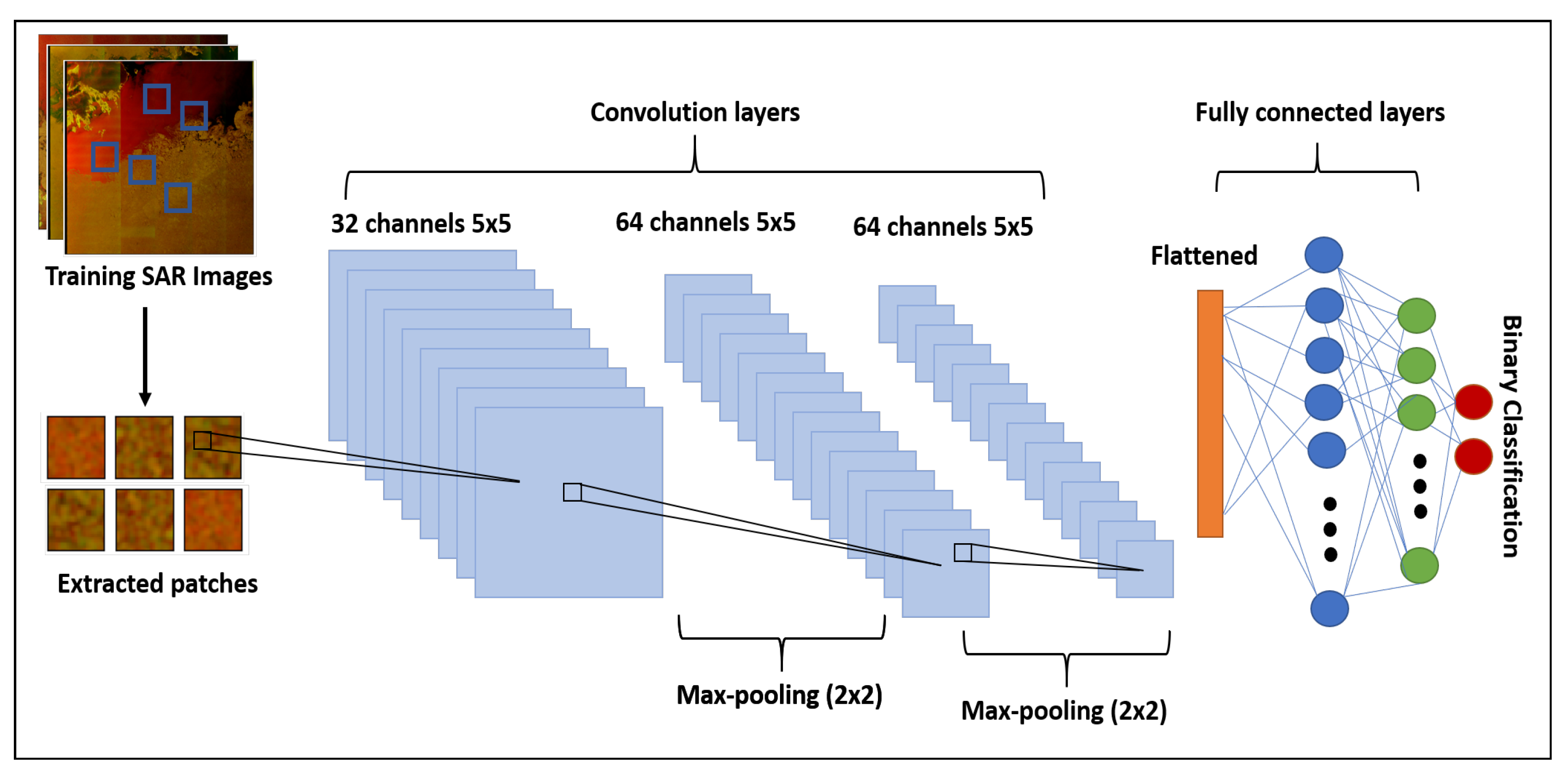
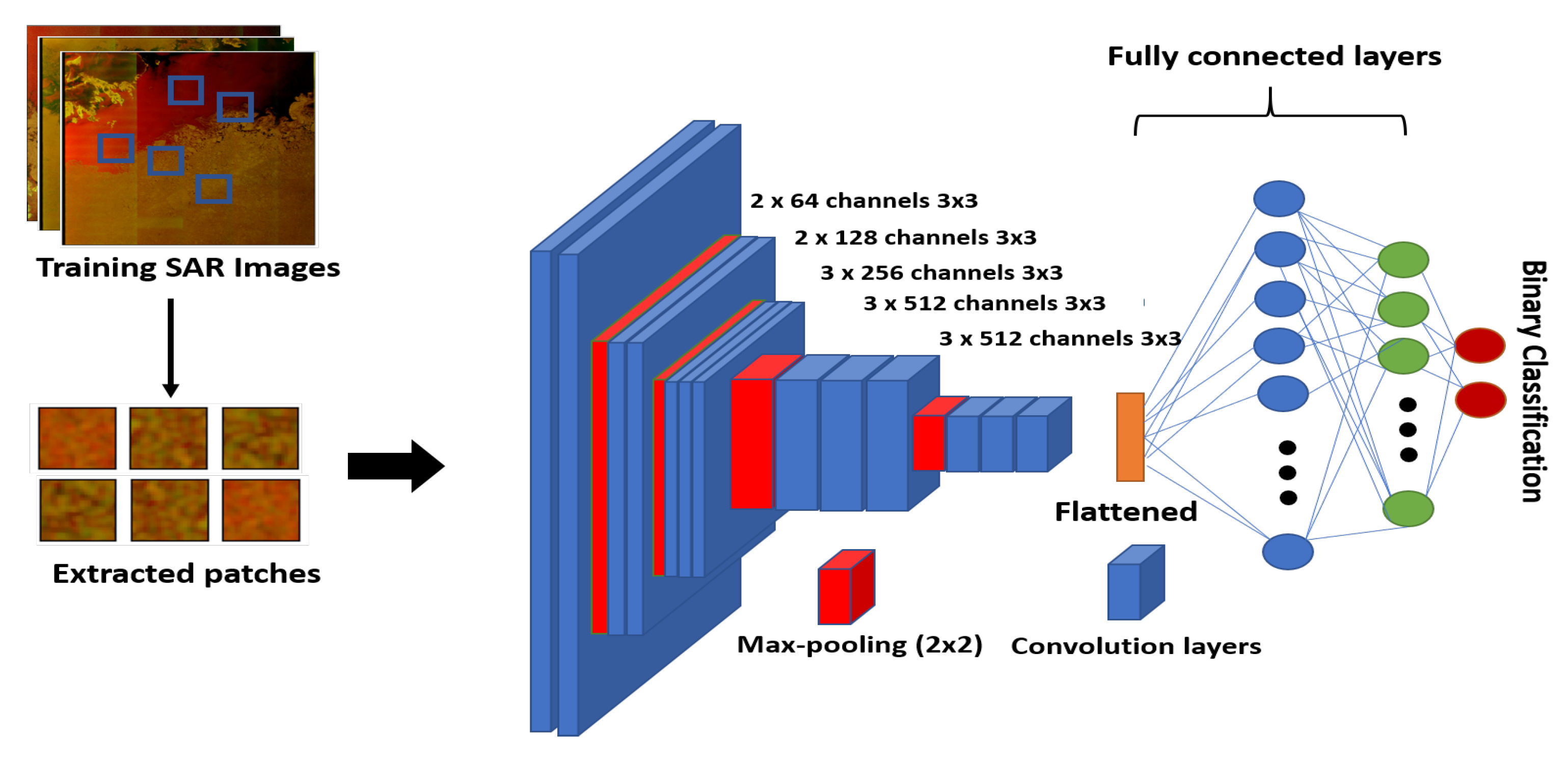
4.1. Dataset
To test the deep CNN models for sea ice classification, we created an annotated dataset building on the work of Lohse et al. [
56]. This is based on 31 Sentinel-1A Extended Wide (EW) Level-1 Ground Range Detected (GRD) scenes, with a spatial resolution of 40 m × 40 m, that were acquired north of the Svalbard archipelago in winter months between September and March during the period 2015–2018. Four sample images from our dataset are shown in
Figure 3. Our dataset can be accessed from the provided link
https://dataverse.no/dataset.xhtml?persistentId=doi:10.18710/QAYI4O (accessed on 1 March 2021). The images were pre-processed by applying a thermal noise removal algorithm in the European Space Agency (ESA) Sentinel Application Platform (SNAP) software [
57], calibrated using the
look-up table, and multi-looked using a
boxcar filter. After conversion to dB scale, the images were clipped and scaled linearly in the range [0, 1], considering the dual-polarization intensity channels individually, and including a third input-channel representing the incident angle. The range for the co-polarization (HH) is −30 to 0 dB, for the cross-polarization (HV) it is −35 to −5 dB, and for the incidence angle 19 to 46 degrees. A set of polygons representing homogeneous sea ice types was subsequently manually annotated with labels for those types, taking into account additional information from co-located and nearly temporally coincident optical image data from Sentinel-2. Patches were then extracted from these polygons for 5 different classes representing: Water (including ice-free water (windy), ice-free water (calm), and open water in leads), Brash/Pancake Ice, Young Ice, Level First-Year Ice, and Deformed Ice (including both first-year and multi-year ice). The stride between patches was 10 pixels. In
Table 1, we provide the code values for the ice types related to the stage of development (ice age), as defined by the SIGRID-3 vector archive format for sea ice georeferenced information and data ([
58]), the class names, and the number of samples for each class for a patch size of 32 × 32. It is worth noticing that we have an imbalanced dataset, where the number of samples for each class has considerable variation. This is a result of the effort we made to accurately annotate the polygons, and hence the number of polygons was small and not representing all classes equally.
For binary Water/Ice classification, we grouped the samples into two classes, namely Water and Ice. Our motivation for performing binary classification is to investigate if deep models can distinguish between sea ice and water, which would subsequently allow for quantitative sea ice concentration mapping. The number of samples of water and ice for different patch sizes are shown in
Table 2, and there is not a class imbalance problem in this case. For all the tests, 80 percent of the dataset was used for training and 20 percent for validation.
We would like to mention that in the inference experiment, we used completely different images. These were another 4 scenes from north of Svalbard, and 8 scenes from Danmarkshavn, East Greenland that were each collected during separate months in 2018.
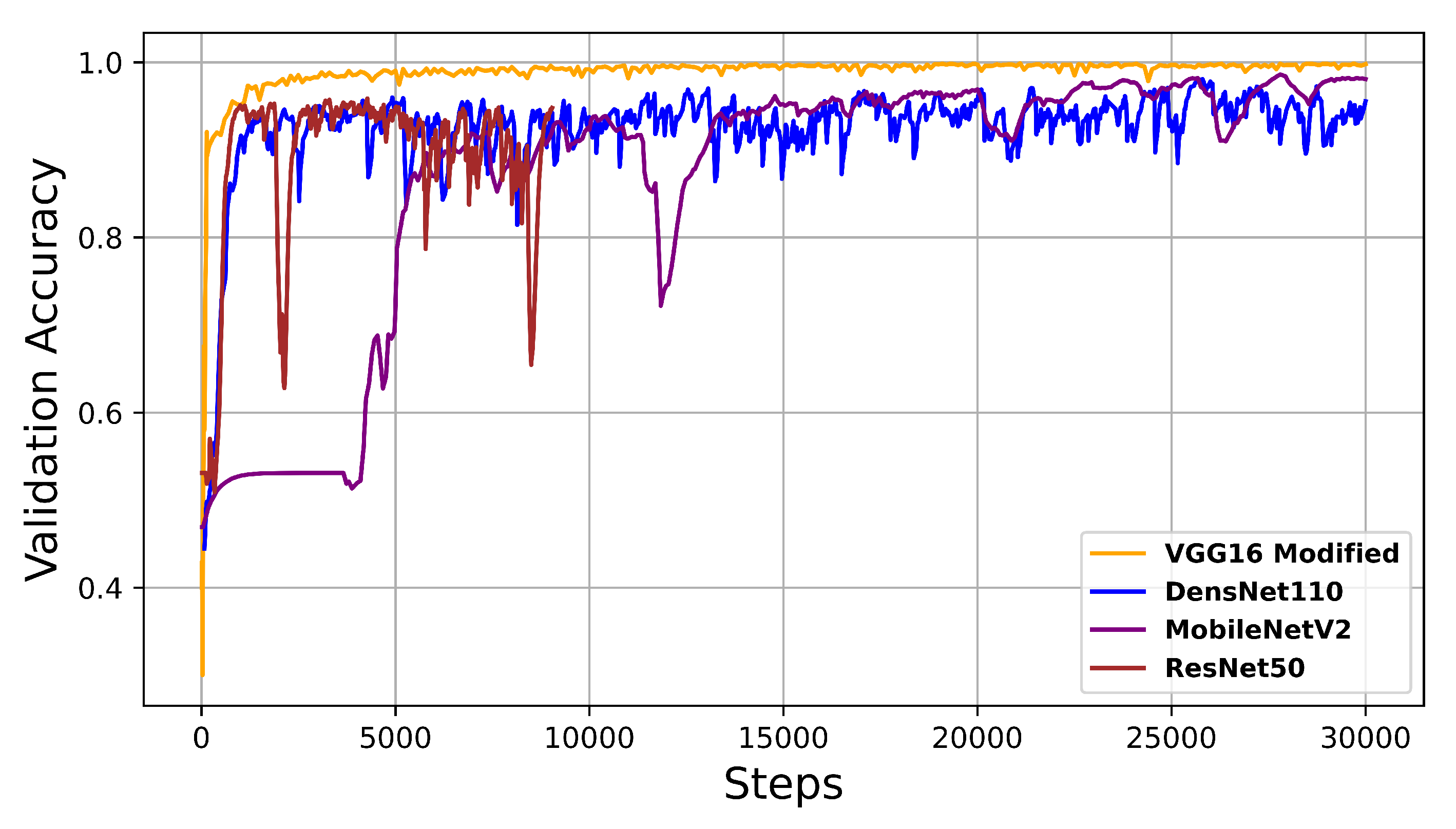
4.3. Inference Results
In order to assess the robustness of the proposed approaches, we investigated the classification results for four new SAR scenes from north of Svalbard, i.e., scenes that are not part of the training data, by presenting the results as qualitative ice versus water maps. To this aim, we set up the inference experiment in a patch-wise manner, where the images are partitioned into non-overlapping patches, and the classification is performed on the entire patches.
Figure 7 shows the four input images from north of Svalbard in the first row. In the same figure, the patch-wise results of the ad hoc CNN are presented in the second row, the results of the VGG-16 model trained with transfer learning are presented in the third row, the results of the VGG-16 model retrained from scratch without the augmented data are presented in the fourth row, the results of the VGG-16 model retrained from scratch with the augmented data are presented in the fifth row, and the results of the modified VGG-16 model trained from scratch with augmented data are presented in the sixth row. Areas consisting of water are annotated in blue and areas consisting of sea ice are annotating in white. For better visualization, we applied a land mask to detect land areas, and the black regions in the images represent land areas. We zoom in on parts of some images to highlight specific details. The classification results obtained with ad hoc CNN (second row) are not satisfactory. The classified images are severely affected by the banding additive noise pattern, as can be clearly seen in columns two and three. The VGG-16 trained with transfer learning (third row) does not classify sea ice areas properly. In fact, open water and newly formed sea ice often have lower radar backscatter values in HV than in HH channels.These cross-polarization values are closer to the noise floor and therefore often have a lower signal-to-noise ratio producing artifacts due to different noise patterns. It can lead to problems during the interpretation of sea ice maps because the added intensity corrupts the true back scattered signal of the sea ice region.
In
Figure 7, The VGG-16 retrained from scratch without using the augmented data (fourth row) is better than ad hoc CNN and VGG-16 trained with transfer learning. However, there are still some misclassifications, as can be seen in the first column. The second last row presents the results obtained with the VGG-16 model retrained from scratch with the augmented data. The last row presents the results obtained with the modified VGG-16 retrained from scratch with the augmented data. For the modified VGG-16 model, we reduced the number of maxpooling layers. In this case, the noise seems to be quite well handled, as can be seen in the second column of the last row. However, there is still some noise effects in the third column. Hence, it is worth noticing how the results are affected by the additive noise, which can be seen in the original images (row one) as distinct bands marking the different sub-swaths, and in particular the case when the ad hoc CNN and VGG-16 with transfer learning are considered. Nevertheless, the results obtained by using VGG-16 trained from scratch appear to be more robust against the noise. From this experimental analysis, we conclude that the patch-wise classification results seem to be better when the training data obtained from data augmentation is used to train the VGG-16 model from scratch. The improvement is evident in the last row of
Figure 7.
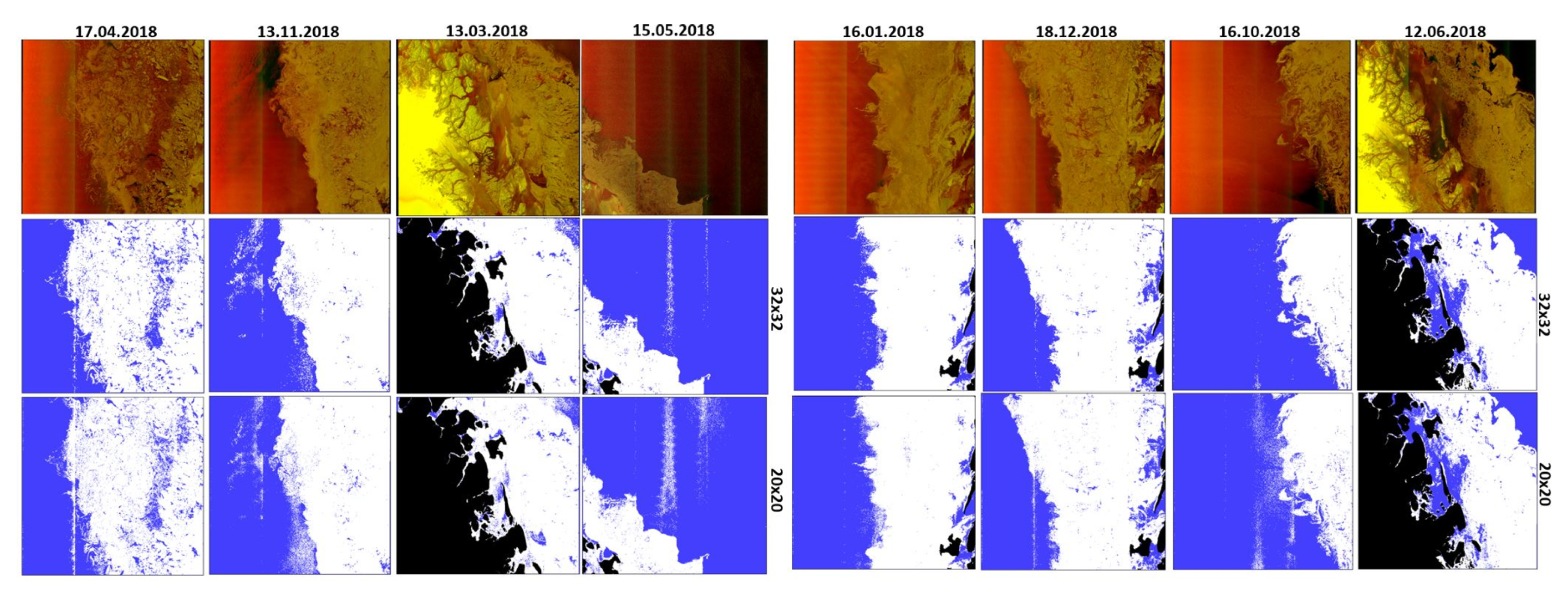
To further show the generalization performance of the CNN models for ice versus water classification, we also tested the models on images acquired from a different Arctic region, the area offshore of Danmarkshavn, East Greenland (76°46′ N, 18°40′ W). Here the Norwegian Meteorological Institute provided vector polygon data representing manually interpreted sea ice areas for the SAR data [
61], which consisted of eight images, corresponding to eight different months of the year. These including both the freezing and melting seasons, and were then analyzed with the trained architectures.
Figure 8 displays the classification results corresponding to the modified VGG network, trained from scratch with data augmentation, using patch sizes of 32 × 32 and 20 × 20.
As can be seen, the overall performance is good. It is also noticed that the results obtained with patch size equal to 32 × 32 are better than the results obtained with patch size equal to 20 × 20. The larger patch-size seems to be less affected by the noise and therefore we conclude that a patch size equal to 32 × 32 is a better choice for Sentinel-1 SAR images corrupted by additive noise. Overall, our experimental analysis shows that the VGG-16, when trained from scratch with augmented data, presents very good classification results when trained in a supervised fashion.
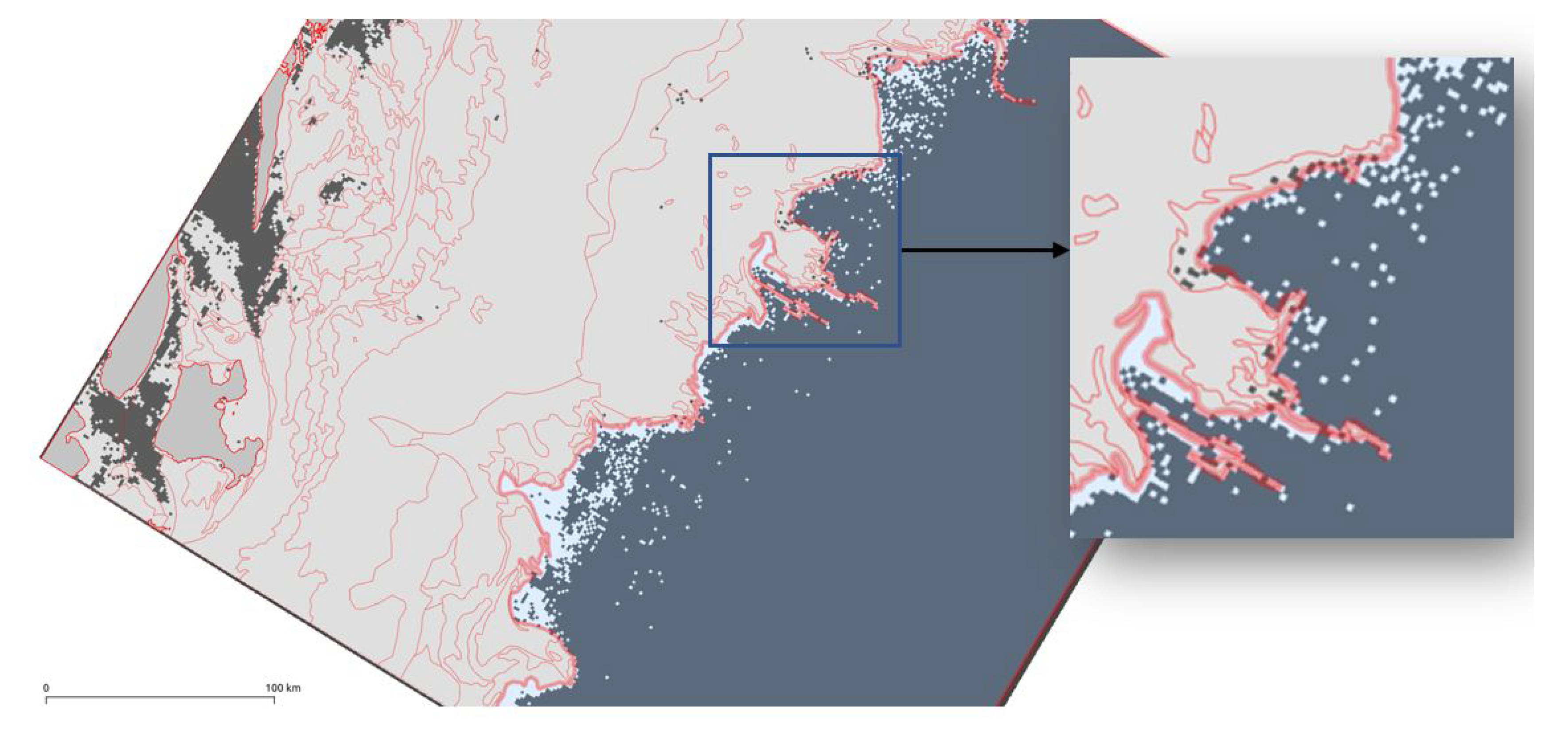
To better characterize the quality of the sea ice classification, it is important to distinguish between ice edges and water. Therefore, we also present the performance of our proposed method considering the ice edges of 16 January 2018 as depicted in
Figure 9. For this purpose, we overlay the ice polygons (Norwegian Meteorological Institute [
61]) from the Danmarkshavn region over the geo-referenced classified image from our method. Overestimation means predicting a larger sea ice area than the manually labelled cover area. Underestimation means predicting a smaller sea ice area than the manually labelled cover area. As can be seen, our proposed method performs effectively to separate ice edges from the water, although there remains some minor overestimation of the sea ice extent in some areas which is preferable to underestimating. However misclassification still occurs in interior areas of the ice pack where there is low backscatter from both cross- and co-polarization such as for areas of level, undeformed landfast ice close to the Greenland coast. An assessment of the accuracy of the ice edge, based on the Integrated Ice Edge Error (IIEE) metric [
62], was performed on this example against a selection of other data sources. In
Table 6 it can be seen that the contribution to the error from classifying ice as water (under-representing the ice) is consistent with all the products (4646 to 6632 km
2) that are compared, as these have fairly good agreement on the presence of landfast ice. There is also a similar level of error against products with accurate ice edges (1522 to 3766 km
2) such as the manually analyzed polygons introduced earlier [
61], the Norwegian Ice Chart from the Norwegian Meteorological Institute (
https://cryo.met.no/en/latest-ice-charts, accessed on 1 March 2021) which is the routine operational analysis produced by an ice analyst, and the sea ice concentration (SIC) produced by the University of Bremen from Advanced Microwave Scanning Radiometer 2 (AMSR2) data [
63]. Products based on low resolution passive microwave radiometry, for example the EUMETSAT Satellite Application Facility on Ocean and Sea Ice (OSI SAF) SIC that uses Special Sensor Microwave Imager/Sounder (SSMIS) [
64], are less capable of resolving the ice edge, and here there is a far greater contribution to the IIEE (10,797 km
2) because the SAR classification correctly identifies sea ice.
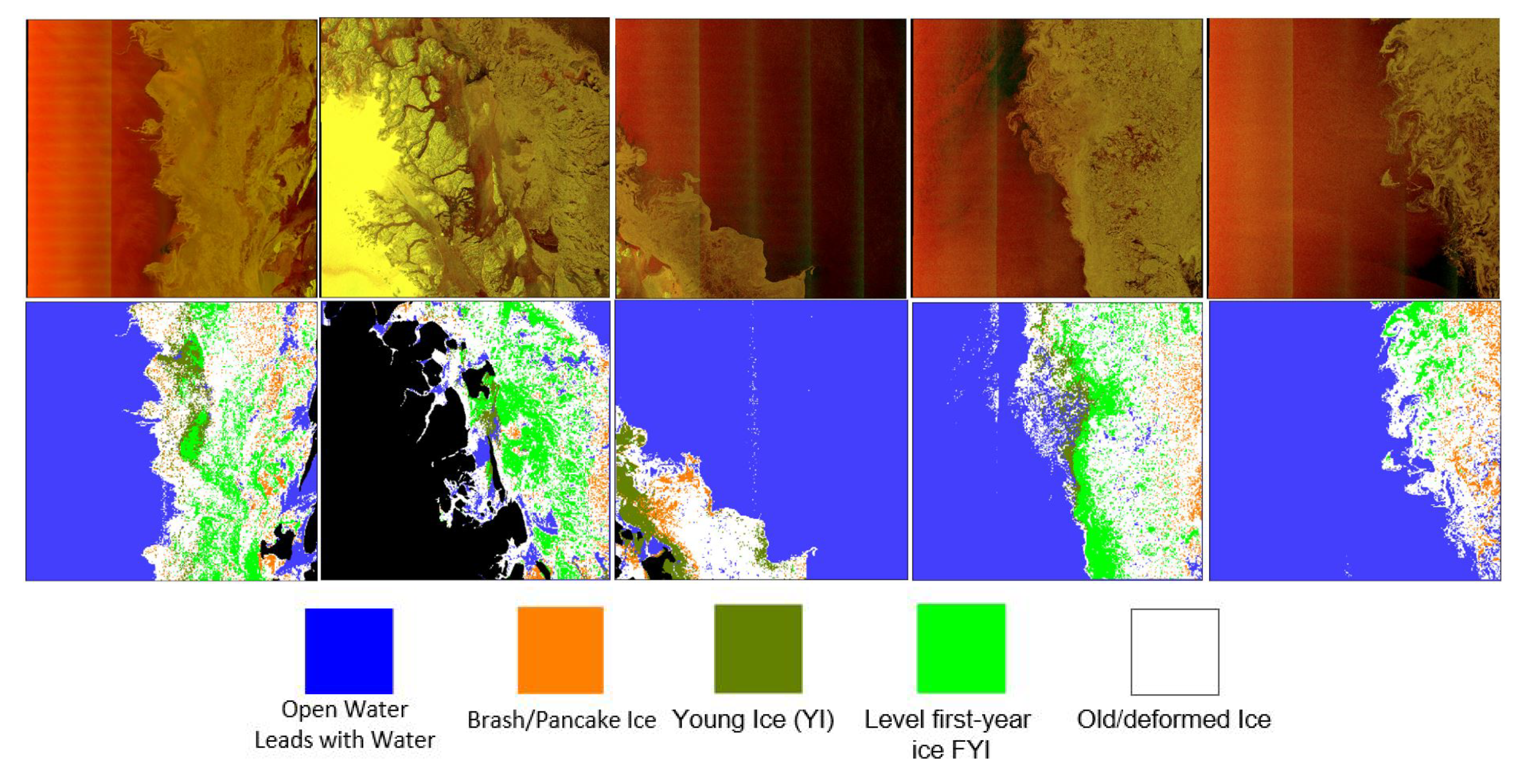
We have also extended our experimental analysis to multi-class sea ice type classification considering five images from the Danmarkshavn region. The results are depicted in
Figure 10. In this classification experiment, we used the modified VGG-16 model trained from scratch with the dataset from north of Svalbard as shown
Table 1.
We would like to emphasize that our dataset is scarce and unbalanced, with an unequal number samples from the ice types. This is affecting the classification performance, and the results presented in
Figure 10 are slightly biased toward ice types where we have more samples than others. The effect of the imbalance data can be seen in
Figure 10, where brash/pancake ice is detected in the right-hand side of the right-most image, which apparently is a dense ice area. In general, brash/pancake ice is located at the edges towards open water. Despite this problem, the results indicate that the VGG-16 trained from scratch shows promising performance in distinguishing different ice types as well as binary ice versus water classification.
We also present the inference result obtained considering only the HH channel. In
Figure 11, the left column shows the input SAR image and the right column shows the inference results. As can be seen, the inference result lacks coherency to distinguish sea ice from water. Therefore, both the HV channel and incident angle contribute to the process of properly training the model.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}