1. Introduction
Hyperspectral images (HSIs), as a branch of remote sensing images, are enjoying considerable interest from researchers owing to the abundant spatial and spectral information embedded within them. Compared with panchromatic images and multispectral remote sensing images, HSIs make it possible to discriminate different targets within a scene more accurately on account of their hundreds of continuous and narrow spectral bands. As a result, HSIs are widely used in many fields, including food [
1], agriculture [
2], and geology [
3].
To implement these applications, a number of tasks have been developed on the basis of HSIs, such as classification [
4], anomaly detection [
5], and image decomposition [
6]. Among these tasks, HSI classification is a fundamental yet challenging problem. To yield superior performance, there are two characteristics of HSIs which need be fully considered by researchers: (1) the rich spectral information and (2) the strong spatial correlation between pixels. Both can be investigated separately and independently or can be considered for joint information extraction, leading to different lines of work, such as spectral classification and spectral–spatial classification [
7].
In the early days, statistical learning and machine learning were dominant. A number of algorithms from these fields were introduced into HSI classification and generated decent performances. Typical examples include principal component analysis (PCA) [
8], linear discriminant analysis (LDA) [
9], and independent component analysis (ICA) [
10]. Due to insufficient training samples, copious spectral information can be a mixed blessing when being imposed upon high-dimensional HSI data suffering from a curve of dimensionality (i.e., the Hughes phenomenon) [
11,
12]. The essence of these techniques in statistical learning is to transform the HSI spectral vector from high-dimensional feature space to a low-dimensional feature space, eliminating redundant information and mitigating interference with subsequent feature extractions. In addition to the above, algorithms in machine learning, such as multinomial logistic regression (MLR) [
13], support vector machine (SVM) [
14], decision trees [
15], and random forests [
16], also played an important role in HSI classification, serving feature extraction or directly as classifiers. However, only exploiting spectral information is of no concern for HSI classification. Extensive experiments have validated that it is beneficial to introduce prior information, such as adjacent pixels located in homogeneous regions, which may be of the same class. There is a consensus that combined spectral–spatial classification is superior to spectral classification, and numerous efforts have been made to probe this possibility. For example, patch-wise-feature-extraction methods were applied instead of pixel-wise feature-extraction approaches in [
17], which allowed for not only the excavation of spectral information but also the exploration of relationships between pixels. Other than that, researchers proposed methods for joint spectral–spatial feature extraction based on spectral–spatial regularized local discriminant embedding [
18] and tensor discriminative locality alignment [
19]. Although these traditional methods meet with some success, they significantly hinge on the handcrafted features. Nevertheless, these features tend to frustrate the expectations of a comprehensive representation of the complex contents within HSIs, bringing the development of HSI classification to a bottleneck.
Recently, deep learning (DL) has been widely embraced by the computer vision community, demonstrating excellent performance in various tasks. The advantage of deep learning is the ability to automatically learn richer features than conventional handcrafted features. Consequently, DL-based methods have been gaining traction with researchers in HSI classification. A range of DL-based methods for HSI classification have been proposed, such as stacked autoencoders (SAEs) [
20,
21], deep belief networks (DBNs) [
22,
23] and convolution neural networks (CNNs) [
24,
25]. In particular, due to the inherent properties of local connectivity and weight sharing, CNNs show better potential. By stacking convolutional layers, CNNs can capture a rich range of features from low-level to high-level. In [
26], 1D-CNN was applied for the first time to extract spectral features. Romero et al. [
27] also made use of 1D-CNNs to process spectral information. To improve feature representation and incorporate spatial information, 2D-CNNs have also attracted much attention. Feng et al. [
28] designed a 2D-CNN framework to fuse spectral–spatial features from multiple layers and enhance feature representation. Lee et al. [
29] drew on the idea of residual networks [
30] to build a deep network to extract richer spectral–spatial features. Also, some works [
29,
31] prefer the application of PCA to reduce the dimensionality of the HSI data and then adopt a 2D-CNN for feature extraction and classification. However, it is obvious that considering spatial and spectral information separately betrays the relationship between them. To combat this problem, a 3D-CNN, as a CNN structure that can jointly extract spectral–spatial information, has been widely deployed to maintain the inherent continuity of the 3D-HSI cube. For instance, in [
32], Zhong et al. developed a HSI classification model equipped with a 3D-CNN and a residual network (SSRN), which was effective at limiting the training samples. Moreover, Roy et al. [
33] proposed a hybrid CNN, comprising a spectral–spatial 3D-CNN and a spatial 2D-CNN. Wang et al. [
34] designed their fast dense spectral–spatial convolution (FDSSC) network based on DenseNet [
35]. Compared to 2D-CNNs, 3D-CNNs perform better but exacerbate the demand on computing.
Although there has been plenty of excellent DL-based work in HSI classification, refining the features and further improving the accuracy of recognition remains challenging. To this end, attention mechanisms are often deployed to optimize the extracted features. As means of re-measuring the importance of information, attention mechanisms can bias the allocation of available computational resources to those signals that contribute more to the task [
36,
37]. Attention mechanisms have demonstrated promising results for computer vision tasks, such as sequence learning [
38], image caption [
39], and scene segmentation [
40]. Inspired by these successful efforts, researchers introduced the attention mechanism to HSI classification. Mei et al. [
41] proposed a spectral–spatial attention network (SSAN). In addition, given that HSI data possess spectral and spatial information simultaneously, it is an intuitive idea to build two branches to extract the features separately and then fuse them before classification. In [
42], a double-branch multi-attention mechanism network (DBMA) was proposed based on the convolutional block attention module (CBAM) [
43]. Furthermore, Li et al. [
44] designed a double-branch dual-attention mechanism network (DBDA) for HSI classification. Also, using a double-branch structure, Shi et al. [
45] designed a subtle attention module and obtained desirable results. Although these networks can achieve promising results, their attention mechanisms are too simple to learn crucial features.
Different from those found in CNNs, the transformer is a completely self-attention-based architecture, which is adept at capturing long-range dependencies. This structure originated from NLP tasks, and Vision Transformer (ViT) [
46] introduced this idea to computer vision tasks for the first time. Then, plenty of models based on the transformer architecture shone in different computer vision tasks. Some work has been carried out with efforts to apply the transformer architecture to HSI classification. Hong et al. [
47] and He et al. [
48] reconceptualized HSI data from a sequence-data perspective, which adopted group-wise spectral embedding and transformer encoder modules to model spectral representations. Sun et al. [
49] developed a new model called spectral–spatial feature tokenization transformer (SSFTT), which can encode the spectral–spatial information into tokens and then process them with a transformer. Similarly, Qing et al. [
50] designed a spectral attention process and incorporated it into the transformer, capturing the continuous spectral information in a decent manner. However, these improved transformer methods all treated a spectral band or a spatial patch as a token and encoded all tokens, resulting in significant redundant calculations since the HSI data already contained substantial redundant information. In addition, given the differences between natural images and HSIs, transferring and processing the transformer, regarding the conversion of natural images directly into HSI classification, may lead to misclassification, especially for boundary pixels across classes. Last but not least, the inherent drawbacks of the transformer architecture, such as the lack of obtaining local information, the difficulty in training, and the requirement of complex parameters tuning, also limit the performance of these models in HSI classification.
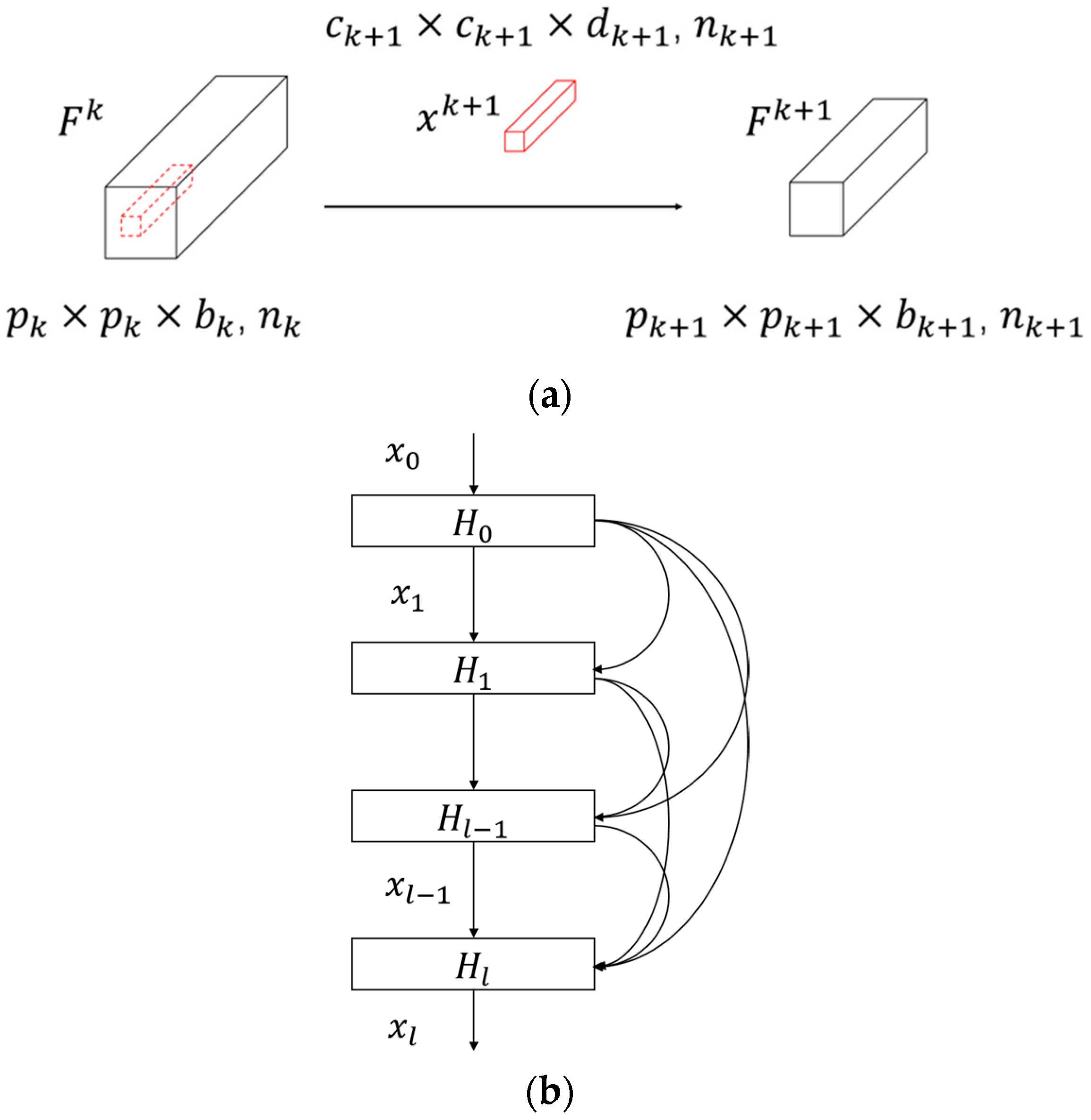
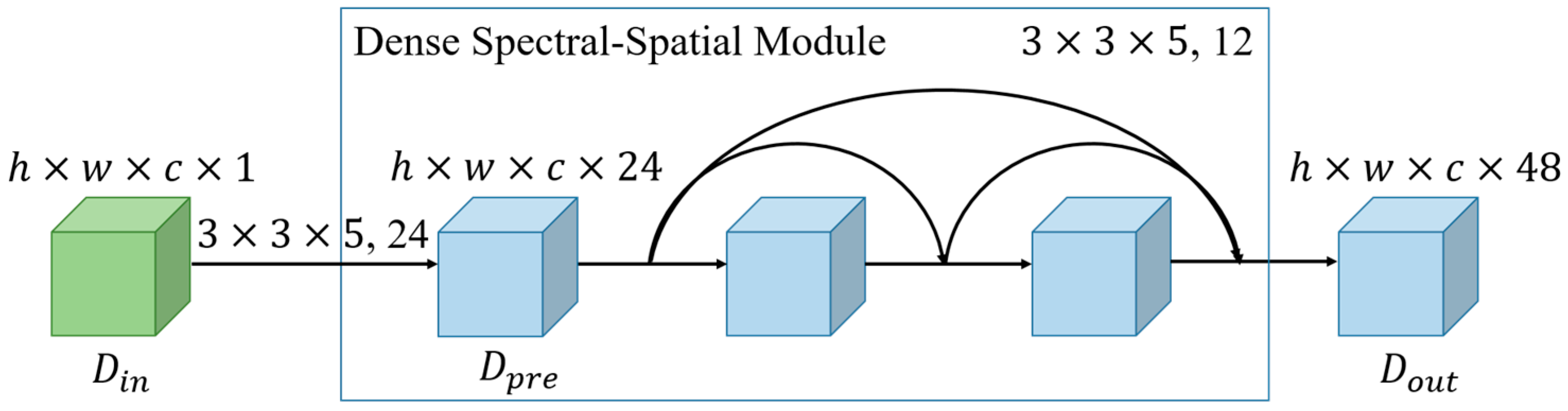
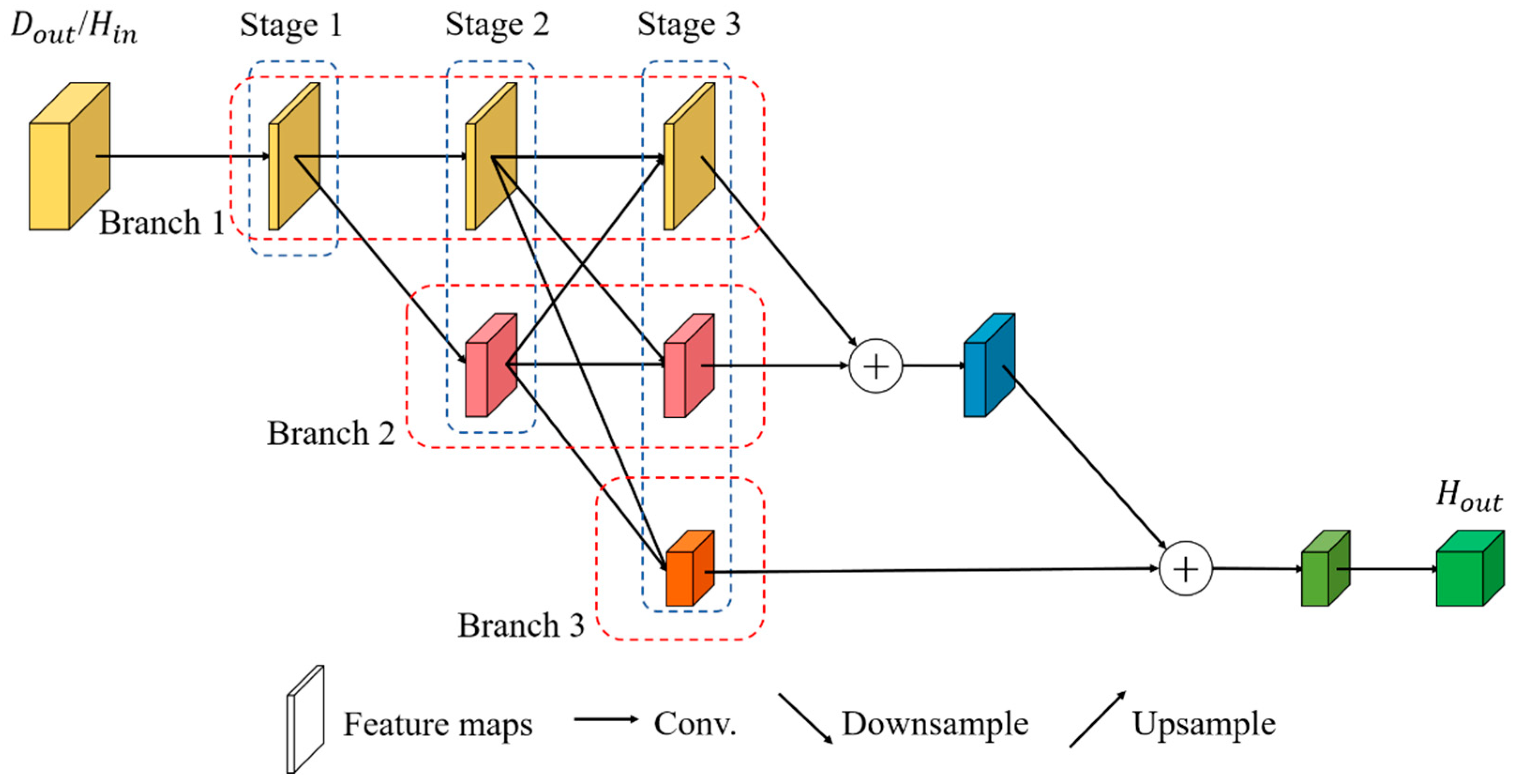
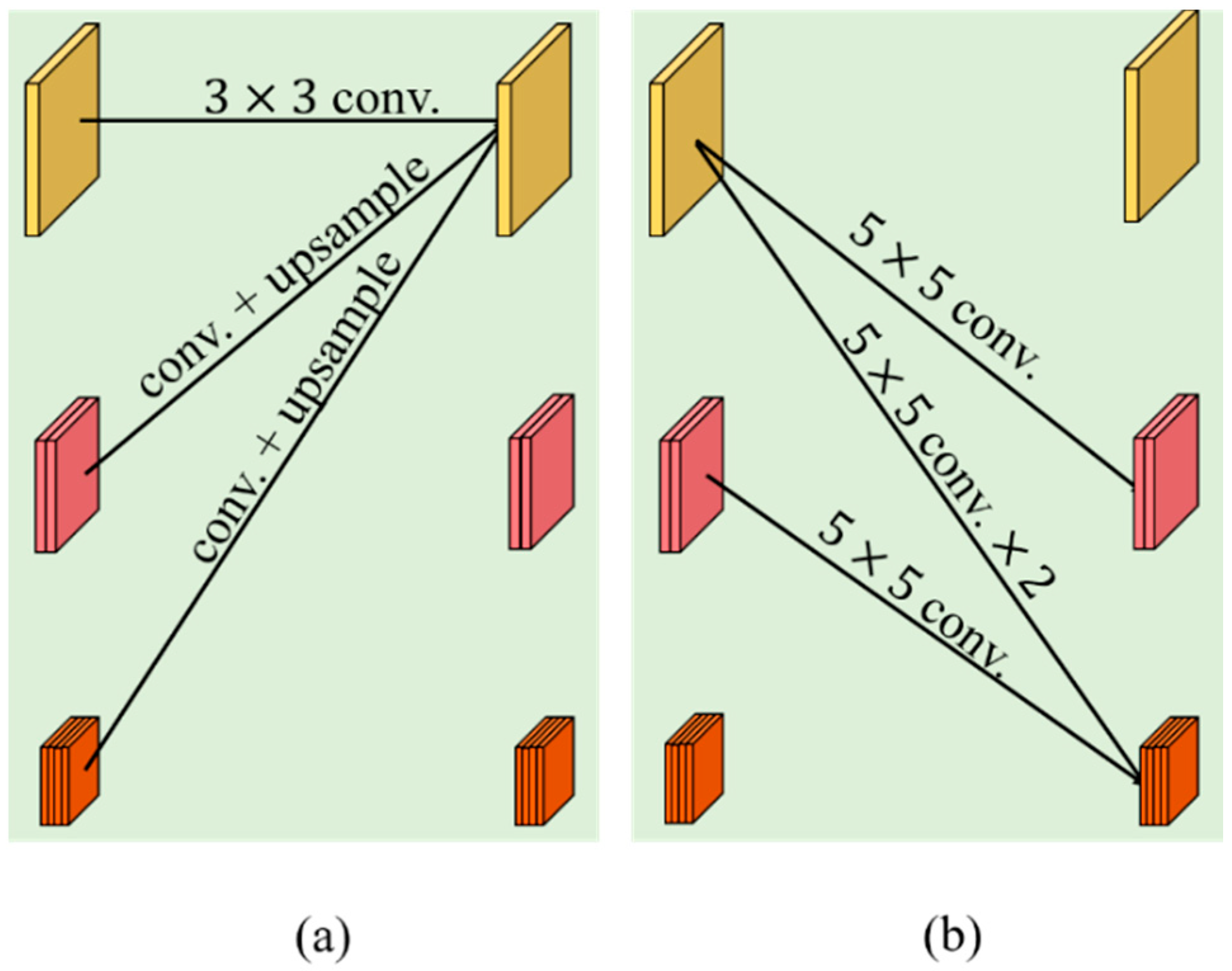
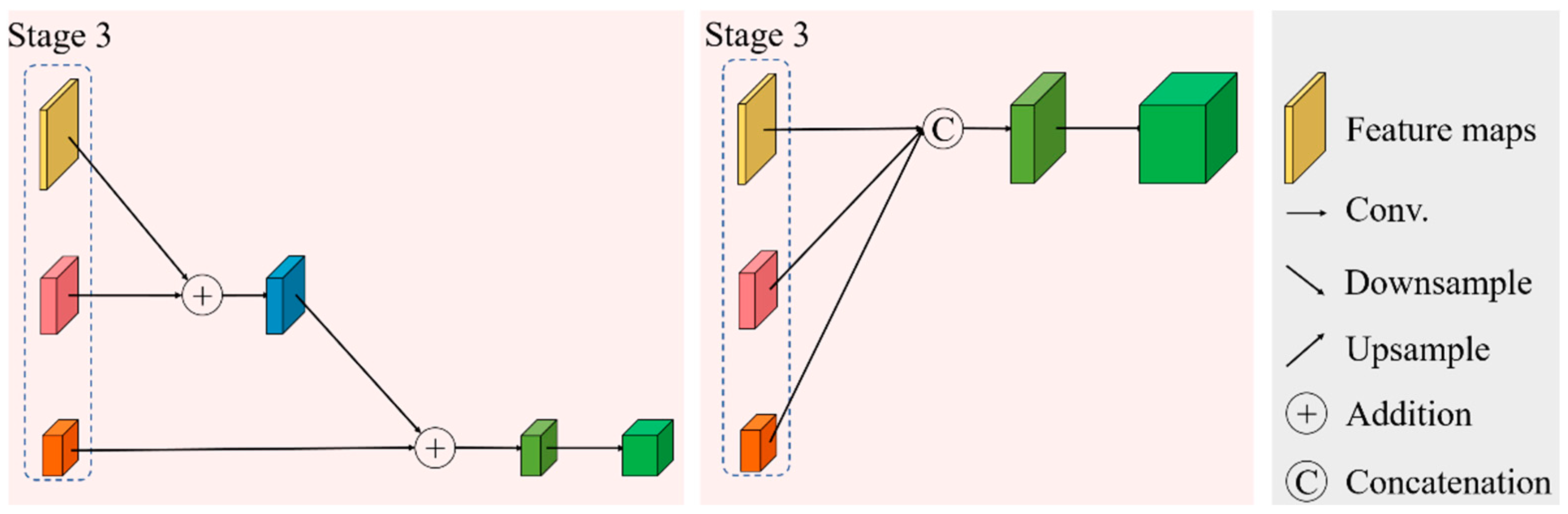
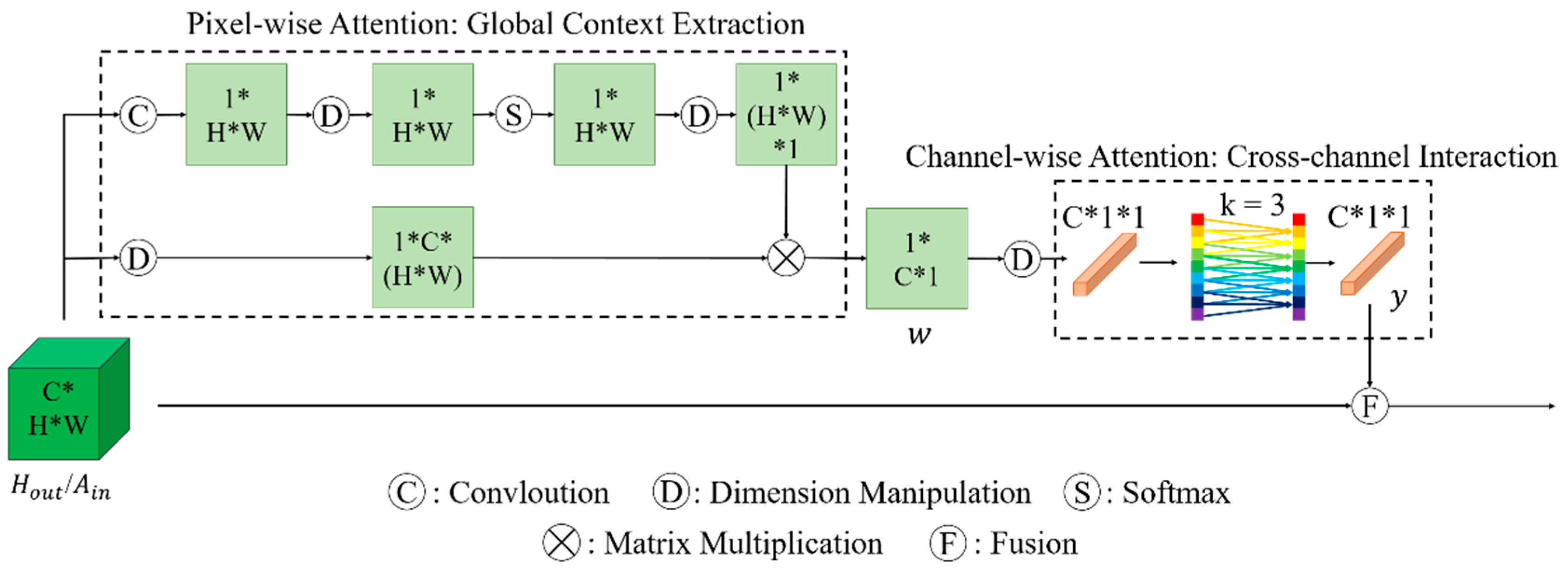
In this article, we propose a novel hybrid-convolution and hybrid-resolution network with double attention named Net. Hybrid convolution means that the 3D-convolution operators and 2D-convolution operators are jointly employed throughout the network to strike a better balance between speed and accuracy. Hybrid resolution means that the features are extracted at different scales. H2 refers to the above two aspects. Double attention means that two attention techniques are applied in combination, which is represented by A2. The Net mainly consists of three modules, namely a dense spectral–spatial module (DSSM), a hybrid resolution module (HRM), and a double attention module (DAM). The DSSM connects the 3D convolutional layers in the form of DenseNet to extract spectral–spatial features from the HSIs. HRM acquires strong semantic information and precise position information by parallelizing those branches with different resolutions, together with the constant interaction between different branches. The DAM is designed to implement two kinds of attention mechanisms in sequence, highlighting spatial and spectral information that is beneficial to the classification at a low computational cost. We investigate the appropriate solution for HSI classification by assembling these modules in different ways. The main contributions of this article can be summarized as follows.
- (1)
A densely connected module with 3D convolutions is integrated into a network, which aims to extract abundant spectral–spatial joint features by leveraging the inherent advantages of 3D convolution;
- (2)
A hybrid resolution module is developed to learn how to extract multiscale spectral–spatial features from HSIs. Here, 2D convolutions are sufficient for our purposes. In addition, due to the cohabitation of high-resolution and low-resolution representations, it is possible for strong semantic information and precise position information to be learned simultaneously;
- (3)
A novel double attention module is designed to capture interested spectral and spatial features, enhancing the informative features and suppressing the extraneous features.
- (4)
Extensive experiments validate the performance of our approach, and the effects of the core ingredients are carefully analyzed.
4. Experiment
4.1. Datasets Description
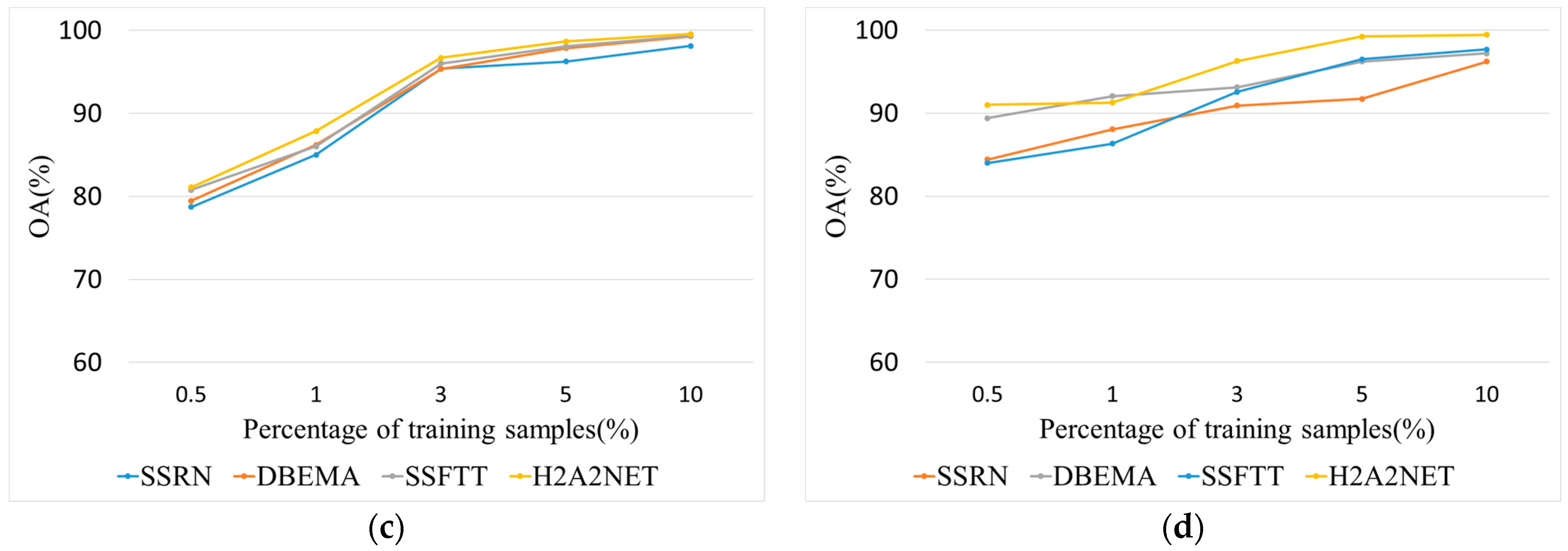
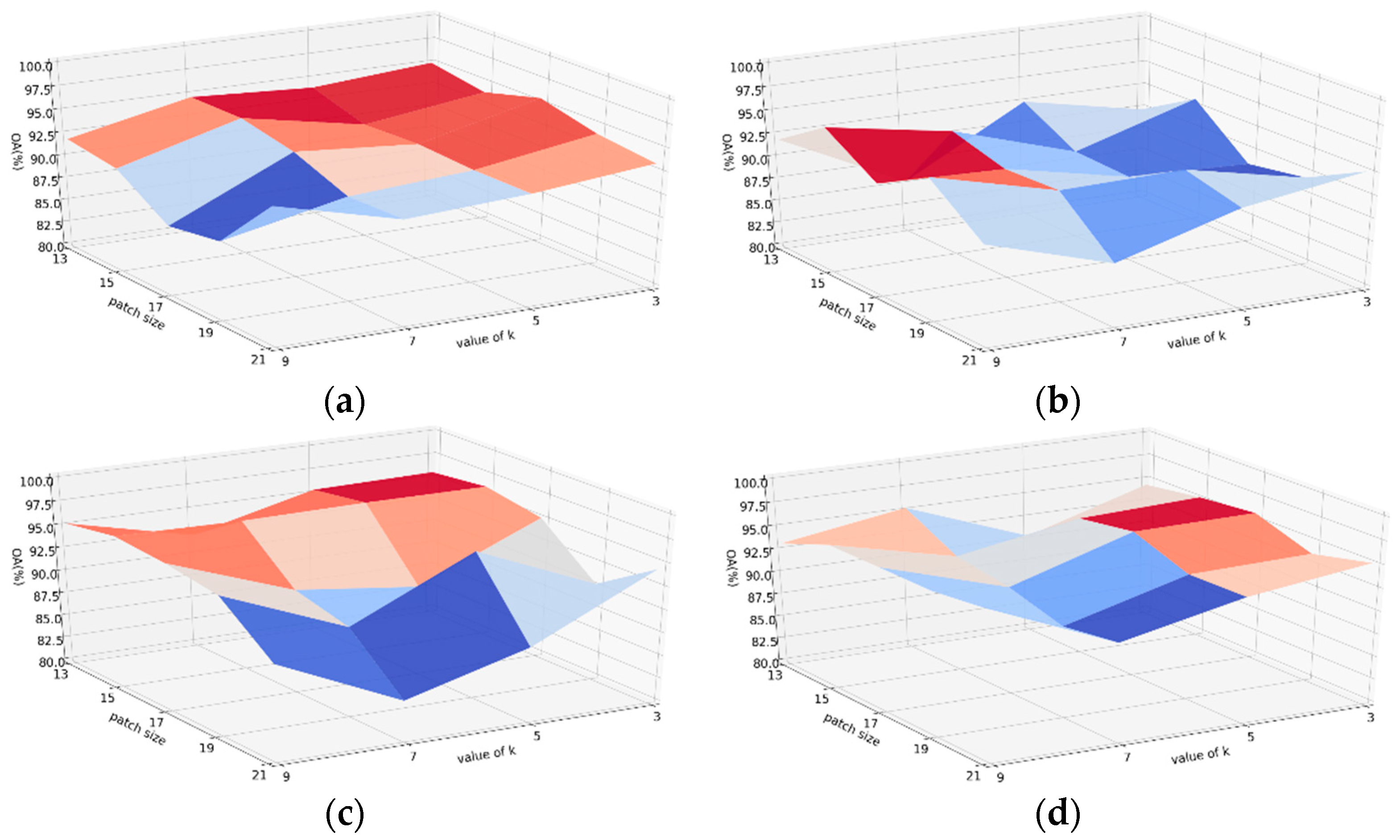
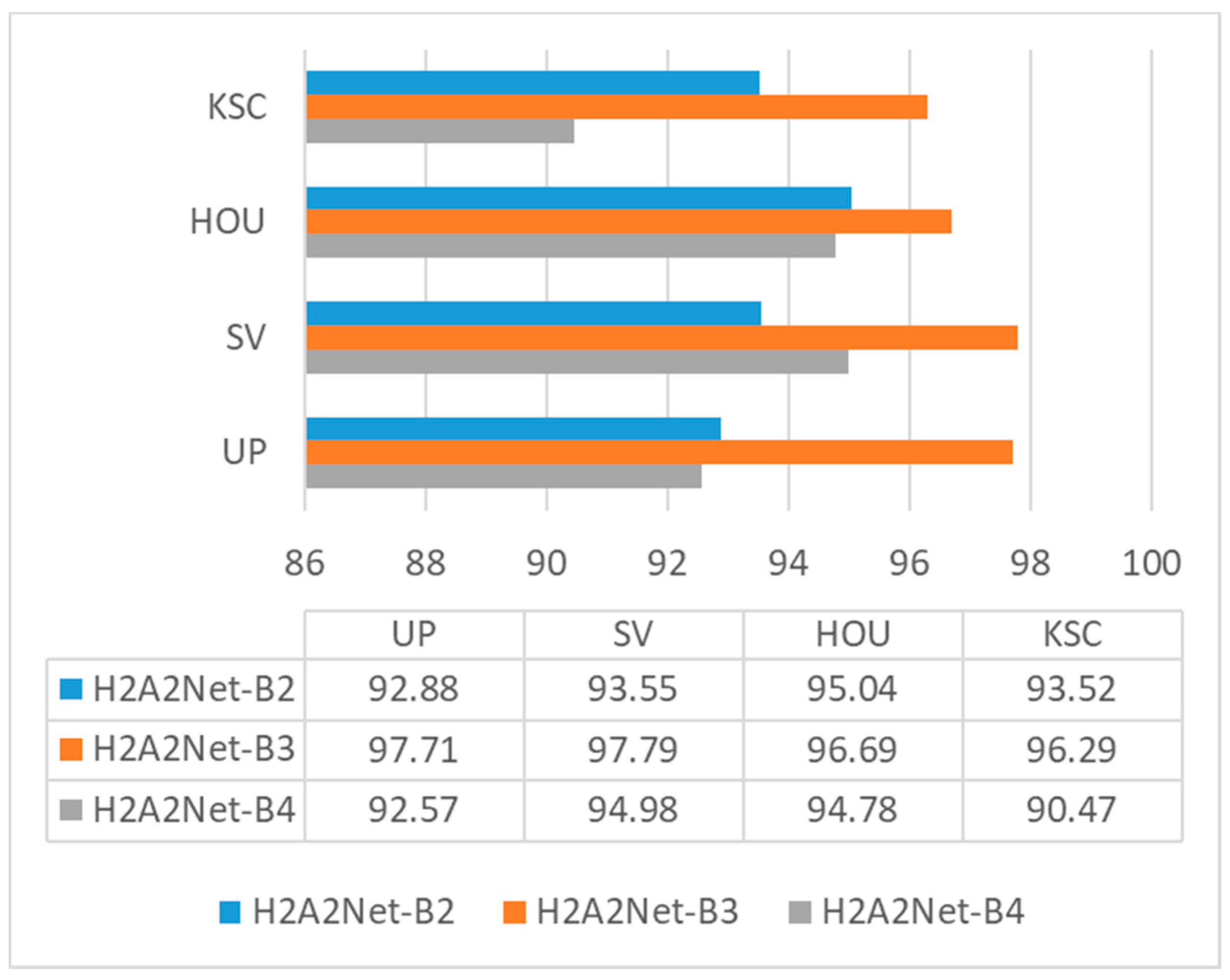
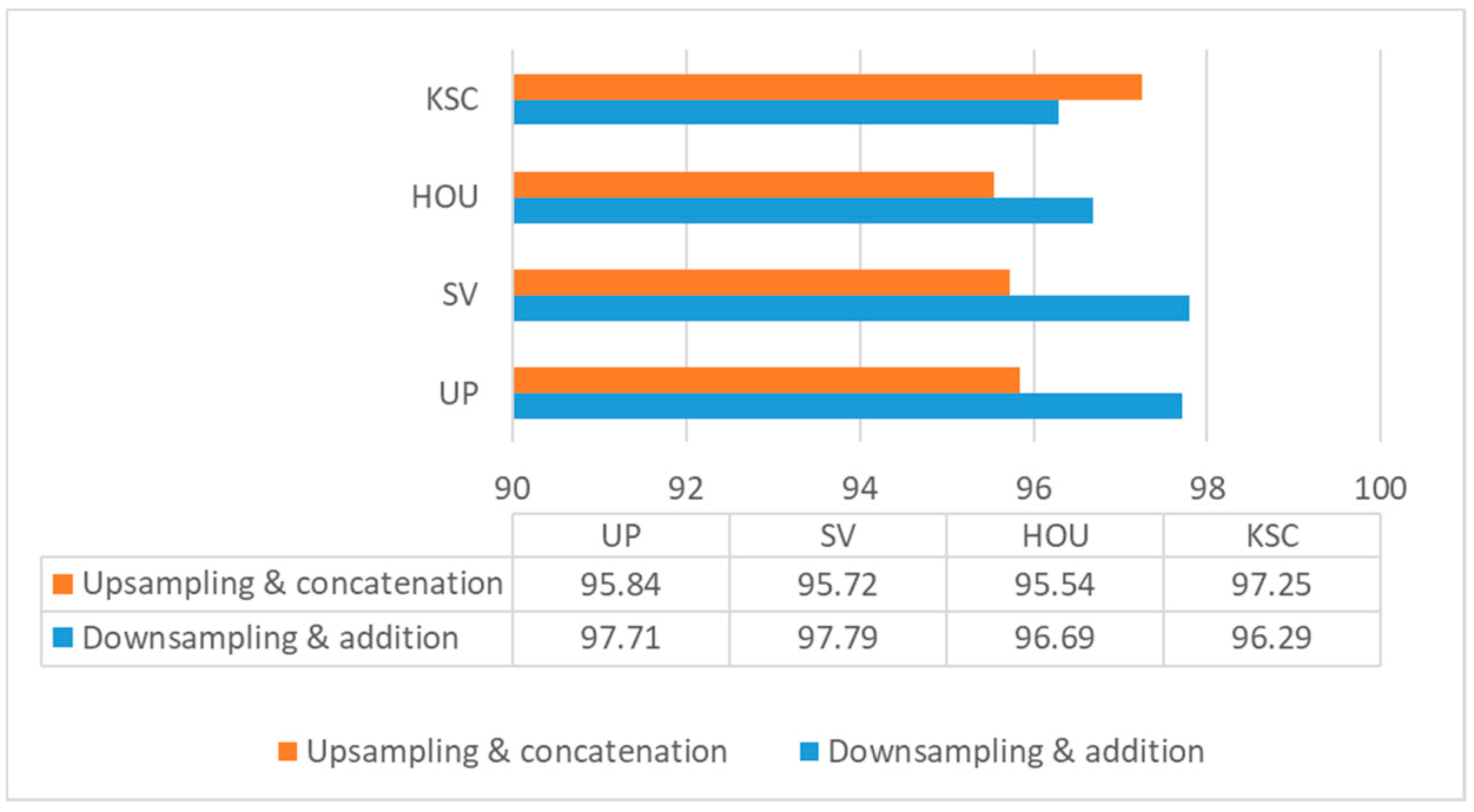
To evaluate the proposed method, we carried out experiments on four well-known HSI datasets: the University of Pavia (UP), Salinas Valley (SV), Houston 2013 (HOU), and Kennedy Space Center (KSC) datasets.
The University of Pavia dataset was acquired by the reflective optics imaging spectrometer (ROSIS-3) sensor at the University of Pavia, northern Italy, 2001. After eliminating 12 noisy bands, it consists of 103 bands with a spatial resolution of 1.3 m per pixel in the wavelength range of 430 to 860 nm. The spatial size of the University of Pavia is 610 × 340 pixels, and 9 land cover classes are contained.
The Salinas Valley dataset was captured by the AVIRIS sensor over the agricultural area described as Salinas Valley in California, CA, USA, 1998. It comprises 204 bands with a spatial resolution of 3.7 m per pixel in the wavelength range of 400 to 2500 nm. The spatial size of the Salinas dataset is 512 × 217 pixels, and 16 land cover classes are involved.
The Houston 2013 dataset was provided by the Hyperspectral Image Analysis Group and the NSF-funded Airborne Laser Mapping Center (NCALM) at the University of Houston, US. It was originally adopted for scientific purposes in the 2013 IEEE GRSS Data Fusion Competition. The Houston 2013 dataset includes 144 spectral bands with a spatial resolution of 2.5 m in the wavelength range of 0.38 to 1.05 µm. The spatial size is 349 × 1905 pixels, and 15 land cover classes are involved.
The Kennedy Space Center dataset was captured by the AVIRIS sensor over the Kennedy Space Center, Florida, on 23 March 1996. It contains 224 bands, 10 nm in width, with a wavelength range of 400 to 2500 nm. After removing the water absorption and low SNR bands, 176 bands were conserved for the analysis. The spatial size of the Kennedy Space Center dataset is 512 × 614 pixels, and 13 land cover classes are contained.
Depending on the size and complexity of the four datasets, we were able to set different sizes of training samples and validation samples to challenge all models. For UP and SV, we only selected 0.5% samples for training, 0.5% samples for validation, and 99% samples for testing. For KSC and HOU, we selected 3% samples for training, 3% samples for validation, and 94% samples for testing. Detailed figures of each category for training, validation, and testing sets are summarized in
Table 1,
Table 2,
Table 3 and
Table 4.
4.2. Experimental Configuration
To evaluate the performance of our model, three criteria were considered: overall accuracy (OA), average accuracy (AA), and kappa coefficient (K). All experiments were conducted on the platform configured with an Intel Core i7-8700K processor at 3.70 GHz, 32 GB of memory, and an NVIDIA GeForce GTX 1080Ti GPU. The software environment was the Windows 10 (64-bit) system for home and deep-learning frameworks of PyTorch.
In order to fully unleash the potential of
Net, an advanced training recipe was used to train the model. The early stopping technique, regularization, and an advanced activation function were introduced to prevent overfitting. Concretely, we choose the Adam optimizer to train the network for 200 epochs under the guidance of the early stopping technique, i.e., the training process was terminated when the loss function no longer decreases within 10 epochs. The learning rate and the batch size were specified as 0.0001 and 64, respectively. In addition, a dropout layer with a 0.5 dropout rate was applied within the training protocol. Mish [
65], as an advanced activation function, was adopted in lieu of ReLU, which is a common choice. The experiments were repeated 10 times, and the classification results for each category are now presented. Our preprocessing was to crop the raw HSI data into 3D cubes and then apply PCA. The number of spectral bands after PCA was set to 30.
Several models have been picked for our comparison. Following the identical recipes, we re-implemented these methods using their open-source code. The parameters were set in accordance with the corresponding article, and the input patch sizes for each model were specified according to the original article. The brief explanations and configurations of them are listed as follows:
- (1)
SVM: each pixel, as well as all the spectral bands, was processed directly by the SVM classifier;
- (2)
CDCNN: the structure of the CDCNN is illustrated in [
29], which combines a 2D-CNN and ResNet. The input patch size is set to 5 × 5 × b, where b represents the number of spectral bands;
- (3)
SSRN: the structure of the SSRN is illustrated in [
32], which combines a 3D-CNN and ResNet. The input patch size is set to 7 × 7 × b;
- (4)
DBDA: the structure of the DBDA is illustrated in [
44], which is a double-branch structure based on a 3D-CNN, DenseNet, and an attention mechanism. The input patch size is set to 9 × 9 × b;
- (5)
DBEMA: the structure of the DBEMA is illustrated in [
45], which uses the pyramidal convolution and an iterative-attention mechanism. The input patch size is set to 9 × 9 × b;
- (6)
ViT: the structure of the ViT is illustrated in [
46], i.e., only including transformer encoders. Instead of patch-wise HSI classification, ViT processes the pixel-wise input in the HSI classification;
- (7)
SSFTT: the structure of the SSFTT is illustrated in [
49], which shows the design of a spectral–spatial feature tokenization transformer. The input patch size is set to 13 × 13 × b.
4.3. Classification Results
4.3.1. Analysis of the Up Dataset
The classification results acquired via the different methods used on the UP dataset are presented in
Table 5. Moreover, the corresponding classification maps of the different methods are shown in
Figure 8. It can be noted from
Figure 8 that the classification map generated by our
Net is clearer than that obtained by any other method. Not only is the intra-class classification error small, but also the inter-class boundaries are clearly delineated. As indicated in
Table 5, the proposed model delivers the best performance in terms of numerical results. In contrast to other methods,
Net affords a 13.54% (SVM), 10.39% (CDCNN), 4.9% (SSRN), 4.08% (DBDA), 1.66% (DBEMA), 13.69% (ViT), 1.08% (SSFTT) accuracy increase over OA, respectively. Such excellent performance demonstrates that our model adequately captures and exploits spatial information as well as spectral information.
From the results, we can see that SVM, CDNN, and ViT had underperformed. The poor performance of SVM is understandable since it is a traditional method. CDCNN performs poorly because 2D-CNNs ignore the 3D nature of HSI data, and the training samples are insufficient. ViT does not work well due to its simple transformer structure and insufficient training samples. Other methods show decent performance as they are well designed, though there is still a gap between the performance of these and our Net. In addition, if we scrutinize the classification results for each category, it is noticeable that the proposed model is the only one that reaches above 90% accuracy for each category. In particular, for category 8, our model is the only method that achieves 90%+ accuracy. These observations demonstrate the stability and robustness of Net. Overall, our Net can consistently deliver superior performance on the UP dataset.
4.3.2. Analysis of the SV Dataset
The classification results acquired via the different methods used on the SV dataset are presented in
Table 6. Moreover, the corresponding classification maps for the different methods are shown in
Figure 9. As illustrated in
Figure 9, the classification map produced by our method is closest to the ground truth. Such positive results are also reflected in
Table 6. As a comparison,
Net has a 10.56% (SVM), 20.12% (CDCNN), 3.7% (SSRN), 3.61% (DBDA), 2.3% (DBEMA), 13.68% (ViT), 1.11% (SSFTT) accuracy increase over OA, respectively. These accuracy improvements suggest that our model can extract better features for classification.
SVM, CDCNN, and ViT still perform poorly. It can be concluded that the limited training samples are a huge limitation for them, especially for the latter two. Moreover, the other models still fail to compete with Net. For some categories in the SV dataset, e.g., categories 1, 2, 4, 6, 7, 9, 13, and 16, Net achieves 100% accuracy, which is greater than all models in terms of the number of categories that are perfectly classified. For the remaining categories, the results obtained by our model are also placed in the first echelon of all the models.
4.3.3. Analysis of the HOU Dataset
The classification results acquired via different methods for the HOU dataset are presented in
Table 7. Moreover, the corresponding classification maps for the different methods are shown in
Figure 10. The specific values of OA, AA, and Kappa are reported in
Table 7. Compared with other methods, the increases of OA obtained by
Net are 9.11% (SVM), 13.04% (CDCNN), 1.3% (SSRN), 3.87% (DBDA), 1.34% (DBEMA), 9.24% (ViT), and 1.65% (SSFTT).
Note that our model achieves the best performance in most of the categories of classification, including several 100% classification results. Due to the small size of the labeled samples and the large size of the HOU dataset, the distribution of the samples is scattered, implying that there are a large number of interfering pixels around the target pixel. Consequently, a side effect is imposed on the classification of certain categories. Nevertheless, since our model is equipped with a module for extracting features at multiple scales and a module for refining features with an attention mechanism, such challenges can be easily addressed. For example, for category 13, the best performance among all compared methods is 96.84% (SSRN), which is surpassed by 99.76% (our model).
4.3.4. Analysis of the KSC Dataset
The classification results acquired via different methods for the KSC dataset are presented in
Table 8. Moreover, the corresponding classification maps for the different methods are shown in
Figure 11. As shown in
Figure 11, the classification map obtained by
Net is still the most similar to Ground Truth. Compared with the other methods, the increases obtained by
Net for OA are 12.18% (SVM), 19.38% (CDCNN), 8.16% (SSRN), 5.98% (DBDA), 1.83% (DBEMA), 15.1% (ViT), and 3.73% (SSFTT). For each comparison, our model provides a significant gain of 1.5%, demonstrating that
Net is adaptable to the KSC dataset.
Within six categories, our model achieved 100% accuracy. In this respect, our model stands out among all methods. For some categories, such as categories 3, 4, 5, and 6, it can be seen that all comparisons are unsatisfactory, except for our model. Using category 5 as an example, the best performance from all of the compared methods is 68.65% (DBEMA), which is inferior to the accuracy (97.91%) achieved by our model. Unfortunately, in category 7, our model did not perform well. However, this does not conceal the overall competence of Net. In general, our model shows convincing performances on the KSC dataset, overall, and individually.
4.3.5. Visualization of Net Features
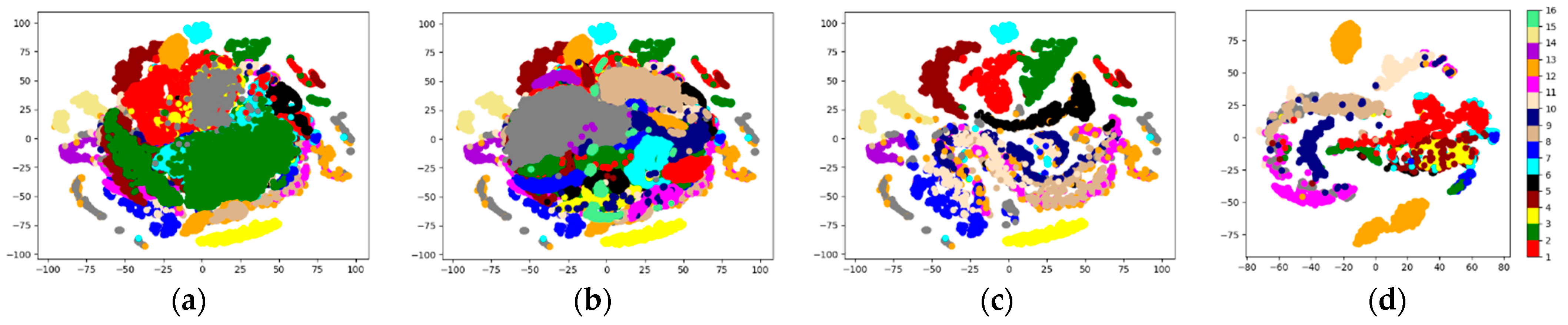
Figure 12 visualizes the original features and
Net features for the four datasets. As can be observed from
Figure 12a–d, plenty of the points in the original feature space are mixed up, posing difficulties to their classification. In contrast, from
Figure 12e–h, it can be concluded that the data points in the transformed features space exhibit improved discriminability, demonstrating the ability of our network. In addition, points with the same color get closer once transformed, forming several clear clusters. In other words,
Net can reduce the intra-class variances and increase the inter-class variances for HSI data, which is beneficial for classification.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}