
Site Selection via Learning Graph Convolutional Neural Networks: A Case Study of Singapore


Abstract
:
1. Introduction
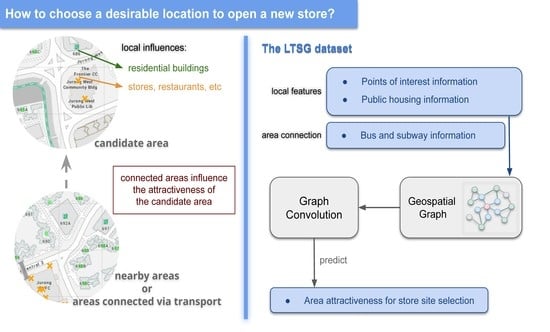
- We provide a comprehensive Land and Transport Singapore (LTSG) dataset that includes detailed residential, transportation and POI information in Singapore that can be used for various related works.
- We propose a GCN-based model which can predict the attractiveness of stores in an area based not only on the local characteristics but also the connected areas by integrating transit networks.
- We apply the proposed GCN model for site selection tasks over the LTSG dataset. We show that GCN can effectively predict the attractiveness by exploiting both local node features and transport networks. This GCN model can generalize well under both the inductive and transductive settings for site selection over previously unseen regions.
2. Related Works
2.1. Traditional Approaches to Site Selection
2.2. Data-Driven Approaches
- Store Popularity Prediction A good store location should be able to attract a high number of customers; therefore the popularity of a store can indicate whether the store placement is suitable. These works focus on predicting the store popularity using its location-based and/or mobility-based features. In [10], the optimal retail store location is chosen by ranking a set of geographic areas by the predicted overall store popularity. The prediction is based on both the POI profiles and the mobility data within the studied areas. The same set of features are used to predict the temporal store popularity in [12] by devising an affinity-based popularity model (API) which constructs a multi-layer graph for retail stores connected by affinity of features, distances and temporal links. Xu et al. [11] proposes the Demand-Driven Store Site Selection (DD3S) model which finds candidate sites using a demand–supply model built on location-based user query data, then ranks them by predicted store popularity.
- Understanding Regional Characteristics These works focus on deciphering the regional characteristics from facility and mobility data. Facility and regional characteristic studies, although targeting at a different scale, are intricately related. The regional characteristics are largely determined by the type of activities people conduct in the POIs within the area, which can be represented by the POI profiles. At the same time, the regional characteristics influence the attractiveness of POIs to an extent. For example, new store placement should cater to the local demand for which [35] proposes the Region POI Demand Identification (RPDI) framework, which derives the POI demands of different categories in an area based on its demographics, POI profiles and mobility patterns. In [36], the optimal locations for retail stores are found based on how different categories of stores within the same region attract or repel each other. This relationship can be reflected in the POI profile of areas and the mobility patterns between them, which is also shown in [37] which identifies functional zones on the map by clustering regions by their POI profiles and mobility patterns.
- POI Recommendation Recommendation tasks find the best existing POI to a user’s liking. It takes into account not only the user’s location, personal preferences and POI quality, but also the POI’s location. Therefore, it reveals a lot about how the location, and the accessibility of a POI affects its attractiveness, as well as user movement tendencies. Some works [38,39] explore the geographical regional characteristics of POIs to help understand user preferences. In [40], mobility, POI profiles and user query data are used to judge whether a user will visit a location after making a query.
- Geographically Weighted Regression (GWR) Another method of data-driven geospatial analysis is Geographically Weighted Regression (GWR). It is a regression model proposed by [41,42] that assigns different weights to observations around the regression point based on their proximity to the regression point. It has been used to predict house prices [43] and traffic flow [14]. It may have the potential to be used for store site selection tasks.
2.3. Graph Convolutional Networks
2.4. GCN in Spatial Analysis
3. The Land and Transport Singapore (LTSG) Dataset
3.1. The POI Data
- Identity Attributes The name, latitude and longitude are used to identify the POI and calculate the distance between different POIs or between a POI and a transport hub. They can also be used to find the planning areas and regions of the POI.
- Rating Attributes On Google Map, each user can give an integer rating among for a POI. The mean of all the user ratings, which is between , will be the POI’s overall rating and shown in the Google search result to the public. If there are too few user ratings, the POI rating will be 0.
- Functionality Attributes There are a total of 104 POI functionality labels returned by the Places API. Each POI can have multiple labels, and some of them have partially overlapping concepts, e.g., convenience_store and food, home_goods_store and furniture_store. Some labels are parent concepts to another, e.g., school and secondary_school.
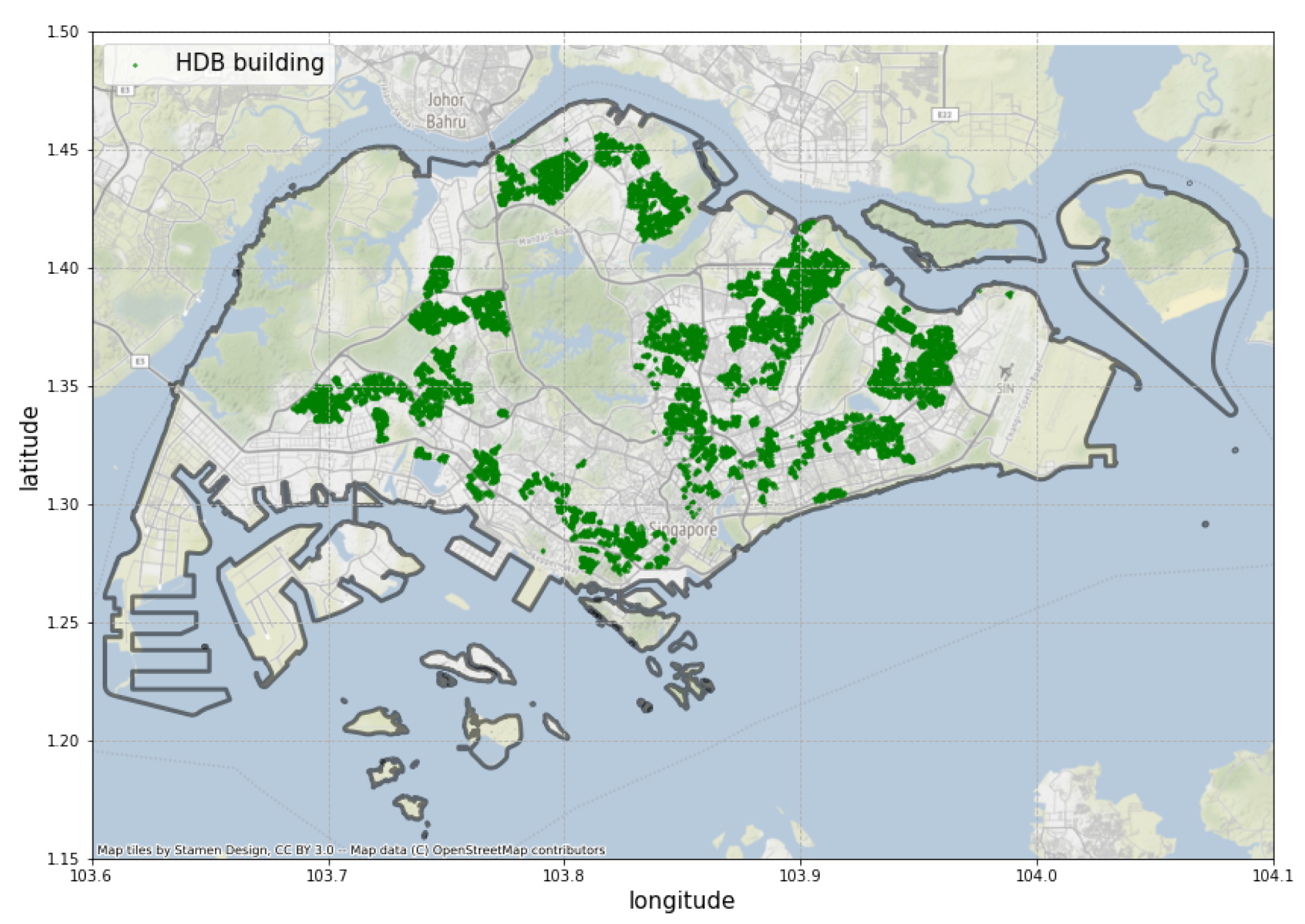
3.2. The HDB Data
- Identity Attributes The identity attributes allow people to find the building on a map. They include block number, street, latitude and longitude of the HDB building. The planning area and region of the building are found using the coordinates.
- Building Attributes The building attributes describe the basic property of the building. They include the number of units in the building, the year when it was built and the number of storeys of the building.
- Functionality Labels The functionality labels describe the type of facilities included in the HDB building. The list of functionality labels include residential, commercial, market hawker, miscellaneous (Examples include admin office, childcare centre, education centre, Residents’ Committees centre), multistorey carpark and precinct pavilion. Similar to the POIs, these labels are non-exclusive.
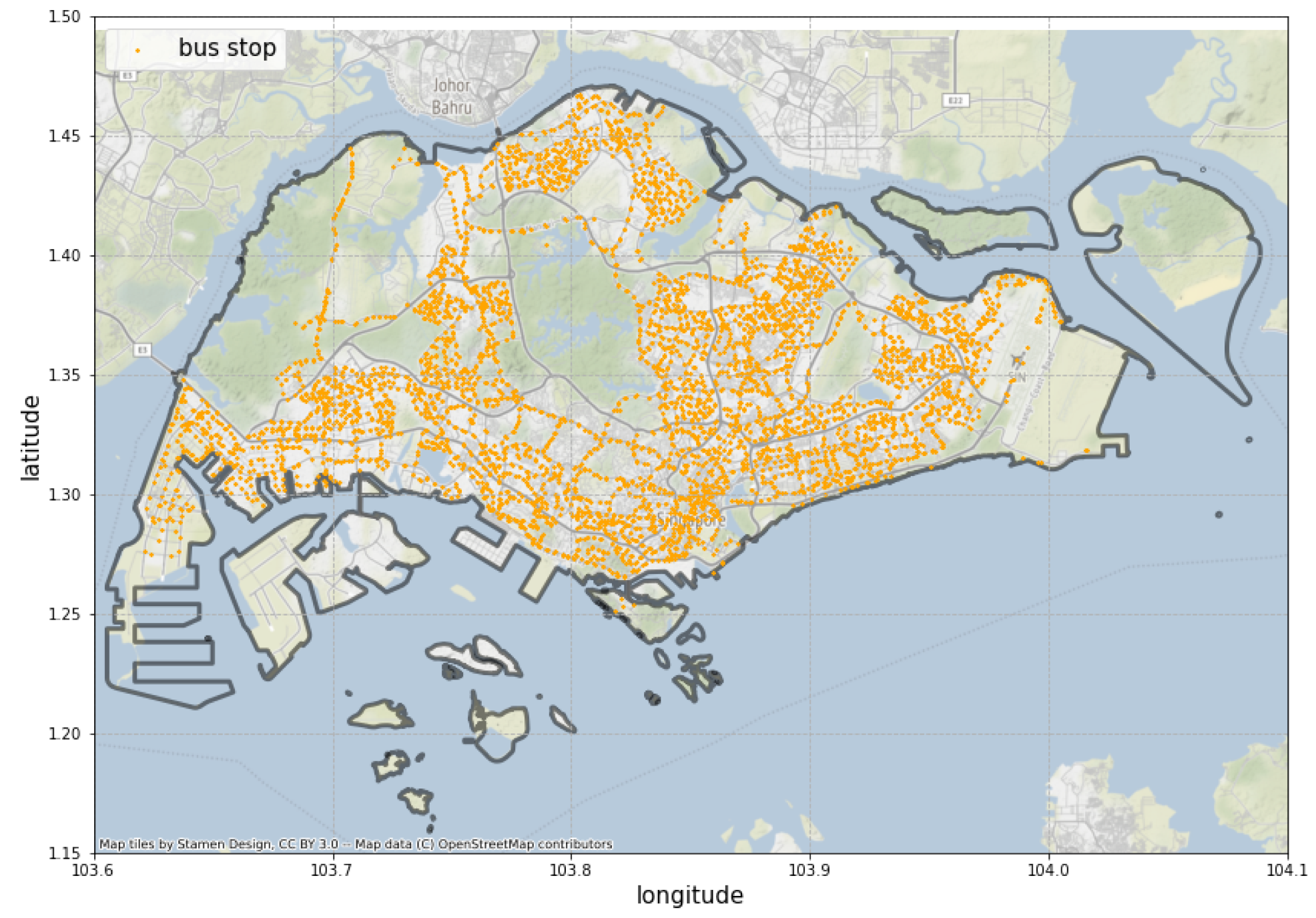
3.3. The Bus Routing Data
- Station Identity and Location Attributes The identity attributes include the coordinate, the identifier code and the name of the bus station. They can be used to find the bus station on the map. The planning area and the region of the station are also included.
- Routing Attributes The routing attributes include the bus line name, bus line direction, the sequence number of the bus stop and the distance of the stop to the starting station on the line. Note that bidirectional bus lines stop at different bus stops. These attributes detail how the bus stations are connected to each other by the lines.
3.4. The Bus Ridership Data
- Identity Attributes The identity attributes include the identifier code of the bus station, as well as the hour and the type of day of the record. The identifier codes of the bus station are the same as the ones used in Section 3.3. The hour is presented in a 24 h format. The type of day has two possible values: WD represents weekdays and H represents weekends or public holidays.
- Passenger Volume Attributes On a typical weekday or weekend/holiday, during the specific time period, the number of passengers tapping in and out of a station is recorded. They are averaged from the monthly numbers over July, August and September 2021.
3.5. The Subway Routing Data
- Identity and Location Attributes The identity attributes include coordinate, identifier code and name of the subway station. They can be used to find the bus station on the map. The planning area and the region of the station are also included.
- Routing Attributes The routing attributes include the subway line code and the sequence number of the station at the default direction. Note that bidirectional subway lines would stop at the same stations on both directions, which is different from bus lines. These attributes detail how the subway stations are connected to each other by the lines.
4. Construction of the Geospatial Transport Graph with the LTSG Dataset
4.1. Network Construction
4.1.1. Node Construction
4.1.2. Adjacency Matrix Construction
- Walking-Based Adjacency MatrixFor two nodes and , if the distance between their central bus stations and is smaller than , they are considered connected and vice versa. This also means that the two areas overlap with each other significantly. This adjacency matrix describes whether two nodes are connected by means of walking. The implication is that, if a potential customer is nearby, it is equally convenient for them to visit these areas.
- Bus-Based Adjacency MatrixFor two nodes and , if their central bus stations and are on the same bus route, they are considered connected. This adjacency matrix described whether two nodes have a direct bus connection.
- Subway-Based Adjacency MatrixFor two nodes and , if they contain subway stations on the same route, they are considered connected. This adjacency matrix indicates whether two nodes have a direct subway connection. The bus and subway adjacency matrices correspond to a traditional P-space transport network, which has proven useful in human mobility studies [78,79].
4.1.3. Feature Construction
- The HDB Features From the HDB data, we can construct an HDB feature matrix , with and denoting the number and the feature number of HDB building properties, including the number of storeys, the number of units, year of completion and the type of facilities in the building. For each node , we aggregate the HDB building properties for all HDB buildings inside the area as its features. For a set of HDB buildings , we can define a binary incidence matrix , which describes whether a HDB building is located in area .Taking into account the number of HDB buildings in the area, we normalize into , where is a diagonal matrix, and is the total number of HDB buildings in node area . Then, the HDB feature matrix can be calculated as .
- The POI Features The number of different types of POI in an area indicates the type of activity people do in this area. It can also reveal information such as the level of business competition or the level of inter-business attractiveness (for example, there are often restaurants around a movie theater, thus restaurants can be considered attracted by movie theaters). Some of the POI types are highly specific services such as casino or cemetery, each with fewer than 10 establishments in the country, thus not providing enough data for analysis. Among the 104 labels, we choose 53 labels which are the most commonly distributed across Singapore and count the number of POIs under each label for each node. Suppose we have number of POIs, forming a set of POIs . contains all POIs of type t, e.g., store, logding, finance, school. contains all the and . The POI feature matrix will be , with . For a set of POIs , we can define a binary incidence matrixThis can be normalized in the same way as , so that where is the total number of POIs in node . Thus, the node feature matrix can be calculated as . Therefore, can be viewed as the distribution of different types of POIs in the node area. Each row in the matrix represents the frequency of each types of POIs within a node area.
4.1.4. Label Construction
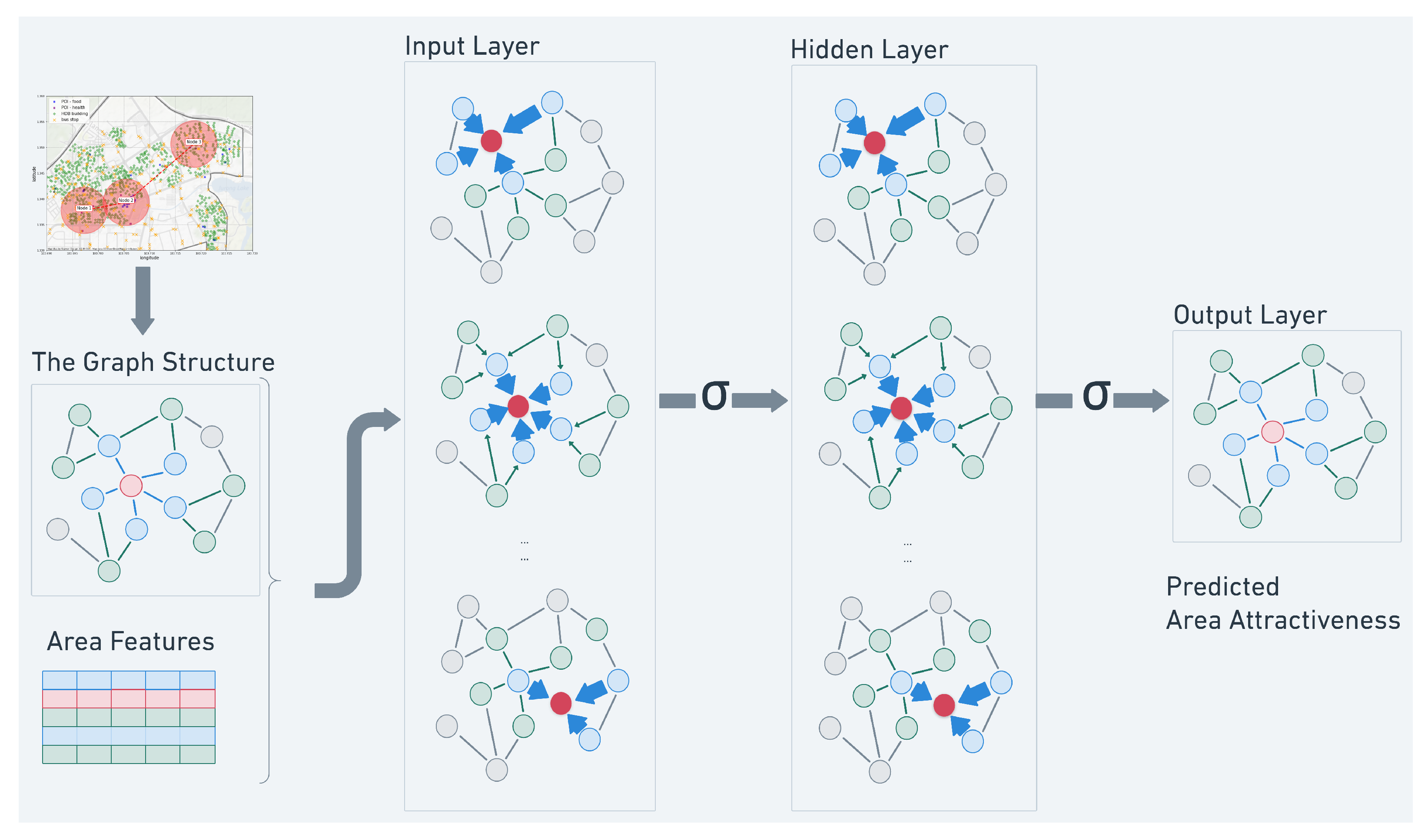
4.2. Model Structure
- is a normalized adjacency matrix. and being the degree matrix that signifies the accessibility of node . For GCN-walking, and for GCN-combine, . The self-connections are added to emphasize the node’s own features.
- and are the trainable weights at the first and second layer.
- is the feature matrix, with N being the total number of bus stations, and F being the number of features. Each row of is a feature representation of the local environment of a node area.
- The leaky ReLU function is chosen as the activation function at the hidden layer to adds non-linearity in the model, and the sigmoid activation function is chosen for the output layer to make sure the predicted attractiveness lies within the range of (0.0, 1.0).
4.3. Loss Function
5. Experiment
5.1. Experimental Settings
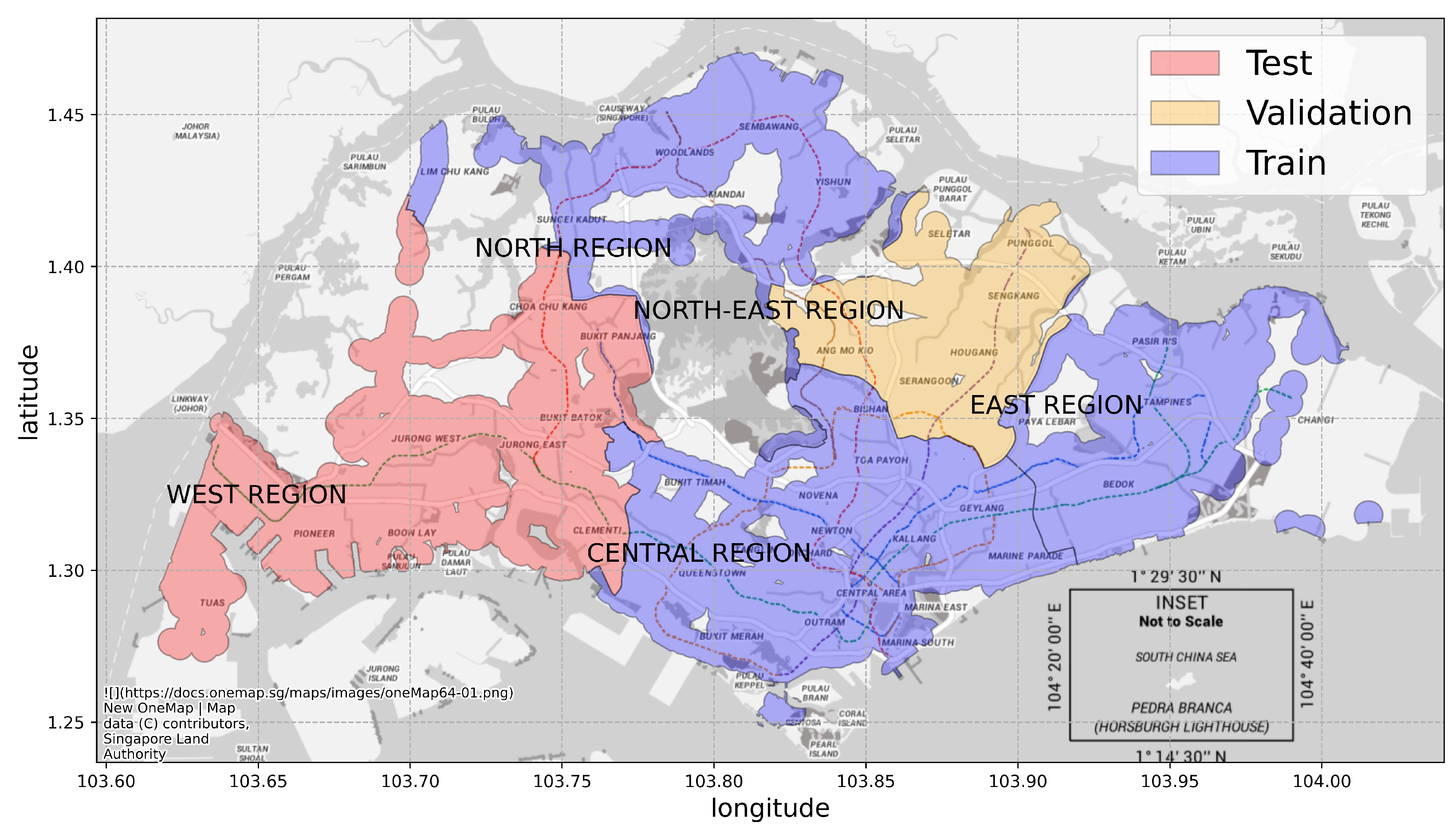
- Transductive Learning In transductive learning, during the training process, we predict the attractiveness of nodes in the testing planning areas or regions based on the housing information and public transport network of all Singapore. In the transductive setting, the model has access to the features and structures of the entire graph during training and testing, but the ground truths of the respective nodes in the training, testing and validation sets will masked. In Scheme 1, we can test if our model is able to fill in the attractiveness of maps based on the rest of the map at the planning area level. In Scheme 2, we can test if it can do the same at the region level.
- -
- During training: input and , train on .
- -
- During testing: input and , predict .
- Inductive Learning The GCN model as described in Section 4.2 is a spectral-based model, which usually requires knowledge of the entire graph beforehand, thus suffering from the inability to be transferred to a new graph [50,51,59]. However, as mentioned in [56], this GCN can also be interpreted from a spatial perspective that aggregates node features from the first-order neighbors of the central node [49,56]. Therefore, it is appropriate to apply it on segments of the entire graph, in this case one or more planning areas or regions in Singapore, essentially forming an inductive learning task where we try to predict the attractiveness of areas on a previously unseen map. In the inductive setting, the model has no access to the features and structures of the testing and validation sub-graphs. The training, testing and validation sets will be considered as individual graphs, and only their internal node connections will be used to make predictions. In Scheme 1, we can test the generalizability of our model to incomplete maps with some unknown parts. In Scheme 2, as the regions vary greatly in their land use design, we can test the ability of our model to be generalized to a different type of area, even if it has no prior knowledge of the area before.
- -
- During training: input and , train on .
- -
- During testing: input and , predict .
5.2. Baselines
- Linear Regression (LR) Linear regression tries to fit a linear equation to the data in the form of where and are and vectors, respectively. It will calculate the value of and by minimizing the residual sum of squares between and the ground truth y of the training set. We adopt the LinearRegression implementation from the sklearn.linear_model module.
- Random Forest Regression (RF) The random forest regression fits a decision tree on the training set. In each split, all features and all samples are examined to find the best split to minimize the squared error in the prediction until the leaves are pure. This will be repeated 100 times, and the final prediction will be the average of the result of the 100 decision trees. We adopt the RandomForestRegressor implementation from the sklearn.ensemble module.
- Multilayer Perceptron (MLP) We also compare our model performance against a multilayer perceptron with 1 hidden layer with 16 units. The formula of the MLP prediction is , where is the same feature matrix as used in the GCN model, and are trainable weights and the activation functions are LeakyReLU and sigmoid at the first and second layer, respectively. Compared to the formulation of the GCN in Equation (7), we can easily see that the MLP can be interpreted as a GCN with only self-connections between nodes.
5.3. Evaluation Metrics
5.4. Results
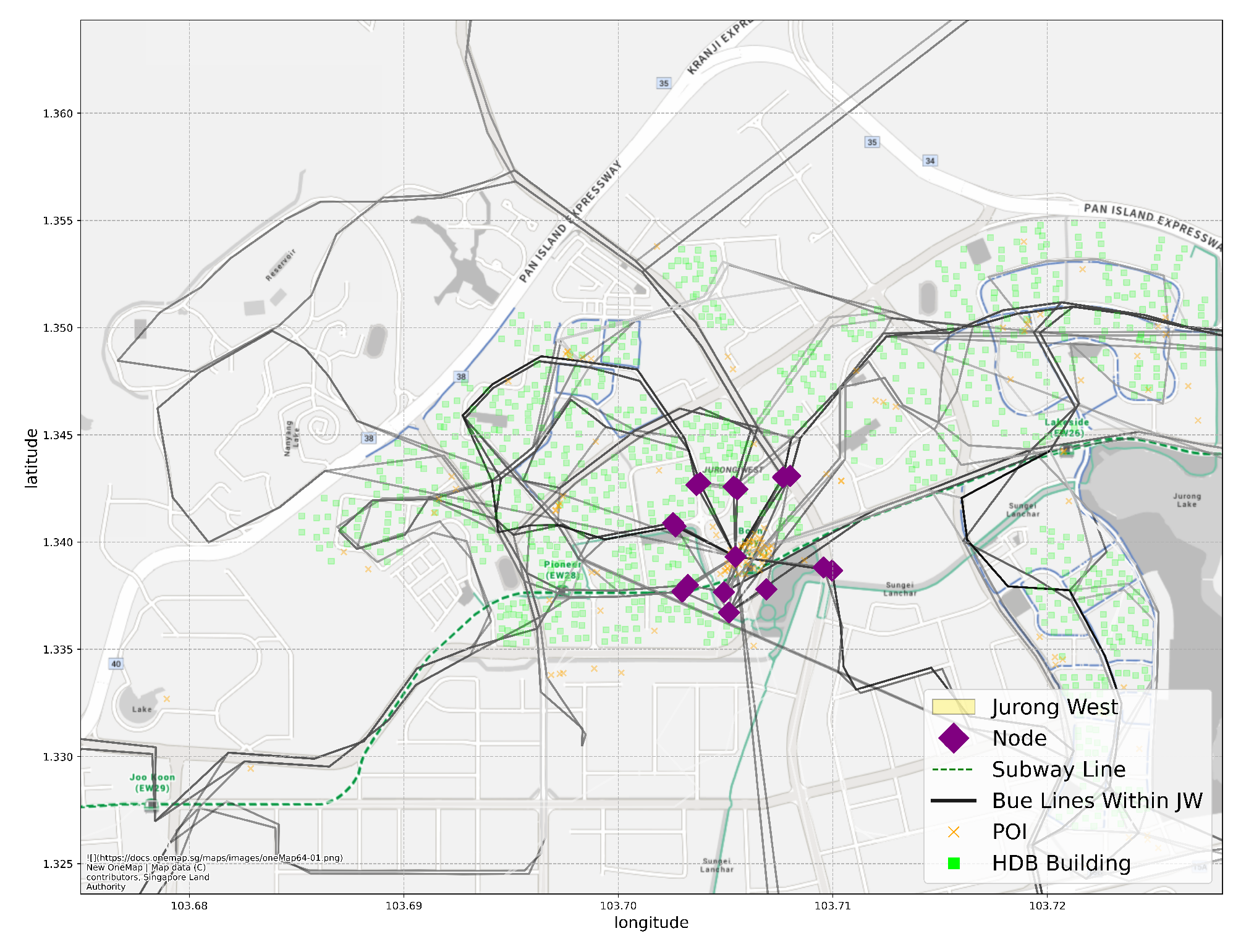
6. Case Study: Site Selection in the Jurong West Planning Area
6.1. Overview of Jurong West
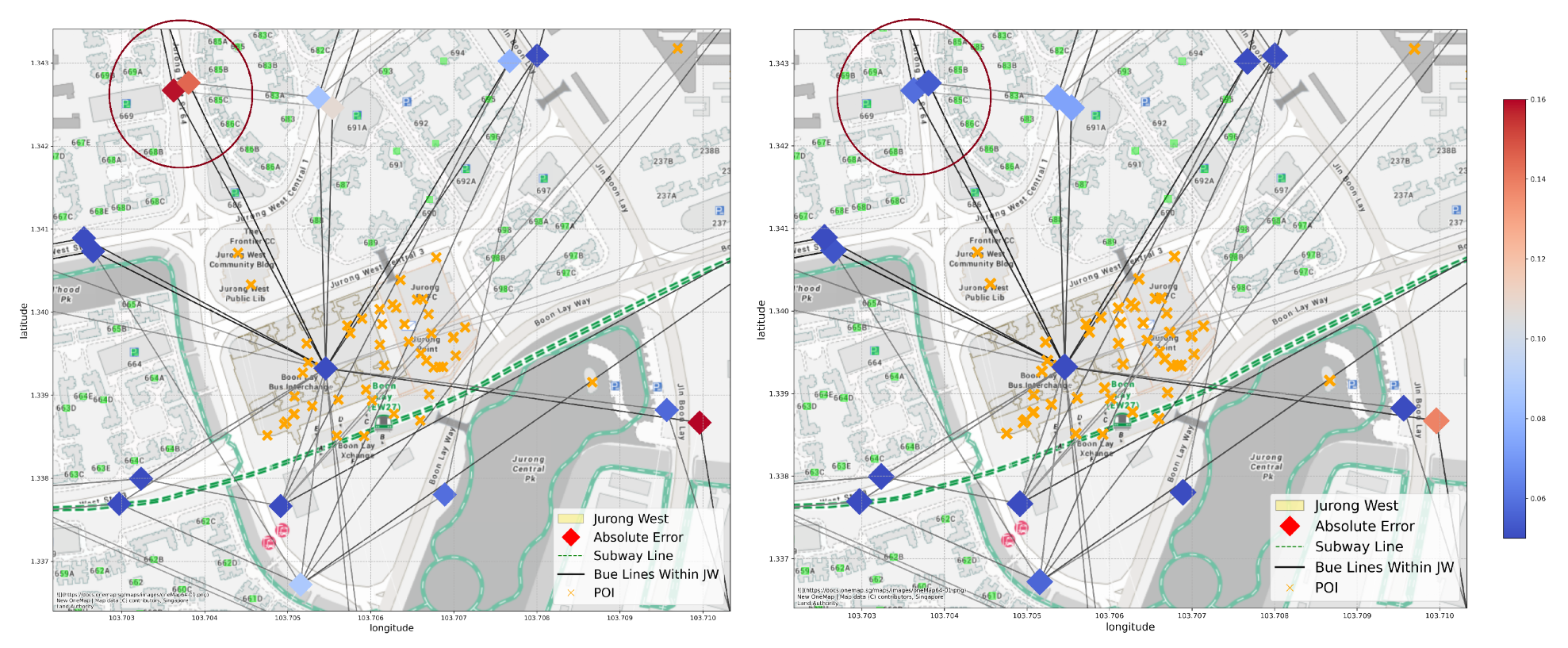
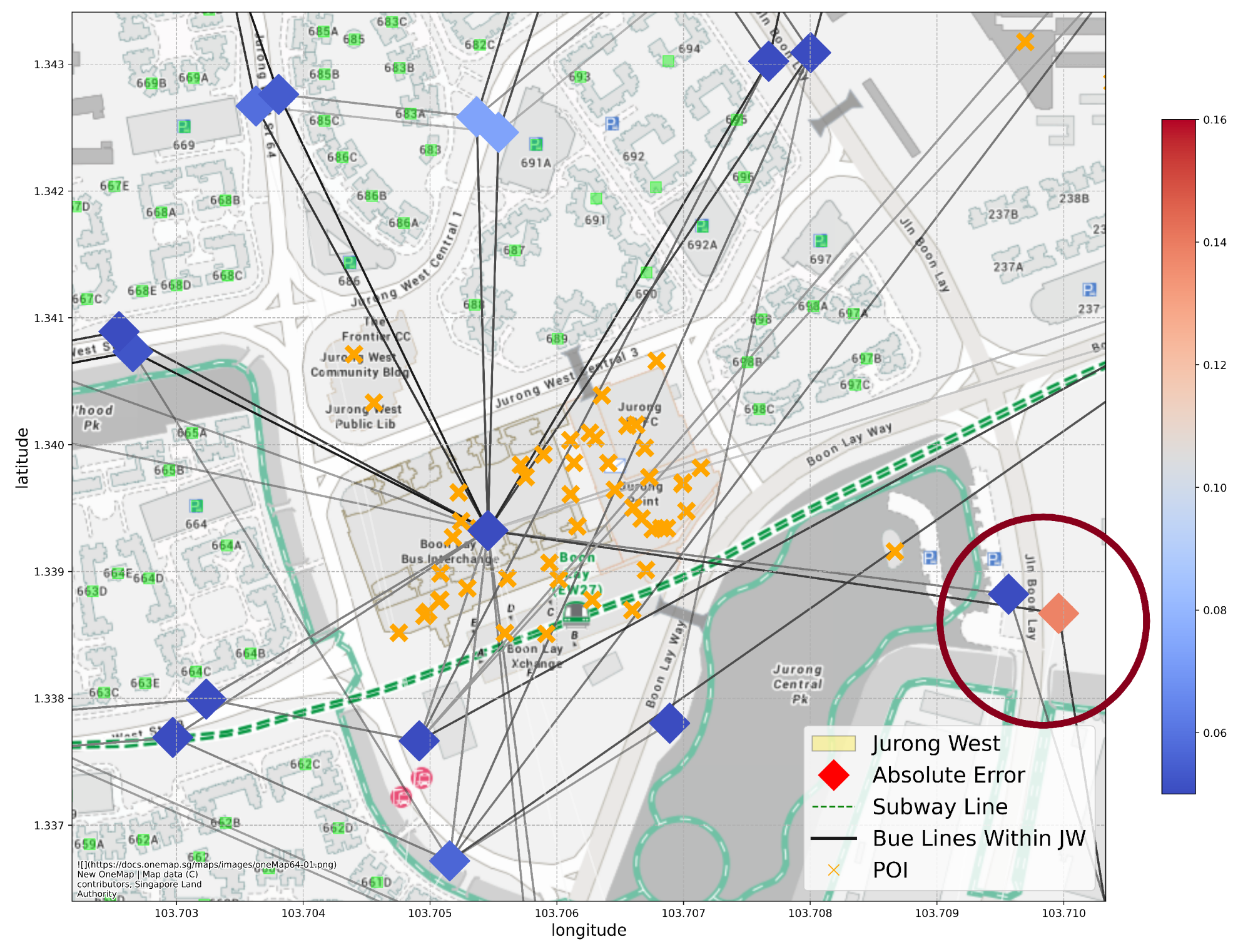
6.2. Evaluation of Prediction Results
- 1.
- In the public transport graphs, all bus stations on the same line are considered connected despite the sequential difference between them; in the walking distance graph, the connection between areas is determined by Euclidean distance. Both of the connection types reflect a level of connection, but they do not correspond to the actual travel time, which seems to be an important factor in people’s travel decisions in real life, and the current edges fail to reflect this.
- 2.
- The current graph we built is undirected. However, the human flow through bus and subway lines is directed, especially for circular lines. This makes the model unable to determine the direction of information propagation during convolution, thus unable to distinguish stops at different sequence or direction of the same line.
7. Conclusions
- Design a better GCN model that will allow us to process directed transport graphs, as well as adjusting the weights based on the connection strength between areas.
- Design a multi-layer geospatial transport graph that can better model the interaction between areas at different levels and for different transport modes. In addition, include travel time as one of the deciding factors for the connection between areas.
- Expand the LTSG dataset to include demographic data, land use data, real estate price data and road network data. This will not only provide more geographic and transport information for site selection tasks but also open the possibilities of the dataset for other tasks such as real estate price prediction, land use planning and transport planning.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. List of Planning Areas in the Training, Testing and Validation Set
Appendix A.1. List of Planning Areas in the Training Set
- Rochor
- Outram
- Marina South
- Straits View
- Museum
- Orchard
- Queenstown
- Bukit Timah
- Southern Islands
- Jurong East
- Boon Lay
- Tuas
- Choa Chu Kang
- Tengah
- Lim Chu Kang
- Newton
- Novena
- Central Water Catchment
- Bukit Batok
- Sungei Kadut
- Woodlands
- Sembawang
- Yishun
- Toa Payoh
- Bishan
- Geylang
- Paya Lebar
- Seletar
- Tampines
- Marine Parade
Appendix A.2. List of Planning Areas in the Testing Set
- Singapore River
- Tanglin
- Jurong West
- Western Water Catchment
- Bukit Panjang
- Serangoon
- Sengkang
- Hougang
- Bedok
Appendix A.3. List of Planning Areas in the Validation Set
- Kallang
- Downtown Core
- Bukit Merah
- River Valley
- Clementi
- Pioneer
- Mandai
- Ang Mo Kio
- Punggol
- Pasir Ris
- Changi
References
- Strauss, S.D. The Small Business Bible: Everything You Need to Know to Succeed in Your Small Business; Wiley: Hoboken, NJ, USA, 2012. [Google Scholar]
- Steingold, F.S. Legal Guide for Starting & Running a Small Business; Nolo: Berkeley, CA, USA, 2011; p. 448. [Google Scholar]
- Moniruzzaman, M.; Páez, A. Accessibility to transit, by transit, and mode share: Application of a logistic model with spatial filters. J. Transp. Geogr. 2012, 24, 198–205. [Google Scholar] [CrossRef]
- Healey, M.J.; Ilbery, B.W. Location and Change: Perspectives on Economic Geography; Oxford University Press: New York, NY, USA, 1990; pp. 343–354. [Google Scholar] [CrossRef]
- Kaufmann, P.J.; Donthu, N.; Brooks, C.M. Multi-Unit Retail Site Selection Processes: Incorporating Opening Delays And Unidentified Competition. J. Retail. 2000, 76, 113–127. [Google Scholar] [CrossRef]
- Ghosh, A.; Craig, C.S. A Franchise Distribution System Location Model. J. Retail. 1991, 67, 466. [Google Scholar]
- Achabal, D.D.; Gorr, W.L.; Mahajan, V. MULTILOC: A Multiple Store Location Decision Model. J. Retail. 1982, 58, 5. [Google Scholar]
- Quan, X.; Wenyin, L.; Dou, W.; Xiong, H.; Ge, Y. Link graph analysis for business site selection. Computer 2012, 45, 64–69. [Google Scholar] [CrossRef]
- Huff, D.L. A Probabilistic Analysis of Shopping Center Trade Areas. Land Econ. 1963, 39, 81. [Google Scholar] [CrossRef]
- Karamshuk, D.; Noulas, A.; Scellato, S.; Nicosia, V.; Mascolo, C. Geo-spotting: Mining online location-based services for optimal retail store placement. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; Volume Part F1288. [Google Scholar] [CrossRef] [Green Version]
- Xu, M.; Wang, T.; Wu, Z.; Zhou, J.; Li, J.; Wu, H. Demand driven store site selection via multiple spatial-temporal data. In Proceedings of the 24th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, New York, NY, USA, 23–26 June 2016; pp. 1–10. [Google Scholar] [CrossRef]
- Hsieh, H.P.; Lin, F.; Li, C.T.; Yen, I.E.H.; Chen, H.Y. Temporal popularity prediction of locations for geographical placement of retail stores. Knowl. Inf. Syst. 2019, 60, 247–273. [Google Scholar] [CrossRef]
- Geurs, K.T.; van Wee, B. Accessibility evaluation of land-use and transport strategies: Review and research directions. J. Transp. Geogr. 2004, 12, 127–140. [Google Scholar] [CrossRef]
- Lu, B.; Charlton, M.; Harris, P.; Fotheringham, A.S. Geographically weighted regression with a non-Euclidean distance metric: A case study using hedonic house price data. Int. J. Geogr. Inf. Sci. 2014, 28, 660. [Google Scholar] [CrossRef]
- Bai, L.; Yao, L.; Kanhere, S.S.; Wang, X.; Sheng, Q.Z. StG2seq: Spatial-temporal graph to sequence model for multi-step passenger demand forecasting. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019. [Google Scholar] [CrossRef] [Green Version]
- Zhu, D.; Zhang, F.; Wang, S.; Wang, Y.; Cheng, X.; Huang, Z.; Liu, Y. Understanding Place Characteristics in Geographic Contexts through Graph Convolutional Neural Networks. Ann. Am. Assoc. Geogr. 2020, 110, 408–420. [Google Scholar] [CrossRef]
- Xiao, L.; Lo, S.; Zhou, J.; Liu, J.; Yang, L. Predicting vibrancy of metro station areas considering spatial relationships through graph convolutional neural networks: The case of Shenzhen, China. Environ. Plan. B Urban Anal. City Sci. 2021, 48, 2363. [Google Scholar] [CrossRef]
- Koschinsky, J.; Talen, E. The Walkable Neighborhood: A Literature Review. Int. J. Sustain. Land Use Urban Plan. 2013, 1, 42–63. [Google Scholar] [CrossRef]
- Chang, N.B.; Parvathinathan, G.; Breeden, J.B. Combining GIS with fuzzy multicriteria decision-making for landfill siting in a fast-growing urban region. J. Environ. Manag. 2008, 87, 139–153. [Google Scholar] [CrossRef] [PubMed]
- Hayter, R. The Dynamics of Industrial Location: The Factory, the Firm and the Production System; Wiley: Hoboken, NJ, USA, 1997. [Google Scholar] [CrossRef]
- Herrington, T.D.; Lu, J. Application of Gravity Model for Restaurants in Lowndes County, Georgia. Pap. Appl. Geogr. 2016, 2, 370–389. [Google Scholar] [CrossRef]
- Kiefer, R.W.; Robbins, M.L. Computer-Based Land Use Suitability Map. J. Surv. Mapp. Div. 1973, 99, 39–62. [Google Scholar] [CrossRef]
- Dobson, J.E. A regional screening procedure for land use suitability analysis. Geogr. Rev. 1979, 69, 224–234. [Google Scholar] [CrossRef]
- Sener, B.; Süzen, M.L.; Doyuran, V. Landfill site selection by using geographic information systems. Environ. Geol. 2006, 49, 376–388. [Google Scholar] [CrossRef]
- Vahidnia, M.H.; Alesheikh, A.A.; Alimohammadi, A. Hospital site selection using fuzzy AHP and its derivatives. J. Environ. Manag. 2009, 90, 3048–3056. [Google Scholar] [CrossRef]
- Chen, C.F. Applying the Analytical Hierarchy Process (AHP) Approach to Convention Site Selection. J. Travel Res. 2016, 45, 167–174. [Google Scholar] [CrossRef]
- Nyimbili, P.H.; Erden, T. GIS-based fuzzy multi-criteria approach for optimal site selection of fire stations in Istanbul, Turkey. Socio-Econ. Plan. Sci. 2020, 71, 100860. [Google Scholar] [CrossRef]
- Saaty, R.W. The Analytic Hierarchy Process: Planning, Priority Setting, Resource Allocation (Decision Making Series). Math. Model. 1982, 9, 97. [Google Scholar]
- Li, X.; He, J.; Liu, X. Intelligent GIS for solving high-dimensional site selection problems using ant colony optimization techniques. Int. J. Geogr. Inf. Sci. 2009, 23, 399–416. [Google Scholar] [CrossRef]
- Li, X.; Yeh, A.G.O. Integration of genetic algorithms and GIS for optimal location search. Int. J. Geogr. Inf. Sci. 2005, 19, 581–601. [Google Scholar] [CrossRef]
- Rushton, G. Use of Location-Allocation Models for Improving the Geographical Accessibility of Rural Services in Developing Countries. Int. Reg. Sci. Rev. 1984, 9, 217. [Google Scholar] [CrossRef]
- Xiao, X.; Yao, B.; Li, F. Optimal location queries in road network databases. In Proceedings of the International Conference on Data Engineering, Washington, DC, USA, 11–16 April 2011. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, Y.; Wong, R.C.W.; Xiong, J.; Mai, G.; Long, C. Efficient algorithms for optimal location queries in road networks. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014. [Google Scholar] [CrossRef] [Green Version]
- Berman, O.; Krass, D. The generalized maximal covering location problem. Comput. Oper. Res. 2002, 29, 563–581. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, C.; Lu, X.; Teng, M.; Zhu, H.; Xiong, H. Point-of-Interest Demand Modeling with Human Mobility Patterns. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; Volume 17. [Google Scholar] [CrossRef]
- Jensen, P. Network-based predictions of retail store commercial categories and optimal locations. Phys. Rev. E-Stat. Nonlinear Soft Matter Phys. 2006, 74, 035101. [Google Scholar] [CrossRef] [Green Version]
- Yuan, N.J.; Zheng, Y.; Xie, X.; Wang, Y.; Zheng, K.; Xiong, H. Discovering urban functional zones using latent activity trajectories. IEEE Trans. Knowl. Data Eng. 2015, 27, 712–725. [Google Scholar] [CrossRef]
- Ye, M.; Yin, P.; Lee, W.C.; Lee, D.L. Exploiting Geographical Influence for Collaborative Point-of-Interest Recommendation. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, 24–28 July 2011. [Google Scholar]
- Liu, Y.; Wei, W.; Sun, A.; Miao, C. Exploiting Geographical Neighborhood Characteristics for Location Recommendation. In Proceedings of the 2014 ACM International Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014. [Google Scholar] [CrossRef]
- Wu, Z.; Wu, H.; Zhang, T. Predict User In-World Activity via Integration of Map Query and Mobility Trace. In Proceedings of the 4th International Workshop on Urban Computing (UrbComp 2015), Sydney, Australia, 10 August 2015; Available online: http://www2.cs.uic.edu/~urbcomp2013/urbcomp2015/papers/User-In-World-Activity-Prediction_Wu.pdf (accessed on 24 June 2022).
- Fotheringham, A.S.; Charlton, M.E.; Brunsdon, C. Geographically weighted regression: A natural evolution of the expansion method for spatial data analysis. Environ. Plan. A 1998, 30, 1905–1927. [Google Scholar] [CrossRef]
- Fotheringham, A.S.; Brunsdon, C.; Charlton, M. Geographically Weighted Regression: The Analysis of Spatially Varying Relationships; Wiley: Hoboken, NJ, USA, 2002. [Google Scholar]
- Zhang, L.; Cheng, J.; Jin, C. Spatial Interaction Modeling of OD Flow Data: Comparing Geographically Weighted Negative Binomial Regression (GWNBR) and OLS (GWOLSR). ISPRS Int. J. Geo-Inf. 2019, 8, 220. [Google Scholar] [CrossRef] [Green Version]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Guo, L.; Wan, R.; Su, G.M.; Kot, A.C.; Wen, B. Multi-Scale Feature Guided Low-Light Image Enhancement. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 554–558. [Google Scholar]
- Wang, Y.; Wan, R.; Yang, W.; Li, H.; Chau, L.P.; Kot, A. Low-light image enhancement with normalizing flow. Proc. AAAI Conf. Artif. Intell. 2022, 36, 2604–2612. [Google Scholar] [CrossRef]
- Wang, T.; Wu, D.J.; Coates, A.; Ng, A.Y. End-to-end text recognition with convolutional neural networks. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 3304–3308. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2019, 32, 4–24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral Networks and Locally Connected Networks on Graphs. In Proceedings of the 2nd International Conference on Learning Representations (ICLR 2014—Conference Track Proceedings), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering. In Advances in Neural Information Processing Systems, Proceedings of the Neural Information Processing Systems Foundation, Barcelona, Spain, 5–10 December 2016; Curran Associates, Inc.: Red Hook, NY, USA, 2016; Volume 29, pp. 3844–3852. [Google Scholar]
- Li, R.; Wang, S.; Zhu, F.; Huang, J. Adaptive Graph Convolutional Neural Networks. Proc. AAAI Conf. Artif. Intell. 2018, 32. [Google Scholar] [CrossRef]
- Zhuang, C.; Ma, Q. Dual Graph Convolutional Networks for Graph-Based Semi-Supervised Classification. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018. [Google Scholar] [CrossRef] [Green Version]
- Atwood, J.; Towsley, D. Diffusion-convolutional neural networks. In Neural Information Processing Systems Foundation, Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Curran Associates, Inc.: Red Hook, NY, USA, 2016. [Google Scholar]
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting. In Proceedings of the 6th International Conference on Learning Representations (ICLR 2018—Conference Track Proceedings), Vancouver, BC, Canada, 30 April–3 May 2018; Available online: OpenReview.net (accessed on 24 June 2022).
- Hamilton, W.L.; Ying, R.; Leskovec, J.; Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Inductive Representation Learning on Large Graphs. In Advances in Neural Information Processing Systems, Proceedings of the Neural Information Processing Systems Foundation, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 1025–1035. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Niepert, M.; Ahmed, M.; Kutzkov, K. Learning convolutional neural networks for graphs. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 2014–2023. [Google Scholar]
- Monti, F.; Boscaini, D.; Masci, J.; Rodolà, E.; Svoboda, J.; Bronstein, M.M. Geometric deep learning on graphs and manifolds using mixture model CNNs. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 5425–5434. [Google Scholar] [CrossRef] [Green Version]
- Gao, H.; Wang, Z.; Ji, S. Large-Scale Learnable Graph Convolutional Networks. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; Volume 18, pp. 1416–1424. [Google Scholar] [CrossRef] [Green Version]
- Yao, X.; Gao, Y.; Zhu, D.; Manley, E.; Wang, J.; Liu, Y. Spatial origin-destination flow imputation using graph convolutional networks. IEEE Trans. Intell. Transp. Syst. 2020, 22, 7474–7484. [Google Scholar] [CrossRef]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Berg, R.v.d.; Titov, I.; Welling, M.; van den Berg, R.; Titov, I.; Welling, M.; Berg, R.V.D.; et al. Modeling Relational Data with Graph Convolutional Networks. In European Semantic Web Conference; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Chai, D.; Wang, L.; Yang, Q. Bike Flow Prediction with Multi-Graph Convolutional Networks. In SIGSPATIAL ’18: Proceedings of the 26th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems; ACM: New York City, NY, USA; Volume 9.
- Zhao, L.; Song, Y.; Zhang, C.; Liu, Y.; Wang, P.; Lin, T.; Deng, M.; Li, H. T-GCN: A Temporal Graph Convolutional Network for Traffic Prediction. IEEE Trans. Intell. Transp. Syst. 2020, 21, 3848–3858. [Google Scholar] [CrossRef] [Green Version]
- Qi, Y.; Li, Q.; Karimian, H.; Liu, D. A hybrid model for spatio-temporal forecasting of PM2.5 based on graph convolutional neural network and long short-term memory. Sci. Total. Environ. 2019, 664, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Miller, H.J. Geographic representation in spatial analysis. J. Geogr. Syst. 2000, 2, 55–60. [Google Scholar] [CrossRef]
- Housing and Development Board. Estimated Singapore Resident Population in HDB Flats. 2022. Available online: https://www20.hdb.gov.sg/fi10/fi10221p.nsf/hdb/2021/assets/ebooks/key-statistics.pdf (accessed on 18 February 2022).
- Public Transit Facts & Statistics for Singapore | Moovit Public Transit Index. Available online: https://moovitapp.com/insights/en/Moovit_Insights_Public_Transit_Index_Singapore_Singapore-1678 (accessed on 18 January 2022).
- Housing and Development Board. HDB Property Information. 2021. Available online: https://data.gov.sg/dataset/hdb-property-information (accessed on 15 May 2022).
- Master Plan 2019 Region Boundary (No Sea)-Data.gov.sg. Available online: https://data.gov.sg/dataset/master-plan-2019-region-boundary-no-sea (accessed on 10 February 2022).
- Deloitte. The Deloitte City Mobility Index: Gauging Global Readiness for the Future of Mobility; Deloitte Insights: Calgary, AB, Canada, 2018; Available online: https://www2.deloitte.com/content/dam/Deloitte/ca/Documents/public-sector/future-of-mobility-2018/ca-future-of-mobility-deloitte-city-aoda-en.pdf (accessed on 10 February 2022).
- Congress for the New Urbanism. The Charter of the New Urbanism. Bull. Sci. Technol. Soc. 2000, 20, 339–341. [Google Scholar] [CrossRef] [Green Version]
- City of Ventura. Development Code Revised, 24S.300 DEFINITIONS. 2012. Available online: https://www.cityofventura.ca.gov/DocumentCenter/View/1431/24S300—Development-Code-Definitions-PDF (accessed on 14 February 2022).
- Urban Design Guidelines—Glossary. Available online: https://www.urban-design-guidelines.planning.vic.gov.au/toolbox/glossary (accessed on 14 February 2022).
- Duany, A.; Plater-Zyberk, E.; Speck, J. Suburban Nation: The Rise of Sprawl and the Decline of the American Dream; Macmillan: Stuttgart, Germany, 2001. [Google Scholar]
- Mehaffy, M.; Porta, S.; Rofè, Y.; Salingaros, N. Urban nuclei and the geometry of streets: The ‘emergent neighborhoods’ model. Urban Des. Int. 2010, 15, 22–46. [Google Scholar] [CrossRef]
- Center for International Earth Science Information Network, Columbia University. Low Elevation Coastal Zone (LECZ) Urban-Rural Population and Land Area Estimates, Version 2; NASA Socioeconomic Data and Applications Center (SEDAC): Palisades, NY, USA, 2013. [Google Scholar] [CrossRef]
- Barbosa, H.; Barthelemy, M.; Ghoshal, G.; James, C.R.; Lenormand, M.; Louail, T.; Menezes, R.; Ramasco, J.J.; Simini, F.; Tomasini, M. Human Mobility: Models and Applications. Phys. Rep. 2018, 734, 1–74. [Google Scholar] [CrossRef] [Green Version]
- Von Ferber, C.; Holovatch, T.; Holovatch, Y.; Palchykov, V. Public transport networks: Empirical analysis and modeling. Eur. Phys. J. B 2009, 68, 261–275. [Google Scholar] [CrossRef] [Green Version]
- Department of Statistics. Singapore Census of Population 2020, Statistical Release 2: Households, Geographic Distribution, Transport and Difficulty in Basic Activities; Technical Report; Ministry of Trade and Industry: Singapore, 2020. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Node | Edge Connection | Edge Weight |
|---|---|---|---|
| QAG [12] | sites | ED + temporal link | node affinity |
| LG [8] | sites | ED | node affinity |
| MSAG [17] | MSA | ED | distance |
| metro network | binary | ||
| passenger flow | flow intensity | ||
| PG [16] | places | spatial adjacency | binary |
| OD flow | flow intensity | ||
| STG2Seq [15] | regions | traffic demand affinity | binary |
| our GCN-walking | pedsheds | ED | binary |
| our GCN-combine | pedsheds | ED + public transport link | binary |
| Source | Description |
|---|---|
| DataMall1 | A portal for datasets published by the Land Transport Authority (LTA) of Singapore. |
| Data.gov.sg | A portal for publicly available datasets offered by the Singapore government. |
| Google Places API | A Google service that returns information from Google Maps from http requests. |
| OneMap API | A service offered by the Singapore Land Authority with detailed authoritative national map. |
| # of Data Points/Nodes | # of Edges | # of Attributes | |
|---|---|---|---|
| The POI Data | 8672 | - | 108 |
| The HDB Data | 12,442 | - | 11 |
| The Bus Ridership Data | 5049 | - | 4 |
| The Bus Routing Data | 5049 | 26,322 | - |
| The Subway Routing Data | 166 | 261 | - |
| Attribute | Unit | Description | Example |
|---|---|---|---|
| name | - | the name of the POI | Crowne Plaza Changi Airport, Westwood Secondary School |
| lat | the latitude of the POI | N | |
| lng | the longitude of the POI | E | |
| pln_area | - | the planning area where this POI is located | Jurong West |
| region | - | the region where this POI is located | Central |
| rating | - | average Google Map user rating | |
| n_rating | - | number of Google Map user rating | 128 |
| type | - | a list of POI type labels | store, logding, airport, school |
| Attribute | Unit | Description | Example |
|---|---|---|---|
| blk_no | - | the block number | 652C |
| street | - | the street name | beach rd |
| lat | the latitude of the building | N | |
| lng | the longitude of the building | E | |
| pln_area | - | the planning area where this building is located | Jurong West |
| region | - | the region where this building is located | Central |
| year | - | the year when the building is completed | 1984 |
| units | - | number of dwelling units in the building | 179 |
| type | - | the functionality of the facilities in the building | residential |
| Attribute | Unit | Description | Example |
|---|---|---|---|
| stop_id | - | a 5-digit identifier code of the bus station | 96109 |
| lat | the latitude of the station | N | |
| lng | the longitude of the station | E | |
| pln_area | - | the planning area where this station is located | Jurong West |
| region | - | the region where this station is located | Central |
| line | - | the Service Number of the bus route | 10 |
| direction | - | 1 for loop lines or the default direction, 2 for the reverse direction | 1 |
| sequence | - | the order of this station on this line in this direction | 5 |
| distance | km | distance from this station to the starting station | 2.7 |
| Attribute | Unit | Description | Example |
|---|---|---|---|
| stop_id | - | a 5-digit identifier code of the bus station | 96109 |
| hour | - | hour of the record in 24-h format. | 15 |
| day | - | the type of day of the record. | WD |
| in | h | the average number of passengers departing from this station during the hour | 695 |
| out | h | the average number of passengers arriving at this station during the hour | 712 |
| Attribute | Unit | Description | Example |
|---|---|---|---|
| stop_id | - | the official code of the station | EW28 |
| name | - | name of the station | Pioneer |
| lat | the latitude of the station | N | |
| lng | the longitude of the station | E | |
| line | - | the name of the MRT/LRT line | EW |
| sequence | - | the order of this station on this line | 28 |
| Scheme | Training | Testing | Validation | |
|---|---|---|---|---|
| # of planning areas | 30 | 9 | 11 | |
| 1 | # of nodes | 2678 | 1281 | 1086 |
| planning areas | See Appendix A | |||
| # of regions | 3 | 1 | 1 | |
| 2 | # of nodes | 1359 | 2904 | 782 |
| regions | North, East, Central | West | North-East | |
| Hyperparameter | GCN | MLP |
|---|---|---|
| 1.00 | - | |
| 1.00 | ||
| hidden layer units | 8 | 8 |
| learning rate | 0.05 | 0.05 |
| dropout rate | 0.00 | 0.00 |
| l2 reg. |
| Setting Model | Transductive | Inductive | ||||
|---|---|---|---|---|---|---|
| MSE | MAE | MAPE | MSE | MAE | MAPE | |
| RF | - | - | - | 0.01331 | 0.04929 | 0.05994 |
| LR | - | - | - | 0.01045 | 0.04860 | 0.05883 |
| MLP | 0.00135 | 0.02698 | 0.03446 | 0.00135 | 0.02696 | 0.03445 |
| GCN-walking | 0.00116 | 0.02575 | 0.03169 | 0.00110 | 0.02458 | 0.03034 |
| GCN-combine | 0.00111 | 0.02545 | 0.03133 | 0.00110 | 0.02465 | 0.03045 |
| Setting Model | Transductive | Inductive | ||||
|---|---|---|---|---|---|---|
| MSE | MAE | MAPE | MSE | MAE | MAPE | |
| RF | - | - | - | 0.02486 | 0.08414 | 0.09990 |
| LR | - | - | - | 0.02241 | 0.07572 | 0.08929 |
| MLP | 0.00315 | 0.03280 | 0.04120 | 0.00325 | 0.03288 | 0.04127 |
| GCN-walking | 0.00226 | 0.03122 | 0.03809 | 0.00216 | 0.03278 | 0.04030 |
| GCN-combine | 0.00264 | 0.03478 | 0.04249 | 0.00207 | 0.03064 | 0.03759 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lan, T.; Cheng, H.; Wang, Y.; Wen, B. Site Selection via Learning Graph Convolutional Neural Networks: A Case Study of Singapore. Remote Sens. 2022, 14, 3579. https://doi.org/10.3390/rs14153579
Lan T, Cheng H, Wang Y, Wen B. Site Selection via Learning Graph Convolutional Neural Networks: A Case Study of Singapore. Remote Sensing. 2022; 14(15):3579. https://doi.org/10.3390/rs14153579
Chicago/Turabian StyleLan, Tian, Hao Cheng, Yi Wang, and Bihan Wen. 2022. "Site Selection via Learning Graph Convolutional Neural Networks: A Case Study of Singapore" Remote Sensing 14, no. 15: 3579. https://doi.org/10.3390/rs14153579
APA StyleLan, T., Cheng, H., Wang, Y., & Wen, B. (2022). Site Selection via Learning Graph Convolutional Neural Networks: A Case Study of Singapore. Remote Sensing, 14(15), 3579. https://doi.org/10.3390/rs14153579