---|---|---|---|
| NWPU-RESISC45 | BM3D | 31.52/0.9316 | 29.05/0.8862 | 27.49/0.8470 | 25.82/0.7977 |
| K-SVD | 29.42/0.8950 | 26.89/0.8146 | 24.56/0.7295 | 22.59/0.6171 | |
| WNNM | 31.44/0.8509 | 29.38/0.8030 | 27.97/0.7515 | 26.54/0.6972 | |
| DnCNN-S | 31.90/0.9345 | 29.51/0.8934 | 28.13/0.8596 | 26.71/0.8158 | |
| DnCNN-B | 31.80/0.9332 | 29.49/0.8924 | 28.07/0.8575 | 26.65/0.8154 | |
| ADNet | 31.83/0.9367 | 29.53/0.8990 | 28.11/0.8655 | 26.71/0.8260 | |
| ECNDNet | 31.72/0.9363 | 29.36/0.8936 | 28.10/0.8660 | 26.74/0.8273 | |
| RSIDNet(ours)-S | 31.94/0.9385 | 29.64/0.9007 | 28.22/0.8692 | 26.82/0.8295 | |
| RSIDNet(ours)-B | 31.81/0.9357 | 29.50/0.8964 | 28.03/0.8628 | 26.60/0.8187 | |
| UCMerced_LandUse | BM3D | 31.31/0.9361 | 28.779/0.8935 | 27.18/0.8564 | 25.43/0.8081 |
| K-SVD | 29.31/0.9007 | 26.50/0.8193 | 24.38/0.7357 | 22.06/0.6257 | |
| WNNM | 31.55/0.8822 | 28.99/0.8174 | 27.42/0.7627 | 25.88/0.7047 | |
| DnCNN-S | 31.79/0.9422 | 29.28/0.9046 | 27.72/0.8717 | 26.13/0.8289 | |
| DnCNN-B | 31.52/0.9380 | 29.05/0.8990 | 27.57/0.8661 | 25.85/0.8204 | |
| ADNet | 31.64/0.9402 | 29.19/0.9041 | 27.66/0.8710 | 26.19/0.8298 | |
| ECNDNet | 31.60/0.9394 | 29.08/0.8990 | 27.60/0.8704 | 26.22/0.8314 | |
| RSIDNet(ours)-S | 31.84/0.9429 | 29.38/0.9065 | 27.88/0.8757 | 26.34/0.8353 | |
| RSIDNet(ours)-B | 31.57/0.9384 | 29.10/0.8998 | 27.56/0.8661 | 25.92/0.8212 |
| Dataset | Methods | σ = 15 PSNR/SSIM | σ = 25 PSNR/SSIM | σ = 35 PSNR/SSIM | σ = 50 PSNR/SSIM |
|---|---|---|---|---|---|
| NWPU-RESISC45 | CBM3D | 33.95/0.9602 | 31.16/0.9277 | 29.32/0.8953 | 27.23/0.8499 |
| K-SVD | 31.05/0.9186 | 28.34/0.8776 | 26.96/0.8205 | 24.68/0.7363 | |
| WNNM | 31.45/0.8508 | 29.35/0.8035 | 27.99/0.7512 | 26.56/0.6974 | |
| DnCNN-S | 34.25/0.9631 | 31.59/0.9356 | 30.00/0.9107 | 28.41/0.8777 | |
| DnCNN-B | 33.98/0.9610 | 31.40/0.9347 | 29.81/0.9090 | 28.30/0.8742 | |
| ADNet | 34.14/0.9621 | 31.54/0.9347 | 29.95/0.9097 | 28.40/0.8774 | |
| ECNDNet | 34.01/0.9602 | 31.36/0.9330 | 29.83/0.9076 | 28.34/0.8755 | |
| RSIDNet(ours)-S | 34.28/0.9635 | 31.61/0.9360 | 30.08/0.9137 | 28.49/0.8791 | |
| RSIDNet(ours)-B | 33.76/0.9602 | 31.44/0.9331 | 29.74/0.9050 | 28.33/0.8741 | |
| UCMerced_LandUse | CBM3D | 33.22/0.9585 | 30.67/0.9299 | 28.97/0.9015 | 27.05/0.8609 |
| K-SVD | 30.85/0.9319 | 28.58/0.8867 | 26.68/0.8333 | 24.46/0.7534 | |
| WNNM | 31.54/0.8820 | 29.95/0.8175 | 27.45/0.7620 | 25.87/0.7052 | |
| DnCNN-S | 33.18/0.9602 | 30.79/0.9347 | 29.29/0.9105 | 27.70/0.8774 | |
| DnCNN-B | 32.94/0.9589 | 30.65/0.9330 | 29.17/0.9086 | 27.62/0.8751 | |
| ADNet | 32.99/0.9588 | 30.71/0.9338 | 29.16/0.9086 | 27.70/0.8774 | |
| ECNDNet | 32.75/0.9572 | 30.42/0.9315 | 28.98/0.9073 | 27.61/0.8762 | |
| RSIDNet(ours)-S | 33.26/0.9609 | 30.82/0.9358 | 29.35/0.9125 | 27.83/0.8809 | |
| RSIDNet(ours)-B | 32.91/0.9570 | 30.67/0.9334 | 29.18/0.9088 | 27.68/0.8755 |
| Image | Airplane | Beach | Forest | Freeway | Island | Ship | Stadium | River |
|---|---|---|---|---|---|---|---|---|
| Noise level | σ = 15 | |||||||
| BM3D | 33.01 | 30.52 | 40.23 | 31.64 | 36.35 | 34.95 | 40.46 | 42.52 |
| K-SVD | 30.32 | 28.55 | 38.94 | 30.39 | 31.99 | 30.41 | 37.71 | 40.62 |
| WNNM | 33.12 | 30.60 | 29.35 | 31.71 | 36.25 | 35.05 | 30.90 | 32.50 |
| DnCNN | 33.40 | 30.95 | 40.74 | 32.04 | 36.51 | 35.29 | 41.20 | 42.96 |
| ADNet | 33.19 | 30.77 | 40.67 | 31.90 | 36.49 | 35.15 | 40.99 | 42.87 |
| ECNDNet | 32.80 | 30.72 | 40.53 | 31.80 | 36.35 | 35.04 | 40.87 | 42.70 |
| RSIDNet(ours) | 33.47 | 30.92 | 40.72 | 32.05 | 36.54 | 35.34 | 41.21 | 43.01 |
| Noise level | σ = 25 | |||||||
| BM3D | 30.42 | 27.89 | 37.01 | 29.68 | 34.04 | 32.47 | 36.98 | 39.35 |
| K-SVD | 27.15 | 25.97 | 35.59 | 27.22 | 28.16 | 27.42 | 34.66 | 36.33 |
| WNNM | 30.62 | 28.07 | 26.78 | 29.94 | 34.07 | 32.91 | 28.43 | 30.15 |
| DnCNN | 30.92 | 28.34 | 37.67 | 30.12 | 34.43 | 33.03 | 37.96 | 36.32 |
| ADNet | 30.84 | 28.34 | 37.67 | 30.04 | 34.35 | 33.07 | 37.95 | 36.31 |
| ECNDNet | 30.67 | 28.31 | 37.55 | 30.08 | 34.29 | 33.06 | 37.87 | 36.23 |
| RSIDNet(ours) | 30.99 | 28.41 | 37.72 | 30.17 | 31.41 | 33.08 | 37.98 | 36.47 |
| Noise level | σ = 35 | |||||||
| BM3D | 28.75 | 26.44 | 35.14 | 28.45 | 32.65 | 30.77 | 34.85 | 37.54 |
| K-SVD | 24.78 | 24.02 | 32.94 | 25.03 | 25.76 | 25.26 | 31.95 | 33.07 |
| WNNM | 29.12 | 26.56 | 25.25 | 28.79 | 32.88 | 31.37 | 26.96 | 28.82 |
| DnCNN | 29.44 | 26.94 | 36.09 | 28.95 | 33.02 | 31.48 | 36.03 | 38.07 |
| ADNet | 29.30 | 26.88 | 35.91 | 28.94 | 32.96 | 31.54 | 36.02 | 38.03 |
| ECNDNet | 29.12 | 26.87 | 35.98 | 28.95 | 33.05 | 31.54 | 35.89 | 37.95 |
| RSIDNet(ours) | 29.47 | 26.96 | 36.07 | 29.11 | 33.12 | 31.65 | 36.04 | 38.14 |
| Noise level | σ = 50 | |||||||
| BM3D | 26.86 | 25.01 | 33.19 | 27.17 | 31.02 | 28.51 | 32.65 | 35.86 |
| K-SVD | 22.30 | 21.97 | 29.98 | 22.57 | 23.27 | 23.05 | 28.90 | 29.71 |
| WNNM | 27.49 | 25.26 | 23.81 | 27.66 | 30.72 | 28.78 | 25.64 | 27.33 |
| DnCNN | 27.85 | 25.55 | 34.35 | 27.89 | 31.70 | 29.91 | 34.20 | 36.32 |
| ADNet | 27.82 | 25.57 | 34.38 | 27.94 | 31.62 | 29.87 | 34.18 | 36.31 |
| ECNDNet | 27.70 | 25.53 | 34.35 | 27.94 | 31.65 | 29.83 | 34.02 | 36.27 |
| RSIDNet(ours) | 27.92 | 25.65 | 34.40 | 28.15 | 31.74 | 30.14 | 34.20 | 36.47 |
| Dataset | Evaluation Methods | Noisy Image | BM3D | K-SVD | DnCNN-B | RSIDNet-B(ours) |
|---|---|---|---|---|---|---|
| AVIRIS Indian Pines dataset | SSEQ↑ | 86.46 | 53.35 | 69.26 | 80.24 | 66.59 |
| BLIINDS-II↑ | 88.50 | 74 | 82.50 | 95 | 98.5 | |
| BRISQUE↓ | 57.35 | 33.53 | 65.77 | 34.98 | 32.43 | |
| ROSIS University of Pavia dataset | SSEQ↑ | 74.57 | 61.74 | 59.85 | 65.5 | 63.82 |
| BLIINDS-II↑ | 63.5 | 49 | 36 | 78 | 81.32 | |
| BRISQUE↓ | 20.17 | 47.62 | 47.02 | 36.47 | 27.14 |
| Description | Different Types of Combinations | ||||||
|---|---|---|---|---|---|---|---|
| Module | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Multi-Kernel Convolution | 🗸 | 🗴 | 🗴 | 🗴 | 🗸 | 🗸 | 🗸 |
| Feature Fusion Structure | 🗴 | 🗸 | 🗴 | 🗸 | 🗴 | 🗸 | 🗸 |
| Channel Attention | 🗴 | 🗴 | 🗸 | 🗸 | 🗸 | 🗴 | 🗸 |
| PSNR/dB | 28.16 | 28.10 | 28.01 | 28.15 | 28.01 | 27.99 | 28.21 |
| SSIM | 0.7684 | 0.7666 | 0.7498 | 0.7685 | 0.7469 | 0.7610 | 0.7721 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, L.; Zhao, Y.; Lv, H.; Zhang, Y.; Liu, H.; Bi, G. Remote Sensing Image Denoising Based on Deep and Shallow Feature Fusion and Attention Mechanism. Remote Sens. 2022, 14, 1243. https://doi.org/10.3390/rs14051243
Han L, Zhao Y, Lv H, Zhang Y, Liu H, Bi G. Remote Sensing Image Denoising Based on Deep and Shallow Feature Fusion and Attention Mechanism. Remote Sensing. 2022; 14(5):1243. https://doi.org/10.3390/rs14051243
Chicago/Turabian StyleHan, Lintao, Yuchen Zhao, Hengyi Lv, Yisa Zhang, Hailong Liu, and Guoling Bi. 2022. "Remote Sensing Image Denoising Based on Deep and Shallow Feature Fusion and Attention Mechanism" Remote Sensing 14, no. 5: 1243. https://doi.org/10.3390/rs14051243
APA StyleHan, L., Zhao, Y., Lv, H., Zhang, Y., Liu, H., & Bi, G. (2022). Remote Sensing Image Denoising Based on Deep and Shallow Feature Fusion and Attention Mechanism. Remote Sensing, 14(5), 1243. https://doi.org/10.3390/rs14051243