1. Introduction
With the rapid development of hyperspectral imaging technology, people can easily obtain hyperspectral images (HSI) containing hundreds of bands of useful information [
1]. Nowadays, hyperspectral imaging technology plays an important role in the military, economics, agriculture, environmental monitoring and other fields. The essence of the application of HSI is to classify them. How to quickly and accurately classify each pixel in HSI is the core issue.
People have done a lot of exploration and adopted many methods on the land cover classification based on HSI. The early-staged methods are mainly based on conventional pattern recognition methods, such as nearest neighbor classifier and linear classifier, including the classic k-nearest-neighbor algorithm [
2] and support vector machine (SVM) [
3]. Besides, there are many methods that have been further used to improve the performance of HSI classification, such as extreme learning machines [
4], and sparse representation-based classifiers [
5].
However, it is difficult to accurately distinguish features using only spectral information [
6]. Many researchers used the spatial texture features of the image to design classifiers for spectral and spatial information and achieved better classification results [
7,
8]. Spectrum-spatial classification methods can generally be divided into two categories. The first method extracts spatial feature information and then combines it with spectral features [
9,
10]. The second method directly combines spatial information with spectral features and uses joint features to classify [
11]. In addition, some scholars divided HSI into superpixels based on the spectral and spatial data of HSI and input the feature data of superpixels into SVM to obtain the classification results of HSI [
12,
13,
14]. Recently, some scholars have proposed a superpixel-based HSI classification method using sparse representation [
15,
16] and achieved good classification results.
Many conventional feature extraction methods are based on hand-made features and heavily depend on professional knowledge and experience. In recent years, deep learning methods have received widespread attention due to their powerful representation ability and have been widely used in HSI classification tasks [
17,
18,
19,
20,
21]. The deep learning method does not rely on artificially designed shallow features. It can automatically acquire the high-level features of the features by gradually aggregating the low-level features in the data. These features have achieved great success in machine vision tasks. Chen et al. [
17] first used deep learning methods for HSI classification. They used stacked autoencoders (SAE) and deep belief networks (DBN) for feature extraction and classification in spectral space. Subsequently, a convolutional neural network (CNN) was widely used in HSI classification due to its powerful image processing capabilities [
22,
23,
24]. Hu et al. [
25] proposed 1-D CNN to directly classify HSI in the spectral domain. Chen et al. [
26] proposed 3-D CNN to extract the spectral and spatial features of HSI at the same time and achieved good results. Haque et al. [
27] proposed a lightweight 3D–2D convolutional neural network framework, which reduces the computational burden through data dimensionality reduction, and uses 3D and 2D convolution operations to extract spatial and spectral features, obtaining good results and achieving high classification accuracy.
However, CNN models only convolve on regular square regions, so they cannot adaptively capture the geometric changes of different object regions in HSI. In addition, when convolving all image blocks, the weight of each convolution kernel is the same. This leads to the CNN possibly losing information regarding the class boundary in the process of feature abstraction, and misclassification may occur due to the fixed convolution kernel. In other words, the convolution kernel with a fixed shape, size, and weight are not suitable for all regions in the HSI. In addition, due to the existence of a large number of parameters, CNN-based methods usually require a long training time.
In addition to CNN, some other categories of networks are also used to classify HSI. As a widely used model in the field of image segmentation, a fully convolutional network (FCN) [
28] has been successfully applied to the HSI classification task. The model uses convolutional layers and pooling layers, which can effectively learn the deep features of HSI and improve the classification performance. Furthermore, as a feedforward neural network, recurrent neural networks (RNN) [
20] have been studied for HSI classification tasks. RNN can build a sequential model to effectively simulate the relationship between adjacent spectral bands. In the meantime, generative adversarial network (GAN)-based [
29] has also been introduced for HSI classification. In recent years, Sun et al. [
30] introduced the Transformer framework to the HSI classification task, and they used a spectral-spatial feature tokenization transformer (SSFTT) method to capture both spectral-spatial features and high-level semantic features and achieved good results.
Compared with the method mentioned above, graph convolutional networks (GCN) [
31] can be directly applied to non-Euclidean data. In [
32,
33], GCN was applied to HSI classification. However, some problems will occur when the conventional GCN is directly applied to HSI classification. First, due to noise pollution in HSI, the edge weights of paired pixels may not represent their inherent similarity, which may lead to inaccuracy in the initial construction of the input image. In addition, GCN can only use the spectral features of the image but ignore the spatial features and the computational cost of directly using pixels as nodes to construct a graph is unbearable. In response to these problems, Wan et al. [
34] proposed a multiscale dynamic graph convolutional network (MDGCN) and achieved good results. However, there are some problems with MDGCN. For example, a multiscale fusion of spectral and spatial embedded information is directly spliced and added, and there are no multiple weights to correspond to different scales of information. The model treats all neighboring nodes equally when constructing the graph and cannot assign different weights to nodes based on their importance. Only the neighborhood information is considered, and the global spatial information of remote sensing images is ignored.
Based on the aforementioned background, we present a method called ‘multiscale fusion-evolution graph convolutional network based on feature-spatial attention mechanism’ (MFEGCN-FSAM). We refer to the method of [
34], using a superpixel segmentation algorithm to segment the image into a certain number of superpixels and regard each superpixel as a node in the graph. Through this method, the computational cost on the graph will be greatly reduced, and the impact of over-fitting can be reduced at the same time. In order to make full use of the multiscale spatial and spectral context information of HSI, this paper establishes input graphs locally and globally at different scales to flexibly capture spatial and spectral features at different scales. This paper proposes a fusion evolution method by which the graph can be automatically evolved to make the feature embeddings more accurate during the convolution process. The model introduces the attention mechanism, which assigns corresponding weights to the nodes in the graph and has achieved good results in experiments.
To sum up, the main contributions of the proposed MFEGCN-FSAM are as follows:
First, we propose a fusion evolution method that enables the graph to be continuously updated during the convolution process to generate feature embeddings more accurately. Instead of using the initial fixed graph for convolution, we designed a fusion and evolution method. In the process of graph convolution, the structural information and node embeddings of the current graph are fused, and the graph structure evolves and updates accordingly. Therefore, this method can make the graph continuously updated during the convolution process to generate more accurate feature embeddings. The operations of graph fusion and evolution are constantly alternated during the training process, which works collaboratively to produce more reasonable graph structures and promising classification results.
Second, we establish input graphs locally and globally at different scales. In order to take the multiscale information into consideration, we construct input graphs locally and globally at different scales to fully utilize the spatial and spectral information of HSI. Unlike the common GCN models that only use one fixed graph, the multiscale design enables MFEGCN-FSAM to extract spectral-spatial features with different receptive fields so that comprehensive contextual information from different levels can be integrated.
Third, we design a feature-spatial attention module, which effectively highlights the important information in the graph by paying attention to the important local structures and features of the graph to enhance the representation ability of the model.
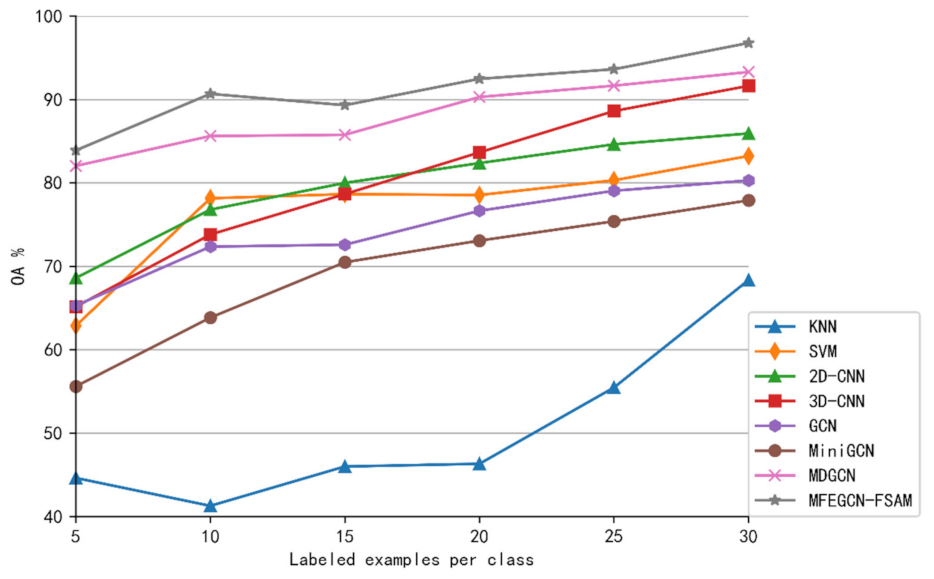
Finally, experimental results on four typical hyperspectral image datasets show that MFEGCN-FSAM achieves good performance compared to existing methods.
The remainder of this paper is organized as follows.
Section 2 first provides an introduction to the relevant background.
Section 3 introduces the MFEGCN-FSAM method we proposed in detail.
Section 4 is the experimental results and analysis. Finally, we summarize the work and conclude this paper in
Section 5.
3. Method
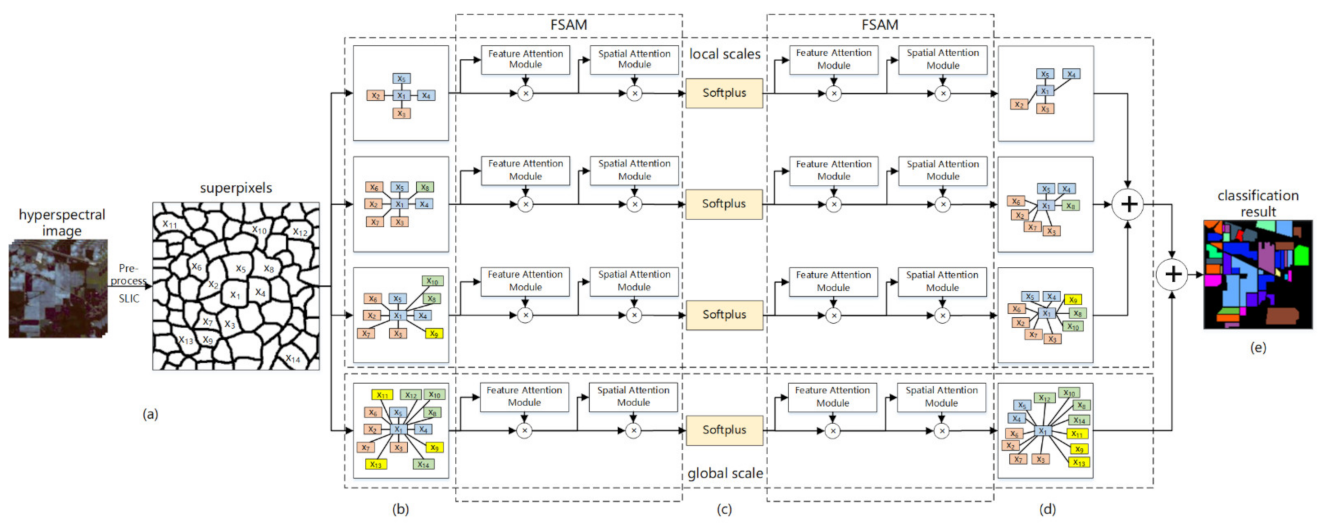
This section details the MFEGCN-FSAM model we proposed (see
Figure 1). There are four different spatial scales in our model, and each scale has two convolutional graphs layers. When the HSI data is given, a series of preprocessing, such as denoising and normalization, are first performed. Then, the image will be segmented into several superpixels by the simple linear iterative clustering method (SLIC) [
42]. The superpixels are used as nodes in different spatial scales to participate in the construction of multiscale graphs. Input the constructed graph into the feature-spatial attention module (FSAM), and the input graph is processed by the FSAM to obtain the output graph features corrected by the feature and spatial attention. The graph convolution operation is performed on these graphs to aggregate the spectral-spatial feature information, our proposed fusion evolution method can make the model fuse the structural information and data embeddings of the current graph during the convolution process, and the graph structure evolves and updates accordingly. Finally, the global and local classification results will be generated by the classifier, and the final result is obtained by adding the trainable weight parameters.
3.1. Graph Convolutional Network Framework
GCN [
36] is a neural network that runs directly on the graph and gradually fuses features in the neighborhood to generate node embeddings. An undirected graph can be defined as
, where
is the set of nodes and
are edges. Here
is defined as the adjacency matrix of
. By referring to the radial basis function (RBF), the calculation formula of
is defined as follows:
where σ is the width parameter of the function, which controls the radial range of the function,
represents a node and
is the set of neighbors of
.
The Laplacian matrix of
is defined as
, and
is the degree matrix of
. The core of GCN is based on the spectral decomposition of the Laplacian matrix
. The spectral decomposition of
is:
where
, is a matrix with column vector as unit eigenvector,
is the column vector,
is a diagonal matrix composed of n eigenvalues. Since
is an orthogonal matrix, so the above formula can be written as
According to the Convolution Theorem, the Fourier transform of the convolution integral of two functions
and
is equal to the product of the transforms of the functions. The convolution formula of
and
is as follows:
According to Inverse Fourier transform,
,
, thus
. The convolution kernel
can be written in the form of a diagonal matrix
according to the following formula:
Therefore, the formula of graph convolution is:
Bruna [
38] et al. optimized the convolution kernel,
is changed to
, that is
. Then the output of the convolution is:
However, this method has drawbacks. Firstly, will be calculated for each forward propagation, which is too expensive. Secondly, the convolution kernel does not have local properties, the matrix calculated by the convolution kernel has non-zero elements in all positions, which means that this is a global, fully connected convolution kernel.
Defferrard et al. [
40] proposed a method without decomposing the Laplacian matrix, which is the Chebyshev polynomial approximation method:
where the parameter
θ is a vector of Chebyshev coefficients,
is a diagonal matrix containing the eigenvalues of Laplacian Matrix
,
is the Chebyshev polynomial of order
evaluated at
,
is the largest eigenvalues of
.
Substituting Formula (8) into Formula (7),
. According to the properties of Chebyshev polynomials,
can be written as,
that is:
where
, and it is easy to notice that
. Now the value of convolution depends on the
Kth-order neighborhood of the central node. Kipf et al. [
31] assumed that
and limited
, thus the Formula (10) is transformed into the following form:
Then assume that the parameters
and
are shared in the entire figure, the Formula (10) becomes as follows:
At this point, the formula has become very concise, but there is still a problem. The value range of the eigenvalue of
is [0, 2]. Repeated calculation of this formula in the network will cause numerical instability and gradient explosion or disappearance. To solve this problem, Kipf et al. [
31] used the renormalization to change
to
, where
,
, the Formula (11) is as follows:
where
is the result of convolution output,
is the input node feature matrix,
is the convolution parameter matrix. To apply the Formula to GCN, we can define that:
where
,
is the first layer,
,
is the weight matrix to be trained, and
is the activation function. Now, the definition of GCN has been completed.
3.2. Superpixel Segmentation
A HSI often contains tens of thousands or more pixels. If the conventional GCN method is used to construct a graph with each pixel as a node, then the computational consumption is unbearable, and the requirements for computing equipment will be greatly increased. Therefore, in order to solve this problem, this article refers to [
34] aggregating the pixels with similar spatial and spectral characteristics in HSI into several superpixels. The average value of the spectra of all pixels in the superpixel in each band is taken as its feature vector. Specifically, the superpixel segmentation algorithm used in this paper is SLIC [
42], which is relatively good in terms of the result of generating superpixels and the running speed. However, the SLIC algorithm is designed for RGB images and cannot be used on images with multiple bands. This paper extends the SLIC algorithm so that it can run on HSI. The algorithm details are as follows:
- (a)
Initialize the seed point
Suppose we perform superpixel segmentation on an HSI with pixels, and the preset number of superpixels is . Let the seed points be evenly distributed in the HSI, the number of pixels contained in each superpixel is , and the distance between each seed point is about . Define the feature vector of each seed point as , where is the spectral vector corresponding to the seed point, is the coordinate value of the seed point, .
- (b)
Move the seed point
The seed point is moved to the position with the lowest gradient in its surrounding 3 × 3 neighborhood. This is done to avoid seed points lying on edges and to reduce the chance that the seed points will pick up noisy pixels.
- (c)
Assign pixels to the seed point
We define the spectral distance between the pixel point and the seed point as , the spatial distance as , where is the number of the pixel. The comprehensive distance between the pixel and the seed point as where is the shape parameter, the larger is, the more regular of superpixels is. Calculate the distance between the pixels within the range of each seed point and the seed point and assign each pixel to the seed point with the smallest distance from it.
- (d)
Update the seed point
Calculate the mean of the feature vector a of all pixels within each superpixel and set it as the new seed point feature vector.
- (e)
Iterative calculation and post-processing
Repeat steps c and d until the preset number of iterations is reached, which is set to 10 in this paper. After the segmentation is completed, the connectivity of the superpixels is detected, and the superpixels with a connected component greater than 1 will be separated. If a superpixel contains less than five pixels, assign it to the superpixel that has the most contact with it. We refer to the design of Ren et al. [
53] and use CUDA tools to accelerate superpixel segmentation by a factor of nearly 80 with GPU acceleration.
3.3. Graph Fusion Evolution
Although GCN can effectively calculate and aggregate information on graph data, one of its main disadvantages is that the graph constructed by GCN is fixed throughout the process. If the initial input graph is not accurate enough, it will affect the accuracy of the final result of the model. In order to solve this problem, this paper proposes a fusion evolution mechanism on the graph, by fusing the result information of the current convolution output with the previous layer’s graph, and then allowing the graph to be automatically updated during the convolution process.
We define the adjacency matrix of the
l layer as
and the data embedding
output by the first layer, where n is the number of nodes in the graph, and
is the feature dimension of each node. Our goal is to obtain the
of next layer. Canonical correlation analysis (CCA) is a method in the field of mathematical statistics to measure the linear relationship between two sets of multidimensional variables [
54]. Drawing on the idea of CCA, we propose a feature-level fusion method for graph structure information and embedding information. This fusion method not only helps the model to perform effective feature fusion, but also eliminates redundant information in the data, which is conducive to accurate and efficient update of the graph. We define
,
to make the embedding self-aggregate.
is a real symmetric matrix, and the shape is the same as
, which is conducive to subsequent calculations.
According to the idea of CCA and taking into account the calculation performance, we define a pair of projection vectors , , project and to obtain and .
Suppose that
and
denote the covariance matrices of
and
, respectively, while
denotes covariance matrices of
and
. Then the overall covariance matrix
which contains all the information on associations between pairs of features, can be denoted as:
Now we hope to find a pair of linear combinations
and
that maximize the correlation coefficient between
and
. We can define the correlation function as follows:
According to the definition, the expressions of variance and covariance of
and
can be obtained as follows:
Thus, Formula (16) can be written as:
According to the characteristics of Function (19), we can define the constraints of
and
:
Now the optimization problem is:
Using the Lagrange multiplier method to solve the problem:
where
and
are Lagrange multipliers.
By transforming the partial derivative of
, we get:
The problem is transformed into solving the largest eigenvalue and the corresponding eigenvectors . Finally, bring the and into (22) to solve :
After solving
and
, we can obtain their corresponding projection matrix
and
. We can obtain fusion of the current layer between
and
by using the summation method, namely:
Referring to the design of [
55], for the node
in
, it is assumed that
obeys Gaussian distribution with the covariance of
and the unknown mean
, namely
. The preliminary fusion result can be defined as:
It can be seen that such a fusion method utilizes the structural information and the data embedding of the current graph to improve the graph, making the graph and the data embedding of the next layer more accurate. However, if it is directly input to the next layer, the fusion may cause performance degradation due to the inaccuracy of and the lack of structural information in the initial graph.
We must emphasize the structural information of the initially constructed graph. The process of constraining the fusion result
of the current layer can be considered as a cross-diffusion process between the initial graphs
and
. Based on the above definition, we define the expression of the node at the next layer as:
where
is white noise, i.e.,
and
is the weight parameter of
. Under this linear operation, we have:
According to the total probability formula, we can obtain the distribution of
:
Recalling the previous assumptions,
should also obey the Gaussian distribution with the covariance
, so that we can obtain
as:
In summary, the design of an automatic update graph has three advantages: firstly, the graph is continuously updated during the convolution process, which can make the graph and embedded information more accurate; secondly, the graph is robust to noise and data scale during the update process; thirdly, the graph retains the intrinsic structure of the similar manifold of the entire dataset during the update process.
3.4. Multiscale Contextual Information Integration
Due to the limitation of the convolution kernel, as the number of network layers and iterations of GCN increase, the characteristics of each node will tend to be smooth. In order to solve this problem, Chiang et al. [
56] modified the regularization method of the convolution kernel to solve the problem of high power operation of the convolution kernel. Sami [
57] et al. abandoned the deep-level convolution features and retained and spliced the results of the multiscale low-level into features. In the classification of HSI, multiscale information has proved to be extremely useful [
58] because, in HSI, ground features usually contain different geometrical characteristics. The semantic information obtained from different scales can help people obtain rich local information about the image area.
3.4.1. Local Contextual Information
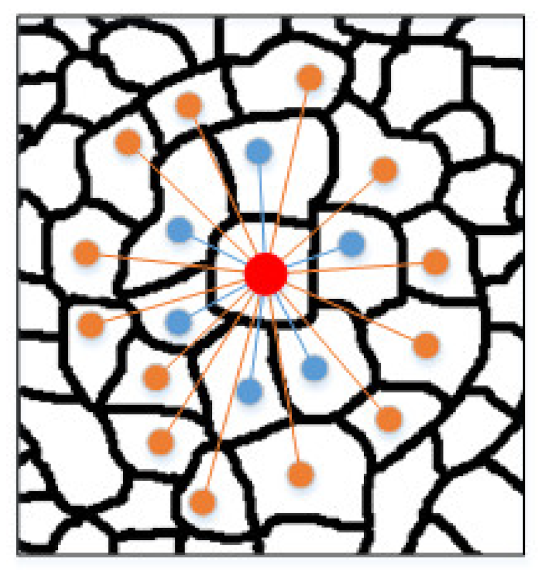
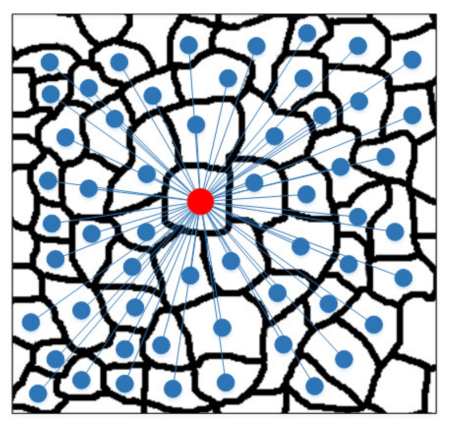
At scale s, each superpixel node
xi will be connected to its s-order neighbors. Taking the two-order scale as an example, the 1-order neighbors and second-order neighbors of the central superpixel node xi will be connected to it, as shown in
Figure 2.
The neighbors of
xi can be expressed as the Formula (28):
where
and
is the 1-order neighbors set of
xi. The neighbors closer to the central node are aggregated more times, which means that the neighbors closer to the central node have a greater impact on the central node.
For the sake of practical significance and efficiency, this paper constructs local graphs as scale 1, 2, and 3. Therefore, the graph convolution layer of scale
s can be defined as Formula (29):
The output of the local-level layers will be added as in Formula (30):
where
is trainable weights corresponding to each layer.
3.4.2. Global Contextual Information
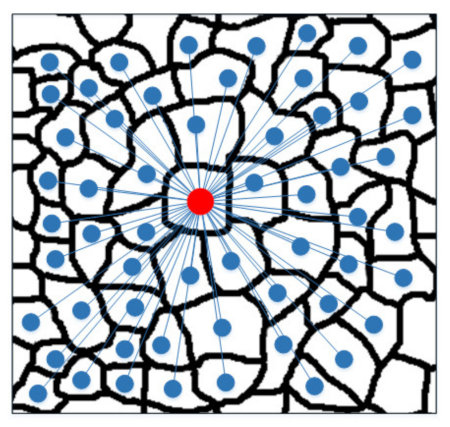
If there are only local graph convolutional layers, the information of the global context in the HSI may not be used, so this paper designs a graph convolutional layer based on the global context. Specifically, we consider that all superpixel nodes in the HSI have an adjacency relationship in pairs and constructed an adjacency matrix as Formula (31).
where
represents a node and
another node in the graph, as shown in
Figure 3.
However, the dense connection of all superpixel nodes in pairs will cause many problems, such as increased computational cost, and some dissimilar nodes are incorrectly connected together. To solve this problem, this paper sets a threshold
β for the global adjacency matrix. The larger the threshold
β, the more similar the two nodes are. Only node connections greater than
β can be retained. Thus, the above formula becomes Formula (32).
where threshold
β is set to 0.8 throughout the experiments.
The global graph convolution layer can be defined as:
The output of the global graph convolution layer is:
The final output of the method is:
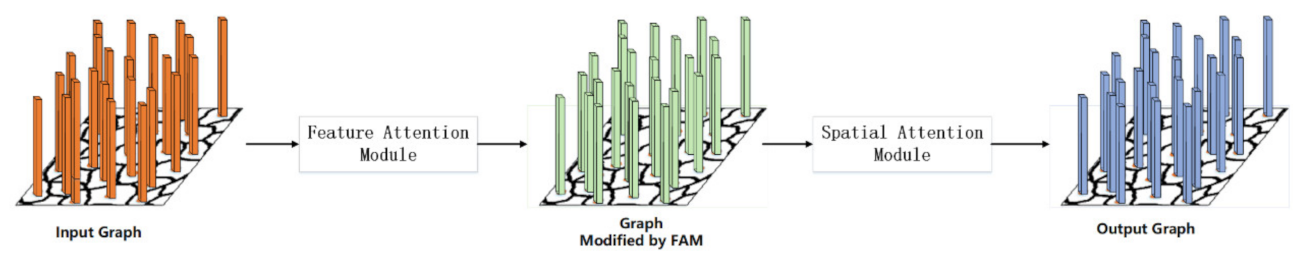
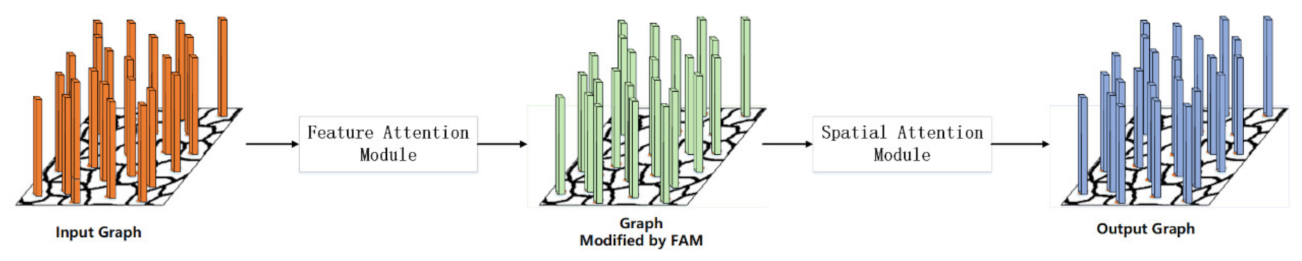
3.5. Feature-Spatial Attention Module
Petar et al. [
59] mentioned that one of the serious shortcomings of GCN is that GCN treats all neighboring nodes equally and cannot assign different weights to nodes based on their importance. This article refers to the design of CBAM [
60] and proposes the FSAM (as shown in
Figure 4) suitable for GCN, which contains two submodules: a feature attention module and a spatial attention module. In order to emphasize the meaningful information of the two dimensions of the feature axis and the spatial axis, the graph will pass through the feature attention module and spatial attention module sequentially. In this way, the model can learn the “what” and “where” in the feature axis and the spatial axis are important, and the information can flow accurately in the network. In summary, FSAM improves the representational ability of the model by focusing on the important information on the graph and suppressing the other.
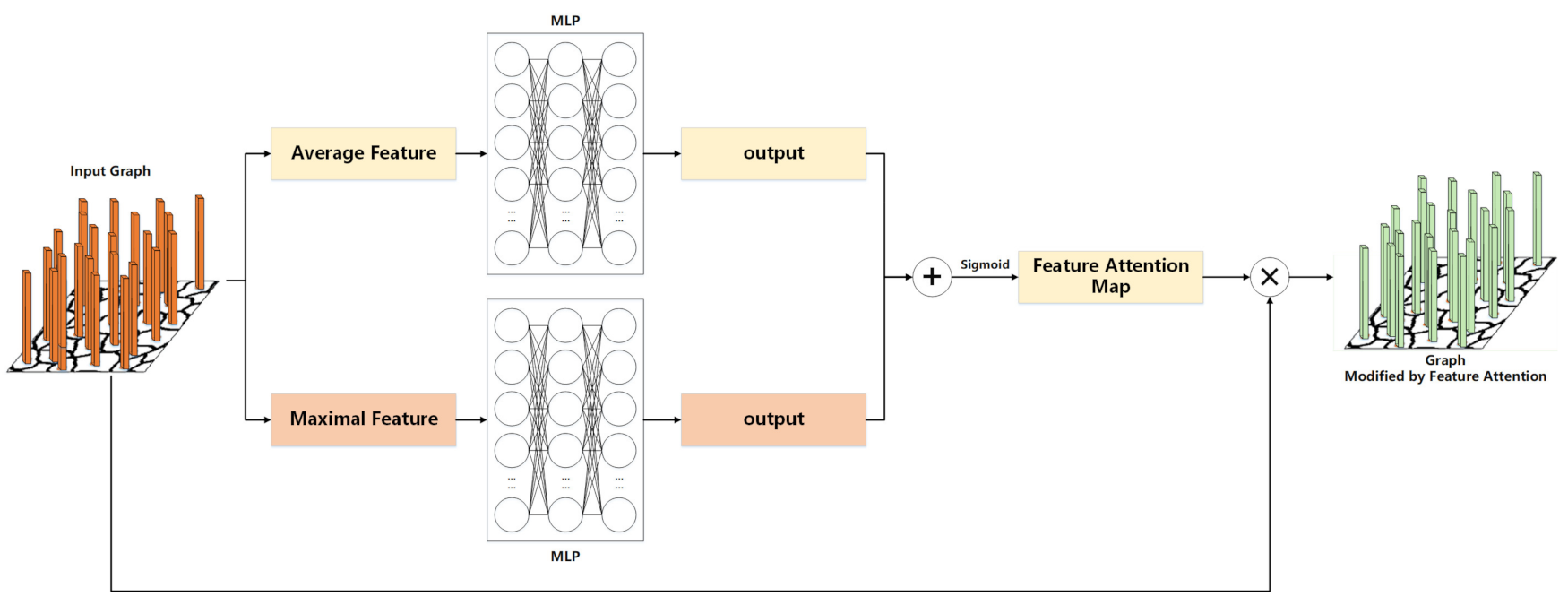
3.5.1. Feature Attention Module
The feature attention module (see
Figure 5) tries to find which features of a graph node are important and which should be ignored. In order to aggregate the spatial information of the graph, the module averages and maximizes the graph on the spatial axis. The realization of the module is as follows.
For the input graph
, we first aggregate the spatial information by averaging and maximizing the spatial dimensions of the input graph to generate
and
, which represent the averaged feature and the maximized feature, respectively.
and
will be input into a fully connected network composed of a multi-layer perceptron (MLP), and then the output feature vectors
and
will be obtained. The elements of
and
are summed and combined to obtain the feature attention map
. The formula for calculating spectral attention is as follows:
where
is the activation function.
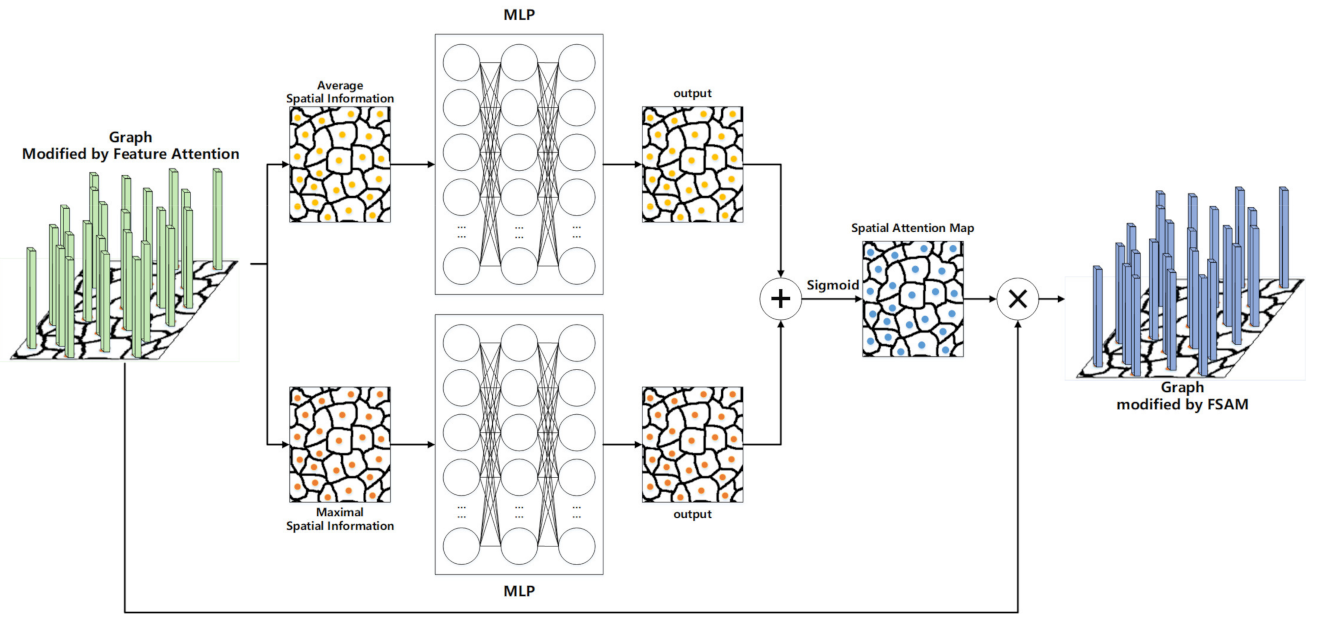
3.5.2. Spatial Attention Module
We generate the spatial attention map by using the spatial relationship between nodes. Unlike the feature attention module, the spatial attention module (see
Figure 6) tries to find where is important in the graph. In order to aggregate the feature information of the nodes, the module averages and maximizes the graph on the feature axis and concatenates the results to generate an effective spatial information representation. The realization of the module is as follows.
For the input graph
, we first aggregate the feature information by averaging and maximizing the feature dimensions of the input graph and splicing the results to obtain
.
will be input into a fully connected network consisting of a MLP, and then the spatial attention map
. The spatial attention is calculated as follows:
where
is the activation function.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}