1. Introduction
Intelligent environmental perception is a necessity for planetary rovers toward autonomous driving, which provides crucial semantic information, e.g., identifying feasible driving areas and surrounding obstacles. For such a panoptic perception mission, terrain segmentation is the most critical procedure, which also can be viewed as a semantic segmentation task. Semantic segmentation is a widely used perception method for self-driving vehicles on earth that can assign a separate predefined class label to each pixel of an image [
1] it is the foundation of many high-level tasks that need to infer relevant semantic information from images for subsequent processing. This applies on self-driving vehicles on Mars as well. Therefore, this study explored the task of terrain segmentation on the Martian surface, aiming to characterize semantic information from rover images. As shown, the
Figure 1a shows the Tianwen-1 Zhurong rover, China’s first Mars rover, which is undergoing its fantastic exploration on the red planet. RGB sample images of the Mars surface and the corresponding terrain segmentation annotation are depicted in
Figure 1b,c, respectively. It can be observed that semantic segmentation is a pixel-level dense prediction task, which requires an in-depth understanding of the semantics of the entire scene and is in some ways more challenging than those image-level prediction tasks.
Early image segmentation approaches dedicated to divide images into regions based on little more than basic color and low-level textual information [
2,
3]. With the rapid development of deep learning techniques in the 2010s, deep convolutional neural networks (CNNs) became dominant in automatic semantic segmentation technology due to their tremendous modeling and learning capabilities, which strive to boost algorithm accuracy on the strength of massively parallel GPUs and large labelled datasets [
4,
5]. Long et al. [
6] first proposed a fully convolutional network (FCNet), which is a revolutionary work and the majority of following state-of-the-art (SOTA) studies are extensions of the FCN architecture. One of the most pioneering works is UNet presented by Ronneberger et al. [
7] for biomedical image segmentation, which adopts the influential encoder–decoder architecture and proved to be very useful for other types of image data [
8,
9,
10,
11]. Meanwhile, inspired by the high precision that CNNs achieved in semantic segmentation, many CNNs-based approaches were proposed for the Martian terrain segmentation (MTS) task. Rothrock et al. [
12] proposed a soil property and object classification (SPOC) system based on DeepLab for visually identifying terrain types as well as terrain features (e.g., scarps, ridges) on a planetary surface. They also presented two successful applications to Mars rover missions, including the landing site traversability analysis and slip prediction. Iwashita et al. [
13] proposed TU-Net and TDeelLab robust to illumination changes via data fusion from visible and thermal images. Liu et al. [
14] proposed a hybrid attention-based terrain segmentation network called HASS for unstructured Martian images. Claudet et al. [
15] employed advanced semantic segmentation algorithms to generate binary safety maps for the spacecraft safe planetary landing problem. Furthermore, several existing studies attempted to resolve the terrain segmentation issue by using wear-supervised techniques. Wang et al. [
16] adopted the element-wise contrastive learning technique and proposed a semi-supervised learning framework for Mars imagery classification and segmentation through introducing online pseudo labels on the unlabeled areas. Goh et al. [
17] proposed another semi-supervised Mars terrain segmentation algorithm with contrastive pretraining techniques. Zhang et al. [
18] proposed a novel hybrid representation learning-based framework, which consists of a self-supervised pre-training stage and a semi-supervised learning phase for sparse data. Li et al. [
19] introduced a stepwise domain adaptation Martian terrain segmentation network, which effectively alleviates covariate shift through unifying the color mapping space to further enhance the segmentation performance.
Furthermore, data-driven deep learning generally refers to learning directly through sufficient experience data. The level of success for deep learning applications is to a great extent determined by the quality and the depth of the data being used for training. In this respect, Mars terrain segmentation is currently attracting more and more attention, and scientific interest for deep learning-based segmentation datasets is growing rapidly. Several large-scale 2D image sets were established for the Mars terrain segmentation problem, the relevant information of which is listed in
Table 1. Swan et al. [
20] built the first large-scale dataset, AI4Mars, for the task of Mars terrain classification and traversability assessment, of which labels were obtained through a crowdsourcing approach and consisted four classes: soil, bedrock, sand, and big rock. Li et al. [
19] extensively released a Mars terrain dataset annotated finely with nine classes, named Mars-Seg. Liu et al. [
14] established a panorama semantic segmentation dataset for Mars rover images, named MarsScapes, which provides pixel-wise annotations for eight fined-grained categories. Zhang et al. [
18] presented a high-resolution Mars terrain segmentation dataset, S
5Mars, annotated with pixel-level sparse labels for nine categories. The Martian surface condition is complicated and the corresponding annotation process is challenging. Hence, we thank all the above dataset creators that enabled us to conduct the research for this paper.
In comparison to natural scene images, the Martian images have their particular characteristics. Objects on the surface of Mars exhibit unstructured characteristics with rich textures, ambiguous boundaries and diverse sizes, such as rocks and gravel [
21]. Understanding unstructured scenes quite heavily depend on modeling the connection between the target pixel and its relevant surrounding content to a certain extent. Therefore, a limited receptive field is hard-pressed to meet demand, and several acquired rare target instances available for training are in small numbers. Class imbalance remains a problem in the MTS task. The above difficulties make it unreliable to directly apply the semantic segmentation methods designed for natural images on Martian terrain segmentation tasks.
On the other hand, CNN-based semantic segmentation methods always made brilliant achievements at the expense of high computational costs, large model size, and inference latency. This situation prevented recent state-of-the-art methods from being applied to real-world applications. Real on-board applications have a strong demand of semantic segmentation algorithms to run on resource-constrained edge devices in a timely manner. Therefore, deep models for the Mars terrain segmentation task should be efficient and accurate. Considering the performance limitations of spacecraft equipment, it is essential to develop efficient networks for accurate Mars terrain segmentation.
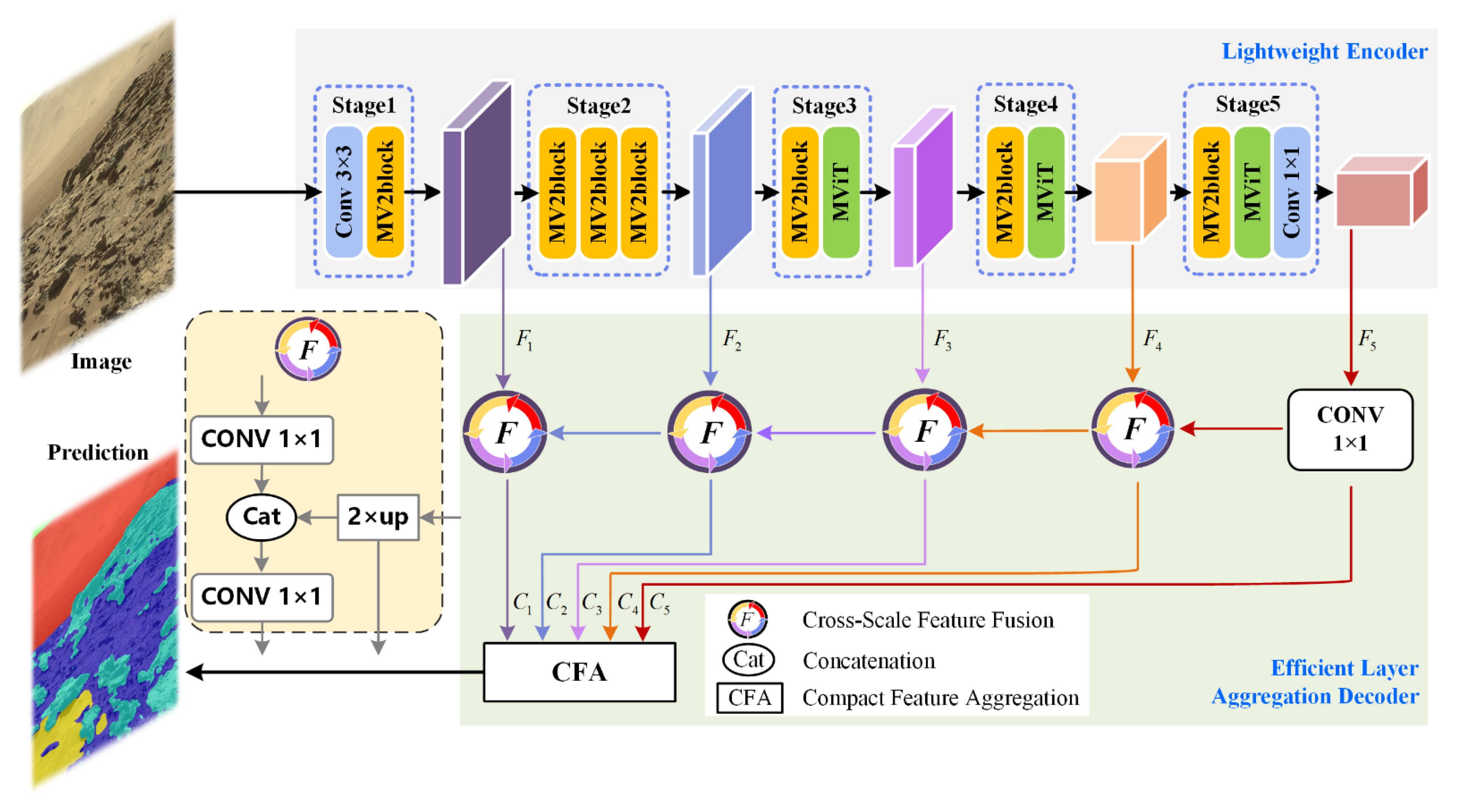
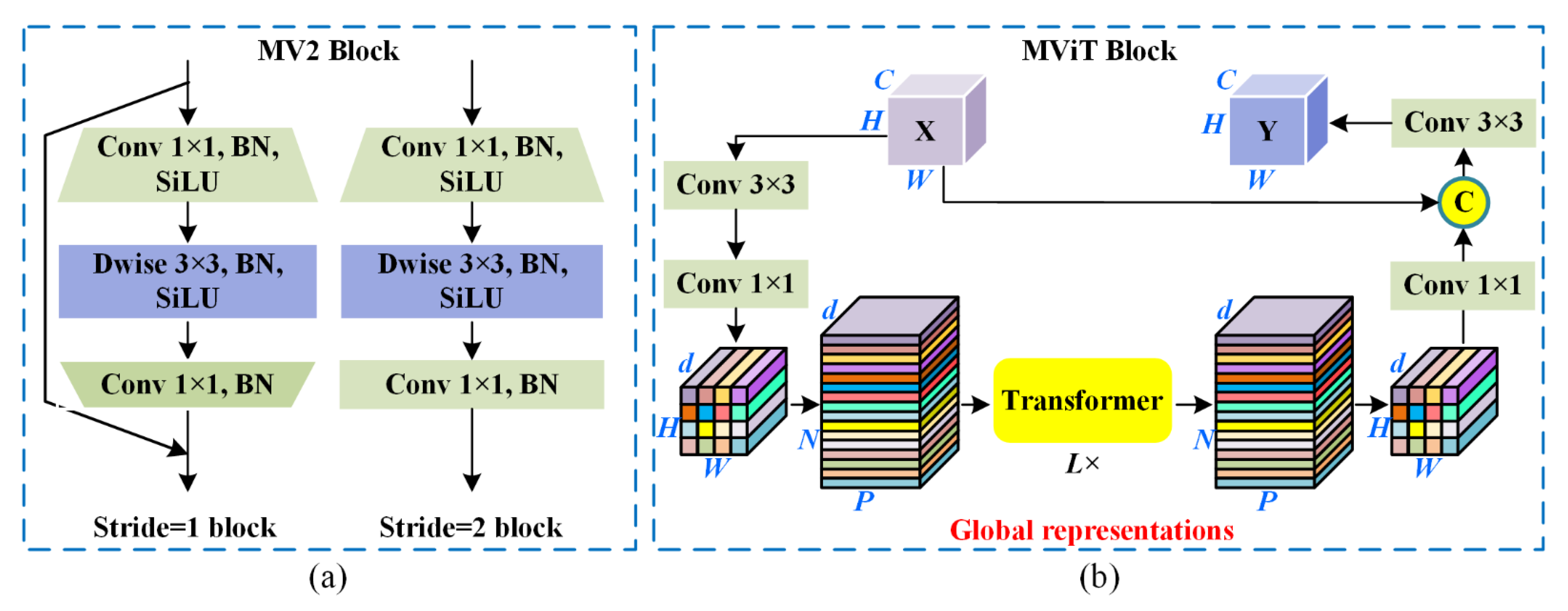
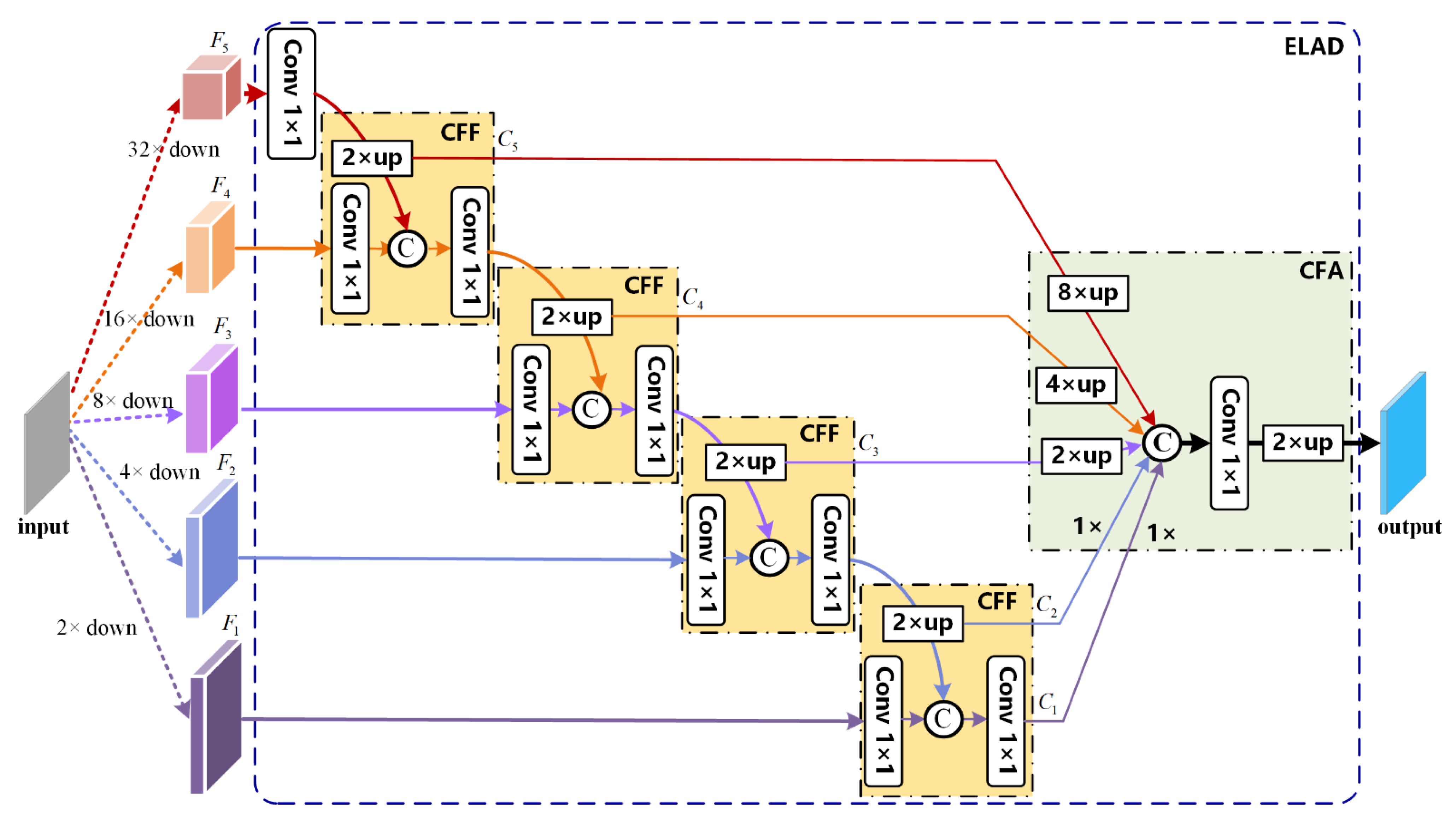
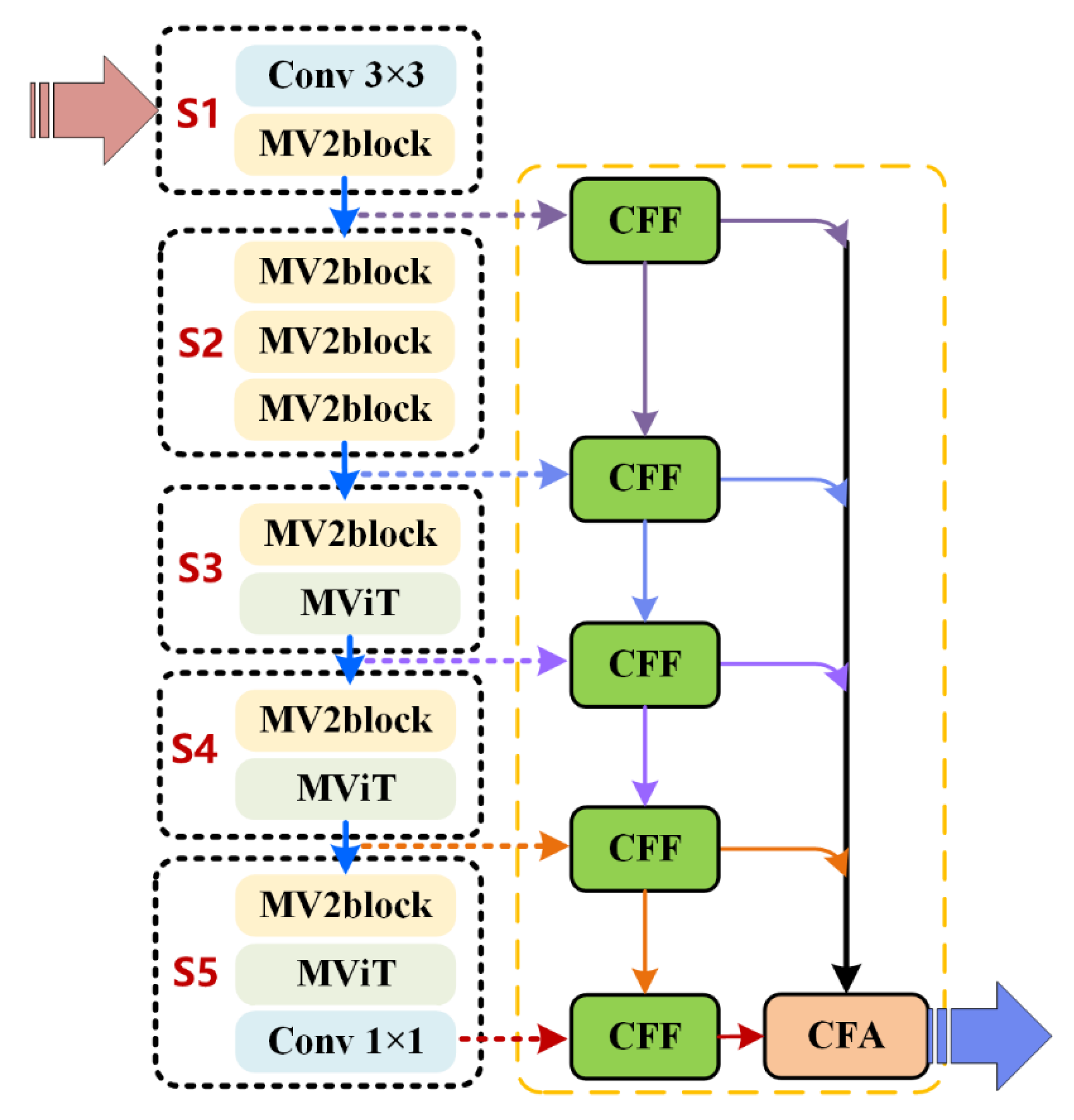
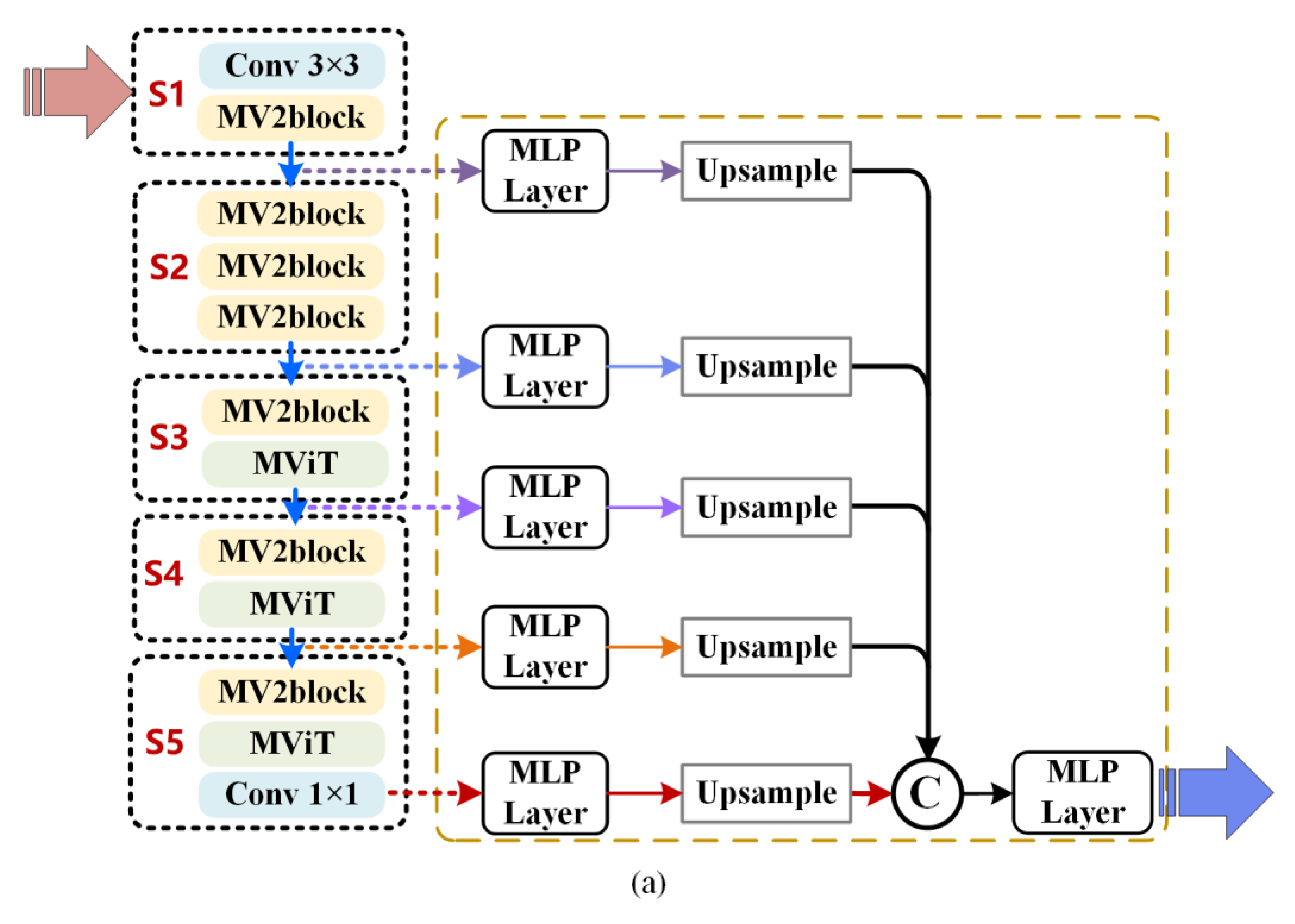
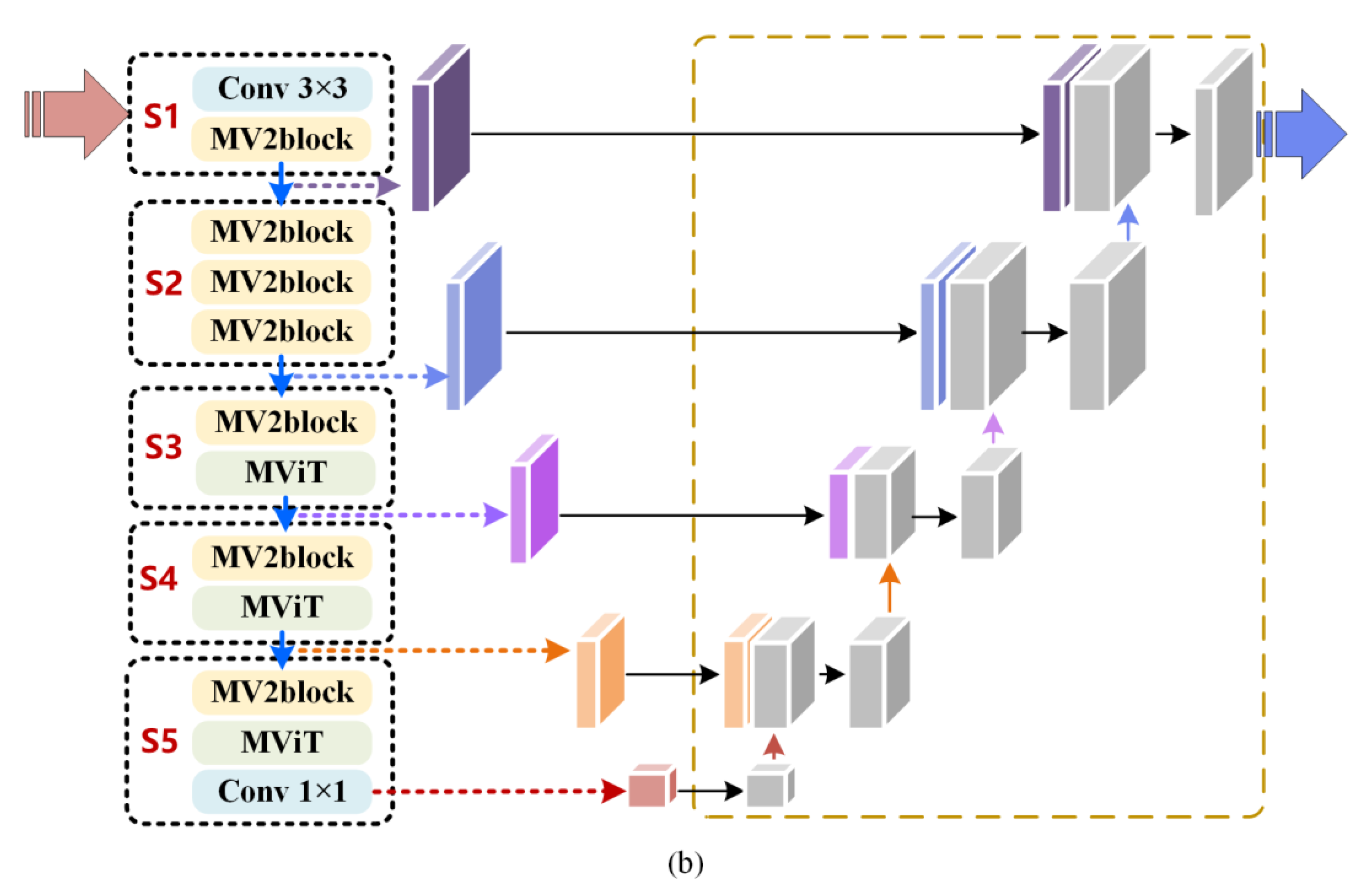
Toward this end, this paper proposes a novel lightweight Martian terrain segmentation model, named SegMarsViT. In the encoder part, the mobile vision transformer (MobileViT) backbone is leveraged to extract local–global spatial and capture high-level multiscale contextual information concurrently. An effective layer aggregation decoder (ELAD) is designed to further integrate hierarchical feature context information and generate powerful representations. Moreover, we evaluate the proposed method on three public datasets: AI4Mars, MSL-Seg, and S5Mars. Extensive experiments demonstrate that the proposed SegMarsViT achieves comparable accuracy as the state-of-the-art semantic segmentation method. In the meantime, SegMarsViT has much less computation burden with a smaller model size.
The main contributions of this work can be summarized as follows:
- (1)
To the best of our knowledge, this is the first effort toward introducing the lightweight semantic segmentation model into the field of Martian terrain segmentation. We evaluate several representative semantic segmentation models and conduct enough comparable experiments. This is expected to facilitate the development and benchmarking of terrain segmentation algorithms in Martian images.
- (2)
We investigate a novel vision transformer-based deep neural network SegMarsViT for real-time and accurate Martian terrain segmentation. In the encoder, we employ a lightweight MobileViT backbone to capture a hierarchical feature. Notably, the proposed SegMarsViT is the first transformer-based network for the Martian terrain segmentation task. In the decoder part, a cross-scale feature fusion (CFF) module and a compact feature aggregation (CFA) technique are designed to strengthen and merge the multi-scale context feature.
- (3)
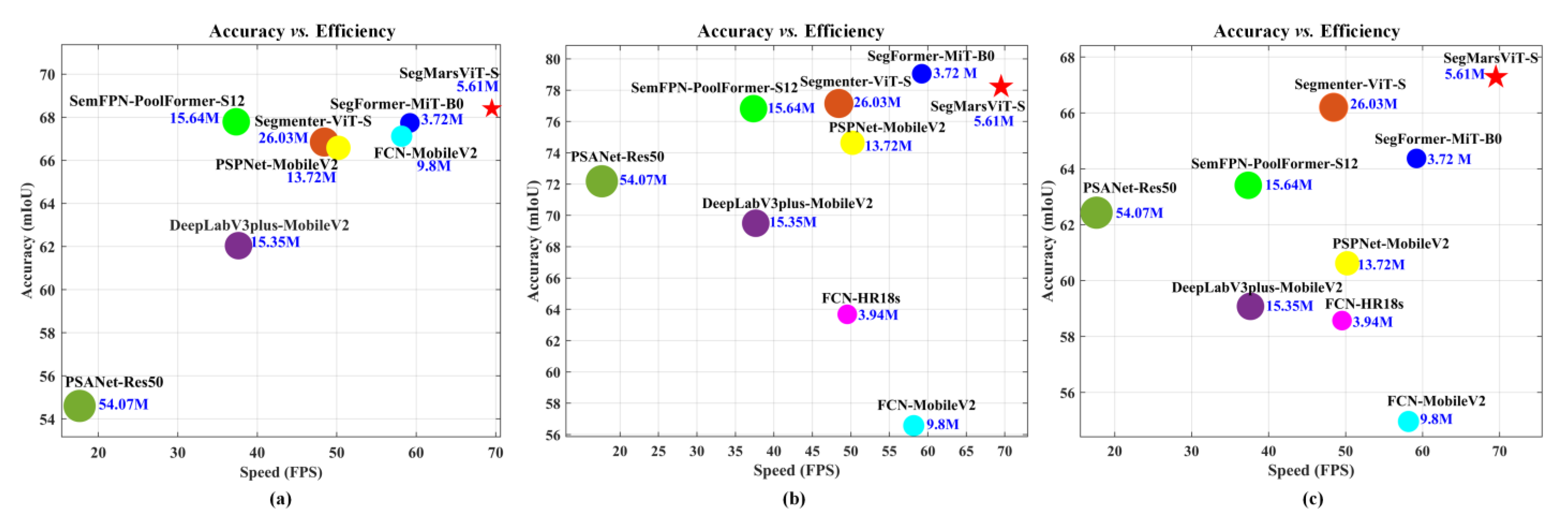
We conduct extensive experiments on AI4Mars, S5Mars, and MSL-Seg datasets. The results validate the effectiveness and efficiency of the proposed model, which can obtain competitive performance with 68.4%, 78.22%, and 67.28% mIoU, respectively. In the meantime, SegMarsViT has much less computation burden with smaller model size.
The remainder of this article is organized as follows: In
Section 2, we will briefly introduce some previous work related to lightweight semantic segmentation and vision transformer.
Section 3 describes the proposed method in detail.
Section 4 provides overall performance and comparison results of the proposed method with analysis and discussion, and
Section 5 concludes this study.
5. Conclusions
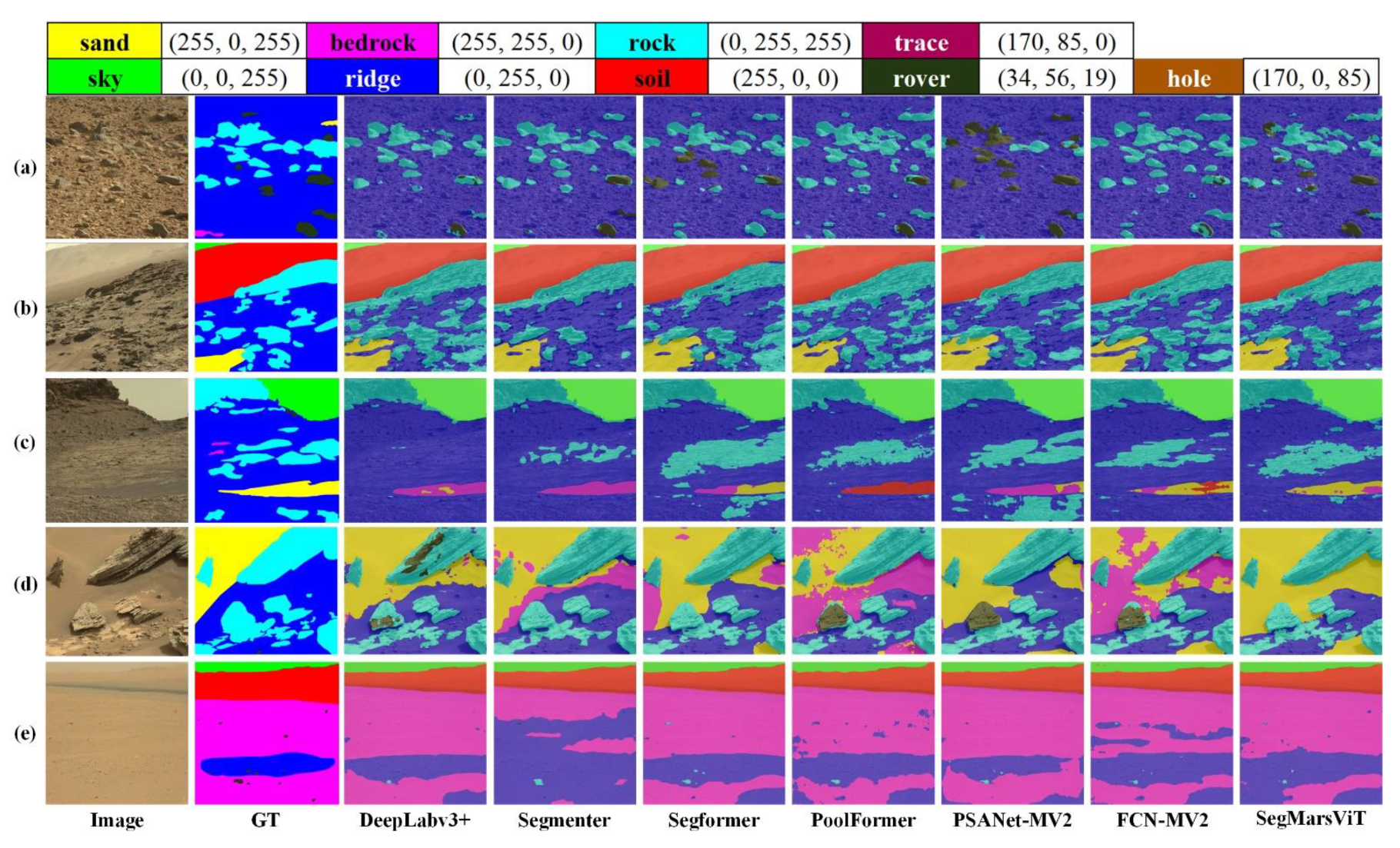
In this paper, we propose SegMarsViT, a lightweight network for the real-time Martian terrain segmentation task. We adopt a deployment-friendly MobileViT backbone to extract discriminative local–global context information from multi-scale feature space. Further, an effective cross-scale feature fusion module was designed to encode context information in the multi-level features, with a cross-scale feature fusion mechanism applied to help further aggregate feature representations. In the end, a compact prediction head is used to aggregate hierarchical features and help enhance feature learning, yielding run-time efficiency. Empirical results validate the superiority of the proposed SegMarsViT over mainstream semantic segmentation methods. The ablation study verifies the effectiveness of each module. More specifically, MobileViT helps obtain the semantic properties of terrain objects in terms of morphology and distribution, while the compact decoder can lead to both high efficiency and performance. Through the comparison of parameters, FLOPs and FPS, the SegMarsViT further demonstrates its advantages in terms of space and computation complexity. All of the results fully demonstrate the capability of the SegMarsViT in efficient and effective Martian terrain segmentation, which provides significant potential for the further development of MTS task.
One potential limitation is that there’s an enormous gap between high-end GPU and a low-memory spacecraft device. Our future work will experiment on a realistic hardware platform to evaluate the model efficiency. Energy consumption and practical performance will be our primary focus. Moreover, we will proceed to refine our approach and be committed to investigate MTS methods for more challenging cases, e.g., multi-source heterogeneous data and a multi-task perception system.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}