1. Introduction
Object detectors for remote sensing images are designed to quickly and accurately search for target objects in images, such as vehicles, aircraft, playgrounds, and bridges. They are essential in traffic management, target detection (military), land use, and urban planning [
1,
2,
3]. As remote sensing images are acquired with a top-view perspective, oriented object detectors use OBBs, which provide more accurate orientation information of the objects than the general object detectors [
4,
5,
6,
7,
8] that use HBBs. This application enables better detections for objects with dense distributions, large aspect ratios, and arbitrary directions.
Many detectors designed for OBB tasks on remote sensing have reported promising results. In order to enhance the robustness and make the detector capable of detecting objects in arbitrary directions, most are devoted to learning the rotation-equivariant features of the objects [
4,
8,
9,
10,
11]. As analyzed in the experiments of this paper, in the commonly used dataset of remote sensing, many categories not only have a small number of samples but also are concentrated in small angle intervals. Traditional detectors based on CNNs cannot learn rotation equivalence accurately because the convolutional kernels do not follow the directional changes of the objects [
9,
12]. Existing detectors can detect arbitrary orientation objects by employing larger capacity networks that fit the feature expression of the object under different directions in the training set [
13]. As shown in
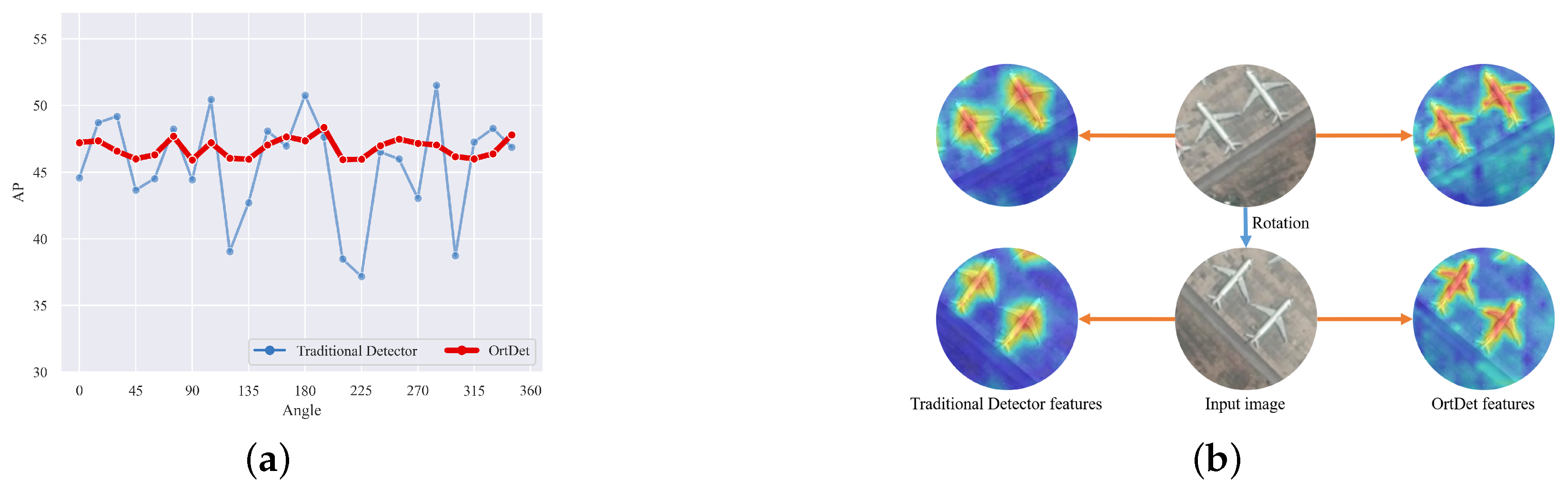
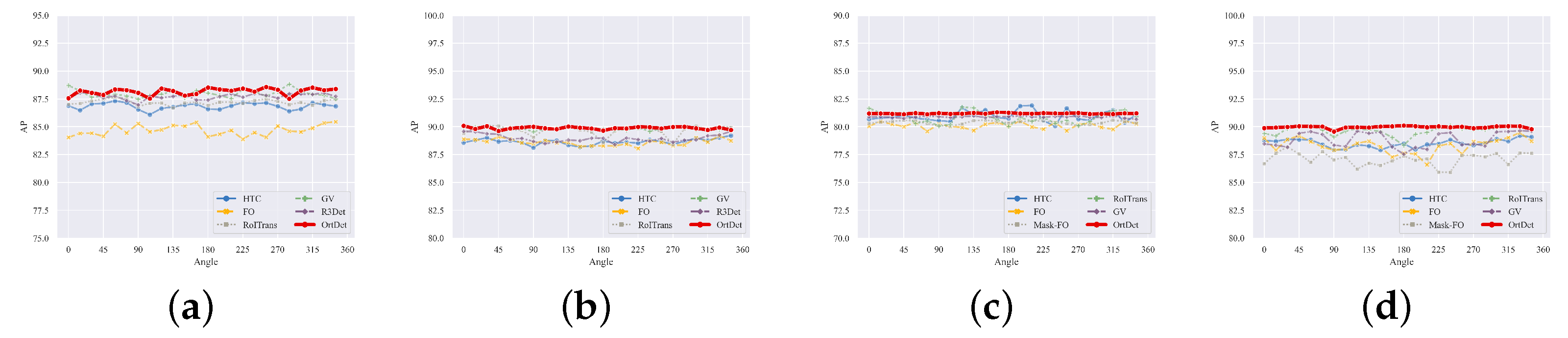
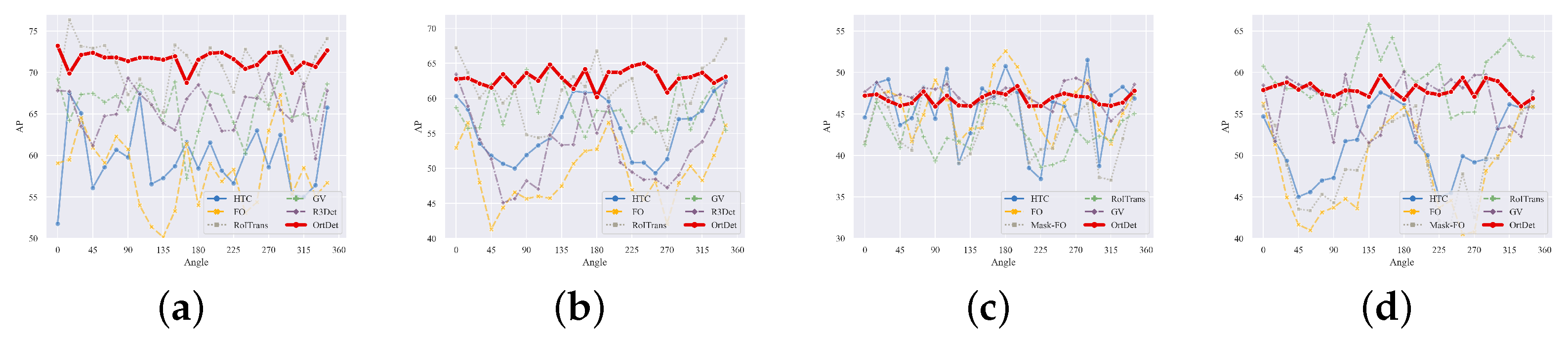
Figure 1a, we found that when the angle in the validation set is rotated to increase its distribution and training set differences, the performance of traditional detectors can differ by nearly 15 AP. Therefore, the robustness of the detector cannot be guaranteed. As shown in
Figure 1b, the features maps extracted by traditional detectors are concentrated in the center of the object no matter how they are rotated, and it is difficult to learn the directional information of the object. It is crucial for the detector to encode the rotational equivalence features of the objects more accurately. For example, the CNNs have translation equivalence feature, so the presence of the object at any position does not have a significant impact.
Recently, to improve the ability of CNNs to encode the rotation equivalence of the object, group convolutions [
14] have been proposed to extend the traditional CNNs to obtain the rotation equivalence features in larger groups, which produce feature maps with dedicated orientation channels to record features in different directions of the image [
15,
16,
17]. The ReDet [
13] builds on this approach by designing a rotation-invariant region of interest (RiRoI) structure to obtain features of the object in the directional channel and successfully confer the CNN models with rotation equivalence in detection tasks. However, such methods not only increase the computational complexity of the CNNs but also introduce a large amount of nonessential computations, e.g., most of the remote sensing image regions are composed of a background, and we do not need to obtain features of multiple directions in the background region. Cheng [
18] et al. explicitly added a rotation-invariant regularizer to the CNN’s features by optimizing a new loss function to force a tight mapping of the feature representations of the training samples before and after rotations to obtain rotation equivalence images. However, such methods force the CNN to learn high-dimensional image-level rotation equivariant/invariant features. In contrast, instance level rotation-equivalence features are more noteworthy in the object detection task.
In addition, the existing detectors [
8,
19,
20,
21] measure the precision using the mean average precision (mAP) metric. There is no specific metric for measuring the robustness of the object direction in the oriented object detection task. To a certain extent, the ability to learn more rotation equivalence features results in a higher mAP metric. However, the higher mAP does not equate to better rotation equivalence features of the object. The training and validation sets are usually divided randomly on the dataset, so there are independent and identically distributed [
22,
23,
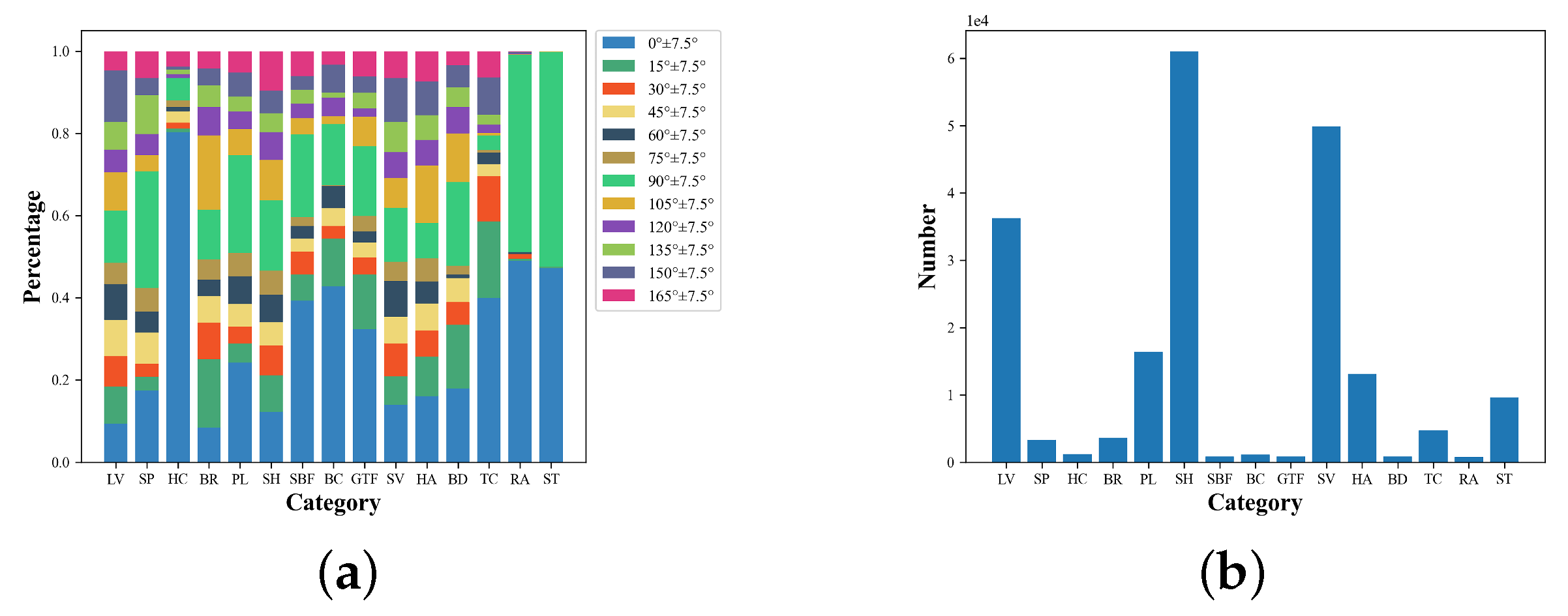
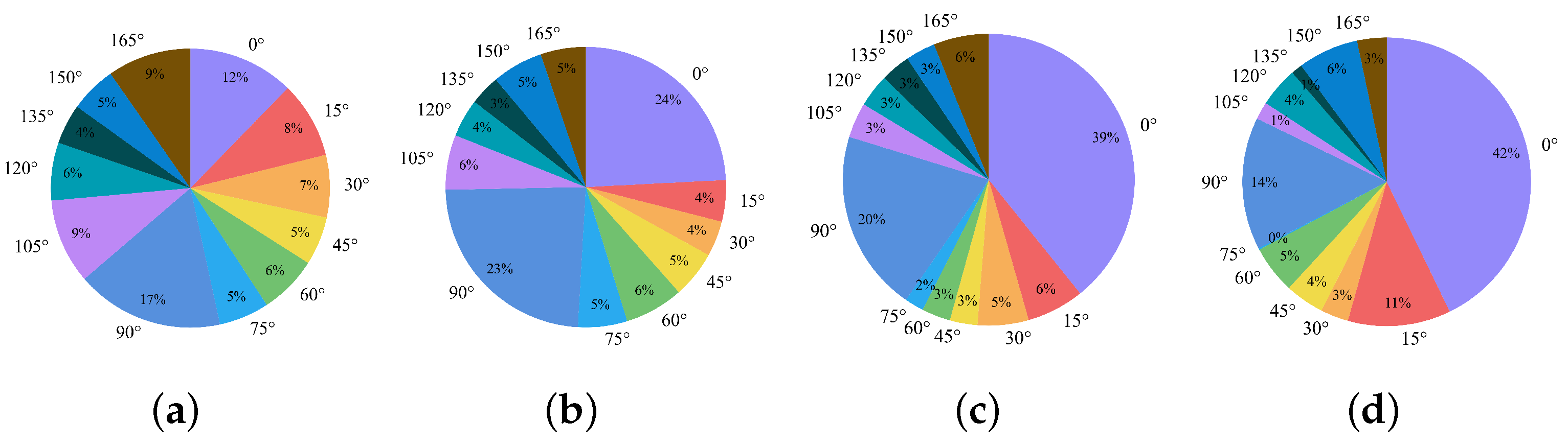
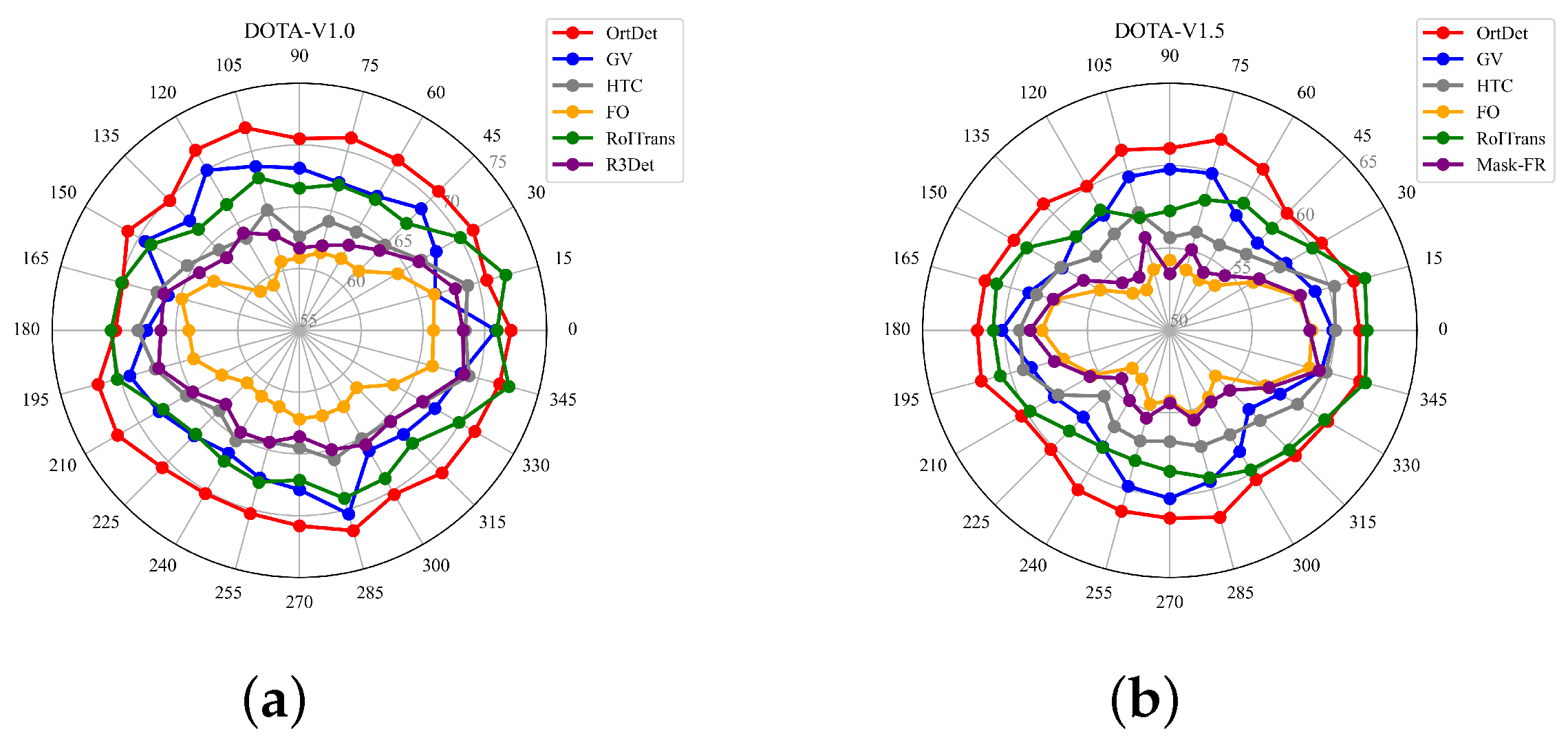
24] in direction distribution. Therefore, the detectors can achieve a high mAP by fitting the feature expression in each direction of the train set. It is equivalent to informing the detector in advance of the test set’s object in the corresponding direction feature, and it cannot learn rotation equivalence features. In particular, for remote sensing dataset bridges, courses and ports, and other objects, due to the limitation of the number of satellites and the limitation of the overhead perspective, the number of objects is not only small but also more than 50% of objects directions are concentrated in the range of 0 ± 15°. When the angle distributions of the training and test dataset are inconsistent, the mAP will be substantially reduced. Thus, the mAP metric can only reflect the accuracy of the detector for the current angle distribution dataset and does not reflect the robustness of the detector.
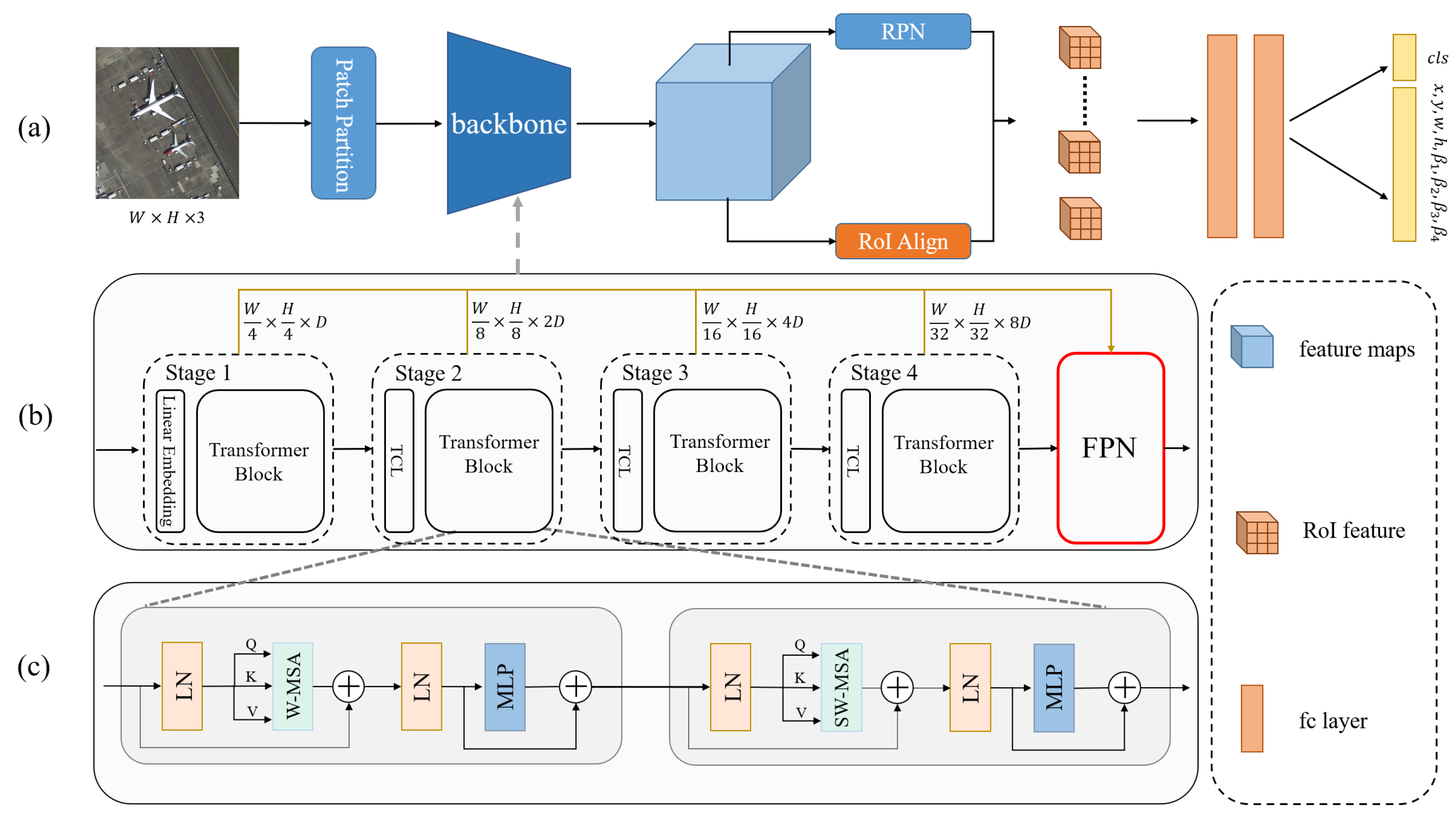
In this paper, we propose a novel OrtDet architecture for remote sensing images to improve robustness by learning the rotation equivalence features of the objects. Firstly, we introduce the vision transformer architecture as the backbone. As shown in
Figure 1b, compared with the traditional detector, which focuses on the central part of the object regardless of how the object is rotated, and the extracted feature is very coarse, the OrtDet can regress the overall features of the object (e.g., nose, fuselage, wings, etc.) more finely and accurately, so we can identify the orientation of the object by its features, which is more suitable for the oriented object detection task. Unlike CNNs with fixed and limited perceptual fields, it relies on an intrinsic self-attentive mechanism as the main module to capture its remote contextual associations via the degree of feature similarity. The feature similarity region can change adaptively according to the object direction. As shown in
Figure 2a, it can be seen that the feature similarity regions obtained by self-attention at each point are treated as nondifferentiated at the beginning of training. When the model is trained, as shown in
Figure 2b, the model learns that the similarity region of the features at each point in the object converges adaptively from the full image range to the region where the object is located, and
Figure 2c shows that this similarity region is consistent with the change in the object’s orientation, thus demonstrating that this approach can better learn rotational equivalence features. This direction also follows the ViT [
25] philosophy to reduce the “induction bias” while pursuing generalized features. Self-attention [
26] computations have fewer inductive bias than CNNs, such as translation equivalence and localization, but it can still learn translation equivalence and scale equivalence features under certain datasets and supervised/self-supervised tasks [
25,
27], so it can also learn object rotation equivalence under the corresponding supervised tasks, i.e., oriented object detection tasks. Secondly, the transformer’s architecture is a plain, nonhierarchical architecture that maintains a single-scale feature map [
25]. We use the Tokens Concatenation Layer (TCL) layer, which reduces its spatial resolution with the increase in network depth and thus generates a multiscale features map.Then, we leverage the Feature Pyramid Network (FPN) [
28] module to assign feature levels according to the scale of objects. To reduce the computational complexity of the model, we use the window mechanism and shift window mechanism to reduce the computational overhead of the model while maintaining the relationship between the windows of the images [
29].
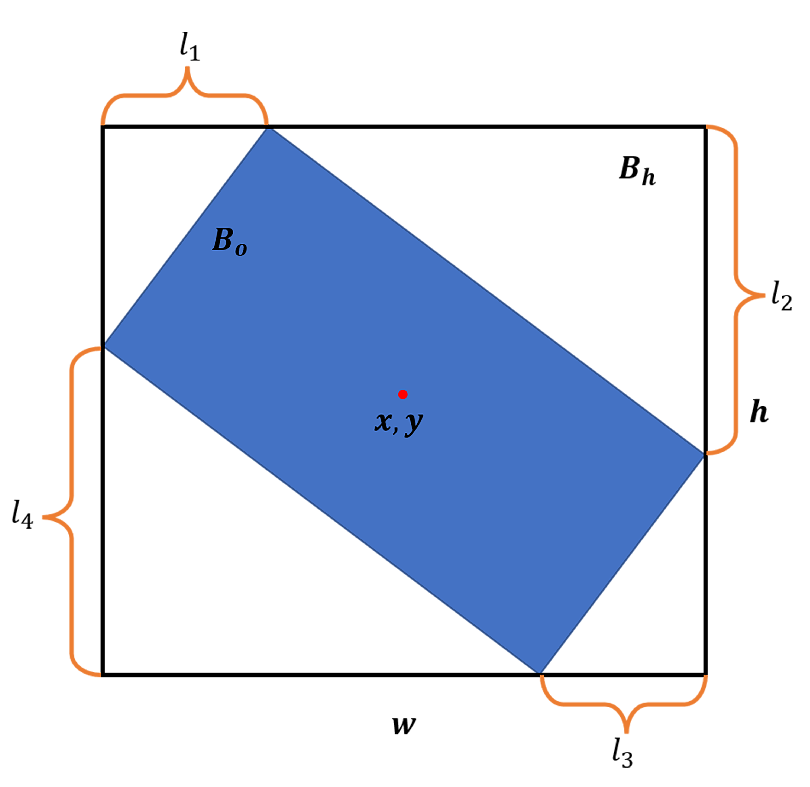
In addition, we use the vertex offset method to accurately describe an oriented object by indirectly regressing the glide of each vertex offset of the object with the smallest HBBs on each corresponding side. The principle is outlined in
Section 3.4. This representation can further alleviate the instability of the regression’s results due to the change in the object’s direction. Furthermore, to quantitatively measure the ability of the detector to learn the object rotation equivalence features, we propose a new evaluation metric: mean Rotation Precision (mRP). It measures the fluctuation of the accuracy of the detector for the same dataset at different angle distributions. A smaller mRP means that the accuracy is less affected by the object direction in the dataset and is more robust. The effectiveness of the proposed method is demonstrated by extensive experiments on the remote sensing datasets DOTA-v1.0, DOTA-v1.5, and HRSC2016.
The significant contributions of this paper can be summarized as follows:
We propose an Orientation Robust Detector for remote sensing images. It adaptively captures remote contextual associations via the degree of feature similarity. The rotation equivalence feature can be learned more accurately for objects at different angles.
We use windowing mechanism and TCL strategy to reduce the computational complexity of transformer and generate multi-scale features. A more efficient and robust method is used to represent the oriented objects to reduce the regression’s confusion problem.
We propose a new metric, mRP, compared to the traditional mAP; it reflects the ability to learn object rotation equivalences by quantitatively describing the fluctuation of the accuracy in the test set for different object angle distributions.
We carry out experiments on the DOTA-V1.0, DOTA-V1.5, and HRSC2016 datasets to demonstrate the effectiveness of our method, which involves significant improvements in detection performances as measured by both mAP and mRP metrics.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}