



Collaborative Consistent Knowledge Distillation Framework for Remote Sensing Image Scene Classification Network

Abstract
1. Introduction
- ⏵
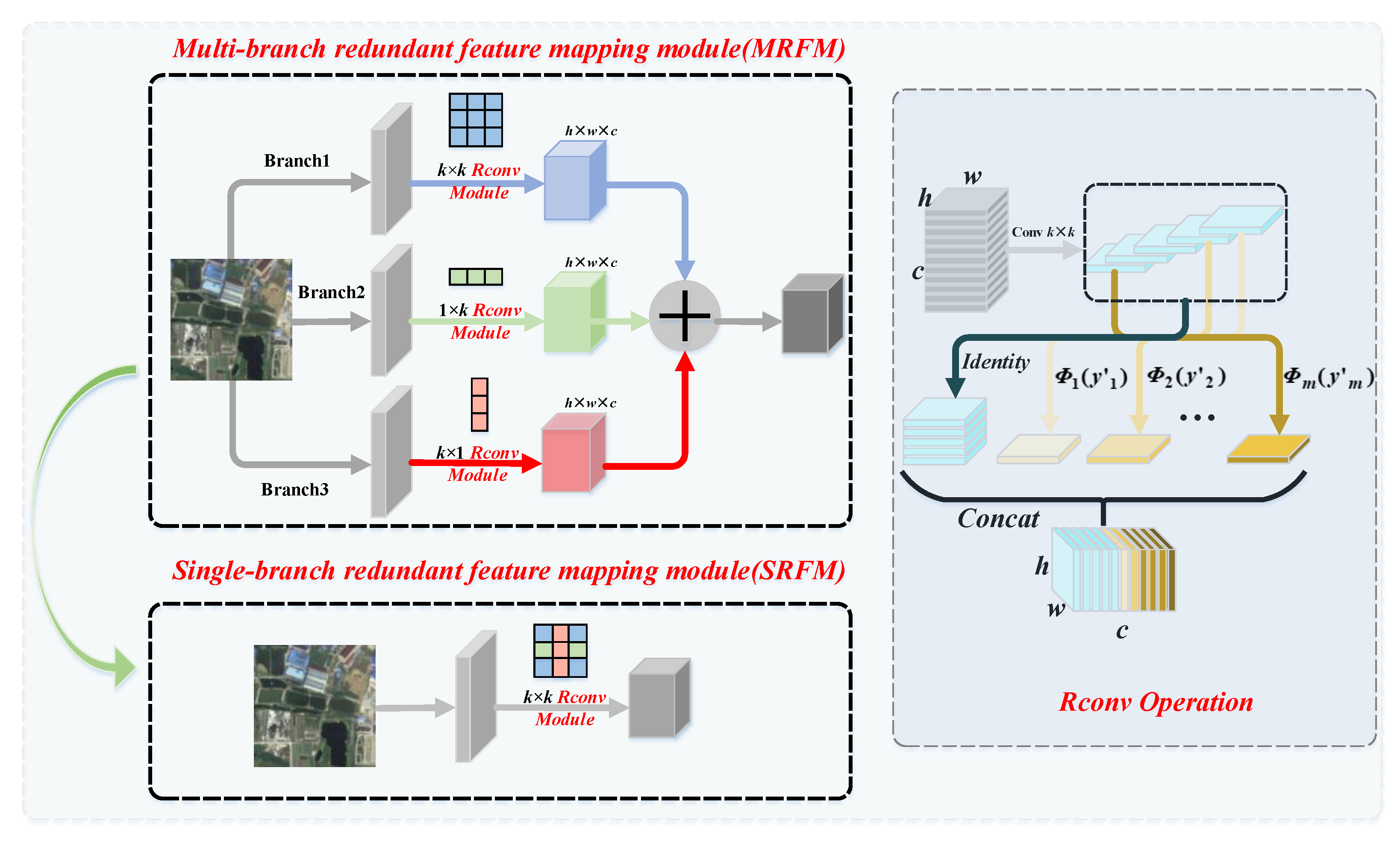
- To reduce the parameter redundancy of remote sensing image classification models and facilitate their deployment on embedded devices with low performance, we propose a plug-and-play multi-branch fused redundant feature mapping module. The equivalent convolutional kernel obtained by this module has a more powerful feature extraction capability and can more effectively optimize the parameter redundancy of the network.
- ⏵
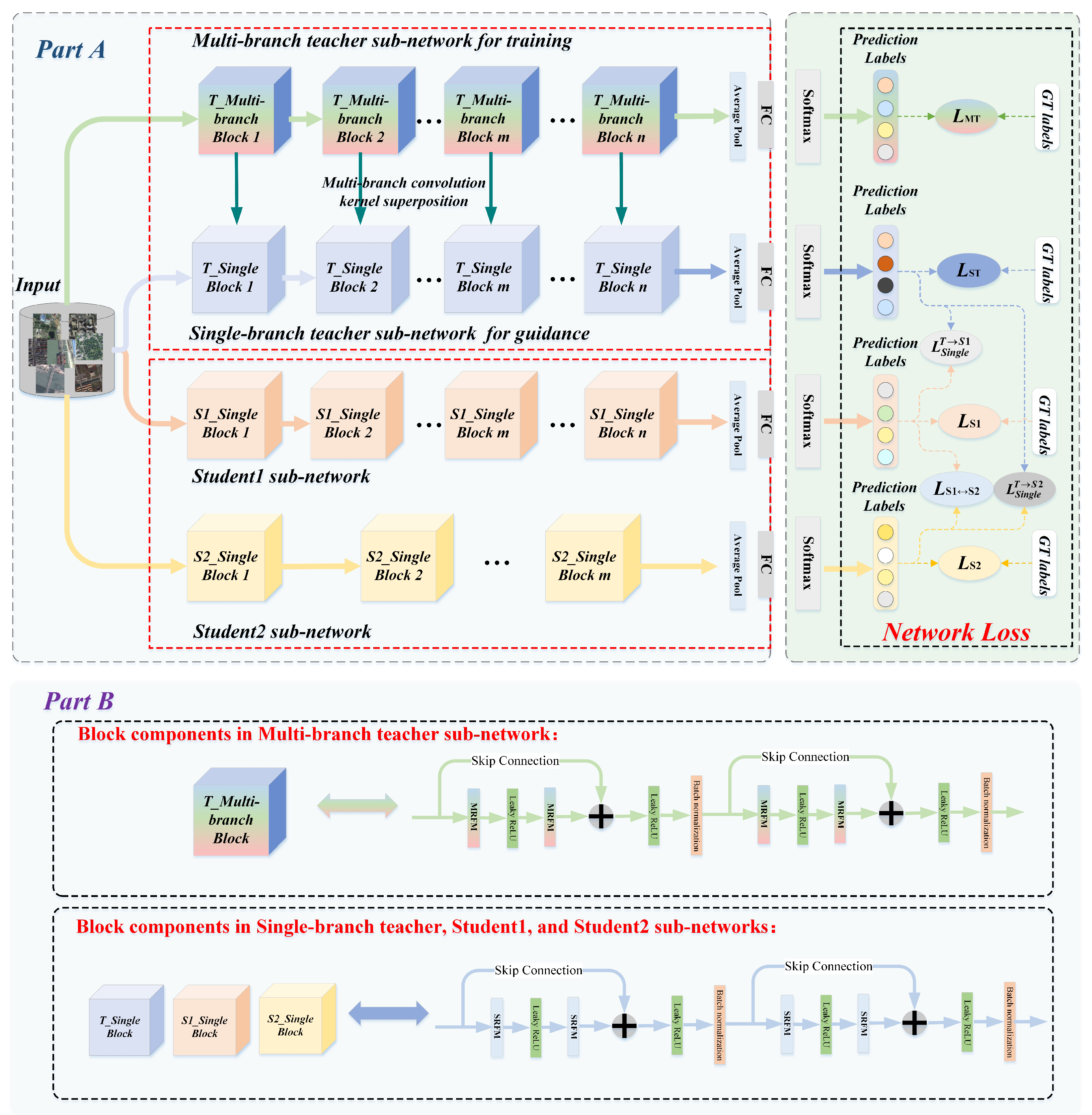
- We propose a collaborative consistent knowledge distillation framework to obtain a more robust backbone network. In contrast to the traditional knowledge distillation framework, we guided a pair of student sub-networks of different depths through a teacher model, where the student sub-networks not only learn prior knowledge deriving from the teacher network, but also acquire prior knowledge possessed by them by the way of mutual supervised learning.
- ⏵
- The experimental results on two benchmark datasets (SIRI-WHU, NWPU-RESISC45) showed that our approach provided a significant improvement over a series of existing depth models and the state-of-the-art knowledge distillation networks on the relevant remote sensing image scene classification task. In addition, the student sub-network obtained based on the CKD framework had a more powerful feature extraction capability, as well as a lower number of parameters, which can be widely used as a feature extraction network in various embedded devices.
2. Related Work
2.1. Remote Sensing Image Scene Recognition
2.2. Knowledge Distillation
3. Methodology
3.1. Redundant Feature Mapping Module
- (1)
- Multi-branch feature extraction and fusion: For multi-branch feature extraction and fusion, different from the previous work, our objective was to obtain equivalent convolutional kernels with stronger feature extraction capability. In other words, the obtained single-branch equivalent convolution kernel has multi-scale feature extraction capability. As shown in Figure 2, MRFM enhances the feature extraction capability of the CNN network with three parallel branches, and each branch employs the , , and convolutional kernel sizes, respectively. When the network training is complete, the convolutional kernels of three sizes are fused into equivalent convolutional kernels of with stronger extraction ability. The process of equivalent fusion mainly consists of two processes, BN fusion and branch fusion.
- (2)
- Redundant mapping convolution operation (Rconv): Due to the significant redundancy in the feature maps extracted by the existing backbone network, to address this problem, the ordinary convolution layer is divided into two parts, as shown in the Rconv module in Figure 2, which fully combines the ordinary convolution operation, as well as the linear transformation operation. Specifically, we first obtained the intrinsic feature maps by ordinary convolutional operations; second, we performed the identical transformation and a series of simple linear transformations on the intrinsic feature maps. The two operate in parallel: On the one hand, the intrinsic feature maps are preserved, and the computational burden of the network is reduced. On the other hand, the redundant information in the feature maps is preserved with the inexpensive linear mapping, which obtains the redundant feature maps.
3.2. Cooperative Consistency Distillation Algorithm
| Algorithm 1 Collaborative consistency distillation algorithm |
| Input: training set , label set Y, learning rate |
| Initialization parameters: for Student Sub-network 1, for Student Sub-network 2 |
| Repeat: |
|
4. Experimentation and Results Discussion
4.1. Datasets
4.2. Implementation Details
4.3. Comparison of Remote Sensing Image Scene Classification Methods on SIRI-WHU and NWPU-RESISC45 Datasets
4.4. Comparison with the State-of-the-Art Knowledge Distillation Methods on the NWPU-RESISC45 and SIRI-WHU Datasets
4.5. Comparison of the Number of Parameters among CKD Student Sub-Networks and Resnet Networks
4.6. Ablation Experimental
4.6.1. The Performance of the Student Sub-Networks with Different Depths in CKD Based on the SIRI-WHU Dataset
- (1)
- For Student Sub-networks 1 and 2, the collaborative consistency distillation algorithm (CKD) significantly improved the classification accuracy of each student sub-network, and the gain values indicate the gains of each student sub-network.
- (2)
- Although Rconv_Res110 is a much larger backbone network than Rconv_Res32, it still benefited from being trained with a smaller student sub-network.
- (3)
- The smaller student sub-networks can usually gain more from the collaborative consistency distillation algorithm.
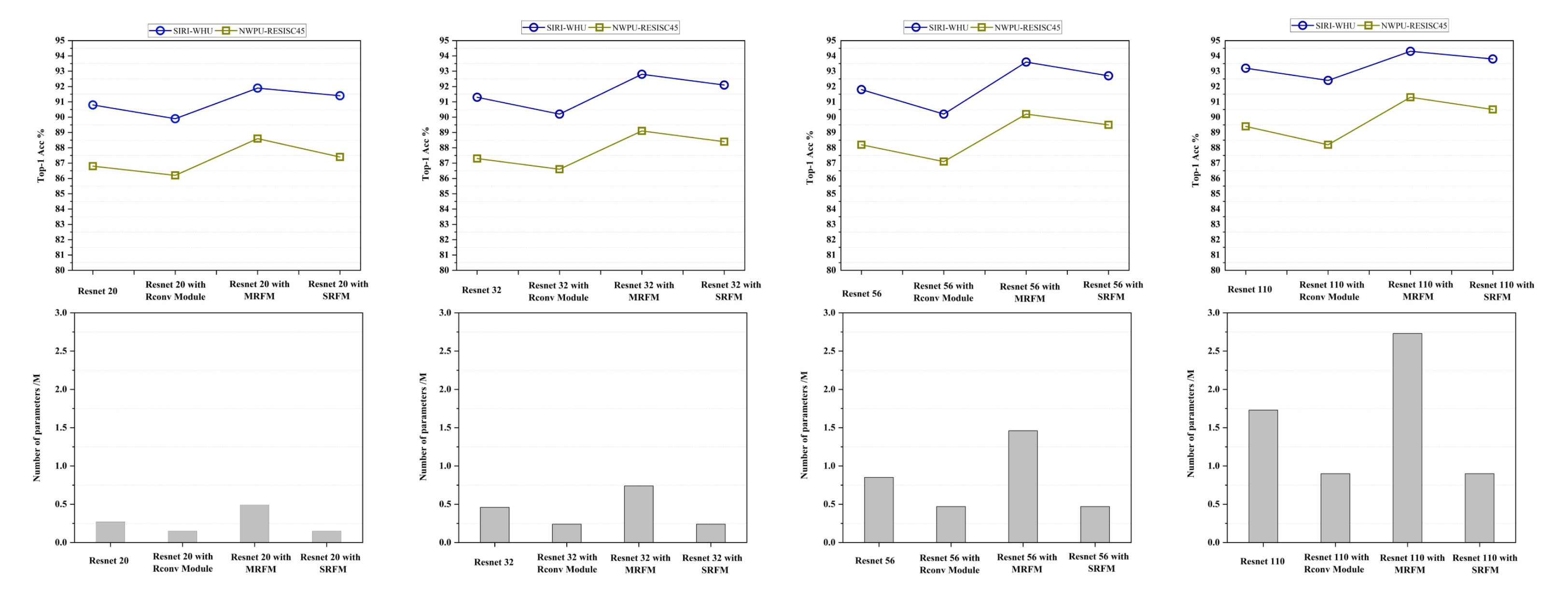
4.6.2. The Effectiveness of Each Component in the Redundant Feature Mapping Operation
- (1)
- Resnet with the Rconv module showed the worst classification performance among the methods for all datasets. This shows that reconstructing the Resent model with only the simple Rconv module, although it can reduce the parameter redundancy of the networks, can also lead to a degradation of the model classification performance.
- (2)
- Resnet with MRFM achieved the best classification performance. However, the number of parameters of the models was relatively more compared to Resnet with SRFM. At the same time, the improvement in classification accuracy of the models was insignificant, and we believe that it is not worthwhile to gain a slight improvement in the classification performance through such a scale of the number of parameters.
- (3)
- With the number of parameters keeping consistent, Resnet with SRFM possessed better classification performance compared to Resnet with the Rconv module. This indicates that the equivalent convolutional kernel obtained by the multi-branch fusion operation exhibited a more powerful feature extraction ability, which effectively improved the classification performance of the model.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alam, E.; Sufian, A.; Das, A.K.; Bhattacharya, A.; Ali, M.F.; Rahman, M.M.H. Leveraging Deep Learning for Computer Vision: A Review. In Proceedings of the 22nd International Arab Conference on Information Technology, ACIT 2021, Muscat, Oman, 21–23 December 2021; IEEE: New York, NY, USA, 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Hassan, H.; Ren, Z.; Zhao, H.; Huang, S.; Li, D.; Xiang, S.; Kang, Y.; Chen, S.; Huang, B. Review and classification of AI-enabled COVID-19 CT imaging models based on computer vision tasks. Comput. Biol. Med. 2022, 141, 105123. [Google Scholar] [CrossRef] [PubMed]
- Wong, P.K.; Luo, H.; Wang, M.; Leung, P.H.; Cheng, J.C.P. Recognition of pedestrian trajectories and attributes with computer vision and deep learning techniques. Adv. Eng. Inform. 2021, 49, 101356. [Google Scholar] [CrossRef]
- Shen, W.; Chen, L.; Liu, S.; Zhang, Y. An image enhancement algorithm of video surveillance scene based on deep learning. IET Image Process. 2022, 16, 681–690. [Google Scholar] [CrossRef]
- Cohen, K.; Fort, K.; Mieskes, M.; Névéol, A.; Rogers, A. Reviewing Natural Language Processing Research. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Tutorial Abstracts, EACL 2021, Online, 19–20 April 2021; Augenstein, I., Habernal, I., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 14–16. [Google Scholar] [CrossRef]
- Jiang, H. Reducing Human Labor Cost in Deep Learning for Natural Language Processing. Ph.D. Thesis, Georgia Institute of Technology, Atlanta, GA, USA, 2021. [Google Scholar]
- Lauriola, I.; Lavelli, A.; Aiolli, F. An introduction to Deep Learning in Natural Language Processing: Models, techniques, and tools. Neurocomputing 2022, 470, 443–456. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Agarwal, R.; Schwarzer, M.; Castro, P.S.; Courville, A.C.; Bellemare, M.G. Deep Reinforcement Learning at the Edge of the Statistical Precipice. In Proceedings of the Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, Virtual, 6–14 December 2021; pp. 29304–29320. [Google Scholar]
- Curi, S.; Bogunovic, I.; Krause, A. Combining Pessimism with Optimism for Robust and Efficient Model-Based Deep Reinforcement Learning. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, Virtual Event, 18–24 July 2021; Volume 139, pp. 2254–2264. [Google Scholar]
- El Kaid, A.; Brazey, D.; Barra, V.; Baïna, K. Top-Down System for Multi-Person 3D Absolute Pose Estimation from Monocular Videos. Sensors 2022, 22, 4109. [Google Scholar] [CrossRef] [PubMed]
- Qiu, J.; Yin, J.; Qian, W.; Liu, J.; Huang, Z.; Yu, H.; Ji, L.; Zeng, X. A Novel Multiresolution-Statistical Texture Analysis Architecture: Radiomics-Aided Diagnosis of PDAC Based on Plain CT Images. IEEE Trans. Med. Imaging 2021, 40, 12–25. [Google Scholar] [CrossRef] [PubMed]
- Huang, F.; Cao, Z.; Jiang, S.H.; Zhou, C.; Huang, J.; Guo, Z. Landslide susceptibility prediction based on a semi-supervised multiple-layer perceptron model. Landslides 2020, 17, 2919–2930. [Google Scholar] [CrossRef]
- Wang, L.; Yoon, K. Knowledge Distillation and Student-Teacher Learning for Visual Intelligence: A Review and New Outlooks. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3048–3068. [Google Scholar] [CrossRef] [PubMed]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge Distillation: A Survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Bucilua, C.; Caruana, R.; Niculescu-Mizil, A. Model compression. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006. [Google Scholar]
- Ba, J.; Caruana, R. Do Deep Nets Really Need to be Deep? In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 2654–2662. [Google Scholar]
- Urban, G.; Geras, K.J.; Kahou, S.E.; Aslan, Ö.; Wang, S.; Mohamed, A.; Philipose, M.; Richardson, M.; Caruana, R. Do Deep Convolutional Nets Really Need to be Deep and Convolutional? In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017.
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Yang, Y.; Newsam, S.D. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th ACM SIGSPATIAL International Symposium on Advances in Geographic Information Systems, ACM-GIS 2010 San Jose, CA, USA 3–5 November 2010; Agrawal, D., Zhang, P., Abbadi, A.E., Mokbel, M.F., Eds.; ACM: New York, NY, USA, 2010; pp. 270–279. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhong, Y.; Wu, S.; Zhang, L.; Li, D. Scene Classification Based on the Sparse Homogeneous-Heterogeneous Topic Feature Model. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2689–2703. [Google Scholar] [CrossRef]
- Liu, L.; Wang, P.; Shen, C.; Wang, L.; van den Hengel, A.; Wang, C.; Shen, H.T. Compositional Model Based Fisher Vector Coding for Image Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2335–2348. [Google Scholar] [CrossRef] [PubMed]
- Yao, Y.; Liang, H.; Li, X.; Zhang, J.; He, J. Sensing Urban Land-Use Patterns by Integrating Google Tensorflow and Scene-Classification Models. arXiv 2017, arXiv:1708.01580. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When Deep Learning Meets Metric Learning: Remote Sensing Image Scene Classification via Learning Discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Gong, X.; Xie, Z.; Liu, Y.; Shi, X.; Zheng, Z. Deep Salient Feature Based Anti-Noise Transfer Network for Scene Classification of Remote Sensing Imagery. Remote Sens. 2018, 10, 410. [Google Scholar] [CrossRef]
- Alkhulaifi, A.; Alsahli, F.; Ahmad, I. Knowledge distillation in deep learning and its applications. PeerJ Comput. Sci. 2021, 7, e474. [Google Scholar] [CrossRef] [PubMed]
- Blakeney, C.; Li, X.; Yan, Y.; Zong, Z. Parallel blockwise knowledge distillation for deep neural network compression. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 1765–1776. [Google Scholar] [CrossRef]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. FitNets: Hints for Thin Deep Nets. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Park, W.; Kim, D.; Lu, Y.; Cho, M. Relational Knowledge Distillation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019 Long Beach, CA, USA 16–20 June 2019; Computer Vision Foundation/IEEE: New York, NY, USA, 2019; pp. 3967–3976. [Google Scholar] [CrossRef]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive Representation Distillation. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Li, X.; Wu, J.; Fang, H.; Liao, Y.; Wang, F.; Qian, C. Local Correlation Consistency for Knowledge Distillation. In Proceedings of the Computer Vision—ECCV 2020—16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XII; Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12357, pp. 18–33. [Google Scholar] [CrossRef]
- Xu, K.; Rui, L.; Li, Y.; Gu, L. Feature Normalized Knowledge Distillation for Image Classification. In Proceedings of the Computer Vision—ECCV 2020—16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXV; Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12370, pp. 664–680. [Google Scholar] [CrossRef]
- Du, S.; You, S.; Li, X.; Wu, J.; Wang, F.; Qian, C.; Zhang, C. Agree to Disagree: Adaptive Ensemble Knowledge Distillation in Gradient Space. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020. [Google Scholar]
- Lan, X.; Zhu, X.; Gong, S. Knowledge Distillation by On-the-Fly Native Ensemble. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montreal, QC, Canada, 3–8 December 2018; pp. 7528–7538. [Google Scholar]
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep Mutual Learning. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; Computer Vision Foundation/IEEE Computer Society: Washington, DC, USA, 2018; pp. 4320–4328. [Google Scholar] [CrossRef]
- Yao, A.; Sun, D. Knowledge Transfer via Dense Cross-Layer Mutual-Distillation. In Proceedings of the Computer Vision—ECCV 2020—16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XV; Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12360, pp. 294–311. [Google Scholar] [CrossRef]
- Wu, G.; Gong, S. Peer Collaborative Learning for Online Knowledge Distillation. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, AAAI 2021, 33rd Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, 2–9 February 2021; AAAI Press: Menlo Park, CA, USA, 2021; pp. 10302–10310. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 764–773. [Google Scholar] [CrossRef]
- Ding, X.; Guo, Y.; Ding, G.; Han, J. ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea, 27 October–2 November 2019; IEEE: New York, NY, USA, 2019; pp. 1911–1920. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; Computer Vision Foundation/IEEE Computer Society: Washington, DC, USA, 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features From Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; Computer Vision Foundation/IEEE: New York, NY, USA, 2020; pp. 1577–1586. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Zhao, B.; Zhong, Y.; Xia, G.; Zhang, L. Dirichlet-Derived Multiple Topic Scene Classification Model for High Spatial Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2016, 54, 2108–2123. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable Person Re-identification: A Benchmark. In Proceedings of the 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 1116–1124. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Dataset | Methods | Image Size | Acc | Precision | Recall | F1 |
|---|---|---|---|---|---|---|
| NWPU-RESISC45 | AlexNet | 200 × 200 | 0.872 | 0.876 | 0.869 | 0.869 |
| GoogLeNet | 200 × 200 | 0.886 | 0.897 | 0.893 | 0.892 | |
| ResNet 50 | 200 × 200 | 0.874 | 0.879 | 0.875 | 0.875 | |
| Inception V1 | 200 × 200 | 0.813 | 0.824 | 0.817 | 0.815 | |
| Inception V2 | 200 × 200 | 0.887 | 0.894 | 0.891 | 0.891 | |
| MobileNet | 200 × 200 | 0.882 | 0.887 | 0.884 | 0.885 | |
| VGG16 | 200 × 200 | 0.879 | 0.884 | 0.882 | 0.881 | |
| Xception | 200 × 200 | 0.872 | 0.879 | 0.874 | 0.875 | |
| Ours | 200 × 200 | 0.916 | 0.923 | 0.917 | 0.917 | |
| SIRI-WHU | AlexNet | 200 × 200 | 0.887 | 0.892 | 0.889 | 0.882 |
| GoogLeNet | 200 × 200 | 0.916 | 0.921 | 0.917 | 0.915 | |
| ResNet 50 | 200 × 200 | 0.912 | 0.918 | 0.913 | 0.914 | |
| Inception V1 | 200 × 200 | 0.873 | 0.882 | 0.875 | 0.876 | |
| Inception V2 | 200 × 200 | 0.928 | 0.932 | 0.924 | 0.926 | |
| MobileNet | 200 × 200 | 0.908 | 0.917 | 0.912 | 0.914 | |
| VGG16 | 200 × 200 | 0.903 | 0.915 | 0.908 | 0.912 | |
| Xception | 200 × 200 | 0.914 | 0.923 | 0.916 | 0.917 | |
| Ours | 200 × 200 | 0.943 | 0.948 | 0.945 | 0.942 |
| Methods | Types | SIRI-WHU | NWPU-RESISC45 |
|---|---|---|---|
| DML [35] | online | 91.3% | 86.9% |
| KD [19] | offline | 91.7% | 87.3% |
| RKD [29] | offline | 91.2% | 86.4% |
| CRD [30] | offline | 91.4% | 87.6% |
| FN [32] | offline | 90.8% | - |
| LKD [31] | offline | - | 88.4% |
| AE-KD [33] | offline | - | 87.1% |
| Ours | offline | 92.0% | 90.5% |
| Methods | Types | SIRI-WHU | NWPU-RESISC45 |
|---|---|---|---|
| DML [35] | online | 92.6% | 85.7% |
| KD [19] | offline | 91.4% | 84.2% |
| RKD [29] | offline | 92.1% | 85.3% |
| CRD [30] | offline | 91.8% | 86.3% |
| DCM [36] | online | - | 87.9% |
| ONE [34] | online | 92.3% | 88.5% |
| PCL [37] | online | 92.5% | 90.3% |
| Ours | offline | 94.3% | 91.6% |
| Network Types | Params | Gain (↑) | ||
|---|---|---|---|---|
| Resnet 20 | Rconv_Res20 | 0.27 M | 0.15 M | 0.12 M |
| Resnet 32 | Rconv_Res32 | 0.46 M | 0.24 M | 0.22 M |
| Resnet 56 | Rconv_Res56 | 0.85 M | 0.47 M | 0.38 M |
| Resnet 110 | Rconv_Res110 | 1.73 M | 0.90 M | 0.83 M |
| Network Types | Independent Acc % | CKD-RPO Acc % | Gain (↑) | ||||
|---|---|---|---|---|---|---|---|
| Sub_Stu1 | Sub_Stu2 | Sub_Stu1 | Sub_Stu2 | Sub_Stu1 | Sub_Stu2 | Sub_Stu1 | Sub_Stu2 |
| Resnet 32 | Resnet 20 | 91.3 | 90.8 | 91.6 | 91.4 | 0.3 | 0.6 |
| Resnet 32 | Resnet 32 | 91.3 | 91.3 | 92.0 | 92.0 | 0.7 | 0.7 |
| Resnet 56 | Resnet 32 | 91.8 | 91.3 | 92.7 | 91.8 | 0.9 | 0.5 |
| Resnet 110 | Resnet 32 | 93.2 | 91.3 | 93.6 | 91.9 | 0.4 | 0.6 |
| Rconv_Res32 | Rconv_Res20 | 92.1 | 91.4 | 92.3 | 92.0 | 0.2 | 0.6 |
| Rconv_Res32 | Rconv_Res32 | 92.1 | 92.1 | 92.9 | 92.9 | 0.8 | 0.8 |
| Rconv_Res56 | Rconv_Res32 | 92.7 | 92.1 | 93.4 | 92.6 | 0.7 | 0.5 |
| Rconv_Res110 | Rconv_Res32 | 93.8 | 92.1 | 94.3 | 92.8 | 0.5 | 0.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xing, S.; Xing, J.; Ju, J.; Hou, Q.; Ding, X. Collaborative Consistent Knowledge Distillation Framework for Remote Sensing Image Scene Classification Network. Remote Sens. 2022, 14, 5186. https://doi.org/10.3390/rs14205186
Xing S, Xing J, Ju J, Hou Q, Ding X. Collaborative Consistent Knowledge Distillation Framework for Remote Sensing Image Scene Classification Network. Remote Sensing. 2022; 14(20):5186. https://doi.org/10.3390/rs14205186
Chicago/Turabian StyleXing, Shiyi, Jinsheng Xing, Jianguo Ju, Qingshan Hou, and Xiurui Ding. 2022. "Collaborative Consistent Knowledge Distillation Framework for Remote Sensing Image Scene Classification Network" Remote Sensing 14, no. 20: 5186. https://doi.org/10.3390/rs14205186
APA StyleXing, S., Xing, J., Ju, J., Hou, Q., & Ding, X. (2022). Collaborative Consistent Knowledge Distillation Framework for Remote Sensing Image Scene Classification Network. Remote Sensing, 14(20), 5186. https://doi.org/10.3390/rs14205186