1. Introduction
With the development of the commercial satellite industry, various countries have launched a large number of video satellites, which provide us with high-resolution satellite videos [
1]. Different from traditional videos, satellite videos have a wider observation range and richer observation information. Based on these advantages, satellite videos are applied in fields, such as:
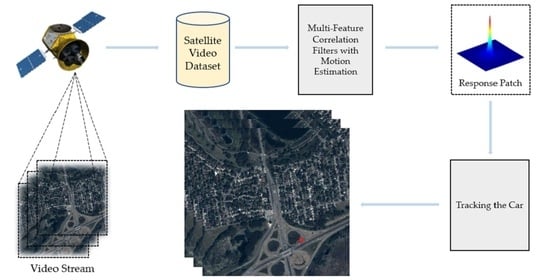
Traffic monitoring, where relevant departments can use satellite videos to monitor road conditions and reasonably regulate the operation of vehicles;
Motion analysis, where satellite videos can be used to observe sea ice in real time and analyse its trajectory;
Fire controlling, where satellite videos are able to monitor the spread trend of fire and control it before it causes major damage.
To make use of satellite videos, a variety of scholars began to pay attention to target tracking in satellite videos. As one of the most popular research directions, target tracking aims to locate the target and calculate the target trajectory [
2]. However, compared with target tracking in traditional videos, target tracking in satellite videos faces more severe challenges. For example, the targets in satellite videos often have lower resolution, which accounts for only dozens of pixels. From
Figure 1a, we can see that the car is just a point. In addition, occlusion is also a great challenge for satellite video tracking. The target has been occluded in
Figure 1b, which is very unfavourable to the whole tracking process and may make it difficult for the algorithm to track the target again. Finally (see
Figure 1c for an example), the target is much like the backdrop, which makes the target hard to distinguish. In this case, there is a great possibility that tracking drift will occur.
To date, many methods for target tracking have been presented. All are roughly classified into generative methods [
3,
4,
5] and discriminant methods [
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16]. The generative methods generate a target template by extracting the representation information of the target and searching the area resembling the template. One obvious disadvantage of generative methods is that they only use the target information and ignore the role of the background. Different from generative methods, discriminant methods treat target tracking as a classification task with positive and negative samples, in which the target is a positive sample and the background is a negative sample. Because discriminant methods obtain robust tracking performance, discriminant methods have become the mainstream tracking methods.
Recently, two kinds of popular discriminant methods are deep learning (DL) based [
6,
7,
8] and correlation filter (CF) based [
9,
10,
11,
12,
13,
14,
15,
16]. DL-based methods use the powerful representation ability of convolution features to realise target tracking. The method using hierarchical convolutional features (HCF) [
6] obtains great tracking performance by using features extracted from the VGG network. Fully-convolutional Siamese networks (SiamFC) [
7] use a Siamese network to train a similarity measure function offline and select the target most similar to the template. Voigtlaender et al. [
8] present Siam R-CNN, a Siamese re-detection architecture, which unleashes the full power of two-stage object detection approaches for visual object tracking. In addition, a novel tracklet-based dynamic programming algorithm is combined to model the full history of both the object to be tracked and potential distractor objects. However, DL-based methods require abundant data for training. In addition, millions of parameters make it difficult for DL-based methods to achieve real-time tracking performance.
The CF-based methods transform the convolution operation into the Fourier domain through a Fourier transform, which greatly speeds up the calculation. In this case, CF-based methods are better suited for target tracking in satellite videos. The minimum output sum of squared error (MOSSE) [
9] applies a correlation filter to target tracking for the first time. Due to the extremely high tracking speed of MOSSE, CF-based methods have been developed. The most famous correlation filter is the kernel correlation filter (KCF) [
10], which defines the multichannel connection mode and enables the correlation filter to use various features. However, KCF is often arduous to track the target with scale change accurately. To settle the impact of scale change on the performance of the tracker, the scale adaptive kernel correlation filter (SAMF) [
11] introduces scale estimation based on KCF. To make the tracker better describe the target, a convolution feature is used in correlation filtering in [
12]. The background-aware correlation filter (BACF) [
13] can effectively simulate the change in background with time by training real sample data. Tang et al. proposed a multikernel correlation filter (MKCF) [
14] and an effective solution method. The hybrid kernel correlation filter (HKCF) [
15] adaptively uses different features in the ridge regression function to improve the representation information of the target. Although the performance gradually improves, the speed advantage of the correlation filter also gradually decreases. To strike a balance between performance and speed, the efficient convolution operator (ECO) [
16] introduces a factorised convolution operator to reduce the number of parameters, which can reduce computational complexity. However, the above methods cannot track the occluded target. In addition, the boundary effects caused by cyclic sampling is also a great challenge to the abovementioned methods.
Inspired by the correlation filter with motion estimation (CFME) [
17], we propose a motion estimation algorithm combining the Kalman filter [
18] and an inertial mechanism [
19]. Because the target in the satellite videos performs uniform linear motion in most cases, the Kalman filter can accurately calculate the location of the target. However, in some cases, the trajectory of the target bends, and the position predicted by Kalman filter is no longer accurate. Therefore, we use an inertial mechanism to correct the position predicted by Kalman filter. The motion estimation algorithm not only places the target in the centre of the image patch to mitigate the boundary effects but also tracks the occluded target. Furthermore, considering the low target resolution in satellite videos, we use the HOG and OF features to improve the representation information of the target. However, background noise is inevitably introduced when fusing features. To weaken the interference of background noise on tracking performance, we introduce the disruptor-aware mechanism used in [
20].
This paper makes the following contributions:
We propose a motion estimation algorithm that combines the Kalam filter and an inertial mechanism to mitigate the boundary effects. Moreover, the motion estimation algorithm can also be used to track the occluded target;
We fuse the HOG feature and OF feature to improve the representation information of the target;
We introduce a disruptor-aware mechanism to attenuate the interference of backdrop noise.
The rest of the paper is arranged as follows.
Section 2 represents the materials and methods.
Section 3 shows the experiments that we have conducted.
Section 4 discusses the results and future work.
Section 5 provides a concise summary.
2. Materials and Methods
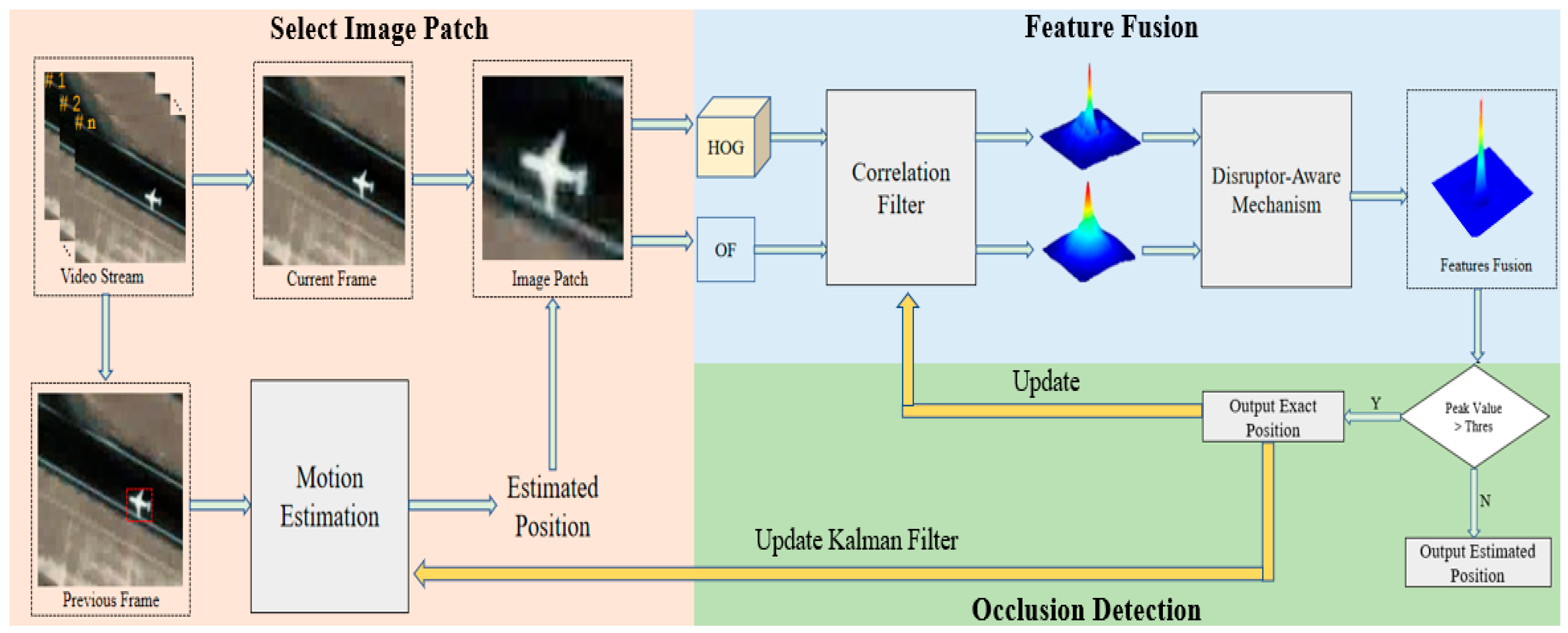
A flowchart of our algorithm is shown in
Figure 2. Based on KCF [
10], our algorithm includes a motion estimation algorithm, feature fusion and a disruptor-aware mechanism. It is noted that we artificially give the position of the target in the first frame, and the proposed algorithm tracks the target according to the position of the target in the first frame. First, we use a motion estimation algorithm to calculate the location of the target in the present time. Second, the image patch is cropped according to the predicted position. Third, the HOG and OF features of the image patch are extracted, and their response maps are denoised by a disruptor-aware mechanism. Fourth, feature fusion is carried out, and the maximum response value is calculated. If the peak value of the response patch is greater than the threshold, then the location predicted by the correlation filter is output; otherwise, the location calculated by the motion estimation algorithm is output.
2.1. Introduction of KCF Tracking Algorithm
KCF trains a detector to detect the target. It constructs training samples by cyclic sampling of the central target. Assume that
is one-dimensional data.
can be obtained by a cyclic shift of
, which is expressed as
. All circular shift results of
are spliced into a cyclic matrix
, which can be expressed by the following equation:
Cyclic matrices have the following properties:
where
is the discrete Fourier transform (DFT) matrix.
means conjugate transpose, and
is the DFT transformation of
. The diagonal matrix is shown as
.
KCF uses ridge regression to train a classifier. At the same time, the label function is a Gaussian function in which the value of the centre point is 1 and the convenient value gradually decays to 0. It initialises the filter
by solving
, which can minimise the difference between training sample
and label
. The objective function is
where
is a regularisation factor.
According to Equation (3), we can obtain the following equation:
where
is the identity matrix. Using the properties of the Fourier transform and substituting Equation (2) into Equation (4), we can obtain Equation (5).
where
,
, and
are the DFT of
,
, and
respectively.
is the complex conjugation of
. The operator
is the Hadamard product of matrix.
The performance of the tracker can be improved by using the kernel trick. Suppose the kernel
is
.
can be written as
For most of the kernel function, the properties of Equation (2) still hold. Then,
can be solved by
where
is the DFT of
, and
is the trained filter. Because we make use of a Gaussian function as the label,
can be shown as
where
is the complex conjugation of
, and
is the Hadamard product of the matrix. The number of characteristic channels is represented by
.
is the inverse transform of the Fourier transform.
When tracking the target, the algorithm cuts out the candidate region centred on the target. Then, the response patch is calculated by
where
is the representation information of the candidate region, and
is the target template.
When the target is moving, the apparent characteristics of the target often vary. Therefore, to better describe the target, the correlation filter also needs to be updated dynamically. The KCF is updated by using
where
is the learning rate.
and
are the new filter and samples, respectively.
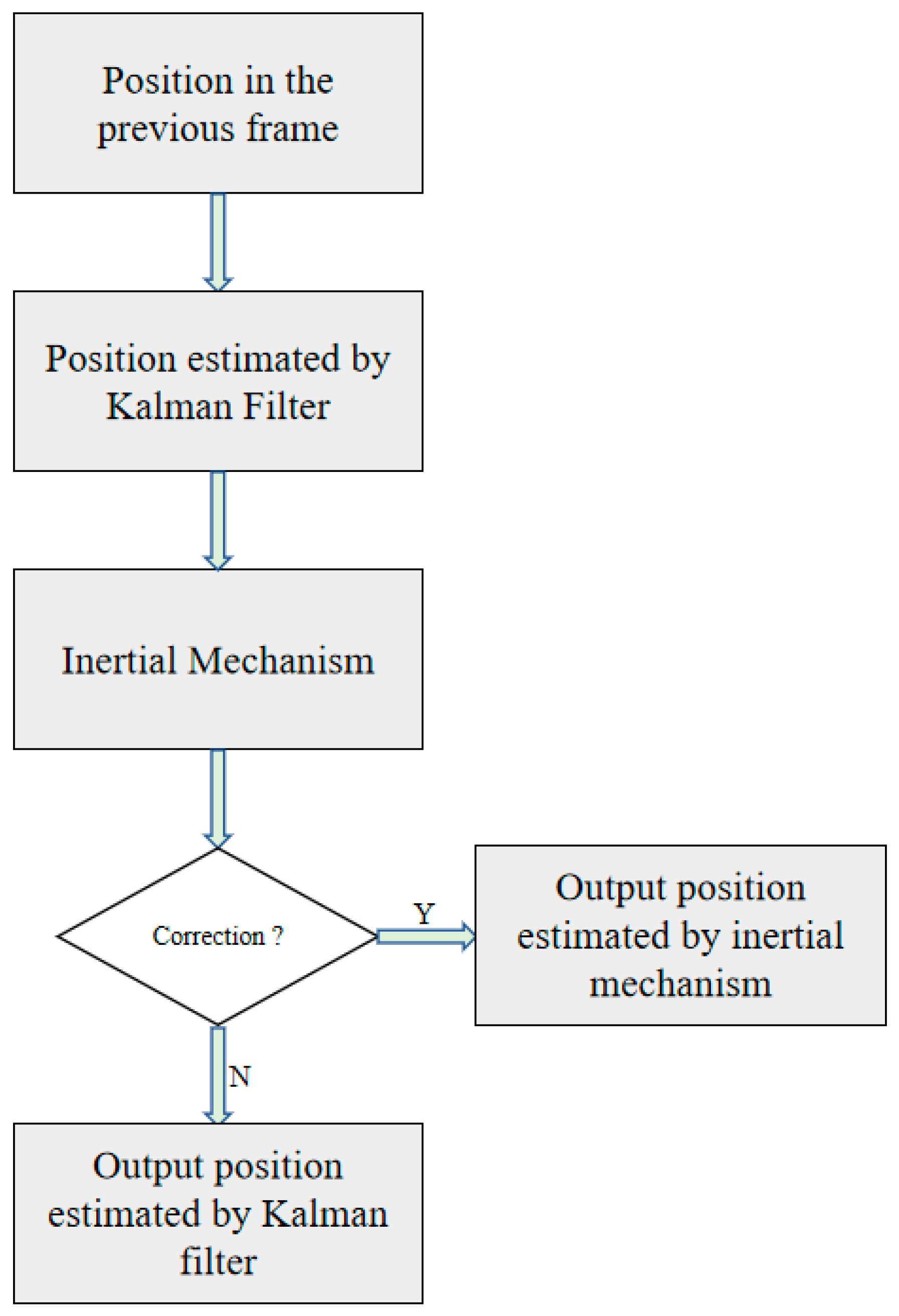
2.2. Motion Estimation Algorithm
We introduce motion estimation to make our tracker work more accurately. This includes the Kalman filter [
18] and an inertial mechanism [
19]. Kalman filter calculates the location of the target in the current time through the location of the target in the previous frame. However, sometimes the position predicted by Kalman filter is not credible. Therefore, an inertial mechanism is used to correct the position predicted by Kalman filter. A flowchart of the motion estimation algorithm is shown in
Figure 3.
2.2.1. Kalman Filter
The state and observation equations are
where
is the state transition matrix in the
frame, and
is the observation transition matrix in the
frame.
and
are the state vector and the observation vector, respectively.
. and
are the white Gaussian noise with covariance matrices
and
.
In our algorithm, the location of the target can be written as
where
and
are the abscissa and ordinate of the target, respectively.
and
are the horizontal velocity and vertical velocity of the target, respectively.
Because the moving distance of the target between adjacent frames is very short, we think that the target moves at a uniform speed. In this situation, the state transition matrix and the observation matrix can be expressed as
The update process of Kalman filter is as follows:
where
is the state vector in frame
and
is the observation vector in frame
.
is the prediction error covariance matrix, and
is the identity matrix.
2.2.2. Inertial Mechanism
A video satellite can observe the long-term motion state of the target. Different from traditional videos, the target moves linearly most of the time, and the Kalman filter can calculate the location of the target well. However, the trajectory sometimes bends. In this case, the Kalman filter cannot accurately calculate the location of the target, so an inertial mechanism is introduced to correct the location estimated by the Kalman filter. From [
19], we can see that the performance of the inertial mechanism is obviously better than the Kalman filter when the target trajectory is curved.
When tracking the target in frame
, position
predicted by the Kalman filter is sent into the inertial mechanism. If the difference between
and position
predicted by the inertial mechanism is beyond the threshold, then
is used to replace
.
can be calculated by using
where
is the inertia distance.
can be updated by linear interpolation:
where
is the inertia factor. The threshold of the triggering inertia mechanism is related to the residual distance
.
can also be updated by linear interpolation:
2.3. Feature Fusion
OF can well describe the moving state of the target. Therefore, OF is well suited for satellite video tracking. OF assumes that pixels within a fixed range have identical speeds. The pixels centred on
satisfy the following equation:
where
are pixels centred on
.
,
and
are the partial derivatives of
with respect to
,
, and
. Equation (22) can be shown by using the matrix
where
We multiply Equation (23) left by
, which can be written as
The following equation can be obtained by solving Equation (25):
The HOG feature is widely used in correlation filtering. It divides the input image into several cells according to a certain proportion and calculates the gradient in the discrete direction to form a histogram. HOG can well represent the contour features of the target. Therefore, HOG and OF can describe the target from different angles to enhance the representation information.
The peak-to-side Lobe ratio (PSR) [
9] is utilised to describe the tracking performance of the tracker. The higher the PSR value, the better the tracking performance. If the value of PSR is lower than a certain value, then it can be considered that the tracking quality is poor. The calculation formula of PSR is as follows:
where
, and
is the maximum response value.
and
are the mean and variance of the sidelobe, respectively. In this paper, we use PSR to fuse the HOG feature and OF feature, which can be expressed as
where
is the final response patch.
and
are the response patches of HOG and OF, respectively.
can be shown as
where
and
are the PSR of the HOG response patch and OF response patch, respectively.
2.4. Disruptor-Aware Mechanism
As we all know, a smooth response patch will make the tracker achieve excellent tracking performance. However, when tracking the target, the target is easily disturbed by a similar background, which makes the response value of noise too large. This may affect the follow-up tracking performance and even lead to tracking failure. Therefore, we must remove points with abnormal response values.
In this paper, we introduce a disruptor-aware mechanism [
20] to suppress background noise. We first divide the response patch into
blocks and find the local maximum
of the block in the
th row and
th column, where
. When
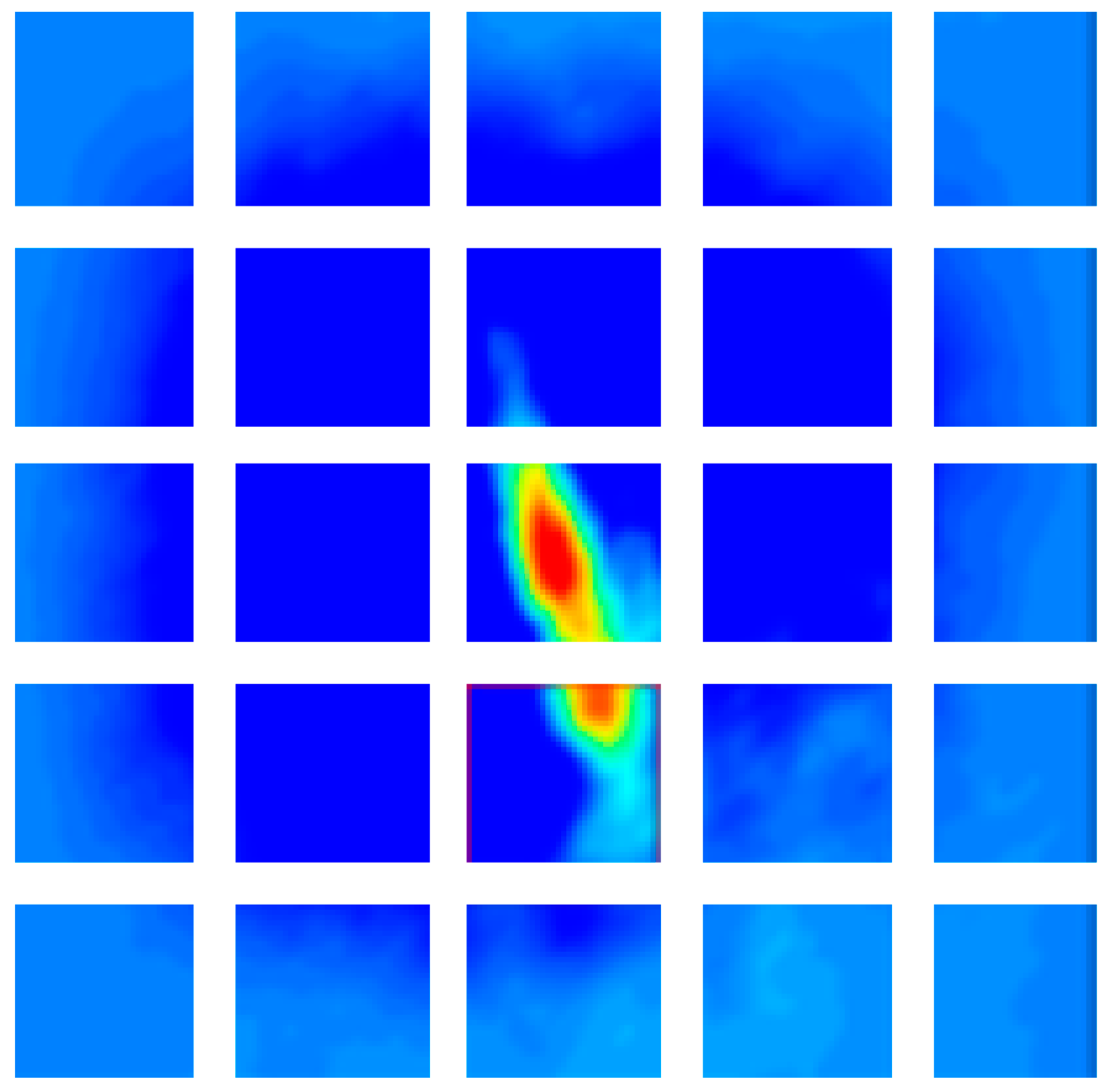
is 5, the divided response patch is shown in
Figure 4. Then, we find the global maximum
and set the penalty mask of its location to 1. Finally, we set the penalty mask for other blocks through Equation (28).
where
is a penalty coefficient, and
is a threshold to trigger the disruptor-aware mechanism.
is calculated as
By using Equations (30) and (31), we can obtain the matrix composed of penalty masks. The matrix is shown as
Finally, we can obtain the denoised response patch by dot multiplying the response patch with Equation (30).
2.5. Occlusion Detection
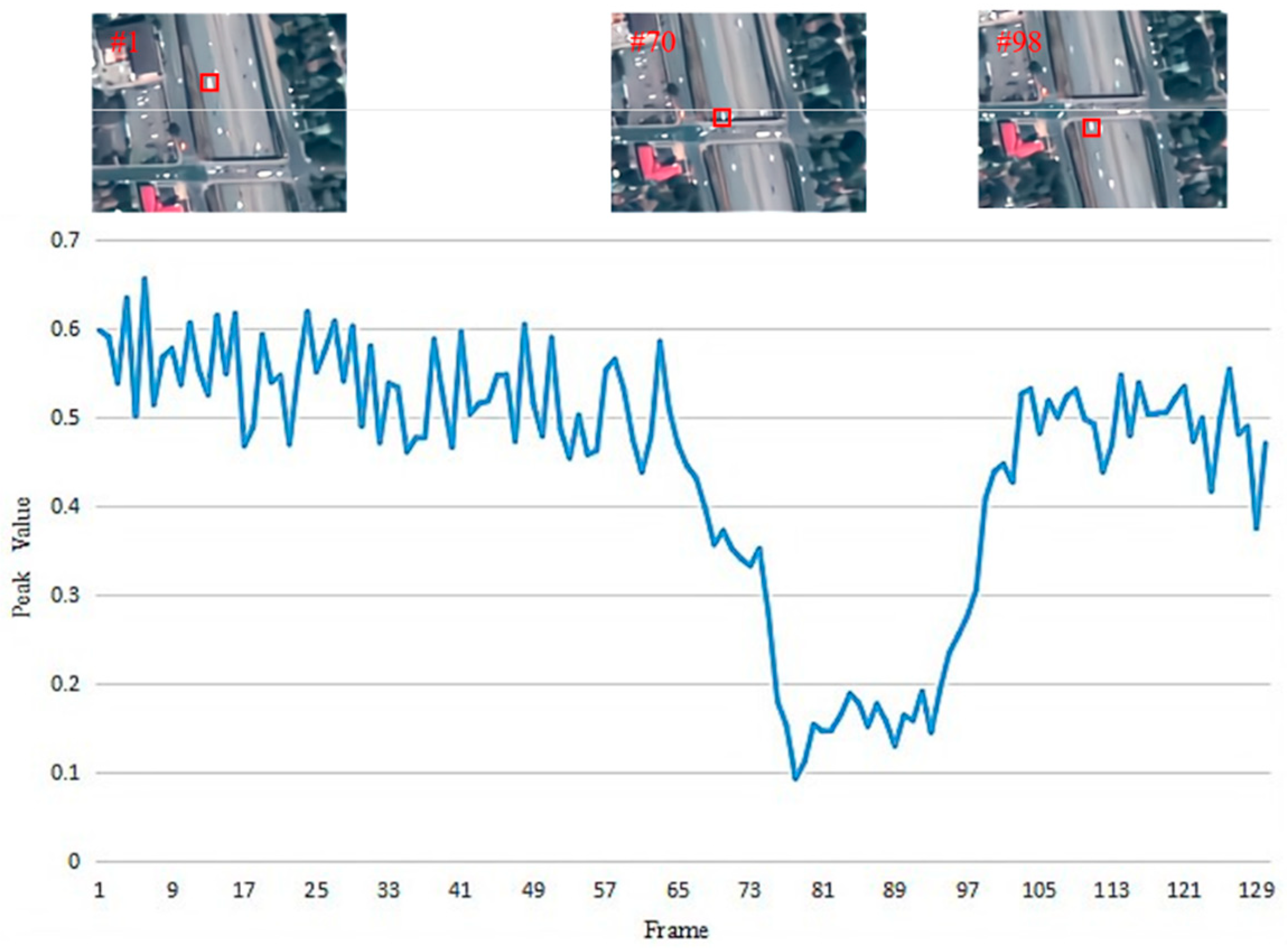
Because the targets in satellite videos have very low resolution, there is a great possibility that occlusion will occur, as shown in
Figure 5. We can see that the movement of the car is divided into three stages.
Before occlusion occurs, the car runs normally.
When occlusion occurs, the car is occluded by the overpass, and the whole car disappears from view. In this case, the correlation filter often fails to track the target.
When the occlusion ends, the car returns to our view.
To make our algorithm able to track the occluded target, we introduce an occlusion detection mechanism. The occlusion detection mechanism should be able to judge when occlusion occurs and when occlusion ends. When the target is occluded, the position predicted by the correlation filter will no longer be credible. In view of the particularity of target motion in satellite videos, we regard the position predicted by the motion estimation algorithm as the position of the target in the current frame. In addition, if we continue to update the template when the target is occluded, it is easy to cause template degradation. To prevent template degradation, the correlation filter will not be updated at this time. When the occlusion is over, we continue to output the position predicted by the correlation filter.
When the target is accurately tracked, it often has a large response value. In contrast, if the tracking quality is poor, then the response value of the response patch will decrease rapidly. Therefore, we use the maximum response value of the response patch to judge whether occlusion occurs. Through experiments, the threshold is set to 0.3. When the maximum response value is less than 0.3, we think that the target is occluded at this time and take the position predicted by the motion estimation algorithm as the position of the target and stop updating the template. The update process is expressed as Equation (33). Otherwise, the location predicted by the correlation filter is output.
where
is the learning rate,
is the trained filter and
is the new filter.




















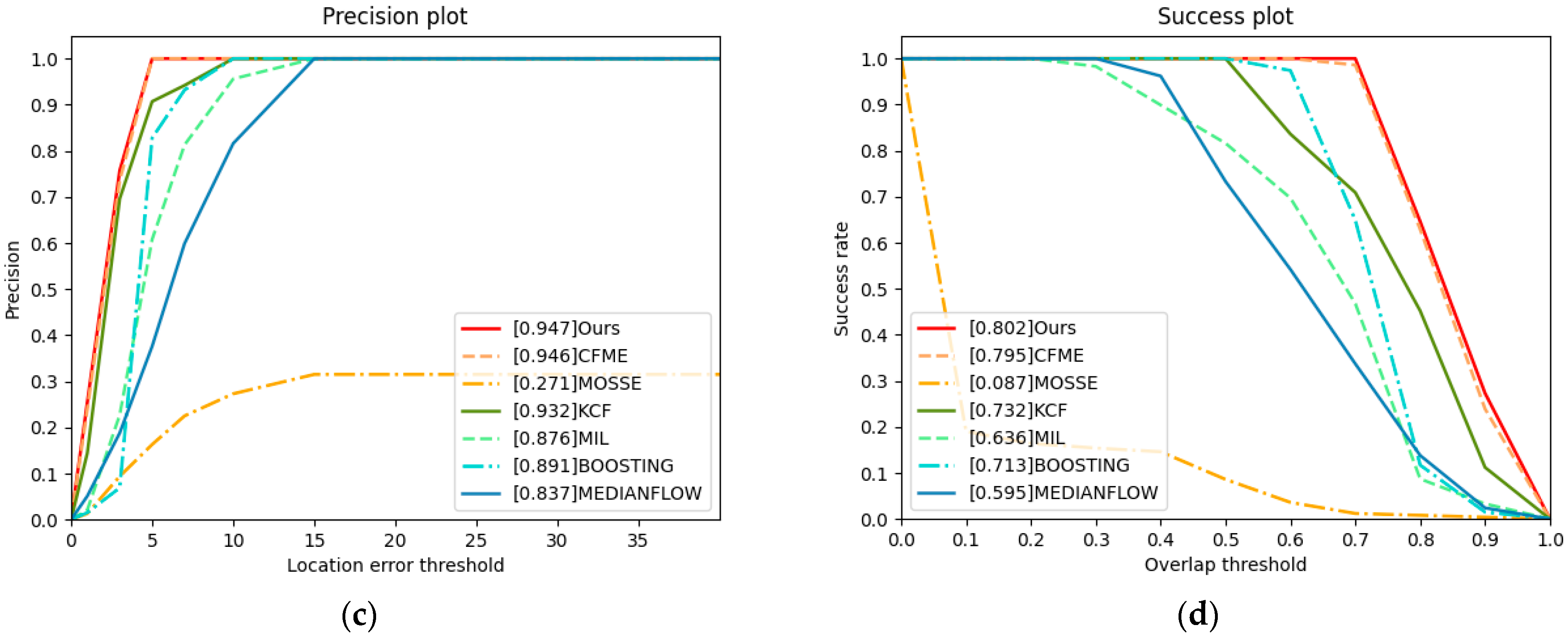
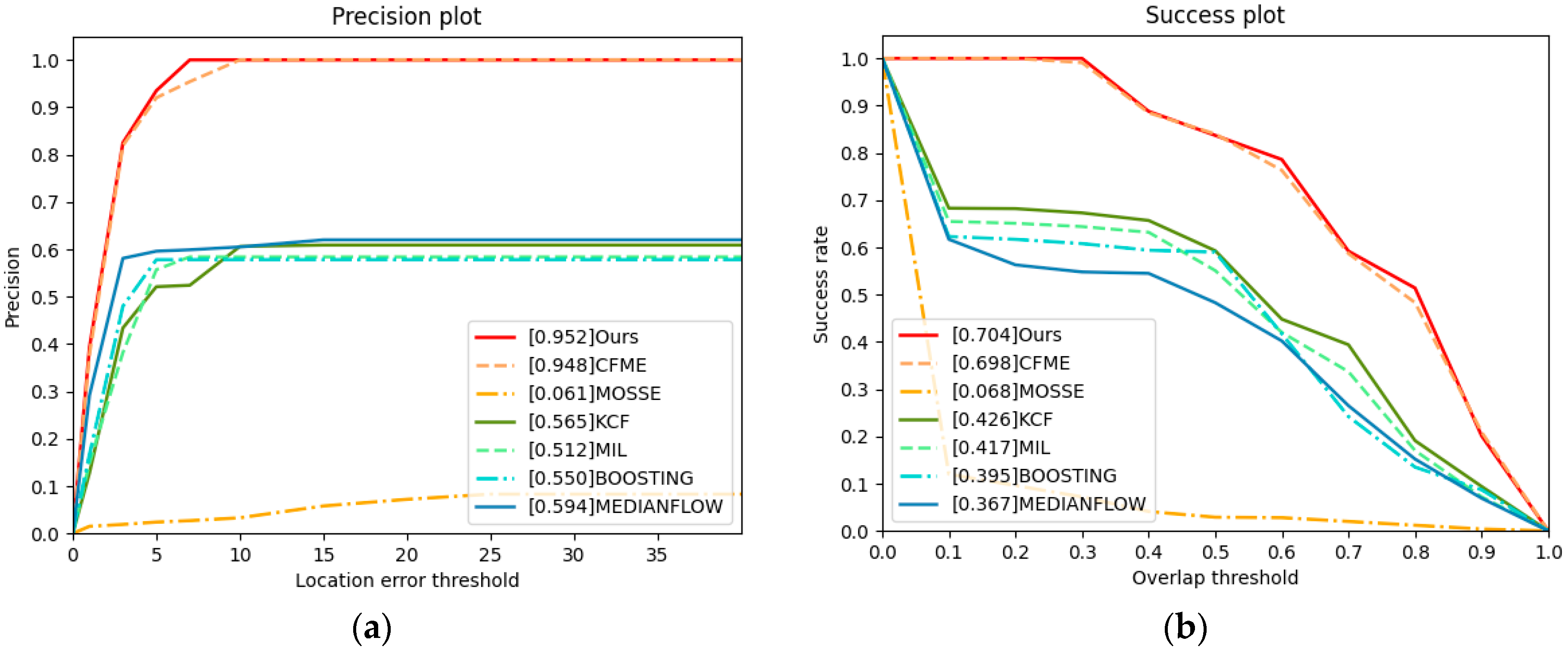
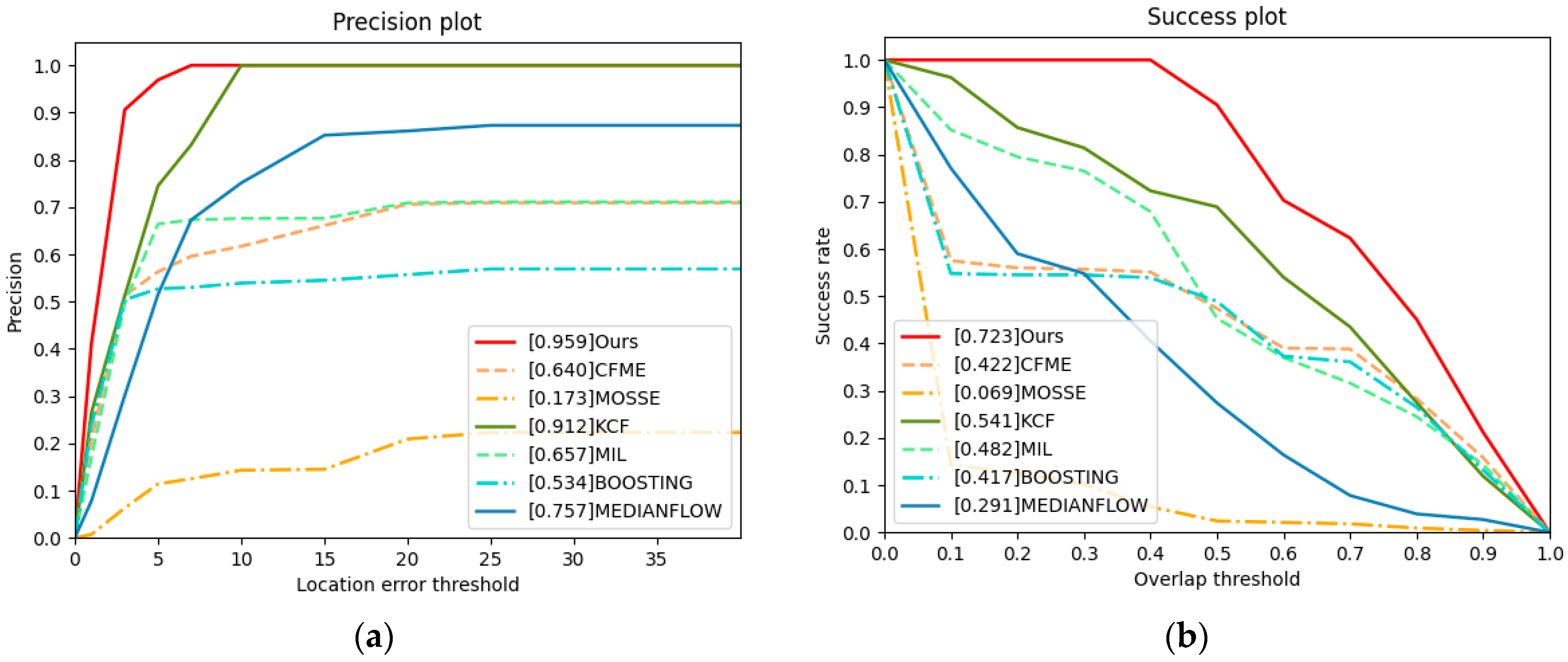
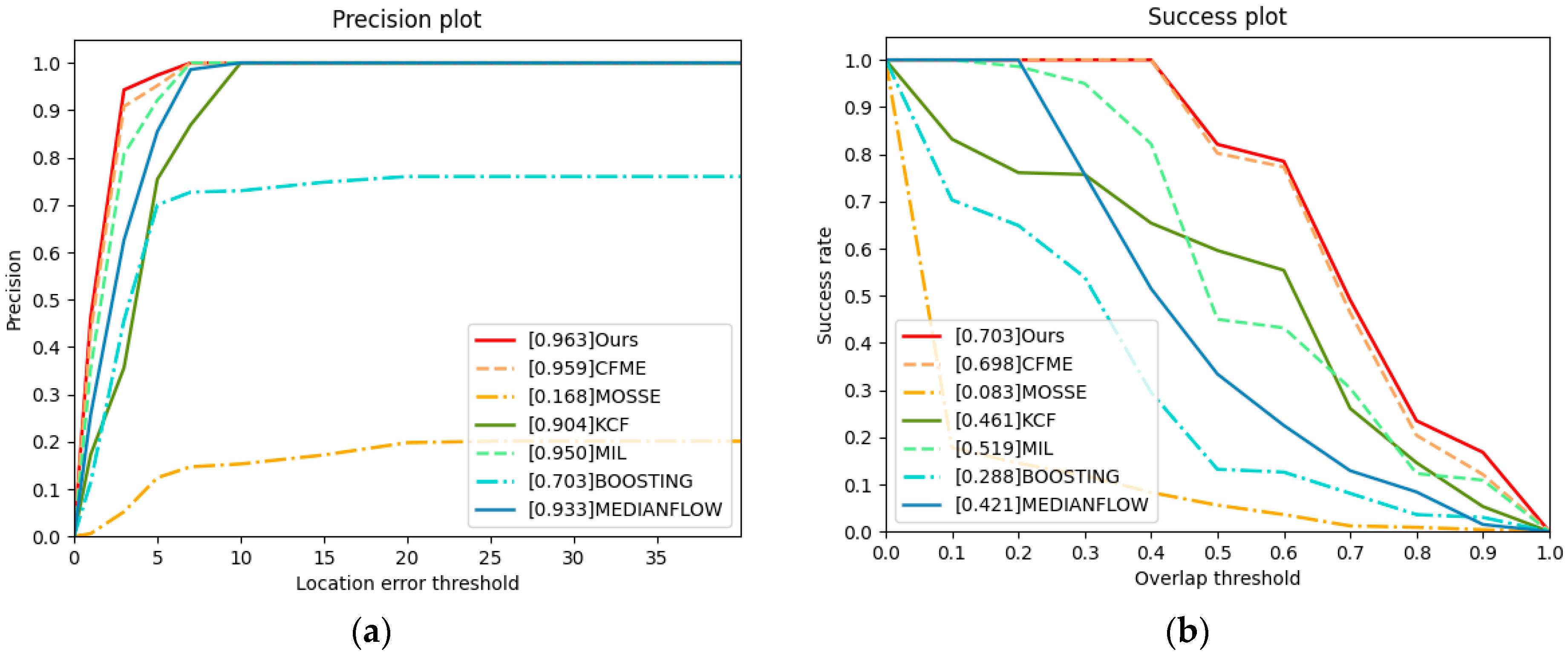
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}