1. Introduction
Unmanned aerial vehicles (UAVs), with their advantages of flexible usage and easy deployment, have been widely used in many fields, including military applications such as battlefield surveillance, air reconnaissance, and tracking, as well as in civilian applications such as disaster monitoring, geophysical exploration, and agricultural plant protection [
1]. At the same time, their malicious use also poses a severe threat to aviation security and the maintenance of social stability [
2]. Radar has proven to be an essential technical method of UAV detection [
3,
4]. However, the strong maneuverability of UAVs, including their unknown motion model parameters and uncertain model switching [
5], brings about great challenges in the stable tracking of targets.
Random finite set (RFS)-based filters provide a theoretically optimal approach to multi-target tracking and are widely used in many fields [
6,
7,
8]. In the RFS formulation, the collection of target states at any given time is regarded as a set-valued multi-target state, and the collection of measurements is regarded as a set-valued multi-target observation [
9,
10]. Then, the problem of dynamically estimating multiple targets can be formulated in a Bayesian filtering framework by propagating the posterior distribution of the multi-target state in time. However, multi-target filtering solutions in their standard form are generally implemented by a fixed motion model. Thus, to characterize the a rapidly maneuvering target with multiple models, the jump Markov system (JMS) approach has been incorporated into the existing RFS-based filters. Mahler derived the probability hypothesis density (PHD) filter and cardinalized probability hypothesis density (CPHD) filter approximations of the jump Markov multitarget Bayes filter [
11]. On this basis, a closed-form solution to the PHD recursion for the linear Gaussian jump Markov multi-target model was derived, and this is referred as the LGJMS-GMPHD filter [
12]. In addition, the JMS approach has also been incorporated into CPHD [
13], multi-Bernoulli [
14], and labeled multi-Bernoulli filters [
7]. However, in the above multiple model filters, the constant velocity (CV) and coordinate turn (CT) models are generally combined as model sets to describe the maneuvering motion. When these are applied to practical UAV tracking scenarios, there are two key problems: (i) the turn rate of the target is generally unknown, resulting in a mismatch between the target’s motion and the CT filtering model; (ii) for complex maneuvering trajectories, the uncertainty of motion model switching leads to the degradation of tracking performance.
There are two common approaches to estimating the turn rate. The first class estimates the turn rate online by using the estimated acceleration magnitude over the estimated speed [
15]. However, the estimated acceleration is generally not accurate enough, leading to inaccurate turn rate estimates. For the second class, the turn rate parameter is augmented into the state vector and the turn rate is estimated as part of the state vector recursively, which creates a difficult nonlinear problem [
16]. Furthermore, target Doppler measurements usually have higher precision compared with position estimates, and thus they have been incorporated to improve the accuracy of the turn rate estimate. In [
17], four possible turn rates were estimated based on the Doppler measurement. Due to the lack of prior information on target motion, the minimum turn rate and its opposite value were chosen to be the possible turn rates, and an interacting multiple model (IMM) algorithm consisting of one CV model and two CT models was adopted, increasing the computational burden.
The uncertainty of motion model switching is also a challenging problem in multiple model (MM) filters. In this case, the filtering state estimate has a delay in its response to target maneuvers, so the tracking precision degrades rapidly in the maneuvering phase. A smoothing process can produce delayed estimates, i.e., obtaining the target state estimates at time
given the measurements up to time
, which contributes to improving the tracking performance of maneuvering targets and has been incorporated into the MM algorithms [
18,
19,
20]. A sequential Monte Carlo (SMC) implementation for MMPHD smoothing was derived in [
21] to improve the capability of PHD-based tracking algorithms. However, the backward smoothing procedure is still model-based and cannot extract temporal correlations, so longer lags do not yield better estimates of the current state. Moreover, closed-form recursion with a smoothing process needs to be derived for different filters respectively and the computation is generally intractable, leading to limitations in its applications. Deep neural networks have strong capability of fitting if there are sufficient training data [
22], which is conducive to solving the problems of model mismatch and estimation delays in existing MM filtering algorithms for targets with complex maneuvering motions. In [
23], a deep learning maneuvering target tracking algorithm was proposed. However, the input of the network was the filtering states estimated by a single-model unscented Kalman filter. For strong maneuvering trajectories, large tracking errors increase the training burden of the network and reduce the convergence rate of training losses. Additionally, an LSTM-based deep recurrent neural network was presented in [
24] to overcome the limits of traditional model-based methods, but only CV and constant acceleration (CA) motions were verified, without considering CT maneuvers. Furthermore, the above methods are not suitable for scenarios with multiple maneuvering targets.
In view of the above problems, within the framework of the LGJMS-GMPHD filter, we propose a deep-learning-based multiple model tracking method for multiple maneuvering targets with complex maneuvering motions. The main contributions of this study are summarized as follows:
An adaptive turn rate estimation network (ATN) is designed. The feature matrix, including multi-frame and multi-dimensional kinematic states, is constructed and used as the input of the network. The temporal correlation information at each previous time step and the weight of different variables are extracted to improve the estimation accuracy of the turn rate. Then, the parameter is fed back to the CT model to enhance the consistency of the target motion and filtering model.
A filter state modification network (FMN) is designed to smooth the state estimates of the filter. The relationship information between all time steps of the state vector, including position estimates, is extracted to improve the adaptability of the filter to complex maneuvering motions, thereby reducing the tracking errors caused by uncertain model switching.
The remainder of this paper is structured as follows.
Section 2 reviews the PHD recursion for the linear Gaussian jump Markov multi-target model.
Section 3 presents the principle of the proposed deep-learning-based multiple model tracking method.
Section 4 designs the network parameters and verifies the effectiveness of the method in improving tracking performance. The simulation results and experimental data verification are analyzed in
Section 5. The discussion and future work are presented in
Section 6, and our conclusions are presented in
Section 7.
3. Deep-Learning-Based Multiple Model Tracking Method
The LGJMS-GMPHD filter described in
Section 2 can realize the tracking of multiple maneuvering targets in a cluttered environment. However, there are two key problems in practical applications in relation to targets with complex maneuvering characteristics:
- (i)
The turn rate parameters of targets are generally unknown and changing, causing a mismatch between the target motion and the filtering model;
- (ii)
The motion models are varied and switch with uncertainty, and the filter state estimate always lags the current target maneuver, causing the degradation of tracking precision in the maneuvering phase.
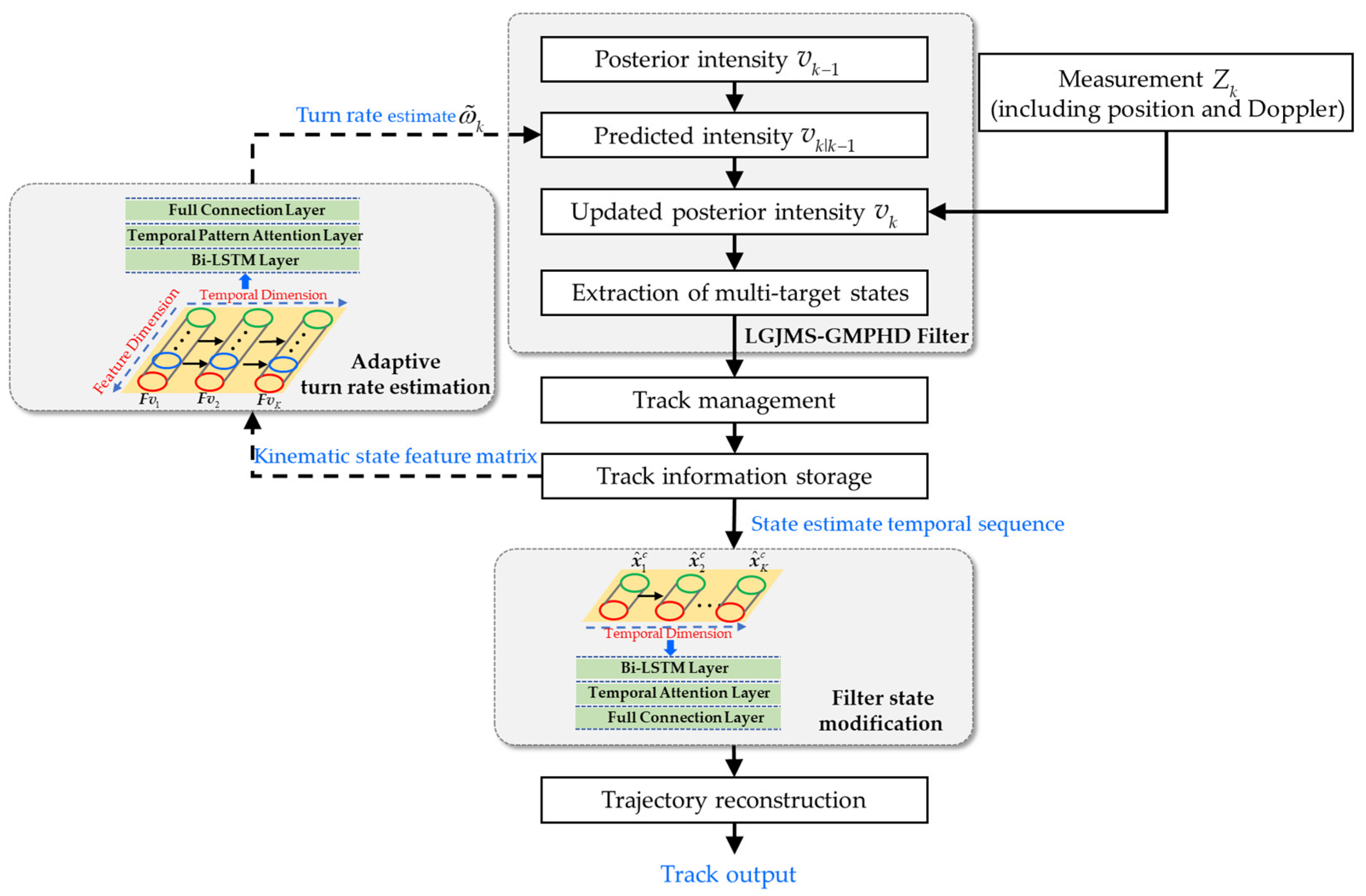
Therefore, a deep-learning-based multiple model tracking method is proposed to improve the adaptability of the LGJMS-GMPHD filter to complex maneuvering motions. The relevant flow diagram is shown in
Figure 1. Firstly, the multi-target state estimate is obtained by the LGJMS-GMPHD filter. At the same time, track management [
27] is performed to obtain the track labels of individual targets. Then, an adaptive turn rate estimation network is designed to realize the real-time estimation of the turn rate, and it is fed back to the filtering process to update the parameters of the CT model, thereby improving the matching degree of the filtering model. On this basis, a filter state modification network is designed to smooth the state estimates. Finally, a trajectory reconstruction is performed to implement the reconstruction of the track segments output by the network, and then the entire target track can be obtained.
3.1. Adaptive Turn Rate Estimation Network
In JMS, the determination of the turn rate parameter is the key point in the successful application of the CT model. However, in existing methods [
15], the turn rate is estimated simply based on the filtering state estimates of the last frame. Additionally, the information dimension is less and the relationship between different variables is not fully utilized, so it is difficult to obtain an accurate estimate of the turn rate.
Deep learning provides an effective means to overcome the limitations of the traditional estimation method [
28,
29]. A proper network module design can mine more dimensional features, and a diverse set of trajectories can be constructed for network training, which contributes to obtaining more accurate parameter estimates for target trajectories with unknown maneuvering motions. Given all this, we designed an adaptive turn rate estimation network and integrated it into the LGJMS-GMPHD filtering process, thereby improving the tracking precision for CT maneuvering targets. The structure of the network is shown in
Figure 2.
Based on the previous track information from time
to
obtained by the filtering process, the turn rate estimate at time
can be obtained by the adaptive turn rate estimation network, where
is the length of the sequence. The length of the sliding window is
. First, the feature matrix
, including multi-dimensional kinematic information, can be obtained and used as the input of the network. It is represented as follows:
The feature vector at time
is represented as follows:
where
and
are the position estimates, and
and
are the velocity estimates. Meanwhile, based on the track labels, we can also obtain the measurements associated with the track, and then obtain the corresponding Doppler
, and positions
and
.
The measurement precision of variables in the feature matrix
is different. For example, the target Doppler usually has a higher precision than the position state estimates. Additionally, for each variable, the variation in the temporal dimension reflects the maneuvering characteristics of the target. Therefore, multi-perspective feature extraction is performed to mine more abundant features and improve the accuracy of the turn rate estimates. The temporal dimension feature of each variable is extracted by means of bidirectional long short-term memory (Bi-LSTM). Then, temporal pattern attention (TPA) [
30] is introduced to determine the weights of different variables. The concrete implementation steps are as follows:
The Bi-LSTM structure is used to capture the temporal correlation information of the feature matrix
at each previous time step. The structure of Bi-LSTM is shown in
Figure 3. The output vector
corresponding to the
-th time point of the
-th Bi-LSTM is the element-wise sum of the forward and backward LSTM outputs
and
at the
-th time point, and is calculated as follows:
In the proposed adaptive turn rate estimate network, two Bi-LSTM layers are integrated, and the output hidden state matrix is represented as , where , is the number of hidden units, and is the hidden state at time step .
For different features in
, the temporal patterns across multiple time steps and the weights are extracted by the temporal pattern attention module. First, the
convolutional neural network (CNN) filters
are applied on the row vector of
to extract temporal pattern features. The convolutional operations yield
, where
represents the convolutional value of the
-th row vector and the
-th filter. Formally, this operation is expressed as
Then, an attention mechanism is carried out.
is calculated as a weighted sum of the row vectors of
to capture the relational information between different variables. Defined below is the scoring function:
to evaluate relevance:
where
is the
-th row of
, and
. The attention weight
is obtained as
The row vectors of
are weighted by
to obtain the context vector
Finally, integrating
and
to yield the turn rate estimate:
where
,
,
,
,
, and
is the turn rate estimate.
In the training stage, the root mean square error (RMSE) is used as the loss function:
where
is the true turn rate. The model is trained by minimizing (40) and is optimized through the adaptive moment estimation (Adam) algorithm [
31] over the training datasets.
3.2. Filter State Modification Network
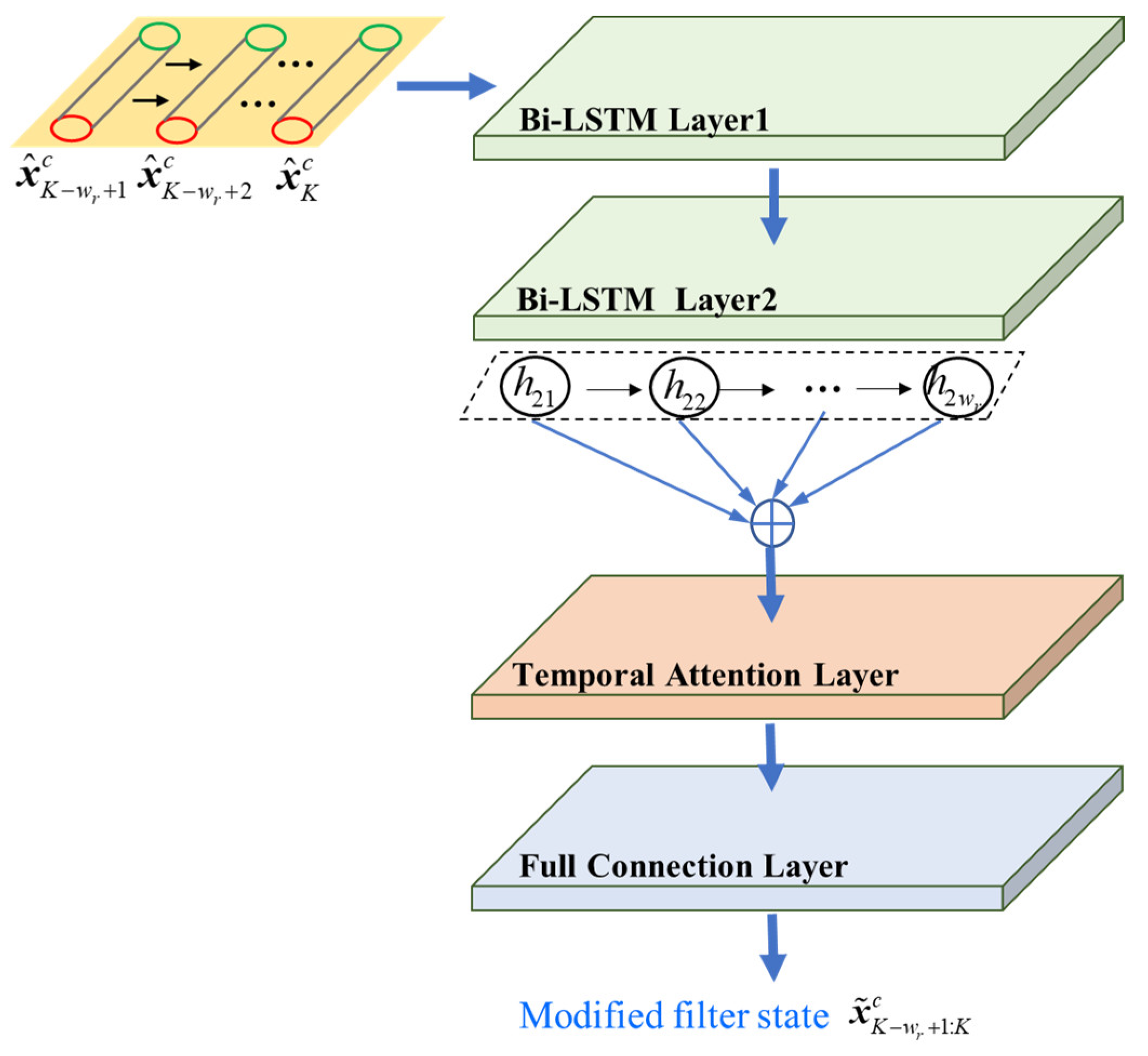
For strong maneuvering targets, the motion switches between multiple models with uncertainty. The multiple model filtering state estimates have a delay in their response to target maneuvering, resulting in the degradation of the tracking performance. Therefore, a filter state modification network is designed here to smooth the state estimates and advance the tracking precision. The diagram is shown in
Figure 4.
The state estimate of each target obtained by the LGJMS-GMPHD filter is first cropped into a state vector of uniform length
, and the length of the sliding window is
. It is used as the input of the network and is represented as follows:
where
is the state vector including position estimates.
The variation of the state estimate vector along the temporal dimension can reflect the maneuvering characteristics of the target. Therefore, in the proposed filter state modification network, Bi-LSTM is also applied to extract the temporal correlation information in the forward and reverse directions. In addition, temporal attention (TA) [
32] is integrated to weight the hidden state vectors at each time step.
The specific implementation of each module is described as follows.
Two Bi-LSTM layers are integrated to capture the temporal correlation information of state vector at each previous time step. The output hidden state matrix is represented as , where , is the number of hidden units, and is the hidden state at time step .
The hidden state matrix after the temporal attention module is represented as
,
, which is obtained by weighting
at each time step. The weight at time
is represented as
and is calculated as follows:
where
εk is a trained parameter vector and the dimension is
. Then
passes through the full connection layer to obtain the modified filter state output:
where
Wfc and
represent the weight and bias matrix of the full connection layer, respectively.
In the training stage, the loss function is:
where
is the modified filter state estimate and
is the ground-truth of the trajectory. The model is trained by minimizing (46) and is optimized through the Adam algorithm over the training datasets.
3.3. Trajectory Reconstruction
In the proposed deep-learning-based multiple model tracking method, the historical track information of the target is clipped into segments of appropriate length and used as the input of the deep learning network. Therefore, to obtain the state estimate of the entire trajectory, the modified trajectory segments
output from the filter state modification network need to be connected through a reconstruction step [
23].
When the length of a trajectory segment is and the sliding window is sl, the overlap region of the adjacent segments is from to . The value of the target states in the overlap region is the average of the two adjacent segments, and the state parameters remain constant for non-overlapping regions. The above process is repeated to complete the reconstruction of trajectory segments at each time, and the entire target trajectory can be obtained.
4. Network Parameter Design and Performance Analysis
To guarantee the flexibility of the designed deep learning network in real scenarios, a training dataset, including trajectories with different positions, speeds, turn rates, and various maneuvering modes, was constructed. In addition, process noise and measurement noise were added to simulate the target trajectories more realistically. Meanwhile, based on the estimation accuracy of the test dataset, the suitable network structure, network parameters, and input sequence length were designed. Finally, we verified the effectiveness of the two network modules in improving the tracking precision in relation to complex maneuver targets.
For the sake of convenience, in the comparisons of results presented below, LGJMS-GMPHD is abbreviated as GMPHD. After introducing adaptive turn rate estimation, it is denoted as GMPHD-ATN, and after introducing filtering state modification, it is denoted as GMPHD-ATN-FMN.
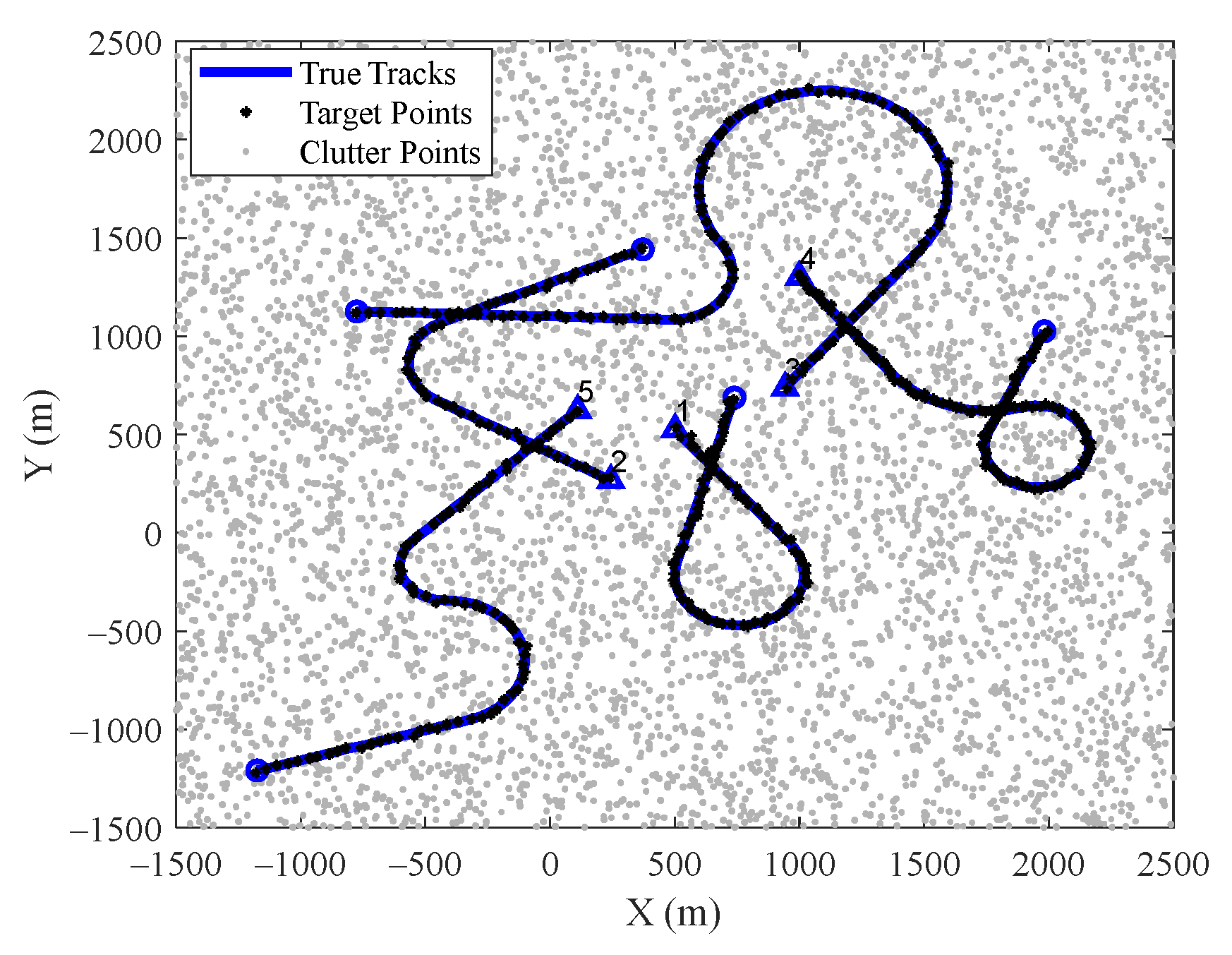
4.1. Dataset Preparation
4.1.1. Parameter Design
We designed five groups of maneuvering trajectories, as shown in
Table 1, including different turn rate parameters. A turn rate equal to
represents the CV stage and a non-
rate represents the CT stage. Meanwhile, two groups of turn rate intervals were designed:
represents a slow turn and
represents a fast turn. In addition, the durations of different motion stages are different. Specifically, CV is 20–25 s,
is 10–50 s, and
is 8–20 s. For each group of trajectories in the training datasets, the kinematic parameters were uniformly extracted according to
Table 1.
For the LGJMS-GMPHD filter process,
is the CV model and
is the CT model. The switching between the motion models is given by the Markov transition probability matrix as
For simplicity, we assume that the probability of target survival and detection is constant. and are assumed for models . Additionally, the interval between the samples is . The standard deviation of process noise and the standard deviation of measurement noise .
4.1.2. Dataset Construction
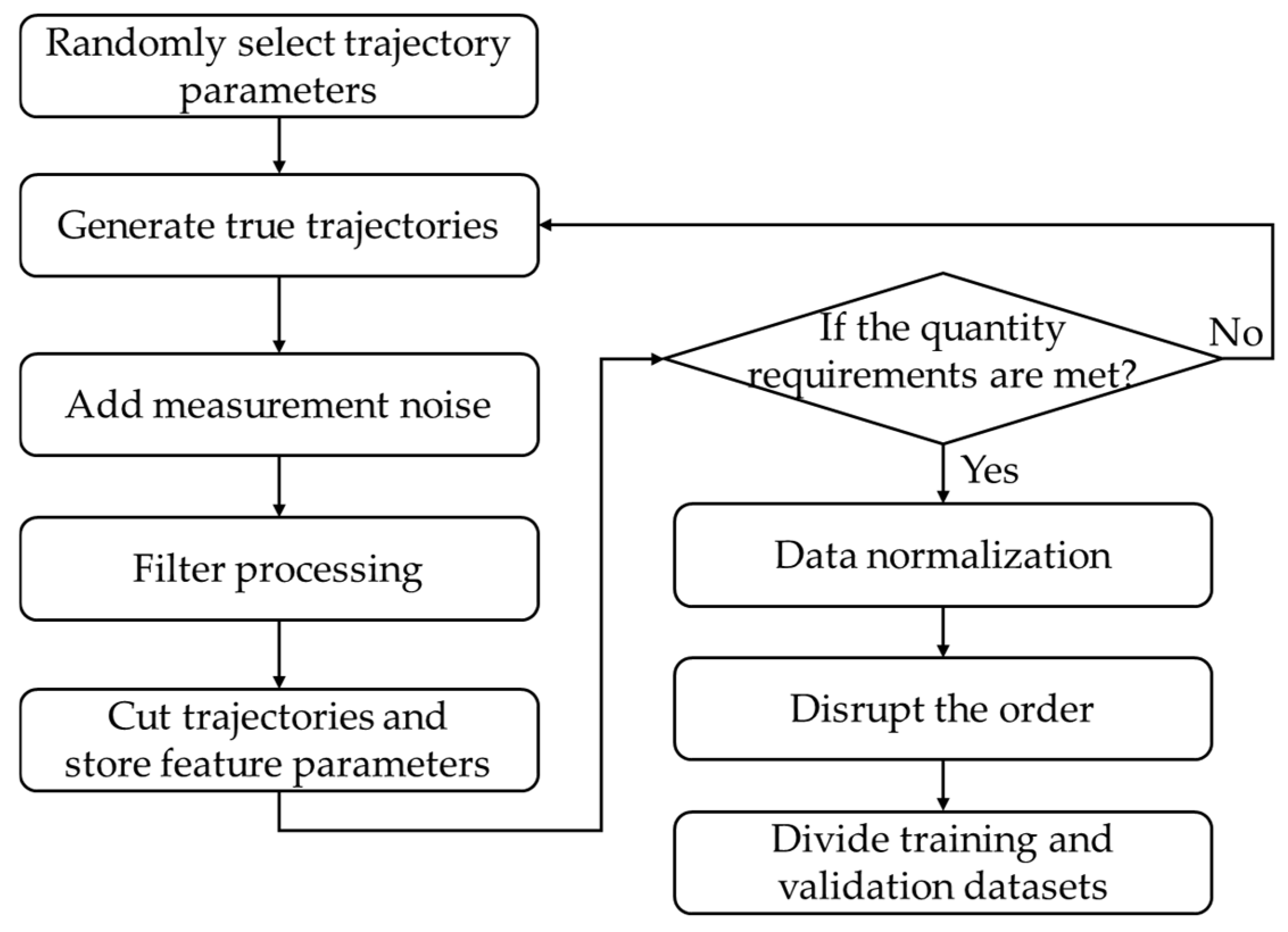
The construction of the datasets for the two networks is summarized in the flowchart shown in
Figure 5. The details are described as follows:
- (a)
The kinematic parameters from
Table 1 are randomly selected to generate real target trajectories.
- (b)
Measurement noise is added and target measurements are obtained.
- (c)
The LGJMS-GMPHD filter process is performed to obtain the state estimate, where the turn rate of CT model is calculated via a physical definition method to obtain the datasets of the adaptive turn rate estimate network, and the true value is used to obtain the datasets of the filter state modification network.
- (d)
The trajectories are clipped to segments of uniform length. For the adaptive turn rate estimation network, the feature matrix defined in (31) is stored. For the filter state modification network, the position state estimate defined in (41) is stored.
- (e)
Data normalization is performed based on min-max scaling.
- (f)
The order is disrupted and the training and validation datasets are divided.
In this paper, the number of trajectory segments in the training and validation datasets for the two networks was 300,000 and 60,000, respectively. In the training procedure, the learning rate was set to 10−4, the batch size was 100 samples, and the training epoch was 300.
Based on the trajectory parameters shown in
Table 1, 100 maneuvering trajectories were constructed for each group to verify the effectiveness of each module in the proposed method in improving tracking performance.
4.2. Network Module Parameter Design
4.2.1. Adaptive Turn Rate Estimation Network
The network structures, parameters, and input sequence length were validated based on the five groups’ trajectories with different maneuvering forms in the test datasets. The evaluation criterion is the RMSE of turn rate estimate and defined as follows:
where
is the output of the adaptive turn rate estimation network, and
is the true value.
is the number of simulations.
The number of Bi-LSTM layers and the module effectiveness were verified based on the RMSE of the turn rate estimate, as shown in
Table 2. Here, we set the number of hidden units of the Bi-LSTM to 64, the sequence length to 10, and the sliding window to 1. Compared to one Bi-LSTM layer, two Bi-LSTM layers can produce a higher accuracy, but the improvement is not significant as the number of layers continues to increase. Therefore, we set the number of Bi-LSTM layers as two. After the TPA module was introduced, it can be seen from the last column that the estimation error was greatly reduced. Especially for the second group, the RMSE was reduced by 0.71°, which verifies the effectiveness of the TPA module.
After the network structure was determined, we analyzed the influence of the number of hidden units of the Bi-LSTM layers on the performance. The RMSE of the turn rate estimates with different numbers of hidden units for the Bi-LSTM layers is shown in
Table 3. Here, we set the sequence length to 10 and the sliding window to one. As the number of hidden units increased, the RMSE decreased, but the reduction was not significant for 64, 96, and 128. Therefore, considering operational efficiency and estimation precision comprehensively, we set the number of hidden units to 64.
Long sequences generally contain more abundant feature information, but this also degrades the real-time performance and increases the difficulty of network training. Therefore, we analyzed the influence of input sequence length on the estimate precision of the network. Here, we set the number of hidden units to 64 and the sliding window to one. The RMSE comparisons for different sequence length are shown in
Table 4. When the sequence length increased from 6 to 12, the RMSE of the turn rate estimate decreased gradually. However, when the length was 14, the RMSE increased slightly compared with 12. Therefore, we set the input sequence length of the turn rate estimation network as 12.
4.2.2. Filter State Modification Network
The network structure, parameters, and input sequence length were validated based on the testing datasets. The evaluation criterion was the RMSE and was defined as follows:
where
and
represent the output of the network, and
and
are the real values;
is the number of simulations.
Comparisons of the RMSE of different network structures are shown in
Table 5. Here, we set the number of hidden units to 64, the length of input sequence to 15, and the sliding window to five. First, when the number of Bi-LSTM layers increased from one to two, the output precision of the network was obviously improved. However, when the number of layers increased to three and four, the RMSE of groups 1, 3, and 4 increased instead; that is, the network was overfitted. Therefore, we set the number of Bi-LSTM layers to two. After the temporal attention module was introduced, as shown in the last column in
Table 5, the RSME was further reduced. Especially for groups 1, 3, and 4, the reduction was remarkable, which verifies the effectiveness of the TA module.
The RMSE of test datasets for different numbers of hidden units is shown in
Table 6. Here, we set the length of the input sequence to 15 and the sliding window to five. First, with the increase in the number of hidden units, the network performance was improved, but the increase was not obvious. The RMSE for 64 hidden units was reduced by about 0.2 m compared with that for 32 hidden units. Compared with 64, the performance improvement for 96 and 128 hidden units was about 0.1 m. Meanwhile, for groups 1–4, overfitting also occurred when the parameter was 128. Hence, we set the number of hidden units to 64.
The influence of the input sequence length on the precision of the filter state modification network was analyzed. Comparisons of the RMSE of the testing datasets are shown in
Table 7. Here, we set the number of hidden units to 64 and the sliding window to five. Horizontally, for each group of test trajectories, the RMSE decreased with the increase in the sequence length. However, when the sequence length was 15, the error was at its minimum, and when the sequence length increased to 16, the performance slightly decreased. Therefore, we set the input sequence length to 15.
4.3. Network Module Performance Validation
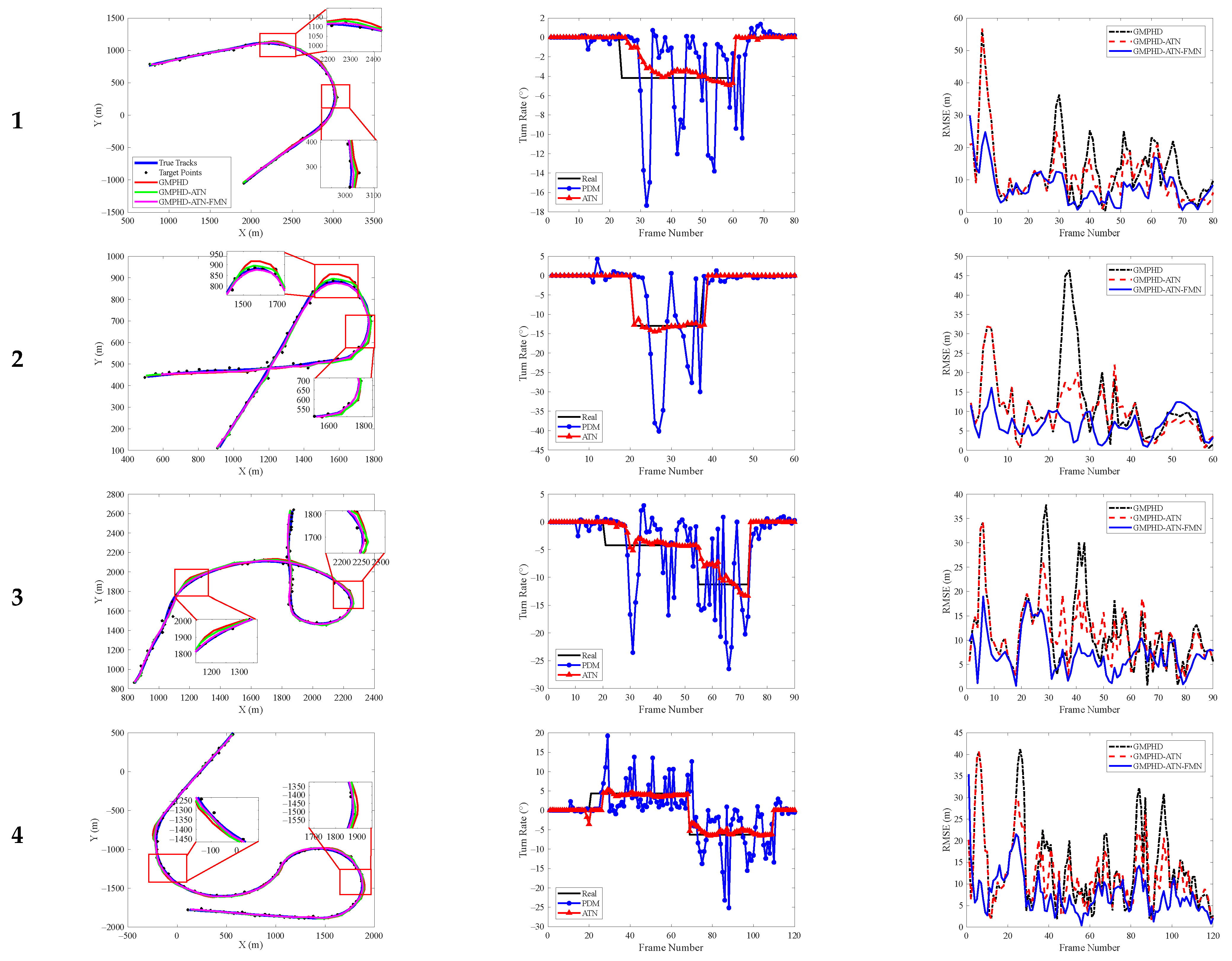
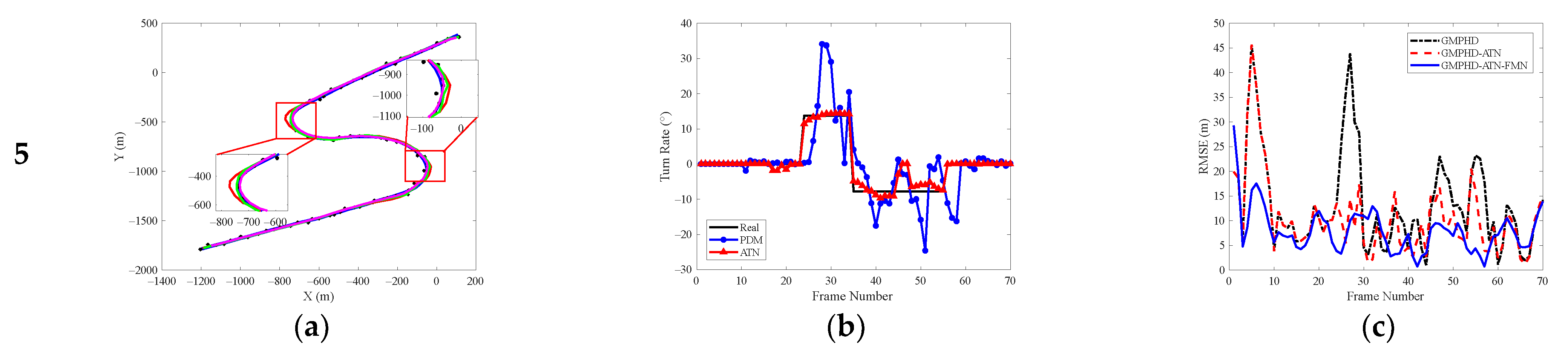
In this section, five groups of target trajectories with different maneuvering modes in the testing datasets were extracted to verify the validity of the two network modules in the proposed deep-learning-based multiple model tracking method. To show the result comparisons more intuitively, we extracted a target trajectory from each group of maneuvering modes, and the comparison of single simulation results is shown in
Figure 6. The first column represents the comparison of the tracking results, the second column represents the comparison of the turn rate estimation results, and the third column represents the comparison of the tracking errors.
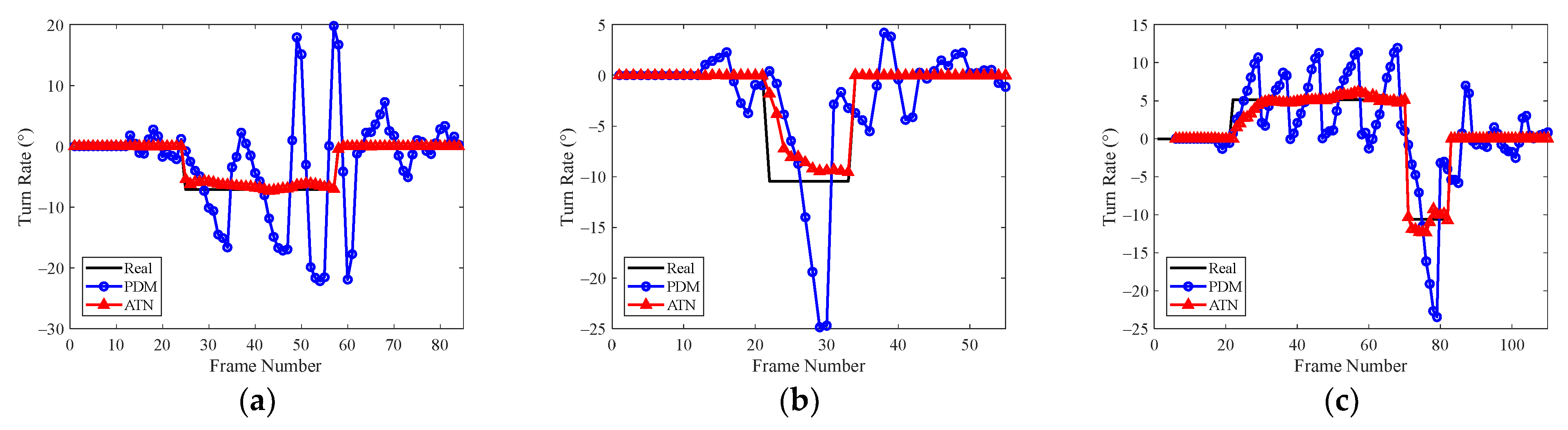
For the traditional physical definition method, only the filtering state estimates in the last frame were used. In the maneuvering phase, the estimation error of the turn rate was large and fluctuated greatly, which led to a decrease in the tracking precision. Especially for the strong maneuvering trajectory with a large turn rate, for example, the second target performed the turning motion with the parameter
between frames 20 and 38, and the tracking RMSE in the corresponding period increased rapidly. For the proposed adaptive turn rate estimation network, multi-frame kinematic features can be utilized and more complex logical relationships between different variables can be extracted, which contributes to obtaining more accurate estimates of turn rates, as shown by the red curve in
Figure 6b. Although the estimation error in the maneuvering phase was slightly larger than that in the non-maneuvering phase, the performance gradually became stable after several frames. The corresponding tracking results are indicated by the red curve in
Figure 6c. Compared with the GMPHD filter, our method can effectively reduce the tracking error in the turn maneuvering phase.
As can be seen from the tracking results in
Figure 6a and the tracking error curve in
Figure 6c, an accurate estimate of the turn rate can improve the tracking performance to a certain extent. However, there is uncertainty in the switching of target motion models, resulting in large tracking errors. The filter state modification network can smooth the target state estimates that are produced by the GMPHD filter. As shown in
Figure 6a, the tracking result of the purple curve is smoother than those of the red and green curves. Additionally, it can also be seen in
Figure 6c that the RMSE corresponding to the blue curve greatly decreased during the turning maneuver phase.
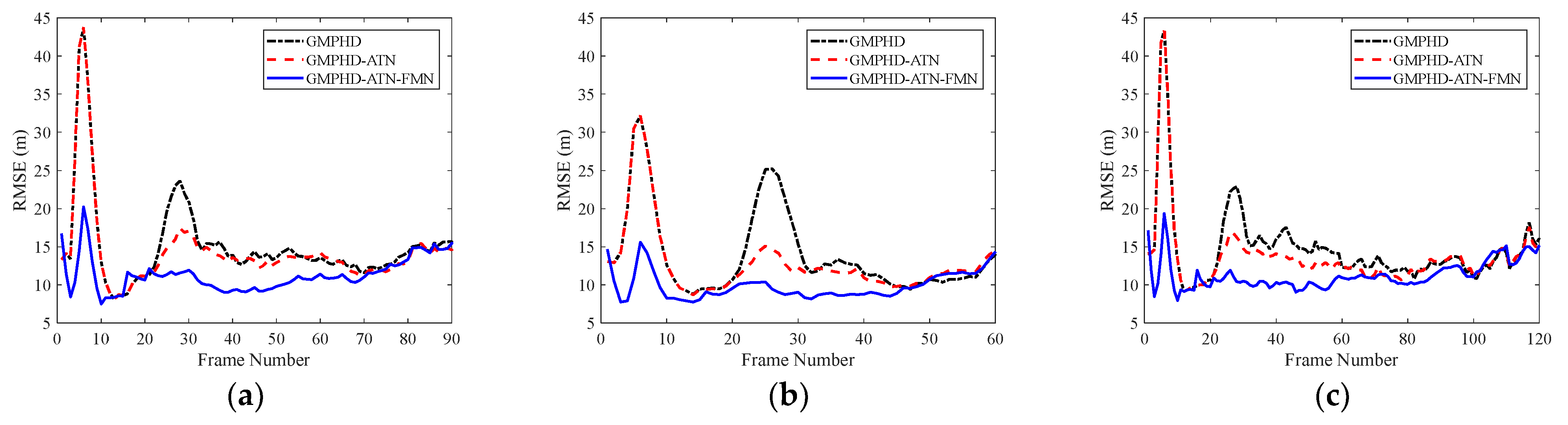
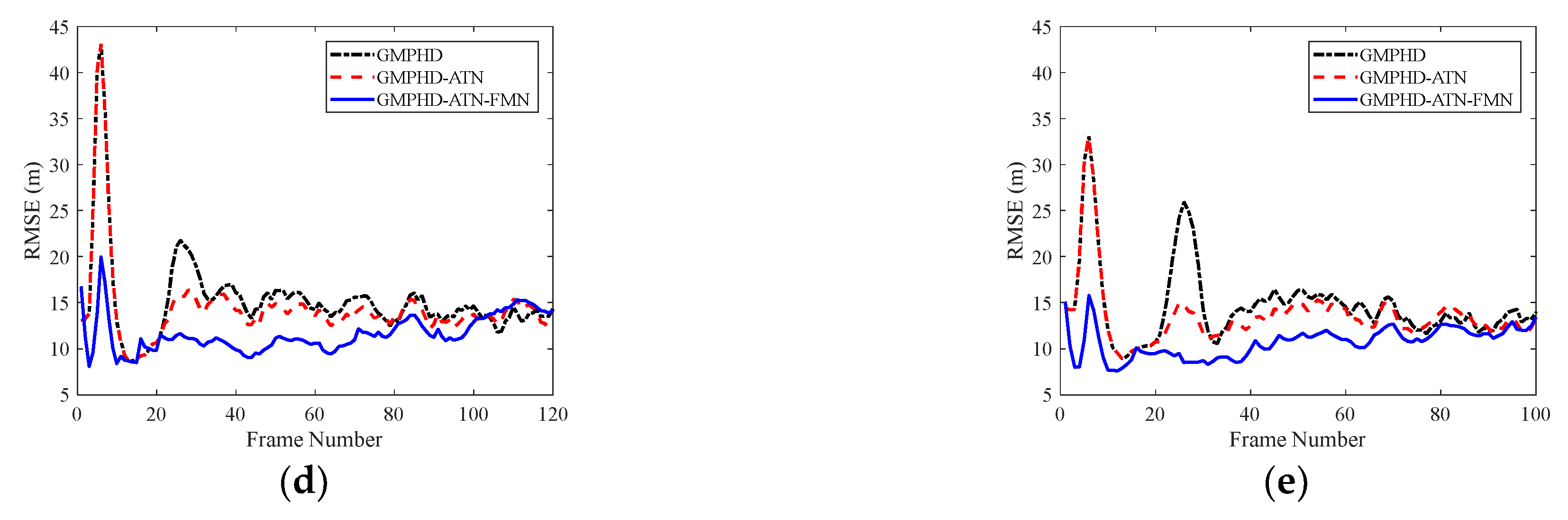
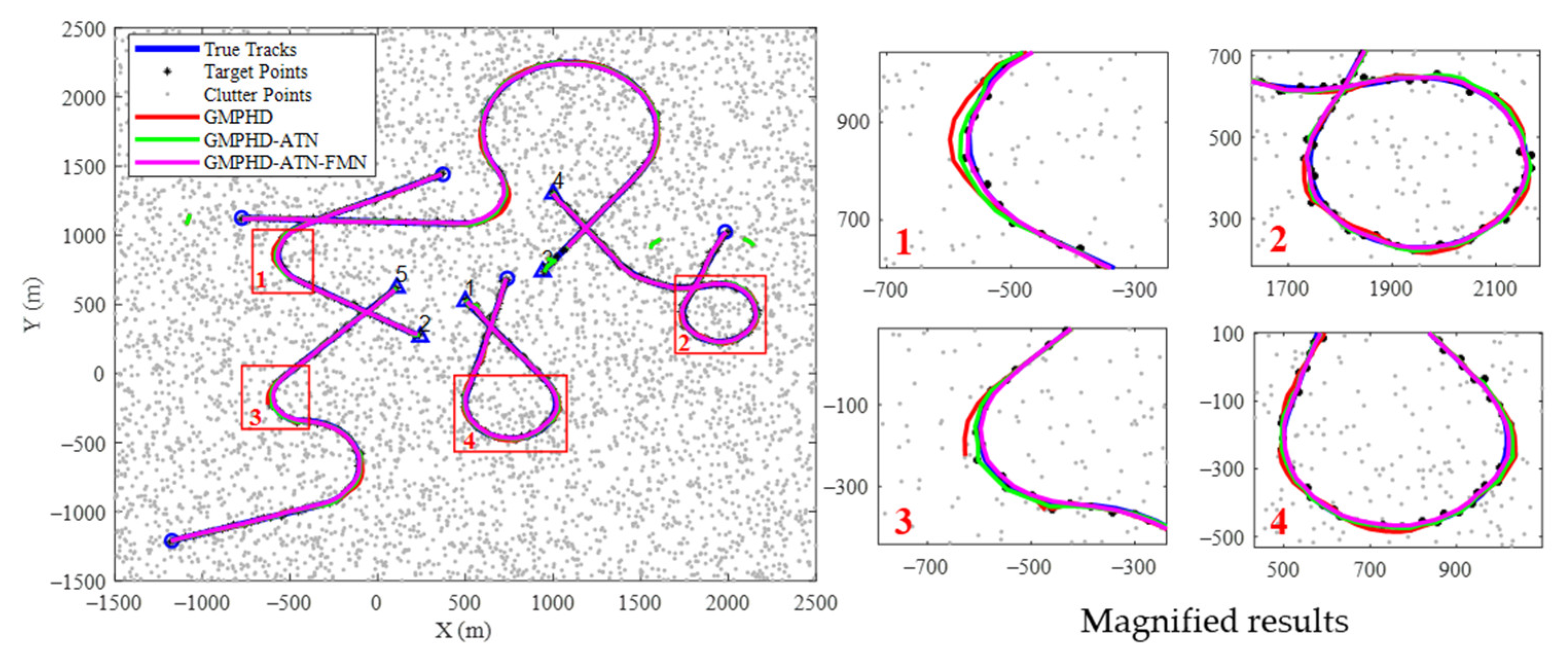
Furthermore, from the tracking result comparisons of all trajectories in the testing datasets shown in
Figure 7, it can be concluded that the proposed method has strong adaptability to multiple maneuvering modes and can effectively enhance the tracking precision of complex maneuvering targets.
6. Discussion
The RFS-based filter incorporating the jump Markov system approach is an effective method for multiple maneuvering target tracking in cluttered environments. However, UAV targets have strong maneuverability and their trajectory forms are diverse, presenting unknown motion model parameters and uncertain model switching. The preset parameters of filter models are difficult to match to the time-varying target motion, leading to a serious decline in tracking performance. Therefore, within the framework of the LGJMS-GMPHD filter, we proposed a deep-learning-based multiple model tracking method to improve maneuvering adaptability.
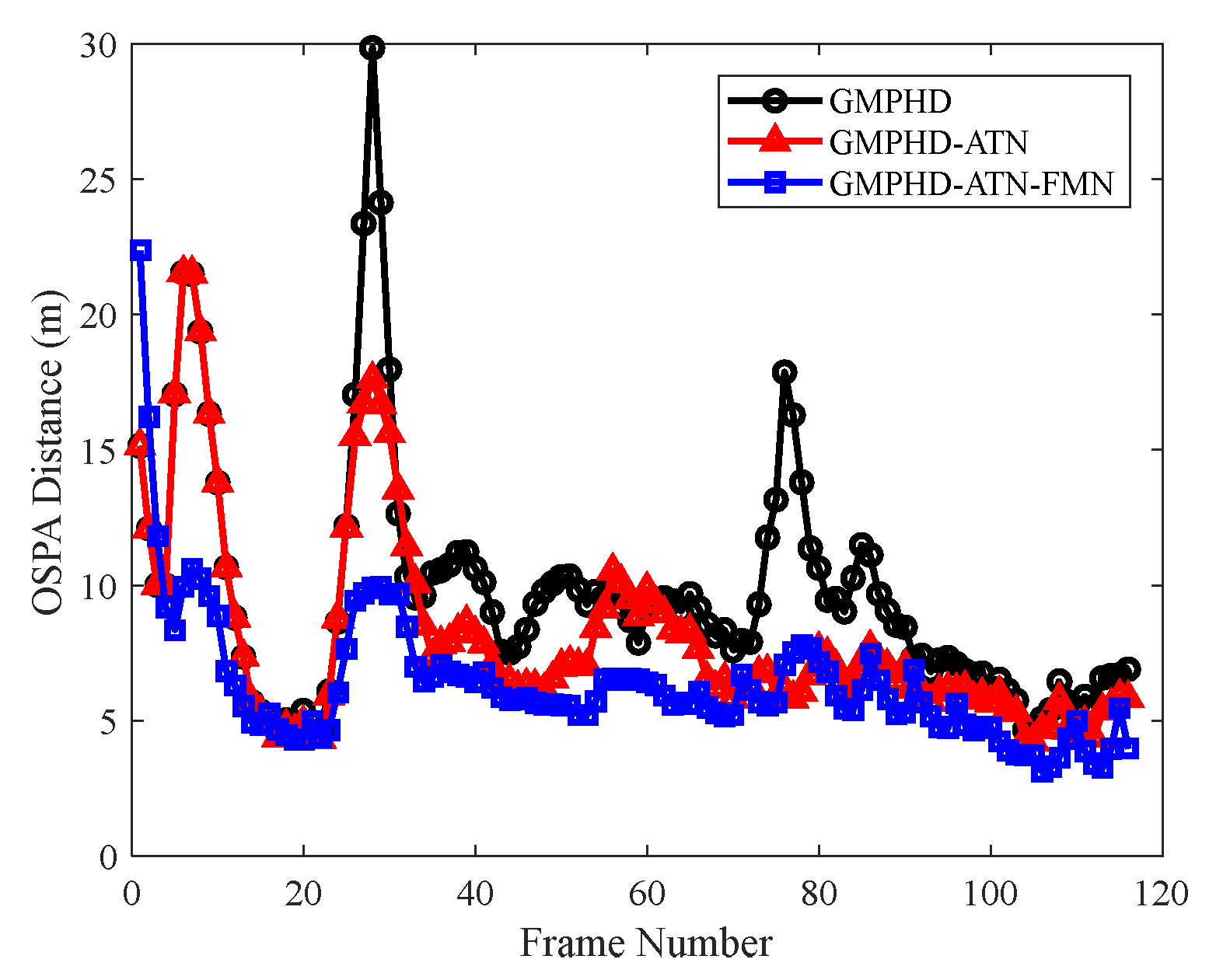
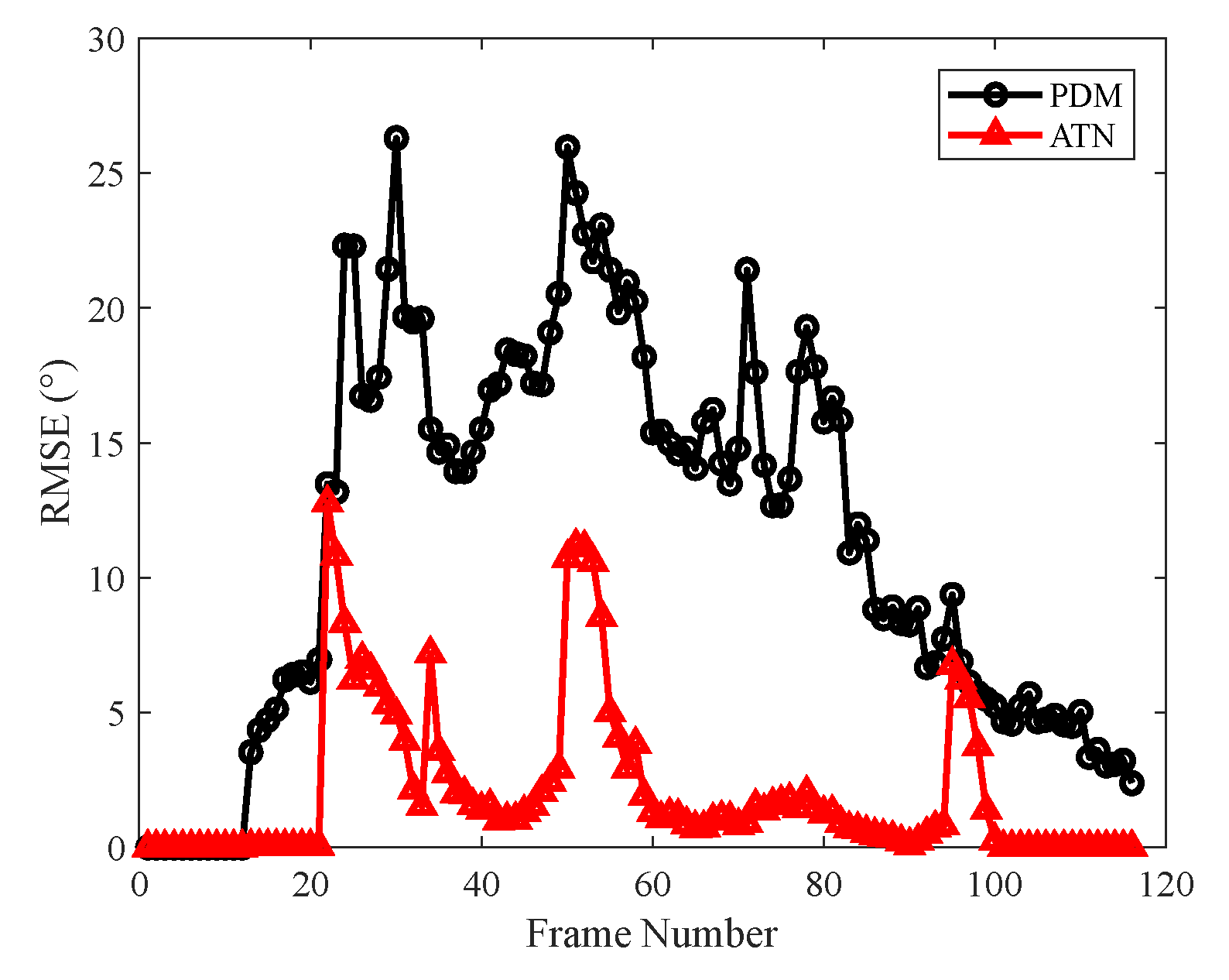
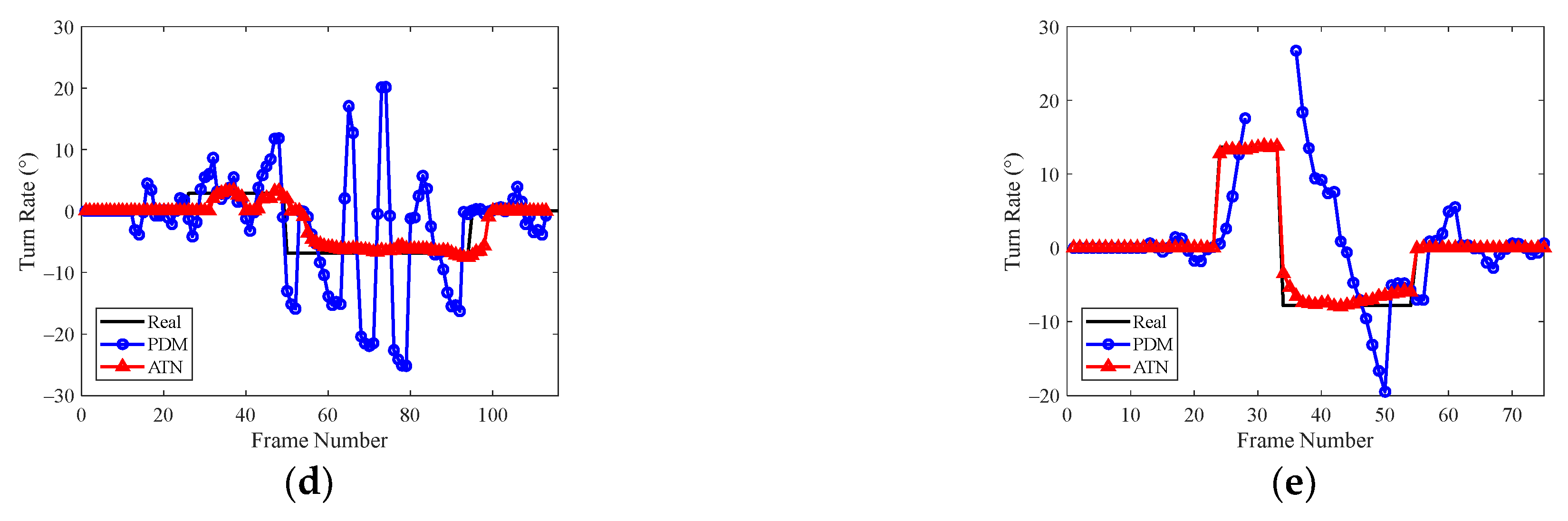
The simulation results indicated that the traditional LGJMS-GMPHD filter has a low tracking precision and the track is prone to breaking in scenarios involving complex maneuvering targets. As shown in
Figure 12, for the PDM, the estimation error of the turn rate was large and fluctuated greatly in the maneuvering phase as only the filtering state estimate in the last frame was considered, whereas the proposed adaptive turn rate estimation network made use of multiple dimensions of kinematic features and extracted the relationship between different features. As shown in the red curve in
Figure 12, a more accurate estimation of turn rate can be obtained, which helps to improve the matching degree of the CT model in the filter. Therefore, as shown in
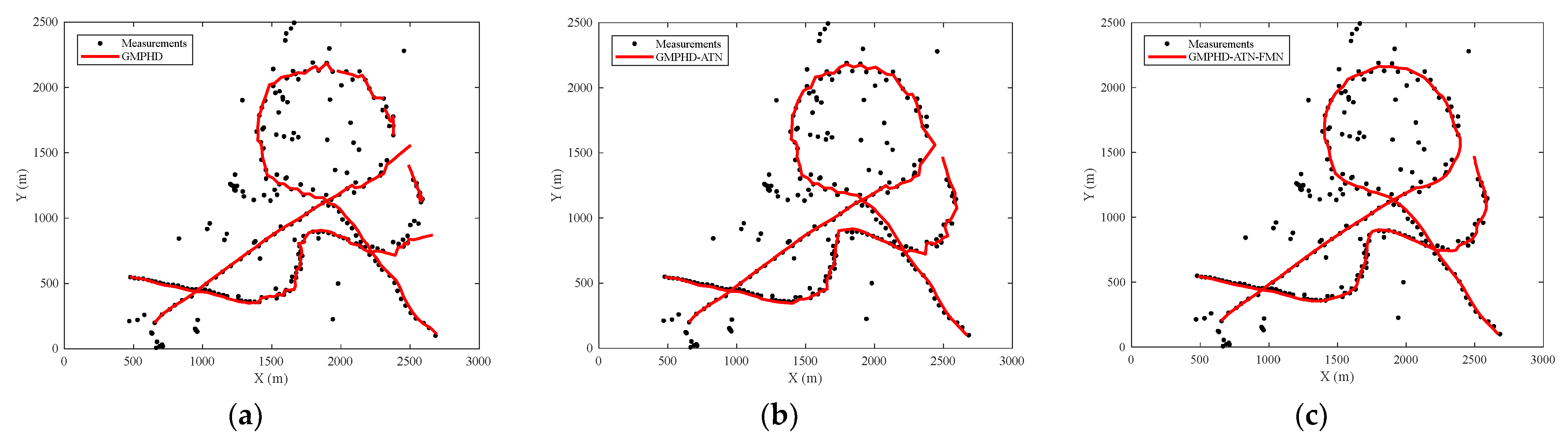
Figure 9, compared with the GMPHD filter, the OSPA distance of GMPHD-ATN was greatly reduced, and the tracking results shown in
Figure 11 indicate that track continuity was optimized.
Another reason for poor tracking performance is the uncertainty of motion model switching. Smoothing results in better estimates for target states by means of a time delay. However, as described in [
21], longer lags do not yield better estimates of the current state because the temporal correlations cannot be extracted. Moreover, backward smoothing is still model-based, which cannot address the substantive problem of tracking performance degradations due to model switching. Deep neural networks have a strong capability of fitting any mapping, providing an effective way to handle target motion uncertainty. However, the LSTM-based deep recurrent neural network in [
24] only considered CV and CA motions, and is not suitable for the scenario of multiple maneuvering targets in the CT model. However, in the proposed filter state modification network, the state estimates output by the LGJMS-GMPHD filter were used as the input, and the temporal correlation information of the state vector was captured, with the ability to handle complex maneuvering motions. Hence, as shown in
Figure 9, the tracking precision was improved in the entire tracking stage, especially in the strong maneuvering phase. The tracking results, shown in
Figure 11, demonstrated that the track was smoothed and the track quality was improved. Moreover, based on the tracking error comparisons of test datasets, shown in
Figure 7, it can be concluded that the proposed method has strong adaptability to different maneuvering forms. The experimental data processing results indicate that the parameters of the training dataset designed in this paper can adapt to practical scenarios, and the method can effectively enhance the track quality of real UAV targets.
However, in this paper, we assumed that the clutter rate was known and remained constant. In future research, more complex detection environments, such as a time-varying clutter rate and detection uncertainty, will be considered. Furthermore, we will also consider extending the proposed method to group target tracking.
7. Conclusions
In this paper, we have proposed a deep-learning-based multiple model tracking method. The adaptive turn rate estimation network employs multi-frame and multi-dimensional kinematic information to improve the accuracy of the turn rate estimates for a maneuvering target with CT motion, thereby enhancing the consistency with the filtering model. Additionally, the filter state modification network uses the temporal features of the multi-frame state estimate to achieve the smoothing of target state estimates, thereby circumventing the large tracking errors caused by uncertain motion model switching. To ensure the applicability of the algorithm, in the training datasets, we designed five switching modes of the movement model. Therefore, the proposed method is suitable for practical maneuvering movements: (i) from CV to CT, (ii) from CT with to CT with , and (iii) from CT to CV. In the end, based on the simulation results of multiple maneuvering target tracking in cluttered environments, it can be concluded that the proposed method can obtain accurate turn rate estimates and output high-quality tracks, and the performance improvement is especially significant in the maneuvering phase. Moreover, for the real UAV observation scenario with measurement noise and detection uncertainties, the proposed method can output more stable and smooth trajectories, which verifies its applicability in real scenarios.




 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}