
Optical Remote Sensing Image Cloud Detection with Self-Attention and Spatial Pyramid Pooling Fusion



Abstract
:
1. Introduction
- (1)
- We innovatively introduce a new attention module with a large convolution kernel and design a cloud detection network model that fuses a global self-attention module with spatial pyramidal pooling, detecting and combining global features with local features to improve the detection accuracy of gauzy cloud regions and cloud pixels of edge regions.
- (2)
- Previous cloud detection experiments were carried out only on a single data source or a few types of sensors, while we have carried out richer cloud detection experiments on only visible three-channel images and various types of commonly used optical data, verifying the reliability and robustness of our proposed new cloud detection model.
- (3)
- The model design idea of our cloud detection can provide some new insights to other remote sensing image information extraction methods, such as change detection, object detection, or object extraction.
1.1. Related Work
1.1.1. Attention Module
1.1.2. Spatial Pyramid Pooling Module
2. Materials and Methods
2.1. Data
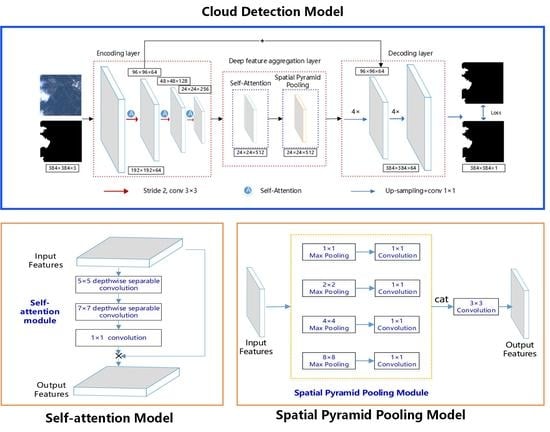
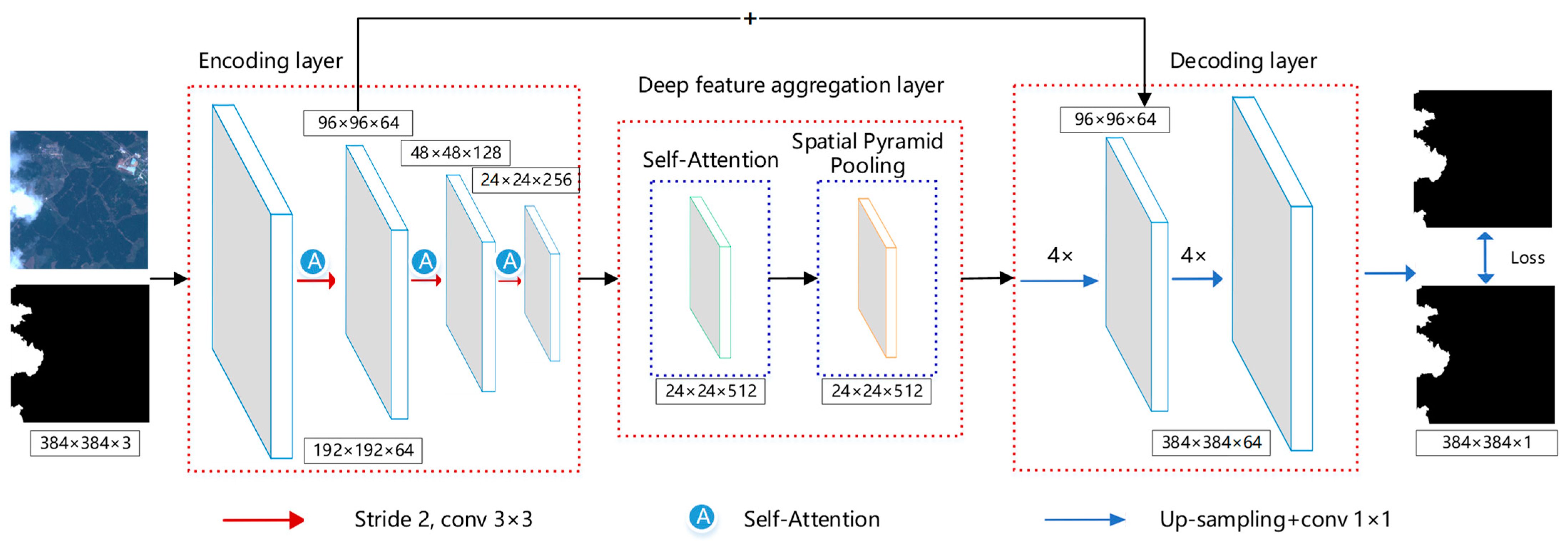
2.2. Proposed Cloud Detection Module
2.3. Encoding Layer
2.4. Deep Feature Integration Layer
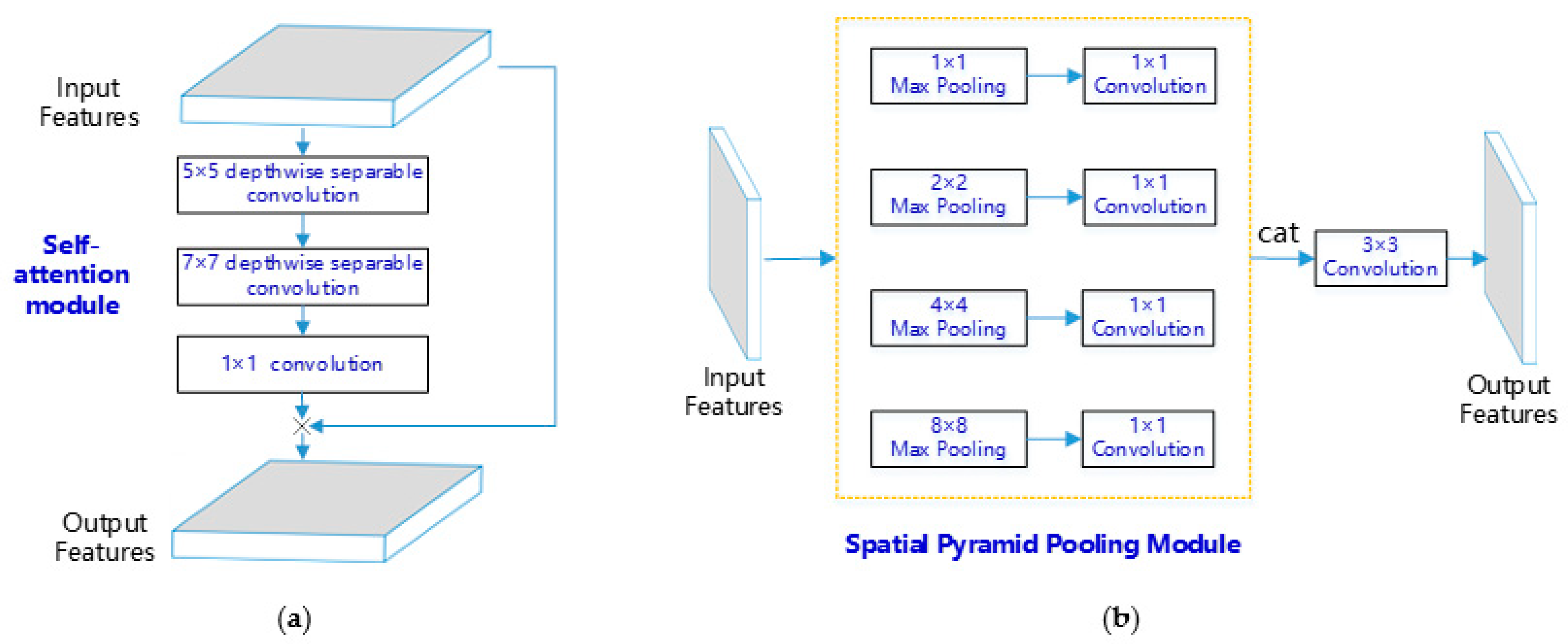
2.4.1. Proposed Self-Attention Module
2.4.2. Spatial Pyramid Pooling Module
2.5. Decoding Layer
2.5.1. Multi-Scale Feature Fusion
2.5.2. Optimization Function
2.6. Accuracy Assessment
3. Results
3.1. Parameter Setting
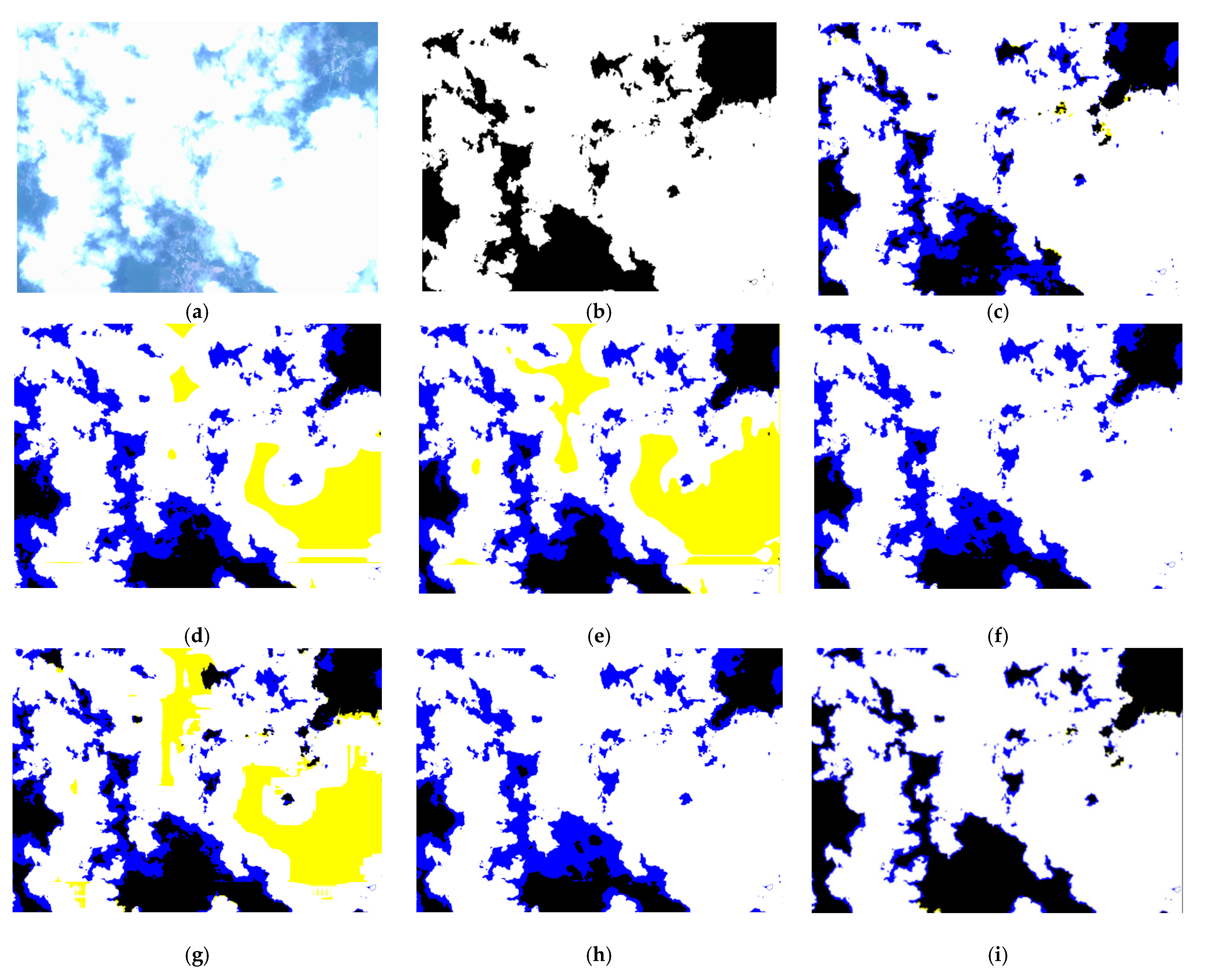
3.2. Comparison with Feature-Based Cloud Detection Methods
3.3. Comparison with Other Cloud Detection Methods Based on Deep Learning Methods
4. Discussion
4.1. Ablation Study
4.2. Generalization Ability Discussion
4.3. Efficiency Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, J.F.; Wang, L.Y.; Liu, S.Q.; Peng, B.A.; Ye, H.P. An automatic cloud detection model for Sentinel-2 imagery based on Google Earth Engine. Remote Sens. Lett. 2022, 13, 196–206. [Google Scholar] [CrossRef]
- Luo, C.; Feng, S.S.; Yang, X.F.; Ye, Y.M.; Li, X.T.; Zhang, B.Q.; Chen, Z.H.; Quan, Y.L. LWCDnet: A Lightweight Network for Efficient Cloud Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5409816. [Google Scholar] [CrossRef]
- Zhang, H.D.; Wang, Y.; Yang, X.L. Cloud detection for satellite cloud images based on fused FCN features. Remote Sens. Lett. 2022, 13, 683–694. [Google Scholar] [CrossRef]
- Li, X.; Yang, X.F.; Li, X.T.; Lu, S.J.; Ye, Y.M.; Ban, Y.F. GCDB-UNet: A novel robust cloud detection approach for remote sensing images. Knowl.-Based Syst. 2022, 238, 107890. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Li, H.; Xia, G.; Gamba, P.; Zhang, L. Multi-feature combined cloud and cloud shadow detection in GaoFen-1 wide field of view imagery. Remote Sens. Environ. 2017, 191, 342–358. [Google Scholar] [CrossRef]
- Qiu, S.; Zhu, Z.; He, B. Fmask 4.0: Improved cloud and cloud shadow detection in Landsats 4–8 and Sentinel-2 imagery. Remote Sens. Environ. 2019, 231, 111205. [Google Scholar] [CrossRef]
- Zhai, H.; Zhang, H.; Zhang, L.; Li, P. Cloud/shadow detection based on spectral indices for multi/hyperspectral optical remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2018, 144, 235–253. [Google Scholar] [CrossRef]
- Satpathy, A.; Jiang, X.D.; Eng, H.L. LBP-Based Edge-Texture Features for Object Recognition. IEEE Trans. Image Process. 2014, 24, 1953–1964. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Cheng, Q.; Liu, Y.; You, S.; He, Z. Deep learning based cloud detection for medium and high resolution remote sensing images of different sensors. ISPRS J. Photogramm. Remote Sens. 2019, 150, 197–212. [Google Scholar] [CrossRef]
- Wei, J.; Huang, W.; Li, Z.Q.; Sun, L.; Zhu, X.L.; Yuan, Q.Q.; Liu, L.; Cribb, M. Cloud detection for Landsat imagery by combining the random forest and superpixels extracted via energy-driven sampling segmentation approaches. Remote Sens. Environ. 2020, 248, 112005. [Google Scholar] [CrossRef]
- Abdar, M.; Pourpanah, F.; Hussain, S.; Rezazadegan, D.; Liu, L.; Ghavamzadeh, M.; Nahavandi, S. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Inf. Fusion 2021, 76, 243–297. [Google Scholar] [CrossRef]
- Jeppesen, J.H.; Jacobsen, R.H.; Inceoglu, F.; Toftegaard, T.S. A cloud detection algorithm for satellite imagery based on deep learning. Remote Sens. Environ. 2019, 229, 247–259. [Google Scholar] [CrossRef]
- Yang, J.Y.; Guo, J.H.; Yue, H.J.; Liu, Z.H.; Hu, H.F.; Li, K. CDnet: CNN-Based Cloud Detection for Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6195–6211. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- He, Q.B.; Sun, X.; Yan, Z.Y.; Fu, K. DABNet: Deformable Contextual and Boundary-Weighted Network for Cloud Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5601216. [Google Scholar] [CrossRef]
- Li, H.; Xiong, P.; Fan, H.; Sun, J. DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9514–9523. [Google Scholar]
- Mohajerani, S.; Saeedi, P. Cloud-Net: An End-to-End Cloud Detection Algorithm for Landsat 8 Imagery. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium (IGARSS 2019), Yokohama, Japan, 28 July–2 August 2019; pp. 1029–1032. [Google Scholar]
- Wu, X.; Shi, Z.W.; Zou, Z.X. A geographic information-driven method and a new large scale dataset for remote sensing cloud/snow detection. ISPRS J. Photogramm. Remote Sens. 2021, 174, 87–104. [Google Scholar] [CrossRef]
- Zhang, J.; Zhou, Q.; Wu, J.; Wang, Y.C.; Wang, H.; Li, Y.S.; Chai, Y.Z.; Liu, Y. A Cloud Detection Method Using Convolutional Neural Network Based on Gabor Transform and Attention Mechanism with Dark Channel Subnet for Remote Sensing Image. Remote Sens. 2020, 12, 3261. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, J.; Wang, H.; Wang, Y.C.; Li, Y.S. Cloud Detection Method Using CNN Based on Cascaded Feature Attention and Channel Attention. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4104717. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.J.; Li, Y.; Bao, Y.J.; Fang, Z.W.; Lu, H.Q. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]
- Huang, Z.L.; Wang, X.G.; Huang, L.C.; Huang, C.; Wei, Y.C.; Liu, W.Y. CCNet: Criss-Cross Attention for Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 603–612. [Google Scholar]
- Lv, N.; Zhang, Z.H.; Li, C.; Deng, J.X.; Su, T.; Chen, C.; Zhou, Y. A hybrid-attention semantic segmentation network for remote sensing interpretation in land-use surveillance. Int. J. Mach. Learn. Cybern. 2022, 1, 1–12. [Google Scholar] [CrossRef]
- Qing, Y.H.; Huang, Q.Z.; Feng, L.Y.; Qi, Y.Y.; Liu, W.Y. Multiscale Feature Fusion Network Incorporating 3D Self-Attention for Hyperspectral Image Classification. Remote Sens. 2022, 14, 742. [Google Scholar] [CrossRef]
- Jamali, A.; Mahdianpari, M. Swin Transformer and Deep Convolutional Neural Networks for Coastal Wetland Classification Using Sentinel-1, Sentinel-2, and LiDAR Data. Remote Sens. 2022, 14, 359. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Zhou, Y.; Han, J.; Ding, G.; Sun, J. Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs. arXiv 2022, arXiv:2203.06717. [Google Scholar]
- Guo, M.-H.; Lu, C.-Z.; Liu, Z.-N.; Cheng, M.-M.; Hu, S.-M. Visual attention network. arXiv 2022, arXiv:2202.09741. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 14 July 2022).
- Lee, J.D.M.C.K.; Toutanova, K. Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Yuan, Y.; Huang, L.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. Ocnet: Object context network for scene parsing. arXiv 2018, arXiv:1809.00916. [Google Scholar]
- Chen, C.F.R.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 357–366. [Google Scholar]
- Sun, Y.; Gao, W.; Pan, S.; Zhao, T.; Peng, Y. An efficient module for instance segmentation based on multi-level features and attention mechanisms. Appl. Sci. 2021, 11, 968. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 783–792. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. Parsenet: Looking wider to see better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- Zhao, L.; Dong, X.; Chen, W.Y.; Jiang, L.F.; Dong, X.J. The combined cloud model for edge detection. Multimed. Tools Appl. 2017, 76, 15007–15026. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. SCA-CNN: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Hassani, I.K.; Pellegrini, T.; Masquelier, T. Dilated convolution with learnable spacings. arXiv 2021, arXiv:2112.03740. [Google Scholar]
- Peng, J.; Liu, Y.; Tang, S.; Hao, Y.; Chu, L.; Chen, G.; Ma, Y. PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model. arXiv 2022, arXiv:2204.02681. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. Med. Image Comput. Comput.-Assist. Interv. 2015, 9351 Pt III, 234–241. [Google Scholar]
- Yuan, Y.; Rao, F.; Lang, H.; Lin, W.; Zhang, C.; Chen, X.; Wang, J. HRFormer: High-Resolution Transformer for Dense Prediction. arXiv 2021, arXiv:2110.09408. [Google Scholar]
- Wang, H.; Xie, S.; Lin, L.; Iwamoto, Y.; Han, X.-H.; Chen, Y.-W.; Tong, R. Mixed transformer u-net for medical image segmentation. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 2390–2394. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Sources | Training Set (Train Model) | Test Set (for Selecting the Optimal Model) | Validation Set (for Comparing Algorithm Accuracy) |
|---|---|---|---|
| Landsat8 | 15,781 | 5260 | 5260 |
| GF-2 | 6590 | 2196 | 2196 |
| Satellite | Spatial Resolution | Data ID | Season | Topography | Land Cover Types |
|---|---|---|---|---|---|
| GF-6 WFV | 16 m | GF6_WFV_E79.7_N29.1_20201230_ L1A1120067165 | Winter | Plateaus, Plains | Snow, forest, grassland, cropland |
| GF-1 WFV | 16 m | GF1_WFV2_E118.3_N49.2_20200527_L1A0004828354 | Spring | Mountains | Urban, forest, cropland, shrubland |
| Landsat9 | 30 m | LC09_L2SP_178026_20220327_20220329_02_T1 | Spring | Plains | Water bodies, cropland, wetlands |
| Beijing-2 | 3.2 m | PMS_L1_20201103023341_003023VI_002_0120201221002001_005 | Autumn | Hills | Urban, forest, cropland |
| Sentinel-2 | 10 m | 20220623T025529_20220623T031001_ T49QGE | Summer | Plains | Urban, water, cropland |
| Algorithm | Journal | Principles | Band List (Landsat8) | Reference Code Address and Parameters Setting |
|---|---|---|---|---|
| Fmask | RSE | For the open-sourced Landsat5-Landsat8, and Sentinel-2 data, which are widely used globally, the authors improve the differentiation between clouds and snow by introducing DEM with global surface water coverage data and combining a new spectral-contextual snow index. By conducting a large number of experimental comparisons in different regions of the world, the authors show that the method is effective and has a high practical value, and it has been used by GEE (Google Earth Engine) as the official optical data cloud masking algorithm. | Visible light (RGB) + Near-infrared (NIR) + Short wave infrared (SWIR) + Thermal infrared (TIR) | We use the official Fmask algorithm at GEE, the source code is: https://code.earthengine.google.com/361fc7a4b6d1b6817030d501b0d2b01e (accessed on 14 March 2022) |
| MFC | RSE | For the Chinese GF-1 WFV data, a cloud and cloud shadow detection algorithm with the fusion of spectral indices and geometric features is proposed. For the problem that it is difficult to distinguish the highlighted object from the cloud target, the authors use shape feature constraints to solve this difficult problem, and for the cloud–snow mixing region, LBP texture is used to assist in the improvement. Finally, cloud and cloud shadow detection experiments are conducted on different scenes to prove the effectiveness of the method. | Visible light (RGB) + Near-infrared (NIR) | The official software is downloaded from http://sendimage.whu.edu.cn/en/mfc/ (accessed on 1 July 2017), and the key parameters are set using the recommended settings of the paper, where the shape feature FRAC is set to 1.4, which is due to the optimal results achieved on the images used in this paper. |
| CSD-SI | ISPRS | Previous feature-based cloud and cloud shadow detection algorithms can only be adapted to the problem of a single sensor. The authors propose a new spectral index for detecting multispectral and hyperspectral optical image cloud and shadow targets, and the literature achieves better experimental results on different data sources such as Landsat5, Landsat7, Landsat8, and GF-1, which verifies the effectiveness and robustness of the new cloud detection feature index. | Visible light (RGB) + Near-infrared (NIR) | The algorithm was replicated using Matlab 2020b, where the T1 parameter was set to 0.02 and t2 was set to 1/4. |
| Methods | Accuracy | Recall | Precision | F1-Score | IOU |
|---|---|---|---|---|---|
| Fmask | 0.8351 | 0.8794 | 0.3895 | 0.5399 | 0.3693 |
| MFC | 0.7766 | 0.2449 | 0.1611 | 0.1943 | 0.1076 |
| CSD-SI | 0.8268 | 0.2866 | 0.2497 | 0.2669 | 0.1539 |
| Proposed method | 0.9419 | 0.8693 | 0.7297 | 0.7934 | 0.5865 |
| Methods | Journal | Model Characteristics |
|---|---|---|
| DeeplabV3+ | ECCV | This model is a semantic segmentation algorithm for natural images. The core idea is the use of a spatial pyramid pooling module to perceive object features of different scales and sizes by fusing multi-scale contextual semantic features, and the overall architecture is simple and effective, with smooth and accurate object segmentation boundaries. In our comparison experiments, ResNet50 is used as the backbone feature network to extract depth features. For the pyramid pooling module of this network, we use {1,6,12,18} as the atrous convolution parameters. |
| MT-Unet | ICASSP | The model is a segmentation network developed for medical images. Unlike the CNN architecture, the core module of this network is developed based on the transformer, and the overall architecture still adopts an encoder-decoder architecture similar to U-net, with the major innovation being the design of a self-attention module with local-global Gaussian adaptive weights, which makes the extracted features richer. Experiments are conducted on medical images, and the results show that the highest accuracy is achieved. Since the attention module we use is also global feature extraction, the transformer network is chosen for comparison. |
| MSCFF | ISPRS | This model is a cloud detection algorithm for optical remote sensing images, and its main idea is to use a segmentation network similar to the U-net architecture, and the core is similar to DeeplabV3+ in employing multi-scale expansion convolution to obtain the depth semantic features of cloud targets at different scales, which has shown good experimental accuracy in different data sources at home and abroad. In our comparison experiments, the original parameter settings are used, the last two encoding modules and the beginning two decoding modules of MSCFF, and the expansion convolution parameters are set to 2 and 4. |
| CDNet | TGRS | This model is a cloud detection algorithm for complex scenarios such as cloud–snow coexistence, and its main idea is to use a multi-scale feature pyramid module with a boundary optimization module, which shows high experimental accuracy on China ZY-3 images. Since the network was originally designed for thumbnail image cloud detection, we use it for the original true-color images for the sake of fairness of comparison, and the backbone features use the improved ResNet50 network from the original paper. |
| RS-net | RSE | This model is a cloud detection algorithm for optical remote sensing images, and its main idea is based on U-net for improvement. The authors use the cloud mask results detected by the Fmask algorithm as training samples and restart training the network model, which has higher accuracy than Fmask on the test dataset and can effectively distinguish cloud–snow mixed pixels, proving the effectiveness and robustness of deep learning methods in cloud detection. |
| GCDB-UNet | KBS | This model is mainly a cloud detection network developed for difficult scenarios such as gauzy clouds. The core idea is to develop a non-local attention module to model complex scenes in context, which effectively improves the detection accuracy of gauzy clouds. The authors demonstrate the effectiveness of the model by conducting experiments on the self-developed MODIS dataset. |
| Methods | Accuracy | Recall | Precision | F1-Score | IOU |
|---|---|---|---|---|---|
| DeeplabV3 | 0.90386 | 0.8754 | 0.8543 | 0.8647 | 0.7614 |
| MT-Unet | 0.8856 | 0.9312 | 0.7836 | 0.8511 | 0.7407 |
| MSCFF | 0.8857 | 0.8750 | 0.8135 | 0.8431 | 0.7288 |
| CDNet | 0.9051 | 0.9961 | 0.7891 | 0.8806 | 0.7867 |
| RS-net | 0.8275 | 0.7719 | 0.7456 | 0.7585 | 0.6110 |
| GCDB-UNet | 0.8915 | 0.9970 | 0.7650 | 0.8657 | 0.7632 |
| Proposed method | 0.9375 | 0.9868 | 0.8568 | 0.9172 | 0.8471 |
| Module Selection | Accuracy | Recall | Precision | F1-Score | IOU |
|---|---|---|---|---|---|
| backbone model | 0.8642 | 0.8541 | 0.8265 | 0.8400 | 0.7551 |
| +PPM | 0.9038 | 0.9173 | 0.8378 | 0.8757 | 0.8097 |
| +self-attention | 0.9281 | 0.9459 | 0.8408 | 0.8902 | 0.8259 |
| +PPM+self-attention | 0.9375 | 0.9868 | 0.8568 | 0.9172 | 0.8417 |
| Image Data Source | Spatial Resolution (m) | Image Size (Pix) | Accuracy | Recall | Precision | F1-Score | IOU |
|---|---|---|---|---|---|---|---|
| GF-1 WFV | 16 | 13,400 × 12,000 × 3 | 0.9733 | 0.9093 | 0.9203 | 0.9147 | 0.8913 |
| GF-6 WFV | 16 | 17,797 × 12,817 × 3 | 0.9861 | 0.9187 | 0.9370 | 0.9278 | 0.9153 |
| Landsat9 | 30 | 7761 × 7861 × 3 | 0.9822 | 0.9574 | 0.9988 | 0.9777 | 0.9563 |
| Beijing-2 | 3.2 | 7815 × 7260 × 3 | 0.9977 | 0.9277 | 0.9458 | 0.9366 | 0.9261 |
| Sentinel-2 | 10 | 10,922 × 10,940 | 0.9828 | 0.9449 | 0.9090 | 0.9266 | 0.9197 |
| Algorithm | Time-Consuming (s) |
|---|---|
| DeeplabV3 | 19.03 |
| MT-Unet | 18.71 |
| MSCFF | 28.21 |
| CDNet | 25.98 |
| RS-net | 19.29 |
| GCDB-UNet | 26.37 |
| Proposed algorithm | 16.08 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pu, W.; Wang, Z.; Liu, D.; Zhang, Q. Optical Remote Sensing Image Cloud Detection with Self-Attention and Spatial Pyramid Pooling Fusion. Remote Sens. 2022, 14, 4312. https://doi.org/10.3390/rs14174312
Pu W, Wang Z, Liu D, Zhang Q. Optical Remote Sensing Image Cloud Detection with Self-Attention and Spatial Pyramid Pooling Fusion. Remote Sensing. 2022; 14(17):4312. https://doi.org/10.3390/rs14174312
Chicago/Turabian StylePu, Weihua, Zhipan Wang, Di Liu, and Qingling Zhang. 2022. "Optical Remote Sensing Image Cloud Detection with Self-Attention and Spatial Pyramid Pooling Fusion" Remote Sensing 14, no. 17: 4312. https://doi.org/10.3390/rs14174312
APA StylePu, W., Wang, Z., Liu, D., & Zhang, Q. (2022). Optical Remote Sensing Image Cloud Detection with Self-Attention and Spatial Pyramid Pooling Fusion. Remote Sensing, 14(17), 4312. https://doi.org/10.3390/rs14174312