
Retrieving Water Quality Parameters from Noisy-Label Data Based on Instance Selection

 , and
, and
Abstract
:1. Introduction
- In case of label-noisy problems for flowing water, an enhanced RegENN instance selection scheme is proposed to identify noisy label instances;
- Experiments on the retrieval of turbidity, chroma and COD are conducted to verify the necessary of noisy-label instance selection for the turbidity parameter;
- Experiment results on retrieval of turbidity, chroma and COD show that it is easy to introduce label noise to turbidity and chroma, while COD is more stable; and
- The 1DCNN network combining Self Attention module is proposed for regression. The network achieves the best retrieving results on turbidity and chroma data.
2. Materials and Methods
2.1. Data Acquisition
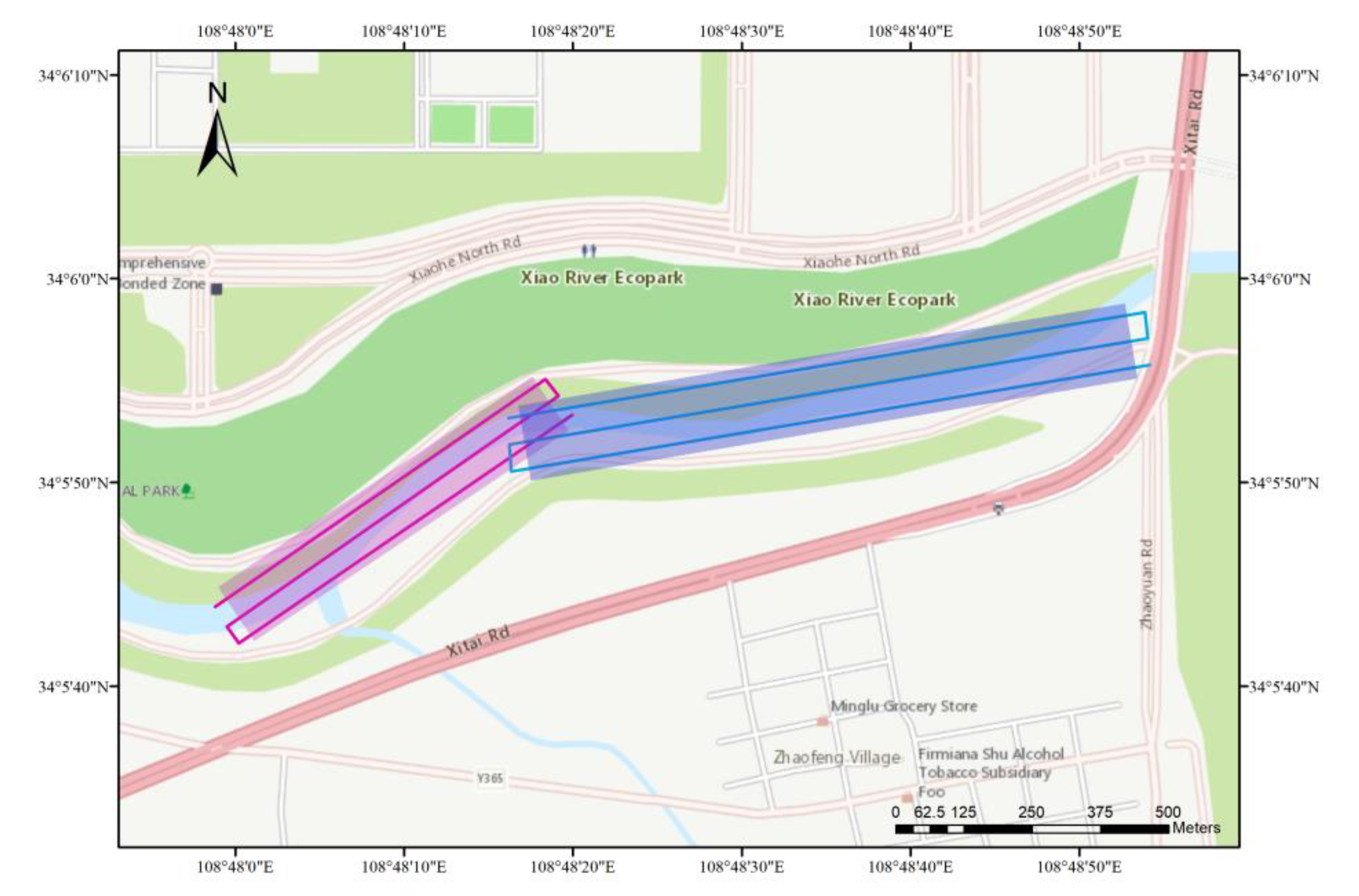
2.1.1. Study Area
2.1.2. Water Sampling and Measurement
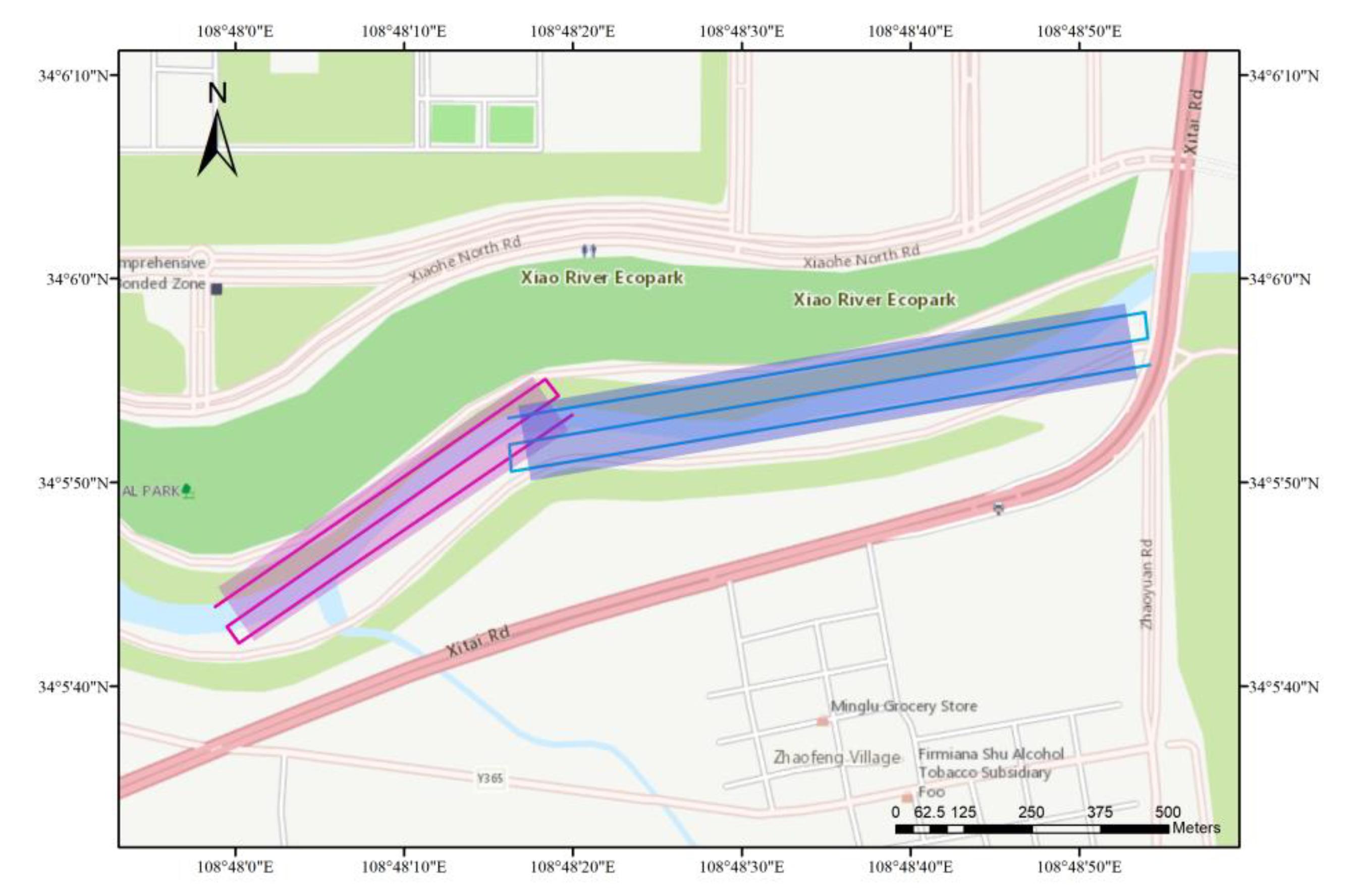
2.1.3. UAV Hyperspectral Image Acquisition
2.2. Methods
2.2.1. Geometric Correction
2.2.2. Radiation Correction and Spectral Reflectivity
2.2.3. Spectral Curve Filtering
2.2.4. Noisy-Label Instance Selection
| Algorithm 1: RegENN: Edited Nearest Neighbor for regression using a threshold |
| Data: Training set , hyper parameter α to control how the threshold is calculated from the standard deviation, the number of neighbors k to train the model. |
| Result: Selected instance set |
2.2.5. Water Quality Parameter Inversion
2.2.6. Accuracy Assessment
3. Experiments and Results
3.1. Experiment Settings
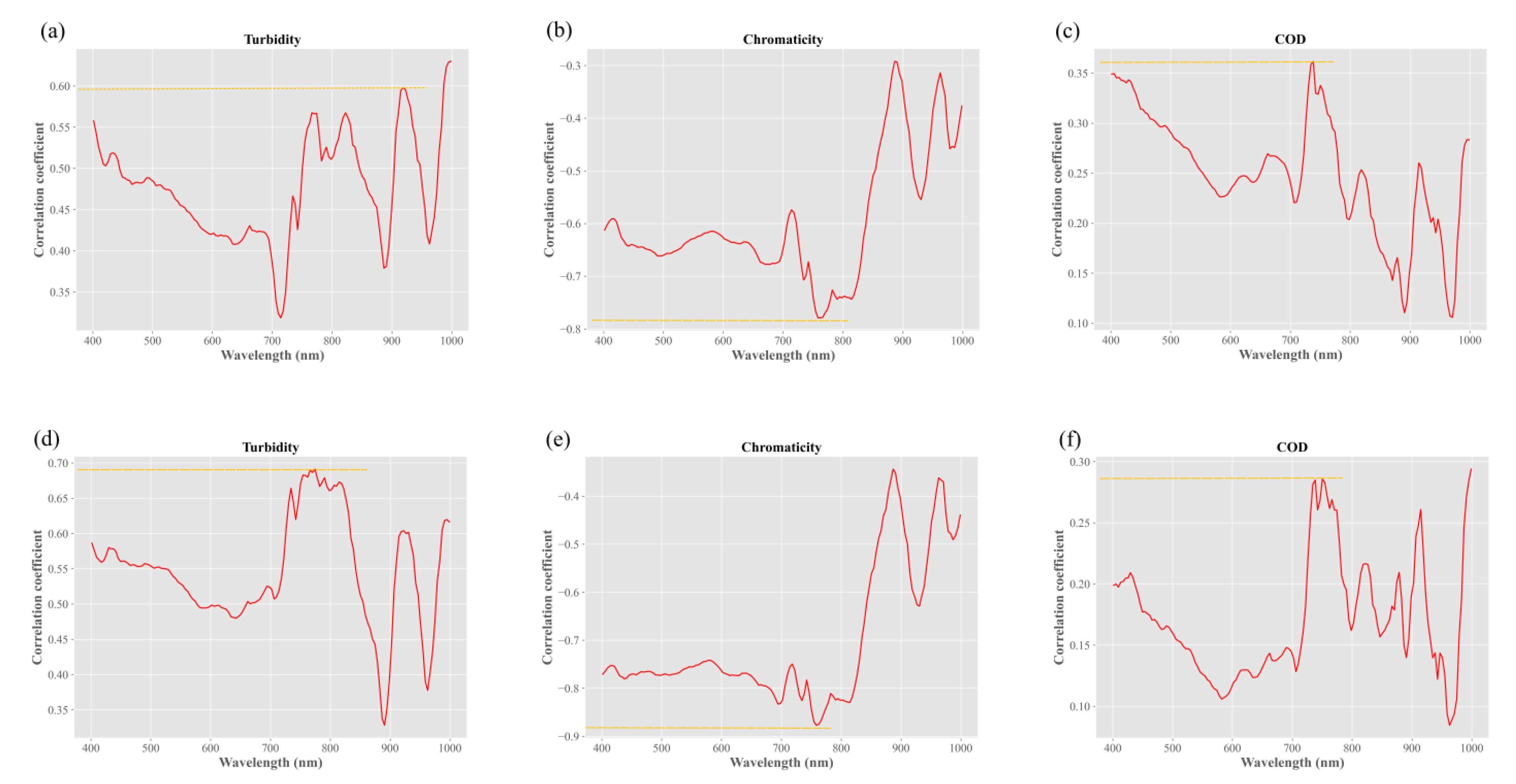
3.2. Spectral Characteristic Analysis
3.3. Water Quality Parameter Retrieving Results
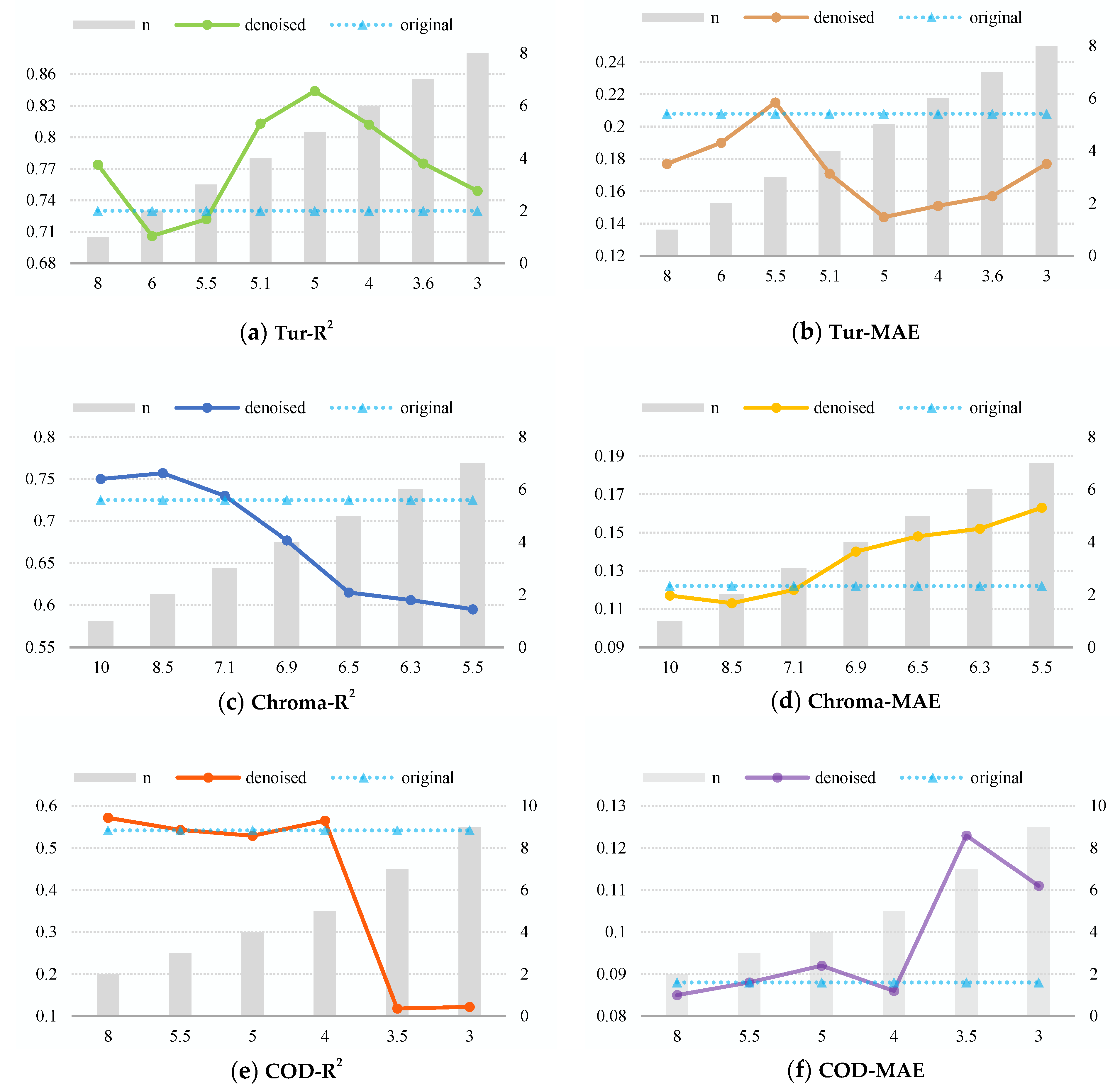
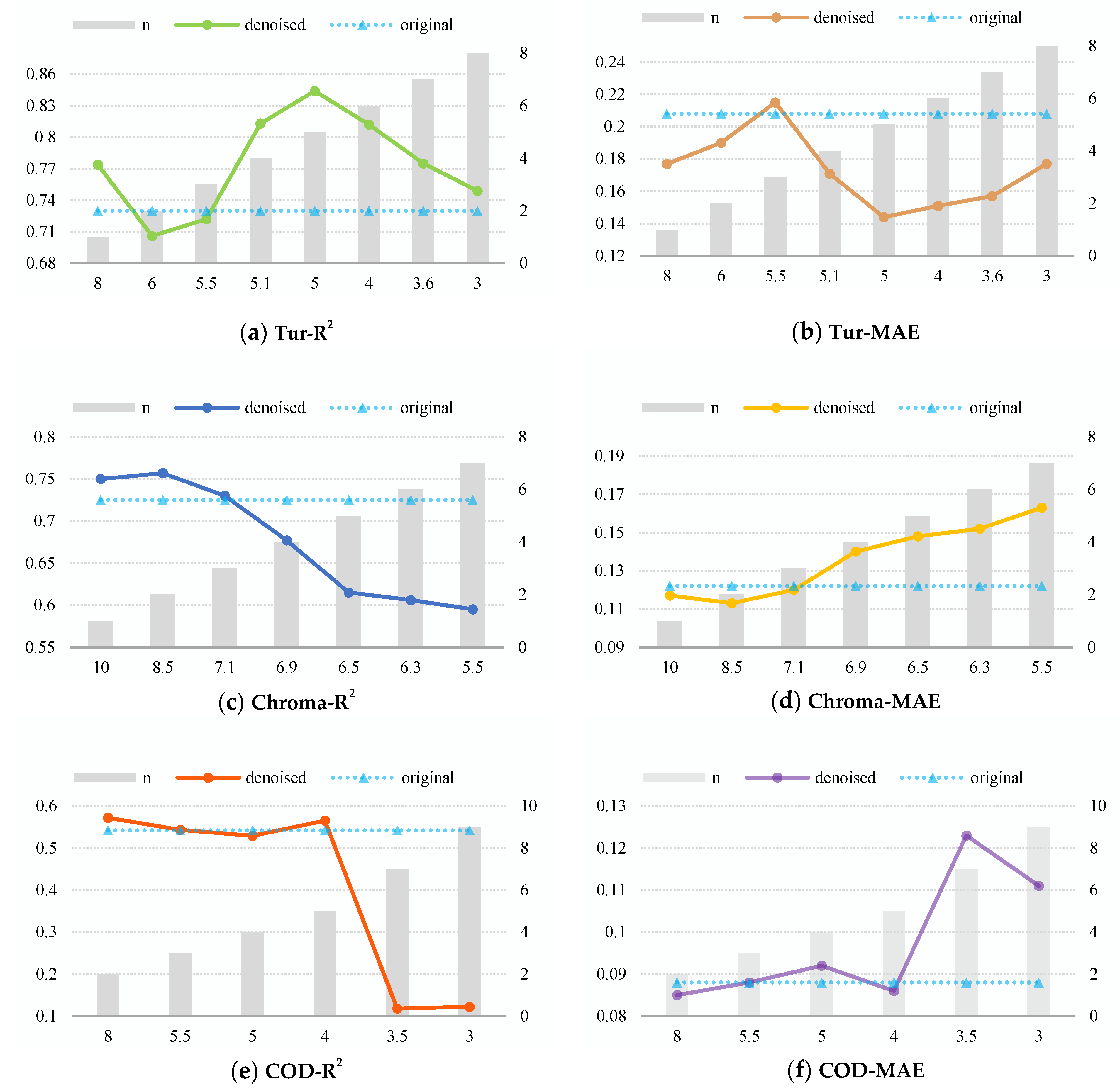
3.4. Parameter Experiment
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cui, M.; Sun, Y.; Huang, C.; Li, M. Water turbidity retrieval based on uav hyperspectral remote sensing. Water 2022, 14, 128. [Google Scholar] [CrossRef]
- Ying, H.; Xia, K.; Huang, X.; Feng, H.; Yang, Y.; Du, X.; Huang, L. Evaluation of water quality based on UAV images and the IMP-MPP algorithm. Ecol. Inform. 2021, 61, 101239. [Google Scholar] [CrossRef]
- Liu, H.; Yu, T.; Hu, B.; Hou, X.; Zhang, Z.; Liu, X.; Liu, J.; Wang, X.; Zhong, J.; Tan, Z.; et al. UAV-Borne Hyperspectral Imaging Remote Sensing System Based on Acousto-Optic Tunable Filter for Water Quality Monitoring. Remote Sens. 2021, 13, 4069. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, L.; Deng, L.; Ouyang, B. Retrieval of water quality parameters from hyperspectral images using a hybrid feedback deep factorization machine model. Water Res. 2021, 204, 117618. [Google Scholar] [CrossRef]
- Lu, Q.; Si, W.; Wei, L.; Li, Z.; Xia, Z.; Ye, S.; Xia, Y. Retrieval of water quality from UAV-borne hyperspectralimagery: A comparative study of machine learning algorithms. Remote Sens. 2021, 13, 3928. [Google Scholar] [CrossRef]
- Xiao, Y.; Guo, Y.; Yin, G.; Zhang, X.; Shi, Y.; Hao, F.; Fu, Y. UAV Multispectral Image-Based Urban River Water Quality MonitoringUsing Stacked Ensemble Machine Learning Algorithms—A Case Study of the Zhanghe River, China. Remote Sens. 2022, 14, 3272. [Google Scholar] [CrossRef]
- Allam, M.; Khan, M.; Meng, Q. Retrieval of turbidity on a spatio-temporal scale using landsat 8 SR: A case study of the ramganga river in the ganges basin, india. Appl. Sci. 2020, 10, 3702. [Google Scholar] [CrossRef]
- Cheng, X.; Li, G.; Xu, J.; Zhao, B.; Zhao, D.; Xiao, X. Combined remote sensing retrieval of river turbidity based on chinese satellite data. J. Yangtze River Sci. Res. Inst. 2021, 38, 128–136. [Google Scholar]
- Myint, S.; Walker, N. Quantification of surface suspended sediments along a river dominated coast with NOAA AVHRR and SeaWiFS measurements: Louisiana, USA. Int. J. Remote Sens. 2002, 23, 3229–3249. [Google Scholar] [CrossRef]
- Haji, G.; Melesse, M.; Reddi, L. A comprehensive review on water quality parameters estimation using remote sensing techniques. Sensors 2016, 16, 1298. [Google Scholar]
- Shi, J.; Shen, Q.; Yao, Y.; Li, J.; Chen, F.; Wang, R.; Xu, W.; Gao, Z.; Wang, L.; Zhou, Y. Estimation of Chlorophyll-a Concentrations in Small Water Bodies: Comparison of Fused Gaofen-6 and Sentinel-2 Sensors. Remote Sens. 2022, 14, 229. [Google Scholar] [CrossRef]
- Sun, X.; Zhang, Y.; Shi, K.; Zhang, Y.; Li, N.; Wang, W.; Huang, X.; Qin, B. Monitoring water quality using proximal remote sensing technology. Sci. Total Environ. 2022, 803, 149805. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, L.; Mu, C.; Huang, X. Water quality change and pollution source accounting of Licun River under long-term governance. Sci. Rep. 2022, 12, 2779. [Google Scholar] [CrossRef]
- Jacob, G.; Ehud, B. Training deep neural-networks using a noise adaptation layer. In Proceedings of the ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Han, B.; Yao, J.; Gang, N.; Zhou, M.; Tsang, I.; Zhang, Y.; Sugiyama, M. Masking: A new perspective of noisy supervision. In Proceedings of the NeurIPS 2018, Montréal, QC, Canada, 3–8 December 2018; pp. 5839–5849. [Google Scholar]
- Chen, X.; Gupta, A. Webly Supervised Learning of Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1431–1439. [Google Scholar]
- Kordos, M.; Biaka, S.; Blachnik, M. Instance selection in logical rule extraction for regression problems. In Artificial Intelligence and Soft Computing; Springer: Berlin/Heidelberg, Germany, 2013; pp. 167–175. [Google Scholar]
- Jiang, G.; Wang, W.; Qian, Y.; Liang, J. A unified sample selection framework for output noise filtering: An error-bound perspective. J. Mach. Learn. Res. 2021, 22, 1–66. [Google Scholar]
- Guillen, A.; Herrera, L.; Rubio, G.; Pomares, H.; Lendasse, A.; Rojas, I. New method for instance or prototype selection using mutual information in time series prediction. Neurocomputing 2010, 73, 2030–2038. [Google Scholar] [CrossRef]
- Shen, Y.; Sanghavi, S. Learning with bad training data via iterative trimmed loss minimization. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; Volume 97, pp. 5739–5748. [Google Scholar]
- Tanno, R.; Saeedi, A.; Sankaranarayanan, S.; Alexander, D.; Silberman, N. Learning from noisy labels by regularized estimation of annotator confusion. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 11236–11245. [Google Scholar]
- Li, J.; Socher, R.; Hoi, S. Dividemix: Learning with noisy labels as semi-supervised learning. arXiv 2020, arXiv:2002.07394. [Google Scholar]
- He, Y.; Xiao, S.; Nie, P.; Dong, T.; Qu, F.; Lin, L. Research on the optimum water content of detecting soil nitrogen using near infrared sensor. Sensors 2017, 17, 2045. [Google Scholar] [CrossRef]
- Tao, Q.; Lu, T.; Sheng, Y.; Li, L.; Lu, W.; Li, M. Machine learning aided design of perovskite oxide materials for photocatalytic water splitting. J. Energy Chem. 2021, 60, 351–359. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT press: Cambridge, MA, USA, 2016. [Google Scholar]
- Mohri, M.; Rostamizadeh, A.; Talwalkar, A. Foundations of Machine Learning; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Yoav, F.; Robert, E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar]
- Tao, W.; Li, C.; Song, R.; Cheng, J.; Liu, Y.; Wan, F.; Chen, X. EEG-based emotion recognition via channel-wise attention and self attention. IEEE Trans. Affect. Comput. 2020. [Google Scholar] [CrossRef]
- Xie, B.; Wu, X.; Zhang, S.; Zhao, S.; Li, M. Learning diverse features with part-level resolution for person re-identification. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Nanjing, China, 16–18 October 2020. [Google Scholar]
- Zhang, Y.; Wu, L.; Ren, H.; Liu, Y.; Zheng, Y.; Liu, Y.; Dong, J. Mapping water quality parameters in urban rivers from hyperspectral images using a new self-adapting selection of multiple artificial neural networks. Remote Sens. 2020, 12, 336. [Google Scholar] [CrossRef]
- Dona, C.; Chang, N.; Caselles, V.; Juan, M.; Camacho, A.; Delegido, J.; Benjamin, W. Integrated satellite data fusion and mining for monitoring lake water quality status of the Albufera de Valencia in Spain. J. Environ. Manag. 2015, 151, 416–426. [Google Scholar] [CrossRef]
- Michaelsen, M.; Meidow, J. Stochastic reasoning for structural pattern recognition: An example from image-based UAV navigation. Pattern Recognit. 2014, 8, 2732–2744. [Google Scholar] [CrossRef]
- Laliberte, A.; Goforth, M.; Steele, C.; Rango, A. Multispectral remote sensing from unmanned aircraft: Image processing workflows and applications for rangeland environments. Remote Sens. 2011, 3, 2529–2551. [Google Scholar] [CrossRef]
- Tang, J.; Tian, G.; Wang, X.; Wang, X.; Song, Q. The methods of water spectra measurement and analysis I: Above-water method. J. Remote Sens. 2004, 8, 37–44. [Google Scholar]
- Curtis, D. Estimation of the remote-sensing reflectance from above-surface measurements. Appl. Opt. 1999, 38, 7442–7455. [Google Scholar]
- Uta, H.; Karl, S.; Sigrid, R.; Hermann, K. Determination of robust spectral features for identification of urban surface materials in hyperspectral remote sensing data. Remote Sens. Environ. 2007, 111, 537–552. [Google Scholar]
- Vaiphasa, C. Consideration of smoothing techniques for hyperspectral remote sensing. ISPRS J. Photogramm. Remote Sens. 2006, 60, 91–99. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.; Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 1–8 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Li, S.; Zhang, L.; Liu, H.; Hugo, A.; Zhai, L.; Zhuang, Y.; Lei, Q.; Hu, W.; Li, W.; Feng, Q.; et al. Evaluating the risk of phosphorus loss with a distributed watershed model featuring zero-order mobilization and first-order delivery. Sci. Total Environ. 2017, 609, 563–576. [Google Scholar] [CrossRef]
- Lerman, P. Fitting segmented regression models by grid search. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1980, 29, 77–84. [Google Scholar] [CrossRef]
- Chen, Q.; Zhang, Y.; Hallikainen, M. Water quality monitoring using remote sensing in support of the EU water framework directive (WFD): A case study in the Gulf of Finland. Environ. Monit. Assess. 2007, 124, 157–166. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Unit | Minimum | Maximum | Mean | Median |
|---|---|---|---|---|---|
| Chroma | Hazen | 32.07 | 69.67 | 50.68 | 52.53 |
| Tur | NTU | 3.37 | 12.52 | 6.58 | 5.96 |
| COD | mg/L | 2.22 | 9.49 | 6.37 | 6.15 |
| Name | Patch Size | Stride | Channel | Padding | Output Size | Pooling/Stride | Channel Ratio |
|---|---|---|---|---|---|---|---|
| Conv1 | 3 | 1 | 8 | 1 | 8 × 75 | Max 2/2 | |
| Conv2 | 3 | 1 | 24 | 1 | 24 × 37 | Max 2/2 | |
| Attention1 | 24 × 37 | 8 | |||||
| Conv3 | 3 | 1 | 32 | 1 | 32 × 18 | Max 2/2 | |
| Attention2 | 32 × 18 | 8 | |||||
| Fc1 | 64 | ||||||
| Fc2 | 32 | ||||||
| Fc3 | 1 |
| Range | Chroma | Tur | COD |
|---|---|---|---|
| RFR | 5–12 | 2–9 | 5–12 |
| KNN | 10–25 | 2–20 | 10–30 |
| Adaboost | 5–15 | 2–7 | 10–25 |
| PLSR | 3–8 | 2–10 | 5–15 |
| 1DCNN | 3–10 | 1–8 | 5–20 |
| Turbidity | Index | rfr | knn | adaboost | 1dcnn | plsr |
|---|---|---|---|---|---|---|
| original | train r2 | 0.893 | 0.321 | 0.972 | 0.992 | 0.471 |
| test r2 | 0.73 | 0.335 | 0.842 | 0.873 | 0.689 | |
| train MAE | 0.102 | 0.258 | 0.055 | 0.001 | 0.252 | |
| test MAE | 0.208 | 0.222 | 0.13 | 0.114 | 0.213 | |
| train acc | 0.928 | 0.357 | 1 | 1 | 0.464 | |
| test acc | 0.75 | 0.5 | 0.75 | 0.75 | 0.5 | |
| denoised | train r2 | 0.922 | 0.461 | 0.983 | 0.997 | 0.696 |
| test r2 | 0.844 | 0.634 | 0.891 | 0.904 | 0.676 | |
| train MAE | 0.088 | 0.201 | 0.042 | 0.001 | 0.149 | |
| test MAE | 0.144 | 0.188 | 0.101 | 0.084 | 0.211 | |
| train acc | 0.869 | 0.578 | 1 | 1 | 0.71 | |
| test acc | 0.75 | 0.5 | 0.75 | 0.875 | 0.5 | |
| n | 5 | 8 | 5 | 5 | 7 | |
| α | 5 | 8.5 | 3.2 | 3.5 | 3.9 |
| Chroma | Index | rfr | knn | adaboost | 1dcnn | plsr |
|---|---|---|---|---|---|---|
| original | train r2 | 0.957 | 0.779 | 0.985 | 0.998 | 0.831 |
| test r2 | 0.725 | 0.71 | 0.714 | 0.834 | 0.749 | |
| train MAE | 0.029 | 0.062 | 0.015 | 0.001 | 0.053 | |
| test MAE | 0.122 | 0.131 | 0.127 | 0.096 | 0.132 | |
| train acc | 1 | 1 | 1 | 1 | 1 | |
| test acc | 0.875 | 0.875 | 0.875 | 1 | 0.75 | |
| denoised | train r2 | 0.954 | 0.853 | 0.989 | 0.998 | 0.941 |
| test r2 | 0.757 | 0.687 | 0.725 | 0.877 | 0.747 | |
| train MAE | 0.028 | 0.051 | 0.013 | 0.001 | 0.035 | |
| test MAE | 0.113 | 0.127 | 0.113 | 0.093 | 0.137 | |
| train acc | 1 | 1 | 1 | 1 | 1 | |
| test acc | 0.875 | 0.75 | 0.875 | 1 | 0.875 | |
| n | 2 | 3 | 1 | 2 | 3 | |
| α | 8.5 | 20 | 8 | 7.5 | 4 |
| COD | Index | rfr | knn | adaboost | 1dcnn | plsr |
|---|---|---|---|---|---|---|
| original | train r2 | 0.847 | 0.243 | 0.964 | 0.997 | 0.634 |
| test r2 | 0.542 | 0.17 | 0.574 | 0.453 | 0.344 | |
| train MAE | 0.066 | 0.161 | 0.025 | 0.001 | 0.114 | |
| test MAE | 0.088 | 0.128 | 0.089 | 0.091 | 0.086 | |
| train acc | 0.964 | / | 1 | 1 | 0.892 | |
| test acc | 0.75 | / | 0.875 | 0.75 | 0.75 | |
| denoised | train r2 | 0.817 | / | 0.971 | 0.998 | 0.603 |
| test r2 | 0.572 | / | 0.662 | 0.518 | 0.143 | |
| train MAE | 0.043 | / | 0.023 | 0.001 | 0.08 | |
| test MAE | 0.088 | / | 0.078 | 0.071 | 0.141 | |
| train acc | 1 | / | 1 | 1 | 0.962 | |
| test acc | 0.875 | / | 1 | 0.75 | 0.75 | |
| n | 2 | / | 2 | 2 | 1 | |
| α | 8 | / | 15 | 15 | 5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Liu, J.; Zhao, Y.; Wang, X.; Song, S.; Liu, H.; Yu, T. Retrieving Water Quality Parameters from Noisy-Label Data Based on Instance Selection. Remote Sens. 2022, 14, 4742. https://doi.org/10.3390/rs14194742
Liu Y, Liu J, Zhao Y, Wang X, Song S, Liu H, Yu T. Retrieving Water Quality Parameters from Noisy-Label Data Based on Instance Selection. Remote Sensing. 2022; 14(19):4742. https://doi.org/10.3390/rs14194742
Chicago/Turabian StyleLiu, Yuyang, Jiacheng Liu, Yubo Zhao, Xueji Wang, Shuyao Song, Hong Liu, and Tao Yu. 2022. "Retrieving Water Quality Parameters from Noisy-Label Data Based on Instance Selection" Remote Sensing 14, no. 19: 4742. https://doi.org/10.3390/rs14194742
APA StyleLiu, Y., Liu, J., Zhao, Y., Wang, X., Song, S., Liu, H., & Yu, T. (2022). Retrieving Water Quality Parameters from Noisy-Label Data Based on Instance Selection. Remote Sensing, 14(19), 4742. https://doi.org/10.3390/rs14194742