
Application of Improved Instance Segmentation Algorithm Based on VoVNet-v2 in Open-Pit Mines Remote Sensing Pre-Survey



Abstract
:
1. Introduction
2. Materials and Methods
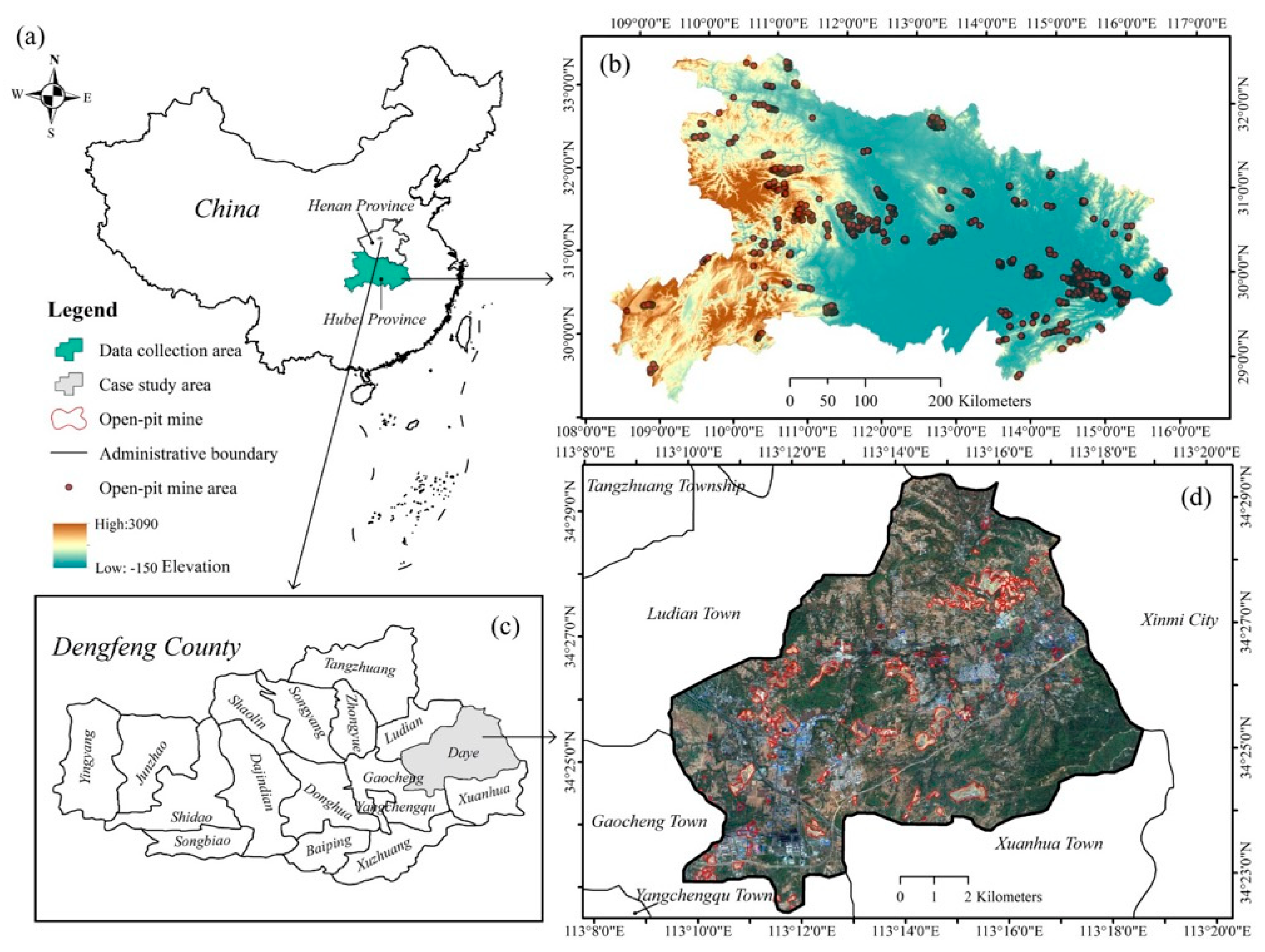
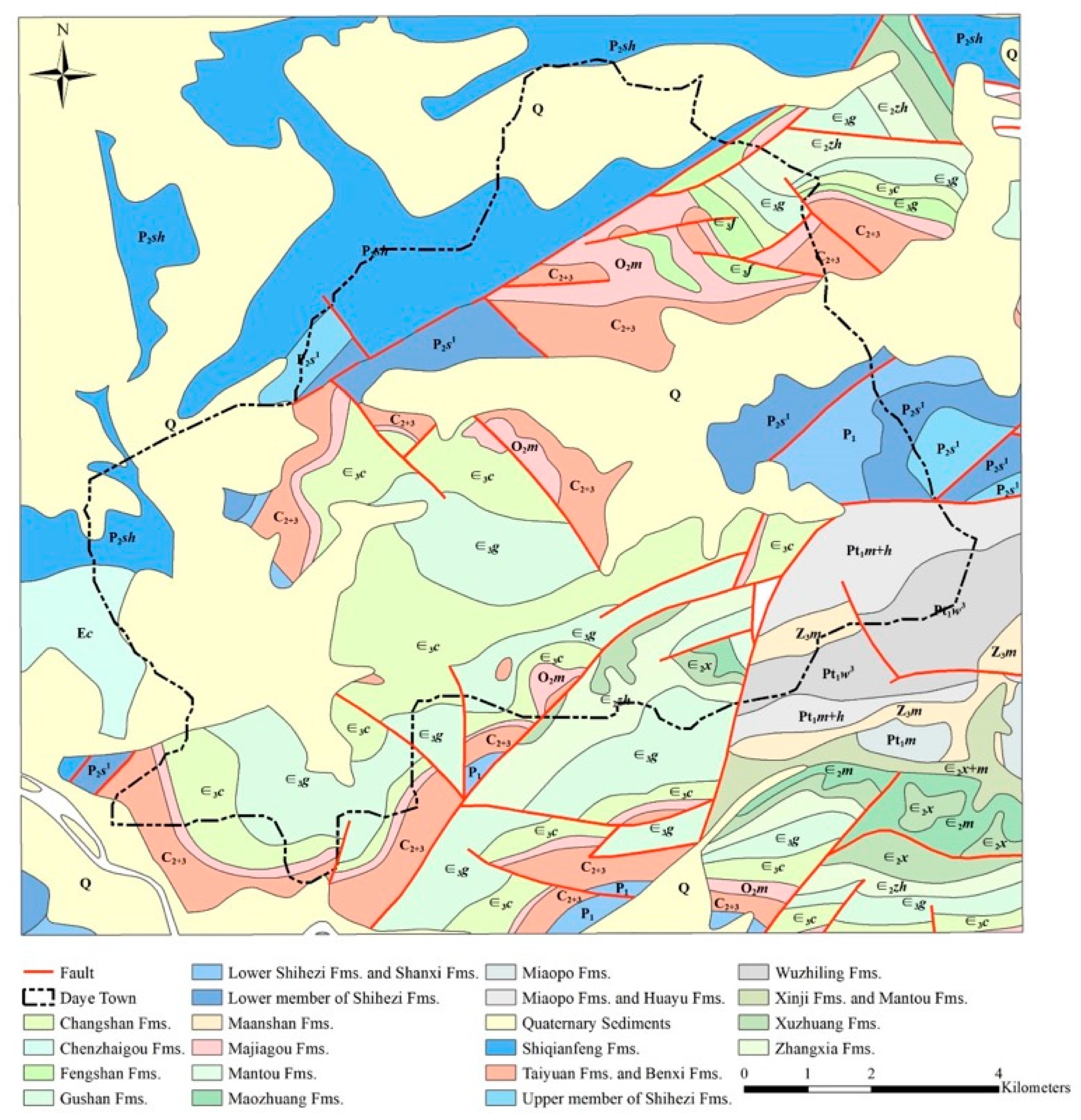
2.1. Datasets and Case Study Area
2.2. Data Description
2.3. Detection Models
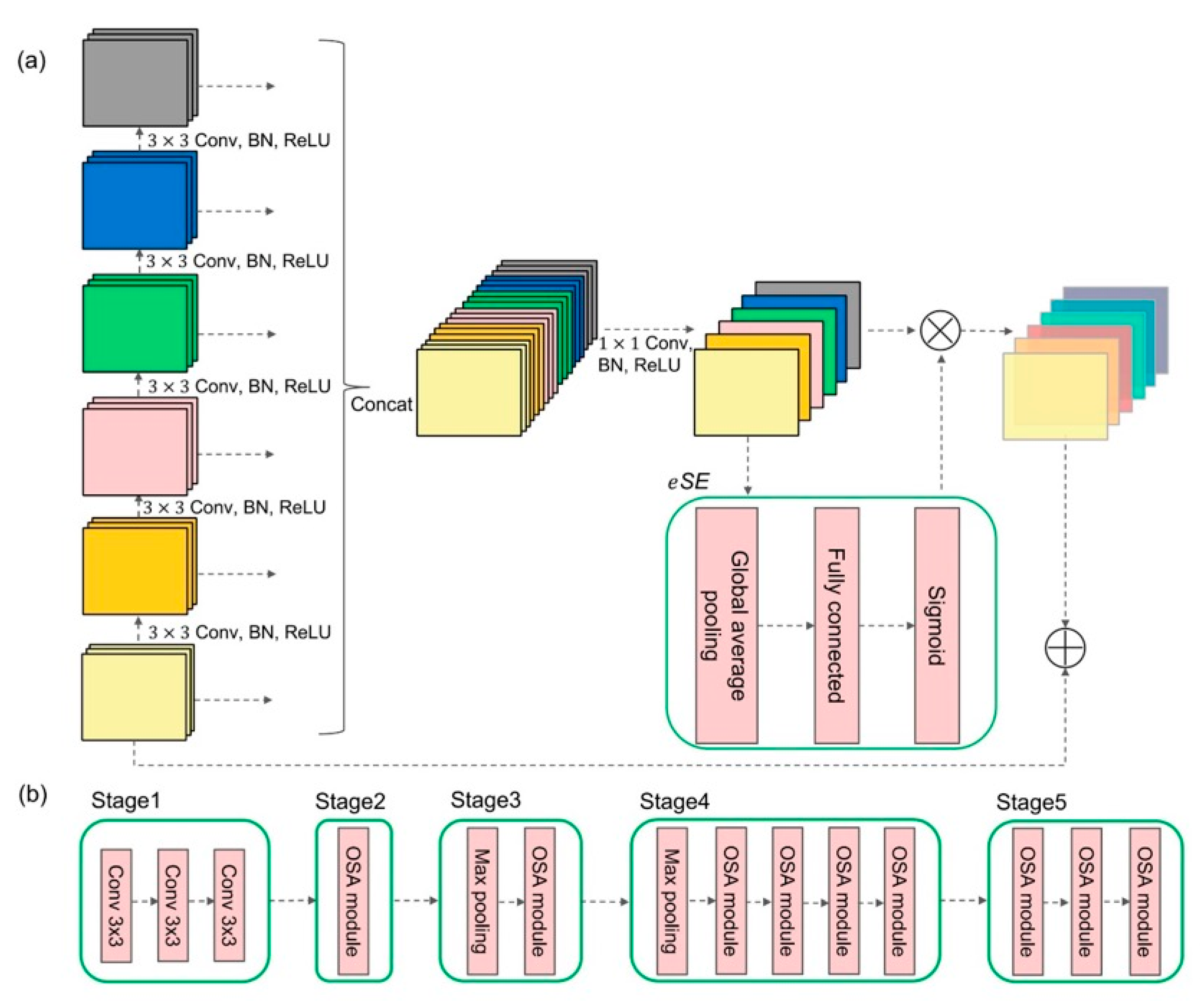
2.3.1. VoVNet-v2
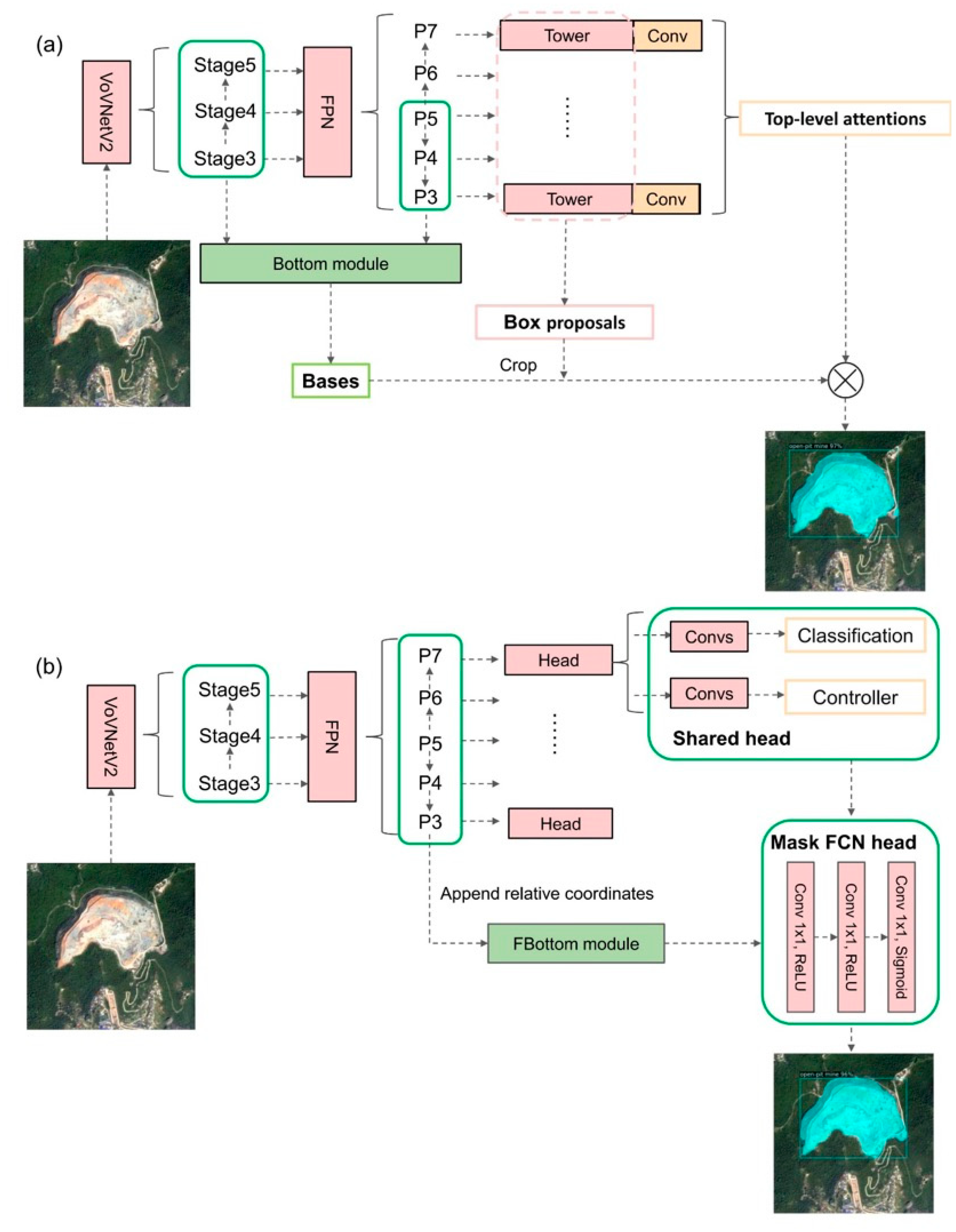
2.3.2. BlendMask
2.3.3. CondInst
3. Results and Analysis
3.1. Experimental Configuration and Setting
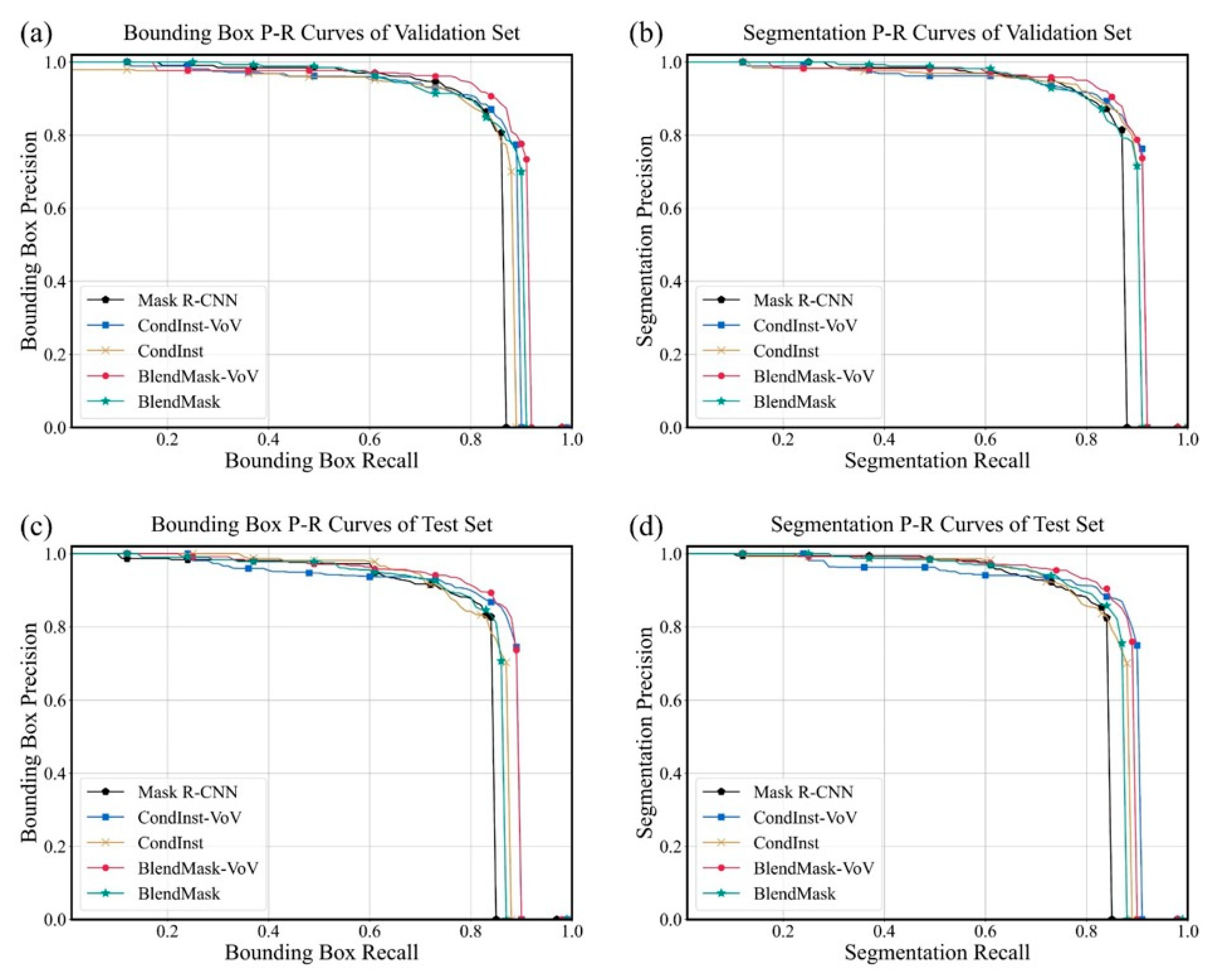
3.2. Model Evaluation
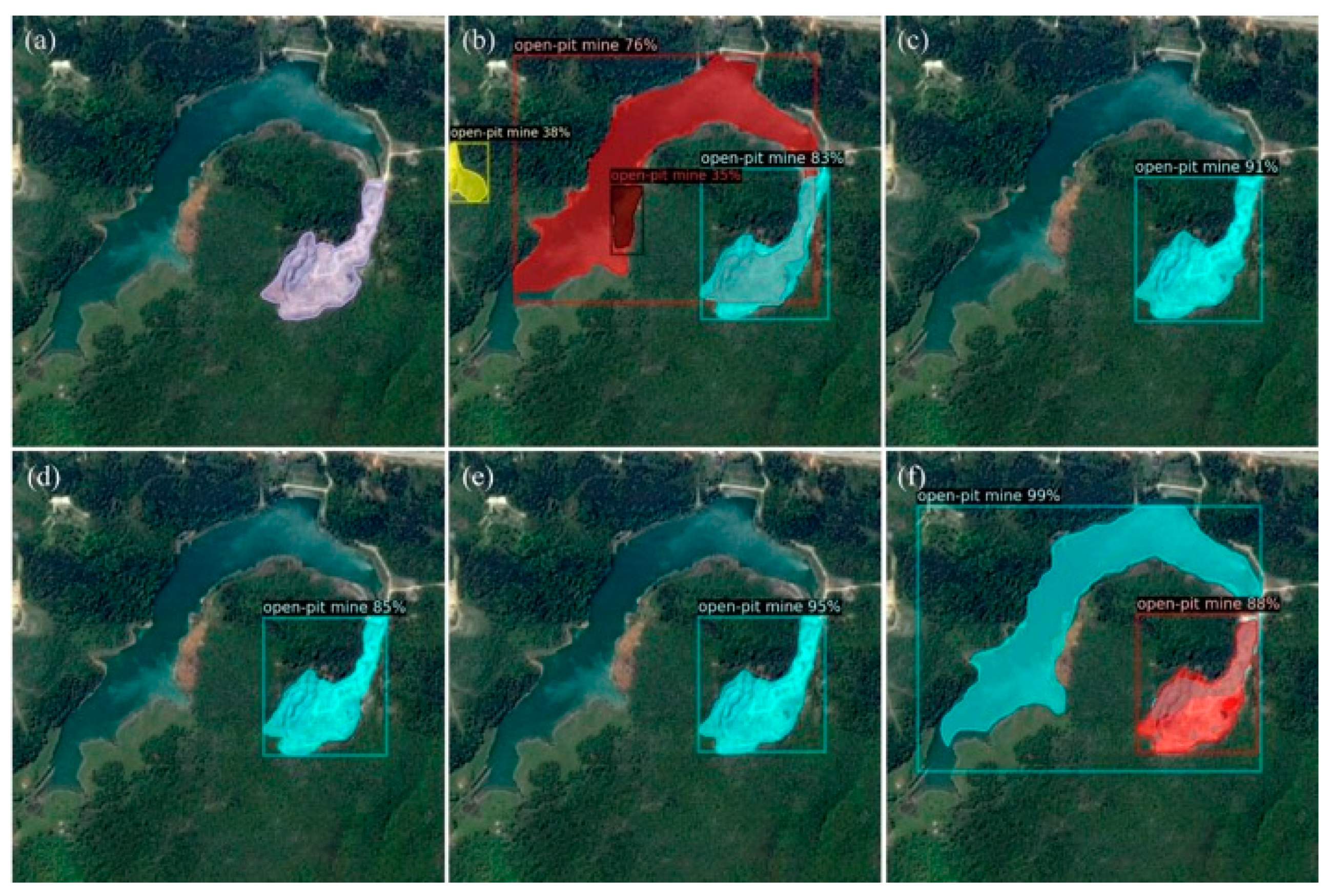
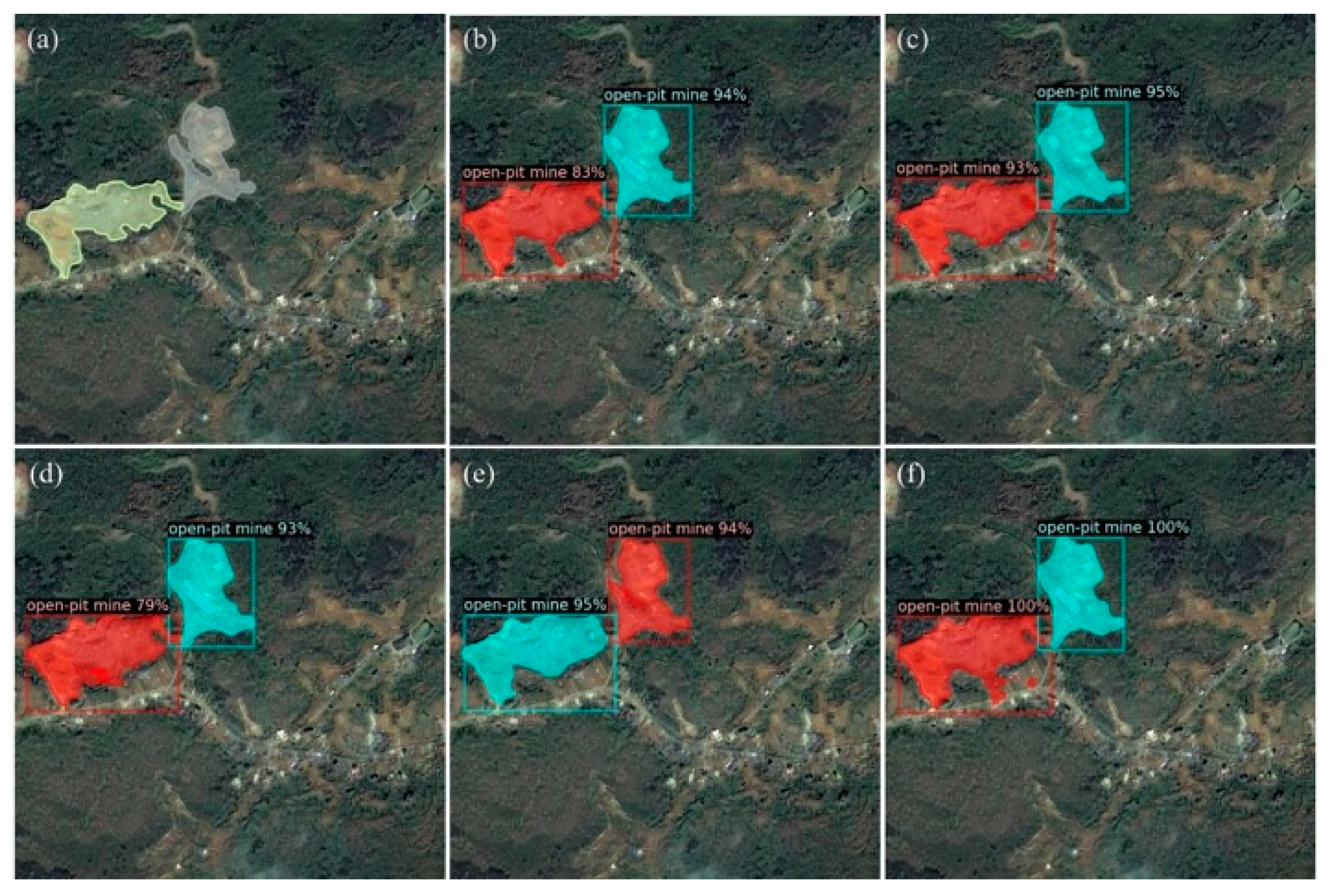
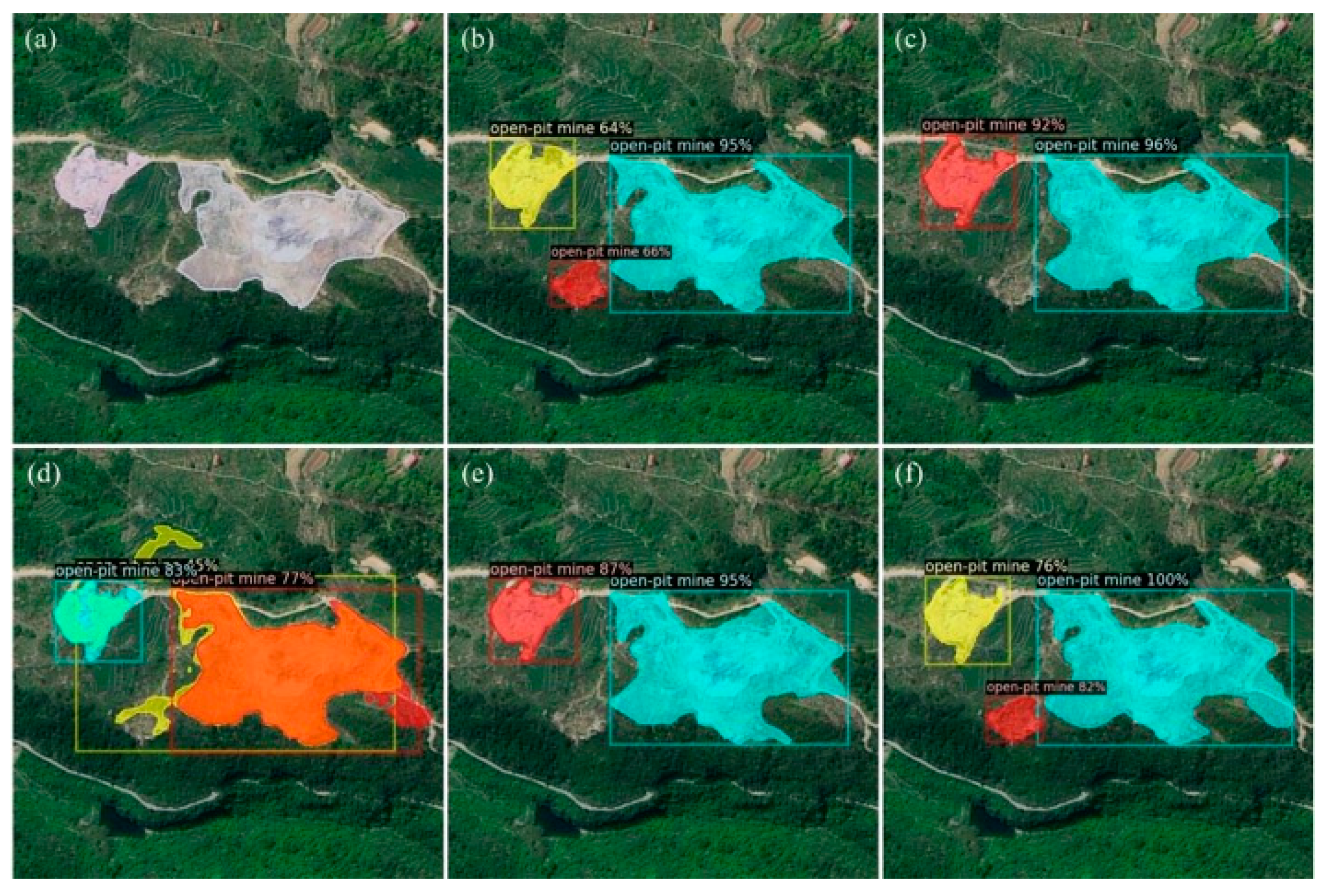
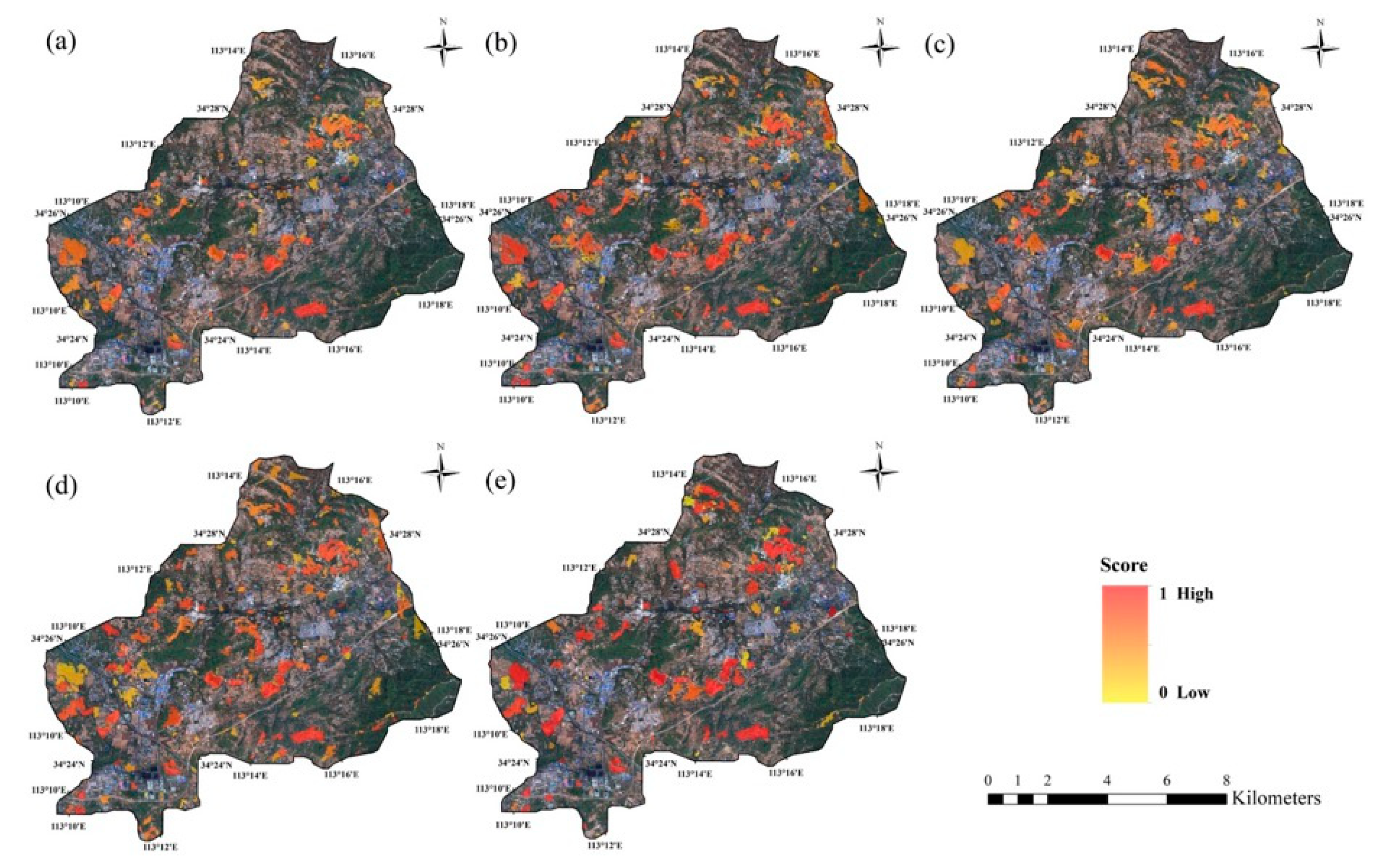
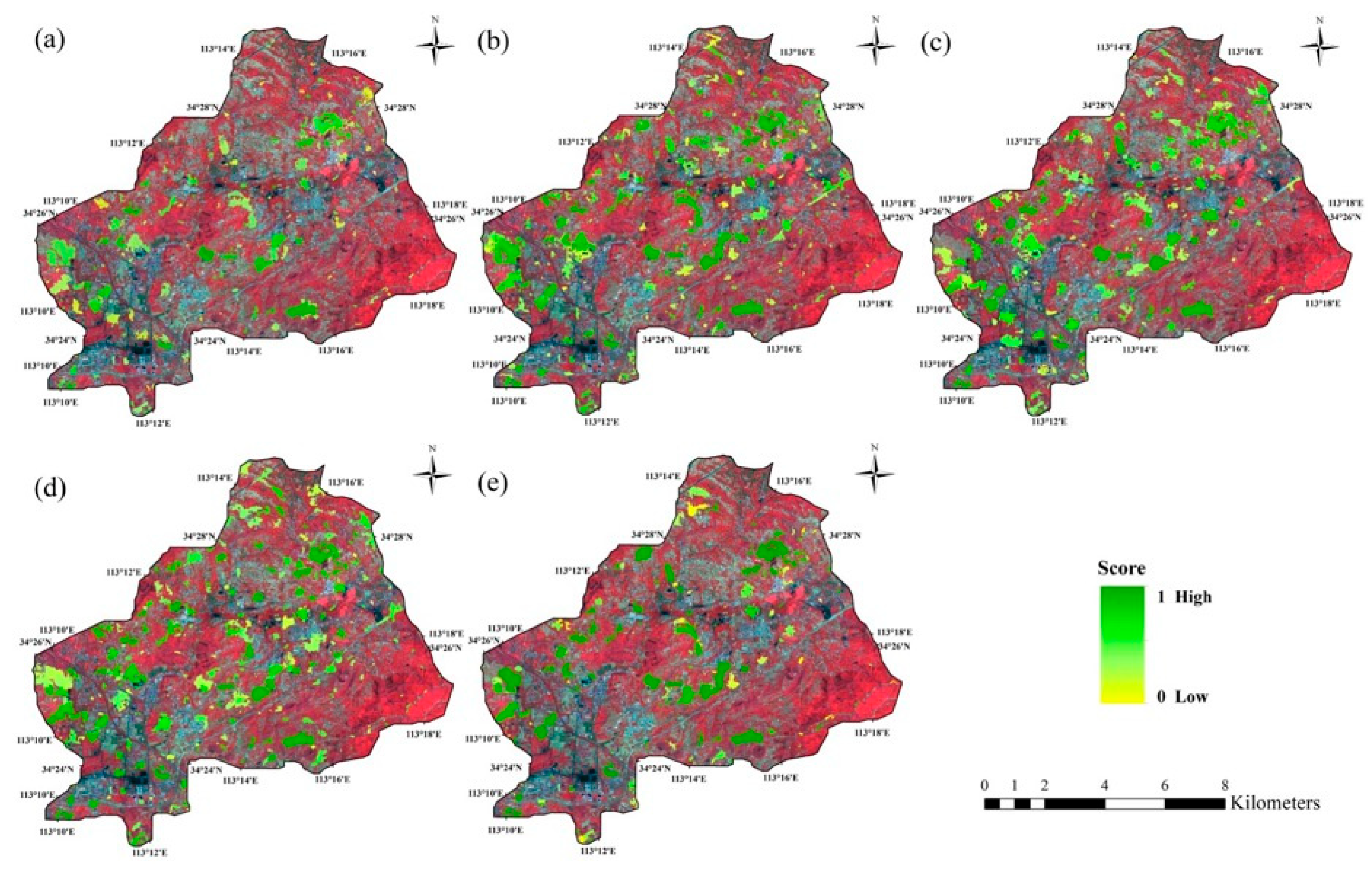
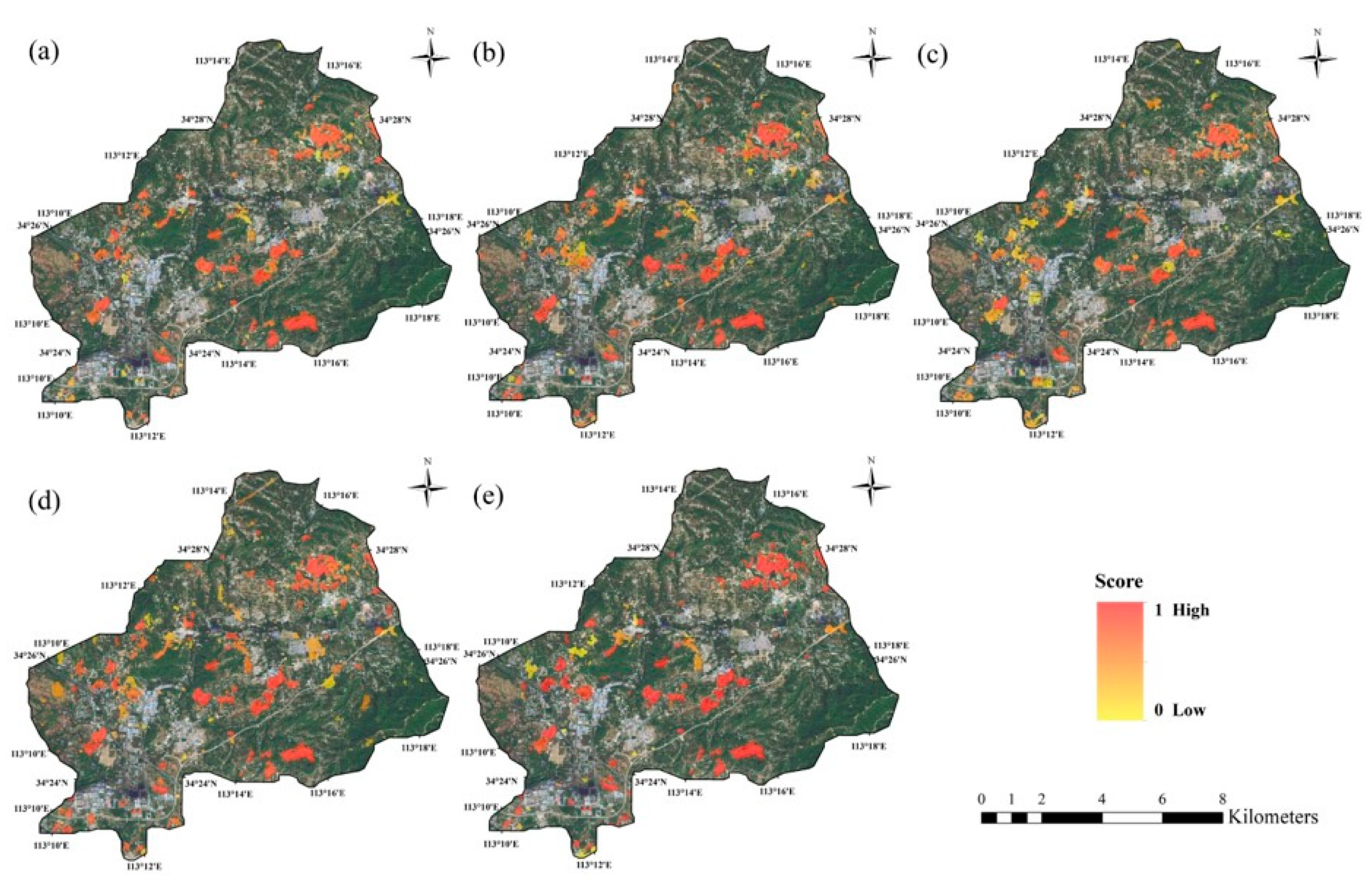
3.3. Case Study
4. Discussion
4.1. Image Types of Open-Pit Mine Remote Rensing Survey
- The types of mineral resources are different. Coal, limestone, bauxite, and gangue are the main minerals in Daye town, but there are no bauxite or gangue mines in the KOMMA dataset.
- The hues and textures of images are different. Daye Town is located in a different geographical region than Hubei, and the climate, topography, and hydrological environment result in significant differences in land cover. Open-pit mine areas in Hubei province are mostly distributed in mountainous areas far away from cities, surrounded by dense vegetation. In false-color images, vegetation is more straightforward to distinguish from mines due to its conspicuous hue. Henan Province has gentle terrain and large farmland. The color and texture of bare farmland may cause some confusion to the edge of objects.
- The proportions of the three types of images are different. The KOMMA dataset does not have a balanced distribution of image types. The small number of Tianditu images makes it easier for lousy samples to reduce the overall evaluation indicators of Tianditu images [54]. In the case study, differences in image proportions have no effect.
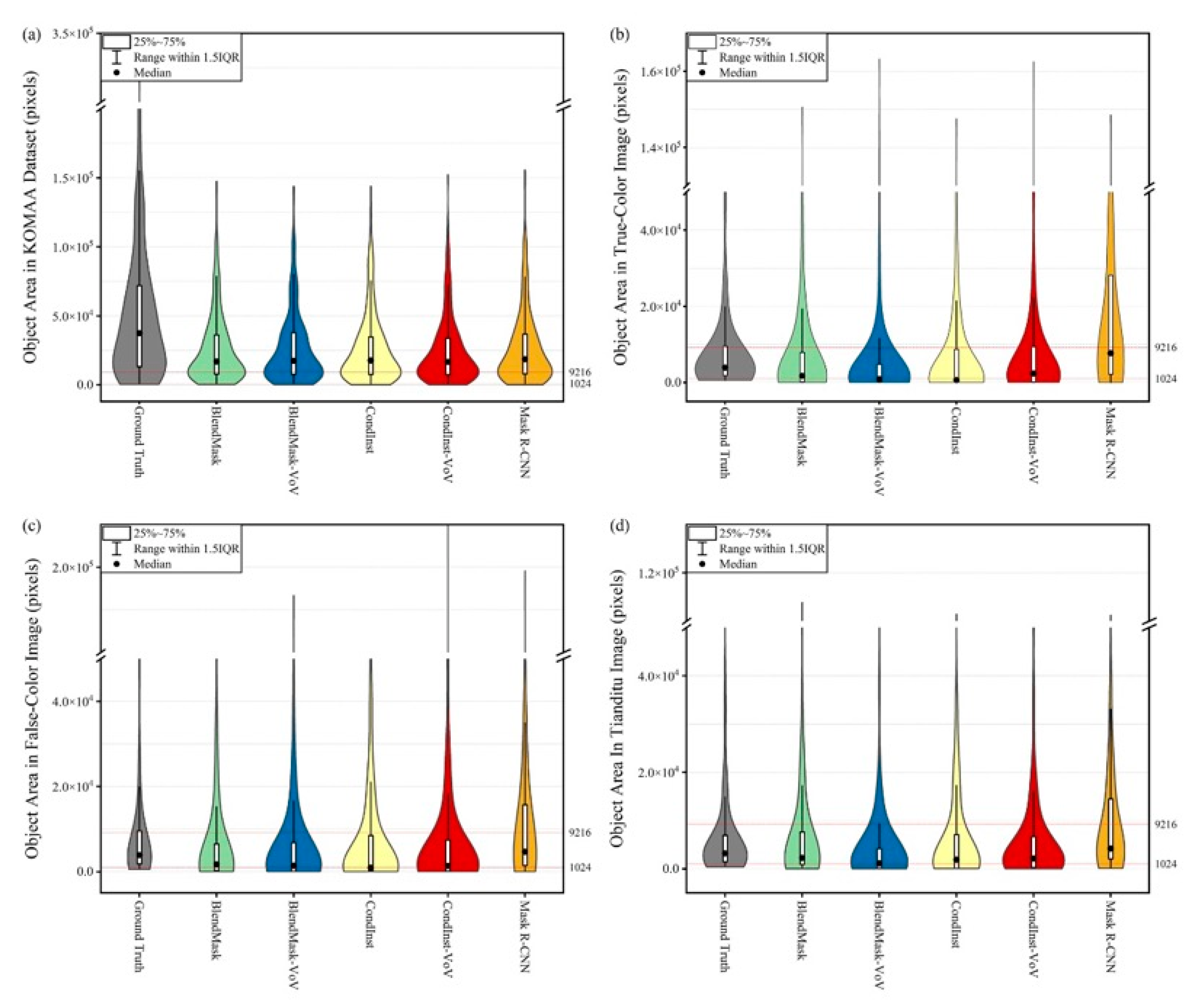
4.2. Object Size Issue in Datasets
4.3. Applicability of Models
5. Conclusions
- Experimental result shows that BlendMask-VoV and CondInst-VoV exceed the baseline in segmentation and localization positioning tasks in the KOMMA dataset.
- The CondInst-VoV model has good generalization and can be applied to geographical areas with different data distribution characteristics. It can meet the accuracy requirements of manual interpretation in mine remote sensing pre-survey tasks.
- In practical case application, the models proposed in this paper can obtain better detection results on Tianditu images than on Gaofen satellite images.
- Mine detection models in this experiment have a better recognition for medium and large objects, but it is easy to divide oversized objects into multiple instances.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zheng, Y.; Xiao, J.; Cheng, J. Industrial Structure Adjustment and Regional Green Development from the Perspective of Mineral Resource Security. Int. J. Environ. Res. Public Health 2020, 17, 6978. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Yin, P.; Hu, W.; Fu, L.; Zhao, H. Assessing the Ecological Regime and Spatial Spillover Effects of a Reclaimed Mining Subsided Lake: A Case Study of the Pan’an Lake Wetland in Xuzhou. PLoS ONE 2020, 15, e0238243. [Google Scholar] [CrossRef] [PubMed]
- Firozjaei, M.K.; Sedighi, A.; Firozjaei, H.K.; Kiavarz, M.; Homaee, M.; Arsanjani, J.J.; Makki, M.; Naimi, B.; Alavipanah, S.K. A Historical and Future Impact Assessment of Mining Activities on Surface Biophysical Characteristics Change: A Remote Sensing-Based Approach. Ecol. Indic. 2021, 122, 107264. [Google Scholar] [CrossRef]
- Zawadzki, J.; Przeździecki, K.; Miatkowski, Z. Determining the Area of Influence of Depression Cone in the Vicinity of Lignite Mine by Means of Triangle Method and LANDSAT TM/ETM+ Satellite Images. J. Environ 2016, 166, 605–614. [Google Scholar] [CrossRef] [PubMed]
- He, H.; Xing, R.; Han, K.; Yang, J. Environmental Risk Evaluation of Overseas Mining Investment Based on Game Theory and an Extension Matter Element Model. Sci. Rep. 2021, 11, 16364. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, L.; Feng, R.; Zhang, C. High-Resolution Remote Sensing Image Classification with RmRMR-Enhanced Bag of Visual Words. Comput. Intel. Neurosc. 2021, 2021, 7589481. [Google Scholar] [CrossRef] [PubMed]
- Harbi, H.; Madani, A. Utilization of SPOT 5 Data for Mapping Gold Mineralized Diorite–Tonalite Intrusion, Bulghah Gold Mine Area, Saudi Arabia. Arab. J. Geosci. 2014, 7, 3829–3838. [Google Scholar] [CrossRef]
- Mezned, N.; Mechrgui, N.; Abdeljaouad, S. Mine Wastes Environmental Impact Mapping Using Landsat ETM+ and SPOT 5 Data Fusion in the North of Tunisia. J. Indian Soc. Remote Sens. 2016, 44, 451–455. [Google Scholar] [CrossRef]
- Quanyuan, W.; Jiewu, P.; Shanzhong, Q.; Yiping, L.; Congcong, H.; Tingxiang, L.; Limei, H. Impacts of Coal Mining Subsidence on the Surface Landscape in Longkou City, Shandong Province of China. Environ. Earth Sci. 2009, 59, 783–791. [Google Scholar] [CrossRef]
- Prakash, A.; Gupta, R.P. Land-Use Mapping and Change Detection in a Coal Mining Area—A Case Study in the Jharia Coalfield, India. Int. J. Remote Sens. 1998, 19, 391–410. [Google Scholar] [CrossRef]
- Duncan, E.E.; Kuma, J.S.; Primpong, S. Open Pit Mining and Land Use Changes: An Example from Bogosu-Prestea Area, South West Ghana. Electr. J. Inf. Sys. Dev. 2009, 36, 1–10. [Google Scholar] [CrossRef]
- Bangian, A.H.; Ataei, M.; Sayadi, A.; Gholinejad, A. Optimizing Post-Mining Land Use for Pit Area in Open-Pit Mining Using Fuzzy Decision Making Method. Int. J. Environ. Sci. Technol. 2012, 9, 613–628. [Google Scholar] [CrossRef] [Green Version]
- Roy, P.; Guha, A.; Kumar, K.V. An Approach of Surface Coal Fire Detection from ASTER and Landsat-8 Thermal Data: Jharia Coal Field, India. Int. J. Appl. Earth Obs. Geoinf. 2015, 39, 120–127. [Google Scholar] [CrossRef]
- Liu, S.; Du, P. Object-Oriented Change Detection from Multi-Temporal Remotely Sensed Images. In Proceedings of the GEOBIA 2010 Geographic Object-Based Image Analysis, Ghent, Belgium, 29 June–2 July 2010; ISPRS: Ghent, Belgium, 2010; Volume 38-4-C7. [Google Scholar]
- Bao, N.; Lechner, A.; Johansen, K.; Ye, B. Object-Based Classification of Semi-Arid Vegetation to Support Mine Rehabilitation and Monitoring. J. Appl. Remote Sens. 2014, 8, 083564. [Google Scholar] [CrossRef]
- Chen, L.; Li, W.; Zhang, X.; Chen, L.; Chen, C. Application of Object-Oriented Classification with Hierarchical Multi-Scale Segmentation for Information Extraction in Nonoc Nickel Mine, the Philippines. In Proceedings of the 2018 Fifth International Workshop on Earth Observation and Remote Sensing Applications (EORSA), Xi’an, China, 18–20 June 2018; pp. 1–3. [Google Scholar]
- Song, X.; He, G.; Zhang, Z.; Long, T.; Peng, Y.; Wang, Z. Visual Attention Model Based Mining Area Recognition on Massive High-Resolution Remote Sensing Images. Clust. Comput. 2015, 18, 541–548. [Google Scholar] [CrossRef]
- Wan, J.; Xie, Z.; Xu, Y.; Chen, S.; Qiu, Q. DA-RoadNet: A Dual-Attention Network for Road Extraction from High Resolution Satellite Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6302–6315. [Google Scholar] [CrossRef]
- Xu, Y.; Chen, Z.; Xie, Z.; Wu, L. Quality Assessment of Building Footprint Data Using a Deep Autoencoder Network. Int. J. Geogr. Inf. Sci. 2017, 31, 1929–1951. [Google Scholar] [CrossRef]
- Fukushima, K. Neocognitron: A Self-Organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Gallwey, J.; Robiati, C.; Coggan, J.; Vogt, D.; Eyre, M. A Sentinel-2 Based Multispectral Convolutional Neural Network for Detecting Artisanal Small-Scale Mining in Ghana: Applying Deep Learning to Shallow Mining. Remote Sens. Environ. 2020, 248, 111970. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. ISBN 978-3-319-24573-7. [Google Scholar]
- Chen, T.; Hu, N.; Niu, R.; Zhen, N.; Plaza, A. Object-Oriented Open-Pit Mine Mapping Using Gaofen-2 Satellite Image and Convolutional Neural Network, for the Yuzhou City, China. Remote Sens. 2020, 12, 3895. [Google Scholar] [CrossRef]
- Chen, T.; Zheng, X.; Niu, R.; Plaza, A. Open-Pit Mine Area Mapping With Gaofen-2 Satellite Images Using U-Net+. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 3589–3599. [Google Scholar] [CrossRef]
- Li, J.; Cai, X.; Qi, J. AMFNet: An Attention-Based Multi-Level Feature Fusion Network for Ground Objects Extraction from Mining Area’s UAV-Based RGB Images and Digital Surface Model. J. Appl. Remote Sens. 2021, 15, 036506. [Google Scholar] [CrossRef]
- Xie, H.; Pan, Y.; Luan, J.; Yang, X.; Xi, Y. Open-Pit Mining Area Segmentation of Remote Sensing Images Based on DUSegNet. J. Indian Soc. Remote Sens. 2021, 49, 1257–1270. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Chang, L.; Zhao, L.; Niu, R. Automatic Identification and Dynamic Monitoring of Open-Pit Mines Based on Improved Mask R-CNN and Transfer Learning. Remote Sens. 2020, 12, 3474. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Chen, H.; Sun, K.; Tian, Z.; Shen, C.; Huang, Y.; Yan, Y. BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8570–8578. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully Convolutional Instance-Aware Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4438–4446. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT: Real-Time Instance Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9156–9165. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; Volume 8693, pp. 740–755. ISBN 978-3-319-10601-4. [Google Scholar]
- Tian, Z.; Zhang, B.; Chen, H.; Shen, C. Instance and Panoptic Segmentation Using Conditional Convolutions. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 1. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. ISBN 978-3-319-46447-3. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Communications of the ACM, Raleigh, NC, USA, 16–18 October 2012; Association for Computing Machinery: New York, NY, USA, 2012; Volume 60, pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Lee, Y.; Hwang, J.; Lee, S.; Bae, Y.; Park, J. An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 752–760. [Google Scholar]
- Lee, Y.; Park, J. CenterMask: Real-Time Anchor-Free Instance Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13903–13912. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- AdelaiDet: A Toolbox for Instance-Level Recognition Tasks. Available online: https://git.io/adelaidet (accessed on 14 July 2021).
- Detectron2. Available online: https://github.com/facebookresearch/detectron2 (accessed on 12 July 2021).
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on Deep Learning with Class Imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- Wu, W.; Li, X. Exploitation of mineral resources and restoration of ecology. China Min. Mag. 2021, 30, 21–24. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Source | Payload | Band Order | Wavelength (μm) | Band Description | Spatial Resolution (m) | Pre-Processing |
|---|---|---|---|---|---|---|
| Gaofen-1 satellite PMS | Panchromatic | Pan 1 | 0.45~0.9 | Panchromatic | 2 | Radiometric calibration, atmospheric correction, orthorectification |
| Multispectral | Band 1 | 0.45~0.52 | Blue | 8 | ||
| Band 2 | 0.52~0.59 | Green | ||||
| Band 3 | 0.63~0.69 | Red | ||||
| Band 4 | 0.77~0.89 | Near-infrared | ||||
| Gaofen-2 satellite PMS | Panchromatic | Pan 1 | 0.45~0.9 | Panchromatic | 1 | |
| Multispectral | Band 1 | 0.45~0.52 | Blue | 4 | ||
| Band 2 | 0.52~0.59 | Green | ||||
| Band 3 | 0.63~0.69 | Red | ||||
| Band 4 | 0.77~0.89 | Near-infrared | ||||
| Tianditu Level 17 production | RGB | Band 1 | - | Red | 2.39 | - |
| Band 2 | Green | |||||
| Band 3 | Blue |
| mAP (%) | mAP50 (%) | mAP75 (%) | mAPS (%) | mAPM (%) | mAPL (%) | F1-Score | |
|---|---|---|---|---|---|---|---|
| BlendMask | 61.351 | 86.423 | 68.901 | 16.337 | 56.017 | 63.363 | 0.652 |
| BlendMask-VoV | 62.689 | 87.827 | 68.721 | 41.617 | 61.677 | 63.724 | 0.665 |
| CondInst | 60.126 | 83.535 | 66.486 | 38.218 | 57.159 | 61.599 | 0.642 |
| CondInst-VoV | 60.535 | 85.156 | 64.824 | 24.653 | 55.329 | 62.905 | 0.646 |
| Mask R-CNN | 59.631 | 83.484 | 66.210 | 27.475 | 51.586 | 62.268 | 0.626 |
| mAP (%) | mAP50 (%) | mAP75 (%) | mAPS (%) | mAPM (%) | mAPL (%) | F1-Score | |
|---|---|---|---|---|---|---|---|
| BlendMask | 57.127 | 86.856 | 65.081 | 14.810 | 48.751 | 59.381 | 0.604 |
| BlendMask-VoV | 59.316 | 88.102 | 67.981 | 38.416 | 52.037 | 61.183 | 0.627 |
| CondInst | 57.082 | 86.515 | 65.856 | 29.901 | 50.975 | 59.124 | 0.605 |
| CondInst-VoV | 55.861 | 87.166 | 64.103 | 25.495 | 44.655 | 58.839 | 0.594 |
| Mask R-CNN | 56.378 | 84.536 | 66.075 | 23.985 | 45.656 | 58.920 | 0.590 |
| mAP (%) | mAP50 (%) | mAP75 (%) | mAPS (%) | mAPM (%) | mAPL (%) | F1-Score | |
|---|---|---|---|---|---|---|---|
| BlendMask | 60.813 | 82.575 | 66.578 | 27.475 | 53.878 | 62.933 | 0.643 |
| BlendMask-VoV | 63.066 | 85.961 | 70.306 | 24.554 | 57.085 | 65.261 | 0.666 |
| CondInst | 61.381 | 83.615 | 68.439 | 46.436 | 56.943 | 63.016 | 0.651 |
| CondInst-VoV | 61.391 | 84.644 | 67.096 | 23.234 | 54.688 | 64.165 | 0.659 |
| Mask R-CNN | 59.427 | 80.876 | 67.289 | 34.653 | 56.730 | 61.004 | 0.627 |
| mAP (%) | mAP50 (%) | mAP75 (%) | mAPS (%) | mAPM (%) | mAPL (%) | F1-Score | |
|---|---|---|---|---|---|---|---|
| BlendMask | 57.452 | 84.342 | 64.327 | 20.776 | 48.088 | 59.973 | 0.604 |
| BlendMask-VoV | 59.402 | 86.625 | 66.968 | 24.554 | 50.841 | 61.735 | 0.626 |
| CondInst | 58.380 | 84.627 | 67.561 | 33.168 | 48.155 | 61.047 | 0.614 |
| CondInst-VoV | 57.250 | 85.971 | 64.287 | 19.835 | 46.261 | 60.382 | 0.609 |
| Mask R-CNN | 55.454 | 81.652 | 64.667 | 28.515 | 49.045 | 57.127 | 0.583 |
| Bounding Box | Segmentation | |||||||
|---|---|---|---|---|---|---|---|---|
| Recall (%) | Precision (%) | F1-Score | Recall (%) | Precision (%) | Accuracy (%) | F1-Score | ||
| GaoFen True-color image | BlendMask | 69.079 | 62.500 | 0.656 | 61.258 | 57.718 | 97.501 | 0.594 |
| BlendMask-VoV | 83.553 | 36.919 | 0.512 | 74.021 | 44.412 | 96.454 | 0.555 | |
| CondInst | 85.526 | 52.846 | 0.653 | 69.367 | 46.604 | 96.709 | 0.558 | |
| CondInst-VoV | 90.789 | 50.000 | 0.645 | 74.628 | 40.615 | 95.980 | 0.526 | |
| Mask R-CNN | 50.327 | 84.615 | 0.631 | 58.974 | 47.133 | 96.797 | 0.524 | |
| GaoFen False-color image | BlendMask | 60.526 | 41.071 | 0.489 | 68.023 | 50.152 | 97.023 | 0.577 |
| BlendMask-VoV | 76.974 | 32.773 | 0.460 | 75.796 | 37.336 | 95.474 | 0.500 | |
| CondInst | 83.553 | 35.574 | 0.499 | 74.941 | 36.021 | 95.273 | 0.487 | |
| CondInst-VoV | 86.184 | 32.832 | 0.475 | 74.295 | 74.295 | 94.404 | 0.743 | |
| Mask R-CNN | 59.211 | 61.224 | 0.602 | 66.292 | 45.037 | 96.574 | 0.536 | |
| Tianditu image | BlendMask | 70.199 | 87.603 | 0.779 | 81.120 | 74.957 | 98.727 | 0.779 |
| BlendMask-VoV | 78.146 | 60.513 | 0.682 | 87.844 | 69.894 | 98.616 | 0.778 | |
| CondInst | 75.497 | 70.807 | 0.731 | 86.749 | 68.864 | 98.547 | 0.768 | |
| CondInst-VoV | 88.816 | 63.679 | 0.742 | 92.351 | 59.372 | 98.038 | 0.723 | |
| Mask R-CNN | 62.252 | 97.917 | 0.761 | 88.277 | 75.922 | 98.900 | 0.816 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Niu, R.; Li, B.; Chen, T.; Wang, Y. Application of Improved Instance Segmentation Algorithm Based on VoVNet-v2 in Open-Pit Mines Remote Sensing Pre-Survey. Remote Sens. 2022, 14, 2626. https://doi.org/10.3390/rs14112626
Zhao L, Niu R, Li B, Chen T, Wang Y. Application of Improved Instance Segmentation Algorithm Based on VoVNet-v2 in Open-Pit Mines Remote Sensing Pre-Survey. Remote Sensing. 2022; 14(11):2626. https://doi.org/10.3390/rs14112626
Chicago/Turabian StyleZhao, Lingran, Ruiqing Niu, Bingquan Li, Tao Chen, and Yueyue Wang. 2022. "Application of Improved Instance Segmentation Algorithm Based on VoVNet-v2 in Open-Pit Mines Remote Sensing Pre-Survey" Remote Sensing 14, no. 11: 2626. https://doi.org/10.3390/rs14112626
APA StyleZhao, L., Niu, R., Li, B., Chen, T., & Wang, Y. (2022). Application of Improved Instance Segmentation Algorithm Based on VoVNet-v2 in Open-Pit Mines Remote Sensing Pre-Survey. Remote Sensing, 14(11), 2626. https://doi.org/10.3390/rs14112626