In this section, we analyze the impact of the different properties of models by considering four evaluation dimensions, namely the accuracy, efficiency, robustness, and proposed specialized and generalized metrics. Finally, we relate their design and experimental properties in order to find performance patterns.
4.3.1. Accuracy
In this section, we investigate the segmentation accuracy of the selected models by analyzing the results presented in
Table 4 and
Table 5.
Initially,
Table 4 depicts the recorded measurements related to segmentation accuracy (described in
Section 3.2) of the learning process. In training, validation, and test sets, we show the best achieved
and
metrics. We also denote the exact number of epochs (
), where the best metric is recorded. In the case of the S3DIS dataset, we display the
metric in the training and test set, as the
metric does not apply and there is no validation set. To clarify, we do not analyze the inner class labels of S3DIS, as explained in
Section 4.2. For this, per-class metrics such as
that can be applied in the ShapeNet-part dataset, do not apply in the analysis of S3DIS in this work.
In the results using the ShapeNet-part dataset, we observe that RSConv is the best method in test data achieving an score of 85.47 and a of 82.73. PointNet++ is second in terms of and metrics, achieving scores of 84.93 and 82.50 respectively. Note that PPNet achieves also the same metric of 82.50 as PointNet++. In addition, PPNet reaches the highest performance in learning-related metrics in the training set with 92.37 in and 92.89 in . However, its poor performance in the test set may indicate overfitting issues.
In the S3DIS dataset, we observe that in Areas 1, 3, 4, and 5 PPNet is first while KPConv is second in the test data. In Area 6 we can see that KSConv surpasses PPNet with a score equal to 56.32 against 55.87. It is worth mentioning, that in the hardest to segment Area, Area 2, RSConv is the winner with , while KPConv takes the second place with an . Similarly, as in the ShapeNet-part dataset, PPNet has the highest performance in the training set in all Areas. However, by observing some poor performance cases in the test set, for example in Area 3 or Area 2, we may have overfitting issues or these Areas are hard to learn.
To analyze in-depth the segmentation behavior of the models, in
Table 5a,b, we present in-depth results with ShapeNet-part and S3DIS datasets, respectively.
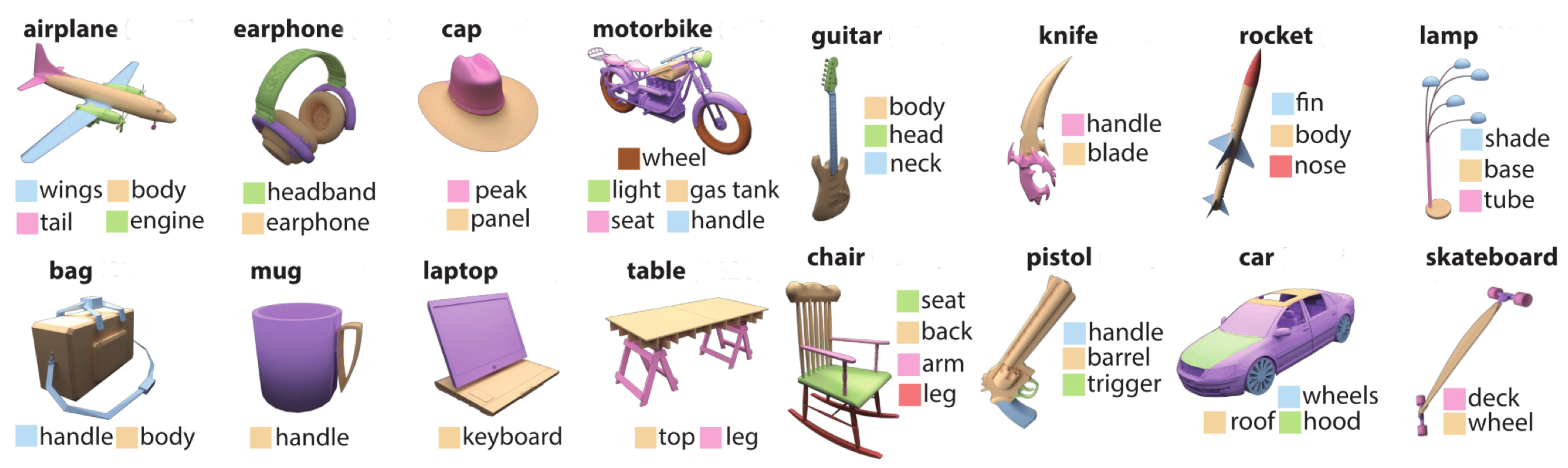
Regarding the results with ShapeNet-part, we report the segmentation accuracy per class () in the epoch where the best is recorded for each model. It seems that all the models perform better in different classes of point cloud objects. By observing the table, we can identify that there is no perfect rule for dividing the models according to their accuracy result in each class. For instance, RSConv outperforms the other models in classes Airplane and Bag but is third or fourth in ranking in other classes such as Car or Chair. Additionally, PointNet seems to deal great with Laptop and Table labeled point clouds, but can not deal effectively with the majority of the others. In addition, it is interesting that, for example, in class Cap with 39 samples PointNet++ is the winner, while on Rocket with 46 samples the winner is PPNet and in Bag with 54 samples the winner is RSConv.
Regarding the results with S3DIS, we report the best achieved per Area. We can see that KPConv, PPNet, and RSConv are ahead of PointNet and PointNet++ in all S3DIS Areas. We can not decide on an all-around winning model for all the Areas, as PPNet is first in Areas 1, 3, 4, and 5, but in Area 2 and Area 6 the winners are RSConv and KPConv, respectively. Thus, we highlight the Observation 1.
Observation 1.
In terms of accuracy, there is not a clearly winning model in all classes of point cloud objects in the ShapeNet-part. Additionally, it seems that there is not a clear winner in classes where the point cloud samples are limited. The worst model is PointNet, which incorporates only Rotation and Permutation invariance properties. The same insights are also observed in scene segmentation (S3DIS dataset), as there is not an absolute winner in all Areas and PointNet is the least accurate model. Finally, in both segmentation tasks, Convolution-based models obtain better results, both in training and testing.
4.3.2. Efficiency
In this section, we explore the segmentation efficiency of the selected models by analyzing the results in
Table 6.
In
Table 6, we display (i) the time spent (in decimal hours) to complete the whole learning process of training, validation, and testing as
, (ii) the time spent to achieve the best performance in relation to
and
metrics in the test data as
,
respectively and (iii) the number of epoch (
) that corresponds to the exact time measurement. Additionally, we display (iv) the average GPU memory allocation in percentage in the whole learning process as
. Please note that the preliminaries of the aforementioned metrics are detailed in
Section 3.2.2. In S3DIS Areas, we report only the
as the
does not apply, as stated earlier.
Regarding the results in ShapeNet-part, an interesting observation is that PointNet++ is the fastest neural network with a total run time (
) of 4.55 h, while being the second best in accuracy, as shown in
Table 4. It also achieves its peak performance in test data faster than all its competitors, i.e.,
and
h. RSConv and PointNet are second in
and
respectively. Additionally, KPConv uses the least amount of epochs to achieve the best
value in test data, i.e.,
. Regarding the best score in
, PointNet++ uses
while PPNet follows with an almost identical number of epochs to achieve its best
score,
.
In terms of average GPU memory usage, PointNet finishes in the first place with 33.7% although the second one, PointNet++, has approximately the same GPU memory usage with a value of 36.3%. Additionally, PPNet utilizes 89% of total GPU memory while needing about 29.28 h of time for its computations, appearing to be the least efficient in terms of memory and time spent. It is worth noticing that the differences in time efficiency across the models are great, wherein on one hand we observe PointNet and PointNet++ models having and and on the other hand KPConv and PPNet having and respectively. Similarly, in average GPU memory allocation, we notice PointNet and PointNet++ models having and , and on the other hand KPConv and PPNet having and respectively.
Regarding the results in S3DIS Areas, we observe that PointNet++ is the fastest neural network in (
), in all Areas of S3DIS, similarly as in ShapeNet-part case. However, in Area 1, PointNet achieves its peak performance
faster than the others. It is noteworthy that in Area 2, RSConv not only achieves the best accuracy of
(
Table 4) but also is faster than the other models in
. Regarding the average GPU memory usage, PointNet is the winner in almost all Areas except Area 2 where PointNet++ is first. It is clear that both PointNet and PointNet++ use fewer memory resources than the others, while PPNet requires the most memory resources almost in all Areas. These remarks lead us to
Observation 2.
Observation 2.
Time and memory efficiency varies greatly across different models. There is not a clearly winning model concerning efficiency in time and memory allocation. Additionally, it seems that neural networks that utilize Point-wise MLP-based operations are the ones that have the lowest time and GPU memory consumption.
4.3.3. Robustness
In this section, we analyze the results presented in
Table 5 and
Table 7 to investigate the segmentation robustness of the selected models.
In order to further clarify the robustness of each deep learning model in each class we denote the results in
format. Regarding the robustness-related results in the ShapeNet-part dataset, in the last row of
Table 5(a), we display the results of
metric for each class that correspond to the
best epoch outcome of
of each model. Additionally, we report the average accuracy obtained in each object. Such information is useful to detect the most difficult and the easiest objects to learn. In the same notion, in
Table 5(b), in the results on the S3DIS dataset, we report the best achieved
per Area and also the model performance averages. We also report the average per Area in order to justify the learning difficulty of each Area.
In ShapeNet-part, PPNet has the lowest error () of the mean (), while the mean performance of 82.50 is almost identical to the RSConv, which achieves 82.73 with an error of . Please note that in the hardest classes to learn, i.e., the ones with the lowest achieved accuracy and highest error, such as "Rocket" or "Motorbike" the winning models are KPConv and RSConv respectively, both of them being based on convolutional operations.
On the other hand, in S3DIS, PPNet achieves the best average performance in all Areas, with a model average of , while KPConv is second with an average of . Additionally, it can be observed that the hardest Areas to learn are Areas 2, 3, and 6, as all the models achieved significantly lower segmentation accuracy than in Areas 1, 4, and 5. Similarly, as in ShapeNet-part results, the winning models in the hardest cases are based on convolutional operations. Following, we highlight another remark in Observation 3.
Observation 3.
In the "hardest" to learn classes (part segmentation) or areas (scene segmentation) the winning models are the Convolution-based ones that incorporate Local Aggregation operations focusing on the local features of the 3D point cloud. Additionally, in some classes (e.g., Earphone) in part segmentation, the Point wise MLP-based models achieve high mean accuracy but they tend to have higher errors than the others.
Furthermore, in
Table 7a, in the ShapeNet-part dataset, we report the
average scores of
per class that are achieved by each neural network in the testing phase of all 200 epochs. It can be observed that highly accurate models in specific classes have higher error (
) than the others. For instance, in class
Cap, PointNet++ has the highest average accuracy of
however its error of the mean seems to be higher than the others
. On the other hand, PPNet has a lower accuracy score of
but the error (
) is approximately half the one of PointNet++.
Regarding the S3DIS results in
Table 7b, we report the
average scores of
in all six Areas, similarly as in ShapeNet-part results. In Area 2, RSConv has the best mean accuracy and also the lowest error (
). KPConv has the best segmentation accuracy in Area 6, but its error is higher than the others. Moreover, PPNet achieves the best mean segmentation accuracy in Areas 1, 3, 4, and 5, but its error of the mean in some cases, such as Area 4 is higher than the one in KPConv or RSConv.
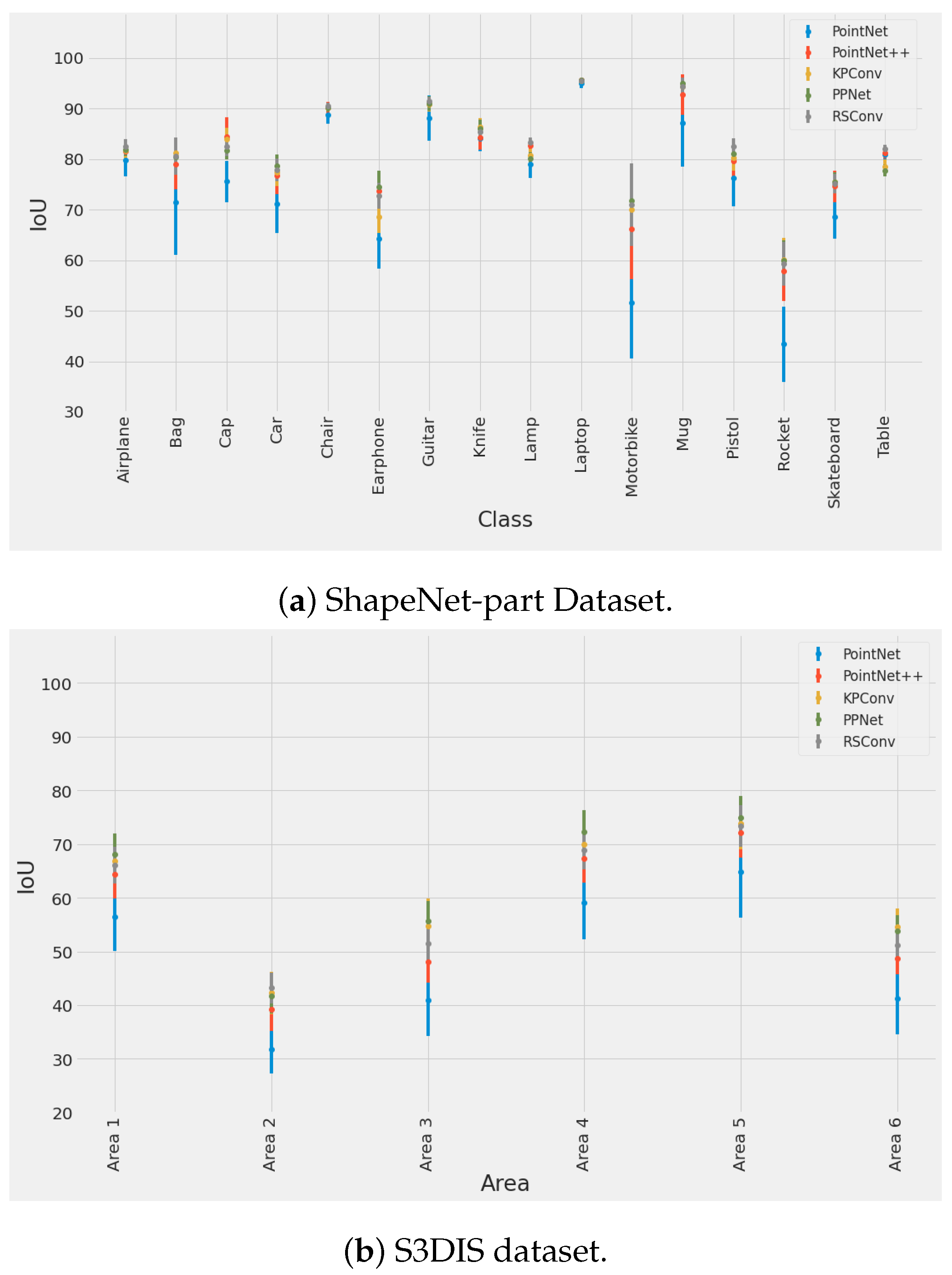
Moreover, we graphically represent the
of
in each class of ShapeNet-part and in each Area of S3DIS in all testing epochs in
Figure 4. In ShapeNet-part, the most accurate method, RSConv, shows also greater robustness than the most efficient PointNet++ model. It is interesting how the models perform in "ill" classes such as the
Motorbike and
Rocket. In such classes, we observe great differences among the models’ performance, although PPNet, KPConv, and RSConv achieve approximately the same segmentation accuracy and robustness. This can be also justified by
Table 7, where in
Rocket class the former three achieve approximately
of
. On the other hand, in the same class of
Rocket, PointNet and PointNet++ seem to be worse with the first one being the worst reporting a
.
In S3DIS, PointNet appears to be the least accurate model since it has the lowest segmentation accuracy and its error is the highest. Observing the error bars, we can say that in some occasions, such as in Area 5, the error is more than twice as high as in other models. Furthermore, we observe that the best model, PPNet, shows also good robustness. In Area 3, we see a great range of accuracy values of all the models combined ranging from approximately 35% to 60%. We can also visually identify that Areas 2, 3, and 6 are hard Areas to learn.
In addition, in order to provide a rigorous statistical evaluation in terms of per-class robustness in test data, first we use the Friedman statistical test [
40], as described in
Section 3.2.3. We apply the Friedman test in our experimental setup, where in the case of ShapeNet-part we have
data classes and
different deep learning models, and in the case of S3DIS, we have
(Areas) and
.
Regarding the ShapeNet-part case, the Friedman test statistic
follows the
F distribution with
and
degrees of freedom. The calculated Friedman test statistic is equal to
, according to Equations (
6) and (
7). Hence, at an
of statistical significance, the critical value is 2.52. Next, we observe that
, so we have enough evidence to reject the null hypothesis
, as described in
Section 3.2.3. Alternatively, at an alpha level of statistical significance
the
, implies that we can reject the null hypothesis.
Table 7 shows the ranking of models according to the aforementioned test.
Regarding the S3DIS case, the Friedman test statistic follows the F distribution with and degrees of freedom. The Friedman test statistic is equal to . At an of statistical significance, the critical value is and by observing that , we can safely reject the null hypothesis .
Once we have successfully rejected the null hypothesis, the Nemenyi test [
40] is applied to check the presence of statistically significant differences among the models. Recall that the two models are statistically significant if their corresponding average ranks differ by at least the critical difference value (
), described in
Section 3.2.3. In the case of ShapeNet-part, the critical value of the two-tailed Nemenyi test (Equation (
8)) that corresponds to 95% statistical significance, i.e.,
, having
and
is equal to
. Thus, the calculated critical difference value is
and for any two pairs of models whose rank difference is higher than
, we can infer with a statistical confidence of 95% that a significant difference exists among them.
In the case of S3DIS, the aforementioned critical value at an while and is equal to . The calculated critical difference value is and we can infer with a statistical confidence of 95% that a significant difference exists among them.
Figure 5 portrays the Nemenyi statistical test of models. In the graph, the bullets represent the mean ranks of each model and the vertical lines indicate the critical difference. Hence, to clarify, the two methods are significantly different if their lines are not overlapping. In ShapeNet-part results, the RSConv model seems to be the winner across all models although, statistically, we can only say that the PointNet model is significantly worst that its competitors. Additionally, PPNet, KPConv, and RSConv perform almost equally according to the Nemenyi test.
By observing the Nemenyi test of S3DIS in
Figure 5b, although the PPNet model appears to be the winning model, we can only justify with statistical significance that PointNet is the worst model and PPNet is better than PointNet and PointNet++ models. Having analyzed our results, we report our
Observation 4.
Observation 4.
Apart from accuracy and efficiency, robustness is also a crucial concern for effective model performance evaluation. There is a great variety of different errors of the mean (ϵ) values and a global robustness comparison rule among the models can not be easily identified. Basically, Convolution-based models that incorporate Adaptive Weight-based or Position Pooling aggregation operators seem to be the winners in the statistical ranking, i.e., RSConv in part segmentation (ShapeNet-part) and PPNet in scene segmentation (S3DIS).
4.3.4. Generalized Metrics
In this section, we provide insights into the generalized performance of the utilized segmentation models by analyzing the results in
Table 8.
In
Table 8, we evaluate the models concerning the proposed generalized metrics (see
Section 3.2.4). We display three different cases that may represent the needs of the final user. Please remind that we use the following parameter rules in the Equations (
9) and (
10):
and
to promote accurate models but also balanced in terms of efficiency and robustness by assigning equal weights to the efficiency and robustness terms of the Equations.
In the first case of ShapeNet-part results, we select values of and , which indicate that the model evaluation process is biased towards the efficiency and robustness of the models. PointNet++ is first in with a value of 0.88, while RSConv is second with a value of 0.81. In , PointNet++ is first again with a value of 0.82, while RSConv is second with a value of 0.81. In the generalized metric , we observe similar behavior as PointNet++ is the winner. In the second case, where and , we portray a balanced approach, giving the same weight in segmentation accuracy, efficiency, and robustness of each model. In this case, RSConv is first in with a value of 0.88, while PointNet++ obtains the best value in with 0.90. Additionally, RSConv outperforms its competitors in the metric. Finally, the third case, where and , displays a segmentation accuracy biased model selection process. Here, RSConv is the winner in all three metrics.
Please note that in all of our portrayed scenarios we use
because we basically want the models to be evaluated in their ability to produce uniformly good results not only in all point cloud instances but also in all classes. As explained in
Section 3.2.1, in multi-class 3D point cloud segmentation task, we seek a model that has equally high
and
(
).
Regarding the generalized metrics in S3DIS, we select the same values of and in the same scenarios in order to uniformly analyze the models. However, the metrics related to can not be applied in this dataset. As a result, we compute only the in all the scenarios. In the first scenario of and , we observe approximately the same behavior in all Areas, as PointNet++ achieves the best result. In Areas 2 and 5 RSConv is second, while in Areas 1, 3, and 6 KPConv is second. In Area 4, we have a tie between RSConv and KPConv with . In the balanced scenario where and , in all Areas, the KPConv model is first, except Area 2, where RSConv is the winner. In Areas 1, 3 and 6 PPNet is second with values of 0.67, 0.67, and 0.65 respectively. In the last scenario, we can visually identify three performance clusters, the first one includes Areas 1, 4, and 5, where we observe similar behavior of the models as PPNet is first with while KPConv achieves the second best values. The second cluster includes Areas 3 and 6 where KPConv and PPNet have the first and second-best scores respectively. Finally, the third performance cluster includes Area 2, where interestingly RSConv and KPConv are the two best ones. It is worth noticing that Area 2 is the “hardest” Area to learn and RSConv is the winner in both balanced and accuracy-biased evaluation scenarios. Additionally, in all scenarios of all Areas of the S3DIS dataset, the fundamental architecture PointNet holds the last position which is clearly indicating that advances have been made in the trade-off of models between accuracy, efficiency, and robustness. The analysis of the results yields Observation 5.
Observation 5.
The deployment of generalized performance evaluation metrics facilitates model selection to a great extent. Such metrics are able to easily highlight the differences among models concerning accuracy, efficiency, and robustness. It is interesting that in all selected scenarios of and values, in part segmentation, the winning models (PointNet++ and RSConv) are the ones that incorporate all the invariance properties (either weak or strong), namely Rotation, Permutation, Size and Density. In scene segmentation, utilizing Convolution-based models with Local Aggregation operators accompanied by an assortment of invariance properties (either weak or strong) is important. It seems that it is advantageous to combine invariance properties, allowing the network to select the invariance it needs.
4.3.5. Relation between Design and Experimental Properties
To sum up, in this section, we emphasize the relation between the design and experimental properties of the selected models in order to pave the way toward an effective 3D point cloud segmentation model selection. We present our results in
Table 9, where the ⋆ in design properties denotes the models that utilize this property. Concerning invariance properties, and specifically in transformation-related ones (rotation, size, density), we assign ⋆ to the models that according to the literature are highly robust to such transformations, or ▿ to the models where their invariance to transformations is considered weak. In experimental properties, the numbering (
1, 2) distinguishes the models that achieve the two highest scores in each property, i.e., the two best ones. Please note that in case of a tie both models are getting the same number of rankings.
By focusing the learning process on the local features of the point cloud object, using
Local Aggregation operators as described in
Section 3.1, we expect a model to have higher
accuracy and greater
robustness than a model that uses only
Global Aggregation operators, but less time and memory
efficiency, because of the use of a greater amount of computations. Indeed, we observe that focusing on the
Global Features of a point cloud is closely related to time
efficiency and GPU-memory
efficiency in both part segmentation and scene segmentation, e.g., PointNet’s performance, but there is a lack of segmentation
accuracy and
robustness. By design, models that focus on the local features of a point cloud object capture better the geometrical topology of the points, leading to higher segmentation
accuracy. For instance, RSConv focuses on the
Local Features of a point cloud and captures well the geometrical topology of its points, as explained in
Section 3.3, resulting in a high segmentation
accuracy value, in both part segmentation and scene segmentation, as shown in
Table 4 and
Table 5. High performance in accuracy is also observed in PPNet and KPConv models, especially in scene segmentation. However, in part segmentation, we do not observe this behavior of RSConv in all classes of the ShapeNet-part dataset, or in classes where the point cloud samples are limited, as detailed in
Observation 1. Additionally, we observe that the worst model in terms of accuracy in both part segmentation and scene segmentation, PointNet, uses only the
Rotation and
Permutation invariance properties and focuses on the
Global Features of the input point clouds.
Convolutional operations often produce more accurate results although there are cases where
Point-wise MLPs outperform them. However,
Point-wise MLP-based models use shared MLP units to extract point features, which are efficient and if they are accompanied by random point sampling can be highly efficient in terms of memory and computations [
9,
47].
Convolution-based models, while, generally, being inefficient in terms of memory and time compared to the
Point-wise MLP-based models, try to improve efficiency by splitting the convolution into multiple smaller highly efficient computations, such as matrix multiplications paired with low dimension convolutions [
9]. In this work, we justify such behavior of the
Convolutional-based models compared to the
Point-wise MLP-based ones, as depicted in
Table 9. Thus, convolutions do not correspond to time or memory
efficiency and the
Point-wise MLP-based models appear to be the ones that have the lowest time and GPU memory consumption on average, as explained in
Observation 2.
Moreover, in the "hardest" to learn classes in part segmentation or areas in scene segmentation the winning models are the Convolution-based ones by focusing on the Local Features of the point cloud, as stated in Observation 3. Additionally, in some classes (Earphone) in part segmentation Point-wise MLP-based models can achieve high mean accuracy but they tend to have higher errors than the others.
In terms of
robustness,
Convolution-based neural networks that incorporate
Adaptive Weight-based or
Position Pooling aggregation appear to be the winners in
robustness statistical ranking, while
Pseudo Grid operations are following in most of the cases, as shown in
Observation 4. Nevertheless, it is worth noticing that paying attention in the learning process on the local features of the point cloud using either
Convolution-based or
Point-wise MLP-based model often leads to greater
accuracy and
robustness, while greatly capturing the points topology, as shown in
Table 9. Summarizing, the best results in
accuracy and
robustness in part segmentation and scene segmentation are recorded in models that focus on the local features of the point cloud while being
Convolution-based and using
Adaptive Weight-based or
Position Pooling local aggregation operators.
Additionally, in
Table 9, we detail the number of parameters of each model. We observe that the low number of parameters is related to
efficiency but also to segmentation
accuracy and
robustness. Thus, the correct utilization of parameters and the architectural design of the network plays a significant role. For instance, PointNet++ and RSConv use approximately 1.4 and 3.4 million parameters respectively, while being two of the best in segmentation accuracy and robustness ranking in part segmentation. However, in scene segmentation tasks it seems that the high number of parameters is strongly correlated with high
accuracy and
robustness but not
efficiency.
Finally, the use of generalized experimental metrics aids the interpretation of all these crucial evaluation dimensions, i.e.,
accuracy,
efficiency,
robustness. Additionally, it emphasizes the trade-off among them across various models and their design properties. For example, in a balanced model evaluation scenario among
accuracy,
efficiency and
robustness (
), the winning models in
,
and
are the ones that are highly
accurate,
efficient and
robust, as shown in
Table 9, and, clearly highlighted in
Observation 5.
Some further remarks in part segmentation, i.e., ShapeNet-part data, could be that high scores in the aforementioned experimental properties correspond to models (PointNet++ and RSConv) that mainly (i) focus on the Local Features of the point cloud and have the ability to capture the topology of the points, (ii) incorporate all the invariance properties (either weak or strong invariance), namely Rotation, Permutation, Size and Density, and (iii) use a low amount of parameters compared to others, although they come from two distinct families of deep learning architectures. For instance, PointNet++ is mainly a Point-wise MLP-based model and RSConv is a Convolution-based neural network that uses Adaptive Weight-based local aggregation operations.
In addition, further remarks in scene segmentation, i.e., S3DIS data, could be that high
scores correspond to models that (i) focus on the
Local Features of the point cloud and (ii) incorporate the majority of invariance properties. It seems that it is advantageous to combine invariance properties, allowing the network to select the invariance it needs. Additionally, all the best models in scene segmentation utilize convolutional operations and use
Pseudo Grid or
Adaptive Weight or
Position Pooling local aggregation type. Without the loss of generality, we can say that local aggregation operators, when properly calibrated, may yield comparable performance, as shown in [
14].










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}