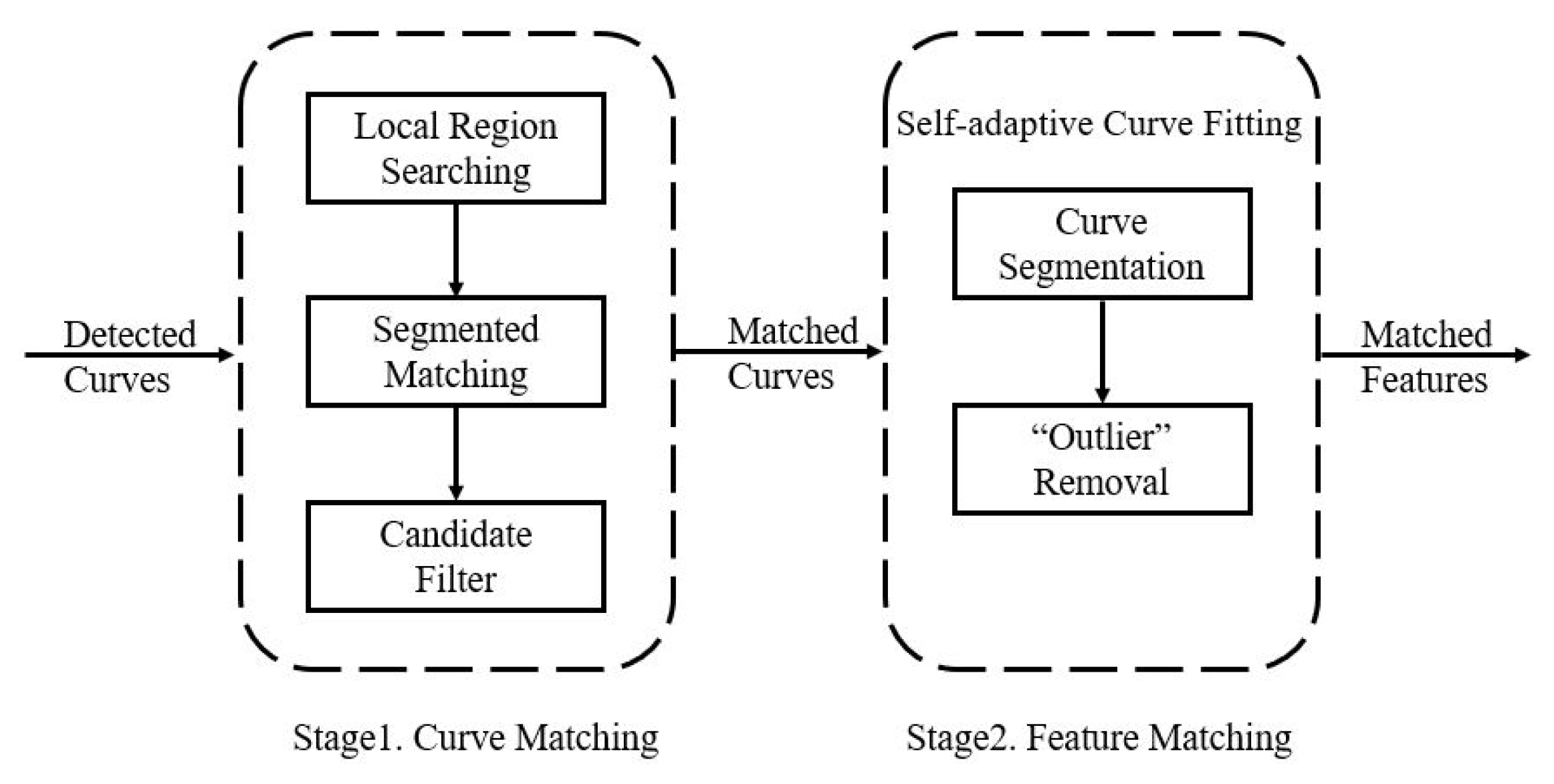
3.1. Curve Matching
For a pair of images
and
, our first step is to detect and match the keypoint matches
and
. As many keypoint detection methods can be used, in our approach we choose SIFT [
13] to obtain the initial keypoints, which is implemented by Vlfeat [
49]. This does not mean that our method relies on SIFT [
13] to obtain an initial homography. Other keypoint detection methods such as SURF [
20], ORB [
14], or BRISK [
23] can also provide the initial keypoints that we need. Then, we conduct RANSAC [
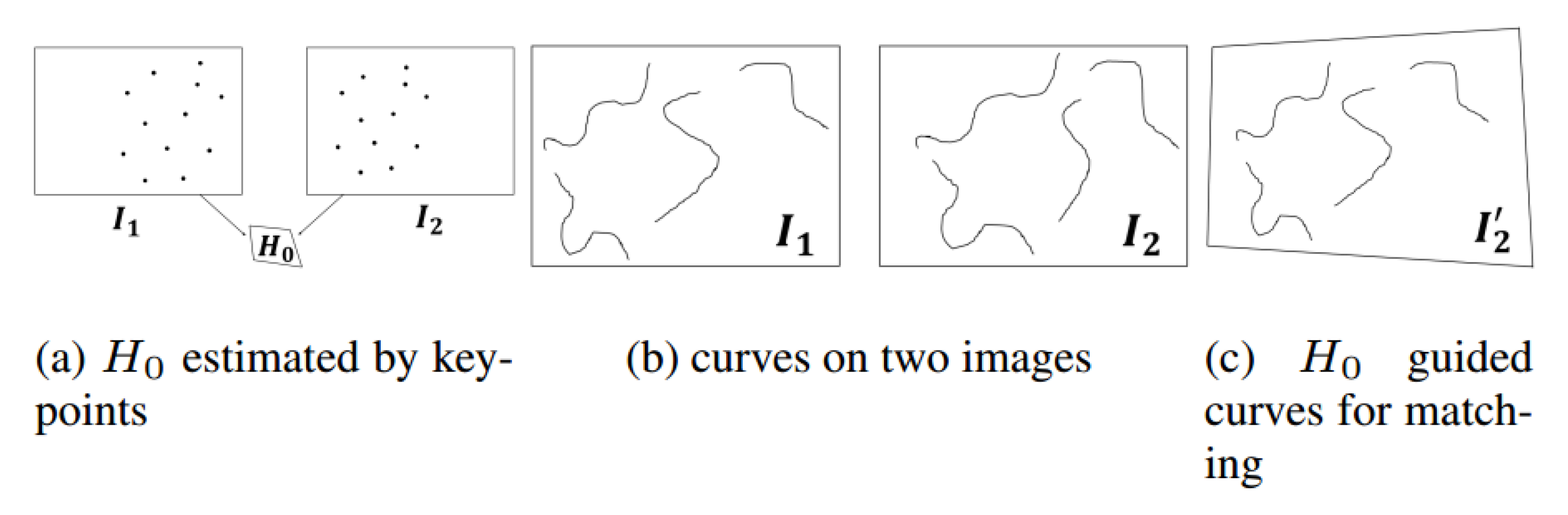
26] to remove the mismatches and leverage the matches to obtain an initial
homography
by function
(
is
in homogeneous coordinates), as shown in
Figure 3a.
is a global transformation of the image pair, which may provide an approximation of the scale or perspective change between images. Note that we use edge drawing [
44] to detect curves in the images. The curve-matching stage includes three steps:
local region searching,
segmented matching and
candidate filtering. Algorithm 1 is given to show the pseudo-code of this stage. Detailed illustrations are as follows.
| Algorithm 1 The pseudo-algorithm of the curve matching stage. |
Input: A pair of images and to be matched. Detect all the curves in and to obtain a curve list for each image. for each detected curve cin the curve list of , Search c’s candidates in the curve list of by the local region searching step. for each in the candidate list ,
(see Algorithm 2 for details). by the candidate filtering step. Output: Accurately-matched curve-segment pairs in and .
|
| Algorithm 2 The pseudo-algorithm of segmented matching. |
Input: Curve c from and one of its candidates in from . Step 1. Find a pair of fiducial points on c and ; Step 2. Starting from the fiducial points, obtain the MSCD description of 5-pixel curve segments respectively on c and , expressed as , ; while<, do MSCD descriptions, expressed as , ; list . Output: Multiple curve-segment matches () on c and .
|
Local region searching. We project
to
by initial homography
and obtain the transformed image
(
Figure 3c). In order to improve the precision of searching, the overlapping region in image
is first partitioned into a grid of 5 × 5 cells. For each cell, an exclusive threshold, which is expressed as
, is adopted for candidate searching.
represents the number of keypoints in the current cell,
represents the largest number of keypoints among all cells, and
is the default threshold, which is set as 2.0. The dynamic threshold can guarantee a desirable searching of curve candidates, even if the initial homography is not satisfying.
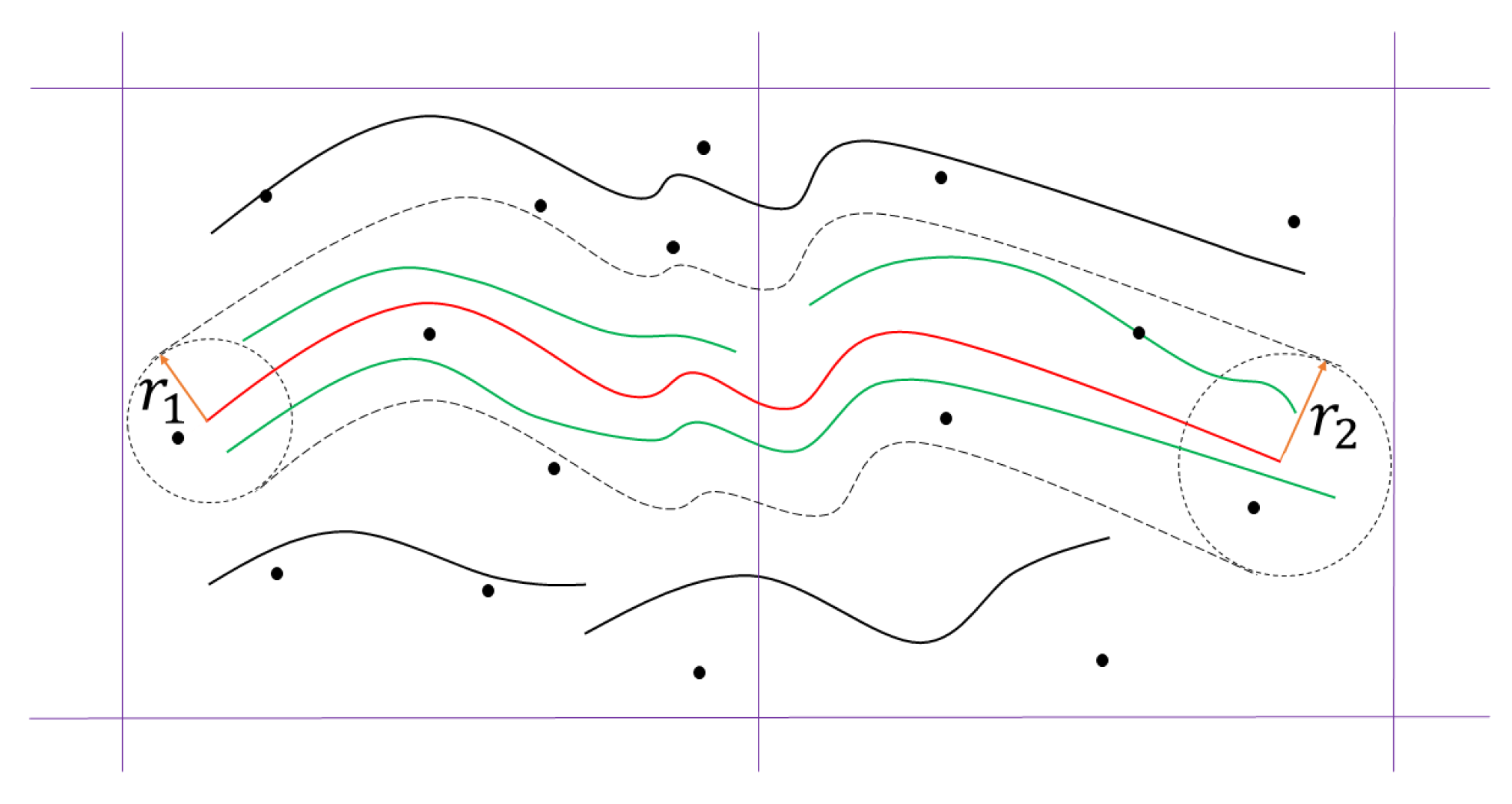
For one curve
c in the overlapping region of image
, we search its potential candidates in image
as follows: each pixel on
c is regarded as a center, and the radius is the exclusive threshold in the corresponding cell (as shown in
Figure 4). The center point slides from the starting point along
c to construct the searching region in
; then, all the curves in this region are denoted as
. The fewer keypoints exist in a grid, the larger the searching radius will be, considering that the alignment of curves in this region is not desirable. In this way, this local searching procedure not only narrows the region of curve candidates, but also prevents the omission of potential candidates due to the changing radius.
Segmented matching. To acquire high-quality correspondences from c and its candidates , we adopt a segmented matching strategy in this step. A pseudo-algorithm is given in Algorithm 2 to make our strategy more understood.
First, we obtain a pair of fiducial points on
c and one of its candidates
. The fiducial points serve as the starting points of segment matching and are determined by the following procedures: (i) for each point on a curve, we describe it together with its five neighboring points on the curve under a threshold
for the similarity of MSCD [
37]; (ii)
nearest/next ratio (NNDR) [
13] is used to find the best matching fiducial point pair under a default NNDR ratio
.
Then, we need to match the fixed-length (set as 5 pixels in our paper) curve segments by evaluating their MSCD. Accordingly, a local threshold and a global threshold are introduced to select curve segments that have enough similarity. Starting from the fiducial points on c and , the Euclidean distance of the corresponding segment’s MSCD is compared with . Next, the matching goes on from the endpoint, and the next two 5-pixel segments are evaluated in the same manner. Then. they are joined to the matching segments as a whole to evaluate their similarity and compare it with . The calculating and comparing is be implemented iteratively. As soon as either threshold is exceeded, the matching stops executing and we consider the joint segments matched.
To enrich the number of correspondences, the segmented matching procedures are executed on the remaining part of curve
c in the same way. That is to say, a new pair of fiducial points are obtained on the remaining curve segments, where the segmented matching algorithm will be executed again. The implementation results on one pair of correspondences are shown in
Figure 5, which illustrates that multiple curve-segment matches can be obtained for one pair of curve correspondences.
As for c and all of its candidates , the matching is implemented independently on each pair of them; namely, the segmented-matching of c is conducted n times.
Candidate filter. In this step, we need to construct an elaborate descriptor to find the best matching candidate as the unique correspondence of one curve segment. The
gradient description matrix (GDM) in [
37] is a widely-used descriptor for curves, which contains the most structural information in the curve neighborhood region, expressed as Equation (
1), where
is used as the description vector of the sub-region
.
consists of four components of the gradients distributed in the sub-region
in four directions, which are the direction of the curve, the normal direction of the curve, and their opposite directions, respectively. In addition, in Equation (
1),
and
N denote the count of sub-regions and points on a curve, respectively;
i ranges from 1 to
and
j ranges from 1 to
N. Furthermore, based on the GDM, the MSCD is obtained by computing the normalized mean vector and the normalized standard deviation vector of the GDM’s column vectors. However, we do not find this effective enough to describe complicated irregular curves. To more accurately distinguish the candidates, we present a
gradient difference descriptor (GDD) based on GDM.
Unlike the overall description of GDM, we adopt the gradient difference between vector
and
(or
) and divide each pixel support region into positive and negative parts, as shown in
Figure 6. The two matrixes are expressed as
and
in Equations (
2) and (
3), where
. Accordingly, two vectors of the gradient difference descriptor can be calculated to describe each side of the curve, thus helping to find the unique corresponding curve in
. Then, we project it back to
to obtain
, which is the unique correspondence of
c.
The above illustration focuses on one curve and its candidates to explain the procedures of curve matching. With all the curves in the image pair implemented according to the same procedures, a set of curve matches can be obtained in the curve-matching stage.
The whole curve-matching stage provides us curve pairs that have been matched as accurately as possible. Next, we need a further stage to extract the invariant features from the matched curves to make good use of them.
3.2. Feature Matching
The potential matching curves of the same object from different views should be the “same”, with one projective transformation between them. However, due to changes of perspective and pixel-level description, two curves in a pair may still have minor differences. In our paper, a curve-fitting approach is adopted to eliminate the diversities.
However, if we directly implement curve fitting on the curve pairs obtained in
Section 3.1, it is not enough to fit the curves well, which would influence the extraction of invariant features. Therefore, a self-adaptive fitting strategy is proposed to fit the curves more accurately, which includes
self-adaptive segmentation and
“outlier” removal under the constraint of fitting error.
As proven in the
Appendix A, the maximal curvature point is translation, rotation, and scale invariant, making it a proper feature of a fitted curve. Since the curvature
depends on the second derivative of the curve, any form of curve function that has the second derivative can be employed to extract the maximal curvature points. For convenience, we employ the cubic polynomial
to fit the matched curves. Hence, we calculate the fitting error between
and the curve as the segmentation and outlier removal criteria, which can be expressed as
. The curve-fitting threshold is set as
, which controls the curve segmentation and the outlier removal at the same time.
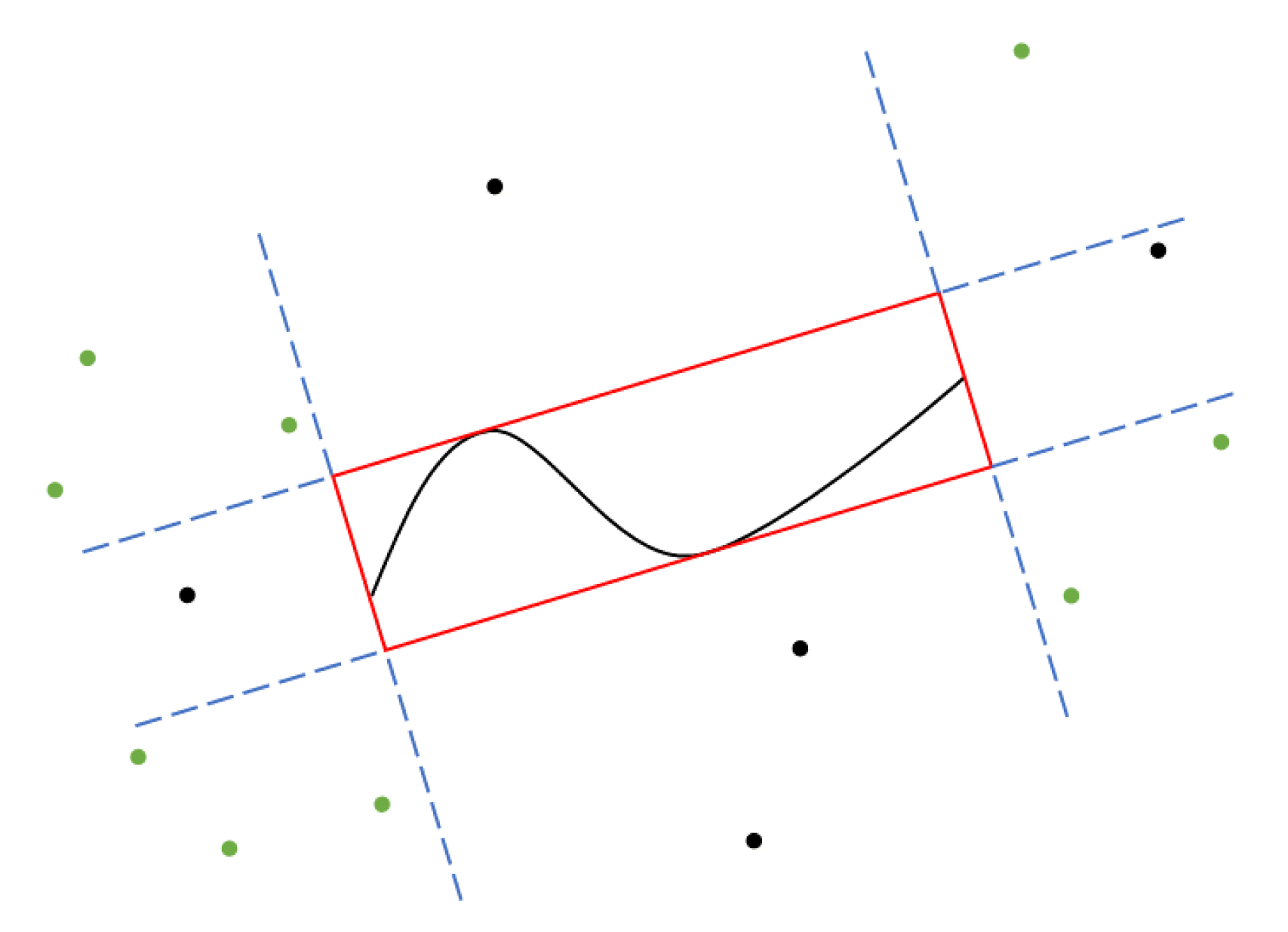
Self-adaptive segmentation. The detected keypoints in an image can provide a strong constraint for their enclosing region, which encourages us to choose the surrounding keypoints of a curve to constrain the curve fitting and matched-feature extraction.
Figure 7 shows the explanation of the surrounding keypoints.
The objective function to estimate the invariant features for a pair of curve segments is expressed as:
where
is the curve fitting term,
is the feature extracting term, and
is the surrounding keypoint constraint term. The
is used to evaluate the fitting of curve matches
and is defined as:
where
,
and
represent the curve fitting function and the number of pixels and pixel coordinate of
, respectively, while
,
and
describe
, accordingly.
The maximal curvature points serve as the features of the fitting curve, and the local homography
estimated by the surrounding keypoints is used to align the corresponding curve segments. There also exists a projective transformation between the matching maximal curvature points on the fitting curves, so the feature extracting term
is:
where
is a pair of maximal curvature points that are the invariant features we expect to obtain, and
is the number of the invariant feature matches.
We resort to the surrounding keypoints as another kind of constraint. The constraint term of keypoints
can be written as:
where
is a pair of surrounding keypoints and
is the number of matches.
Outlier removal. During the process of curve fitting, some defective points exist that would disturb the error calculation if added, which are regarded as the “outliers” in our paper. To this end, we evaluate the RMSE of the fitted curves to remove those points. The outlier removal process is executed along with the optimization of the objective function. In the ablation study of
Section 4.5, we can notice that the number of final matched features increases when adding our “outlier” removal operation.
Please note that our outlier-removal process is quite different from conventional methods such as RANSAC [
26]. These methods often serve as a post-processing procedure and aim to remove some poorly-matched points that would reduce the number of final matches. Conversely, our outlier removal aims to remove the defective points that would affect the curve fitting performance, which contributes to the whole optimization of our fitting process and further boosts the quality and quantity of the extracted features.
Ultimately, the selection of maximal curvature points of and are determined by a RMSE threshold . According to the procedures above, a set of matching features (Q represents the number of matched maximal curvature point pairs) from the curve pair can be obtained.
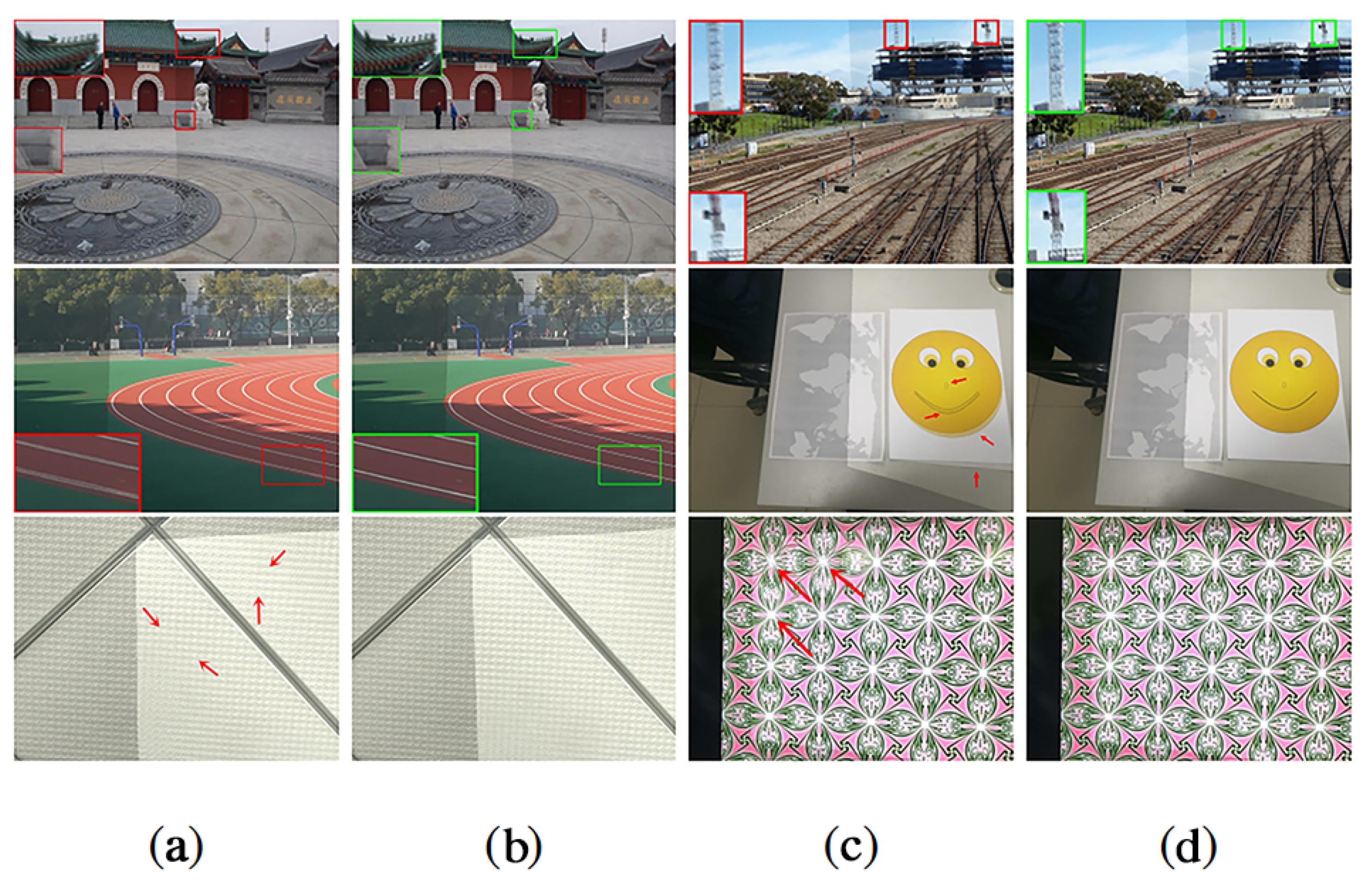
Note that conventional methods are relatively weak in dealing with two situations: (1) in low-texture scenes, keypoints cannot be detected easily, which directly influences feature matching; (2) in repeated-texture scenes, although keypoints can be detected, the following feature matching is quite difficult due to the similarity of descriptions. Therefore, an insufficient number of keypoints may lead to an unsatisfactory homography and perspective transformation. When using our elaborate matching steps, the matching of our invariant features derived from the curve is not be affected.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}