
Feature Engineering of Geohazard Susceptibility Analysis Based on the Random Forest Algorithm: Taking Tianshui City, Gansu Province, as an Example


 ,
,
Abstract
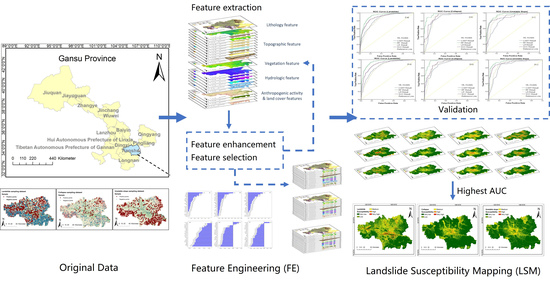
1. Introduction
- (1)
- Explore the most suitable data-preprocessing principles.
- (2)
- Determine whether using the elected features to retrain the model would improve the accuracy.
- (3)
- Compare the simple ranking feature selection idea and the iteration feature election idea.
2. Materials and Methods
2.1. Geological Conditions of the Study Area
2.2. Landslide Inventories
2.3. Feature Engineering
2.3.1. Feature Extraction
- Lithology feature:
- 2.
- Topographic features:
- 3.
- Vegetation feature:
- 4.
- Hydrologic features:
- 5.
- Anthropogenic activity and land cover features:
2.3.2. Feature Enhancement
- Normalization (Min–Max scaling):
- 2.
- Standardization:
2.3.3. Feature Selection
- Random Forest algorithm:
- (1)
- Construct the original training sample dataset for DTs, the number of cases is while the number of input variables is .
- (2)
- Generate sub-training datasets by sampling with the replacement bootstrap method for times, meaning that the generated RF has trees in total.
- (3)
- To select the features for each non-leaf node (internal node), the model first randomly selects a certain number of features from all features and uses them as split features and then selects the best-performing one for node splits.
- (4)
- The classifier output is determined by a majority vote of by each tree in the RF.
- 2.
- Feature selection methods:
2.4. Landslide Susceptibility Modeling
2.4.1. Logistic Regression Model
2.4.2. Classification and Regression Tree Model
2.4.3. Support Vector Machine (for Classification)
2.5. Validation
3. Results
3.1. Sampling Dataset Preparations and Feature Extraction
3.2. Results and Comparison of Feature Enhancement Methods
3.3. Results and Comparison of Feature Selection Methods
3.3.1. Results of Filter-MDI
3.3.2. Results of Filter-MDA
3.3.3. Results of Wrapper-MDI
3.3.4. Results of Wrapper-MDA
3.4. Landslide Susceptibility Mapping
4. Discussion
- Effectiveness of the FE:
- 2.
- High susceptibility area distribution analysis and the correlated domain conditioning features for different geohazards:
- (1)
- Slope gradient, elevation, precipitation, NDVI, lithology, land cover, and groundwater volume (landslide);
- (2)
- Precipitation, elevation, slope gradient, distance to roads, distance to faults, groundwater volume, and lithology (collapse);
- (3)
- Precipitation, NDVI, lithology, slope gradient, elevation, distance to roads, distance to faults, and road density (unstable slope).
- 3.
- Accuracy and validation of LSM:
- 4.
- The correlating mitigation advice:
5. Conclusions
- (1)
- Slope gradient, elevation, precipitation, NDVI, lithology, land cover, and groundwater volume (landslide);
- (2)
- Precipitation, elevation, slope gradient, distance to roads, distance to faults, groundwater volume, and lithology (collapse);
- (3)
- Precipitation, NDVI, lithology, slope gradient, elevation, distance to roads, distance to faults, and road density (unstable slope).
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Highland, L.; Bobrowsky, P.T. The Landslide Handbook: A Guide to Understanding Landslides; US Geological Survey Reston: Reston, VA, USA, 2008.
- Nadim, F.; Kjekstad, O.; Peduzzi, P.; Herold, C.; Jaedicke, C. Global landslide and avalanche hotspots. Landslides 2006, 3, 159–173. [Google Scholar] [CrossRef]
- Petley, D. Global patterns of loss of life from landslides. Geology 2012, 40, 927–930. [Google Scholar] [CrossRef]
- Xu, C.; Xu, X.; Shen, L.; Yao, Q.; Tan, X.; Kang, W.; Ma, S.; Wu, X.; Cai, J.; Gao, M.J. Optimized volume models of earthquake-triggered landslides. Sci. Rep. 2016, 6, 29797. [Google Scholar] [CrossRef] [PubMed]
- Qing, Y.; Ming, D.; Wen, Q.; Weng, Q.; Xu, L.; Chen, Y.; Zhang, Y.; Zeng, B. Operational earthquake-induced building damage assessment using CNN-based direct remote sensing change detection on superpixel level. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102899. [Google Scholar] [CrossRef]
- Brabb, E.E. Innovative approaches to landslide hazard and risk mapping. In Proceedings of the International Landslide Symposium Proceedings, Toronto, ON, Canada, 23–31 August 1985; pp. 17–22. [Google Scholar]
- Chacón, J.; Irigaray, C.; Fernandez, T.; El Hamdouni, R. Engineering geology maps: Landslides and geographical information systems. Bull. Eng. Geol. Environ. 2006, 65, 341–411. [Google Scholar] [CrossRef]
- Neuland, H. A prediction model of landslips. Catena 1976, 3, 215–230. [Google Scholar] [CrossRef]
- Shahabi, H.; Ahmad, B.; Khezri, S. Evaluation and comparison of bivariate and multivariate statistical methods for landslide susceptibility mapping (case study: Zab basin). Arab. J. Geosci. 2013, 6, 3885–3907. [Google Scholar] [CrossRef]
- He, Y.; Beighley, R. GIS-based regional landslide susceptibility mapping: A case study in southern California. Earth Surf. Processes Landf. J. Br. Geomorphol. Res. Group 2008, 33, 380–393. [Google Scholar] [CrossRef]
- Van Westen, C. Statistical landslide hazard analysis. Ilwis 1997, 2, 73–84. [Google Scholar]
- Chen, W.; Pourghasemi, H.R.; Kornejady, A.; Zhang, N. Landslide spatial modeling: Introducing new ensembles of ANN, MaxEnt, and SVM machine learning techniques. Geoderma 2017, 305, 314–327. [Google Scholar] [CrossRef]
- Liu, Y.; Zhao, L.; Bao, A.; Li, J.; Yan, X. Chinese High Resolution Satellite Data and GIS-Based Assessment of Landslide Susceptibility along Highway G30 in Guozigou Valley Using Logistic Regression and MaxEnt Model. Remote Sens. 2022, 14, 3620. [Google Scholar] [CrossRef]
- Van Westen, C.J. Application of Geographic Information Systems to Landslide Hazard Zonation. Ph.D. Thesis, Delft University of Technology, Delft, The Netherlands, 1993. [Google Scholar]
- El Abidine, R.Z.; Abdelmansour, N. Landslide susceptibility mapping using information value and frequency ratio for the Arzew sector (North-Western of Algeria). Bull. Miner. Res. Explor. 2019, 160, 197–211. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Das, I.; Sahoo, S.; van Westen, C.; Stein, A.; Hack, R. Landslide susceptibility assessment using logistic regression and its comparison with a rock mass classification system, along a road section in the northern Himalayas (India). Geomorphology 2010, 114, 627–637. [Google Scholar] [CrossRef]
- Mao, Y.-m.; Zhang, M.-s.; Wang, G.-l.; Sun, P.-P. Landslide hazards mapping using uncertain Naïve Bayesian classification method. J. Cent. South Univ. 2015, 22, 3512–3520. [Google Scholar] [CrossRef]
- Bui, D.T.; Ho, T.-C.; Pradhan, B.; Pham, B.-T.; Nhu, V.-H.; Revhaug, I. GIS-based modeling of rainfall-induced landslides using data mining-based functional trees classifier with AdaBoost, Bagging, and MultiBoost ensemble frameworks. Environ. Earth Sci. 2016, 75, 1101. [Google Scholar]
- Catani, F.; Lagomarsino, D.; Segoni, S.; Tofani, V. Landslide susceptibility estimation by random forests technique: Sensitivity and scaling issues. Nat. Hazards Earth Syst. Sci. 2013, 13, 2815–2831. [Google Scholar] [CrossRef]
- Hong, H.; Miao, Y.; Liu, J.; Zhu, A.-X. Exploring the effects of the design and quantity of absence data on the performance of random forest-based landslide susceptibility mapping. Catena 2019, 176, 45–64. [Google Scholar] [CrossRef]
- Hong, H.; Liu, J.; Bui, D.T.; Pradhan, B.; Acharya, T.D.; Pham, B.T.; Zhu, A.-X.; Chen, W.; Ahmad, B.B. Landslide susceptibility mapping using J48 Decision Tree with AdaBoost, Bagging and Rotation Forest ensembles in the Guangchang area (China). Catena 2018, 163, 399–413. [Google Scholar] [CrossRef]
- Zhao, L.; Wu, X.; Niu, R.; Wang, Y.; Zhang, K.J. Using the rotation and random forest models of ensemble learning to predict landslide susceptibility. Nat. Hazards Risk 2020, 11, 1542–1564. [Google Scholar] [CrossRef]
- Huang, Y.; Zhao, L. Review on landslide susceptibility mapping using support vector machines. Catena 2018, 165, 520–529. [Google Scholar] [CrossRef]
- Marjanović, M.; Kovačević, M.; Bajat, B.; Voženílek, V. Landslide susceptibility assessment using SVM machine learning algorithm. Eng. Geol. 2011, 123, 225–234. [Google Scholar] [CrossRef]
- Moayedi, H.; Mehrabi, M.; Mosallanezhad, M.; Rashid, A.S.A.; Pradhan, B. Modification of landslide susceptibility mapping using optimized PSO-ANN technique. Eng. Comput. 2019, 35, 967–984. [Google Scholar] [CrossRef]
- Chen, Y.; Ming, D.; Ling, X.; Lv, X.; Zhou, C. Landslide Susceptibility Mapping Using Feature Fusion-Based CPCNN-ML in Lantau Island, Hong Kong. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3625–3639. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Hong, H. Comparison of convolutional neural networks for landslide susceptibility mapping in Yanshan County, China. Sci. Total Environ. 2019, 666, 975–993. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, Y.; Ming, D.; Zhu, Y.; Ling, X.; Zhang, X.; Lian, X. Landslide Hazard Analysis Based on SBAS-InSAR and MCE-CNN Model: A case study of Kongtong, Pingliang. Geocarto Int. 2022, 1–20, just-accepted. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Sahin, E.K.; Colkesen, I. Landslide susceptibility mapping using GIS-based multi-criteria decision analysis, support vector machines, and logistic regression. Landslides 2014, 11, 425–439. [Google Scholar] [CrossRef]
- Tsangaratos, P.; Ilia, I. Comparison of a logistic regression and Naïve Bayes classifier in landslide susceptibility assessments: The influence of models complexity and training dataset size. Catena 2016, 145, 164–179. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Wang, J.; Pradhan, B.; Hong, H.; Bui, D.T.; Duan, Z.; Ma, J. A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility. Catena 2017, 151, 147–160. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R.; Pourtaghi, Z.S.; Al-Katheeri, M.M. Landslide susceptibility mapping using random forest, boosted regression tree, classification and regression tree, and general linear models and comparison of their performance at Wadi Tayyah Basin, Asir Region, Saudi Arabia. Landslides 2016, 13, 839–856. [Google Scholar] [CrossRef]
- Luo, X.; Lin, F.; Zhu, S.; Yu, M.; Zhang, Z.; Meng, L.; Peng, J.J. Mine landslide susceptibility assessment using IVM, ANN and SVM models considering the contribution of affecting factors. PLoS ONE 2019, 14, e0215134. [Google Scholar] [CrossRef] [PubMed]
- Hong, H.; Pourghasemi, H.R.; Pourtaghi, Z.S. Landslide susceptibility assessment in Lianhua County (China): A comparison between a random forest data mining technique and bivariate and multivariate statistical models. Geomorphology 2016, 259, 105–118. [Google Scholar] [CrossRef]
- Pham, B.T.; Prakash, I.; Bui, D.T. Spatial prediction of landslides using a hybrid machine learning approach based on random subspace and classification and regression trees. Geomorphology 2018, 303, 256–270. [Google Scholar] [CrossRef]
- Chen, T.; Zhu, L.; Niu, R.-Q.; Trinder, C.J.; Peng, L.; Lei, T. Mapping landslide susceptibility at the Three Gorges Reservoir, China, using gradient boosting decision tree, random forest and information value models. J. Mt. Sci. 2020, 17, 670–685. [Google Scholar] [CrossRef]
- Cheng, Y.-S.; Yu, T.-T.; Son, N.-T. Random Forests for Landslide Prediction in Tsengwen River Watershed, Central Taiwan. Remote Sens. 2021, 13, 199. [Google Scholar] [CrossRef]
- Zhou, X.; Wen, H.; Zhang, Y.; Xu, J.; Zhang, W. Landslide susceptibility mapping using hybrid random forest with GeoDetector and RFE for factor optimization. Geosci. Front. 2021, 12, 101211. [Google Scholar] [CrossRef]
- Sun, D.; Wen, H.; Wang, D.; Xu, J. A random forest model of landslide susceptibility mapping based on hyperparameter optimization using Bayes algorithm. Geomorphology 2020, 362, 107201. [Google Scholar] [CrossRef]
- Zhou, X.; Chen, F.; Wu, X.; Qian, R.; Liu, X.; Wang, S. Variation Characteristics of Stable Isotopes in Precipitation and Response to Regional Climate Conditions during Pre-monsoon, Monsoon and Post-monsoon Periods in the Tianshui Area. Water 2020, 12, 2391. [Google Scholar] [CrossRef]
- Zhang, Z.-l.; Wang, T.; Wu, S.-R. Distribution and features of landslides in the Tianshui Basin, Northwest China. J. Mt. Sci. 2020, 17, 686–708. [Google Scholar] [CrossRef]
- Reichenbach, P.; Rossi, M.; Malamud, B.D.; Mihir, M.; Guzzetti, F. A review of statistically-based landslide susceptibility models. Earth-Sci. Rev. 2018, 180, 60–91. [Google Scholar] [CrossRef]
- Ling, X.; Liu, J.; Wang, T.; Zhu, Y.; Yuan, L.; Chen, Y. Application of information value model based on symmetrical factors classification method in landslide hazard assessment. Remote Sens. Nat. Resour. 2021, 33, 172–181. [Google Scholar]
- Weiss, A. Topographic position and landforms analysis. In Proceedings of the Poster Presentation, ESRI User Conference, San Diego, CA, USA, 9–13 July 2001. [Google Scholar]
- Pham, B.T.; Pradhan, B.; Bui, D.T.; Prakash, I.; Dholakia, M. A comparative study of different machine learning methods for landslide susceptibility assessment: A case study of Uttarakhand area (India). Environ. Model. Softw. 2016, 84, 240–250. [Google Scholar] [CrossRef]
- Lee, S. Application of logistic regression model and its validation for landslide susceptibility mapping using GIS and remote sensing data. Int. J. Remote Sens. 2005, 26, 1477–1491. [Google Scholar] [CrossRef]
- McFeeters, S. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Su, L.-J.; Hu, K.-H.; Zhang, W.-F.; Wang, J.; Lei, Y.; Zhang, C.-L.; Cui, P.; Pasuto, A.; Zheng, Q.-H. Characteristics and triggering mechanism of Xinmo landslide on 24 June 2017 in Sichuan, China. J. Mt. Sci. 2017, 14, 1689–1700. [Google Scholar] [CrossRef]
- Liu, H.; Setiono, R. A probabilistic approach to feature selection-a filter solution. In Proceedings of the ICML, Bari, Italy, 3–6 July 1996; pp. 319–327. [Google Scholar]
- Sánchez-Marono, N.; Alonso-Betanzos, A.; Tombilla-Sanromán, M. Filter methods for feature selection–a comparative study. In International Conference on Intelligent Data Engineering and Automated Learning; Springer: Berlin/Heidelberg, Germany, 2007; pp. 178–187. [Google Scholar]
- Yu, L.; Liu, H. Feature selection for high-dimensional data: A fast correlation-based filter solution. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 856–863. [Google Scholar]
- Zhukov, A.V.; Sidorov, D.N.; Foley, A.M. Random forest based approach for concept drift handling. In Proceedings of the International Conference on Analysis of Images, Social Networks and Texts, Yekaterinburg, Russia, 7–9 April 2016; pp. 69–77. [Google Scholar]
- Hall, M.A.; Smith, L.A. Feature selection for machine learning: Comparing a correlation-based filter approach to the wrapper. In Proceedings of the FLAIRS Conference, Orlando, FL, USA, 1–5 March 1999; pp. 235–239. [Google Scholar]
- Maldonado, S.; Weber, R. A wrapper method for feature selection using support vector machines. Inf. Sci. 2009, 179, 2208–2217. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Stumpf, A.; Kerle, N. Object-oriented mapping of landslides using Random Forests. Remote Sens. Environ. 2011, 115, 2564–2577. [Google Scholar] [CrossRef]
- Yesilnacar, E.; Topal, T. Landslide susceptibility mapping: A comparison of logistic regression and neural networks methods in a medium scale study, Hendek region (Turkey). Eng. Geol. 2005, 79, 251–266. [Google Scholar] [CrossRef]
- Yilmaz, I. Comparison of landslide susceptibility mapping methodologies for Koyulhisar, Turkey: Conditional probability, logistic regression, artificial neural networks, and support vector machine. Environ. Earth Sci. 2010, 61, 821–836. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Raw Data Resource | Obtaining Resources |
|---|---|---|
| DEM | ASTER GEM (30 m) | Geospatial Data Cloud (http://www.gscloud.cn/, accessed on 28 October 2020) |
| Vegetation | Landsat 8-OLT images (2012~2017) | Google Earth Engine (https://explorer.earthengine.google.com/) |
| Building | ||
| Precipitation | CHIRPS (Climate Hazards Group InfraRed Precipitation with Station data) data (2012~2017) | |
| Groundwater volume | GRACE (Gravity Recovery and Climate Experiment) data (2012~2017) | |
| Roads, rivers, faults, and boundary | Geographical vectors | Geological surveys |
| Geological map | Digital geological map (1:250,000, public ver.) | |
| Land cover | Global 30 m land cover classification products by the Chinese Academy of Sciences (2020) | http://data.casearth.cn/, accessed on 12 January 2021 |
| Landslide inventories | Ground survey sheet | Geological field surveys |
| Feature Name | Types | Classification Standard |
|---|---|---|
| Lithology | 15 | 1. 1-I; 2. 1-II; 3. 1-III; 4. 2-I; 5. 2-II; 6. 2-III; 7. 3-I; 8. 3-II; 9. 3-III; 10. 4-I; 11. 4-II; 12. 4-III; 13. 5-I; 14. 5-II; 15. 5-III. |
| Aspect | 9 | 1. 0~22.5 and 337.5~360°; 2. 22.5~67.5°; 3. 67.5~112.5°; 4. 112.5~157.5°; 5. 157.5~202.5°; 6. 202.5~ 247.5°. |
| Distance to faults | 11 | 1. <2 km; 2. 2~4; 3. 4~6; 4. 6~8; 5. 8~10; 6. 10~12; 7. 12~14; 8. 14~16; 9. 16~18; 10. 18~20; 11. >20 km. |
| Distance to rivers | 11 | 1. <0.2; 2. 0.2~0.4; 3. 0.4~0.6; 4. 0.6~0.8; 5. 0.8~1; 6. 1~1.2; 7. 1.2~1.4; 8. 1.4~1.6; 9. 1.6~1.8; 10. 1.8~2; 11. >2 km. |
| Distance to roads | 11 | 1. <0.2; 2. 0.2~0.4; 3. 0.4~0.6; 4. 0.6~0.8; 5. 0.8~1; 6. 1~1.2; 7. 1.2~1.4; 8. 1.4~1.6; 9. 1.6~1.8 km. |
| Landcover | 8 | 1. farmland; 2. forest land; 3. grassland; 4. shrubs; 5. wetlands. |
| Primary Category | Secondary Category | Representative Lithology Types | Strata |
|---|---|---|---|
| 1 | I | Diorite and granite | Hercynian, Caledonian, Himalayan, Upper Paleozoic, Mesozoic |
| II | Acidic volcanic rocks, quartzite, dacite, phyllite | Caledonian, Sinian, Lower Paleozoic | |
| III | Quartz sandstone, pebbled sandstone, siltstone | Devonian, Permian | |
| 2 | I | Schist, gneiss, mixed rock with volcanic rock | Caledonian, Pre-Sinian, Upper Paleozoic |
| II | Pegmatite, syenite, volcanic metamorphic rock, purple and purple-red rhyolite porphyry | Hercynian, Caledonian, Himalayan, Sinian | |
| III | Limestone, gray-green slate | Permian, Upper Paleozoic | |
| 3 | I | Argillaceous purple-red siltstone, mudstone, sandy shale, gray-green SLATE shale, pebbly sandstone | Devonian, Cenozoic, Upper Paleozoic |
| II | Conglomerate, glutenite, siltstone, sandy mudstone | Cretaceous, Tertiary, Triassic, Permian | |
| III | Biotite calcarenite schist, bimica schist, hornblende schist, chlorite Muscovite schist | Lower Paleozoic | |
| 4 | I | Melaleite, metamorphosed siltstone, metamorphosed fine sandstone | Sinian, Devonian, Permian, Carboniferous |
| II | Shale, siltstone, sandstone, sandy limestone, shell limestone, oolitic limestone | Cretaceous, Permian, Triassic, Upper Paleozoic | |
| III | Conglomerate, sandy conglomerate, clay rock with calcareous nodules, purplish-red sandy mudstone with sandstone | Tertiary, Triassic | |
| 5 | I | Red, purplish-red clay with gray matter nodules, red sandstone, conglomerate, conglomerate | Tertiary |
| II | Alluvial secondary loess, silty loess, gravel | Quaternary | |
| III | Riverbed alluvial gravel, sand, silt, boulders, sub-sandy soil, secondary alluvial loess and loam | Quaternary, modern |
| Geohazards | Positive Samples | Negative Samples | Total |
|---|---|---|---|
| Landslide | 968 | 2958 | 3926 |
| Collapse | 183 | 732 | 915 |
| Unstable slope | 243 | 972 | 1215 |
| Geohazards | ML Model | Normalization | Standardization | Range | |||
|---|---|---|---|---|---|---|---|
| Model Score | AUC | Model Score | AUC | Model Score | AUC | ||
| Landslide | CART | 79.17 | 0.827 | 81.24 | 0.845 | 2.07 | 0.018 |
| RF | 85.97 | 0.927 | 87.52 | 0.932 | 1.55 | 0.005 | |
| LR | 76.08 | 0.794 | 78.31 | 0.826 | 2.24 | 0.032 | |
| SVC | 74.1 | 0.818 | 83.13 | 0.878 | 9.04 | 0.06 | |
| Collapse | CART | 86.91 | 0.858 | 84.36 | 0.917 | −2.55 | 0.059 |
| RF | 89.82 | 0.946 | 91.27 | 0.97 | 1.45 | 0.025 | |
| LR | 78.91 | 0.816 | 84.36 | 0.911 | 5.45 | 0.095 | |
| SVC | 78.91 | 0.868 | 87.27 | 0.929 | 8.36 | 0.061 | |
| Unstable slope | CART | 81.48 | 0.805 | 84.05 | 0.848 | 2.56 | 0.042 |
| RF | 85.75 | 0.919 | 92.31 | 0.938 | 6.55 | 0.019 | |
| LR | 76.35 | 0.845 | 84.33 | 0.881 | 7.98 | 0.036 | |
| SVC | 75.5 | 0.862 | 88.03 | 0.886 | 12.54 | 0.023 | |
| Geohazards | Before Feature Selection | Before Feature Selection | Range | |||
|---|---|---|---|---|---|---|
| Model Score | AUC | Model Score | AUC | Model Score | AUC | |
| Landslide | 87.09 | 0.929 | 87.87 | 0.942 | 0.77 | 0.013 |
| Collapse | 88.36 | 0.951 | 89.82 | 0.969 | 1.45 | 0.018 |
| Unstable slope | 91.17 | 0.939 | 91.74 | 0.944 | 0.57 | 0.006 |
| Geohazards | Before Feature Selection | Before Feature Selection | Range | |||
|---|---|---|---|---|---|---|
| Model Score | AUC | Model Score | AUC | Model Score | AUC | |
| Landslide | 86.64 | 0.936 | 87.69 | 0.948 | 1.05 | 0.012 |
| Collapse | 89.38 | 0.955 | 90.55 | 0.965 | 1.17 | 0.011 |
| Unstable slope | 89.01 | 0.935 | 89.17 | 0.947 | 0.16 | 0.012 |
| Geohazards | Landslide | Collapse | Unstable Slope |
|---|---|---|---|
| Ranking | Precipitation | Precipitation | Precipitation |
| Slope | Slope | Elevation | |
| Elevation | Elevation | Slope | |
| NDVI | Groundwater volume | Groundwater volume | |
| MNDWI | Distance to faults | Lithology | |
| Ground water volume | Lithology | NDVI | |
| Distance to roads | Cumulative solar radiation | Distance to faults | |
| Lithology | Distance to roads | Cumulative solar radiation | |
| Cumulative solar radiation | NDVI | MNDWI | |
| Land cover | MNDWI | Road density | |
| NDBI | NDBI | NDBI | |
| Plan curvature | Plan curvature | NDWI | |
| NDWI | Profile curvature | Profile curvature | |
| Profile curvature | Road density | TRI | |
| TRI | TRI | Plan curvature | |
| Distance to faults | NDWI | Land cover | |
| Road density | Land cover | Distance to roads | |
| Curvature | Curvature | River density | |
| River density | River density | Curvature | |
| TWI | TWI | Aspect | |
| Fault density | Aspect | Distance to rivers | |
| Distance to rivers | Distance to rivers | TWI | |
| Aspect | Fault density | Fault density |
| Geohazards | Before Feature Selection | After Feature Selection | Range |
|---|---|---|---|
| Landslide | 0.926 | 0.943 | 0.017 |
| Collapse | 0.958 | 0.975 | 0.016 |
| Unstable slope | 0.939 | 0.952 | 0.013 |
| Geohazards | Landslide | Collapse | Unstable Slope |
|---|---|---|---|
| Ranking | NDBI | TWI | NDWI |
| River density | Rainfall | Lithology | |
| NDVI | Aspect | Distance to roads | |
| NDWI | NDWI | NDVI | |
| Distance to faults | Slope | TRI | |
| Rainfall | Distance to roads | Distance to faults | |
| Slope | Curvature | Rainfall | |
| Plan curvature | Elevation | NDBI | |
| Ground water volume | Distance to faults | Plan curvature | |
| Elevation | Lithology | Cumulative solar radiation | |
| Land cover | NDBI | Ground water volume | |
| Aspect | Profile curvature | Elevation | |
| Road density | Cumulative solar radiation | Land cover | |
| Distance to roads | Fault density | Slope | |
| Distance to rivers | NDVI | Profile curvature | |
| Curvature | Distance to rivers | Aspect | |
| Profile curvature | Land cover | Fault density | |
| TWI | MNDWI | Road density | |
| Lithology | TRI | Distance to rivers | |
| MNDWI | Ground water volume | TWI | |
| TRI | River density | River density | |
| Cumulative solar radiation | Road density | MNDWI | |
| Fault density | Plan curvature | Curvature |
| Geohazards | Before Feature Selection | After Feature Selection | Range |
|---|---|---|---|
| Landslide | 0.932 | 0.943 | 0.011 |
| Collapse | 0.948 | 0.970 | 0.022 |
| Unstable slope | 0.938 | 0.960 | 0.022 |
| Geohazards | Landslide | Collapse | Unstable Slope |
|---|---|---|---|
| Eliminated features | Fault density | River density | River density |
| TWI | Aspect | Curvature | |
| Road density | Land cover | TWI | |
| River density | Distance to rivers | Fault density | |
| Curvature | Fault density | Distance to rivers | |
| MNDWI | Curvature | Aspect | |
| Aspect | MNDWI | MNDWI |
| Geohazards | CART | RF | LR | SVC | |
|---|---|---|---|---|---|
| landslide | Before FE | 0.844 | 0.933 | 0.836 | 0.877 |
| After FE | 0.854 | 0.941 | 0.85 | 0.896 | |
| Range | 0.009 | 0.008 | 0.014 | 0.019 | |
| Collapse | Before FE | 0.874 | 0.952 | 0.903 | 0.905 |
| After FE | 0.878 | 0.957 | 0.898 | 0.913 | |
| Range | 0.004 | 0.005 | −0.0056 | 0.008 | |
| Unstable Slope | Before FE | 0.854 | 0.936 | 0.881 | 0.901 |
| After FE | 0.878 | 0.949 | 0.901 | 0.912 | |
| Range | 0.024 | 0.013 | 0.019 | 0.011 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ling, X.; Zhu, Y.; Ming, D.; Chen, Y.; Zhang, L.; Du, T. Feature Engineering of Geohazard Susceptibility Analysis Based on the Random Forest Algorithm: Taking Tianshui City, Gansu Province, as an Example. Remote Sens. 2022, 14, 5658. https://doi.org/10.3390/rs14225658
Ling X, Zhu Y, Ming D, Chen Y, Zhang L, Du T. Feature Engineering of Geohazard Susceptibility Analysis Based on the Random Forest Algorithm: Taking Tianshui City, Gansu Province, as an Example. Remote Sensing. 2022; 14(22):5658. https://doi.org/10.3390/rs14225658
Chicago/Turabian StyleLing, Xiao, Yueqin Zhu, Dongping Ming, Yangyang Chen, Liang Zhang, and Tongyao Du. 2022. "Feature Engineering of Geohazard Susceptibility Analysis Based on the Random Forest Algorithm: Taking Tianshui City, Gansu Province, as an Example" Remote Sensing 14, no. 22: 5658. https://doi.org/10.3390/rs14225658
APA StyleLing, X., Zhu, Y., Ming, D., Chen, Y., Zhang, L., & Du, T. (2022). Feature Engineering of Geohazard Susceptibility Analysis Based on the Random Forest Algorithm: Taking Tianshui City, Gansu Province, as an Example. Remote Sensing, 14(22), 5658. https://doi.org/10.3390/rs14225658