
HyperLiteNet: Extremely Lightweight Non-Deep Parallel Network for Hyperspectral Image Classification


Abstract
:1. Introduction
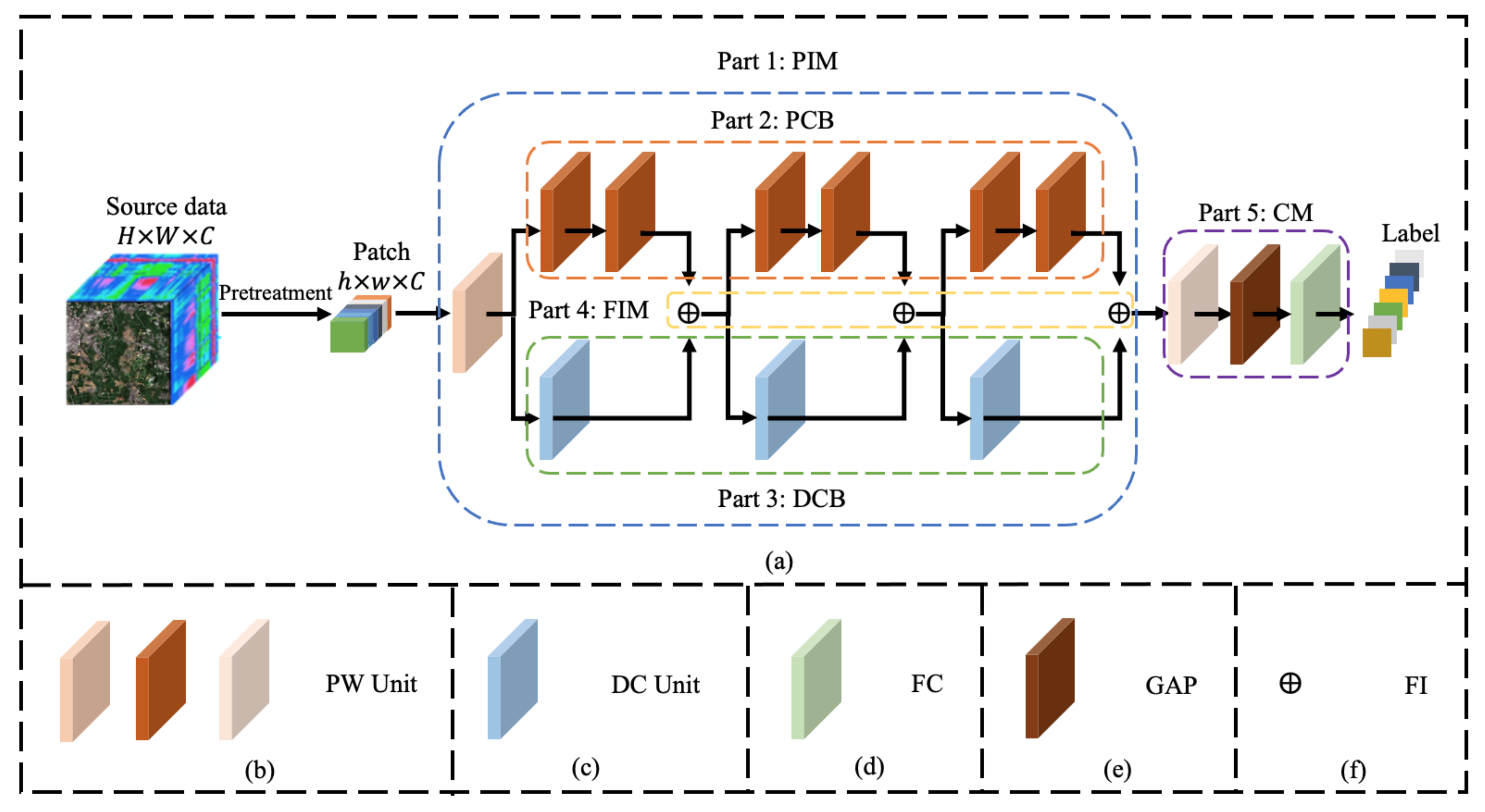
2. Proposed Methods
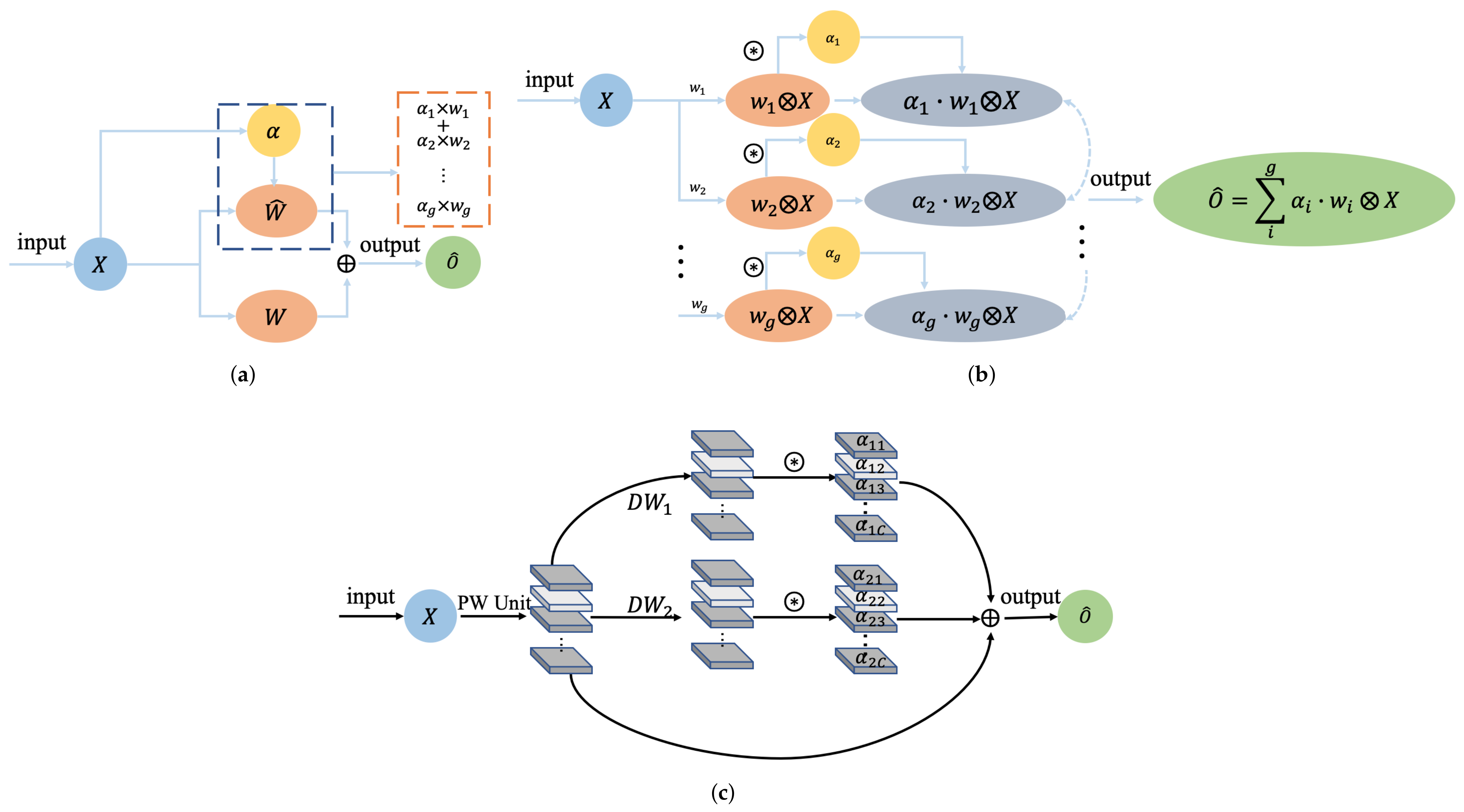
2.1. Parallel Interconnection Module (PIM)
2.2. Pointwise Convolution Branch (PCB) and Dynamic Convolution Branch (DCB)
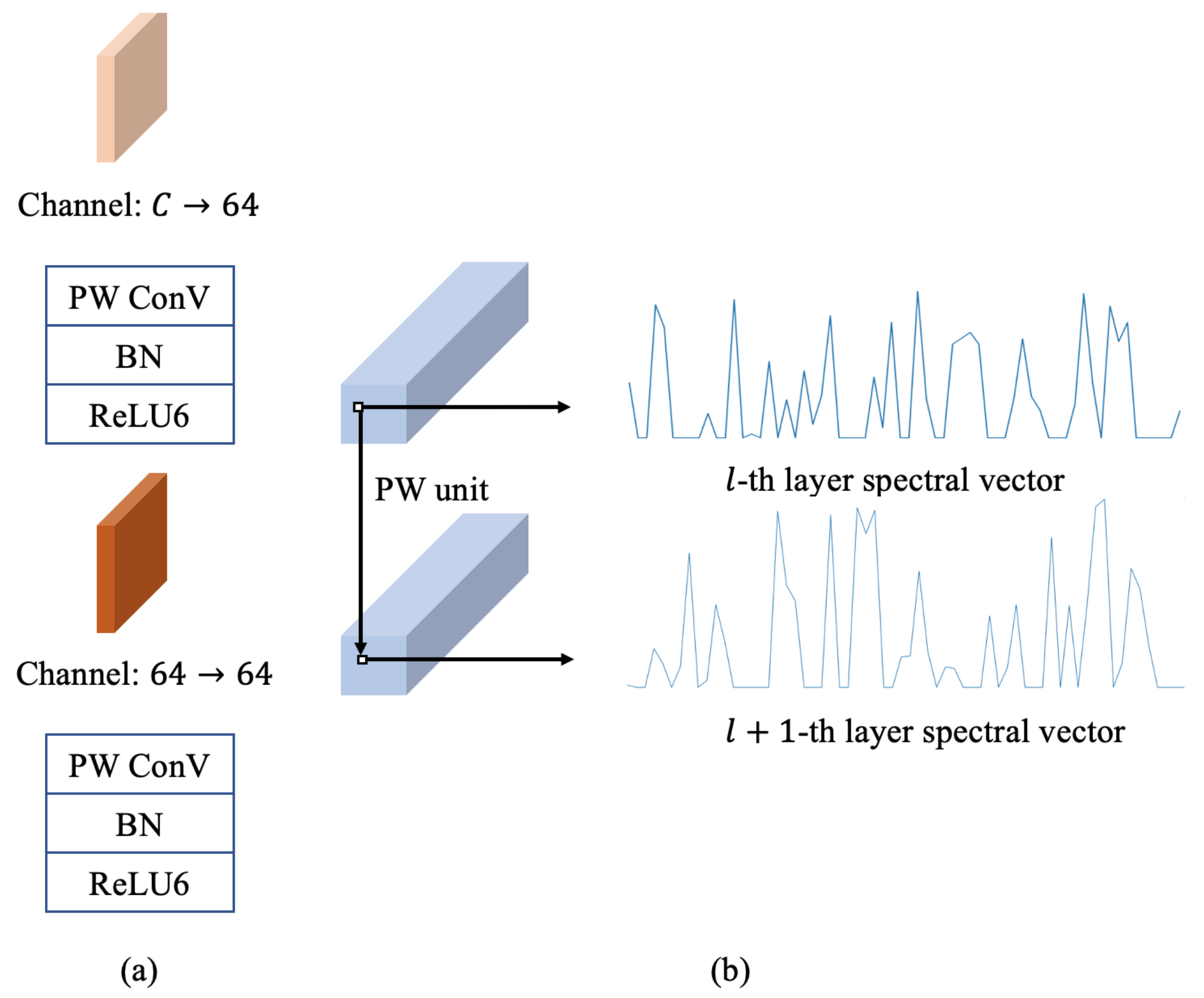
2.2.1. Pointwise Convolution Branch (PCB)
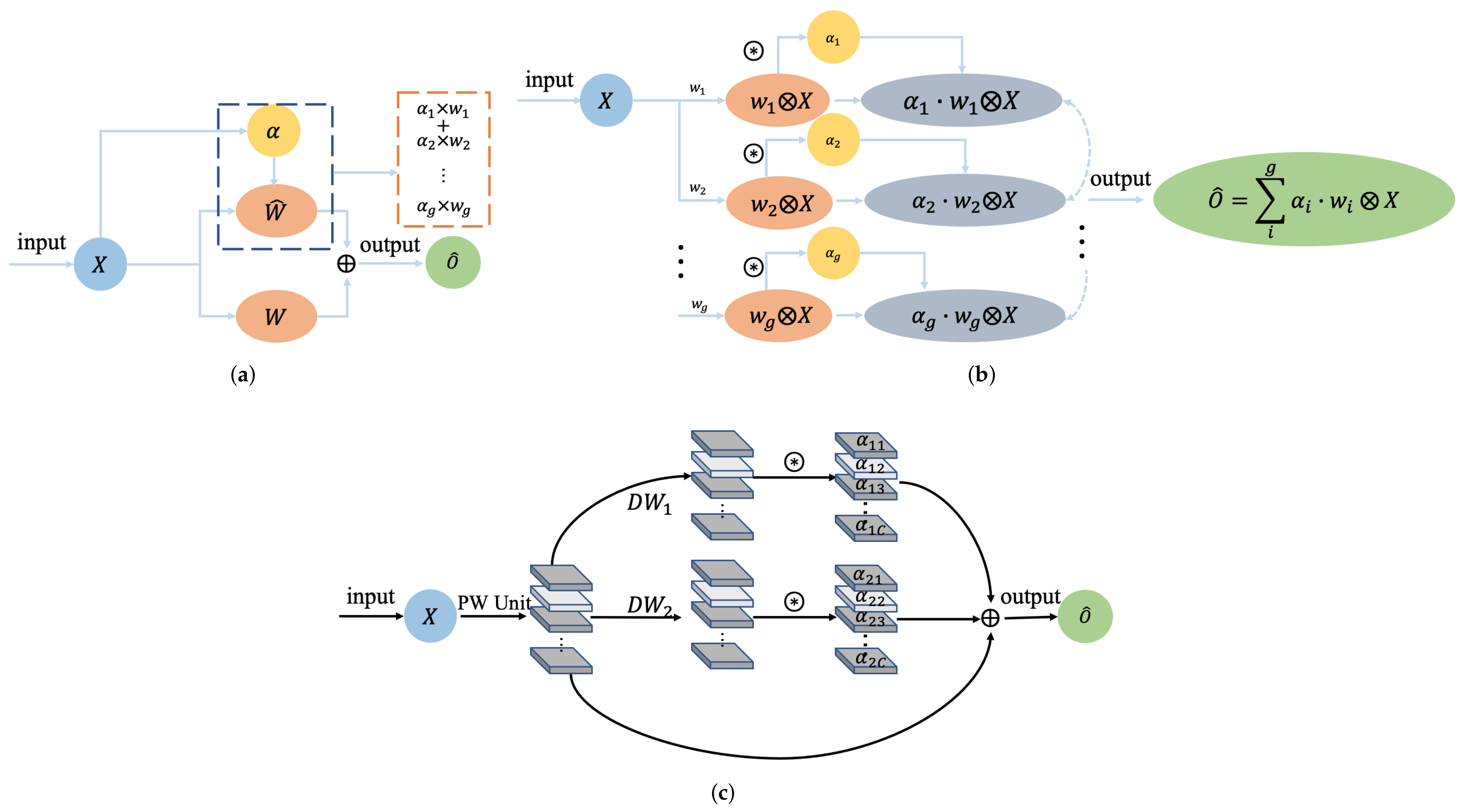
2.2.2. Dynamic Convolution Branch (DCB)
2.3. Feature Interconnection Module (FIM) and Classification Module (CM)
3. Experiments and Analysis
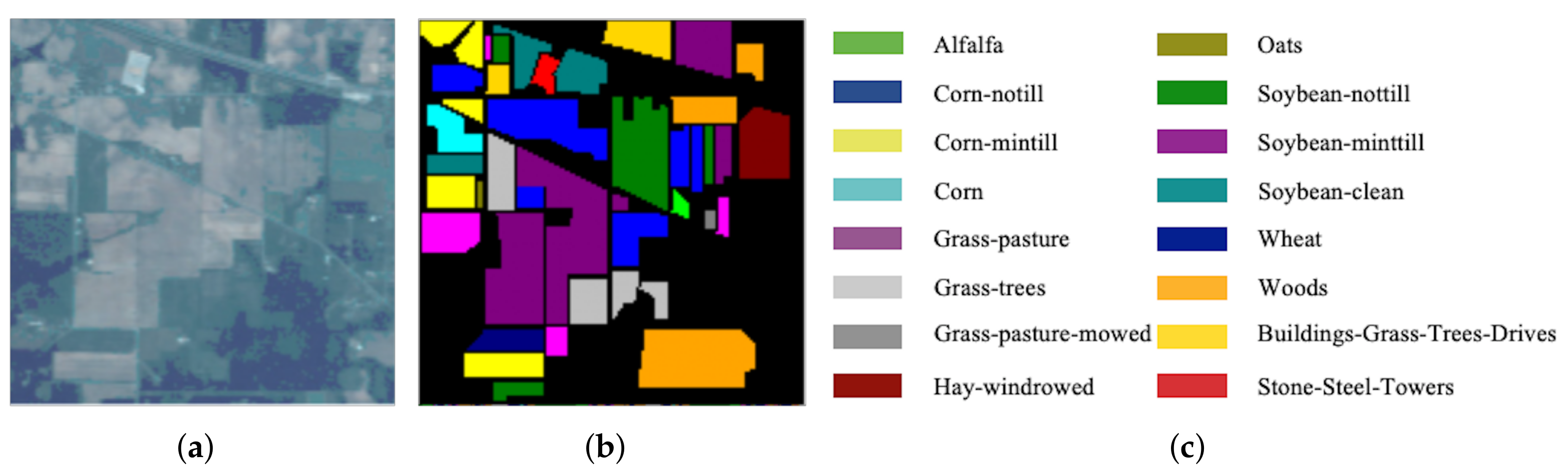
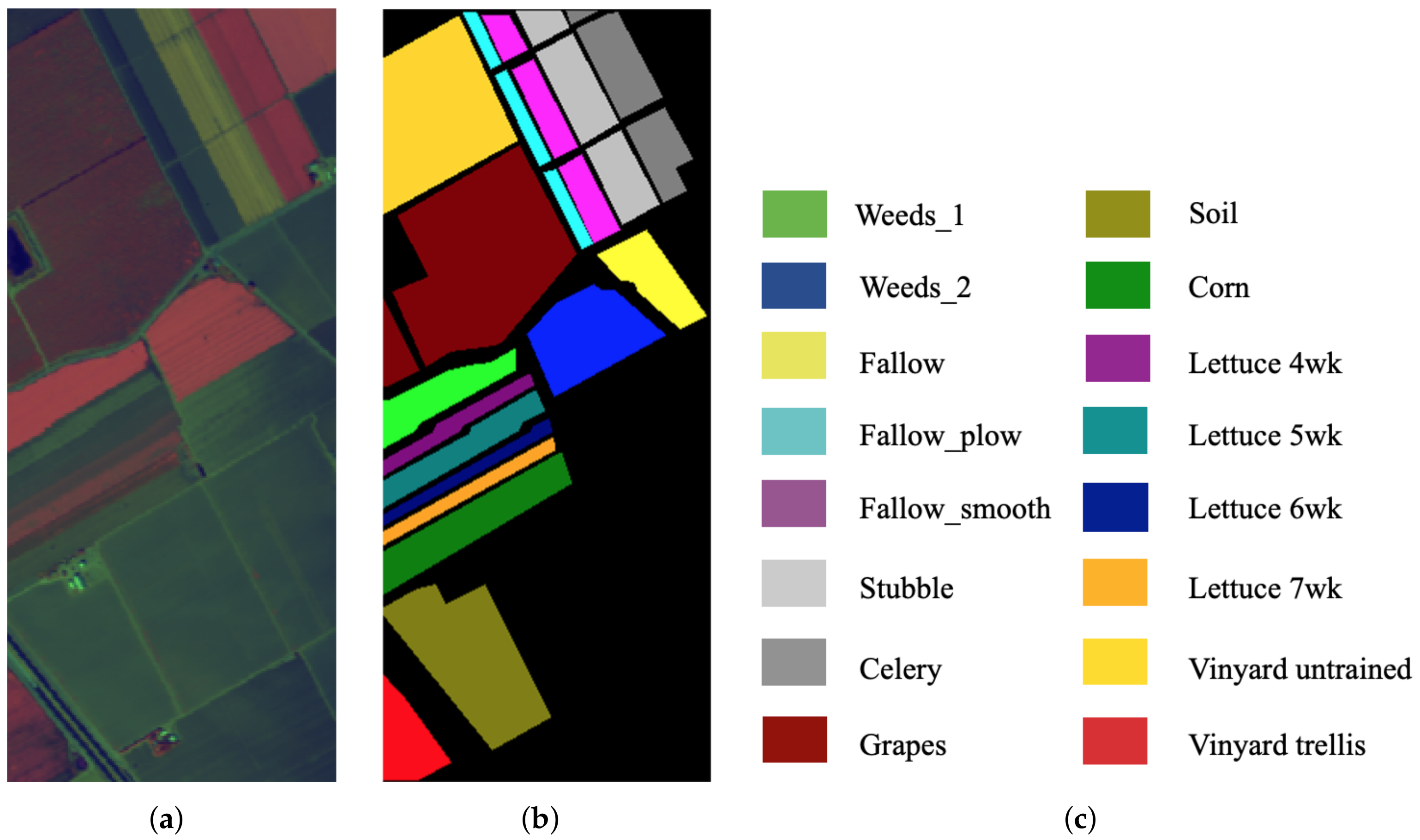
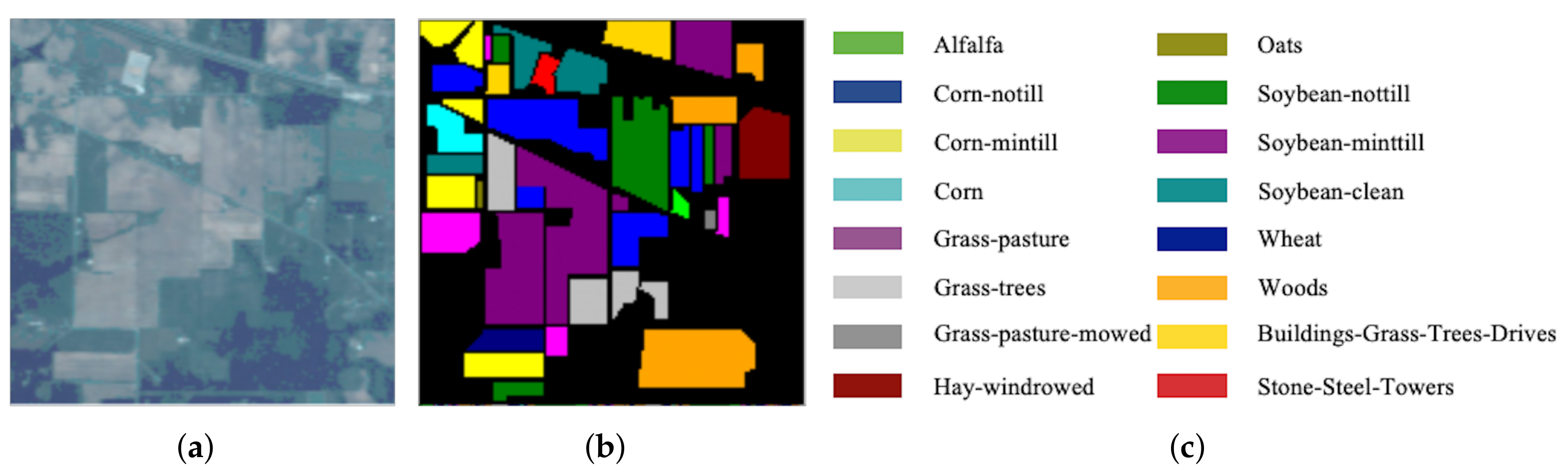
3.1. Datasets Descriptions
3.2. Experimental Configuration and Parameter Analysis
3.2.1. Experimental Configuration
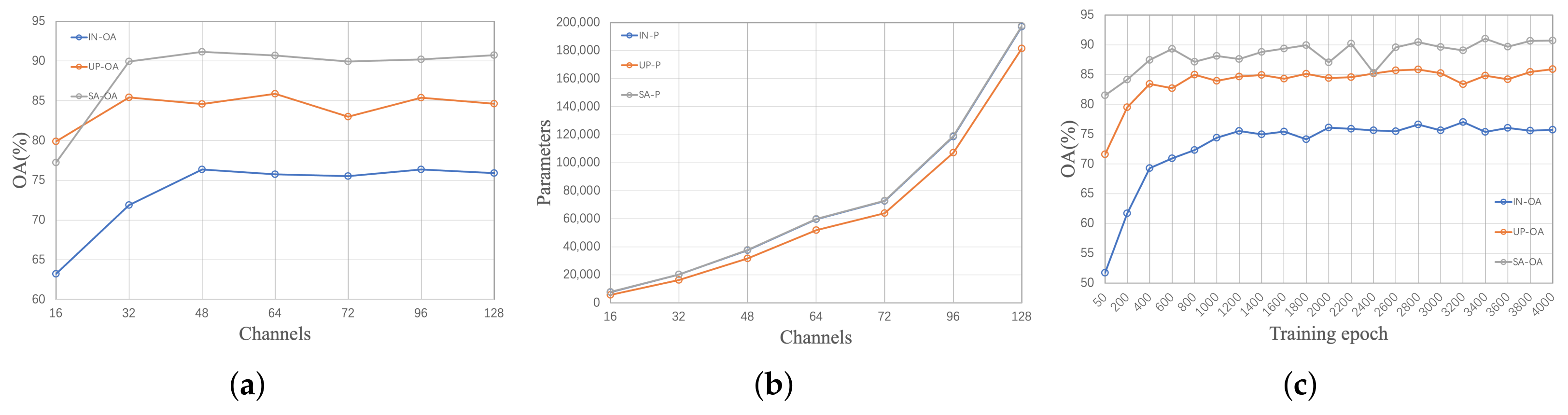
3.2.2. Experimental Parameter Analysis
3.3. Ablation Study for DW Dynamic Convolution
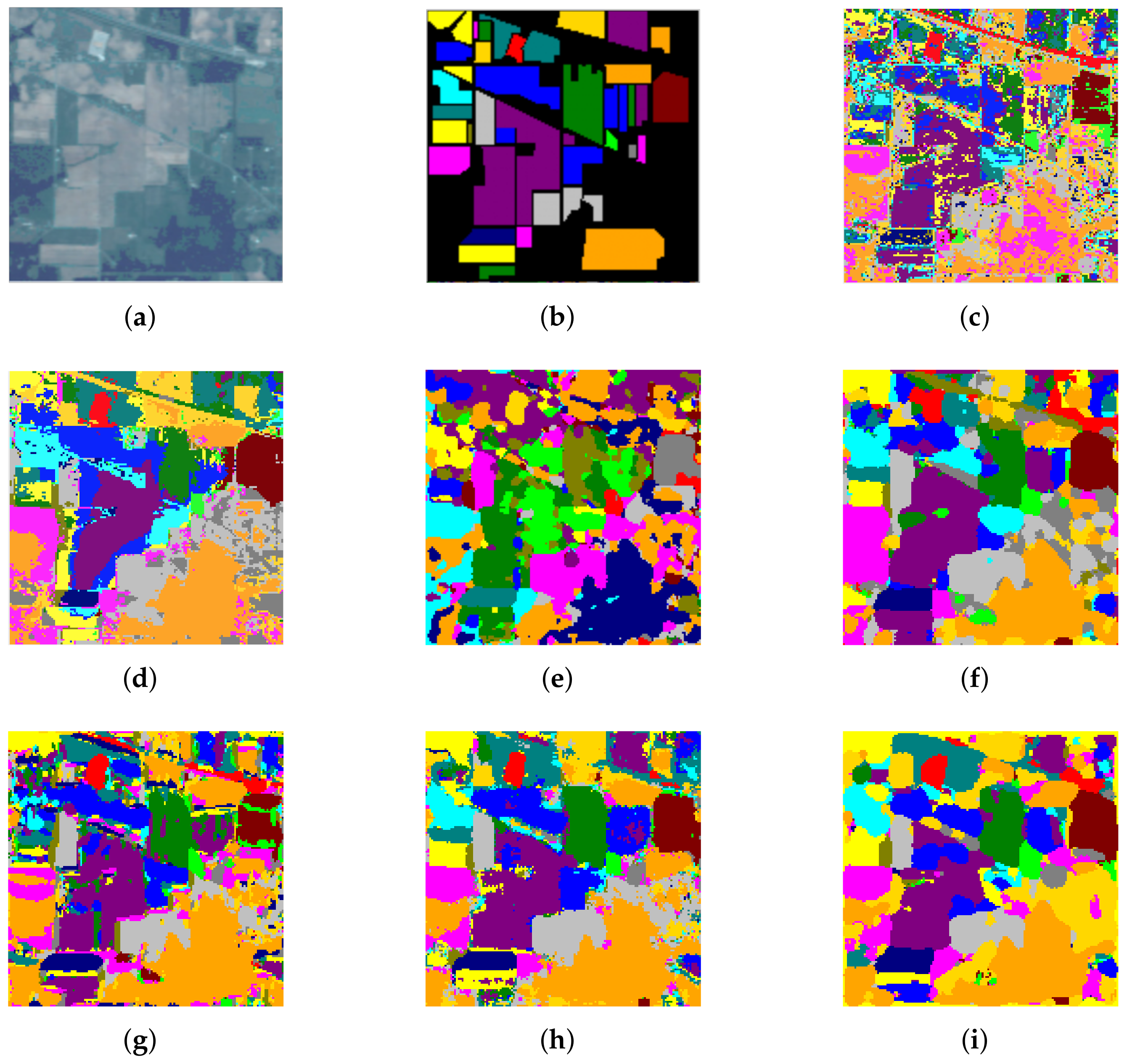
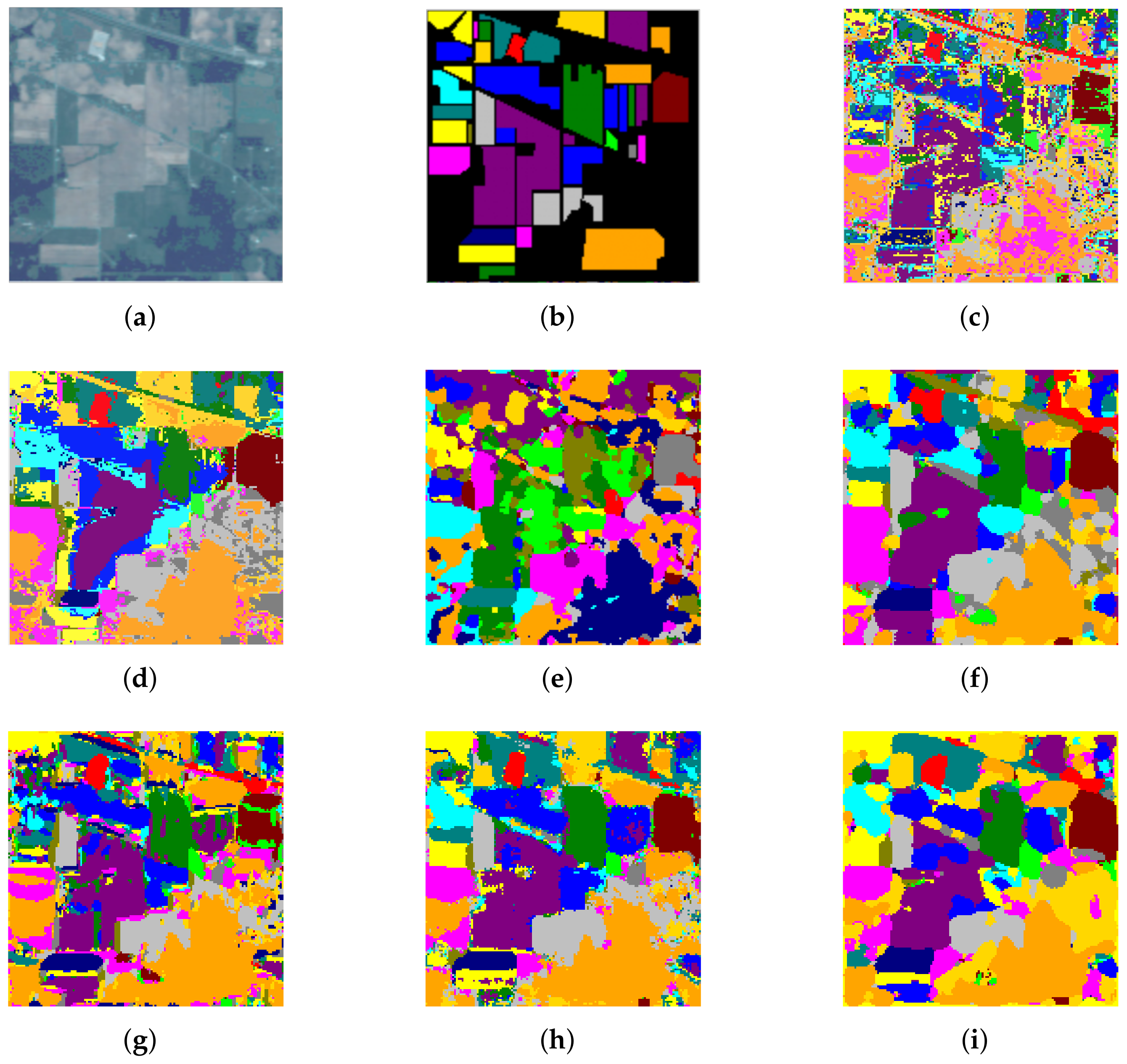
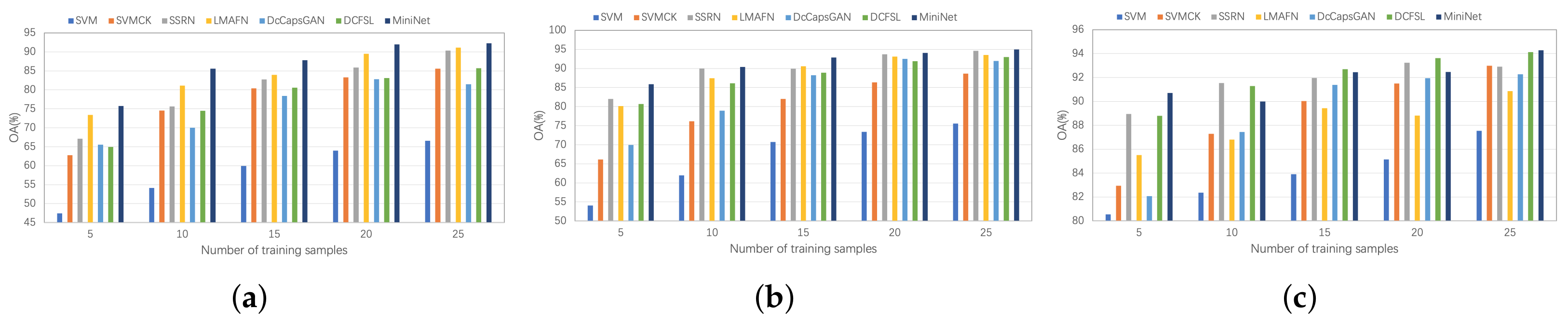
3.4. Classification Accuracy and Performance
4. Discussion
4.1. Assessment of the Model Design
4.2. Assessment of the Model Performances
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xue, Z.; Li, J.; Cheng, L.; Du, P. Spectral–spatial classification of hyperspectral data via morphological component analysis-based image separation. IEEE Trans. Geosci. Remote Sens. 2014, 53, 70–84. [Google Scholar]
- Zhang, L.; Zhang, L.; Tao, D.; Huang, X.; Du, B. Hyperspectral remote sensing image subpixel target detection based on supervised metric learning. IEEE Trans. Geosci. Remote Sens. 2013, 52, 4955–4965. [Google Scholar] [CrossRef]
- Wan, Y.; Hu, X.; Zhong, Y.; Ma, A.; Wei, L.; Zhang, L. Tailings reservoir disaster and environmental monitoring using the UAV-ground hyperspectral joint observation and processing: A case of study in Xinjiang, the belt and road. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 9713–9716. [Google Scholar]
- Coppin, P.; Jonckheere, I.; Nackaerts, K.; Muys, B.; Lambin, E. Digital change detection methods in ecosystem monitoring: A review. Int. J. Remote Sens. 2004, 25, 1565–1596. [Google Scholar] [CrossRef]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Li, H.C.; Xue, B.; Chang, C.I. Constrained band subset selection for hyperspectral imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2032–2036. [Google Scholar] [CrossRef]
- Palsson, F.; Sveinsson, J.R.; Ulfarsson, M.O.; Benediktsson, J.A. Model-based fusion of multi-and hyperspectral images using PCA and wavelets. IEEE Trans. Geosci. Remote Sens. 2014, 53, 2652–2663. [Google Scholar] [CrossRef]
- Falco, N.; Benediktsson, J.A.; Bruzzone, L. A study on the effectiveness of different independent component analysis algorithms for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2183–2199. [Google Scholar] [CrossRef]
- Gordon, C. A generalization of the maximum noise fraction transform. IEEE Trans. Geosci. Remote Sens. 2000, 38, 608–610. [Google Scholar] [CrossRef] [Green Version]
- Tarabalka, Y.; Fauvel, M.; Chanussot, J.; Benediktsson, J.A. SVM-and MRF-based method for accurate classification of hyperspectral images. IEEE Geosci. Remote Sens. Lett. 2010, 7, 736–740. [Google Scholar] [CrossRef] [Green Version]
- Song, W.; Li, S.; Kang, X.; Huang, K. Hyperspectral image classification based on KNN sparse representation. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 2411–2414. [Google Scholar]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Spectral–spatial hyperspectral image segmentation using subspace multinomial logistic regression and Markov random fields. IEEE Trans. Geosci. Remote Sens. 2011, 50, 809–823. [Google Scholar] [CrossRef]
- Joelsson, S.R.; Benediktsson, J.A.; Sveinsson, J.R. Random forest classifiers for hyperspectral data. In Proceedings of the 2005 IEEE International Geoscience and Remote Sensing Symposium, Seoul, Korea, 29 July 2005; Volume 1, pp. 4–8. [Google Scholar]
- Camps-Valls, G.; Gomez-Chova, L.; Muñoz-Marí, J.; Vila-Francés, J.; Calpe-Maravilla, J. Composite kernels for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2006, 3, 93–97. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Classification for hyperspectral imagery based on sparse representation. In Proceedings of the 2010 2nd Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing, Reykjavik, Iceland, 14–16 June 2010; pp. 1–4. [Google Scholar]
- Wang, J.; Jiao, L.; Liu, H.; Yang, S.; Liu, F. Hyperspectral image classification by spatial–spectral derivative-aided kernel joint sparse representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2485–2500. [Google Scholar] [CrossRef]
- Wang, J.; Jiao, L.; Wang, S.; Hou, B.; Liu, F. Adaptive nonlocal spatial–spectral kernel for hyperspectral imagery classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4086–4101. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, X.; Jia, X. Spectral–spatial classification of hyperspectral data based on deep belief network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2381–2392. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–spatial residual network for hyperspectral image classification: A 3-D deep learning framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- Gao, H.; Zhang, Y.; Chen, Z.; Li, C. A Multiscale Dual-Branch Feature Fusion and Attention Network for Hyperspectral Images Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8180–8192. [Google Scholar] [CrossRef]
- Li, S.; Luo, X.; Wang, Q.; Li, L.; Yin, J. H2AN: Hierarchical Homogeneity-Attention Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 1–16. [Google Scholar] [CrossRef]
- Zhang, T.; Shi, C.; Liao, D.; Wang, L. A Spectral Spatial Attention Fusion with Deformable Convolutional Residual Network for Hyperspectral Image Classification. Remote Sens. 2021, 13, 3590. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic Routing Between Capsules. arXiv 2017, arXiv:1710.09829. [Google Scholar]
- Lei, R.; Zhang, C.; Liu, W.; Zhang, L.; Zhang, X.; Yang, Y.; Huang, J.; Li, Z.; Zhou, Z. Hyperspectral Remote Sensing Image Classification Using Deep Convolutional Capsule Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8297–8315. [Google Scholar] [CrossRef]
- Wang, J.; Guo, S.; Huang, R.; Li, L.; Zhang, X.; Jiao, L. Dual-Channel Capsule Generation Adversarial Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Bianchini, M.; Scarselli, F. On the complexity of neural network classifiers: A comparison between shallow and deep architectures. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 1553–1565. [Google Scholar] [CrossRef] [PubMed]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Wu, Z.; Shen, C.; Van Den Hengel, A. Wider or deeper: Revisiting the resnet model for visual recognition. Pattern Recognit. 2019, 90, 119–133. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning; PMLR: Long Beach, CA, USA, 2019; pp. 6105–6114. [Google Scholar]
- Goyal, A.; Bochkovskiy, A.; Deng, J.; Koltun, V. Non-deep Networks. arXiv 2021, arXiv:2110.07641. [Google Scholar]
- Iandola, F.N.; Moskewicz, M.W.; Ashraf, K.; Han, S.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <1 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 9 May 2019; pp. 1314–1324. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Zhang, C.; Xu, Y.; Shen, Y. CompConv: A Compact Convolution Module for Efficient Feature Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3012–3021. [Google Scholar]
- Li, D.; Hu, J.; Wang, C.; Li, X.; She, Q.; Zhu, L.; Zhang, T.; Chen, Q. Involution: Inverting the inherence of convolution for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 10 March 2021; pp. 12321–12330. [Google Scholar]
- Li, Y.; Chen, Y.; Dai, X.; Chen, D.; Liu, M.; Yuan, L.; Liu, Z.; Zhang, L.; Vasconcelos, N. MicroNet: Towards Image Recognition with Extremely Low FLOPs. arXiv 2020, arXiv:2011.12289. [Google Scholar]
- Chen, H.; Wang, Y.; Xu, C.; Shi, B.; Xu, C.; Tian, Q.; Xu, C. AdderNet: Do we really need multiplications in deep learning? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1468–1477. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Zhang, H.; Li, Y.; Jiang, Y.; Wang, P.; Shen, Q.; Shen, C. Hyperspectral classification based on lightweight 3-D-CNN with transfer learning. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5813–5828. [Google Scholar] [CrossRef] [Green Version]
- Jia, S.; Lin, Z.; Xu, M.; Huang, Q.; Zhou, J.; Jia, X.; Li, Q. A lightweight convolutional neural network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4150–4163. [Google Scholar] [CrossRef]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing network design spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10428–10436. [Google Scholar]
- Wang, J.; Huang, R.; Guo, S.; Li, L.; Zhu, M.; Yang, S.; Jiao, L. NAS-Guided Lightweight Multiscale Attention Fusion Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8754–8767. [Google Scholar] [CrossRef]
- Cui, B.; Dong, X.M.; Zhan, Q.; Peng, J.; Sun, W. LiteDepthwiseNet: A Lightweight Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5502915. [Google Scholar] [CrossRef]
- Yang, B.; Bender, G.; Le, Q.V.; Ngiam, J. Soft Conditional Computation. arXiv 2019, arXiv:1904.04971. [Google Scholar]
- Zhang, Y.; Zhang, J.; Wang, Q.; Zhong, Z. DyNet: Dynamic Convolution for Accelerating Convolutional Neural Networks. arXiv 2020, arXiv:2004.10694. [Google Scholar]
- Li, Y.; Yuan, L.; Chen, Y.; Wang, P.; Vasconcelos, N. Dynamic Transfer for Multi-Source Domain Adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10998–11007. [Google Scholar]
- Liu, B.; Yu, X.; Yu, A.; Zhang, P.; Wan, G.; Wang, R. Deep few-shot learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2290–2304. [Google Scholar] [CrossRef]
- Li, S.; Zhang, J.; Ma, W.; Liu, C.H.; Li, W. Dynamic Domain Adaptation for Efficient Inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 10 March 2021; pp. 7832–7841. [Google Scholar]
- Zhong, C.; Zhang, J.; Wu, S.; Zhang, Y. Cross-Scene Deep Transfer Learning With Spectral Feature Adaptation for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2861–2873. [Google Scholar] [CrossRef]
- Hospedales, T.M.; Antoniou, A.; Micaelli, P.; Storkey, A.J. Meta-Learning in Neural Networks: A Survey. arXiv 2020, arXiv:2004.05439. [Google Scholar] [CrossRef]
- Li, Z.; Liu, M.; Chen, Y.; Xu, Y.; Li, W.; Du, Q. Deep Cross-Domain Few-Shot Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5501618. [Google Scholar] [CrossRef]
- Liang, X.; Zhang, Y.; Zhang, J. Attention Multisource Fusion-Based Deep Few-Shot Learning for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8773–8788. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | OA | P | OA | P | OA | P | |
|---|---|---|---|---|---|---|---|
| Type | |||||||
| DC | 75.75 ± 3.25 | 59,658 | 85.89 ± 4.60 | 51,939 | 90.70 ± 1.76 | 59,914 | |
| SC | 75.19 ± 3.16 | 153,840 | 83.96 ± 4.88 | 146,121 | 90.35 ± 2.07 | 154,096 | |
| MSC | 75.34 ± 3.62 | 461,616 | 83.11 ± 3.89 | 453,897 | 88.72 ± 4.21 | 461,872 | |
| Dataset | IN | UP | SA | ||||
| Class | SVM | SVMCK | SSRN | LMAFN | DcCapsGAN | DCFSL | HyperLiteNet |
|---|---|---|---|---|---|---|---|
| 1 | |||||||
| 2 | |||||||
| 3 | |||||||
| 4 | |||||||
| 5 | |||||||
| 6 | |||||||
| 7 | |||||||
| 8 | |||||||
| 9 | |||||||
| 10 | |||||||
| 11 | |||||||
| 12 | |||||||
| 13 | |||||||
| 14 | |||||||
| 15 | |||||||
| 16 | |||||||
| OA | |||||||
| AA | |||||||
| KP | |||||||
| PA | − | − | 346,784 | 161,451 | 33,521,328 | 4,270,121 | 59,658 |
| Flops (M) | − | − | − | ||||
| Train(s) | − | − | |||||
| Test(s) | − | − |
| Class | SVM | SVMCK | SSRN | LMAFN | DcCapsGAN | DCFSL | HyperLiteNet |
|---|---|---|---|---|---|---|---|
| 1 | |||||||
| 2 | |||||||
| 3 | |||||||
| 4 | |||||||
| 5 | |||||||
| 6 | |||||||
| 7 | |||||||
| 8 | |||||||
| 9 | |||||||
| OA | |||||||
| AA | |||||||
| KP | |||||||
| PA | − | − | 199,153 | 153,060 | 21,468,326 | 4,259,294 | 51,939 |
| Flops (M) | − | − | − | ||||
| Train(s) | − | − | |||||
| Test(s) | − | − |
| Class | SVM | SVMCK | SSRN | LMAFN | DcCapsGAN | DCFSL | HyperLiteNet |
|---|---|---|---|---|---|---|---|
| 1 | |||||||
| 2 | |||||||
| 3 | |||||||
| 4 | |||||||
| 5 | |||||||
| 6 | |||||||
| 7 | |||||||
| 8 | |||||||
| 9 | |||||||
| 10 | |||||||
| 11 | |||||||
| 12 | |||||||
| 13 | |||||||
| 14 | |||||||
| 15 | |||||||
| 16 | |||||||
| OA | |||||||
| AA | |||||||
| KP | |||||||
| PA | − | − | 352,928 | 161,707 | 34,627,364 | 4,270,521 | 59,914 |
| Flops (M) | − | − | − | ||||
| Train(s) | − | − | |||||
| Test(s) | − | − |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Huang, R.; Guo, S.; Li, L.; Pei, Z.; Liu, B. HyperLiteNet: Extremely Lightweight Non-Deep Parallel Network for Hyperspectral Image Classification. Remote Sens. 2022, 14, 866. https://doi.org/10.3390/rs14040866
Wang J, Huang R, Guo S, Li L, Pei Z, Liu B. HyperLiteNet: Extremely Lightweight Non-Deep Parallel Network for Hyperspectral Image Classification. Remote Sensing. 2022; 14(4):866. https://doi.org/10.3390/rs14040866
Chicago/Turabian StyleWang, Jianing, Runhu Huang, Siying Guo, Linhao Li, Zhao Pei, and Bo Liu. 2022. "HyperLiteNet: Extremely Lightweight Non-Deep Parallel Network for Hyperspectral Image Classification" Remote Sensing 14, no. 4: 866. https://doi.org/10.3390/rs14040866
APA StyleWang, J., Huang, R., Guo, S., Li, L., Pei, Z., & Liu, B. (2022). HyperLiteNet: Extremely Lightweight Non-Deep Parallel Network for Hyperspectral Image Classification. Remote Sensing, 14(4), 866. https://doi.org/10.3390/rs14040866