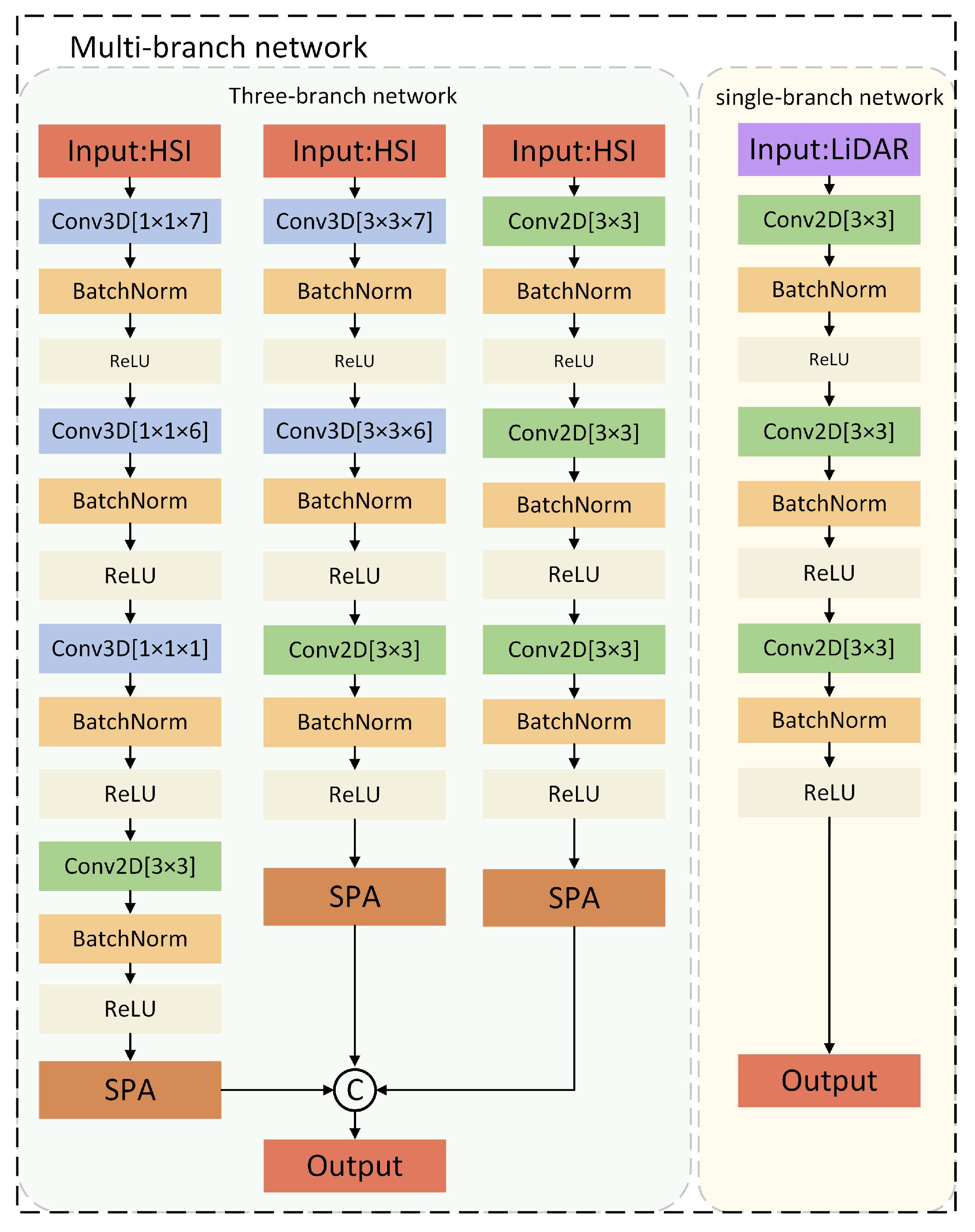
3.2. Experimental Setup
Two different data sets were used to evaluate the effectiveness of the model through the overall accuracy (OA), average accuracy (AA), and Kappa coefficient, and compared with several different models. Among them, the overall accuracy (OA) defines the ratio between all pixels that are correctly classified and the total number of pixels in the test set. Averaged Accuracy (AA) is the average probability that the accuracy of each class of element is added and divided by the number of categories. Kappa Coefficient is also used to evaluate the classification accuracy to check the consistency between the remote sensing classification result map and the real landmark map.
The experimental environment is under the framework of Pytorch, using cross entropy loss function and Adam optimizer, and the learning rate is set to 0.001. Batch size and the numbers of training epochs are set to 64 and 200.
To verify the proposed , the classification results of different patch sizes are compared, other parameters are fixed, and different patches are selected from the candidate set {5 × 5, 7 × 7, 9 × 9, 11 × 11} to evaluate the effect of patches.
Figure 6 shows the change of OA value under different patch sizes. Experimental results show that the features extracted by different patch sizes have different classification effects. In the 2012 Houston dataset, when the patch increases from 5 × 5 to 9 × 9, the OA keeps increasing. However, when the patch is 11× 11, the OA decreases greatly and reaches the peak when the patch is 9 × 9. In the Trento dataset, OA reaches its peak when the patch is 5 × 5. Different data sets have different features and information. Therefore, it is necessary to select the appropriate patch according to different feature information to get better results.
3.3. Experimental Results
(1) Effectiveness of module: The comparative experiment of single-source image classification after adding module to LiDAR image and HSI is listed. HSI means feature extraction and classification of HSI through the multiscale network, LiDAR means feature extraction and classification of LiDAR images through the single-branch network. LiDAR- means that LiDAR image adds the position-channel collaborative attention module, and HSI- means that HSI adds the position-channel collaborative attention module. In order to ensure the authenticity and effectiveness of the comparative experiment, the standard data set is adopted uniformly, and all the training and test samples are the same.
Table 3 lists the overall accuracy (OA), average accuracy (AA), and Kappa coefficient of the five models on the 2012 Houston data set and Trento data set, and the best results are shown in bold. Obviously, the classification accuracy of single-source images with
module is higher than that without
module. In the Houston dataset, the OA of the LiDAR-
model is 60.87%, that of the LiDAR model is 58.25%, and the accuracy is improved by 2.62% after adding
module. The OA of the HSI-
model is 97.31% and that of the HSI model is 96.72% on the Trento dataset, and the accuracy is improved by 0.59% after adding
module.
Figure 7 shows the classification results of the five models listed in
Table 3 on the Houston data set. It can be seen that from
Figure 7a–e, the category classification becomes clearer and the results become more obvious.
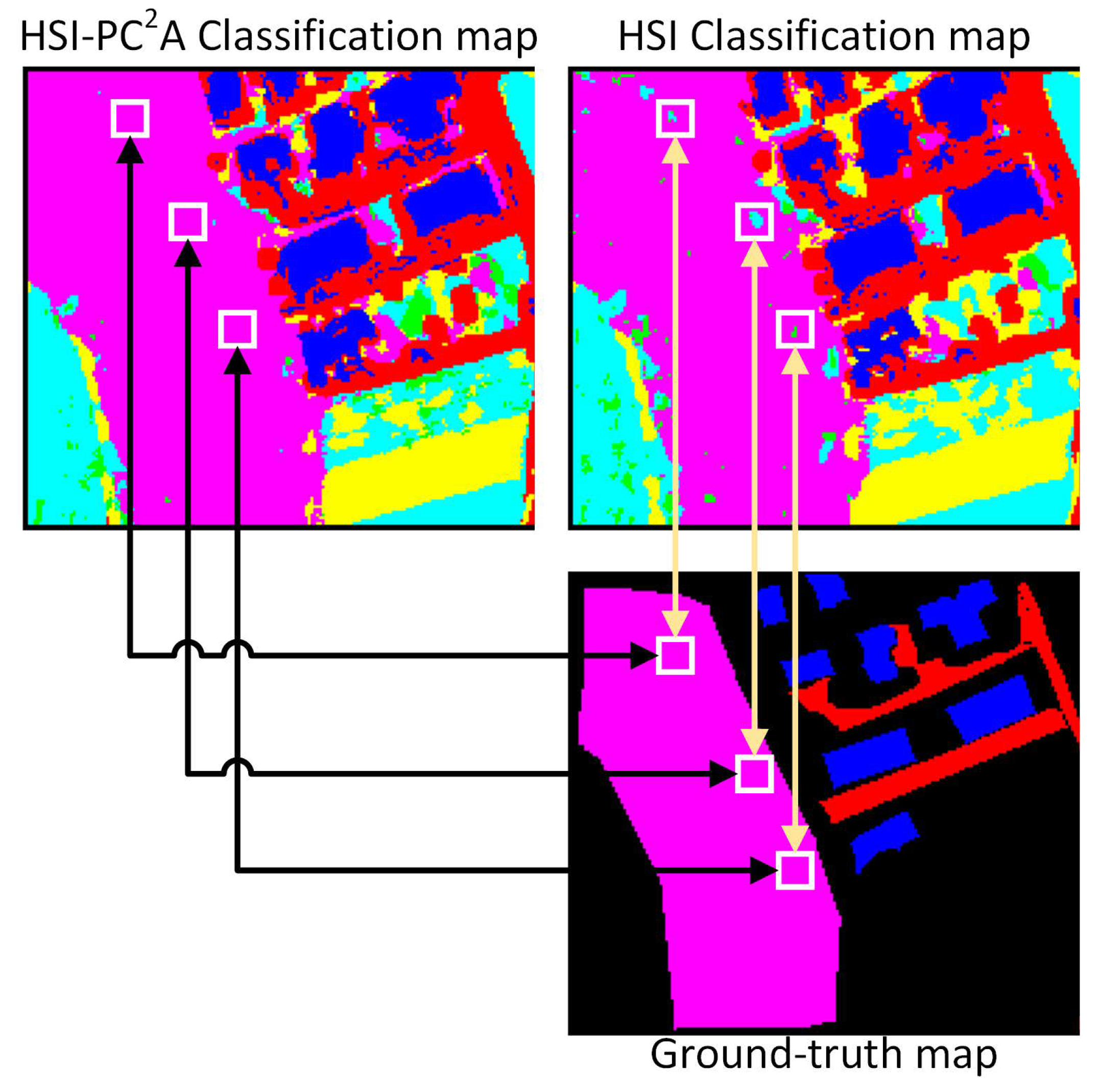
Figure 8 shows the partial sorting results on the Trento data set, which is primarily used to compare the classification details of HSI and HSI-
models. In this partial map, the class of Wood occupies a large area, and when using the HSI model for classification, some Wood will be mistakenly classified as vineyard and apple trees. With the addition of
module, the model pays more attention to the detailed information of categories and can make better identification. It can be seen from
Figure 8 that the classification effect of the HSI-
model on the wood category is obviously better than that of the HSI model.
The result of single-source classification of LiDAR images is the worst among the methods listed in
Table 3. However, LiDAR data can provide potential details for HSI, including the height and shape information of ground objects, which is a necessary supplement to HSI defects. The OA of LiDAR image and HSI after feature fusion classification is also much higher than that of HSI single source classification, which verifies the indispensability of LiDAR data and fully demonstrates the effectiveness of feature fusion.
(2) Effectiveness of the proposed
: To validate the effectiveness of the proposed method, the proposed model
is compared with advanced deep learning models such as Two-Branch CNN [
40], EndNet [
41], MDL-Middle [
42], FusAtNet [
49], IP-CNN [
43], CRNN [
4],
[
50] and HRWN [
37]. To make a fair comparison, all training and testing samples are the same. In which, two-branch CNN realizes feature fusion by combining the spatial and spectral features extracted from HSI with LiDAR image features extracted from cascade networks. EndNet is a deep encoder–decoder network architecture, which fuses multi-modal information by strengthening fusion features. MDL-Middle is a baseline CNN model through intermediate fusion. FusAtNet is a method that generates an attention map through “self-attention” mechanism to highlight its own spectral features and highlights spatial features through “cross-attention” mechanism to realize classification. IP-CNN designed a bidirectional automatic encoder to reconstruct HSI and LiDAR data, and the reconstruction process does not depend on the labeling information. The convolutional recurrent neural network (CRNN) was proposed to learn more discriminant features in HSI data classification.
enhances the spectral and spatial representation of images through the spatial–spectral enhancement module of cross-modal information interaction to achieve the purpose of feature fusion. HRWN jointly optimizes the dual-tunnel CNN and pixel-level affinity through a random walk layer, which strengthens the spatial consistency in the deeper layer of the network.
Table 4 and
Table 5, respectively, list the OA, AA, and Kappa coefficient of the 2012 Houston data set and Trento data set, the precision of each class is also listed, among which the best results are shown in bold. Obviously, the experimental results of
are better than those of other methods. Taking the 2012 Houston data set as an example, the OA of the proposed
method is 95.02%, AA is 94.97% and Kappa is 94.59, which is the best among the listed methods. Specifically, using the Houston dataset for evaluation, it shows approximately 7.04%, 6.50%, 5.47%, 5.04%, 2.96%, 6.47%, 0.83%, and 1.41% improvements over Two-branch, EndNet, MDL-Middle, FusAtNet, IP-CNN, CRNN,
, and HRWN, respectively. For the Trento data set, the categorization effect of the
model for the two categories of Ground and Roads are significantly higher than other models. Although the classification accuracy of different models on this data set has reached a relatively high level, the taxonomy effect for the two categories Ground and Roads is less than ideal. As can be seen from
Table 2, the number of samples in the categories Ground and Roads is relatively small. Due to the imbalance of sample categories, the classification results of the first category are better than that of the last category. However, the presented
model concentrates on the detailed information of categories through the attention mechanism and learns the difference of various categories accurately for precise classification, which indicates the superiority of this model.
In terms of single category classification effect, the model proposed in this paper has the best classification results in the categories of healthy grass, tree, residential, commercial, road, and highway. Especially in the case of poor classification effect of healthy grass, commercial and highway, our model can show a better classification effect, which is greatly improved compared with other models.
In order to qualitatively evaluate the classification performance,
Figure 9 and
Figure 10 show the classification results of different methods, and the visual results are consistent with the data results in
Table 4 and
Table 5. The classification result of EndNet is shown in
Figure 9b has more detailed information, but the OA, AA, and Kappa are far lower than that of the proposed method
. Because the input of EndNet is pixel by pixel, not pixel block, which makes the classified figures show more details. However, the correlation of adjacent pixels is not fully utilized, and only the current pixel category is considered, so the detailed information displayed by the classification results is probably wrong, which limits the classification accuracy of this model. It further demonstrates the significance of considering neighborhood information.
(3) Training and testing time cost analysis:
Table 6 and
Table 7 show the training and testing time cost of different models. All experiments are implemented under the same software configuration. The training process takes a long time, while the testing process takes a short time.
Table 6 presents the training and testing times for the unfused model and the fused model. Obviously, the time cost of LiDAR-
is greater than that of LiDAR, and that of HSI-
is greater than that of HSI, which shows that the attention mechanism will increase the computational cost of the network, but at the same time it will improve the performance of the network. In
Table 7, the training and testing time of EndNet on both datasets is short, because the neighborhood information is not considered in EndNet during training and testing. Using a single pixel as the input can save training and testing time, but ignoring the neighborhood information leads to a drop in accuracy. The training and testing times of FusAtNet,
, and
networks are relatively high. The common point of these networks is that the attention module is added, which increases the computational cost of the model, but at the same time improves the classification performance. As can be seen from
Table 7, the training and testing time of the FusAtNet model is much longer than that of other models, because the model uses multiple cross-attentions, and the network is deeper than others, which extremely increases the calculation cost.
3.4. Ablation Studies
As the proposed model includes two modules to improve classification performance, namely, the module and the decision fusion module, in order to verify the effectiveness of these three modules, respectively, a series of ablation experiments were conducted on the 2012 Houston data set and Trento data set. Specifically, while keeping other parts of the model unchanged, the experiment was conducted in two cases: With/Without Module, and With/Without Decision Fusion, and the experimental data were compared.
(1) With/Without
Module:
module consists of SPA, FCA, and FPA. By weighting the position and channel features to different degrees, the extracted features contain more effective information, which is beneficial to classification, thus improving the expression ability of the model. In order to analyze the effectiveness of the
module,
Table 8 shows the results with and without the
module. It is obvious that the OA, AA, and Kappa of the model with
are higher than those without
.
Part of the categories of OA are shown in
Figure 11. In the 2012 Houston data set, the classification results of most categories by this model are higher than those of other models, especially those with plenty of samples, which shows that the model has a strong learning ability. Under the condition of enough samples, it can learn the detailed information of different categories effectively, thus making accurate classification. As can be seen from
Figure 11, the accuracy of most categories is improved after adding the module
, which proves the superiority of this module.
(2) With/Without Decision Fusion: The decision fusion (DS) module fuses the output of the HSI feature extraction network, LiDAR image feature extraction network, and the result after feature fusion. The three classification results obtained by the classification module are fused. Through the automatic learning of the network, the weight coefficient is constantly updated to obtain the optimal weight addition result. To analyze the effectiveness of the decision fusion module,
Table 9 shows the results with and without the decision fusion module (DS). It is obvious that the OA, AA, and Kappa of the model with DS are higher than those without DS.
Figure 12 shows OA for part classes. In the 2012 Houston data set, there are nine classes of OA that are higher than those without DS. In the Trento data set, the classification results of each class are higher than those without DS. Experiments can effectively prove that the decision fusion module can obviously improve the performance of the model.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}