
Graph-Based Embedding Smoothing Network for Few-Shot Scene Classification of Remote Sensing Images



Abstract
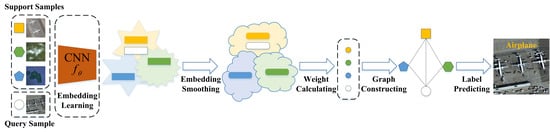
:
1. Introduction
- A novel graph neural network, referred to as GES-Net, is presented to enhance the performance of scene classification in few-shot settings. GES-Net adopts a new regularization technology to urge the model to learn discriminative and robust embedding features;
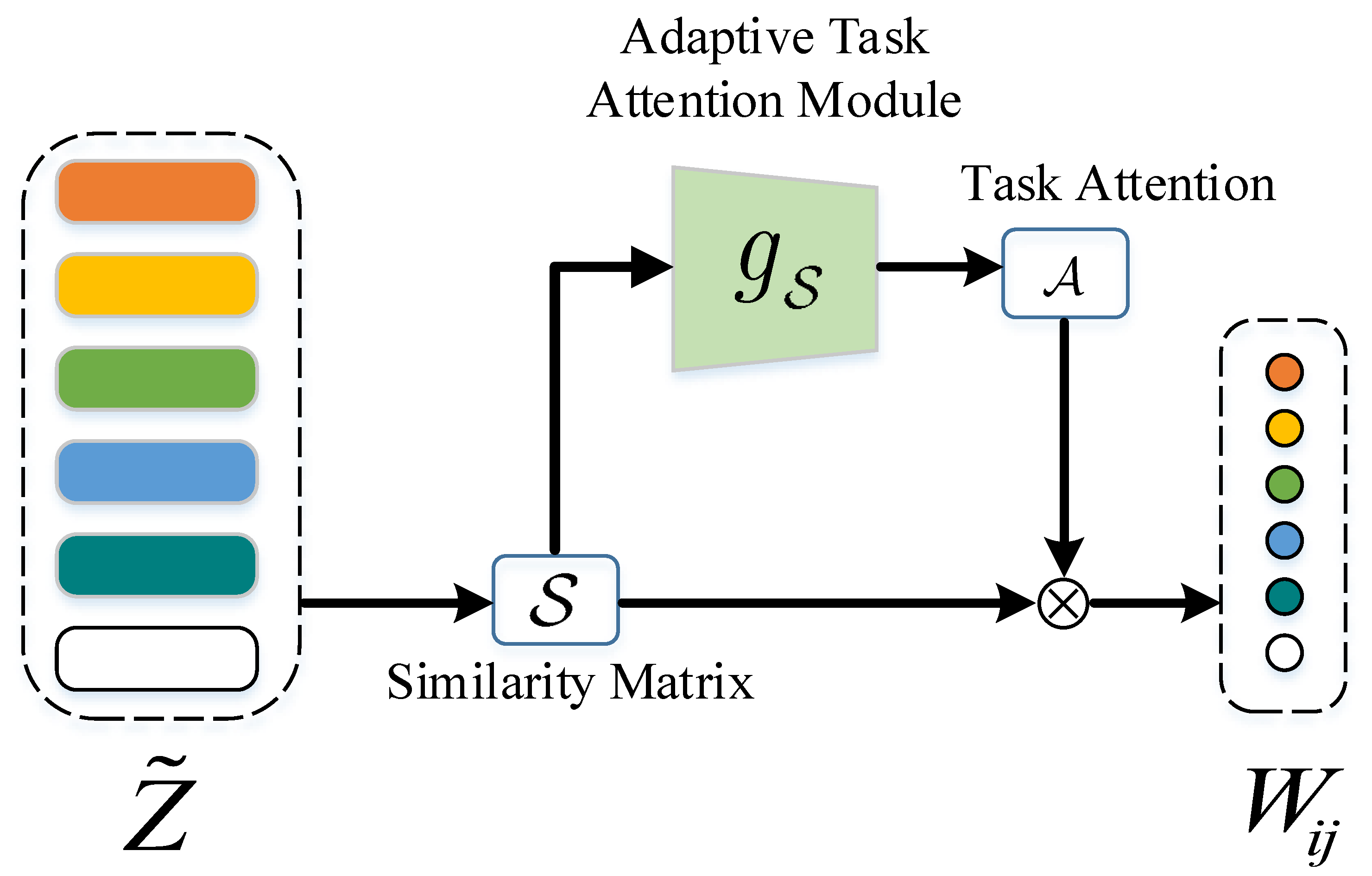
- The attention mechanism is further adopted to measure the relation representation at the task level. It can consider the relations between samples from the task level and improve the discrimination of the relation representation;
- The experimental results obtained on three publicly available remote sensing datasets showed that our proposed GES-Net method significantly outperformed state-of-the-art approaches in few-shot settings and obtained new state-of-the-art results in the case of limited labeled samples.
2. Related Work
2.1. Remote Sensing Scene Classification
2.2. Few-Shot Learning
2.3. Regularization for Generalization
2.4. Transductive Learning
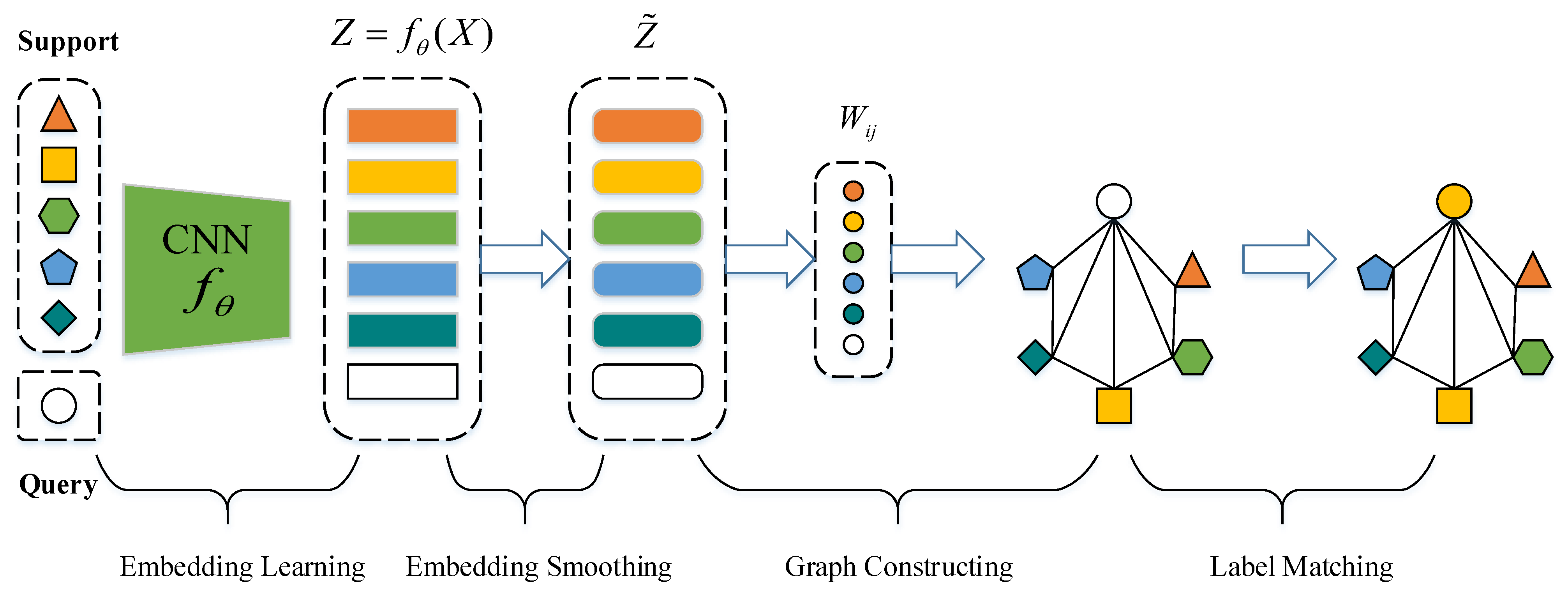
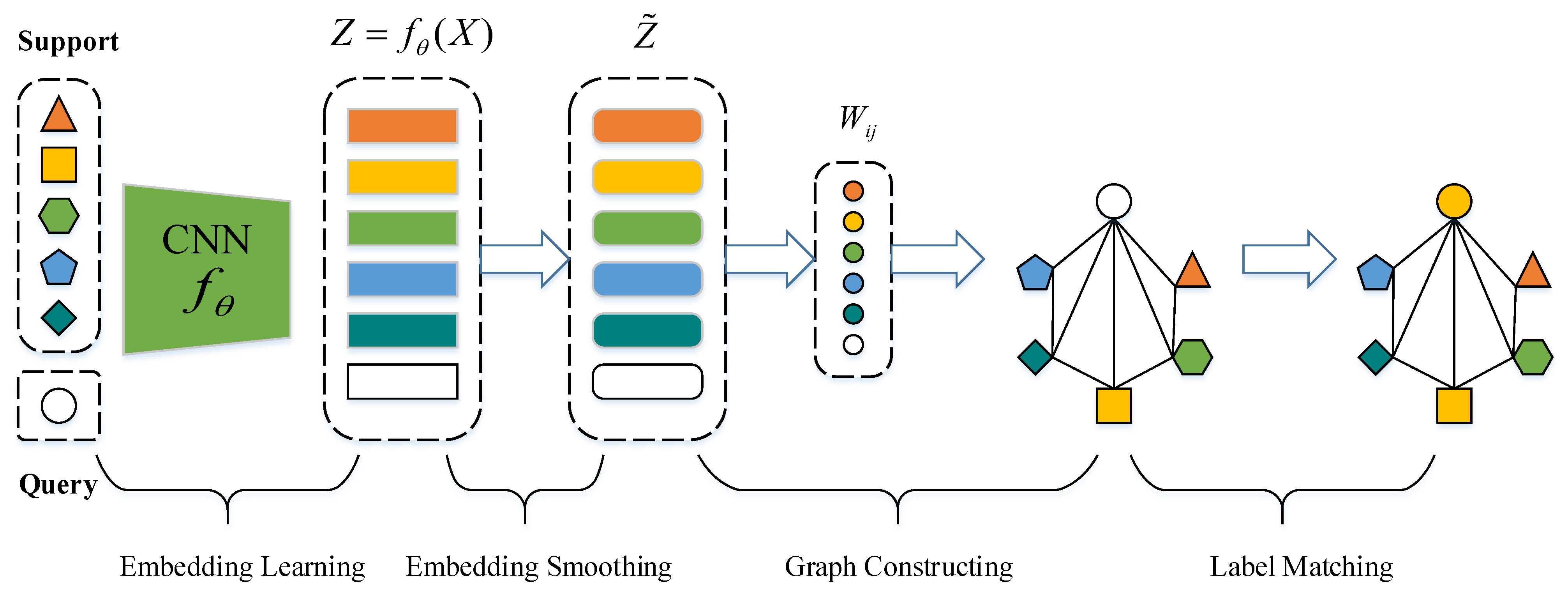
3. Proposed Method
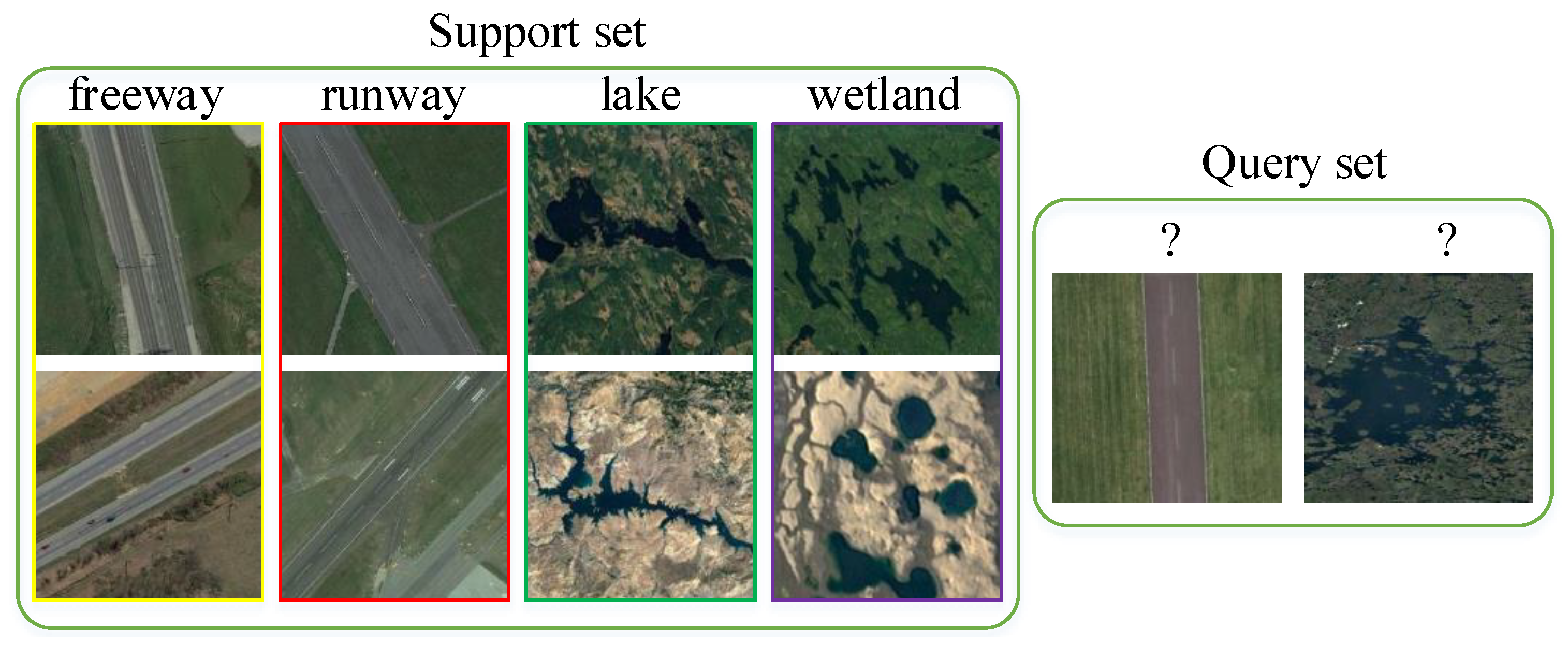
3.1. Few-Shot Setting Setup
3.2. Embedding Learning
3.3. Embedding Smoothing
3.4. Graph Constructing
3.5. Label Matching
4. Results and Discussion
4.1. Dataset Description
4.2. Experimental Settings
4.3. Evaluation Metrics
4.4. Time Complexity Analysis
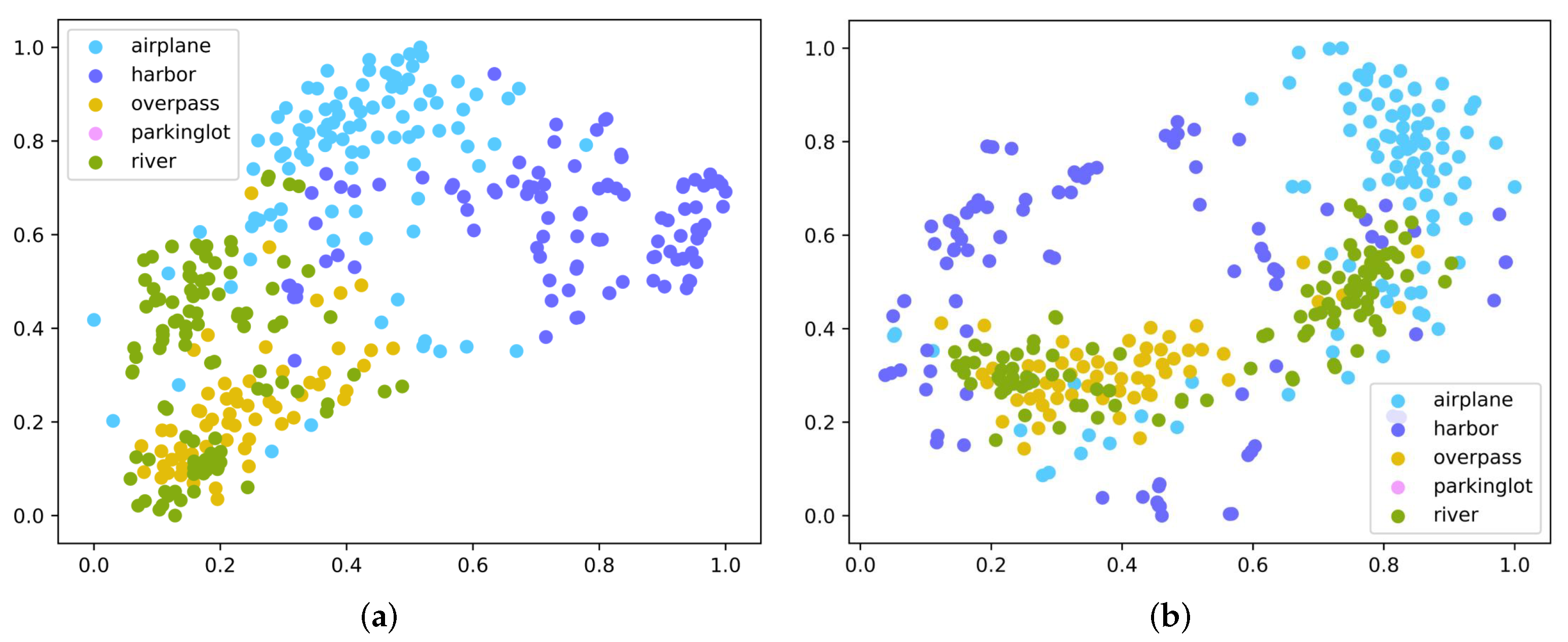
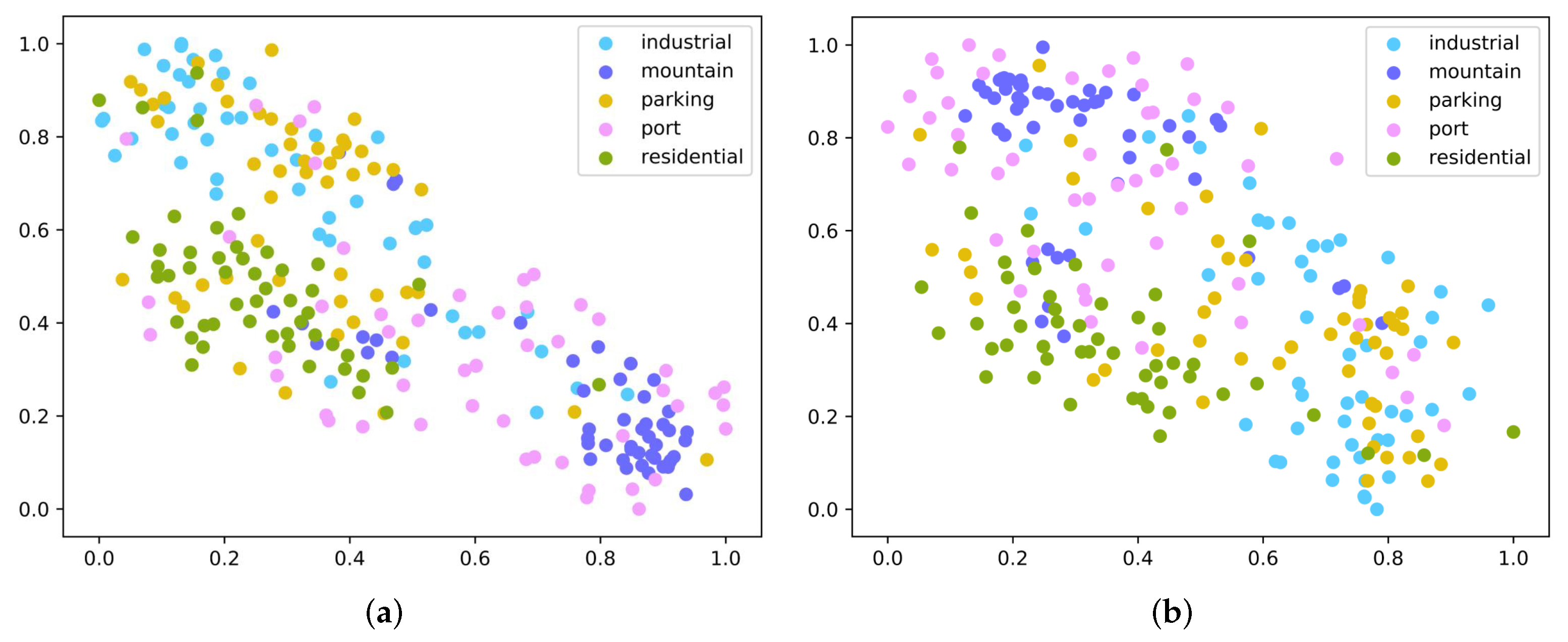
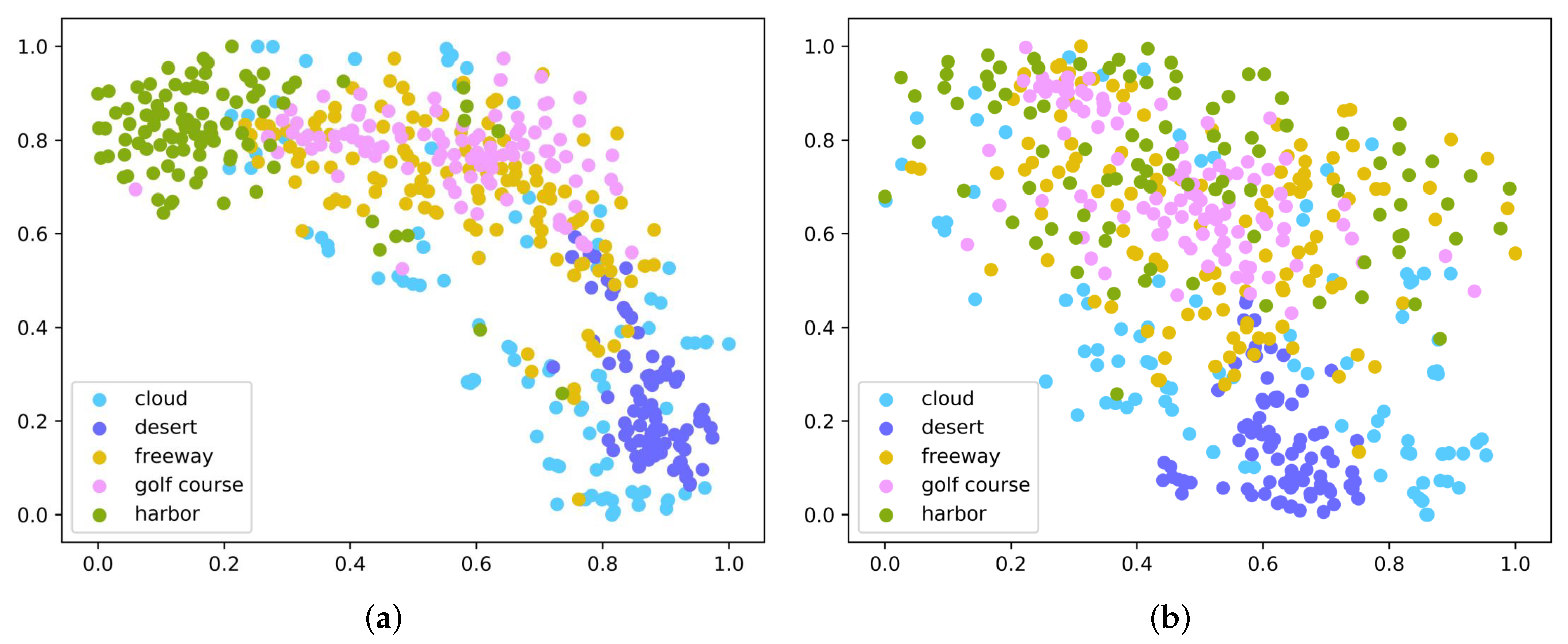
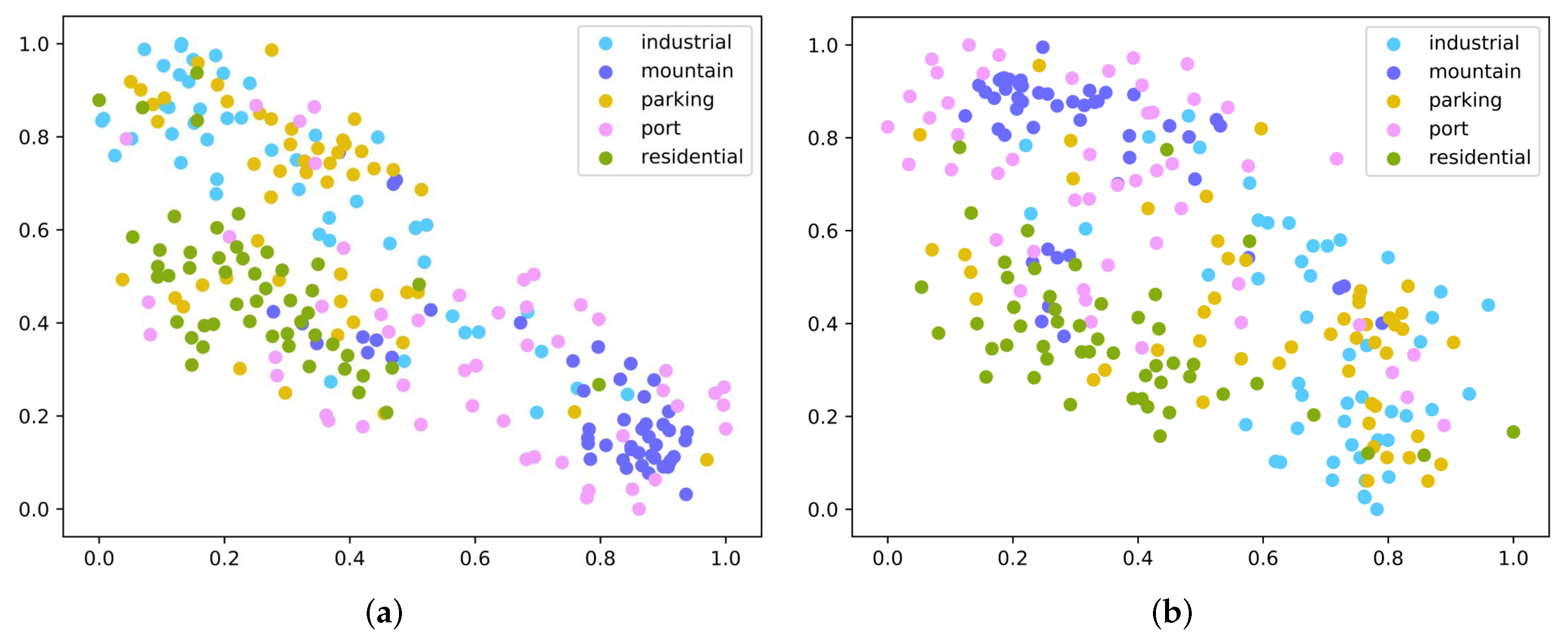
4.5. Embedding Space Analysis
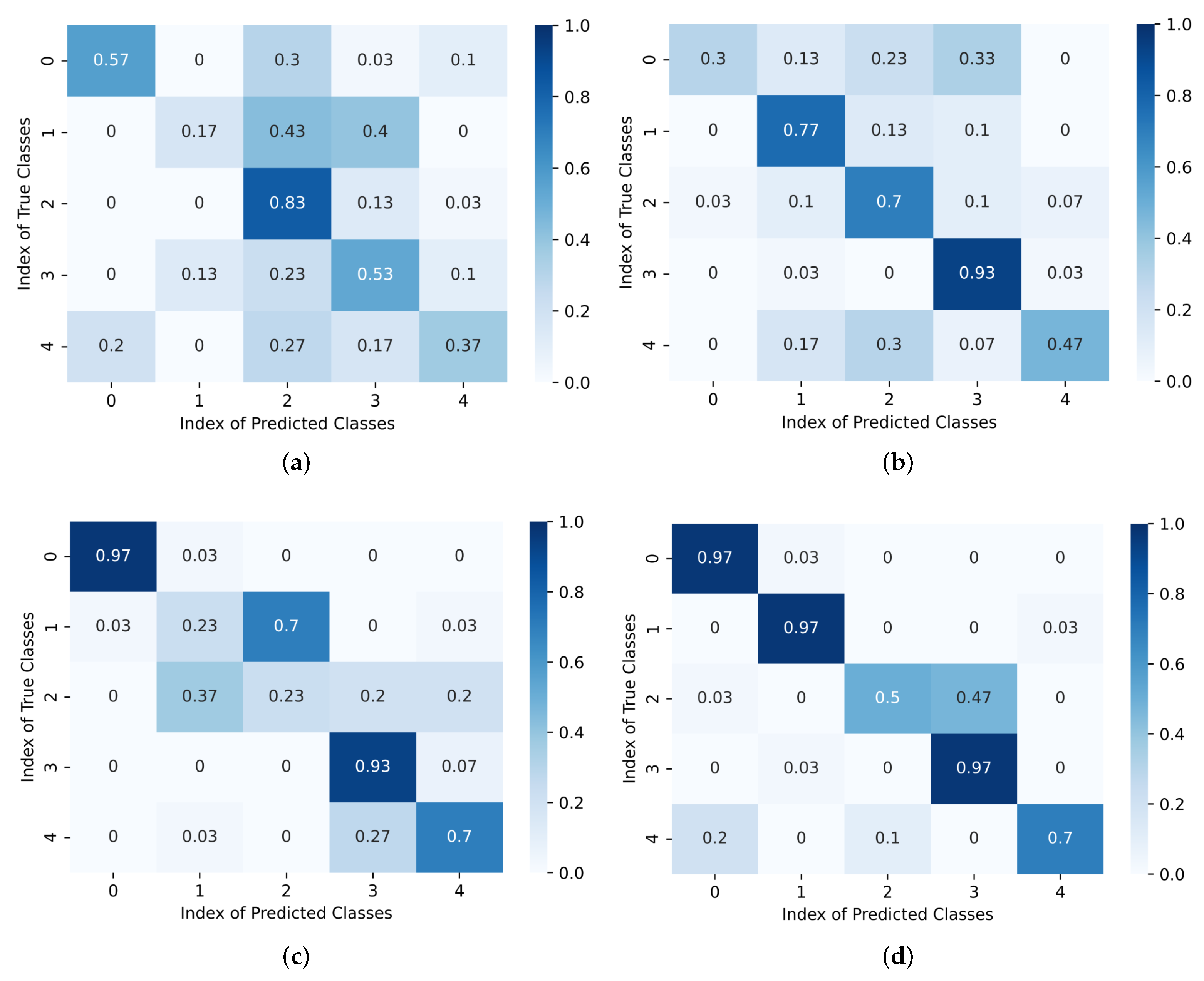
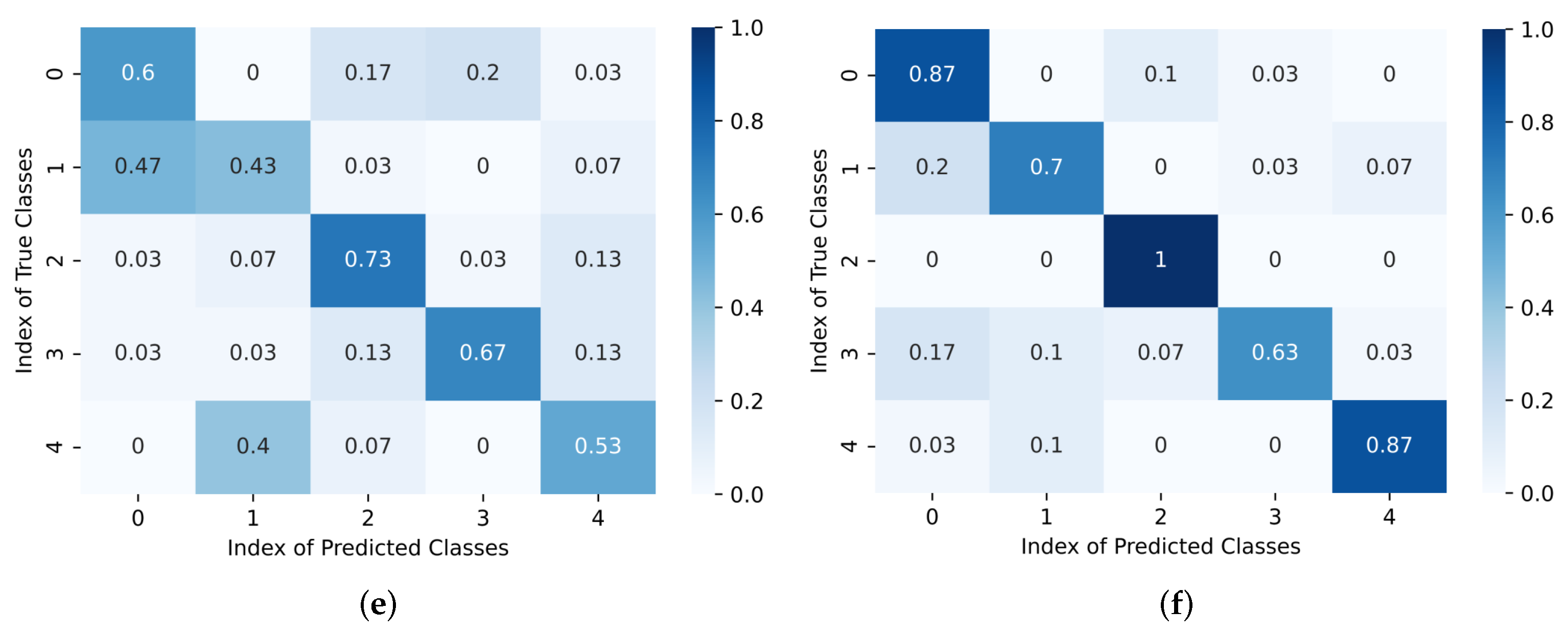
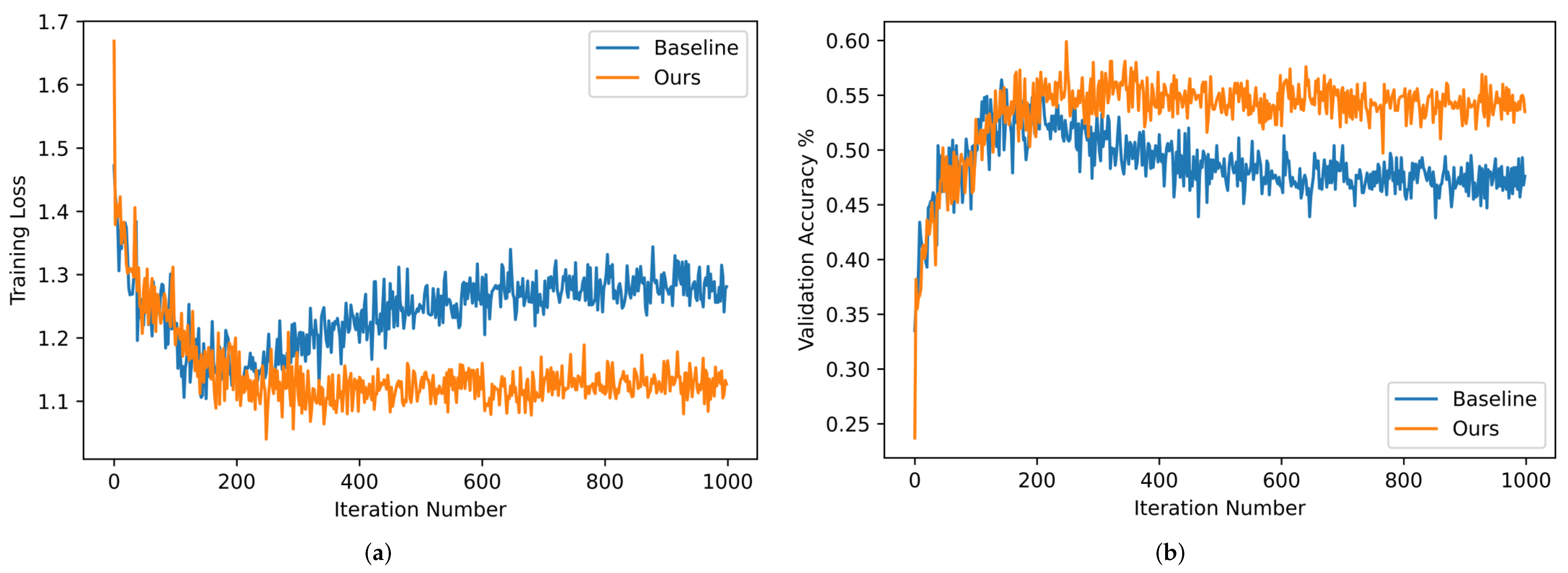
4.6. Ablation Study
4.6.1. Baseline
4.6.2. Baseline+ES
4.6.3. Baseline+TR
4.7. Comparison with the State-of-the-Art Approaches
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, B.; Zhong, Y.; Xia, G.S.; Zhang, L. Dirichlet-derived multiple topic scene classification model for high spatial resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2015, 54, 2108–2123. [Google Scholar] [CrossRef]
- Yao, X.; Han, J.; Cheng, G.; Qian, X.; Guo, L. Semantic annotation of high-resolution satellite images via weakly supervised learning. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3660–3671. [Google Scholar] [CrossRef]
- Huang, X.; Wang, Y. Investigating the effects of 3D urban morphology on the surface urban heat island effect in urban functional zones by using high-resolution remote sensing data: A case study of Wuhan, Central China. ISPRS J. Photogramm. Remote Sens. 2019, 152, 119–131. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S. Learning multiscale and deep representations for classifying remotely sensed imagery. ISPRS J. Photogramm. Remote Sens. 2016, 113, 155–165. [Google Scholar] [CrossRef]
- Huang, X.; Han, X.; Ma, S.; Lin, T.; Gong, J. Monitoring ecosystem service change in the City of Shenzhen by the use of high-resolution remotely sensed imagery and deep learning. Land Degrad. Dev. 2019, 30, 1490–1501. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhong, Y.; Zhang, L.; Li, D. Adaptive deep sparse semantic modeling framework for high spatial resolution image scene classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6180–6195. [Google Scholar] [CrossRef]
- Wu, Z.; Li, Y.; Plaza, A.; Li, J.; Xiao, F.; Wei, Z. Parallel and distributed dimensionality reduction of hyperspectral data on cloud computing architectures. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2270–2278. [Google Scholar] [CrossRef]
- Chen, J.; Wang, C.; Ma, Z.; Chen, J.; He, D.; Ackland, S. Remote sensing scene classification based on convolutional neural networks pre-trained using attention-guided sparse filters. Remote Sens. 2018, 10, 290. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Q.; Zhong, Y.; Wu, S.; Zhang, L.; Li, D. Scene classification based on the sparse homogeneous–heterogeneous topic feature model. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2689–2703. [Google Scholar] [CrossRef]
- Liu, Y.; Zhong, Y.; Qin, Q. Scene classification based on multiscale convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 7109–7121. [Google Scholar] [CrossRef] [Green Version]
- Zhao, B.; Huang, B.; Zhong, Y. Transfer learning with fully pretrained deep convolution networks for land-use classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1436–1440. [Google Scholar] [CrossRef]
- Gidaris, S.; Bursuc, A.; Komodakis, N.; Pérez, P.; Cord, M. Boosting few-shot visual learning with self-supervision. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea, 27 October–2 November 2019; pp. 8059–8068. [Google Scholar]
- Chu, W.H.; Li, Y.J.; Chang, J.C.; Wang, Y.C.F. Spot and learn: A maximum-entropy patch sampler for few-shot image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6251–6260. [Google Scholar]
- Zhai, M.; Liu, H.; Sun, F. Lifelong learning for scene recognition in remote sensing images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1472–1476. [Google Scholar] [CrossRef]
- Garcia, V.; Bruna, J. Few-shot learning with graph neural networks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–13. [Google Scholar]
- Bartlett, P.; Shawe-Taylor, J. Generalization performance of support vector machines and other pattern classifiers. In Advances in Kernel Methods: Support Vector Learning; MIT Press: Cambridge, MA, USA, 1999; pp. 43–54. [Google Scholar]
- Lee, W.S.; Bartlett, P.L.; Williamson, R.C. Lower bounds on the VC dimension of smoothly parameterized function classes. Neural Comput. 1995, 7, 1040–1053. [Google Scholar] [CrossRef]
- Verma, V.; Lamb, A.; Beckham, C.; Najafi, A.; Mitliagkas, I.; Lopez-Paz, D.; Bengio, Y. Manifold mixup: Better representations by interpolating hidden states. In Proceedings of the 36th International Conference on Machine Learning (PMLR), Long Beach, CA, USA, 9–15 June 2019; pp. 6438–6447. [Google Scholar]
- Wang, S.; Wang, X.; Zhang, L.; Zhong, Y. Auto-AD: Autonomous Hyperspectral Anomaly Detection Network Based on Fully Convolutional Autoencoder. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–4. [Google Scholar] [CrossRef]
- Zhan, T.; Song, B.; Xu, Y.; Wan, M.; Wang, X.; Yang, G.; Wu, Z. SSCNN-S: A Spectral-Spatial Convolution Neural Network with Siamese Architecture for Change Detection. Remote Sens. 2021, 13, 895. [Google Scholar] [CrossRef]
- Wang, Y.; Hou, J.; Hou, X.; Chau, L.P. A Self-Training Approach for Point-Supervised Object Detection and Counting in Crowds. IEEE Trans. Image Process. 2021, 30, 2876–2887. [Google Scholar] [CrossRef] [PubMed]
- Zhu, S.; Du, B.; Zhang, L.; Li, X. Attention-Based Multiscale Residual Adaptation Network for Cross-Scene Classification. IEEE Trans. Geosci. Remote Sens. 2021, 60. [Google Scholar] [CrossRef]
- Chen, J.; Qiu, X.; Ding, C.; Wu, Y. CVCMFF Net: Complex-Valued Convolutional and Multifeature Fusion Network for Building Semantic Segmentation of InSAR Images. IEEE Trans. Geosci. Remote Sens. 2021, 60. [Google Scholar] [CrossRef]
- Xu, C.; Zhu, G.; Shu, J. A Lightweight and Robust Lie Group-Convolutional Neural Networks Joint Representation for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2021, 60. [Google Scholar] [CrossRef]
- Wang, X.; Wang, S.; Ning, C.; Zhou, H. Enhanced Feature Pyramid Network With Deep Semantic Embedding for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7918–7932. [Google Scholar] [CrossRef]
- Penatti, O.A.; Nogueira, K.; Dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015; pp. 44–51. [Google Scholar]
- Lu, X.; Zheng, X.; Yuan, Y. Remote sensing scene classification by unsupervised representation learning. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5148–5157. [Google Scholar] [CrossRef]
- Lu, X.; Gong, T.; Zheng, X. Multisource compensation network for remote sensing cross-domain scene classification. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2504–2515. [Google Scholar] [CrossRef]
- Lu, X.; Sun, H.; Zheng, X. A feature aggregation convolutional neural network for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7894–7906. [Google Scholar] [CrossRef]
- Nogueira, K.; Penatti, O.A.; Dos Santos, J.A. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching Networks for One Shot Learning. Proc. Neural Inf. Process. Syst. 2016, 29, 3630–3638. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning PMLR, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Santoro, A.; Bartunov, S.; Botvinick, M.; Wierstra, D.; Lillicrap, T. Meta-learning with memory-augmented neural networks. In Proceedings of the International Conference on Machine Learning PMLR, New York, NY, USA, 19–24 June 2016; pp. 1842–1850. [Google Scholar]
- Tokmakov, P.; Wang, Y.X.; Hebert, M. Learning compositional representations for few-shot recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6372–6381. [Google Scholar]
- Li, H.; Dong, W.; Mei, X.; Ma, C.; Huang, F.; Hu, B.G. Lgm-net: Learning to generate matching networks for few-shot learning. In Proceedings of the International Conference on Machine Learning PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 3825–3834. [Google Scholar]
- Liu, B.; Yu, X.; Yu, A.; Zhang, P.; Wan, G.; Wang, R. Deep few-shot learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2290–2304. [Google Scholar] [CrossRef]
- Gao, K.; Liu, B.; Yu, X.; Qin, J.; Zhang, P.; Tan, X. Deep relation network for hyperspectral image few-shot classification. Remote Sens. 2020, 12, 923. [Google Scholar] [CrossRef] [Green Version]
- Rostami, M.; Kolouri, S.; Eaton, E.; Kim, K. Deep transfer learning for few-shot sar image classification. Remote Sens. 2019, 11, 1374. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Cui, Z.; Zhu, Z.; Chen, L.; Zhu, J.; Huang, H.; Tao, C. RS-MetaNet: Deep Metametric Learning for Few-Shot Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6983–6994. [Google Scholar] [CrossRef]
- Li, L.; Han, J.; Yao, X.; Cheng, G.; Guo, L. DLA-MatchNet for Few-Shot Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 7844–7853. [Google Scholar] [CrossRef]
- Guo, Y.; Codella, N.C.; Karlinsky, L.; Codella, J.V.; Smith, J.R.; Saenko, K.; Rosing, T.; Feris, R. A broader study of cross-domain few-shot learning. In European Conference on Computer Vision; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; pp. 124–141. [Google Scholar]
- Gong, T.; Zheng, X.; Lu, X. Cross-Domain Scene Classification by Integrating Multiple Incomplete Sources. IEEE Trans. Geosci. Remote Sens. 2020, 59, 10035–10046. [Google Scholar] [CrossRef]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? Proc. Adv. Neural Inf. Process. Syst. 2014, 27, 3320–3328. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning PMLR, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localization using convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 648–656. [Google Scholar]
- Rodríguez, P.; Gonzalez, J.; Cucurull, G.; Gonfaus, J.M.; Roca, X. Regularizing cnns with locally constrained decorrelations. arXiv 2016, arXiv:1611.01967. [Google Scholar]
- Salimans, T.; Kingma, D.P. Weight normalization: A simple reparameterization to accelerate training of deep neural networks. Proc. Adv. Neural Inf. Process. Syst. 2016, 29, 901–909. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Belkin, M.; Niyogi, P.; Sindhwani, V. Manifold regularization: A geometric framework for learning from labeled and unlabeled examples. J. Mach. Learn. Res. 2006, 7, 2399–2434. [Google Scholar]
- Cho, K.; Zhao, J. Retrieval-augmented convolutional neural networks against adversarial examples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 11563–11571. [Google Scholar]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Iscen, A.; Tolias, G.; Avrithis, Y.; Chum, O. Label propagation for deep semi-supervised learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5070–5079. [Google Scholar]
- Liu, B.; Wu, Z.; Hu, H.; Lin, S. Deep metric transfer for label propagation with limited annotated data. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshops, ICCV Workshops 2019, Seoul, Korea, 27–28 October 2019; pp. 1–10. [Google Scholar]
- Liu, Y.; Lee, J.; Park, M.; Kim, S.; Yang, E.; Hwang, S.J.; Yang, Y. Learning to propagate labels: Transductive propagation network for few-shot learning. arXiv 2018, arXiv:1805.10002. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4080–4090. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1199–1208. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the International Conference Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Zhou, D.; Bousquet, O.; Lal, T.N.; Weston, J.; Schölkopf, B. Learning with local and global consistency. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 13–18 December 2004; pp. 321–328. [Google Scholar]
- Chung, F.R.; Graham, F.C. Spectral Graph Theory; Number 92; AMS, American Mathematical Society: Providence, RI, USA, 1997. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM SIGSPATIAL GIS 2010), San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Sheng, G.; Yang, W.; Xu, T.; Sun, H. High-resolution satellite scene classification using a sparse coding based multiple feature combination. Int. J. Remote Sens. 2012, 33, 2395–2412. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the Workshop Advances Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1–4. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2016; pp. 770–778. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Li, Z.; Zhou, F.; Chen, F.; Li, H. Meta-sgd: Learning to learn quickly for few-shot learning. arXiv 2017, arXiv:1707.09835. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | 5-Way 1-Shot Accuracy | FLOPs |
|---|---|---|
| ProtoNet | 40.33 ± 0.18 | |
| MatchingNet | 37.61 | |
| MAML | 48.40 ± 0.82 | |
| RelationNet | 66.43 ± 0.73 | |
| GES-Net (ours) | 70.83 ± 0.85 |
| Model | 5-Way | |
|---|---|---|
| 1-Shot | 5-Shot | |
| Baseline | 66.51 ± 0.87 | 78.50 ± 0.56 |
| Baseline+ES | 68.93 ± 0.91 | 81.73 ± 0.59 |
| Baseline+TR | 67.40 ± 0.85 | 80.93 ± 0.61 |
| GES-Net (ours) | 70.83 ± 0.85 | 82.27 ± 0.55 |
| Model | 5-Way | |
|---|---|---|
| 1-Shot | 5-Shot | |
| TPN | 53.36 ± 0.77 | 68.23 ± 0.52 |
| ProtoNet | 52.27 ± 0.20 | 69.86 ± 0.15 |
| MatchingNet | 34.70 | 52.71 |
| MAML | 48.86 ± 0.74 | 60.78 ± 0.62 |
| Meta-SGD | 50.52 ± 2.61 | 60.82 ± 2.00 |
| LLSR | 39.47 | 57.40 |
| RelationNet | 48.08 ± 1.67 | 61.88 ± 0.50 |
| RS-MetaNet | 57.23 ± 0.56 | 76.08 ± 0.28 |
| DLA-MatchNet | 53.76 ± 0.60 | 63.01 ± 0.51 |
| GES-Net (ours) | 58.88 ± 0.81 | 81.66 ± 0.50 |
| Model | 5-Way | |
|---|---|---|
| 1-Shot | 5-Shot | |
| TPN | 59.28 ± 0.72 | 71.20 ± 0.55 |
| ProtoNet | 58.01 ± 0.16 | 80.70 ± 0.11 |
| MatchingNet | 50.13 | 54.10 |
| MAML | 49.13 ± 0.65 | 62.49 ± 0.51 |
| Meta-SGD | 51.54 ± 2.31 | 61.74 ± 2.02 |
| LLSR | 57.10 | 70.65 |
| RelationNet | 60.92 ± 1.86 | 79.75 ± 1.19 |
| DLA-MatchNet | 68.27 ± 1.83 | 79.89 ± 0.33 |
| GES-Net (ours) | 75.84 ± 0.78 | 82.37 ± 0.38 |
| Model | 5-Way | |
|---|---|---|
| 1-Shot | 5-Shot | |
| TPN | 66.51 ± 0.87 | 78.50 ± 0.56 |
| ProtoNet | 40.33 ± 0.18 | 63.82 ± 0.56 |
| MatchingNet | 37.61 | 47.10 |
| MAML | 48.40 ± 0.82 | 62.90 ± 0.69 |
| Meta-SGD | 60.63 ± 0.90 | 75.75 ± 0.65 |
| LLSR | 51.43 | 72.90 |
| RelationNet | 66.43 ± 0.73 | 78.35 ± 0.51 |
| RS-MetaNet | 52.78 ± 0.09 | 71.49 ± 0.81 |
| DLA-MatchNet | 68.80 ± 0.70 | 81.63 ± 0.46 |
| GES-Net (ours) | 70.83 ± 0.85 | 82.27 ± 0.55 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, Z.; Huang, W.; Tang, C.; Yang, A.; Luo, X. Graph-Based Embedding Smoothing Network for Few-Shot Scene Classification of Remote Sensing Images. Remote Sens. 2022, 14, 1161. https://doi.org/10.3390/rs14051161
Yuan Z, Huang W, Tang C, Yang A, Luo X. Graph-Based Embedding Smoothing Network for Few-Shot Scene Classification of Remote Sensing Images. Remote Sensing. 2022; 14(5):1161. https://doi.org/10.3390/rs14051161
Chicago/Turabian StyleYuan, Zhengwu, Wendong Huang, Chan Tang, Aixia Yang, and Xiaobo Luo. 2022. "Graph-Based Embedding Smoothing Network for Few-Shot Scene Classification of Remote Sensing Images" Remote Sensing 14, no. 5: 1161. https://doi.org/10.3390/rs14051161
APA StyleYuan, Z., Huang, W., Tang, C., Yang, A., & Luo, X. (2022). Graph-Based Embedding Smoothing Network for Few-Shot Scene Classification of Remote Sensing Images. Remote Sensing, 14(5), 1161. https://doi.org/10.3390/rs14051161