
Unsupervised Adversarial Domain Adaptation with Error-Correcting Boundaries and Feature Adaption Metric for Remote-Sensing Scene Classification


Abstract

1. Introduction
- To improve the performance of aligning data distribution of source domain and target domain, we propose an adversarial framework with the help of target-domain-specific classifier boundaries and domain invariant features.
- To improve the ability of target-domain-specific classifier boundaries, we design an error-correcting boundaries mechanism to correct errors of misclassification for target samples, which can reduce distinguished uncertainty for difficultly classified target samples.
- To achieve adaptation for ambiguous features, we propose a feature adaptation metric structure to build the domain invariant features and semantically meaningful features simultaneously.
- We conduct comprehensive experiments to demonstrate the effect of the ECB-FAM structure with optional variants for each component. The results show the proposed method can enhance feature extraction and domain matching to improve accuracy of scene classification. In addition, the sub-experiments show the effect of each component.
2. Materials and Methods
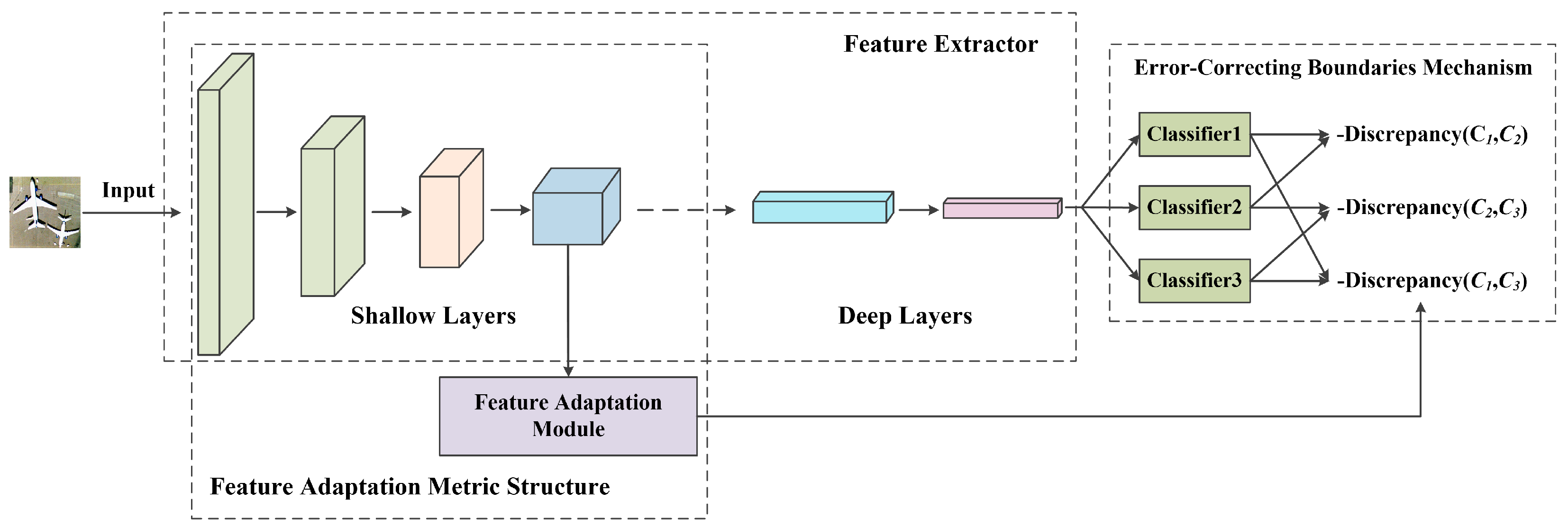
2.1. Notation and Model Overview
2.2. The Architecture of Error-Correcting Boundaries Mechanism with Feature Adaptation Metric (ECB-FAM)
2.2.1. Adversarial Manner
2.2.2. Error-Correcting Boundaries Mechanism
2.2.3. Feature Adaptation Metric Structure
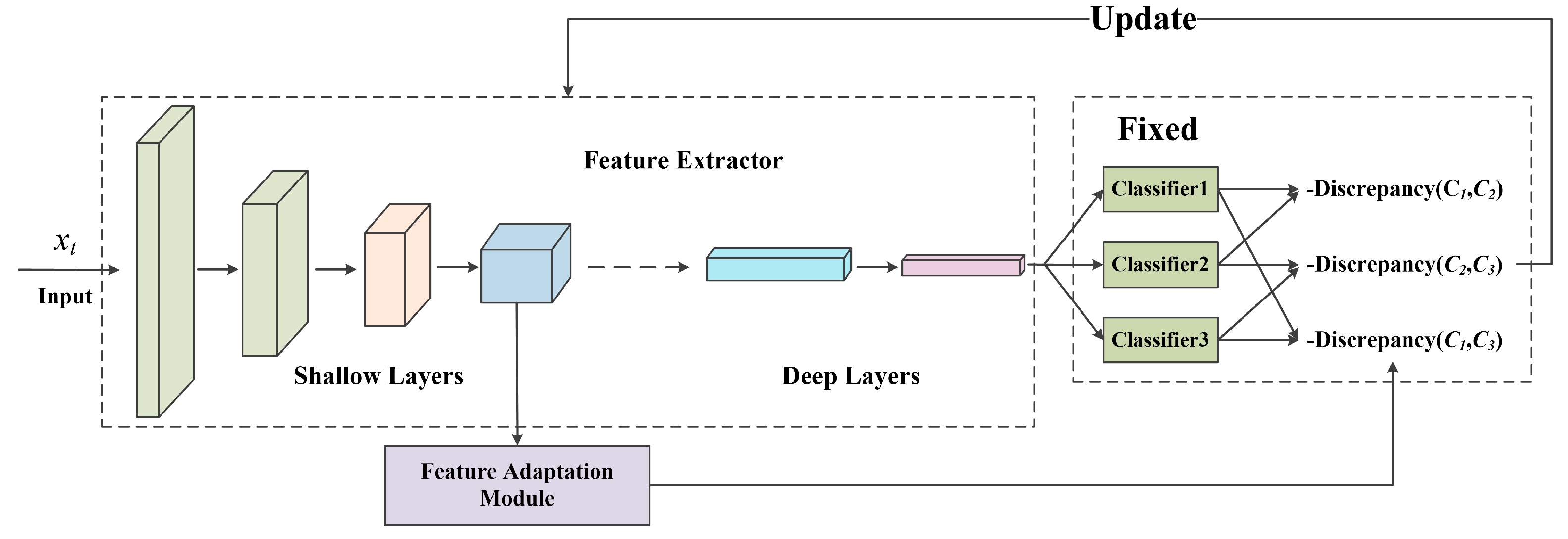
2.3. Training Step
| Algorithm 1. Algorithm for training the ECA-FAM structure. |
| Training Steps |
| Input: , y, and , Output: accuracy of classifying |
|
3. Results
3.1. Datasets and Experimental Setting
3.2. Experimental Results
4. Discussion
4.1. Influence of Feature Adaptation Metric Structure
4.2. Influence of Multiple Classifiers on the Error-Correcting Boundaries Mechanism
4.3. Influence of Different Convolutional Neural Networks (CNNs)
4.4. Time Complexity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| ECB-FAM | Error-correcting boundaries with feature adaptation metric |
| TCA | Transfer component analysis |
| DDC | Deep domain confusion |
| MMD | Maximum mean discrepancy |
| DAN | Deep adaptation network |
| DANN | Deep adversarial neural network |
| UCM, U | UC Merced |
| NWPU, N | NWPU-RESISC45 |
| RSI, R | RSI-CB256 |
| WHU, W | WHU-RS19 |
| JDA | Joint distribution adaptation |
| CycleGAN | Cycle consistent generative adversarial network |
| GTA | Generate to adapt |
| ADA-BDC | Unsupervised adversarial domain adaptation method boosted by a domain confusion network |
| ECB | Error-correcting boundaries |
| ECB-FAM-1 | ECB with shallow distribution alignment with one convolutional layer |
| ECB-FAM-2 | ECB with shallow distribution alignment with two convolutional layers |
| ECB-FAM-3 | ECB with shallow distribution alignment with three convolutional layers |
| ECB-FAM-4 | ECB with shallow distribution alignment with four convolutional layers |
| ECB-FAM-5 | ECB with shallow distribution alignment with five convolutional layers |
References
- Lu, Q.; Huang, X.; Li, J.; Zhang, L. A novel MRF-based multifeature fusion for classification of remote sensing images. IEEE Geosci. Remote Sens. Lett. 2016, 13, 515–519. [Google Scholar] [CrossRef]
- Zhang, X.; Du, S. A linear dirichlet mixture model for decomposing scenes: Application to analyzing urban functional zonings. Remote Sens. Environ. 2015, 169, 37–49. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Tao, D.; Huang, X. On combining multiple features for hyperspectral remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2012, 50, 879–893. [Google Scholar] [CrossRef]
- He, N.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Remote sensing scene classification using multilayer stacked covariance pooling. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6899–6910. [Google Scholar] [CrossRef]
- Nogueira, K.; Penatti, O.A.B.; dos Santos, J.A. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhao, Z.; Luo, Z.; Li, J.; Chen, C.; Piao, Y. When self-supervised learning meets scene classification: Remote sensing scene classification based on a multitask learning framework. Remote Sens. 2020, 12, 3276. [Google Scholar] [CrossRef]
- Kalajdjieski, J.; Zdravevski, E.; Corizzo, R.; Lameski, P.; Kalajdziski, S.; Pires, I.M.; Garcia, N.M.; Trajkovik, V. Air pollution prediction with multi-modal data and deep neural networks. Remote Sens. 2020, 12, 4142. [Google Scholar] [CrossRef]
- Sun, H.; Li, S.; Zheng, X.; Lu, X. Remote sensing scene classification by gated bidirectional network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 82–96. [Google Scholar] [CrossRef]
- Akodad, S.; Bombrun, L.; Xia, J.; Berthoumieu, Y.; Germain, C. Ensemble learning approaches based on covariance pooling of CNN features for high resolution remote sensing scene classification. Remote Sens. 2020, 12, 3292. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, L.; Wang, Z.; Yu, Y.; Liu, X.; Xu, F. Intelligent ship detection in remote sensing images based on multi-layer convolutional feature fusion. Remote Sens. 2020, 12, 3316. [Google Scholar] [CrossRef]
- Chang, Z.; Yu, H.; Zhang, Y.; Wang, K. Fusion of hyperspectral CASI and airborne LiDAR data for ground object classification through residual network. Sensors 2020, 20, 3961. [Google Scholar] [CrossRef]
- Mao, Z.; Zhang, F.; Huang, X.; Jia, X.; Gong, Y.; Zou, Q. Deep neural networks for road sign detection and embedded modeling using oblique aerial images. Remote Sens. 2021, 13, 879. [Google Scholar] [CrossRef]
- Ma, A.; Wan, Y.; Zhong, Y.; Wang, J.; Zhang, L. SceneNet: Remote sensing scene classification deep learning network using multi-objective neural evolution architecture search. ISPRS J. Photogramm. Remote Sens. 2021, 172, 171–188. [Google Scholar] [CrossRef]
- Yu, Y.; Li, X.; Liu, F. Attention GANs: Unsupervised deep feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 519–531. [Google Scholar] [CrossRef]
- Lu, X.; Gong, T.; Zheng, X. Multisource compensation network for remote sensing cross-domain scene classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2504–2515. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, J.; Pan, B.; Shi, Z. Domain adaptation based on correlation subspace dynamic distribution alignment for remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7920–7930. [Google Scholar] [CrossRef]
- Xu, Y.; Du, B.; Zhang, L. Assessing the threat of adversarial examples on deep neural networks for remote sensing scene classification: Attacks and defenses. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1604–1617. [Google Scholar] [CrossRef]
- Han, W.; Wang, L.; Feng, R.; Gao, L.; Chen, X.; Deng, Z.; Chen, J.; Liu, P. Sample generation based on a supervised Wasserstein generative adversarial network for high-resolution remote-sensing scene classification. Inf. Sci. 2020, 539, 177–194. [Google Scholar] [CrossRef]
- Bi, Q.; Qin, K.; Zhang, H.; Li, Z.; Xu, K. RADC-Net: A residual attention based convolution network for aerial scene classification. Neurocomputing 2020, 377, 345–359. [Google Scholar] [CrossRef]
- Liu, Y.; Suen, C.Y.; Liu, Y.; Ding, L. Scene classification using hierarchical Wasserstein CNN. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2494–2509. [Google Scholar] [CrossRef]
- Paoletti, M.; Haut, J.; Plaza, J.; Plaza, A. A new deep convolutional neural network for fast hyperspectral image classification. Deep learning RS data. ISPRS J. Photogramm. Remote Sens. 2018, 145, 120–147. [Google Scholar] [CrossRef]
- Li, F.; Feng, R.; Han, W.; Wang, L. High-resolution remote sensing image scene classification via key filter bank based on convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8077–8092. [Google Scholar] [CrossRef]
- Zhang, W.; Tang, P.; Zhao, L. Remote sensing image scene classification using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, J.; Tian, J.; Zhuo, L.; Zhang, J. Residual dense network based on channel-spatial attention for the scene classification of a high-resolution remote sensing image. Remote Sens. 2020, 12, 1887. [Google Scholar] [CrossRef]
- Liu, X.; Zhou, Y.; Zhao, J.; Yao, R.; Liu, B.; Zheng, Y. Siamese convolutional neural networks for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1200–1204. [Google Scholar] [CrossRef]
- Adayel, R.; Bazi, Y.; Alhichri, H.S.; Alajlan, N. Deep open-set domain adaptation for cross-scene classification based on adversarial learning and pareto ranking. Remote Sens. 2020, 12, 1716. [Google Scholar] [CrossRef]
- Zhang, R.; Chen, Z.; Zhang, S.; Song, F.; Zhang, G.; Zhou, Q.; Lei, T. Remote sensing image scene classification with noisy label distillation. Remote Sens. 2020, 12, 2376. [Google Scholar] [CrossRef]
- Pan, X.; Zhao, J.; Xu, J. A scene images diversity improvement generative adversarial network for remote sensing image scene classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1692–1696. [Google Scholar] [CrossRef]
- Dai, X.; Wu, X.; Wang, B.; Zhang, L. Semisupervised scene classification for remote sensing images: A method based on convolutional neural networks and ensemble learning. IEEE Geosci. Remote Sens. Lett. 2019, 16, 869–873. [Google Scholar] [CrossRef]
- Kang, J.; Fernández-Beltran, R.; Ye, Z.; Tong, X.; Ghamisi, P.; Plaza, A. High-rankness regularized semi-supervised deep metric learning for remote sensing imagery. Remote Sens. 2020, 12, 2603. [Google Scholar] [CrossRef]
- Zhang, P.; Bai, Y.; Wang, D.; Bai, B.; Li, Y. Few-shot classification of aerial scene images via meta-learning. Remote Sens. 2021, 13, 108. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep domain confusion: Maximizing for domain invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M.I. Learning transferable features with deep adaptation networks. In Proceedings of the 32nd International Conference Machine Learning, ICML 2015, Lille, France, 6–11 July 2015; pp. 97–105. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2011, 22, 199–210. [Google Scholar] [CrossRef] [PubMed]
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer feature learning with joint distribution adaptation. In Proceedings of the IEEE Conference Computer Vision Pattern Recognition (CVPR), Sydney, NSW, Australia, 23–28 June 2013; pp. 2200–2207. [Google Scholar]
- Borgwardt, K.M.; Gretton, A.; Rasch, M.J.; Kriegel, H.; Schölkopf, B.; Smola, A.J. Integrating structured biological data by kernel maximum mean discrepancy. In Proceedings of the 14th International Conference on Intelligent Systems for Molecular Biology 2006, Fortaleza, Brazil, 6–10 August 2006; pp. 49–57. [Google Scholar]
- Gretton, A.; Sriperumbudur, B.K.; Sejdinovic, D.; Strathmann, H.; Balakrishnan, S.; Pontil, M.; Fukumizu, K. Optimal kernel choice for large-scale two-sample tests. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1214–1222. [Google Scholar]
- Yan, L.; Zhu, R.; Mo, N.; Liu, Y. Cross-domain distance metric learning framework with limited target samples for scene classification of aerial images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3840–3857. [Google Scholar] [CrossRef]
- Song, S.; Yu, H.; Miao, Z.; Zhang, Q.; Lin, Y.; Wang, S. Domain adaptation for convolutional neural networks-based remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1324–1328. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Annual Conference Neural Information Processing System, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Rahhal, M.M.A.; Bazi, Y.; Al-Hwiti, H.; Alhichri, H.; Alajlan, N. Adversarial learning for knowledge adaptation from multiple remote sensing sources. IEEE Geosci. Remote Sens. Lett. 2020, 1–5. [Google Scholar] [CrossRef]
- Bejiga, M.B.; Melgani, F.; Beraldini, P. Domain adversarial neural networks for large-scale land cover classification. Remote Sens. 2019, 11, 1153. [Google Scholar] [CrossRef]
- Liu, W.; Su, F. A novel unsupervised adversarial domain adaptation network for remotely sensed scene classification. Int. J. Remote Sens. 2020, 41, 6099–6116. [Google Scholar] [CrossRef]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the Annual Conference Neural Information Processing System, Montreal, QC, Canada, 8–13 December 2014; pp. 3320–3328. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Smolley, S.P. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Yang, Y.; Newsam, S.D. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th ACM SIGSPATIAL International Symposium Advances Geographic Information Systems, ACM-GIS 2010, San Jose, CA, USA, 3–5 November 2010; pp. 270–279. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Li, H.; Tao, C.; Wu, Z.; Chen, J.; Gong, J.; Deng, M. RSI-CB: A large scale remote sensing image classification benchmark via crowdsource data. arXiv 2017, arXiv:1705.10450. [Google Scholar] [PubMed]
- Sheng, G.; Yang, W.; Xu, T.; Sun, H. High-resolution satellite scene classification using a sparse coding based multiple feature combination. Int. J. Remote Sens. 2012, 33, 2395–2412. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Sun, B.; Saenko, K. Deep coral: Correlation alignment for deep domain adaptation. In Proceedings of the Computer Vision—ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–16 October 2016; Volume 9915, pp. 443–450. [Google Scholar]
- Sankaranarayanan, S.; Balaji, Y.; Castillo, C.D.; Chellappa, R. Generate to adapt: Aligning domains using generative adversarial networks. In Proceedings of the IEEE Conference Computer Vision Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 20018; pp. 8503–8512. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| i, k, m | Index |
| Source domain | |
| Target domain | |
| Data distribution | |
| Sample of source domain | |
| Sample of target domain | |
| y | Label for source domain sample |
| Classifier (discriminator) | |
| G | Generator (feature extractor) |
| T | Number of classes |
| N,, M, | Number of samples for source domain or target domain |
| Prediction of classifier for y | |
| L | Loss |
| Loss from classifier k for | |
| Adversarial loss | |
| Loss of shallow alignment for the source or target domain | |
| p | class probability of classifier for |
| Classifier discrepancy | |
| Output of a certain layer | |
| W or H | Width of or height of |
| w or h | Index for width or height of the matrix of |
| output of alignment module in each location |
| Datasets | Common Categories |
|---|---|
| U and N | Airplane, baseball diamond, beach, chaparral, dense residential, forest, freeway, golf course, harbor, intersection, medium residential, mobile home park, overpass, parking lot, river, runway, sparse residential, storage tank, and tennis court |
| U and R | Airplane, beach, forest, harbor, intersection, parking lot, residential, river, and storage tank |
| U and W | Beach, dense residential, forest, parking lot, and river |
| N and R | Airplane, beach, bridge, desert, forest, harbor, intersection, medium residential, mountain, parking lot, river, and storage tank |
| N and W | Airport, beach, bridge, commercial area, dense residential, desert, forest, harbor, industrial area, meadow, mountain, parking lot, railway station, and river |
| R and W | Beach, bridge, desert, forest, harbor, mountain, parking lot, residential, and river |
| Methods | Settings |
|---|---|
| TCA |
|
| JDA |
|
| DAN |
|
| CORAL |
|
| CycleGAN |
|
| GTA |
|
| DANN ADA-BDC |
|
| Methods | U→N | N→U | U→R | R→U | U→W | N→R | R→N | N→W | R→W |
|---|---|---|---|---|---|---|---|---|---|
| TCA | 35.68 | 67.41 | 71.52 | 62.27 | 42.09 | 44.55 | 45.64 | 80.38 | 54.69 |
| JDA | 41.57 | 63.74 | 76.07 | 63.36 | 67.33 | 45.67 | 48.05 | 81.24 | 61.48 |
| DAN | 48.85 | 62.34 | 81.91 | 74.35 | 71.57 | 55.26 | 43.72 | 77.68 | 70.03 |
| CORAL | 36.73 | 57.85 | 78.61 | 66.04 | 82.37 | 55.17 | 45.38 | 78.62 | 70.33 |
| CycleGAN | 55.83 | 61.72 | 87.53 | 77.71 | 73.06 | 62.51 | 47.69 | 67.35 | 74.08 |
| GTA | 57.42 | 73.63 | 86.13 | 81.23 | 89.51 | 74.65 | 55.77 | 84.03 | 74.98 |
| DANN | 52.33 | 66.58 | 84.93 | 76.57 | 88.14 | 72.28 | 52.91 | 79.36 | 71.18 |
| ADA-BDC | 56.01 | 74.44 | 88.47 | 82.04 | 91.15 | 79.58 | 59.66 | 82.49 | 76.57 |
| ECB-FAM | 59.10 | 79.37 | 90.81 | 83.74 | 91.31 | 81.54 | 62.64 | 86.38 | 79.77 |
| Methods | TCA | JDA | DAN | CORAL | CycleGAN | GTA | DANN | ADA-BDC | ECB-FAM |
| Execution Time | 315 s | 1 h 19 min | 3 h 47 min | 4 h 18 min | 12 h 26 min | 9 h 3 min | 8 h 46 min | 10 h 14 min | 9 h 52 min |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, C.; Sha, D.; Mu, X. Unsupervised Adversarial Domain Adaptation with Error-Correcting Boundaries and Feature Adaption Metric for Remote-Sensing Scene Classification. Remote Sens. 2021, 13, 1270. https://doi.org/10.3390/rs13071270
Ma C, Sha D, Mu X. Unsupervised Adversarial Domain Adaptation with Error-Correcting Boundaries and Feature Adaption Metric for Remote-Sensing Scene Classification. Remote Sensing. 2021; 13(7):1270. https://doi.org/10.3390/rs13071270
Chicago/Turabian StyleMa, Chenhui, Dexuan Sha, and Xiaodong Mu. 2021. "Unsupervised Adversarial Domain Adaptation with Error-Correcting Boundaries and Feature Adaption Metric for Remote-Sensing Scene Classification" Remote Sensing 13, no. 7: 1270. https://doi.org/10.3390/rs13071270
APA StyleMa, C., Sha, D., & Mu, X. (2021). Unsupervised Adversarial Domain Adaptation with Error-Correcting Boundaries and Feature Adaption Metric for Remote-Sensing Scene Classification. Remote Sensing, 13(7), 1270. https://doi.org/10.3390/rs13071270