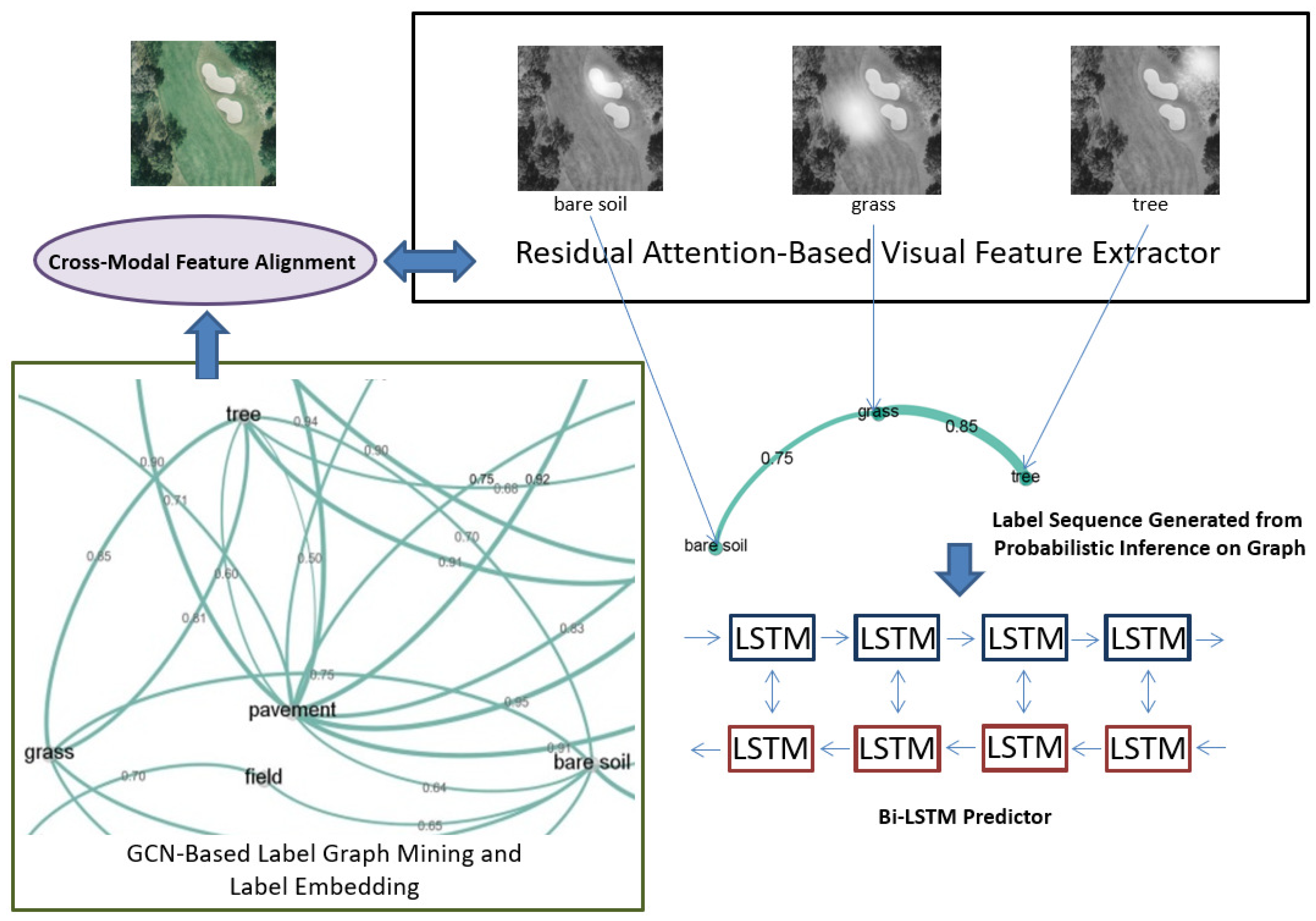
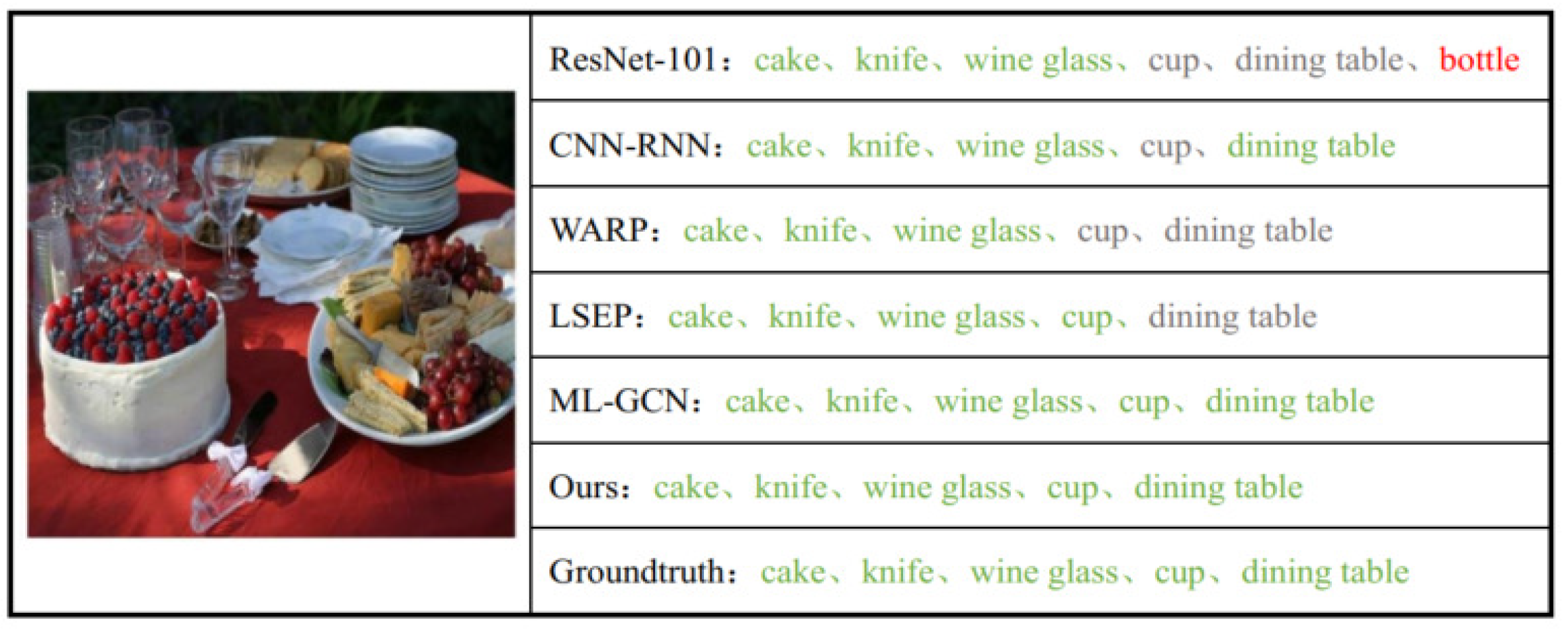
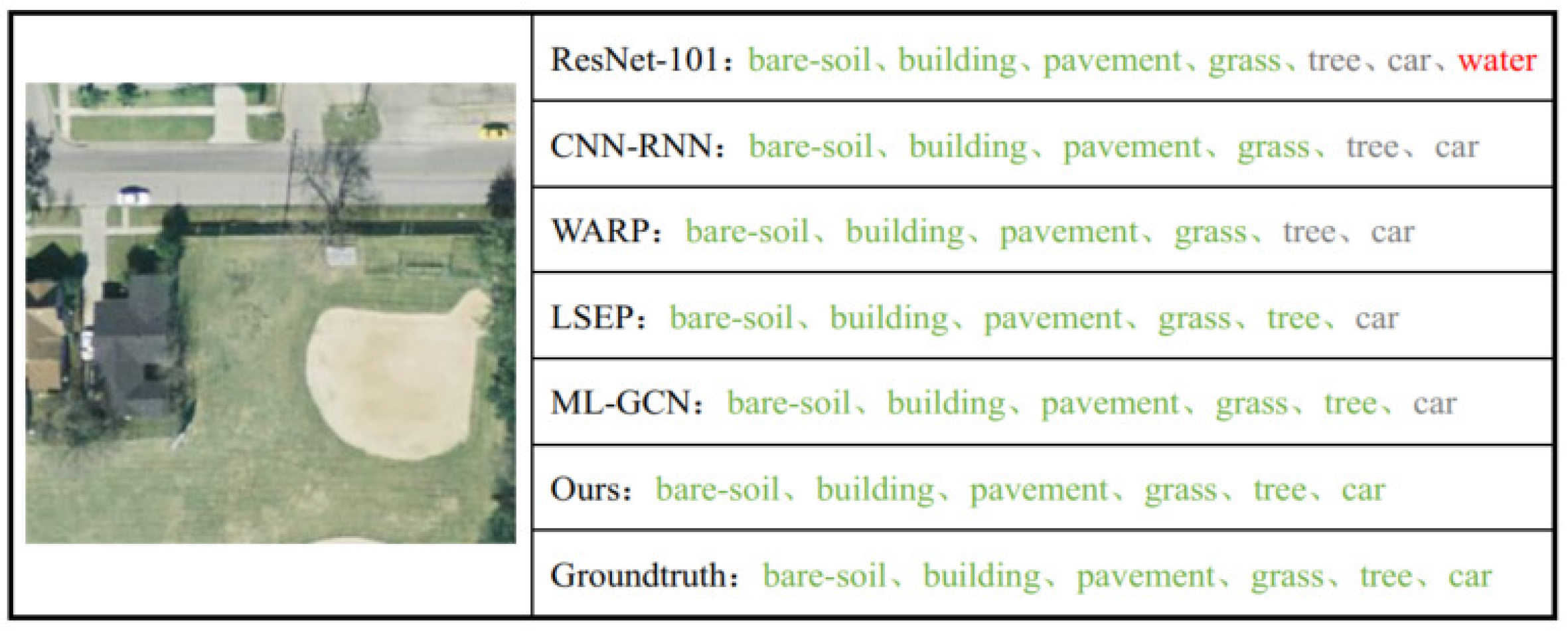
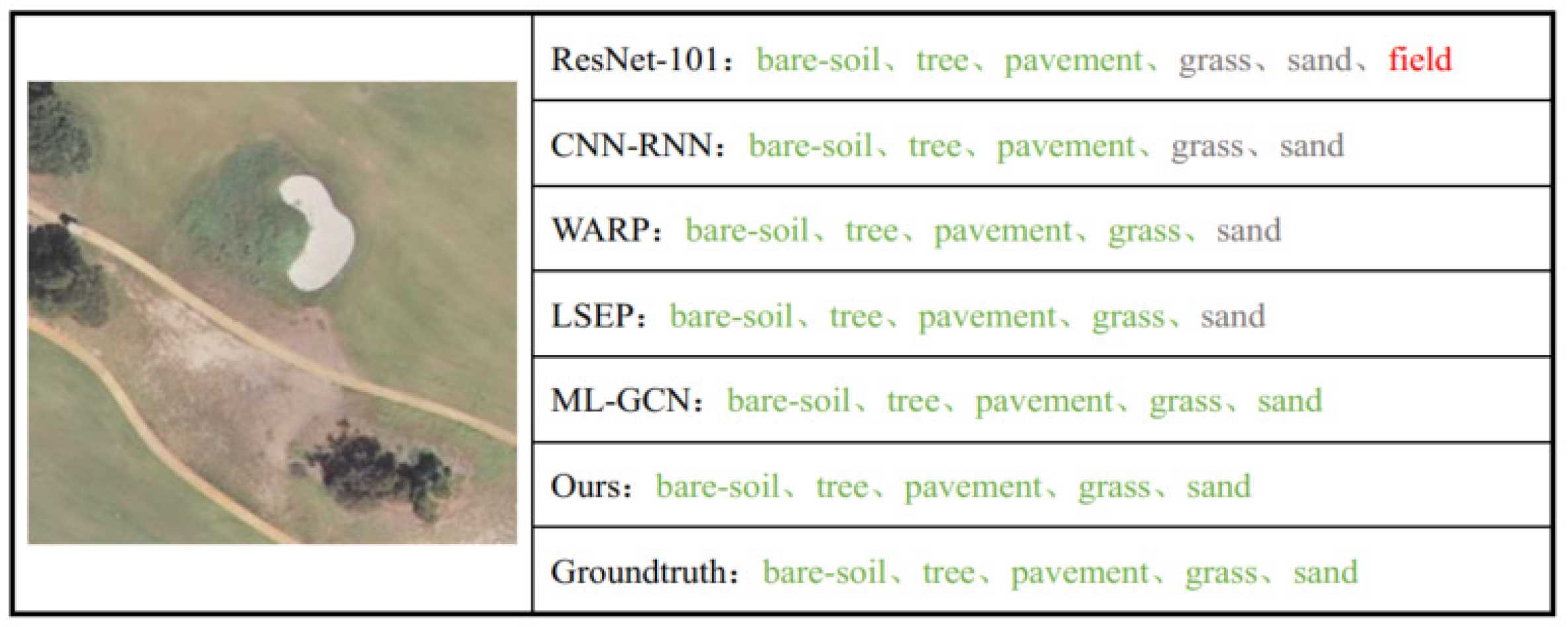
How to represent pictures and labels and then measure their relevance in a shared space is the key point for multi-label image annotation. Correspondingly, there are three basic sub-tasks in multi-label scene recognition: representing images, modeling label dependencies, and matching the sample with related labels. Classical works mainly focus on the modeling of pictures, e.g., designing effective feature descriptors [
21,
22,
23] and making improvements in deep learning-based feature extractors [
8,
9]. There are also some works which tried to model images and labels uniformly, generating sub-graphs with similar strategies (e.g., sparse matrix [
21,
27]) so as to match them easily with related attributes.
In this paper, we pay more attention to labels. Considering the structure gap between the data in different modes, we map them with different strategies so as to have a good use of advanced representation learning algorithms. In addition to CNN-based image representation, the
advanced language model and the graph model are introduced for the representation of labels.
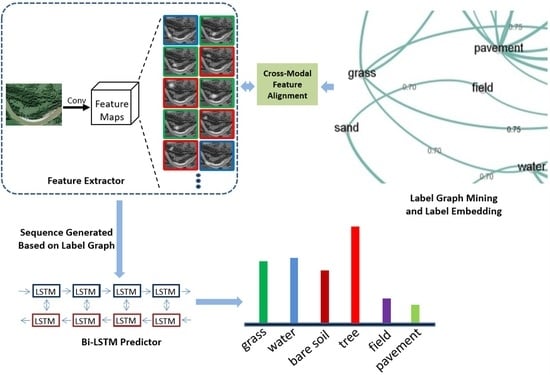
In the framework above, the object-level visual features would be extracted by the improved channel-wise multi-attentional CNN and then aligned to label vectors. After cross-modal mapping, we feed those object-level signals to a Bi-LSTM [
19] predictor
according to a label sequence that is generated by the probabilistic inference on label graph. The framework will be presented in detail in the following sections.
3.1. Residual Multi-Attention Mechanism
In this article, we introduce the advanced attention mechanism, MA-CNN [
20], and further improve it for multi-label tasks. MA-CNN is proposed for fine-grained image categorization. For all training samples, the coordinates of peak response in each CNN layer are selected as the feature vector. With these vectors, CNN layers can be clustered into
N groups, generating related discriminative attention parts. This is understandable, since the region with the peak response is always the most distinctive. This grouping operation is executed for the initialization of
N attention parts. Correspondingly,
N c-dimensional fully connected layers are designed to generate the weights of different channels (
c channels) for these
N attention parts. The fully connected layers will be optimized during the further end-to-end part learning. More details are described in reference [
20].
Due to the fact that MA-CNN is proposed for fine-grained categorization for which the label for each sample is only one, we further improve MA-CNN in three aspects so as to make it appropriate for multi-label classification.
Firstly, the attention parts in MA-CNN [
20] are proposed adaptively according to related labels. It is possible that more than one attention part is associated with the same tag. We utilize a pre-trained CNN to predict the labels for different attention parts. The part with the higher response value will be selected, as written in Equation (
1):
where
is the
predicted label for the No.n attention part ;
is the final feature representation of this attention part;
is the pre-trained CNN predictor;
c is the number of channels;
denotes the CNN parameters for the feature extraction and attention proposal; the dot product means element-wise multiplication;
denotes the input samples; and ∗ means the convolutional and attention-proposal operation.
Secondly, because of the above, the attention proposal in MA-CNN is implemented by channel grouping; the channels in the CNN kernels always distribute unevenly in different groups. This can be improved by channel-wise normalization, as written in Equation (
2):
where
denotes the extracted feature associated with No.
n attention mask,
;
is one of the weights of the CNN channels generated from the fully-connected layers in MA-CNN;
denotes the trainable CNN parameters; and the dot product means element-wise multiplication.
In addition, we introduce the residual attentional learning [
41] in different channel groups, mining the residual, channel-wise, and regional information not only in depth but also crosswise, as in Equation (
3):
This
residual, multi-attention mechanism (RMAM) is suitable for the analysis of complex remote sensing pictures with many labels. We visualize the generated attention parts in the picture “golfcourse79” (UC-Merced [
16,
17]) using the basic attention layer, MA-CNN, and the proposed RMAM, as in
Figure 4. In these experiments, ResNet-50 [
5] is selected as the backbone.
As illustrated in
Figure 4, MA-CNN is more sensitive for object-level features than the basic attention layer. The perceived attention parts by our RMAN are most obvious, especially for label “tree” and the label “grass”.
Figure 5,
Figure 6 and
Figure 7 show the generated attention parts associated with different labels by RMAN on three typical pictures. It is evident that RMAM is able to perceive object-level visual features effectively.
These extracted object-level visual signals will be further processed and then utilized for a sequence prediction which will be described in
Section 3.3 and
Section 3.4.
3.2. GCN-Based Label Representation Learning
As mentioned in
Section 1 the most important issue in multi-label classification is to match visual features to semantic labels. If we pay more attention to label representation, multi-label classification can be regarded as a typical cross-modal learning process which tries to translate the high-level semantic concepts in pictures to a group of words. In this paper,
we adopt a language model and label a graph to represent the labels, then map them to visual features. The mapping strategy will be described in
Section 3.3.
Over the past few years, with the development of multi-media techniques, the data resource in the new period is characterized as multi-source and heterogeneous but highly correlated with high-level semantics [
56]. Multi-modal machine learning has become a research hotpot in the past few years. As defined by [
57], “modality” has a more fine-grained meaning compared with “medium”. It refers to a typical data source with a standard structure in a unified channel. On this precondition, pictures, texts, vocal signals, time series, or graphs can all be regarded as independent modes, respectively.
Textual data present valuable cross-modal supplementary information for the comprehension of label semantics. On a large scale corpus, images and texts, similar concepts (objects in pictures and entities in sentences), will always co-occur in specialized scenes. Most word-representation models are based on word distribution, e.g., close prediction in sentences, which is similar to object co-occurrence in pictures. In this article, in addition to mapping remote sensing images by CNN with residual multi-attention module (RMAM in
Section 3.1 with attention masks optimized in the training process for associated labels),
we also adopt an advanced language model, Bert [58], to initialize label representation with a large textual corpus.
Language model-based label representation is effective due to the fact that related entities always co-occur in large scale textual corpora.
From another perspective, the large-scale data will also dilute the valuable information among specific words about the multi-label dataset. In order to ensure the good use of label dependencies, we further
exploit them in a graph which is mined by GCN [18]. This is the so-called “label graph mining”-based label (node in graph), which embeds strategy in the proposed framework.
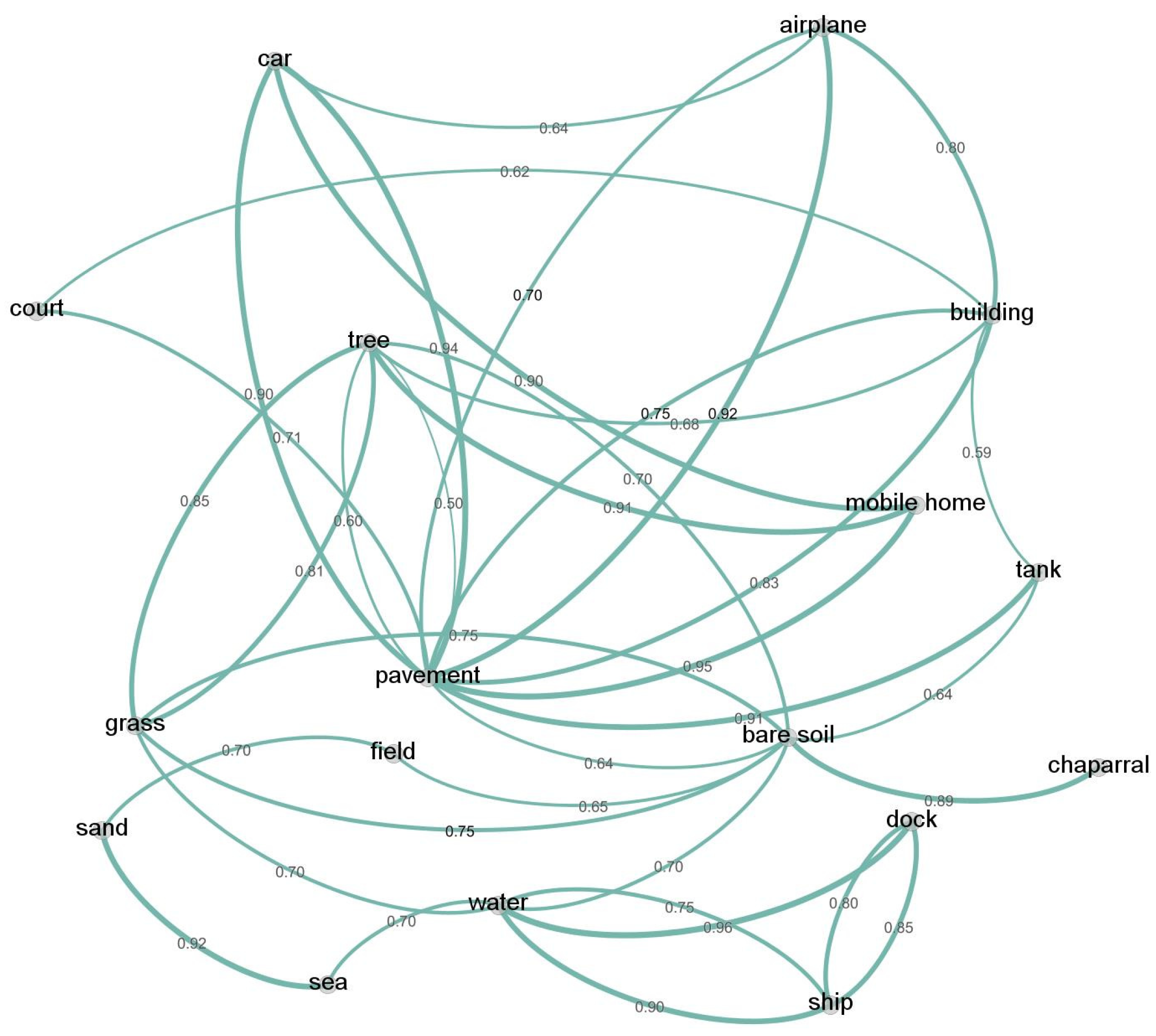
To begin, we built the label graph referred to as labels’ co-occurrence conditional probabilities, as Equation (
4):
where
and
denote label
a and label
b.
If is greater than a threshold (in this article, we set it 0.4), we consider that if appears, will also appear. The connection from
to
exists in the graph (such as in
Figure 1).
Through the statistical analysis of training data, we can obtain a label graph. This graph can further be modeled by GCN [
18]. The function for one GCN layer can be written in Equation (
5):
where
is the result of the convolutional operation in No.
l GCN layer;
is the adjacency matrix of the graph;
is initialized by a matrix of node feature vectors
;
, where the introduction of
is to normalize adjacency matrix;
is a matrix of trainable variables in GCN; and
is an nonlinear activation function, such as ReLU [
59].
As mentioned above, we employ a language model to extract semantics in a textual corpus cross-modally, leveraging Bert [58] to embed labels initially. These label vectors will form the initial states (nodes) of the graph, also the and in Equation (5). Our CM-GM framework can not only extract word semantics in large corpus, but also take advantage of label dependencies by label graph mining.
It can be seen in
Figure 8, compared with initial label vectors by Bert in
Figure 8d, that further GCN mapping can make the related labels in one typical scene appear closer to each other, as shown in
Figure 8e. In these experiments, we chose a pre-trained Bert model [
58]. The dimension of the label vectors were set to 1000. t-SNE [
60] is employed to reduce the dimensions of the label vectors for visualization.
3.3. Cross-Modal Feature Alignment and Training Approach
For multi-label classification and other multi-modal learning tasks, cross-modal feature alignment is a key point. With those visual embeddings (such as attentional feature vectors in
Figure 5,
Figure 6 and
Figure 7) and graph-based label embeddings (such as in
Figure 8), it is an important issue to align feature representations between 2 modes. In this article, we proposed an improved cross-modal representation learning strategy to enhance features in the framework cross-modally. That is minimizing hinge rank loss [
61] to optimize the CNN layer, as Equation (
6):
where
is a column vector generated from object-level attention mechanism as mentioned in
Section 3.1;
denotes the label embedding, a row vector, of the matched label;
are those embeddings of other labels (nodes) in the graph; and
are trainable parameters in
Cross Modal Alignment module (CMA).
,
and
can be calculated as Equations (7)–(9),
where
is the input sample, and
is the label vector generated by Bert [
58], and this label is associated with
.
In
Figure 9, we visualize the extracted label–level feature vectors from three typical pictures. The vectors in
Figure 9d are generated by RMAM, as mentioned in
Section 3.1. After cross-modal feature alignment, visual vectors in the same scene become closer to each other and farther from those in other pictures, as shown in
Figure 9e. Similarly, we use t-SNE [
60] for dimensionality reduction. In fact, it has been analyzed that related objects and attributes are always distributed similarly in large corpora of different modes, and this data character is useful. This cross-modal similarity has been utilized in many complex computer vision tasks, e.g., zero-shot image classification based on semantic embedding [
61,
62].
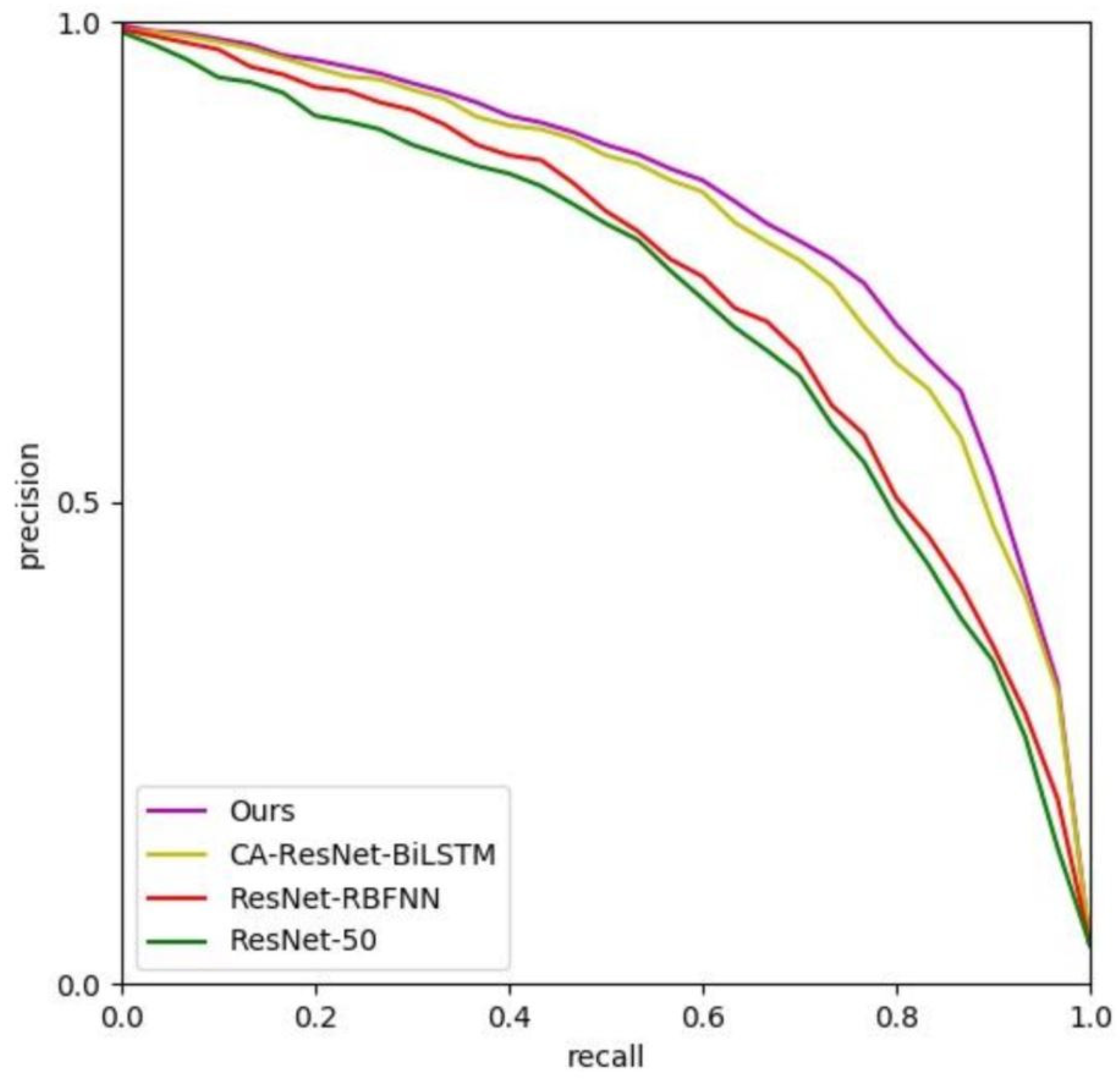
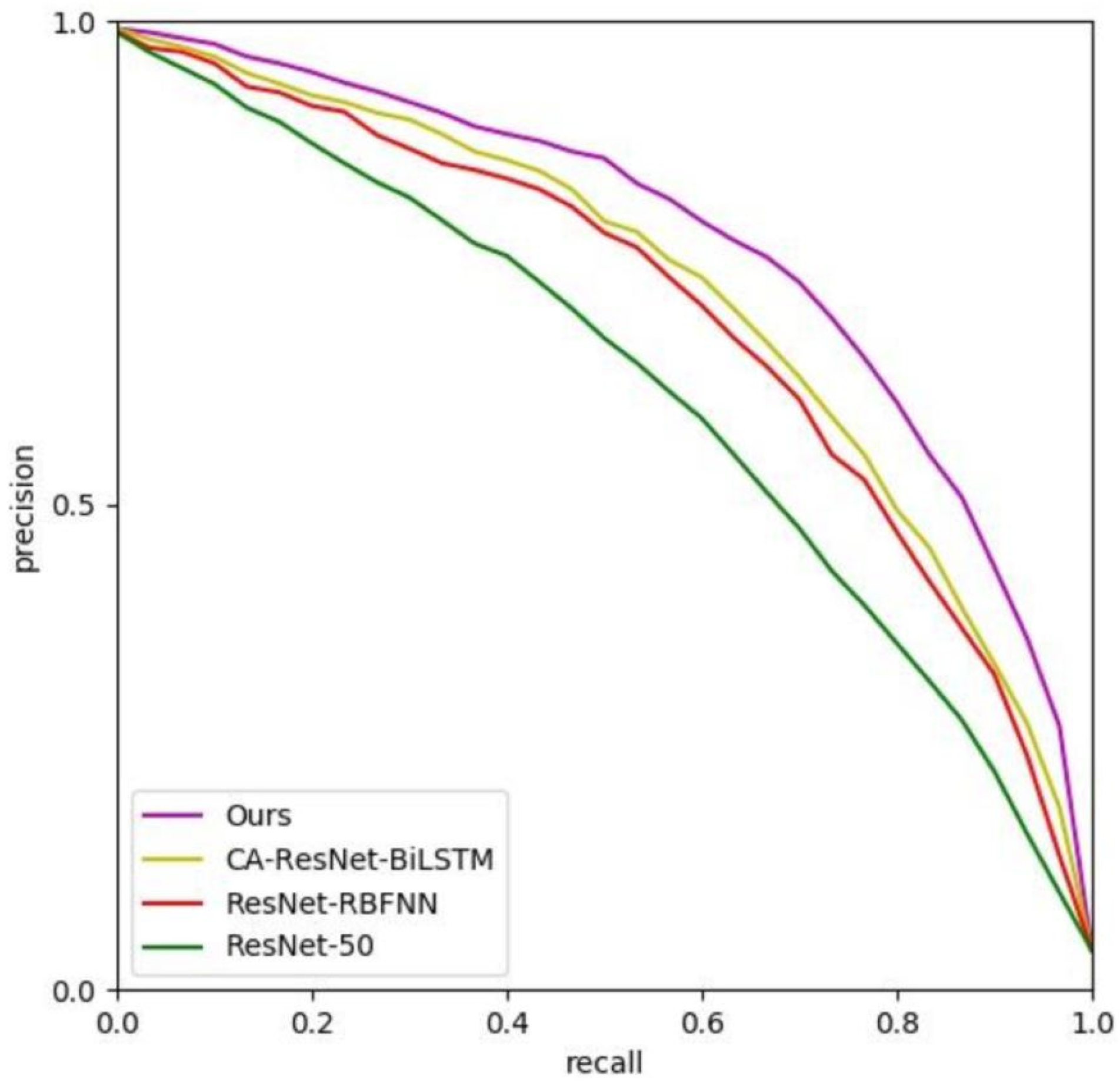
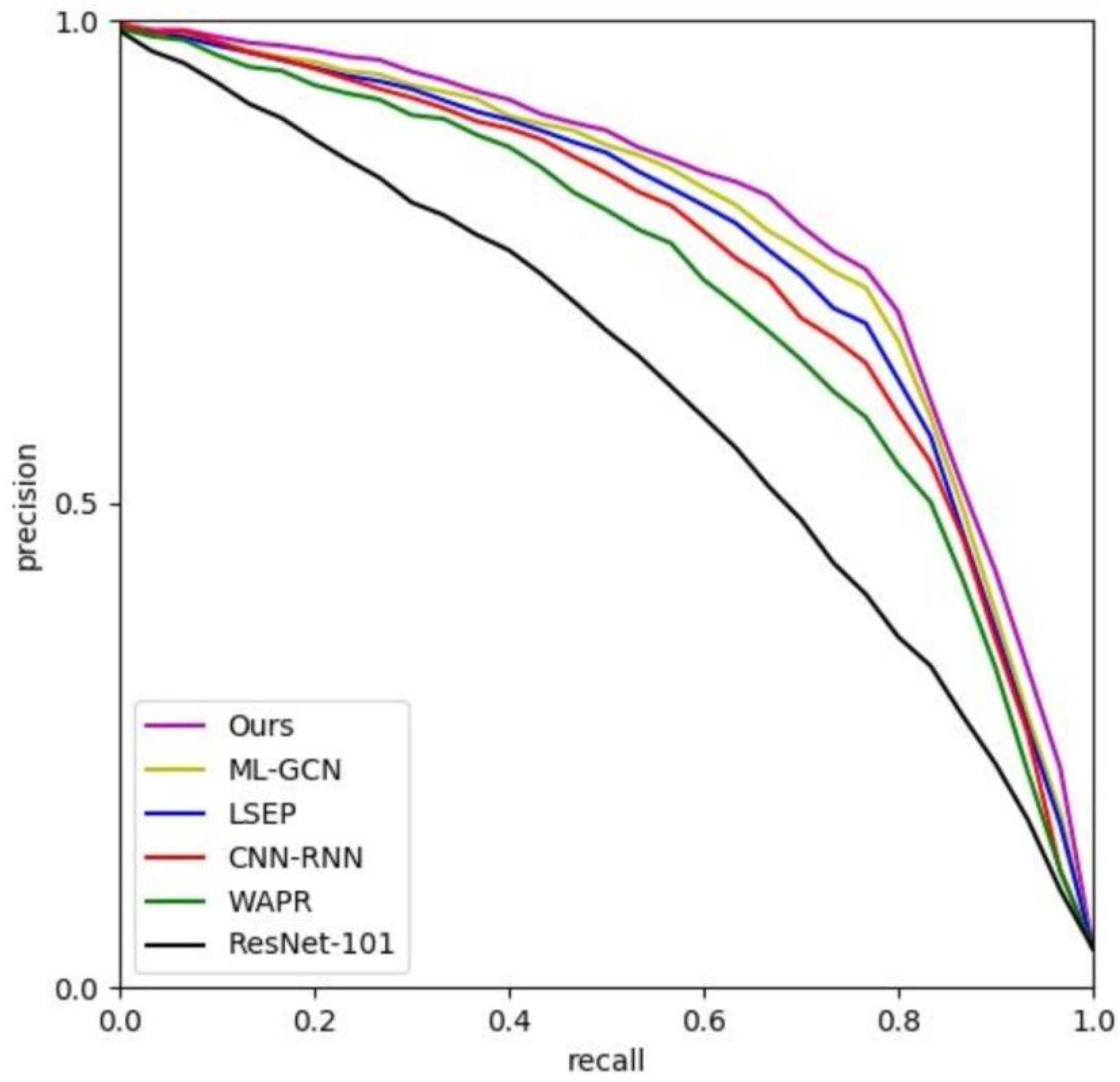
In the training,
we preserve two groups of trainable CNN parameters in the CM-GM framework, and , for attention propose and cross-modal alignment, respectively. is to be used for the object-level visual feature extraction in RMAM, as mentioned in
Section 3.1. ResNet-50 [
5] is selected as the backbone. We use a similar training strategy for
to MA-CNN, with the accumulation of binary cross-entropy loss and channel-grouping loss [
20].
and the fully connected layer (FC layer) designed in the original MA-CNN can help our CM-GM framework to generate appropriate attention parts for different labels. With these attention parts, object (label)-level visual signals can be extracted one by one and aligned with associated label vectors by another CNN-based mapping with
, as written in Equation (
6). The training processes for
,
and the
fully-connected layer (FC layer) for channel grouping in MA-CNN are individual and alternative. It can be summarized as follows:
Train with fixed FC layer;
Train FC layer with fixed generated in step 1;
Train with attention parts generated by fixed and FC layer (updated in this loop); go to step 1 (next loop): train with the fixed and updated FC layer generated in this loop.
3.4. Credible Labels for LSTM Predictor
After being aligned and enhanced by a cross-modal alignment module, those object-level visual features would be fed into a LSTM [
19] predictor for training and testing. In this paper, we model the label dependencies by GCN-based graph. After graph mining and embedding, we deal with these label (object)-level visual representations as a sequence generated from the graph (such as in
Figure 1) by probabilistic inference. For example, the most obvious object, also the one with the peak response value, e.g., the “airplane” in
Figure 10b, can be regarded as the starting point of the sequence. Another object with the
highest co-occurrence probability is sequentially selected as the second one. Since
, the label sequence in
Figure 10b for LSTM can be determined like the purple curve in
Figure 10d. Similarly, the label sequences for
Figure 10a,c are also built and shown in
Figure 10d. These three paths are cut from the label graph in
Figure 1.
In the training process, we feed those mapped visual feature vectors (generated from the residual attentional CNN and aligned by cross-modal module) to the LSTM [
19,
44] predictor. Compared to the classical RNN, LSTM is more applicable for a sequence process with a higher memory ability. In LSTM, different memory units and gates are designed. Their updating formula is written in Equations (10)–(14):
where,
,
, and
denote the outputs of “input gate”, “forgetting gate”, and “output gate” at time
t, respectively (in this paper, these outputs are calculated for the
nth label; one label corresponds to one step);
means the state of the LSTM [
19] cell;
is the hidden variable of the LSTM cell, the activation of
;
denotes trainable variables in different units, and
is the corresponding bias;
is the visual feature vector of attention part
n as Equation (
15), related with label
n;
is a nonlinear activation function, “sigmod”, in LSTM; and • denotes element-wise multiplication.
where
denotes cross modal alignment; we let
be the No.
k sample and
be the visual features generated by RMAM associated with No.
n label in sample
k.
Considering the rich information in the sequence and the differences in label directions (For 2 labels, A and B, it is normal that
), we improve the LSTM to Bi-directional LSTM as Equation (
16):
where
denotes the final hidden variable, which is the concatenation of
in two opposite directions,
and
.
In the testing, we consider the labels with higher CNN output values (top
K or bigger than a threshold) as
“credible labels”, then predict the last labels in the sequence by LSTM [
19]. With these output vectors of LSTM, label vectors can be determined by mapping or inverse mapping, as mentioned in
Section 3.2.
We adopt a pre-trained CNN classifier (e.g., ResNet [
5] on MS-COCO or the large remote sensing archive) to predict labels. If the predicted labels (not in a credible label set) are also in the predictions of LSTM, we consider these predicted labels to also be positive. Our experiments show that this LSTM predictor is very effective.
This is understandable, since the prediction about obvious objects is more likely to be correct in a multi-label classification. For those inconspicuous objects, the CM-GM framework is also valid due to its advantage in graph mining and sequence analysis.Moreover, considering the the co-occurrence of related labels and the actual situation that some of the objects are obvious in one picture while inconspicuous in another one, it is reasonable to believe that we can utilize partially significant objects to illustrate a special scene in a large image archive on the condition that the labels are jointly represented by the graph cross-modally. In this way, the manual labeling work for training data can be reduced significantly.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}