
Three-Dimensional Urban Land Cover Classification by Prior-Level Fusion of LiDAR Point Cloud and Optical Imagery


Abstract
:
1. Introduction
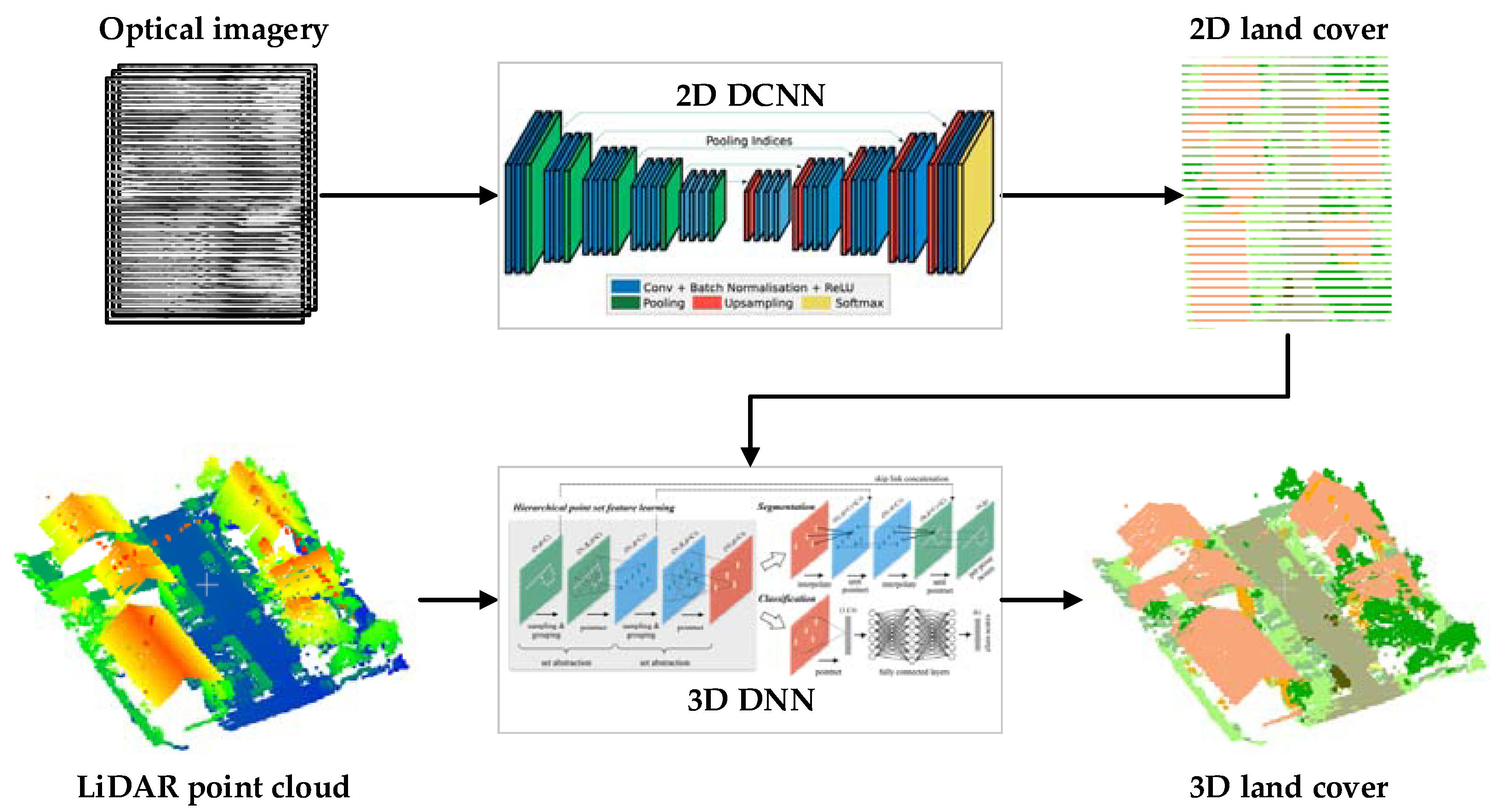
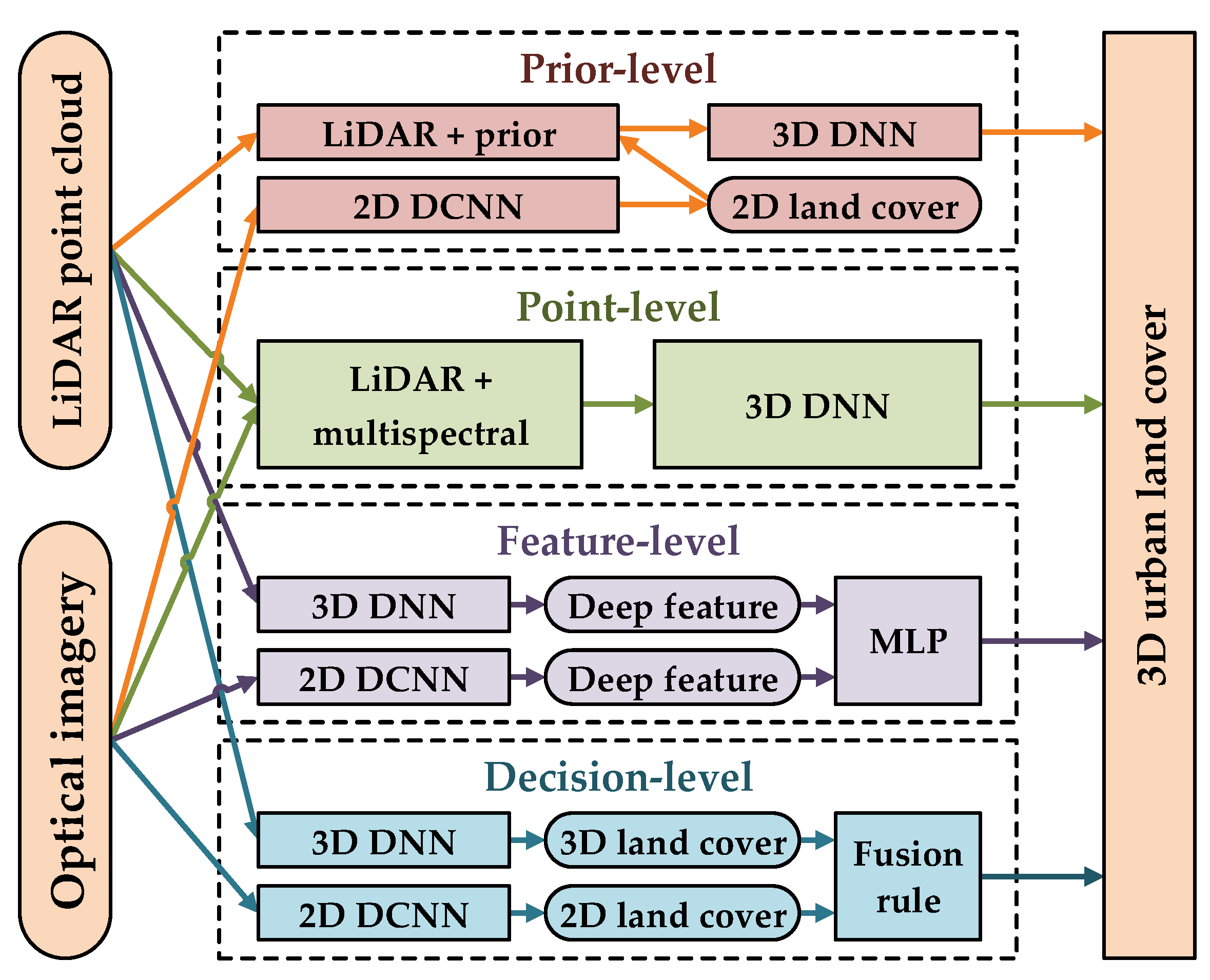
2. Methods
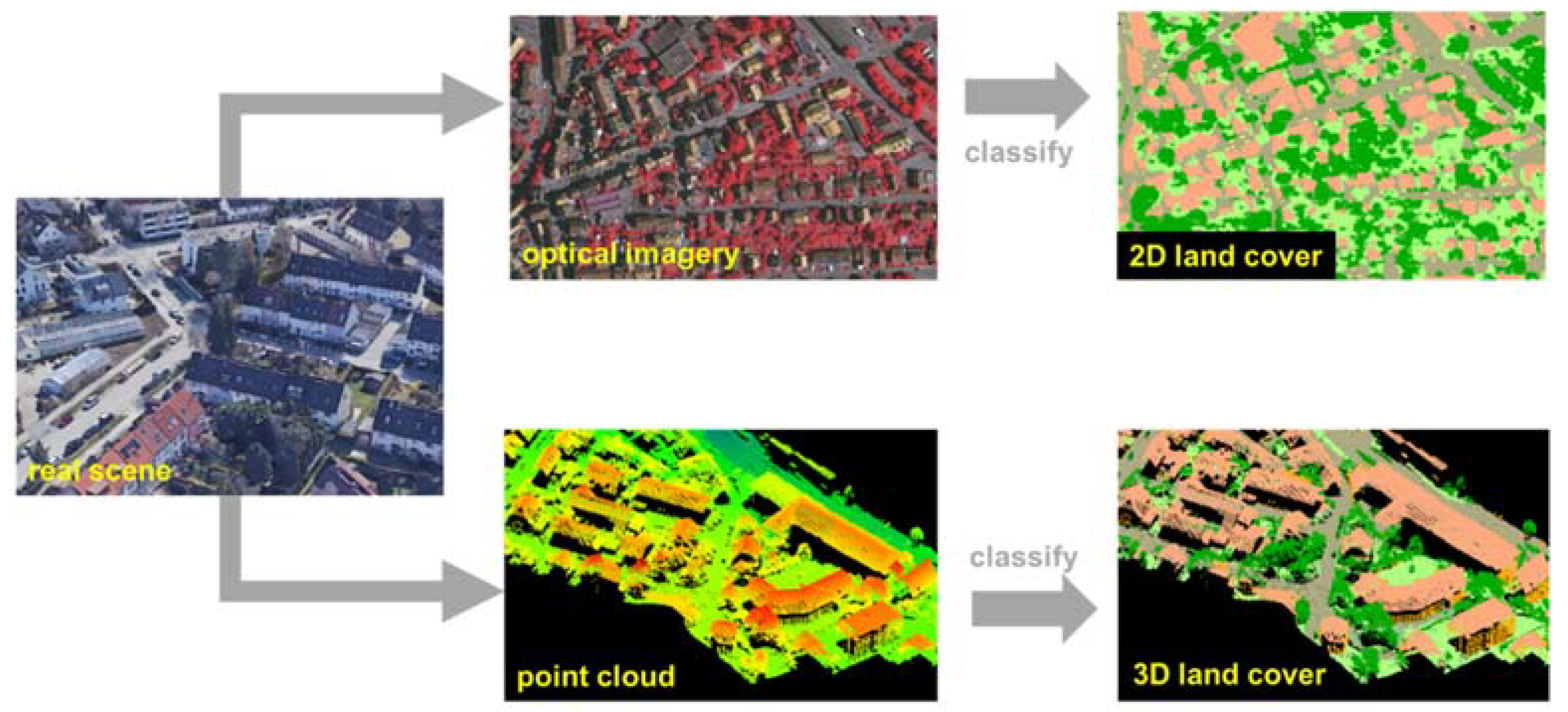
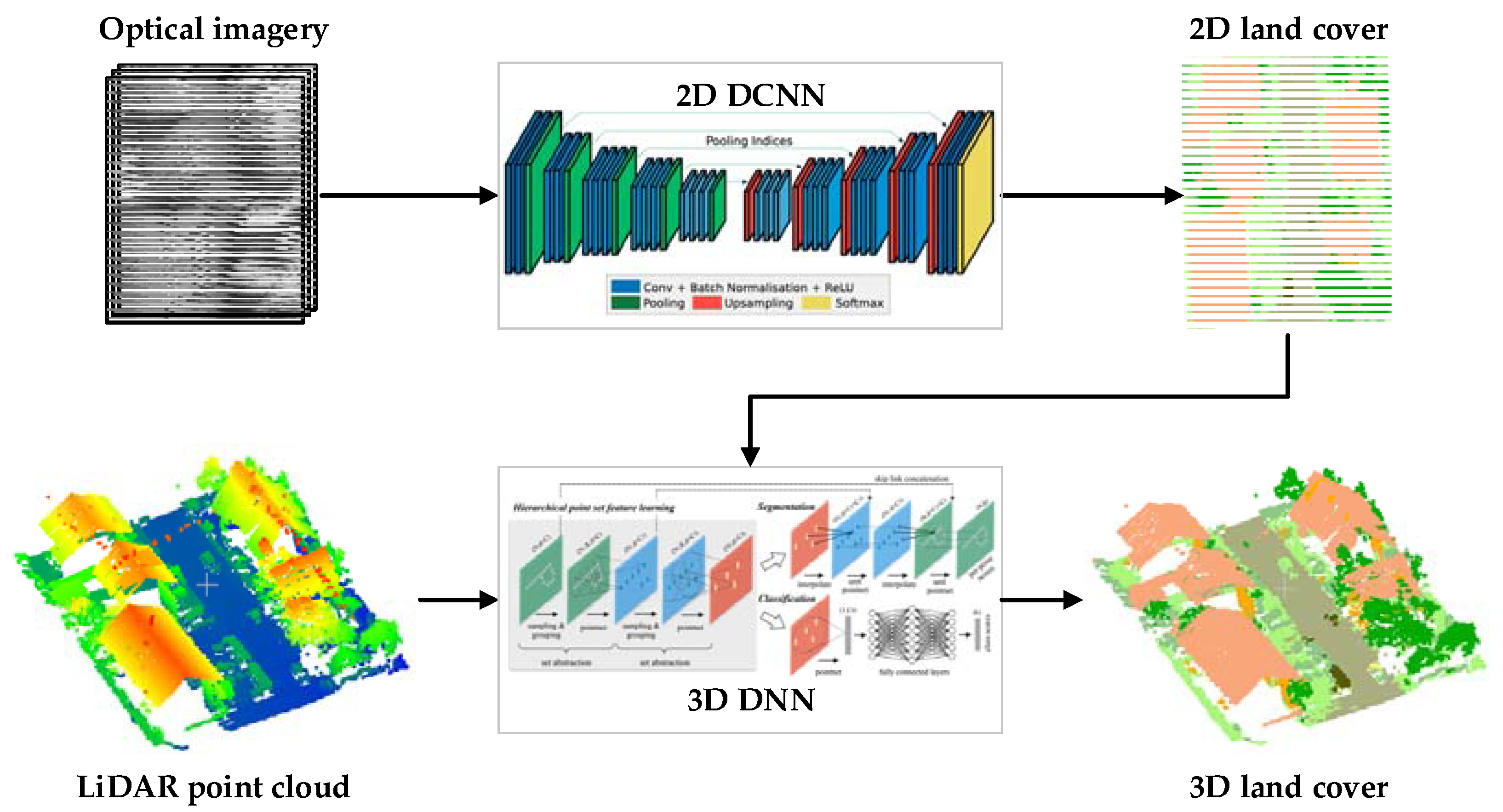
2.1. Obtaining Prior Knowledge from Optical Image Using Deep Convolutional Neural Network (DCNN)
2.2. Assigning Prior Knowledge to the Light Detection and Ranging (LiDAR) Point Cloud
2.3. Classification of LiDAR Point Cloud Assigned Prior to Three-Dimensional Deep Neural Network (DNN)
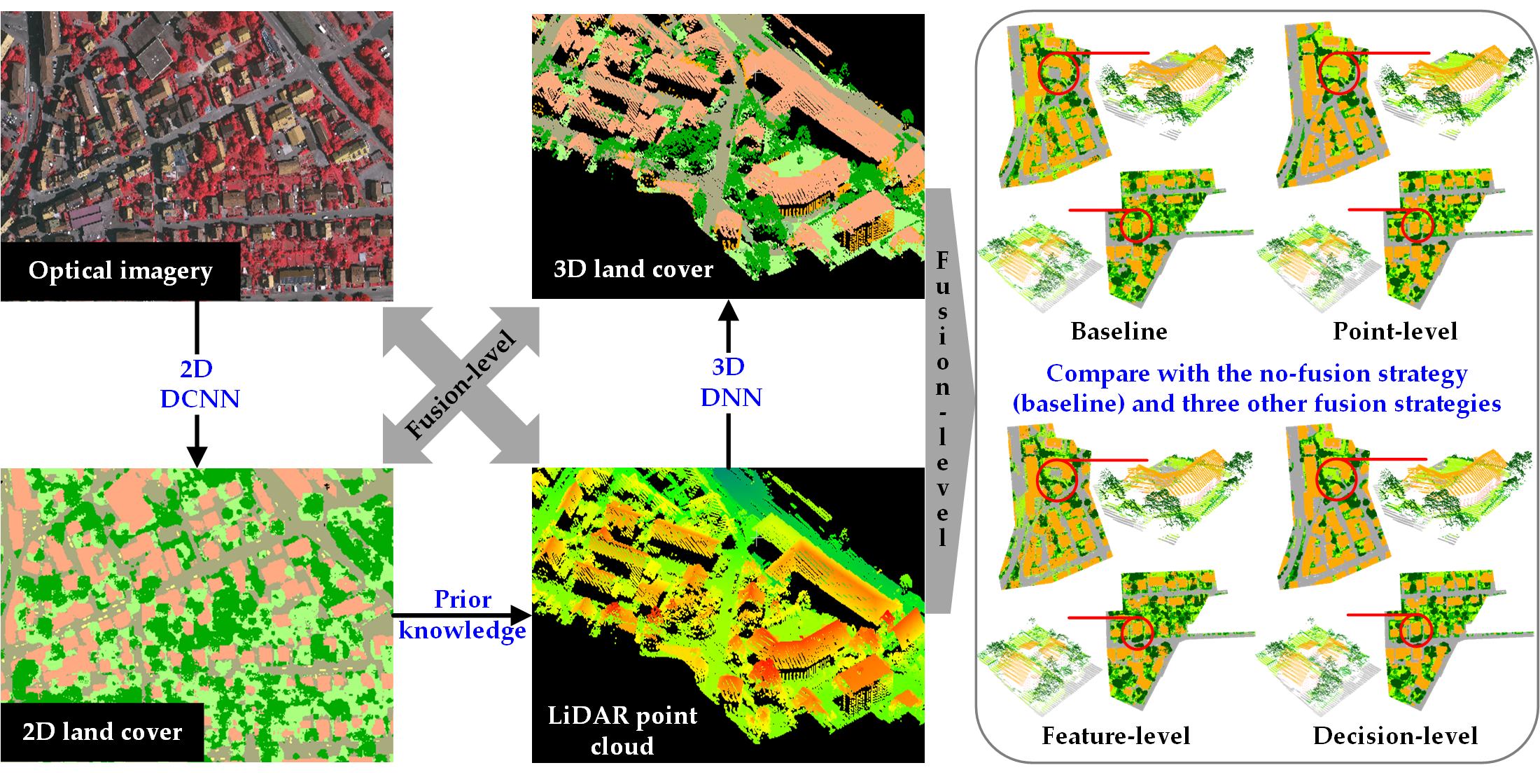
2.4. Fusion Strategies on Three Other Different Levels
3. Experimental Data and Results
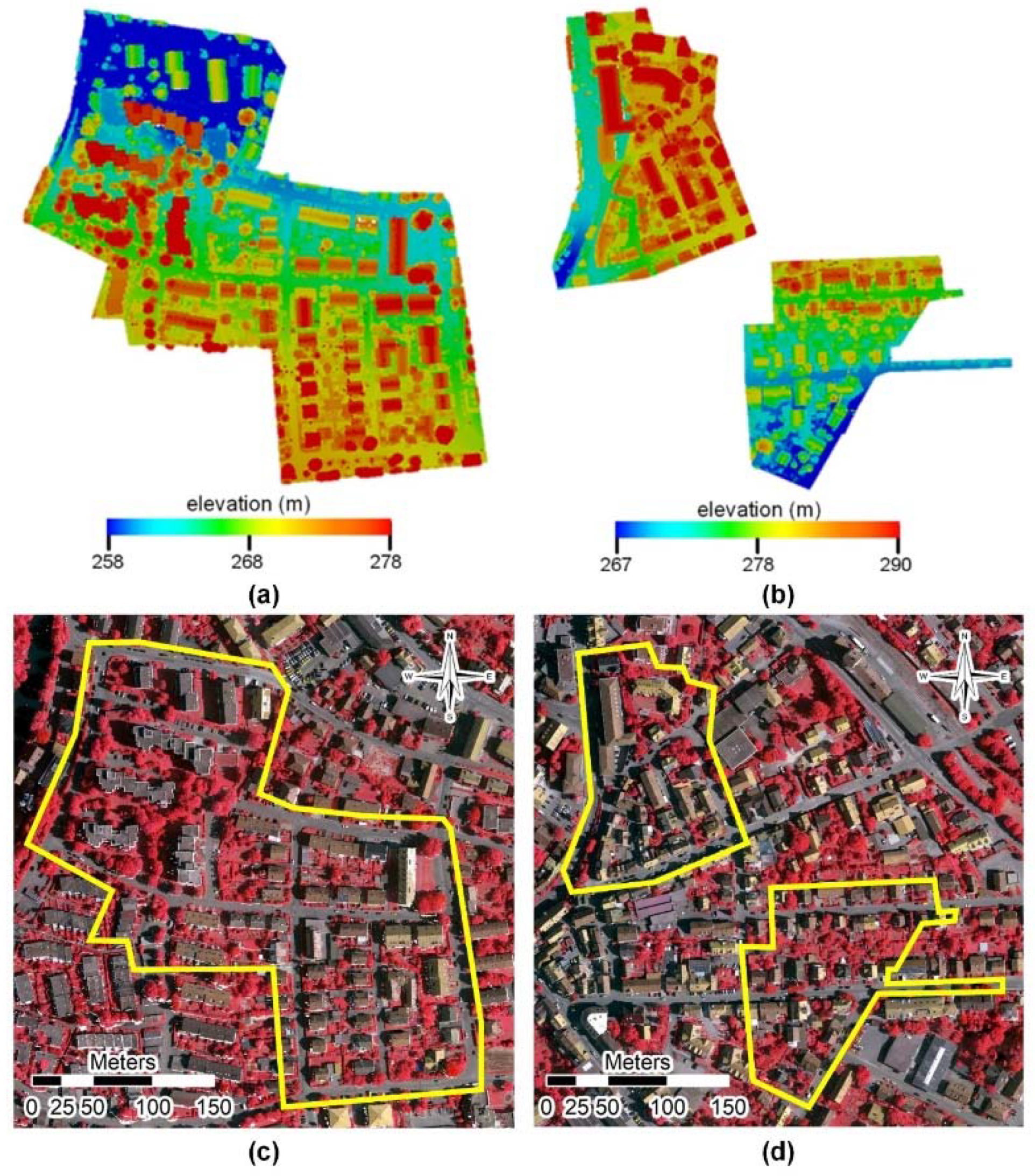
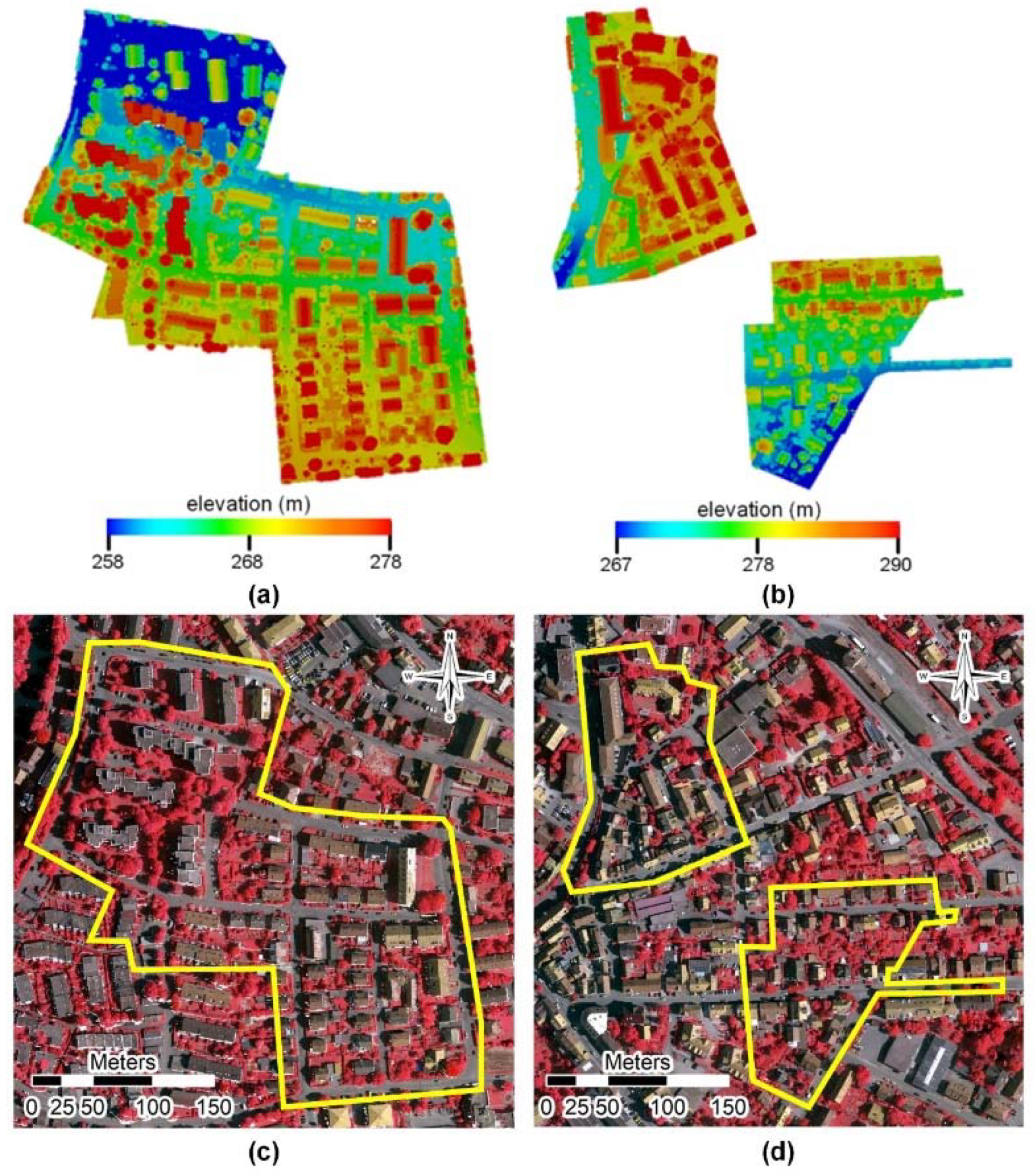
3.1. Experimental Data
3.2. Details of Experimental Setting
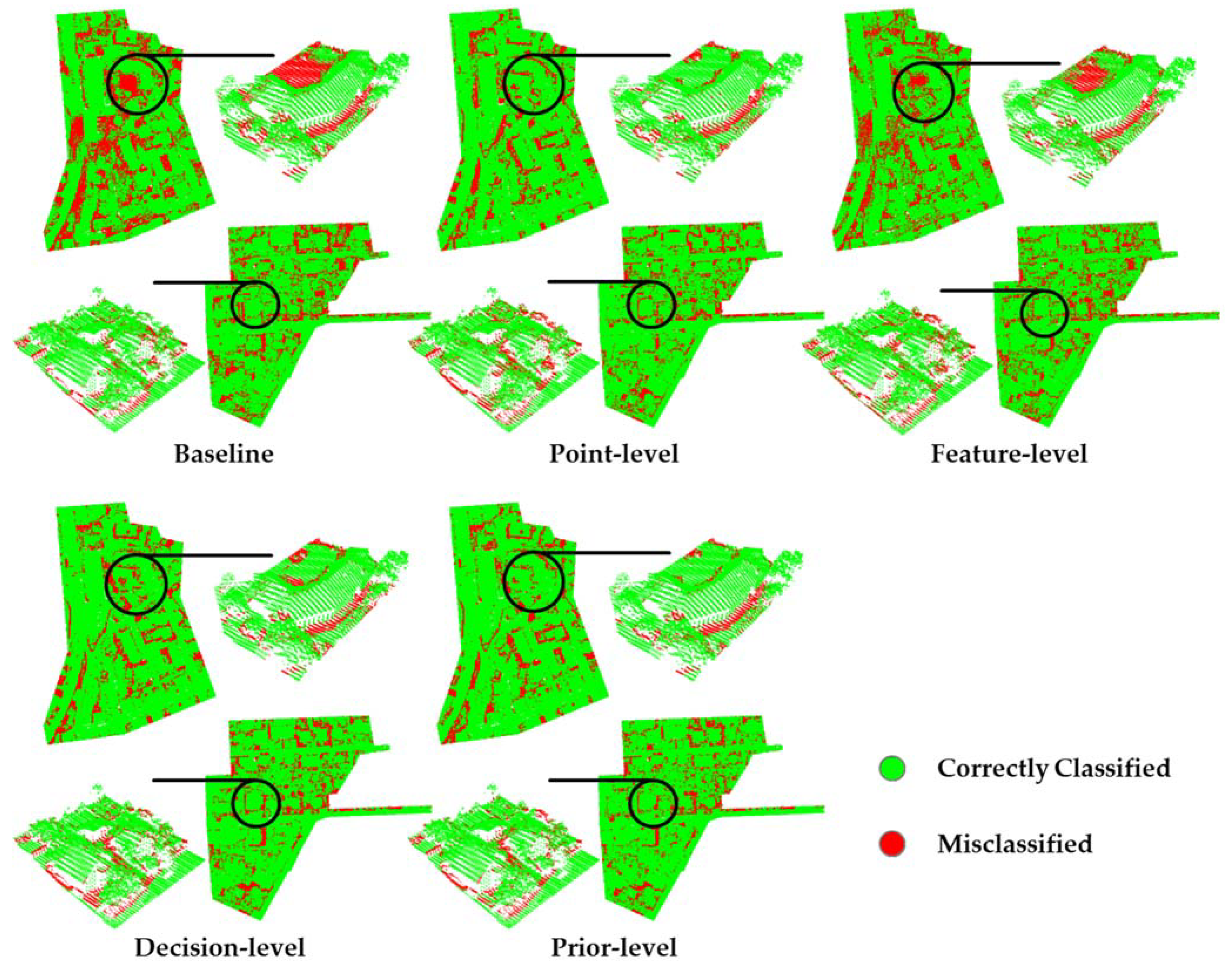
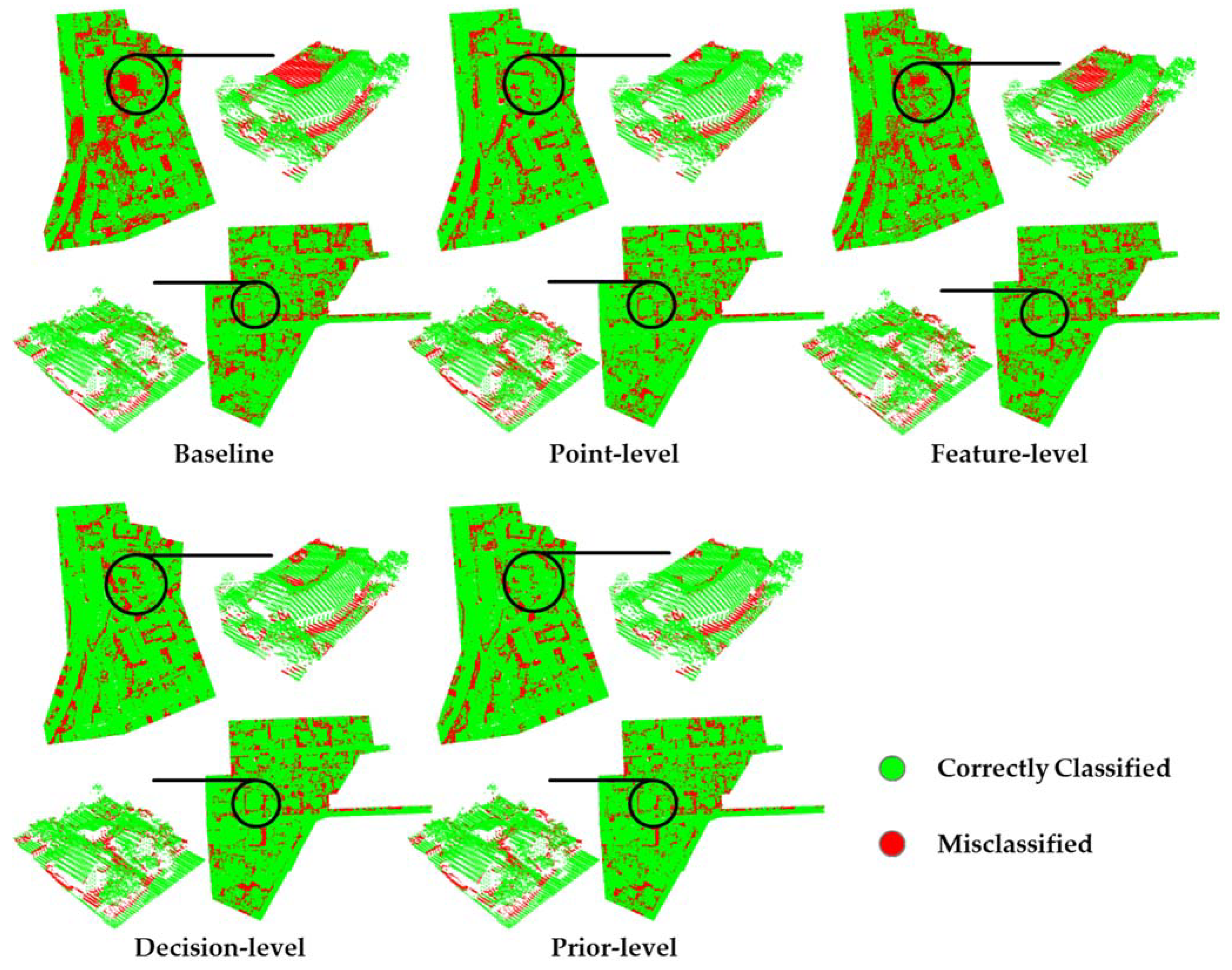
3.3. Classification of the Prior-Level Strategy with other Fusion Strategies
4. Discussion
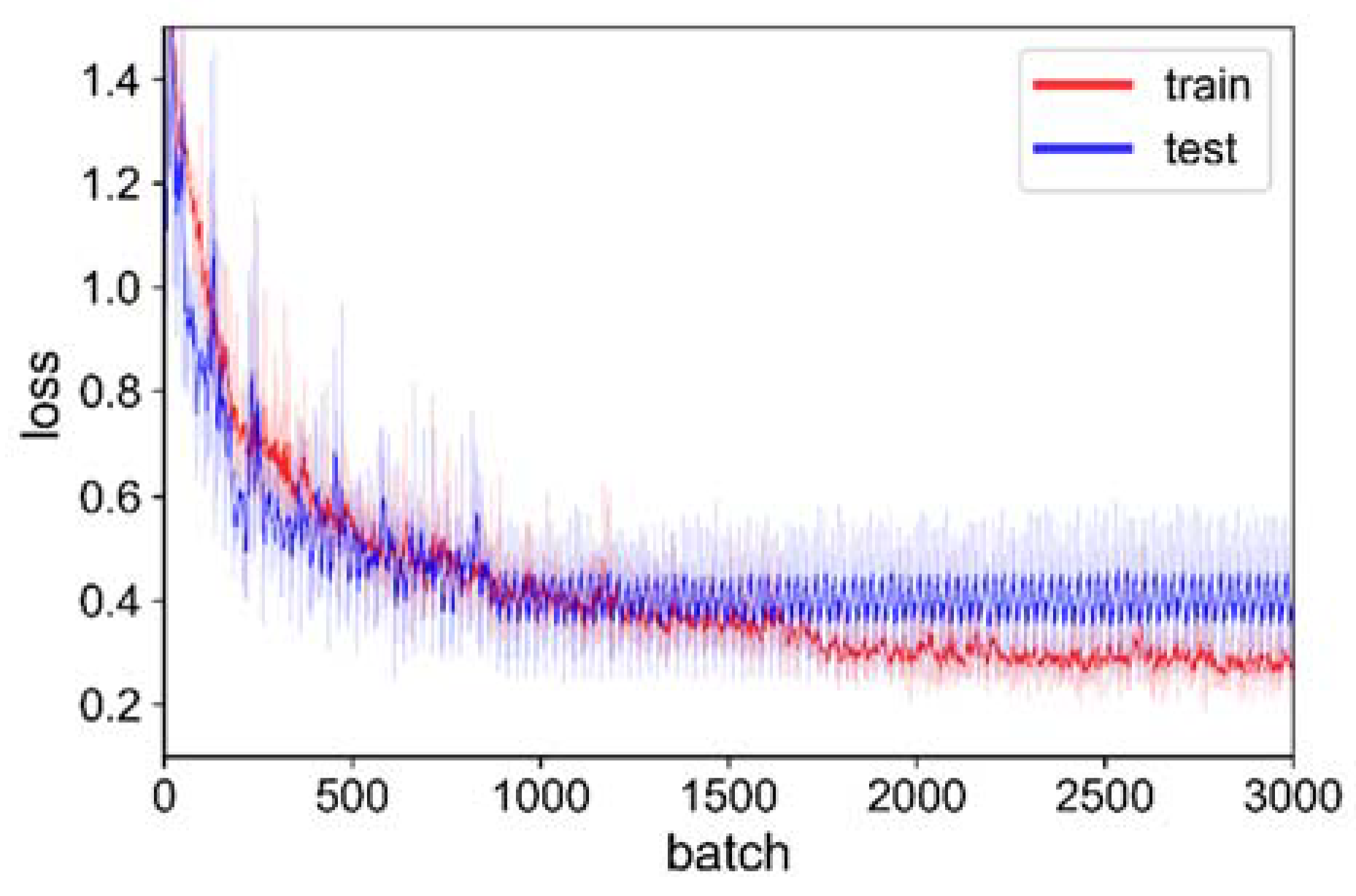
4.1. Loss Variation during Training
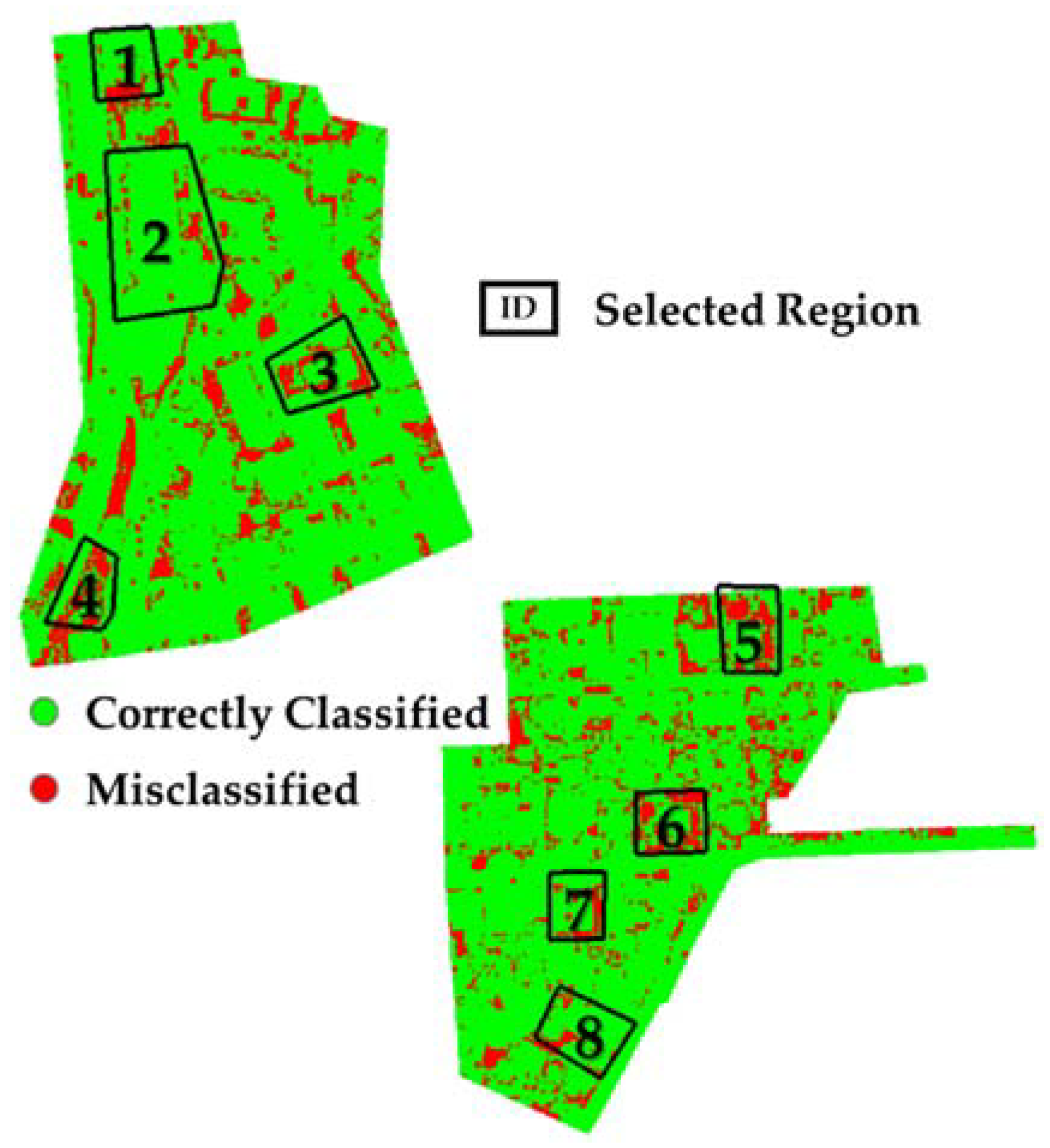
4.2. Detailed Analysis of the Error Region
4.3. Comparison with Other Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cadenasso, M.L.; Pickett, S.T.A.; Schwarz, K. Spatial heterogeneity in urban ecosystems: Reconceptualizing land cover and a framework for classification. Front. Ecol. Environ. 2007, 5, 80–88. [Google Scholar] [CrossRef]
- Grimm, N.B.; Faeth, S.H.; Golubiewski, N.E.; Redman, C.L.; Wu, J.; Bai, X.; Briggs, J.M. Global Change and the Ecology of Cities. Science 2008, 319, 756–760. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Z.; Zhou, Y.; Seto, K.C.; Stokes, E.C.; Deng, C.; Pickett, S.T.; Taubenböck, H. Understanding an urbanizing planet: Strategic directions for remote sensing. Remote Sens. Environ. 2019, 228, 164–182. [Google Scholar] [CrossRef]
- Wentz, E.A.; York, A.M.; Alberti, M.; Conrow, L.; Fischer, H.; Inostroza, L.; Jantz, C.; Pickett, S.T.; Seto, K.C.; Taubenböck, H. Six fundamental aspects for conceptualizing multidimensional urban form: A spatial mapping perspective. Landsc. Urban Plan. 2018, 179, 55–62. [Google Scholar] [CrossRef]
- Stewart, I.D.; Oke, T.R. Local Climate Zones for Urban Temperature Studies. Bull. Am. Meteorol. Soc. 2012, 93, 1879–1900. [Google Scholar] [CrossRef]
- Wang, V.; Gao, J. Importance of structural and spectral parameters in modelling the aboveground carbon stock of urban vegetation. Int. J. Appl. Earth Obs. Geoinform. 2019, 78, 93–101. [Google Scholar] [CrossRef]
- Mallet, C.; Bretar, F.; Roux, M.; Soergel, U.; Heipke, C. Relevance assessment of full-waveform lidar data for urban area classification. ISPRS J. Photogramm. Remote Sens. 2011, 66, S71–S84. [Google Scholar] [CrossRef]
- Guo, B.; Huang, X.; Zhang, F.; Sohn, G. Classification of airborne laser scanning data using JointBoost. ISPRS J. Photogramm. Remote Sens. 2015, 100, 71–83. [Google Scholar] [CrossRef]
- Liu, X.; Chen, Y.; Li, S.; Cheng, L.; Li, M. Hierarchical Classification of Urban ALS Data by Using Geometry and Intensity Information. Sensors 2019, 19, 4583. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast Point Feature Histograms (FPFH) for 3D registration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar]
- Blomley, R.; Weinmann, M.; Leitloff, J.; Jutzi, B. Shape distribution features for point cloud analysis—A geometric histogram approach on multiple scales. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, II-3, 9–16. [Google Scholar] [CrossRef] [Green Version]
- Osada, R.; Funkhouser, T.; Chazelle, B.; Dobkin, D. Shape distributions. ACM Trans. Graph. 2002, 21, 807–832. [Google Scholar] [CrossRef]
- Weinmann, M.; Urban, S.; Hinz, S.; Jutzi, B.; Mallet, C. Distinctive 2D and 3D features for automated large-scale scene analysis in urban areas. Comput. Graph. 2015, 49, 47–57. [Google Scholar] [CrossRef]
- Dittrich, A.; Weinmann, M.; Hinz, S. Analytical and numerical investigations on the accuracy and robustness of geometric features extracted from 3D point cloud data. ISPRS J. Photogramm. Remote Sens. 2017, 126, 195–208. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on x-transformed points. Adv. Neural 2018, 31, 820–830. [Google Scholar]
- Graham, B.; Engelcke, M.; van der Maaten, L. 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9224–9232. [Google Scholar]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep Learning for 3D Point Clouds: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4338–4364. [Google Scholar] [CrossRef]
- Yousefhussien, M.; Kelbe, D.J.; Ientilucci, E.J.; Salvaggio, C. A multi-scale fully convolutional network for semantic labeling of 3D point clouds. ISPRS J. Photogramm. Remote Sens. 2018, 143, 191–204. [Google Scholar] [CrossRef]
- Zhang, R.; Li, G.; Li, M.; Wang, L. Fusion of images and point clouds for the semantic segmentation of large-scale 3D scenes based on deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 143, 85–96. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, X. Advances in fusion of optical imagery and LiDAR point cloud applied to photogrammetry and remote sensing. Int. J. Image Data Fusion 2017, 8, 1–31. [Google Scholar] [CrossRef]
- Ghamisi, P.; Gloaguen, R.; Atkinson, P.M.; Benediktsson, J.A.; Rasti, B.; Yokoya, N.; Wang, Q.; Hofle, B.; Bruzzone, L.; Bovolo, F.; et al. Multisource and Multitemporal Data Fusion in Remote Sensing: A Comprehensive Review of the State of the Art. IEEE Geosci. Remote Sens. Mag. 2019, 7, 6–39. [Google Scholar] [CrossRef] [Green Version]
- Singh, K.K.; Vogler, J.B.; Shoemaker, D.A.; Meentemeyer, R.K. LiDAR-Landsat data fusion for large-area assessment of urban land cover: Balancing spatial resolution, data volume and mapping accuracy. ISPRS J. Photogramm. Remote Sens. 2012, 74, 110–121. [Google Scholar] [CrossRef]
- Paisitkriangkrai, S.; Sherrah, J.; Janney, P.; Hengel, A.V.-D. Effective semantic pixel labelling with convolutional networks and Conditional Random Fields. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015; pp. 36–43. [Google Scholar]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef] [Green Version]
- Rasti, B.; Ghamisi, P.; Gloaguen, R. Hyperspectral and LiDAR Fusion Using Extinction Profiles and Total Variation Component Analysis. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3997–4007. [Google Scholar] [CrossRef]
- Debes, C.; Merentitis, A.; Heremans, R.; Hahn, J.; Frangiadakis, N.; Van Kasteren, T.; Liao, W.; Bellens, R.; Pizurica, A.; Gautama, S.; et al. Hyperspectral and LiDAR Data Fusion: Outcome of the 2013 GRSS Data Fusion Contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2405–2418. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Semantic Segmentation of Earth Observation Data Using Multimodal and Multi-Scale Deep Networks; Lai, S., Lepetit, V., Nishino, K., Sato, Y., Eds.; Asian Conference on Computer Vision; Springer: Cham, Germany, 2017; pp. 180–196. [Google Scholar] [CrossRef] [Green Version]
- Guo, L.; Chehata, N.; Mallet, C.; Boukir, S. Relevance of airborne lidar and multispectral image data for urban scene clas-sification using Random Forests. ISPRS J. Photogramm. Remote Sens. 2011, 66, 56–66. [Google Scholar] [CrossRef]
- Ghassemian, H. A review of remote sensing image fusion methods. Inf. Fusion 2016, 32, 75–89. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction from an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. DeepGlobe 2018: A Challenge to Parse the Earth through Satellite Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–181. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image seg-mentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical. feature learning on point sets in a metric space. Advances in Neural Information Processing Systems. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6245. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ramiya, A.M.; Nidamanuri, R.R.; Ramakrishnan, K. A supervoxel-based spectro-spatial approach for 3D urban point cloud labelling. Int. J. Remote Sens. 2016, 37, 4172–4200. [Google Scholar] [CrossRef]
- Mongus, D.; Lukač, N.; Žalik, B. Ground and building extraction from LiDAR data based on differential morphological profiles and locally fitted surfaces. ISPRS J. Photogramm. Remote Sens. 2014, 93, 145–156. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U.; Heipke, C. Hierarchical higher order crf for the classification of airborne lidar point clouds in urban areas. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 655–662. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Tan, B.; Pei, H.; Jiang, W. Segmentation and Multi-Scale Convolutional Neural Network-Based Classification of Airborne Laser Scanner Data. Sensors 2018, 18, 3347. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arief, H.A.; Indahl, U.G.; Strand, G.-H.; Tveite, H. Addressing overfitting on point cloud classification using Atrous XCRF. ISPRS J. Photogramm. Remote Sens. 2019, 155, 90–101. [Google Scholar] [CrossRef] [Green Version]
- Thomas, H.; Qi, C.R.; Deschaud, J.-E.; Marcotegui, B.; Goulette, F.; Guibas, L. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 6411–6420. [Google Scholar]
- Cramer, M. The DGPF-Test on Digital Airborne Camera Evaluation Overview and Test Design. Photogramm. Fernerkund. Geoinform. 2010, 2010, 73–82. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Parameter |
|---|---|
| Sampling and grouping | N = 1024, r = 2, K = 32 |
| Feature extraction | [32, 32, 64] |
| Sampling and grouping | N = 256, r = 4, K = 32 |
| Feature extraction | [64, 64, 128] |
| Sampling and grouping | N = 64, r = 8, K = 32 |
| Feature extraction | [128, 128, 256] |
| Sampling and grouping | N = 16, r = 16, K = 32 |
| Feature extraction | [256, 256, 512] |
| Feature set propagation | [256, 256] |
| Feature set propagation | [256, 256] |
| Feature set propagation | [256, 128] |
| Feature set propagation | [128, 128, 128] |
| Classification Performance | Baseline | Point-Level | Feature-Level | Decision-Level | Prior-Level | |
|---|---|---|---|---|---|---|
| Low vegetation | Precision | 73.18 | 84.27 | 75.97 | 91.91 | 89.83 |
| Recall | 63.58 | 68.40 | 66.94 | 65.46 | 72.69 | |
| F1-score | 68.04 | 75.51 | 71.17 | 76.46 | 80.36 | |
| Shrub | Precision | 33.25 | 31.12 | 34.51 | 34.50 | 35.58 |
| Recall | 71.60 | 58.61 | 58.15 | 66.02 | 66.19 | |
| F1-score | 45.42 | 40.66 | 43.31 | 45.32 | 46.28 | |
| Tree | Precision | 77.37 | 83.02 | 75.38 | 85.21 | 85.45 |
| Recall | 74.68 | 80.21 | 81.70 | 80.67 | 80.74 | |
| F1-score | 76.00 | 81.59 | 78.41 | 82.88 | 83.03 | |
| Impervious surface | Precision | 80.59 | 86.61 | 81.64 | 84.23 | 88.38 |
| Recall | 79.99 | 91.99 | 83.42 | 95.99 | 94.74 | |
| F1-score | 80.29 | 89.22 | 82.52 | 89.73 | 91.45 | |
| Roof | Precision | 94.27 | 94.68 | 95.23 | 96.57 | 96.52 |
| Recall | 86.27 | 91.73 | 40.84 | 91.45 | 91.27 | |
| F1-score | 90.10 | 93.18 | 90.25 | 93.94 | 93.82 | |
| Facade | Precision | 49.04 | 41.31 | 85.76 | 42.73 | 44.08 |
| Recall | 67.69 | 53.69 | 65.31 | 71.88 | 70.90 | |
| F1-score | 56.87 | 46.69 | 50.25 | 53.60 | 54.36 | |
| Weighted Average | Precision | 76.73 | 81.45 | 77.51 | 83.70 | 84.39 |
| Recall | 74.62 | 79.86 | 76.22 | 81.12 | 82.47 | |
| F1-score | 75.08 | 80.15 | 76.46 | 81.35 | 82.79 | |
| Classification Result | Non-Deep Learning | Deep Learning | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ISS_7 | UM | HM1 | LUH | RIT1 | WhuY4 | PointCNN | A-XCRF | Ours | |
| Power line | 54.4 | 46.1 | 69.8 | 59.6 | 37.5 | 42.5 | 61.5 | 63.0 | 27.5 |
| Low vegetation | 65.2 | 79.0 | 73.8 | 77.5 | 77.9 | 82.7 | 82.7 | 82.6 | 79.8 |
| Impervious surface | 85.0 | 89.1 | 91.5 | 91.1 | 91.5 | 91.4 | 91.8 | 91.9 | 91.9 |
| Car | 57.9 | 47.7 | 58.2 | 73.1 | 73.4 | 74.7 | 75.8 | 74.9 | 71.4 |
| Fence | 28.9 | 05.2 | 29.9 | 34.0 | 18.0 | 53.7 | 35.9 | 39.9 | 29.0 |
| Roof | 90.9 | 92.0 | 91.6 | 94.2 | 94.0 | 94.3 | 92.7 | 94.5 | 92.7 |
| Façade | - | 52.7 | 54.7 | 56.3 | 49.3 | 53.1 | 57.8 | 59.3 | 53.8 |
| Shrub | 39.5 | 40.9 | 47.8 | 46.6 | 45.9 | 47.9 | 49.1 | 50.8 | 44.3 |
| Tree | 75.6 | 77.9 | 80.2 | 83.1 | 82.5 | 82.8 | 78.1 | 82.7 | 82.3 |
| Average F1 | 55.3 | 59.0 | 66.4 | 68.4 | 63.3 | 69.2 | 69.5 | 71.1 | 63.6 |
| Overall Accuracy | 76.2 | 80.8 | 80.5 | 81.6 | 81.6 | 84.9 | 83.3 | 85.0 | 81.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Liu, X.; Xiao, Y.; Zhao, Q.; Wan, S. Three-Dimensional Urban Land Cover Classification by Prior-Level Fusion of LiDAR Point Cloud and Optical Imagery. Remote Sens. 2021, 13, 4928. https://doi.org/10.3390/rs13234928
Chen Y, Liu X, Xiao Y, Zhao Q, Wan S. Three-Dimensional Urban Land Cover Classification by Prior-Level Fusion of LiDAR Point Cloud and Optical Imagery. Remote Sensing. 2021; 13(23):4928. https://doi.org/10.3390/rs13234928
Chicago/Turabian StyleChen, Yanming, Xiaoqiang Liu, Yijia Xiao, Qiqi Zhao, and Sida Wan. 2021. "Three-Dimensional Urban Land Cover Classification by Prior-Level Fusion of LiDAR Point Cloud and Optical Imagery" Remote Sensing 13, no. 23: 4928. https://doi.org/10.3390/rs13234928
APA StyleChen, Y., Liu, X., Xiao, Y., Zhao, Q., & Wan, S. (2021). Three-Dimensional Urban Land Cover Classification by Prior-Level Fusion of LiDAR Point Cloud and Optical Imagery. Remote Sensing, 13(23), 4928. https://doi.org/10.3390/rs13234928