
Dimensionality Reduction of Hyperspectral Image Based on Local Constrained Manifold Structure Collaborative Preserving Embedding


Abstract
1. Introduction
2. Related Works
2.1. Graph Embedding
2.2. Collaborative Representation
3. Local Constrained Manifold Structure Collaborative Preserving Embedding
3.1. Local Constrained Collaborative Graph Analysis Model
3.2. Local Neighborhood Graph Analysis Model
4. Experimental Setup and Parameters Discussion
4.1. Data Set Description
4.2. Experimental Setup
4.3. Analysis of Neighbors Number k
4.4. Analysis of Regularization Parameters and
4.5. Analysis of Trade-Off Parameter a
4.6. Investigation of Embedding Dimension d
5. Experimental Results and Discussion
5.1. Analysis of Training Sample Size
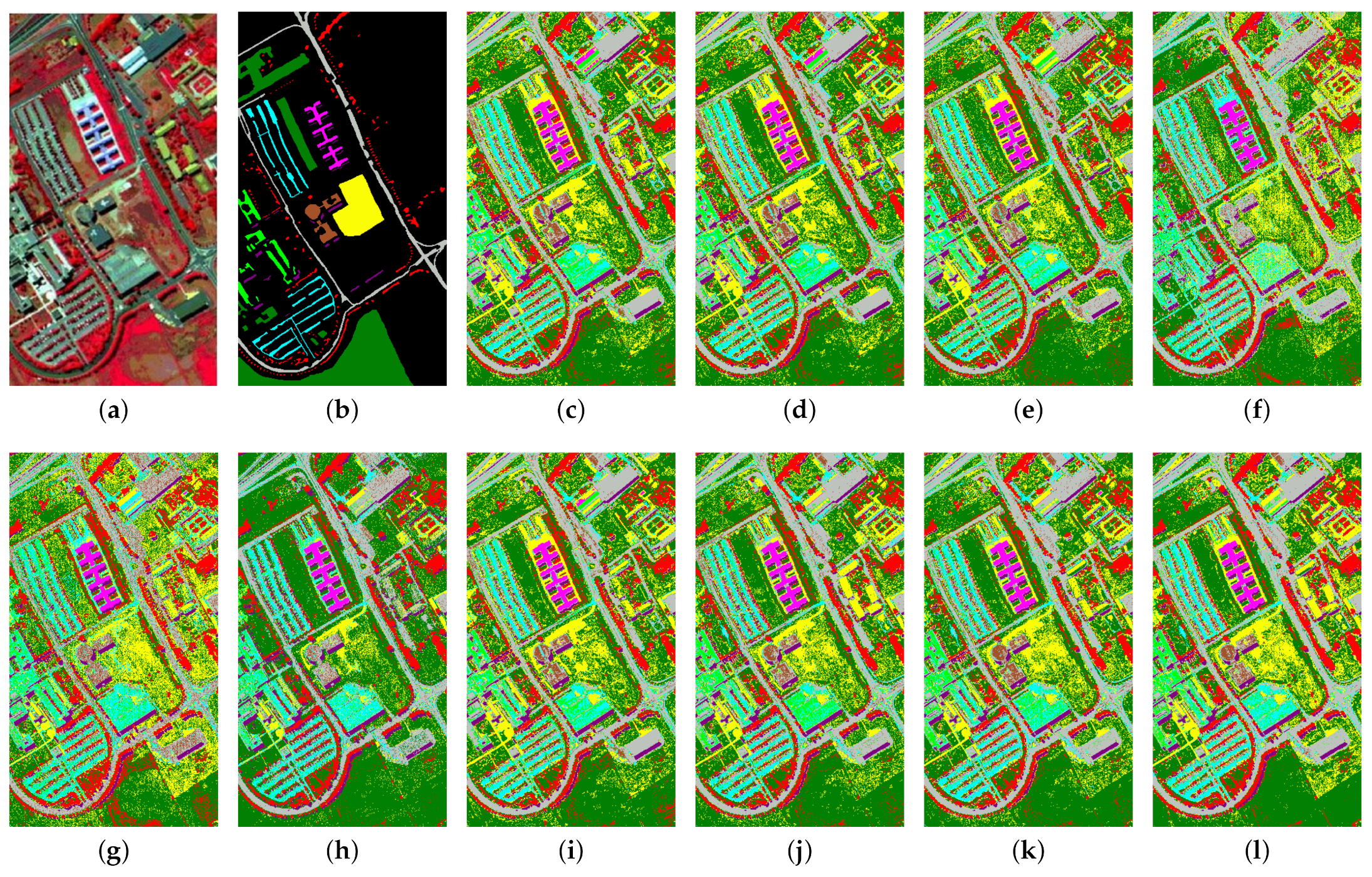
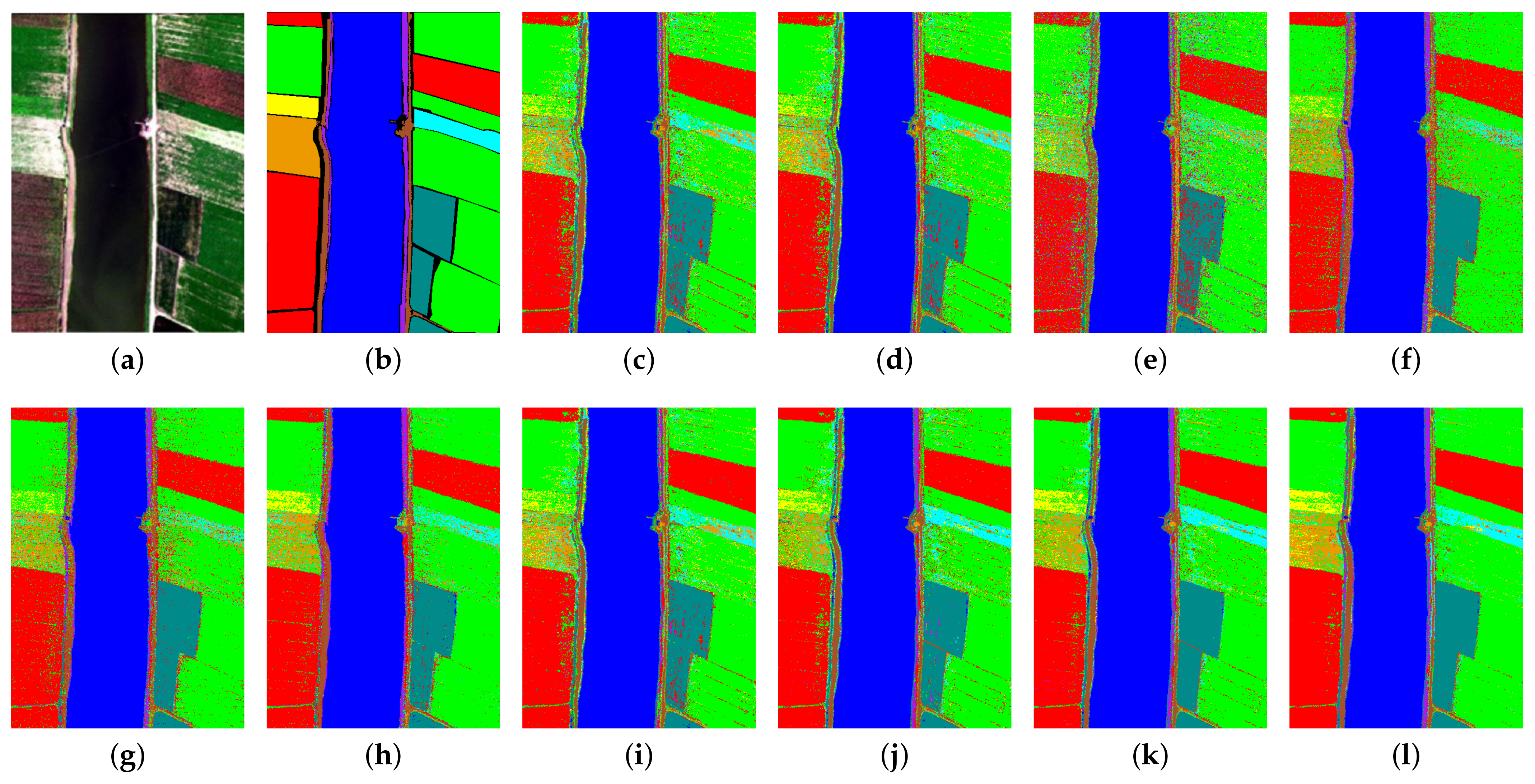
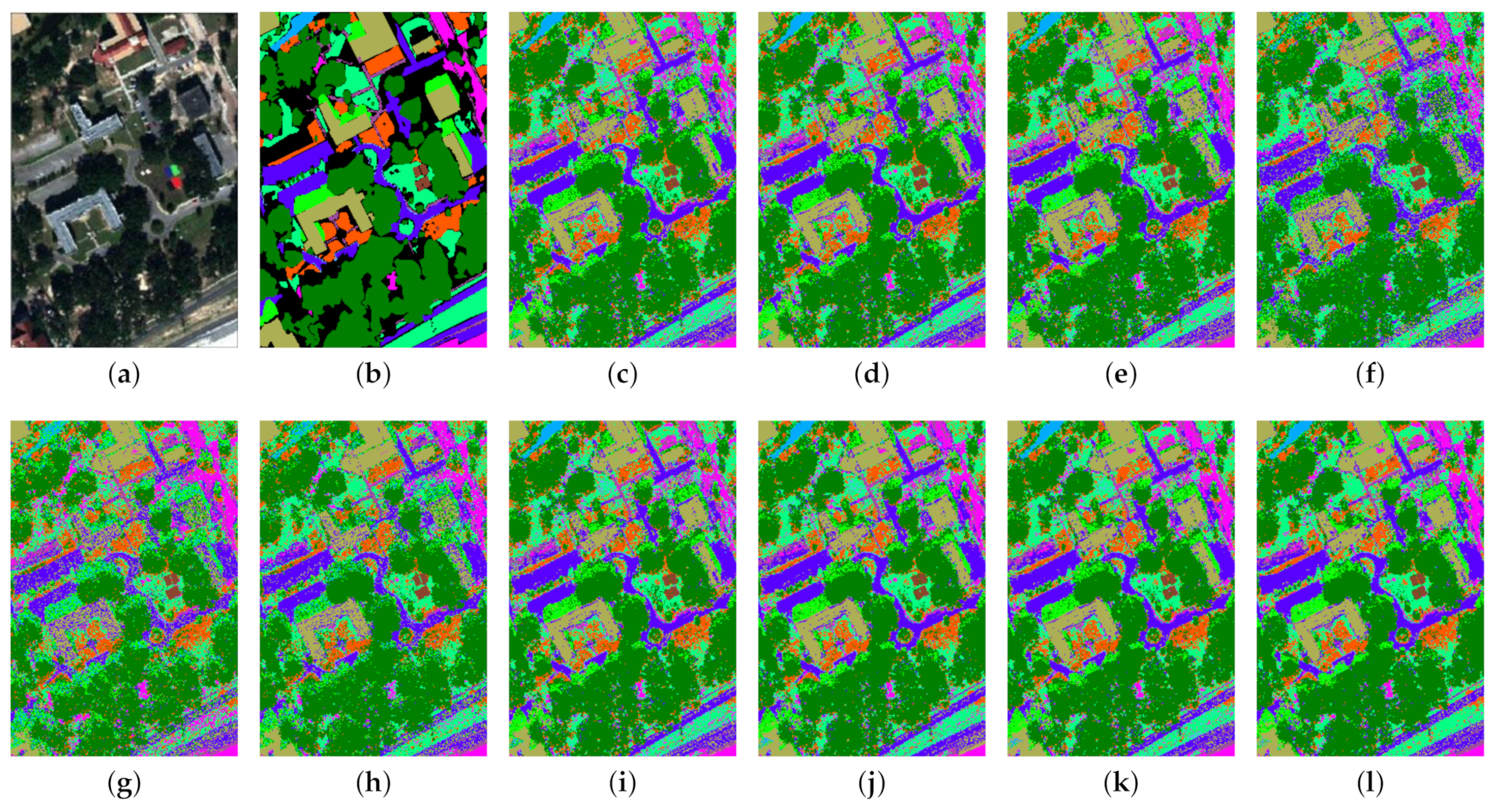
5.2. Analysis of Classification Results
5.3. Analysis of Computational Efficiency
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, P.H.; Jiao, L.C.; Liu, F.; Zhao, J.Q.; Zhao, Z.Q. Dimensionality reduction for hyperspectral image classification based on multiview graphs ensemble. J. Appl. Remote Sens. 2016, 10, 030501. [Google Scholar] [CrossRef]
- Tao, C.N.; Zhu, H.Z.; Sun, P.; Wu, R.M.; Zheng, Z.R. Hyperspectral image recovery based on fusion of coded aperture snapshot spectral imaging and RGB images by guided filtering. Opt. Commun. 2020, 458, 124804. [Google Scholar] [CrossRef]
- Xue, Z.H.; Du, P.J.; Li, J.; Su, H.J. Simultaneous Sparse Graph Embedding for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 6114–6133. [Google Scholar] [CrossRef]
- Jia, S.; Hu, J.; Xie, Y.; Shen, L.L.; Jia, Q.Q. Gabor Cube Selection Based Multitask Joint Sparse Representation for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3174–3187. [Google Scholar] [CrossRef]
- Sun, Y.B.; Wang, S.J.; Liu, Q.S.; Hang, R.L.; Liu, G.C. Hypergraph embedding for spatial-spectral joint feature extraction in hyperspectral images. Remote Sens. 2017, 9, 506. [Google Scholar]
- Ren, J.S.; Wang, R.X.; Liu, G.; Feng, R.Y.; Wang, Y.N.; Wu, W. Partitioned Relief-F Method for Dimensionality Reduction of Hyperspectral Images. Remote Sens. 2020, 12, 1104. [Google Scholar] [CrossRef]
- Liu, B.; Yu, X.C.; Zhang, P.Q.; Tan, X.; Wang, R.R.; Zhi, L. Spectral-spatial classification of hyperspectral image using three-dimensional convolution network. J. Appl. Remote Sens. 2018, 12, 016005. [Google Scholar]
- Huang, X.; Zhang, L.P. An SVM ensemble approach combining spectral, structural, and semantic features for the classification of high-resolution remotely sensed imagery. IEEE Trans. Geosci. Remote Sens. 2012, 51, 257–272. [Google Scholar] [CrossRef]
- Zhang, L.F.; Song, L.C.; Du, B.; Zhang, Y.P. Nonlocal low-rank tensor completion for visual data. IEEE Trans. Cybern. 2021, 51, 673–685. [Google Scholar] [CrossRef]
- Lan, M.; Zhang, Y.P.; Zhang, L.F.; Du, B. Global Context Based Automatic Road Segmentation Via Dilated Convolutional Neural Network. Inf. Sci. 2020, 535, 156–171. [Google Scholar] [CrossRef]
- Zhang, Q.; Tian, Y.; Yang, Y.P.; Pan, C.H. Automatic spatial-spectral feature selection for hyperspectral image via discriminative sparse multimodal learning. IEEE Trans. Geosci. Remote Sens. 2014, 53, 261–279. [Google Scholar] [CrossRef]
- Zhou, F.; Hang, R.L.; Liu, Q.S.; Yuan, X.T. Hyperspectral image classification using spectral-spatial LSTMs. Neurocomputing 2019, 328, 39–47. [Google Scholar] [CrossRef]
- Yi, C.; Zhao, Y.Q.; Chan, J.C.W. Spectral super-resolution for multispectral image based on spectral improvement strategy and spatial preservation strategy. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9010–9024. [Google Scholar] [CrossRef]
- Jiang, J.J.; Ma, J.Y.; Chen, C.; Wang, Z.Y.; Cai, Z.H.; Wang, L.Z. SuperPCA: A Superpixelwise PCA Approach for Unsupervised Feature Extraction of Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4581–4593. [Google Scholar] [CrossRef]
- Xia, J.S.; Falco, N.; Benediktsson, J.A.; Du, P.J.; Chanussot, J. Hyperspectral Image Classification with Rotation Random Forest Via KPCA. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2017, 10, 1601–1609. [Google Scholar] [CrossRef]
- Shao, Y.; Lan, J.H. A Spectral Unmixing Method by Maximum Margin Criterion and Derivative Weights to Address Spectral Variability in Hyperspectral Imagery. Remote Sens. 2019, 11, 1045. [Google Scholar] [CrossRef]
- Feng, F.B.; Li, W.; Du, Q.; Zhang, B. Dimensionality reduction of hyperspectral image with graph-based discriminant analysis considering spectral similarity. Remote Sens. 2017, 9, 323. [Google Scholar] [CrossRef]
- Li, W.; Prasad, S.; Fowler, J.E.; Bruce, L.M. Locality-preserving dimensionality reduction and classification for hyperspectral image analysis. IEEE Trans. Geosci. Remote Sens. 2012, 50, 1185–1198. [Google Scholar] [CrossRef]
- Zhang, Z.; Chow, T.; Zhao, M. M-Isomap: Orthogonal constrained marginal isomap for nonlinear dimensionality reduction. IEEE Trans. Cybern. 2013, 43, 1292–1303. [Google Scholar] [CrossRef] [PubMed]
- Shi, G.Y.; Huang, H.; Wang, L.H. Unsupervised Dimensionality Reduction for Hyperspectral Imagery via Local Geometric Structure Feature Learning. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1425–1429. [Google Scholar] [CrossRef]
- Shi, G.Y.; Huang, H.; Liu, J.M.; Li, Z.Y.; Wang, L.H. Spatial-Spectral Multiple Manifold Discriminant Analysis for Dimensionality Reduction of Hyperspectral Imagery. Remote Sens. 2019, 11, 2414. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Z.; Jie, Q.; Zhang, L.; Li, B.; Li, F.Z. Semi-supervised local multi-manifold Isomap by linear embedding for feature extraction. Pattern Recognit. 2018, 76, 662–678. [Google Scholar] [CrossRef]
- Li, Q.; Ji, H.B. Multimodality image registration using local linear embedding and hybrid entropy. Neurocomputing 2013, 111, 34–42. [Google Scholar] [CrossRef]
- Tu, S.T.; Chen, J.Y.; Yang, W.; Sun, H. Laplacian Eigenmaps-Based Polarimetric Dimensionality Reduction for SAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2012, 50, 170–179. [Google Scholar] [CrossRef]
- Li, W.; Zhang, L.P.; Zhang, L.F.; Du, B. GPU Parallel Implementation of Isometric Mapping for Hyperspectral Classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1532–1536. [Google Scholar] [CrossRef]
- Pu, H.Y.; Chen, Z.; Wang, B.; Jiang, G.M. A novel spatial-spectral similarity measure for dimensionality reduction and classification of hyperspectral image. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7008–7022. [Google Scholar]
- Fang, L.Y.; Li, S.T.; Kang, X.D.; Benediktssonet, J.A. Spectral-spatial classification of hyperspectral images with a superpixel-based discriminative sparse model. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4186–4201. [Google Scholar] [CrossRef]
- Yuan, H.L.; Tang, Y.Y. Learning with hypergraph for hyperspectral image feature extraction. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1695–1699. [Google Scholar] [CrossRef]
- Zhou, Y.C.; Wei, Y.T. Learning Hierarchical Spectral-Spatial Features for Hyperspectral Image Classification. IEEE Trans. Cybern. 2016, 46, 1667–1678. [Google Scholar] [CrossRef] [PubMed]
- Luo, R.B.; Liao, W.Z.; Pi, Y.G. Discriminative Supervised Neighborhood Preserving Embedding Feature Extraction for Hyperspectral-image Classification. Telkomnika 2012, 10, 1051–1056. [Google Scholar] [CrossRef]
- Yang, W.K.; Sun, C.Y.; Zhang, L. A multi-manifold discriminant analysis method for image feature extraction. Pattern Recognit. 2012, 10, 1051–1056. [Google Scholar] [CrossRef]
- Luo, F.L.; Du, B.; Zhang, L.P.; Zhang, L.F.; Tao, D.C. Feature Learning Using Spatial-Spectral Hypergraph Discriminant Analysis for Hyperspectral Image. IEEE Trans. Cybern. 2019, 49, 2406–2419. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.Y.; Jia, X.P.; Hu, J.K. Superpixel-based graphical model for remote sensing image mapping. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5861–5871. [Google Scholar] [CrossRef]
- Gao, Y.; Ji, R.R.; Cui, P.; Dai, Q.H.; Hua, G. Hyperspectral image classification through bilayer graph-based learning. IEEE Trans. Image Process. 2014, 23, 2769–2778. [Google Scholar] [CrossRef]
- Chen, M.L.; Wang, Q.; Li, X.L. Discriminant Analysis with Graph Learning for Hyperspectral Image Classification. Remote Sens. 2018, 10, 836. [Google Scholar] [CrossRef]
- Zhang, C.J.; Li, G.D.; Du, S.H.; Tan, W.Z.; Gao, F. Three-dimensional densely connected convolutional network for hyperspectral remote sensing image classification. J. Appl. Remote Sens. 2019, 13, 016519. [Google Scholar] [CrossRef]
- Pan, B.; Shi, Z.W.; Zhang, N.; Xie, S.B. Hyperspectral image classification based on nonlinear spectral-spatial network. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1782–1786. [Google Scholar] [CrossRef]
- Zhang, L.P.; Zhong, Y.F.; Huang, B.; Gong, J.Y.; Li, P.X. Dimensionality reduction based on clonal selection for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2007, 45, 4172–4186. [Google Scholar] [CrossRef]
- Tang, Y.Y.; Yuan, H.L.; Li, L.Q. Manifold-based sparse representation for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7606–7618. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Hyperspectral image classification using dictionary-based sparse representation. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3973–3985. [Google Scholar] [CrossRef]
- Gui, J.; Sun, Z.N.; Jia, W.; Hu, R.X.; Lei, Y.K.; Ji, S.W. Discriminant sparse neighborhood preserving embedding for face recognition. Pattern Recognit. 2012, 45, 2884–2893. [Google Scholar] [CrossRef]
- Li, W.; Liu, J.B.; Du, Q. Sparse and low-rank graph for discriminant analysis of hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4094–4105. [Google Scholar] [CrossRef]
- Huang, H.; Luo, F.L.; Liu, J.M.; Yang, Y.Q. Dimensionality reduction of hyperspectral images based on sparse discriminant manifold embedding. ISPRS J. Photogramm. Remote Sens. 2015, 106, 42–54. [Google Scholar] [CrossRef]
- Zang, F.; Zhang, J.S. Discriminative learning by sparse representation for classification. Neurocomputing 2011, 74, 2176–2183. [Google Scholar] [CrossRef]
- Luo, F.L.; Huang, H.; Liu, J.M.; Ma, Z.Z. Fusion of graph embedding and sparse representation for feature extraction and classification of hyperspectral imagery. Photogramm. Eng. Remote Sens. 2017, 83, 37–46. [Google Scholar] [CrossRef]
- Zhong, Y.F.; Wang, X.Y.; Zhao, L.; Feng, R.Y.; Zhang, L.P.; Xu, Y.Y. Blind spectral unmixing based on sparse component analysis for hyperspectral remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2016, 119, 49–63. [Google Scholar] [CrossRef]
- Ye, Z.; Dong, R.; Bai, L.; Nian, Y.J. Adaptive collaborative graph for discriminant analysis of hyperspectral imagery. Eur. J. Remote Sens. 2020, 53, 91–103. [Google Scholar] [CrossRef]
- Lv, M.; Hou, Q.L.; Deng, N.Y.; Jing, L. Collaborative Discriminative Manifold Embedding for Hyperspectral Imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 272–281. [Google Scholar] [CrossRef]
- Ly, N.H.; Du, Q.; Fowler, J.E. Collaborative Graph-Based Discriminant Analysis for Hyperspectral Imagery. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2014, 7, 2688–2696. [Google Scholar] [CrossRef]
- Lou, S.J.; Ma, Y.H.; Zhao, X.M. Manifold aware discriminant collaborative graph embedding for face recognition. In Proceedings of the Tenth International Conference on Digital Image Processing, Chengdu, China, 12–14 December 2018. [Google Scholar]
- Huang, P.; Li, T.; Gao, G.W.; Yao, Y.Z.; Yang, G. Collaborative representation based local discriminant projection for feature extraction. Digit. Signal Prog. 2018, 76, 84–93. [Google Scholar] [CrossRef]
- Zhang, X.R.; He, Y.D.; Zhou, N.; Zheng, Y.G. Semisupervised Dimensionality Reduction of Hyperspectral Images via Local Scaling Cut Criterion. IEEE Geosci. Remote Sens. Lett. 2013, 10, 1547–1551. [Google Scholar] [CrossRef]
- Wong, W.K.; Zhao, H.T. Supervised optimal locality preserving projection. Pattern Recognit. 2012, 45, 186–197. [Google Scholar] [CrossRef]
- Li, W.; Du, Q. Collaborative Representation for Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 2014, 53, 1463–1474. [Google Scholar] [CrossRef]
- Li, W.; Du, Q.; Zhang, B. Combined sparse and collaborative representation for hyperspectral target detection. Pattern Recognit. 2015, 48, 3904–3916. [Google Scholar] [CrossRef]
- Zhu, P.F.; Zuo, W.M.; Zhang, L.; Shiu, S.C.; Zhang, D. Image Set-Based Collaborative Representation for Face Recognition. IEEE Trans. Inf. Forensic Secur. 2014, 9, 1120–1132. [Google Scholar]
- Zhang, L.F.; Zhang, L.P.; Tao, D.C.; Huang, X. A modified stochastic neighbor embedding for multi-feature dimension reduction of remote sensing images. ISPRS J. Photogramm. Remote Sens. 2013, 83, 30–39. [Google Scholar] [CrossRef]
- Shi, Q.; Zhang, L.P.; Du, B. Semisupervised discriminative locally enhanced alignment for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2013, 51, 4800–4815. [Google Scholar] [CrossRef]
- Dong, Y.N.; Du, B.; Zhang, L.P.; Zhang, L.F. Exploring locally adaptive dimensionality reduction for hyperspectral image classification: A maximum margin metric learning aspect. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2017, 10, 1136–1150. [Google Scholar] [CrossRef]
- Dong, Y.N.; Du, B.; Zhang, L.P.; Zhang, L.F. Dimensionality reduction and classication of hyperspectral images using ensemble discriminative local metric learning. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2509–2524. [Google Scholar] [CrossRef]
- Sun, W.W.; Halevy, A.; Benedetto, J.J.; Czaja, W.; Liu, C.; Wu, H.B.; Shi, B.Q.; Li, Q.Y. UL-Isomap based nonlinear dimensionality reduction for hyperspectral imagery classification. ISPRS J. Photogramm. Remote Sens. 2014, 89, 25–36. [Google Scholar] [CrossRef]
- Sun, W.W.; Yang, G.; Du, B.; Zhang, L.P.; Zhang, L.P. A sparse and low-rank near-isometric linear embedding method for feature extraction in hyperspectral imagery classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4032–4046. [Google Scholar] [CrossRef]
- Datta, A.; Ghosh, S.; Ghosh, A. Unsupervised band extraction for hyperspectral images using clustering and kernel principal component analysis. Int. J. Remote Sens. 2017, 38, 850–873. [Google Scholar] [CrossRef]
- Huang, H.; Li, Z.Y.; Pan, Y.S. Multi-Feature Manifold Discriminant Analysis for Hyperspectral Image Classification. Remote Sens. 2019, 11, 651. [Google Scholar] [CrossRef]
- Fang, L.Y.; Wang, C.; Li, S.T.; Benediktsson, J.A. Hyperspectral image classification via multiple-feature based adaptive sparse representation. IEEE Trans. Instrum. Meas. 2017, 66, 1646–1657. [Google Scholar] [CrossRef]
- Fang, L.Y.; Zhuo, H.J.; Li, S.T. Super-resolution of hyperspectral image via superpixel-based sparse representation. Neurocomputing 2018, 273, 171–177. [Google Scholar] [CrossRef]
- He, L.; Li, J.; Liu, C.Y.; Li, S.T. Recent advances on spectral-spatial hyperspectral image classification: An overview and new guidelines. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1579–1597. [Google Scholar] [CrossRef]
- Zhang, L.F.; Zhang, Q.; Du, B.; Huang, X.; Tang, Y.Y.; Tao, D.C. Simultaneous Spectral-Spatial Feature Selection and Extraction for Hyperspectral Images. IEEE Trans. Cybern. 2018, 48, 16–28. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | 20 | 30 | 40 | 50 | 60 |
|---|---|---|---|---|---|
| RAW | 68.77 ± 1.74 (0.607) | 70.48 ± 1.93 (0.628) | 71.21 ± 2.04 (0.637) | 72.79 ± 1.03 (0.655) | 73.29 ± 0.76 (0.661) |
| PCA | 68.75 ± 1.73 (0.607) | 70.44 ± 1.94 (0.628) | 71.23 ± 1.97 (0.637) | 72.77 ± 1.01 (0.655) | 73.28 ± 0.79 (0.661) |
| LPP | 66.12 ± 0.91 (0.578) | 70.91 ± 2.90 (0.634) | 72.56 ± 1.48 (0.654) | 74.58 ± 0.89 (0.677) | 76.13 ± 1.05 (0.695) |
| LDA | 67.28 ± 4.54 (0.589) | 72.53 ± 2.21 (0.652) | 75.38 ± 0.85 (0.683) | 77.36 ± 1.10 (0.709) | 77.57 ± 1.56 (0.711) |
| LFDA | 61.88 ± 2.44 (0.525) | 69.95 ± 2.84 (0.622) | 74.03 ± 1.80 (0.670) | 75.39 ± 1.02 (0.687) | 77.42 ± 1.89 (0.711) |
| LGSFA | 65.08 ± 1.96 (0.560) | 71.02 ± 1.71 (0.634) | 73.01 ± 1.51 (0.657) | 75.18 ± 3.02 (0.683) | 75.60 ± 0.98 (0.686) |
| SGDA | 73.04 ± 1.19 (0.659) | 75.62 ± 1.77 (0.690) | 76.13 ± 2.33 (0.696) | 78.43 ± 1.29 (0.723) | 79.06 ± 1.15 (0.730) |
| LGDA | 71.55 ± 1.90 (0.642) | 73.85 ± 1.60 (0.669) | 75.30 ± 2.44 (0.682) | 75.65 ± 0.93 (0.690) | 77.25 ± 0.81 (0.709) |
| CGDA | 72.22 ± 2.60 (0.651) | 75.20 ± 1.03 (0.686) | 76.03 ± 2.62 (0.696) | 77.20 ± 1.44 (0.709) | 78.95 ± 1.47 (0.730) |
| LMSCPE | 76.81 ± 1.55 (0.705) | 78.11 ± 1.53 (0.722) | 78.91 ± 2.50 (0.732) | 79.89 ± 0.64 (0.742) | 81.62 ± 2.19 (0.763) |
| Method | 20 | 30 | 40 | 50 | 60 |
|---|---|---|---|---|---|
| RAW | 79.39 ± 1.52 (0.740) | 81.39 ± 0.68 (0.765) | 82.20 ± 0.84 (0.775) | 82.49 ± 0.78 (0.778) | 83.53 ± 0.89 (0.791) |
| PCA | 79.38 ± 1.53 (0.740) | 81.38 ± 0.68 (0.764) | 82.18 ± 0.84 (0.774) | 82.48 ± 0.80 (0.778) | 83.52 ± 0.91 (0.791) |
| LPP | 66.70 ± 1.81 (0.592) | 73.26 ± 0.39 (0.668) | 76.66 ± 1.38 (0.708) | 80.06 ± 1.69 (0.749) | 82.45 ± 0.67 (0.777) |
| LDA | 83.94 ± 1.93 (0.795) | 85.60 ± 0.74 (0.816) | 87.73 ± 0.68 (0.843) | 89.74 ± 1.06 (0.868) | 91.16 ± 0.63 (0.886) |
| LFDA | 77.76 ± 2.43 (0.719) | 83.43 ± 2.33 (0.789) | 83.02 ± 0.55 (0.784) | 89.47 ± 0.57 (0.865) | 91.68 ± 0.47 (0.893) |
| LGSFA | 83.46 ± 0.66 (0.789) | 83.54 ± 2.16 (0.790) | 85.78 ± 1.13 (0.818) | 90.12 ± 0.36 (0.873) | 91.79 ± 0.40 (0.894) |
| SGDA | 87.47 ± 2.04 (0.839) | 89.05 ± 0.65 (0.859) | 89.93 ± 0.91 (0.870) | 90.59 ± 0.65 (0.879) | 91.62 ± 0.44 (0.892) |
| LGDA | 84.73 ± 2.62 (0.805) | 85.02 ± 0.62 (0.809) | 85.50 ± 1.23 (0.815) | 85.79 ± 0.50 (0.819) | 86.77 ± 0.53 (0.831) |
| CGDA | 88.03 ± 2.82 (0.847) | 89.61 ± 0.94 (0.866) | 89.92 ± 1.01 (0.870) | 90.17 ± 0.72 (0.874) | 90.99 ± 0.69 (0.884) |
| LMSCPE | 90.74 ± 1.31 (0.881) | 91.28 ± 0.98 (0.887) | 91.57 ± 0.73 (0.891) | 91.85 ± 0.82 (0.895) | 92.06 ± 0.94 (0.897) |
| Method | 20 | 30 | 40 | 50 | 60 |
|---|---|---|---|---|---|
| RAW | 68.72 ± 3.60 (0.610) | 70.55 ± 1.02 (0.632) | 71.41 ± 1.19 (0.641) | 72.58 ± 1.36 (0.655) | 72.70 ± 0.40 (0.656) |
| PCA | 68.71 ± 3.58 (0.610) | 70.55 ± 1.02 (0.632) | 71.42 ± 1.17 (0.642) | 72.57 ± 1.32 (0.654) | 72.74 ± 0.40 (0.657) |
| LPP | 63.08 ± 4.46 (0.545) | 67.32 ± 1.70 (0.594) | 68.86 ± 2.25 (0.612) | 70.90 ± 1.29 (0.635) | 72.16 ± 1.01 (0.649) |
| LDA | 62.23 ± 4.26 (0.532) | 65.65 ± 1.70 (0.570) | 65.76 ± 2.23 (0.571) | 66.89 ± 0.77 (0.583) | 67.04 ± 1.18 (0.586) |
| LFDA | 62.65 ± 4.03 (0.537) | 65.68 ± 2.88 (0.574) | 68.45 ± 2.09 (0.606) | 70.89 ± 1.25 (0.636) | 71.56 ± 0.74 (0.643) |
| LGSFA | 63.04 ± 4.68 (0.544) | 67.32 ± 1.38 (0.593) | 68.24 ± 2.50 (0.605) | 69.97 ± 2.23 (0.625) | 70.42 ± 0.73 (0.630) |
| SGDA | 70.03 ± 3.78 (0.625) | 72.61 ± 1.10 (0.656) | 73.32 ± 0.95 (0.664) | 73.87 ± 1.36 (0.671) | 74.89 ± 0.42 (0.682) |
| LGDA | 71.33 ± 3.75 (0.640) | 72.71 ± 0.72 (0.658) | 73.54 ± 0.86 (0.667) | 74.11 ± 0.20 (0.673) | 74.34 ± 1.19 (0.676) |
| CGDA | 71.12 ± 3.52 (0.638) | 72.40 ± 0.98 (0.654) | 73.04 ± 1.08 (0.661) | 74.62 ± 1.33 (0.679) | 74.71 ± 0.44 (0.680) |
| LMSCPE | 72.43 ± 4.31 (0.654) | 73.96 ± 1.62 (0.672) | 74.54 ± 1.83 (0.679) | 76.46 ± 1.39 (0.702) | 76.57 ± 0.93 (0.708) |
| Class | Land Covers | Training | Test | RAW | PCA | LPP | LDA | LFDA | LGSFA | SGDA | LGDA | CGDA | LMSCPE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Asphalt | 66 | 6565 | 84.54 | 84.42 | 84.74 | 84.49 | 69.72 | 84.04 | 85.35 | 84.78 | 88.26 | 91.36 |
| 2 | Meadows | 186 | 18,463 | 89.87 | 89.84 | 89.43 | 88.93 | 77.56 | 96.91 | 89.60 | 90.88 | 92.83 | 95.54 |
| 3 | Gravel | 21 | 2078 | 49.09 | 48.89 | 41.29 | 38.69 | 48.85 | 31.57 | 52.17 | 56.59 | 60.59 | 64.87 |
| 4 | Trees | 31 | 3033 | 75.70 | 75.77 | 79.59 | 86.25 | 92.65 | 88.16 | 75.37 | 78.37 | 78.57 | 85.23 |
| 5 | Metal | 13 | 1332 | 98.57 | 98.57 | 99.17 | 99.62 | 99.02 | 99.70 | 99.10 | 98.57 | 99.32 | 99.55 |
| 6 | Soil | 50 | 4979 | 54.25 | 54.35 | 53.99 | 55.79 | 66.98 | 38.24 | 56.92 | 61.54 | 66.94 | 69.65 |
| 7 | Bitumen | 13 | 1317 | 64.54 | 64.77 | 51.86 | 20.12 | 51.94 | 32.73 | 65.60 | 63.86 | 72.74 | 63.33 |
| 8 | Bricks | 37 | 3645 | 72.98 | 72.62 | 65.24 | 62.09 | 64.20 | 73.39 | 73.77 | 73.20 | 78.38 | 76.27 |
| 9 | Shadows | 10 | 937 | 99.89 | 99.89 | 99.79 | 88.26 | 99.89 | 98.40 | 99.89 | 99.15 | 99.36 | 99.79 |
| AA | 76.60 | 76.57 | 73.90 | 69.36 | 74.53 | 71.46 | 77.53 | 78.55 | 81.89 | 82.84 | |||
| OA | 80.09 | 80.05 | 78.76 | 77.56 | 73.99 | 80.28 | 80.66 | 81.97 | 84.95 | 87.16 | |||
| KC | 73.29 | 73.23 | 71.55 | 70.02 | 66.59 | 72.92 | 74.10 | 75.87 | 79.84 | 82.76 | |||
| Class | Land Covers | Training | Test | RAW | PCA | LPP | LDA | LFDA | LGSFA | SGDA | LGDA | CGDA | LMSCPE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Corn | 69 | 34,442 | 93.36 | 93.30 | 82.20 | 93.03 | 94.56 | 96.90 | 95.46 | 96.85 | 97.77 | 98.81 |
| 2 | Cotton | 17 | 8357 | 47.24 | 47.24 | 34.79 | 47.79 | 52.02 | 56.19 | 53.05 | 45.14 | 54.83 | 66.02 |
| 3 | Sesame | 10 | 3021 | 37.80 | 37.54 | 15.33 | 33.40 | 32.54 | 65.18 | 40.19 | 56.04 | 64.71 | 68.42 |
| 4 | Broad-leaf soybean | 126 | 63,086 | 87.33 | 87.32 | 80.98 | 88.89 | 90.57 | 95.36 | 89.74 | 90.09 | 92.22 | 96.67 |
| 5 | Narrow-leaf soybean | 10 | 4141 | 53.39 | 53.34 | 27.58 | 33.30 | 35.69 | 57.38 | 54.94 | 74.50 | 76.33 | 76.45 |
| 6 | Rice | 24 | 11,830 | 90.51 | 90.45 | 78.88 | 98.08 | 97.98 | 95.58 | 91.62 | 96.13 | 99.82 | 99.80 |
| 7 | Water | 134 | 66,922 | 99.93 | 99.93 | 99.95 | 99.92 | 99.91 | 99.98 | 99.93 | 99.94 | 99.91 | 99.91 |
| 8 | Roads and houses | 14 | 7110 | 75.09 | 75.08 | 60.03 | 62.57 | 67.33 | 79.54 | 76.17 | 83.36 | 85.54 | 85.23 |
| 9 | Mixed weed | 10 | 5219 | 28.68 | 28.66 | 29.70 | 60.80 | 57.14 | 58.59 | 34.68 | 50.89 | 59.11 | 65.97 |
| AA | 68.15 | 68.10 | 56.60 | 68.64 | 69.75 | 78.30 | 70.64 | 76.99 | 81.14 | 84.14 | |||
| OA | 87.67 | 87.65 | 81.30 | 88.47 | 89.52 | 92.84 | 89.33 | 90.91 | 92.78 | 95.01 | |||
| KC | 83.80 | 83.77 | 75.47 | 84.78 | 86.13 | 90.52 | 85.96 | 88.03 | 90.49 | 93.42 | |||
| Class | Land Covers | Training | Test | RAW | PCA | LPP | LDA | LFDA | LGSFA | SGDA | LGDA | CGDA | LMSCPE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Trees | 465 | 22,781 | 88.98 | 89.02 | 89.41 | 90.06 | 81.71 | 89.83 | 89.06 | 89.65 | 89.81 | 90.95 |
| 2 | Mostly grass | 85 | 4185 | 67.78 | 67.68 | 65.65 | 60.82 | 67.64 | 65.27 | 67.14 | 70.95 | 69.43 | 70.43 |
| 3 | Mixed ground surface | 138 | 6744 | 62.64 | 62.70 | 65.14 | 69.03 | 53.00 | 64.60 | 63.09 | 65.49 | 66.84 | 71.64 |
| 4 | Dirt/sand | 37 | 1789 | 58.13 | 58.08 | 64.88 | 62.39 | 80.53 | 72.84 | 57.52 | 62.94 | 67.87 | 71.24 |
| 5 | Road | 134 | 6553 | 86.60 | 86.66 | 83.56 | 72.01 | 66.89 | 77.92 | 86.27 | 88.17 | 87.34 | 87.70 |
| 6 | Water | 10 | 456 | 77.19 | 76.97 | 73.90 | 27.41 | 53.51 | 49.78 | 76.75 | 80.92 | 78.29 | 76.75 |
| 7 | Building shadow | 45 | 2188 | 61.28 | 60.83 | 57.49 | 30.08 | 52.92 | 41.75 | 60.83 | 62.78 | 64.36 | 65.31 |
| 8 | Buildings | 125 | 6115 | 77.78 | 77.70 | 75.17 | 69.96 | 64.45 | 76.21 | 77.97 | 82.03 | 83.20 | 82.10 |
| 9 | Sidewalk | 28 | 1357 | 43.25 | 43.25 | 44.42 | 32.82 | 50.69 | 41.06 | 43.76 | 45.95 | 43.03 | 41.79 |
| 10 | Yellow curb | 10 | 173 | 47.40 | 46.82 | 43.35 | 78.03 | 82.66 | 82.08 | 47.98 | 57.23 | 53.76 | 70.52 |
| 11 | Cloth panels | 10 | 259 | 88.80 | 88.80 | 89.96 | 94.98 | 94.59 | 94.98 | 88.42 | 89.19 | 87.64 | 89.58 |
| AA | 69.08 | 68.96 | 68.45 | 62.51 | 68.05 | 68.76 | 68.98 | 72.30 | 71.96 | 74.36 | |||
| OA | 78.70 | 78.69 | 78.42 | 74.98 | 70.84 | 77.39 | 78.69 | 80.65 | 80.93 | 82.21 | |||
| KC | 72.06 | 72.04 | 71.65 | 66.61 | 62.44 | 70.05 | 72.04 | 74.64 | 74.97 | 76.60 | |||
| Dataset | PCA | LPP | LDA | LFDA | LGSFA | SGDA | LGDA | CGDA | LMSCPE |
|---|---|---|---|---|---|---|---|---|---|
| PaviaU | 0.025 | 0.031 | 0.013 | 0.037 | 0.292 | 0.659 | 3.009 | 0.315 | 2.650 |
| LongKou | 0.014 | 0.124 | 0.023 | 0.040 | 0.616 | 0.308 | 1.655 | 0.112 | 0.887 |
| MUUFL | 0.031 | 0.042 | 0.012 | 0.019 | 0.356 | 0.287 | 2.038 | 0.125 | 1.038 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, G.; Luo, F.; Tang, Y.; Li, Y. Dimensionality Reduction of Hyperspectral Image Based on Local Constrained Manifold Structure Collaborative Preserving Embedding. Remote Sens. 2021, 13, 1363. https://doi.org/10.3390/rs13071363
Shi G, Luo F, Tang Y, Li Y. Dimensionality Reduction of Hyperspectral Image Based on Local Constrained Manifold Structure Collaborative Preserving Embedding. Remote Sensing. 2021; 13(7):1363. https://doi.org/10.3390/rs13071363
Chicago/Turabian StyleShi, Guangyao, Fulin Luo, Yiming Tang, and Yuan Li. 2021. "Dimensionality Reduction of Hyperspectral Image Based on Local Constrained Manifold Structure Collaborative Preserving Embedding" Remote Sensing 13, no. 7: 1363. https://doi.org/10.3390/rs13071363
APA StyleShi, G., Luo, F., Tang, Y., & Li, Y. (2021). Dimensionality Reduction of Hyperspectral Image Based on Local Constrained Manifold Structure Collaborative Preserving Embedding. Remote Sensing, 13(7), 1363. https://doi.org/10.3390/rs13071363