





Forest Fire Occurrence Prediction in China Based on Machine Learning Methods


 ,
,
Abstract
1. Introduction
2. Materials and Methods
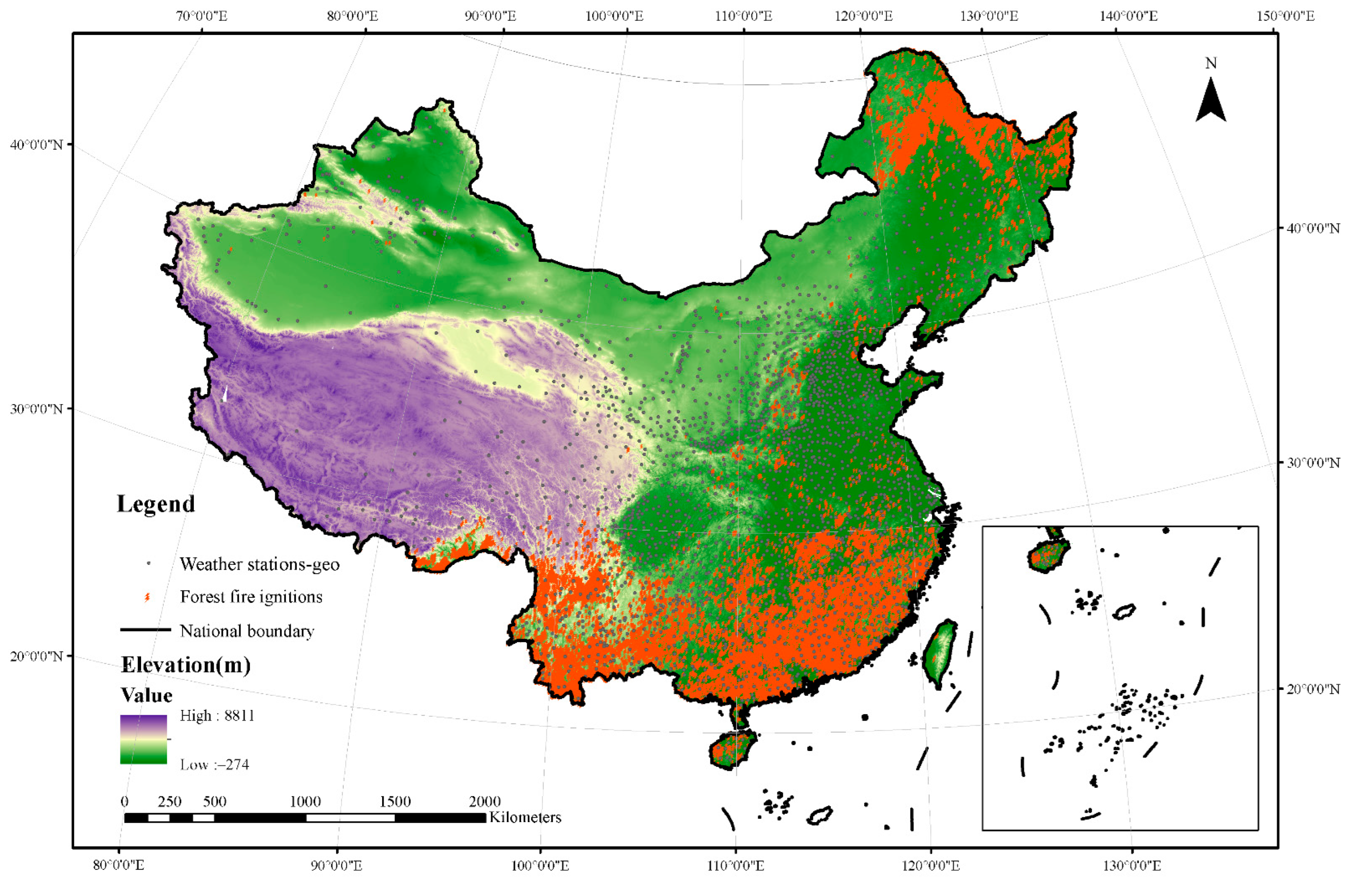
2.1. Study Area and Data Resources
2.2. Data Pre-Processing
2.2.1. Variable Handling
2.2.2. Data Normalization
2.3. Method
2.3.1. Artificial Neural Networks
2.3.2. Radial Basis Function Neural Network
2.3.3. Support-Vector Machines
2.3.4. Feature Selection and Random Forest
2.3.5. Model Performance Evaluation
3. Results
3.1. Feature Selection
3.2. Model Fitting Results
3.2.1. Artificial Neural Network
3.2.2. Radial Basis Function Neural Network
3.2.3. Support-Vector Machine
3.2.4. Random Forest
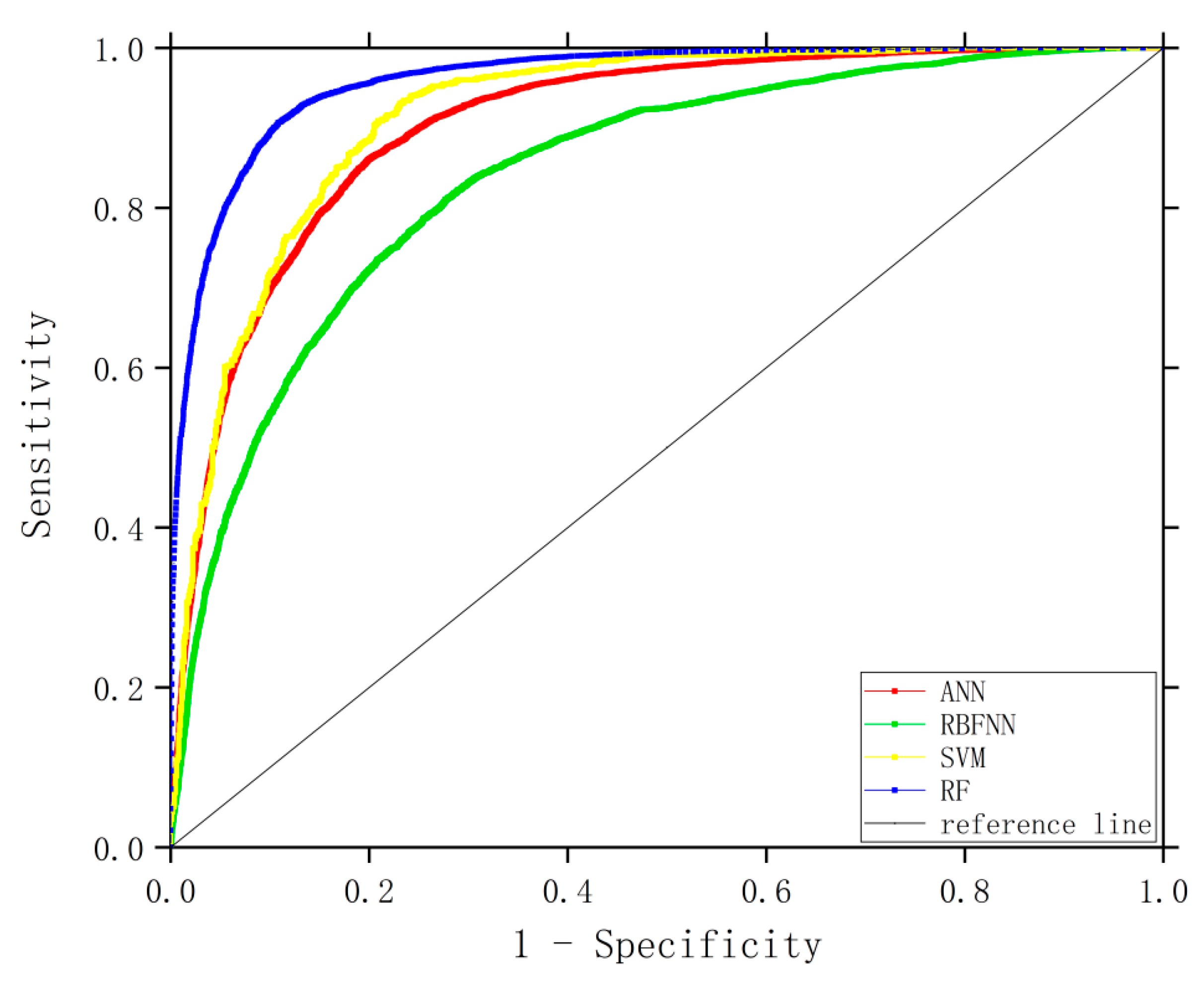
3.3. Accuracy Evaluation
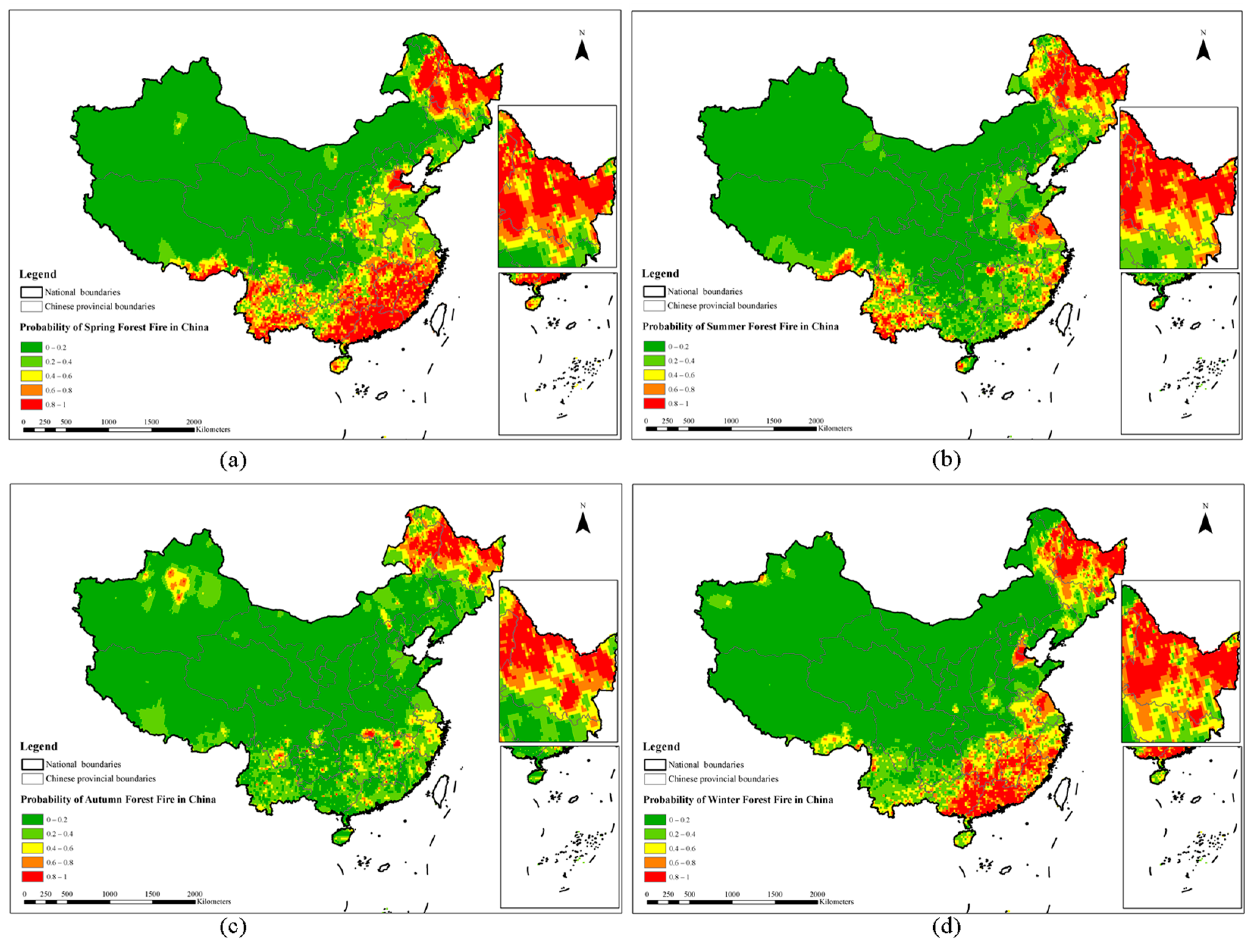
3.4. Forest Fire Risk Classification
4. Discussion
4.1. Major Forest Fire Driving Factors in China and Their Impacts
4.2. Optimal Choice of Forest Fire Prediction Model
4.3. Recommendations for Forest Fire Prevention
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Venkatesh, K.; Preethi, K.; Ramesh, H. Evaluating the effects of forest fire on wa-ter balance using fire susceptibility maps. Ecol. Indic. 2020, 110, 105856. [Google Scholar] [CrossRef]
- Sachdeva, S.; Bhatia, T.; Verma, A.K. GIS-based evolutionary optimized Gradient Boosted Decision Trees for forest fire susceptibility mapping. Nat. Hazards 2018, 92, 1399–1418. [Google Scholar] [CrossRef]
- Zeng, X.; Yang, J.; Li, S. Spatial and temporal distribution patterns of forest fires in China from 2003–2018. For. Surv. Plan. 2021, 46, 53–58+168. [Google Scholar]
- Hantson, S.; Pueyo, S.; Chuvieco, E. Global fire size distribution: From power law to log-normal. Int. J. Wildland Fire 2016, 25, 403. [Google Scholar] [CrossRef]
- Prasad, A.M.; Iverson, L.R.; Liaw, A. Newer classification and regression tree techniques: Bagging and random forests for ecological prediction. Ecosystems 2006, 9, 181–199. [Google Scholar] [CrossRef]
- Artés, T.; Cencerrado, A.; Cortés, A.; Margalef, T. Time aware genetic algorithm for forest fire propagation prediction: Exploiting multi-core platforms. Concurr. Comput. Pract. Exp. 2017, 29, 3837. [Google Scholar] [CrossRef]
- Avilaflores, D.Y.; Pompagarcia, M.; Antonionemiga, X.; Rodrigueztrejo, D.A.; Vargasperez, E.; Santillan-Perez, J. Driving factors for forest fire occurrence in Durango State of Mexico: A geospatial perspective. Chin. Geogr. Sci. 2010, 20, 491–497. [Google Scholar] [CrossRef]
- Ko, B.C.; Cheong, K.H.; Nam, J.Y. Fire detection based on vision sensor and support vector machines. Fire Saf. J. 2009, 44, 322–329. [Google Scholar] [CrossRef]
- Liao, B.Q.; Wei, J.; Song, W.G.; Tan, C.C. Logistic and ZIP Regression Model for Forest Fire Data. Fire Saf. Sci. 2008, 3, 143–149. Available online: http://en.cnki.com.cn/Article_en/CJFDTOTAL-HZKX200803002.htm (accessed on 2 March 2008).
- Bhusal, S.; Mandal, R. Forest fire occurrence, distribution and future risks in Arghakhanchi district, Nepal. J. Geogr. 2020, 2, 10–20. Available online: https://www.researchgate.net/publication/341701669 (accessed on 13 January 2021).
- Bisquert, M.; Caselles, E.; Sanchez, J.M.; Caselles, V. Application of artificial neural networks and logistic regression to the prediction of forest fire danger in Galicia using MODIS data. Int. J. Wildland Fire 2012, 21, 1025–1029. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 15–32. [Google Scholar] [CrossRef]
- Camp, A.; Oliver, C.; Hessburg, P.; Everett, R. Predicting late-successional fire refugia pre-dating European settlement in the Wenatchee Mountains. For. Ecol. Manag. 1997, 95, 63–77. [Google Scholar] [CrossRef]
- Cardille, J.A.; Ventura, S.J.; Turner, M.G. Environmental and social factors influencing wildfires in the upper midwest, United States. Ecol. Appl. 2001, 11, 111–127. [Google Scholar] [CrossRef]
- Catry, F.X.; Damasceno, P.; Silva, J.S.; Galante, M.; Moreira, F. Spatial Distribution Patterns of Wildfire Ignitions in Portugal. Modelação Espacial do Risco de Ignição em Portugal Continental, 8. In Proceedings of the 4th International Wildland Fire Conference, Sevilla, Spain, 13–17 May 2007; Project: Fire Ecology and Post-Fire Restoration. Available online: https://www.researchgate.net/publication/240613824_Spatial_Distribution_Patterns_of_Wildfire_Ignitions_in_Portugal (accessed on 1 January 2007).
- Elmas, C.; Sönmez, Y. A data fusion framework with novel hybrid algorithm for multi-agent Decision Support System for Forest Fire. Expert Syst. Appl. 2011, 38, 9225–9236. [Google Scholar] [CrossRef]
- Chan, C.W.; Paelinckx, D. Evaluation of random forest and adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sens. Environ. 2008, 112, 2999–3011. [Google Scholar] [CrossRef]
- Chang, Y.; Zhu, Z.L.; Bu, R.C.; Chen, H.W.; Feng, Y.T.; Li, Y.H.; Hu, Y.M.; Wang, Z.C. Predicting fire occurrence patterns with logistic regression in Heilongjiang Province, China. Landsc. Ecol. 2013, 28, 1989–2004. [Google Scholar] [CrossRef]
- Chang, Y.; Zhu, Z.L.; Bu, R.C.; Li, Y.H.; Hu, Y.M. Environmental controls on the characteristics of mean number of forest fires and mean forest area burned (1987–2007) in China. For. Ecol. Manag. 2015, 356, 13–21. [Google Scholar] [CrossRef]
- Chuvieco, E.; Aguadoa, I.; Yebraa, M. Development of a framework for fire risk assessment using remote sensing and geographic information system technologies. Ecol. Model. 2010, 221, 46–58. [Google Scholar] [CrossRef]
- Cutler, D.R.; Edwards, T.C.; Beard, K.H. Random forests for classification in Ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef] [PubMed]
- Mandallaz, D.; Ye, R. Prediction of forest fires with Poisson models. Can. J. For. Res. 1997, 27, 1685–1694. [Google Scholar] [CrossRef]
- Lin, J.; He, P.; Yang, L.; He, X.; Lu, S.; Liu, D. Predicting future urban waterlogging-prone areas by coupling the maximum entropy and FLUS model. Sustain. Cities Soc. 2022, 80, 103812. [Google Scholar] [CrossRef]
- Adab, H.; Atabati, A.; Oliveira, S.; Moghaddam, G.A. Assessing fire hazard potential and its main drivers in Mazandaran province, Iran: A data-driven approach. Environ. Monit. Assess. 2018, 190, 670. [Google Scholar] [CrossRef]
- Javidan, N.; Kavian, A.; Pourghasemi, H.R.; Conoscenti, C.; Jafarian, Z.; Rodrigo-Comino, J. Evaluation of multi-hazard map produced using MaxEnt machine learning technique. Sci. Rep. 2021, 11, 6496. [Google Scholar] [CrossRef] [PubMed]
- Chen, D. Prediction of Forest Fire Occurrence in Daxing’an Mountains Based on Logistic Regression Model. For. Resour. Manag. 2019, 116–122. Available online: http://en.cnki.com.cn/Article_en/CJFDTotal-LYZY201901018.htm (accessed on 1 January 2019).
- Bui, D.T.; Bui, Q.T.; Nguyen, Q.P.; Pradhan, B.; Nampak, H.; Trinh, P.T. A hybrid artificial intelligence approach using GIS-based neural-fuzzy inference system and particle swarm optimization for forest fire susceptibility modeling at a tropical area, Agric. Agric. For. Meteorol. 2017, 233, 32–44. [Google Scholar] [CrossRef]
- Xie, D.W.; Shi, S.L. Prediction for burned area of forest fires based on SVM model. Appl. Mech. Mater. 2014, 513, 4084–4089. [Google Scholar] [CrossRef]
- Dhall, A.; Dhasade, A.; Nalwade, A.; Velayudhan Kumar, M.R.; Kulkarni, V. A survey on systematic approaches in managing forest fires. Appl. Geogr. 2020, 121, 102266. [Google Scholar] [CrossRef]
- Dickson, B.G.; Prather, J.W.; Xu, Y.; Hampton, H.M.; Aumack, E.N.; Sisk, T.D. Mapping the probability of large fire occurrence in northern Arizona, USA. Landsc. Ecol. 2006, 21, 747–761. [Google Scholar] [CrossRef]
- Dimopoulou, M.; Giannikos, I. Towards an integrated framework for forest fire control. Eur. J. Oper. Res. 2004, 152, 476–486. [Google Scholar] [CrossRef]
- Epifanio, I. Intervention in prediction measure: A new approach to assessing variable importance for random forests. BMC Bioinform. 2017, 18, 230. [Google Scholar] [CrossRef] [PubMed]
- Erten, E.; Kurgun, V.; Musaoglu, N. Forest fire risk zone mapping from satellite imagery and GIS: A case study. In Proceedings of the XXth Congress of the International Society for Photogrammetry and Remote Sensing, Istanbul, Turkey, 12–23 July 2004; pp. 222–230. [Google Scholar]
- Guo, F.T.; Hu, H.Q.; Jin, S.; Ma, H.Z.; Zhang, Y. Relationship between forest lighting fire occurrence and weather factors in Daxing’an Mountains based on negative binomial model and zero-inflated negative binomial models. Chin. J. Plant Ecol. 2010, 21, 159–164. Available online: http://en.cnki.com.cn/Article_en/CJFDTOTAL-ZWSB201005014.htm (accessed on 1 May 2010).
- Guo, F.T.; Su, Z.W.; Wang, G.Y.; Sun, L.; Tigabu, M.; Yang, X.J.; Hu, H.Q. Understanding fire drivers and relative impacts in different Chinese forest ecosystems. Sci. Total Environ. 2017, 605, 411–425. [Google Scholar] [CrossRef]
- Flannigan, M.D.; Krawchuk, M.A.; Groot, W.J.D.; Wotton, B.M. Implications of changing climate for global wildland fire. Int. J. Wildland Fire 2009, 18, 483–507. [Google Scholar] [CrossRef]
- Guo, F.; Selvalakshmi, S.; Lin, F.; Wang, G.; Wang, W.; Su, Z.; Liu, A. Geospatial information on geographical and human factors improved anthropogenic fire occurrence modeling in the Chinese boreal forest. Can. J. For. Res. 2016, 46, 582–594. [Google Scholar] [CrossRef]
- Ganteaume, A.; Camia, A.; Jappiot, M.; San-Miguel-Ayanz, J.; Long-Fournel, M.; Lampin, C. A review of the main driving factors of forest fire ignition over Europe. Environ. Manag. 2013, 51, 651–662. [Google Scholar] [CrossRef]
- Govil, K.; Welch, M.L.; Ball, J.T.; Pennypacker, C.R. Preliminary results from a wildfire detection system using deep learning on remote camera images. Remote Sens. 2020, 12, 166. [Google Scholar] [CrossRef]
- Gromping, U. Variable importance assessment in regression: Linear regression versus random forest. Am. Stat. 2009, 63, 308–319. [Google Scholar] [CrossRef]
- Guo, F.; Wang, G.; Su, Z.; Liang, H.; Wang, W.; Lin, F.; Liu, A. What drives forest fire in Fujian, China? Evidence from logistic regression and random forests. Int. J. Wildland Fire 2016, 25, 505–519. [Google Scholar] [CrossRef]
- Hong, H.; Naghibi, S.A.; Dashtpagerdi, M.M.; Pourghasemi, H.R.; Chen, W. A comparative assessment between linear and quadratic discriminant analyses (LDA-QDA) with frequency ratio and weights-of-evidence models for forest fire susceptibility mapping in China. Arab. J. Geosci. 2017, 10, 167. [Google Scholar] [CrossRef]
- Soliman, H.; Sudan, K.; Mishra, A. A smart forest-fire early detection sensory system: Another approach of utilizing wireless sensor and neural networks. In Proceedings of the SENSORS, 2010 IEEE, Kona, HI, USA, 1–4 November 2010; pp. 1900–1904. [Google Scholar] [CrossRef]
- Liang, H.L.; Lin, Y.R.; Yang, G.; Su, Z.; Wang, W.; Guo, F. Application of random forest algorithm on the forest fire prediction in Tahe area based on meteorological factors. Sci. Silvae Sin. 2016, 52, 89–98. [Google Scholar] [CrossRef]
- Hong, H.; Tsangaratos, P.; Ilia, I.; Liu, J.; Zhu, A.X.; Xu, C. Applying genetic algorithms to set the optimal combination of forest fire related variables and model forest fire susceptibility based on data mining models. The case of Dayu County, China. Sci. Total Environ. 2018, 630, 1044–1056. [Google Scholar] [CrossRef] [PubMed]
- Pourghasemi, H.; Beheshtirad, M.; Pradhan, B. A comparative assessment of prediction capabilities of modified analytical hierarchy process (M-AHP) and Mamdani fuzzy logic models using Netcad-GIS for forest fire susceptibility mapping. Geomat. Nat. Hazards Risk 2016, 7, 861–885. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, Z.; Han, S.; Qu, C.; Yuan, Z.; Zhang, D. SVM based forest fire detection using static and dynamic features. Comput. Sci. Inf. Syst. 2011, 8, 821–841. [Google Scholar] [CrossRef]
- Liu, K.Z.; Shu, L.F.; Zhao, F.J.; Zhang, Y.S.; Li, Y.Y. Research on spatial distribution of forest fire based on satellite hotspots data and forecasting model. J. For. Eng. 2017, 2, 128–133. Available online: http://en.cnki.com.cn/Article_en/CJFDTOTAL-LKKF201704021.htm (accessed on 1 April 2014).
- Kane, V.R.; Lutz, J.A.; Alina Cansler, C.; Povak, N.A.; Churchill, D.J. Water balance and topography predict fire and forest structure patterns. Forest Ecol. Manag. 2015, 338, 1–13. [Google Scholar] [CrossRef]
- Kanga, S.; Kumar, S.; Singh, S.K. Climate induced variation in forest fire using remote sensing and GIS in Bilaspur district of Himachal Pradesh. International J. Eng. Comput. Sci. 2017, 6, 21695–21702. [Google Scholar] [CrossRef]
- Kubosova, K.; Brabec, K.; Jarkovsky, J.; Syrovatka, V. Selection of indicative taxa for river habitats: A case study on benthic macroinvertebrates using indicator species analysis and the random forest methods. Hydrobiologia 2010, 651, 101–114. [Google Scholar] [CrossRef]
- Li, Z.; Huang, Y.; Li, X.; Xu, L. Wildland Fire Burned Areas Prediction Using Long Short-Term Memory Neural Network with Attention Mechanism. Fire Technol. 2020, 57, 1–23. [Google Scholar] [CrossRef]
- Liu, Z.; Yang, J.; Chang, Y.; Weisberg, P.J.; He, H.S. Spatial patterns and drivers of fire occurrence and its future trend under climate change in a boreal forest of northeast China. Glob. Change Biol. 2012, 18, 2041–2056. [Google Scholar] [CrossRef]
- Lu, A.F. Study on the relationship among forest fire, temperature and precipitation and its spatial-temporal variability in China. Agric. Sci. Technol. Hunan 2011, 12, 1396–1400. Available online: http://en.cnki.com.cn/Article_en/CJFDTOTAL-HNNT201109040.htm (accessed on 1 September 2011).
- Denham, M.; Cortés, A.; Margalef, T.; Luque, E. Applying a dynamic data driven genetic algorithm to improve forest fire spread prediction. In Proceedings of the International Conference on Computational Science, Kraków, Poland, 23–25 June 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 36–45. [Google Scholar] [CrossRef]
- Ma, W.; Feng, Z.; Cheng, Z.; Chen, S.; Wang, F. Identifying Forest Fire Driving Factors and Related Impacts in China Using Random Forest Algorithm. Forests 2020, 11, 507. [Google Scholar] [CrossRef]
- Maffei, C.; Menenti, M. Predicting forest fires burned area and rate of spread from pre-fire multispectral satellite measurements. ISPRS J. Photogramm. Remote Sens. 2019, 158, 263–278. [Google Scholar] [CrossRef]
- Maingi, K.J.; Henry, M.C. Factors influencing wildfire occurrence and distribution in eastern Kentucky, USA. Int. J. Wildland Fire 2007, 16, 23–33. [Google Scholar] [CrossRef]
- Boubeta, M.; Lombardía, M.J.; Marey-Pérez, M.F.; Morales, D. Prediction of forest fires occurrences with area-level poisson mixed models. J. Environ. Manag. 2015, 154, 151–158. [Google Scholar] [CrossRef]
- Naderpour, M.; Rizeei, H.M.; Khakzad, N.; Pradhan, B. Forest fire induced Natech risk assessment: A survey of geospatial technologies. Reliab. Eng. Syst. Saf. 2019, 191, 106558. [Google Scholar] [CrossRef]
- Oliveira, S.; Oehler, F.; San-Miguel-Ayanz, J.; Camia, A.; Pereira, J. Modeling spatial patterns of fire occurrence in Mediterranean Europe using multiple regression and random forest. Forest Ecol. Manag. 2012, 275, 117–129. [Google Scholar] [CrossRef]
- Satir, O.; Berberoglu, S.; Donmez, C. Mapping regional forest fire probability using artificial neural network model in a Mediterranean forest ecosystem. Geomat. Nat. Hazards Risk 2016, 7, 1645–1658. [Google Scholar] [CrossRef]
- Cortez, P.; Morais, A. New trends in artificial intelligence. In Proceedings of the 13th Portuguese Conference on Artificial Intelligence (EPIA 2007), Guimarães, Portugal, 3–7 December 2007; pp. 512–523. [Google Scholar]
- Pew, K.L.; Larsen, C.P.S. GIS analysis of spatial and temporal patterns of human-caused wildfires in the temperate rainforest of Vancouver Island, Canada. Forest Ecol. Manag. 2001, 140, 1–18. [Google Scholar] [CrossRef]
- Pourtaghi, Z.S.; Pourghasemi, H.R.; Aretano, R.; Semeraro, T. Investigation of general indicators influencing on forest fire and its susceptibility modeling using different data mining techniques. Ecol. Indic. 2016, 64, 72–84. [Google Scholar] [CrossRef]
- Rodrigucs, M.; Dc la Riva, J. An insight into machines learning algorithms to model humarrcaused wildfire or currence. Environ. Model. Softw. 2014, 57, 192–201. [Google Scholar] [CrossRef]
- Sakr, G.E.; Elhajj, I.H.; Mitri, G. Efficient forest fire occurrence prediction for developing countries using two weather parameters. Eng. Appl. Artif. Intell. 2011, 24, 888–894. [Google Scholar] [CrossRef]
- Al-Janabia, S.; Al Shourbaji, I.; Salman, M.A. Assessing the suitability of soft computing approaches for forest fires prediction. Appl. Comput. Inform. 2018, 14, 214–224. [Google Scholar] [CrossRef]
- Shang, C.; Wulder, M.A.; Coops, N.C.; White, J.C.; Hermosilla, T. Spatially-Explicit Prediction of Wildfire Burn Probability Using Remotely-Sensed and Ancillary Data. Can. J. Remote Sens. 2020, 46, 1–17. [Google Scholar] [CrossRef]
- Singh, B.K.; Kumar, N.; Tiwari, P. Extreme Learning Machine Approach for Prediction of Forest Fires using Topographical and Metrological Data of Vietnam. In Proceedings of the 2019 Women Institute of Technology Conference on Electrical and Computer Engineering (WITCON ECE), Dehradun, India, 22–23 November 2019; pp. 104–112. [Google Scholar] [CrossRef]
- Su, Z.W.; Liu, A.Q.; Guo, F.T.; Liang, H.L.; Wang, W.H. Driving factors and spatial distribution patteren of forest fire in Fujian Province. J. Nat. Disasters 2016, 25, 110–119. [Google Scholar] [CrossRef]
- Syphard, A.D.; Radeloff, V.C.; Keuler, N.S.; Taylor, R.S.; Hawbaker, T.J.; Stewart, S.I.; Clayton, M.K. Predicting spatial patterns of fire on a southern California landscape. Int. J. Wildland Fire 2008, 17, 602–613. [Google Scholar] [CrossRef]
- Tian, X.; Zhao, F.; Shu, L.; Wang, M. Distribution characteristics and the influence factors of forest fires in China. For. Ecol. Manag. 2013, 310, 460–467. [Google Scholar] [CrossRef]
- Sevinca, V.; Kucukb, O.; Goltasc, M. A Bayesian network model for prediction and analysis of possible forest fire causes. For. Ecol. Manag. 2020, 457, 117723. [Google Scholar] [CrossRef]
- Wang, X.C. 43 Cases of MATLAB Neural Network Analysis; Bei Hang University Press: Beijing, China, 2013. [Google Scholar]
- Xu, X.L. Spatial Distribution Data Set of Quarterly Vegetation Index (NDVI) in China; Data Registration and Publishing System of Resources and Environmental Science Data Center of Chinese Academy of Sciences: Beijing, China, 2018; Available online: http://www.resdc.cn/ (accessed on 1 September 2011). [CrossRef]
- Xu, Z.Q.; Su, X.Y.; Zhang, Y. Forest Fire Prediction Based on Support Vector Machine. Chin. Agric. Sci. Bull. 2012, 28, 126–131. Available online: http://en.cnki.com.cn/Article_en/CJFDTOTAL-ZNTB201213025.htm (accessed on 24 February 2012).
- Ying, L.; Han, J.; Du, Y.; Shen, Z. Forest fire characteristics in China: Spatial patterns and determinants with thresholds. For. Ecol. Manag. 2018, 424, 345–354. [Google Scholar] [CrossRef]
- You, Y.; Lu, C.; Wang, W.; Tang, C.-K. Relative CNN-RNN: Learning relative atmospheric visibility from images. IEEE Trans. Image Process. 2019, 28, 45–55. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Feng, Z.; Chen, S.; Zhao, Z.; Wang, F. Application of the Artificial Neural Network and Support Vector Machines in Forest Fire Prediction in the Guangxi Autonomous Region, China. Discret. Dyn. Nat. Soc. 2020, 2020, 14. [Google Scholar] [CrossRef]
- Zhang, F.; Yang, X. Improving land cover classification in an urbanized coastal area by random forests: The role of variable selection. Remote Sens. Environ. 2020, 251, 112105. [Google Scholar] [CrossRef]
- Su, Z.; Hu, H.; Wang, G.; Ma, Y.; Yang, X.; Guo, F. Using GIS and Random Forests to identify fire drivers in a forest city, Yichun, China. Geomat. Nat. Hazards Risk 2018, 9, 1207–1229. [Google Scholar] [CrossRef]
- Feng, Z.; Liu, L. Estimation of forest biomass in Beijing (China) using multisource remote sensing and forest inventory data. Forests 2020, 11, 163. [Google Scholar] [CrossRef]
- Zumbrunnen, T.; Pezzatti, G.B.; Menéndez, P.; Bugmann, H.; Bürgi, M.; Conedera, M. Weather and human impacts on forest fires: 100 years of fire history in two climatic regions of Switzerland. For. Ecol. Manag. 2011, 261, 2188–2199. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aspect | Azimuth (Degree) | Classification |
|---|---|---|
| Gentle Slope | −1 | 0 |
| Shady Slope | 0~67.5, 337.5~360 | 1 |
| Semi-shady Slope | 67.5~112.5, 292.5~337.5 | 2 |
| Sunny Slope | 157.5~247.5 | 3 |
| Semi-sunny Slope | 112.5~157.5, 247.5~292.5 | 4 |
| Category | Independent Variable | Symbol | Variable Type | Source | Resolution, Units |
|---|---|---|---|---|---|
| Location | Longitude (°) | Lon | Continuous Variable | https://daac.ornl.gov/ (accessed on 1 January 2021) | - |
| Latitude (°) | Lat | Continuous Variable | https://daac.ornl.gov/ (accessed on 1 January 2021) | - | |
| Topographic | Altitude (m) | Alt | Continuous Variable | https://www.resdc.cn (accessed on 10 January 2021) | 1 km |
| Slope (°) | Slo | Continuous Variable | https://www.resdc.cn (accessed on 10 January 2021) | 1 km | |
| Aspect | Asp | Categorical Variable | https://www.resdc.cn (accessed on 10 January 2021) | 1 km | |
| Climatic | Average Surface Temperature (°C) | Avst | Continuous Variable | China Ground Climate Da ta(V3.0) Daily Dataset, National Meteorological Information Centre (https://data.cma.cn (accessed on 7 January 2021) | 0.1 °C |
| Daily Maximum Surface temperature (°C) | Mast | Continuous Variable | 0.1 °C | ||
| Cumulative Precipitation at 20–20 (mm) | Pre | Continuous Variable | 0.1 mm | ||
| Average Relative Humidity (%) | Arh | Continuous Variable | 1% | ||
| Hours of Sunshine (h) | Suh | Continuous Variable | 0.1 h | ||
| Average Temperature (°C) | Ate | Continuous Variable | 0.1 °C | ||
| Daily Maximum Temperature (°C) | Mate | Continuous Variable | 0.1 °C | ||
| Average Wind Speed (m/s) | Aws | Continuous Variable | 0.1 m/s | ||
| Maximum Wind Speed (m/s) | Mws | Continuous Variable | 0.1 m/s | ||
| Infrastructure | Distance from Fire Point to Highway (m) | Hig | Continuous Variable | https://www.webmap.cn (accessed on 13 January 2021) | 1:1,000,000 |
| Closest Distance from Fire Point to Residential Area (m) | Set | Continuous Variable | https://www.webmap.cn (accessed on 13 January 2021) | 1:1,000,000 | |
| Socioeconomic | Population | Pop | Continuous Variable | https://www.resdc.cn (accessed on 15 January 2021) | 1 km |
| GDP | GDP | Continuous Variable | https://www.resdc.cn (accessed on 15 January 2021) | 1 km | |
| Special Festival | Sfe | Categorical Variable | - | - | |
| Vegetation | NDVI | NDVI | Continuous Variable | https://www.resdc.cn (accessed on 10 January 2021) | 1 km |
| No. | Formula | Explanation | Variables Using This Formula |
|---|---|---|---|
| (1) | and are the values before and after data normalization, respectively; and are the maximum and minimum values of the full sample data, respectively. | Lon, Lat, Alt, Avst, Mast, Pre, Suh, Ate, Mate, Aws, Mws, Hig, Set, Pop, GDP | |
| (2) | is the slope value. | Slo | |
| (3) | is the humidity value. | Arh |
| No. | Variable | Sample 1 | Sample 2 | Sample 3 | Sample 4 | Sample 5 | Frequency |
|---|---|---|---|---|---|---|---|
| 1 | Lat | + | + | + | + | + | 5 |
| 2 | Lon | + | + | + | + | + | 5 |
| 3 | Avst | + | + | + | + | + | 5 |
| 4 | Mast | + | + | + | + | 4 | |
| 5 | Pre | + | + | + | + | 4 | |
| 6 | Arh | + | + | + | + | + | 5 |
| 7 | Suh | + | + | + | + | + | 5 |
| 8 | Ate | + | + | + | + | + | 5 |
| 9 | Mate | + | + | + | + | + | 5 |
| 10 | Aws | 0 | |||||
| 11 | Mws | 0 | |||||
| 12 | Alt | + | + | + | + | + | 5 |
| 13 | Slo | 0 | |||||
| 14 | Asp | 0 | |||||
| 15 | Set | 0 | |||||
| 16 | Hig | 0 | |||||
| 17 | GDP | + | + | + | + | 5 | |
| 18 | Pop | + | + | + | + | + | 5 |
| 19 | NDVI | + | + | + | + | + | 5 |
| 20 | Sfe | 0 |
| Total Variable Sample | OOB Estimate of Error Rate | 10.89% | |
|---|---|---|---|
| Confusion matrix: | 0 | 1 | Classification error rate |
| 0 | 20,224 | 2716 | 12.3% |
| 1 | 2168 | 20,737 | 9.5% |
| Sample of screened variables | OOB estimate of error rate | 10.65% | |
| Confusion matrix: | 0 | 1 | Classification error rate |
| 0 | 20,038 | 2810 | 11.8% |
| 1 | 2171 | 20,717 | 9.5% |
| Model | Accuracy (%) | Precision (%) | Recall (%) | f1 Value (%) | AUC |
|---|---|---|---|---|---|
| ANN | 83.0 | 85.4 | 79.6 | 82.4 | 0.904 |
| RBFNN | 75.8 | 73.1 | 81.6 | 77.1 | 0.840 |
| SVM | 84.3 | 83.0 | 86.8 | 84.8 | 0.917 |
| RF | 89.2 | 90.2 | 87.9 | 89.0 | 0.960 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pang, Y.; Li, Y.; Feng, Z.; Feng, Z.; Zhao, Z.; Chen, S.; Zhang, H. Forest Fire Occurrence Prediction in China Based on Machine Learning Methods. Remote Sens. 2022, 14, 5546. https://doi.org/10.3390/rs14215546
Pang Y, Li Y, Feng Z, Feng Z, Zhao Z, Chen S, Zhang H. Forest Fire Occurrence Prediction in China Based on Machine Learning Methods. Remote Sensing. 2022; 14(21):5546. https://doi.org/10.3390/rs14215546
Chicago/Turabian StylePang, Yongqi, Yudong Li, Zhongke Feng, Zemin Feng, Ziyu Zhao, Shilin Chen, and Hanyue Zhang. 2022. "Forest Fire Occurrence Prediction in China Based on Machine Learning Methods" Remote Sensing 14, no. 21: 5546. https://doi.org/10.3390/rs14215546
APA StylePang, Y., Li, Y., Feng, Z., Feng, Z., Zhao, Z., Chen, S., & Zhang, H. (2022). Forest Fire Occurrence Prediction in China Based on Machine Learning Methods. Remote Sensing, 14(21), 5546. https://doi.org/10.3390/rs14215546