1. Introduction
Road networks are a type of typical geographic information that plays an essential role in various applications including urban planning, traffic control, disaster assessment, change detection, etc. [
1,
2,
3,
4]. However, road networks, mainly composed of asphalted pavement, evolve with changes in the city constantly and road information in cadastral databases needs periodical supplement and improvement. Manual marking to update the road network is costly in terms of human resources, with heavy workloads, and it is hard to reach real-time requirements such as emergency rescue in severe natural disasters. With the development of remote sensing, researchers have explored the extraction of road networks automatically from satellite images. Unfortunately, the commonly used optical remote sensing images are severely affected by weather. With all-day, all-weather, and high-resolution imaging capabilities, synthetic aperture radar (SAR) images have gained extensive attention and are popular in road extraction tasks. However, road network extraction from SAR images is still a challenging task due to the special side-view imaging mechanism, diversity road targets, and complex surroundings.
Among various reported methods, road network extraction algorithms consist of two stages in general, that is road element recognition and road network reconstruction. The purpose of the first stage is to highlight the road area and to discriminate road candidates. The second stage aims to discard redundant pixels and to fill the gaps to generate smooth and continuous road lines. With regard to road element recognition, local detectors such as ratio edge detector [
5,
6] and morphological line detector [
7] are applied to extract road features. Moreover, direction [
8], contrast [
9], and some other spatial characteristics are considered to generate multiple road feature maps. After that, feature fusion [
10,
11] and threshold method [
6] are adopted to distinguish road pixels from background pixels. With the rapid growth of deep learning, road segmentation based on deep fully convolutional neural networks has been developed [
12]. For road network reconstruction, thinning and spatial optimization are two important parts. The thinning algorithm was employed on binary segmented road maps to extract road centerlines, in which morphological thinning is simple and fast to implement but sensitive to noise. Later, regression-based thinning methods [
13,
14] with noise robustness were proposed. In [
15], boundary distance field and source distance field were generated via the fast marching method (FMM) algorithm, and then, branch backing-tracking method was employed to produce the initial road centerline. Commonly used methods for spatial optimization contain Markov random fields (MRFs) [
6,
9] and genetic algorithm [
16]. In [
17], the conditional random field (CRF) model was utilized to implement road network optimization in a Bayesian framework. Region growing [
18,
19] and parallel particle filter [
20] were adopted to track road networks based on the automatically extracted seed points.
It has been well accepted that human vision is an inherently multiscale phenomenon [
21]. We hope that a similar system can be installed in computers to automatically extract spatial information from different image scales. Thereupon, many algorithms derived from human visual were proposed, which can be regarded as a series of scaled filters or repeatedly used filter on different spatial scales. Recently, several multi-scale geometric analysis (MGA) [
22] tools were developed and have been successfully applied in the field of image processing. In [
23], shearlet was used to detect road edges from SAR images with strong speckle noise. With the ability to represent linear and curvilinear features, beamlet analysis was employed to extract guidance lines from the response map in [
24]. As an efficient and convenient representation of image expression in multiple resolutions, image pyramid was originally designed for image compression and has been widely used in computer vision tasks including image registration [
25], image fusion, and target detection [
26].
In high-resolution SAR images, we suppose that road targets have the following characteristics. (1) Local uniformity: a road surface is at least locally homogeneous. Considering the low surface roughness and low permittivity [
27], roads always appear as uniform dark areas. (2) Local directionality: the curvature of roads change slowly in a local area, which means that the adjacent road pixels usually have similar directions. (3) Continuity: roads are generally elongated structures with a certain width and seldom shown as small separate fragments. The combination of these features can be rarely found in other objects; thus, we are dedicated to making full use of these features for a promising extraction result.
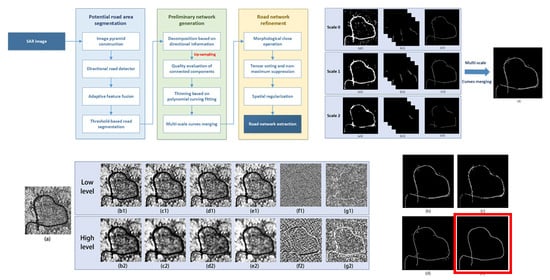
In this paper, we propose a road network extraction algorithm under a multiscale framework for high-resolution SAR images. Our method consists of three stages: potential road area segmentation, preliminary network generation, and road network refinement. The first stage corresponds to the road element recognition mentioned above. To capture road targets with different widths, an image pyramid is constructed together with a fixed filter for multiscale analysis. A directional road detector with slender detection templates is developed as the fixed-size filter to extract road features including radiance, texture, direction, and invariant moment. Then, adaptive fusion is performed to integrate the feature maps of each scale separately, following by threshold segmentation to obtain the binary road maps. In preliminary network generation, to overcome the difficulty in fitting road targets with irregular structures, image decomposition is firstly conducted on multiscale binary road maps according to the direction map generated in the first stage. To further select regions that are likely to be road segments, we evaluate the quality of each connected component (CC) based on the combination of four predefined indicators. It is worth noting that multiscale image layers are upsampled to the input image size to ensure the evaluation fairness. After that, polynomial curve fitting is performed as a thinning method on all CCs. Based on the results of the evaluation function, the weighted sum of curves realizes multiscale information fusion and produces the preliminary road network. Road network refinement aims to ensure the smoothness and continuity of a network. Tensor voting (TV) and spatial regularization are implemented to obtain the final road network extraction result. Qualitative and quantitive analyses on extracted results of three TerraSAR images prove the validity of our method.
The remainder of this paper is organized as follows. Details of the road network extraction method are described in
Section 2. Parameter analysis and experiment results are shown in
Section 3. Comparisons with related methods and discussions on algorithm performance are provided in
Section 4. Finally, conclusions are given in
Section 5.
2. Method
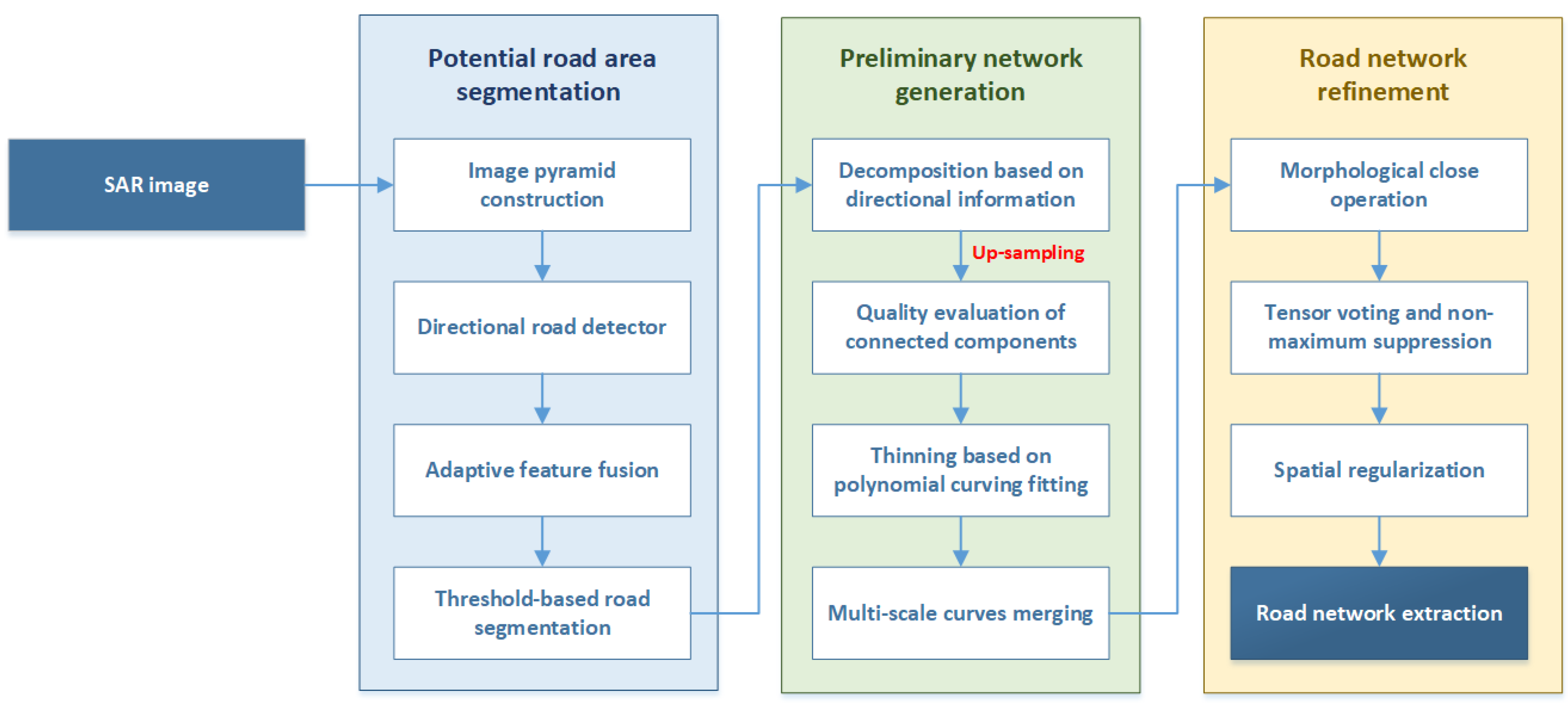
In this section, we introduce a multiscale road network extraction method for high-resolution SAR images. The flowchart of the proposed algorithm is displayed in
Figure 1. Details of the aforementioned steps are presented in the following subsections.
2.1. Image Pyramid Construction
The width of lanes varies with the road level. Generally speaking, urban lanes are wider than rural ones. Along with the change in the number of lanes, road widths vary significantly in remote sensing images. At the same time, image resolution also has great influence on the road pixel width. In low-resolution images, road targets appear as curves approximately, while in high-resolution images, road targets present as elongate areas with a certain width. In [
18], road width is essential to setting appropriate filter parameters and obtaining satisfying extraction results. However, in actual road network extraction task, road width is always unknowable. The widely used D1D2 road detector [
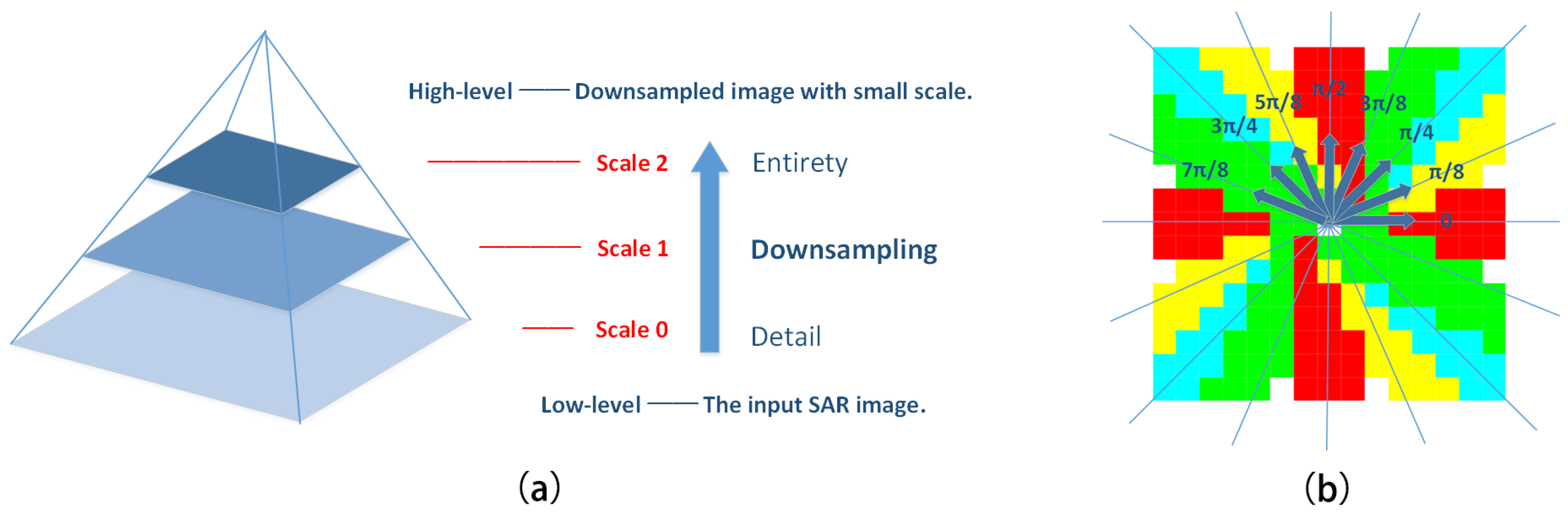
28] adopts multi-direction and multi-size detection templates, and the maximum response value is obtained when the template is fully matched with the width and direction of the road. It has a high time complexity and low operation efficiency. In this paper, we conduct multiscale analysis based on the pyramid model to overcome the unpredictability and diversity of road width and to improve the efficiency of road detection.
The pyramid model is shown in
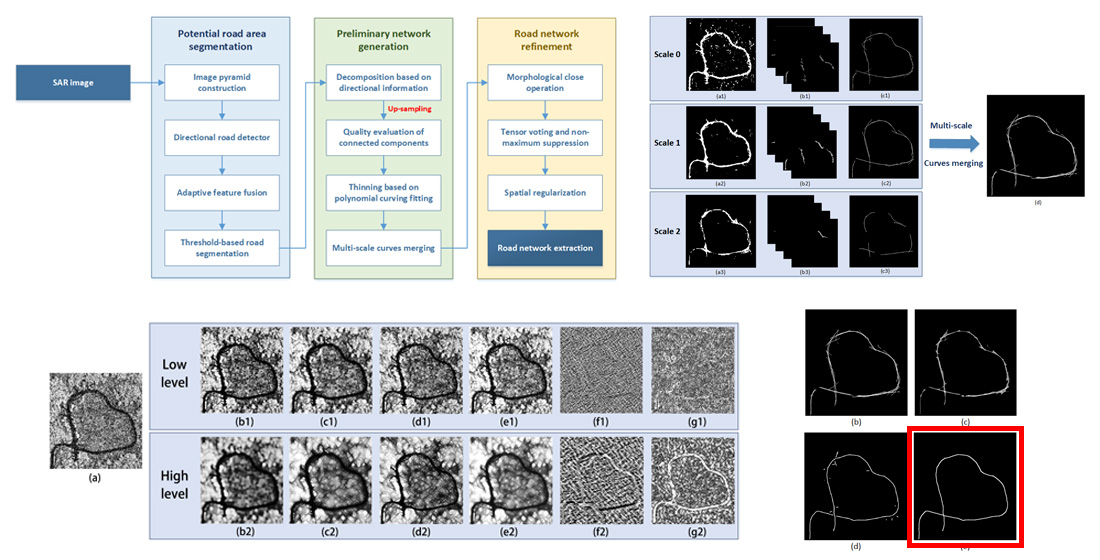
Figure 2a. The image size is reduced by half with each downsampling operation from the bottom up. Scale 0 corresponds to the input SAR image, which depicts image details and facilitates the extraction of narrow roads. In the high-level images, features of narrow roads gradually disappear while features of wide roads are retained, which benefit the extraction of the basic trends of roads and emphasize the location of main roads. Empirically, we find that three image scales are enough for the road network extraction task. The steps of multiscale analysis are as follows. Firstly, road area segmentation and directional-based image decomposition are performed on various image scales independently. After that, the decomposed image layers with different sizes are interpolated to the original image size through the nearest neighbor interpolation algorithm. Then, regional quality evaluation and the thinning operation are carried out. Finally, multiscale information fusion is implemented by the combination of weighted curve images.
2.2. Directional Road Detector
Affected by the surroundings and speckle noise in SAR images, the mere use of intensity information is insufficient to segment the complete road area. Therefore, a directional road detector is designed according to the road features, aiming at identifying road area from the output response maps.
Eight matrices with fixed size and different directions are used as detection templates, as shown in
Figure 2b. The direction of the eight templates satisfies
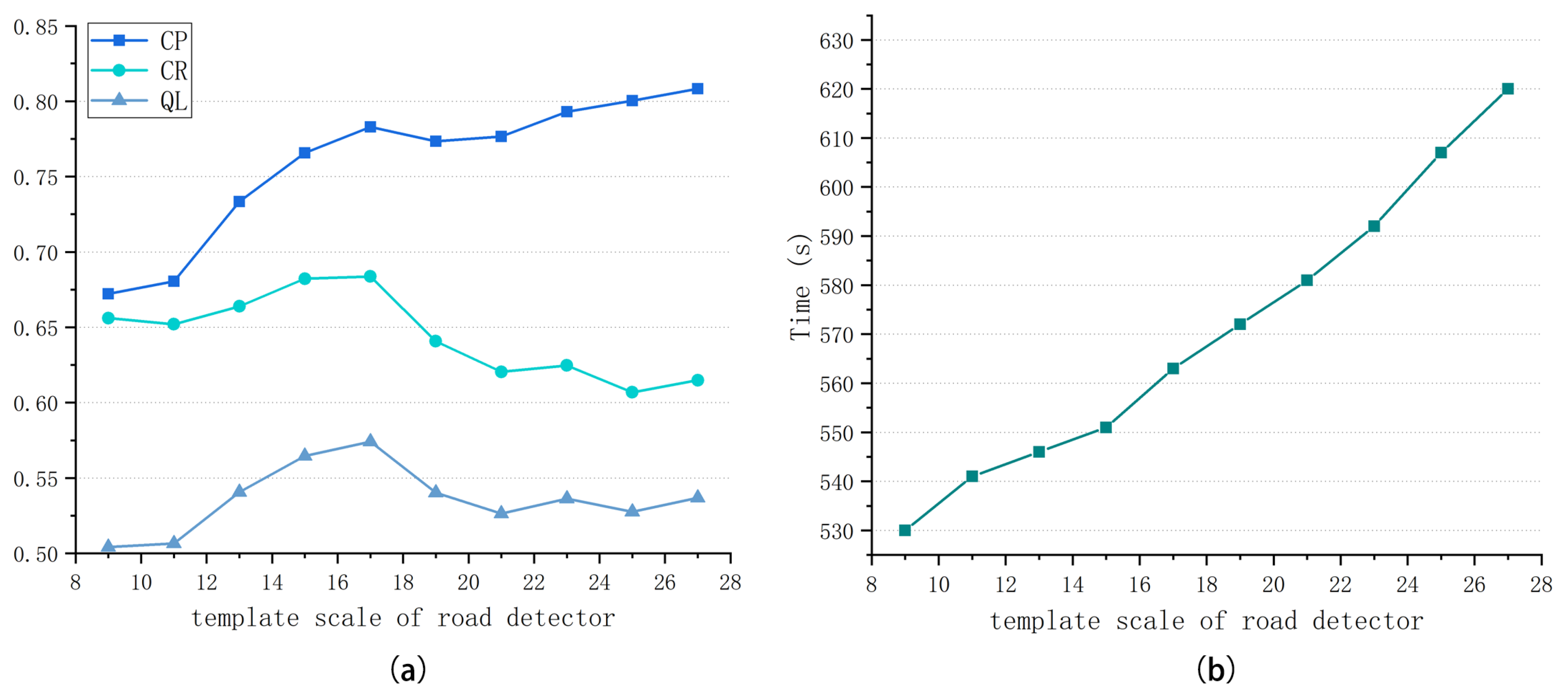
. To fit the elongated structure of road targets, detection is conducted in a slender rectangular area. Road targets show definite directionality; thus, we conduct detection in multiple directions and retain the direction information of the optimal response. Based on the multi-scale framework, a fixed-size template can meet the demands of extracting roads with different widths. An appropriate size is carefully selected for detection templates according to the image resolution. If the size is too small, the response map will be seriously affected by noise and fail to highlight road area. If the size is too large, it will neglect some road details and bring about heavy calculation burdens.
Firstly, we calculate the statistical characteristics of eight rectangular regions centered on pixel
p. The mean and variance of region
k are denoted as
and
, respectively. Then, we use two different operators to generate the radiance response map and texture response map, which can distinguish dark uniform areas from the original SAR images. As is mentioned above, roads appear as dark and elongated regions in SAR images. A small value of
indicates a high probability of region
k to be located in road areas [
9]. Therefore, the minimum mean value among eight templates is selected as the radiance response
of pixel
p, which can be expressed as
The corresponding direction is denoted as
, that is
The multiplicative noise in SAR image has more influence on the brighter area than the darker one. Beyond that, road targets have local uniformity, which appear as homogenous regions with low grayscale. Obviously, a small value of
means a high probability of region
k being located in road areas. We select the minimum value of
among eight templates as the texture response
of pixel
p, which is written as
Due to the limitation of the slender neighborhood, the slight changes along a certain orientation are obviously reflected in directional road response maps. As shown in
Figure 3c,d, the dark streaks in non-road areas are disorderly and bring disturbance to road area segmentation. In order to facilitate the road extraction task, a fast and effective method is employed to produce a feature map with smooth change within each region and significant differences between regions. As known, the moment is a statistical characteristic of random variables and can describe various geometric features of a given image. For a two-dimensional digital image, the
-order original moment is defined as
where
R and
C stand for the number of rows and columns, respectively. The central moment of the
-order is given by
where
. The normalized central moment of the
-order can be written as
The first invariant moment in [
29] is adopted to generate an invariant moment feature map in this paper, which is expressed as
2.3. Adaptive Feature Fusion
Considering the complementarity of the radiance response map, texture response map, and invariant moment feature map, we adopt the adaptive multifeature fusion method in [
30] to separately combine the extracted information from different image scales. At a certain image scale, three feature maps are normalized to
. It should be noted that road targets have large values in the invariant moment feature map, which is inconsistent with the other two feature maps. Thus, inverse operation is performed on the normalized invariant moment feature map. Then, three segmentation thresholds generated by OSTU method [
31] should be transformed to the same location before fusion. The preliminary road segmented map is obtained after the threshold segmentation of the fusion map.
The directional road detector is capable of dividing uniform dark areas from the original SAR images. However, due to the similarity of features, some regions are misclassified into road targets, such as shadows, rivers, and squares. Fortunately, they are not exactly the same as road targets in SAR images. In the subsequent processing, we will eliminate the discrete regions from potential road areas through the continuity of road targets and exclude the interference of regions with low shape compactness (such as squares) according to the regional directivity.
2.4. Binary Image Decomposition Based on Directional Information
Practically, roads are arranged in a crisscross pattern with diverse distributions. CCs in the binary segmented maps often have irregular and complex shapes resulting in difficulty fitting the connected regions directly. However, road targets have local directionality, which assumes that the direction of the road within the local area remains unchanged. Inspired by the idea of direction feature grouping [
32], we decompose the road binary segmented map with the help of direction information.
In this paper, the direction map
A acquired in
Section 2.2 serves as the guidance of binary map decomposition.
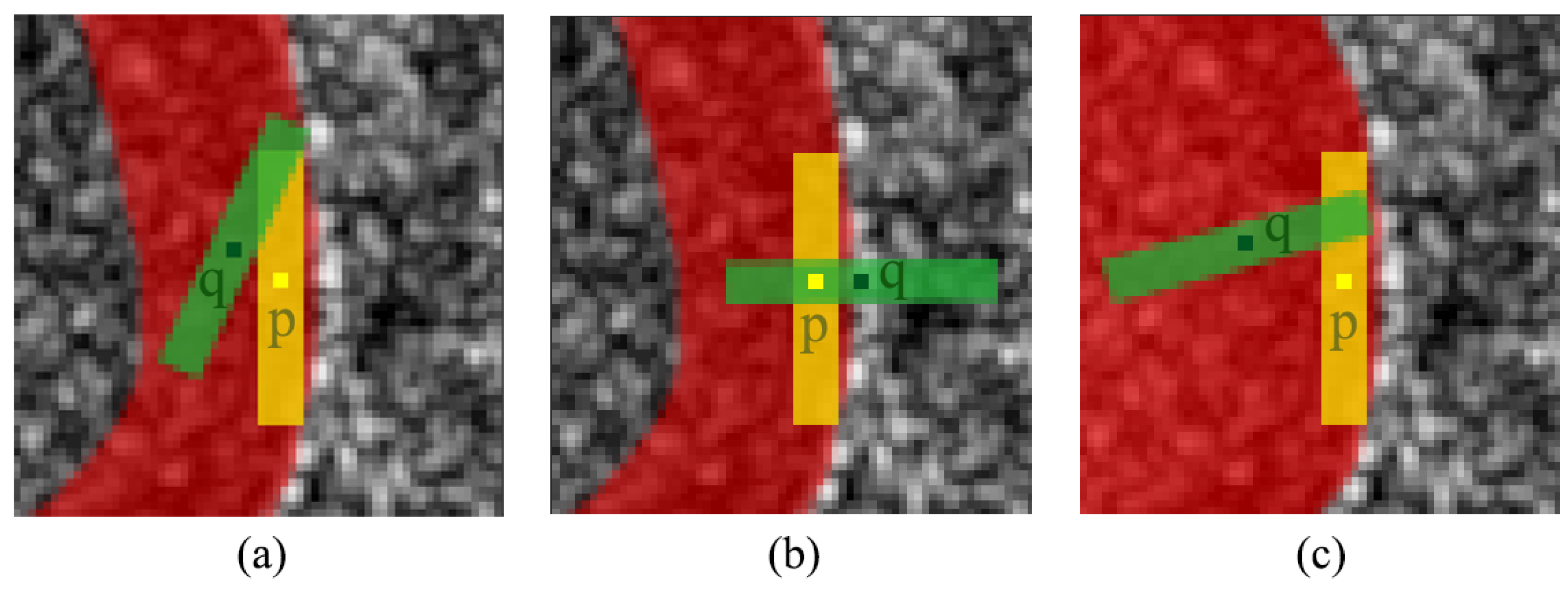
Figure 4 is used to discuss the relationship between the value of
A and road position. We suppose that the potential road area is painted in red, wherein the yellow pixel
p is located in the potential road area close to the road edge and the green pixel
q is in the neighborhood of pixel
p. The rectangular regions along the directions of
and
are shown in light yellow and light green, respectively. The direction of
is parallel to the road edge. In
Figure 4a, pixel
q is located in the road area and the value of
is similar to
. Pixel q in
Figure 4b is outside the road area, meanwhile the direction of A(
q) is perpendicular to the road edge. In
Figure 4c, the green pixel
q is also located in the potential road area. However, the shape of the red area is incongruent with the elongate structure of road targets, leading to the relatively random direction of pixel
. To sum up, the value of
A changes smoothly in the elongated road area while the value of
A changes abruptly when crossing the road edge. In the broad dark area, the value of
A is unpredictable. In the non-potential road area, the value of
A changes irregularly under the influence of complex environment. Therefore, the direction map
A is taken as a reference of direction-based image decomposition. In the decomposed image, road targets present as long and narrow CCs whereas the dark area with low compactness appears as discrete points.
In order to prevent CCs from being too scattered in decomposed layers and from reducing the complexity of image combination, eight values in the direction map A are divided into four groups according to the direction similarity. That is,
,
,
, and
. Image decomposition can be written as follows:
where & represents the per-pixel logical “AND” operation,
is the potential road map obtained by threshold segmentation,
marks the positions that have similar directions to
, and
represents the decomposed image layer k. Clearly, the direction of CCs in image layer
mostly remains consistent with the direction guidance
.
Due to the influence of speckle noise, road width, shelter, and some other factors, there exist multiple fragments and dense point sets in the decomposed layers. The dense point sets are formed for two reasons. Firstly, the direction of road where the point set is located is halfway between two adjacent decomposition directions, thus, the road area is decomposed into two parts forming two complementary discrete point sets. Secondly, the distribution of direction map A is highly random in dark regions with low compactness, resulting in discrete point sets after image decomposition. It should be noted that road targets tend to form discrete point sets in decomposed layers when the road width is about equal to or greater than the length of a detection template. In a low-level image, narrow roads show regularity while wide roads show high randomness in direction map A. In high-level image, the width of roads is reduced to ensure that the largest width is significantly smaller than the length of the detection template and that the regularity of wide roads emerges in direction map A.
To connect the dense point sets into a whole, a morphological CLOSE operation is performed on the decomposed layers. The operation not only improves the continuity of the road area but also benefits the following work, making it easier to fit each CC to a straight line or curve. Whether a point set is located in a road area will be discussed in the next subsection. Subsequently, all decomposed layers with multiple scales are upsampled to the original image scale through the nearest neighbor interpolation to ensure the fairness that regional quality assessment is carried out at the same scale.
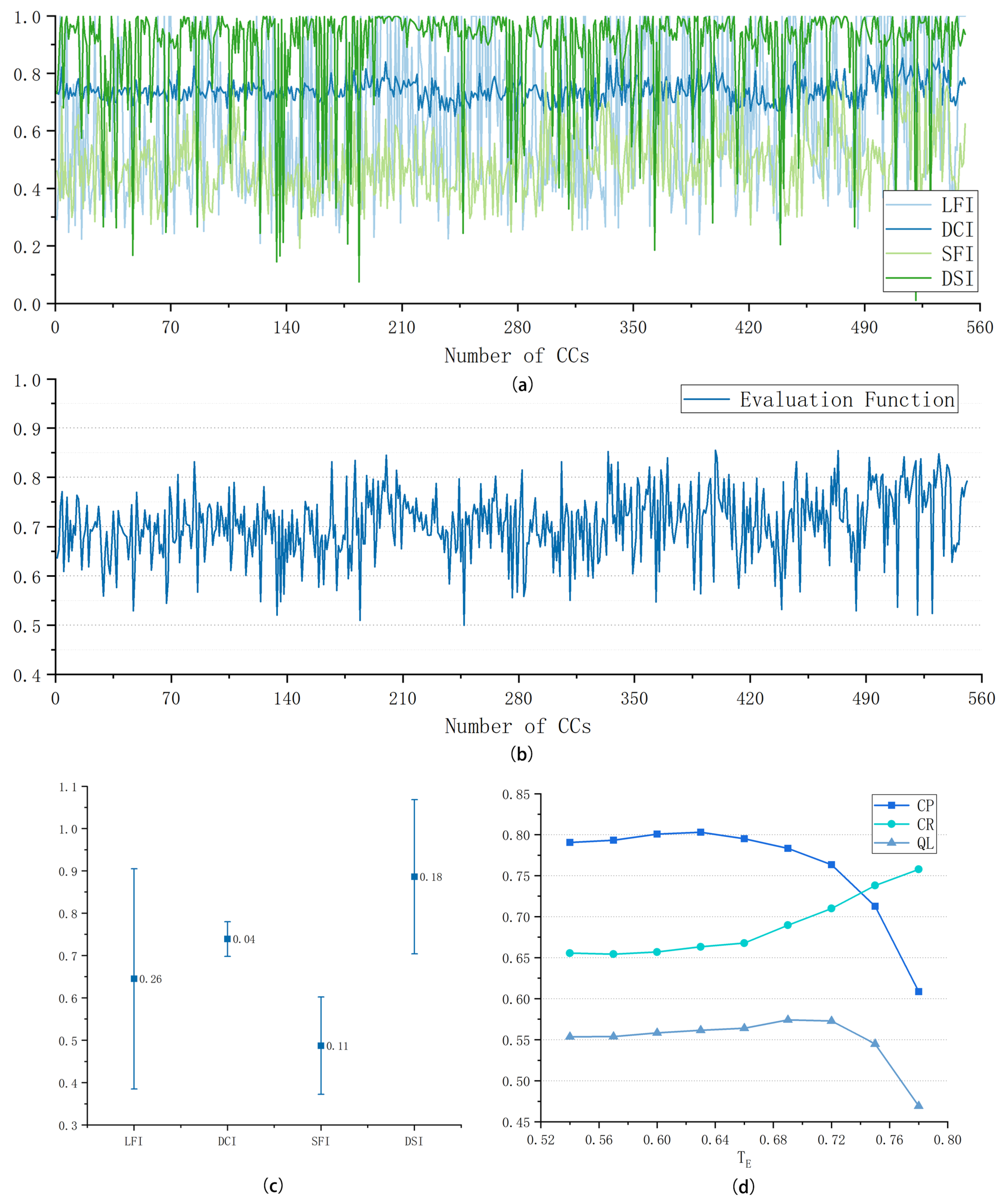
2.5. Quality Evaluation on Connected Components
After binary image decomposition, each layer contains multiple CCs with different areas, directions, and shapes. CCs involve both multiscale road segments and the wrongly divided dark regions. According to the characteristics of the road targets, we set several indexes to evaluate the quality of CCs. The value of evaluation function is correlated with the probability that the current CC is located in a road area. On the one hand, we can select road segments at the appropriate scale and further eliminate the non-road segments resulting from inaccurate segmentation. On the other hand, different weights can be given to CCs during image merging, providing meaningful information for global network optimization.
The first indicator is Linearity Feature Index (LFI). Ideally, road targets appear as continuous strips in decomposed image layers. The straighter and longer the shape of the area, the higher probability it is a part of a road. Referring to the LFIe index in [
33] (
), we define the measure of the linearity of CC in this paper:
where
and
represent the length of the long axis and the short axis of the ellipse for which the standard second-order central moment is the same as the CC.
is the upper limit of
. Setting the threshold is convenient for normalization and comprehensive assessment with other indexes. We believe that CCs with
index greater than 5 have satisfied the shape characteristics of road targets. Thus, the value of
is set as 5 in our method.
The second indicator is the Directional Consistency Index (DCI). The locally statistical directivity
D is defined by the cosine sum of the intersection angles between the direction of center pixel and neighborhood pixels in the direction map
A:
where
is a normalization factor and
is the absolute value operation. A large value of
D indicates the high similarity of pixel directions in the neighborhood and a high probability of being located in the elongated road area. The mean value of
D is regulated as a directional consistency of CC:
where
counts the number of pixels in connected region
. A high DCI value means that the current CC stands a good chance of being a road area. Dense point sets in the road area have similar directions as their neighborhoods, leading to a high DCI value. In contrast, the point sets in the dark region with low compactness usually have different directions with their neighborhoods, resulting in a low value of DCI.
The third indicator is the Solidity Feature Index (SFI). If the road width does not match the image scale, wide roads will appear as small aggregated fragments or regions with irregular boundaries and large holes. If processed at an appropriate scale, road targets will appear as solid strip regions in decomposed layers. Therefore, solidity is employed to select CCs generated at a proper image scale, which is defined as the area ratio between the region and its minimum convex polygon:
where
counts the number of pixels in the minimum convex polygon of CC. A high SFI value represents that the current image scale is appropriate for the road width and that the CC makes a great contribution to the road network generation.
The fourth indicator is the direction similarity between CC and decomposition guidance (DSI). Since the binary image is decomposed based on direction information, the pixels have the same direction in each decomposed layer. Therefore, the direction of CC is likely to be consistent with the corresponding decomposition guidance. DSI is regulated as follows:
where
represents the intersection angle between the long axis of the ellipse for which the standard second-order central moment is the same as the CC and the horizontal direction.
represents the main direction of the decomposition, which is the average value of the directions in group
. In this paper, the four main directions are
,
,
, and
. A larger DSI value indicates a higher credibility of the current region in the road network composition.
To comprehensively access each CC, we combine four indicators and define the evaluation function as follows:
where
,
,
, and
are weight parameters, which can be used to adjust the importance of four indexes in quality evaluation. The values of LFI, DCI, SFI, and DSI have been normalized in the previous formulas; thus, the value of
E is between 0 and 1. A high value of E means a high quality of CC, which has a great possibility to be a road region and has a large weight in the image merging process.
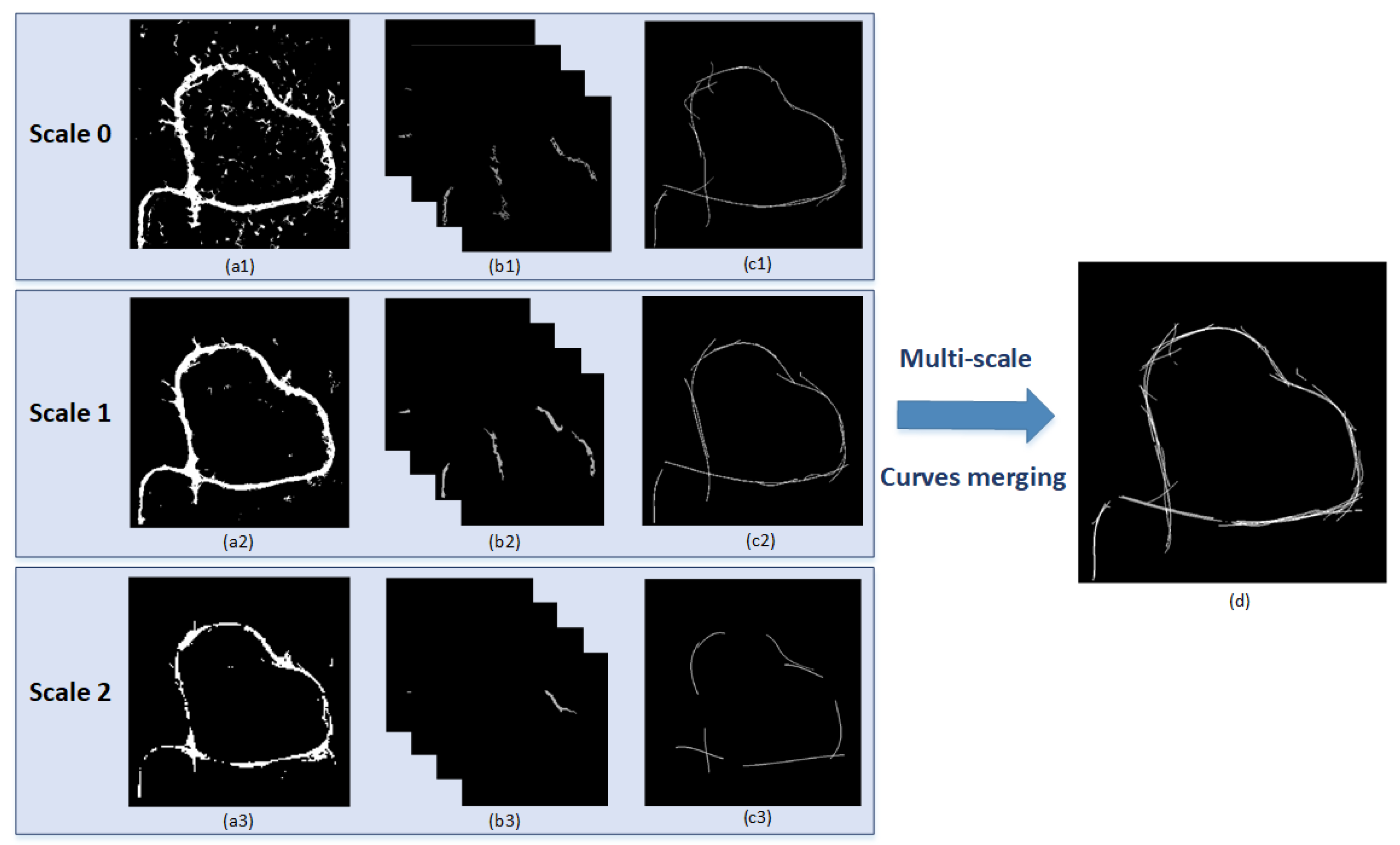
2.6. Thinning Based on Polynomial Curve Fitting and Preliminary Road Network Generation
A thinning operation is necessary for the purpose of extracting the centerline from the binary segmented map. In this paper, thinning is firstly conducted on each CC in upsampled image layers, and then, we integrate all curves by weighted summation. A road centerline presents as straight line or smooth curve in the actual scene. In order to obtain accurate road networks, the polynomial curve fitting method [
32] is adopted to conduct thinning operation on each CC, in which the order of polynomial is set as 3.
After that, thinned image layers generated by different image scales are merged to produced a complete road network. Image merging is the weighted sum of the fitting curves, which can be written as follows:
where
is the preliminary road network,
is the thinned binary map of region
in image layer
i, and the evaluation result
of region
is the weight coefficient in image merging. The preliminary road network is a simple stack of several weighted curves, which contains redundant duplicates, protruded lines, and unconnected gaps, as shown in
Figure 5d.
2.7. Tensor Voting and Non-Maximum Suppression
Tensor voting [
34] has been widely used for thinning and refinement in the task of road network extraction, which also shows strong robustness on SAR images. Relying on tensor representation and data communication between adjacent tensors, salient information can be effectively perceived from sparse and noisy two-dimensional images. The time-consumption of tensor voting is positively correlated with the sparsity of the input image. In this paper, morphological CLOSE operation is firstly performed on the preliminary network to fill the blank between adjacent curves and to construct a connected region; then, tensor voting is conducted on the consolidated road network, which greatly reduces the runtime compared with tensor voting conducted on the binary segmented map [
13,
33]. Meanwhile, the consolidated road network has a clearer structure and definitely produces more accurate results than the segmented map.
In the framework of tensor voting, the input information is some point clouds called tokens. Each token is encoded as a symmetric tensor, and then, a tensor field is generated. For a two-dimensional image, the input is sparse pixels that only contain location and amplitude information. Firstly, each pixel is transformed into a second-order anisotropic tensor [
35]. Each tensor can be denoted as a linear combination of eigenvectors and eigenvalues:
where
is the
ith eigenvalue of the tensor satisfying
and
is the eigenvector corresponding to
. The spectral theory states that any second-order tensor can be expressed as a linear combination of ball tensor and stick tensor [
33]:
The first term is the component of stick tensor, and the second term is the component of ball tensor. and denote the saliency values of stick tensor and ball tensor, respectively. The stick tensor contains both position and normal information, while the ball tensor merely contains position information.
In the first stage of sparse voting, each token propagates its own information with a two-dimensional ball kernel. The saliency decay function of the ball voting can be written as follows:
where
represents the distance from the voting point to the receiving point and
is the decay factor, which controls the range of the voting. The intensity of tensor field is calculated by collecting all votes received at a certain position in the form of tensor addition. Specifically, votes are gathered only at the positions where tokens appear, which is expressed as follows:
where
represents the cumulative tensor intensity of the receiver,
N represents the number of voters in the neighborhood, and
is a tensor in the neighborhood. After this process, each token transforms into a generic second-order symmetric tensor.
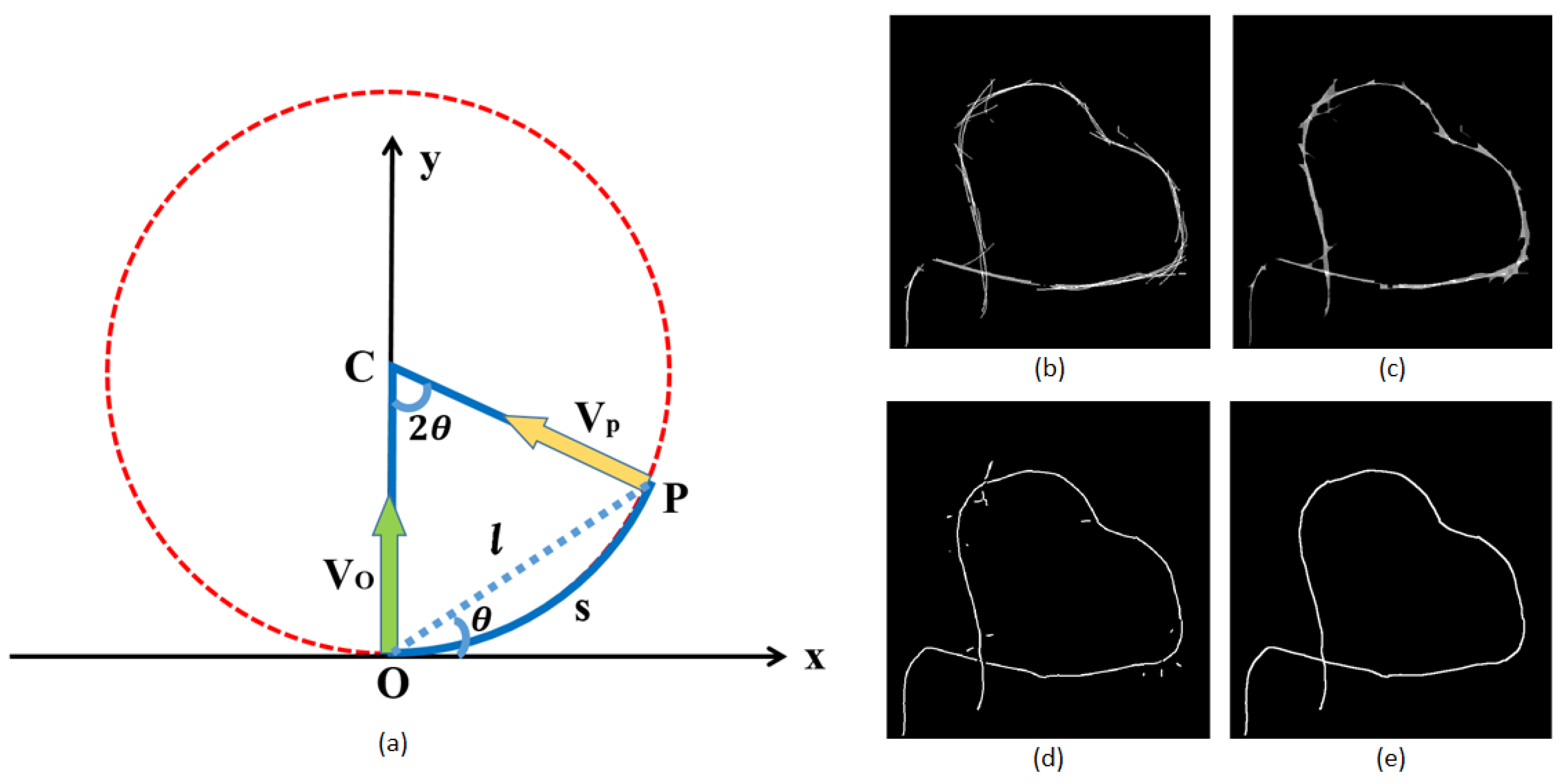
In the second stage of dense voting, the ball component of each tensor is discarded and the stick component is retained for voting with stick kernel. The diagram of stick voting is illustrated in
Figure 6a. Suppose that
and
represent the normal vectors of voter
O and receiver
P, respectively. The most likely path from
O to
P is a circular arc with constant curvature. The saliency decay function of the stick voting can be written as follows:
where
s is the arc length between
O and
P;
k is the curvature; and
c controls the degree of curvature decay, which is related to
. In this stage, voting is conducted from tokens to all locations in the neighborhood and the receivers accumulate the votes by tensor addition as well.
A new tensor field is created after tensor voting, and then, tensor analysis based on the saliency value is performed to classify all points into three types:
According to the classification criterions, we can obtain the stick saliency map, in which the road centerline tends to have local maximum values. Thus, Non-Maximum Suppression (NMS) is applied to extract the road centerline and to construct the road network. In the neighborhood, the non-maximum pixel is denoted as 0 and the maximum pixel is denoted as 1. As depicted in
Figure 6d, the extraction result of TV-NMS consists of smooth curves. However, there still exists noisy fragments and discontinuities especially around junctions that need further refinement. The advantage of tensor voting is that the globally optimization is conducted automatically. As the only free parameter in tensor voting,
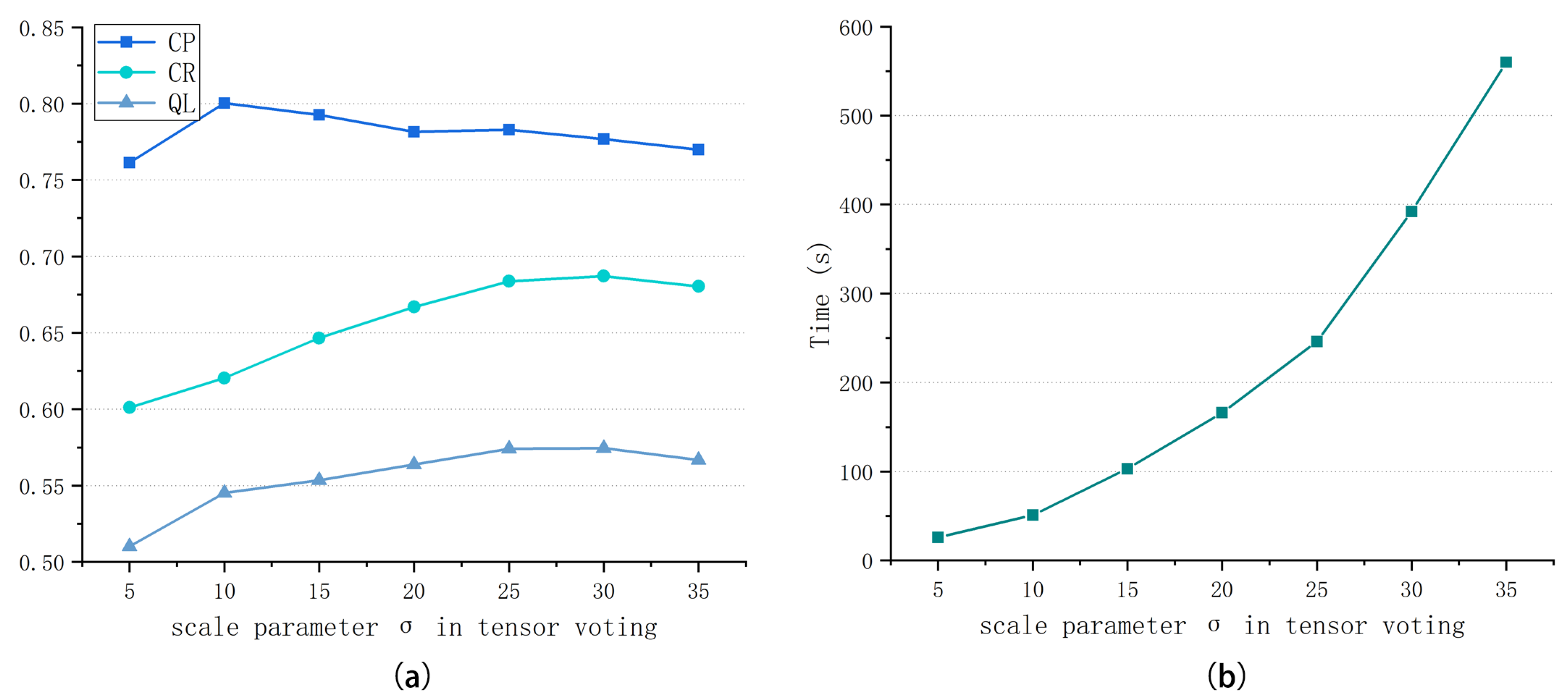
determines the range of data communication and will be discussed in the next section.
2.8. Spatial Regularization
Referring to previous works [
8], a final spatial regularization algorithm is implemented based on perceptual grouping concepts. Regularization rules related to proximity and collinearity are used in this step aiming to eliminate undesired gaps and noisy line segments in the coarse road network. The rules have been completely described in [
24,
36]; thus, four criteria are briefly outlined as follows: (1) separate short centerlines are removed; (2) centerlines for which the endpoint distances are extremely short are merged; (3) centerlines which are collinear or nearly collinear are merged; and (4) when centerline
intersects another extended centerline
close to one of its ends,
is lengthened to the intersection point. A continuous road network is generated after this basic and fast procedure. The final result is displayed in
Figure 6e.
4. Discussion
In this section, related experiments are conducted to comparatively demonstrate the effectiveness of the proposed method, as shown in
Figure 11. The numerical evaluation is reported in
Table 2. It is worth mentioning that parameters in related experiments are adjusted to gain best networks for fair comparison.
To test the practicality of the multiscale framework in the road network extraction task, a similar algorithm conducted on a single scale (original scale) is implemented, denoted as Comparison 1. As the template size of directional road detector is fixed in this paper, the multiscale framework plays an important role in extracting road targets with different widths; thus, a D1D2 operator [
6] with diverse template orientations and sizes is used as the road detector in the single-scale contrast experiment. Beyond that, we use the same thinning and refinement method to obtain extracted results. As shown in
Figure 11a, the completeness and continuity of road networks obtained by Comparison 1 are inferior to that extracted by our method for more gaps. Furthermore, the values of CP, CR, and QL distinctly decline in Comparison 1. In the image pyramid, high-level images can reflect the overall trend of the road network and tend to extract wider main roads. In contrast, low-level images are rich in details and used to extract narrower paths. The employment of the multiscale framework combines the extraction results of different levels; hence, a relatively complete network can be obtained. Although the multi-direction and multi-size D1D2 operator adopted in Comparison 1 likewise has the ability to detect road targets with different widths, its fault tolerance rate is not up to the proposed method. The quality of extracted network is closely related to the quality of CCs in directional decomposed image layers. However, the CCs in Comparison 1 are determined by the once generated direction map, which is less reliable due to the randomness of local information. Considering both scattering CCs from well-detailed low-level images and regular CCs from trend-salient high-level images, the proposed method integrates the multiscale information based on weighted summation and tensor voting to produce promising results.
To prove the availability of regional quality evaluation, an identical algorithm without quality evaluation on CCs is implemented, denoted as Comparison 2, in which only CCs with small pixel area are removed as described in [
32]. We can find from
Figure 11b that, compared with networks generated from our method, the networks without regional quality evaluation are less regular and contain more redundant curves, especially in the uniform dark areas. As noted in
Table 2, the lack of quality evaluation on CCs has a little effect on CP but a large effect on CR. The evaluation function is regarded as the probability that the current CC is located in a road area. On the one hand, the regional assessment can further screen out the road area through the threshold method. On the other hand, different weights are given to CCs according to different credibilities. Due to the sole use of the pixel area as the criterion to select valuable regions, many CCs located in non-road area are retained, resulting in a redundant extracted network with low correctness. Meanwhile, there is no distinction between high-quality and low-quality road segments. During road network optimization, road curves with low quality tend to deviate the network from the correct road centerline, leading to irregular results.
Comparison 3 refers to a recently proposed method [
32] that develops the idea of direction feature grouping. In this paper, we introduce an improved algorithm on the basis of directional decomposition; thus, Comparison 3 is implemented to verify the effectiveness of our method. A support vector machine is used to classify road and non-road regions in [
32]; therefore, the value of CR tends to be high in Comparison 3. In our method, rational quality evaluation achieves a similar purpose. With the constructed multiscale framework, our method obviously balances the completeness and correctness, performing better than Comparison 3 visually and numerically.
The effectiveness of the proposed method has been analyzed and validated comparatively. Although the general structure of road targets has been almost completely extracted, the method still has some drawbacks. Objects that have similar appearance to road targets in SAR images cannot be distinguished, such as rivers and long buildings. As the only input in our method, intensity information hardly provides sufficient features for accurate road detection. Moreover, straight roads are likely to be smooth curves in the extracted results because of the polynomial curve fitting thinning method. The performance of the proposed method depends on the parameter setting, which requires parameter adjustments in special scenarios.
For road network optimization, TV-NMS plays an important role in automatically learning the correct road position from repetitious road curves. In most cases, road targets can be accurately located through TV-NMS. However, output networks may deviate from the road centerlines when crisscross roads densely distribute and seriously interfere with each other. Meanwhile, the missing parts always occur around road intersections, which needs further processing such as spatial regularization. In our method, the input of tensor voting merely contains sparse pixels with location and amplitude information, whereas direction information is also capable of guiding the voting operation. We believe that it is a worthy attempt to directly input road pixels with credible direction information to tensor voting.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}