1. Introduction
The widespread application of artificial intelligence has not only made our daily lives more convenient but also gained considerable attention and development in agriculture, communications, medical care, transportation, military, and many other scientific research fields. As one of the core technologies of intelligent transportation applications, the detection of drivable areas in road scenes directly affects the performance and popularization of systems such as autonomous driving and assisted driving. The actual road environment scene contains plenty of target information such as road traffic signs, lane lines, and obstacles, etc. Meanwhile, this target information also has diversified, complex, and uncertain feature attributes. Road detection is certainly a tough project; it needs to meet the strict requirements of real-time and high precision. Moreover, it should objectively reflect the complex actual situation of real scene. In order to reach these requirements, some large-scale complex network algorithms even need detailed annotations for each region of interest and target information in the image, which greatly increases the amount of computation. Although researchers face piles of challenges, road detection algorithms are still emerging in recent years. Image segmentation is not only an independent image processing task but also one of the realization methods of road target detection, which is of great significance for helping perceive road scenes. Evidently, road images have both the conventional attributes of ordinary images and their particularities, which is also reflected in the segmentation task. Therefore, in the existing literature, we divide these valuable research work into two categories, general image segmentation methods and road image segmentation methods, to analyze and understand their commonalities and contributions.
- (1)
General Image Segmentation Methods. Up to now, many popular image segmentation algorithms have been applied to road area detection and extraction. These methods mainly focus on improving classic algorithms or combining with other algorithms [
1,
2,
3,
4,
5], such as the graph-based method, clustering method, deep learning, and multitheory combination method. The core idea of the graph-based method is to transform the global segmentation of an image into a graph partition problem through a top-down traversal process and optimize the objective function. Shi et al. [
6] proposed the normalization algorithm NCut after the min-cut, which defined the similarity and difference between the two regions in the image and determined the global minimization objective function. Boykov et al. [
7] proposed the graph-cut theory, which is mainly to construct an energy function and to minimize this energy function through the combination of optimization methods. It can be considered as a human–computer interactive algorithm. Unlike the graph-based methods, as a segmentation method pays more attention to the information of pixel itself, the clustering method calculates certain features between pixels in each neighborhood and then divides the pixels with similarity into the same attribute region [
8]. The meanshift algorithm was proposed in [
9]. Its basic idea is to find the local optimum through the trapezoidal rise of the probability density in space, which is of great significance in image segmentation and target tracking. The simple linear iterative clustering (SLIC) algorithm can preserve the contour of the object and clearly generate groups of superpixel blocks with uniform size, which is usually more in line with the expected segmentation results [
10]. Among the various methods of deep learning, the convolutional neural network (CNN) has been highly sought after in the field of computer vision since it was proposed. The advantage is that its multilayer structure can autonomously learn multiple shallow or deep hierarchical features. The fully convolutional networks (FCN) method can restore the categories of individual pixels from some abstract features of the image, which is a new direction for researchers in classification-based image segmentation methods [
11]. In addition to the fully connected layer structure, the semantic segmentation method also solves the problem of the neural network pooling layer from another angle, which enhances the receptive field of the convolution kernel. Typical semantic segmentation networks include SegNet [
12], DeepLabv3 [
13], and PSPNet [
14]. Ensemble learning can be regarded as a type of paradigm. By utilizing several weak classifiers to solve the classification problem, the final prediction result is usually better than a single classifier and closer to the global optimal. In addition, the generalization ability is even enhanced [
15,
16,
17,
18].
- (2)
Road Image Segmentation Methods. In order to perform related driving-assistance functions in the intelligent transportation system, road detection and extraction technology is required to make correct and real-time processing and classification of image information. Some scholars put forward the innovative thought of applying image segmentation technology to road images. However, the road image itself is complicated and often affected by interference information such as illumination, shadows, road conditions, obstacles, etc., which makes the implementation of road detection a challenge. Researchers from various countries have combined the characteristics and commonalities of general images and road images. Algorithms for road image detection can be divided into three categories: methods based on regional features, methods based on road boundary features, and methods based on deep learning. The method based on regional characteristics comprehensively considers the color and spatial dimension information and combines the prior knowledge of the road area and other theories, and the segmentation results obtained are generally ideal [
19,
20,
21]. Based on road boundary features, it can be obtained by boundary detection [
22]. This type of segmentation method is simple and has good performance, but the adaptability to unstructured road scenes still needs to be improved. Therefore, Andrade [
23] provided a novel strategy for lane detection and tracking, which divides the image processing into three levels to assist the DAS function. Some researchers have also proposed to obtain higher-level information to segment images by using 3D radar remote-sensing images. Chen et al. [
24] introduced a progressive LiDAR adaptation-aided road detection approach to adapt LiDAR information into visual image-based road detection and improve detection performance. Kong et al. [
25] used Gabor wavelets to extract texture information in different directions and perform statistical analysis and then extracted road regions based on adaptive vanishing points and road boundaries.
With the development of deep-learning technology, methods based on deep learning have also been introduced into road area detection research. In particular, semantic segmentation has become one of the most commonly used technologies for road scene understanding in recent years [
26,
27]. Liu [
28] proposed a multitask CNN method, which can obtain the road network in the complex urban scene. Sun et al. [
29] designed a network architecture containing residual optimization modules for road segmentation and successfully improved the segmentation accuracy. Alvarez et al. [
30] obtained high-level features in outdoor scenes through the CNN algorithm, which reduced the computation intensity to a certain extent, but the problem of over-segmentation still existed. In spite of the fact that the deep-learning method has excellent computing power, its execution ability depends on the depth and complexity of the network. It contains dozens of network parameters and high computational complexity and relies on millions of labeled sample data. As a conventional machine-learning algorithm, random forest is a superior algorithm. Through reasonable modification, the calculation result can be further improved, and it can also process small dataset faster. This is also one of the reasons why plenty of studies are currently more inclined to try to make model lightweight.
Despite the rapid development of assisted driving technology, the existing road detection algorithms based on machine learning still have some shortcomings for complex real-road scenes. Although some achievements on research have been obtained, considering their own diversity and complex variability, most methods are only suitable for images of a certain fixed scene. The main issue of road detection is that the algorithm needs to overcome objective factors such as different road conditions and natural environments in the actual scene and also needs to meet certain execution efficiency and segmentation accuracy. For the purpose of addressing the above issues, this article combines two meaningful research perspectives, which is different from conventional machine learning methods to help the assisted-driving function generate accurate road-area detection results. The conventional random-forest method is prone to leakage of boundary seed points, which may cause errors in segmentation results and cannot guarantee the reliability of technical applications in real scenes. Therefore, we merged the superpixel method to address this problem, which not only protects the integrity of the boundary pixels in the road image, increases the accuracy of road detection, but also shortens the execution time of the drivable area extraction and improves driving experience. On the other hand, since plenty of current road detection methods only extract and segment the lane lines in road images, the segmentation target is relatively single. With regards to this, our experiment combines the idea of transfer learning to increase the training samples of random forests, improve the learning ability of the model, and avoid under-segmentation of some images during the training process due to randomness. Moreover, the model proposed in this paper is not only able to accurately identify the drivable area in road images but also detect obstacles in the front visible range including vehicles, traffic signs, etc., thereby further enhancing the safety performance of the driving-assistance system.
The main contributions of this paper are as follows:
- (1)
In accordance with the principles of accuracy, robustness, and efficiency required for road image detection, we integrate the idea of shallow machine-learning model and propose a novel hierarchical multifeature road image segmentation integration framework. Then, it is applied to different road image datasets for comparison and evaluation to verify the detection effect in the multitarget complex road environment.
- (2)
We design a fast and stable feature extraction structure. The SLIC superpixel method is used to extract the local feature subregions of the image, which have higher granularity expression characteristics and richer feature attributes. It not only retains the complete boundary information but also reduces the occurrence of over-segmentation. In order to adapt to wider range of road images, we adjust the corresponding weights of the method.
- (3)
In order to achieve the extraction and classification of multiple targets in the complex road environment and to improve the accuracy and efficiency of the classification effect, we use the ensemble-learning random-forest method, which is superior to the conventional single classifier as the pattern classifier, to effectively deal with data loss and feature loss in the training set. Moreover, an improved bootstrap learning strategy is integrated to optimize the training sample selection parameters.
The rest of this paper is organized as follows: The second section introduces the road detection method based on ensemble-learning environment used in this study in detail.
Section 3 evaluates the performance of the model and presents the experimental results. The next section is the discussion part. The last section summarizes the related work and proposes research directions for the next stage.
2. Methodology
The methodology mainly consists of two procedures: superpixel generation and ensemble segmentation. After obtaining the main geometric structure of the image in CIELAB color space, we use the SLIC superpixel algorithm to obtain the superpixel block. The random forest is selected as a pattern classifier to effectively deal with data loss and feature loss in the training set. Moreover, we combine the improved bootstrap learning strategy to optimize the training sample selection parameters. In this way, a hierarchical multifeature road image segmentation integration framework is constructed and applied to road image detection. For high-dimensional training sets with large amounts of data, no explicit feature selection is required to distinguish road area and surrounding environments. The experimental results indicate that the classification accuracy is improved, and the road segmentation image is closer to the actual situation.
2.1. Superpixel Generation and SLIC
The superpixel method clusters similar pixels in the neighborhood into superpixel blocks by calculating the similarity between pixels, which greatly reduces the degree of redundancy of image information that needs to be processed and ensures the validity of all boundary information in the image. It also reduces the complexity of the subsequent work of image processing. Lucchi et al. [
31,
32] initially applied the superpixel segmentation method to the preprocessing stage in the field of machine vision and have since been widely used in fields such as image segmentation, pattern recognition, and target tracking.
The SLIC [
10] algorithm comprehensively considers the color and position of pixels in the neighborhood and has a higher granularity than pixels. The feature vector of the color image is converted into a five-dimensional feature vector
Labxy including
Lab color and two-dimensional planar space.
Lab is the color model in the CIELAB color space.
L represents brightness,
ab represents two colors, and
xy is the spatial position in a flat image. Next, the distance metric between pixels needs to be calculated as the basis for the similarity measurement. The algorithm calculates the similarity between pixels in the neighborhood, assigns labels to similar pixels, and finally iterates until convergence. The distance
is defined as follows:
where
is the color difference between pixels (color distance component in CIELAB space),
is the spatial distance between pixels (position distance component),
is the similarity of two pixels (final distance measure),
is the step size between pixels, and
is a compactness parameter, which is used to determine the relative proportion of different color distances
and position distances
.
The SLIC algorithm steps are described below.
| Algorithm 1 SLIC |
Input: RGB raw images
Output: segmented images containing superpixel blocks
1 Initialization:
Distribute seed points evenly in the image containing pixels
Set up and generate superpixel blocks
Set the step between pixels to
Initialize cluster center
Initialize distance
2 Pixel clustering:
for each cluster center do
for shift cluster center, each pixel in the range of twice the size around do
calculate the similarity between pixel and cluster center
if then
set
end if
end for
end for
3 Assign label: assign a class label to the cluster center of each generated small superpixel block
4 Iterate the cluster center until convergence is reached
5 Enforce connectivity |
Taking into account the homogeneity of each pixel in the super pixel block, this paper combines the statistical thinking to express the feature information of the entire road image through the generated superpixel blocks and the pixel-level features of its internal pixels. In other words, the conventional pixel-level features of image are transformed into several superpixel blocks to convey characteristic attributes. This can reduce the amount of computation for image segmentation, which not only enhances the feature expression level of superpixel but also improves the execution efficiency of subsequent tasks.
2.2. Conventional Random Forest
The introduction of ensemble learning has led many researchers to study it [
33,
34]. Bagging and boosting are representative methods for ensemble learning. They mainly have three steps: generate different classification members, choose the most suitable ensemble classifier, and combine classifiers according to a certain strategy. In fact, random forest [
35] is an extension of bagging's thoughts. It can process high-dimensional training sets with a large amount of data and has a fast classification speed. Moreover, it is not prone to overfitting and has strong anti-noise capabilities. However, due to its combination of theory and application, there are still many novel ideas for improving its performance [
36,
37,
38].
Random forest contains several tree-like classifiers , where represents the input variable and is a random vector that is independent and distributed on the bootstrap set. Each classifier votes for the input variable , and the classification with the most votes is used as the classification result of .
Generalization error of random forest:
Plenty of experiments have signified that with the increase of decision tree classifiers, the global generalization error can almost reach convergence:
which indicates that random forest is less prone to overfitting due to the increase in decision trees.
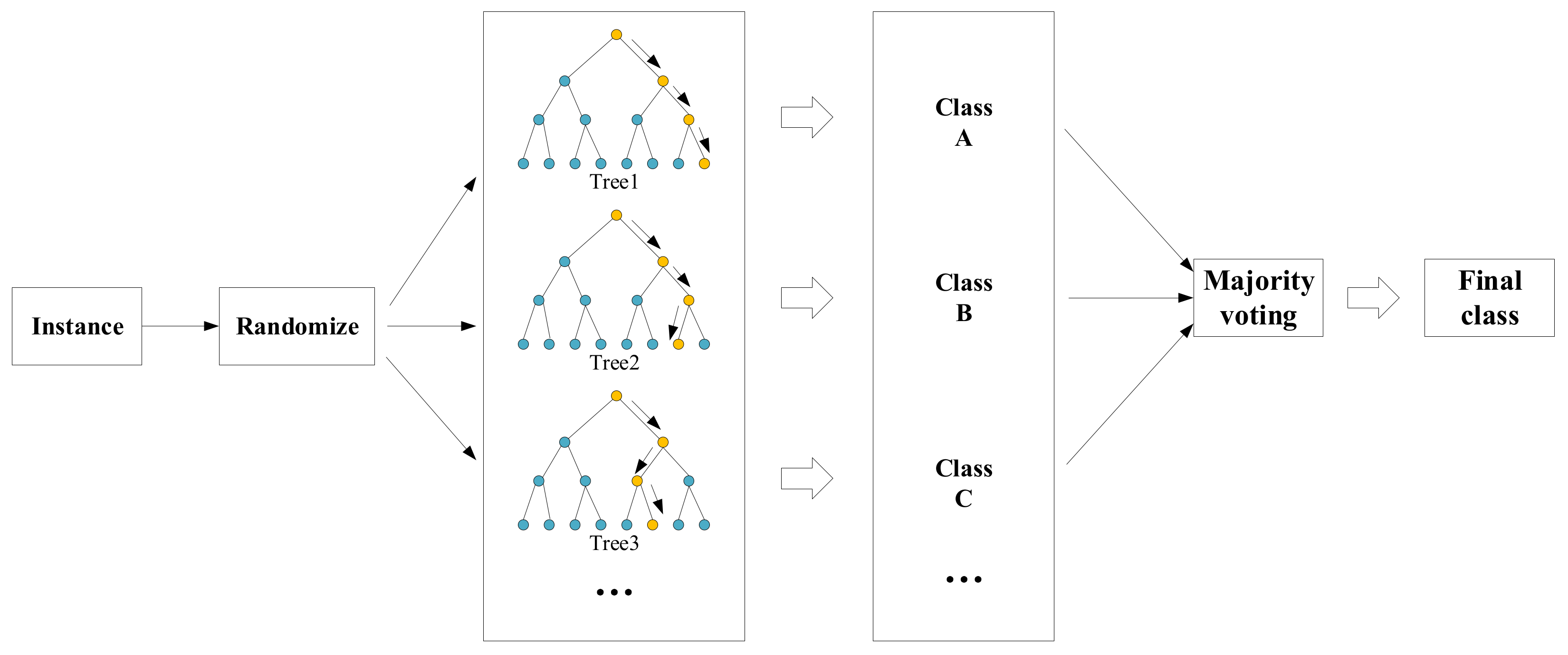
The growth process of the random forest integrated classifier is given below, as shown in
Figure 1:
Step 1: If there are samples in the dataset, then we randomly select samples for replacement (one sample is randomly selected at a time, and then it is put back in, and the selection process is repeated continuously). The selected samples are used to train a decision tree as samples at the root node of the decision tree.
Step 2:
attributes were randomly selected from all attributes of each sample in the classification tree, and then a split method (such as Gini, IG method) was taken from these attributes to select one as the root node attribute. For instance, the formula
is:
Step 3: During the formation of the classification tree, each node must be split according to step 2 until all trees are generated (If the attribute selected by the node next time is the attribute that was used when its parent node was split, then this node is used as a leaf node and stop splitting). There is no need for pruning during the entire formation process to make it fully grow.
Step 4: Steps 1 to 3 are followed to train a large quantity of classification trees. The data samples to be predicted are put into the trained model for classification processing, and the prediction of each tree is counted, and the maximum number of votes is used as the final classification result.
Random forest is a process of continuously categorizing and voting for randomly extracted feature attributes. In this article, all the processes are based on superpixel blocks. The superpixel blocks in road images contain rich feature attributes. These feature attribute sets composed of diverse information undergo continuous division and growth of the classification tree to form a reasonable random-forest model to obtain the final classification result.
Random-forest algorithm is noticeably a classification model with mature technology. It uses the characteristics of ensemble learning to make the classification results of datasets with multidimensional features better. At the same time, specific feature selection can be performed according to the importance of sample features, which is more flexible in operation. However, in the case of a large amount of data noise, it is also prone to overfitting. Therefore, we use superpixel algorithm to increase the performance of feature extraction, combined with the actual situation of road detection, to improve the ability to accurately distinguish road boundaries.
2.3. Proposed Detection Model Construction
2.3.1. Feature Representation based on Superpixel
In this paper, SLIC is used as a preprocessing method to obtain the superpixel features of the image. From a macro perspective, the feature attributes of all pixels in a superpixel block can be represented by randomly selected pixels . Based on this characteristic, this paper first randomly selects the pixels in a superpixel block to calculate its feature values and then uses statistical knowledge to represent the attributes of the entire superpixel block with its pixel-level features for subsequent processing.
As we know, the super pixel block contains several pixels and the randomly selected pixel . When the pixel is used as the basic unit for segmentation, it only contains its own feature attribute . However, if we take the superpixel block as the basic unit for segmentation, it should also have all the attributes of the pixel .
We assume that each pixel has a feature set of
and each superpixel has a feature set of
. When several features
of the superpixel block
are extracted for classification, the accuracy of the features is not fine enough and sufficient. According to the above analysis, we know that
not only has its own superpixel block features but also contains pixel features. We define that
then
Therefore, the superpixel-based feature expression method used in this paper contains more features than the number of features in conventional pixel blocks. It not only makes full use of the advantages of the superpixel method but also highlights the extensiveness of superpixel feature expression.
2.3.2. Bootstrap Learning Strategy
Random-forest classifier training process uses resampling techniques. It differs from ordinary sampling in that the latter estimates the statistical results by drawing a small number of samples, while the sampling technique used in the former classifier training focuses more on dividing the sample into training and test samples. One is used to train the classifier, and the other is used to judge the error rate and accuracy of the classifier.
Common resampling methods include the reuse method, nearest neighbor method, and bootstrap method. Among them, the bootstrap method randomly draws training samples from the training samples with replacement and generates bootstrap sample sets through repeated operations. This improves classification accuracy by avoiding misleading samples. Without changing the number of samples, when the training samples of each tree are sampled with replacement, the variance of the random forest can be reduced by increasing the number of samples. However, the training samples are unfiltered and uncertain, which can easily lead to data impurities and overfitting. Therefore, based on the random-forest method for processing road images, this paper attempts to filter the original samples in combination with the instance-based transfer learning method. The obtained auxiliary dataset helps the classifier to achieve classification, thereby avoiding negative transfer or overfitting.
The main idea of instance-based transfer learning method [
39] is to assume that some data in the source domain can assist the learning of the target domain data. The usual approach is to apply this part of the data to the learning of the target task through weighting operations, so that the machine itself has the ability to perform incremental learning.
In this paper, source domain data are used to construct a random-forest classifier set for target data to improve classification accuracy. If the random forest is constructed only from the target domain data, it may cause a lower accuracy to a certain extent due to the lack of labeled data and reduce the classification performance. Therefore, the labeled data that can be correctly classified in the source domain are used as an auxiliary dataset to help the target domain data be classified. The auxiliary dataset and target domain data still use the bootstrap method for multiple sampling operations to obtain multiple bootstrap sample sets. The random forest is used to construct a classifier for the data in the target domain, and then all samples in the target domain are voted on to classify based on the obtained classifier set.
2.3.3. Hierarchical Model Framework
This paper takes ensemble-learning methods as cluster classification and uses bagging to build a random-forest and bootstrap-sampling strategy for data filtering. The labeled data in the source domain is used as an auxiliary dataset to help the target domain data be classified. Furthermore, the SLIC algorithm is used to generate superpixels as input features, which consolidates the local feature consistency and clustering of the image and retains the image boundary information, which is very meaningful for road image detection and segmentation.
In summary, we propose a hierarchical multifeature road image segmentation integration framework. The basic steps of the HMRF model are given below:
| Algorithm 2 MODEL: HMRF |
Input: RGB image S
Output: Road segmentation image
1 Convert to in color space and use the Sobel operator to get the color gradient map of .
2 Set superpixel cluster center points.
3 Assign corresponding class labels to each pixel and calculate the distance .
4 Continue to calculate new cluster centers until convergence and strengthen connectivity.
5 Get the edge image based on the generated superpixel block, calculate the probability and get the edge pixels.
6 Perform pixel-level feature extraction on all pixels.
7 Use the labeled dataset obtained from the source domain data as auxiliary dataset.
8 Take the bootstrap method to sample the target data and auxiliary dataset multiple times to generate a labeled training set.
9 Construct decision tree and train the random forest.
10 Randomly select several features as the feature attribute set.
11 Design a split strategy of for pruning-free growth.
12 Import data into the trained model for classification, count the prediction of each tree classifier, and use the one with the most votes as the final classification result.
13 Subsequent processing. |
3. Experimental Results and Analysis
3.1. Description of Datasets and Evaluation Criteria
In order to verify the effectiveness of our proposed model, we adopted two sets of different datasets as the source domain data for the experiments to evaluate the proposed algorithm. Firstly, the HMRF was trained and evaluated on the famous road segmentation dataset from Karlsruhe Institute of Technology and Toyota Institute of Technology (KITTI) [
40]. Among them, the road dataset contained more than 200 labeled training images and test images. Considering that only the drivable area of interest was extracted from the image, we made some adjustments to its image size. Meanwhile, in order to demonstrate the universality and robustness of the proposed model, the model was also verified on the local dataset collected from the network. Through the method introduced in
Section 2.3, the number of training samples of the image increased, and finally the effectiveness of the model proposed in this article for road image segmentation was verified on the test set.
For scientifically evaluating the performance of image segmentation algorithms, it is often required to use consistent standards for quantitative comparison. Common evaluation criteria include boundary recall (BR), boundary precision (BP), and achievable segmentation accuracy (ASA). Boundary recall (BR) is used to measure the ratio of the boundary classified by the classifier to the boundary of the real image. Boundary precision (BP) is used to measure the ratio of the boundary divided by the classifier to the true segmentation boundary. They jointly measure the accuracy of boundary segmentation and logically influence each other. True positive (TP) represents the pixels in the true value of the boundary and the number of pixels that simultaneously appear in the boundary obtained by the algorithm; false negative (FN) represents the number of pixels in the true value of the boundary, but they do not appear in the boundary pixels obtained by the algorithm; false positive (FP) is the number of boundary pixels obtained by the algorithm, but they do not appear in the true value of the boundary. Achievable segmentation accuracy (ASA) is a measure of the upper limit of algorithm performance. It can measure the optimal accuracy of the segmentation results obtained with superpixels as input. In addition, compactness, dice coefficient, jaccard, etc., are also frequently utilized to evaluate the performance of image segmentation algorithms. These criteria measure the degree of overlap between the algorithm segmentation results and the actual situation. Moreover, their values also indicate the degree of classification effect.
Table 1 gives a detailed description.
3.2. Details of the Experiments and Preprocessing
In order to verify the feasibility and performance of the road detection model proposed in this paper, two sets of images containing multiple clear roads and nonclear roads under natural exposure were selected for experiments. First, we performed several sets of experiments similar to the ablation experiment to select the relatively optimal parameters of the SLIC. Then, we carried out multiple experiments on different datasets to present the segmentation results visually and quantitatively. Finally, we also discussed the parameter setting of the proposed HMRF model. During the construction of the random forest, each sample set generated by bagging sampling, some samples in the dataset may not have been selected. They were called out-of-bag data (OOB) and were used to test and evaluate the final classification effect.
The experiment was implemented on the Matlab platform under the Windows 10 operating system. It should be noted that, for the purpose of testing the execution ability of the model proposed in this article on non-GPU platforms, all the training and validation work in this article was performed in a CPU environment. It used 14-dimensional pixel-level features as split-node attributes: texture feature, shape feature, variance filtering, Sobel operator gradient feature, maximum and minimum filtering, Gaussian filtering, mean filtering, median filtering, and the three-dimensional color space features and two-dimensional space position features of SLIC superpixels. Since statistical classifiers generally do not consider the correlation between voxels, they may cause scattered noise. In order to eliminate the influence of this noise, the classification data need to be postprocessed.
Pixels are often used as the basic unit in image processing. A pixel whose adjacent pixels change is defined as a boundary. The model is designed to identify the drivable area on the road and the obstacles in front of vehicles. In general, road boundary can be geometric boundary that can be distinguished by the naked eye. If the recognition result of the model fits the geometric boundary of the road, the optimal segmentation effect is achieved.
The evaluation criteria of the superpixel include the controllability of the number of superpixels generated, compactness, and the degree of boundary fit.
Figure 2 demonstrates the result of preprocessing a road image using the SLIC algorithm. Each over-segmented object is a superpixel block, which can maintain the contour of the object well. Since the compactness
and the number of superpixels
are the two most important parameters of the SLIC algorithm, we compared multiple sets of experiments and removed some of the insufficient parameter settings. By adjusting the values of
and
, the segmentation results with different effects can be obtained. The number of superpixel blocks should not be too large. The smaller the number of
, the less time it consumes. In the case where the number
of superpixel blocks remains unchanged, as the
value gradually increases, the shape and size of the generated superpixels also become more regular, but the degree of boundary fit also decreases. It can be seen intuitively from
Figure 2 that different
values all produce superpixel blocks containing boundary information. In
Figure 2b, although the superpixel blocks roughly match the color and texture characteristics of the road, its shape, size and compactness still need to be improved. There is also an obvious discrepancy for the boundary of the lane line, which is due to the inappropriate setting of parameters. Meanwhile, in
Figure 2c, the road boundary is basically complete, but the shape and size of the superpixel blocks appear to be a bit messy since the compactness parameter is not large enough. Therefore, the superpixel block and compactness parameters are set to:
, and other parameters are set by default. As the result show in
Figure 2d, SLIC generates superpixels with a more stable shape, which better preserves the boundary information of the center of the road and the lane lines on both sides, which is convenient for subsequent processing and segmentation. Since the SLIC method uses a relatively small number of superpixel blocks instead of pixels to express the feature attributes of images, it helps to reduce the complexity of the entire framework.
3.3. Evaluation Based on KITTI Dataset
Firstly,
Figure 3 shows the result of applying the HMRF model to the road images in the KITTI dataset. The figure shows the original images, the superpixel segmentation results, and the final output images from left to right. It can be seen that superpixel blocks are regular and uniform, and the corresponding road area in output road images are well segmented. The boundary texture change of the target area remains relatively complete, the lane lines and traffic signs on the road are all preserved, and the boundary is regular and continuous. By adjusting random-forest training parameters and different weak classifiers, over-segmentation can be reduced, but it is still susceptible to speckle noise and may cause an increase in detection time. It can be seen through the experiment that it proves that the model proposed in this paper is not affected by the road condition and has brilliant road-area detection performance.
In order to further evaluate the performance and feasibility of the proposed HMRF model in outdoor-scene road detection, we used the boundary recall, boundary precision, and Dice as the evaluation metrics. Meanwhile, the proposed model is compared with the classification results of the commonly used SVM, radial basis function (RBF), and conventional random-forest method, and the average quantitative evaluation results of road image detection by different classification algorithms are discussed. The quantitative evaluation outcomes of the HMRF segmentation results are listed in
Table 2. It demonstrates that the HMRF algorithm proposed in this paper performs well in all the results of various evaluation metrics, which is closer to the ideal value than other traditional segmentation methods. HMRF model combines the advantages of the superpixel algorithm, enriches the feature description, and completes the sampling assistance of random-forest training samples by combining the idea of transfer learning, which reduces the error rate and has general applicability.
Execution efficiency has always been an important evaluation basis for image segmentation algorithms. An excellent algorithm must maintain a balance between segmentation accuracy and execution efficiency. The execution times of different image segmentation algorithms are listed in
Table 3. Although the SLIC algorithm included in the HMRF framework is similar to the preprocessing operation during execution, it plays a rather important role in the subsequent multifeature extraction of the entire framework. The excellent segmentation speed of the SLIC algorithm has been demonstrated on our dataset, with an average processing time of only 0.96 s, which helps the test performance of the HMRF model to be significantly improved. It indicates that HMRF algorithm has obvious advantages in the test segmentation stage, and its execution efficiency is better than that of the other three algorithms. In particular, the execution efficiency which compared with the traditional SVM algorithm is increased by one third, while achieving effective segmentation. Since the model proposed in this paper combines the strategy of transfer learning in the processing of nonclear roads, the correctly classified labeled clear road images are used as auxiliary dataset for detection and classification; therefore, the accuracy and execution efficiency of the algorithm are improved compared with the conventional RF algorithm.
3.4. Evaluation based on Local Dataset
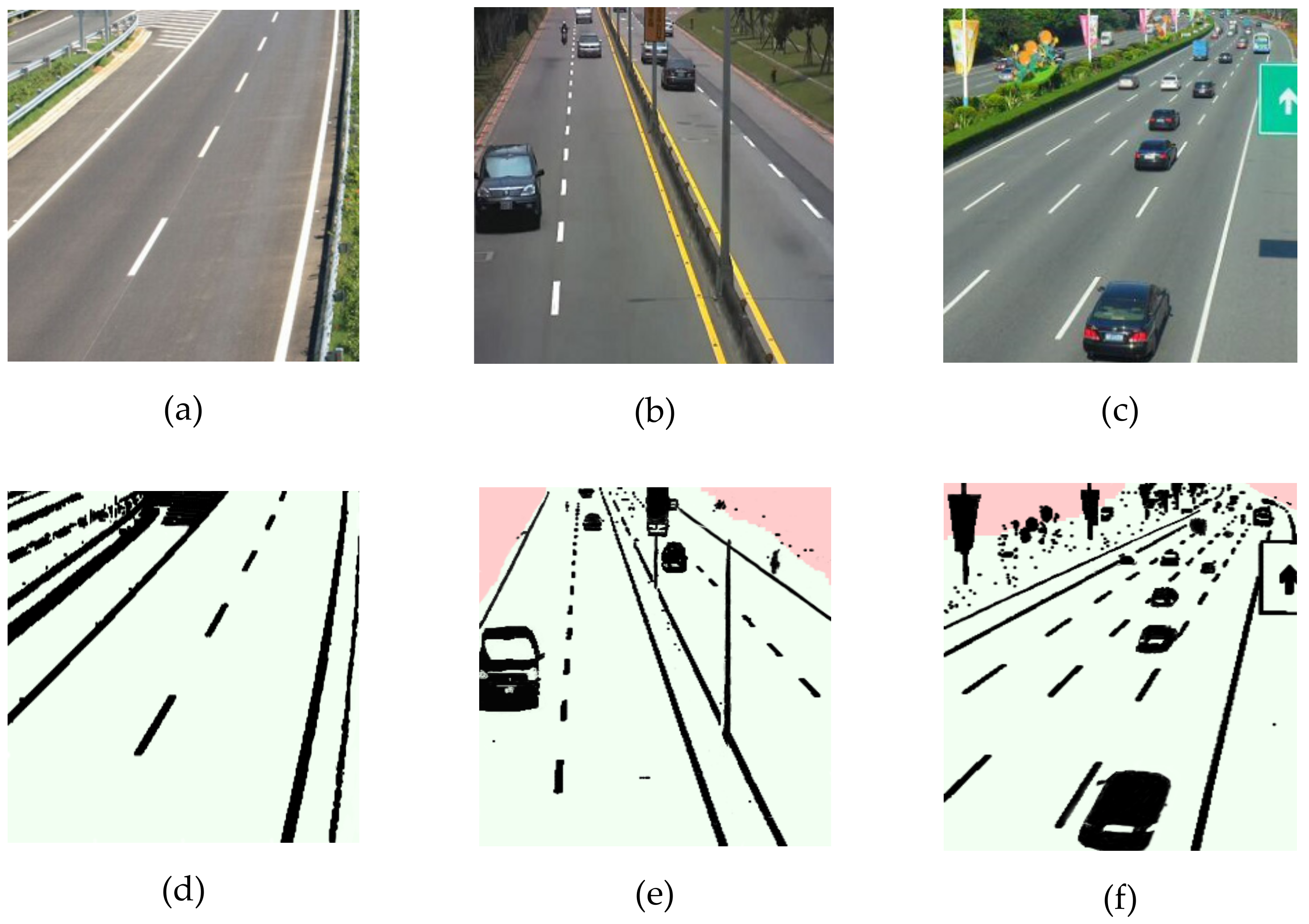
Since the data contained in the KITTI dataset are relatively complete, the image size is consistent, and the pixel distribution is relatively regular, these factors make the segmentation result and execution time of the KITTI dataset more stable. It is worth mentioning that the image segmentation process may be affected by various natural and objective factors, including natural light, shooting angle, image size, and other noise factors. We additionally utilize the locally collected dataset for further validation, which serves as an unlabeled weakly supervised auxiliary dataset to prove the rationality of the proposed model. In the local dataset, we selectively show the segmentation results of some typical road images.
Figure 4 intuitively suggests the results of the HMRF model applied to outdoor road images and selects pictures of typical clear roads and nonclear roads for display.
Figure 4a–c is the original images of clear and nonclear roads respectively, and
Figure 4d–f is the corresponding detected road areas. It can be clearly observed from
Figure 4d that the clear road can be well detected, and the boundary texture change of the target area remains relatively complete, which indicates that it has good robustness to the texture change.
Figure 4e–f clearly demonstrates that the detected lane lines and traffic signs on the nonnclear roads have been well preserved in detail. The texture of the target area is smooth and even, the boundaries of the lane lines and the traffic signs are regular and continuous, and only some speckle noise exists in the vehicle.
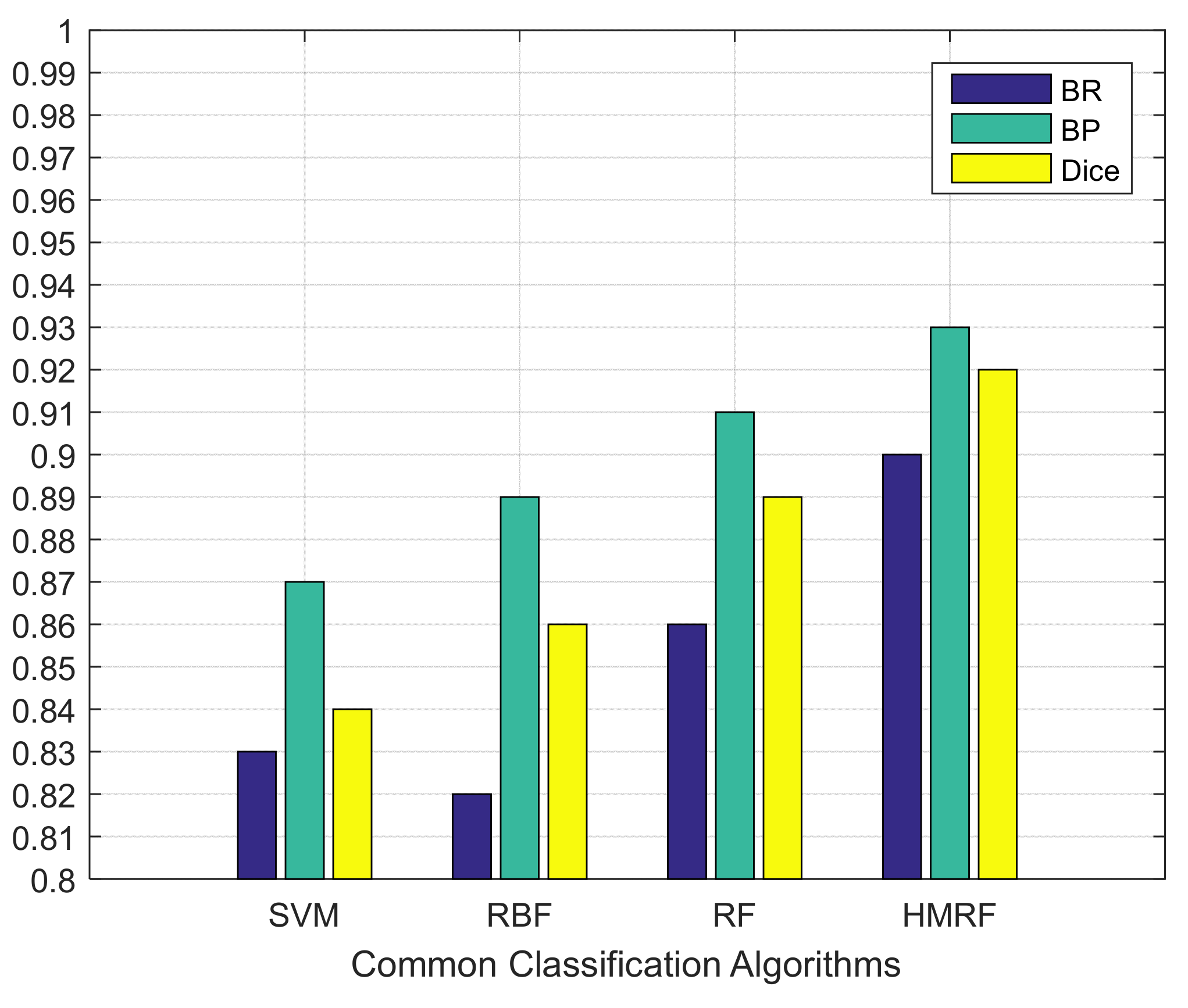
Table 4 demonstrates the comparison of the number of nodes with different algorithms. Similar to the KITTI dataset, the algorithm execute in the local dataset has achieved better segmentation accuracy in all evaluation metrics. It can be seen in
Figure 5 that under the same experimental conditions, the BP, BR, and Dice values of the HMRF algorithm all reached 0.9 or more. Although SVM and RBF methods perform well in terms of boundary accuracy, the boundary recall rate is generally relatively low.
In addition, the operating efficiency of the algorithm is also crucial.
Table 5 details the training time, test time, and total execution time of the HMRF model for different road images during the detection process. We can see that the method proposed in this paper is excellent in the execution time of the training phase and the test phase.
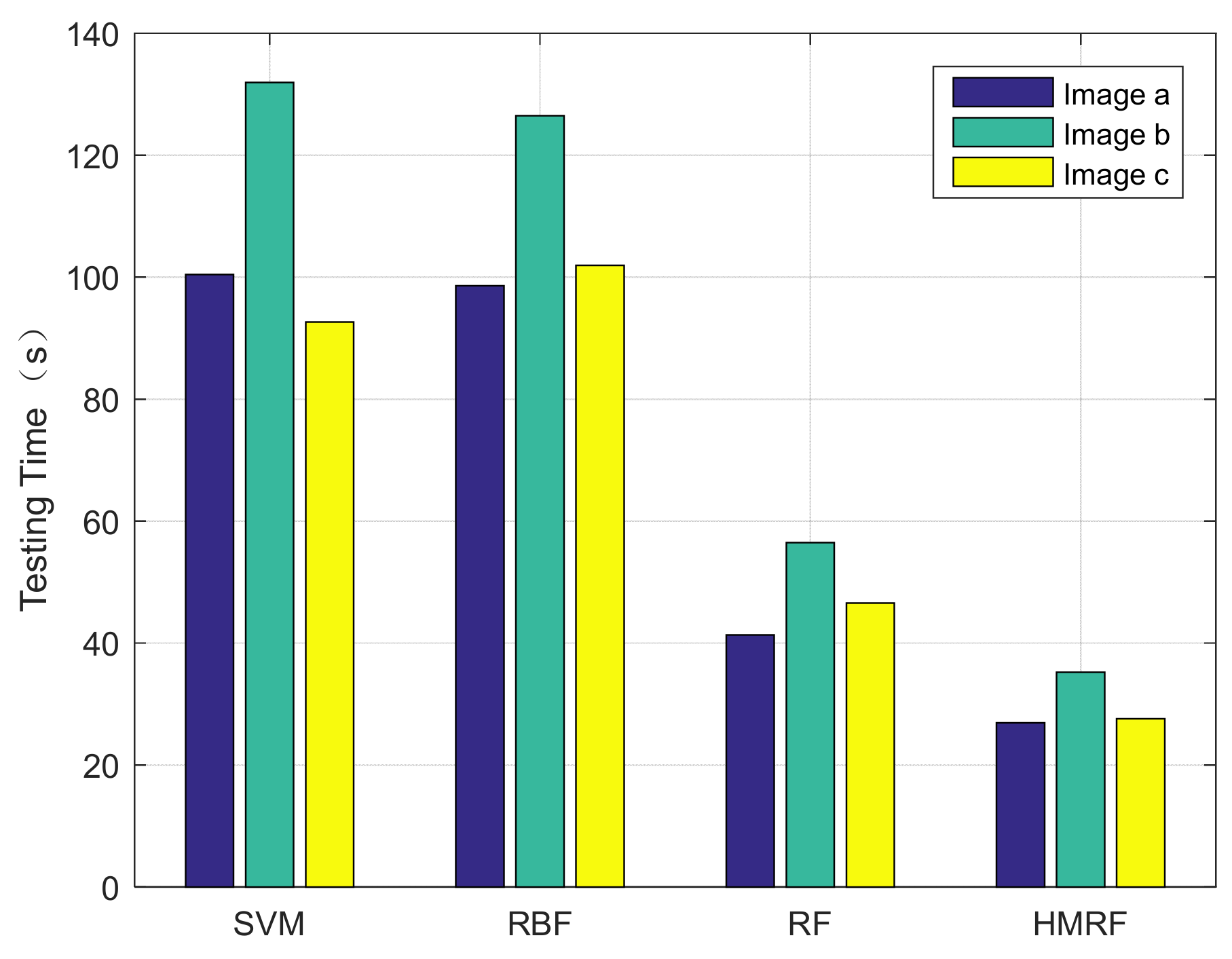
Table 6 lists the testing time of different methods on road images. It can be clearly seen in
Figure 6 that the HMRF model proposed in this paper is more superior in the execution of clear road and nonclear road images. Although the conventional random-forest algorithm has a certain advantage in the test time of the clear road image, the efficiency of the nonclear road image is insufficient because the classifier needs to relearn the features of the nonclear road image, so that its average execution efficiency is at a medium level. The network of RBF algorithm is relatively large, which leads to a significant increase in its calculation time. The test time of the SVM algorithm is roughly equivalent to the RBF algorithm, and it also has no advantage.
4. Discussion
It is well known that the experimental parameter settings are of great importance to image segmentation algorithms. As one of the widely used superpixel algorithms, SLIC is able to generate superpixel blocks with a controllable number and uniform shape, which pay more attention to color and spatial information and smoothly maintain the contour of objects. The evaluation metrics of the superpixel algorithm include the controllability of quantity, compactness, and boundary fit of generated superpixels.
Since the compactness and the number of superpixels are the two most important parameters of the SLIC algorithm, we performed multiple sets of comparisons similar to ablation experiments for these two parameters, while ensuring that other parameters remain unchanged. After evaluating the impact on results, we removed some sets where the segmentation results were not ideal and only selected a few sets for display. Three typical comparison parameter setting diagrams were placed in
Figure 2 to suggest the effects of superpixels generated by different parameters on the size controllability, compactness, and boundary fit.
During the experiment, due to the need to preprocess the road image using the SLIC algorithm, the quality of the superpixel blocks generated halfway may have affected the performance of the subsequent algorithm, and the appropriate shape of the superpixel blocks could maintain the contour of the object well. In order to obtain a suitable segmentation result, the values of parameters and needed to be adjusted continuously. The smaller the number of , the less time it consumes. In the case where the number of superpixel blocks remains unchanged, as the value gradually increases, the shape and size of the generated superpixels also become more regular, but the degree of boundary fit also decreasse.
For the purpose of examining the robustness of the HMRF model to parameters, we conducted robust analysis experiments. Experimental results in
Section 3.3 and
Section 3.4 suggest that the performance of HMRF is significantly improved compared to the classification effect of other methods and the detection effect for different road images is generally superior. Meanwhile, the second section mentions that random forest has its inherent randomness. Therefore, when analyzing the results, it is essential to consider the influence of the number of trees
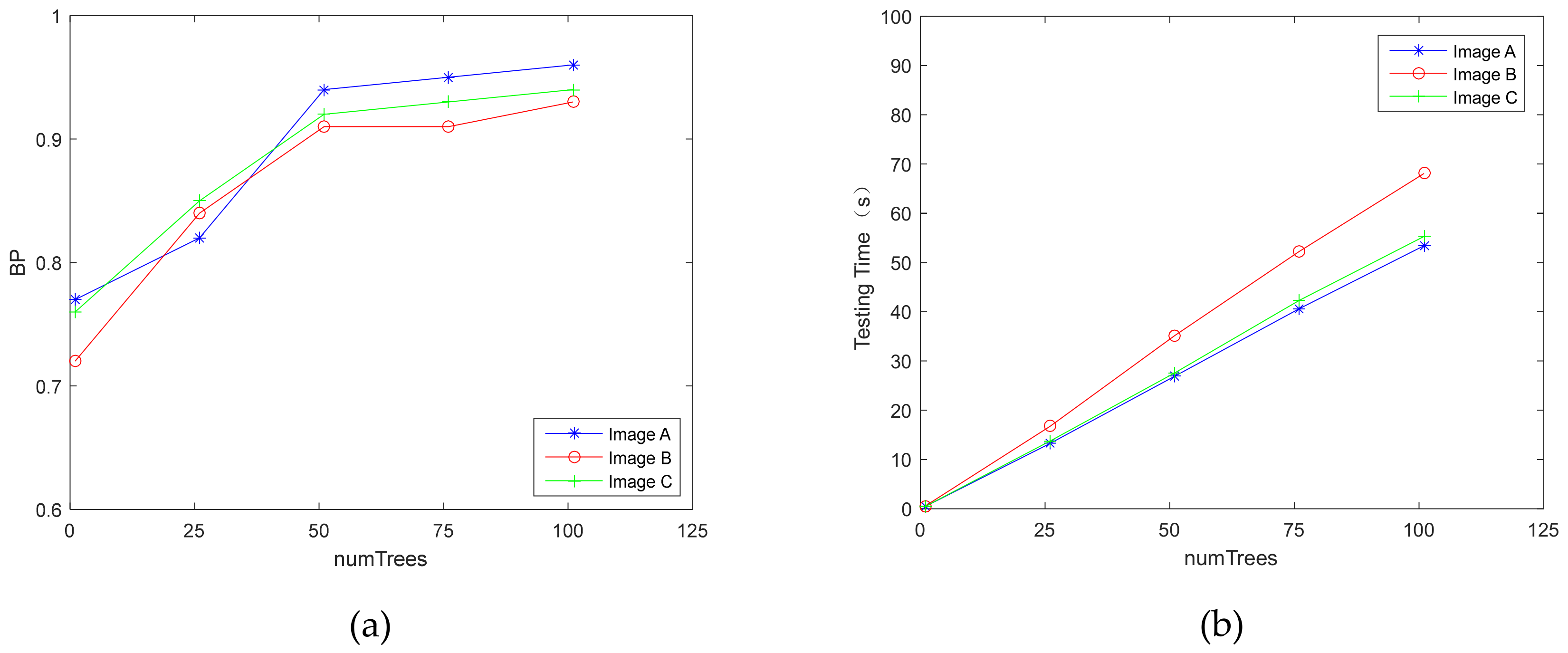
in the random forest on accuracy. Taking the local dataset as an example,
Figure 7 displays the effect of the parameter
on multiple road images in the experiments. The maximum depth
of each tree is set to the default value. As shown in
Figure 7a, the BP value increases with the change of
and gradually stabilizes. When
reaches about 50, BP value tends to stabilize. Considering the execution time as another criterion that can judge the performance of HMRF,
Figure 7b mainly indicates the relationship between the number of trees and execution time. In general, the greater the number of trees, the better the performance, but it also increases the calculation time. According to the charts in
Figure 7, it can be concluded that when the number of trees is equal to 50, the HMRF model could achieve the optimal results. Not only does the accuracy tend to be stable, but the execution time also tends to be linear as the number of trees increases. This could demonstrate that when the number of trees is 50, the model proposed in this paper can obtain acceptable detection results, while the execution time is kept within a reasonable range.
This paper presents a classification approach for road images detection using a hierarchical multifeature road image segmentation integration framework. Overall, the novelty of this article is that it improves the boundary related issues and enhances the multifeature learning ability of the road detection method. Specifically, it effectively integrates transfer learning ideas and improves bootstrap learning strategy for optimizing training process and utilizes the proposed HMRF model framework to analyze images in order to obtain diversified road target information. Our method makes full use of image texture, color, location information, etc., and adjusts various parameters in the algorithm. Several sets of experiments demonstrate that the proposed HMRF model can obtain better segmentation accuracy and efficiency compared with other classification methods. Moreover, the qualitative detection effect is presented visually, which lays a good application foundation for advanced road image processing such as assisted driving.
Road image detection originates from one of the computer vision tasks of intelligent transportation, and image segmentation technology can greatly improve the processing efficiency of road image detection. The research on road image detection methods is not limited to the usual methods in this field. We may attempt to integrate more general image-processing methods to enhance the performance of road detection, which is also the direction we will pay more attention to in the future. Nevertheless, we also found out some objective problems in the process of research. For instance, due to the particularity and complexity of the application field, the execution time still needs to be shortened. In addition, owing to the influence of objective factors such as image acquisition and outdoor environment, the leakage of pixels during the segmentation may cause local areas to be undetectable, which indicates that the model is not sufficiently sensitive to obstacle boundaries. We suppose that these problems will be improved in further research to achieve more accurate and convenient detection, which will become the focus of our future work.
5. Conclusions
In this paper, we propose an effective HMRF model for road image detection. Considering some key issues in this field, a crucial advantage of our model is to improve the boundary-related problems and enhance the multifeature learning ability of the road detection method. First, aiming at the instability of road image feature processing, we propose a novel hierarchical multifeature road image segmentation integration framework, which improves the detection performance. It is applied to different datasets for comparison and evaluation to verify the detection effect in the multitarget complex road environment. Then, for most segmentation algorithms that are sensitive to noisy data, we integrate an improved bootstrap-learning strategy to optimize the selection of training samples for random forest. It effectively handles the data loss and feature loss in the training set and reduces the phenomenon of redundant information or excessive segmentation. Moreover, road detection undertakes the complexity of objective factors such as natural environment. Therefore, we adopt two datasets to multidimensionally verify that the model can still ensure certain execution efficiency and segmentation accuracy in an objective and natural environment. Finally, the HMRF framework in this paper not only reflects the road boundary information of the real scene, shortens the time for extracting the drivable area, but also detects obstacles in front visible range, thereby further enhancing the safety performance of the driving-assistance system. The experimental results signify that the HMRF model performs well on real-road datasets, and the execution time has certain advantages. Besides, it has good antinoise capabilities and robustness, especially for the drivable area on nonclear road images. At present, machine-vision technology has been widely used in various industries. In the future, how to process larger datasets in parallel and further improve the performance of the algorithm is still a topic worthy of research.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}