
Scalability and Performance of LiDAR Point Cloud Data Management Systems: A State-of-the-Art Review


 ,
,
Abstract
1. Introduction
1.1. Contributions
- A novel review of PCDM literature, which analyses the scalability and performance of existing solutions.
- A thorough discussion of the impact of architectures and data models toward scalability and performance in the context of PCDM.
- An in-depth analysis of the implementation aspects of PCDM systems.
- An overview of research experiments published in the PCDM literature, including the synthesis of different queries of interests, data sets, and performance measures obtained in the experiments, to demonstrate the spectrum of research conducted in the PCDM area.
- A novel, concrete workflow for the selection of parallel architectures and data models for PCDM system development.
- A list of notable research gaps in the PCDM literature.
- A discussion of the most promising future research directions, including the identification of the need for an agile extensible framework for methodical testing and evaluation of the performance and scalability of PCDM systems.
1.2. Paper Organization
2. Related Work
2.1. File-Based PCDM
2.2. PCDMs Relying on Database Technology

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Main Contribution(s) in Terms of Reviewing PCDM | Relevance to Scalability and Performance in PCDM |
|---|---|---|
| [17] | Comprehensive survey on georeferenced PCs and PCDM in a file-based environment | No explicit focus on scalability or performance is discussed |
| [18] | Detailed overview of LiDAR point cloud data, their encoding formats, and LAS specification | No explicit focus on scalability or performance is discussed |
| Justifies the use of PCDM in database environment for random retrieval of point cloud data | ||
| [3,5,20,22,23,24,31,32] | Limitations of file-based systems and benefits of adopting databases for PCDM | Recognizes scalability as an important element in PCDM |
| Does not review scalability or performance of state-of-the-art PCDM systems | ||
| [19] | Methodology to assess the scalability of PCDM systems | Recognizes scalability as an important element in PCDM |
| Does not review scalability or performance of state-of-the-art PCDM systems | ||
| [5] | In-depth review of the data types for PCDM in Oracle and PostgreSQL is presented | Recognizes scalability as a pivotal element of PCDM |
| Does not review scalability or performance of state-of-the-art PCDM systems | ||
| [3,22,27,33] | Leading works that demonstrate the possibility of PCDM in the context of shared-nothing-architecture oriented non-relational databases | Does not review scalability or performance of state-of-the-art PCDM systems |
3. Background
3.1. Scalability and Performance of Data-Intensive Systems
3.2. Scaling Techniques and Parallel Architectures in Data-Intensive Systems
3.2.1. Advent of Parallel Data-Intensive Systems
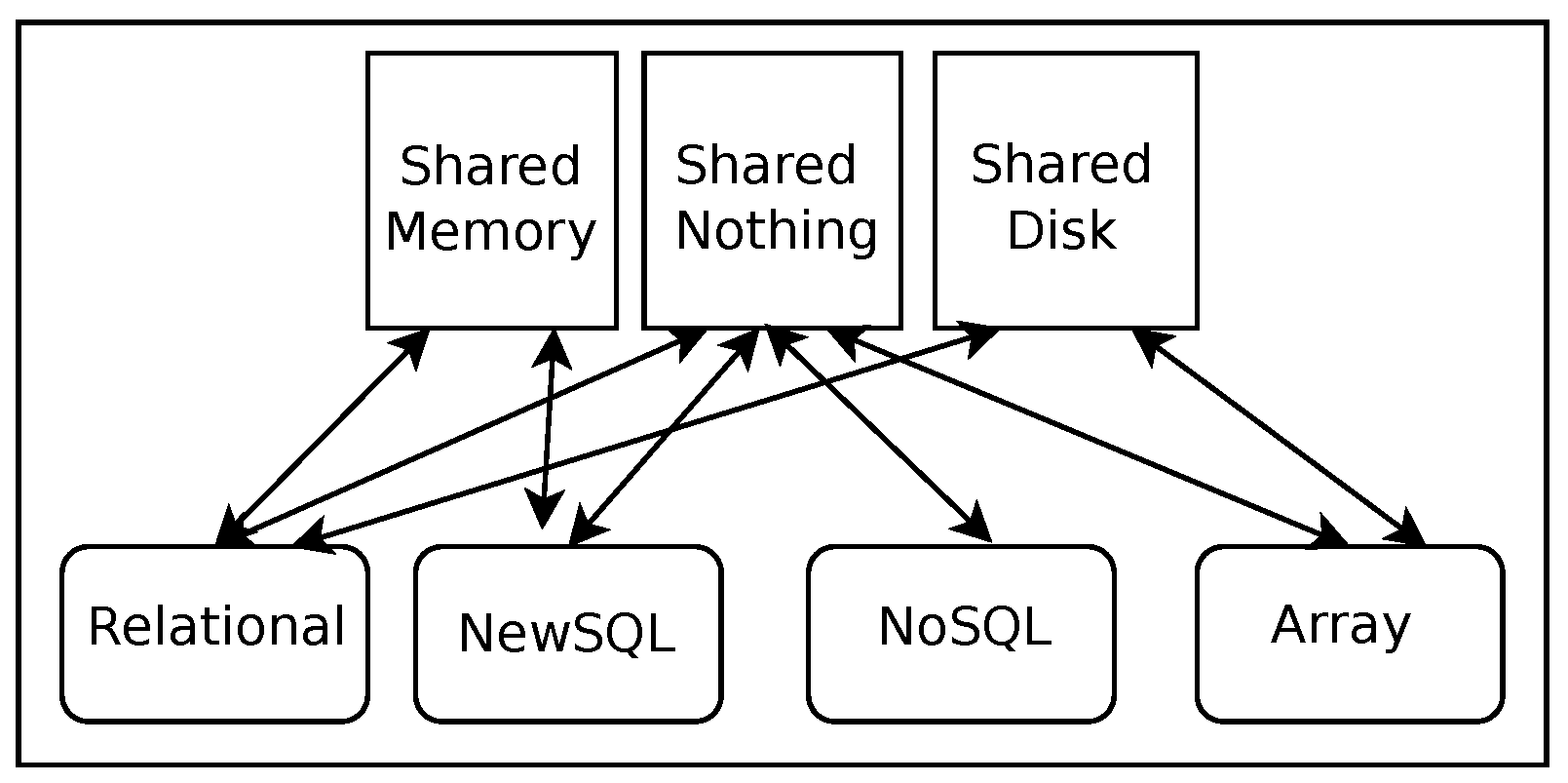
3.2.2. Architectures of Data-Intensive Systems (Parallel Data System Architectures)
3.3. Use of Databases in Data-Intensive Systems
4. Parallel Architectures toward Scalability and Performance
5. Data Models toward Scalability and Performance
6. Analysis of State-of-the-Art PCDM Systems
6.1. Shared-Memory Based PCDM Systems
6.2. Shared-Disk Oriented PCDM Systems
6.3. Shared-Nothing Architecture-Oriented PCDM Systems
6.4. Comparison of Scalability and Performance of Current PCDM Systems
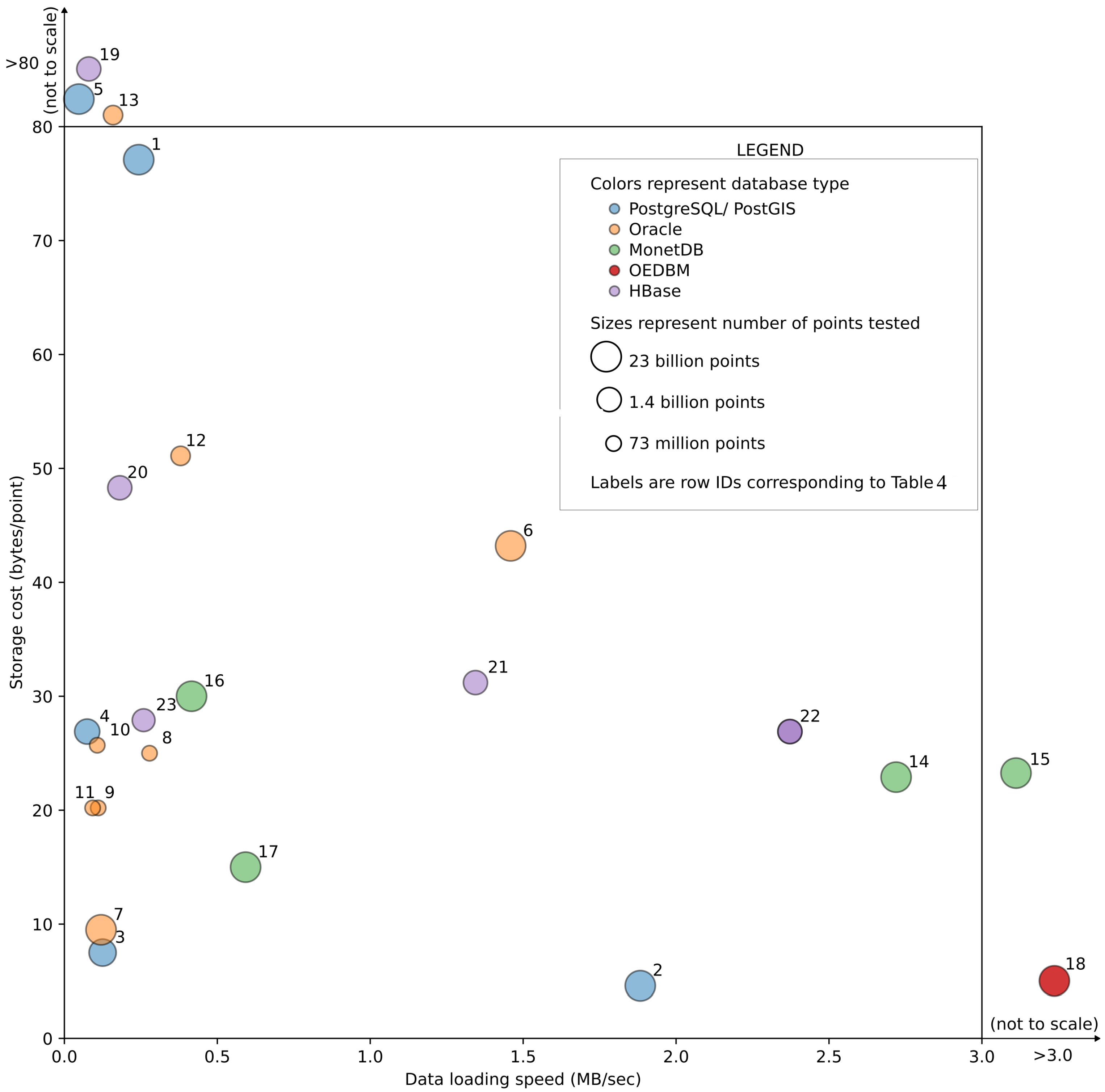
Inspect Performance Results of Current PCDM Systems
- In scenarios where different data set sizes were tested, the results obtained from the largest are reported herein.
- Additional information such as the number of threads used for loading, nature of the window query, spatial index used, and storage model implemented are provided where appropriate.
- Data storage is mainly ascertained by considering the total disk/memory usage, i.e., in experiments where the size of the index and data are provided separately, the summation of the two (i.e., total storage consumption) is reported.
- While the results reported are impacted by data heterogeneity, there is not an easy means of characterization and, thus, must be considered as an uncertainty in the reporting.
- The OEDBM PCDM system—a multi-node shared-disk architecture-based relational database-oriented PCDM system had the best (highest) reported points/seconds ratio.
- The OEDBM PCDM system also had the best (lowest) bytes/points ratio (i.e., the number of bytes per point), with the aid of an in-built compression mechanism (i.e., query high compression mode).
- Among the PostgreSQL/PostGIS-oriented PCDM systems:
- –
- The block model implemented in [19] yielded the lowest bytes/points ratio (using blocks of 3000 points).
- –
- This system also yielded the highest points/loading time and ratio among the PostgreSQL/PostGIS systems.
- Among the Oracle database-oriented PCDM systems:
- Amongst the MonetDB-based systems:
- Investigation of the 2D window queries is more common compared to the investigation of the 3D range or kNN queries for LiDAR point cloud data.
- Data loading and concurrent data querying can be done in parallel. However, many researchers have not explicitly explored parallelism under data loading and querying.
7. Discussion
7.1. Guide to Selecting Parallel Architectures and Data Models for PCDM
7.2. Further Research Avenues
- Existing PCDM systems:
- –
- Perform experiments on scalability and performance with respect to growing traffic volumes.
- –
- Design experiments that demonstrate scalability and performance with respect to data complexity.
- Developing new PCDM systems:
- –
- Deploy relational databases, both row-oriented and column-oriented, in shared-nothing architecture and explore scalability and performance.
- –
- Explore avenues with NewSQL databases for PCDM in shared-nothing architecture. This includes exploring the suitability of graph databases, document databases, and key-value databases (NoSQL databases other than wide-column) for PCDM.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 3D | three-dimensional |
| DBMS | database management system |
| DM | data management |
| FWF | full waveform |
| kNN | k nearest neighbor |
| LiDAR (LiDAR) | Light Detection and Ranging |
| OEDBM | Oracle Exadata Database Machine |
| PCDM | point cloud data management |
| PCs | point clouds |
| RDBMSs | relational database management systems |
| NoSQL | Not only SQL |
| SFC | space-filling curve |
| SFCs | space-filling curves |
| SQL | structured query language |
References
- Alvanaki, F.; Goncalves, R.; Ivanova, M.; Kersten, M.; Kyzirakos, K. GIS navigation boosted by column stores. Proc. VLDB Endow. 2015, 8, 1956–1959. [Google Scholar] [CrossRef]
- Mosa, A.; Schön, B.; Bertolotto, M.; Laefer, D. Evaluating the benefits of octree-based indexing for LiDAR data. Photogramm. Eng. Remote Sens. 2012, 78, 927–934. [Google Scholar] [CrossRef]
- Vo, A.; Konda, N.; Chauhan, N.; Aljumaily, H.; Laefer, D. Lessons learned with laser scanning point cloud management in Hadoop HBase. In Lecture Notes in Computer Science; Springer: Lausanne, Switzerland, 2018; pp. 231–253. [Google Scholar]
- Stanley, M.H.; Laefer, D.F. Metrics for aerial, urban lidar point clouds. ISPRS J. Photogramm. Remote Sens. 2021, 175, 268–281. [Google Scholar] [CrossRef]
- Vo, A.; Laefer, D.; Bertolotto, M. Airborne laser scanning data storage and indexing: State of the art review. Int. J. Remote Sens. 2016, 37, 6187–6204. [Google Scholar] [CrossRef]
- Lagmay, A.; Racoma, B.; Aracan, K.; Alconis-Ayco, J.; Saddi, I. Disseminating near-real-time hazards information and flood maps in the Philippines through Web-GIS. J. Environ. Sci. 2017, 59, 13–23. [Google Scholar] [CrossRef]
- GSI. Geographical Survey Institute Map Service. 2016. Available online: http://maps.gsi.go.jp/ (accessed on 20 December 2021).
- AHN. Actueel Hoogtebestand Nederland—Actualisatie Van Het 2. 2014. Available online: https://www.ahn.nl/ (accessed on 30 July 2017).
- US Geological Survey. USGS Program Updates. 2022. Available online: https://www.usgs.gov/3d-elevation-program/what-3dep#publications (accessed on 20 May 2022).
- OpenTopography. USGS 3DEP Data Now Available to Academic Users in OpenTopography Pilot. 2020. Available online: https://opentopography.org/news/usgs-3dep-data-now-available-academic-users-opentopography-pilot (accessed on 20 May 2022).
- Laefer, D.; Abuwarda, S.; Vo, A.; Truong-Hong, L.; Gharibi, H. 2015 Aerial Laser and Photogrammetry Survey of Dublin City Collection Record. 2017. Available online: https://doi.org/10.17609/N8MQ0N (accessed on 20 October 2019).
- Wang, Y.; Chen, Q.; Zhu, Q.; Liu, L.; Li, C.; Zheng, D. A survey of mobile laser scanning applications and key techniques over urban areas. Remote Sens. 2019, 11, 1540. [Google Scholar] [CrossRef]
- Cura, R.; Perret, J.; Paparoditis, N. Point cloud server (pcs): Point clouds in-base management and processing. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 2, 531. [Google Scholar] [CrossRef]
- Bauwens, S.; Bartholomeus, H.; Calders, K.; Lejeune, P. Forest inventory with terrestrial LiDAR: A comparison of static and hand-held mobile laser scanning. Forests 2016, 7, 127. [Google Scholar] [CrossRef]
- Zhu, L.; Hyyppa, J. The use of airborne and mobile laser scanning for modeling railway environments in 3D. Remote Sens. 2014, 6, 3075–3100. [Google Scholar] [CrossRef]
- Kleppmann, M. Designing Data-Intensive Applications: The Big Ideas behind Reliable, Scalable, and Maintainable Systems; O’Reilly Media, Inc.: Newton, MA, USA, 2017. [Google Scholar]
- Otepka, J.; Ghuffar, S.; Waldhauser, C.; Hochreiter, R.; Pfeifer, N. Georeferenced point clouds: A survey of features and point cloud management. ISPRS Int. J. Geo-Inf. 2013, 2, 1038–1065. [Google Scholar] [CrossRef]
- Graham, L. Data Management of Light Detection and Ranging. In Topographic Laser Ranging and Scanning Principles and Processing, 2nd ed.; Shan, J., Toth, C., Eds.; CRC Press: Boca Raton, FL, USA, 2018; Chapter 10; pp. 314–346. [Google Scholar] [CrossRef]
- van Oosterom, P.; Martinez-Rubi, O.; Ivanova, M.; Horhammer, M.; Geringer, D.; Ravada, S.; Tijssen, T.; Kodde, M.; Gonçalves, R. Massive point cloud data management: Design, implementation and execution of a point cloud benchmark. Comput. Graph. 2015, 49, 92–125. [Google Scholar] [CrossRef]
- Cura, R.; Perret, J.; Paparoditis, N. A scalable and multi-purpose point cloud server (PCS) for easier and faster point cloud data management and processing. ISPRS J. Photogramm. Remote Sens. 2017, 127, 39–56. [Google Scholar] [CrossRef]
- Psomadaki, S. Using a Database for Dynamic Point Cloud Data Management. (Doctoral Dissertation, Master’s Thesis, Delft University of Technology, 2016. (Graduation Plan)). Available online: https://repository.tudelft.nl/islandora/object/uuid:c1e625b0-0a74-48b5-b748-6968e7f83e2b/datastream/OBJ2/download (accessed on 20 May 2022).
- Boehm, J.; Liu, K. NoSQL for storage and retrieval of large LiDAR data collections. ISPRS Int. Arch. Photogramm. Remote Spat. Inf. Sci. 2015, 40, 577–582. [Google Scholar] [CrossRef]
- Janecka, K.; Karki, S.; van Oosterom, P.; Zlatanova, S.; Kalantari, M.; Ghawana, T. 3D Cadastres Best Practices, Chapter 4: 3D Spatial DBMS for 3D Cadastres. In Proceedings of the 26th FIG Congress 2018 Embracing our Smart World Where the Continents Connect, Istanbul, Turkey, 6–11 May 2018. [Google Scholar]
- El-Mahgary, S.; Virtanen, J.P.; Hyyppä, H. A Simple Semantic-Based Data Storage Layout for Querying Point Clouds. ISPRS Int. J. Geo-Inf. 2020, 9, 72. [Google Scholar] [CrossRef]
- Ott, M. Towards storing point clouds in PostgreSQL. Ph.D. Thesis, HSR Hochschule für Technik Rapperswil, Rapperswil, Switzerland, 2012. [Google Scholar]
- Godfrind, A. Oracle’s Point Cloud Datatype. 2009. Available online: https://ncgeo.nl/downloads/PointCloud_14_AlbertGodfrind.pdf (accessed on 20 May 2022).
- Vo, A.; Laefer, D.; Trifkovic, M.; Hewage, C.; Bertolotto, M.; Le-Khac, N.; Ofterdinger, U. A highly scalable data management system for point cloud and full waveform lidar data. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 507–512. [Google Scholar] [CrossRef]
- Boehm, J. File-centric organization of large LiDAR Point Clouds in a Big Data context. In Proceedings of the IQmulus First Workshop on Processing Large Geospatial Data, Cardiff, UK, July 2014; Volume 8, pp. 69–76. [Google Scholar]
- Li, Z.; Hodgson, M.; Li, W. A general-purpose framework for parallel processing of large-scale LiDAR data. Int. J. Digit. Earth 2017, 11, 26–47. [Google Scholar] [CrossRef]
- Vo, A.; Laefer, D. A Big Data approach for comprehensive urban shadow analysis from airborne laser scanning point clouds. ISPRS Ann. Photogramm. Remote Spat. Inf. Sci. 2019, 4, 131–137. [Google Scholar] [CrossRef]
- Psomadaki, S.; van Oosterom, P.; Tijssen, T.P.M.; Baart, F. Using a Space Filling Curve Approach for the Management of Dynamic Point Clouds. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, IV-2/W1, 107–118. [Google Scholar] [CrossRef]
- van Oosterom, P.; Martinez-Rubi, O.; Tijssen, T.; Gonçalves, R. Realistic benchmarks for point cloud data management systems. In Advances in 3D Geoinformation; Springer: Cham, Switzerland, 2017; pp. 1–30. [Google Scholar]
- Pajić, V.; Govedarica, M.; Amović, M. Model of Point Cloud Data Management System in Big Data Paradigm. ISPRS Int. J. Geo-Inf. 2018, 7, 265. [Google Scholar] [CrossRef]
- Vo, A.V.; Hewage, C.N.L.; Russo, G.; Chauhan, N.; Laefer, D.F.; Bertolotto, M.; Le-Khac, N.A.; Oftendinger, U. Efficient LiDAR point cloud data encoding for scalable data management within the Hadoop eco-system. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 5644–5653. [Google Scholar]
- Fowler, M. Patterns of Enterprise Application Architecture; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 2002. [Google Scholar]
- Bondi, A.B. Characteristics of scalability and their impact on performance. In Proceedings of the 2nd International Workshop on Software and Performance, New York, NY, USA, September 2000; pp. 195–203. [Google Scholar]
- Weinstock, C.B.; Goodenough, J.B. On System Scalability; Technical Report; Carnegie-Mellon Univ Pittsburgh Pa Software Engineering Inst: Pittsburgh, PA, USA, 2006. [Google Scholar]
- Pacheco, P. Parallel Programming with MPI; Morgan Kaufmann: Burlington, MA, USA, 1997. [Google Scholar]
- Özsu, M.T.; Valduriez, P. Principles of Distributed Database Systems; Springer: Cham, Switzerland, 2020; Volume 4. [Google Scholar]
- Leopold, C. Parallel and Distributed Computing: A survey of Models, Paradigms and Approaches; John Wiley & Sons, Inc.: New York, NY, USA, 2001. [Google Scholar]
- Dumitru, A.M.; Merticariu, V.; Baumann, P. Array database scalability: Intercontinental queries on petabyte datasets. In Proceedings of the 28th International Conference on Scientific and Statistical Database Management, Budapest, Hungary, 18–20 July 2016; pp. 1–5. [Google Scholar]
- Gorelik, E. Cloud Computing Models. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2013. [Google Scholar]
- Singh, D.; Reddy, C.K. A survey on platforms for big data analytics. J. Big Data 2015, 2, 8. [Google Scholar] [CrossRef]
- Hwang, K.; Shi, Y.; Bai, X. Scale-out vs. scale-up techniques for cloud performance and productivity. In Proceedings of the 2014 IEEE 6th International Conference on Cloud Computing Technology and Science, Singapore, 15–18 December 2014; pp. 763–768. [Google Scholar]
- Ben Stopford. Shared Nothing v.s. Shared Disk Architectures: An Independent View. 2009. Available online: http://www.benstopford.com/2009/11/24/understanding-the-shared-nothing-architecture (accessed on 21 October 2021).
- Rieg, L.; Wichmann, V.; Rutzinger, M.; Sailer, R.; Geist, T.; Stötter, J. Data infrastructure for multitemporal airborne LiDAR point cloud analysis—Examples from physical geography in high mountain environments. Comput. Environ. Urban Syst. 2014, 45, 137–146. [Google Scholar] [CrossRef]
- Martinez-Rubi, O.; van Oosterom, P.; Tijssen, T. Managing massive point clouds: Performance of DBMS and file-based solutions. GIM Int. 2015, 29, 33–35. [Google Scholar]
- Kersten, M.; Ivanova, M.; Pereira Goncalves, R.A.; Martinez-Rubi, O. In FOSS4G-Europe 2014: Independent Innovation for INSPIRE, Big Data and Citizen Participation: OSGEO’s European Conference on Free and Open Source Software for Geospatial. Academic Track Open Source Geospatial Foundation. Available online: http://europe.foss4g.org/2014/sites/default/files/11-Martinez-Rubi_0.pdf (accessed on 20 May 2022).
- Pavlovic, M.; Bastian, K.N.; Gildhoff, H.; Ailamaki, A. Dictionary compression in point cloud data management. In Proceedings of the 25th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 7–10 November 2017; pp. 1–10. [Google Scholar]
- Aji, A.; Wang, F.; Vo, H.; Lee, R.; Liu, Q.; Zhang, X.; Saltz, J. Hadoop-GIS: A high performance spatial data warehousing system over MapReduce. Proc. VLDB Endow. 2013, 6, 1009–1020. [Google Scholar] [CrossRef]
- Zhong, Y.; Han, J.; Zhang, T.; Li, Z.; Fang, J.; Chen, G. Towards parallel spatial query processing for big spatial data. In Proceedings of the 2012 IEEE 26th International Parallel and Distributed Processing Symposium Workshops & PhD Forum, Shanghai, China, 21–25 May 2012; pp. 2085–2094. [Google Scholar]
- Martinez-Rubi, S.; van Oosterom, P.; Gonçalves, R.; Tijssen, T.; Ivanova, M. Benchmarking and improving point cloud data management in MonetDB. SIGSPATIAL Spec. Big Spat. Data 2015, 6, 11–18. [Google Scholar] [CrossRef]
- Laefer, D.F.; Vo, A.V.; Bertolotto, M. A spatio-temporal index for aerial full waveform laser scanning data. ISPRS J. Photogramm. Remote Sens. 2018, 138, 232–251. [Google Scholar] [CrossRef]
- Codd, E.F. A relational model of data for large shared data banks. In Software Pioneers; Springer: Cham, Switzerland, 2002; pp. 263–294. [Google Scholar]
- Elmasri, R. Fundamentals of Database Systems; Pearson Education: Chennai, India, 2008. [Google Scholar]
- Garcia-Molina, H. Database Systems: The Complete Book; Pearson Education: Chennai, India, 2008. [Google Scholar]
- Davoudian, A.; Chen, L.; Liu, M. A survey on NoSQL stores. ACM Comput. Surv. (CSUR) 2018, 51, 1–43. [Google Scholar] [CrossRef]
- Baumann, P.; Mazzetti, P.; Ungar, J.; Barbera, R.; Barboni, D.; Beccati, A.; Bigagli, L.; Boldrini, E.; Bruno, R.; Calanducci, A.; et al. Big data analytics for earth sciences: The EarthServer approach. Int. J. Digit. Earth 2016, 9, 3–29. [Google Scholar] [CrossRef]
- Baumann, P.; Furtado, P.; Ritsch, R.; Widmann, N. The RasDaMan approach to multidimensional database management. In Proceedings of the 1997 ACM Symposium on Applied Computing, San Jose, CA, USA, April 1997; pp. 166–173. [Google Scholar]
- Vo, A.; Hewage, C.; Le Khac, N.; Bertolotto, M.; Laefer, D. A parallel algorithm for local point density index computation of large point clouds. ISPRS Ann. Photogramm. Remote Sens. Spat. Inform. Sci. 2021, 8, 75–82. [Google Scholar] [CrossRef]
- Vo, A.; Laefer, D.; Smolic, A.; Zolanvari, S. Per-point processing for detailed urban solar estimation with aerial laser scanning and distributed computing. ISPRS J. Photogramm. Remote Sens. 2019, 155, 119–135. [Google Scholar] [CrossRef]
- Pavlo, A.; Aslett, M. What’s really new with NewSQL? ACM Sigmod Rec. 2016, 45, 45–55. [Google Scholar] [CrossRef]
- Klein, J.; Gorton, I.; Ernst, N.; Donohoe, P.; Pham, K.; Matser, C. Performance evaluation of NoSQL databases: A case study. In Proceedings of the 1st Workshop on Performance Analysis of Big Data Systems, Austin, TX, USA, 1 February 2015; pp. 5–10. [Google Scholar]
- Gandini, A.; Gribaudo, M.; Knottenbelt, W.J.; Osman, R.; Piazzolla, P. Performance evaluation of NoSQL databases. In Proceedings of the European Workshop on Performance Engineering; Springer: Cham, Switzerland, 2014; pp. 16–29. [Google Scholar]
- Hendawi, A.; Gupta, J.; Jiayi, L.; Teredesai, A.; Naveen, R.; Mohak, S.; Ali, M. Distributed NoSQL data stores: Performance analysis and a case study. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 1937–1944. [Google Scholar]
- Li, Y.; Manoharan, S. A performance comparison of SQL and NoSQL databases. In Proceedings of the 2013 IEEE Pacific Rim Conference on Communications, Computers and Signal Processing (PACRIM), Victoria, BC, Canada, 27–29 August 2013; pp. 15–19. [Google Scholar]
- Whitby, M.; Fecher, R.; Bennight, C. GeoWave: Utilizing distributed key-value stores for multidimensional data. In Advances in Spatial and Temporal Databases; Springer International Publishing: Cham, Switzerland, 2017; pp. 105–122. [Google Scholar]
- Liu, H.; van Oosterom, P.; Meijers, M.; Verbree, E. Towards 10 15-level point clouds management-a nD PointCloud structure. In Proceedings of the 21th AGILE Conference on Geographic Information Science; Lund University: Lund, Sweden, 2018; p. 7. [Google Scholar]
- Van Oosterom, P.; Meijers, M.; Verbree, E.; Liu, H.; Tijssen, T. Towards a relational database Space Filling Curve (SFC) interface specification for managing nD-PointClouds. In Münchner GI-Runde 2019; Runder Tisch GIS: München, Germany, 2019. [Google Scholar]
- Osborne, K.; Johnson, R.; Põder, T.; Closson, K. Expert Oracle Exadata; Springer: Cham, Switzerland, 2011. [Google Scholar]
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The hadoop distributed file system. In Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Incline Village, NV, USA, 3–7 May 2010; pp. 1–10. [Google Scholar]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107. [Google Scholar] [CrossRef]
- Baumann, P.; Misev, D.; Merticariu, V.; Huu, B.P.; Bell, B. Rasdaman: Spatio-temporal datacubes on steroids. In Proceedings of the 26th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 6–9 November 2018; pp. 604–607. [Google Scholar]
- Baumann, P.; Dehmel, A.; Furtado, P.; Ritsch, R.; Widmann, N. Spatio-temporal retrieval with RasDaMan. In Proceedings of the VLDB, Scotland, UK, 7–10 September 1999; pp. 746–749. [Google Scholar]
- Papadopoulos, S.; Datta, K.; Madden, S.; Mattson, T. The TileDB array data storage manager. Proc. VLDB Endow. 2016, 10, 349–360. [Google Scholar] [CrossRef]
- Dayan, N.; Idreos, S. The log-structured merge-bush & the wacky continuum. In Proceedings of the 2019 International Conference on Management of Data, Amsterdam, The Netherlands, 30 June–5 July 2019; pp. 449–466. [Google Scholar]
- Aiyer, A.S.; Bautin, M.; Chen, G.J.; Damania, P.; Khemani, P.; Muthukkaruppan, K.; Ranganathan, K.; Spiegelberg, N.; Tang, L.; Vaidya, M. Storage infrastructure behind Facebook messages: Using HBase at scale. IEEE Data Eng. Bull. 2012, 35, 4–13. [Google Scholar]
- Nishimura, S.; Das, S.; Agrawal, D.; El Abbadi, A. Md-hbase: A scalable multi-dimensional data infrastructure for location aware services. In Proceedings of the 2011 IEEE 12th International Conference on Mobile Data Management, Lulea, Sweden, 6–9 June 2011; Volume 1, pp. 7–16. [Google Scholar]
- Vo, A.; Chauhan, N.; Laefer, D.; Bertolotto, M. A 6-Dimensional Hilbert approach to index Full Waveform LiDAR data in a distributed computing environment. In Proceedings of the ISPRS International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Delft, The Netherlands, 1–5 October 2018; Volume XLII-4, pp. 671–678. [Google Scholar]
- Eldawy, A.; Mokbel, M.F. Spatialhadoop: A mapreduce framework for spatial data. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Korea, 13–17 April 2015; pp. 1352–1363. [Google Scholar]
- Alarabi, L.; Mokbel, M.F.; Musleh, M. St-hadoop: A mapreduce framework for spatio-temporal data. GeoInformatica 2018, 22, 785–813. [Google Scholar] [CrossRef]
- Dimiduk, N.; Khurana, A. HBase in Action; Manning Publications: Shelter Island, NY, USA, 2012; p. 334. [Google Scholar]




| References | Max: Points Tested | Database | Data Model |
|---|---|---|---|
| [46] | 20 billion | PostGIS/ PostgreSQL | Object relational |
| [47,48] | 23 billion | PostGIS/ PostgreSQL | Object relational |
| MonetDB | Relational (columnar) | ||
| [19] | 23 billion | PostGIS/ PostgreSQL | Object relational |
| MonetDB | Relational (columnar) | ||
| Oracle | Object relational | ||
| [20] | 5.2 billion | PostGIS/ PostgreSQL | Object relational |
| [31] | 74 million | Oracle IOT | Object relational |
| [24] | 496.7 million | PostGIS/ PostgreSQL | Object relational |
| [49] | 1 billion | SAP HANA | Relational (columnar) |
| Reference | Database/ Storage Medium | Data Model | Storage Engine’s Access Method | Index Implemented | Computing Technique |
|---|---|---|---|---|---|
| [3] | HBase | Wide- column | LSM-tree | Single Hilbert SFC and Dual Hilbert SFC | Hadoop and MapReduce |
| [33] | HBase | Wide- column | LSM-tree | Z-order SFC | Hadoop and Spark |
| [34] | HBase | Wide- column | LSM-tree | timestamp as the row key (i.e., the index) | Hadoop and MapReduce |
| GeoWave ** | Accumulo | Wide- column | LSM-tree | Hilbert SFC, Z-order SFC | Hadoop and MapReduce |
| EarthServer/ RASDAMAN ** | PostGIS/ PostgreSQL | Array | B-tree | R+-tree, Directory index, Regular computed index | MPI |
| TileDB ** | HDFS/ S3 | Array | B-tree | R-tree | MPI |
| Ref: | Database | Storage Model | Index Strategy | Queries of Interest | Dataset (by Project/City/ Country) | Max: Points Tested | Data Loading (bytes/s) | Data Storage (bytes/point) | Query Response Times (s) | Points Returned | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Window | Point | temp: | ||||||||||||
| 2D | 3D | |||||||||||||
| [19] | PostgreSQL/ PostGIS | flat | B-tree (x,y) | ✓ | ✓ | AHN2 | 23 B | 243,022 | 77.1 | 18.02 | 718,131 | |||
| [19] | PostgreSQL/ PostGIS | block | NA | ✓ | ✓ | AHN2 | 23 B | 1,882,931 | 4.6 | 2.19 | 718,131 | |||
| [20] | PostgreSQL/ PostGIS | block | R-tree, B-tree | ✓ | Vosges | 5.2 B | 125,000 | 7.5 | NA | NA | ||||
| [20] | PostgreSQL/ PostGIS | block | R-tree, B-tree | ✓ | Paris | 2.15 B | 74,500 | 26.9 | 0.6 | 1,200,000 | ||||
| [46] | PostgreSQL/ PostGIS | block | 2D tile index with metadata | ✓ | ✓ | Italy, Austria | 20 B | 30,000 | 190 | NA | NA | |||
| [19] | Oracle | flat | B-tree | ✓ | AHN2 | 23 B | 1,459,065 | 43.2 | 18.2 | 718,021 | ||||
| [19] | Oracle | block | Hilbert-R-tree | ✓ | AHN2 | 23 B | 119,881 | 9.5 | 1.3 | 718,131 | ||||
| [31] | Oracle | flat | Hilbert (x,y) | ✓ | AHN2 | 73 M | 278,427 | 25 | 0.33 | 3927 | ||||
| [31] | Oracle | flat | Hilbert (x,y,z) | ✓ | AHN2 | 73 M | 110,570 | 20.2 | 1.12 | 3927 | ||||
| [31] | Oracle | flat | Hilbert (x,y,t) | ✓ | AHN2 | 73 M | 107,444 | 25.7 | 0.06 | 3927 | ||||
| [31] | Oracle | flat | Hilbert (x,y,z,t) | ✓ | AHN2 | 73 M | 92,420 | 20.2 | 0.11 | 3927 | ||||
| [68] | Oracle | flat | Morton (x,y) | NA | AHN2 | 273 M | 380,011 | 51.1 | NA | NA | ||||
| [68] | Oracle | flat | SDO_ Point(x,y,z), scale(LoD) | NA | AHN2 | 273 M | 123,247 | 153 | NA | NA | ||||
| [19] | MonetDB | flat | Imprints | ✓ | ✓ | AHN2 | 23 B | 2,719,439 | 22.9 | 16.74 | 718,021 | |||
| [52] | MonetDB | flat | Imprints | ✓ | AHN2 | 23 B | 5,888,822 | 22.9 | 0.32 | 718,021 | ||||
| [52] | MonetDB | flat | Morton- added | ✓ | AHN2 | 23 B | 415,725 | 30 | 0.2 | 718,021 | ||||
| [52] | MonetDB | flat | Morton- replaceXY | ✓ | AHN2 | 23 B | 592,492 | 15 | 0.3 | 718,021 | ||||
| [19] | OEDBM | flat | no indexes | ✓ | AHN2 | 21 B | 22,706,269 | 4.5 | 0.59 | 369,352 | ||||
| [3] | HBase | flat | Hilbert | ✓ | ✓ | Dublin | 1.4 B | 41,283 | 235.5 | 0.05 | NA | |||
| [3] | HBase | flat | Hilbert | ✓ | ✓ | Dublin | 1.4 B | 181,110 | 48.3 | 0.04 | NA | |||
| [3] | HBase | block | Hilbert | ✓ | ✓ | Dublin | 1.4 B | 1,344,047 | 31.2 | 0.07 | NA | |||
| [3] | HBase | block | Hilbert | ✓ | ✓ | Dublin | 1.4 B | 2,372,243 | 26.9 | 0.08 | NA | |||
| [34] | HBase | flat | NA (time-stamp) | ✓ | Dublin | 812 M | 259,011 | 12.3 | 48 | 13,498,454 | ||||
| Requirement/Characteristics | Data Models | |||
|---|---|---|---|---|
| Relational | NewSQL | Wide- Column | Array | |
| Assemblage of heterogeneous point cloud data/ (Schemaless storage) | ✓ | |||
| ACID requirement | ✓ | ✓ | ✓ | |
| High scalability and performance are inherent characteristics of the data model | ✓ | ✓ | ** | |
| Fixed schema | ✓ | ✓ | ✓ | |
| Relationship among point cloud data /datasets (one-one, one-many, many-many) | ✓ | ✓ | ✓ | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lokugam Hewage, C.N.; Laefer, D.F.; Vo, A.-V.; Le-Khac, N.-A.; Bertolotto, M. Scalability and Performance of LiDAR Point Cloud Data Management Systems: A State-of-the-Art Review. Remote Sens. 2022, 14, 5277. https://doi.org/10.3390/rs14205277
Lokugam Hewage CN, Laefer DF, Vo A-V, Le-Khac N-A, Bertolotto M. Scalability and Performance of LiDAR Point Cloud Data Management Systems: A State-of-the-Art Review. Remote Sensing. 2022; 14(20):5277. https://doi.org/10.3390/rs14205277
Chicago/Turabian StyleLokugam Hewage, Chamin Nalinda, Debra F. Laefer, Anh-Vu Vo, Nhien-An Le-Khac, and Michela Bertolotto. 2022. "Scalability and Performance of LiDAR Point Cloud Data Management Systems: A State-of-the-Art Review" Remote Sensing 14, no. 20: 5277. https://doi.org/10.3390/rs14205277
APA StyleLokugam Hewage, C. N., Laefer, D. F., Vo, A.-V., Le-Khac, N.-A., & Bertolotto, M. (2022). Scalability and Performance of LiDAR Point Cloud Data Management Systems: A State-of-the-Art Review. Remote Sensing, 14(20), 5277. https://doi.org/10.3390/rs14205277