
A Model-Driven-to-Sample-Driven Method for Rural Road Extraction


Abstract
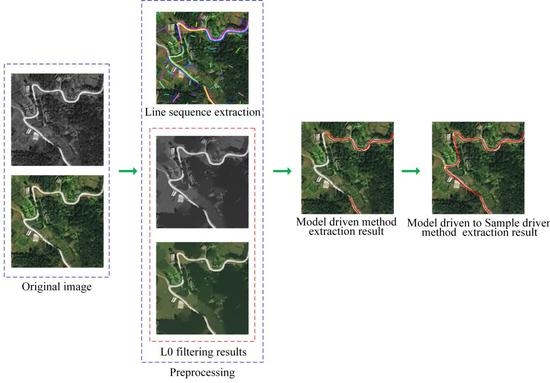
1. Introduction
2. Related Work
3. Materials and Methods
3.1. Experimental Data
3.2. Methodology
3.2.1. Preprocessing
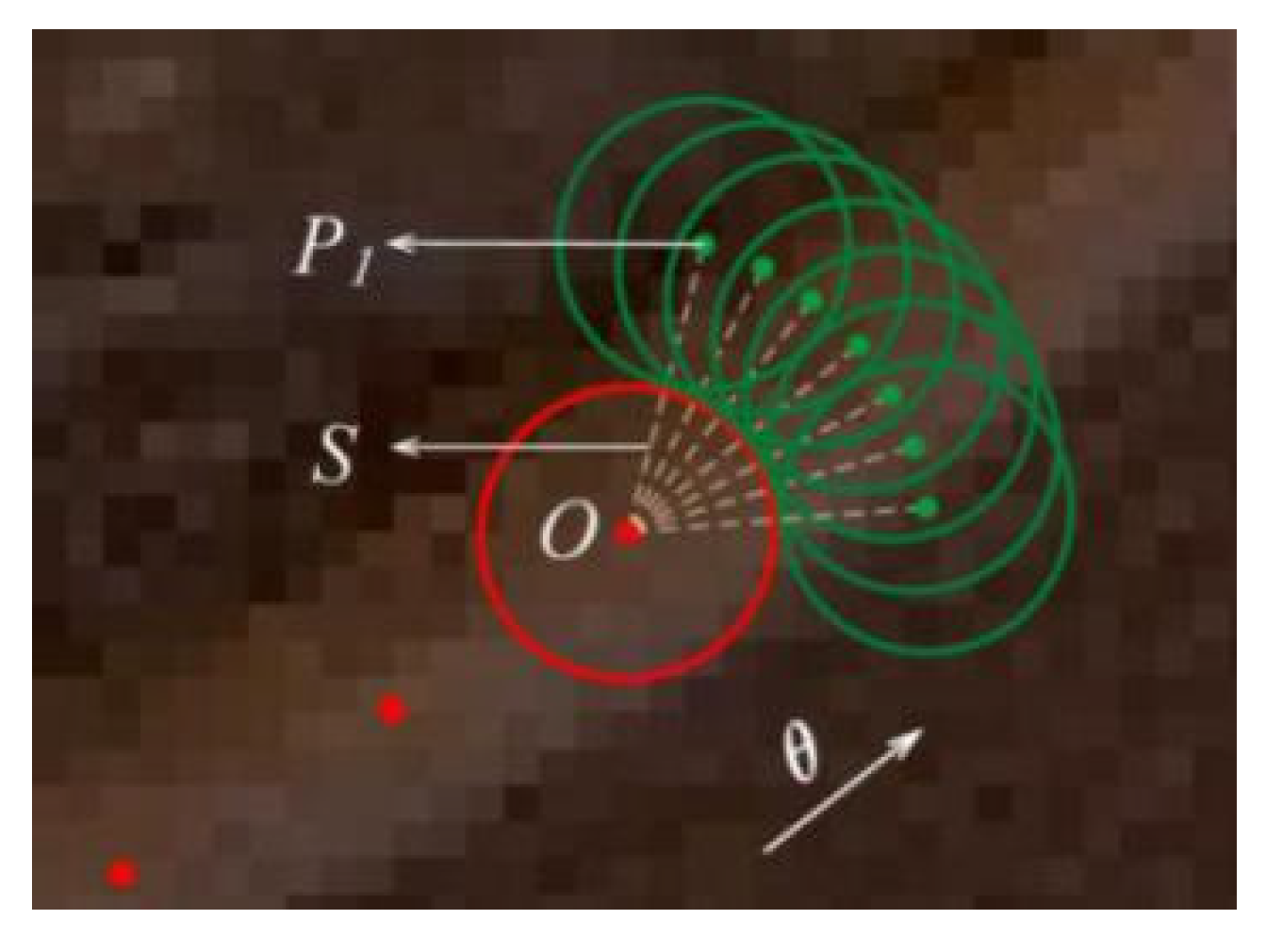
3.2.2. Model Driven Approach
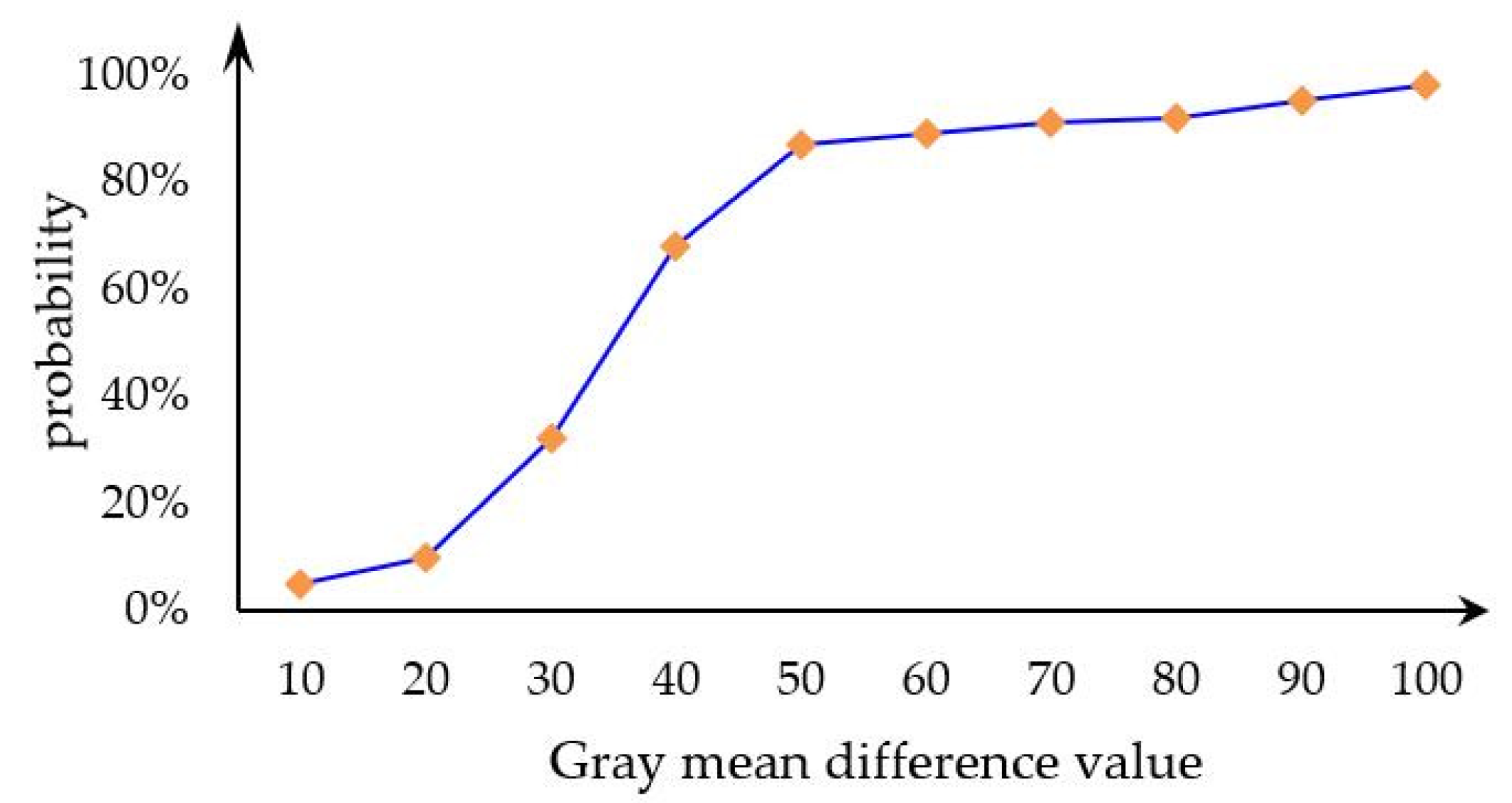
3.2.3. Sample Driven Method
4. Experimental Analysis and Evaluation
4.1. Comparison Method
4.2. Parameter Analysis
4.3. Evaluation Index
4.4. Test Set
4.5. Experimental Results and Analysis
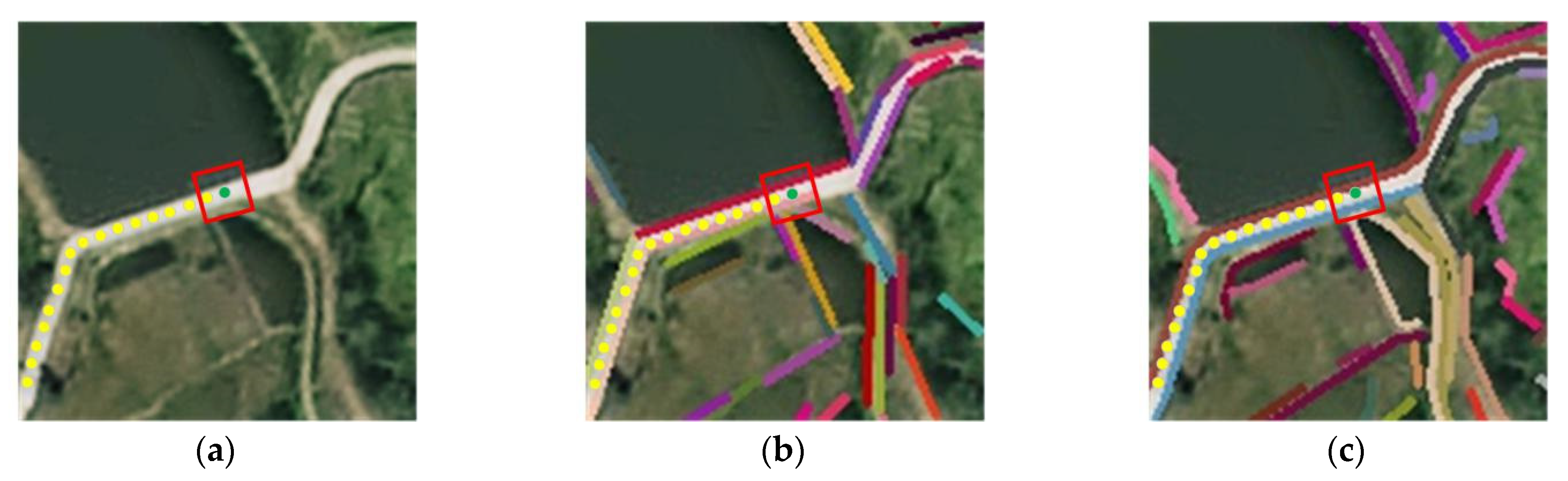
4.5.1. Experiment 1
4.5.2. Experiment 2
4.5.3. Experiment 3
4.5.4. Analysis of Experimental Results
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abdullahi, S.; Pradhan, B.; Jebur, M.N. GIS-based sustainable city compactness assessment using integration of MCDM, Bayes theorem and RADAR technology. Geocarto Int. 2015, 30, 365–387. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Wang, Z.; Yan, H.; Lu, X. High-resolution Remote Sensing Image Road Extraction Method for Improving U-Net. Remote Sens. Technol. Appl. 2020, 35, 741–748. [Google Scholar]
- Frizzelle, B.G.; Evenson, K.R.; Rodríguez, D.A.; Laraia, B.A. The importance of accurate road data for spatial applications in public health: Customizing a road network. Int. J. Health Geogr. 2009, 8, 24. [Google Scholar] [CrossRef] [PubMed]
- Tunde, A.; Adeniyi, E. Impact of Road Transport on Agricultural Development: A Nigerian Example. Ethiop. J. Environ. Stud. Manag. 2012, 5, 232–238. [Google Scholar] [CrossRef]
- Wang, W.; Yang, N.; Zhang, Y.; Wang, F.; Cao, T.; Eklund, P. A review of road extraction from remote sensing images. J. Traffic Transp. Eng. 2016, 3, 271–282. [Google Scholar] [CrossRef]
- Zhang, W.; Tang, P.; Corpetti, T.; Zhao, L. WTS: A Weakly towards Strongly Supervised Learning Framework for Remote Sensing Land Cover Classification Using Segmentation Models. Remote Sens. 2021, 13, 394. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Feitosa, R.Q.; van der Meer, F.; van der Werff, H.; van Coillie, F.; et al. Geographic Object-Based Image Analysis–Towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Huang, P.; Su, Y. A method for road extraction from remote sensing imagery. Remote Sens. Land Resour. 2015, 27, 56–62. [Google Scholar]
- Maboudi, M.; Amini, J.; Hahn, M.; Saati, M. Object-based road extraction from satellite images using antcolony optimization. Int. J. Remote Sens. 2017, 38, 179–198. [Google Scholar] [CrossRef]
- Zhou, T.; Sun, C.; Fu, H. Road Information Extraction from High-Resolution Remote Sensing Images Based on Road Reconstruction. Remote Sens. 2019, 11, 79. [Google Scholar] [CrossRef]
- Ameri, F.; Zoej, M.J.V. Road vectorisation from high-resolution imagery based on dynamic clustering using particle swarm optimisation. Photogramm. Rec. 2015, 30, 363–386. [Google Scholar] [CrossRef]
- Alshehhi, R.; Marpu, P.R. Hierarchical graph-based segmentation for extracting road networks from high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2017, 126, 245–260. [Google Scholar] [CrossRef]
- Miao, Z.; Shi, W.; Gamba, P.; Li, Z. An Object-Based Method for Road Network Extraction in VHR Satellite Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 4853–4862. [Google Scholar] [CrossRef]
- Maboudi, M.; Amini, J.; Hahn, M.; Saati, M. Road Network Extraction from VHR Satellite Images Using Context Aware Object Feature Integration and Tensor Voting. Remote Sens. 2016, 8, 637. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, Q.; Chen, G.; Dai, F.; Zhu, K.; Gong, Y.; Xie, Y. An object-based supervised classification framework for very-high-resolution remote sensing images using convolutional neural networks. Remote Sens. Lett. 2018, 9, 373–382. [Google Scholar] [CrossRef]
- Myint, S.W.; Gober, P.; Brazel, A.; Grossman-Clarke, S.; Weng, Q. Per-pixel vs. object-based classification of urban land cover extraction using high spatial resolution imagery. Remote Sens. Environ. 2011, 115, 1145–1161. [Google Scholar] [CrossRef]
- Liu, W.; Wu, Z.; Luo, J.; Sun, Y.; Wu, T.; Zhou, N.; Hu, X.; Wang, L.; Zhou, Z. A divided and stratified extraction method of high-resolution remote sensing information for cropland in hilly and mountainous areas based on deep learning. Acta Geod. Cartogr. 2021, 50, 105–116. [Google Scholar]
- Zhang, Y.; Zhang, Z.; Gong, J.Y. Generalized photogrammetry of spaceborne, airborne and terrestrial multi-source remote sensing datasets. Acta Geod. Cartogr. 2021, 50, 1–11. [Google Scholar]
- Treash, K.; Amaratunga, K. Automatic road detection in grayscale aerial images. J. Comput. Civ. Eng. 2000, 14, 60–69. [Google Scholar] [CrossRef]
- Sghaier, M.O.; Lepage, R. Road Extraction From Very High Resolution Remote Sensing Optical Images Based on Texture Analysis and Beamlet Transform. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1946–1958. [Google Scholar] [CrossRef]
- Shao, Y.; Guo, B.; Hu, X.; Di, L. Application of a Fast Linear Feature Detector to Road Extraction From Remotely Sensed Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 626–631. [Google Scholar] [CrossRef]
- Dai, J.; Miao, Z.; Ge, L.; Wang, X.; Zhu, T. Road extraction method based on path morphology for high resolution remote sensing imagery. Remote Sens. Inf. 2019, 34, 28–35. [Google Scholar]
- Mnih, V.; Hinton, G.E. Learning to detect roads in high-resolution aerial images. In Proceedings of the European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; pp. 210–223. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI; Lecture Notes in Computer Science; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; Springer: Cham, Switzerland, 2015; p. 9351. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Road Segmentation of Remotely-Sensed Images Using Deep Convolutional Neural Networks with Landscape Metrics and Conditional Random Fields. Remote Sens. 2017, 9, 680. [Google Scholar] [CrossRef]
- Gao, L.; Song, W.; Dai, J.; Chen, Y. Road Extraction from High-Resolution Remote Sensing Imagery Using Refined Deep Residual Convolutional Neural Network. Remote Sens. 2019, 11, 552. [Google Scholar] [CrossRef]
- Zhou, M.T.; Sui, H.G.; Chen, S.X.; Wang, J.D.; Chen, X. BT-RoadNet: A boundary and topologically-aware neural network forroad extraction from high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2020, 168, 288–306. [Google Scholar] [CrossRef]
- Ren, S.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, H.; Yang, D.; Wang, S.; Wang, S.; Li, Y. Road extraction by using atrous spatial pyramid pooling integrated encoder-decoder network and structural similarity loss. Remote Sens. 2019, 11, 1015. [Google Scholar] [CrossRef]
- Wang, S.; Mu, X.; He, H. Feature-representation-transfer based road extraction method for cross-domain aerial images. Acta Geod. Cartogr. 2020, 49, 611–621. [Google Scholar]
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road Extraction from High-Resolution Remote Sensing Imagery Using Deep Learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef]
- Leninisha, S.; Vani, K. Water flow based geometric active deformable model for road network. ISPRS J. Photogramm. Remote Sens. 2015, 102, 140–147. [Google Scholar] [CrossRef]
- Sun, C.; Zhou, T.; Chen, S. Semi automatic extraction of linear features based on rectangular template matching. J. Southwest. 2015, 37, 155–160. [Google Scholar]
- Lin, X.; Zhang, J.; Liu, Z.; Shen, J.; Duan, M. Semi-automatic extraction of road networks by least squares interlaced template matching in urban areas. Int. J. Remote Sens. 2011, 32, 4943–4959. [Google Scholar] [CrossRef]
- Lian, R.; Wang, W.; Li, J. Road extraction from high-resolution remote sensing images based on adaptive circular template and saliency map. Acta Geod. Cartogr. Sin. 2018, 47, 950–958. [Google Scholar]
- Dai, J.; Zhu, T.; Zhang, Y.; Ma, R.; Li, W. Lane-Level Road Extraction from High-Resolution Optical Satellite Images. Remote Sens. 2019, 11, 2672. [Google Scholar] [CrossRef]
- Dai, J.; Zhu, T.; Wang, Y.; Ma, R.; Fang, X. Road Extraction From High-Resolution Satellite Images Based on Multiple Descriptors. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 227–240. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, X.; Liu, Z.; Shen, J. Semi-automatic road tracking by template matching and distance transformation in urban areas. Int. J. Remote Sens. 2011, 32, 8331–8347. [Google Scholar] [CrossRef]
- Liu, B.; Guo, W.; Chen, X.; Gao, K.; Zuo, X.; Wang, R.; Yu, A. Morphological Attribute Profile Cube and Deep Random Forest for Small Sample Classification of Hyperspectral Image. IEEE Access 2020, 8, 117096–117108. [Google Scholar] [CrossRef]
- Shao, Z.; Zhou, Z.; Huang, X.; Zhang, Y. MRENet: Simultaneous Extraction of Road Surface and Road Centerline in Complex Urban Scenes from Very High-Resolution Images. Remote Sens. 2021, 13, 239. [Google Scholar] [CrossRef]
- Zhang, Y.; Xiong, Z.; Zang, Y.; Wang, C.; Li, J.; Li, X. Topology-Aware Road Network Extraction via Multi-Supervised Generative Adversarial Networks. Remote Sens. 2019, 11, 1017. [Google Scholar] [CrossRef]
- Ren, Y.; Yu, Y.; Guan, H. DA-CapsUNet: A Dual-Attention Capsule U-Net for road extraction from remote sensing imagery. Remote Sens. 2020, 12, 2866. [Google Scholar] [CrossRef]
- Cao, C.; Sun, Y. Automatic Road Centerline Extraction from Imagery Using Road GPS Data. Remote Sens. 2014, 6, 9014–9033. [Google Scholar] [CrossRef]
- Xu, L.; Lu, C.; Xu, Y.; Jia, J. Image smoothing via L 0 gradient minimization. ACM Trans. Graph. 2011, 30, 1–12. [Google Scholar] [CrossRef]
- Dai, J.; Li, Z.; Li, J.; Fang, X. A line extraction method for chain code tracking with phase verification. Acta Geod. Geophys. 2017, 46, 218–227. [Google Scholar]
- Ma, J.-Q. Content-Based Image Retrieval with HSV Color Space and Texture Features. In Proceedings of the 2009 International Conference on Web Information Systems and Mining, Institute of Electrical and Electronics Engineers (IEEE). Shanghai, China, 7–8 November 2009; pp. 61–63. [Google Scholar]
- Akinlar, C.; Topal, C. EDLines: A real-time line segment detector with a false detection control. Pattern Recognit. Lett. 2011, 32, 1633–1642. [Google Scholar] [CrossRef]
- Dai, J.; Wang, Y.; Du, Y. Development and prospect of road extraction method for optical remote sensing image. J. Remote Sens. 2020, 24, 804–823. (In Chinese) [Google Scholar]
- Vosselman, G.; de Knech, J. Automatic Extraction of Man-Made Objects from Aerial and Space Images; Birkhauser Verlag: Basel, Switzerland, 1995; pp. 65–74. [Google Scholar]
- Von Gioi, R.G.; Jakubowicz, J.; Morel, J.-M.; Randall, G. LSD: A Fast Line Segment Detector with a False Detection Control. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 722–732. [Google Scholar] [CrossRef]
- Land Use Status Classification. GB/T 21010–2017. Available online: https://www.chinesestandard.net/PDF/English.aspx/GBT21010-2017 (accessed on 1 November 2017).
- Su, X.; Chen, X.; Xu, H. Adaptive window local matching algorithm based on hsv color space. Laser Optoelectron. Prog. 2018, 55, 281–288. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Spectral Region | Band Range (nm) | Spatial Resolution (m) |
|---|---|---|---|
| Geoeye-1 | Panchromatic | 450–800 | 0.41 |
| Blue | 450–510 | 1.65 | |
| Green | 510–580 | 1.65 | |
| Red | 655–690 | 1.65 | |
| GF-2 | Panchromatic | 450–900 | 1 |
| Blue | 450–520 | 4 | |
| Green | 520–590 | 4 | |
| Red | 630–690 | 4 | |
| Pleiades | Panchromatic | 470–830 | 0.5 |
| Blue | 430–550 | 2 | |
| Green | 500–620 | 2 | |
| Red | 590–710 | 2 |
| Model-Driven Approach | Model-Driven + Panchromatic Match | Proposed Method | |
|---|---|---|---|
| Recall (%) | 71.99% | 99.64% | 99.71% |
| Precision (%) | 99.43% | 99.49% | 99.54% |
| IoU (%) | 71.69% | 99.14% | 99.26% |
| F1 (%) | 83.51% | 99.57% | 99.63% |
| Seed Points | 0 | 91 | 83 |
| Time(s) | 136 | 1159 | 1006 |
| Circle Method | T-Shape Method | Sector Method | Proposed Method | |
|---|---|---|---|---|
| Recall (%) | 99.52% | 99.49% | 99.61% | 99.73% |
| Precision (%) | 99.66% | 99.40% | 98.93% | 99.39% |
| IoU (%) | 99.19% | 98.90% | 98.54% | 99.12% |
| F1 (%) | 99.59% | 99.45% | 99.27% | 99.56% |
| Seed Points | 162 | 356 | 78 | 28 |
| Time(s) | 2698 | 4201 | 1358 | 310 |
| Circle Method | T-Shape Method | Sector Method | Proposed Method | |
|---|---|---|---|---|
| Recall (%) | 99.42% | 99.37% | 99.44% | 99.47% |
| Precision (%) | 98.19% | 98.73% | 98.36% | 98.82% |
| IoU (%) | 97.63% | 98.12% | 97.82% | 98.31% |
| F1 (%) | 98.80% | 99.05% | 98.90% | 99.15% |
| Seed Points | 142 | 152 | 68 | 54 |
| Time(s) | 2016 | 2648 | 1149 | 722 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, J.; Ma, R.; Gong, L.; Shen, Z.; Wu, J. A Model-Driven-to-Sample-Driven Method for Rural Road Extraction. Remote Sens. 2021, 13, 1417. https://doi.org/10.3390/rs13081417
Dai J, Ma R, Gong L, Shen Z, Wu J. A Model-Driven-to-Sample-Driven Method for Rural Road Extraction. Remote Sensing. 2021; 13(8):1417. https://doi.org/10.3390/rs13081417
Chicago/Turabian StyleDai, Jiguang, Rongchen Ma, Litao Gong, Zimo Shen, and Jialin Wu. 2021. "A Model-Driven-to-Sample-Driven Method for Rural Road Extraction" Remote Sensing 13, no. 8: 1417. https://doi.org/10.3390/rs13081417
APA StyleDai, J., Ma, R., Gong, L., Shen, Z., & Wu, J. (2021). A Model-Driven-to-Sample-Driven Method for Rural Road Extraction. Remote Sensing, 13(8), 1417. https://doi.org/10.3390/rs13081417