A Dual-Model Architecture with Grouping-Attention-Fusion for Remote Sensing Scene Classification



Abstract
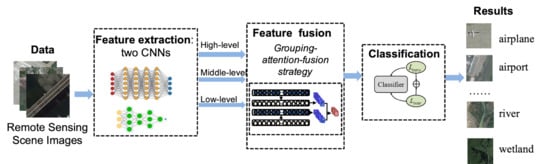
1. Introduction
- We propose a novel dual-model architecture to boost the performance of remote sensing scene classification, which compensates for the deficiency of a single CNN model in feature extraction.
- An improved loss function is proposed for training, which can alleviate the issue of high intra-class diversity and high inter-class similarity in remote sensing data.
- Extensive experimental results demonstrate the state-of-the-art performance of the proposed model.
2. Related Work
2.1. The Hand-Crafted Methods
2.2. The Deep Learning-Based Methods
3. The Proposed Method
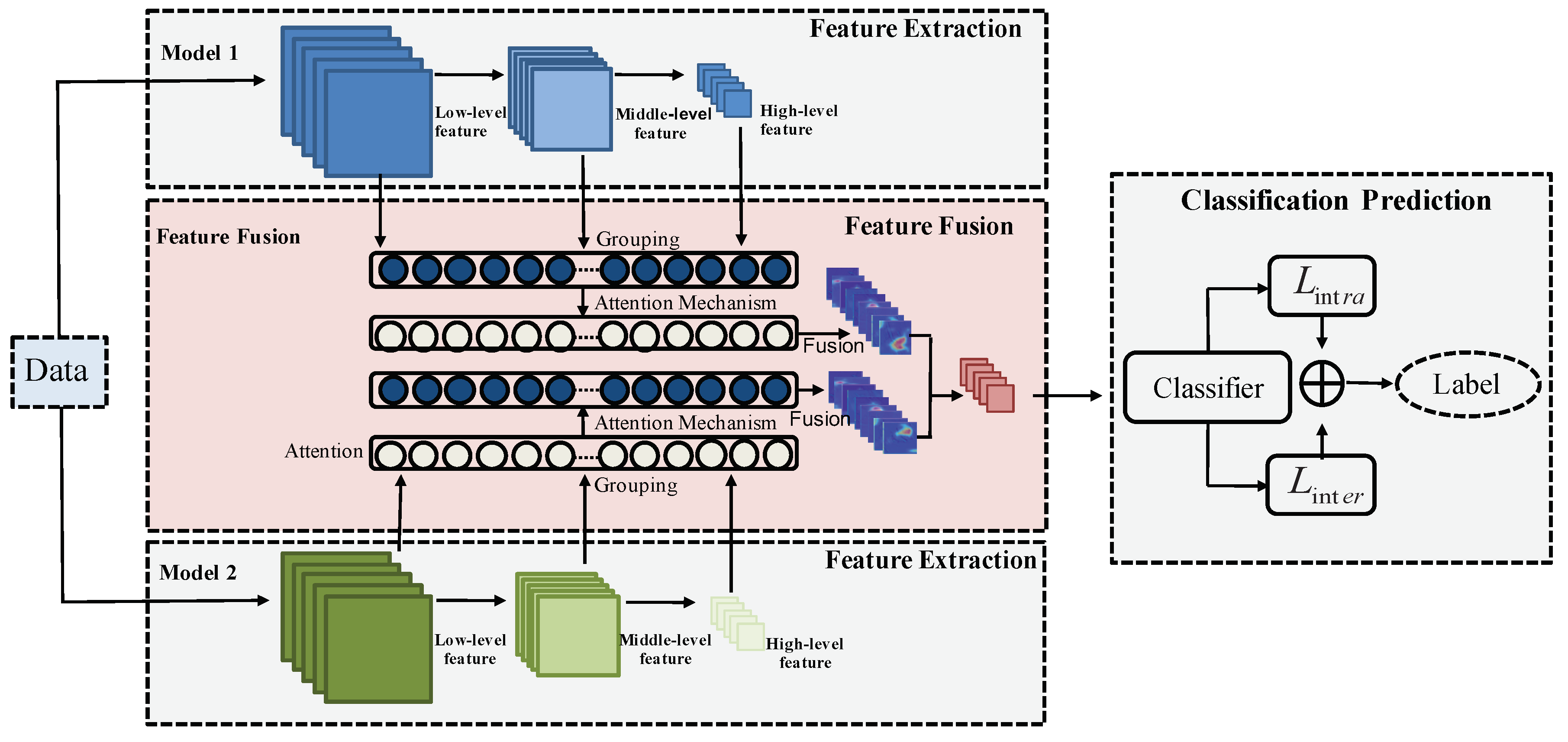
3.1. The Dual-Model Architecture
- ResNetResNet [8] is the most popular CNN for feature extraction, which solves the problem that the classification accuracy decreases by deepening the number of layers in some common CNNs. The lowest layer cannot only obtain the input from the middle layer, but also can obtain the input from the top layer through shortcut connection, which has the benefit of avoiding gradient vanishing. Although the network has an increased depth, it can easily enjoy accuracy gains. In our work, ResNet-50 is used for feature extraction, where we select the conv-2 layer for low-level feature extraction, the conv-3 layer for middle-level feature extraction, and the conv-4 layer for high-level feature extraction. These three layers produce features of 128 dimensions, 128 dimensions, and 128 dimensions, respectively.
- DenseNetCompared with other networks, DenseNet [9] alleviates gradient vanishing, strengthens feature propagation, encourages feature reusing, and reduces the number of parameters. A novel connectivity is proposed by DenseNet to make the information flow from low-level layers to high-level layers. Each layer obtains the input from all preceding layers and the resultant features are then transferred to subsequent layers. Consequently, both the low-level features and the high-level semantic features are used for final decision. In our architecture, we use DenseNet-121 as the feature extractor by extracting multi-level features from the conv-2 layer as the low-level feature with 128 dimensions, from the conv-3 layer as the middle-level feature with 128 dimensions, and from the conv-4 layer as the high-level feature with 128 dimensions.
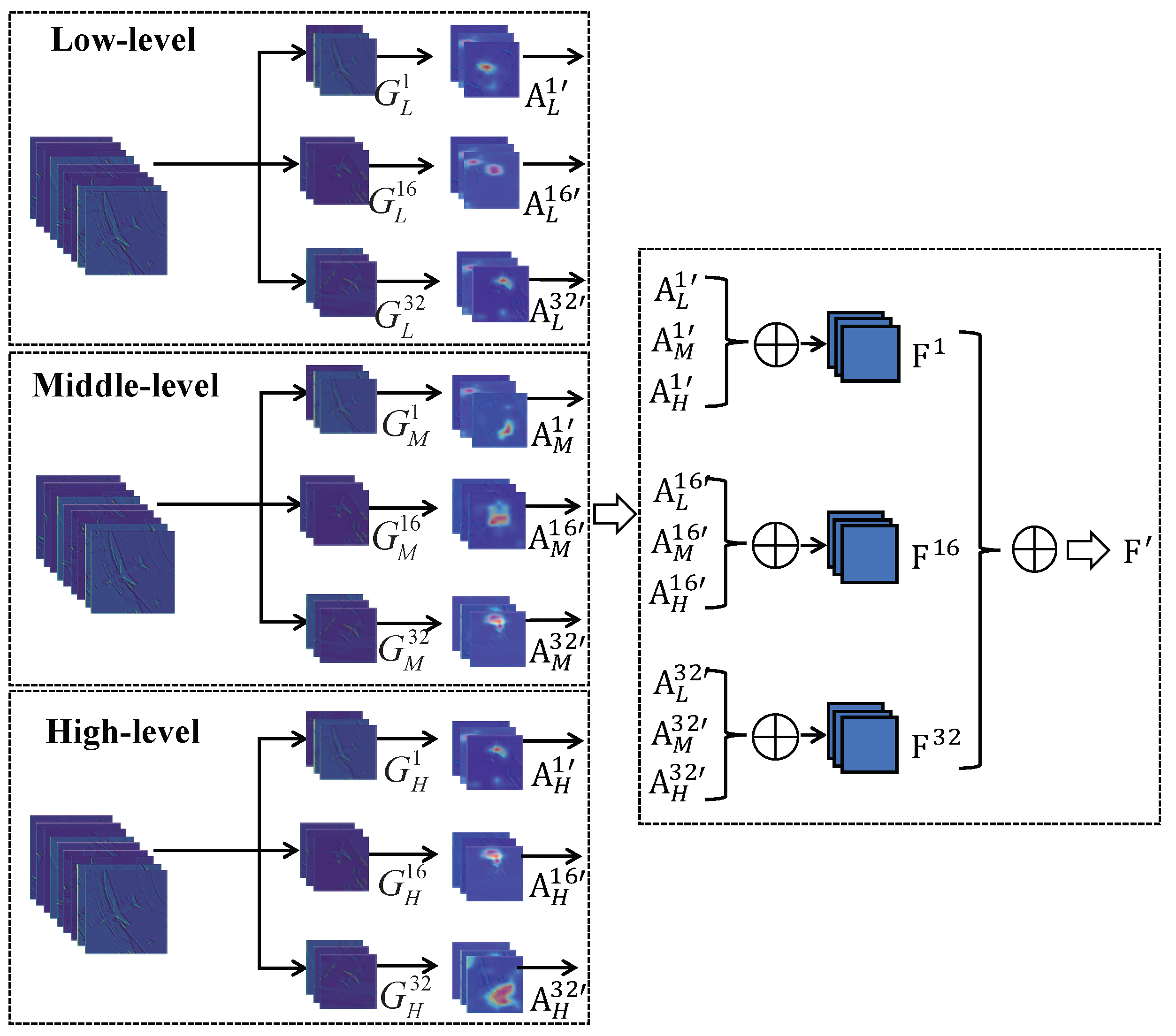
3.2. Grouping-Attention-Fusion
3.2.1. Grouping
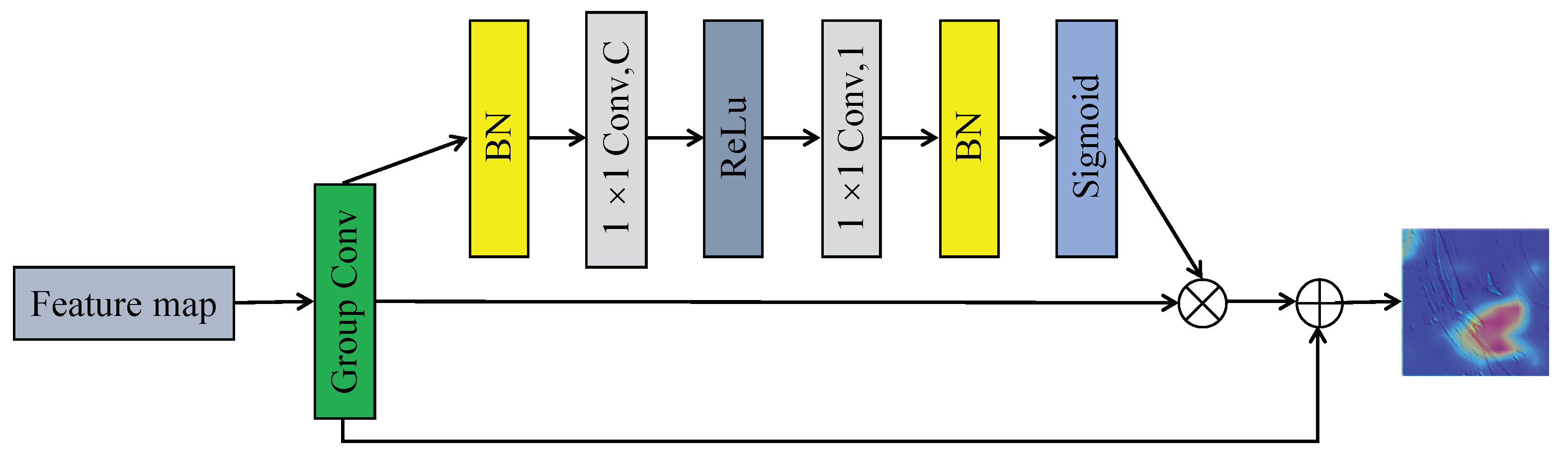
3.2.2. Attention
3.2.3. Fusion
3.3. Classification with Metric Learning
4. Experiments
4.1. Datasets
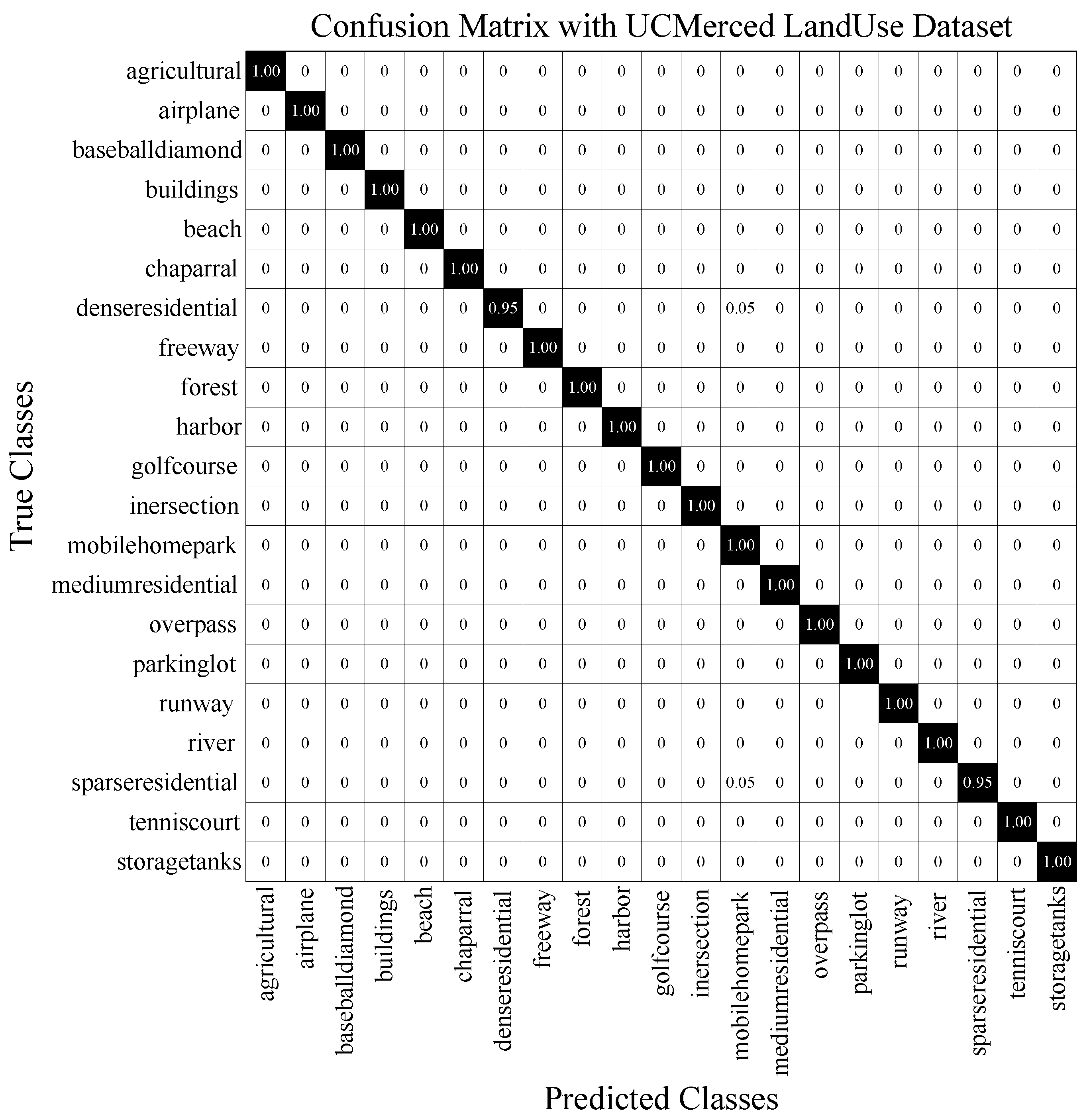
- UC Merced Land-Use Dataset [39]: This dataset contains land-use scenes, which has been widely used in remote sensing scene classification. It consists of 21 scene categories and each category has 100 images with the size of . The ground sampling distance is 1 inch per pixel. This dataset is challenging because of high inter-class similarity, such as dense residential and sparse residential.
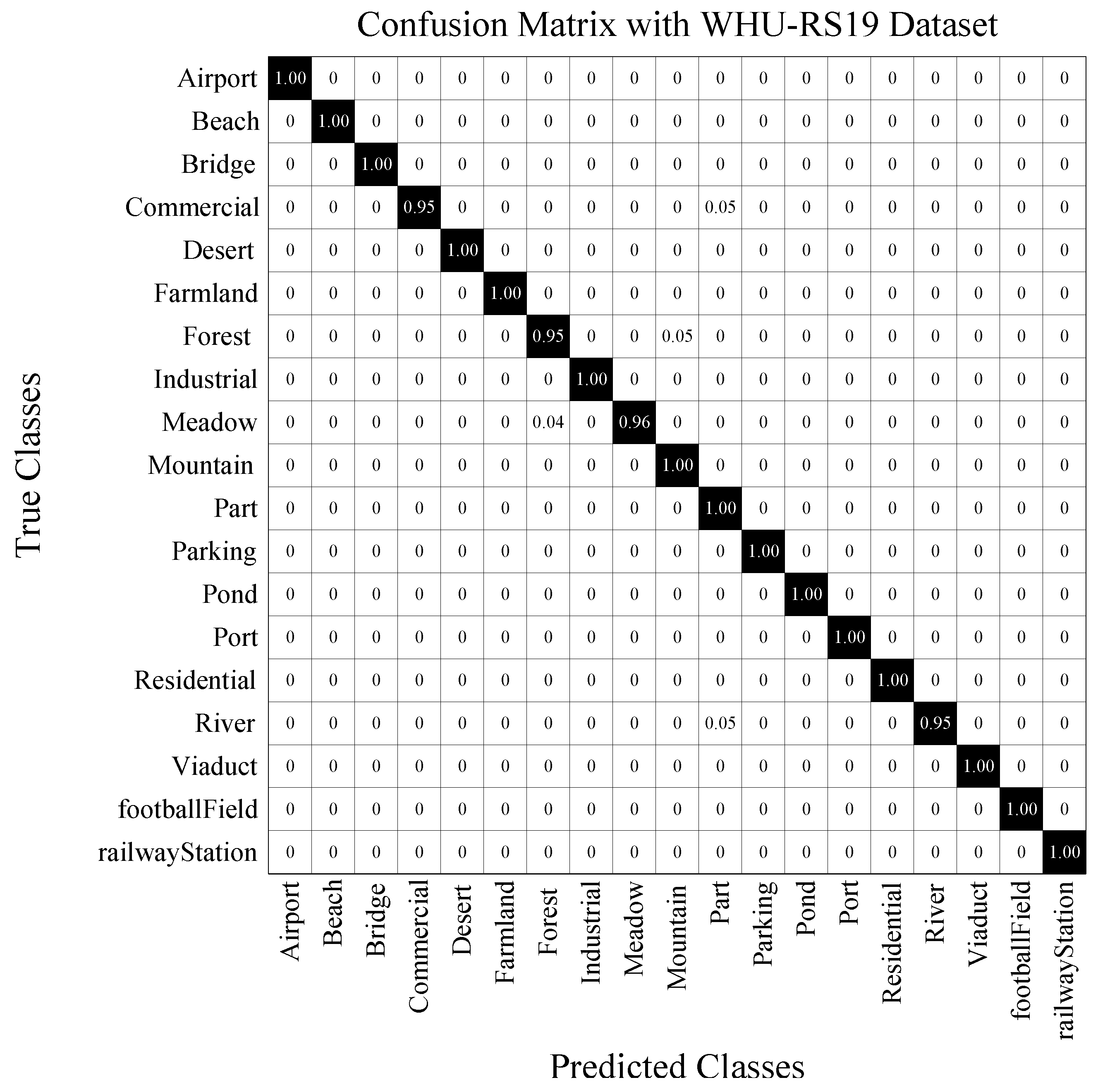
- WHU-RS19 Dataset [40]: The images of this dataset are collected from Google Earth, containing in total 950 images with the size of . The ground sampling distance is 0.5 m per pixel. There are 19 categories with great variation, such as commercial area, pond, football field, and desert, imposing great difficulty for classification.
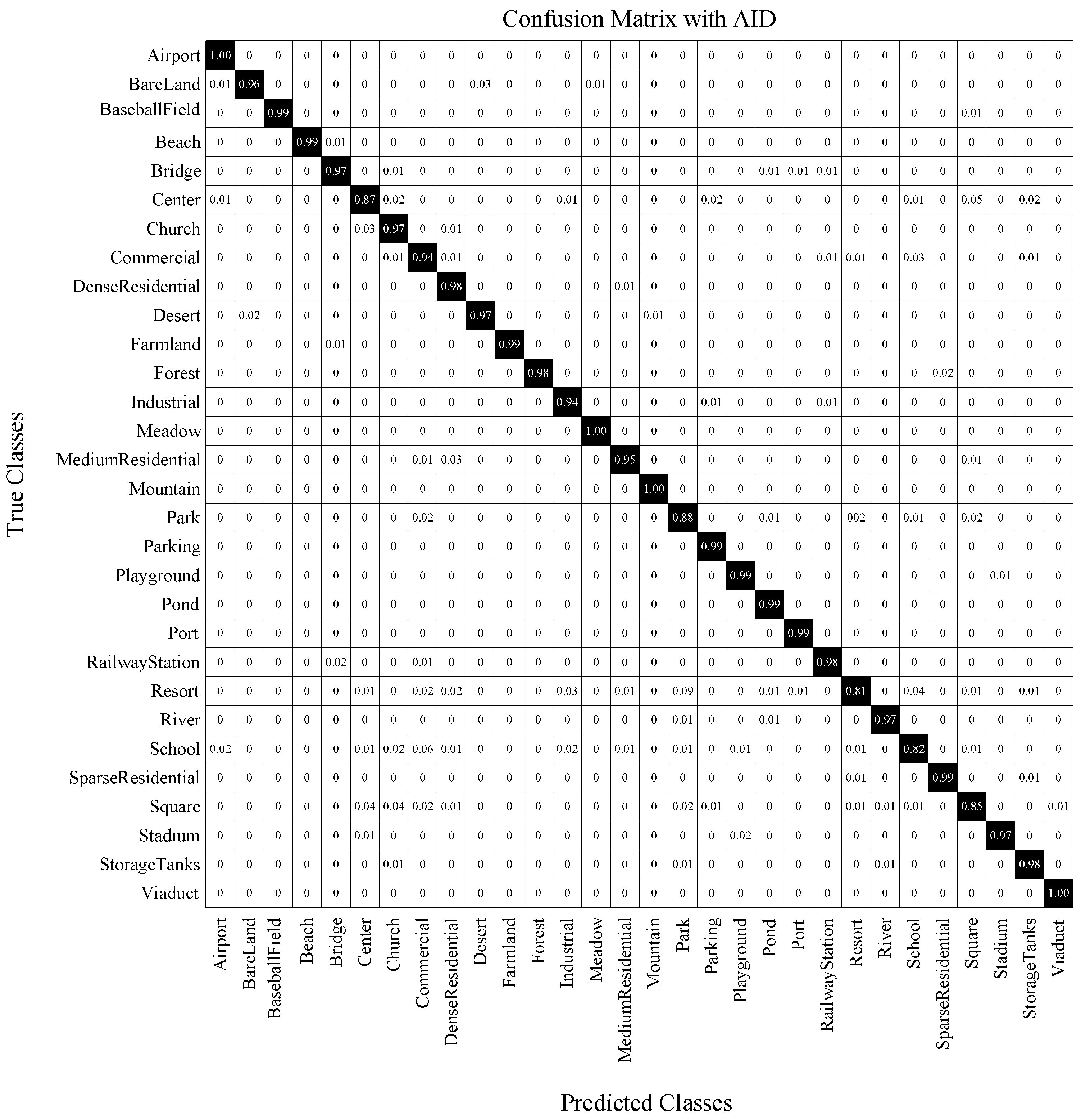
- Aerial Image Dataset (AID) [42]: It is a large-scale dataset collected from Google Earth, containing 30 classes and 10000 images with the size of . The ground sampling distance ranges from 0.5 m per pixel to 8 m per pixel. The characteristic of this dataset is high intra-class diversity, since the same scene is captured under different imaging conditions and at different time, generating the images with the same content but different appearances.
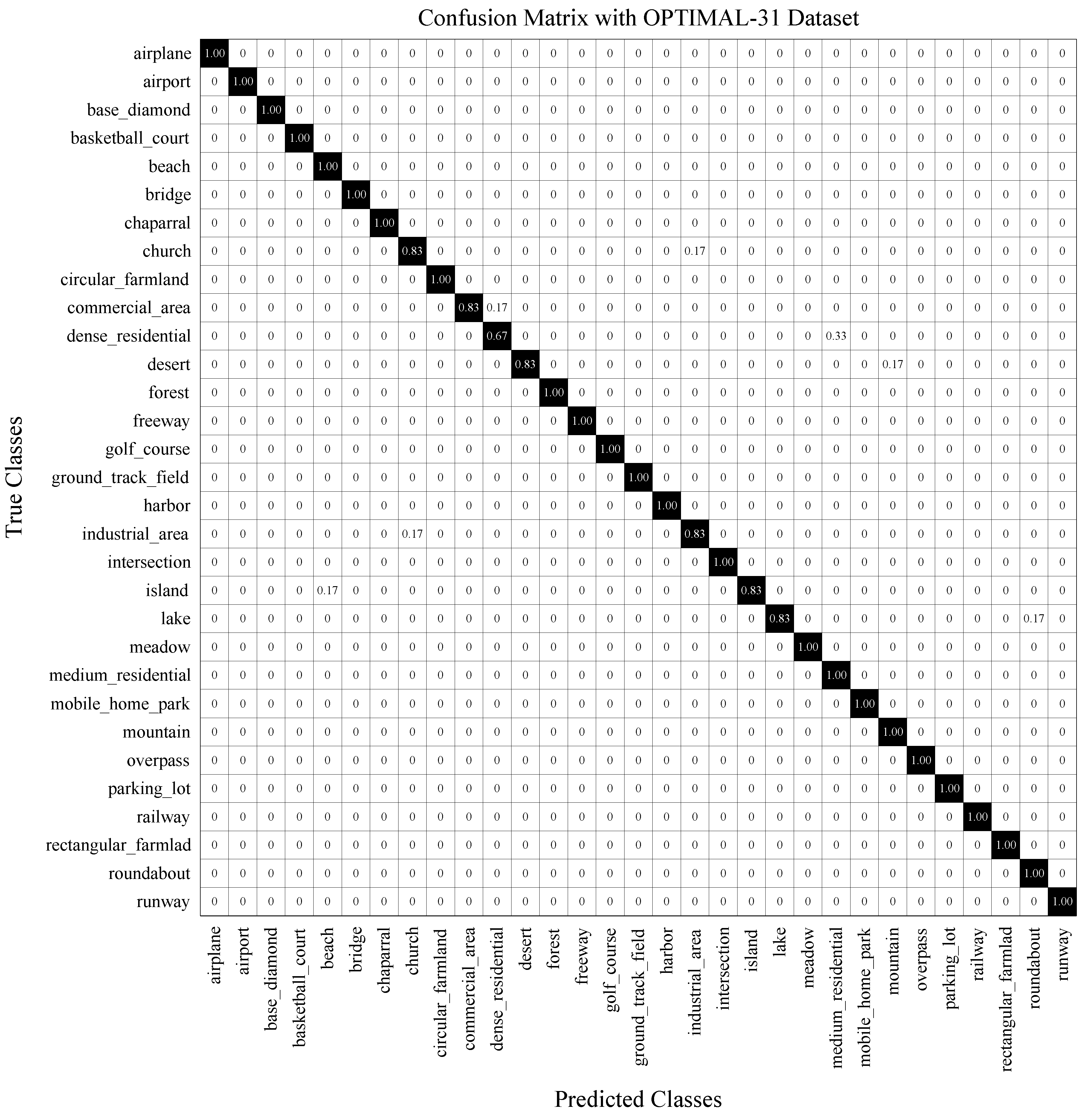
- OPTIMAL-31 Dataset [43]: The dataset has 31 categories with each category collecting 60 images with the size of .
4.2. Evaluation Metrics
- Overall accuracy (OA) is computed as the ratio of the correctly classified images to all images.
- Confusion matrix (CM) is constructed as the relation between the ground-truth label (in each row) and the predicted label (in each column). CM illustrates which category is easily confused with other categories in a visual way.
4.3. Experimental Settings
4.4. Ablation Study
4.4.1. Discussion on Cardinality
4.4.2. Discussion on
4.4.3. Discussion on
4.5. Comparison with State-of-the-Arts
- UC Merced Land-Use Dataset:
- WHU-RS19 Dataset:
- Aerial Image Dataset (AID):
- OPTIMAL-31 Dataset:
4.6. Discussions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | convolutional neural networks |
| UCM | UC Merced Land-Use Dataset |
| AID | Aerial Image Dataset |
| GAP | grouping-attention-fusion |
| OA | overall accuracy |
| CM | confusion matrix |
| SGD | stochastic gradient descent |
References
- Cheng, G.; Han, J.; Guo, L.; Liu, Z.; Bu, S.; Ren, J. Effective and efficient midlevel visual elements-oriented land-use classification using VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4238–4249. [Google Scholar] [CrossRef]
- Hu, F.; Yang, W.; Chen, J.; Sun, H. Tile-level annotation of satellite images using multi-level max-margin discriminative random field. Remote Sens. 2013, 5, 2275–2291. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Cheng, G.; Li, Z.; Yao, X.; Guo, L.; Wei, Z. Remote sensing image scene classification using bag of convolutional features. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1735–1739. [Google Scholar] [CrossRef]
- Xu, K.; Huang, H.; Li, Y.; Shi, G. Multilayer Feature Fusion Network for Scene Classification in Remote Sensing. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1894–1898. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Yu, Y.; Liu, F. A two-stream deep fusion framework for high-resolution aerial scene classification. Comput. Intell. Neurosci. 2018, 2018, 8639367. [Google Scholar] [CrossRef]
- Zhou, Z.; Zheng, Y.; Ye, H.; Pu, J.; Sun, G. Satellite image scene classification via ConvNet with context aggregation. In Pacific Rim Conference on Multimedia; Springer: Berlin/Heidelberg, Germany, 2018; pp. 329–339. [Google Scholar]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Bian, X.; Chen, C.; Tian, L.; Du, Q. Fusing local and global features for high-resolution scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 2889–2901. [Google Scholar] [CrossRef]
- Huang, L.; Chen, C.; Li, W.; Du, Q. Remote sensing image scene classification using multi-scale completed local binary patterns and fisher vectors. Remote Sens. 2016, 8, 483. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, B.; Su, H.; Li, W.; Wang, L. Land-use scene classification using multi-scale completed local binary patterns. Signal Image Video Process. 2016, 10, 745–752. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J.; Guo, L.; Han, J. Auto-encoder-based shared mid-level visual dictionary learning for scene classification using very high resolution remote sensing images. IET Comput. Vis. 2015, 9, 639–647. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Guo, L.; Liu, T. Learning coarse-to-fine sparselets for efficient object detection and scene classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1173–1181. [Google Scholar]
- Zou, J.; Li, W.; Chen, C.; Du, Q. Scene classification using local and global features with collaborative representation fusion. Inf. Sci. 2016, 348, 209–226. [Google Scholar] [CrossRef]
- Lu, X.; Li, X.; Mou, L. Semi-supervised multitask learning for scene recognition. IEEE Trans. Cybern. 2014, 45, 1967–1976. [Google Scholar]
- Chaib, S.; Liu, H.; Gu, Y.; Yao, H. Deep feature fusion for VHR remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4775–4784. [Google Scholar] [CrossRef]
- Othman, E.; Bazi, Y.; Melgani, F.; Alhichri, H.; Alajlan, N.; Zuair, M. Domain adaptation network for cross-scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4441–4456. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L. Scene classification via a gradient boosting random convolutional network framework. IEEE Trans. Geosci. Remote Sens. 2015, 54, 1793–1802. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Li, E.; Xia, J.; Du, P.; Lin, C.; Samat, A. Integrating multilayer features of convolutional neural networks for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5653–5665. [Google Scholar] [CrossRef]
- Wang, G.; Fan, B.; Xiang, S.; Pan, C. Aggregating rich hierarchical features for scene classification in remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4104–4115. [Google Scholar] [CrossRef]
- Yao, X.; Han, J.; Cheng, G.; Qian, X.; Guo, L. Semantic annotation of high-resolution satellite images via weakly supervised learning. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3660–3671. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S. Scene classification using multi-scale deeply described visual words. Int. J. Remote Sens. 2016, 37, 4119–4131. [Google Scholar] [CrossRef]
- Luus, F.P.; Salmon, B.P.; Van den Bergh, F.; Maharaj, B.T.J. Multiview deep learning for land-use classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2448–2452. [Google Scholar] [CrossRef]
- Marmanis, D.; Datcu, M.; Esch, T.; Stilla, U. Deep learning earth observation classification using ImageNet pretrained networks. IEEE Geosci. Remote Sens. Lett. 2015, 13, 105–109. [Google Scholar] [CrossRef]
- Nogueira, K.; Penatti, O.A.; Dos Santos, J.A. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Risojević, V.; Babić, Z. Fusion of global and local descriptors for remote sensing image classification. IEEE Geosci. Remote Sens. Lett. 2012, 10, 836–840. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhong, Y.; Zhao, B.; Xia, G.S.; Zhang, L. Bag-of-visual-words scene classifier with local and global features for high spatial resolution remote sensing imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 747–751. [Google Scholar] [CrossRef]
- Wu, Z.; Shi, L.; Li, J.; Wang, Q.; Sun, L.; Wei, Z.; Plaza, J.; Plaza, A. GPU parallel implementation of spatially adaptive hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 11, 1131–1143. [Google Scholar] [CrossRef]
- Wu, Z.; Li, Y.; Plaza, A.; Li, J.; Xiao, F.; Wei, Z. Parallel and distributed dimensionality reduction of hyperspectral data on cloud computing architectures. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2270–2278. [Google Scholar] [CrossRef]
- Fukui, H.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. Attention branch network: Learning of attention mechanism for visual explanation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10705–10714. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Sheng, G.; Yang, W.; Xu, T.; Sun, H. High-resolution satellite scene classification using a sparse coding based multiple feature combination. Int. J. Remote Sens. 2012, 33, 2395–2412. [Google Scholar] [CrossRef]
- Kalajdjieski, J.; Zdravevski, E.; Corizzo, R.; Lameski, P.; Kalajdziski, S.; Pires, I.M.; Garcia, N.M.; Trajkovik, V. Air Pollution Prediction with Multi-Modal Data and Deep Neural Networks. Remote Sens. 2020, 12, 4142. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1155–1167. [Google Scholar] [CrossRef]
- Othman, E.; Bazi, Y.; Alajlan, N.; Alhichri, H.; Melgani, F. Using convolutional features and a sparse autoencoder for land-use scene classification. Int. J. Remote Sens. 2016, 37, 2149–2167. [Google Scholar] [CrossRef]
- Scott, G.J.; England, M.R.; Starms, W.A.; Marcum, R.A.; Davis, C.H. Training deep convolutional neural networks for land–cover classification of high-resolution imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 549–553. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, F. Aerial scene classification via multilevel fusion based on deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 287–291. [Google Scholar] [CrossRef]
- Boualleg, Y.; Farah, M.; Farah, I.R. Remote sensing scene classification using convolutional features and deep forest classifier. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1944–1948. [Google Scholar] [CrossRef]
- Guo, Y.; Ji, J.; Lu, X.; Huo, H.; Fang, T.; Li, D. Global-local attention network for aerial scene classification. IEEE Access 2019, 7, 67200–67212. [Google Scholar] [CrossRef]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Xiong, W.; Lv, Y.; Cui, Y.; Zhang, X.; Gu, X. A discriminative feature learning approach for remote sensing image retrieval. Remote Sens. 2019, 11, 281. [Google Scholar] [CrossRef]
- Zhao, Z.; Luo, Z.; Li, J.; Chen, C.; Piao, Y. When Self-Supervised Learning Meets Scene Classification: Remote Sensing Scene Classification Based on a Multitask Learning Framework. Remote Sens. 2020, 12, 3276. [Google Scholar] [CrossRef]
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land use classification in remote sensing images by convolutional neural networks. arXiv 2015, arXiv:1508.00092. [Google Scholar]
- Shao, W.; Yang, W.; Xia, G.S.; Liu, G. A hierarchical scheme of multiple feature fusion for high-resolution satellite scene categorization. In Proceedings of the International Conference on Computer Vision Systems, St. Petersburg, Russia, 16–18 July 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 324–333. [Google Scholar]
- Liu, Y.; Liu, Y.; Ding, L. Scene classification based on two-stage deep feature fusion. IEEE Geosci. Remote Sens. Lett. 2017, 15, 183–186. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, F. Dense connectivity based two-stream deep feature fusion framework for aerial scene classification. Remote Sens. 2018, 10, 1158. [Google Scholar] [CrossRef]
- Petrovska, B.; Zdravevski, E.; Lameski, P.; Corizzo, R.; Štajduhar, I.; Lerga, J. Deep learning for feature extraction in remote sensing: A case-study of aerial scene classification. Sensors 2020, 20, 3906. [Google Scholar] [CrossRef]
- He, N.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Remote Sensing Scene Classification Using Multilayer Stacked Covariance Pooling. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6899–6919. [Google Scholar] [CrossRef]
- Akodad, S.; Bombrun, L.; Xia, J.; Berthoumieu, Y.; Germain, C. Ensemble Learning Approaches Based on Covariance Pooling of CNN Features for High Resolution Remote Sensing Scene Classification. Remote Sens. 2020, 12, 3292. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, L.; Wang, Z.; Yu, Y.; Liu, X.; Xu, F. Intelligent Ship Detection in Remote Sensing Images Based on Multi-Layer Convolutional Feature Fusion. Remote Sens. 2020, 12, 3316. [Google Scholar] [CrossRef]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A discriminative feature learning approach for deep face recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 499–515. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Chen, S.; Tian, Y. Pyramid of spatial relatons for scene-level land use classification. IEEE Trans. Geosci. Remote Sens. 2014, 53, 1947–1957. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L. Saliency-guided unsupervised feature learning for scene classification. IEEE Trans. Geosci. Remote Sens. 2014, 53, 2175–2184. [Google Scholar] [CrossRef]
- Cheriyadat, A.M. Unsupervised feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2013, 52, 439–451. [Google Scholar] [CrossRef]
- Li, J.; Lin, D.; Wang, Y.; Xu, G.; Zhang, Y.; Ding, C.; Zhou, Y. Deep Discriminative Representation Learning with Attention Map for Scene Classification. Remote Sens. 2020, 12, 1366. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cardinality | OA(%) |
|---|---|
| 1 | 94.62 |
| 4 | 94.09 |
| 8 | 94.62 |
| 16 | 95.70 |
| 32 | 96.24 |
| 64 | 93.28 |
| OA (%) | |
|---|---|
| = 0 | 94.09 |
| = 1 | 95.16 |
| = 2 | 95.70 |
| OA (%) | |
|---|---|
| 0.0001 | 93.28 |
| 0.0005 | 95.16 |
| 0.005 | 94.62 |
| 0.01 | 94.09 |
| 0.05 | 93.55 |
| Methods | 80% Images for Training | w.r.t. Baseline (80%) | 50% Images for Training | w.r.t. Baseline (50%) |
|---|---|---|---|---|
| ARCNet-VGG16 [43] | 99.12 ± 0.40 | +4.81 | 96.81 ± 0.14 | +4.11 |
| Combing Scenarios I and II [3] | 98.49 | +4.18 | ||
| D-CNN with VGGNet-16 [12] | 98.93 ± 0.10 | +4.62 | ||
| Fusion by Addition [21] | 97.42 ± 1.79 | +3.11 | ||
| ResNet-TP-50 [11] | 98.56 ± 0.53 | +4.25 | 97.68 ± 0.26 | +4.98 |
| Two-Stream Fusion [10] | 98.02 ± 1.03 | +3.71 | 96.97 ± 0.75 | +4.27 |
| CNN-NN [44] | 97.19 | +2.88 | ||
| Fine-tuning GoogLeNet [52] | 97.10 | +2.79 | ||
| GoogLeNet [42] | 94.31 ± 0.89 | 0 | 92.70 ± 0.60 | 0 |
| CaffeNet [42] | 95.02 ± 0.81 | +0.71 | 93.98 ± 0.67 | +1.28 |
| Overfeat [31] | 90.91 ± 1.19 | −3.4 | ||
| VGG-VD-16 [42] | 95.21 ± 1.20 | +0.9 | 94.14 ± 0.69 | +1.44 |
| MS-CLBP+FV [14] | 93.00 ± 1.20 | −1.31 | 88.76 ± 0.76 | −3.94 |
| Gradient Boosting Random CNNS [23] | 94.53 | +0.22 | ||
| SalM3LBPCLM [13] | 95.75 ± 0.80 | +1.44 | 94.21 ± 0.75 | +1.51 |
| Partlets-based [1] | 91.33 ± 1.11 | −2.98 | ||
| Multifeature Concatenation [53] | 92.38 ± 0.62 | −1.93 | ||
| Pyramid of Spatial Relations [54] | 89.10 | −5.21 | ||
| Saliency-guided Feature Learning [62] | 82.72 ± 1.18 | −11.59 | ||
| Unsupervised Feature Learning [63] | 82.67 ± 1.23 | −11.64 | ||
| BoVW [64] | 76.81 | −17.5 | ||
| BiMobileNet (MobileNetv2) [52] | 99.03 ± 0.28 | +4.72 | 98.45 ± 0.27 | +5.75 |
| DDRL-AM [65] | 99.05 ± 0.08 | +4.74 | ||
| AlexNet+MSCP [57] | 97.29 ± 0.63 | +2.98 | ||
| AlexNet+MSCP+MRA [57] | 97.32 ± 0.52 | +3.01 | ||
| VGG-VD16+MSCP [57] | 98.36 ± 0.58 | +4.05 | ||
| VGG-VD16+MSCP+MRA [57] | 98.40 ± 0.34 | +4.09 | ||
| Ours | 99.52 ± 0.23 | +5.21 | 98.19 ± 0.39 | +5.49 |
| Methods | 20% Images for Training | w.r.t. Baseline |
|---|---|---|
| AlexNet [43] | 88.35 ± 0.85 | −0.84 |
| CaffeNet [43] | 90.48 ± 0.78 | +1.29 |
| GoogLeNet [43] | 89.19 ± 1.19 | 0 |
| VGG-16 [42] | 90.70 ± 0.68 | +1.51 |
| VGG-19 [43] | 89.76 ± 0.69 | +0.57 |
| ResNet-50 [43] | 91.93 ± 0.61 | +2.74 |
| ResNet-152 [43] | 92.47 ± 0.43 | +3.28 |
| Ours | 95.60 ± 0.39 | +6.41 |
| Methods | 60% Images for Training | w.r.t. Baseline (60%) | 40% Images for Training | w.r.t. Baseline (40%) |
|---|---|---|---|---|
| ARCNet-VGG16 [43] | 99.75 ± 0.25 | +5.04 | 97.50 ± 0.49 | +4.38 |
| Combing Scenarios I and II [3] | 98.89 | +4.18 | ||
| Fusion by Addition [21] | 98.65 ± 0.43 | +3.94 | ||
| Two-Stream Fusion [10] | 98.92 ± 0.52 | +4.21 | 98.23 ± 0.56 | +5.11 |
| VGG-VD-16 [42] | 96.05 ± 0.91 | +1.34 | 95.44 ± 0.60 | +2.32 |
| CaffeNet [42] | 96.24 ± 0.56 | +1.53 | 95.11 ± 1.20 | +1.99 |
| GoogLeNet [42] | 94.71 ± 1.33 | 0 | 93.12 ± 0.82 | 0 |
| SalM3LBPCLM [13] | 96.38 ± 0.82 | +1.67 | 95.35 ± 0.76 | +2.23 |
| Multifeature Concatenation [53] | 94.53 ± 1.01 | −0.18 | ||
| MS-CLBP+FV [14] | 94.32 ± 1.02 | −0.39 | ||
| MS-CLBP+BoVW [14] | 89.29 ± 1.30 | −5.42 | ||
| Bag of SIFT [62] | 85.52 ± 1.23 | −9.19 | ||
| Ours | 98.96 ± 0.78 | +4.25 | 97.98 ± 0.84 | +4.86 |
| Methods | 50% Images for Training | w.r.t. Baseline (50%) | 20% Images for Training | w.r.t. Baseline (20%) |
|---|---|---|---|---|
| ARCNet-VGG16 [43] | 93.10 ± 0.55 | +6.71 | 88.75 ± 0.40 | +5.31 |
| Fusion by Addition [21] | 91.87 ± 0.36 | +5.48 | ||
| Two-Stream Fusion [10] | 94.58 ± 0.25 | +8.19 | 92.32 ± 0.41 | +8.88 |
| D-CNN with AlexNet [12] | 94.47 ± 0.12 | +8.08 | 85.62 ± 0.10 | +2.18 |
| VGG-VD-16 [42] | 89.64 ± 0.36 | +3.25 | 86.59 ± 0.29 | +3.15 |
| CaffeNet [42] | 89.53 ± 0.31 | +3.14 | 86.86 ± 0.47 | +3.42 |
| GoogLeNet [42] | 86.39 ± 0.55 | 0 | 83.44 ± 0.40 | 0 |
| AlexNet+MSCP [57] | 92.36 ± 0.21 | +8.92 | 88.99 ± 0.38 | +2.6 |
| AlexNet+MSCP+MRA [57] | 94.11 ± 0.15 | +10.67 | 90.65 ± 0.19 | +4.26 |
| VGG-VD16+MSCP [57] | 94.42 ± 0.17 | +10.98 | 91.52 ± 0.21 | +5.13 |
| VGG-VD16+MSCP+MRA [57] | 96.56 ± 0.18 | +13.12 | 92.21 ± 0.17 | +5.82 |
| Ours | 96.12 ± 0.14 | +9.73 | 94.05 ± 0.10 | +10.61 |
| Methods | 80% Images for Training | w.r.t. Baseline |
|---|---|---|
| ARCNet-VGGNet16 [43] | 92.70 ± 0.35 | +10.13 |
| ARCNet-ResNet34 [43] | 91.28 ± 0.45 | +8.71 |
| ARCNet-Alexnet [43] | 85.75 ± 0.35 | +3.18 |
| VGG-VD-16 [42] | 89.12 ± 0.35 | +6.55 |
| Fine-tuning VGGNet16 [43] | 87.45 ± 0.45 | +4.88 |
| Fine-tuning GoogLeNet [43] | 82.57 ± 0.12 | 0 |
| Fine-tuning AlexNet [43] | 81.22 ± 0.19 | −1.35 |
| Ours | 96.24 ± 1.10 | +13.67 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, J.; Zhang, T.; Wang, Y.; Wang, R.; Wang, Q.; Qi, M. A Dual-Model Architecture with Grouping-Attention-Fusion for Remote Sensing Scene Classification. Remote Sens. 2021, 13, 433. https://doi.org/10.3390/rs13030433
Shen J, Zhang T, Wang Y, Wang R, Wang Q, Qi M. A Dual-Model Architecture with Grouping-Attention-Fusion for Remote Sensing Scene Classification. Remote Sensing. 2021; 13(3):433. https://doi.org/10.3390/rs13030433
Chicago/Turabian StyleShen, Junge, Tong Zhang, Yichen Wang, Ruxin Wang, Qi Wang, and Min Qi. 2021. "A Dual-Model Architecture with Grouping-Attention-Fusion for Remote Sensing Scene Classification" Remote Sensing 13, no. 3: 433. https://doi.org/10.3390/rs13030433
APA StyleShen, J., Zhang, T., Wang, Y., Wang, R., Wang, Q., & Qi, M. (2021). A Dual-Model Architecture with Grouping-Attention-Fusion for Remote Sensing Scene Classification. Remote Sensing, 13(3), 433. https://doi.org/10.3390/rs13030433