



Continual Contrastive Learning for Cross-Dataset Scene Classification

Abstract
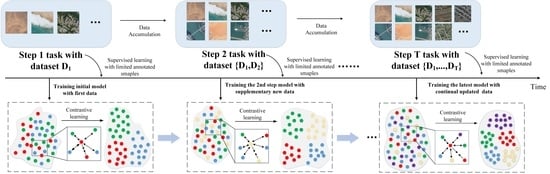
1. Introduction
- (1)
- contrastive learning for continual learning enables the model to learn invariant and robustness features of complex scene images under limited annotated samples.
- (2)
- the designed spatial and class distillation to effectively distill the latent shape and other knowledge of previous model into the current model thus facilitating continual learning.
2. Related Work
2.1. Deep-Learning-Based Scene Classification
2.2. Contrastive Learning for Scene Classification
2.3. Knowledge Distillation for Continual Contrastive Learning
3. Methods
3.1. Spatial Feature and Class Matching Distillation for Knowledge Preservation
3.2. Supervise and Contrastive Learning for Knowledge Learning
| Algorithm 1 The proposed continual contrastive learning for scene classification |
|
4. Datasets Description and Experiments Set up
4.1. Datasets Description
- AID data set: the AID dataset collected from google earth was proposed by Xia et al. [47] in 2016 for aerial scene classification. The large-scale dataset contains 10,000 images in 30 categories. The number of images in each category is 220~420 with size of 600 × 600 pixels. The acquired image is in RGB color space with a spatial resolution of 8~0.5 m. The sample images of AID dataset are shown in Figure 2.
- NWPU-45 dataset: the NWPU-45 dataset was proposed by Cheng et al. [48] in 2017 for remote sensing scene classification. This large-scale dataset contains 31,500 images and covers 45 scene categories, with 700 images in each category. The images in this dataset showed significant differences in spatial resolution, viewpoint, background, and occlusion, etc. The within-class diversity and between-class similarity problem means the classification task on this dataset becomes more challenging. The sample images of NWPU dataset are shown in Figure 3.
- RSI-CB256 dataset: the dataset was proposed as a scene classification benchmark by Li et al. in 2017. It contains six main categories with 35 subclasses among 24,000 images. The spatial resolution reaches 3~0.3 m with image pixel size 256 × 256. The six main categories in this dataset are agricultural land, construction land and facilities, woodland, water and water conservancy facilities, transportation and facilities, construction land and facilities, etc. Several samples are shown in Figure 4.
4.2. Experiments Setup
4.3. Evaluation Metrics
5. Results of Experiments
5.1. Ablation Study
5.1.1. Effect of Different Loss
5.1.2. Weights Effect
5.1.3. Average Accuracy and Average Forgetting
5.2. Comparison with Other Methods
5.3. Class Incremental Learning
5.4. Confusion Matrix
5.5. Visualization Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Huang, X.; Han, X.; Ma, S.; Lin, T.; Gong, J. Monitoring ecosystem service change in the City of Shenzhen by the use of high-resolution remotely sensed imagery and deep learning. L. Degrad. Dev. 2019, 30, 1490–1501. [Google Scholar] [CrossRef]
- Ghazouani, F.; Farah, I.R.; Solaiman, B. A Multi-Level Semantic Scene Interpretation Strategy for Change Interpretation in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8775–8795. [Google Scholar] [CrossRef]
- Cheng, G.; Guo, L.; Zhao, T.; Han, J.; Li, H.; Fang, J. Automatic landslide detection from remote-sensing imagery using a scene classification method based on boVW and pLSA. Int. J. Remote Sens. 2013, 34, 45–59. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Huang, X.; Yuille, A.L. Deep networks under scene-level supervision for multi-class geospatial object detection from remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 146, 182–196. [Google Scholar] [CrossRef]
- Chen, C.; Gong, W.; Chen, Y.; Li, W. Object detection in remote sensing images based on a scene-contextual feature pyramid network. Remote Sens. 2019, 11, 339. [Google Scholar] [CrossRef]
- de Lima, R.P.; Marfurt, K. Convolutional neural network for remote-sensing scene classification: Transfer learning analysis. Remote Sens. 2020, 12, 86. [Google Scholar] [CrossRef]
- Li, W.; Wang, Z.; Wang, Y.; Wu, J.; Wang, J.; Jia, Y.; Gui, G. Classification of high-spatial-resolution remote sensing scenes method using transfer learning and deep convolutional neural network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1986–1995. [Google Scholar] [CrossRef]
- Song, S.; Yu, H.; Miao, Z.; Zhang, Q.; Lin, Y.; Wang, S. Domain adaptation for convolutional neural networks-based remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1324–1328. [Google Scholar] [CrossRef]
- De Lange, M.; Aljundi, R.; Masana, M.; Parisot, S.; Jia, X.; Leonardis, A.; Slabaugh, G.; Tuytelaars, T. A continual learning survey: Defying forgetting in classification tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3366–3385. [Google Scholar]
- Rebuffi, S.-A.; Kolesnikov, A.; Sperl, G.; Lampert, C.H. iCaRL: Incremental Classifier and Representation Learning Sylvestre-Alvise. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2001–2010.
- Kamra, N.; Gupta, U.; Liu, Y. Deep Generative Dual Memory Network for Continual Learning. arXiv 2017, arXiv:1710.10368. [Google Scholar]
- Rostami, M.; Kolouri, S.; Pilly, P.; McClelland, J. Generative continual concept learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5545–5552. [Google Scholar]
- Shin, H.; Lee, J.K.; Kim, J.; Kim, J. Continual learning with deep generative replay. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Verma, V.K.; Liang, K.J.; Mehta, N.; Rai, P.; Carin, L. Efficient feature transformations for discriminative and generative continual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 13865–13875. [Google Scholar]
- James, K.; Razvan, P.; Neil, R.; Joel, V.; Guillaume, D.; Rusu, A.A.; Kieran, M.; John, Q.; Tiago, R.; Agnieszka, G.-B.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef]
- Aljundi, R.; Babiloni, F.; Elhoseiny, M. Memory Aware Synapses: Learning what ( not ) to forget. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 139–154. [Google Scholar]
- Parisi, G.I.; Kemker, R.; Part, J.L.; Kanan, C.; Wermter, S. Continual lifelong learning with neural networks: A review. Neural Networks 2019, 113, 54–71. [Google Scholar] [CrossRef]
- Yoon, J.; Yang, E.; Lee, J.; Hwang, S.J. Lifelong Learning with Dynamically Expandable Networks. arXiv 2017, arXiv:1708.01547. [Google Scholar]
- Rusu, A.A.; Rabinowitz, N.C.; Desjardins, G.; Soyer, H.; Kirkpatrick, J.; Kavukcuoglu, K.; Pascanu, R.; Hadsell, R. Progressive Neural Networks. arXiv 2016, arXiv:1606.04671. [Google Scholar]
- Fernando, C.; Banarse, D.; Blundell, C.; Zwols, Y.; Ha, D.; Rusu, A.A.; Pritzel, A.; Wierstra, D. Pathnet: Evolution channels gradient descent in super neural networks. arXiv 2017, arXiv:1701.08734. [Google Scholar]
- Mallya, A.; Lazebnik, S. PackNet: Adding Multiple Tasks to a Single Network by Iterative Pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7765–7773. [Google Scholar]
- Lee, J. Co2L: Contrastive Continual Learning. arXiv 2021, arXiv:2106.14413. [Google Scholar]
- Zhao, Z.; Luo, Z.; Li, J.; Chen, C.; Piao, Y. When self-supervised learning meets scene classification: Remote sensing scene classification based on a multitask learning framework. Remote Sens. 2020, 12, 3276. [Google Scholar] [CrossRef]
- Tao, C.; Qi, J.; Lu, W.; Wang, H.; Li, H. Remote Sensing Image Scene Classification with Self-Supervised Paradigm Under Limited Labeled Samples. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Stojnić, V.; Risojević, V. Self-Supervised Learning of Remote Sensing Scene Representations Using Contrastive Multiview Coding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Nashville, TN, USA, 19–25 June 2021; pp. 1182–1191. [Google Scholar]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Marmanis, D.; Datcu, M.; Esch, T.; Stilla, U. Using ImageNet Pretrained Networks. IEEE Trans. Geosci. Remote Sens. Lett. 2016, 13, 105–109. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.-S.; Wang, Z.; Huang, X.; Zhang, L.; Sun, H. Unsupervised Feature Learning Via Spectral Clustering of Multidimensional Patches for Remotely Sensed Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2015–2030. [Google Scholar] [CrossRef]
- Chaib, S.; Liu, H.; Gu, Y.; Yao, H. Deep Feature Fusion for VHR Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4775–4784. [Google Scholar] [CrossRef]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9726–9735. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Chen, T.; Kornblith, S.; Swersky, K.; Norouzi, M.; Hinton, G. Big Self-Supervised Models are Strong Semi-Supervised Learners. Adv. Neural Inf. Process. Syst. 2020, 33, 22243–22255. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised Learning of Visual Features by Contrasting Cluster Assignments. Adv. Neural Inf. Process. Syst. 2020, 33, 9912–9924. [Google Scholar]
- Grill, J.-B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap Your Own Latent—A New Approach to Self-Supervised Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Chen, X.; Ai, F. Exploring Simple Siamese Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 15750–15758. [Google Scholar]
- Gomez, P.; Meoni, G. MSMatch: Semisupervised Multispectral Scene Classification with Few Labels. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11643–11654. [Google Scholar] [CrossRef]
- Li, X.; Shi, D.; Diao, X.; Xu, H. SCL-MLNet: Boosting Few-Shot Remote Sensing Scene Classification via Self-Supervised Contrastive Learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Huang, H.; Mou, Z.; Li, Y.; Li, Q.; Chen, J.; Li, H. Spatial-Temporal Invariant Contrastive Learning for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Müller, R.; Kornblith, S.; Hinton, G. When does label smoothing help? Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. FitNets: Hints for thin deep nets. Proc. ICLR 2015, 1–13. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–13. [Google Scholar]
- Ji, M.; Heo, B.; Park, S. Show, Attend and Distill: Knowledge Distillation via Attention-based Feature Matching. Proc. AAAI Conf. Artif. Intell. 2021, 35, 7945–7952. [Google Scholar] [CrossRef]
- Li, Z.; Hoiem, D. Learning without Forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2935–2947. [Google Scholar] [CrossRef]
- Castro, F.M.; Mar, M.J.; Schmid, C. End-to-End Incremental Learning Francisco. Proc. Eur. Conf. Comput. Vis. 2018, 16–18. [Google Scholar]
- Wu, Y.; Chen, Y.; Wang, L.; Ye, Y.; Liu, Z.; Guo, Y.; Fu, Y. Large scale incremental learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 374–382. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Zhang, L. AID: A Benchmark Data Set for Performance Evaluation of Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. In Proceedings of the British Machine Vision Conference (BMVC), York, UK, 19–22 September 2016; pp. 87.1–87.12. [Google Scholar] [CrossRef]
- Mai, Z.; Li, R.; Jeong, J.; Quispe, D.; Kim, H.; Sanner, S. Online continual learning in image classification: An empirical survey. Neurocomputing 2022, 469, 28–51. [Google Scholar] [CrossRef]
- Zenke, F.; Poole, B.; Ganguli, S. Continual Learning Through Synaptic Intelligence. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3987–3995. [Google Scholar]
- Masse, N.Y.; Grant, G.D.; Freedman, D.J. Alleviating catastrophic forgetting using context- dependent gating and synaptic stabilization. Proc. Natl. Acad. Sci. USA 2018, 115, E10467–E10475. [Google Scholar] [CrossRef]
- Huszár, F. Note on the quadratic penalties in elastic weight consolidation. Proc. Natl. Acad. Sci. USA 2018, 115, E2496–E2497. [Google Scholar] [CrossRef]
- Laurens, V.D.M.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CE | Spa | Class | Contra | Step1 | Step2 | Step3 | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| AID | AID | RSI | AID | RSI | NWPU | |||||
| 1 | √ | 83.37 | 67.74 | 90.00 | 61.46 | 82.21 | 72.57 | |||
| 2 | √ | √ | 83.37 | 70.79 | 89.01 | 66.53 | 83.78 | 70.22 | ||
| 3 | √ | √ | 83.37 | 70.38 | 87.70 | 66.12 | 86.07 | 71.75 | ||
| 4 | √ | √ | 83.37 | 70.99 | 89.18 | 60.44 | 86.31 | 74.60 | ||
| 5 | √ | √ | √ | 83.37 | 71.81 | 87.30 | 67.34 | 85.90 | 73.65 | |
| 6 | √ | √ | √ | √ | 83.37 | 72.41 | 90.49 | 67.74 | 87.79 | 74.65 |
| Ratio (KL:KR) | Step1 | Step2 | Step3 | |||||
|---|---|---|---|---|---|---|---|---|
| AID | AID | RSI | Average | AID | RSI | NWPU | Average | |
| 0.1:0.9 | 81.14 | 69.57 | 86.72 | 78.15 | 66.28 | 85.08 | 65.26 | 71.21 |
| 0.3:0.7 | 81.14 | 70.58 | 88.20 | 79.39 | 68.35 | 84.59 | 66.29 | 73.08 |
| 0.5:0.5 | 81.14 | 70.18 | 90.16 | 80.17 | 67.74 | 84.90 | 71.62 | 74.75 |
| 0.6:0.4 | 81.14 | 68.15 | 89.59 | 78.87 | 61.05 | 84.42 | 73.20 | 72.89 |
| 0.9:0.1 | 81.14 | 67.74 | 91.63 | 79.69 | 61.05 | 84.34 | 71.55 | 72.21 |
| Method | Step1 | Step2 | Step3 | |||
|---|---|---|---|---|---|---|
| AID | AID | RSC-256 | AID | RSC-256 | NWPU-45 | |
| EWC | 37.12 | 22.11 | 65.66 | 24.75 | 32.46 | 29.40 |
| Online-ewc | 32.25 | 11.56 | 64.02 | 8.32 | 30.82 | 27.75 |
| LWF | 30.22 | 26.77 | 68.93 | 30.02 | 61.64 | 31.56 |
| XDG | 39.35 | 28.19 | 78.36 | 32.45 | 43.44 | 34.86 |
| SI | 31.85 | 11.16 | 65.57 | 11.16 | 21.15 | 30.35 |
| Fine-tuning | 80.43 | 67.51 | 83.64 | 62.55 | 81.26 | 70.24 |
| Ours | 83.37 | 72.41 | 90.49 | 67.74 | 87.79 | 74.65 |
| Step1 | Step2 | Step3 | ||||
|---|---|---|---|---|---|---|
| Category | AID | AID | RSC-256 | AID | RSC-256 | NWPU-45 |
| 0 | 77.78 | 100.0 | 77.78 | 83.33 | 64.71 | 80.0 |
| 1 | 73.33 | 100.0 | 66.67 | 53.33 | 100.0 | 88.57 |
| 2 | 100.0 | 78.57 | 90.91 | 63.64 | 57.14 | 91.43 |
| 3 | 100.0 | 74.07 | 50.0 | 50.0 | 77.78 | 80.0 |
| 4 | 94.44 | 81.4 | 88.89 | 61.11 | 83.72 | 57.14 |
| 5 | 69.23 | 69.57 | 69.23 | 53.85 | 86.96 | 71.43 |
| 6 | 75.0 | 90.0 | 41.67 | 75.0 | 88.0 | 82.86 |
| 7 | 94.12 | 68.18 | 76.47 | 100.0 | 63.64 | 48.57 |
| 8 | 85.0 | 100.0 | 70.0 | 75.0 | 100.0 | 91.43 |
| 9 | 60.0 | 100.0 | 73.33 | 33.33 | 92.59 | 88.57 |
| 10 | 100.0 | 43.75 | 61.11 | 66.67 | 43.75 | 51.43 |
| 11 | 100.0 | 88.89 | 91.67 | 91.67 | 68.52 | 74.29 |
| 12 | 73.68 | 95.38 | 73.68 | 63.16 | 98.46 | 68.57 |
| 13 | 78.57 | 98.15 | 85.71 | 50.0 | 98.15 | 77.14 |
| 14 | 92.86 | 90.62 | 71.43 | 85.71 | 62.5 | 57.14 |
| OA | 84.78 | 76.47 | 91.80 | 70.38 | 86.72 | 71.93 |
| K | 0.84 | 0.76 | 0.92 | 0.70 | 0.86 | 0.71 |
| Dataset | Step1 | Step2 | Step3 | Step4 | Step5 | Step6 | Step7 | Step8 | Step9 | Step10 |
|---|---|---|---|---|---|---|---|---|---|---|
| AID | 100 | 99.43 | 95.13 | 92.59 | 87.71 | 87.20 | 89.04 | 89.34 | 86.13 | 86.21 |
| RSI | 99.47 | 97.23 | 96.08 | 93.97 | 93.27 | 87.06 | 87.14 | 87.65 | 86.65 | 89.63 |
| NWPU | 94.28 | 93.81 | 92.26 | 88.57 | 86.97 | 82.17 | 80.08 | 81.31 | 80.62 | 78.66 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, R.; Zhao, W.; Li, K.; Ji, F.; Rong, C. Continual Contrastive Learning for Cross-Dataset Scene Classification. Remote Sens. 2022, 14, 5105. https://doi.org/10.3390/rs14205105
Peng R, Zhao W, Li K, Ji F, Rong C. Continual Contrastive Learning for Cross-Dataset Scene Classification. Remote Sensing. 2022; 14(20):5105. https://doi.org/10.3390/rs14205105
Chicago/Turabian StylePeng, Rui, Wenzhi Zhao, Kaiyuan Li, Fengcheng Ji, and Caixia Rong. 2022. "Continual Contrastive Learning for Cross-Dataset Scene Classification" Remote Sensing 14, no. 20: 5105. https://doi.org/10.3390/rs14205105
APA StylePeng, R., Zhao, W., Li, K., Ji, F., & Rong, C. (2022). Continual Contrastive Learning for Cross-Dataset Scene Classification. Remote Sensing, 14(20), 5105. https://doi.org/10.3390/rs14205105