

Real-Time Detection of Winter Jujubes Based on Improved YOLOX-Nano Network


Abstract
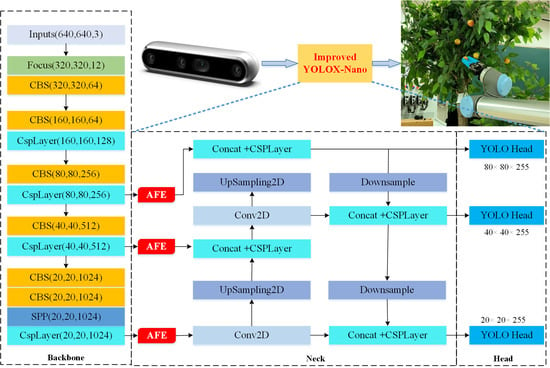
:
1. Introduction
- (1)
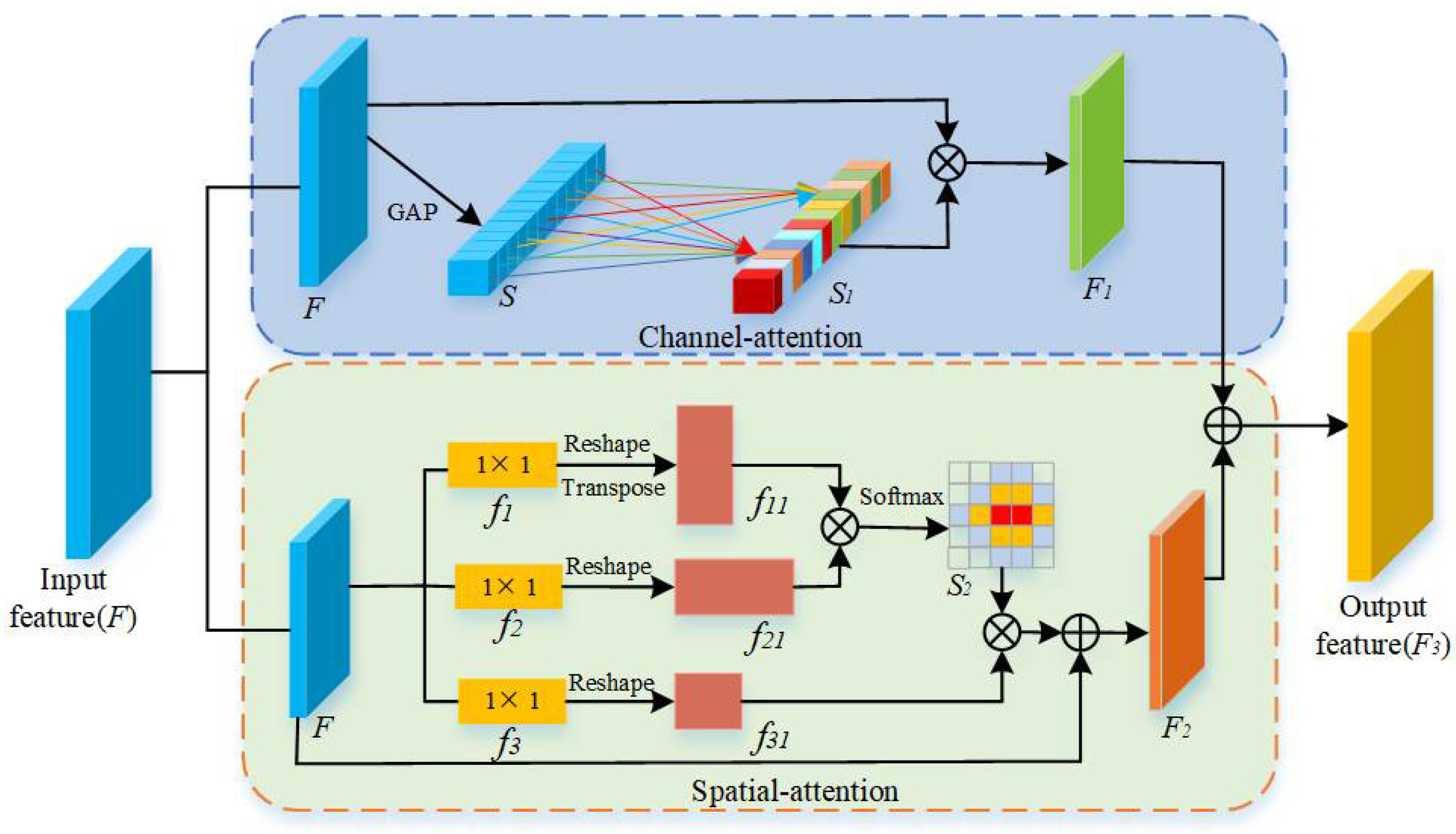
- An attention feature enhancement (AFE) module was proposed to establish connections between channels and spatial features for maximizing feature utilization.
- (2)
- DIoU loss was used to replace IoU loss to optimize training and obtain a more robust model.
- (3)
- A positioning error evaluation method was proposed to measure positioning error.
- (4)
- Model size was only 4.47 MB and can meet the requirement of embedded systems deployment.
- (5)
- An improved lightweight YOLOX-Nano network combined with an RGB-D camera was applied to provide 3D coordinates.
2. Materials and Methods
2.1. Image Acquisition
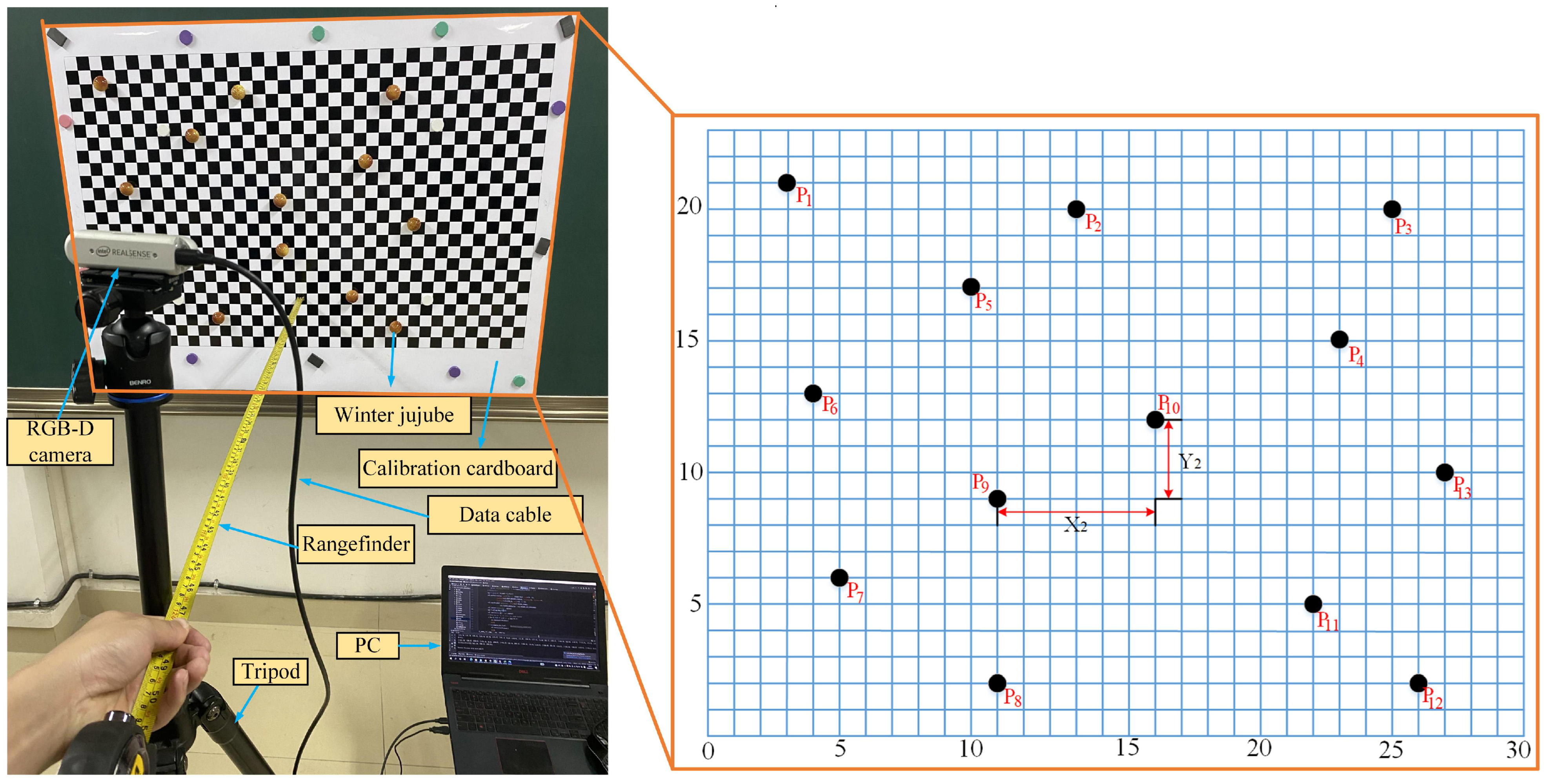
2.2. Localization System
2.3. Methodologies
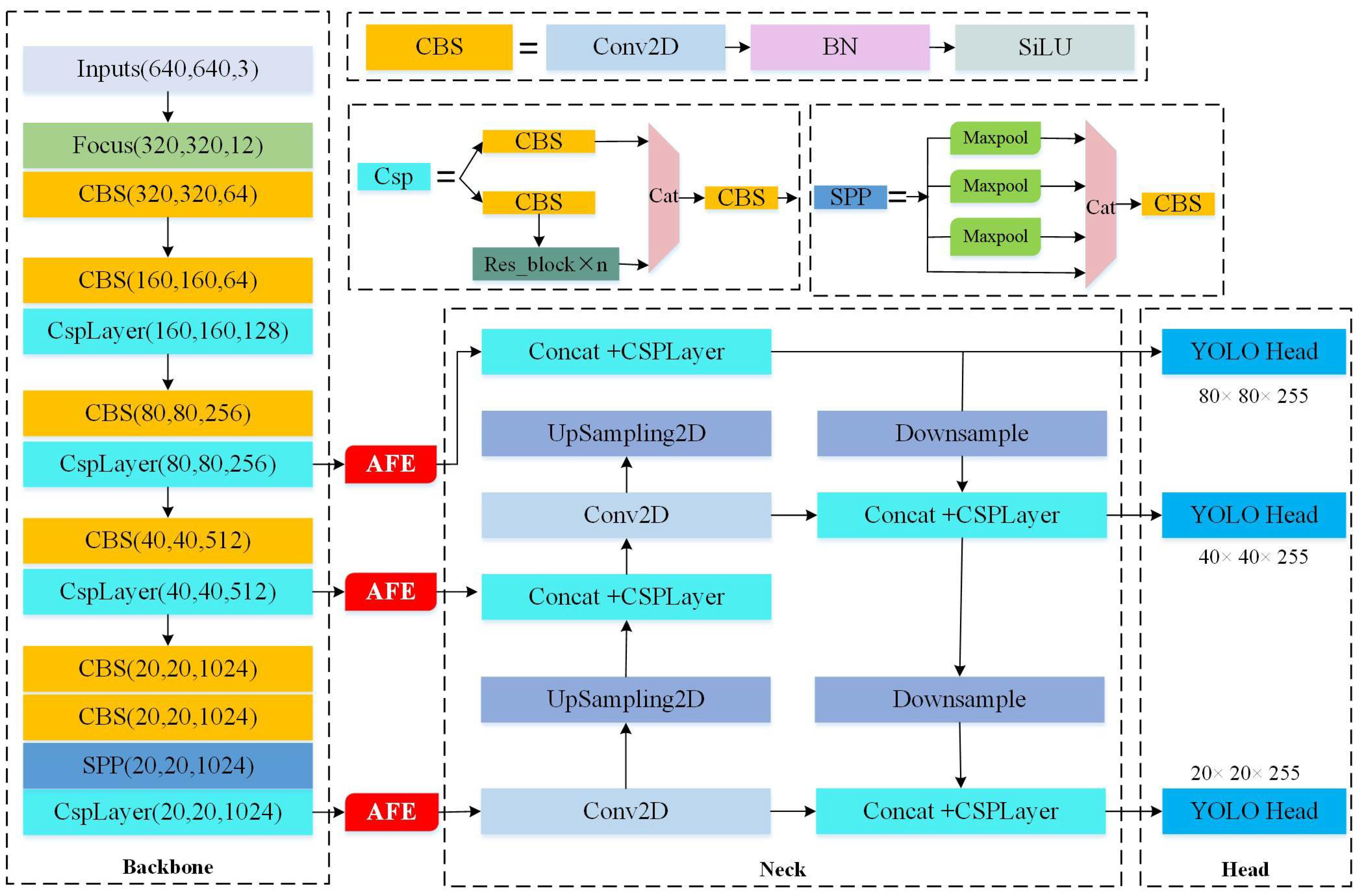
2.3.1. Improved YOLOX-Nano
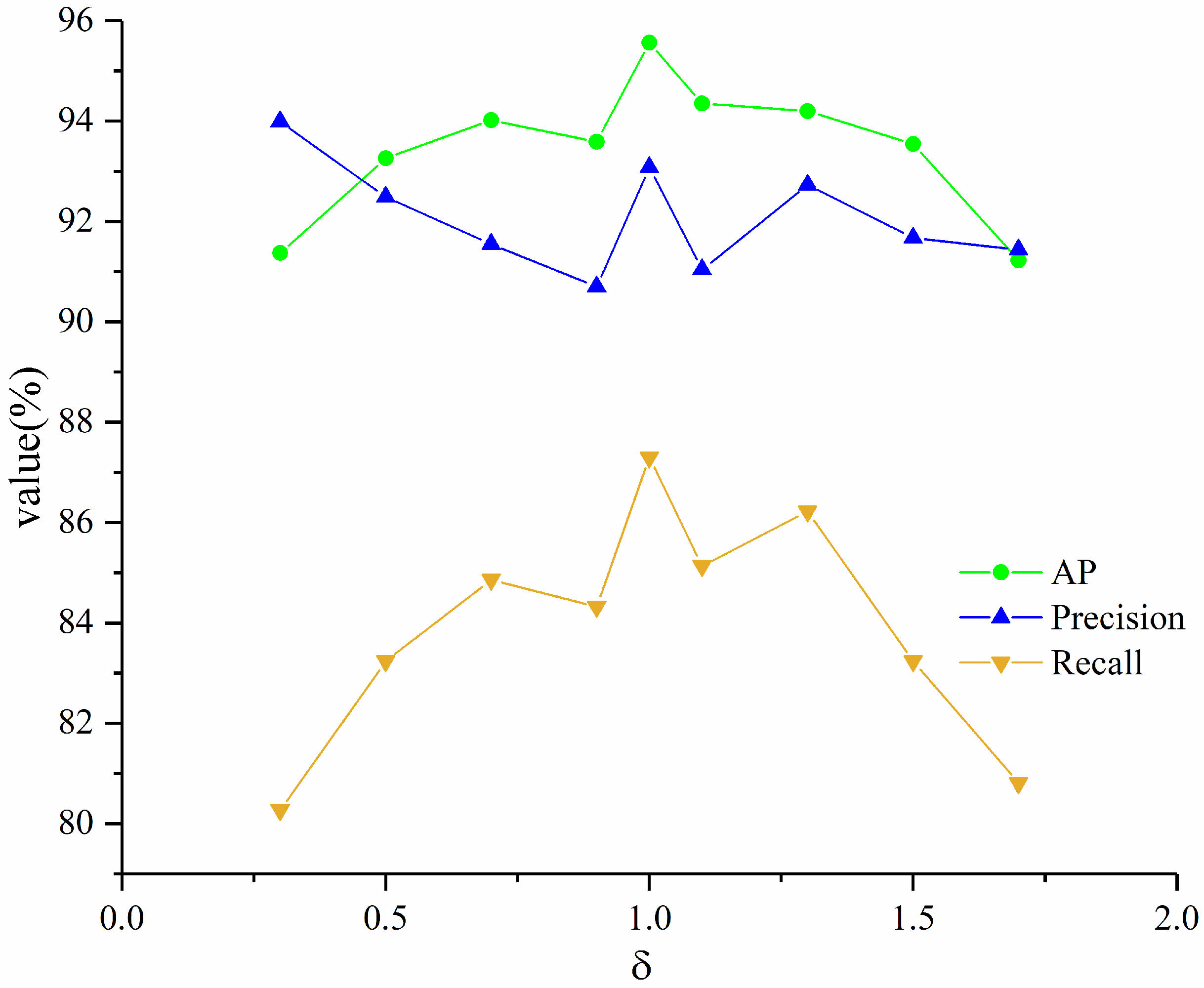
2.3.2. Attention Feature Enhancement Module
2.3.3. Loss Function
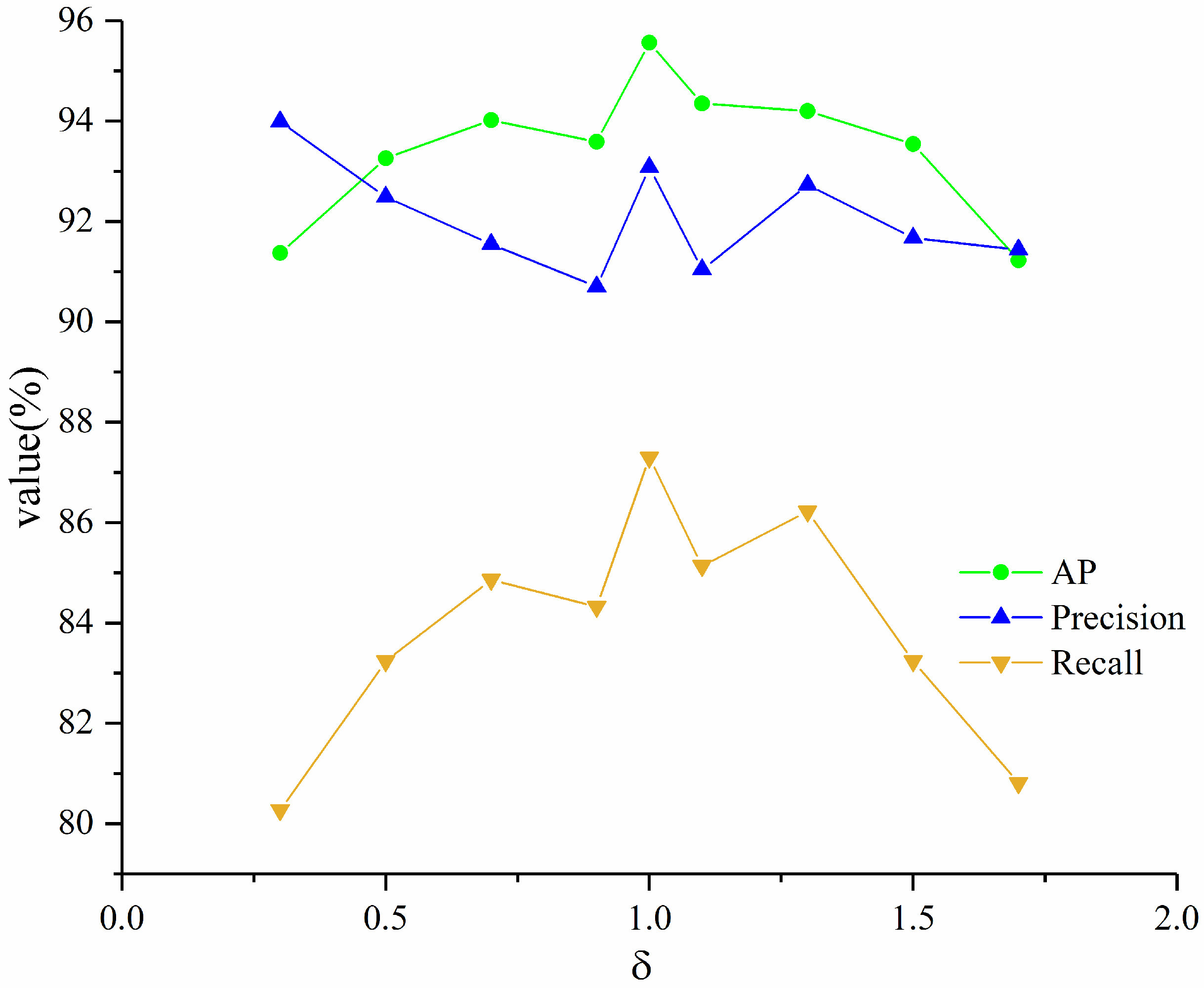
2.4. Network Training
2.5. Evaluation Indexes
3. Results
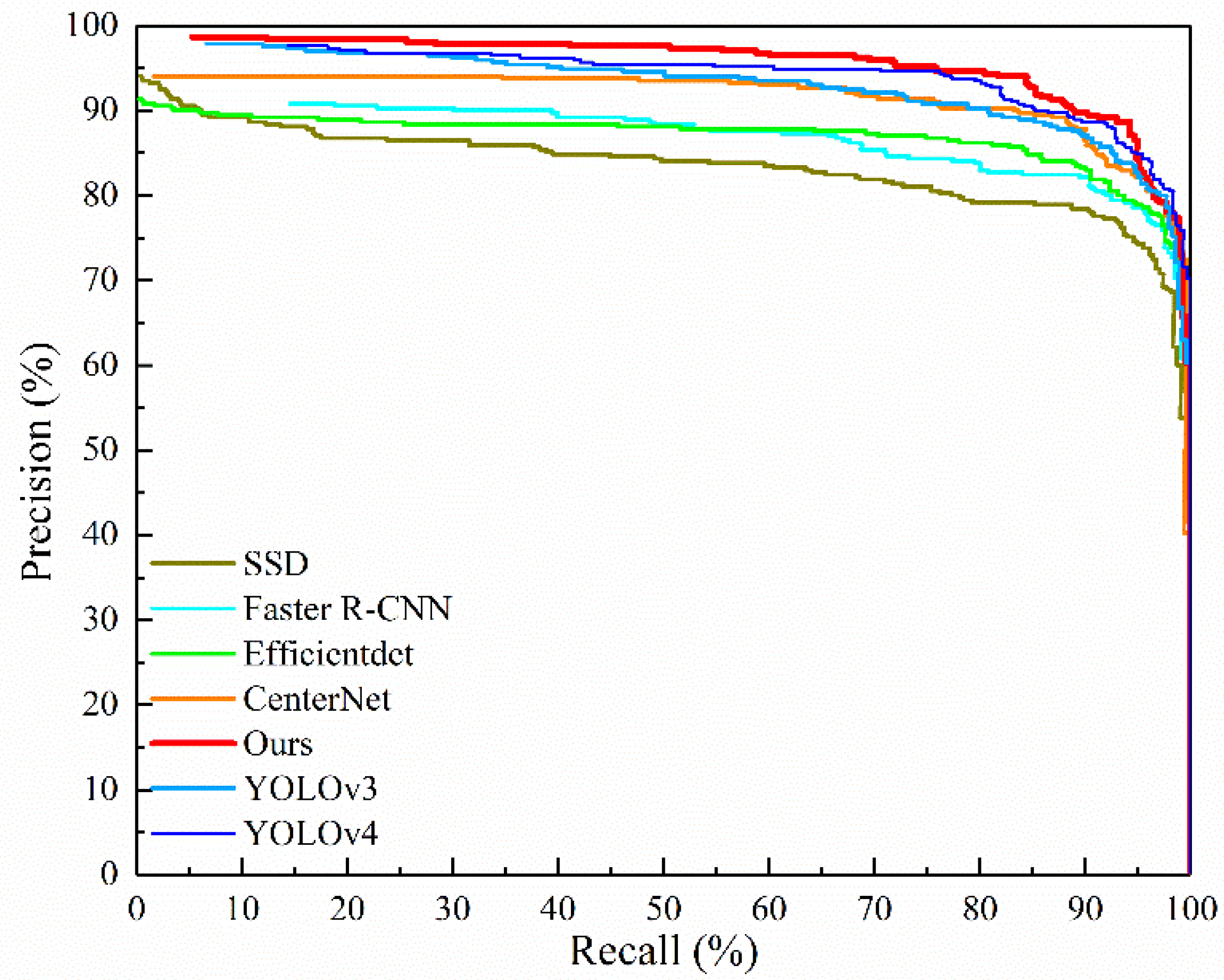
3.1. Comparison of Different Object Detection Algorithms
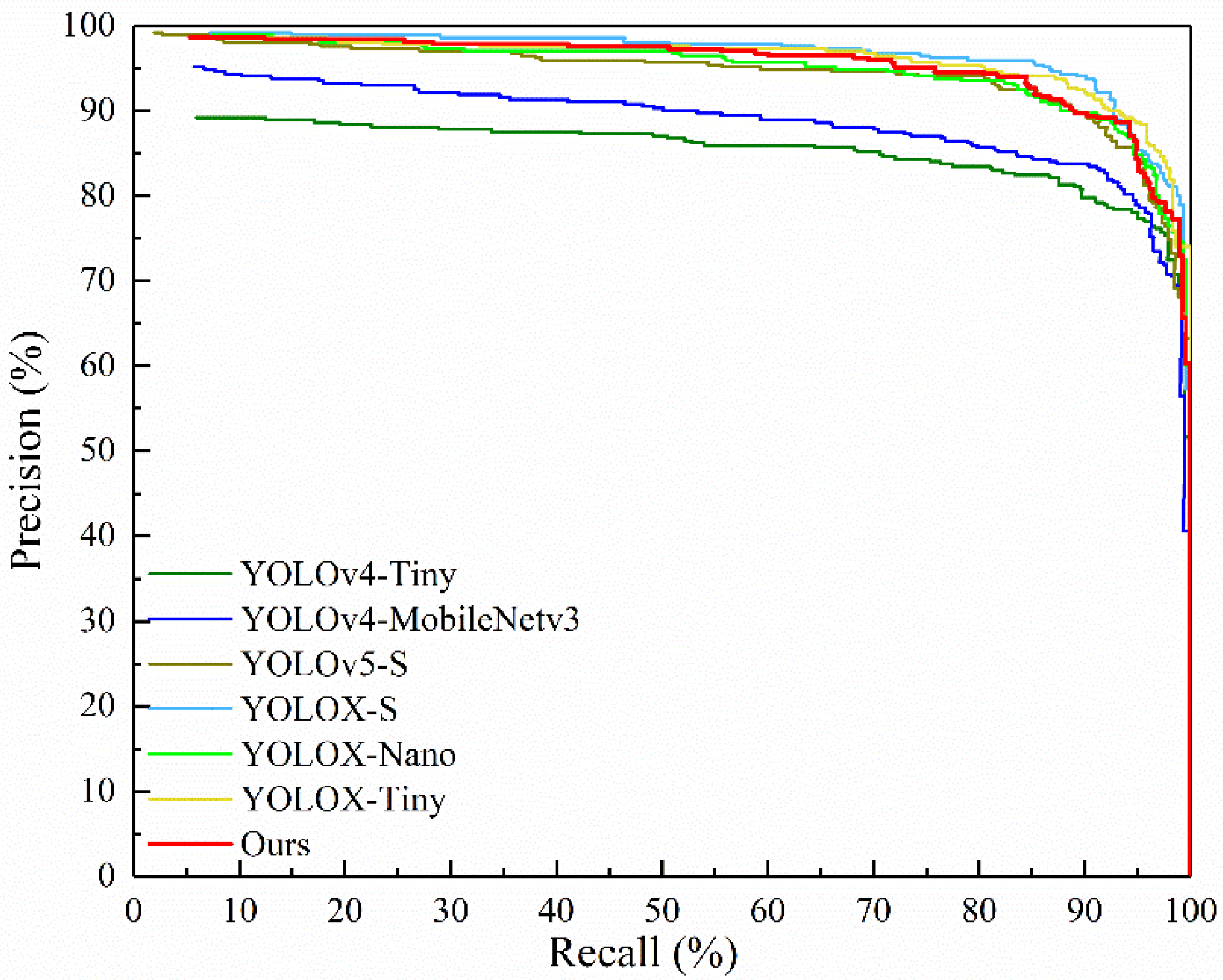
3.2. Comparison of Different Lightweight Models
3.3. Positioning Error Evaluation
4. Discussion
4.1. Effect of the Illumination on the Winter Jujube Detection
4.2. Failure Samples Analysis
4.3. Data Reliability Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ji, W.; Zhao, D.; Cheng, F.; Xu, B.; Zhang, Y.; Wang, J. Automatic recognition vision system guided for apple harvesting robot. Comput. Electr. Eng. 2012, 38, 1186–1195. [Google Scholar] [CrossRef]
- Linker, R. Machine learning based analysis of night-time images for yield prediction in apple orchard. Biosyst. Eng. 2018, 167, 114–125. [Google Scholar] [CrossRef]
- Yao, J.; Qi, J.; Zhang, J.; Shao, H.; Yang, J.; Li, X. A real-time detection algorithm for Kiwifruit defects based on YOLOv5. Electronics 2021, 10, 1711. [Google Scholar] [CrossRef]
- Liu, G.; Nouaze, J.C.; Touko Mbouembe, P.L.; Kim, J.H. YOLO-tomato: A robust algorithm for tomato detection based on YOLOv3. Sensors 2020, 20, 2145. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Song, H.; Tie, Z.; Zhang, W.; He, D. Recognition and localization of occluded apples using K-means clustering algorithm and convex hull theory: A comparison. Multimed. Tools Appl. 2016, 75, 3177–3198. [Google Scholar] [CrossRef]
- Tian, Y.; Duan, H.; Luo, R.; Zhang, Y.; Jia, W.; Lian, J.; Zheng, Y.; Ruan, C.; Li, C. Fast recognition and location of target fruit based on depth information. IEEE Access 2019, 7, 170553–170563. [Google Scholar] [CrossRef]
- Fu, L.; Majeed, Y.; Zhang, X.; Karkee, M.; Zhang, Q. Faster R–CNN–based apple detection in dense-foliage fruiting-wall trees using RGB and depth features for robotic harvesting. Biosyst. Eng. 2020, 197, 245–256. [Google Scholar] [CrossRef]
- Wang, J.; Yang, Y.; Mao, J.; Huang, Z.; Huang, C.; Xu, W. Cnn-rnn: A unified framework for multi-label image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2285–2294. [Google Scholar]
- Kang, K.; Li, H.; Yan, J.; Zeng, X.; Yang, B.; Xiao, T.; Zhang, C.; Wang, Z.; Wang, R.; Wang, X. T-cnn: Tubelets with convolutional neural networks for object detection from videos. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 2896–2907. [Google Scholar] [CrossRef]
- Li, Y.; Xu, W.; Chen, H.; Jiang, J.; Li, X. A novel framework based on mask R-CNN and Histogram thresholding for scalable segmentation of new and old rural buildings. Remote Sens. 2021, 13, 1070. [Google Scholar] [CrossRef]
- Zheng, Z.; Yang, H.; Zhou, L.; Yu, B.; Zhang, Y. HLU 2-Net: A Residual U-Structure Embedded U-Net With Hybrid Loss for Tire Defect Inspection. IEEE Trans. Instrum. Meas. 2021, 70, 1–11. [Google Scholar]
- Zheng, Z.; Zhang, S.; Shen, J.; Shao, Y.; Zhang, Y. A two-stage CNN for automated tire defect inspection in radiographic image. Meas. Sci. Technol. 2021, 32, 115403. [Google Scholar] [CrossRef]
- Zhao, M.; Jha, A.; Liu, Q.; Millis, B.A.; Mahadevan-Jansen, A.; Lu, L.; Landman, B.A.; Tyska, M.J.; Huo, Y. Faster mean-shift: GPU-accelerated clustering for cosine embedding-based cell segmentation and tracking. Med. Image Anal. 2021, 71, 102048. [Google Scholar] [CrossRef]
- Zhao, M.; Liu, Q.; Jha, A.; Deng, R.; Yao, T.; Mahadevan-Jansen, A.; Tyska, M.J.; Millis, B.A.; Huo, Y. VoxelEmbed: 3D instance segmentation and tracking with voxel embedding based deep learning. In Proceedings of the International Workshop on Machine Learning in Medical Imaging, Strasbourg, France, 27 September 2021; pp. 437–446. [Google Scholar]
- Fan, S.; Liang, X.; Huang, W.; Zhang, V.J.; Pang, Q.; He, X.; Li, L.; Zhang, C. Real-time defects detection for apple sorting using NIR cameras with pruning-based YOLOV4 network. Comput. Electron. Agric. 2022, 193, 106715. [Google Scholar] [CrossRef]
- Zheng, Z.; Hu, Y.; Yang, H.; Qiao, Y.; He, Y.; Zhang, Y.; Huang, Y. AFFU-Net: Attention feature fusion U-Net with hybrid loss for winter jujube crack detection. Comput. Electron. Agric. 2022, 198, 107049. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Zhang, J.; Karkee, M.; Zhang, Q.; Zhang, X.; Yaqoob, M.; Fu, L.; Wang, S. Multi-class object detection using faster R-CNN and estimation of shaking locations for automated shake-and-catch apple harvesting. Comput. Electron. Agric. 2020, 173, 105384. [Google Scholar] [CrossRef]
- Sozzi, M.; Cantalamessa, S.; Cogato, A.; Kayad, A.; Marinello, F. Automatic bunch detection in white grape varieties using YOLOv3, YOLOv4, and YOLOv5 deep learning algorithms. Agronomy 2022, 12, 319. [Google Scholar] [CrossRef]
- Zhou, J.; Hu, W.; Zou, A.; Zhai, S.; Liu, T.; Yang, W.; Jiang, P. Lightweight Detection Algorithm of Kiwifruit Based on Improved YOLOX-S. Agriculture 2022, 12, 993. [Google Scholar] [CrossRef]
- Lu, Z.; Zhao, M.; Luo, J.; Wang, G.; Wang, D. Design of a winter-jujube grading robot based on machine vision. Comput. Electron. Agric. 2021, 186, 106170. [Google Scholar] [CrossRef]
- Li, S.; Zhang, S.; Xue, J.; Sun, H.; Ren, R. A Fast Neural Network Based on Attention Mechanisms for Detecting Field Flat Jujube. Agriculture 2022, 12, 717. [Google Scholar] [CrossRef]
- Wu, L.; Ma, J.; Zhao, Y.; Liu, H. Apple detection in complex scene using the improved YOLOv4 model. Agronomy 2021, 11, 476. [Google Scholar] [CrossRef]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A real-time apple targets detection method for picking robot based on improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Wang, D.; He, D. Channel pruned YOLO V5s-based deep learning approach for rapid and accurate apple fruitlet detection before fruit thinning. Biosyst. Eng. 2021, 210, 271–281. [Google Scholar] [CrossRef]
- Liu, R.; Tao, F.; Liu, X.; Na, J.; Leng, H.; Wu, J.; Zhou, T. RAANet: A Residual ASPP with Attention Framework for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 3109. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. Eca-net: Efficient channel attention for deep convolutional neural networks. arXiv 2020, arXiv:1910.03151. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Zhang, Y.; Yu, J.; Chen, Y.; Yang, W.; Zhang, W.; He, Y. Real-time strawberry detection using deep neural networks on embedded system (rtsd-net): An edge AI application. Comput. Electron. Agric. 2022, 192, 106586. [Google Scholar] [CrossRef]
- Wu, D.; Lv, S.; Jiang, M.; Song, H. Using channel pruning-based YOLO v4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments. Comput. Electron. Agric. 2020, 178, 105742. [Google Scholar] [CrossRef]
- Fu, L.; Yang, Z.; Wu, F.; Zou, X.; Lin, J.; Cao, Y.; Duan, J. YOLO-Banana: A Lightweight Neural Network for Rapid Detection of Banana Bunches and Stalks in the Natural Environment. Agronomy 2022, 12, 391. [Google Scholar] [CrossRef]
- You, L.; Jiang, H.; Hu, J.; Chang, C.H.; Chen, L.; Cui, X.; Zhao, M. GPU-accelerated Faster Mean Shift with euclidean distance metrics. In Proceedings of the 2022 IEEE 46th Annual Computers, Software, and Applications Conference (COMPSAC), Torino, Italy, 27 June–1 July 2022; pp. 211–216. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 7354–7363. [Google Scholar]
- De Boer, P.-T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- He, D.; Zou, Z.; Chen, Y.; Liu, B.; Yao, X.; Shan, S. Obstacle detection of rail transit based on deep learning. Measurement 2021, 176, 109241. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhou, J.; Zhang, D.; Zhang, W. Underwater image enhancement method via multi-feature prior fusion. Appl. Intell. 2022, 1–23. [Google Scholar] [CrossRef]
- Zhou, J.; Yang, T.; Chu, W.; Zhang, W. Underwater image restoration via backscatter pixel prior and color compensation. Eng. Appl. Artif. Intell. 2022, 111, 104785. [Google Scholar] [CrossRef]
- Hu, G.; Wang, H.; Zhang, Y.; Wan, M. Detection and severity analysis of tea leaf blight based on deep learning. Comput. Electr. Eng. 2021, 90, 107023. [Google Scholar] [CrossRef]
- Chen, P.; Li, W.; Yao, S.; Ma, C.; Zhang, J.; Wang, B.; Zheng, C.; Xie, C.; Liang, D. Recognition and counting of wheat mites in wheat fields by a three-step deep learning method. Neurocomputing 2021, 437, 21–30. [Google Scholar] [CrossRef]
- Cheng, X.; Zhang, Y.; Chen, Y.; Wu, Y.; Yue, Y. Pest identification via deep residual learning in complex background. Comput. Electron. Agric. 2017, 141, 351–356. [Google Scholar] [CrossRef]
- Zhang, J.; Rao, Y.; Man, C.; Jiang, Z.; Li, S. Identification of cucumber leaf diseases using deep learning and small sample size for agricultural Internet of Things. Int. J. Distrib. Sens. Netw. 2021, 17, 15501477211007407. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Backbone | Precision (%) | Recall (%) | AP (%) | Model Size (MB) | Detection Time (s) |
|---|---|---|---|---|---|---|
| SSD | VGG16 | 94.83 | 74.32 | 83.37 | 99.76 | 0.041 |
| Faster R-CNN | VGG16 | 66.46 | 86.76 | 86.89 | 522.91 | 0.054 |
| CenterNet | ResNet50 | 97.93 | 76.76 | 91.58 | 124.61 | 0.031 |
| Efficientdet | EfficientNet-D0 | 93.93 | 79.46 | 86.92 | 14.90 | 0.044 |
| YOLOv3 | DarkNet53 | 92.40 | 85.41 | 92.94 | 236.32 | 0.047 |
| YOLOv4 | CSPDarkNet53 | 91.36 | 88.65 | 94.27 | 245.53 | 0.060 |
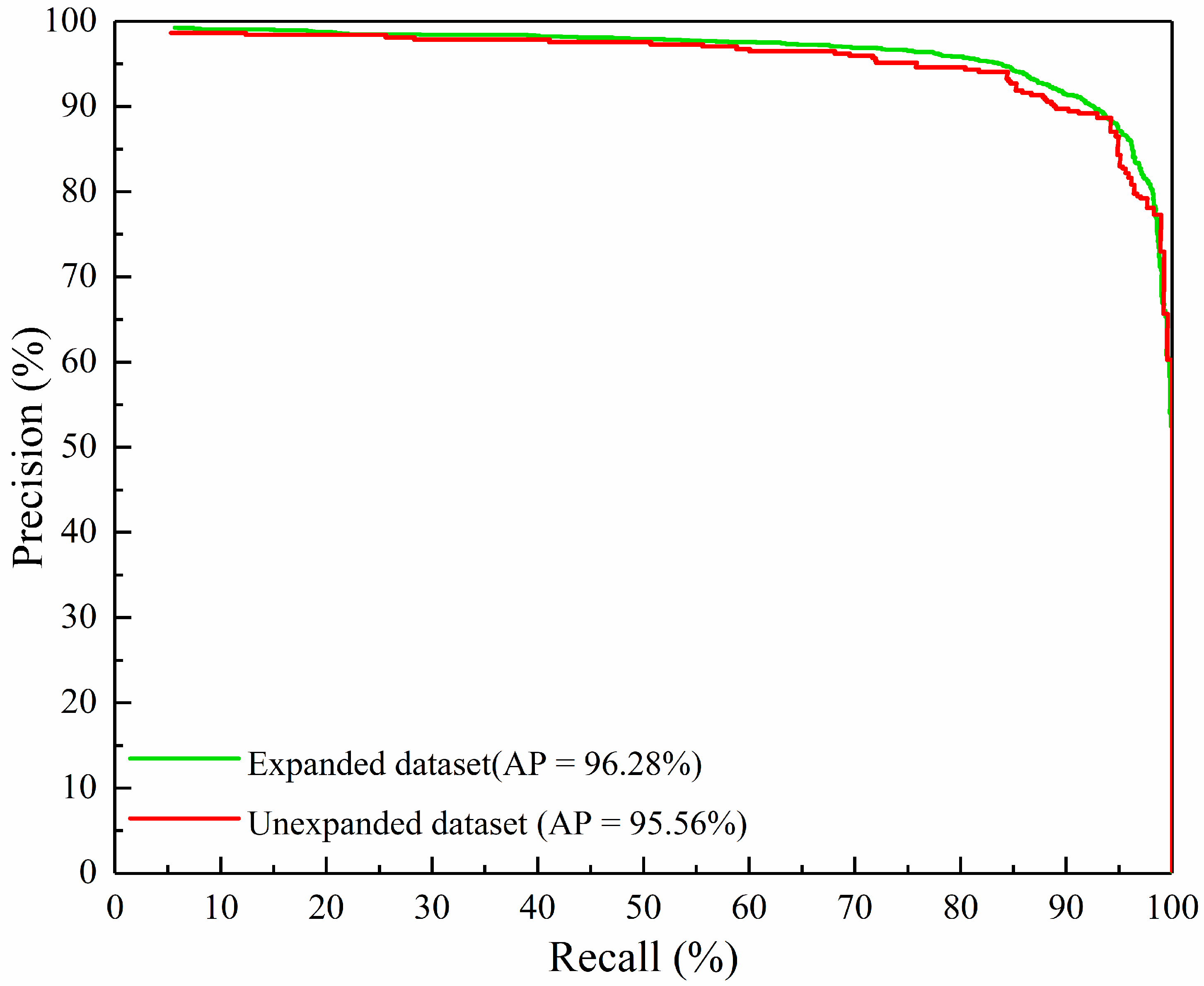
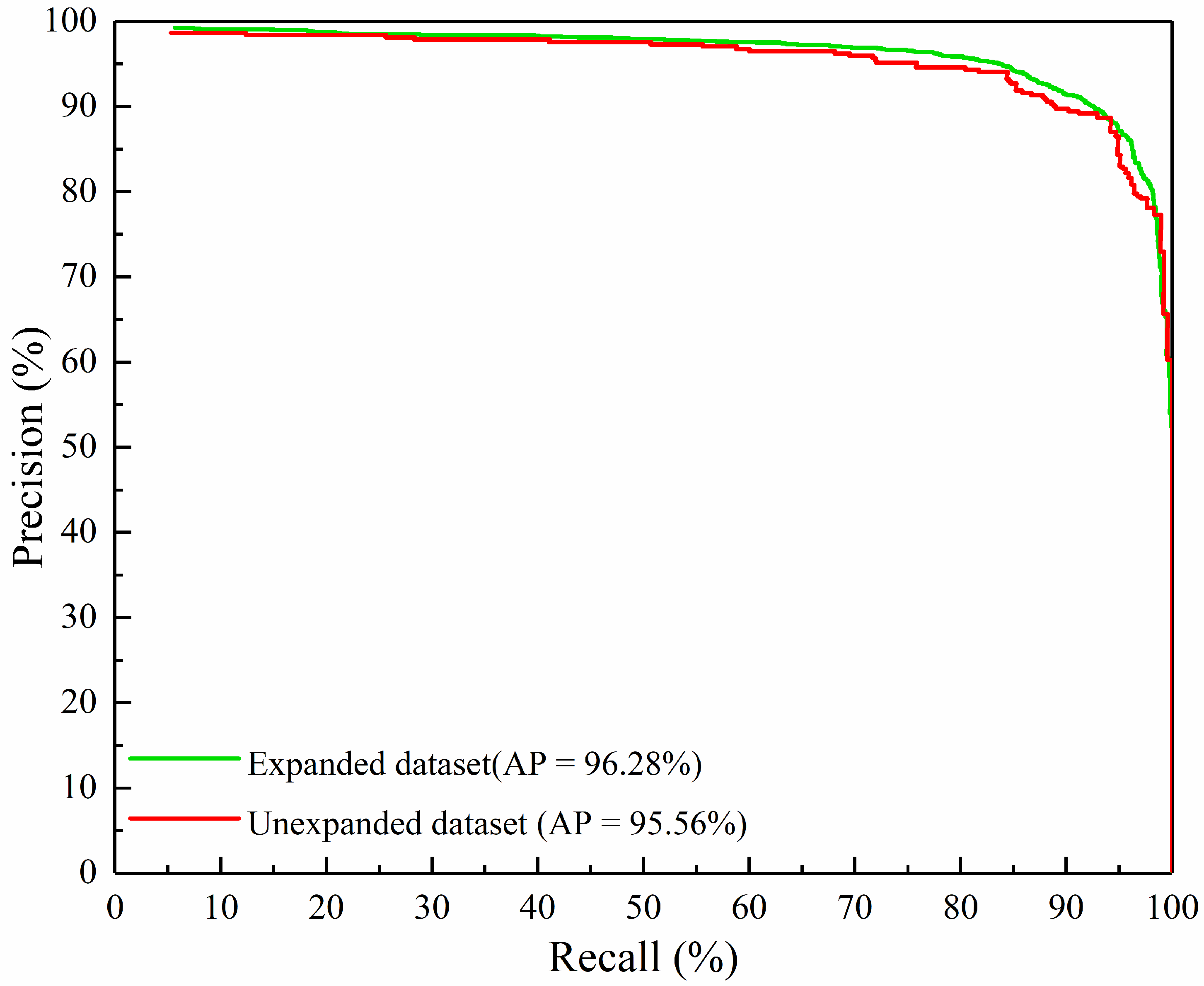
| Ours | CSPDarkNet53 | 93.08 | 87.83 | 95.56 | 4.47 | 0.022 |
| Scene | Precision (%) | Recall (%) | AP (%) |
|---|---|---|---|
| Front light | 93.64 | 88.21 | 96.02 |
| Backlight | 93.01 | 87.92 | 95.63 |
| Occluded scene | 92.42 | 87.02 | 95.09 |
| Methods | Precision (%) | Recall (%) | AP (%) | Model Size (MB) | Detection Time (s) |
|---|---|---|---|---|---|
| YOLOv4-Tiny | 93.55 | 78.38 | 85.52 | 23.10 | 0.010 |
| YOLOv4-MobileNetv3 | 96.00 | 77.84 | 88.95 | 44.74 | 0.024 |
| YOLOv5-S | 92.49 | 86.49 | 94.41 | 27.76 | 0.016 |
| YOLOX-S | 91.42 | 92.16 | 96.66 | 34.21 | 0.018 |
| YOLOX-Tiny | 91.11 | 91.35 | 96.09 | 19.29 | 0.017 |
| Ours | 93.08 | 87.83 | 95.56 | 4.47 | 0.022 |
| YOLOX-Nano@640 | IoU | DIoU | AFE | AP (%) | Model Size (MB) | Detection Time (s) |
|---|---|---|---|---|---|---|
| √ | √ | 94.66 | 3.48 | 0.020 | ||
| √ | √ | √ | 95.48 | 4.47 | 0.022 | |
| √ | √ | √ | 95.56 | 4.47 | 0.022 |
| Samples | ΔX | ΔY | ΔZ | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| −453.2 | −275.3 | 1076.0 | 337.9 | 330.0 | 7.9 | 23.1 | 30.0 | 6.9 | 3.0 | 0.0 | 3.0 | |
| −115.3 | −252.2 | 1073.0 | ||||||||||
| 244.3 | −254.1 | 1081.0 | 56.9 | 60.0 | 3.1 | 151.7 | 150.0 | 1.7 | 1.0 | 0.0 | 1.0 | |
| 187.4 | −102.4 | 1080.0 | ||||||||||
| −230.4 | −155.1 | 1068.0 | 172.5 | 180.0 | 7.5 | 127.7 | 120.0 | 7.7 | 7.0 | 0.0 | 7.0 | |
| −402.9 | −27.4 | 1061.0 | ||||||||||
| −375.3 | 182.9 | 1075.0 | 189.3 | 180.0 | 9.3 | 116.6 | 120.0 | 3.4 | 0.0 | 0.0 | 0.0 | |
| −186.0 | 299.5 | 1075.0 | ||||||||||
| −189.3 | 86.8 | 1080.0 | 173.7 | 180.0 | 6.3 | 94.6 | 90.0 | 4.6 | 8.0 | 0.0 | 8.0 | |
| −15.6 | −7.8 | 1072.0 | ||||||||||
| 169.0 | 224.3 | 1076.0 | 119.2 | 120.0 | 0.8 | 81.9 | 90.0 | 8.1 | 4.0 | 0.0 | 4.0 | |
| 288.2 | 306.2 | 1082.0 | ||||||||||
| Average positioning errors | 5.8 | 5.4 | 3.8 | |||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Z.; Hu, Y.; Qiao, Y.; Hu, X.; Huang, Y. Real-Time Detection of Winter Jujubes Based on Improved YOLOX-Nano Network. Remote Sens. 2022, 14, 4833. https://doi.org/10.3390/rs14194833
Zheng Z, Hu Y, Qiao Y, Hu X, Huang Y. Real-Time Detection of Winter Jujubes Based on Improved YOLOX-Nano Network. Remote Sensing. 2022; 14(19):4833. https://doi.org/10.3390/rs14194833
Chicago/Turabian StyleZheng, Zhouzhou, Yaohua Hu, Yichen Qiao, Xing Hu, and Yuxiang Huang. 2022. "Real-Time Detection of Winter Jujubes Based on Improved YOLOX-Nano Network" Remote Sensing 14, no. 19: 4833. https://doi.org/10.3390/rs14194833
APA StyleZheng, Z., Hu, Y., Qiao, Y., Hu, X., & Huang, Y. (2022). Real-Time Detection of Winter Jujubes Based on Improved YOLOX-Nano Network. Remote Sensing, 14(19), 4833. https://doi.org/10.3390/rs14194833