A Multitemporal Mountain Rice Identification and Extraction Method Based on the Optimal Feature Combination and Machine Learning

Abstract
1. Introduction
2. Materials and Methods
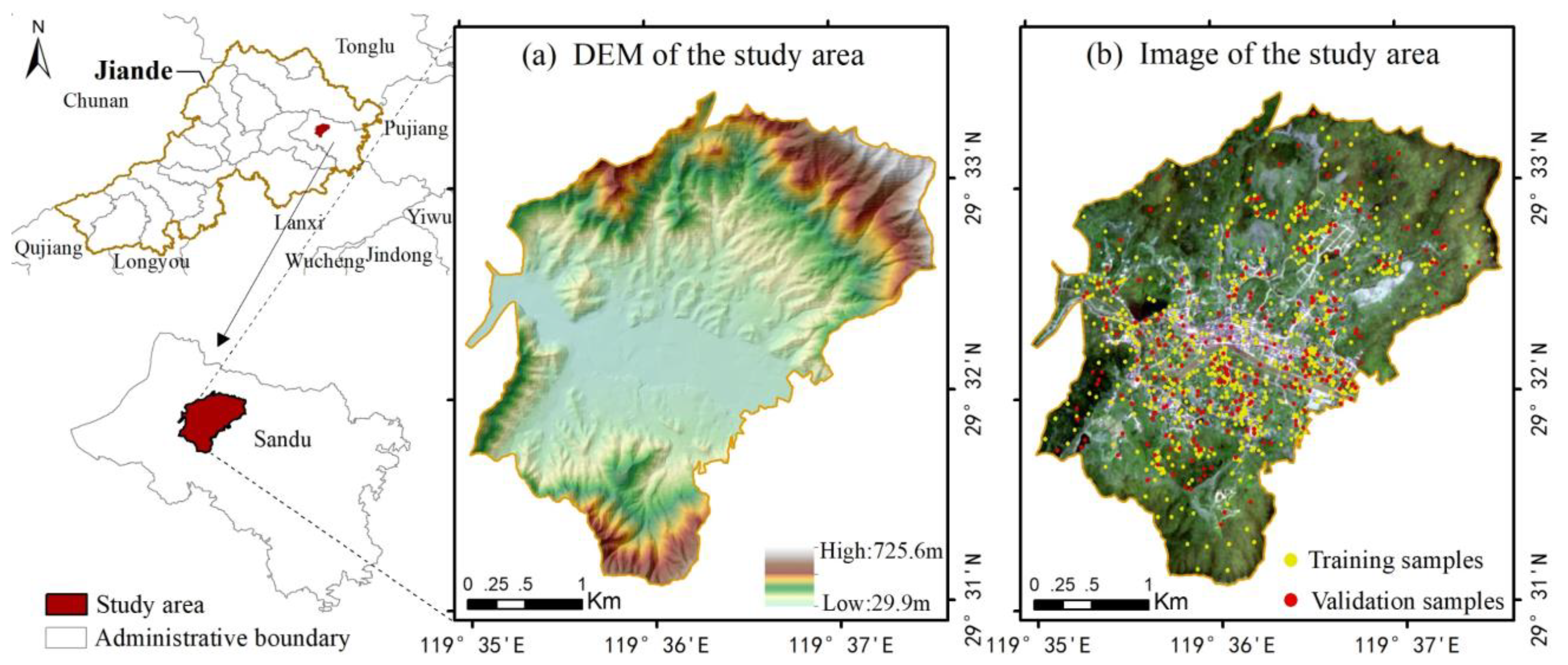
2.1. Study Area
2.2. Data
2.2.1. Image Data
2.2.2. Ground Survey Data and Sample Datasets
2.2.3. Digital Terrain Data
2.3. Methods
2.3.1. Feature Extraction
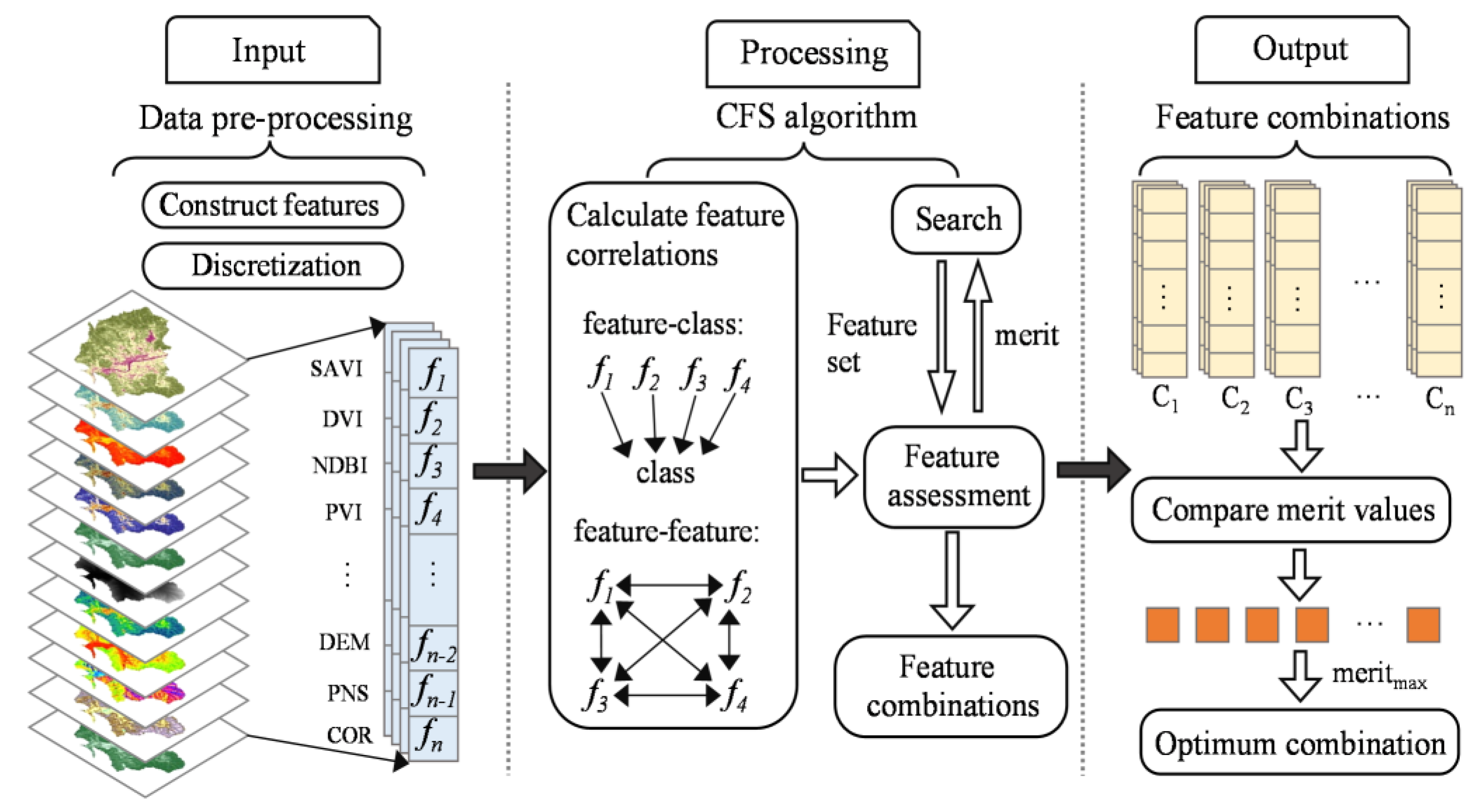
2.3.2. Feature Selection
- (A)
- Determine the optimal extraction period for each feature
- (B)
- Feature-selection algorithm
2.3.3. Machine Learning Classification Algorithms
- (A)
- Random Forest
- (B)
- CatBoost
- (C)
- ExtraTrees
2.3.4. Accuracy Assessment
3. Results
3.1. Analysis of the Spectral Time-Series Curves of Different Land Types
3.2. Optimal Extraction Periods of Features
3.3. Results of Feature Selection
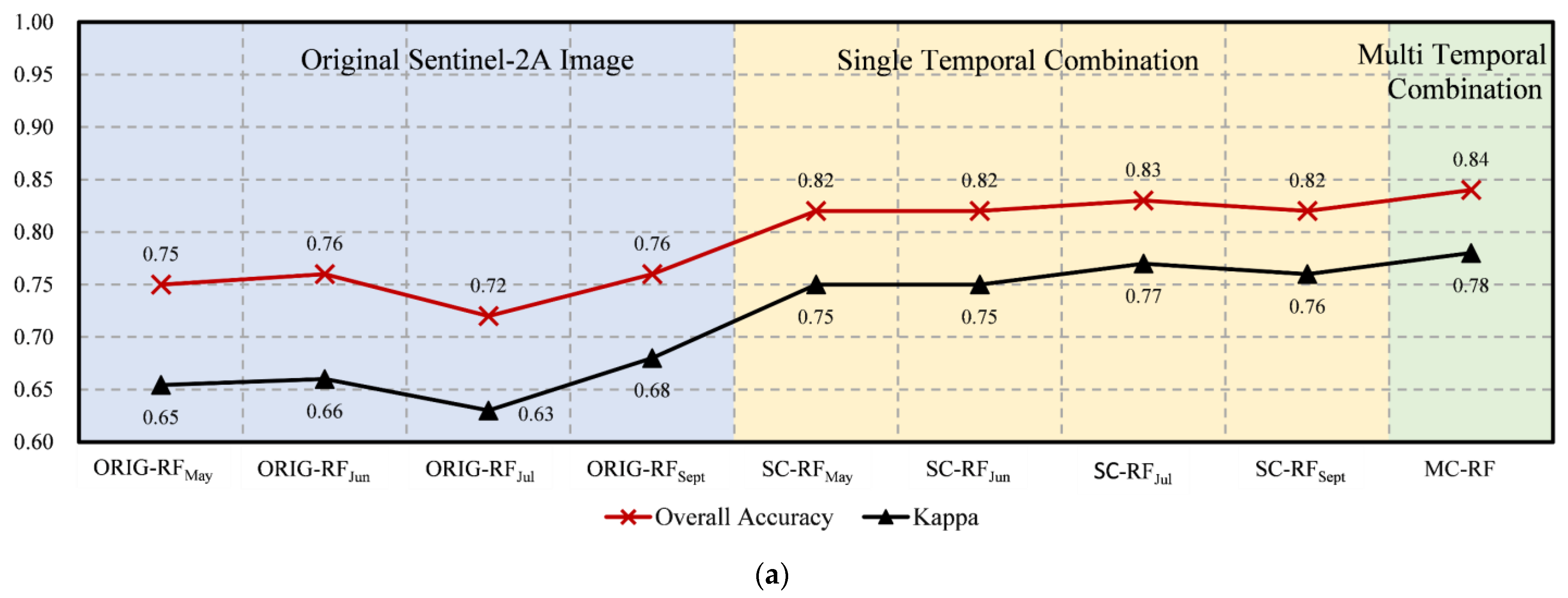
3.4. Accuracy Assessment and Classification Results
4. Discussion
4.1. Feature Analysis
4.2. Analysis of Feature Selection Using OPFSM
4.3. Performance of Machine Learning Classifiers when Extracting Mountain Rice
4.4. Variability of the Rice Growth Cycle
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhai, Y.; Wang, N.; Zhang, L.; Hao, L.; Hao, C. Automatic Crop Classification in Northeastern China by Improved Nonlinear Dimensionality Reduction for Satellite Image Time Series. Remote Sens. 2020, 12, 2726. [Google Scholar] [CrossRef]
- Boschetti, M.; Busetto, L.; Manfron, G.; Laborte, A.; Asilo, S.; Pazhanivelan, S.; Nelson, A. PhenoRice: A method for automatic extraction of spatio-temporal information on rice crops using satellite data time series. Remote Sens. Environ. 2017, 194, 347–365. [Google Scholar] [CrossRef]
- Conrad, C.; Colditz, R.R.; Dech, S.; Klein, D.; Vlek, P.L.G. Temporal segmentation of MODIS time series for improving crop classification in Central Asian irrigation systems. Int. J. Remote Sens. 2011, 32, 8763–8778. [Google Scholar] [CrossRef]
- Liu, M.; Liu, X.; Liu, M.; Liu, F.; Jin, M.; Wu, L. Root mass ratio: Index derived by assimilation of synthetic aperture radar and the improved World Food Study model for heavy metal stress monitoring in rice. J. Appl. Remote Sens. 2016, 10, 026038. [Google Scholar] [CrossRef]
- Liu, Y.; Zhao, W.; Chen, S.; Ye, T. Mapping Crop Rotation by Using Deeply Synergistic Optical and SAR Time Series. Remote Sens. 2021, 13, 4160. [Google Scholar] [CrossRef]
- Mrinal, S.; Wu, B.; Zhang, M. An Object-Based Paddy Rice Classification Using Multi-Spectral Data and Crop Phenology in Assam, Northeast India. Remote Sens. 2016, 8, 479. [Google Scholar] [CrossRef]
- Pittman, K.; Hansen, M.C.; Becker-Reshef, I.; Potapov, P.V.; Justice, C.O. Estimating Global Cropland Extent with Multi-year MODIS Data. Remote Sens. 2010, 2, 1844–1863. [Google Scholar] [CrossRef]
- Evans, T.L.; Costa, M. Landcover classification of the Lower Nhecolândia subregion of the Brazilian Pantanal Wetlands using ALOS/PALSAR, RADARSAT-2 and ENVISAT/ASAR imagery. Remote Sens. Environ. 2013, 128, 118–137. [Google Scholar] [CrossRef]
- Martone, M.; Rizzoli, P.; Wecklich, C.; González, C.; Bueso-Bello, J.-L.; Valdo, P.; Schulze, D.; Zink, M.; Krieger, G.; Moreira, A. The global forest/non-forest map from TanDEM-X interferometric SAR data. Remote Sens. Environ. 2018, 205, 352–373. [Google Scholar] [CrossRef]
- Baghdadi, N.; Boyer, N.; Todoroff, P.; Hajj, M.E.; Bégué, A. Potential of SAR sensors TerraSAR-X, ASAR/ENVISAT and PALSAR/ALOS for monitoring sugarcane crops on Reunion Island. Remote Sens. Environ. 2011, 113, 1724–1738. [Google Scholar] [CrossRef]
- Emile, N.; Dinh, H.; Nicolas, B.; Dominique, C.; Laure, H. Deep Recurrent Neural Network for Agricultural Classification using multitemporal SAR Sentinel-1 for Camargue, France. Remote Sens. 2018, 10, 1217. [Google Scholar] [CrossRef]
- Choi, H.; Jeong, J. Speckle Noise Reduction Technique for SAR Images Using Statistical Characteristics of Speckle Noise and Discrete Wavelet Transform. Remote Sens. 2019, 11, 1184. [Google Scholar] [CrossRef]
- Shahtahmassebi, A.; Yang, N.; Wang, K.; Moore, N.; Shen, Z. Review of shadow detection and de-shadowing methods in remote sensing. Chin. Geogr. Sci. 2013, 23, 403–420. [Google Scholar] [CrossRef]
- Huang, H.; Zhang, Z.; Ni, W.; Chai, L.; Qin, W.; Liu, G.; Xie, D.; Jiang, L.; Liu, Q. Extending RAPID model to simulate forest microwave backscattering. Remote Sens. Environ. 2018, 217, 272–291. [Google Scholar] [CrossRef]
- Peng, G.; Deng, L.; Cui, W.; Shen, M.W. Remote sensing monitoring of tobacco field based on phenological characteristics and time series image—A case study of Chengjiang County, Yunnan Province, China. Chin. Geogr. Sci. 2009, 19, 186–193. [Google Scholar] [CrossRef]
- Zhou, G.; Liu, X.; Liu, M. Assimilating Remote Sensing Phenological Information into the WOFOST Model for Rice Growth Simulation. Remote Sens. 2019, 11, 268. [Google Scholar] [CrossRef]
- d’Andrimont, R.; Taymans, M.; Lemoine, G.; Ceglar, A.; Yordanov, M.; van der Velde, M. Detecting flowering phenology in oil seed rape parcels with Sentinel-1 and -2 time series. Remote Sens. Environ. 2020, 239, 111660. [Google Scholar] [CrossRef]
- Biradar, C.M.; Xiao, X. Quantifying the area and spatial distribution of double- and triple-cropping croplands in India with multi-temporal MODIS imagery in 2005. Int. J. Remote Sens. 2011, 32, 367–386. [Google Scholar] [CrossRef]
- Sibanda, M.; Murwira, A. The use of multi-temporal MODIS images with ground data to distinguish cotton from maize and sorghum fields in smallholder agricultural landscapes of Southern Africa. Int. J. Remote Sens. 2012, 33, 4841–4855. [Google Scholar] [CrossRef]
- Astola, H.; Häme, T.; Sirro, L.; Molinier, M.; Kilpi, J. Comparison of Sentinel-2 and Landsat 8 imagery for forest variable prediction in boreal region. Remote Sens. Environ. 2019, 223, 257–273. [Google Scholar] [CrossRef]
- Franch, B.; Bautista, A.S.; Fita, D.; Rubio, C.; Tarrazó-Serrano, D.; Sánchez, A.; Skakun, S.; Vermote, E.; Becker-Reshef, I.; Uris, A. Within-Field Rice Yield Estimation Based on Sentinel-2 Satellite Data. Remote Sens. 2021, 13, 4095. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Lin, J.; Jin, X.; Ren, J.; Liu, J.; Liang, X.; Zhou, Y. Rapid Mapping of Large-Scale Greenhouse Based on Integrated Learning Algorithm and Google Earth Engine. Remote Sens. 2021, 13, 1245. [Google Scholar] [CrossRef]
- Cui, B.; Cui, J.; Hao, S.; Guo, N.; Lu, Y. Spectral-spatial hyperspectral image classification based on superpixel and multi-classifier fusion. Int. J. Remote Sens. 2020, 41, 6157–6182. [Google Scholar] [CrossRef]
- Dong, Y.; Liang, T.; Zhang, Y.; Du, B. Spectral-Spatial Weighted Kernel Manifold Embedded Distribution Alignment for Remote Sensing Image Classification. IEEE Trans. Cybern. 2021, 51, 3185–3197. [Google Scholar] [CrossRef] [PubMed]
- Paneque-Gálvez, J.; Mas, J.-F.; Moré, G.; Cristóbal, J.; Orta-Martínez, M.; Luz, A.C.; Guèze, M.; Macía, M.J.; Reyes-García, V. Enhanced land use/cover classification of heterogeneous tropical landscapes using support vector machines and textural homogeneity. Int. J. Appl. Earth Obs. Geoinf. 2013, 23, 372–383. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. An Adaptive Mean-Shift Analysis Approach for Object Extraction and Classification From Urban Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2008, 46, 4173–4185. [Google Scholar] [CrossRef]
- Jimenez-Rodriguez, L.O.; Arzuaga-Cruz, E.; Velez-Reyes, M. Unsupervised Linear Feature-Extraction Methods and Their Effects in the Classification of High-Dimensional Data. IEEE Trans. Geosci. Remote Sens. 2007, 45, 469–483. [Google Scholar] [CrossRef]
- Imani, M.; Ghassemian, H. Feature extraction using median–mean and feature line embedding. Int. J. Remote Sens. 2015, 36, 4297–4314. [Google Scholar] [CrossRef]
- Zhu, J.; Pan, Z.; Wang, H.; Huang, P.; Sun, J.; Qin, F.; Liu, Z. An Improved Multi-temporal and Multi-feature Tea Plantation Identification Method Using Sentinel-2 Imagery. Sensors 2019, 19, 2087. [Google Scholar] [CrossRef]
- Cheng, M.; Penuelas, J.; McCabe, M.F.; Atzberger, C.; Jiao, X.; Wu, W.; Jin, X. Combining multi-indicators with machine-learning algorithms for maize yield early prediction at the county-level in China. Agric. For. Meteorol. 2022, 323, 109057. [Google Scholar] [CrossRef]
- Zhu, Q.; Guo, H.; Zhang, L.; Liang, D.; Liu, X.; Wan, X.; Liu, J. Tropical Forests Classification Based on Weighted Separation Index from Multi-Temporal Sentinel-2 Images in Hainan Island. Sustainability 2021, 13, 13348. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Zhou, H. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Gumma, M.K. Mapping rice areas of South Asia using MODIS multitemporal data. J. Appl. Remote Sens. 2011, 5, 053547. [Google Scholar] [CrossRef]
- Alibakhshi, Z.; Ahmadi, M.; Farajzadeh Asl, M. Modeling Biophysical Variables and Land Surface Temperature Using the GWR Model: Case Study—Tehran and Its Satellite Cities. J. Indian Soc. Remote Sens. 2019, 48, 59–70. [Google Scholar] [CrossRef]
- Kupidura, P. The Comparison of Different Methods of Texture Analysis for Their Efficacy for Land Use Classification in Satellite Imagery. Remote Sens. 2019, 11, 1233. [Google Scholar] [CrossRef]
- Li, X.; Yang, C.; Huang, W.; Tang, J.; Tian, Y.; Zhang, Q. Identification of Cotton Root Rot by Multifeature Selection from Sentinel-2 Images Using Random Forest. Remote Sens. 2020, 12, 3504. [Google Scholar] [CrossRef]
- Yang, S.; Gu, L.; Li, X.; Jiang, T.; Ren, R. Crop Classification Method Based on Optimal Feature Selection and Hybrid CNN-RF Networks for Multi-Temporal Remote Sensing Imagery. Remote Sens. 2020, 12, 3119. [Google Scholar] [CrossRef]
- Yang, X.; Qin, Q.; Grussenmeyer, P.; Koehl, M. Urban surface water body detection with suppressed built-up noise based on water indices from Sentinel-2 MSI imagery. Remote Sens. Environ. 2018, 219, 259–270. [Google Scholar] [CrossRef]
- South, S.; Qi, J.; Lusch, D.P. Optimal classification methods for mapping agricultural tillage practices. Remote Sens. Environ. 2004, 91, 90–97. [Google Scholar] [CrossRef]
- Kruse, F.A.; Lefkoff, A.B.; Boardman, J.W.; Heidebrecht, K.B.; Shapiro, A.T.; Barloon, P.J.; Goetz, A.F.H. The spectral image processing system (SIPS)—Interactive visualization and analysis of imaging spectrometer data. Remote Sens. Environ. 1993, 44, 145–163. [Google Scholar] [CrossRef]
- Ullah, S.; Schlerf, M.; Skidmore, A.K.; Hecker, C. Identifying plant species using mid-wave infrared (2.5–6μm) and thermal infrared (8–14μm) emissivity spectra. Remote Sens. Environ. 2012, 118, 95–102. [Google Scholar] [CrossRef]
- Hall, M.A. Practical feature subset selection for machine learning. In Proceedings of the 21st Australasian Computer Science Conference ACSC’98, Perth, Australia, 4–6 February 1998; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Dev, V.A.; Eden, M.R. Formation lithology classification using scalable gradient boosted decision trees. Comput. Chem. Eng. 2019, 128, 392–404. [Google Scholar] [CrossRef]
- Samat, A.; Li, E.; Wang, W.; Liu, S.; Lin, C.; Abuduwaili, J. Meta-XGBoost for Hyperspectral Image Classification Using Extended MSER-Guided Morphological Profiles. Remote Sens. 2020, 12, 1973–1995. [Google Scholar] [CrossRef]
- Joanes, D.N.; Gill, C.A. Comparing measures of sample skewness and kurtosis. J. R. Stat. Soc. (Ser. D) 1998, 47, 183–189. [Google Scholar] [CrossRef]
- Tu, B.; Li, N.; Fang, L.; He, D.; Ghamisi, P. Hyperspectral Image Classification with Multi-Scale Feature Extraction. Remote Sens. 2019, 11, 534. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, S.; Liu, Q.; Hang, R.; Liu, G. Hypergraph Embedding for Spatial-Spectral Joint Feature Extraction in Hyperspectral Images. Remote Sens. 2017, 9, 506. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Q.; Du, B.; Huang, X.; Tang, Y.Y.; Tao, D. Simultaneous Spectral-Spatial Feature Selection and Extraction for Hyperspectral Images. IEEE Trans. Cybern. 2016, 48, 16–28. [Google Scholar] [CrossRef]
- Teffahi, H.; Yao, H.; Chaib, S.; Belabid, N. A novel spectral-spatial classification technique for multispectral images using extended multi-attribute profiles and sparse autoencoder. Remote Sens. Lett. 2019, 10, 30–38. [Google Scholar] [CrossRef]
- Wang, P.; Xu, S.; Li, Y.; Wang, J.; Liu, S. Hyperspectral image classification based on joint sparsity model with low-dimensional spectral–spatial features. J. Appl. Remote Sens. 2017, 11, 015010. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. A multiscale urban complexity index based on 3D wavelet transform for spectral-spatial feature extraction and classification: An evaluation on the 8-channel WorldView-2 imagery. Int. J. Remote Sens. 2012, 33, 2641–2656. [Google Scholar] [CrossRef]
- Liu, B.; Yu, A.; Tan, X.; Wang, R. Slow feature extraction for hyperspectral image classification. Remote Sens. Lett. 2021, 12, 429–438. [Google Scholar] [CrossRef]
- Qian, Y.; Ye, M.; Zhou, J. Hyperspectral Image Classification Based on Structured Sparse Logistic Regression and Three-Dimensional Wavelet Texture Features. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2276–2291. [Google Scholar] [CrossRef]
- Linlin, S.; Sen, J. Three-Dimensional Gabor Wavelets for Pixel-Based Hyperspectral Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2011, 49, 5039–5046. [Google Scholar] [CrossRef]
- Cosgriff, C.V.; Celi, L.A. Deep learning for risk assessment: All about automatic feature extraction. Br. J. Anaesth. 2020, 124, 131–133. [Google Scholar] [CrossRef]
- Li, Y.; Xu, L.; Rao, J.; Guo, L.; Yan, Z.; Jin, S. A Y-Net deep learning method for road segmentation using high-resolution visible remote sensing images. Remote Sens. Lett. 2019, 10, 381–390. [Google Scholar] [CrossRef]
- Huang, B.; He, B.; Wu, L.; Lin, Y. A Deep Learning Approach to Detecting Ships from High-Resolution Aerial Remote Sensing Images. J. Coast. Res. 2020, 111, 16–20. [Google Scholar] [CrossRef]
- Maggipinto, M.; Beghi, A.; Mcloone, S.; Susto, G.A. DeepVM: A Deep Learning-based approach with automatic feature extraction for 2D input data Virtual Metrology. J. Process Control 2019, 84, 24–34. [Google Scholar] [CrossRef]
- Song, Q.; Xiang, M.; Hovis, C.; Zhou, Q.; Lu, M.; Tang, H.; Wu, W. Object-based feature selection for crop classification using multi-temporal high-resolution imagery. Int. J. Remote Sens. 2018, 40, 2053–2068. [Google Scholar] [CrossRef]
- Kabir, M.; Hasan, A.S.; Billah, A.M. Failure mode identification of column base plate connection using data-driven machine learning techniques. Eng. Struct. 2021, 240, 112389. [Google Scholar] [CrossRef]
- Ahmad, M.W.; Mourshed, M.; Rezgui, Y. Tree-based ensemble methods for predicting PV power generation and their comparison with support vector regression. Energy 2018, 164, 465–474. [Google Scholar] [CrossRef]
- Kibbey, T.; Jabrzemski, R.; O’Carroll, D.M. Supervised machine learning for source allocation of per- and polyfluoroalkyl substances (PFAS) in environmental samples. Chemosphere 2020, 252, 126593. [Google Scholar] [CrossRef] [PubMed]
- Cai, Y.; Guan, K.; Peng, J.; Wang, S.; Seifert, C.; Wardlow, B.; Li, Z. A high-performance and in-season classification system of field-level crop types using time-series Landsat data and a machine learning approach. Remote Sens. Environ. Interdiscip. J. 2018, 210, 35–47. [Google Scholar] [CrossRef]
- Meng, Z.; Hui, L. Object-based rice mapping using time-series and phenological data. Adv. Space Res. 2019, 63, 190–202. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Growth Stage | Agricultural Stage | Agricultural Time | Imaging Date |
|---|---|---|---|
| Seeding | Nursery | Mid-April | 3 May 2021 |
| Emergence | End of April | ||
| Transplanting | Early to mid-May | ||
| Growth | Tiller | Early June | 28 June 2021 22 July 2021 |
| Jointing | End of June | ||
| Booting | Early July | ||
| Heading | Mid to late July | ||
| Maturity | Maturity | Early September to mid-October | 25 September 2021 |
| Feature Category | Specific Features |
|---|---|
| Spectral features | Chlorophyll Absorption Ratio Index (CARI), Ratio Vegetation Index (RVI), Difference Vegetation Index (DVI), Enhanced Vegetation Index (EVI), Perpendicular Vegetation Index (PVI), Normalised Difference Vegetation Index (NDVI), Soil Adjusted Vegetation Index (SAVI), Normalised Difference Vegetation Index Red-Edge3 (NDVIre3), Normalised Difference Water Index (NDWI), Land Surface Water Index (LSWI), Normalised Difference Built-up Index (NDBI), First Principal Component (PCA1), Second Principal Component (PCA2) |
| Textural features | Mean, Homogeneity (HOM), Entropy (ENT), Correlation (COR) |
| Terrain features | DEM, Slope, Aspect, Curvature |
| Spectral-spatial features | Pixel Neighbourhood Similarity Index (PNS) |
| PNS | SAVI | RVI | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| May | Jun | Jul | Sept | May | Jun | Jul | Sept | May | Jun | Jul | Sept | |||
| Kurtosis | −2.45 | −2.09 | −1.68 | −1.73 | −0.20 | −0.73 | −1.55 | −1.18 | 0.48 | 0.42 | −0.50 | 0.44 | ||
| Skewness | 1.82 | 2.64 | 0.88 | 0.98 | −1.04 | −0.34 | 2.29 | 1.55 | −0.83 | −1.01 | −0.33 | −0.63 | ||
| NDWI | NDVIre3 | NDVI | ||||||||||||
| May | Jun | Jul | Sept | May | Jun | Jul | Sept | May | Jun | Jul | Sept | |||
| Kurtosis | 0.14 | 0.60 | 1.06 | 0.80 | 0.17 | −0.25 | −0.29 | −0.07 | −0.20 | −0.73 | −1.55 | −1.18 | ||
| Skewness | −0.86 | −0.6 | 1.16 | 0.34 | 0.55 | 0.47 | 0.15 | 0.30 | −1.04 | −0.34 | 2.29 | 1.55 | ||
| NDBI | LSWI | EVI | ||||||||||||
| May | Jun | Jul | Sept | May | Jun | Jul | Sept | May | Jun | Jul | Sept | |||
| Kurtosis | −0.08 | 0.41 | 0.45 | 0.56 | 0.09 | −0.52 | −0.43 | −0.41 | −0.06 | −0.67 | −1.03 | −0.81 | ||
| Skewness | −1.01 | −0.33 | 0.39 | 0.18 | −0.97 | −0.42 | 0.45 | 0.10 | −1.07 | −0.01 | 1.39 | 0.40 | ||
| DVI | CARI | PVI | ||||||||||||
| May | Jun | Jul | Sept | May | Jun | Jul | Sept | May | Jun | Jul | Sept | |||
| Kurtosis | 0.33 | 0.13 | −0.22 | −0.26 | 0.03 | 0.18 | 0.34 | −0.42 | 0.33 | 0.13 | −0.21 | −0.25 | ||
| Skewness | −0.82 | −0.76 | 0.06 | 0.00 | −0.71 | −0.89 | −0.14 | 0.22 | −0.81 | −0.75 | 0.05 | −0.03 | ||
| Mean | HOM | ENT | ||||||||||||
| May | Jun | Jul | Sept | May | Jun | Jul | Sept | May | Jun | Jul | Sept | |||
| Kurtosis | −0.30 | −0.22 | −0.13 | 0.47 | −0.1 | 0.25 | 0.05 | 0.18 | −0.77 | −0.89 | −0.79 | −0.93 | ||
| Skewness | 0.27 | −0.74 | 0.16 | 0.17 | −0.36 | −0.15 | −0.35 | −0.26 | 0.17 | 0.41 | 0.27 | 0.30 | ||
| COR | PCA1 | PCA2 | ||||||||||||
| May | Jun | Jul | Sept | May | Jun | Jul | Sept | May | Jun | Jul | Sept | |||
| Kurtosis | −0.78 | −0.73 | −0.80 | −0.81 | −0.45 | −0.17 | −0.16 | 0.49 | 0.16 | −0.40 | 1.64 | −1.31 | ||
| Skewness | −0.18 | −0.43 | −0.17 | −0.31 | 0.01 | −0.77 | 0.17 | 0.15 | −0.92 | −0.35 | 5.77 | 2.91 | ||
| PNS | SAVI | RVI | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| May | Jun | Jul | Sept | May | Jun | Jul | Sept | May | Jun | Jul | Sept | |||
| Partial η2 | 0.06 | 0.15 | 0.18 | 0.08 | 0.67 | 0.57 | 0.12 | 0.31 | 0.66 | 0.60 | 0.13 | 0.10 | ||
| Cohen’s f | 0.25 | 0.42 | 0.46 | 0.29 | 1.42 | 1.14 | 0.36 | 0.67 | 1.40 | 1.23 | 0.38 | 0.33 | ||
| NDWI | NDVIre3 | NDVI | ||||||||||||
| May | Jun | Jul | Sept | May | Jun | Jul | Sept | May | Jun | Jul | Sept | |||
| Partial η2 | 0.70 | 0.57 | 0.05 | 0.45 | 0.03 | 0.12 | 0.06 | 0.05 | 0.67 | 0.57 | 0.12 | 0.31 | ||
| Cohen’s f | 1.52 | 1.19 | 0.23 | 0.90 | 0.19 | 0.37 | 0.25 | 0.24 | 1.42 | 1.14 | 0.36 | 0.67 | ||
| NDBI | LSWI | EVI | ||||||||||||
| May | Jun | Jul | Sept | May | Jun | Jul | Sept | May | Jun | Jul | Sept | |||
| Partial η2 | 0.50 | 0.19 | 0.01 | 0.05 | 0.55 | 0.24 | 0.00 | 0.03 | 0.63 | 0.39 | 0.17 | 0.35 | ||
| Cohen’s f | 0.99 | 0.48 | 0.08 | 0.23 | 1.11 | 0.56 | 0.03 | 0.17 | 1.31 | 0.79 | 0.45 | 0.74 | ||
| DVI | CARI | PVI | ||||||||||||
| May | Jun | Jul | Sept | May | Jun | Jul | Sept | May | Jun | Jul | Sept | |||
| Partial η2 | 0.61 | 0.48 | 0.10 | 0.11 | 0.46 | 0.53 | 0.11 | 0.12 | 0.61 | 0.48 | 0.10 | 0.11 | ||
| Cohen’s f | 1.26 | 0.96 | 0.33 | 0.34 | 0.93 | 1.06 | 0.35 | 0.40 | 1.26 | 0.95 | 0.34 | 0.35 | ||
| Mean | HOM | ENT | ||||||||||||
| May | Jun | Jul | Sept | May | Jun | Jul | Sept | May | Jun | Jul | Sept | |||
| Partial η2 | 0.46 | 0.45 | 0.24 | 0.26 | 0.03 | 0.03 | 0.01 | 0.01 | 0.02 | 0.02 | 0.00 | 0.01 | ||
| Cohen’s f | 0.93 | 0.90 | 0.56 | 0.59 | 0.17 | 0.16 | 0.10 | 0.09 | 0.15 | 0.12 | 0.06 | 0.12 | ||
| COR | PCA1 | PCA2 | ||||||||||||
| May | Jun | Jul | Sept | May | Jun | Jul | Sept | May | Jun | Jul | Sept | |||
| Partial η2 | 0.00 | 0.01 | 0.01 | 0.01 | 0.43 | 0.42 | 0.21 | 0.26 | 0.68 | 0.47 | 0.07 | 0.21 | ||
| Cohen’s f | 0.06 | 0.12 | 0.11 | 0.09 | 0.88 | 0.85 | 0.52 | 0.59 | 1.46 | 0.94 | 0.28 | 0.51 | ||
| Combinations | Preferred Features |
|---|---|
| SC-Seeding | DEM, Slope, PNS, NDWI, EVI, Mean, SAVI |
| SC-Joining | DEM, Slope, PNS, PVI, NDVIre3, NDBI, CARI, Mean, SAVI |
| SC-Heading | DEM, Slope, PNS, NDWI, NDVIre3, NDBI, EVI, DVI, Mean, Curvature |
| SC-Maturity | DEM, Slope, PNS, NDWI, NDVIre3, NDBI, PCA1, CARI |
| Multitemporal | DEM, Slope, PNSJul, NDWIMay, NDVIre3Jun, ENTMay, EVIMay, CARIJun, MeanMay, SAVIMay |
| ORIG-RF | SC-RF | MC-RF | ||||||||
| May | Jun | Jul | Sept | May | Jun | Jul | Sept | |||
| F1 Score | 0.86 | 0.83 | 0.77 | 0.84 | 0.90 | 0.88 | 0.91 | 0.91 | 0.93 | |
| ORIG-CatBoost | SC-CatBoost | MC-CatBoost | ||||||||
| May | Jun | Jul | Sept | May | Jun | Jul | Sept | |||
| F1 Score | 0.87 | 0.87 | 0.80 | 0.85 | 0.89 | 0.88 | 0.90 | 0.91 | 0.93 | |
| ORIG-ET | SC-ET | MC-ET | ||||||||
| May | Jun | Jul | Sept | May | Jun | Jul | Sept | |||
| F1 Score | 0.86 | 0.84 | 0.82 | 0.85 | 0.90 | 0.89 | 0.90 | 0.91 | 0.95 | |
| Comparison Schemes | Features |
|---|---|
| Scheme 1 | DEM, Slope, Curvature, NDBIJul, NDBISept, CARIJun, CARISept, PNSJun, PNSSept, NDWIMay, NDWISept, NDVIre3Jun, NDVIre3Jul, SAVIMay, SAVIJun, EVIMay, EVIJul, MeanJun, DVIJul, PCASept |
| Scheme 2 | DEM, Slope, NDWIMay, NDWISept, NDWIJul, NDBIJul, CARIJun, EVIJul, DVIJul, PCASept |
| MC | DEM, Slope, PNSJul, NDWIMay, NDVIre3Jun, ENTMay, EVIMay, CARIJun, MeanMay, SAVIMay |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, K.; Chen, Y.; Zhang, B.; Hu, J.; Wang, W. A Multitemporal Mountain Rice Identification and Extraction Method Based on the Optimal Feature Combination and Machine Learning. Remote Sens. 2022, 14, 5096. https://doi.org/10.3390/rs14205096
Zhang K, Chen Y, Zhang B, Hu J, Wang W. A Multitemporal Mountain Rice Identification and Extraction Method Based on the Optimal Feature Combination and Machine Learning. Remote Sensing. 2022; 14(20):5096. https://doi.org/10.3390/rs14205096
Chicago/Turabian StyleZhang, Kaili, Yonggang Chen, Bokun Zhang, Junjie Hu, and Wentao Wang. 2022. "A Multitemporal Mountain Rice Identification and Extraction Method Based on the Optimal Feature Combination and Machine Learning" Remote Sensing 14, no. 20: 5096. https://doi.org/10.3390/rs14205096
APA StyleZhang, K., Chen, Y., Zhang, B., Hu, J., & Wang, W. (2022). A Multitemporal Mountain Rice Identification and Extraction Method Based on the Optimal Feature Combination and Machine Learning. Remote Sensing, 14(20), 5096. https://doi.org/10.3390/rs14205096