
Application of Deep Learning Architectures for Satellite Image Time Series Prediction: A Review


Abstract
:1. Introduction
- This paper presents, in a single document, the main elements necessary to design and evaluate DL models for SITS prediction (data, methods, and parameters), and provides an excellent starting point for researchers interested in the field.
- It describes the major applications of SITS prediction using DL methods, including weather forecasting, precipitation nowcasting, spatio-temporal analysis, and missing data reconstruction.
- This review presents most DL-based approaches for SITS prediction, which are grouped into three main types of architecture (recurrent neural networks, feed-forward neural networks, and hybrid architectures).
- The document gives an overview of the optimizer and evaluation metrics used by authors for SITS prediction.
- The paper identifies the major limitations of using DL for SITS prediction and presents proposed solutions to address these issues.
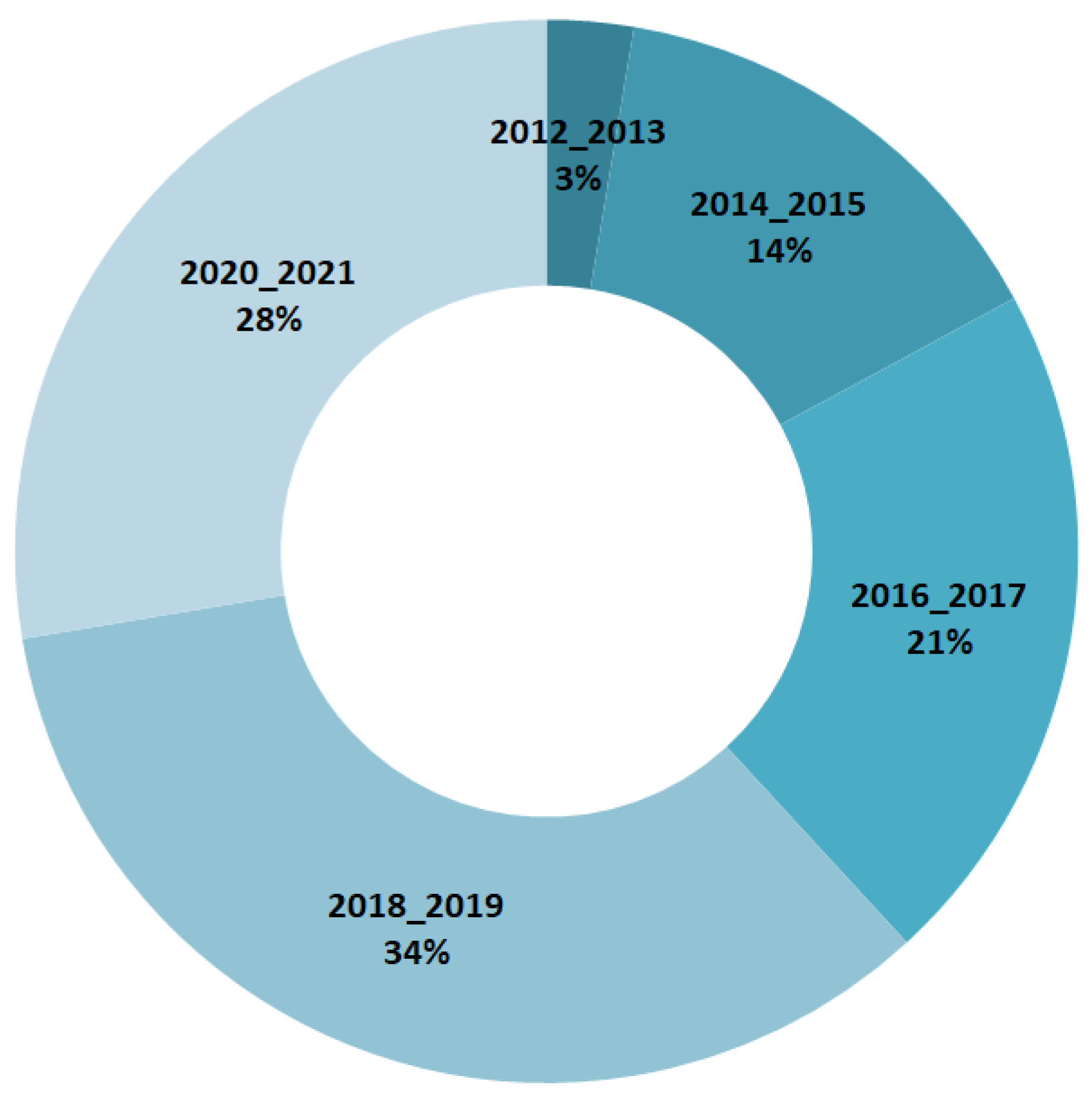
2. Survey Methodology
- Papers that did not use DL to make predictions;
- Works that used DL for predictions but not from SITS; and
- Publications that focused on the use of DL and SITS but whose applications were not prediction, such as classification, segmentation, and others (in the cope of this study, prediction is related to forecasting or missing data reconstruction).
3. Background on Deep Learning
3.1. Generalities
3.2. Main DL Architectures
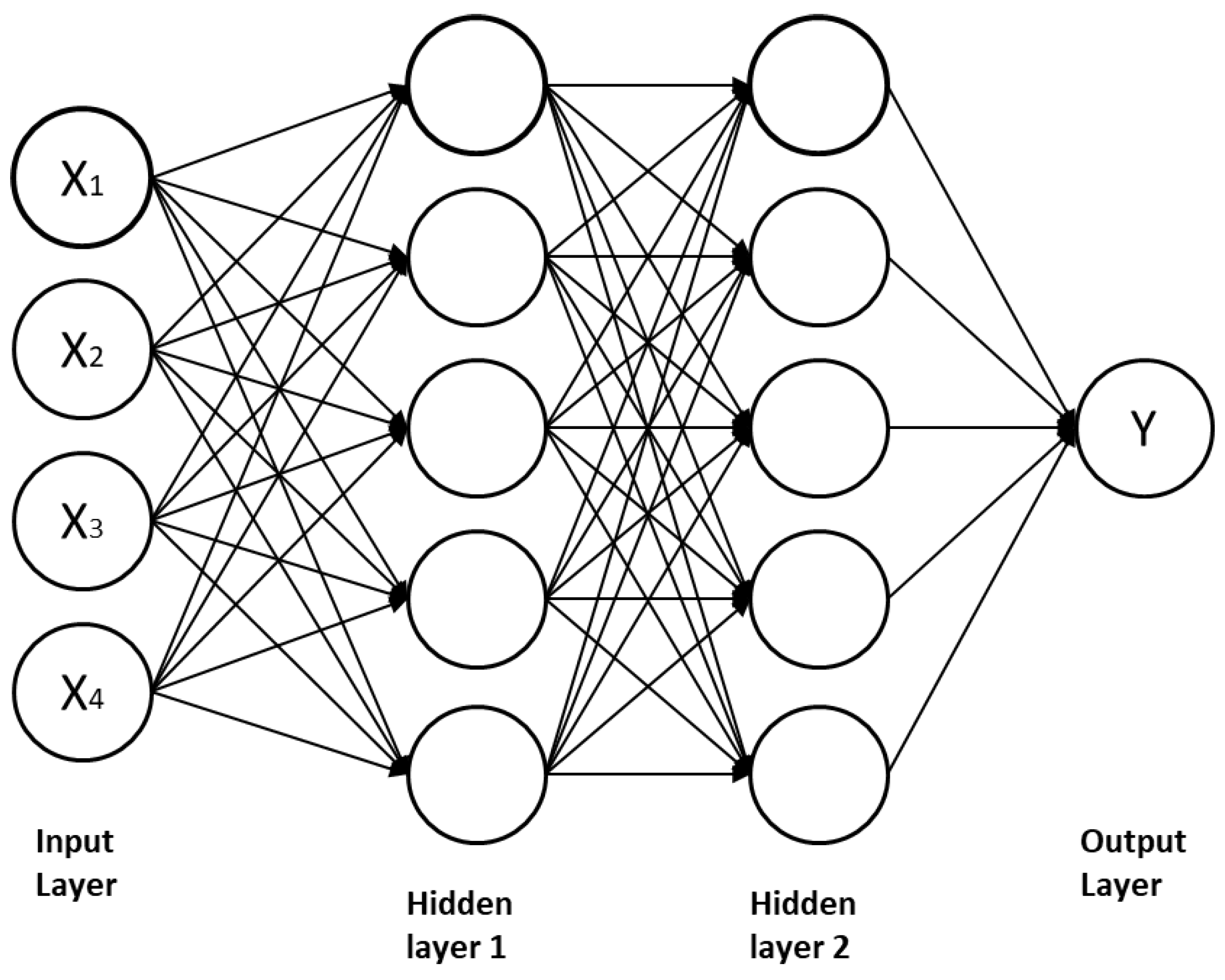
3.2.1. The Multi-Layer Perceptron (MLP)
3.2.2. The Convolutional Neural Networks (CNN)
3.2.3. The Recurrent Neural Network (RNN)
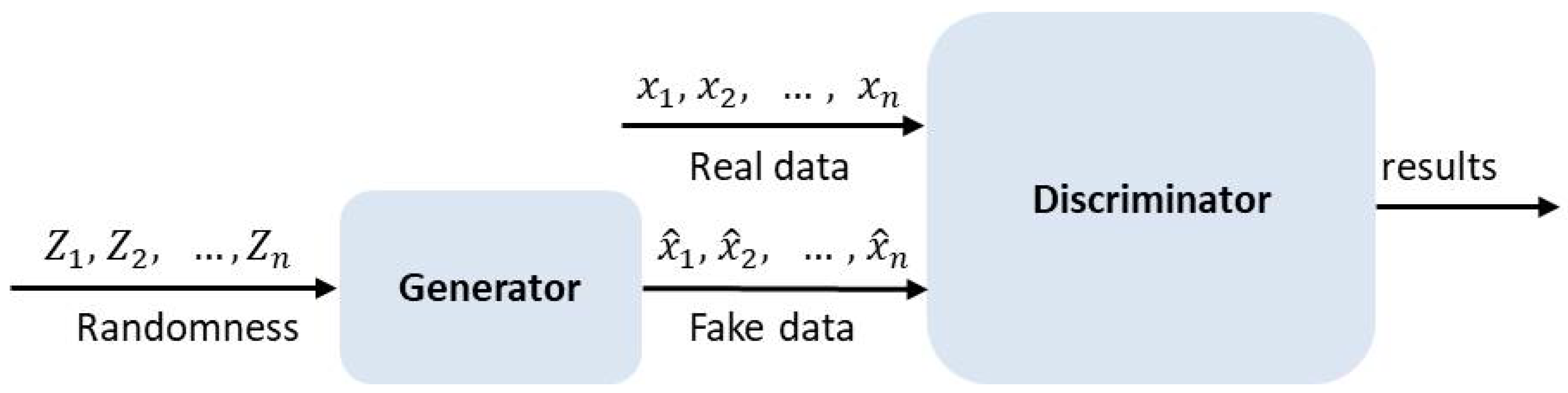
3.2.4. The Generative Adversarial Network (GAN)
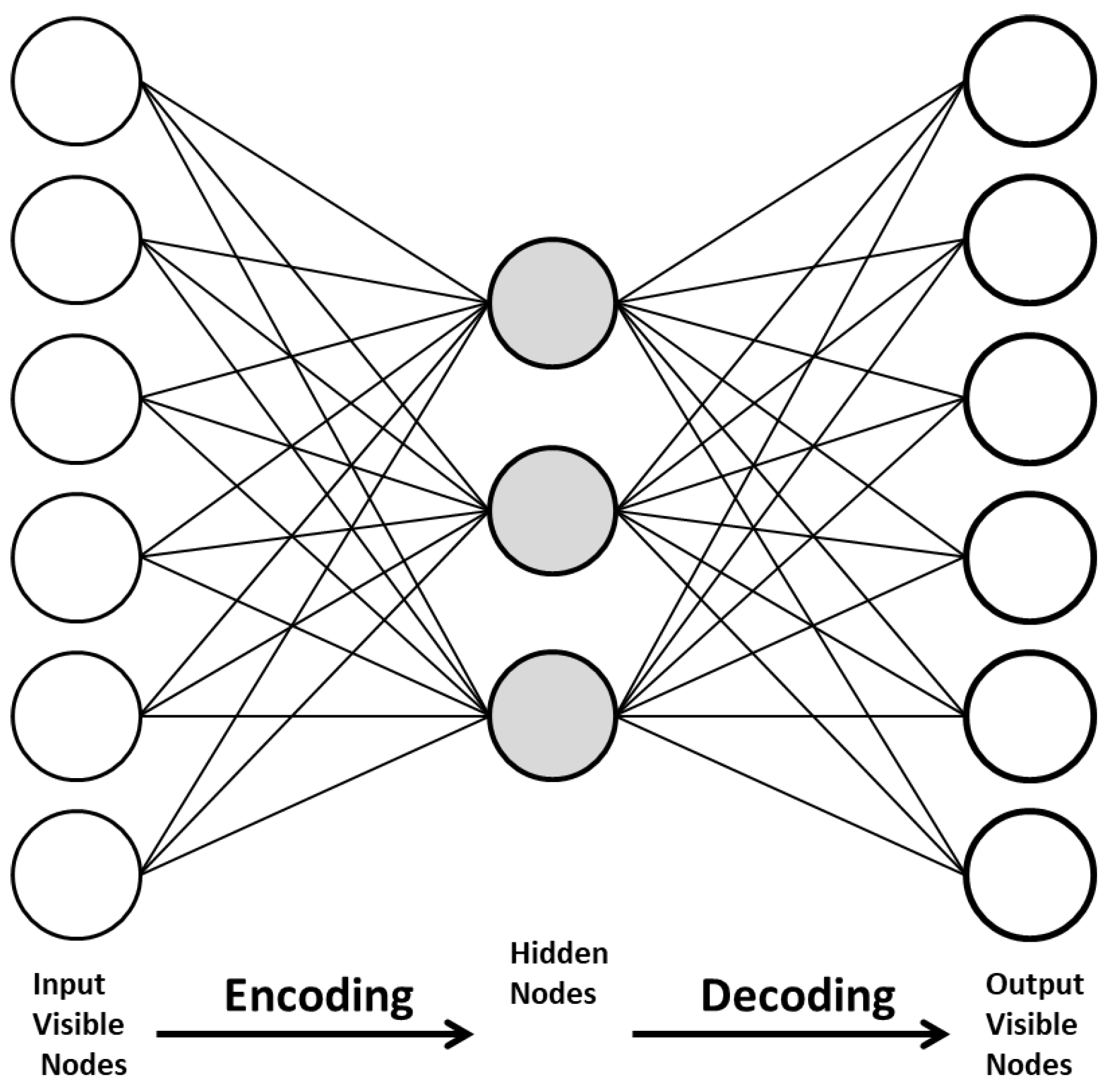
3.2.5. The Auto-Encoders (AE)
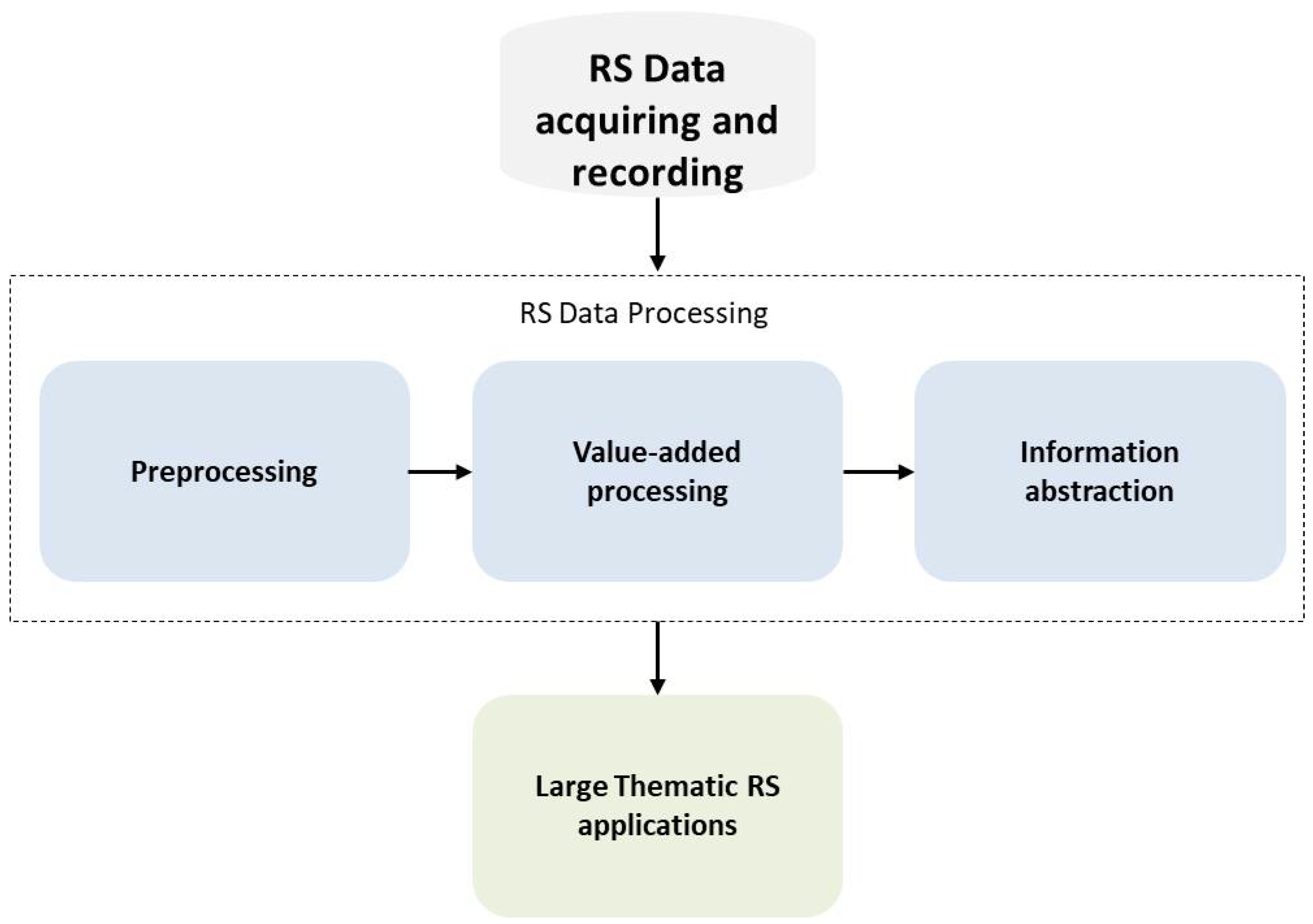
4. Background on SITS
4.1. Description of Satellite Images
- First, SI usually have many more pixels than a classical image considering that a photograph can already contain thousands of pixels;
- Second, SI and natural images do not have the same number of channels. Natural pictures have three channels: one for the red color, one for the green color, and one for the blue color (RGB). In addition to the three previous channels, SI can contain dozens of other channels; and
- Finally, SI are all geo-referenced.
- Spatial resolution: the size of the smallest element that can be observed by the sensor. Satellite image resolutions range from low to high and very high spatial resolution.
- Spectral resolution: refers to the bandwidth of each channel.
- Radiometric resolution: describes the ability to differentiate fine nuances in magnitudes of the electromagnetic energy (coding).
- Temporal resolution: the time between the acquisition of two images representing the same scene (satellite revisiting time).
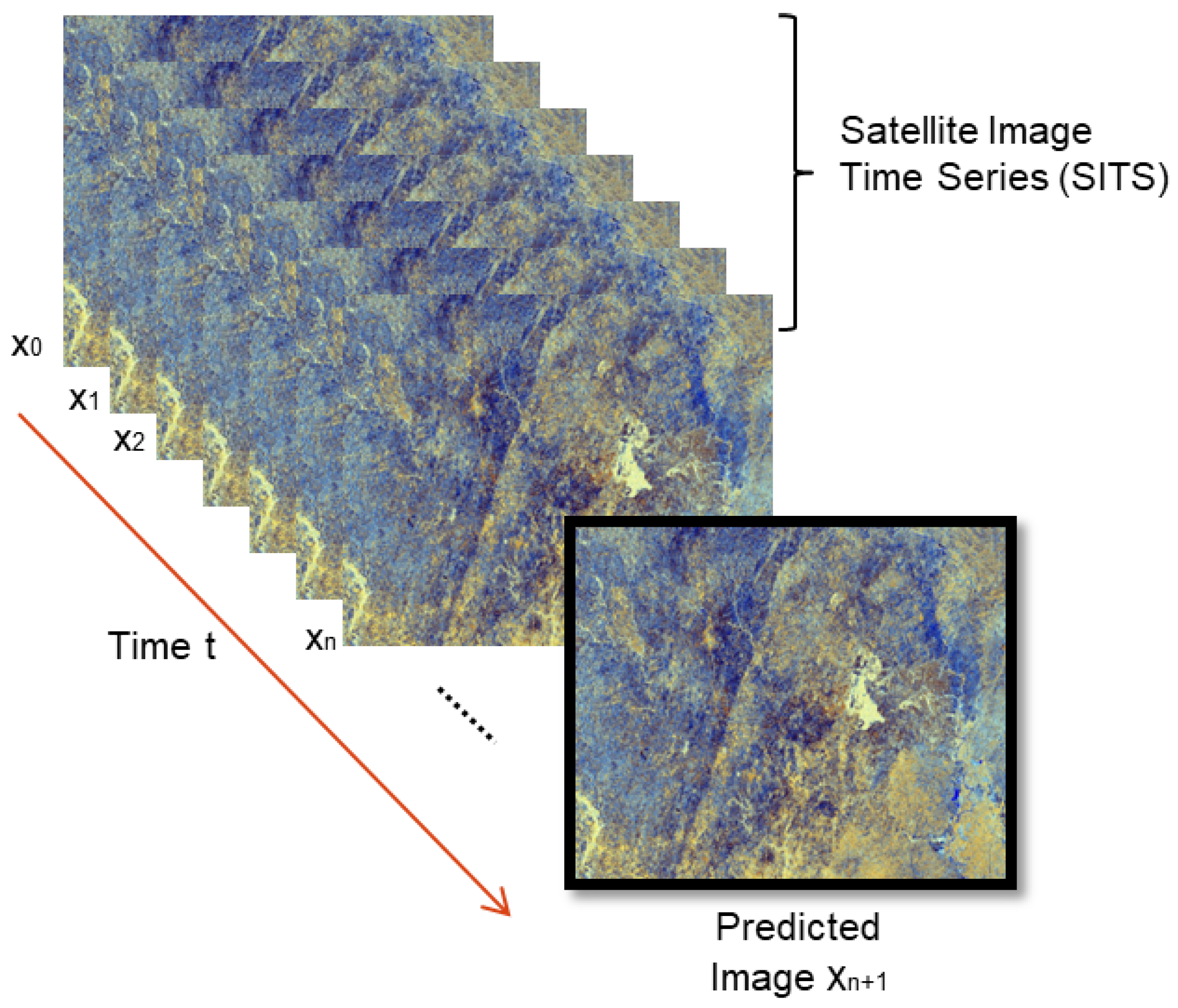
4.2. Description of the SITS Prediction Problem
- “one-to-sequence”: from one input, the model generates many outputs. For instance, from one image provided as input, a sequence of words are generated as output (image captioning);
- “sequence-to-one”: here, inputs are a sequence and only one occurrence is produced as an output. That is, for example, the case of the next frame forecasting problem in time series, as illustrated in Figure 7; and
- “sequence-to-sequence”: in this case, both of the inputs and outputs are sequences, as in text translation tasks, for instance.
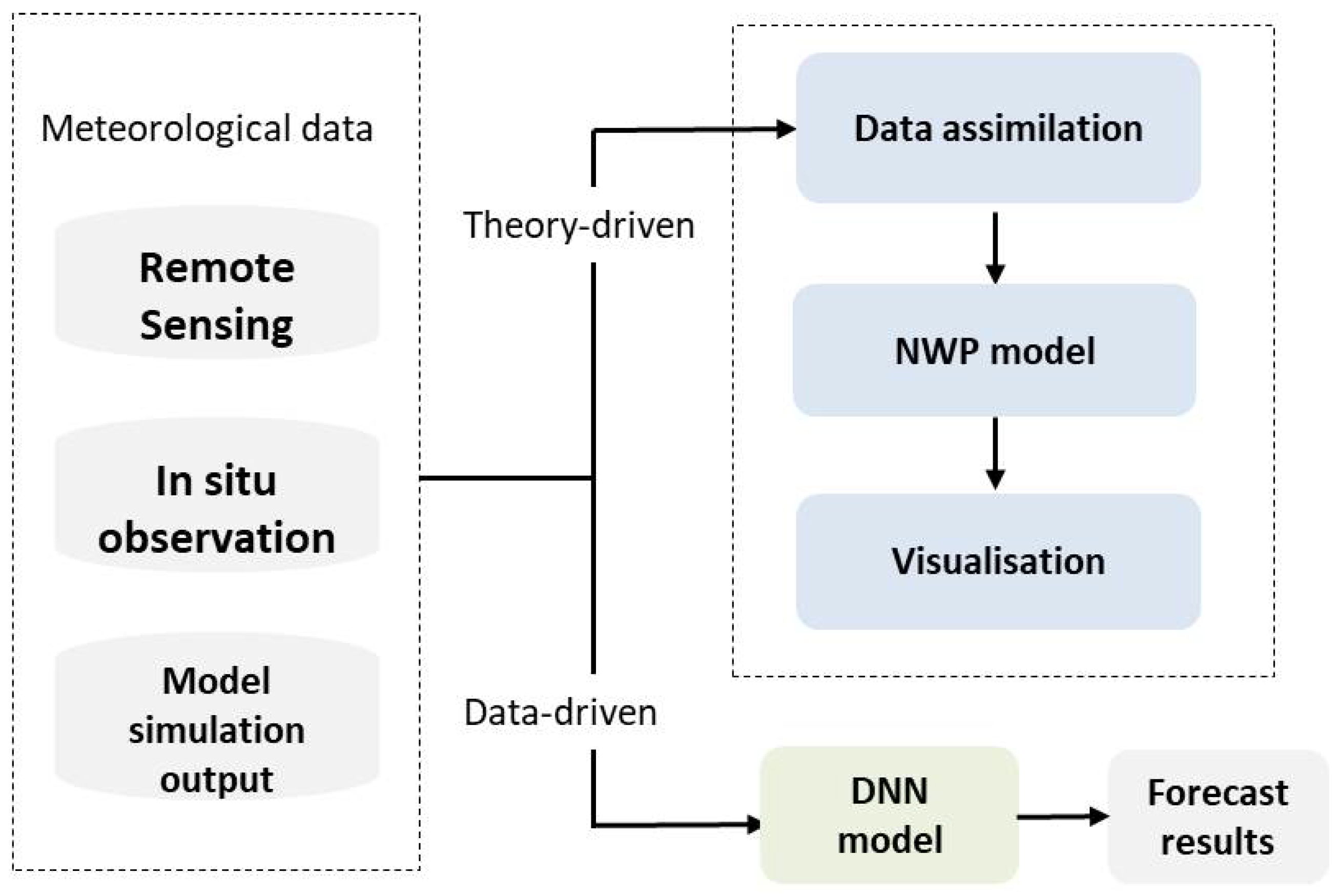
5. Major Applications of SITS Prediction Using DL
5.1. Weather Forecasting
5.2. Precipitation Nowcasting
5.3. Spatio-Temporal Analysis
5.4. Missing Data Reconstruction
6. Deep Learning-Based Methods for SITS Prediction
6.1. RNN-Based Models
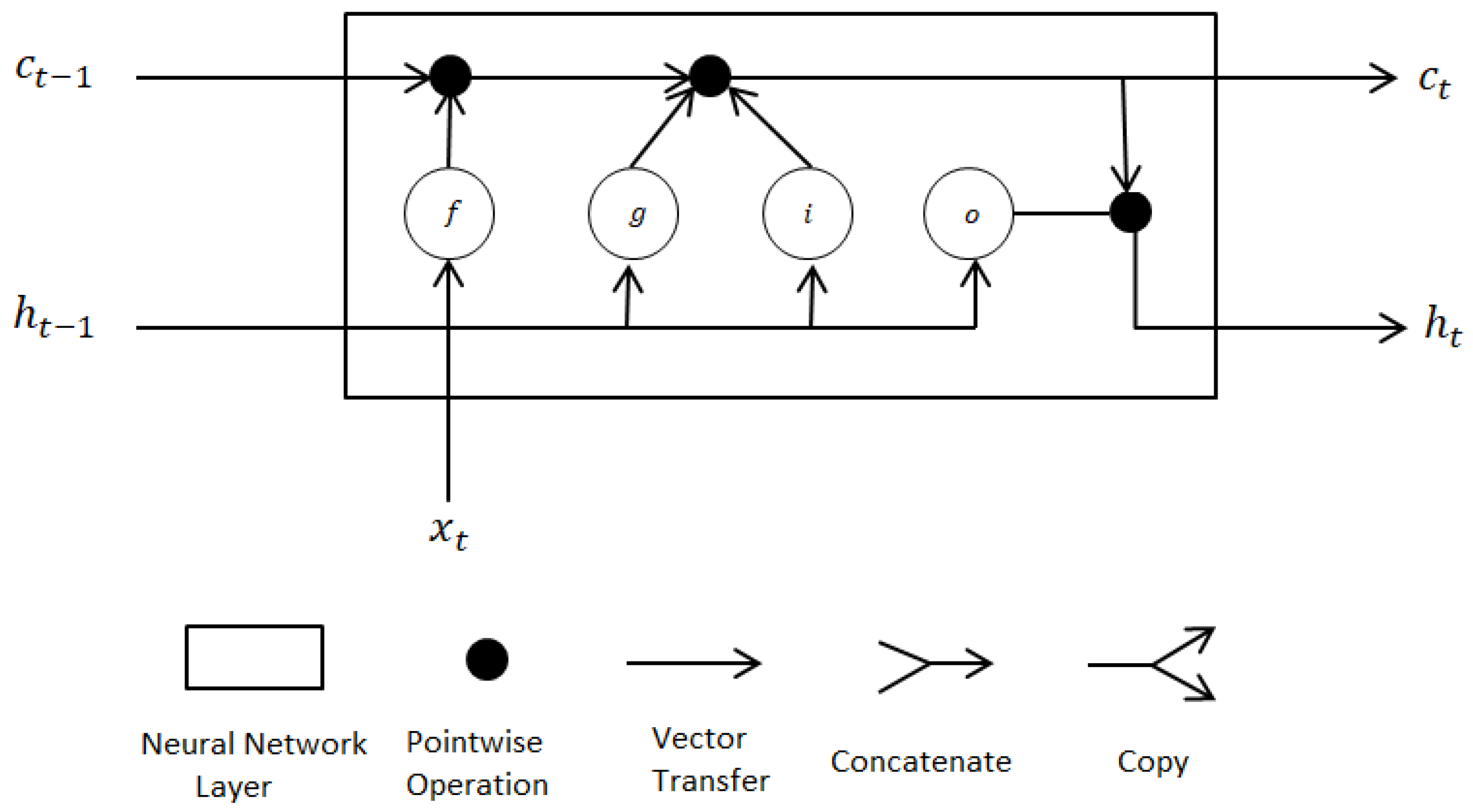
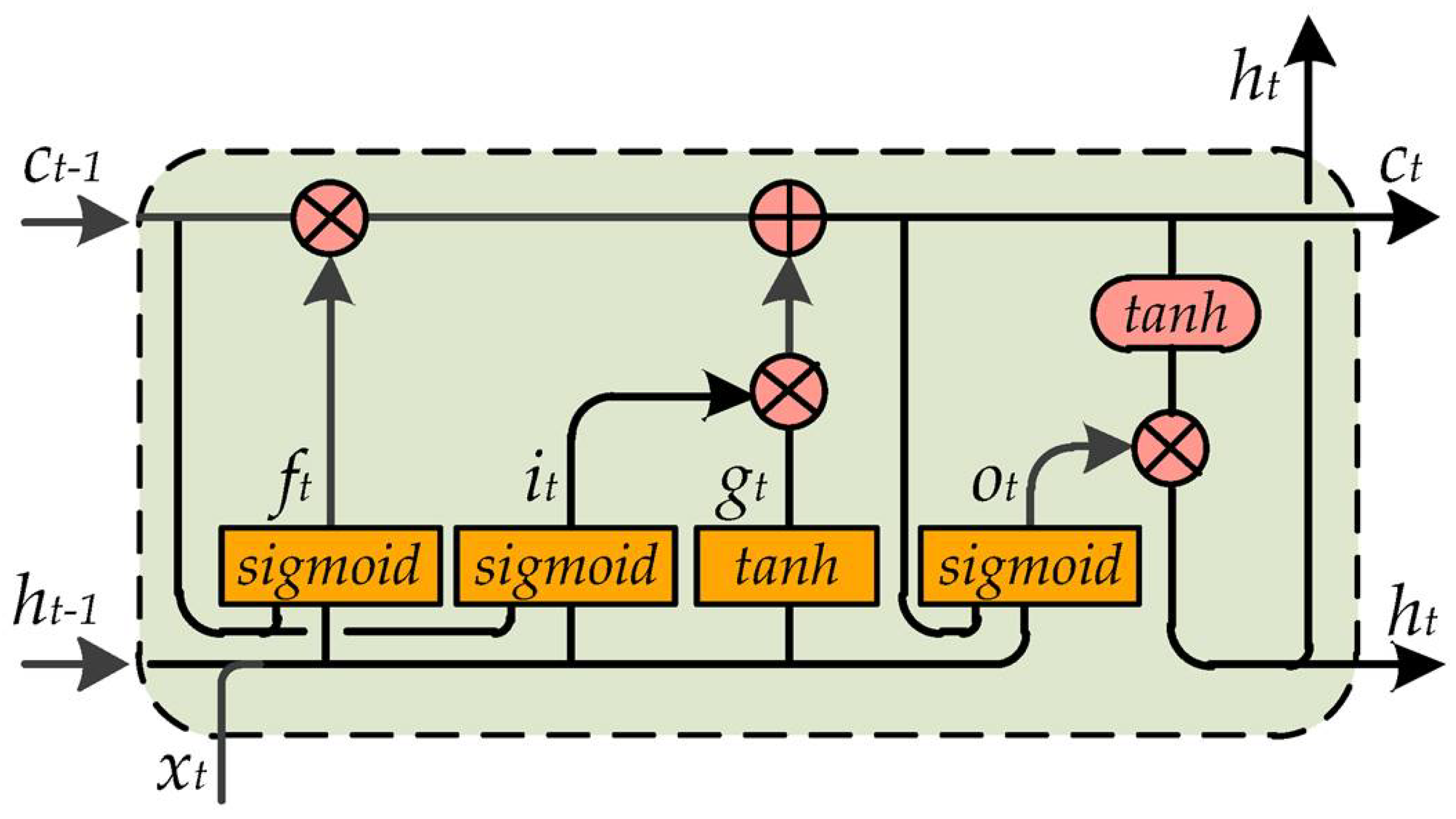
6.1.1. Long/Short-Term Memory
- and represent the cell state and hidden state at time t, respectively;
- , , and are the input, the forget, and the output gate at time t, respectively;
- is the cell candidate at time t;
- is the input vector to the LSTM unit;
- are the input weights for each component;
- represent the recurrent weight for each component;
- are the bias parameters for each component;
- is the gate activation function (by default sigmoid);
- defines the state activation function (by default tanh); and
- ⊙ is the Hadamart product.
6.1.2. Convolutional LSTM
6.1.3. Trajectory-Gated Recurrent Unit (TrajGRU)
- L represents the number of allowed links;
- denote the flow fields;
- are the weights;
- is the function that selects the positions pointed out by from ;
- represent the memory gate, reset gate, update gate, and new information, respectively;
- is the input;
- f is the activation function; and
- ∘ denotes the Hadamart product.
6.2. Hybrid Models
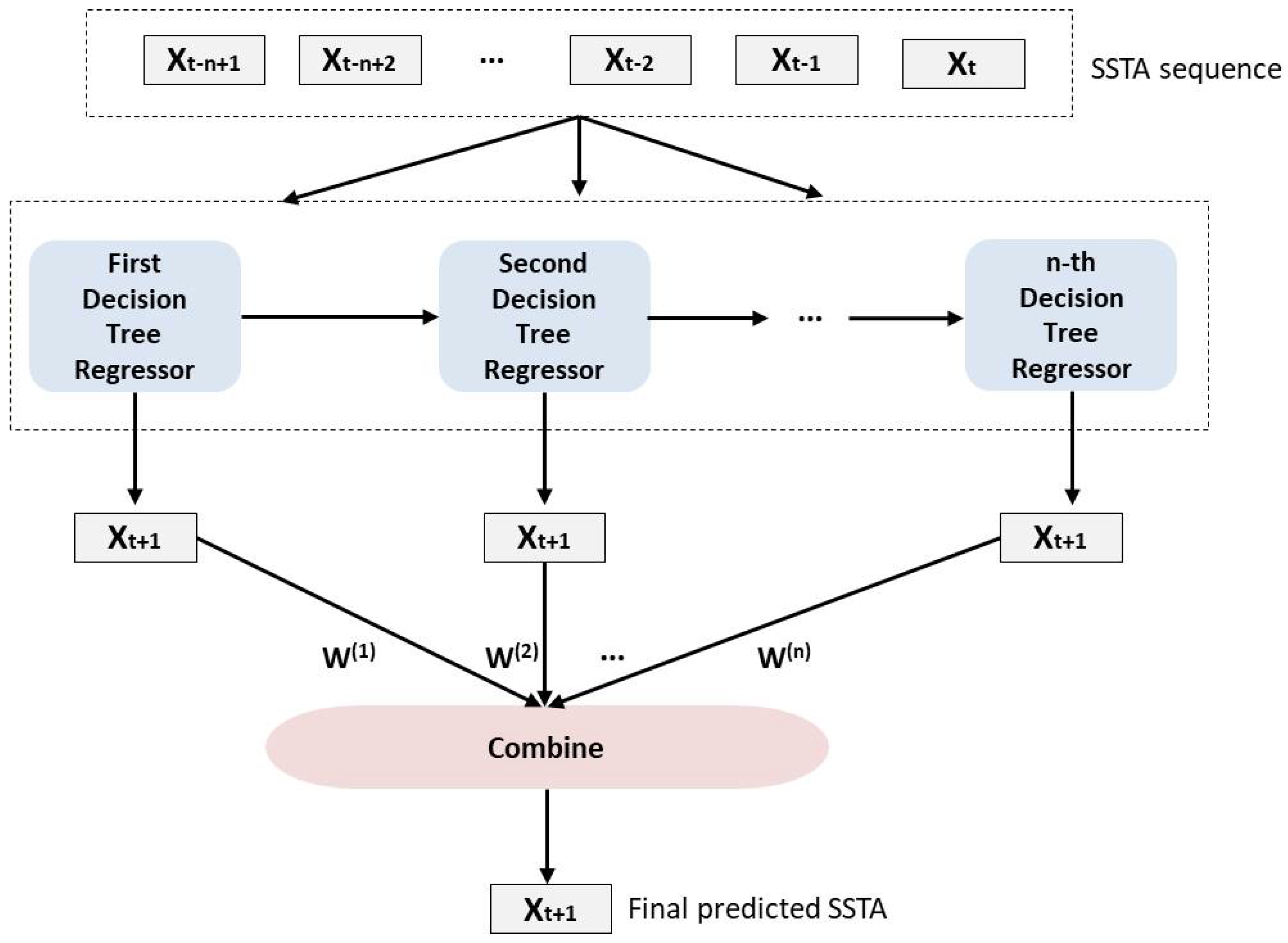
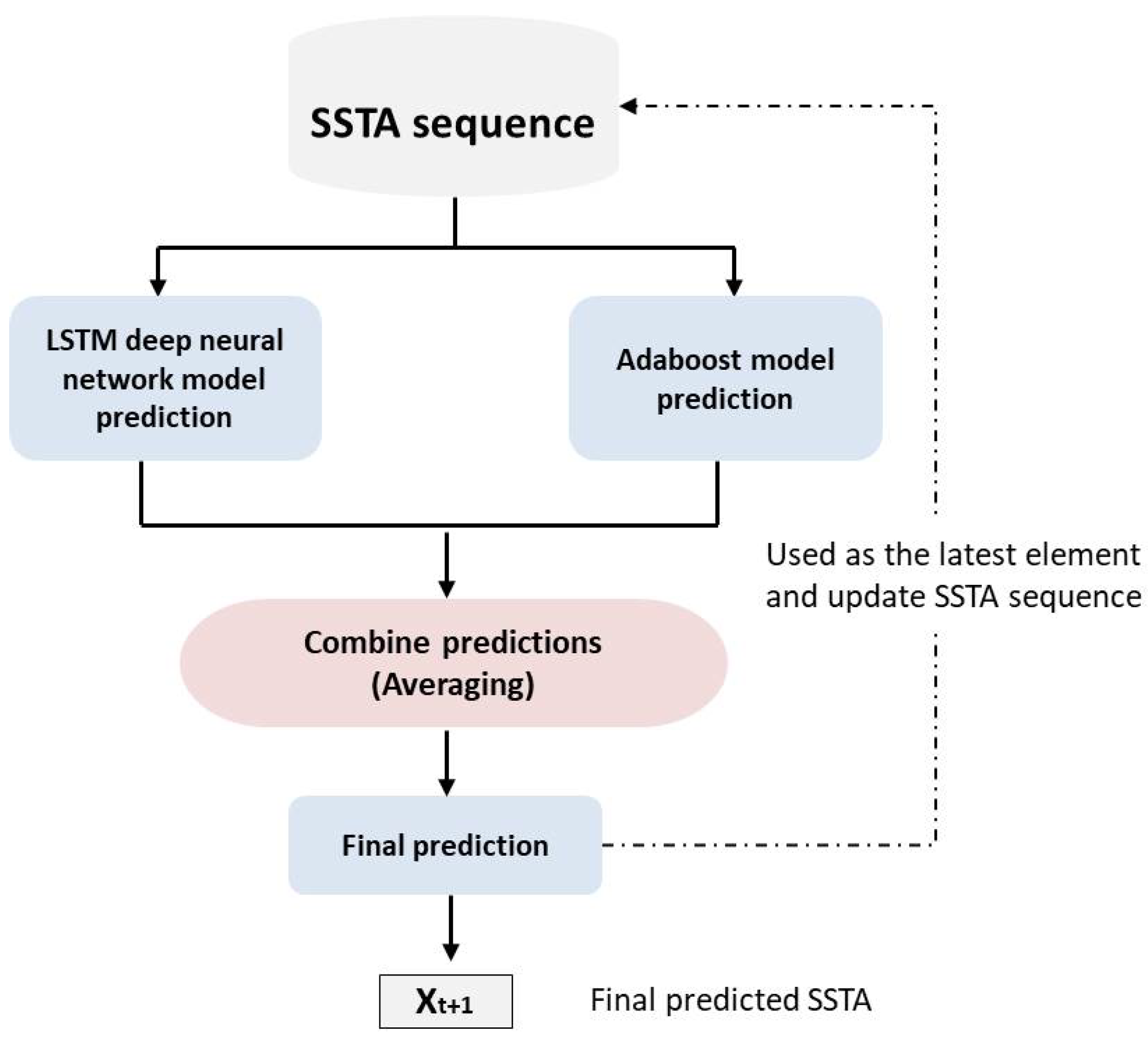
6.2.1. LSTM–AdaBoost
6.2.2. Generative Adversarial Network–LSTM (GAN–LSTM)
| Algorithm 1 GAN Training Algorithm. |
Require:, the learning rate; m, the batch size; and , the number of iterations of the discriminator per generator iteration. Require:, the initial discriminators parameters, and , the initial generators parameters. for number of training iterations do for ,…, do sample : a batch from the real data. sample : a batch from the noise prior. end for sample : a batch from the noise prior. end for |
| Algorithm 2 GAN–LSTM Training Algorithm. |
Require:, the learning rate, and m, the batch size. Require:, the initial LSTM’s parameters. Train GAN with Algorithm 1 Cut the generator of the trained GAN and attach it to the LSTM for number of training iterations do sample : a batch from the real data. where . end for |
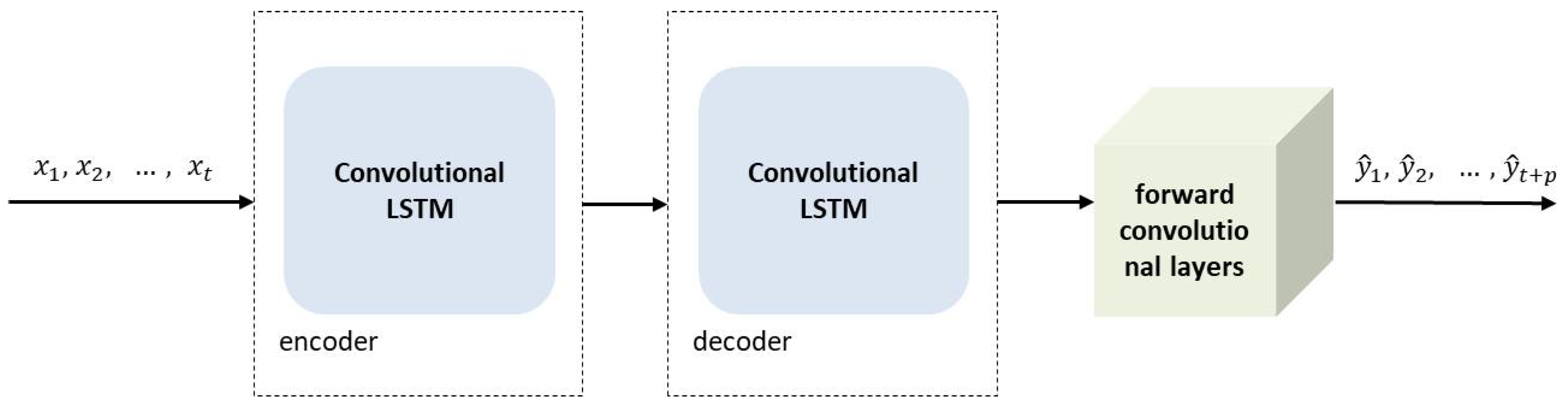
6.2.3. Convolutional LSTM Auto-Encoder
6.3. Feed-Forward-Based Models
6.3.1. DeepstepFE
6.3.2. CNN-Based Approaches

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Class | Ref. | Architecture | Dataset | Weakness | Advantage | Result |
|---|---|---|---|---|---|---|
| FF | [46] | CNN | MODIS and Landsat 7 | Presence of spectral distortion and blurring | Use of multi-source data | |
| [61] | CNN | S1 and S2 | Presence of residual blur | Use of multi-source data | ||
| [62] | CNN | MODIS | Necessity to choose data for input | Accurate predictions | ||
| [60] | MLP | Landsat 7 | Not working with raw satellite imagery | Use of the earlier and subsequent data | ||
| [44] | MLP | Landsat 7 | Needs to create the NDVI map first | Good execution time | 2118 seconds | |
| [63] | FFNN | TS-X, SP4-5, F-2, and RSAT2 | Does not perform well on optical images | Use of multi-source data | ||
| [64] | FFNN | Meteosat 7 | Not optimal for operational uses | High prediction accuracy | ||
| RNN | [47] | LSTM | MODIS | Depends on the time of day | Accurate predictions | |
| [49] | LSTM | MODIS | Depends on weather conditions | Can be applied to other regions | ||
| [51] | ConvLSTM | Radar echo | Can not perform many-to-many prediction | Applied on four-channel data | ||
| [40] | ConvLSTM | Radar echo | Not suitable for long series | Accurate predictions of future rainfull | ||
| [45] | ConvLSTM | OISST2 | Adapted to restricted cases | Can capture both the spatial and temporal correlations | ||
| [52] | ConvLSTM | FY-2Y | Blur effect on the predicted images | Good accuracy | ||
| [53] | Radar echo | ConvGRU and TrajGRU | Needs to be trained several times | Cheap and effective solution | ||
| Hybrid | [55] | LSTM–Adaboost | AVHRR | Series need to be deseasonalized first | Less overfitting | : |
| [65] | ConvGRU–CNN | S1 and S2 | Requires many radar images | Transferable to other study areas | ||
| [57] | GAN–LSTM | FY-2F | Only one channel of the images is considered | Robust solution | ||
| [25] | ESS–MLP | Radar echo | Many steps before predictions | Good accuracy | ||
| [43] | CNN–LSTM | AMSR E2 | Only one channel of the images is considered | Can perform predictions several days in the future | ||
| [42] | RNN–NARX | HJ-1A/1BCCD | Needs to create the index map first | Robust solution | ||
| [66] | RNN–LSTM | Radar echo | Tested on small images | Performs well on videos | ||
| [59] | ConvLSTM–AE | COMS1 | Resolution of predicted images is not good | Predicts unseen weather situations |
7. Optimizer and Evaluation Metrics Used for SITS Prediction
7.1. Optimizer
7.1.1. The Stochastic Gradient Descent (SGD)
7.1.2. The Root Mean Square Propagation (RMSProp)
7.1.3. The Adaptive Moment (Adam)
- denotes the initial learning rate;
- is the gradient at time t;
- represents the exponential average of the gradient;
- represents the exponential average of the square of the gradient;
- and are hyperparameters; and
- and each parameter is replaced by w for more clarity.
7.2. Evaluation Metrics
7.2.1. Regression Metrics
7.2.2. Computer Vision Metrics
| Prediction Domain | Ref. | Dataset | Architecture | Optimizer | Categories of Evaluation Metrics | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Adam | RMSProp | SGD | Class. | CV | Proc. | Prop. | Regres. | Stat. | ||||
| Missing data | [65] | Sentinel 1 and Sentinel 2 | ConvGRU + CNN | NA | NA | NA | √ | |||||
| [46] | MODIS and Landsat 7 | CNN | √ | √ | √ | |||||||
| [61] | Sentinel 1 and Sentinel 2 | CNN | NA | NA | NA | √ | √ | |||||
| [60] | Landsat 7 | Deep MLP | NA | NA | NA | √ | √ | √ | ||||
| [47] | MODIS | LSTM | √ | √ | √ | |||||||
| Precipitation | [53] | Radar echo | ConvLSTM, Conv, and Traj–GRU | NA | NA | NA | √ | |||||
| [51] | Radar echo | ConvLSTM | √ | √ | ||||||||
| [40] | Radar echo | ConvLSTM | NA | NA | NA | √ | √ | |||||
| [58] | Radar echo | GAN + ConvGRU | NA | NA | NA | √ | ||||||
| [48] | Radar echo | LSTM | √ | √ | √ | |||||||
| [64] | Meteosat 7 | Deep FFNN | NA | NA | NA | √ | √ | |||||
| [25] | Radar echo | SOM and ESS + MLP | NA | NA | NA | √ | ||||||
| Spatio-temp | [45] | OISST2 | ConvLSTM | √ | √ | √ | ||||||
| [44] | Landsat 7 | Deep MLP | √ | √ | √ | |||||||
| [43] | AMSR E-2 | CNN + LSTM | √ | √ | √ | |||||||
| [42] | HJ-1A/1B CCD | RNN + NARX | NA | NA | NA | √ | √ | |||||
| [27] | MODIS | RNN + NARX | NA | NA | NA | √ | √ | |||||
| [66] | Radar echo | RNN + LSTM | √ | √ | √ | |||||||
| Weather | [59] | COMS-1 | ConvLSTM + AE | √ | √ | |||||||
| [57] | FY-2F | GAN + LSTM | NA | NA | NA | |||||||
| [52] | FY-2F | ConvLSTM | √ | √ | √ | √ | ||||||
| [55] | AVHRR | AdaBoost + LSTM | NA | NA | NA | √ | ||||||
| Crop yield | [62] | MODIS | CNN | NA | NA | NA | √ | |||||
| [49] | MODIS | LSTM | √ | √ | ||||||||
| [63] | T.SAR-X and FORMOSAT2 | Deep FFNN | NA | NA | NA | √ | ||||||
7.2.3. Statistical Metrics
7.2.4. Processing Metrics
7.2.5. Classification Metrics
7.2.6. Proposed Metrics
8. Limitations in the Use of DL for SITS Prediction
8.1. Limits Related to Training Dataset Availability
8.2. Preprocessing of Datasets
8.3. Architecture of DL-Networks
8.4. Complexity of SI
8.5. Generalization of DL Models
9. Conclusions
- Dimensionality reduction;
- Few-shot learning for SITS prediction;
- Meta-learning and transfer-learning;
- Future land cover change prediction using DL;
- Application of DL method to raw SITS; and
- Data augmentation techniques for SITS.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Gamboa, J.C.B. Deep learning for time-series analysis. arXiv 2017, arXiv:1701.01887. [Google Scholar]
- Purnamasayangsukasih, P.R.; Norizah, K.; Ismail, A.A.; Shamsudin, I. A review of uses of satellite imagery in monitoring mangrove forests. IOP Conf. Ser. Earth Environ. Sci. 2016, 37, 012034. [Google Scholar] [CrossRef]
- Huang, Y.; Chen, Z.X.; Tao, Y.; Huang, X.Z.; Gu, X.F. Agricultural remote sensing big data: Management and applications. J. Integr. Agric. 2018, 17, 1915–1931. [Google Scholar] [CrossRef]
- Brownlee, J. Deep Learning for Time Series Forecasting: Predict the Future with MLPs, CNNs and LSTMs in Python; Machine Learning Mastery: New York, NY, USA, 2018. [Google Scholar]
- El Jazouli, A.; Barakat, A.; Khellouk, R.; Rais, J.; El Baghdadi, M. Remote sensing and GIS techniques for prediction of land use land cover change effects on soil erosion in the high basin of the Oum Er Rbia River (Morocco). Remote Sens. Appl. Soc. Environ. 2019, 13, 361–374. [Google Scholar] [CrossRef]
- Fauvel, M.; Lopes, M.; Dubo, T.; Rivers-Moore, J.; Frison, P.L.; Gross, N.; Ouin, A. Prediction of plant diversity in grasslands using Sentinel-1 and-2 satellite image time series. Remote Sens. Environ. 2020, 237, 111536. [Google Scholar] [CrossRef]
- Oancea, B.; Ciucu, Ş.C. Time series forecasting using neural networks. arXiv 2014, arXiv:1401.1333. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Chi, J.; Kim, H.c. Prediction of arctic sea ice concentration using a fully data driven deep neural network. Remote Sens. 2017, 9, 1305. [Google Scholar] [CrossRef] [Green Version]
- Tealab, A. Time series forecasting using artificial neural networks methodologies: A systematic review. Future Comput. Inform. J. 2018, 3, 334–340. [Google Scholar] [CrossRef]
- Shi, X.; Yeung, D.Y. Machine learning for spatiotemporal sequence forecasting: A survey. arXiv 2018, arXiv:1808.06865. [Google Scholar]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- van Klompenburg, T.; Kassahun, A.; Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
- Patrício, D.I.; Rieder, R. Computer vision and artificial intelligence in precision agriculture for grain crops: A systematic review. Comput. Electron. Agric. 2018, 153, 69–81. [Google Scholar] [CrossRef] [Green Version]
- Salcedo-Sanz, S.; Ghamisi, P.; Piles, M.; Werner, M.; Cuadra, L.; Moreno-Martínez, A.; Izquierdo-Verdiguier, E.; Muñoz-Marí, J.; Mosavi, A.; Camps-Valls, G. Machine learning information fusion in Earth observation: A comprehensive review of methods, applications and data sources. Inf. Fusion 2020, 63, 256–272. [Google Scholar] [CrossRef]
- Shen, H.; Li, X.; Cheng, Q.; Zeng, C.; Yang, G.; Li, H.; Zhang, L. Missing information reconstruction of remote sensing data: A technical review. IEEE Geosci. Remote Sens. Mag. 2015, 3, 61–85. [Google Scholar] [CrossRef]
- Torres, J.F.; Hadjout, D.; Sebaa, A.; Martínez-Álvarez, F.; Troncoso, A. Deep Learning for Time Series Forecasting: A Survey. Big Data 2021, 9, 3–21. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Patterson, J.; Gibson, A. Deep Learning: A Practitioner’s Approach; O’Reilly Media, Inc.: Newton, MA, USA, 2017. [Google Scholar]
- Dong, Z.; Yang, D.; Reindl, T.; Walsh, W.M. Satellite image analysis and a hybrid ESSS/ANN model to forecast solar irradiance in the tropics. Energy Convers. Manag. 2014, 79, 66–73. [Google Scholar] [CrossRef]
- Lago, J.; De Brabandere, K.; De Ridder, F.; De Schutter, B. Short-term forecasting of solar irradiance without local telemetry: A generalized model using satellite data. Sol. Energy 2018, 173, 566–577. [Google Scholar] [CrossRef] [Green Version]
- Sauter, T.; Weitzenkamp, B.; Schneider, C. Spatio-temporal prediction of snow cover in the Black Forest mountain range using remote sensing and a recurrent neural network. Int. J. Climatol. 2010, 30, 2330–2341. [Google Scholar] [CrossRef]
- Alzahrani, A.; Shamsi, P.; Dagli, C.; Ferdowsi, M. Solar irradiance forecasting using deep neural networks. Procedia Comput. Sci. 2017, 114, 304–313. [Google Scholar] [CrossRef]
- Stepchenko, A.; Chizhov, J.; Aleksejeva, L.; Tolujew, J. Nonlinear, non-stationary and seasonal time series forecasting using different methods coupled with data preprocessing. Procedia Comput. Sci. 2017, 104, 578–585. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Khokhlova, M.; Migniot, C.; Morozov, A.; Sushkova, O.; Dipanda, A. Normal and pathological gait classification LSTM model. Artif. Intell. Med. 2019, 94, 54–66. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Ballas, N.; Yao, L.; Pal, C.; Courville, A. Delving deeper into convolutional networks for learning video representations. arXiv 2015, arXiv:1511.06432. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Mao, W.; Feng, W.; Liu, Y.; Zhang, D.; Liang, X. A new deep auto-encoder method with fusing discriminant information for bearing fault diagnosis. Mech. Syst. Signal Process. 2021, 150, 107233. [Google Scholar] [CrossRef]
- Eibedingil, I.G.; Gill, T.E.; Van Pelt, R.S.; Tong, D.Q. Combining Optical and Radar Satellite Imagery to Investigate the Surface Properties and Evolution of the Lordsburg Playa, New Mexico, USA. Remote Sens. 2021, 13, 3402. [Google Scholar] [CrossRef]
- Petitjean, F.; Inglada, J.; Gançarski, P. Satellite image time series analysis under time warping. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3081–3095. [Google Scholar] [CrossRef]
- Simoes, R.; Camara, G.; Queiroz, G.; Souza, F.; Andrade, P.R.; Santos, L.; Carvalho, A.; Ferreira, K. Satellite Image Time Series Analysis for Big Earth Observation Data. Remote Sens. 2021, 13, 2428. [Google Scholar] [CrossRef]
- Ren, X.; Li, X.; Ren, K.; Song, J.; Xu, Z.; Deng, K.; Wang, X. Deep Learning-Based Weather Prediction: A Survey. Big Data Res. 2021, 23, 100178. [Google Scholar] [CrossRef]
- Xingjian, S.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 1, pp. 802–810. [Google Scholar]
- Shi, X.; Gao, Z.; Lausen, L.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Deep learning for precipitation nowcasting: A benchmark and a new model. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5617–5627. [Google Scholar]
- Chen, B.; Wu, Z.; Wang, J.; Dong, J.; Guan, L.; Chen, J.; Yang, K.; Xie, G. Spatio-temporal prediction of leaf area index of rubber plantation using HJ-1A/1B CCD images and recurrent neural network. ISPRS J. Photogramm. Remote Sens. 2015, 102, 148–160. [Google Scholar] [CrossRef]
- Petrou, Z.I.; Tian, Y. Prediction of Sea Ice Motion with Convolutional Long Short-Term Memory Networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6865–6876. [Google Scholar] [CrossRef]
- Das, M.; Ghosh, S.K. Deep-STEP: A deep learning approach for spatiotemporal prediction of remote sensing data. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1984–1988. [Google Scholar] [CrossRef]
- Xiao, C.; Chen, N.; Hu, C.; Wang, K.; Xu, Z.; Cai, Y.; Xu, L.; Chen, Z.; Gong, J. A spatiotemporal deep learning model for sea surface temperature field prediction using time-series satellite data. Environ. Model. Softw. 2019, 120, 104502. [Google Scholar] [CrossRef]
- Zhang, Q.; Yuan, Q.; Zeng, C.; Li, X.; Wei, Y. Missing data reconstruction in remote sensing image with a unified spatial–temporal–spectral deep convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4274–4288. [Google Scholar] [CrossRef] [Green Version]
- Arslan, N.; Sekertekin, A. Application of Long Short-Term Memory neural network model for the reconstruction of MODIS Land Surface Temperature images. J. Atmos. Sol.-Terr. Phys. 2019, 194, 105100. [Google Scholar] [CrossRef]
- Zaytar, M.A.; El Amrani, C. Sequence to sequence weather forecasting with long short-term memory recurrent neural networks. Int. J. Comput. Appl. 2016, 143, 7–11. [Google Scholar]
- Schwalbert, R.A.; Amado, T.; Corassa, G.; Pott, L.P.; Prasad, P.V.; Ciampitti, I.A. Satellite-based soybean yield forecast: Integrating machine learning and weather data for improving crop yield prediction in southern Brazil. Agric. For. Meteorol. 2020, 284, 107886. [Google Scholar] [CrossRef]
- Li, Y.; Xu, H.; Bian, M.; Xiao, J. Attention based CNN-ConvLSTM for pedestrian attribute recognition. Sensors 2020, 20, 811. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.; Hong, S.; Joh, M.; Song, S.K. Deeprain: Convlstm network for precipitation prediction using multichannel radar data. arXiv 2017, arXiv:1711.02316. [Google Scholar]
- Tan, C.; Feng, X.; Long, J.; Geng, L. FORECAST-CLSTM: A new convolutional LSTM network for cloudage nowcasting. In Proceedings of the 2018 IEEE Visual Communications and Image Processing (VCIP), Taichung, Taiwan, 9–12 December 2018; pp. 1–4. [Google Scholar]
- Tran, Q.K.; Song, S.K. Computer Vision in Precipitation Nowcasting: Applying Image Quality Assessment Metrics for Training Deep Neural Networks. Atmosphere 2019, 10, 244. [Google Scholar] [CrossRef] [Green Version]
- Xie, S.; Wu, W.; Mooser, S.; Wang, Q.; Nathan, R.; Huang, Y. Artificial neural network based hybrid modeling approach for flood inundation modeling. J. Hydrol. 2021, 592, 125605. [Google Scholar] [CrossRef]
- Xiao, C.; Chen, N.; Hu, C.; Wang, K.; Gong, J.; Chen, Z. Short and mid-term sea surface temperature prediction using time-series satellite data and LSTM-AdaBoost combination approach. Remote Sens. Environ. 2019, 233, 111358. [Google Scholar] [CrossRef]
- Nelson, M.; Hill, T.; Remus, W.; O’Connor, M. Time series forecasting using neural networks: Should the data be deseasonalized first? J. Forecast. 1999, 18, 359–367. [Google Scholar] [CrossRef]
- Xu, Z.; Du, J.; Wang, J.; Jiang, C.; Ren, Y. Satellite Image Prediction Relying on GAN and LSTM Neural Networks. In Proceedings of the ICC 2019–2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–21 May 2019; pp. 1–6. [Google Scholar]
- Tian, L.; Li, X.; Ye, Y.; Xie, P.; Li, Y. A Generative Adversarial Gated Recurrent Unit Model for Precipitation Nowcasting. IEEE Geosci. Remote Sens. Lett. 2019, 17, 601–605. [Google Scholar] [CrossRef]
- Hong, S.; Kim, S.; Joh, M.; Song, S.K. Psique: Next sequence prediction of satellite images using a convolutional sequence-to-sequence network. arXiv 2017, arXiv:1711.10644. [Google Scholar]
- Das, M.; Ghosh, S.K. A deep-learning-based forecasting ensemble to predict missing data for remote sensing analysis. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 5228–5236. [Google Scholar] [CrossRef]
- Mazza, A.; Gargiulo, M.; Scarpa, G.; Gaetano, R. Estimating the NDVI from SAR by Convolutional Neural Networks. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1954–1957. [Google Scholar]
- Terliksiz, A.S.; Altỳlar, D.T. Use Of Deep Neural Networks For Crop Yield Prediction: A Case Study Of Soybean Yield in Lauderdale County, Alabama, USA. In Proceedings of the 2019 8th International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Istanbul, Turkey, 16–19 July 2019; pp. 1–4. [Google Scholar]
- Fieuzal, R.; Baup, F. Forecast of wheat yield throughout the agricultural season using optical and radar satellite images. Int. J. Appl. Earth Obs. Geoinf. 2017, 59, 147–156. [Google Scholar] [CrossRef]
- Rivolta, G.; Marzano, F.; Coppola, E.; Verdecchia, M. Artificial neural-network technique for precipitation nowcasting from satellite imagery. Adv. Geosci. 2006, 7, 97–103. [Google Scholar] [CrossRef] [Green Version]
- Ienco, D.; Interdonato, R.; Gaetano, R.; Minh, D.H.T. Combining Sentinel-1 and Sentinel-2 Satellite Image Time Series for land cover mapping via a multi-source deep learning architecture. ISPRS J. Photogramm. Remote Sens. 2019, 158, 11–22. [Google Scholar] [CrossRef]
- Wang, Y.; Long, M.; Wang, J.; Gao, Z.; Philip, S.Y. Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 879–888. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Tieleman, T.; Hinton, G. Neural Networks for Machine Learning. (Lect. 65-Rmsprop); Coursera. 2012. Available online: https://www.youtube.com/watch?v=defQQqkXEfE (accessed on 15 January 2021).
- Kathuria, A. Intro to Optimization in Deep Learning: Momentum, Rmsprop and Adam. 2018. Available online: https://blog.paperspace.com/intro-to-optimization-momentum-rmsprop-adam/ (accessed on 12 January 2021).
- Botchkarev, A. Performance metrics (error measures) in machine learning regression, forecasting and prognostics: Properties and typology. arXiv 2018, arXiv:1809.03006. [Google Scholar]
- Balti, H.; Abbes, A.B.; Mellouli, N.; Farah, I.R.; Sang, Y.; Lamolle, M. A review of drought monitoring with big data: Issues, methods, challenges and research directions. Ecol. Inform. 2020, 60, 101136. [Google Scholar] [CrossRef]
- Ma, Y.; Wu, H.; Wang, L.; Huang, B.; Ranjan, R.; Zomaya, A.; Jie, W. Remote sensing big data computing: Challenges and opportunities. Future Gener. Comput. Syst. 2015, 51, 47–60. [Google Scholar] [CrossRef] [Green Version]
- Ball, J.E.; Anderson, D.T.; Chan Sr, C.S. Comprehensive survey of deep learning in remote sensing: Theories, tools, and challenges for the community. J. Appl. Remote Sens. 2017, 11, 042609. [Google Scholar] [CrossRef] [Green Version]
- Moskolaï, W.; Abdou, W.; Dipanda, A.; Kolyang, D.T. Application of LSTM architectures for next frame forecasting in Sentinel-1 images time series. arXiv 2020, arXiv:2009.00841. [Google Scholar]
- Osco, L.P.; Junior, J.M.; Ramos, A.P.M.; de Castro Jorge, L.A.; Fatholahi, S.N.; de Andrade Silva, J.; Matsubara, E.T.; Pistori, H.; Gonçalves, W.N.; Li, J. A review on deep learning in UAV remote sensing. arXiv 2021, arXiv:2101.10861. [Google Scholar] [CrossRef]
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-learning in neural networks: A survey. arXiv 2020, arXiv:2004.05439. [Google Scholar] [CrossRef]

















| Ref. | Title of the Review | Pub. Year | Was the Review Dedicated to | ||
|---|---|---|---|---|---|
| DL | SITS | Pred. | |||
| [20] | Missing information reconstruction of remote sensing data | 2015 | No | Yes | Yes |
| [1] | Deep Learning for Time-Series Analysis | 2017 | Yes | No | Yes |
| [15] | Deep learning in remote sensing: A comprehensive review and list of resources | 2017 | Yes | Yes | No |
| [12] | Time series forecasting using artificial neural networks methodologies: A systematic review | 2018 | No | No | Yes |
| [13] | Machine Learning for Spatiotemporal Sequence Forecasting: A Survey | 2018 | No | Yes | Yes |
| [18] | Computer vision and artificial intelligence in precision agriculture for grain crops: A systematic review | 2018 | Yes | No | Yes |
| [14] | Deep learning for time series classification: a review | 2019 | Yes | No | No |
| [10] | Deep learning in remote sensing applications: A meta-analysis and review | 2019 | Yes | Yes | No |
| [16] | Deep learning in environmental remote sensing: Achievements and challenges | 2020 | Yes | Yes | No |
| [17] | Crop yield prediction using machine learning: A systematic literature review | 2020 | No | No | Yes |
| [19] | Machine learning information fusion in Earth observation: A comprehensive review of methods, applications and data sources | 2020 | No | Yes | No |
| [9] | A survey of the recent architectures of deep convolutional neural networks | 2020 | Yes | No | No |
| [8] | Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions | 2021 | Yes | No | No |
| [21] | Deep Learning for Time Series Forecasting: A Survey | 2021 | Yes | No | Yes |
| Machine Learning | Deep Learning | |
|---|---|---|
| Input data organization | Structured data | Unstructured data |
| Output data type | Numerical | Anything: sound, image, text, numerical, etc. |
| Optimal data volume | Thousands of data points | Millions of data points: Big Data |
| Features extraction step | Yes | No |
| Transfer learning | No | Yes |
| Complexity | Low to medium | Very high to extremely high |
| Recommended processing unit | CPU | GPU or TPU |
| Applications | Simple problems: classification, regression, etc. | Complex problems: robotics, computer vision, etc. |
| Python libraries | Scikit-learn, Scipy, Pandas, etc. | TensorFlow, PyTorch, Keras, etc. |
| Tool | Description | Hyperlink |
|---|---|---|
| MAJA (MACCS ATCOR Joint Algorithm) | A cloud detection and atmospheric correction chain. It is adapted to the processing of high resolution image time series. | https://logiciels.cnes.fr/fr/node/57?type=desc (accessed on 3 November 2021) |
| OTB (Orfeo toolbox) | An open-source project for state-of-the-art remote sensing. | https://www.orfeo-toolbox.org/ (accessed on 3 November 2021) |
| Monteverdi | A satellite image viewer. | https://www.orfeo-toolbox.org/CookBook/Monteverdi.html (accessed on 3 November 2021) |
| SNAP (Sentinel Application Platform) | A software for Sentinel image processing. | http://step.esa.int/main/download/ (accessed on 3 November 2021) |
| NEST (Next ESA SAT Toolbox) | A software for the processing and analysis of radar and optical spatial data. | http://step.esa.int/main/ (accessed on 3 November 2021) |
| Emmah tools | A tool for image validations. | https://www6.paca.inrae.fr/emmah/ (accessed on 3 November 2021) |
| ILWIS (Integrated Land and Water Information System) | A remote sensing and GIS software that integrates image, vector, and thematic data in one unique and powerful package. | http://52north.org/communities/ilwis (accessed on 3 November 2021) |
| ImageJ | A tool for SI processing and analysis in Java. | http://rsbweb.nih.gov/ij/ (accessed on 3 November 2021) |
| GRASS GIS (Geographic Resources Analysis Support System) | A GIS technology built for vector and raster geospatial data management, geoprocessing, spatial modeling, and visualization. | https://grass.osgeo.org/ (accessed on 3 November 2021) |
| Quantum GIS | A GIS that allows to view, edit, and print maps. | http://qgis.org/ (accessed on 3 November 2021) |
| GuidosToolbox (GTB) | Contains a wide variety of generic raster image processing routines. | https://forest.jrc.ec.europa.eu/en/activities/lpa/gtb/ (accessed on 3 November 2021) |
| SPRING | This represents the latest in GIS, remote sensing, and image processing systems with an object-oriented data model that allows for the integration of vector and raster data representations in a simple environment. | http://www.dpi.inpe.br/spring/francais/index.html (accessed on 3 November 2021) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moskolaï, W.R.; Abdou, W.; Dipanda, A.; Kolyang. Application of Deep Learning Architectures for Satellite Image Time Series Prediction: A Review. Remote Sens. 2021, 13, 4822. https://doi.org/10.3390/rs13234822
Moskolaï WR, Abdou W, Dipanda A, Kolyang. Application of Deep Learning Architectures for Satellite Image Time Series Prediction: A Review. Remote Sensing. 2021; 13(23):4822. https://doi.org/10.3390/rs13234822
Chicago/Turabian StyleMoskolaï, Waytehad Rose, Wahabou Abdou, Albert Dipanda, and Kolyang. 2021. "Application of Deep Learning Architectures for Satellite Image Time Series Prediction: A Review" Remote Sensing 13, no. 23: 4822. https://doi.org/10.3390/rs13234822
APA StyleMoskolaï, W. R., Abdou, W., Dipanda, A., & Kolyang. (2021). Application of Deep Learning Architectures for Satellite Image Time Series Prediction: A Review. Remote Sensing, 13(23), 4822. https://doi.org/10.3390/rs13234822