
Cloud Removal with SAR-Optical Data Fusion and Graph-Based Feature Aggregation Network



Abstract
:
1. Introduction
- (1)
- Spatial information-based methods
- (2)
- Temporal information-based methods
- (3)
- Multi-source auxiliary information-based methods
- ■
- Based on deep learning theory and data-driven principles, we propose a novel deep neural network called G-FAN to remove thick clouds and cloud shadows in Sentinel-2 satellite optical images with contemporary SAR images from the Sentinel-1 satellite. The proposed deep neural network, combined with the advantages of the residual network (ResNet) and graph attention network (GAT), utilizes SAR imaging without the influence of clouds in order to reconstruct multi-band reflectance in optical remote sensing images by learning and extracting the non-linear correlation between the electromagnetic backscattering information in the SAR images, the spectral information of the neighborhood pixels, and the non-neighborhood pixels in the optical images.
- ■
- Since SAR images used as auxiliary data for cloud removal may be blurred and noisy, and the convolution of the traditional deep learning model for cloud removal mainly uses neighborhood information, spectral information and electromagnetic backscattering information (i.e., non-neighborhood information) cannot be effectively used. A feature information aggregation method based on the graph attention mechanism is proposed for cloud removal and restoration of remote sensing images. A proposed network architecture, in which the multi-head graph-based feature aggregation modules (M-GFAM) and residual modules are constructed alternately, achieves the simultaneous processing of cloud removal, image deblurring, and image denoising.
- ■
- A loss function based on the smooth L1 loss function and the Multi-Scale Structural Similarity Index (MS-SSIM) is proposed and used in our model. The smooth L1 loss function is used as a basic error function to reduce the gap between the predicted cloud-free image and the ground truth image. When the error between the predicted value and the true value becomes smaller, our model can obtain a smooth and steady gradient descent. Equipped with MS-SSIM, our loss function is more suitable for the human visual system than others, and can maintain a stable performance in remote sensing images with different resolutions.
2. Methods
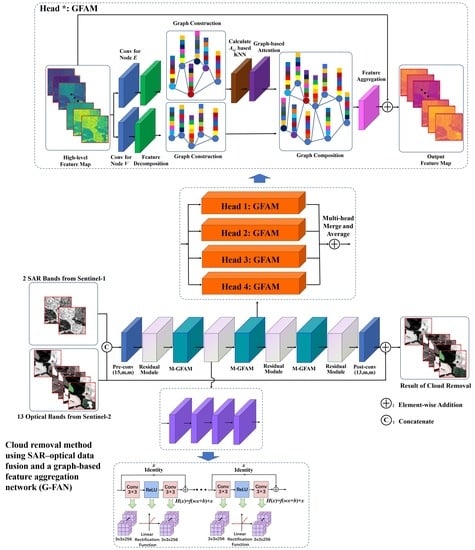
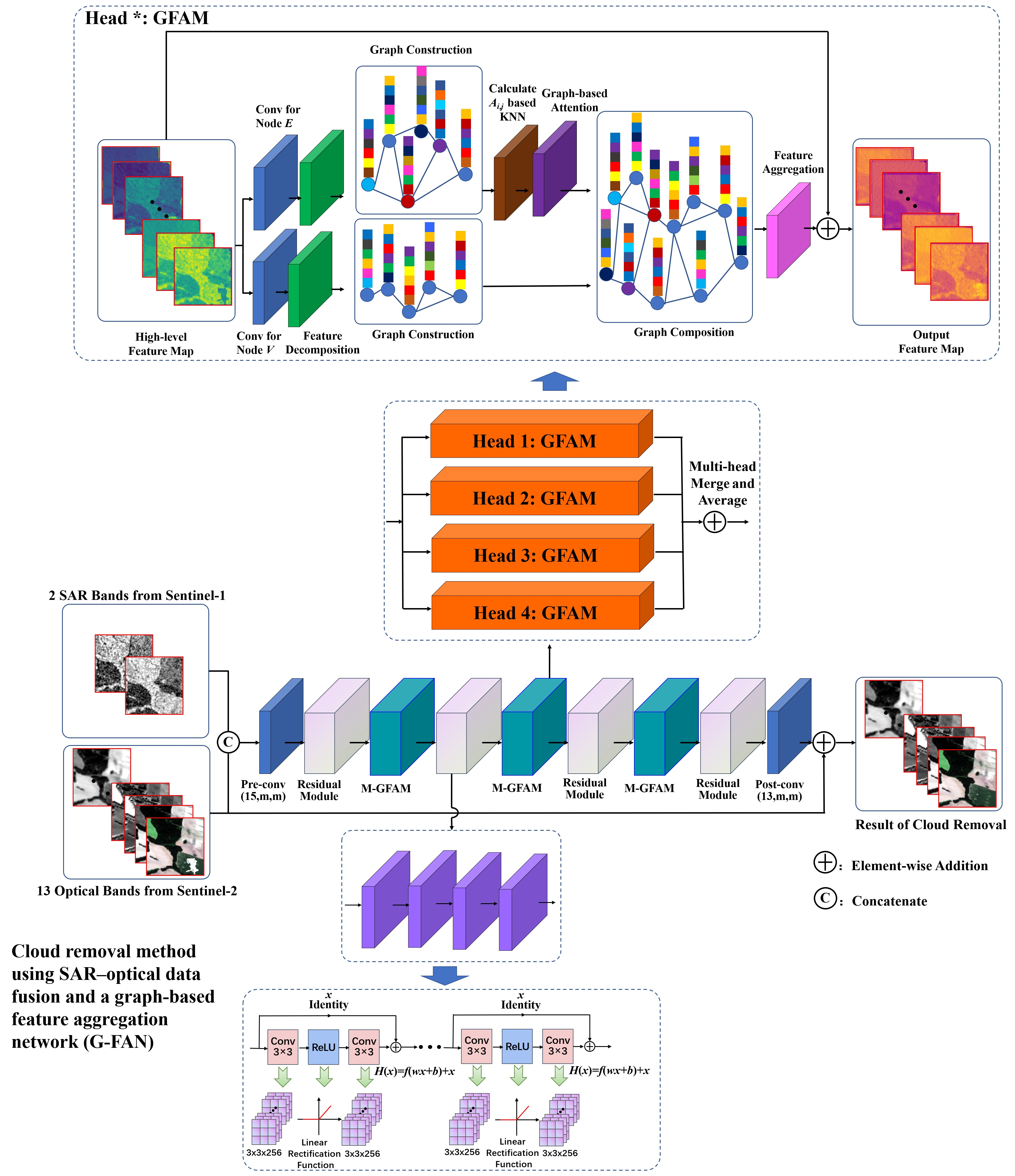
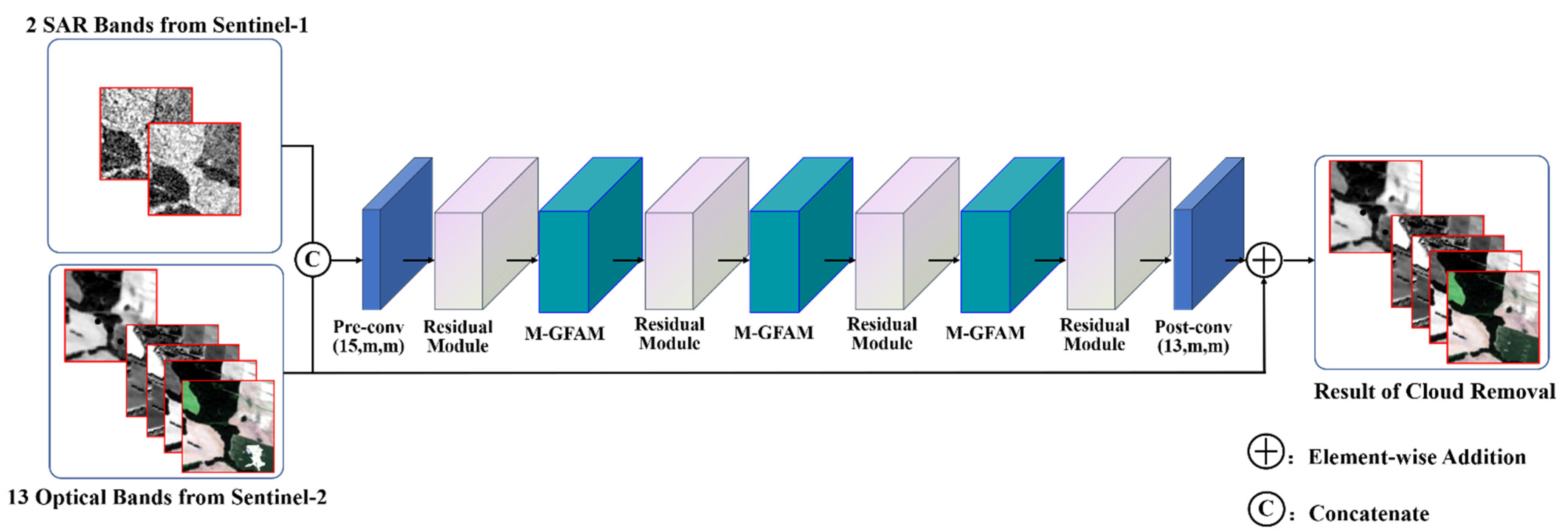
2.1. Overview of the Proposed Framework
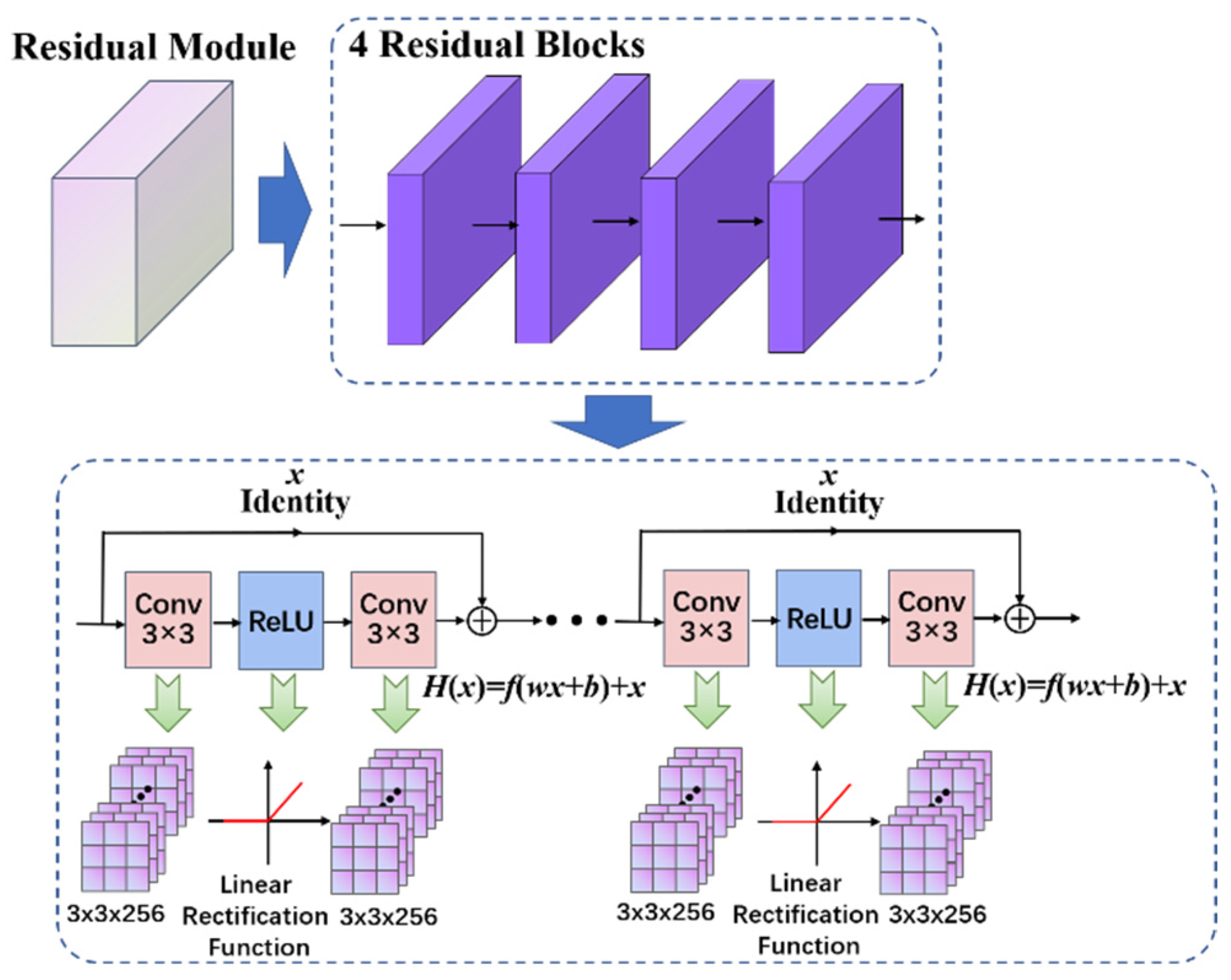
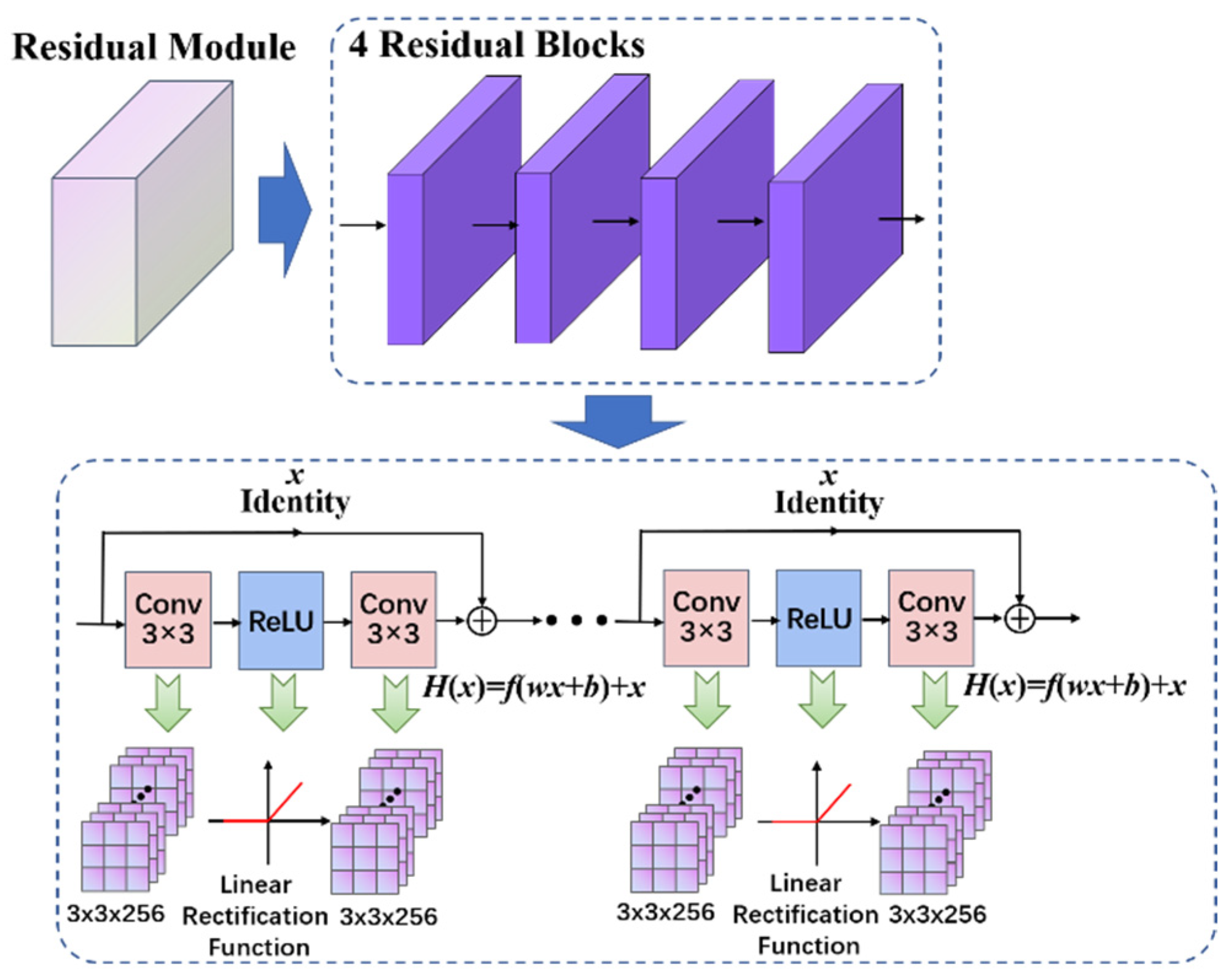
2.2. Residual Module Construction
2.3. Graph Attention Network
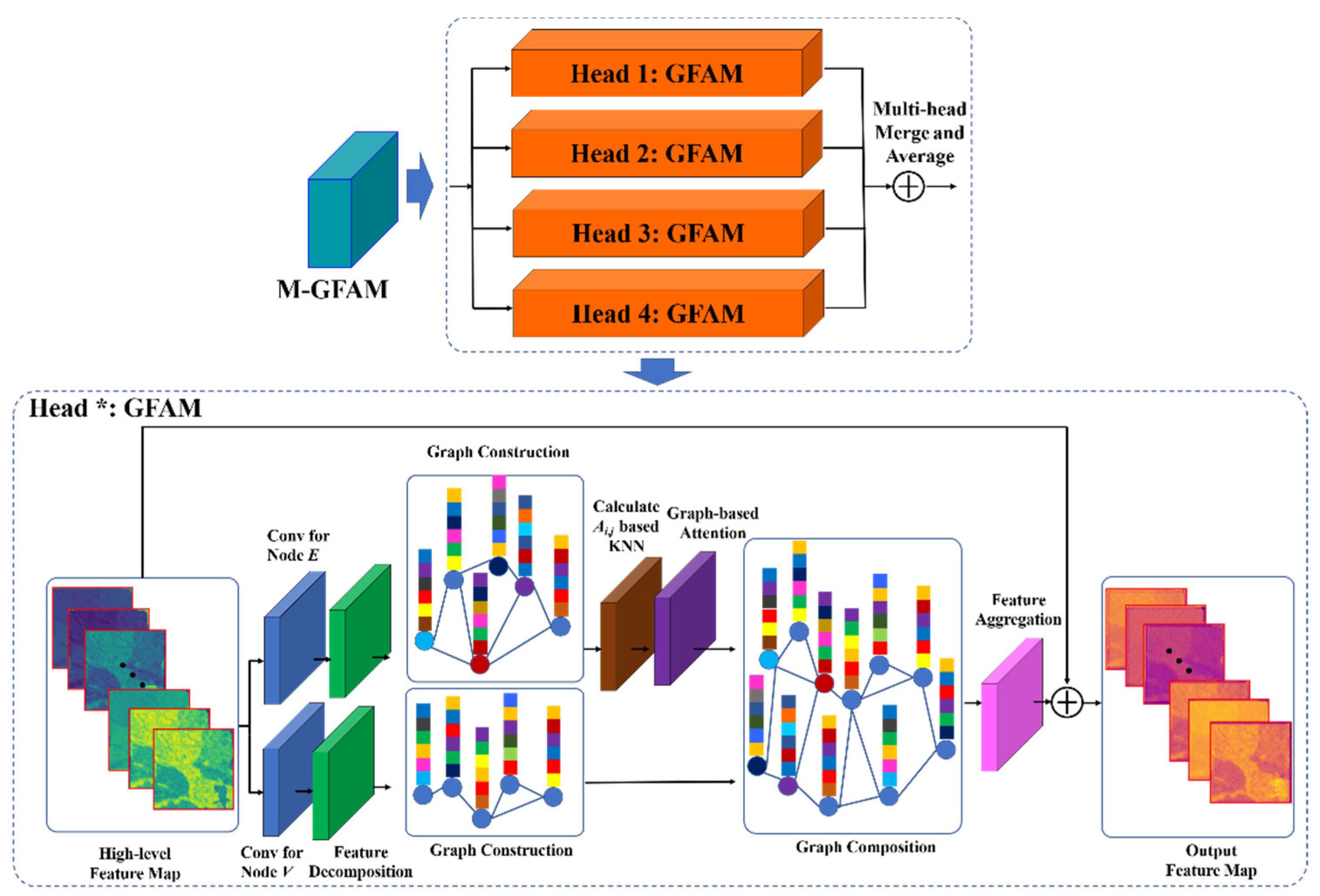
2.4. Application of the Graph-Based Feature Aggregation Mechanism
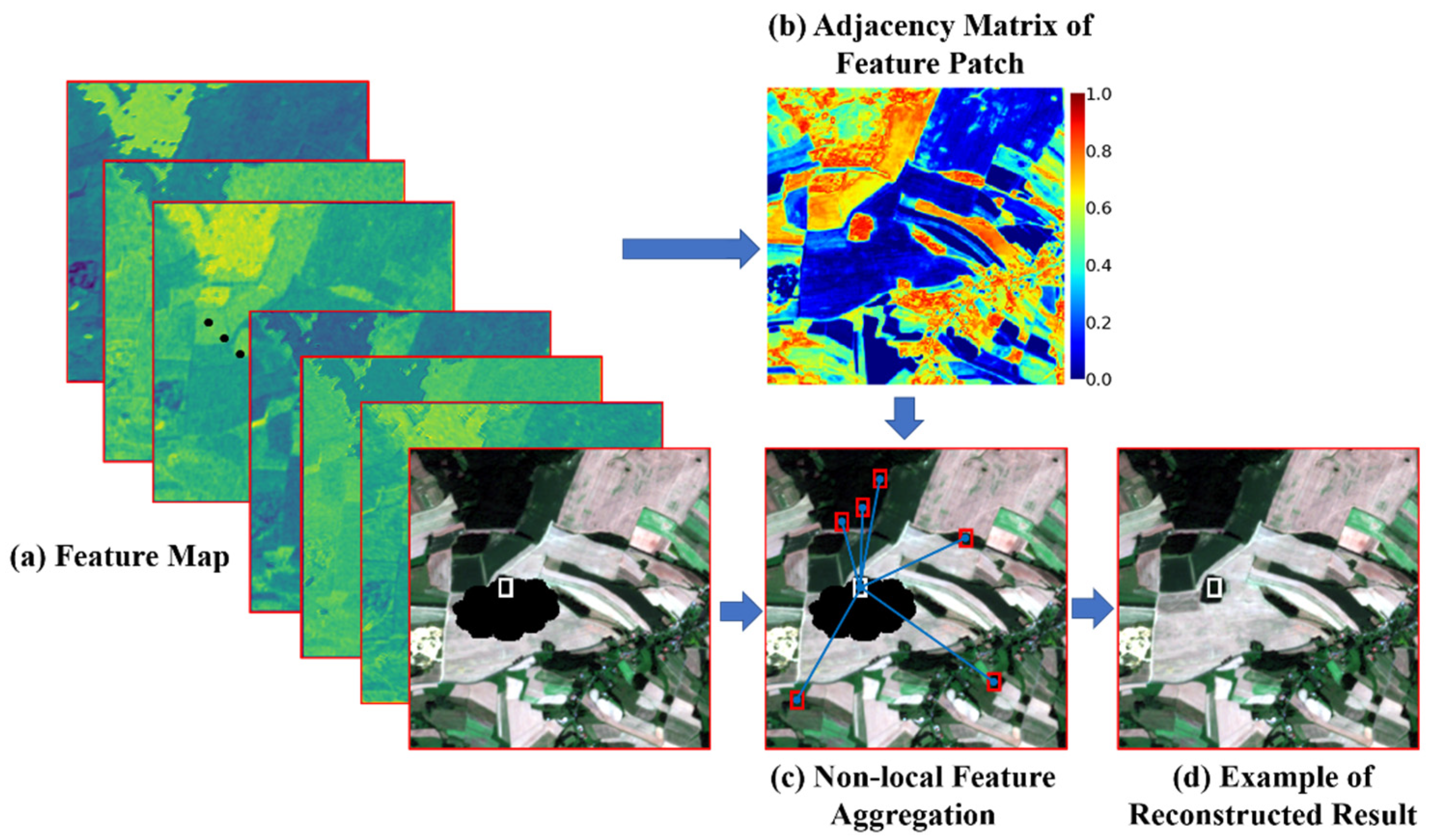
2.4.1. Graph-Based Feature Extraction and Modeling
2.4.2. Dynamic Graph Connection Optimization
2.4.3. Graph-Based Feature Aggregation with Multi-Head Attention
2.5. Loss Function of G-FAN
3. Experiments
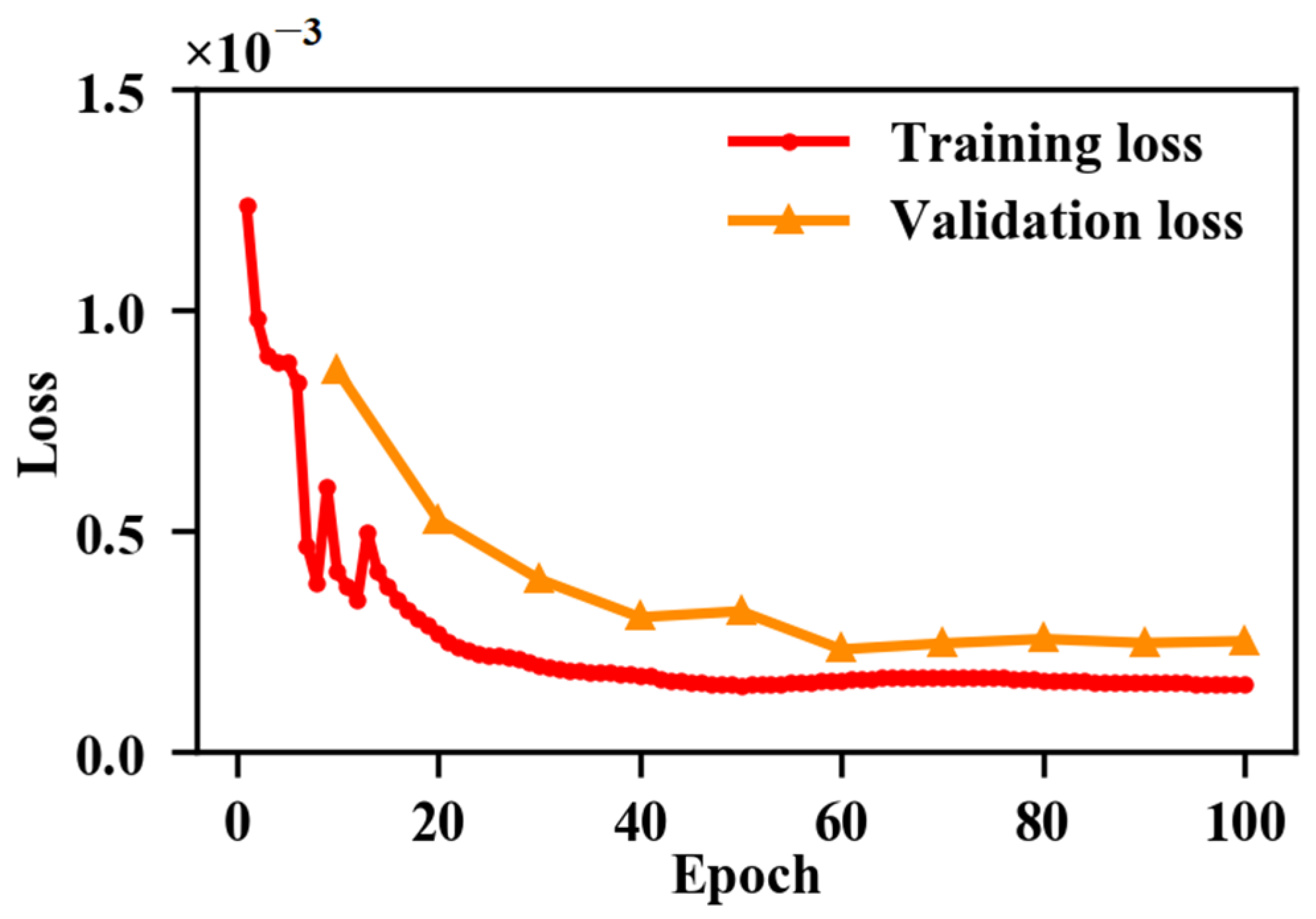
3.1. Model Training and Experiment Settings
3.1.1. Dataset Introduction and Preparation
3.1.2. Evaluation Methods
3.1.3. Implementation Details
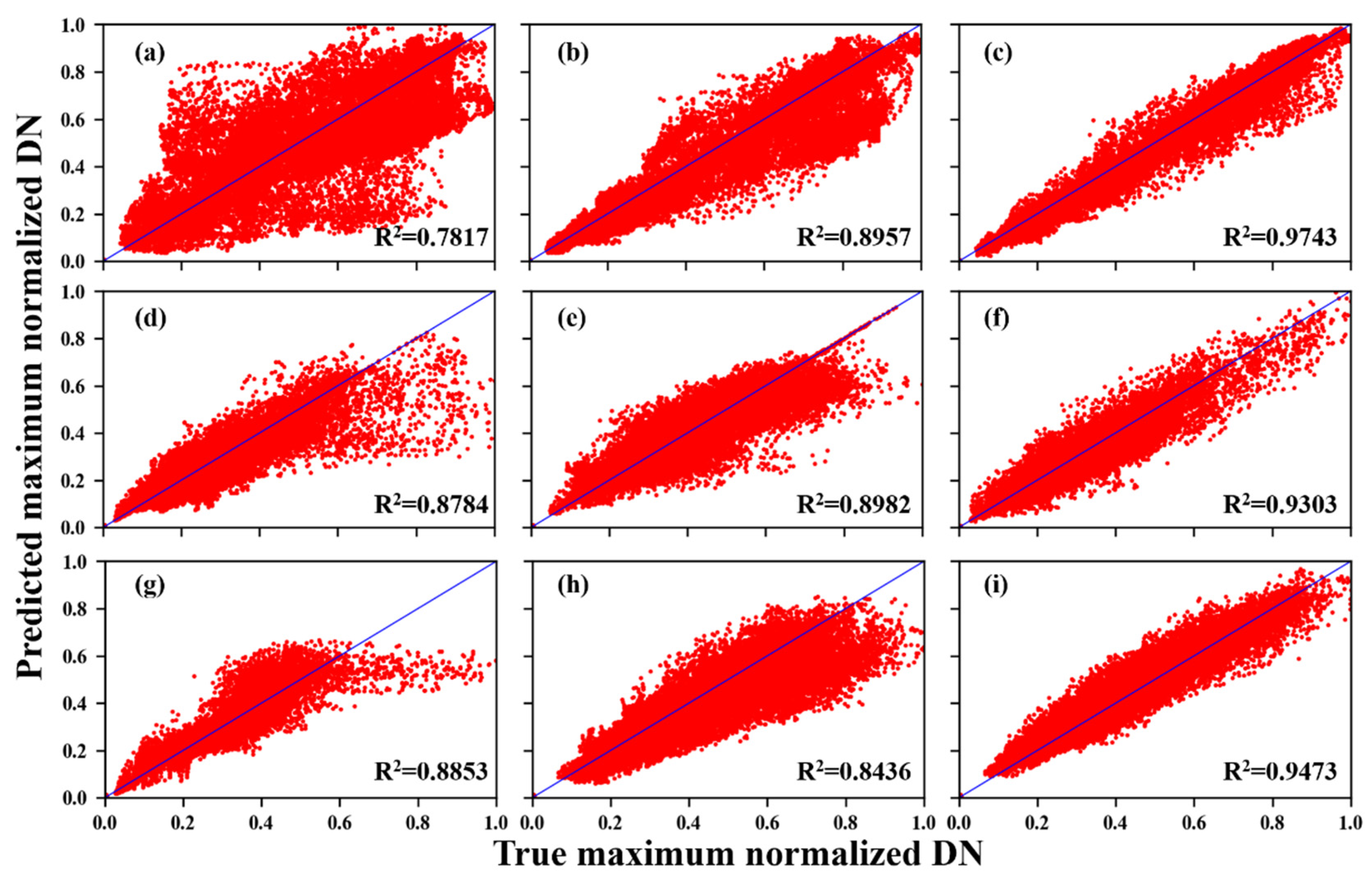
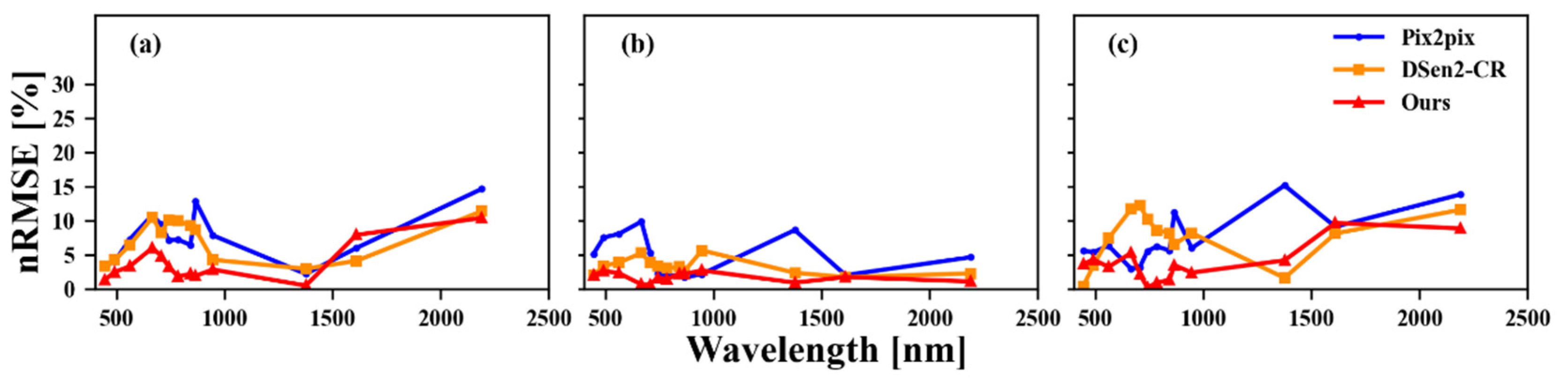
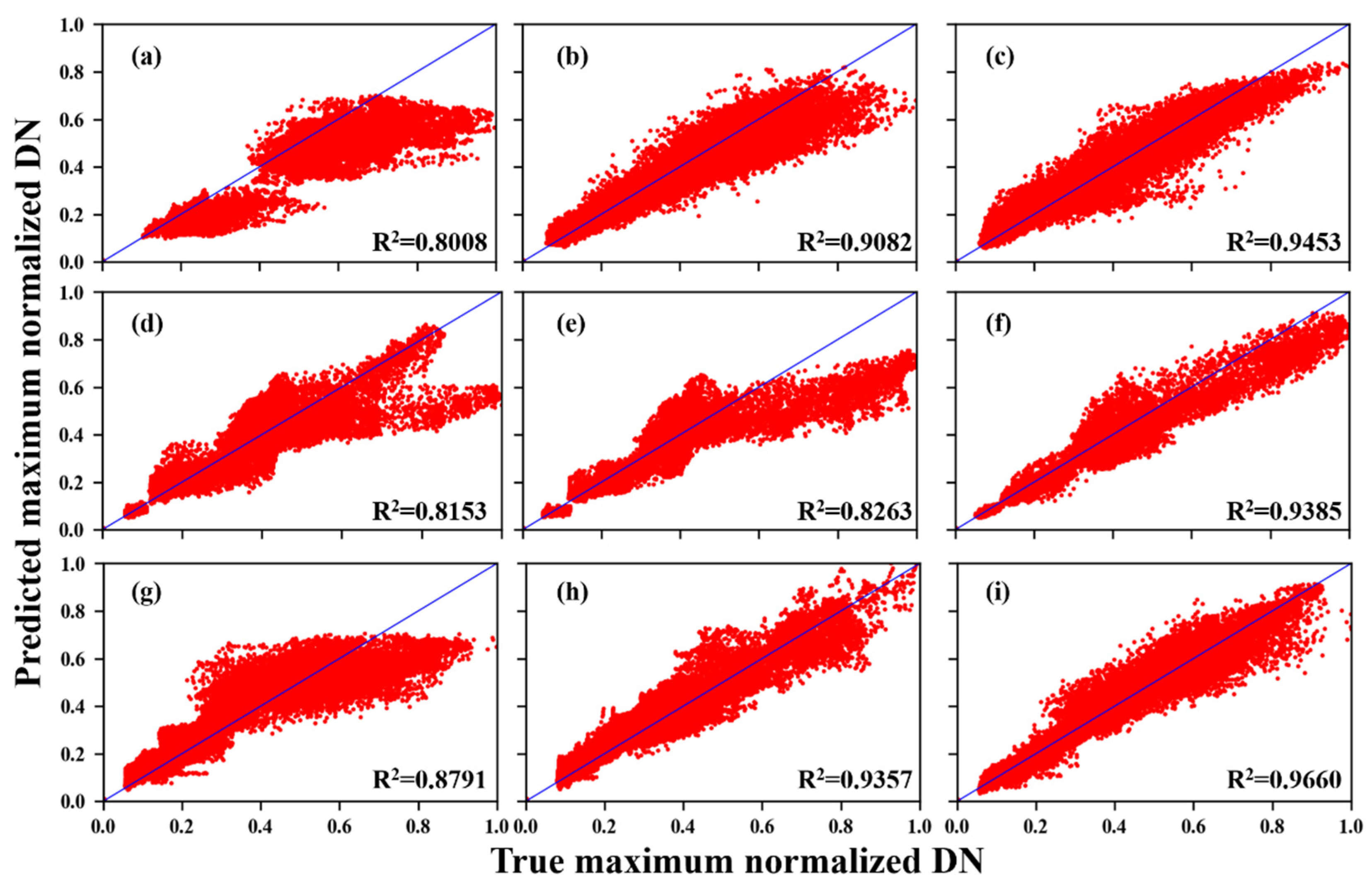
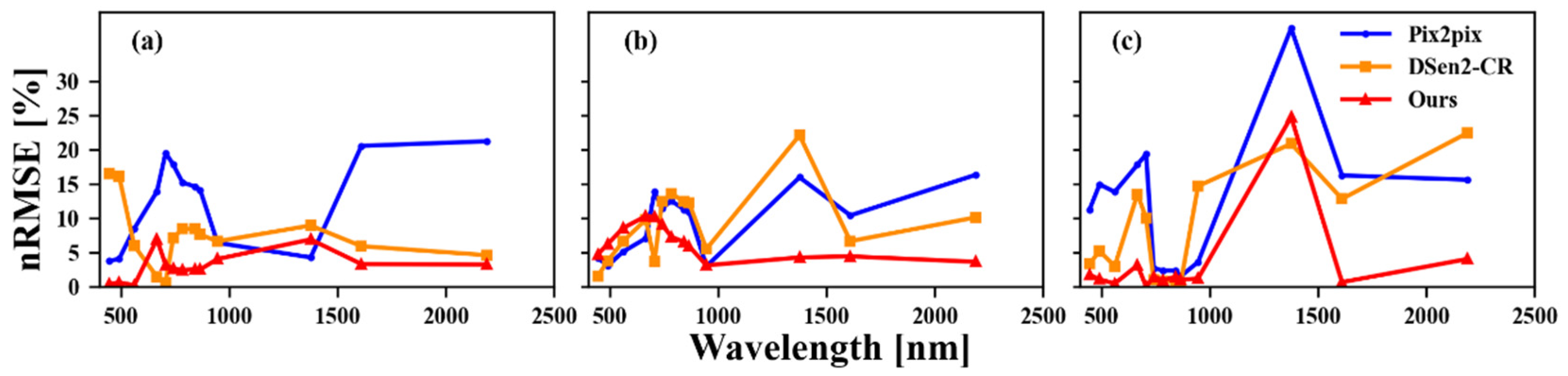
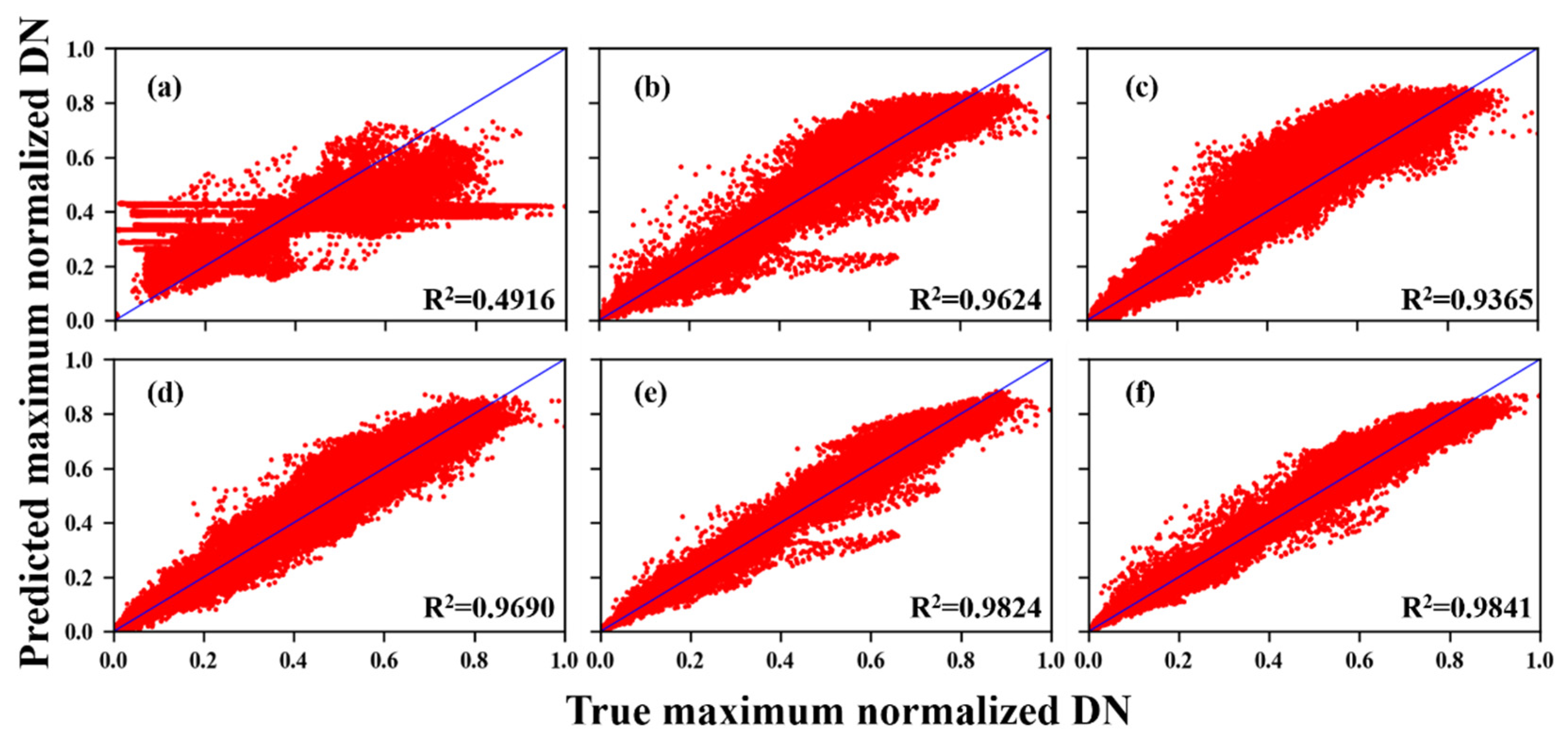
3.2. Simulated Data Experiments
3.3. Real Data Experiments
3.4. Ablation Experiments
3.4.1. Effect of SAR-Optical Data Fusion
3.4.2. Performance with Different Numbers of Residual Blocks
3.4.3. Effect of M-GFAM
3.4.4. Influence of Loss Function
4. Discussion
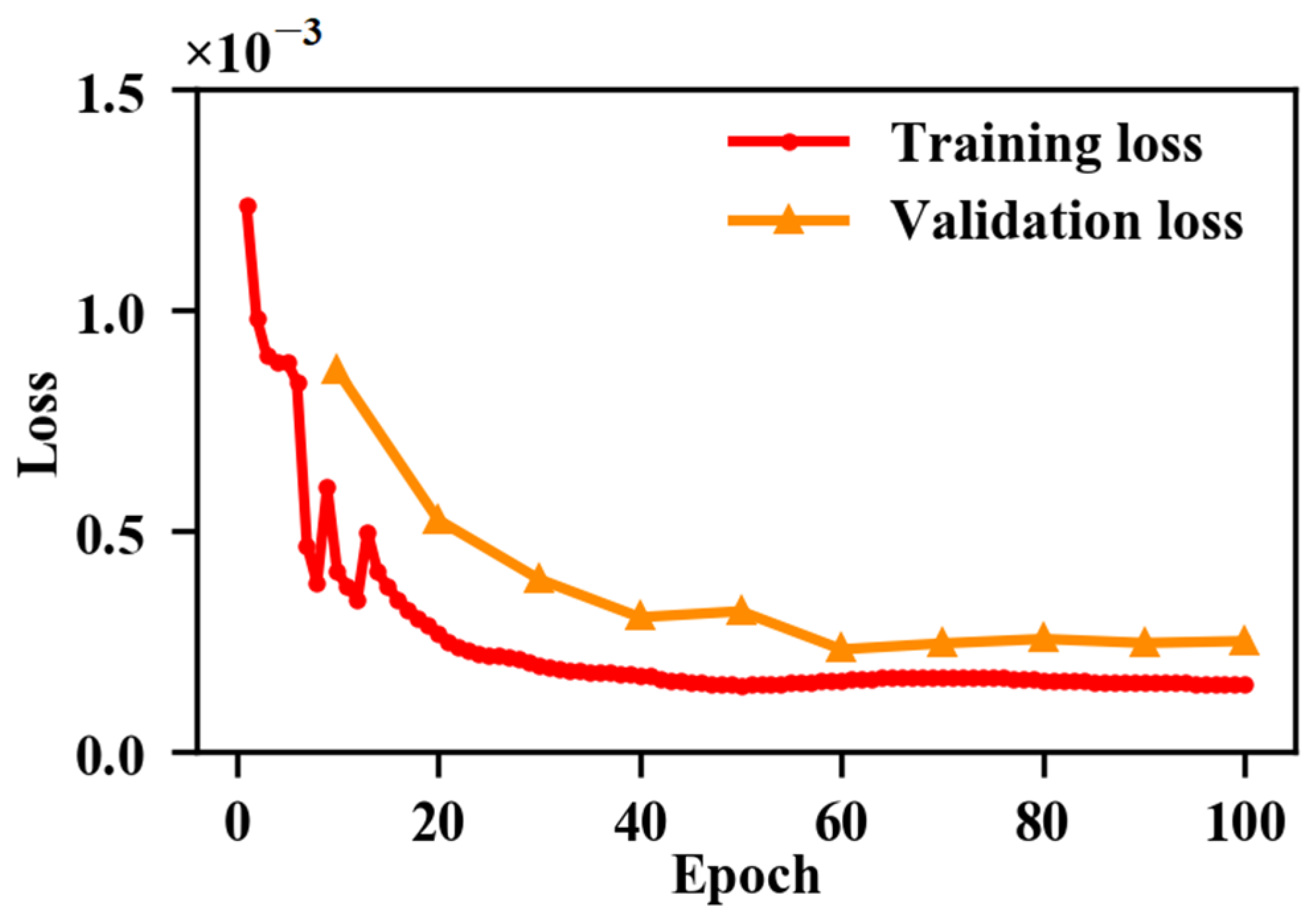
4.1. Overfitting Issues of Model
4.2. Computation Complexity
4.3. Comparisons of Difference Cloud Detection Methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CC | correlation coefficient |
| GAN | generative adversarial network |
| GAT | graph attention network |
| GCN | graph convolutional network |
| GFAM | graph-based feature aggregation module |
| G-FAN | graph-based feature aggregation network |
| MAE | mean absolute error |
| M-GFAM | multi-head graph-based feature aggregation modules |
| MODIS | moderate resolution imaging spectroradiometer |
| MS-SSIM | multi-scale structural similarity index |
| nRMSE | normalized root mean square error |
| PSNR | peak signal-to-noise ratio |
| ResNet | residual network |
| SAM | spectral angle mapper |
| SAR | synthetic aperture radar |
| SSIM | structural similarity index |
Appendix A





References
- Zhang, B.; Wu, Y.; Zhao, B.; Chanussot, J.; Hong, D.; Yao, J.; Gao, L. Progress and challenges in intelligent remote sensing satellite systems. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1814–1822. [Google Scholar] [CrossRef]
- Liu, Y.; Zuo, X.; Tian, J.; Li, S.; Cai, K.; Zhang, W. Research on generic optical remote sensing products: A review of scientific exploration, technology research, and engineering application. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3937–3953. [Google Scholar] [CrossRef]
- Wang, S.; Li, J.; Zhang, B.; Lee, Z.; Spyrakos, E.; Feng, L.; Liu, C.; Zhao, H.; Wu, Y.; Zhu, L.; et al. Changes of water clarity in large lakes and reservoirs across China observed from long-term MODIS. Remote Sens. Environ. 2020, 247, 111949. [Google Scholar] [CrossRef]
- Zhao, X.; Hong, D.; Gao, L.; Zhang, B.; Chanussot, J. Transferable deep learning from time series of Landsat data for national land-cover mapping with noisy labels: A case study of China. Remote Sens. 2021, 13, 4194. [Google Scholar] [CrossRef]
- Youssefi, F.; Zoej, M.J.V.; Hanafi-Bojd, A.A.; Dariane, A.B.; Khaki, M.; Safdarinezhad, A.; Ghaderpour, E. Temporal monitoring and predicting of the abundance of malaria vectors using time series analysis of remote sensing data through Google Earth Engine. Sensors 2022, 22, 1942. [Google Scholar] [CrossRef]
- Duan, C.; Pan, J.; Li, R. Thick cloud removal of remote sensing images using temporal smoothness and sparsity regularized tensor optimization. Remote Sens. 2020, 12, 3446. [Google Scholar] [CrossRef]
- Xia, M.; Jia, K. Reconstructing missing information of remote sensing data contaminated by large and thick clouds based on an improved multitemporal dictionary learning method. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5605914. [Google Scholar] [CrossRef]
- Ju, J.; Roy, D.P. The availability of cloud-free landsat etm plus data over the conterminous United States and globally. Remote Sens. Environ. 2008, 112, 1196–1211. [Google Scholar] [CrossRef]
- Liu, C.; Zhang, Y.; Chen, P.; Lai, C.; Chen, Y.; Cheng, J.; Ko, M. Clouds classification from Sentinel-2 imagery with deep residual learning and semantic image segmentation. Remote Sens. 2019, 11, 119. [Google Scholar] [CrossRef] [Green Version]
- Jeppesen, J.H.; Jacobsen, R.H.; Inceoglu, F.; Toftgaard, T.S. A cloud detection algorithm for satellite imagery based on deep learning. Remote Sens. Environ. 2019, 229, 247–259. [Google Scholar] [CrossRef]
- Sun, L.; Yang, X.; Jia, S.; Jia, C.; Wang, Q.; Liu, X.; Wei, J.; Zhou, X. Satellite data cloud detection using deep learning supported by hyperspectral data. Int. J. Remote Sens. 2019, 41, 1349–1371. [Google Scholar] [CrossRef] [Green Version]
- Lu, C.; Xia, M.; Qian, M.; Chen, B. Dual-branch network for cloud and cloud shadow segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5410012. [Google Scholar] [CrossRef]
- Zhao, W.; Qu, Y.; Chen, J.; Yuan, Z. Deeply synergistic optical and SAR time series for crop dynamic monitoring. Remote Sens. Environ. 2020, 247, 111952. [Google Scholar] [CrossRef]
- Santangelo, M.; Cardinali, M.; Bucci, F.; Fiorucci, F.; Mondini, A. Exploring event landslide mapping using Sentinel-1 SAR backscatter products. Geomorphology 2022, 397, 108021. [Google Scholar] [CrossRef]
- Liu, Y.; Qian, J.; Yue, H. Combined Sentinel-1A with Sentinel-2A to estimate soil moisture in farmland. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1292–1310. [Google Scholar] [CrossRef]
- Maalouf, A.; Carre, P.; Augereau, B.; Fernandez-Maloigne, C. A bandelet-based inpainting technique for clouds removal from remotely sensed images. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2363–2371. [Google Scholar] [CrossRef]
- Zheng, J.; Liu, X.; Wang, X. Single image cloud removal using U-Net and generative adversarial networks. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6371–6384. [Google Scholar] [CrossRef]
- Meng, F.; Yang, X.; Zhou, C.; Li, Z. A sparse dictionary learning-based adaptive patch inpainting method for thick clouds removal from high-spatial resolution remote sensing imagery. Sensors 2017, 17, 2130. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Wen, F.; Gao, Z.; Ling, X. A coarse-to-fine framework for cloud removal in remote sensing image sequence. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5963–5974. [Google Scholar] [CrossRef]
- Li, X.; Wang, L.; Cheng, Q.; Wu, P.; Gan, W.; Fang, L. Cloud removal in remote sensing images using nonnegative matrix factorization and error correction. ISPRS J. Photogramm. Remote Sens. 2019, 148, 103–113. [Google Scholar] [CrossRef]
- Cao, R.; Chen, Y.; Chen, J.; Zhu, X.; Shen, M. Thick cloud removal in Landsat images based on autoregression of Landsat time-series data. Remote Sens. Environ. 2020, 249, 112001. [Google Scholar] [CrossRef]
- Zhang, Q.; Yuan, Q.; Zeng, C.; Li, X.; Wei, Y. Missing data reconstruction in remote sensing image with a unified spatial–temporal–spectral deep convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4274–4288. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.; Dai, P.; Lu, M.; Zhang, Y. Simultaneous cloud detection and removal from bitemporal remote sensing images using cascade convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2020, 59, 732–748. [Google Scholar] [CrossRef]
- Xu, M.; Deng, F.; Jia, S.; Jia, X.; Plaza, A. Attention mechanism-based generative adversarial networks for cloud removal in Landsat images. Remote Sens. Environ. 2022, 271, 112902. [Google Scholar] [CrossRef]
- Shen, H.; Wu, J.; Cheng, Q.; Aihemaiti, M.; Zhang, C.; Li, Z. A spatiotemporal fusion based cloud removal method for remote sensing images with land cover changes. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 862–874. [Google Scholar] [CrossRef]
- Angel, Y.; Houborg, R.; McCabe, M.F. Reconstructing cloud contaminated pixels using spatiotemporal covariance functions and multitemporal hyperspectral imagery. Remote Sens. 2019, 11, 1145. [Google Scholar] [CrossRef] [Green Version]
- Meraner, A.; Ebel, P.; Zhu, X.; Schmitt, M. Cloud removal in Sentinel-2 imagery using a deep residual neural network and SAR-optical data fusion. ISPRS J. Photogramm. Remote Sens. 2020, 166, 333–346. [Google Scholar] [CrossRef]
- Grohnfeldt, C.; Schmitt, M.; Zhu, X. A conditional generative adversarial network to fuse Sar and multispectral optical data for cloud removal from Sentinel-2 images. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1726–1729. [Google Scholar]
- Bermudez, J.; Happ, P.; Oliveira, D.; Feitosa, R. Sar to optical image synthesis for cloud removal with generative adversarial networks. In Proceedings of the ISPRS Mid-Term Symposium Innovative Sensing—From Sensors to Methods and Applications, Karlsruhe, Germany, 10–12 October 2018; pp. 5–11. [Google Scholar]
- Gao, J.; Yi, Y.; Wei, T.; Zhang, G. Sentinel-2 cloud removal considering ground changes by fusing multitemporal SAR and optical images. Remote Sens. 2021, 13, 3998. [Google Scholar] [CrossRef]
- He, W.; Yokoya, N. Multi-temporal sentinel-1 and-2 data fusion for optical image simulation. ISPRS Int. J. Geo-Inf. 2018, 7, 389. [Google Scholar] [CrossRef] [Green Version]
- Eckardt, R.; Berger, C.; Thiel, C.; Schmullius, C. Removal of optically thick clouds from multi-spectral satellite images using multi-frequency SAR data. Remote Sens. 2013, 5, 2973–3006. [Google Scholar] [CrossRef] [Green Version]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 21–25 May 2018; pp. 1243–1255. [Google Scholar]
- Baroud, S.; Chokri, S.; Belhaous, S.; Mestari, M. A brief review of graph convolutional neural network based learning for classifying remote sensing images. Procedia Comput. Sci. 2021, 191, 349–354. [Google Scholar] [CrossRef]
- Hong, D.; Yokoya, N.; Chanussot, J.; Zhu, X. CoSpace: Common subspace learning from hyperspectral-multispectral correspondences. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4349–4359. [Google Scholar] [CrossRef] [Green Version]
- Hong, D.; Yokoya, N.; Ge, N.; Chanussot, J.; Zhu, X. Learnable manifold alignment (LeMA): A semi-supervised cross-modality learning framework for land cover and land use classification. ISPRS J. Photogramm. Remote Sens. 2019, 147, 193–205. [Google Scholar] [CrossRef] [PubMed]
- Hong, D.; Gao, L.; Yao, J.; Zhang, B.; Plaza, A.; Chanussot, J. Graph convolutional networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5966–5978. [Google Scholar] [CrossRef]
- Kipf, T.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017; pp. 1–14. [Google Scholar]
- Yang, Z.; Pan, D.; Shi, P. Joint image dehazing and super-resolution: Closed shared source residual attention fusion network. IEEE Access 2021, 9, 105477–105492. [Google Scholar] [CrossRef]
- Valsesia, D.; Fracastoro, G.; Magli, E. Deep graph-convolutional image denoising. IEEE Trans. Image Process. 2020, 29, 8226–8237. [Google Scholar] [CrossRef]
- Valsesia, D.; Fracastoro, G.; Magli, E. Image denoising with graph-convolutional neural networks. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Taipei, China, 22–25 September 2019; pp. 2399–2403. [Google Scholar]
- Yu, J.; Liu, M.; Feng, H.; Xu, Z.; Li, Q. Split-attention multiframe alignment network for image restoration. IEEE Access 2020, 8, 39254–39272. [Google Scholar] [CrossRef]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss functions for image restoration with neural networks. IEEE Trans. Comput. Imaging 2017, 3, 47–57. [Google Scholar] [CrossRef]
- Schmitt, M.; Hughes, L.; Qiu, C.; Zhu, X. Aggregating cloud-free Sentinel-2 images with Google Earth Engine. In Proceedings of the ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Munich, Germany, 18–20 September 2019; pp. 145–152. [Google Scholar]
- Zhai, H.; Zhang, H.; Zhang, L.; Li, P. Cloud/shadow detection based on spectral indices for multi/hyperspectral optical remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2018, 144, 235–253. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A. Image-to-image translation with conditional adversarial networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Qiu, S.; Zhu, Z.; He, B. Fmask 4.0: Improved cloud and cloud shadow detection in Landsats 4-8 and Sentinel-2 imagery. Remote Sens. Environ. 2019, 231, 111205. [Google Scholar] [CrossRef]
- Frantz, D.; Hab, E.; Uhl, A.; Stoffels, J.; Hill, J. Improvement of the Fmask algorithm for Sentinel-2 images: Separating clouds from bright surfaces based on parallax effects. Remote Sens. Environ. 2018, 215, 471–481. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PSNR↑ | SSIM↑ | CC↑ | SAM (°)↓ | MAE↓ | |
|---|---|---|---|---|---|
| Pix2pix | 29.8322 | 0.8806 | 0.7605 | 8.8129 | 0.0249 |
| DSen2-CR | 31.5108 | 0.9048 | 0.8115 | 6.2634 | 0.0198 |
| Our Model | 35.5591 | 0.9261 | 0.8826 | 2.8895 | 0.0157 |
| PSNR↑ | SSIM↑ | CC↑ | SAM (°)↓ | MAE↓ | |
|---|---|---|---|---|---|
| Pix2pix | 28.7996 | 0.8725 | 0.7504 | 11.6827 | 0.0277 |
| DSen2-CR | 30.1207 | 0.8930 | 0.8013 | 7.6163 | 0.0250 |
| Our Model | 34.4016 | 0.9164 | 0.8264 | 4.2715 | 0.0172 |
| PSNR↑ | SSIM↑ | CC↑ | SAM (°)↓ | MAE↓ | |
|---|---|---|---|---|---|
| w/o SAR | 27.8501 | 0.8267 | 0.6840 | 9.6827 | 0.0296 |
| 8 Residual blocks (M-GFAM + 8 residual blocks + ) | 28.6487 | 0.8627 | 0.7989 | 7.8166 | 0.0207 |
| Single GFAM (Single GFAM + 16 residual blocks + ) | 33.7955 | 0.8843 | 0.8147 | 5.0221 | 0.0195 |
| Smooth L1 (M-GFAM + 16 residual blocks + Smooth L1) | 34.2943 | 0.9047 | 0.8129 | 4.3182 | 0.0179 |
| 32 Residual blocks (M-GFAM + 32 residual blocks + ) | 34.4770 | 0.9089 | 0.8295 | 4.2890 | 0.0168 |
| Ours (M-GFAM + 16 residual blocks + ) | 34.4016 | 0.9164 | 0.8264 | 4.2715 | 0.0172 |
| Pix2pix | DSen2-CR | Ours | 32 Residual Blocks | |
|---|---|---|---|---|
| Time | 0.14 s | 0.22 s | 0.32 s | 0.41 s |
| PSNR↑ | SSIM↑ | CC↑ | SAM (°)↓ | MAE↓ | |
|---|---|---|---|---|---|
| F-mask [47,48] + G-FAN | 34.5342 | 0.9033 | 0.8196 | 4.2487 | 0.0164 |
| cloud/cloud shadow detection [44,45] + G-FAN(Our model) | 34.4016 | 0.9164 | 0.8264 | 4.2715 | 0.0172 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Zhang, W.; Li, Z.; Wang, Y.; Zhang, B. Cloud Removal with SAR-Optical Data Fusion and Graph-Based Feature Aggregation Network. Remote Sens. 2022, 14, 3374. https://doi.org/10.3390/rs14143374
Chen S, Zhang W, Li Z, Wang Y, Zhang B. Cloud Removal with SAR-Optical Data Fusion and Graph-Based Feature Aggregation Network. Remote Sensing. 2022; 14(14):3374. https://doi.org/10.3390/rs14143374
Chicago/Turabian StyleChen, Shanjing, Wenjuan Zhang, Zhen Li, Yuxi Wang, and Bing Zhang. 2022. "Cloud Removal with SAR-Optical Data Fusion and Graph-Based Feature Aggregation Network" Remote Sensing 14, no. 14: 3374. https://doi.org/10.3390/rs14143374
APA StyleChen, S., Zhang, W., Li, Z., Wang, Y., & Zhang, B. (2022). Cloud Removal with SAR-Optical Data Fusion and Graph-Based Feature Aggregation Network. Remote Sensing, 14(14), 3374. https://doi.org/10.3390/rs14143374