4.1. Experiment Setting and Evaluation Metrics
To test and verify the availability, consistency, and generality of the UAVSwarm dataset, this study applies the dataset to the UAV detection tasks of the Faster R-CNN and YOLOX [
39], and the UAV swarm MOT tasks of the GNMOT [
40] and ByteTrack [
41], and uses the standards defined in Reference [
42] to evaluate the performance of the UAV detection tasks and UAV swarm MOT tasks. The evaluation metrics are mainly as follows:
mAP (↑): mean average precision. A widely used evaluation metric in the object detection because of the ability to measure the performance of the localization and classification.
FPS (↑): frames per second. To measure the speed of models.
MOTA (↑): multiple object tracking accuracy. The accuracy in determining the number of objects and related attributes of the object is used to count the error accumulation in tracking, including the total number of false positives (FP), the total number of false negatives (FN), and the total number of identity switches (IDSW).
Among them, GTt represents the number of ground truth in the t frame, FNt represents the number of false negatives in the t frame, FPt represents the number of false positive in the t frame, and IDSWt represents the number of identity switch in the t frame.
MOTP (↑): multiple object tracking precision. MOTP mainly quantizes the positioning accuracy of the detector, and almost does not contain information related to the actual performance of the tracker.
where c
t represents the number of detection boxes successfully matched with ground truth in frame t, and dt,i represents the distance measurement between matching pairs.
IDF1 (↑): The ratio of correct recognition detection to average true number and calculated detection number. To measure whether a tracker tracks an object, if possible, that is, the quality of data association.
Among them, IDTP and IDFP represent true positive ID number and false positive ID number, respectively, like P in the confusion matrix, but now it is the calculation of ID recognition accuracy; IDFN is the false negative ID number.
MT (↑): mostly tracked objects. The ratio of ground-truth trajectories that are covered by a track hypothesis for at least 80% of their respective life span.
ML (↓): mostly lost objects. The ratio of ground-truth trajectories that are covered by a track hypothesis for at most 20% of their respective life span.
FP (↓): the total number of false positives.
FN (↓): the total number of false negatives (missed objects).
Frag (↓): the total number of times a trajectory is fragmented (i.e., interrupted during tracking).
IDswitch (↓): the total number of identity switches.
In the above metrics, ↓ means that the greater the index, the better the performance, and ↓ means that the smaller the index, the better the performance.
All the experiments are carried out on a computer with 16-GB memory, Intel Corei7-10700 CPU and NVIDIA RTX2080Ti GPU. Faster R-CNN, YOLOX, GNMOT and ByteTrack models adopt public codes, and all codes are trained using the default parameter set recommended by the authors.
4.2. Experimental Results and Analysis
4.2.1. UAV Detection
Most object detection methods include two parts: (1) a backbone model as the feature extractor to extract feature from images, and (2) a detection head as the detector to find out the classification and localization feature of objects. Nowadays, most object detection models are based on CNNs [
43] to extract feature of inputs. In this study, the advanced CNN model is integrated, with Resnet-50 [
44] and Darknet-53 [
45] as the backbone of these object detect methods, and Faster R-CNN and YOLOX to extract UAV features in images. The baseline models are listed in
Table 5.
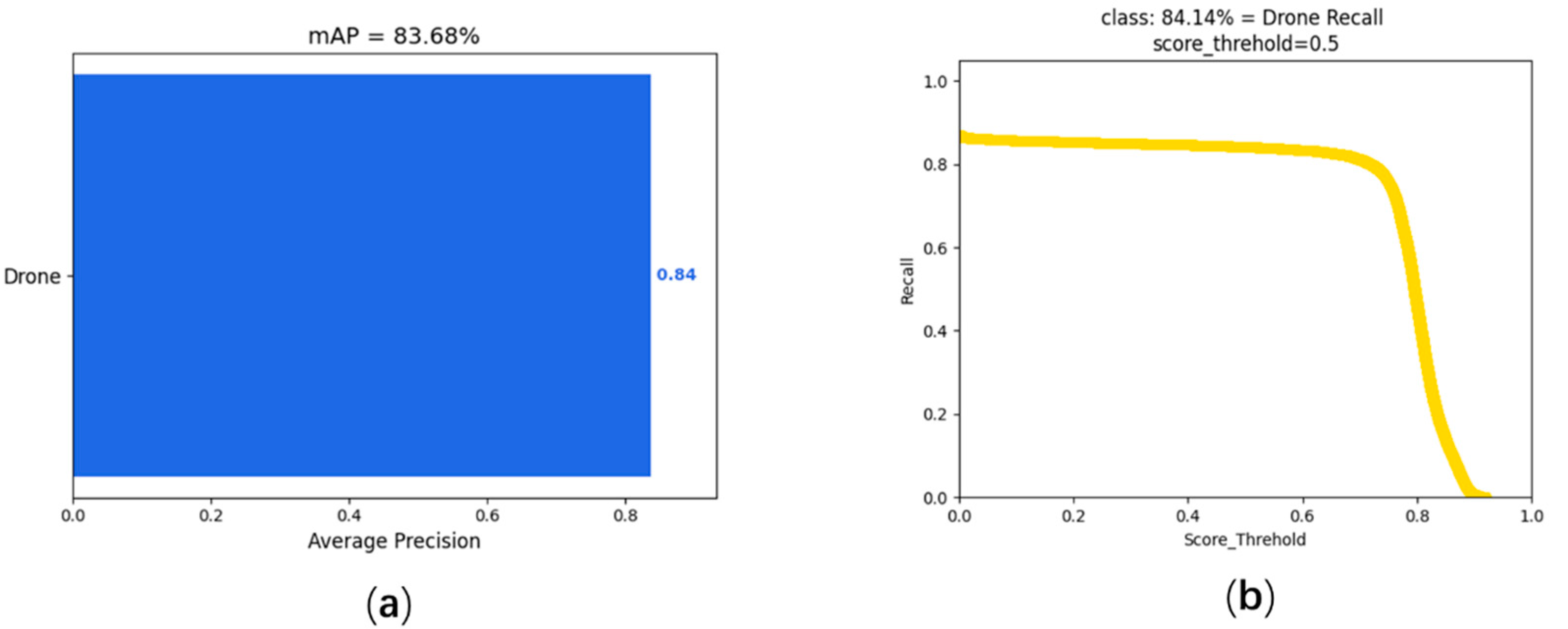
A detector is trained to localize and identify more than 19 types of UAV in the UAVSwarm dataset. A total of 6844 images of UAV were used to train the detector and evaluate on the testing sequence of the UAVSwarm dataset. For speed of detection, despite different feature extractors, the FPS results of the YOLOX is always the best compared with Faster R-CNN UAV detection. For performance of detection, YOLOX has the best performance for Darknet-53 in the UAV detection task, and mAP reached 83.68. The results of Faster R-CNN and YOLOX on the testing sequence of the UAVSwarm dataset are listed in
Table 6.
To visualize the effects of the two detectors more intuitively, 24, 30, 40, and 68 testing sequences of the same frame image were compared; the visualization results are shown in
Figure 6.
All in all, on the UAV detection task, whichever model has the best results in terms of speed and accuracy, these widely recognized object detection methods have a reasonable and accurate result on our dataset. This is enough to show that our dataset provides data support for UAV detection. In addition, the CNN models of these detection methods have indeed helped the baselines to achieve better results in speed or mAP.
4.2.2. UAV Swarm MOT
GNMOT is a new near online MOT method with an end-to-end graph network. Specifically, GNMOT designs an appearance graph network and a motion graph network to capture the appearance and the motion similarity separately. The updating mechanism is carefully designed in the graph network, which means that nodes, edges, and the global variable in the graph can be updated. The global variable can capture the global relationship to help tracking. Finally, a strategy to handle missing detections is proposed to remedy the defect of the detectors.
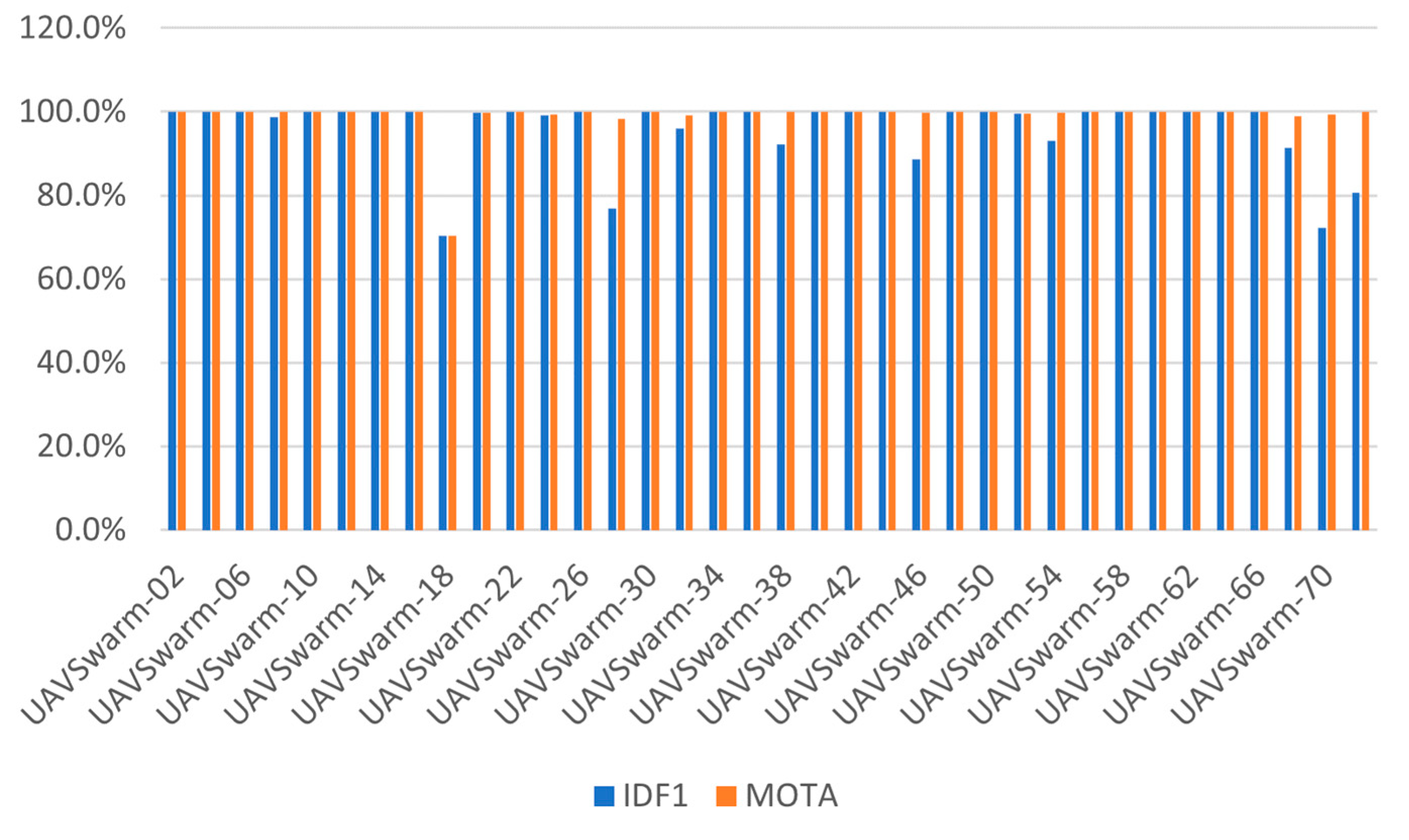
The GNMOT model is applied to UAV swarm MOT tasks. To focus on evaluating the tracking performance of GNMOT, an annotation file that removes ID information is used as a detection file. Then, experiments were carried out in 36 testing sequences in the UAVSwarm dataset. The experimental results of evaluation indexes IDF1 and MOTA are shown in
Figure 7. The experimental results show that MOTA and IDF1 of 25 testing sequences reaches 100%. However, sequences 28,70, and 72 have nearly 100% MOTA, but IDF1 does not reach 80%; this is because the MOT tasks introduce the ID information, which will pay more attention to whether the ID of the initial trajectory created by the tracker can be ‘from one to the end ‘. If the ID switch is too early, the final trajectory ID must be far from the initial trajectory ID when the number of IDswitch is the same; this makes the IDF1 score lower. So, measuring whether a model is suitable for UAV swarm MOT tasks requires not only excellent small target detectors, but also a tracker that can accurately match the trajectory.
ByteTrack is a tracking method based on tracking-by-detection, and it proposes a simple and efficient data association method BYTE. The biggest difference between it and the previous tracking model is that it is not simply to remove the low-score detection results. By using the similarity between the detection box and the tracking trajectory, the background is removed from the low-resolution detection results while retaining the high-resolution detection results, and the real objects (occlusion, blur, and other difficult samples) are excavated, to reduce the missed detection and improve the coherence of the trajectory. However, it should be noted that since ByteTrack does not use the appearance feature to match, the tracking effect is very dependent on the detection effect. If the effect of the detector is good, the tracking will also achieve good results; however, if the detection effect is not good, it will seriously affect the tracking effect. At present, as the state-of-the-art model of the MOT Challenge, the ByteTrack model uses the detector YOLOX with excellent performance to get the detection results. In the process of data association, like SORT, only Kalman filter is used to predict the position of the tracking trajectory of the current frame in the next frame. The distance metric between the predicted frame and the actual detection frame is used as the similarity of the two matching, and the matching is completed by the Hungarian algorithm.
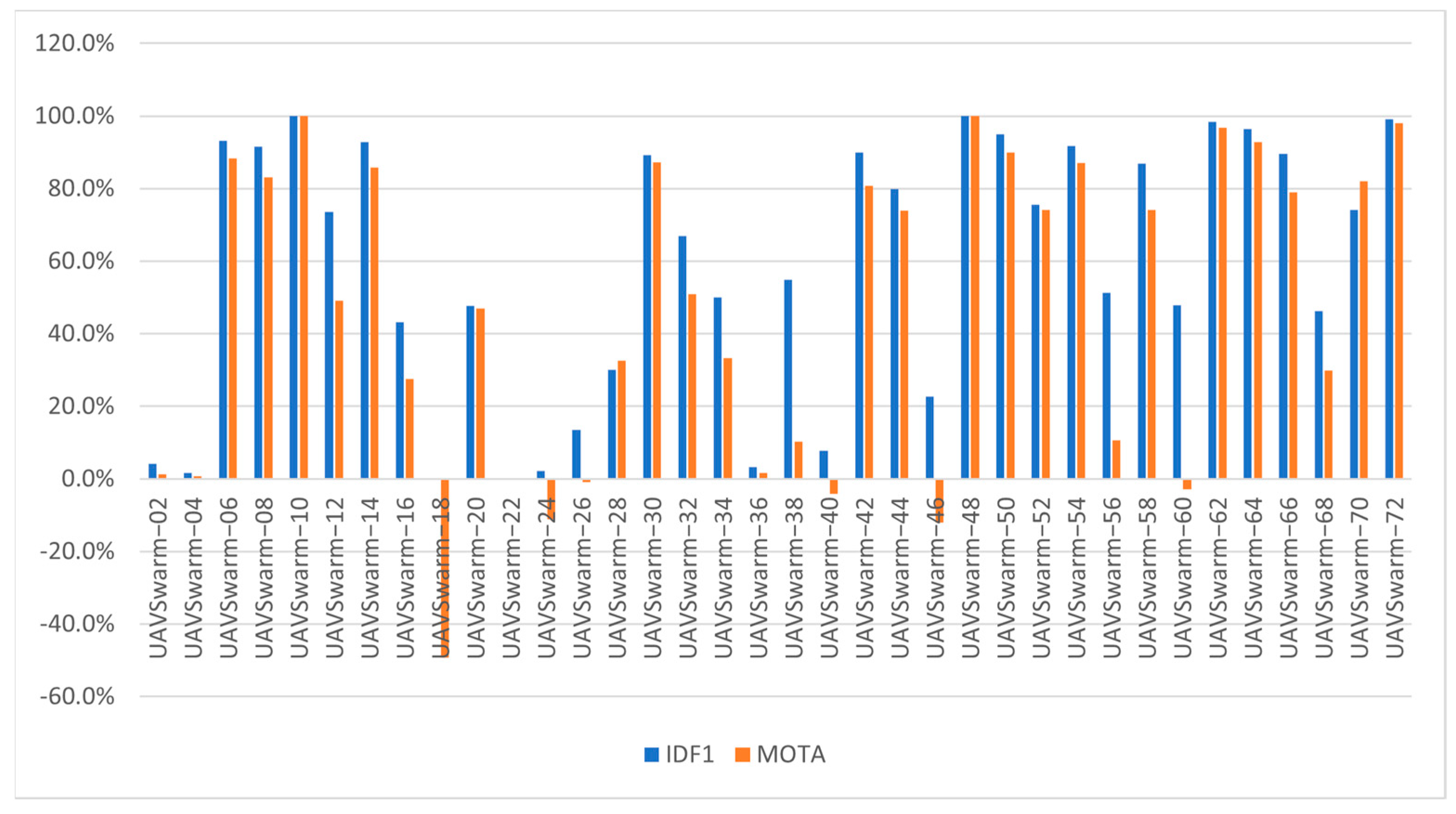
In this study, the UAVSwarm dataset is used in ByteTrack model, and the experimental results are shown in
Figure 8. The experimental results show that 13 sequences have MOTA higher than 80%, 7 sequences have negative MOTA (the MOTA can become negative when the error generated by the tracker exceeds the object in the scene), and 14 sequences have MOTA between 0% and 80%. The 13 sequences that have MOTA higher than 80% are all a simple way of movement, and the scene is relatively not complex, so it is easy for the tracker to generate the correct trajectory. The 7 sequences with negative MOTA are all complex modes of motion: UAV move fast, the UAV continue to fly into the out of the screen, and the trajectories overlap with each other. The experimental results show that even if the YOLOX detector can reach 83.68 mAP, the tracking results will also produce negative numbers due to the large scale change, fast moving speed, frequent access to the screen and trajectory overlap of the UAV. Therefore, the completion of UAV swarm MOT tasks requires not only excellent detectors, but also excellent trackers to maintain tracking consistency and avoid object jumping.
Therefore, the MOT tasks with the object of UAV swarm are very challenging. This experiment further verifies the availability and versatility of the UAVSwarm dataset constructed in this study.
4.3. Visual Tracking Results
To illustrate the model performance more intuitively,
Figure 9,
Figure 10,
Figure 11 and
Figure 12 show the visual tracking results of the above two models on some UAVSwarm dataset videos. The detection box ID number of each sequence in the ByteTrack model is accumulated according to the ID number of the previous sequence, and the detection box ID of each sequence in GNMOT model starts from 1. The ByteTrack model uses the detector YOLOX with excellent current performance to obtain the detection results, and the GNMOT model uses the detection files provided by us (the length, width, and position of the detection box in the detection files are consistent with the bounding box of the annotation files).
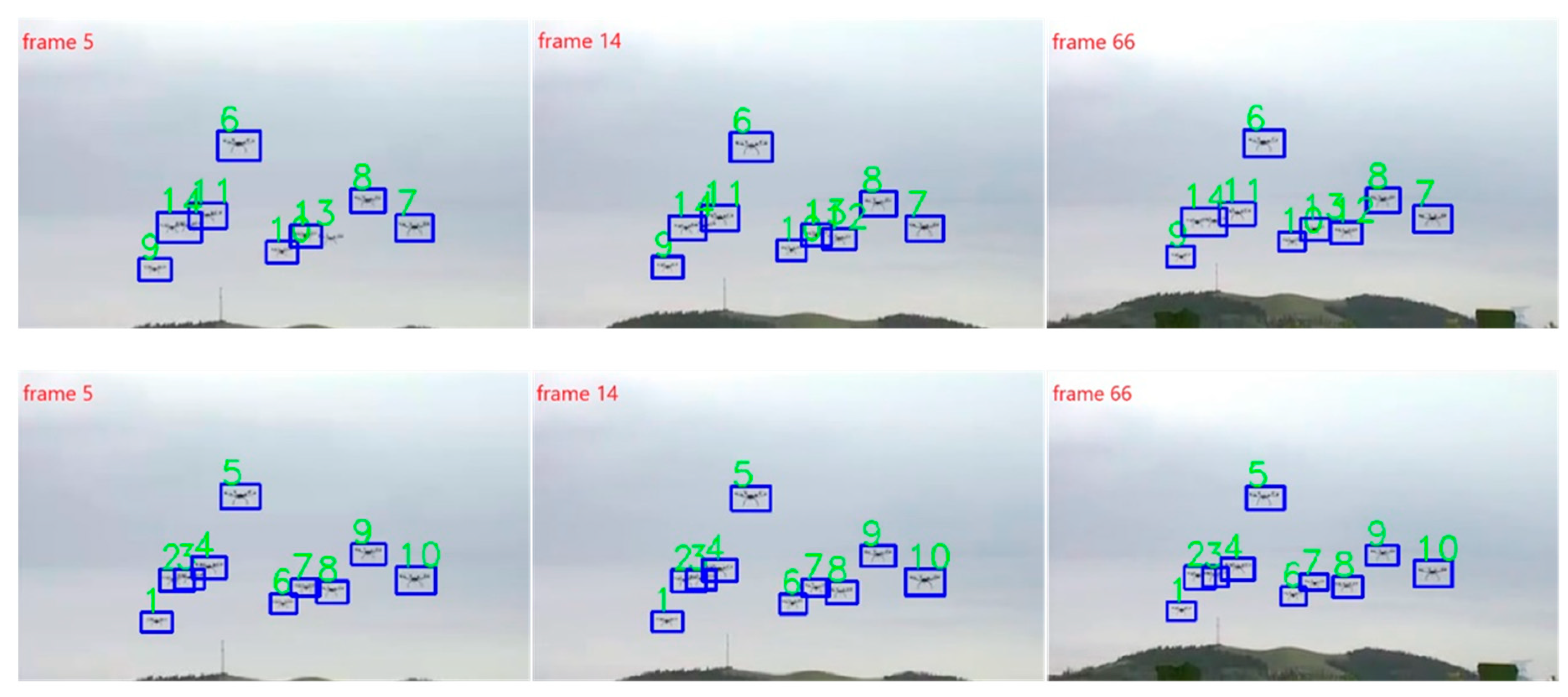
Figure 9 shows a video of UAVSwarm−06. The shooting background of this video is the sky, and the background is relatively simple and clean. However, the UAV is close to each other, and UAV are overlapped and occluded. In frame 5, the detection box of ByteTrack model ID 14 contains two UAV, and the GNMOT model uses the detecting files provided by us to distinguish two UAV that are close to each other, with IDs of 2 and 3, respectively. In the 14th frame, the ByteTrack model re-recognizes the detection box with the previous missing ID of 12. In the 66th frame, there is still no distinction between two UAV in the detection box of ByteTrack model ID 14. Although the UAV with ID number 2 and 3 of GNMOT model continues to block, it can always be accurately tracked.
Figure 10 shows a video of UAVSwarm−28. The shooting background of this video is complex, and the lens deviates. The two models have multiple ID switching because of lens jitter, and the houses in the background and the dark clouds have brought great challenges to tracking.
Figure 11 shows a video of UAVSwarm−30. The shooting background of this video is complex, but the lens does not deviate. In the 11th frame, ByteTrack and GNMOT detected four UAV. In the 51st frame, the UAV with ID of 199 in the ByteTrack model misses the detection box because it is like the window background. In the 81st frame, the UAV with ID of 199 in the ByteTrack model is re-identified, and the ID number is 203. The GNMOT model can accurately track five UAV in frame 11, 51, and 81, and the ID number has not been switched.
Figure 12 shows a video of UAVSwarm−46. The background of the video is simple, but the object is too small, occluded, and moves fast. The ByteTrack model makes more errors than objects in the scene because of the tracker, and MOTA becomes negative.
Table 7 presents the tracking results of the UAVSwarm dataset testing sequence and mostly tracked tracklets (MT) represents the number of tracking trajectories that at least 80 % of the video frames of each object can be correctly tracked in the tracking process, mostly lost tracklets (ML) represents the number of tracking trajectories that at most 20 % of the video frames of each object can be correctly tracked in the tracking process.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}