

Rapid Target Detection of Fruit Trees Using UAV Imaging and Improved Light YOLOv4 Algorithm



Abstract
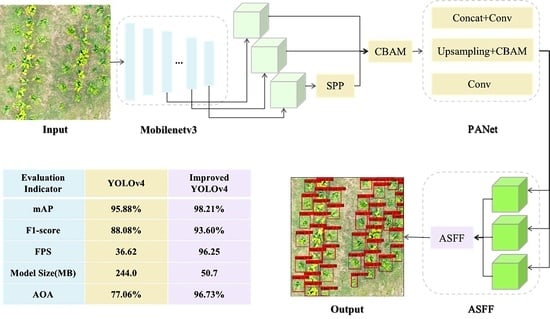
:
1. Introduction
2. Materials and Methods
2.1. Data Collection
2.1.1. Overview of the Study Region
2.1.2. Data Acquisition
2.1.3. Dataset Production
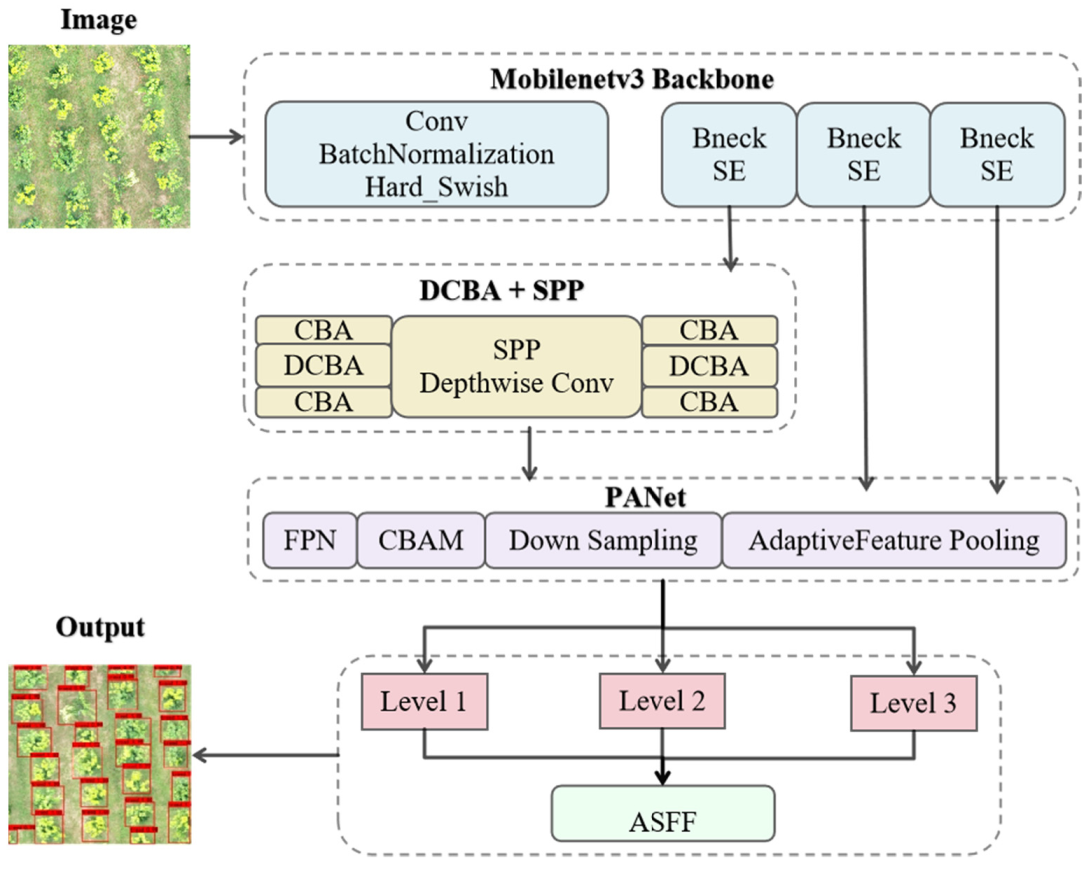
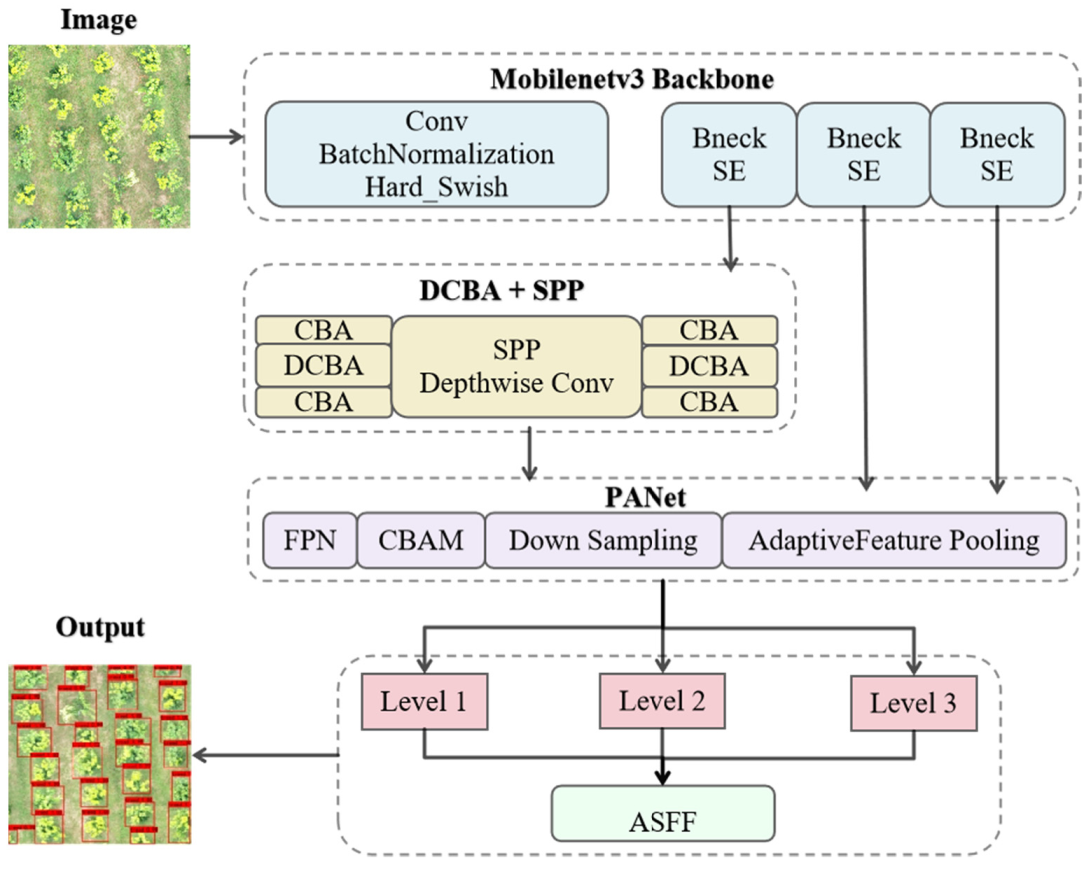
2.2. Methods
2.2.1. Test Environment and Parameter Settings
2.2.2. Overview of the YOLOv4 Model
2.2.3. Lightweight Backbone Network
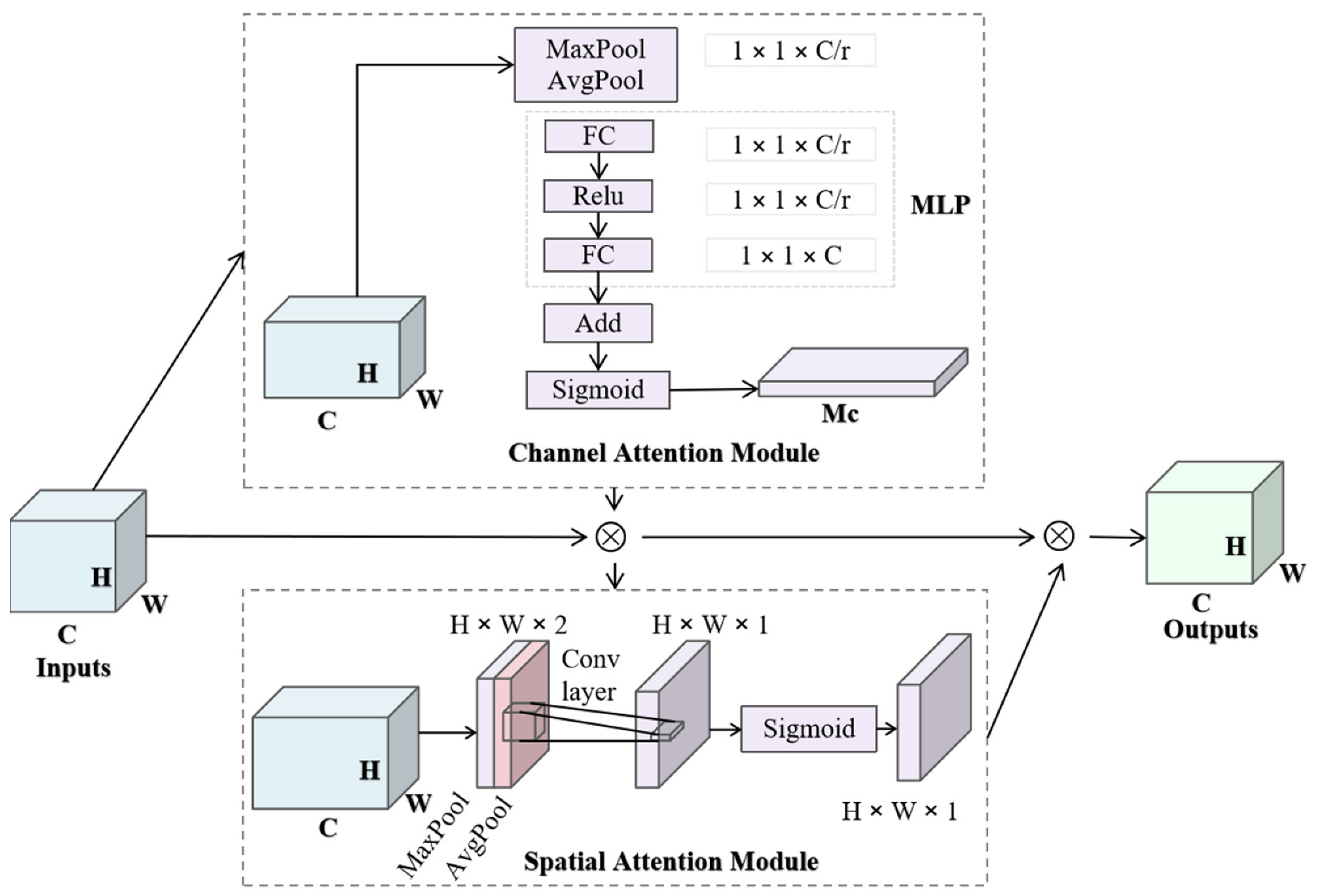
2.2.4. Channel Attention Module and Spatial Attention Module
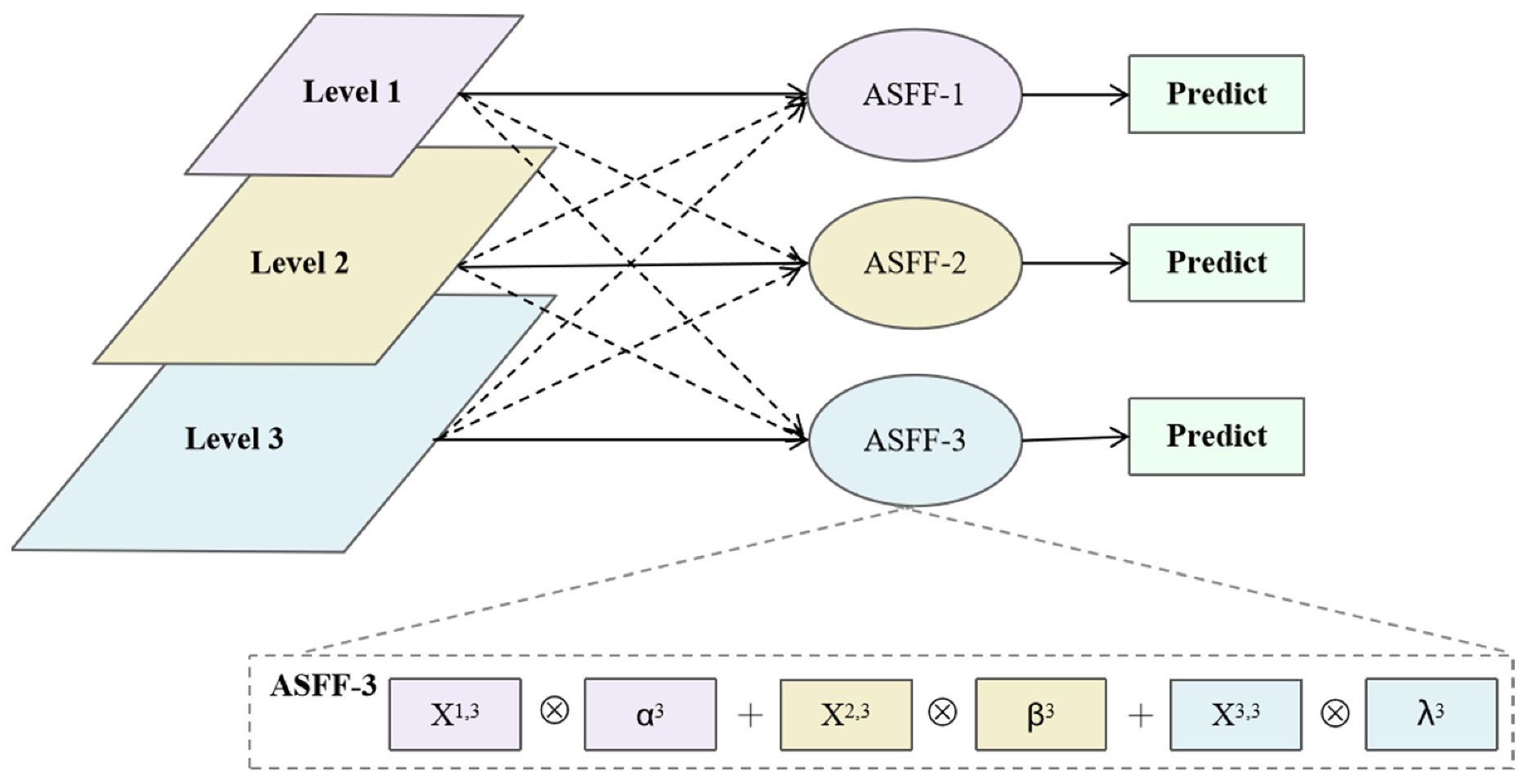
2.2.5. Adding Feature Fusion Effects—Adaptive Spatial Feature Fusion
2.3. Improved Generation Method of Pre-Selection Boxes
3. Results
3.1. Evaluation Indicators
3.2. Results of Detecting in Different Models
3.2.1. Result of Achieving Light Weight by Using Mobilenetv3
3.2.2. Result of Applying the Attention Mechanism
3.2.3. Result of Applying the ASFF
3.2.4. Result of Optimizing Preselected Boxes
3.3. Results of Counting in Different Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, B. Research on Crop Classification Based on UAV Remote Sensing Images; Chinese Academy of Agricultural Sciences: Beijing, China, 2019. [Google Scholar]
- Rasmussen, J.; Ntakos, G.; Nielsen, J.; Svensgaard, J.; Poulsen, R.N.; Christensen, S. Are vegetation indices derived from consumer-grade cameras mounted on UAVs sufficiently reliable for assessing experimental plots? Eur. J. Agron. 2016, 74, 75–92. [Google Scholar] [CrossRef]
- Tan, L.; Lv, X.; Lian, X.; Wang, G. YOLOv4_Drone: UAV image target detection based on an improved YOLOv4 algorithm. Comput. Electr. Eng. 2021, 93, 107261. [Google Scholar] [CrossRef]
- Kou, M.; Zhuo, L.; Zhang, J.; Zhang, H. Research advances on object detection in Unmanned Aerial Vehicle imagery. Meas. Control. Technol. 2020, 39, 47–61. [Google Scholar] [CrossRef]
- Deng, J.; Ren, G.; Lan, Y.; Huang, H.; Zhang, Y. UAV ultra-low altitude remote sensing image processing based on visible light band. J. South China Agric. Univ. 2016, 37, 16–22. [Google Scholar]
- Fang, Y.; Qiu, X.; Guo, T.; Wang, Y.; Cheng, T.; Zhu, Y.; Chen, Q.; Cao, W.; Yao, X.; Niu, Q.; et al. An automatic method for counting wheat tiller number in the field with terrestrial LiDAR. Plant Methods 2020, 16, 132. [Google Scholar] [CrossRef]
- Fernandez-Gallego, J.A.; Buchaillot, M.L.; Aparicio Gutiérrez, N.; Nieto-Taladriz, M.T.; Araus, J.L.; Kefauver, S.C. Automatic wheat ear counting using thermal imagery. Remote Sens. 2019, 11, 751. [Google Scholar] [CrossRef]
- Zhou, C.; Liang, D.; Yang, X.; Xu, B.; Yang, G. Recognition of wheat spike from field based phenotype platform using multi-sensor fusion and improved maximum entropy segmentation algorithms. Remote Sens. 2018, 10, 246. [Google Scholar] [CrossRef]
- Li, Y.; Du, S.; Yao, M.; Yi, Y.; Yang, J.; Ding, Q.; He, R. Method for wheatear counting and yield predicting based on image of wheatear population in field. Nongye Gongcheng Xuebao Trans. Chin. Soc. Agric. Eng. 2018, 34, 185–194. [Google Scholar]
- Shrestha, B.L.; Kang, Y.M.; Yu, D.; Baik, O.D. A two-camera machine vision approach to separating and identifying laboratory sprouted wheat kernels. Biosyst. Eng. 2016, 147, 265–273. [Google Scholar] [CrossRef]
- Cao, M.; Zhang, L.; Wang, Q. Rapid extraction of street tree information from UAV remote sensing images. J. Cent. South Univ. For. Sci. Technol. 2016, 36, 89–93. [Google Scholar]
- He, Y.; Zhou, X.; Huang, H.; Xue, Q. Extraction of subtropical forest stand numbers based on UAV remote sensing. Remote Sens. Technol. Appl. 2018, 33, 168–176. [Google Scholar]
- Teng, W.; Wen, X.; Wang, N.; Shi, H. Single-wood canopy extraction from high-resolution remote sensing images based on iterative H-minima improved watershed algorithm. Adv. Lasers Optoelectron. 2018, 55, 499–507. [Google Scholar]
- Narkhede, P.R.; Gokhale, A.V. Color image segmentation using edge detection and seeded region growing approach for CIELab and HSV color spaces. In Proceedings of the 2015 International Conference on Industrial Instrumentation and Control (ICIC), Pune, India, 28–30 May 2015; pp. 1214–1218. [Google Scholar]
- Jermsittiparsert, K.; Abdurrahman, A.; Siriattakul, P.; Sundeeva, L.A.; Hashim, W.; Rahim, R.; Maseleno, A. Pattern recognition and features selection for speech emotion recognition model using deep learning. Int. J. Speech Technol. 2020, 23, 799–806. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ren, S.; He, K.; Girshick, R. Faster R-CNN: Towards real-time object detection with region proposal net-works. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, Y.; He, K. R-fcn: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Processing Syst. 2016, 29. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Chen, R.C. Automatic License Plate Recognition via sliding-window darknet-YOLO deep learning. Image Vis. Comput. 2019, 87, 47–56. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Mahto, P.; Garg, P.; Seth, P.; Panda, J. Refining Yolov4 for vehicle detection. Int. J. Adv. Res. Eng. Technol. (IJARET) 2020, 11, 409–419. [Google Scholar]
- Huang, Y.; Fang, L.; Huang, S.; Gao, H.; Yang, L.; Lou, X. Research on tree crown extraction based on improved Faster R-CNN model. For. Resour. Manag. 2021, 1, 173–179. [Google Scholar] [CrossRef]
- Jing, W.; Hu, H.; Cheng, C.; Li, C.; Jing, X.; Guo, Z. Ground apple identification and counting based on deep learning. Jiangsu Agric. Sci. 2020, 48, 210–219. [Google Scholar]
- Chen, F.; Zhu, X.; Zhou, W.; Gu, M.; Zhao, Y. Spruce counting method based on improved YOLOv3 model in UAV images. J. Agric. Eng. 2020, 36, 22–30. [Google Scholar]
- Zheng, Y.; Wu, G. YOLOv4-Lite–Based Urban plantation tree detection and positioning with high-resolution remote sensing imagery. Front. Environ. Sci. 2022, 9, 756227. [Google Scholar] [CrossRef]
- Yang, B.; Gao, Z.; Gao, Y.; Zhu, Y. Rapid detection and counting of wheat ears in the field using YOLOv4 with attention module. Agronomy 2021, 11, 1202. [Google Scholar] [CrossRef]
- Wu, D.; Lv, S.; Jiang, M.; Song, H. Using channel pruning-based YOLO v4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments. Comput. Electron. Agric. 2020, 178, 105742. [Google Scholar] [CrossRef]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Yu, B.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 325–341. [Google Scholar]
- Ba, R.; Chen, C.; Yuan, J.; Song, W.; Lo, S. SmokeNet: Satellite smoke scene detection using convolutional neural network with spatial and channel-wise attention. Remote Sens. 2019, 11, 1702. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. Adv. Neural Inf. Processing Syst. 2015, 28, 2017–2025. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1314–1324. [Google Scholar]
- Liang, X.; Zhang, J.; Zhuo, L.; Li, Y.; Tian, Q. Small object detection in unmanned aerial vehicle images using feature fusion and scaling-based single shot detector with spatial context analysis. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1758–1770. [Google Scholar] [CrossRef]
- Huang, L.; Wang, Y.; Xu, Q.; Liu, Q. Recognition of abnormally discolored trees caused by pine wilt disease using YOLO algorithm and UAV images. J. Agric. Eng. 2021, 37, 197–203. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Yang, J.; Feng, Q.; Wang, S.; Zhang, J.; Yang, S. Method for detection of farmland dense small target based on improved YOLOv4. J. Northeast. Agric. Univ. 2022, 53, 69–79. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Map | 13 × 13 | 26 × 26 | 52 × 52 |
|---|---|---|---|
| Anchors | (16, 18) | (22, 44) | (279, 218) |
| (94, 45) | (125, 115) | (355, 355) | |
| (70, 69) | (156, 162) | (684, 654) |
| Model | mAP | F1-Score | FPS | Model Size (MB) |
|---|---|---|---|---|
| YOLOv4 | 95.88% | 88.08% | 36.62 | 244.0 |
| YOLOv4—SE | 96.69% | 88.54% | 40.00 | 245.0 |
| YOLOv4—CBAM | 96.99% | 88.72% | 36.28 | 246.0 |
| YOLOv4-Mobilenetv3 | 96.73% | 88.42% | 95.70 | 44.3 |
| YOLOv4-Attention-Mobilenetv3 | 97.50% | 90.08% | 104.91 | 44.5 |
| YOLOv4-Attention-Mobilenetv3-ASFF | 97.68% | 90.38% | 101.58 | 50.7 |
| YOLOv4-Attention-Mobilenetv3-ASFF-P | 98.21% | 93.60% | 96.25 | 50.7 |
| Counts | P1 | P2 | P3 | P4 | P5 | P6 | P7 | P8 | P9 | P10 | AOA |
|---|---|---|---|---|---|---|---|---|---|---|---|
| nums | 13 | 10 | 21 | 11 | 23 | 20 | 31 | 73 | 71 | 55 | / |
| Model A | 9 | 8 | 26 | 10 | 14 | 19 | 33 | 53 | 50 | 34 | 77.06% |
| Model B | 11 | 9 | 20 | 10 | 15 | 20 | 27 | 60 | 57 | 41 | 85.01% |
| Model C | 12 | 9 | 21 | 10 | 20 | 20 | 29 | 69 | 63 | 49 | 92.61% |
| Model D | 13 | 10 | 21 | 11 | 21 | 20 | 30 | 78 | 65 | 52 | 96.73% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Y.; Zhou, J.; Yang, Y.; Liu, L.; Liu, F.; Kong, W. Rapid Target Detection of Fruit Trees Using UAV Imaging and Improved Light YOLOv4 Algorithm. Remote Sens. 2022, 14, 4324. https://doi.org/10.3390/rs14174324
Zhu Y, Zhou J, Yang Y, Liu L, Liu F, Kong W. Rapid Target Detection of Fruit Trees Using UAV Imaging and Improved Light YOLOv4 Algorithm. Remote Sensing. 2022; 14(17):4324. https://doi.org/10.3390/rs14174324
Chicago/Turabian StyleZhu, Yuchao, Jun Zhou, Yinhui Yang, Lijuan Liu, Fei Liu, and Wenwen Kong. 2022. "Rapid Target Detection of Fruit Trees Using UAV Imaging and Improved Light YOLOv4 Algorithm" Remote Sensing 14, no. 17: 4324. https://doi.org/10.3390/rs14174324
APA StyleZhu, Y., Zhou, J., Yang, Y., Liu, L., Liu, F., & Kong, W. (2022). Rapid Target Detection of Fruit Trees Using UAV Imaging and Improved Light YOLOv4 Algorithm. Remote Sensing, 14(17), 4324. https://doi.org/10.3390/rs14174324