1. Introduction
With the rapid development of the remote sensing technology, the quantity and quality of remote sensing images used to characterize various objects (such as airports, aircraft, buildings, etc.) on the earth’s surface have been greatly improved. Thus, the research of intelligent earth observation for analyzing and understanding these satellite and aerial images has attracted extensive attention. The aim of the object counting task is to estimate the number of objects of a certain class in a given image, which plays a crucial role in image and video analysis for the applications such as crowd behavior analysis [
1,
2,
3], public security, traffic monitoring, urban planning, et al. Benefiting from the development of deep learning, object counting has achieved great performance in natural images, and a few works have applied object counting in remote sensing images. However, due to the gap between remote sensing and natural images, there is still great space for improvement in remote sensing object counting.
The existing object counting methods can be divided into detection-based and regression-based. Detection-based methods obtain the number of objects by counting the detected bounding boxes. Dijkstra et al. [
4] propose a network named CentroidNet, which obtains the detection results by detecting the centroids. the detection-based method works fine for sparse and large targets, but it suffers a huge performance decrease while dealing with dense and tiny objects. Compared to the detection-based method, the regression-based method requires less annotation and is more stable. In the early stage, researchers extract the manually designed features from the input image [
5] and generate target density by general regression methods, which is also known as the direct regression method. A significant milestone in the development of object counting is converting object counting to density map estimation, which was proposed by Lempitsky et al. [
6]. Following this work, Zhang et al. propose a multi-branch network. Each branch has a different size of convolution kernel to capture the objects. Sam et al. [
7] propose a switch convolutional neural network to select the final regressor by training a switch classifier to obtain the results. Liu et al. [
8] blend the perspective and density maps by adding an extra branch. Jiang et al. [
9] propose a novel encoder-decoder structure that can effectively facilitate the fusion of feature maps at multiple scales. All those approaches mentioned above can obtain relatively good results when dealing with uniformly distributed objects, but they all failed while dealing with uneven distribution and targets with large scales variations.
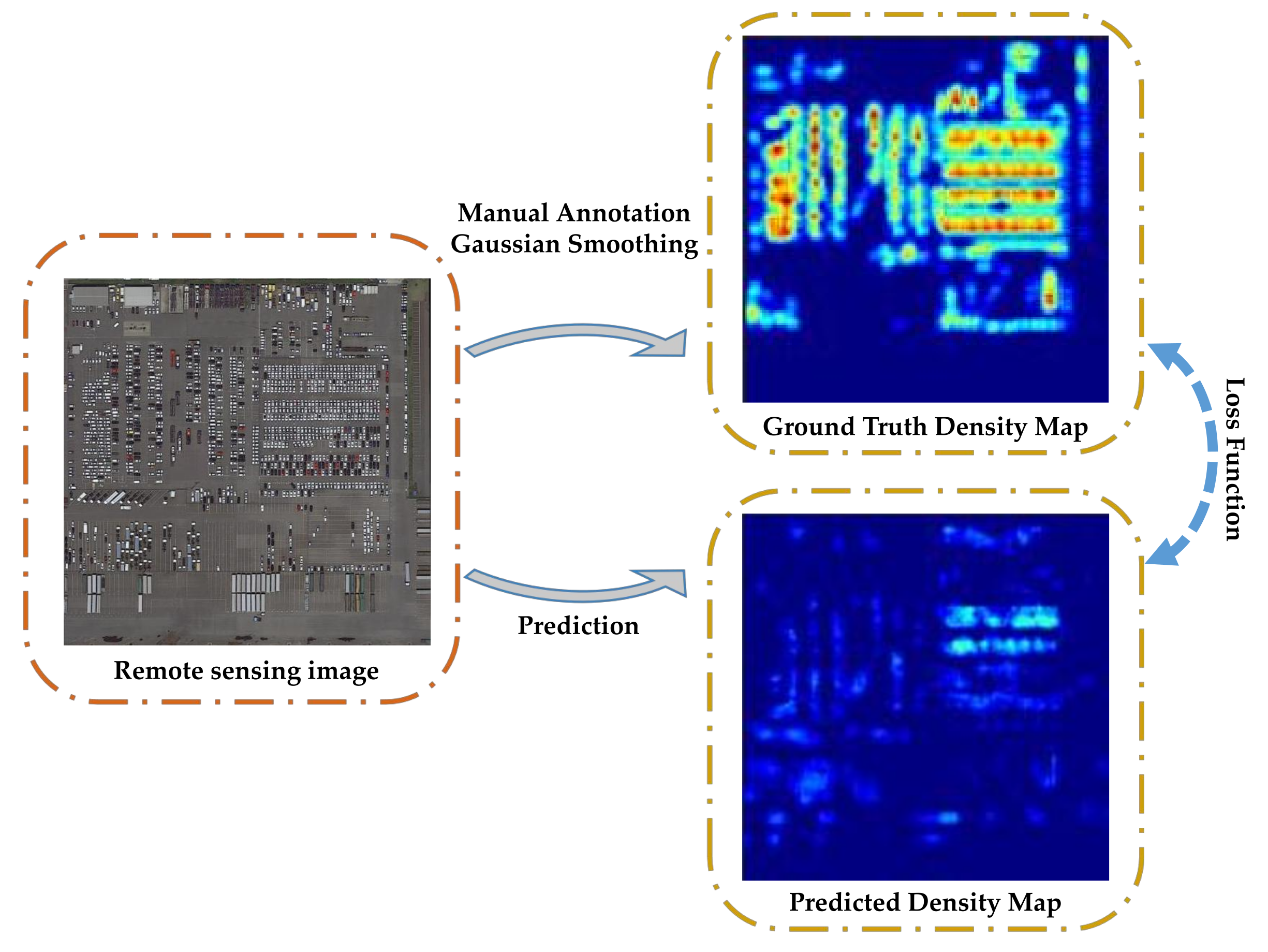
As shown in
Figure 1, compared with object counting in natural images, remote sensing object counting is a more challenging task. Different from natural images, remote sensing images appear to be taken from a high altitude vertical angle by an onboard camera of a satellite or aircraft. Therefore, remote sensing object counting mainly faces the following challenges:
- 1.
As the remote sensing images are collected by various space-borne or airborne cameras under different locations with diverse conditions, the scale of objects of different categories in remote sensing images varies greatly, and even the same target could suffer large-scale variation between each collection.
- 2.
Remote sensing images have more complex backgrounds than natural images, and the acquisition process of remote sensing images is prone to different degrees of occlusion by light, weather, and other factors. These complex backgrounds and occlusion are prone to mislead the model with wrong predictions.
- 3.
Remote sensing images are large in scale and cover a wide range. It may contain extremely dense small objects, such as vehicles, ships, aircraft, etc., so it is difficult to accurately count all these tiny objects within one model.
Aiming at the problems in remote sensing target counting mentioned above, to alleviate the interference brought by scale variation and complex backgrounds, the vision transformer is introduced here to suppress background interference while capturing multi-scale information. To further alleviate the problem of unbalanced samples in training samples, the Balanced MSE loss function is introduced to solve the imbalance of labels from the perspective of statistics. Overall, there are three main contributions of this paper:
- 1.
To our best knowledge, this is the first time that the transformer has been introduced into remote sensing object counting. Due to the attention mechanism of the transformer, it can find some finer objects than the traditional method, thereby increasing the robustness of our model when facing objects of different scales.
- 2.
Achieve competitive results in the commonly used Remote Sensing Object Counting (RSOC) dataset, which contains the Large-vehicle, Small-vehicle, Building, and Ship sub-datasets.
- 3.
To tackle the sample imbalance problem for the targets within remote sensing images, we exploit the Balanced MSE loss to replace the standard MSE loss. the experiments demonstrate that the loss function effectively improves the overall performance of the model.
2. Related Work
This section mainly introduces the related work of four parts, namely remote sensing object counting, object counting, imbalanced data distribution, and tiny object detection.
2.1. Remote Sensing Object Counting
Remote sensing object counting is to estimate the number of objects in remote sensing images. It is a hot issue in the field of computer vision and remote sensing image analysis [
10,
11,
12]. Remote sensing images mainly include satellite images and aerial images, the former obtained by scanning with scanners by adjusting the angle of the satellite, the latter obtained by photographing with optical lenses carried by aircraft. Remote sensing image existences more challenges for the object counting task compared with natural scenes. This is because long-distance aerial photography has problems such as a wider field of view, more complex scenes, and larger-scale variation.
Previously, remote sensing object counting is tackled by combining classification and detection [
13,
14,
15,
16,
17,
18]. Tan et al. [
19] use image segmentation and edge detection algorithms to detect and classify road vehicles. Bazi et al. [
20] propose an automatic counting method using the Gaussian Process Classifier (GPC) to calculate the number of olive trees in remote sensing images. Santoro et al. [
21] adopt a four-step algorithm, mainly using sensor data to calculate the number of fruit trees. Xue et al. [
22] propose a semi-supervised animal counting method. Salam í et al. [
23] use the parallel architecture to connect the UAV and computer, and finally obtain a real-time information processing of images on the UAV for counting.
Recently, deep learning-based remote sensing object counting dominates the mainstream trend, which benefits from the strong representation ability of convolution neural networks. Mubin et al. [
24] use basic LeNet to realize the detection and counting of oil palm. Shao et al. [
25] construct the YOLO-based CNN framework to detect and count cattle on the images collected by UAVs, and finally realize the management of grazing cattle. Wan et al. [
26] propose an end-to-end framework to learn the density map of the counter and achieve good performance. Gao et al. [
27] propose a new remote sensing object counting network PSGCNet, which includes a Pyramid Scale Module (PSM) and a Global Context Module (GCM).
2.2. Object Counting
Generally, we divide existing counting methods [
28,
29,
30] into three types: (1) the detection-based method, (2) regression-based method, and (3) density map estimation-based method.
Detection-based object counting method realizes counting through the sum of detection results. It can be divided into an instance-based [
31] and partial-base [
32] type. the former uses the complete object instance as the detection target, while the latter uses part of the instance to alleviate the interference caused by occlusion. However, all detection-based counting fails while dealing with extremely crowded scenes.
Regression-based methods treat counting as the global density prediction task to avoid the occlusion problem faced by the detection-based method. This means directly estimating the number of the target from the given input image and generated feature. Tan et al. [
33] design a semi-supervised elastic net regression method. Chan et al. [
34] design a new regression method for crowd counting and link the approximate Bayesian Poisson regression with the Gaussian process. However, the solution based on regression only focuses on the global image features, which may lead to large errors and suffer a low fault tolerance rate.
Density map estimation-based methods disperse the target point distribution information to the position around it to generate the intermediate variable, called the density map, and archives counting task through estimating the density map of the given input. A Multi-Column Neural Network (MCNN) is proposed by Zhang et al. [
35], which inputs images of any resolution, learning multi-scale features through each column of MCNN. Then, it obtains the predicted density map, and finally obtains the number of people. a Congestion Scene Recognition Network (CSRNet) is developed by Li et al. CERNet [
36], by performing extended convolution, understands highly crowded scenes. Singagi et al. [
37] combine a high-level prior with the network to learn a model that meets various density levels in the dataset. Ma et al. [
38] design a Bayesian loss function for the point-supervised crowd counting task. Gao et al. [
2] design a Domain Adaptive Crowd Counting (DACC) framework, which can generate pseudo tags in real scenes to improve the prediction quality.
2.3. Imbalanced Data Distribution
Imbalanced data distribution is a common problem in the real world. Recently, researchers have begun to pay attention to the problem of imbalanced regression in computer vision. Branco et al. [
39] use the Gaussian noise enhancement method, and the following year they design a resampling REBAGG [
40] algorithm based on BAGGing. Yang et al. [
41] also propose new methods of Label Distribution Smoothing (LDS) and Feature Distribution Smoothing (FDS). However, the common problem in visual regression is the imbalance of labels. the performance of commonly used MSE loss functions on rare samples is often unsatisfactory. As a result, Ren et al. [
42] propose a balanced MSE for imbalanced visual regression. Balanced MSE uses a probability method to solve label imbalance from the perspective of statistics, and gets rid of the impact of imbalanced label distribution on MSE. We introduce balanced MSE into our work to deal with the problem of label imbalance.
2.4. Tiny Object Detection
Tiny object detection [
43,
44,
45] is a hot issue in the field of computer vision. It faces the problems of image blur, less information, high-level noise, and low resolution. The corresponding solutions are: the Feature Pyramid Network (FPN) proposed in [
46], which adopts the method of multi-scale feature fusion and uses the results of feature fusion at different levels for detection. There are also other works [
47,
48] following the idea of FPN, adding insights to improve the performance. Kisantal et al. [
49] propose the oversampling and copy-paste operations on images containing tiny objects (without obscuring the original targets). In addition, more accurate results can be obtained by applying appropriate training methods, such as SNIP [
50], SNIPER [
51], and SAN [
52]. For tiny objects, the dense anchor sampling and matching strategy S
FD [
53], FaceBoxes [
54] are adopted, which are also common methods.
3. Methodology
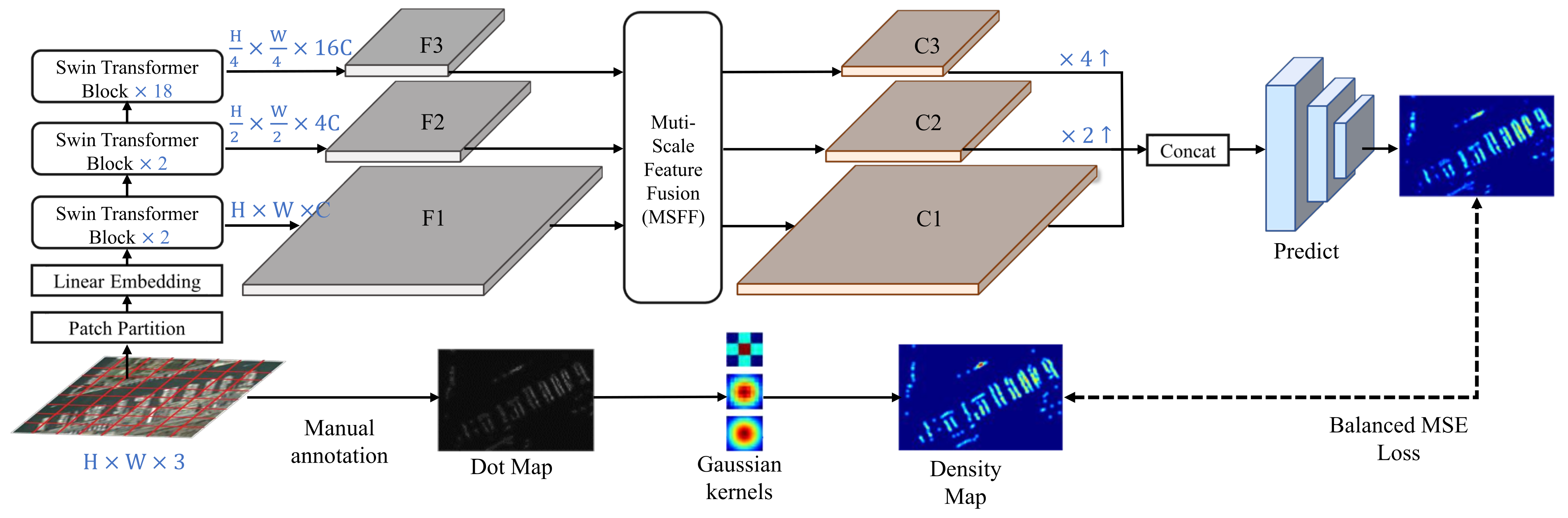
As shown in
Figure 2, the pipeline of our method can be divided into the following stages: Firstly, the input remote sensing image is cut into a set of image paths to form the linear patch embedding. Then, some Swin Transformer blocks [
55], the core of a powerful backbone in a computer vision task, are used to extract features with different scales. These multi-scale features are fused with a Multi-Scale Feature Fusion (MSFF) module, which can effectively aggregate features from coarse to fine resolution. Finally, the prediction block is used to generate the predicted density map according to the concatenated multi-scale fused feature. The balanced MSE is used to calculate the distance between the ground truth density map and the predicted one. It also alleviates the impact of data imbalance on the training process at the same time. For the details of the different steps of the entire framework and the balanced MSE loss function, please refer to the following subsections.
3.1. Multi-Scale Feature Extraction
There are many challenges in remote sensing object detection such as large-scale variation and complex backgrounds. Most existing methods use the convolution neural network to extract the image feature. However, due to the physical properties of the CNNs, it is difficult to model the dependencies between global pixels. Here, the “global pixel” represents the global information of a given input image. Some works use the multi-layer CNN to increase the scope of the receptive field, but it is not efficient and still cannot deal with tiny objects in the remote sensing images. The self-attention mechanism provides an effective method to capture global context information. To achieve better performance for the remote sensing counting task, we introduce the Swin Transformer [
55] based on self-attention for richer feature extraction. Swin Transformer uses the shifted window mechanism with a hierarchical design to divide the image into non-overlapping local windows and calculate self-attention within each window. In this way, the background noise can be suppressed and the object features can be highlighted even for the tiny targets.
Given an RGB image as the input, first, we use the patch partition operation to divide the input I into patches by using a simple convolutional layer of the same size of kernel size and stride, which is set to 4 here. Then, all the patches are projected to the pre-defined dimension (denoted as C) through the linear embedding operation.
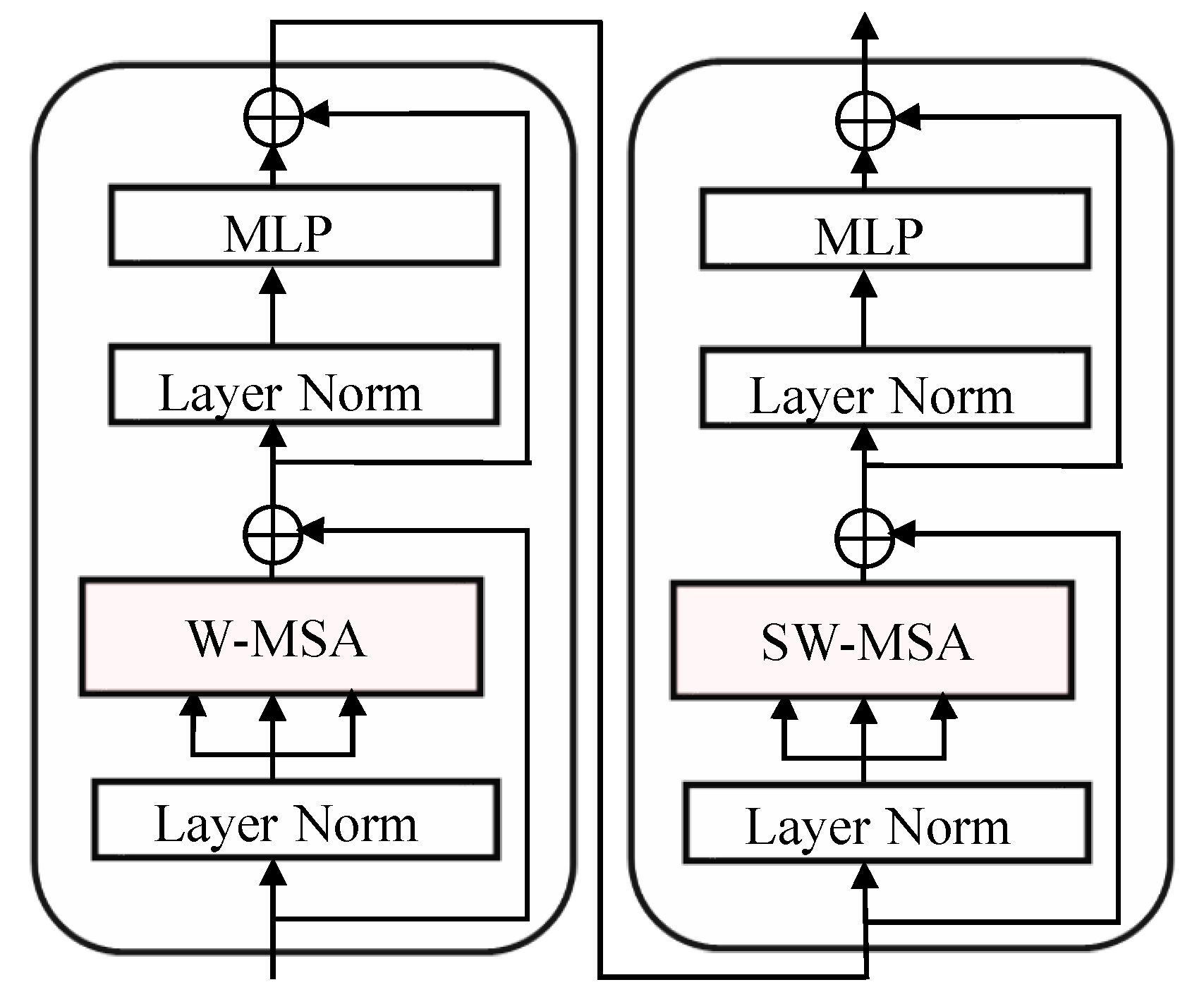
After that, each patch is flattened and input into Swin Transformer blocks as a “token”. As shown in
Figure 3, different from the original ViT [
56], the Swin Transformer uses Window-based Multi-head Self-Attention (W-MSA) to calculate attention in a window of limited size (set to 7 by default). At the same time, it enhances the connection between different windows through a Shifted Window-based Multi-head Self-Attention(SW-MSA) operation. Specifically, the Swin Transformer block uses a linear layer to project the input token onto three elements:
Q (query),
K (key), and
V (value), where d is the query/key dimension. the three elements are used to calculate attention in the fixed window. the process can be formulated as follows
As shown in
Figure 2, in the proposed method, we use a 3-layer Swin Transformer to extract feature information under 3 different scales. Specifically, 2 Swin Transformer blocks are used to extract shallow feature information at first, and 18 Swin Transformer blocks are then utilized to extract more elaborate feature information. Specifically, the process of multi-scale feature extraction can be expressed as
where
I represents the original image.
,
, and
represent feature maps of three scales, and their dimensions are
,
×
×
, and
×
×
, respectively.
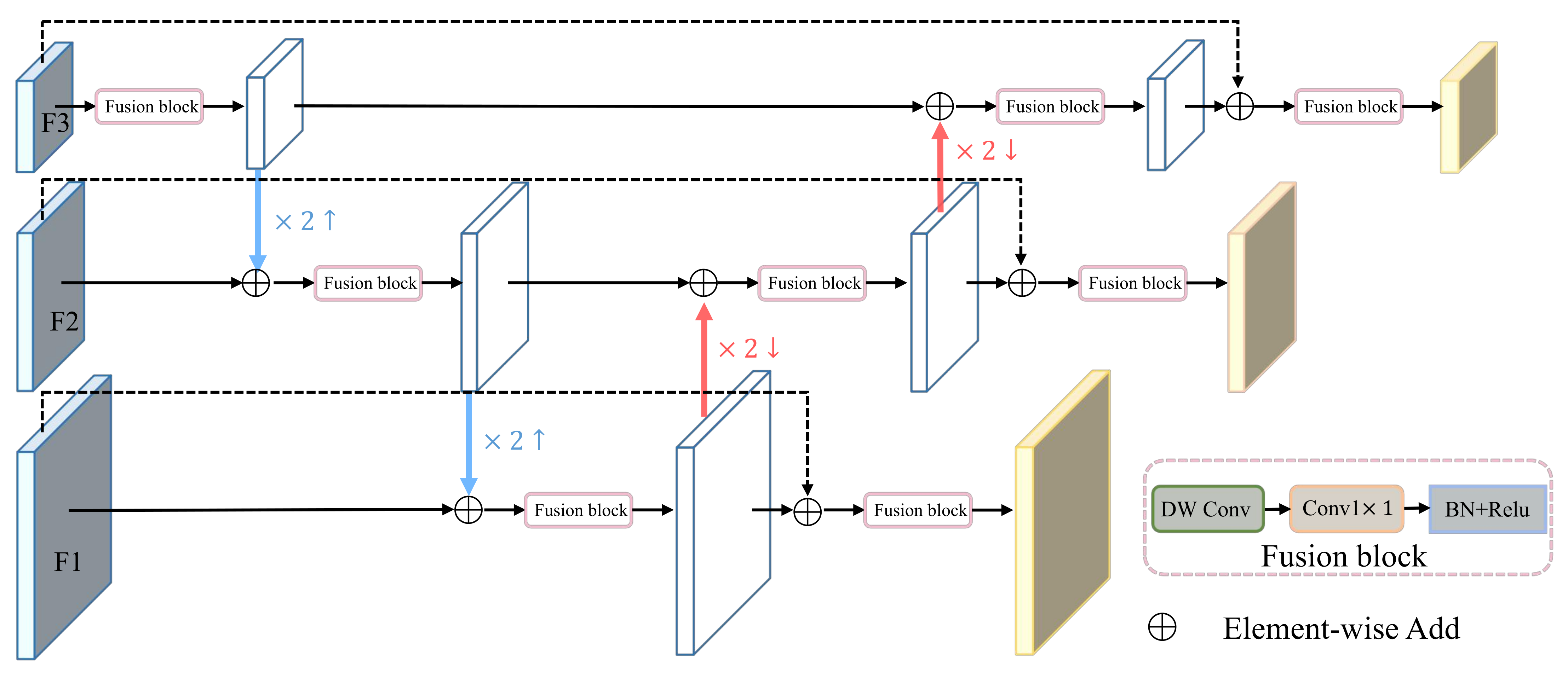
3.2. Muti-Scale Feature Fusion Module
As mentioned above, the proposed method uses three Swin Transformer layers to extract features with different scales from coarse to fine. To further make use of the information contained in features of different scales, we propose the Multi-Scale Feature Fusion (MSFF) module inspired by FPN. As shown in
Figure 4, the feature vector under each scale is applied to the fusion block and element—wisely added to feature vectors under other scales, which transmits the feature information repeatedly between different scales. In the last stage, each fused vector is added to the original one and passes through the fusion block to form the final output. Each fusion block contains a depth-wise convolutional layer and a
convolutional layer, and then followed by batch normalization and the Relu activation.
In general, the feature map
extracted by the backbone is sent to the feature fusion module, and the 1 × 1 and 3 × 3 convolutional layers are used to obtain the feature layer after the feature fusion, which can be formulated as follow
where
,
, and
represent feature maps generated by MSFF. Their sizes are
,
×
×
, and
×
×
, respectively. These feature maps are then upsampled and concatenated.
3.3. Density Map Estimation
The final step is to generate density maps from the output features of MSFF. The prediction block of the SwinCounter contains a
convolution layer to further integrate the input feature. the following two transposed convolutions are used to align the output size while reducing the channel dimension to 1. The ground truth density map is generated by the Gaussian filtering result of the dot map, which can be formulated as
where
represents the process of mapping the initial labels to density labels and
g represents the final generated density map used in training.
3.4. Balanced MSE Loss Function
As shown in
Figure 5, in the RSOC dataset [
57], we statistically analyze the sample distribution among four different categories. There is a serious imbalanced sample distribution in the data set. Most remote sensing object counting methods use the MSE loss function. It can be formulated as
where
represents the ground truth of the label and
represents the predicted value output by the prediction model.
However, the imbalance of target labels, a major problem in computer vision research, also exists in the research field of object counting. We can observe from
Figure 5 that the distribution of positive and negative samples within this dataset is extremely unbalanced.
Therefore, we introduce Balanced MSE Loss [
42] as the loss function of our model, which has obvious advantages in theory and practice compared to traditional MSE Loss. We first use
to represent the distribution of the data during training, and
to represent the distribution of the data during testing. It can be formulated as
The balanced MSE loss estimates
by minimizing the Negative Log Likelihood (NLL) loss of
The NLL loss is formally defined as
Accordingly, the balanced MSE loss
can be expressed as:
For more details, please refer to the original work [
42].
4. Experiment
In this section, we firstly introduce the dataset and evaluation metrics used in the experiments. Then, we compare the proposed SwinCounter with other state-of-the-art methods on the RSOC dataset. Finally, we show our ablation experiments, where we validate the effectiveness of the proposed method.
4.1. Remote Sensing Object Counting (RSOC) Dataset
The RSOC [
57] dataset contains a total of 3057 images and 286,539 target instances. This dataset is currently the largest in the field of remote sensing counting. This dataset is divided into four datasets, namely Building, Small-vehicle, Large-vehicle, and Ship, and the training set of each dataset contains 1205, 222, 108, and 97 images, respectively. the test set of each dataset includes 1263, 58, 64, and 60 images, respectively. More detailed information is presented in
Table 1.
4.2. Evaluation Metrics
For the counting tasks, the most widely used evaluation metrics are MAE and MSE; we also use these metrics here. We compare the performance of the proposed SwinCounter with other state-of-the-art methods under this evaluation criterion. The MAE is defined as follows:
The MSE is defined as follows:
where
n represents the number of tested images.
is the ground truth density map of the
ith image, and
represents the predicted density map of the countering models for the
ith image.
4.3. Object Counting Result on the RSOC Dataset
To demonstrate the effectiveness of the proposed method, we perform the validation experiments on the RSOC dataset. The performance of the proposed SwinCounter on each sub-dataset is compared with other SOTA methods in
Table 2. From it, we find that SwinCounter archives the best on the Building, Small-vehicle, and Ship sub-datasets, and second for the Large-vehicle. The Swin Transformer-based feature extractor and MSFF provides a more efficient feature vector and finally bring improvements to counting performance. Due to the use of Balanced MSE Loss, the problem of unbalanced sample labels has been alleviated to a certain extent. In particular, compared with the sub-optimal approach ASPDNet [
57], the SwinCounter improves by 0.39 MAE and 0.56 MSE on the RSOC_building subset, 22.03 MAE and 37.29 MSE on the RSOC_ship subset, and 5.95 MAE on the RSOC_small_vehicle subset. From the evaluation metrics, our method does achieve a state-of-the-art performance on multiple datasets, and the performance is considerable for larger objects, but for dense and small object counting, the method still suffers large room for improvement. Moreover, our method achieves good results for objects of different scales in multiple datasets, which also proves the robustness of the method.
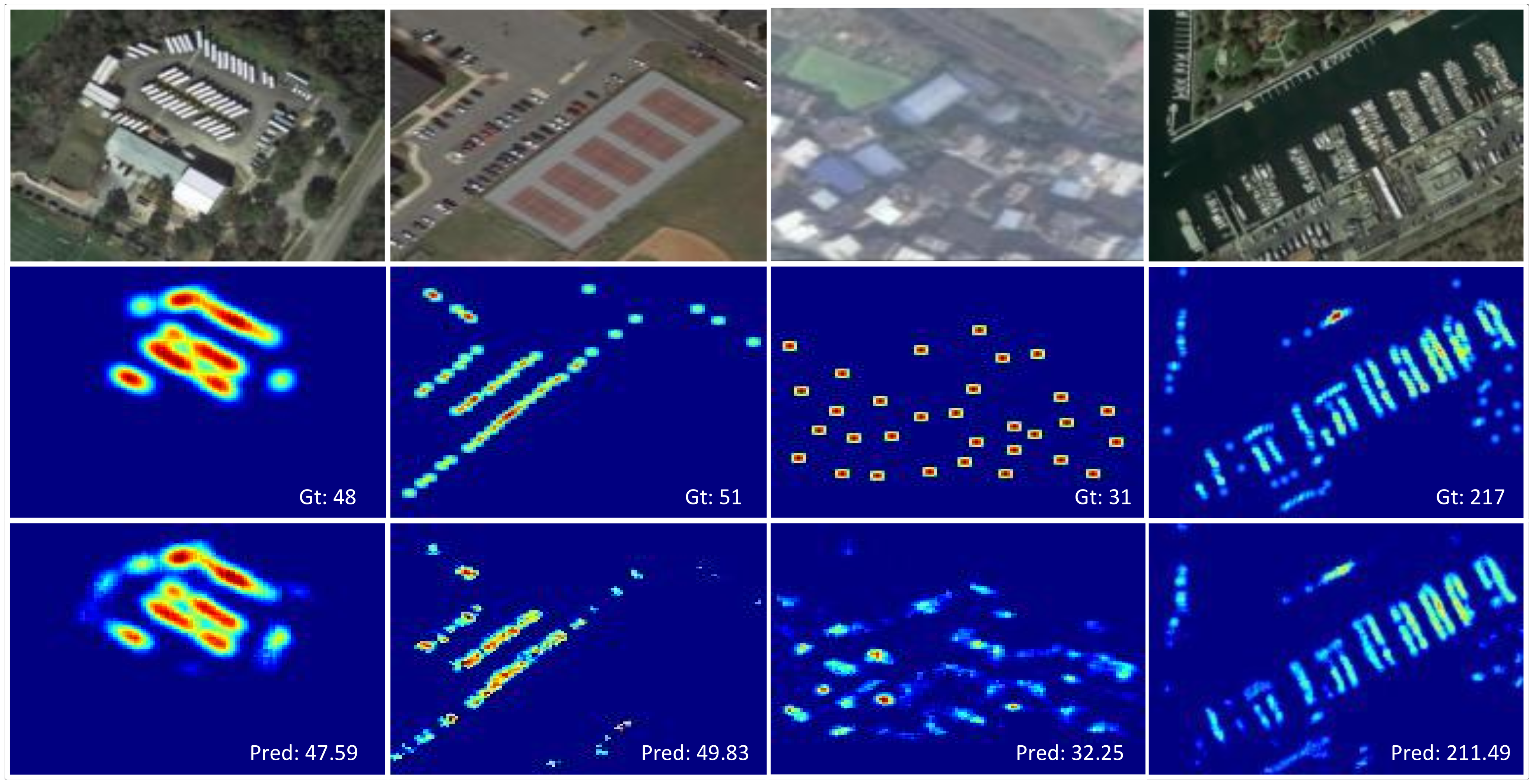
The visualization results of the input image ground truth and predicted density map of the four specific sub-datasets are shown in
Figure 6. By visualizing the results, it can be concluded that our method has achieved good results.
To verify the effectiveness of each proposed block, we conducted ablation experiments on the Small-Vehicle dataset and set up four different network combinations (baseline, baseline + feature addition, baseline + MSFF, and baseline + MSFF+ Balanced MSE loss). The detailed setting of each combination is introduced as follows:
Baseline: We set the baseline as an original Swin Transformer backbone, and directly output the prediction results by upsampling the last layer of the feature layer. It can be concluded from
Table 3 that the model output results at this time are relatively unsatisfactory.
Baseline + feature addition: This group directly adds the feature layers extracted by the Swin Transformer to obtain the final feature layer, and, finally, obtain the density prediction through a simple convolution layer. According to the results in
Table 3, we can see that after simple feature addition, the model effect has a certain improvement.
Baseline + MSFF: the third group uses the newly proposed MSFF as the feature fusion block to perform a pyramid-style feature fusion on the multi-scale features provided by the baseline and uses the normal MSE loss function during the training process.
Baseline + MSFF + Balanced MSE loss: The last group adopts the Balanced MSE loss function to tackle the label imbalance problem, which is the full model, namely SwinCounter.
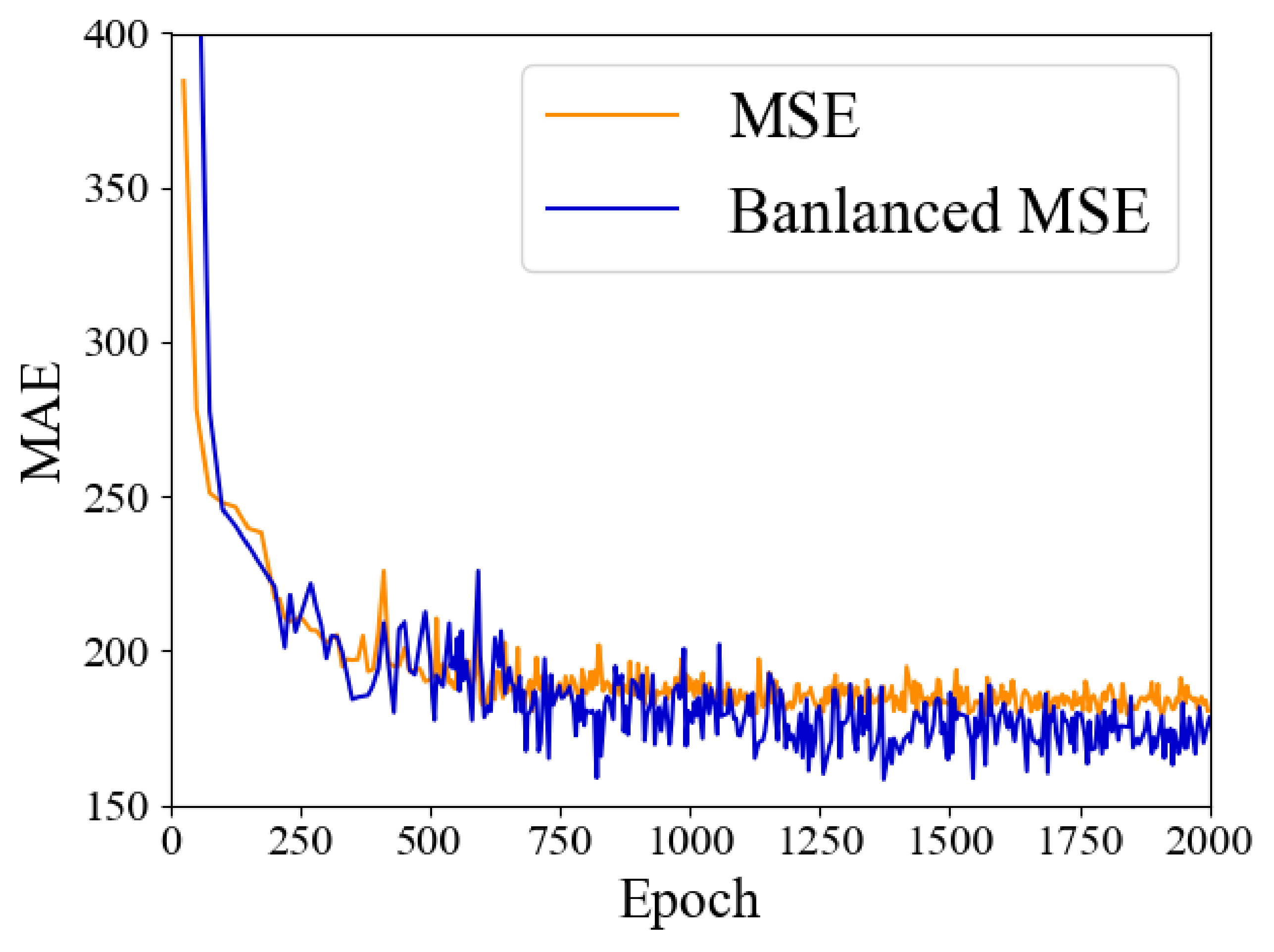
The comparison results are shown in
Table 3. Together with
Figure 7, the MAE of the balanced MSE loss function is much higher than the normal MSE loss at the beginning, but it also drops faster and, finally, performs better. After introducing each block (MSFF and balanced MSE loss), the MAE and MSE are becoming better than the baseline model, which shows the effectiveness of the proposed approaches. The visualization for each group’s predicted density map is shown in
Figure 8. Where the first and third columns are scenarios of large-scale dense objects, according to the visualization, we can observe the effectiveness of the proposed SwinCounter. the other images are less dense scenes, and the effect of the proposed approach is more obvious. The counting result of the proposed SwinCounter is more close to the ground truth and it generates density maps with better details.
4.4. Ablation Study
At the same time, we also conducted comparative experiments with different window sizes of the Swin Transformer block. the results are given in
Table 4. Through this experimental result, we found that the best result can be obtained when the window size is set to
, this is also the final setting for the SwinCounter.
5. Conclusions
In this paper, we propose the SwinCounter based on the Swin Transformer and achieve the state-of-the-art performance of remote sensing object counting on some mainstream datasets. As far as we know, it is the first time that the vision transformer has been introduced into the remote sensing object counting task. The use of the multi-level Swin Transformer encoder provides stronger representation ability without introducing too many parameters, while MSFF further optimizes the fusion and transmission of multi-scale information. Finally, we also use the Balanced MSE loss function to alleviate the problems caused by label imbalance. The proposed method has achieved considerable performance for relatively larger objects. However, for the processing of extremely dense small targets, there is still room for improvements in the current method, which is also the goal of our future challenges.
Author Contributions
Conceptualization, J.G., M.G. and X.L.; methodology, J.G. and X.L.; software, J.G.; validation, J.G., M.G. and X.L.; formal analysis, J.G.; investigation, J.G.; resources, M.G.; writing, J.G.; supervision, M.G. and X.L.; project administration, J.G. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by National Natural Science Foundation of China (No. 61871470, No. 62036006, and No. 62106182), China Postdoctoral Science Foundation (No. 2021TQ0257 and No. 2021M692500) and the Fundamental Research of Funds for the Central Universities (No. XJS222216).
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gao, J.; Wang, Q.; Li, X. Pcc net: Perspective crowd counting via spatial convolutional network. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3486–3498. [Google Scholar] [CrossRef]
- Gao, J.; Han, T.; Yuan, Y.; Wang, Q. Domain-adaptive crowd counting via high-quality image translation and density reconstruction. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Gao, J.; Yuan, Y.; Wang, Q. Feature-aware adaptation and density alignment for crowd counting in video surveillance. IEEE Trans. Cybern. 2020, 51, 4822–4833. [Google Scholar] [CrossRef] [PubMed]
- Dijkstra, K.; Loosdrecht, J.; Schomaker, L.; Wiering, M.A. Centroidnet: A deep neural network for joint object localization and counting. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Dublin, Ireland, 10–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 585–601. [Google Scholar]
- Chen, K.; Loy, C.C.; Gong, S.; Xiang, T. Feature mining for localised crowd counting. In Proceedings of the BMVC, Surrey, UK, 3–7 September 2012; Volume 1, p. 3. [Google Scholar]
- Lempitsky, V.; Zisserman, A. Learning To Count Objects in Images. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010; Lafferty, J., Williams, C., Shawe-Taylor, J., Zemel, R., Culotta, A., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2010; Volume 23. [Google Scholar]
- Babu Sam, D.; Surya, S.; Venkatesh Babu, R. Switching Convolutional Neural Network for Crowd Counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, W.; Salzmann, M.; Fua, P. Context-aware crowd counting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5099–5108. [Google Scholar]
- Jiang, X.; Xiao, Z.; Zhang, B.; Zhen, X.; Cao, X.; Doermann, D.; Shao, L. Crowd Counting and Density Estimation by Trellis Encoder-Decoder Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhang, H.; Li, G.; Huang, M.; Zhang, L.; Xie, J.; Tian, C. Bibliometric analysis on global remote sensing research during 2010–2014. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 5510–5513. [Google Scholar]
- Li, Y.; Zhang, Y.; Huang, X.; Ma, J. Learning Source-Invariant Deep Hashing Convolutional Neural Networks for Cross-Source Remote Sensing Image Retrieval. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6521–6536. [Google Scholar] [CrossRef]
- Wang, M.; Dong, Z.; Cheng, Y.; Li, D. Optimal Segmentation of High-Resolution Remote Sensing Image by Combining Superpixels With the Minimum Spanning Tree. IEEE Trans. Geosci. Remote Sens. 2018, 56, 228–238. [Google Scholar] [CrossRef]
- Chen, Q.; Yin, Q. Extract agricultural land use information from remote sensing image based on object-oriented classification algorithm. In Proceedings of the 2011 International Conference on Remote Sensing, Environment and Transportation Engineering, Nanjing, China, 24–26 June 2011; pp. 4983–4986. [Google Scholar]
- Zhang, Z.; Yang, M.Y.; Zhou, M.; Zeng, X.Z. Simultaneous remote sensing image classification and annotation based on the spatial coherent topic model. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 1698–1701. [Google Scholar]
- Hu, J.; Xia, G.S.; Hu, F.; Sun, H.; Zhang, L. A comparative study of sampling analysis in scene classification of high-resolution remote sensing imagery. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 2389–2392. [Google Scholar]
- Palubinskas, G.; Kurz, F.; Reinartz, P. Detection of Traffic Congestion in Optical Remote Sensing Imagery. In Proceedings of the IGARSS 2008—2008 IEEE International Geoscience and Remote Sensing Symposium, Boston, MA, USA, 8–11 July 2008; Volume 2, pp. II-426–II-429. [Google Scholar]
- Jangal, F.; Saillant, S.; Helier, M. Wavelet Contribution to Remote Sensing of the Sea and Target Detection for a High-Frequency Surface Wave Radar. IEEE Geosci. Remote Sens. Lett. 2008, 5, 552–556. [Google Scholar] [CrossRef]
- Yao, Q.; Hu, X.; Lei, H. Geospatial Object Detection In Remote Sensing Images Based On Multi-Scale Convolutional Neural Networks. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1450–1453. [Google Scholar]
- Tan, Q.; Wang, J.; Aldred, D. Road Vehicle Detection and Classification from Very-High-Resolution Color Digital Orthoimagery based on Object-Oriented Method. In Proceedings of the IEEE International Geoscience & Remote Sensing Symposium, IGARSS 2008, Boston, MA, USA, 8–11 July 2008; pp. 475–478. [Google Scholar]
- Bazi, Y.; Melgani, F.; Al-Sharari, H.D. An Automatic Method for Counting Olive Trees in Very High Spatial Remote Sensing Images. In Proceedings of the IEEE International Geoscience & Remote Sensing Symposium, IGARSS 2009, Cape Town, South Africa, 12–17 July 2009; pp. 125–128. [Google Scholar]
- Santoro, F.; Tarantino, E.; Figorito, B.; Gualano, S.; D’Onghia, A.M. a tree counting algorithm for precision agriculture tasks. Int. J. Digit. Earth 2013, 6, 94–102. [Google Scholar] [CrossRef]
- Xue, Y.; Wang, T.; Skidmore, A.K. Automatic Counting of Large Mammals from Very High Resolution Panchromatic Satellite Imagery. Remote Sens. 2017, 9, 878. [Google Scholar] [CrossRef]
- Salamí, E.; Gallardo, A.; Skorobogatov, G.; Barrado, C. On-the-Fly Olive Tree Counting Using a UAS and Cloud Services. Remote Sens. 2019, 11, 316. [Google Scholar] [CrossRef]
- Mubin, N.A.; Nadarajoo, E.; Shafri, H.Z.M.; Hamedianfar, A. Young and mature oil palm tree detection and counting using convolutional neural network deep learning method. Int. J. Remote Sens. 2019, 40, 7500–7515. [Google Scholar] [CrossRef]
- Shao, W.; Kawakami, R.; Yoshihashi, R.; You, S.; Naemura, T. Cattle detection and counting in UAV images based on convolutional neural networks. Int. J. Remote Sens. 2019, 41, 31–52. [Google Scholar] [CrossRef]
- Wan, J.; Wang, Q.; Chan, A.B. Kernel-Based Density Map Generation for Dense Object Counting. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1357–1370. [Google Scholar] [CrossRef]
- Gao, G.; Liu, Q.; Hu, Z.; Li, L.; Wen, Q.; Wang, Y. PSGCNet: A Pyramidal Scale and Global Context Guided Network for Dense Object Counting in Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5619412. [Google Scholar] [CrossRef]
- Stahl, T.; Pintea, S.L.; van Gemert, J.C. Divide and Count: Generic Object Counting by Image Divisions. IEEE Trans. Image Process. 2019, 28, 1035–1044. [Google Scholar] [CrossRef]
- Go, H.; Byun, J.; Park, B.; Choi, M.A.; Yoo, S.; Kim, C. Fine-Grained Multi-Class Object Counting. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 509–513. [Google Scholar]
- Shang, H.; Li, R.; He, X.; Wang, J.; Peng, X. Real-time Accurate Object Counting for Smart Farms. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Felzenszwalb, P.; Girshick, R.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Robust real-time face detection. In Proceedings of the IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, p. 747. [Google Scholar] [CrossRef]
- Tan, B.; Zhang, J.; Wang, L. Semi-supervised Elastic net for pedestrian counting. Pattern Recognit. 2011, 44, 2297–2304. [Google Scholar] [CrossRef]
- Chan, A.; Vasconcelos, N. Bayesian Poisson Regression for Crowd Counting. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 545–551. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-Image Crowd Counting via Multi-Column Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Li, Y.; Zhang, X.; Chen, D. CSRNet: Dilated convolutional neural networks for understanding the highly congested scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1091–1100. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. Cnn-based cascaded multi-task learning of high-level prior and density estimation for crowd counting. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Ma, Z.; Wei, X.; Hong, X.; Gong, Y. Bayesian loss for crowd count estimation with point supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6142–6151. [Google Scholar]
- Branco, P.; Torgo, L.; Ribeiro, R.P. SMOGN: A pre-processing approach for imbalanced regression. In Proceedings of the First International Workshop on Learning with Imbalanced Domains: Theory and Applications, Skopje, North Macedonia, 22 September 2017; pp. 36–50. [Google Scholar]
- Branco, P.; Torgo, L.; Ribeiro, R.P. Rebagg: Resampled bagging for imbalanced regression. In Proceedings of the Second International Workshop on Learning with Imbalanced Domains: Theory and Applications, Dublin, Ireland, 10 September 2018; pp. 67–81. [Google Scholar]
- Yang, Y.; Zha, K.; Chen, Y.; Wang, H.; Katabi, D. Delving into Deep Imbalanced Regression. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, Virtual Event, 18–24 July 2021; Meila, M., Zhang, T., Eds.; Volume 139, pp. 11842–11851. [Google Scholar]
- Ren, J.; Zhang, M.; Yu, C.; Liu, Z. Balanced MSE for Imbalanced Visual Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, New Orleans, LA, USA, 19–24 June 2022; pp. 7926–7935. [Google Scholar]
- Raghunandan, A.; Mohana; Raghav, P.; Aradhya, H.V.R. Object Detection Algorithms for Video Surveillance Applications. In Proceedings of the 2018 International Conference on Communication and Signal Processing (ICCSP), Guiyang, China, 16–19 March 2018; pp. 0563–0568. [Google Scholar]
- Mane, S.; Mangale, S. Moving Object Detection and Tracking Using Convolutional Neural Networks. In Proceedings of the 2018 Second International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 14–15 June 2018; pp. 1809–1813. [Google Scholar]
- Deshmukh, S.; Moh, T.S. Fine Object Detection in Automated Solar Panel Layout Generation. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 1402–1407. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Deng, J.; Guo, J.; Zhou, Y.; Yu, J.; Kotsia, I.; Zafeiriou, S. RetinaFace: Single-stage Dense Face Localisation in the Wild. arXiv 2019, arXiv:1905.00641. [Google Scholar]
- Najibi, M.; Samangouei, P.; Chellappa, R.; Davis, L.S. SSH: Single Stage Headless Face Detector. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; pp. 4885–4894. [Google Scholar]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for small object detection. arXiv 2019, arXiv:1902.07296. [Google Scholar]
- Singh, B.; Davis, L.S. An Analysis of Scale Invariance in Object Detection SNIP. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3578–3587. [Google Scholar]
- Singh, B.; Najibi, M.; Davis, L.S. SNIPER: Efficient Multi-Scale Training. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montréal, QC, Canada, 3–8 December 2018; pp. 9333–9343. [Google Scholar]
- Kim, Y.; Kang, B.; Kim, D. SAN: Learning Relationship Between Convolutional Features for Multi-scale Object Detection. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part XV. Lecture Notes in Computer Science 11219. Springer: Berlin/Heidelberg, Germany, 2018; pp. 328–343. [Google Scholar]
- Zhang, S.; Zhu, X.; Lei, Z.; Shi, H.; Wang, X.; Li, S.Z. S3FD: Single Shot Scale-invariant Face Detector. arXiv 2017, arXiv:1708.05237. [Google Scholar]
- Zhang, S.; Zhu, X.; Lei, Z.; Shi, H.; Wang, X.; Li, S.Z. FaceBoxes: A CPU real-time face detector with high accuracy. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics, IJCB 2017, Denver, CO, USA, 1–4 October 2017; pp. 1–9. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Gao, G.; Liu, Q.; Wang, Y. Counting from sky: A large-scale data set for remote sensing object counting and a benchmark method. IEEE Trans. Geosci. Remote Sens. 2020, 59, 3642–3655. [Google Scholar] [CrossRef]
- Wang, Q.; Gao, J.; Lin, W.; Yuan, Y. Learning from synthetic data for crowd counting in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8198–8207. [Google Scholar]
- Chen, X.; Bin, Y.; Sang, N.; Gao, C. Scale pyramid network for crowd counting. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1941–1950. [Google Scholar]
- Gao, J.; Wang, Q.; Yuan, Y. SCAR: Spatial-/channel-wise attention regression networks for crowd counting. Neurocomputing 2019, 363, 1–8. [Google Scholar] [CrossRef]
- Zhu, L.; Zhao, Z.; Lu, C.; Lin, Y.; Peng, Y.; Yao, T. Dual path multi-scale fusion networks with attention for crowd counting. arXiv 2019, arXiv:1902.01115. [Google Scholar]
Figure 1.
Remote sensing image object counting. For remote sensing image with manually annotated point label, the Gaussian smoothing on the dot map is used to generate corresponding density map. Different from natural images, remote sensing images suffer from large target scale variation and unbalanced target distribution.
Figure 1.
Remote sensing image object counting. For remote sensing image with manually annotated point label, the Gaussian smoothing on the dot map is used to generate corresponding density map. Different from natural images, remote sensing images suffer from large target scale variation and unbalanced target distribution.
Figure 2.
Pipeline of proposed proposed remote sensing object counting framework (SwinCounter). Firstly, Swin Transformer is used to extract multi-scale feature and send it into MSFF module to fuse multi-scale information. Finally, the fused feature information is used to predict density map.
Figure 2.
Pipeline of proposed proposed remote sensing object counting framework (SwinCounter). Firstly, Swin Transformer is used to extract multi-scale feature and send it into MSFF module to fuse multi-scale information. Finally, the fused feature information is used to predict density map.
Figure 3.
Two successive Swin Transformer blocks.
Figure 3.
Two successive Swin Transformer blocks.
Figure 4.
Multi-scale feature fusion module.
Figure 4.
Multi-scale feature fusion module.
Figure 5.
The sample distribution of four objects (i.e., Small Vehicle, Large Vehicle, Building, and Ship) in the RSOC dataset [
57], the ordinate represents the number of samples, and the abscissa represent the proportion of pixels of the target object in the sample to pixels of the whole sample.
Figure 5.
The sample distribution of four objects (i.e., Small Vehicle, Large Vehicle, Building, and Ship) in the RSOC dataset [
57], the ordinate represents the number of samples, and the abscissa represent the proportion of pixels of the target object in the sample to pixels of the whole sample.
Figure 6.
The first row is the input image from four sub-datasets, the second row is the corresponding ground truth, and the last row is the predicted density map of the proposed SwinCounter.
Figure 6.
The first row is the input image from four sub-datasets, the second row is the corresponding ground truth, and the last row is the predicted density map of the proposed SwinCounter.
Figure 7.
The MAE convergence curve during the training process on the RSOC Small-vehicle dataset under the MSE and Balanced MSE loss function. the orange one is the curve under MSE loss, and the blue one represents Balanced MSE loss.
Figure 7.
The MAE convergence curve during the training process on the RSOC Small-vehicle dataset under the MSE and Balanced MSE loss function. the orange one is the curve under MSE loss, and the blue one represents Balanced MSE loss.
Figure 8.
The images in the first row are the original input images from the Small-vehicle sub-dataset, and the second row is the ground truth. The last row is the final density estimation result of the complete SwinCounter, while the rest are the density maps generated by the incomplete models for comparison.
Figure 8.
The images in the first row are the original input images from the Small-vehicle sub-dataset, and the second row is the ground truth. The last row is the final density estimation result of the complete SwinCounter, while the rest are the density maps generated by the incomplete models for comparison.
Table 1.
Relevant statistics for the four sub-datasets of the RSOC dataset.
Table 1.
Relevant statistics for the four sub-datasets of the RSOC dataset.
| Dataset | Platform | Images | Train/Test | Average Resolution | Annotation Format | Total |
|---|
| Building | Satellite | 2468 | 1205/163 | 512 × 512 | Center point | 71.3 |
| Small_vehicle | Satellite | 280 | 222/58 | 2473 × 2339 | Bounding box | 82.4 |
| Large_vehicle | Satellite | 172 | 108/64 | 1552 × 1573 | Bounding box | 83.4 |
| Ship | Satellite | 137 | 97/40 | 2558 × 2668 | Bounding box | 87.3 |
Table 2.
Comparing with other state-of-the-art methods, the Large-vehicle and Ship sub datasets of the RSOC dataset are compared, and MAE and MSE are selected as evaluation metrics. the best-performing method is marked in red, and the second-best performing method is marked in blue.
Table 2.
Comparing with other state-of-the-art methods, the Large-vehicle and Ship sub datasets of the RSOC dataset are compared, and MAE and MSE are selected as evaluation metrics. the best-performing method is marked in red, and the second-best performing method is marked in blue.
| Methods | Year/Venue | Large_Vehicle | Ship | Building | Small_Vehicle |
|---|
| MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE |
|---|
| MCNN [35] | 2016 CVPR | 36.56 | 55.55 | 263.91 | 412.30 | 13.65 | 16.56 | 488.65 | 1317.44 |
| CMLT [37] | 2017 AVSS | 61.02 | 78.25 | 251.17 | 403.07 | 12.78 | 15.99 | 490.53 | 1321.11 |
| CSRNet [36] | 2018 CVPR | 62.78 | 79.65 | 302.37 | 436.91 | 29.01 | 32.96 | 497.22 | 1276.66 |
| SANeT [8] | 2018 ECCV | 62.78 | 79.65 | 302.37 | 436.91 | 29.01 | 32.96 | 497.22 | 1276.66 |
| SFCN [58] | 2019 CVPR | 33.93 | 49.74 | 240.16 | 394.81 | 8.94 | 12.87 | 440.70 | 1248.27 |
| SPN [59] | 2019 WACV | 36.21 | 50.65 | 241.43 | 392.88 | 7.74 | 11.48 | 445.16 | 1252.92 |
| SCAR [60] | 2019 NC | 62.78 | 79.64 | 302.37 | 436.92 | 26.90 | 31.35 | 497.22 | 1276.65 |
| CAN [8] | 2019 CVPR | 34.56 | 49.63 | 282.69 | 423.44 | 9.12 | 13.38 | 457.36 | 1260.39 |
| SFANet [61] | 2019 CVPR | 29.04 | 47.01 | 201.61 | 332.87 | 8.18 | 11.75 | 435.29 | 1284.15 |
| ASPDNet [57] | 2020 TGRS | 18.76 | 31.06 | 193.83 | 318.95 | 7.59 | 10.66 | 433.23 | 1238.61 |
| PSGCNet [27] | 2022 TGRS | 11.00 | 17.65 | 74.91 | 112.11 | 7.54 | 10.52 | 157.55 | 245.31 |
| SwinCounter | Ours | 14.38 | 22.7 | 52.88 | 74.82 | 7.2 | 10.1 | 151.5 | 436.0 |
Table 3.
The experimental results of the SwinCounter under different network blocks are embodied in the MAE and MSE.
Table 3.
The experimental results of the SwinCounter under different network blocks are embodied in the MAE and MSE.
| Method | MAE | MSE |
|---|
| Baseline | 216.7 | 541.5 |
| Baseline + feature addition | 201.57 | 515.9 |
| Baseline + FPN | 178.9 | 441.3 |
| Baseline + FPN + Balanced MSE | 151.5 | 436.0 |
Table 4.
The influence of the window size; the measurement indicator is MAE and MSE.
Table 4.
The influence of the window size; the measurement indicator is MAE and MSE.
| Window Size | MAE | MSE |
|---|
| 3 × 3 | 193.8 | 713.9 |
| 7 × 7 | 151.5 | 436.0 |
| 15 × 15 | 192.4 | 629.7 |
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}