

Deep Pansharpening via 3D Spectral Super-Resolution Network and Discrepancy-Based Gradient Transfer


Abstract
:
1. Introduction
2. Related Work
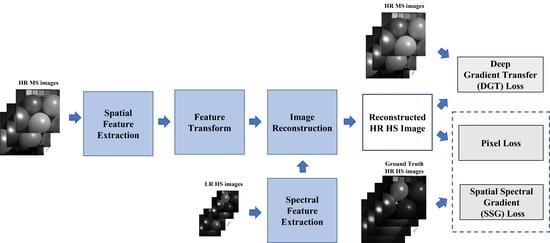
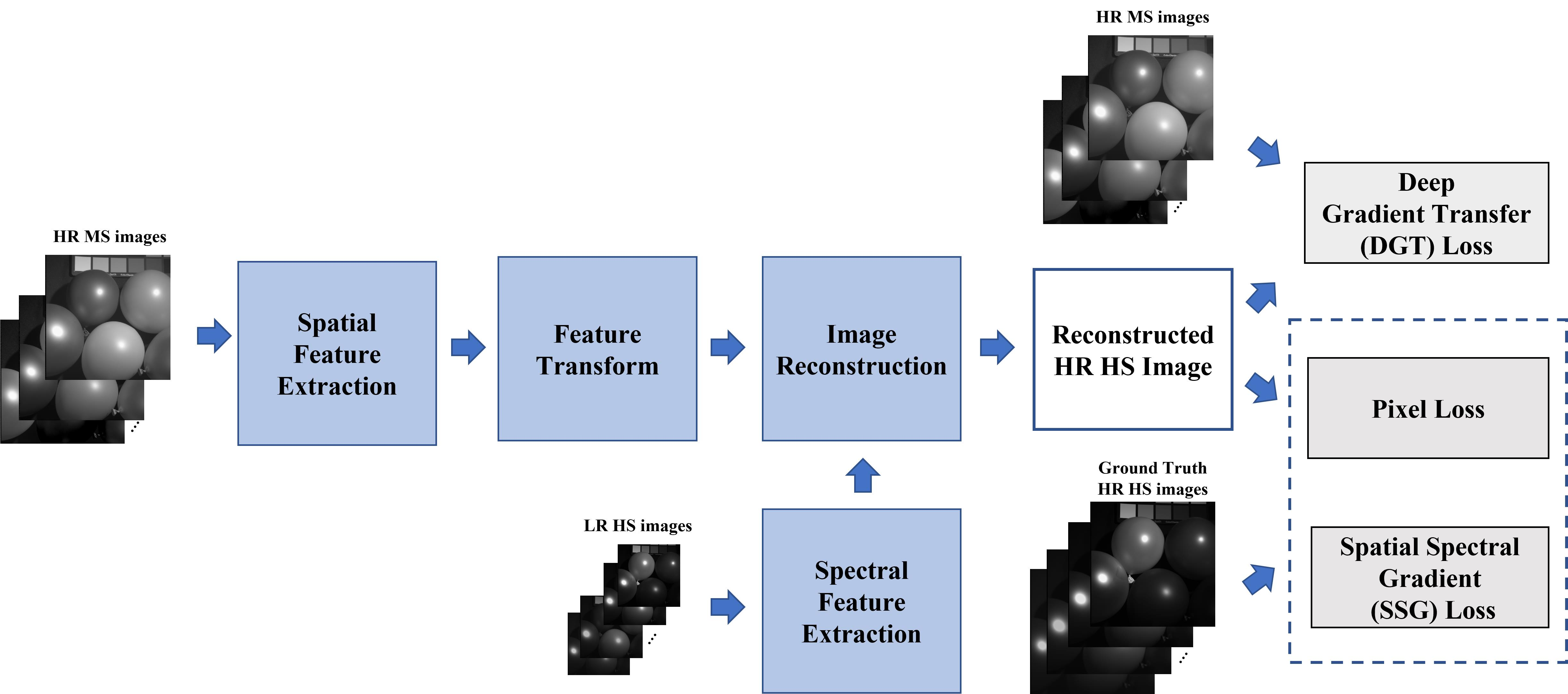
- We propose a supervised 3D-CNN-based spectral super-resolution network of HR MS images for pansharpening. The 3D CNN is employed to consider the spatial and spectral correlation simultaneously with thespectral super-resolution. Compared to the state-of-the-art methods, extensive experiments show that the proposed method achieves the best performance in spectral and spatial preservation from HR HS images.
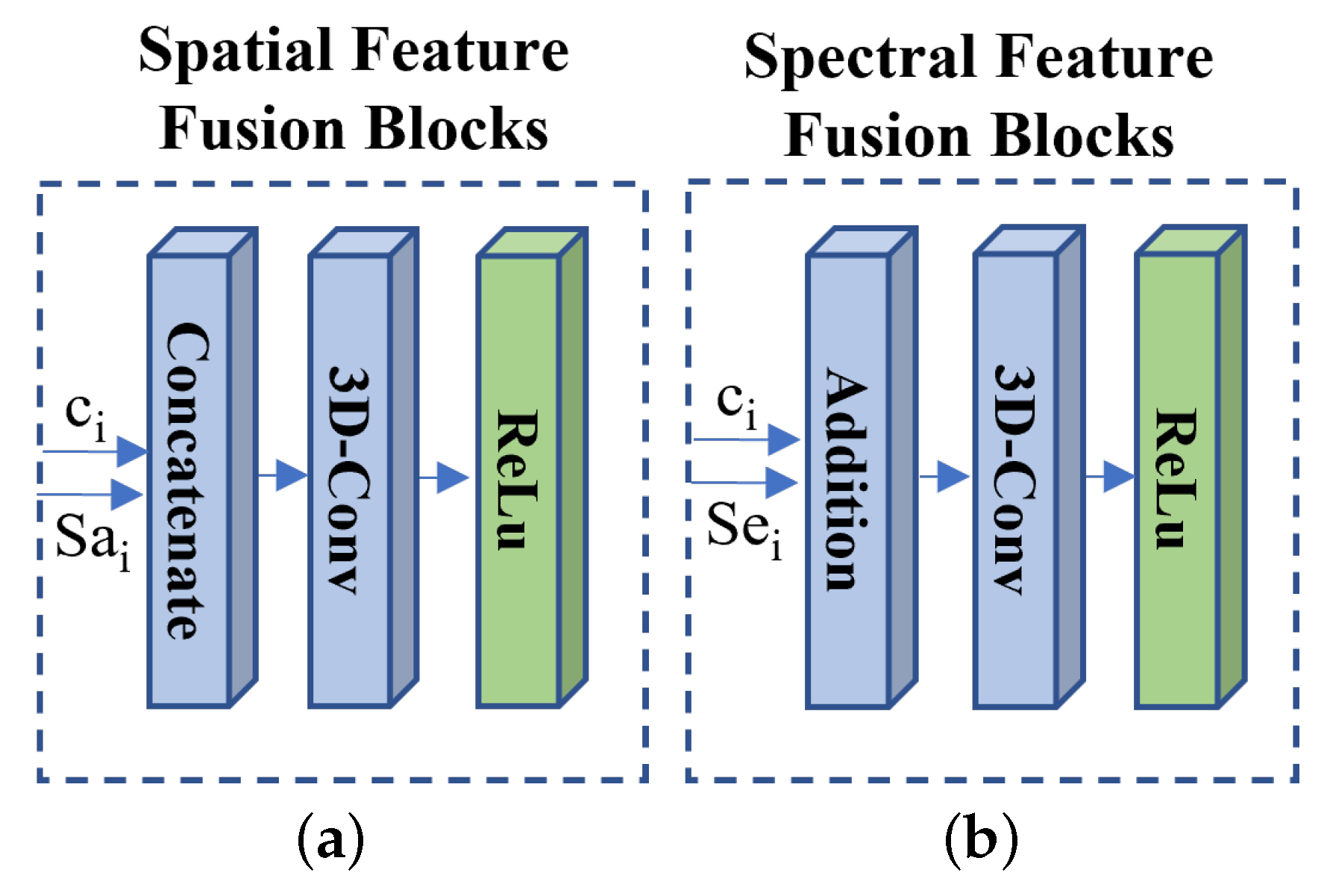
- The 3D spectral super-resolution network constructs the encoder–decoder framework. In the decoder part, we design the image reconstruction network with a set of skip connections and spatial–spectral fusion (SSF) blocks, which fuse the spatial and spectral features efficiently.
- We define the discrepancy-based deep hybrid gradient (DDHG) losses, which contain the spatial–spectral gradient (SSG) loss and deep gradient transfer (DGT) losses. The losses are developed to constrain the spatial and spectral consistency from the ground truth HS images and HR MS images. To overcome the spatial and spectral discrepancy between two images, we design the spectral downsampling (SD) network and gradient consistency estimation (GCE) network in the DDHG losses.
3. Proposed Method
3.1. Motivation
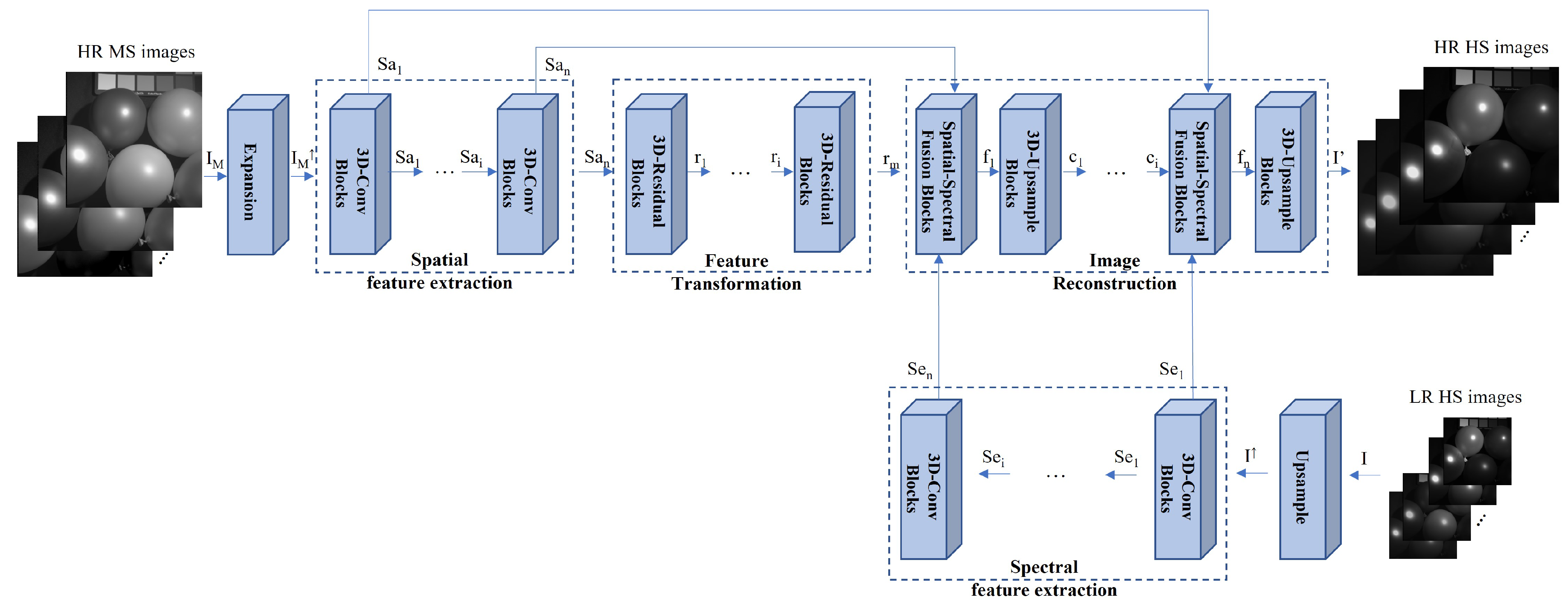
3.2. Spectral Super-Resolution Network
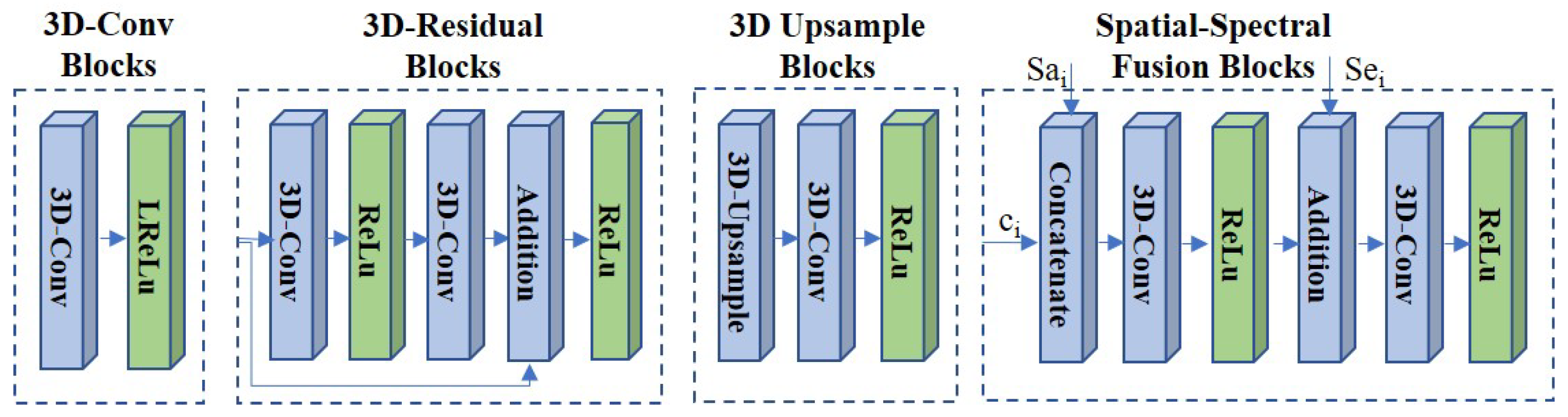
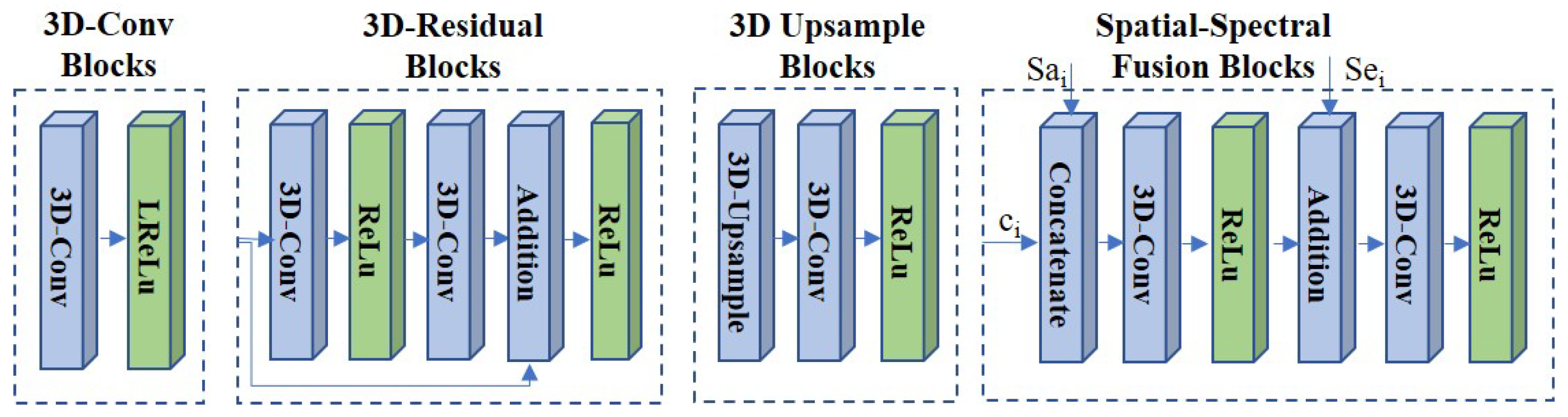
- The 3D-Conv blocks: In the SFE network, we employed the 3D-Conv blocks with the kernel size of and stride of . Then, the leaky rectified linear unit (LReLU) activation is used. The 3D-Conv block is introduced to extract the spatial–spectral feature and from HR MS image and LR HS image I.
- The 3D residual blocks: In the FT network, 3D residual blocks are used to learn the extracted feature more efficiently in deep layers via residual learning [26]. In each block, we applied the 3D-Conv blocks with a kernel size of and stride of . The ReLU layers are utilized as the output layer. The addition layer is employed to concatenate the input feature and the learned residual feature.
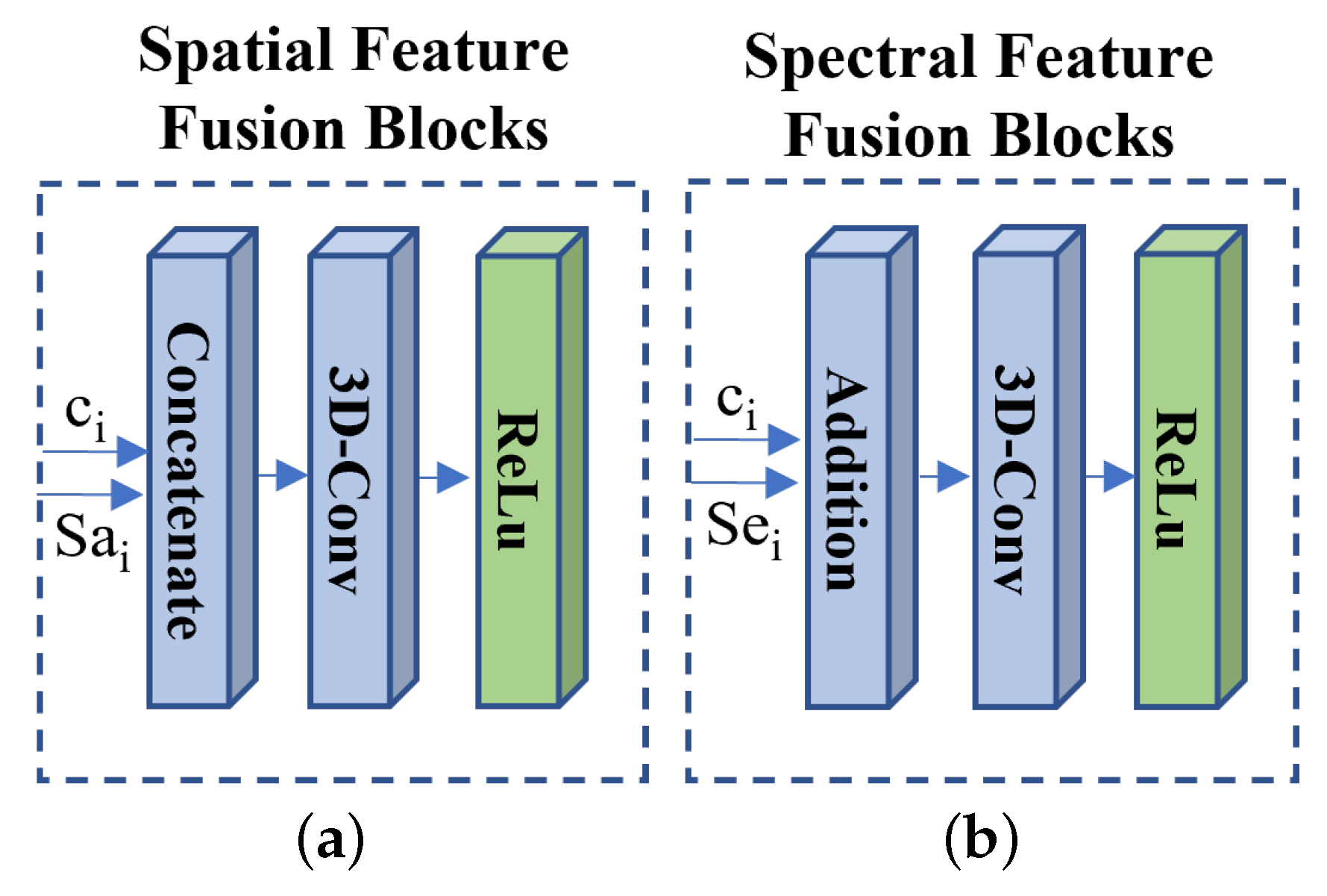
- The spatial–spectral fusion (SSF) blocks: In the image reconstruction network, the SSF blocks with a set of skip connections are utilized to fuse the reconstructed feature with the extracted spatial feature and the spectral feature efficiently. It can overcome the extracted feature distortion in the feature transform network. We utilized the concatenate operation and addition operation to fuse the spatial feature and the spectral feature respectively. We employed the 3D-Conv layer (kernel size: and stride: ) with the ReLU activation to transform the fused feature.
- The 3D upsample blocks: After the SSF blocks, we introduced the 3D upsample blocks to increase the spatial and spectral resolution. In each block, the 3D upsample layer with the nearest neighbor interpolation is first applied to generate the upsampled feature with enhanced spatial and spectral resolution. Then, the 3D-Conv layer (kernel size: and stride: ) with the ReLU activation is employed to generate the reconstructed feature . The 3D upsample blocks are applied to provide the spatial and spectral super-resolution of the reconstructed feature and obtain the resulting images .
3.3. Loss Function
- (1)
- Pixel loss: The pixel loss function enforces the pixel intensity consistency (content loss), which is defined as the -norm between the reconstructed image and the ground truth :where i, j, and k are the pixel location in the image. The -norm has been widely used in super-resolution with less blurring results compared to the -norm [27].
- (2)
- Spatial–spectral gradient (SSG) loss: To enforce the gradient consistency in terms of the spatial and spectral domains from the ground truth, we designed the 3D spatial–spectral gradient loss using the -norm as follows:where , , and are the gradient operators (i.e., forward difference operator) to obtain the x-, y-, and z-direction gradients of images. is the ground truth HS image. This loss can preserve the spatial and spectral gradients from the ground truth HS images. and measure the spatial gradient consistency estimation between the reconstructed HS images and HR MS images (we mention them in the next section).
- (3)
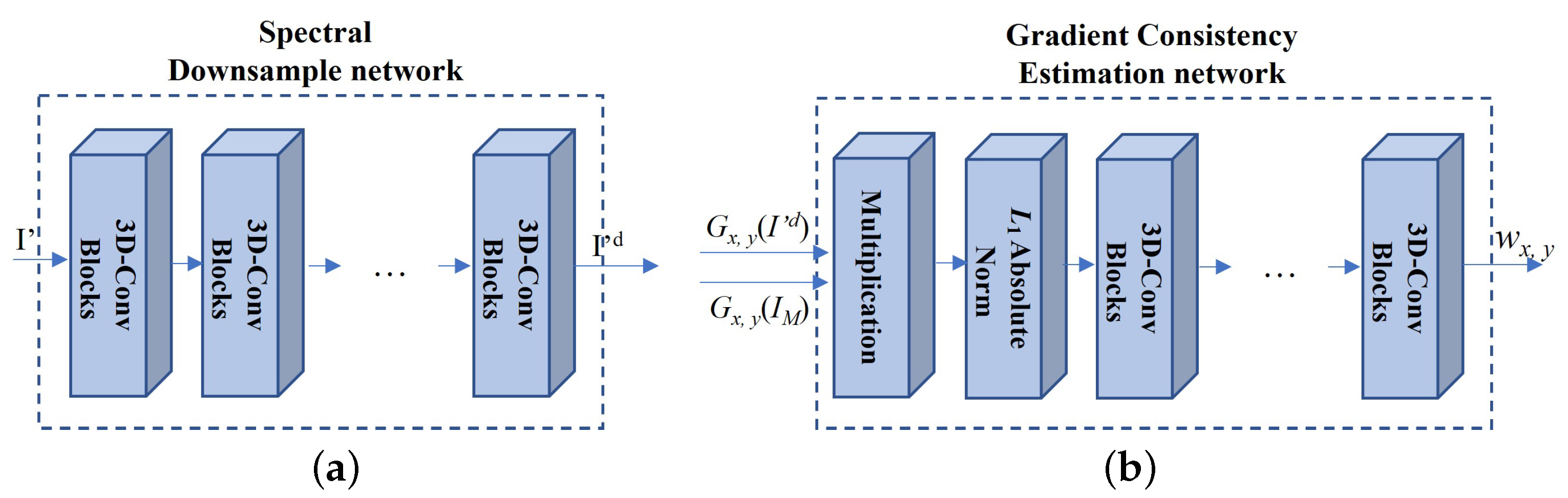
- Deep gradient transfer (DGT) loss: deep gradient transfer loss is designed to transfer the structure of HR MS images to the reconstructed HS images. However, HS and MS images have a large discrepancy in the spatial gradient and spectral channels. To overcome the spatial and spectral discrepancy, the GCE net and SD net are utilized while transferring the structure of the HR MS images. The DGT loss is designed as follows:where is the spectral downsampled version of the reconstructed HS images. It is generated by , which is the spectral downsample network (SD network) (see Figure 4) with several 3D-Conv blocks (see the left subfigure in Figure 3) (kernel size: (3, 3, 3) and stride: (1, 1, 2)). The output images have the same spectral channels as the HR MS images. To tackle the spatial discrepancy, the deep spatial gradient consistency (i.e., and ) between the spectral downsampled HS images and HR MS images is estimated as follows:where is the gradient consistency estimation (GCE) network with one multiplication operation, one absolute norm operation, and several 3D-Conv blocks (see the right subfigure in Figure 4) (kernel size: (3, 3, 3) and the stride: (1, 1, 1)). The multiplication operation is utilized to obtain the consistency gradient of the downsampled HS images and the HR MS images. Then, the absolute norm of the consistency gradient is obtained. Finally, the convolution symbol is included in the GCE network, which learns the consistency structure from the multiplication of the two image gradients. is the weight of the output of GCE network and is set to 10 in the proposed method.
4. Experiments
4.1. Dataset and Evaluation Metrics
- (1)
- CAVE dataset: The CAVE dataset consists of 32 images with a spatial size of and the total spectral channels of 31 bands. The band range is from 400 nm to 700 nm. The size of the HR MS image is . The first 20 images were set as the training data, and we randomly cropped the patches from each HS image as the ground truth, i.e., HR HS images. The LR HS images were generated by downsampling the ground truth HS images by a factor of 4. The average operation over was used in the downsampling operation, which refers to [31]. Thus, the training HR HS, HR MS, and LR MS images had a size of , , and . We utilized the remaining 12 images as the test data. The LR HS images and the HR HS images were utilized as the input and the ground truth.
- (2)
- Chikusei dataset: The Chikusei dataset (http://naotoyokoya.com/Download.html, accessed on 20 August 2020) is airborne HS images captured over Chikusei on 29 July 2014 [23]. The size of the HR HS image is and the size of the HR MS image is . The band range is from 363 nm to 1018 nm. We selected the top-left portion with a size of as the training data, and the remaining parts were treated as the test data. The training and test datasets were generated like the CAVE dataset. The training HR HS, HR MS, and LR HS images had a size of , , and . During the test procedure, we extracted 16,320 -spatial-size patches from the test data of HR HS and HR MS images. The HR HS patches were employed as the ground truth, and the LR HS patches were generated as the input.
- (3)
- World View-2 (WV-2) dataset: The World View-2 dataset is a real dataset consisting of LR multispectral images with a size of and HR panchromatic images with a size of . We employed the Wald protocol [32] to prepare the training samples for the real data. We treated the LR multispectral images as the HR HS images and downsampled the HR panchromatic images by a factor of 4. The downsampled HR panchromatic images were considered as the HR MS images. We utilized the top portion (size: ) of the HR HS and HR MS images as the training data and the remaining part as the test data. As with the CAVE dataset, the extracted training HR HS, HR MS, and LR HS patches are , , and . In the test data, we extracted -spatial-size patches from the test data of the HR HS and HR MS images. The HR HS patches were employed as the ground truth, and the LR HS patches were generated as the input.
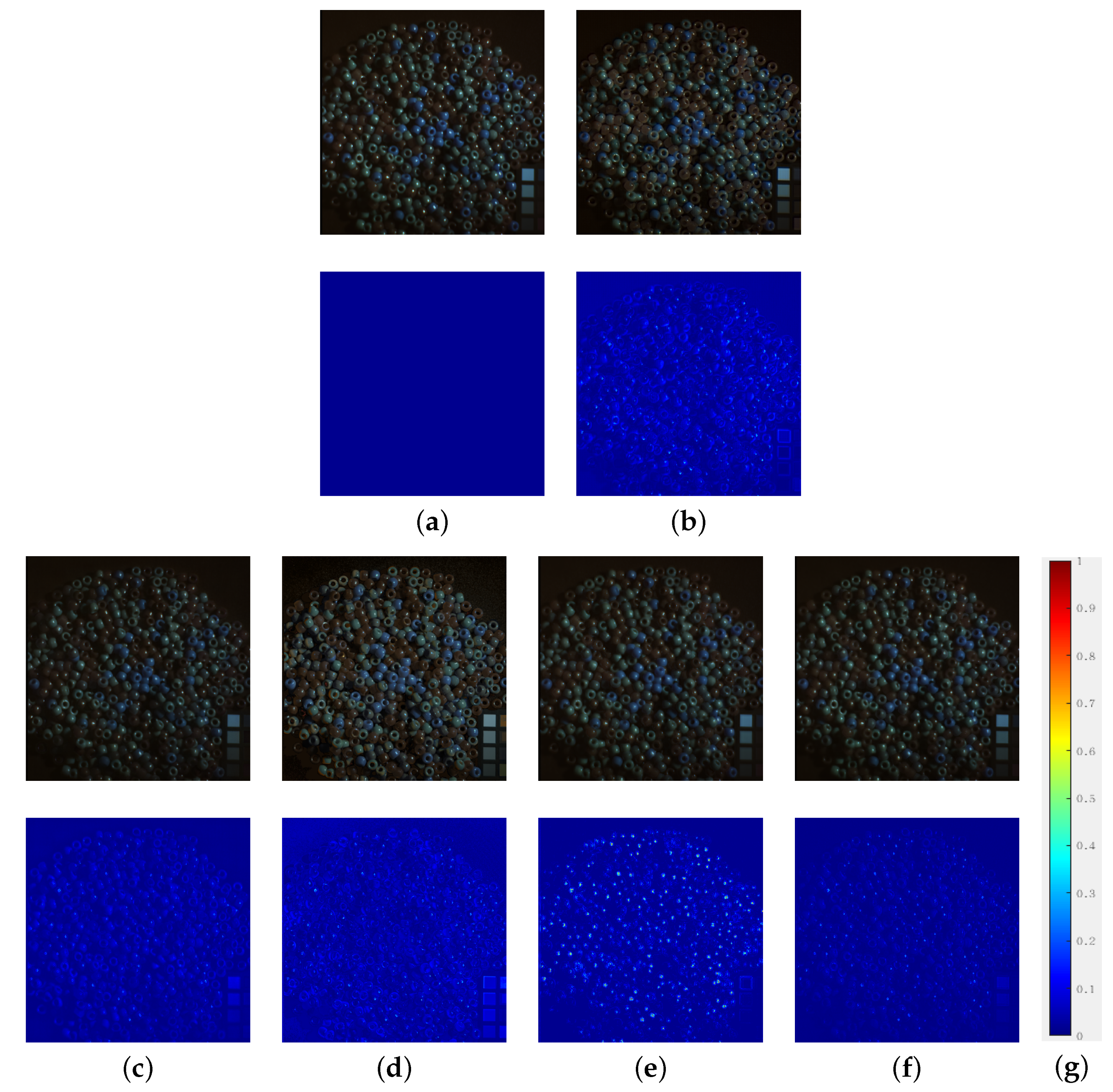
4.2. Comparison to State-of-the-Art
4.3. Model Analysis
4.3.1. Loss Function
4.3.2. Component Analysis
4.4. Compared to 2D Convolutional Neural Network
4.5. Extension to Different Downsampling Factors
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lin, C.; Chen, S.Y.; Chen, C.C.; Tai, C.H. Detecting Newly Grown Tree Leaves from Unmanned-Aerial-Vehicle Images using Hyperspectral Target Detection Techniques. ISPRS J. Photogramm. Remote Sens. 2018, 142, 174–189. [Google Scholar] [CrossRef]
- Yuan, Q.; Zhang, Q.; Li, J.; Shen, H.; Zhang, L. Hyperspectral Image Denoising Employing a Spatial–Spectral Deep Residual Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1205–1218. [Google Scholar] [CrossRef]
- Mei, S.; Ji, J.; Geng, Y.; Zhang, Z.; Li, X.; Du, Q. Unsupervised Spatial–Spectral Feature Learning by 3D-Convolutional Autoencoder for Hyperspectral Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6808–6820. [Google Scholar] [CrossRef]
- Xie, J.; He, N.; Fang, L.; Ghamisi, P. Multiscale Densely-Connected Fusion Networks for Hyperspectral Images Classification. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 246–259. [Google Scholar] [CrossRef]
- Shettigara, V.K. A generalized component substitution technique for spatial enhancement of multispectral images using a higher resolution data set. Photogramm. Eng. Remote Sens. 1992, 58, 561–567. [Google Scholar]
- Xu, Y.; Wu, Z.; Chanussot, J.; Wei, Z. Hyperspectral Computational Imaging via Collaborative Tucker3 Tensor Decomposition. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 98–111. [Google Scholar] [CrossRef]
- Vivone, G.; Restaino, R.; Mura, M.D.; Licciardi, G.; Chanussot, J. Contrast and Error-Based Fusion Schemes for Multispectral Image Pansharpening. IEEE Geosci. Remote Sens. Lett. 2014, 11, 930–934. [Google Scholar] [CrossRef]
- Aiazzi, B.; Alparone, L.; Baronti, S.; Garzelli, A.; Selva, M. MTF-tailored multiscale fusion of high-resolution MS and pan imagery. Photogramm. Eng. Remote Sens. 2006, 72, 591–596. [Google Scholar] [CrossRef]
- Choi, J.; Park, H.; Seo, D. Pansharpening Using Guided Filtering to Improve the Spatial Clarity of VHR Satellite Imagery. Remote Sens. 2019, 11, 633. [Google Scholar] [CrossRef]
- Fasbender, D.; Radoux, J.; Bogaert, P. Bayesian Data Fusion for Adaptable Image Pansharpening. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1847–1857. [Google Scholar] [CrossRef]
- Chen, C.; Li, Y.; Liu, W.; Huang, J. Image Fusion with Local Spectral Consistency and Dynamic Gradient Sparsity. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014; pp. 2760–2765. [Google Scholar]
- Wang, T.; Fang, F.; Li, F.; Zhang, G. High-Quality Bayesian Pansharpening. IEEE Trans. Image Process. 2019, 28, 227–239. [Google Scholar] [CrossRef]
- Masi, G.; Cozzolino, D.; Verdoliva, L.; Scarpa, G. Pansharpening by Convolutional Neural Networks. Remote Sens. 2016, 8, 594. [Google Scholar] [CrossRef]
- Shao, Z.; Cai, J. Remote Sensing Image Fusion with Deep Convolutional Neural Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1656–1669. [Google Scholar] [CrossRef]
- Li, K.; Xie, W.; Du, Q.; Li, Y. DDLPS: Detail-Based Deep Laplacian Pansharpening for Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8011–8025. [Google Scholar] [CrossRef]
- Dian, R.; Li, S.; Guo, A.; Fang, L. Deep Hyperspectral Image Sharpening. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5345–5355. [Google Scholar] [CrossRef]
- Xie, W.; Lei, J.; Cui, Y.; Li, Y.; Du, Q. Hyperspectral Pansharpening with Deep Priors. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 1529–1543. [Google Scholar] [CrossRef]
- Wang, X.; Chen, J.; Wei, Q.; Richard, C. Hyperspectral Image Super-Resolution via Deep Prior Regularization with Parameter Estimation. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1708–1723. [Google Scholar] [CrossRef]
- Luo, S.; Zhou, S.; Feng, Y.; Xie, J. Pansharpening via Unsupervised Convolutional Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4295–4310. [Google Scholar] [CrossRef]
- Zhou, C.; Zhang, J.; Liu, J.; Zhang, C.; Fei, R.; Xu, S. PercepPan: Towards Unsupervised Pan-Sharpening Based on Perceptual Loss. Remote Sens. 2020, 12, 2318. [Google Scholar] [CrossRef]
- Ozcelik, F.; Alganci, U.; Sertel, E.; Unal, G. Rethinking CNN-Based Pansharpening: Guided Colorization of Panchromatic Images via GANs. IEEE Trans. Geosci. Remote Sens. 2020, 59, 3486–3501. [Google Scholar] [CrossRef]
- Yasuma, F.; Mitsunaga, T.; Iso, D.; Nayar, S. Generalized Assorted Pixel Camera: Post-Capture Control of Resolution, Dynamic Range and Spectrum. Technical Report. 2008. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.360.7873&rep=rep1&type=pdf (accessed on 20 July 2022).
- Yokoya, N.; Iwasaki, A. Airborne Hyperspectral Data over Chikusei; Technical Report SAL-2016-05-27; Space Application Laboratory, University of Tokyo: Tokyo, Japan, 2016. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In MICCAI 2015, Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Xue, Y.; Xu, T.; Zhang, H.; Long, L.R.; Huang, X. SegAN: Adversarial Network with Multi-scale L1 Loss for Medical Image Segmentation. Neuroinformatics 2018, 16, 383–392. [Google Scholar] [CrossRef] [PubMed]
- Yokoya, N.; Yairi, T.; Iwasaki, A. Coupled Nonnegative Matrix Factorization Unmixing for Hyperspectral and Multispectral Data Fusion. IEEE Trans. Geosci. Remote Sens. 2012, 50, 528–537. [Google Scholar] [CrossRef]
- Wei, Q.; Dobigeon, N.; Tourneret, J.; Bioucas-Dias, J.; Godsill, S. R-FUSE: Robust Fast Fusion of Multiband Images Based on Solving a Sylvester Equation. IEEE Signal Process. Lett. 2016, 23, 1632–1636. [Google Scholar] [CrossRef]
- Deng, L.J.; Vivone, G.; Jin, C.; Chanussot, J. Detail Injection-Based Deep Convolutional Neural Networks for Pansharpening. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6995–7010. [Google Scholar] [CrossRef]
- Xie, Q.; Zhou, M.; Zhao, Q.; Meng, D.; Zuo, W.; Xu, Z. Multispectral and Hyperspectral Image Fusion by MS/HS Fusion Net. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1585–1594. [Google Scholar]
- Wald, L.; Ranchin, T.; Mangolini, M. Fusion of satellite images of different spatial resolution: Assessing the quality of resulting images. Photogramm. Eng. Remote Sens. 1997, 63, 691–699. [Google Scholar]
- Zhou, W.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar]
- Yuhas, R.H.; Goetz, A.B.J. Discrimination among semi-arid landscape endmembers using the spectral angle mapper (SAM) algorithm. In Proceedings of the Summaries 3rd Annual JPL Airborne Geoscience Workshop, Pasadena, CA, USA, 1–5 June 1992; Volume 1, pp. 147–149. [Google Scholar]
- Ranchin, T.; Wald, L. Fusion of high spatial and spectral resolution images: The ARSIS concept and its implementation. Photogramm. Eng. Remote Sens. 2000, 66, 49–61. [Google Scholar]
- Garzelli, A.; Nencini, F. Hypercomplex Quality Assessment of Multi/Hyperspectral Images. IEEE Geosci. Remote Sens. Lett. 2009, 6, 662–665. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | CAVE | Chikusei |
|---|---|---|
| HR MS images | 6.41 | 7.07 |
| HR HS images | 5.21 | 4.58 |
| Datasets | CAVE | Chikusei | WV2 |
|---|---|---|---|
| SFE Net | 3 × 3D-Conv | 5 × 3D-Conv | 2 × 3D-Conv |
| FT Net | 8 × 3D-Residual | 8 × 3D-Residual | 8 × 3D-Residual |
| IR Net | 3 × SSF + 3 × 3D Upsample | 5 × SSF + 5 × 3D Upsample | 2 × SSF + 2 × 3D Upsample |
| SD Net | 3 × 3D-Conv | 5 × 3D-Conv | 2 × 3D-Conv |
| GCE Net | 2 × 3D-Conv | 2 × 3D-Conv | 2 × 3D-Conv |
| Methods | SSIM | SAM | ERGAS | PSNR | Q2N |
|---|---|---|---|---|---|
| RFuse | 0.840 | 17.233 | 10.528 | 30.947 | 0.853 |
| MHF | 0.973 | 8.741 | 3.485 | 40.590 | 0.939 |
| CNMF | 0.903 | 16.106 | 9.606 | 31.703 | 0.844 |
| DI-DCNN | 0.975 | 8.585 | 3.906 | 42.648 | 0.946 |
| Proposed | 0.989 | 4.416 | 2.158 | 43.034 | 0.940 |
| Methods | SSIM | SAM | ERGAS | PSNR | Q2N |
|---|---|---|---|---|---|
| RFuse | 0.794 | 7.568 | 7.300 | 29.015 | 0.770 |
| MHF | 0.834 | 3.006 | 4.087 | 35.629 | 0.932 |
| CNMF | 0.677 | 4.882 | 7.238 | 29.417 | 0.772 |
| DI-DCNN | 0.778 | 4.144 | 5.704 | 31.450 | 0.872 |
| Proposed | 0.884 | 2.416 | 3.319 | 37.152 | 0.951 |
| Methods | SSIM | SAM | ERGAS | PSNR | Q2N |
|---|---|---|---|---|---|
| RFuse | 0.949 | 1.082 | 0.949 | 32.933 | 0.870 |
| MHF | 0.955 | 0.958 | 1.021 | 32.195 | 0.777 |
| CNMF | 0.951 | 1.015 | 0.869 | 33.714 | 0.883 |
| DI-DCNN | 0.871 | 1.850 | 1.853 | 30.660 | 0.718 |
| Proposed | 0.968 | 0.780 | 0.684 | 35.847 | 0.920 |
| Dataset | Loss | SSIM | SAM | ERGAS | PSNR | Q2N |
|---|---|---|---|---|---|---|
| CAVE | 0.980 | 6.200 | 2.935 | 40.310 | 0.920 | |
| 0.984 | 5.840 | 2.608 | 41.595 | 0.926 | ||
| 0.981 | 5.774 | 2.837 | 40.685 | 0.924 | ||
| 0.989 | 4.416 | 2.158 | 43.034 | 0.940 | ||
| Chikusei | 0.716 | 6.031 | 6.828 | 31.604 | 0.868 | |
| 0.876 | 2.538 | 3.991 | 36.814 | 0.946 | ||
| 0.830 | 3.636 | 4.291 | 35.234 | 0.925 | ||
| 0.884 | 2.416 | 3.319 | 37.152 | 0.951 | ||
| WV-2 | 0.962 | 0.853 | 0.748 | 35.167 | 0.908 | |
| 0.967 | 0.797 | 0.687 | 35.821 | 0.919 | ||
| 0.967 | 0.792 | 0.694 | 35.746 | 0.918 | ||
| 0.968 | 0.780 | 0.684 | 35.847 | 0.920 |
| Dataset | Comp. | SSIM | SAM | ERGAS | PSNR | Q2N |
|---|---|---|---|---|---|---|
| CAVE | Spa | 0.734 | 31.449 | 13.767 | 27.374 | 0.831 |
| Spe | 0.978 | 5.262 | 3.123 | 39.700 | 0.915 | |
| Spa + Spe | 0.989 | 4.416 | 2.158 | 43.034 | 0.940 | |
| Chikusei | Spa | 0.555 | 11.204 | 13.444 | 26.855 | 0.708 |
| Spe | 0.716 | 3.483 | 6.533 | 31.059 | 0.861 | |
| Spa + Spe | 0.884 | 2.416 | 3.319 | 37.152 | 0.951 | |
| WV2 | Spa | 0.888 | 2.763 | 1.737 | 29.013 | 0.752 |
| Spe | 0.964 | 0.803 | 0.720 | 35.412 | 0.912 | |
| Spa + Spe | 0.968 | 0.780 | 0.684 | 35.847 | 0.920 |
| Dataset | Methods | SSIM | SAM | ERGAS | PSNR | Q2N |
|---|---|---|---|---|---|---|
| CAVE | RFuse | 0.585 | 28.925 | 4.070 | 24.030 | 0.818 |
| MHF | 0.791 | 13.337 | 2.744 | 30.219 | 0.793 | |
| CNMF | 0.878 | 10.797 | 6.194 | 31.223 | 0.799 | |
| DI-DCNN | 0.852 | 11.843 | 3.900 | 27.547 | 0.809 | |
| Proposed | 0.961 | 8.314 | 1.268 | 35.701 | 0.893 | |
| Chikusei | RFuse | 0.737 | 12.297 | 10.740 | 26.354 | 0.391 |
| MHF | 0.945 | 3.863 | 4.980 | 32.563 | 0.991 | |
| CNMF | 0.784 | 5.936 | 8.153 | 28.516 | 0.350 | |
| DI-DCNN | 0.885 | 6.126 | 9.923 | 27.676 | 0.974 | |
| Proposed | 0.951 | 3.649 | 4.870 | 32.770 | 0.994 | |
| WV-2 | RFuse | 0.911 | 2.005 | 1.381 | 30.152 | 0.791 |
| MHF | 0.955 | 1.458 | 1.021 | 32.990 | 0.777 | |
| CNMF | 0.937 | 1.468 | 1.061 | 32.287 | 0.842 | |
| DI-DCNN | 0.940 | 1.578 | 1.172 | 31.763 | 0.823 | |
| Proposed | 0.970 | 1.311 | 0.978 | 33.324 | 0.845 |
| Dataset | Methods | SSIM | SAM | ERGAS | PSNR | Q2N |
|---|---|---|---|---|---|---|
| CAVE | RFuse | 0.578 | 28.694 | 4.673 | 23.584 | 0.800 |
| MHF | 0.791 | 13.971 | 3.810 | 29.800 | 0.776 | |
| CNMF | 0.877 | 9.860 | 6.277 | 30.247 | 0.802 | |
| DI-DCNN | 0.788 | 15.918 | 5.298 | 24.614 | 0.770 | |
| Proposed | 0.953 | 9.122 | 1.516 | 33.968 | 0.885 | |
| Chikusei | RFuse | 0.726 | 14.794 | 11.687 | 25.778 | 0.391 |
| MHF | 0.923 | 4.648 | 5.461 | 30.819 | 0.988 | |
| CNMF | 0.778 | 6.720 | 8.861 | 27.894 | 0.343 | |
| DI-DCNN | 0.862 | 8.593 | 11.242 | 25.510 | 0.979 | |
| Proposed | 0.942 | 4.503 | 5.394 | 31.288 | 0.996 | |
| WV-2 | RFuse | 0.878 | 2.668 | 1.681 | 28.772 | 0.772 |
| MHF | 0.935 | 1.667 | 1.150 | 31.963 | 0.810 | |
| CNMF | 0.926 | 1.798 | 1.211 | 31.469 | 0.821 | |
| DI-DCNN | 0.923 | 2.003 | 1.523 | 30.337 | 0.792 | |
| Proposed | 0.961 | 1.660 | 1.131 | 32.240 | 0.821 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, H.; Jin, H.; Sun, C. Deep Pansharpening via 3D Spectral Super-Resolution Network and Discrepancy-Based Gradient Transfer. Remote Sens. 2022, 14, 4250. https://doi.org/10.3390/rs14174250
Su H, Jin H, Sun C. Deep Pansharpening via 3D Spectral Super-Resolution Network and Discrepancy-Based Gradient Transfer. Remote Sensing. 2022; 14(17):4250. https://doi.org/10.3390/rs14174250
Chicago/Turabian StyleSu, Haonan, Haiyan Jin, and Ce Sun. 2022. "Deep Pansharpening via 3D Spectral Super-Resolution Network and Discrepancy-Based Gradient Transfer" Remote Sensing 14, no. 17: 4250. https://doi.org/10.3390/rs14174250
APA StyleSu, H., Jin, H., & Sun, C. (2022). Deep Pansharpening via 3D Spectral Super-Resolution Network and Discrepancy-Based Gradient Transfer. Remote Sensing, 14(17), 4250. https://doi.org/10.3390/rs14174250