Abstract
Land use is used to reflect the expression of human activities in space, and land use classification is a way to obtain accurate land use information. Obtaining high-precision land use classification from remote sensing images remains a significant challenge. Traditional machine learning methods and image semantic segmentation models are unable to make full use of the spatial and contextual information of images. This results in land use classification that does not meet high-precision requirements. In order to improve the accuracy of land use classification, we propose a land use classification model, called DADNet-CRFs, that integrates an attention mechanism and conditional random fields (CRFs). The model is divided into two modules: the Dual Attention Dense Network (DADNet) and CRFs. First, the convolution method in the UNet network is modified to Dense Convolution, and the band-hole pyramid pooling module, spatial location attention mechanism module, and channel attention mechanism module are fused at appropriate locations in the network, which together form DADNet. Second, the DADNet segmentation results are used as a priori conditions to guide the training of CRFs. The model is tested with the GID dataset, and the results show that the overall accuracy of land use classification obtained with this model is 7.36% and 1.61% higher than FCN-8s and BiSeNet in classification accuracy, 11.95% and 1.81% higher in MIoU accuracy, and with a 9.35% and 2.07% higher kappa coefficient, respectively. The proposed DADNet-CRFs model can fully use the spatial and contextual semantic information of high-resolution remote sensing images, and it effectively improves the accuracy of land use classification. The model can serve as a highly accurate automatic classification tool for land use classification and mapping high-resolution images.
1. Introduction
Land use information is fundamental to understanding the dynamic changes on the surface of the earth and socio-ecological interactions [1], and is essential in a number of fields of earth observations, such as urban and regional planning [2], environmental impact assessment, etc., [3,4]. Land use classification is a key way to obtaining land use information, and it is also a necessary means to deepen the interrelationship between human activities and the spatial environment [5,6,7]. With the continuous development of remote sensing technology, the spatial and temporal resolutions of remote sensing images have improved. The Worldview, SPOT and Ikonos series of satellites are capable of acquiring remote sensing images with high spatial resolution. Chinese satellite remote sensing technology has also entered the era of sub-meter level, with for instance the panchromatic band of Gaofen-2 reaching 0.8 m spatial resolution [8]. High-resolution remote sensing images contain rich spatial information and have become an important tool for land use classification research. Under the condition of high-resolution remote sensing images, it is especially important how to obtain high-precision land use information.
Traditional land use classification methods include visual interpretation classification, cluster analysis, and spectral classification. For example, Huang et al. [9] proposed geometric probability-based cluster analysis to improve land classification accuracy, and Tehrany et al. [10] used SPOT5 remote sensing images and an object-oriented k-nearest neighbor algorithm to effectively improve image land use classification. With the improvement of computer and remote sensing image technology, classification and spatial statistical techniques such as fuzzy, artificial neural network, support vector machine (SVM), and geo-detector have emerged [11,12,13,14,15,16,17]. For example, Li et al. [14] fused fuzzy and decision tree algorithms to achieve object-oriented land use classification in the Dongjiang River Basin. Talukdar et al. [15] used six machine-learning algorithms methods to assess land use classification and the six methods were random forest, SVM, artificial neural network, fuzzy adaptive resonance theory-supervised predictive mapping, spectral angle mapper, and Mahalanobis distance. Abdi et al. [16] used Sentinel-2 images and machine learning methods to obtain accurate land use classifications. Wang et al. [17] used a geo-detector to evaluate the spatial variation of prediction results in order to confirm the validity and applicability of their classification results.
Traditional land use classification methods have reduced labor costs to a certain extent, but their accuracy and timeliness still cannot meet the current demand in the era of big data. Obtaining high-precision land use classification is a serious challenge. Therefore, it is critical to improve the learning ability of land use classification models such that they can use spatial features and contextual semantic information from high-resolution remote sensing images to achieve high-precision land use classification.
Along with the rapid development of artificial intelligence technology, semantic segmentation techniques have gradually replaced traditional land use classification methods. Image semantic segmentation is the process of subdividing a digital image into multiple superpixels with the aim of simplifying or changing the presentation of the image to make it simpler and easier to understand and analyze [18]. Image semantic segmentation techniques are divided into traditional semantic segmentation techniques and deep learning based semantic segmentation techniques. Traditional semantic segmentation techniques include threshold-based image semantic segmentation, edge-based image semantic segmentation, region-based image semantic segmentation, and specific theory-based image semantic segmentation [19]. For example, in 2000, Shi and Malik proposed N-cut (Normalized Cut), a semantic segmentation method based on graph partitioning [20]. Based on this, Microsoft Cambridge Research proposed the famous interactive image semantic segmentation method, Grab Cut [21].
Traditional semantic segmentation techniques tend to use the low-order visual information of the image pixels themselves for segmentation without a training phase, and the results are not satisfactory in more difficult segmentation tasks. The birth of deep learning, with the continuous development of computer technology and hardware, essentially provide algorithms that use artificial neural networks as an architecture for learning representations of information [22]. More recently, models combining deep learning with image semantic segmentation have emerged and can be used for semantic segmentation. These include: The fully convolutional network (FCN) [23], based on a traditional convolutional neural network to solve the semantic segmentation problem at the pixel level; the residual convolutional network (ResNet), which uses residual structure to make the network deeper and converge faster compared to FCN-8s, effectively preventing gradient explosion and solving the problem of training difficulties as the number of network layers increases [24]; the dense convolutional network (DenseNet), which improves the computational efficiency and compresses the number of parameters compared to ResNet, solves the problem of large number of parameters and slow computational efficiency of ResNet, and achieves performance comparable to ResNet [25]; the dual attention network (DANet), which proposes a spatial location attention module and a channel attention module to capture the rich semantic information of images [26].
At present, it is difficult to further improve the accuracy of land use classification in the process of changing from traditional semantic segmentation techniques to deep learning-based semantic segmentation techniques. Sun et al. [27] showed that combining LiDAR data and high-resolution image data with a deep convolutional neural network can improve land use classification. Wang et al. [28] proposed a multi-scale neural network model based on a deep convolutional neural network using 0.5 m resolution optical aerial remote sensing images of Zhejiang Province as the data source, and compared it with traditional FCN and SVM methods. They showed that the multi-scale neural network model has higher accuracy and stronger overall classification results than traditional methods. Huang et al. [29] used Nanshan in Shenzhen City and Kowloon Peninsula, northern Hong Kong Island and Shatin, New Territories in Hong Kong City as study areas, using worldview-2 and worldview-3 as sample datasets, and the semi-transfer deep convolutional neural network (STDCNN) classification method. The STDCNN method can directly classify using multispectral image data, thus solving the problem of many classical networks which can only input three channels. Although semantic segmentation techniques based on deep learning have been widely used in the field of land use classification, due to the lack of constraints on image context information, only the local information of the image is used. Without the full spatial and contextual information of the image, the segmentation results are too smooth, other phenomena occur, and classification accuracy cannot be sufficiently improved.
To overcome the above difficulties, we propose a land use classification model combining attention mechanism and conditional random fields (CRFs). These models focus on spatial and contextual features, combining multi-scale semantic information of features, and improving the generalization ability of the model. CRFs introduce contextual information, fully consider the semantic linkage between pixels, refine the segmentation effect of edges, and improve the classification accuracy of land use. This study will help to improve the accuracy and applicability of land use classification models and provide a more effective modeling tool for land use classification and mapping research.
2. DADNet-CRFs
2.1. General Framework of the Model
The DADNet-CRFs model combines the DADNet and CRFs modules (Figure 1). DADNet is the application of the dense convolutional module of DenseNet to the encoding-decoding structure of U-Net model [30], and incorporates the channel attention mechanism and spatial attention mechanism atrous spatial pyramid pooling (ASPP) [31] method to enhance the model’s ability to learn contextual semantics and spatial features. Deep separable convolution is used to reduce the number of parameters and improve the training efficiency of the model. The input of the CRFs module is the result of DADNet, thus further optimizing the model results for edge segmentation and improving the overall continuity of the segmentation results.
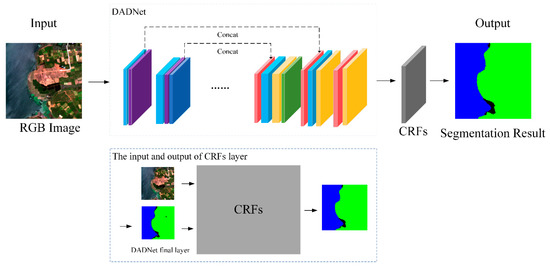
Figure 1.
General framework of DADNet-CRFs model.
2.2. DADNet
The DADNet model is a convolutional neural network built based on DenseNet and a channel and spatial location attention mechanism. The former features reduces the number of parameters and improves the computational efficiency of a model; the latter is able to solve the semantic segmentation of objects at different scales, as well as the fusion of similar features. The model framework uses the classical full convolutional network U-Net with the addition of DenseNet, a two-way attention module, and ASPP in the encoder and decoder, as shown in Figure 2.
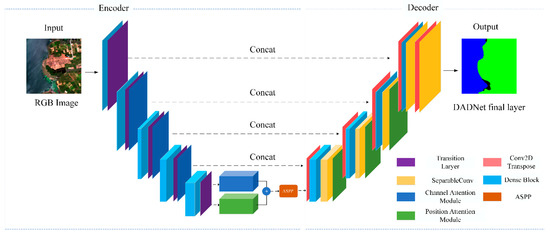
Figure 2.
DADNet network structure.
The encoder of DADNet includes the densely connected block and transition layer of DenseNet, as well as the spatial attention module (SAM) and the channel attention module (CAM), in which the sizes of the convolution kernels are 32 × 32, 64 × 64, 128 × 128, 256 × 256, and 512 × 512, respectively. After a series of downsampling, the feature maps are input to SAM and CAM respectively. The size of the feature maps is kept consistent before and after the application of the module, and then the two features are fused by summing. The decoder includes Transpose Convolution and CAM, and the fused feature maps are upsampled using Transpose Convolution, before and after the jump-connected tandem, combining the high-level semantic features from the decoder and the high-level semantic features from the encoder for the corresponding size feature maps. Finally, the segmentation result is output using the softmax activation function.
2.2.1. DenseNet
DenseNet is a densely connected network improved on ResNet. The combinatorial function is assumed to be , l refers to the number of layers, and the output of each layer is defined as . The conventional convolutional network connects the layer and the layer by forward propagation as follows.
ResNet adds jump connections, which short-circuit the lth layer to the previous 2 to 3 layers. The connections are summed at the element level, and the output is as in Equation (2). This solves the gradient explosion to a certain extent and enables feature sharing, but the connection by summation may lead to a loss of network information flow.
DenseNet aims to improve the utilization of information flow in the network. It uses dense connections, and the input of the lth layer is the output feature map of all the previous layers through forward feedback, which is directly connected using a series connection, as follows. This significant improvement of DenseNet over ResNet enables feature reuse and improves utilization efficiency.
The DenseNet network structure is mainly composed of densely connected blocks and transition layers, as shown in Figure 3. The feature maps of each layer of the densely connected blocks are of the same size and can be connected in series over the channels. The combined function structure is a 3 × 3 Separable Convolution layer + Batch Normal layer + Rectified Linear Units activation function layer.
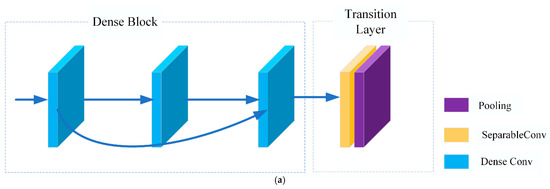
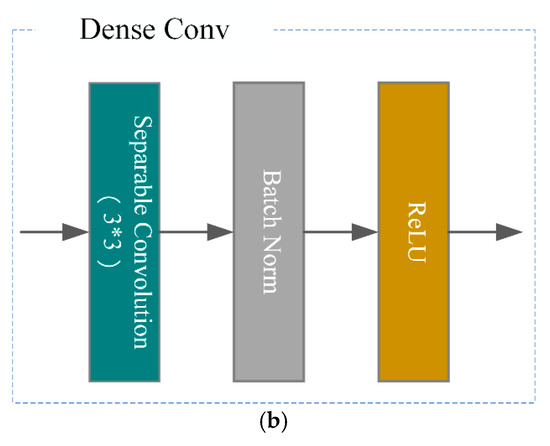
Figure 3.
DenseNet schematic showing (a) overall structure and (b) dense convolutional blocks.
The transition layer is used to connect two adjacent densely connected blocks and to reduce the feature map size. In DADNet, the structure of the encoder transition layer is 1 × 1 Separable Convolution + 2 × 2 MaxPooling layer, and in decoder it is 1 × 1 Separable Convolution + 3 × 3 Transpose Convolution layer.
2.2.2. SAM and CAM
For forward propagating convolutional neural networks, the convolutional block attention module (CBAM) is a simple and effective attention mechanism [32]. In this paper, embedding SAM and CAM, CBAM solves the global dependency problem, fuses similar features of objects of different sizes to some extent and avoids the labeling of large object features affecting inconspicuous small objects.
CAM is used to specify useful features and to fuse these features with each other as shown in Figure 4. The whole module has no convolution layer, and the input feature map A is subjected to reshape, multiply, transpose, softmax, sum, and multiply operations to complete the output feature map E. Specifically, Equations (4) and (5). A and E represent the input and output feature maps, respectively, ij is the number of rows and columns, β is a self-learnable parameter with an initial value of 0, and x is obtained by doing softmax operations on each row.
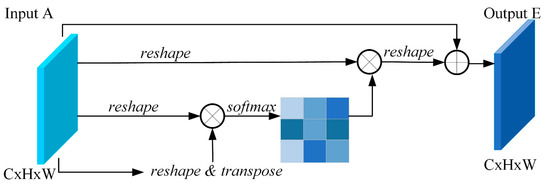
Figure 4.
CAM schematic [18].
SAM can make local features link contextual semantics for feature enhancement purposes, and similar features are fused after module computation. This is conducive to semantic segmentation, as shown in Figure 5, Equations (6) and (7). Unlike the channel attention module, the input feature map is first subjected to a convolution operation to obtain three feature maps B, C, and D. Then a series of calculations such as reshape, transpose, and phase multiplication are performed to output the feature map E, which is consistent with the shape of A. The parameter Sij is a softmax activation function after multiplying B and C. It can be understood that the greater the similarity between B and C, the greater the value of S, where the two are symmetrically related.
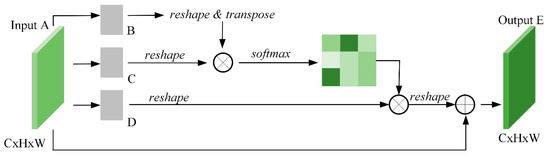
Figure 5.
SAM schematic [18].
Finally, the feature map E is output by linear combination with D. α is also a self-learning parameter with an initial value of 0. The formula is as follows.
2.2.3. ASPP
In high-resolution images, different scale features have obvious boundaries. The ASPP structure is used to fuse multi-scale information in order to increase the recognition ability of the model for multi-scale features. It learns the features of different scales by a set of dilated convolutions [33] with different sampling rates to improve the multi-scale feature segmentation accuracy. The ASPP structure is shown in Figure 6, and the specific calculation process is as follows.
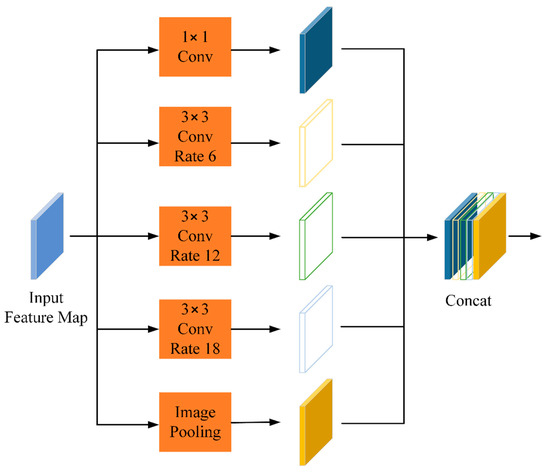
Figure 6.
ASPP structure.
denotes the stitching operation on feature results of different scales, is the convolution of holes with different sampling rates r and convolution kernel size n, and is the pooling operation on the input feature map.
2.3. CRFs
Lafferty et al. [34] proposed CRFs in 2001 as a family of discriminative probabilistic models that incorporates the features of maximum entropy models and Markov models. These models are mainly used for sequence labeling tasks and have been commonly used in recent years for semantic segmentation with good results. For example, Krahenbuhl et al. [35] used improved fully connected CRFs for effective image segmentation, and Chunjiao et al. [36] performed semantic segmentation of remote sensing images by deep fusion network CRFs for accurate recognition of edge contours.
CRFs are commonly used in the field of image semantic segmentation to compare the contextual information of the original image and the predicted labeled image simultaneously, and then model the class validation probabilities based on the relationship between pixels. Based on the proof of Hammersley–Clifford theorem, I in equation denotes a given high-resolution remote sensing image, and X is the posterior probability of the corresponding labeled image, which obeys a Gibbs distribution as follows.
Z(I) is the normalization factor and φc is the conditional potential energy function on the group c. Depending on the number of variables contained in c, the potential energy function is divided into first-order potential, second-order potential, and higher-order potential, as expressed below.
where is a first-order potential function and is a second-order potential function of the following form.
In the above equation, if , then , otherwise 0. is the weight of the Gaussian kernel function and is the Gaussian kernel function. The model is a linear combination of two Gaussian kernel functions as second-order potential functions, one Gaussian kernel function depends on both position and spectral information, and the other depends on position information only. The linear combination forms a model of CRFs to learn spatial contextual relationships, thus refining edge contours and improving segmentation accuracy. The details are as follows.
2.4. Accuracy Evaluation
Here, the semantic segmentation results are evaluated according to both qualitative and quantitative criteria. The qualitative evaluation is based on subjective judgment, such as whether the classification result is complete, the edge contour is clear, and the edges are consistent. For the quantitative evaluation, Recall, Precision, F1-score, overall accuracy (OA), and mean intersection over union (MIoU) are mainly used. TP is the predicted positive sample among positive samples, FN is the predicted negative sample among positive samples, FP is the predicted positive sample among negative samples, and TN is the predicted negative sample among negative samples.
Recall is the ratio of the number of correctly classified positive samples to the number of positive samples and is given by the following formula.
Precision is the ratio of the number of correctly classified positive samples to the number of all positive samples in the classification result, as follows.
F1 score is the index proposed to evaluate the model based on Precision and Recall, and to evaluate Precision and Recall as a whole, as defined below.
OA is the ratio of the number of correctly classified samples to the number of all samples and is defined as follows.
MIoU is used to calculate the ratio of the intersection and concatenation of the two sets of true and predicted values. It results in a global evaluation of the semantic segmentation results, as defined below.
The kappa coefficient is also used as a measure of classification accuracy. In practical classification problems, the kappa coefficient is often used as an indicator of the “bias” of the penalty model instead of OA when there is a poor balance between the samples. The more unbalanced the classification result, the lower the kappa coefficient value. The number of true samples in each category is assumed to be , the number of predicted samples for each category is , the total number of samples is , and is the chance consistency error.
The significance test performed in this paper is Independent Samples Z-Test. The Independent Samples Z-Test is a statistical test used to determine if there is a significant difference between two different groups of samples. The samples should be continuous and satisfy a normal distribution. There is also a similar distribution between the samples.
3. Experiments and Results
3.1. Experimental Data
GID (see Table 1) is a high-resolution remote sensing image dataset for land use/land cover (LULC) classification, collected from December 2014 to October 2016 [37]. It consists of two parts. One part is a large-scale classification set, which includes 150 high resolution GaoFen-2 remote sensing images from more than 60 different cities in China, covering a geographical area of more than 50,000 km2. The individual image size is 6800 × 7200 pixels, with a spatial resolution of 1 m, in RGB form and NIR+RGB form. The land types are Built-up, Farmland, Forest, Meadow and Water, a total of five categories (see Figure 7); the other part is the secondary land use type, comprising 25 HIS-2 images. The secondary land use types are industrial land, urban residential, rural residential, traffic land, paddy field, irrigated land, dry cropland, garden land, arbor forest, shrub land, natural meadow, artificial meadow, river, lake and pond, totaling 15 categories.

Table 1.
Introduction of experiment image data.
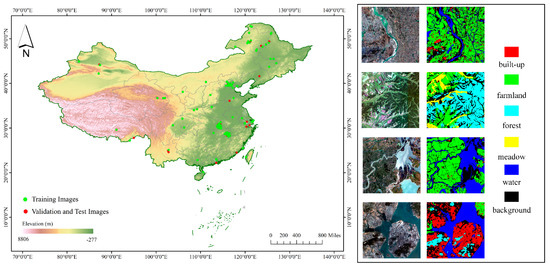
Figure 7.
(Left): The geographical locations of GID images. This experiment selects 120 training images and 30 validation test images, which are marked with green and red respectively. (Right): Examples of GID images and their corresponding label. The RGB of each feature in labels: built-up (255,0,0), farmland (0,255,0), forest (0,255,255), meadow (255,255,0), water (0,0,255), background (0,0,0).
We used GID large-scale data for our experiment, this is because the GID large-scale data basically covers the major cities and basic landscapes in China, and its land use category is based on the Chinese Land Use Classification Criteria (GB/T21010-2017) as a reference. The experiment randomly selected 120 images from 150 remote sensing images as the training set, 15 images from the remaining 30 images as the validation set, and other images as the test set. All images were cropped to the size of 224 × 224 pixels. A large-scale experimental dataset was obtained, then put into the model for training and validation, and finally, the accuracy of the cropped images was compared after prediction. The details are shown in Table 2.
Table 2.
Number of experiment data categories.
3.2. Experimental Results and Analysis
To verify the superiority of DADNet-CRFs, it was compared with the model without fused CRFs, as well as with the two models, FCN-8s and Bilateral Segmentation Network (BiSeNet) [38] in terms of accuracy and segmentation details. The classical semantic segmentation model, FCN-8s, achieves semantic segmentation at the pixel level, and its adoption of jumping structure is widely used in other algorithmic models. BiSeNet is a model proposed in recent years which adopts feature fusion and attention optimization modules and retains sufficient spatial and visual field domain information while improving calculation speed.
3.2.1. Visual Analysis of Classification Results
To further compare the classification results of different models, four cropped images were selected for analysis. The results are shown in Figure 8.
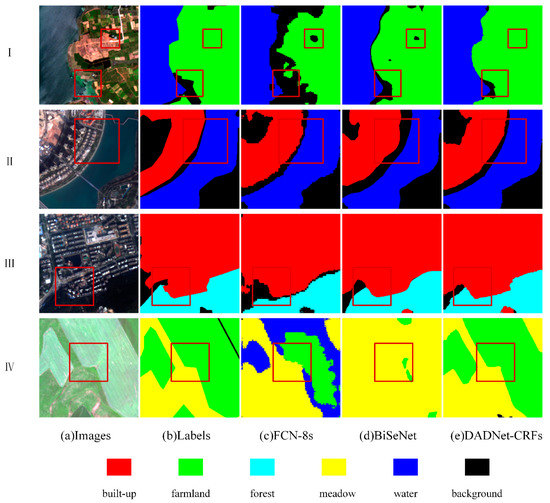
Figure 8.
Comparison of segmentation results of different models. The red square is where DADNet-CRFs perform even better.
In Group I, the classification results of FCN-8s were more fragmented than those of the BiSeNet method for Farmland, and the boundary between Farmland and Water appeared obviously incorrect. The overall segmentation effect of DADNet-CRFs Farmland was not only continuous, but the model also distinguished well Water, Farmland, and Background.
In Group II: all three methods showed over-segmentation of the Built-up area. FCN-8s had an obvious jagged segmentation result, and DADNet-CRFs segmented the Built-up area fringes better than the first two.
In Group III: BiSeNet segmented the areas better than FCN-8s, but the Built-up area and Forest contours were too smooth, and DADNet-CRFs preserved the spatial patterns of land types well.
In Group IV: FCN-8s and BiSeNet showed obvious classification errors. FCN-8s could not distinguish Water, Meadow, and Farmland well. BiSeNet identified a large amount of Farmland as Meadow, but DADNet-CRFs had a better overall classification recognition effect. Overall, the DADNet-CRFs model was better than both FCN-8s and BiSeNet in terms of classification effect.
3.2.2. Analysis of the Accuracy of Classification Results
The classification results of the test set were statistically compared with the semantic segmentation accuracy evaluation results of the three models, see Table 3. In the recall comparison, DADNet-CRFs performed best and had the highest recall of all types. In the precision comparison, FCN-8s had the highest precision in the Forest category, BiSeNet had the highest precision in the Water category, and DADNet-CRFs had the highest accuracy in the three categories of Built-up, Farmland and Meadow. In the F1-score comparison, DADNet-CRFs had the highest F1-score in all categories, except for the Water category of BiSeNet model, which had the highest F1-score. In the OA comparison, the OA of FCN-8s was 80.62% and that of BiSeNet was 86.37%, and the OA of DADNet-CRFs improved by 7.36% and 1.61% compared to FCN-8s and BiSeNet, respectively. In the MIoU comparison, DADNet-CRFs had the highest MIoU of 69.47%, while the MIoU of FCN-8s and BiSeNet were 57.52% and 67.66%, respectively. The kappa coefficient of DADNet-CRFs reached 84.70%, which was 9.35% and 2.07% higher than that of FCN-8s and BiSeNet, respectively.
Table 3.
Evaluation table of classification results. The bolded numbers are the best performing models in terms of accuracy.
Based on the prediction results, we conducted further significance tests for the FCN-8s, BiSeNet, and DADNet-CRFs models by taking Independent Sample Z-tests. The results show that the significance levels among the models are all less than 0.05, and there are significant differences. Then, we performed a pre- and post-CRF optimization analysis on the experimental models.
3.2.3. Analysis of Model Performance Differences before and after Optimization Using CRFs
The maximum number of iterations of CRFs was adjusted, a test set image was randomly selected, and the number of iterations with the highest OA and MIoU accuracy was chosen to optimize the model classification results. Differences in model performance before and after optimization using CRFs were used to analyze the effectiveness of including CRFs in classification models.
We performed a visual judgment analysis on Figure 9.

Figure 9.
Classification results before and after combining models with CRFs. The red square is where DADNet-CRFs perform even better.
In Group I: Farmland showed obvious holes in the DADNet classification results, while this category remained more intact in the DADNet-CRFs classification results.
In Group II: the DADNet and DADNet-CRFs classifications were clearer for the Water segmentation, and the feature integrity was better maintained. DADNet-CRFs were smoother on the edges of Water and Built-up.
In Group III: DADNet and DADNet-CRFs showed clearer classification for Forest and Built-up area, but the Built-up area was enlarged to different degrees. Moreover, there was a gap between Forest and Built-up in DADNet classification results, while DADNet-CRFs did not have this problem and showed smoother performance on the edges.
In Group IV: both DADNet and DADNet-CRFs classification results misclassified Farmland into Meadow in the upper right and bottom regions of the sample area, but DADNet-CRFs still effectively reduced the effect of noise, and the classification results were smoother. Overall, DADNet-CRFs had better classification results than DADNet.
To further demonstrate the classification effect after adopting CRFs, the FCN-8s, BiSeNet and DADNet models were combined with CRFs, and a single test set image was randomly selected for accuracy comparison before and after the combination. Table 4 shows that the classification accuracy of land use types was improved after combining FCN-8s, BiSeNet, and DADNet models with CRFs. Among them, the Forest classification accuracy of FCN-8s-CRFs model improved the most, reaching 2.12%; the Farmland classification accuracy of BiSeNet-CRFs model improved the most, reaching 3.64%; the Forest classification accuracy of DADNet-CRFs model improved the most, reaching 1.13%.
Table 4.
Comparison of accuracy before and after combining the land classification models with CRFs. The bolded numbers are the best performing models in terms of accuracy.
The overall classification accuracies of FCN-8s-CRFs, BiSeNet- CRFs, and DADNet-CRFs were 90.70%, 92.44%, and 93.04%, respectively, higher by 0.70%, 1.23%, and 0.42% respectively than before combining with CRFs. Among all models, the overall accuracy of DADNet-CRFs was the highest, except for Farmland. The classification accuracy of all other types was the highest, including 93.09% for Built-up and 97.30% for Water.
In summary, combining CRFs with FCN-8s, BiSeNet and DADNet models can improve the classification accuracy of the models to some extent, and the DADNet-CRFs model provides the best accuracy, from both visual and quantitative comparisons.
3.3. Time Consumption
About the time consumption of DADNet-CRFs model, tests were performed on the small sample GID dataset, and the training times of different models were compared (Table 5), with time units in seconds. From the table, we can find that the time consumption of the model in this paper is approximately equal to that of the BiSeNet model. Compared with than the FCN-8s model, the computation time is more than 1000 s faster, and the average time consumed per step is a few 10 s faster.
Table 5.
Training time comparison.
4. Discussion
Classical deep learning semantic segmentation models are not very effective in land use classification due to the loss of spatial and contextual semantic features, since they use only local information in images. To solve this problem, we fully integrated the advantages of attention mechanisms and CRFs and proposed a new land use classification model, DADNet-CRFs. Both visual analysis and evaluation metrics showed that DADNet-CRFs have better classification accuracy than FCN-8s and BiSeNet models [23,38]. The overall accuracy was improved by 7.36% and 1.61% compared to FCN-8s and BiSeNet models, respectively. CRFs were also found to enhance the accuracy of classification results for FCN-8s, BiSeNet, and DADNet models. The results were tested by randomly selecting single test set images and found to be improved by 0.70%, 1.23%, and 0.42%, respectively, compared with those before combining CRFs. Among the three combined models, DADNet-CRFs had the highest overall classification accuracy of 93.04%. Under the same conditions of environment, the DADNet-CRFs model has shorter training time and higher classification efficiency compared with the FCN-8s and BiSeNet models. The DADNet-CRFs model can effectively enhance the accuracy of land use classification results and improve the classification effect.
First, to improve the model’s ability to learn contextual semantic features and spatial connections, Hou Biao et al. [39] modified the DeepLab V3+ network by adding a path for upsampling, thus realizing the union of feature maps at different scales. Compared to the research method in their study, DADNet uses the SAM module to fuse the pixel with the location information of every other pixel, associating similar spatial features with each other, thereby preventing the occurrence of feature classification errors, and cooperating with ASPP to learn features at different scales in space. Li Rui et al. [40] developed the Attention Aggregation Feature Pyramid Network (A2-FPN) by adding an attention aggregation module to the FPN pyramid. Although the attention aggregation module can enhance the learning of multi-scale features, compared to A2-FPN, DADNet-CRFs incorporates both spatial location attention and channel attention mechanisms [33]. In the model, the spatial location attention module is used for multi-scale feature learning and the channel attention module, by constructing interdependencies between channel feature maps to improve the semantic-specific feature representation.
In addition, when processing details in the segmentation results, such as image edge optimization and overall continuity, the Edge-FCN network introduces a holistically nested edge detection (HED) network to detect edge information. This significantly improves edge segmentation [41], although the problem of mis-segmentation between significantly different features such as forest and water arise. The graph convolutional network (GCN) is a new type of deep neural network that can use the structural information of graphs and work directly on images [42], with significant nulling problems and insufficient edge smoothing in the classification results with the GID dataset. Compared to GCN, DADNet-CRFs uses DADNet results as a priori condition. CRFs further optimize the classification results by encouraging similar pixels to be assigned the same labels, while pixels with large differences are assigned different labels. This results in more precise refinement of edge contours, less problems with voids, and a more continuous classification effect overall [35].
To a certain extent, the DADNet-CRFs model still results in misclassification of similar features, especially misclassifying Background as Built-up and Farmland as Meadow. The ability of the model to learn feature characteristics is not perfect, especially in distinguishing features that are very similar. The GID dataset has an excessive amount of Background, a very small number of Meadow and Forest pixels, and it is extremely unbalanced in terms of types [43,44]. This can easily lead to misclassification of the corresponding land cover types and lower classification accuracy. In addition, the GID dataset may also have inaccurate data for some of the labels, and the research method in this paper does not adopt relevant strategies like Updating Iteration Strategy [39] for this situation. The above two types of problems will aggravate the misclassification by models such as DADNet-CRFs, leading to a decrease in classification accuracy. The overall accuracy improvement was relatively limited after combining FCN-8s, BiSeNet, and DADNet with CRFs. The classification accuracy of FCN-8s-CRFs, BiSeNet-CRFs, and DADNet-CRFs was dependent on the classification performance of the original model. The classification accuracy of Farmland was generally at a low level with more misclassifications compared to other land use types (Table 4). The large difference with the classification accuracy of Farmland in the test set (Table 4) may be related to the label quality of the single test data in the GID dataset.
Going forward, we suggest further optimizing the method of coupling land classification models with CRFs and deep learning models to maximize the learning migration capability of the model and applies to land use classification in different spatial and temporal resolution situations. At the same time, data enhancement, expansion of the dataset, and elimination of inaccurate data could all improve the classification accuracy of the model. The DADNet model parameters have a larger number of parameters and longer training time compared to the other two models. Therefore, the DADNet model needs to be improved and optimized to reduce the parameters as much as possible and improve the training efficiency of the model without losing its classification ability.
5. Conclusions
This paper proposed DADNet-CRFs, a land use classification model integrating attention mechanism and CRFs. At the beginning, this paper draws on the UNet network structure and combines Dense Convolution, ASPP, SAM, and CAM to complete the construction of the DADNet model. Then, the DADNet model classification results are input into CRFs and used to guide the CRFs training. In this paper, experiments are conducted on the basis of GID large-scale dataset to compare the DADNet-CRFs model with FCN-8s and BiSeNet models. The results show that DADNet-CRFs can improve the model’s ability to learn spatial features of land use features, enhance the semantic links between contexts, and achieve high-precision land use classification.
In future research, we will further optimize the method in terms of model structure and data set to improve the model training efficiency and classification accuracy. At the same time, we will enhance the generality and learning migration capability of the model so that it can be applied to land use classification and mapping applications at different spatial and temporal resolutions.
Author Contributions
Conceptualization, K.Z.; methodology, H.W. and K.Z.; formal analysis, Z.H.; investigation, K.Z., H.W. and F.Q.; data curation, K.Z.; writing—original draft preparation, K.Z.; writing—review and editing, H.W.; visualization, K.Z.; supervision, H.W. and F.Q. All authors have read and agreed to the published version of the manuscript.
Funding
The authors gratefully acknowledge support by the National Nature Science Foundation of China, Grant/Award Number: 41871316, 41401457; Young Key Teacher Training Plan of Henan, Grant/Award Number: 2020GGJS028; Natural Science Foundation of Henan, Grant/Award Number: 202300410096; Natural Resources Science and Technology Innovation Project of Henan Province, Grant/Award Number: 202016511; Key Scientific Research Project Plans of Higher Education Institutions of Henan, Grant/Award Number: 21A170008; Technology Development Plan Project of Kaifeng, Grant/Award Number: 2003009.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The research was also supported by the National Earth System Science Data Sharing Infrastructure, National Science & Technology Infrastructure of China-Data Center of Lower Yellow River Regions (http://henu.geodata.cn accessed on 19 September 2021).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
| CRFs | conditional random fields |
| DADNet | dual attention dense network |
| N-cut | normalized cut |
| FCN | fully convolutional network |
| ResNet | residual convolutional network |
| DenseNet | dense convolutional network |
| DANet | dual attention network |
| STDCNN | semi-transfer deep convolutional neural network |
| ASPP | atrous spatial pyramid pooling |
| SAM | spatial attention module |
| CAM | channel attention module |
| CBAM | convolutional block attention module |
| OA | overall accuracy |
| MIoU | mean intersection over union |
| LULC | land use/land cover |
| BiSeNet | bilateral segmentation network |
| A2-FPN | attention aggregation feature pyramid network |
| HED | holistically nested edge detection |
| GCN | graph convolutional network |
References
- Liu, X.; He, J.; Yao, Y.; Zhang, J.; Liang, H.; Wang, H.; Hong, Y. Classifying Urban Land Use by Integrating Remote Sensing and Social Media Data. Int. J. Geogr. Inf. Sci. 2017, 31, 1675–1696. [Google Scholar] [CrossRef]
- Hashem, N.; Balakrishnan, P. Change Analysis of Land Use/Land Cover and Modelling Urban Growth in Greater Doha, Qatar. Ann. GIS 2015, 21, 233–247. [Google Scholar] [CrossRef]
- Nguyen, K.-A.; Liou, Y.-A. Mapping Global Eco-Environment Vulnerability Due to Human and Nature Disturbances. MethodsX 2019, 6, 862–875. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, K.-A.; Liou, Y.-A. Global Mapping of Eco-Environmental Vulnerability from Human and Nature Disturbances. Sci. Total Environ. 2019, 664, 995–1004. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. Joint Deep Learning for Land Cover and Land Use Classification. Remote Sens. Environ. 2019, 221, 173–187. [Google Scholar] [CrossRef] [Green Version]
- Patino, J.E.; Duque, J.C. A Review of Regional Science Applications of Satellite Remote Sensing in Urban Settings. Comput. Environ. Urban Syst. 2013, 37, 1–17. [Google Scholar] [CrossRef]
- Cassidy, L.; Binford, M.; Southworth, J.; Barnes, G. Social and Ecological Factors and Land-Use Land-Cover Diversity in Two Provinces in Southeast Asia. J. Land Use Sci. 2010, 5, 277–306. [Google Scholar] [CrossRef]
- Bing, Z. Current Status and Future Prospects of Remote Sensing. Bull. Chin. Acad. Sci. Chin. Version 2017, 32, 774–784. [Google Scholar] [CrossRef]
- Li-wen, H. The Cluster Analysis Approaches Based on Geometric Probability and Its Application in the Classification of Remotely Sensed Images. J. Image Graph. 2007, 12, 633–640. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebuv, M.N. A Comparative Assessment between Object and Pixel-Based Classification Approaches for Land Use/Land Cover Mapping Using SPOT 5 Imagery. Geocarto Int. 2014, 29, 351–369. [Google Scholar] [CrossRef]
- Halder, A.; Ghosh, A.; Ghosh, S. Supervised and Unsupervised Landuse Map Generation from Remotely Sensed Images Using Ant Based Systems. Appl. Soft Comput. 2011, 11, 5770–5781. [Google Scholar] [CrossRef]
- Adam, E.; Mutanga, O.; Odindi, J.; Abdel-Rahman, E.M. Land-Use/Cover Classification in a Heterogeneous Coastal Landscape Using RapidEye Imagery: Evaluating the Performance of Random Forest and Support Vector Machines Classifiers. Int. J. Remote Sens. 2014, 35, 3440–3458. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of Machine-Learning Classification in Remote Sensing: An Applied Review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Hengkai, L.; Jiao, W.; Xiuli, W. Object Oriented Land Use Classification of Dongjiang River Basin Based on GF-1 Image. Trans. Chin. Soc. Agric. Eng. 2018, 34, 245–252. [Google Scholar] [CrossRef]
- Talukdar, S.; Singha, P.; Mahato, S.; Shahfahad, P.S.; Liou, Y.-A.; Rahman, A. Land-Use Land-Cover Classification by Machine Learning Classifiers for Satellite Observations—A Review. Remote Sens. 2020, 12, 1135. [Google Scholar] [CrossRef] [Green Version]
- Abdi, A.M. Land Cover and Land Use Classification Performance of Machine Learning Algorithms in a Boreal Landscape Using Sentinel-2 Data. GIScience Remote Sens. 2020, 57, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Qin, F.; Xu, C.; Li, B.; Guo, L.; Wang, Z. Evaluating the Suitability of Urban Development Land with a Geodetector. Ecol. Indic. 2021, 123, 107339. [Google Scholar] [CrossRef]
- Shapiro, L.G.; Stockman, G.C. Computer Vision; Prentice Hall: Hoboken, NJ, USA, 2001; ISBN 978-0-13-030796-5. [Google Scholar]
- Liang, X.; Luo, C.; Quan, J.; Xiao, K.; Gao, W. Research on Progress of Image Semantic Segmentation Based on Deep Learning. Comput. Eng. Appl. 2020, 56, 18–28. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized Cuts and Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar] [CrossRef] [Green Version]
- Rother, C.; Kolmogorov, V.; Blake, A. “GrabCut”: Interactive Foreground Extraction Using Iterated Graph Cuts. ACM Trans. Graph. 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Deng, L. Deep Learning: Methods and Applications. FNT Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef] [Green Version]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition; IEEE: Piscataway Township, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks; IEEE: Piscataway Township, NJ, USA, 2017; pp. 4700–4708. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. arXiv 2019, arXiv:1809.02983, 3146–3154. [Google Scholar]
- Sun, Y.; Zhang, X.; Xin, Q.; Huang, J. Developing a Multi-Filter Convolutional Neural Network for Semantic Segmentation Using High-Resolution Aerial Imagery and LiDAR Data. ISPRS J. Photogramm. Remote Sens. 2018, 143, 3–14. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, X.; Su, C. Land use classification of remote sensing images based on multi-scale learning and deep convolution neural network. J. ZheJiang Univ. Sci. Ed. 2020, 47, 715–723. [Google Scholar] [CrossRef]
- Huang, B.; Zhao, B.; Song, Y. Urban Land-Use Mapping Using a Deep Convolutional Neural Network with High Spatial Resolution Multispectral Remote Sensing Imagery. Remote Sens. Environ. 2018, 214, 73–86. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11211, pp. 3–19. ISBN 978-3-030-01233-5. [Google Scholar]
- Liu, R.; Shen, J.; Wang, H.; Chen, C.; Cheung, S.; Asari, V.K. Enhanced 3D Human Pose Estimation from Videos by Using Attention-Based Neural Network with Dilated Convolutions. Int. J. Comput. Vis. 2021, 129, 1596–1615. [Google Scholar] [CrossRef]
- Lafferty, J.D.; McCallum, A.; Pereira, F.C.N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the Eighteenth International Conference on Machine Learning; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2001; pp. 282–289. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2011; Volume 24. [Google Scholar]
- Xiao, C.; Li, Y.; Zhang, H.; Chen, J. Semantic segmentation of remote sensing image based on deep fusion networks and conditional random field. Zggx 2021, 24, 254–264. [Google Scholar] [CrossRef]
- Tong, X.-Y.; Xia, G.-S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-Cover Classification with High-Resolution Remote Sensing Images Using Transferable Deep Models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef] [Green Version]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral Segmentation Network for Real-Time Semantic Segmentation. arXiv 2018, arXiv:1808.00897, 325–341. [Google Scholar]
- Hou, B.; Liu, Y.; Rong, T.; Ren, B.; Xiang, Z.; Zhang, X.; Wang, S. Panchromatic Image Land Cover Classification Via DCNN with Updating Iteration Strategy. In Proceedings of the IGARSS 2020–2020 IEEE International Geoscience and Remote Sensing Symposium, 2 October–26 September 2020; pp. 1472–1475. [Google Scholar]
- Li, R.; Wang, L.; Zhang, C.; Duan, C.; Zheng, S. A2-FPN for Semantic Segmentation of Fine-Resolution Remotely Sensed Images. Int. J. Remote Sens. 2022, 43, 1131–1155. [Google Scholar] [CrossRef]
- He, C.; Li, S.; Xiong, D.; Fang, P.; Liao, M. Remote Sensing Image Semantic Segmentation Based on Edge Information Guidance. Remote Sens. 2020, 12, 1501. [Google Scholar] [CrossRef]
- He, S.; Lu, X.; Gu, J.; Tang, H.; Yu, Q.; Liu, K.; Ding, H.; Chang, C.; Wang, N. RSI-Net: Two-Stream Deep Neural Network for Remote Sensing Images-Based Semantic Segmentation. IEEE Access 2022, 10, 34858–34871. [Google Scholar] [CrossRef]
- Li, J.; Xiu, J.; Yang, Z.; Liu, C. Dual Path Attention Net for Remote Sensing Semantic Image Segmentation. ISPRS Int. J. Geo-Inf. 2020, 9, 571. [Google Scholar] [CrossRef]
- Yang, K.; Liu, Z.; Lu, Q.; Xia, G.-S. Multi-Scale Weighted Branch Network for Remote Sensing Image Classification; IEEE: Piscataway Township, NJ, USA, 2019; pp. 1–10. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).