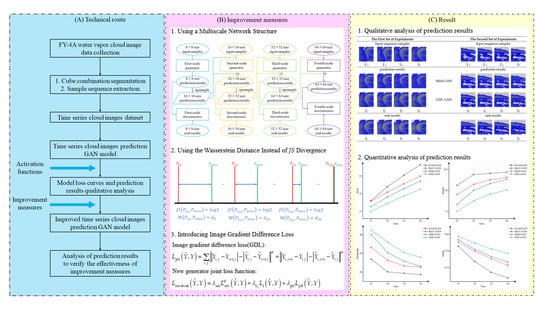
3.2. Experiments and Qualitative Analysis
Based on the Mish-GAN model and the above three improvement measures, this section adopts the training mode of Wasserstein GAN and uses the Adam optimizer instead of SGD. The initial learning rate is the same as that of
Section 2,
and
are 0.5 and 0.9, respectively. The weight coefficients
,
, and
of the joint loss function are 1, 0.1, and 0.05, respectively.
The discriminator no longer classifies the prediction results and real results but calculates the Wasserstein distance between the two. Therefore, in the training process, the adversarial loss between the generator and discriminator is no longer calculated by Log, and the final sigmoid function of the discriminator is removed. The loss curves of the improved model (GDL-GAN) training 1000 epochs are shown in
Figure 7.
As shown in
Figure 7a, the adversarial loss of the generator increases and gradually converges after 700th epochs, indicating that the score of the discriminator obtained by the prediction result is increased to a stable value range. As shown in
Figure 7b, the discriminator loss curve continues to decline and finally reaches a convergence state after 700th epochs, which means that the difference between the generated distribution and the real distribution gradually narrows and tends to be stable. Therefore, the Wasserstein distance is used instead of the
JS divergence as the metric of the loss function of the prediction model. While ensuring the stability of the model and improving the prediction quality, it enters the convergence state earlier and achieves the goal of “confusing” the discriminator with the prediction results. The problem of nonconvergence of the discriminator loss curve in
Figure 4 is improved.
For a more intuitive demonstration of the prediction effect of the improved model (GDL-GAN), this section still selects the same two sets of samples as in
Section 2 and compares the Mish-GAN model, as shown in
Table 4. We show the prediction results of more sets of experiments in
Table A1,
Table A2 and
Table A3 of
Appendix A.
From the truth of
Table 4, it is observed that in the first set of experiments, the spiral air flow rotates counterclockwise, and the cloud image moves slowly eastward as a whole. In the second set of experiments, the banded cloud clusters gradually move eastward, accompanied by partial dissipation. For the Mish-GAN model, the first set of experiments can roughly predict the location of the cyclone, but the last two prediction results are only a U-shaped block lacking the details of air flow rotation and motion trend. In the second set of prediction results, the upper cloud cluster boundary has fuzzy bright spots, and the dissipation characteristics of banded cloud clusters are not obvious. In contrast, the prediction effect of the GDL-GAN model is improved, which is mainly reflected in the following two aspects: (1) not only the evolution law of cyclones and banded cloud clusters in the two sets of prediction results is accurately modeled but also the textural details of the spiral cyclone center structure and the air flow distribution on the west side in the first set of results can be predicted more accurately in the last two times, and the dissipation prediction of the cloud clusters in the second set of results is more accurate. (2) The contour of cloud clusters and airflow edge is clear, which is closer to the real results. The overall sharpness of the prediction cloud images is improved, and the visual effect is better.
3.3. Quantitative Analysis of Time Series Cloud Images Prediction Results
In the previous experimental process, we analyzed the quality of the prediction results through visual interpretation. To accurately measure the prediction performance of the improved model (GDL-GAN), this section continues to use the peak signal-to-noise ratio (PSNR) [
27], structural similarity (SSIM) [
28], mean absolute error (MAE), and root mean square error (RMSE) four evaluation indicators for quantitative comparison. Among them, MAE and RMSE are pixel-level indicators to calculate the difference between the prediction results and the real results. The smaller the values of MAE and RMSE, the closer the pixel values between the prediction results and the real results. PSNR is a method to estimate the image quality of prediction results based on error sensitivity. SSIM is used to measure the structural similarity between the prediction and real results. It was proposed under the assumption that the quality perception of human visual system (HVS) is correlated with structural information of the scene. The larger the values of PSNR and SSIM, the better the image quality of the prediction results and the higher the similarity with the real results.
Table 5 shows the quantitative performance of the unimproved model using the three activation functions and the improved model on the test set of four evaluation indicators, which are the average of the prediction results at the next four times.
Table 5 shows that the GDL-GAN model performs best in four indicators. The GDL-GAN model is higher than the other three models in terms of prediction accuracy and image quality. Compared with Mish-GAN, which has the highest index among the unimproved models, the GDL-GAN model significantly reduces the MAE and RMSE values by 18.84% and 7.60%, respectively; the PSNR and SSIM values also increase by 0.44 and 0.02, respectively.
To reflect the differences between different models in more detail, this section also compares the prediction results at each time and plots the change curves of the four evaluation indicators, as shown in
Figure 8 and
Figure 9. It can be seen intuitively from
Figure 8 and
Figure 9 that the GDL-GAN model shows the best results and the slowest performance degradation on the evaluation indicators at the next four times. The prediction accuracy and quality at each time have been steadily improved. The maximum improvement of PSNR, SSIM, MAE, and RMSE at a single time is 1.93%, 4.19%, 21.84%, and 8.23%, respectively. This shows that the GDL-GAN model improves the imaging quality of the prediction results while ensuring the dynamic accuracy of the prediction sequence cloud images.
Reference comparison of GDL-GAN model with optical flow model and computer vision model:
Based on the quantitative analysis in this section, the relevant literatures on satellite cloud images prediction are consulted for reference comparison. Su et al. [
29] constructed a Multi-GRU-RCN prediction model for FY-2G infrared satellite cloud images based on gated recurrent unit (GRU) and recurrent convolutional network (RCN). The results show that the average PSNR and SSIM of the satellite cloud images at the next time are 29.62 and 0.79, respectively, and the average RMSE is 8.54. The applicability of the model is better than that of deep learning models such as LSTM, GRU and ConvLSTM. Shi et al. [
6] extrapolated the FY-4A infrared satellite cloud images by using a dense optical flow model. The average MAE and RMSE of the prediction cloud images at the next four times are below 15.
In terms of the quality of the prediction results, the average PSNR and SSIM of the GDL-GAN model constructed in this paper are 30.25 and 0.83 at the next time. Compared with the Multi-GRU-RCN model, the image quality of the prediction results is enhanced. This improvement is due to the combination of L1 loss, adversarial loss and image gradient difference loss to form a joint loss function to guide model training, which reduces the ambiguity of the prediction results caused by relying solely on L1 loss or L2 loss.
In terms of the accuracy of the prediction cloud images, the average RMSE of the GDL-GAN model in predicting the next time is 7.53, and the average MAE and RMSE of the next four times are 18.05 and 8.39. MAE is slightly inferior to the dense optical flow model, but the accuracy level of MAE is kept in the same range. For the RMSE index, the GDL-GAN model achieves values smaller than the Multi-GRU-RCN model and the dense optical flow model. It shows that the improvement measure of step-by-step prediction through multiscale network structure improves the accuracy and long-term effectiveness of prediction results to a certain extent.
Based on the qualitative and quantitative analysis, three improvement measures have achieved corresponding results. The Wasserstein distance instead of JS divergence avoids the problem that the generator reaches the convergence state before improvement, but the prediction results are still easily distinguished by the discriminator, the overall stable update and convergence of the model are realized. Through the step-by-step prediction of multiscale network structure, the prediction cloud images can always maintain a high degree of similarity with real cloud images in terms of overall motion trend and texture details in the next four times. The generator loss function introduces the image gradient difference loss to jointly guide the generated prediction sequence images to have more obvious image sharpness and visual realism. This section is effective for the improvement of the time series prediction GAN model.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
















































































































































































