1. Introduction
Unoccupied aircraft systems (UASs) with fine spatial resolution (centimeter-scale) sensors have opened the door to new capabilities in the field of remote sensing [
1]. Furthermore, known as unoccupied aerial vehicles (UAVs) or drones, these systems typically capture images with spatial resolutions in the centimeter range, small enough to measure fine-scale land surface texture and spectral reflectance. Highly detailed analyses, such as species-level vegetation classification, are possible at these resolutions [
1]. For a given sensor, lower flight altitudes produce images with a higher spatial resolution, while reducing the spatial extent captured by a single image. This tradeoff is of critical importance for classifying land cover from UAS data—spatial resolution must be sufficiently fine to produce high classification accuracy, but spatial coverage must be sufficiently extensive to map the area of concern. It is possible to increase coverage by planning many flights, although at the expense of time and equipment cost, and longer duration acquisition campaigns can introduce issues with illumination conditions caused by solar zenith angle and cloud cover. Therefore, it is crucial to consider this tradeoff and the best UAS flight parameters for an application.
In the early history of remote sensing land cover classification, Markham and Townshend [
2] described the relationship between classification accuracy and sensor spatial resolution. The authors documented the impact of boundary pixels—the pixels that form a transition between land cover classes—as one of the causes of reduced classification accuracy at a coarser spatial resolution. Larger pixels are likely to encompass several land cover types; these pixels are referred to as mixed pixels. The thematic precision of the classification scheme used to map land cover (e.g., ecosystem type, lifeform, or individual species for vegetation) is also dependent on the spatial resolution [
3]. In vegetated ecosystems where texture provides important information for distinguishing classes, less precise classification schemes (e.g., ecosystem type) can be mapped using coarser spatial resolution data, whereas more precise classification schemes (e.g., individual species) require finer spatial resolution data.
Alongside the proliferation of UAS remote sensing in recent years, there have been significant developments in algorithms for classifying fine spatial resolution imagery. Deep learning techniques, especially convolutional neural network (CNN)-based models, have been frequently applied in recent literature [
4]. An advantage of CNNs is that they utilize the spatial detail contained within imagery to learn textures, shapes, and edges and make land cover predictions through the application of pixel convolutions. CNNs incorporate context through their ‘sliding window’ nature; classes are identified as a kernel passes through the image, as opposed to operating on a single pixel like a multilayer perceptron. Advanced deep learning models integrate several convolution layers and include techniques specifically designed to deal with fine details, such as Cheng et al. [
5], who produced a new discriminative objective function for training models.
CNNs have proven particularly useful for fine-scale mapping of invasive species from UAS data [
6,
7,
8,
9,
10]. Detecting invasive species using remote sensing benefits from the use of high spatial resolution image data that enable the precise mapping of invasives at incipient levels and provide for targeted management strategies. In addition, the use of a UAS allows for repeat, opportunistic monitoring of invasions at a scale that would be much more costly and time-consuming using ground surveys alone. Recent examples of CNN-based models applied to UAS data for invasive species mapping includes trees [
7,
11], reeds [
10], and several herbaceous species [
6,
8,
9]. The ability of CNNs to take advantage of vegetation texture fits well with the fine spatial resolution provided by UAS imagery; however, the tradeoffs between spatial resolution and CNN classification accuracy are not well quantified.
In a review of CNNs in vegetation remote sensing, Kattenborn et al. [
12] found recent studies that have compared classification accuracies at very fine spatial resolutions [
13,
14,
15]. These studies compared resolutions from 0.3 to 32 cm and found substantial reductions in classification performance as the spatial resolution was coarsened. However, these studies mapped large plants (trees and banana plants) in forest or farm ecosystems, hence the need for a more in-depth analysis of spatial resolution’s impact on CNN classification accuracy for smaller-leaved graminoid (grass-like) plants in a wetland environment. Only Schiefer et al. [
15] implemented a semantic segmentation model but did not explicitly test the effects of different approaches for simulating coarser resolution imagery on model accuracy.
The objective of this research is to investigate changes in CNN classification accuracy for mapping wetland graminoid species with changes in spatial resolution to better understand the tradeoffs between spatial resolution and classification accuracy for UAS image acquisition campaigns. This research uses data acquired in a wetland habitat dominated by three graminoid species that share similarities in appearance but have differing canopy structures. While the focus of this study is on one particular environment, changes in CNN accuracy with coarsening resolution can provide insight into the loss of spatial detail that can occur in other vegetation types and reveal tradeoffs between spatial resolution and accuracy.
2. Materials and Methods
2.1. Study Area and Data
The study area was in the Howard Slough Waterfowl Management Area, approximately 45 km northwest of Salt Lake City, Utah, USA (
Figure 1). The habitat was a marshy wetland with permanently wet or intermittently flooded areas that can be difficult to access on foot. Water levels depend on the season, recent weather events, and manual flood management. Vascular plant cover at the site was dominated by three herbaceous vegetation types: the invasive common reed (
Phragmites australis), native cattail (
Typha latifolia), and bulrushes (
Schoenoplectus americanus,
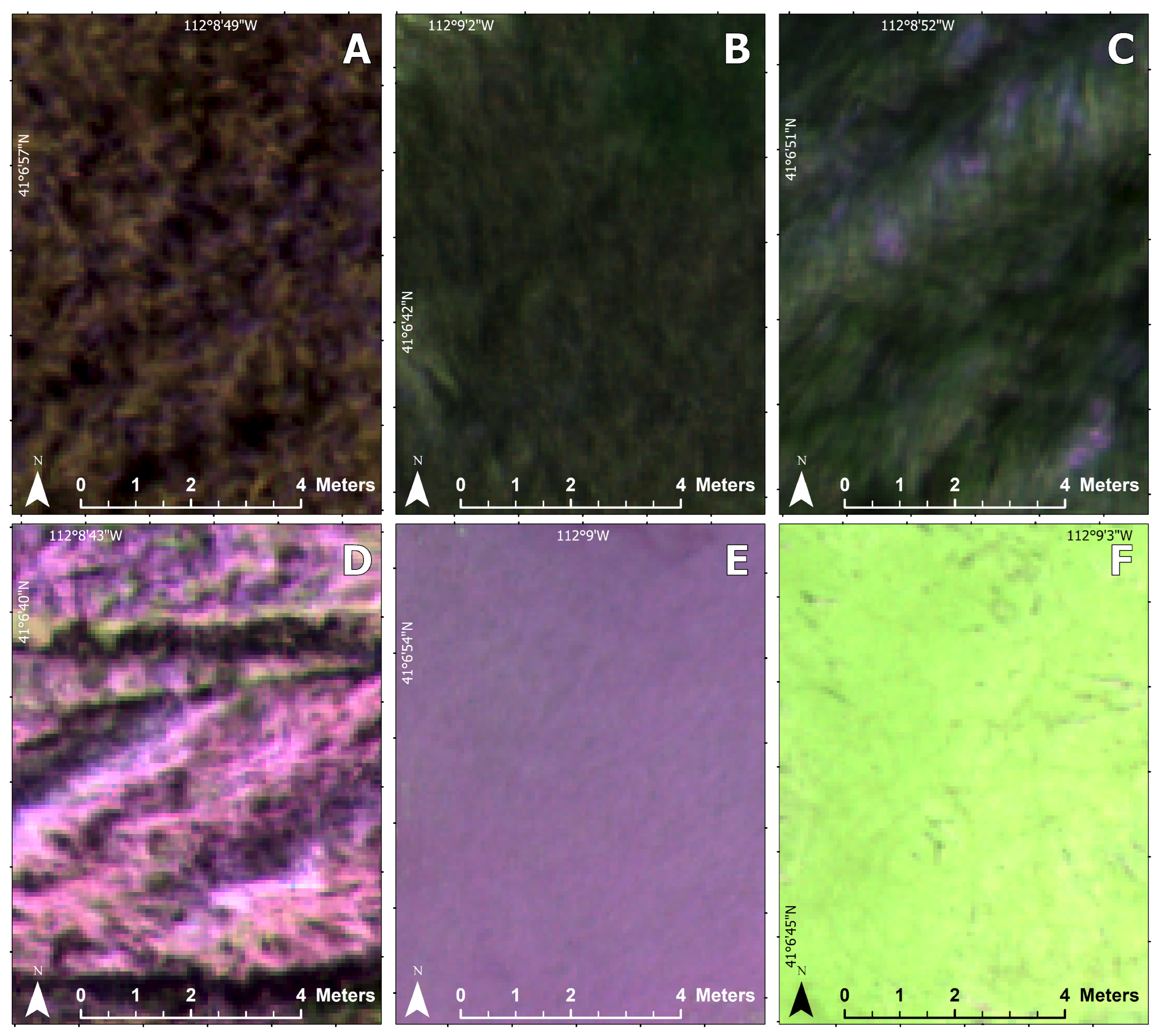
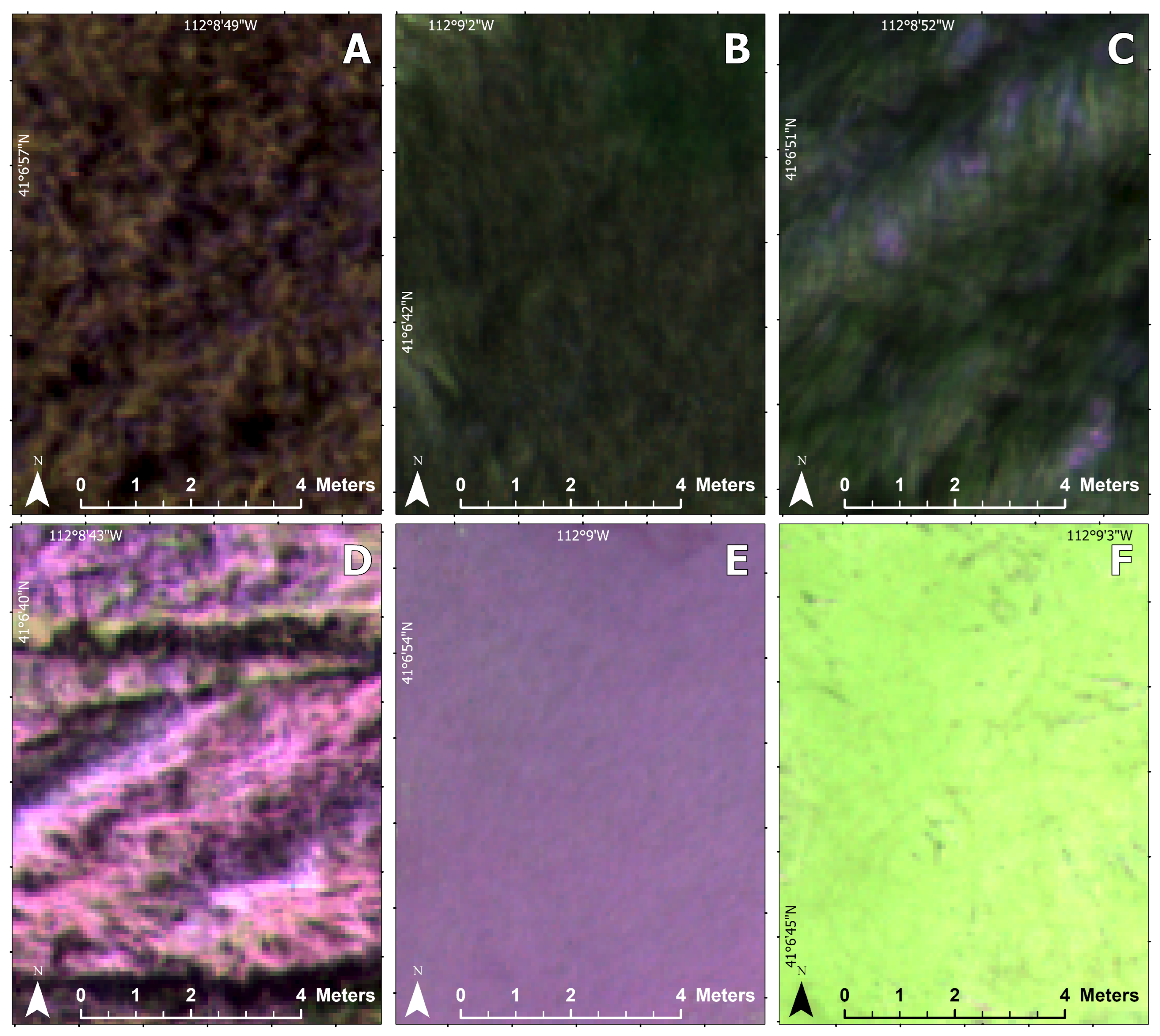
Schoenoplectus acutus). Additional land cover types included water, non-photosynthetic vegetation, and algae (
Figure 2). There was very little elevation change at the site, and it was at about 1280 m in elevation.
The images analyzed in this study were acquired in August 2020. A Parrot Disco fixed-wing UAS (Paris, France) was modified to house a MicaSense RedEdge-MX sensor (Seattle, WA, USA). This sensor measured five spectral bands: blue, green, red, red edge, and near infrared (
Table 1). The data were processed in Pix4D (Prilly, Switzerland), which stitched the imagery together using image overlap to produce a color-balanced orthomosaic. The image dimensions were approximately 8000 pixels × 15,000 pixels × 5 bands with a 7.6 cm spatial resolution in the 16-bit TIFF image format. The orthomosaic covered approximately 60 hectares.
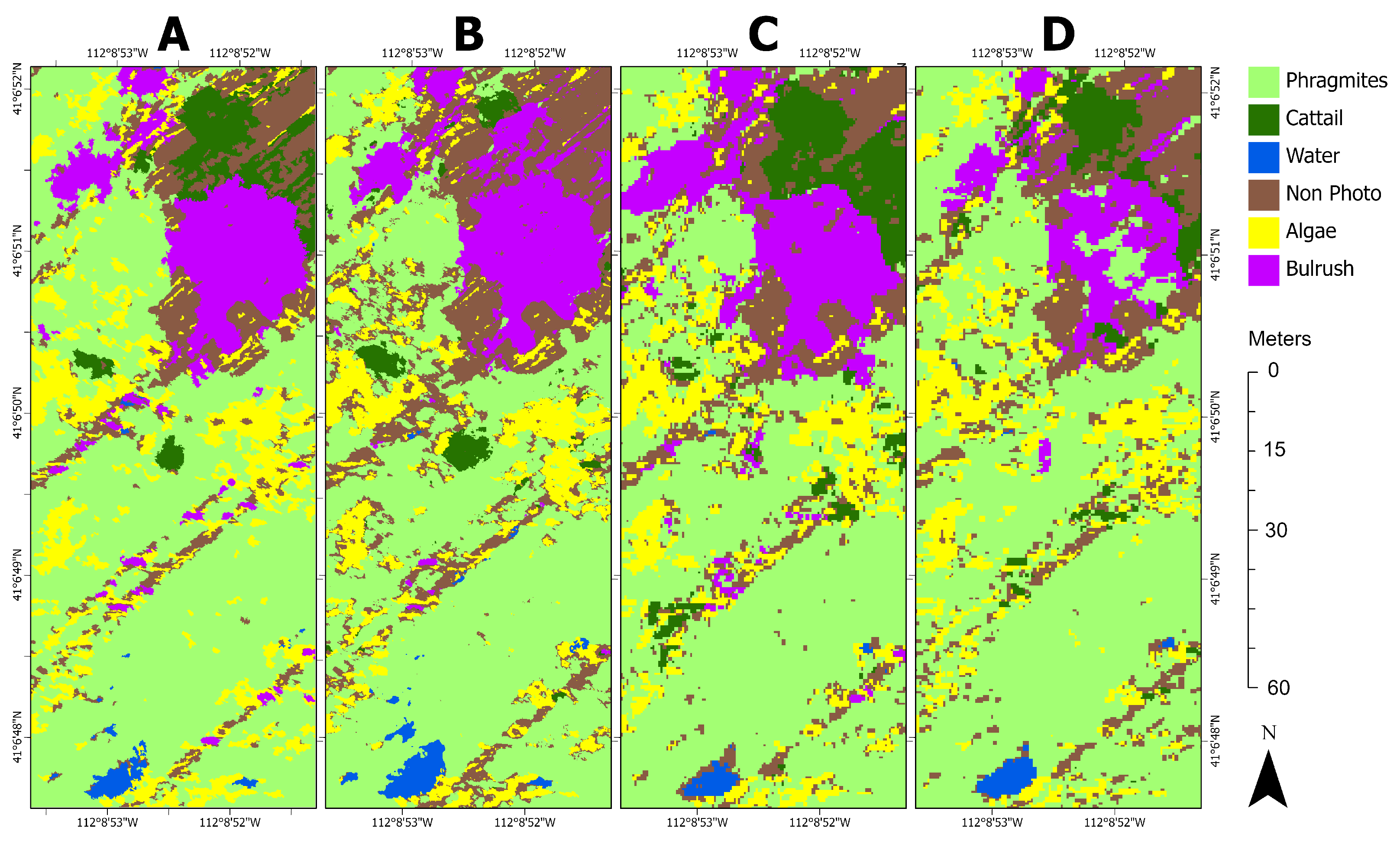
Figure 3 shows an example of each land cover class in the orthomosaic.
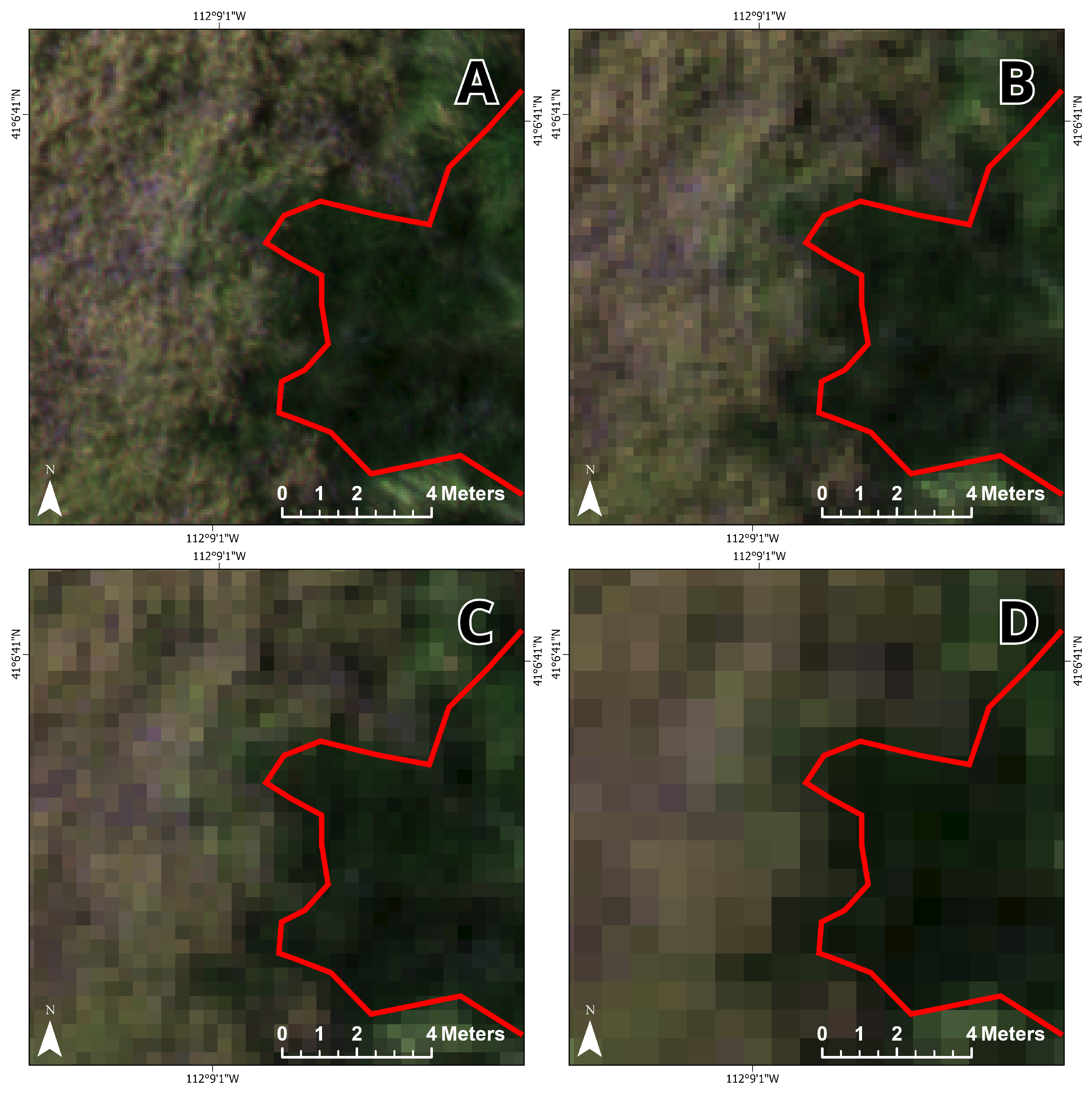
Ground reference data were collected in late July 2020. Reference data were collected opportunistically due to the difficulty of traversing the wetland landscape. Fifty-two points were captured in ArcGIS QuickCapture with a GPS-enabled smartphone (5 m accuracy) by the Utah Department of Natural Resources’ invasive species coordinator and labeled as belonging to one of the six classes (
Figure 2). Each point represents a circular area of at least 1 m
2, and photos (with camera pointing direction) were taken at each point (
Figure 4). There is active management of the invasive
Phragmites at the site involving the operation of an amphibious vehicle, resulting in a ‘striped’ appearance of vegetation in the imagery where the vehicle traveled.
2.2. Image Processing
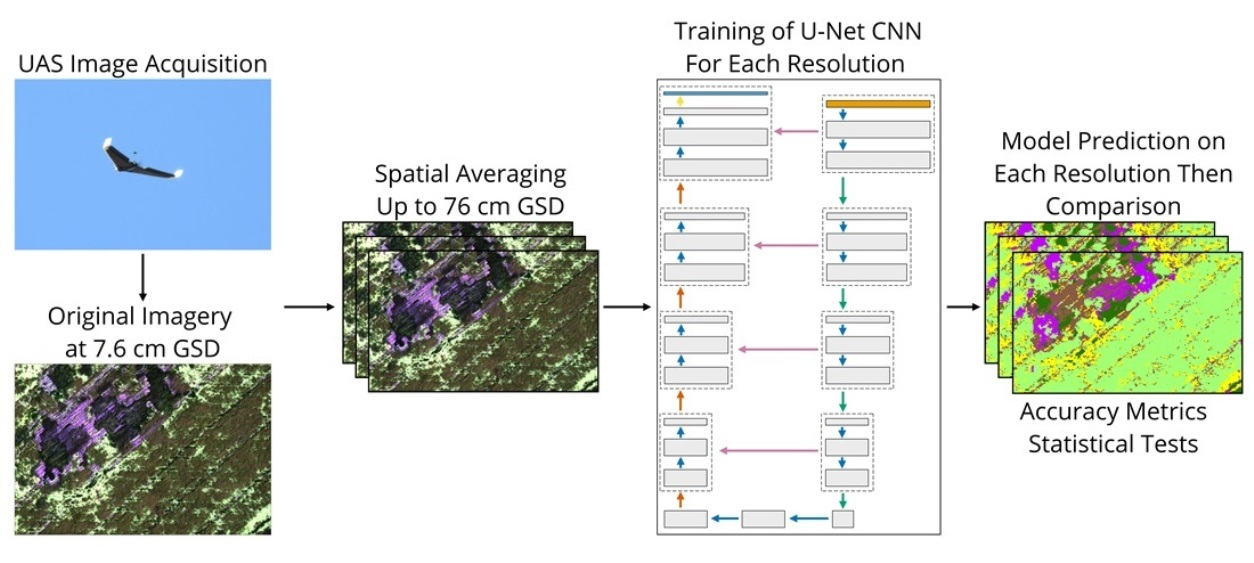
Images with a range of spatial resolutions over the same area can be created through two methods: independent data acquisitions or simulation. Independent data acquisitions require multiple flights at different altitudes over the same study area. Lighting conditions change throughout the day, as well as weather conditions and potentially vegetation conditions over several days. Additionally, georeferencing errors between the flights can influence the accuracy assessment. The simulation method only requires a single capture and post-processing to resample the imagery to coarser resolutions, reducing the number of uncontrolled variables.
A detector’s instantaneous field of view (IFOV) and the instrument flight altitude determine a pixel’s spatial resolution [
16]. The area measured on the surface—referred to as the ground instantaneous field of view (GIFOV)—does not equally contribute to the reflected solar radiance measured by the detector; the area near the center of the GIFOV is more heavily weighted, and areas outside of a square pixel can also be within the GIFOV [
17,
18]. The point spread function (PSF) describing the weighting of the area measured within the GIFOV is unique to the instrument’s optics, the detector and electronics, atmospheric effects, and any resampling used on measurements [
17]. While the simulation method can explicitly account for the sensor’s PSF, a spatial averaging approach is typically used to simulate coarser resolution imagery [
19,
20,
21] and can closely approximate resampling by incorporating a sensor’s PSF [
22]. Spatial averaging is an unweighted average of the original pixels onto a coarser resolution grid, where a pixel at ½ resolution (‘2× resample factor’) would be computed by the average value of the nearest four original pixels.
Two different approaches were taken for spatial averaging of the UAS image data: (1) the before orthomosaic resampling (BOR) method and (2) the after orthomosaic resampling (AOR) method. For the BOR method, spatial averaging was performed per each RedEdge-MX band before image mosaicking and orthorectification in Pix4D to simulate a range of spatial resolutions. The BOR method was applied to coarser spatial resolutions until orthorectification metrics exceeded thresholds for assessing the output quality. The AOR method averaged pixels after orthorectification and was applied across a wider range of spatial resolutions. This comparison was undertaken because BOR was believed to more accurately represent the process of mosaicking images captured at varying spatial resolutions, either by using a lower-resolution sensor or by flying at a higher altitude, but can only be simulated over a narrow range of resolutions due to limitations in mosaicking images with relatively few pixels. In contrast, AOR enables analysis across a broader range of spatial resolutions but does not independently mosaic each spatial resolution.
Pix4D processing parameters include image width and height, camera focal length, principal point image coordinates, and radial and tangential distortion factors. Pix4D has a database for common sensors such as the RedEdge-MX, and the original resolution imagery was processed using the parameters from the database. For the spatially averaged imagery, the image width and height, focal length, and principal point image coordinates were downscaled proportionately to the image resolution. The radial and tangential distortion factors were not varied, as these distortions are due to the camera’s lenses [
23] and remain spatially consistent through resampling. Once processing was completed, Pix4D computed a quality report (
Table 2). The number of keypoints, or distinct points in the image, represents the amount of visual content in the image that can be used for matching between overlapping images for stitching. The calibration percentage indicates the number of images that share a sufficient number of keypoints with other images and can be reliably stitched. The optimization percentage specifies the deviation from the input parameters (e.g., scene center coordinates) after Pix4D tunes the parameters. Matching is the median number of matching keypoints between images, indicating the reliability of the results. Beyond a 5× coarsening in spatial resolution (from 7.6 cm to 38.0 cm), the quality report showed that the results were no longer reliable; the median number of keypoints dropped below 1000, the calibration was below 95%, optimization above 5%, and the median number of matches were below 500.
For the AOR method, the 7.6 cm orthomosaic was spatially degraded with average resampling to between 2× (15.2 cm) and 10× (76.0 cm) spatial resolutions. Given that the AOR method does not require that image matching, mosaicking, and orthorectification take place with degraded imagery, the resolution can be coarsened to any level of interest. For comparison purposes, both the BOR and AOR aggregation methods were used for 2×, 3×, 4×, and 5× resolution. The AOR method was used for 7× and 10× spatial resolutions.
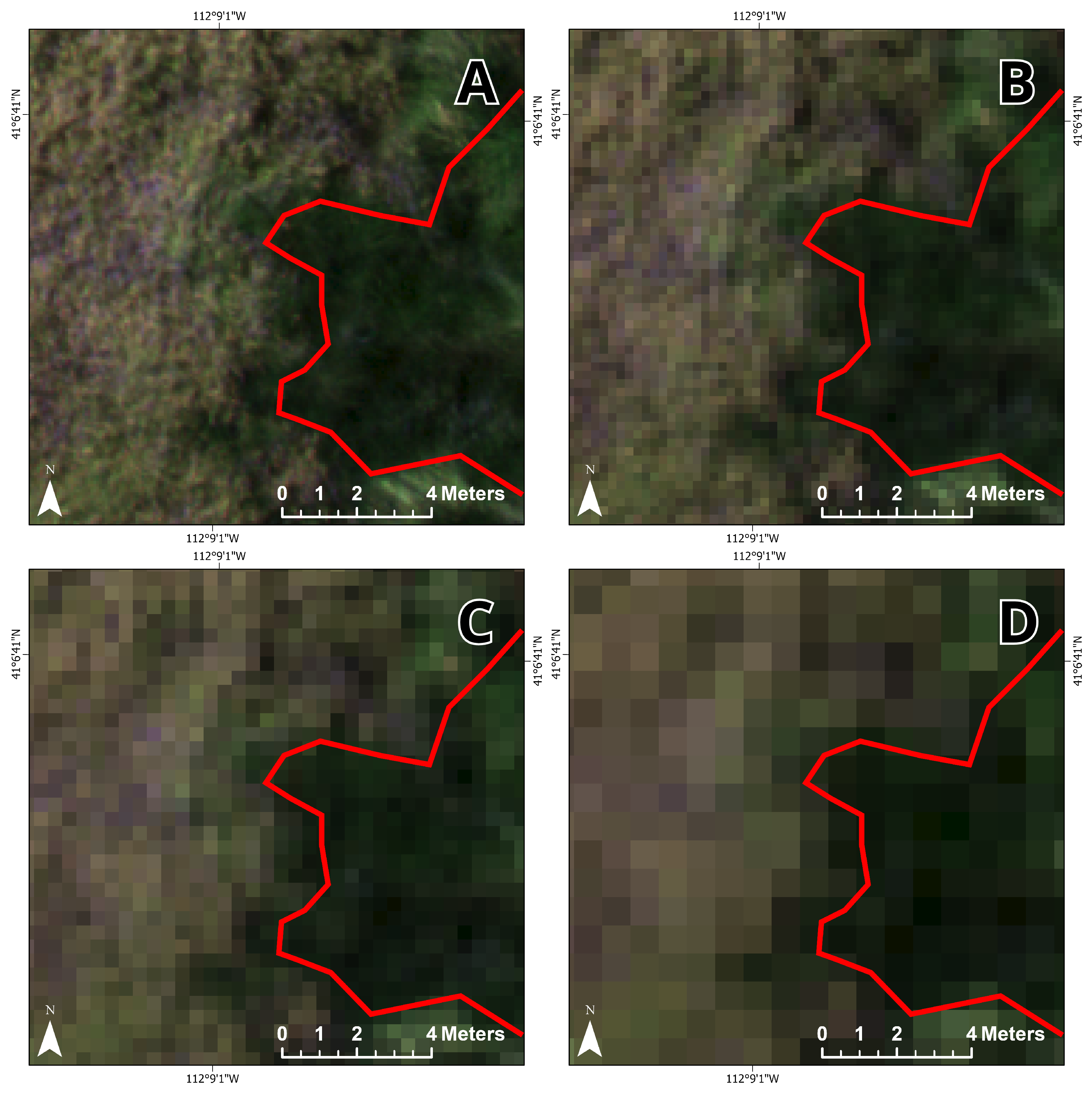
2.3. Training and Test Data Production
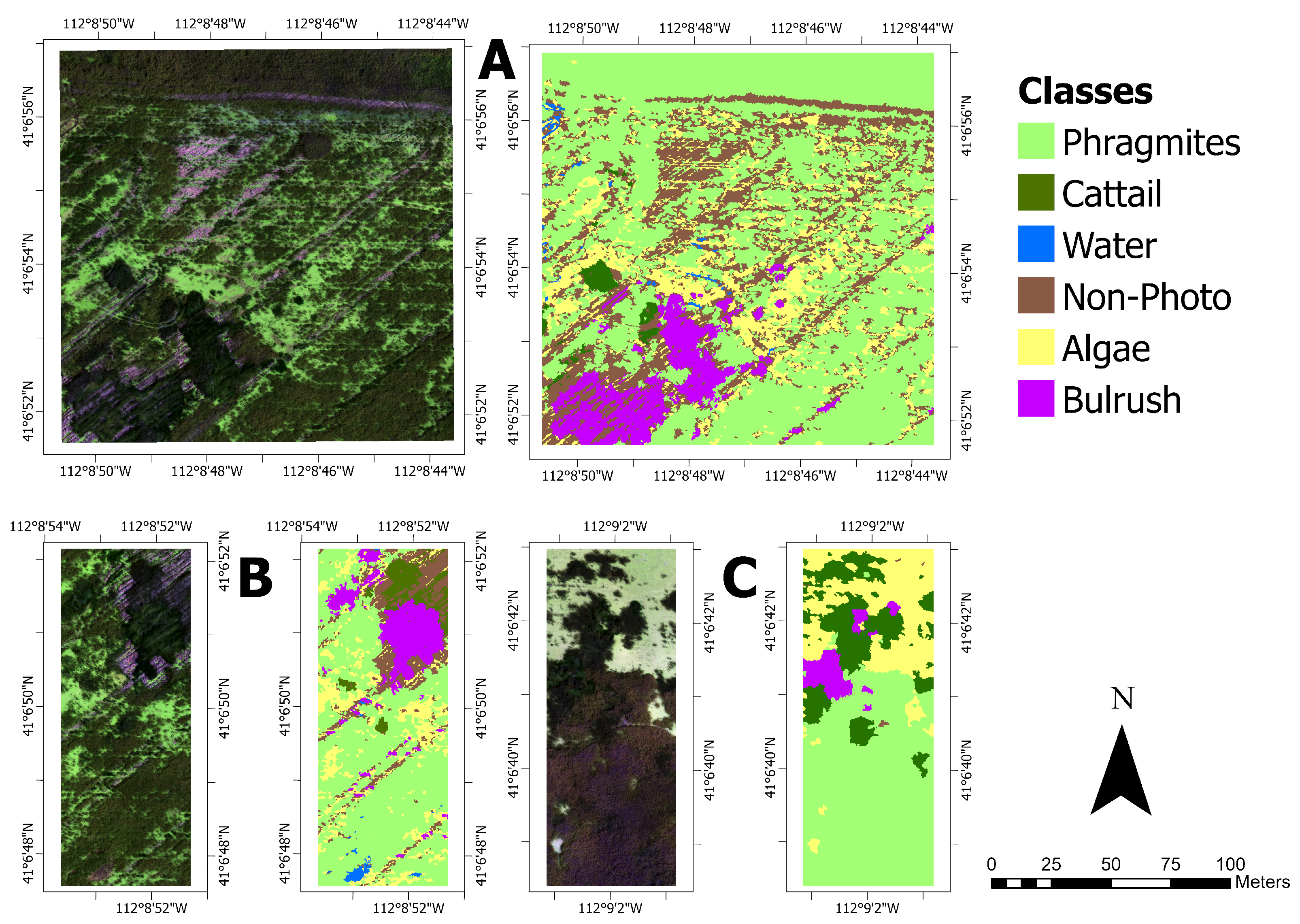
Although the ground reference points described in
Section 2.1 provide field-validated insight into the study area’s land cover, CNNs require training data that are spatially exhaustive within an entire image subset, such that every pixel is classified. To that end, we visually interpreted the imagery with aid from the ground reference data and field-collected photographs to generate three image subsets, representative of land cover distribution, as reference sites. Our study combined in situ data and visual interpretation of imagery for reference data collection, whereas Kattenborn et al. [
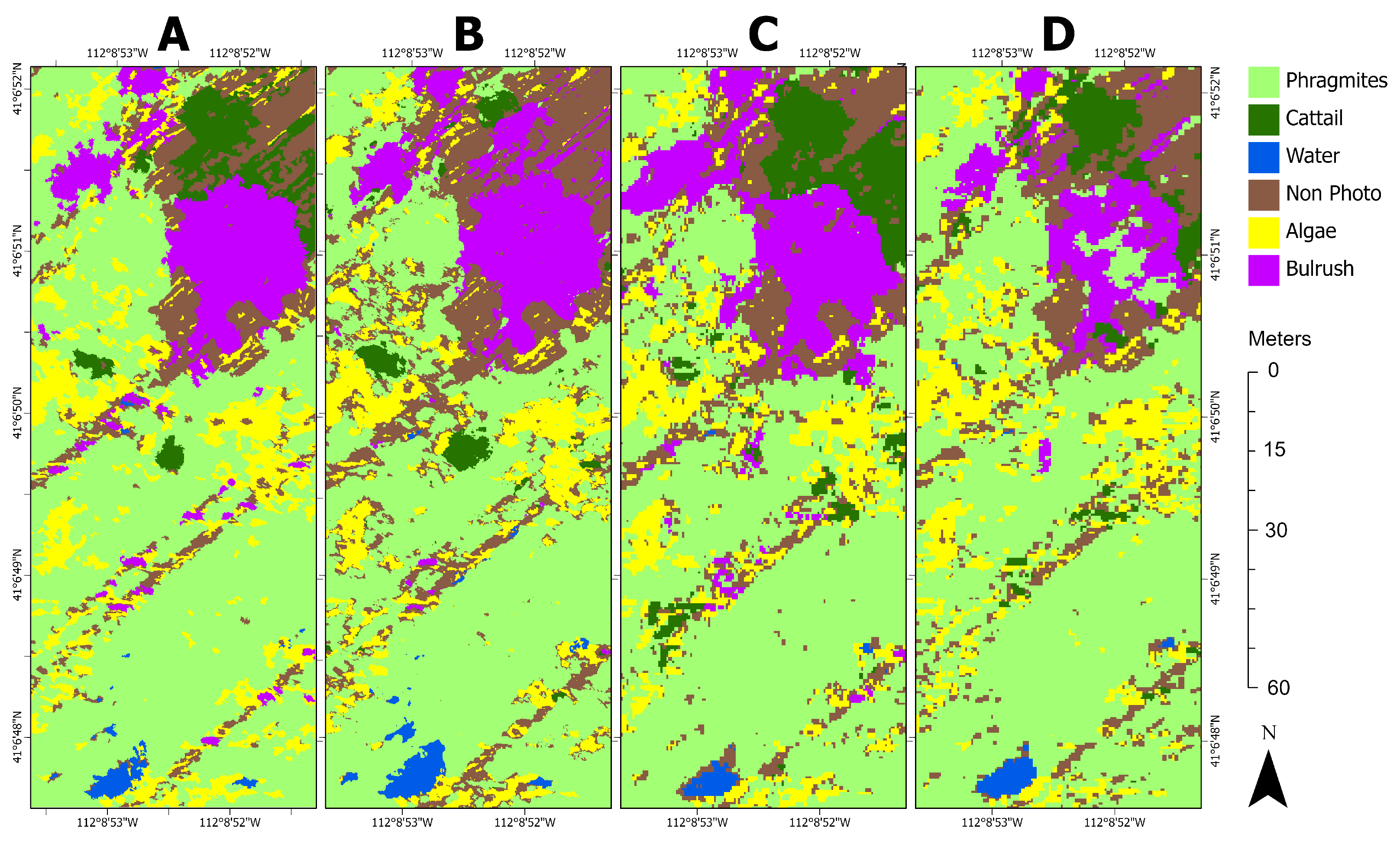
12] found that 62% of CNN-based vegetation remote sensing applications used visual interpretation alone. Due to the GPS accuracy (5 m) of the in situ data, we also verified any suspect points with a local expert (invasive species coordinator). The reference images were created at each of the tested spatial resolutions using both the AOR and BOR methods by clipping each orthomosaic to the polygon features in
Figure 4. Segments were then generated to avoid labeling individual pixels. Segmentation was performed using Esri’s mean shift segmentation algorithm with spatial and spectral detail set to 15 out of 20, where 20 retains the most detail, and the minimum segment size was 200 pixels (1.15 m
2 area) [
24,
25]. Labeled segments were converted to a raster at the original resolution. One training dataset was produced covering 2.56 hectares (4.27% of the orthomosaic), and two test datasets were made covering 0.71 hectares each (2.37% combined of the orthomosaic;
Figure 5).
Table 3 describes the class prevalence proportions for each image. For each resolution, training labels were resampled from the original resolution to the BOR and AOR orthomosaics using majority resampling.
The training dataset (
Figure 5A) was chosen to be representative of the entire orthomosaic.
Phragmites dominated the study site, while native vegetation, cattail, and bulrush were minor constituents. Test site 1 (
Figure 5B) contained a heterogeneous distribution of classes and similar class proportions to the training data. Due to less intensive management, the distribution of classes at test site 2 was more homogeneous than at test site 1, and test site 2 lacks the linear features found at the training site and test site 1 (
Figure 5C). Notably, there was much more cattail, less non-photosynthetic material, and no water at test site 2 (
Table 3).
2.4. CNN Semantic Segmentation
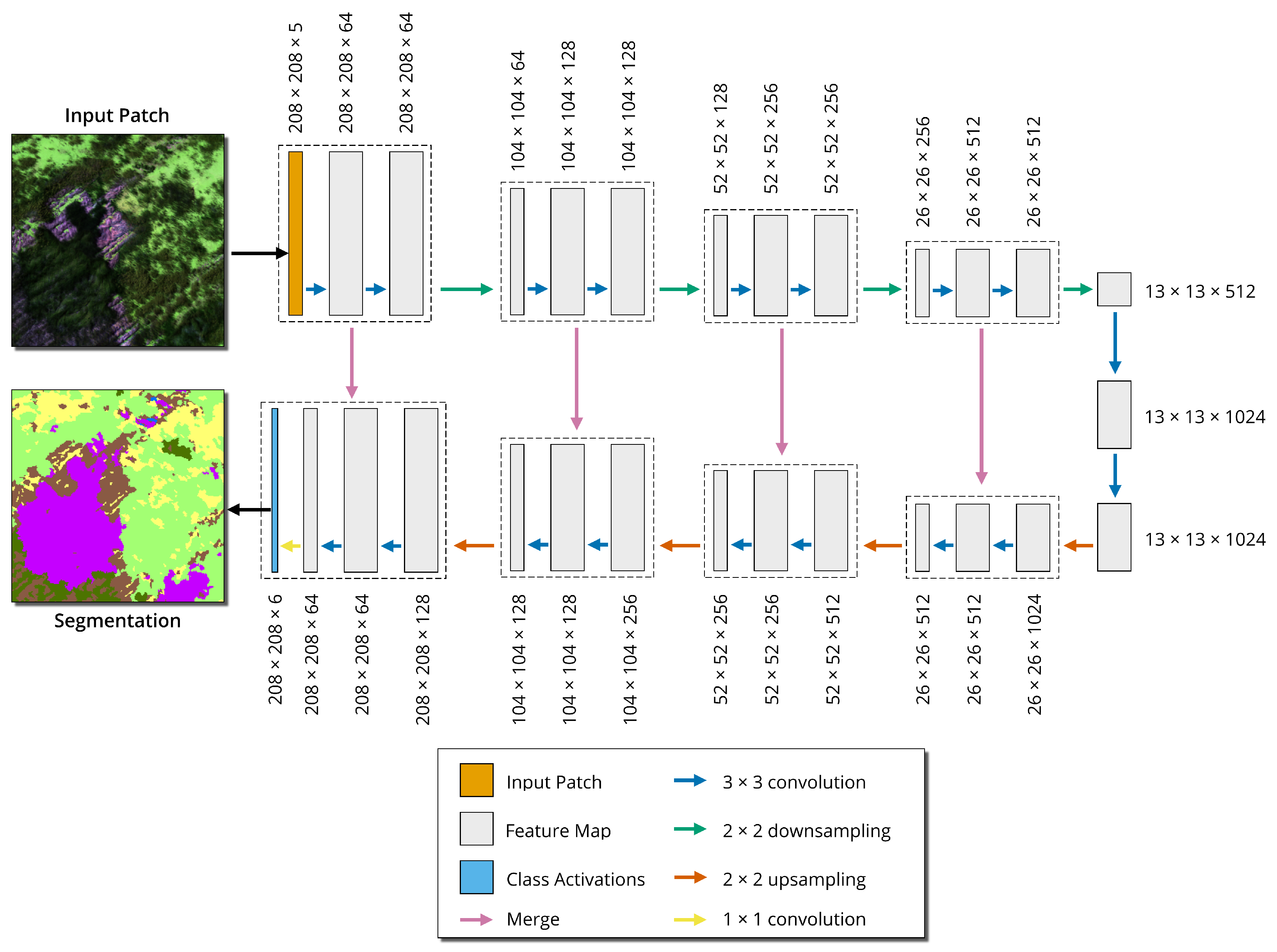
The CNN model was produced with ENVI version 5.6 and Deep Learning module version 1.1.2 (L3Harris Geospatial Solutions Inc., Boulder, CO, USA). ENVI Deep Learning implements a U-Net CNN architecture [
26] with a TensorFlow backend, referred to as ENVINet5. The U-Net architecture is a popular type of CNN in remote-sensing-based semantic image classification [
27]. The architecture is an encoder-decoder network, where the input images are downsampled several times by pooling layers, then upsampled with up-convolution layers to recover the spatial resolution. ENVINet5 has a total of 27 convolution layers and 5 ‘levels’, where each level is a different pixel resolution (
Figure 6). ENVINet5 is patch-based; the full image is divided into smaller image patches, then dense prediction (all pixels within the patch are assigned a label) is performed on each patch. U-Net has several advantages over a traditional CNN. The architecture requires relatively few training samples to predict outcomes precisely. An overlap tile strategy is employed to allow for seamless prediction on large datasets. Data augmentation is possible to supplement limited training data and to make the model more generalizable. The model learns border pixels with a weighted loss [
26]. Border pixels are where two objects’ borders meet, a complex region to define but essential for a spatially contiguous classification. The U-Net architecture was preferred because it is well-studied and has performance comparable to other state-of-the-art architectures [
28].
U-Net CNN model parameters include patch size, augmentation scale, augmentation rotation, number of epochs, number of patches per batch, number of patches per epoch, patch sampling rate, class weight, and loss weight. The number of epochs (
E) is given by Equation (
1), where
y is the scale factor.
The number of epochs was increased as the image resolution decreased because there was less training data for the model to converge at a minimum loss value (
Table 4). Equation (
1) was determined by experimentation to ensure each model converged. ENVI automatically sets the number of patches per batch and the number of patches per epoch because these parameters are impacted by the graphics card video random access memory (VRAM; Nvidia Tesla T4 with 16 GB of VRAM). The rest of the parameters were set to their default values and not varied; the augmentation scale and rotation were set to on, the patch size was 208 pixels, the number of patches per batch and number of patches per epoch were determined by ENVI, the patch sampling rate was 16, the class weight was 2, and the loss weight was 0.
Training a CNN model with the same data and parameters produces different classification results since their optimization is non-convex. There may be multiple global minima and a bad global minimum will cause poor generalization performance, which is reflected by poor accuracy on the test dataset [
30]. This was increasingly the case as the spatial resolution coarsened and the amount of training data decreased. To account for variability in classification accuracy, three models were repeated for each scenario. There were 11 unique scenarios and three repetitions for each scenario for a total of 33 models.
2.5. Model Evaluation
The output models were evaluated using the two test datasets. An error matrix was produced for each test dataset, along with several accuracy metrics. As class-independent measures, the overall accuracy (Equation (
2), where
TP is true positive,
TN is true negative,
FP is false positive, and
FN is false negative), kappa (Equation (
3), where
c is the class,
N is the total number of classified pixels compared to reference pixels,
mc,c is the number of values belonging to reference pixels that have also been classified as class
c,
Dc is the total number of predicted values belonging to class
c, and
Gc is the total number of reference values belonging to class
c; [
31]), and mean F1 score (Equation (
4), where
p is precision and
r is recall; [
32]) metrics were used. For per-class measures, the precision (also known as user accuracy; Equation (
5)) and recall (also known as producer accuracy; Equation (
6)) were used.
Accuracy metrics for the different spatial averaging methods (BOR and AOR) were compared with the Wilcoxon signed-rank test. The Wilcoxon test is a nonparametric test similar to the parametric paired
t-test that compares the differences between two independent samples of the same community [
33,
34]. The test assumes that the differences are distributed symmetrically around the median [
35]. The Wilcoxon test’s null hypothesis is that the median difference between paired samples is zero, and the alternative hypothesis is that the median difference between paired samples is not zero [
36]. The testing was conducted at the alpha level of 0.01, where a significance test indicates that the method results are different. The tests were completed for each class-independent accuracy metric (overall accuracy, kappa, and the mean F1 score) at both test sites.
Tukey’s honestly significant difference (HSD) test was used to test for significant differences between the original and spatially averaged spatial resolutions’ class-independent accuracy metrics. The data were grouped by resolution, and the AOR and BOR methods were analyzed separately. Tukey’s HSD assumes that the data are normally distributed, the observations are independent, and variance is homogeneous in each group. The Shapiro–Wilkes test and Levene’s test were used to test for the normality and homogeneity of variance, respectively. These tests indicate that the data did not violate the assumptions of Tukey’s HSD at the alpha level of 0.01. A significance test (alpha = 0.01) of Tukey’s HSD indicates a difference between the original and spatially averaged resolutions. The tests were completed for each class-independent accuracy metric, overall accuracy, kappa, and the mean F1 score at both test sites.
4. Discussion
The U-Net CNN model had relatively good performance at the original resolution even though this study did not prioritize best performance. To isolate the effect of spatial resolution, this study omitted common practices to improve classification accuracy for individual models, such as model pretraining and hyperparameter tuning, instead opting for a uniform training approach. While U-Net is an established CNN-based model in the literature, there are other model architectures that may offer improved performance. Cheng et al. [
37] developed ISNet, a deep learning network for improved separability of the boundaries between semantics. Zhang et al. [
38] created a transformer and CNN hybrid deep neural network for the semantic segmentation of very-high-resolution imagery. This work sought to establish a baseline comparison of CNN-based model performance using a well-studied architecture, U-Net; however, future work should study model performance of new approaches, such as those of Cheng et al. [
37] and Zhang et al. [
38], at different spatial resolutions.
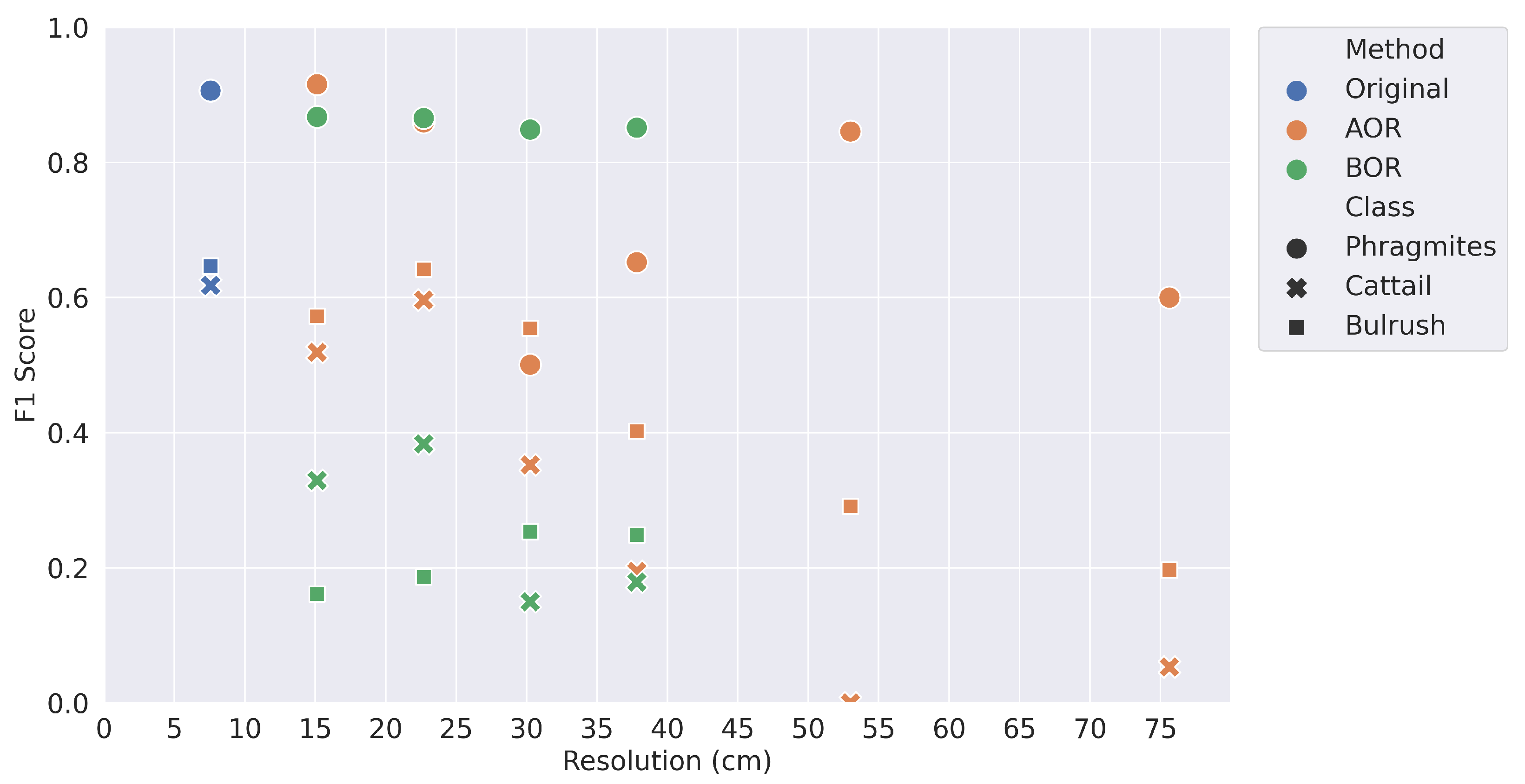
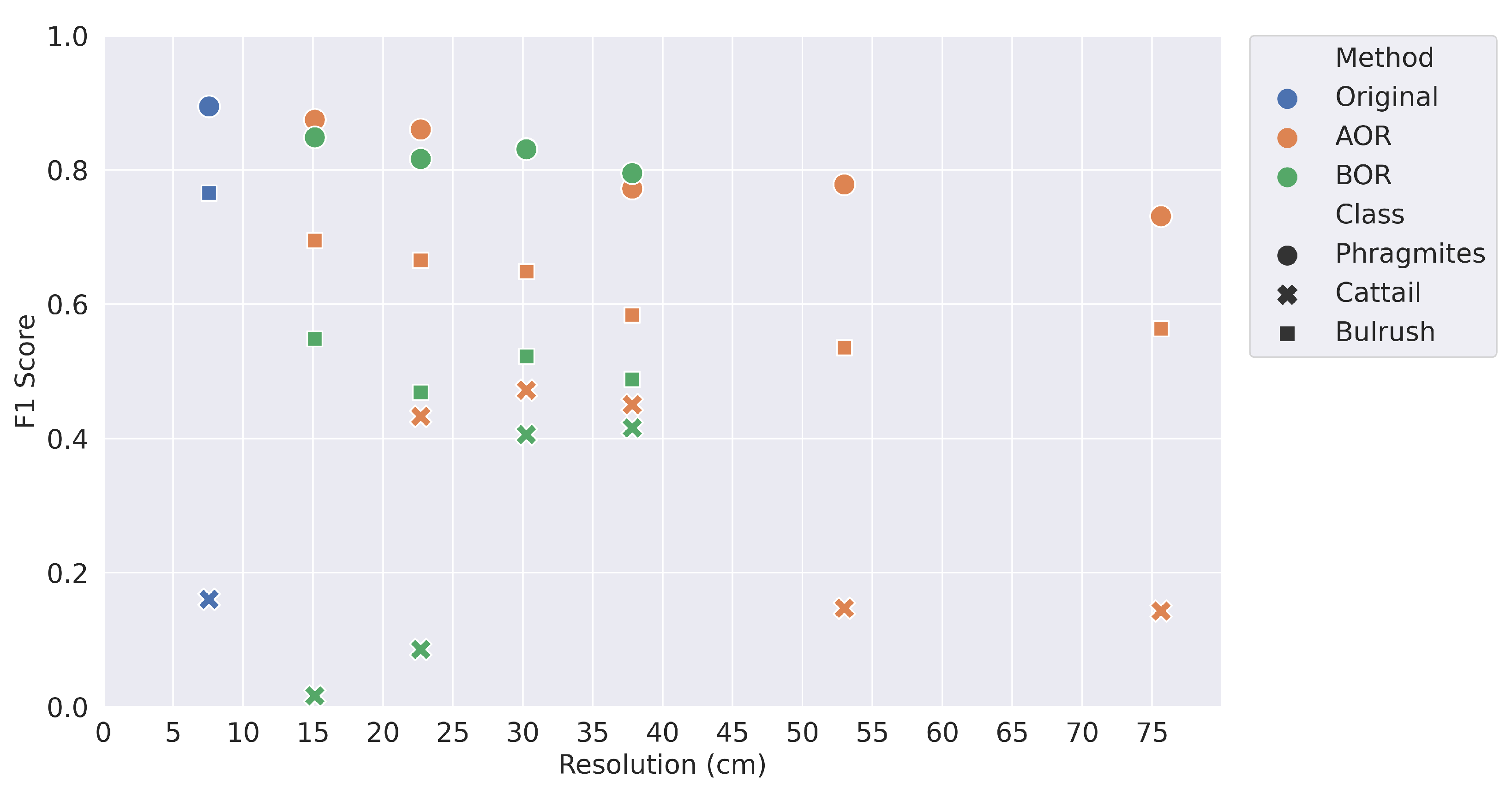
The BOR spatial averaging method was a more accurate representation of independently acquired imagery at a coarser spatial resolution. While only the mean F1 score at test site 2 was significantly different than the AOR Method, the BOR method generally had worse performance compared to the original resolution with more statistically significant differences and, frequently, lower accuracy. There were three main contributors to the reduced model accuracy: the reduction in spatial information, the geolocation accuracy between the resampled imagery and reference data, and the lower quality of image stitching during orthomosaic production. It is unknown how much each factor contributes to reduced model performance. For this reason, the BOR processed imagery could be considered a worst-case scenario and the AOR processed imagery a best-case, while it is most likely that model performance with newly collected imagery at a coarser resolution would fall somewhere between the two.
In addition to the loss of spatial detail at coarser resolutions, the amount of training data also decreased. At a 76.0 cm resolution, the 217 × 217 pixel training image provided about 1% as much training data as the original resolution (7.6 cm) 2171 × 2171 pixel training image. It is rather impressive that the CNN model could converge on a prediction for the 76.0 cm resolution imagery, achieving nearly 60% overall accuracy at both test sites. It is evident that a 76.0 cm resolution was too coarse for the categorical scale used in this study (species-level classification). Additionally, it would have been difficult to visually interpret imagery coarser than the original (7.6 cm) to create training data, even if there were more ground-collected reference data.
The classification accuracy on a per-class basis demonstrates the importance of plant morphology. The overall accuracy was almost always highest for
Phragmites, and the precision and recall values showed no trends of over or under prediction. The
Phragmites at the site were seeding, creating a texture distinct from bulrush and cattail. Bulrush was also distinct, with thinner leaves and a tendency to blow over in the wind. Cattail shared characteristics of both
Phragmites and bulrush from the aerial imagery, as some of the cattails were seeding, causing confusion with
Phragmites, but the spectral response was more similar to bulrush, also causing confusion with bulrush. Additionally, cattail was a minor constituent of the field site, only covering 1.1% of the training site. As a result, the classification accuracy was lowest for cattail, which had consistently low recall values. The low classification accuracies for cattail underscores the importance of class prevalence. In most cases, cattail had the lowest F1 score, regardless of spatial resolution. There is a potential that an analysis with a spatial resolution finer than 7.6 cm could provide further insights. Several studies, such as Fromm et al., Neupane et al., and Schiefer et al. [
13,
14,
15], have applied CNNs at finer resolutions as small as 0.3 cm. For instance, perhaps more detail is required to accurately map cattail, and class prevalence is not the sole issue. There would also be more training samples available. With a 0.76 cm resolution, there would be 100× more pixels than at 7.6 cm resolution. Again, the reduction in ground sample distance will reduce the flight coverage area, so such a reduction would be more appropriate for highly targeted scenarios or potentially a multi-scale analysis.
Based on our results, coarsening the spatial resolution from 7.6 cm to 22.8 cm in this study area could allow for increased spatial coverage or reduce image acquisition time while only moderately reducing accuracy. Acquisition time represents a significant cost and limits mapping large study areas at fine spatial resolutions. Processing software provides an additional cost tradeoff that should be considered before undertaking similar projects. This research relied on commercial software (Pix4D and ENVI) requiring licensing that may be prohibitively expensive for small projects. Free and open source alternatives exist, such as OpenDroneMap [
39] for image stitching and Tensorflow [
40] or PyTorch [
41] for modeling, but require additional experience and/or programming skills.
The evaluation of this study was based on geographically stratified test sites. In an ideal situation, a stratified random sample would be generated to meet the basic statistical assumption. In this case, random points would be generated across the entire study site, then an image patch would be produced, centered at this point. However, the ground reference data were limited (
Figure 4), and it would have been difficult to visually interpret the ground reference labels throughout the entirety of the image, causing additional human error. Considering the coarser resolution imagery and a patch size of 208 pixels, a stratified random sample would require a much larger study area and time investment for field data collection and image labeling.
The CNN architecture used in this study did not convolve the spectral dimension of the image data. With only five bands, a three-dimensional CNN would be unlikely to appreciably improve accuracy over the results shown here. However, the impacts of the spectral resolution and the number of bands on classification accuracy should be further explored in future research. While this work demonstrates a decrease in accuracy as spatial resolution coarsens, additional spectral information may improve differentiation between vegetation species [
42,
43]. Hyperspectral image data could maintain high accuracy even at coarser spatial resolutions, effectively sidestepping tradeoffs between spatial resolution, areal coverage, and classification accuracy; however, hyperspectral sensors are typically more costly than RGB or multispectral sensors. Recent work has demonstrated applying three-dimensional CNNs to hyperspectral imagery for tree species classification [
44,
45]. Hyperspectral UAS data can provide a complementary assessment of species cover when combined with coarser resolution hyperspectral data, as demonstrated for wetland vegetation by Bolch et al. [
42].
5. Conclusions
This study has demonstrated a negative correlation between spatial resolution and CNN-based model accuracy; as spatial resolution becomes coarser, classification accuracy decreases. However, there is potential for similar model performance between the original 7.6 cm resolution imagery and spatial resolutions up through 22.8 cm resolution imagery based on simulated imagery. The slight decrease in model accuracy between these resolutions may be worth the potential tradeoff for greater coverage area. At resolutions coarser than 22.8 cm, there is less confidence that a deep learning model can reliably predict at the plant species level in this ecosystem.
While each land cover classification project is unique, and there is no optimal spatial or spectral resolution for every situation, the lessons learned here can be broadly applied. The land cover types at a study site may require a certain level of spatial and spectral detail for a CNN-based model to learn patterns. In this study, seeding Phragmites required less detail than bulrush, and, consequently, the classification accuracy of Phragmites was higher than bulrush at coarser spatial resolutions. The level of detail required by the land covers will influence the UAS flight parameters. At coarser resolutions, there was low confidence in the cattail and bulrush classes and much confusion between the two. Finally, it is essential in project planning to find the best balance between spatial detail and the amount of coverage area. The capture rate originally used in this project—1.2 km2/day—could cause difficulties outside of highly targeted projects. In this case study of species-level classification of graminoid plants, a 22.8 cm resolution and 10.8 km2/day capture rate could offer better balance between classification accuracy and spatial coverage.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}