
An Improved Swin Transformer-Based Model for Remote Sensing Object Detection and Instance Segmentation


Abstract
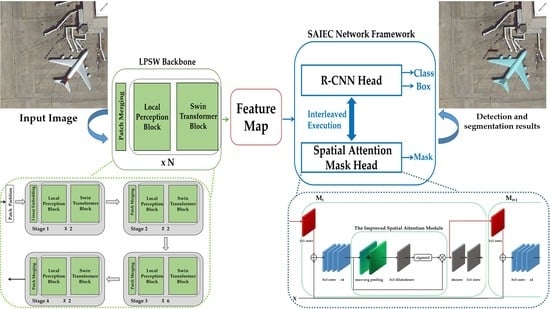
:
1. Introduction
- Low detection performance for small-scale objects, and weak local information acquisition capabilities.
- The current transformer-based framework is mostly used for image classification, but it is difficult for a single-level transformer to produce good results for the instance segmentation of densely predicted scenes. This has a great impact on object detection and instance segmentation in remote sensing images with a high resolution, a complex background, and small objects.
- In order to overcome the shortcomings of CNNs’ poor ability to extract global information, we chose the Swin transformer as a basic backbone network to build a network model for remote sensing image object detection and instance segmentation.
- According to the characteristics of remote sensing images, we propose a local perception Swin transformer (LPSW) backbone network. The LPSW combines the advantages of CNNs and transformers to enhance local perception capabilities and improve the detection accuracy of small-scale objects.
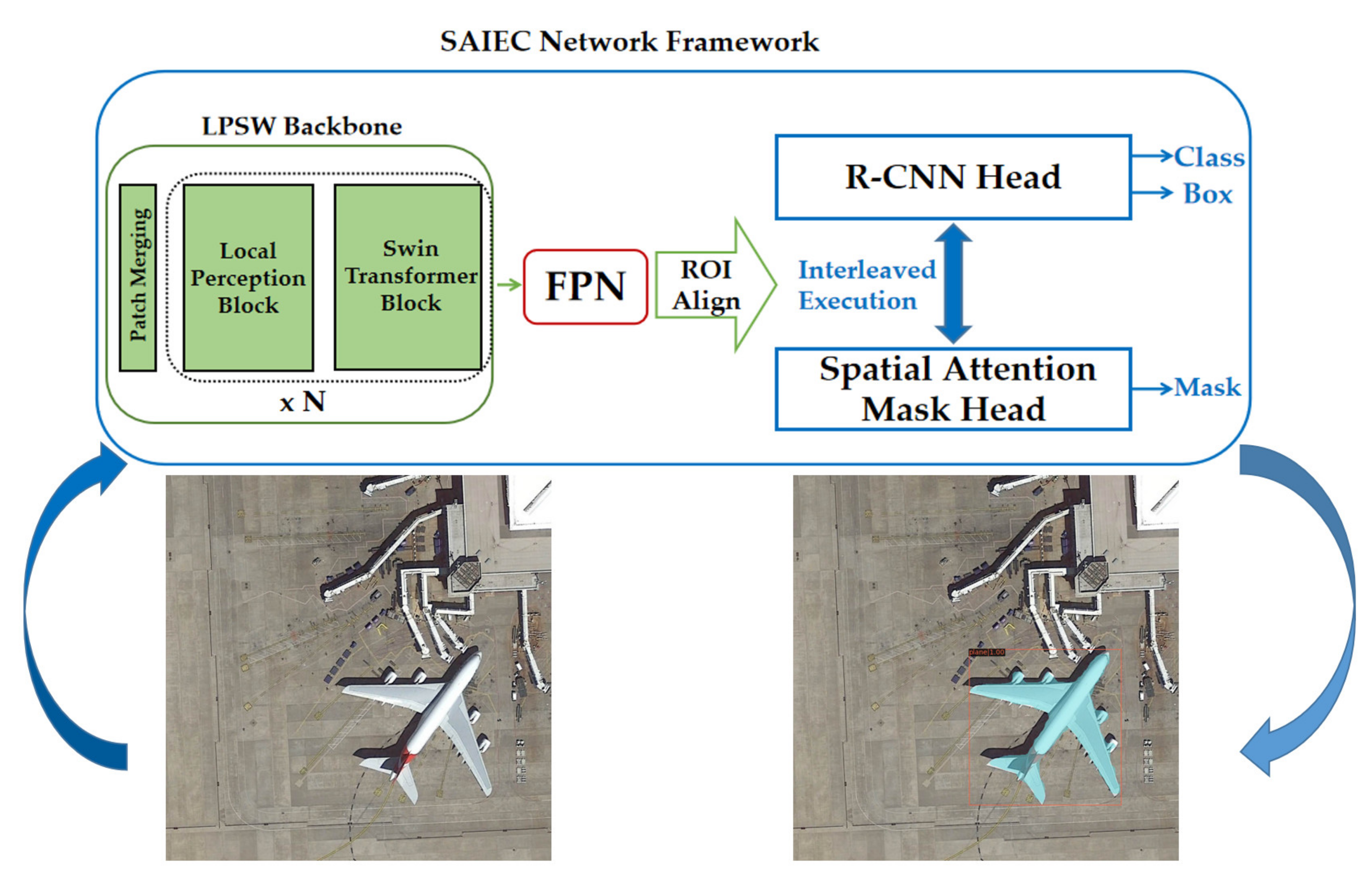
- The spatial attention interleaved execution cascade (SAIEC) network framework is proposed. The mask prediction of the network is enhanced through the multi-tasking manner and the improved spatial attention module. Finally, the LPSW is inserted into the designed network framework as the backbone to establish a new network model that further improves the accuracy of model detection and segmentation.
- Based on the shortage of existing remote sensing instance segmentation datasets, we selected a total of 1800 multi-object types of images from existing public datasets for annotation and created the MRS-1800 remote sensing mask dataset as the experimental resource for this paper.
2. Related Works
2.1. CNN-Based Object Detection and Instance Segmentation
2.2. Transformer-Based Object Detection and Instance Segmentation
3. Materials and Methods
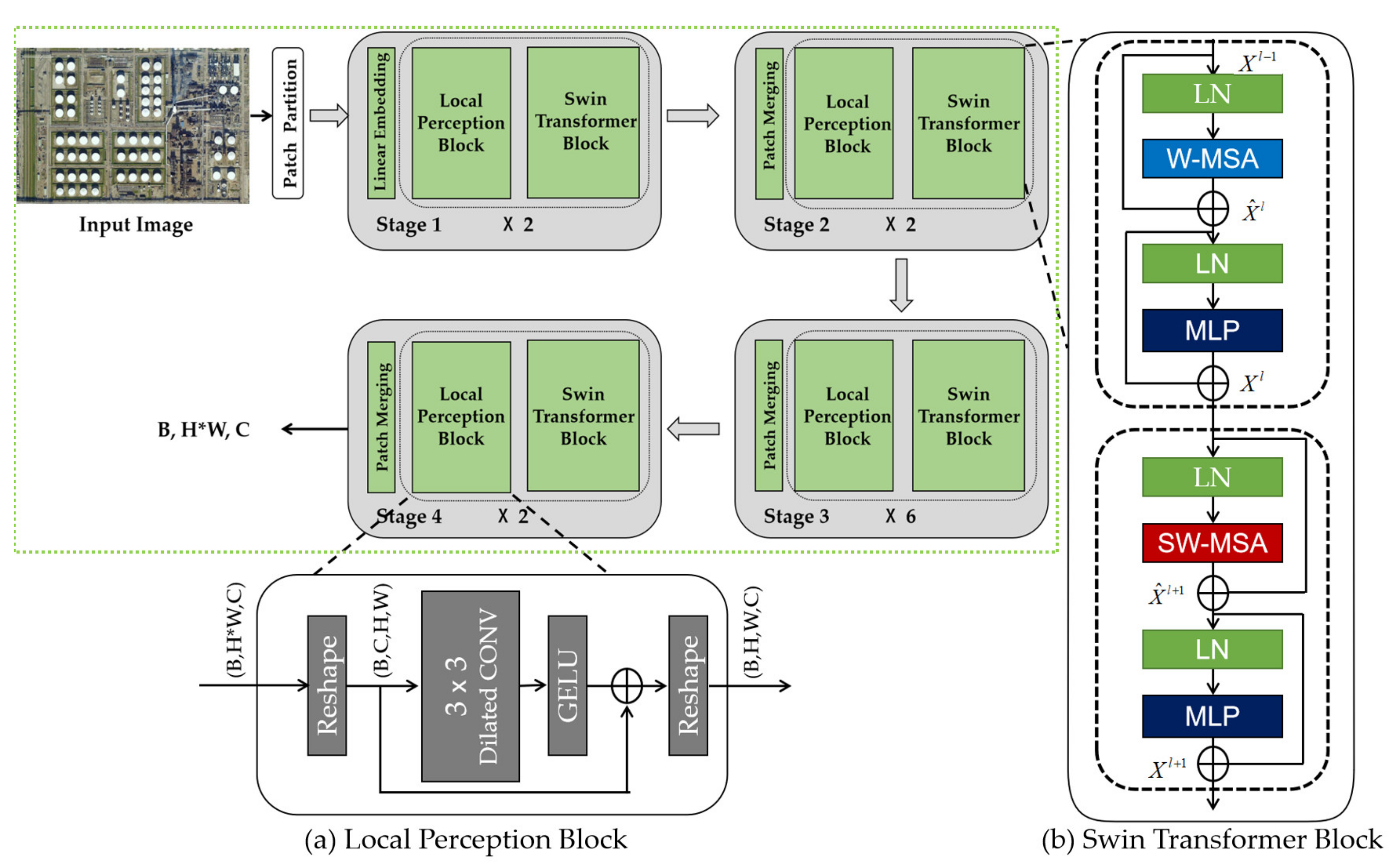
3.1. Local Perception Swin Transformer (LPSW) Backbone
3.1.1. Swin Transformer Block
3.1.2. W-MSA and SW-MSA
3.1.3. Local Perception Block (LPB)
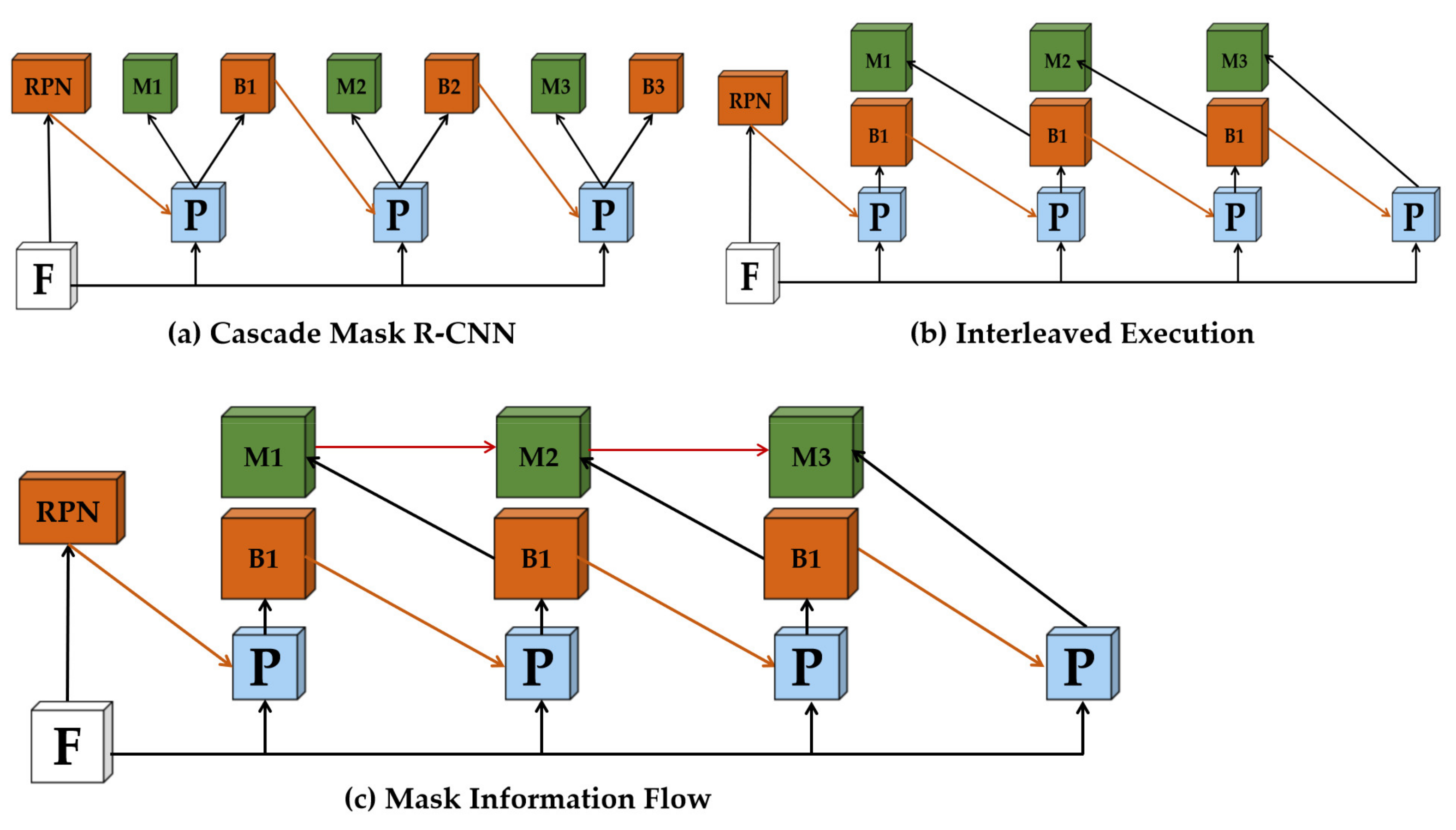
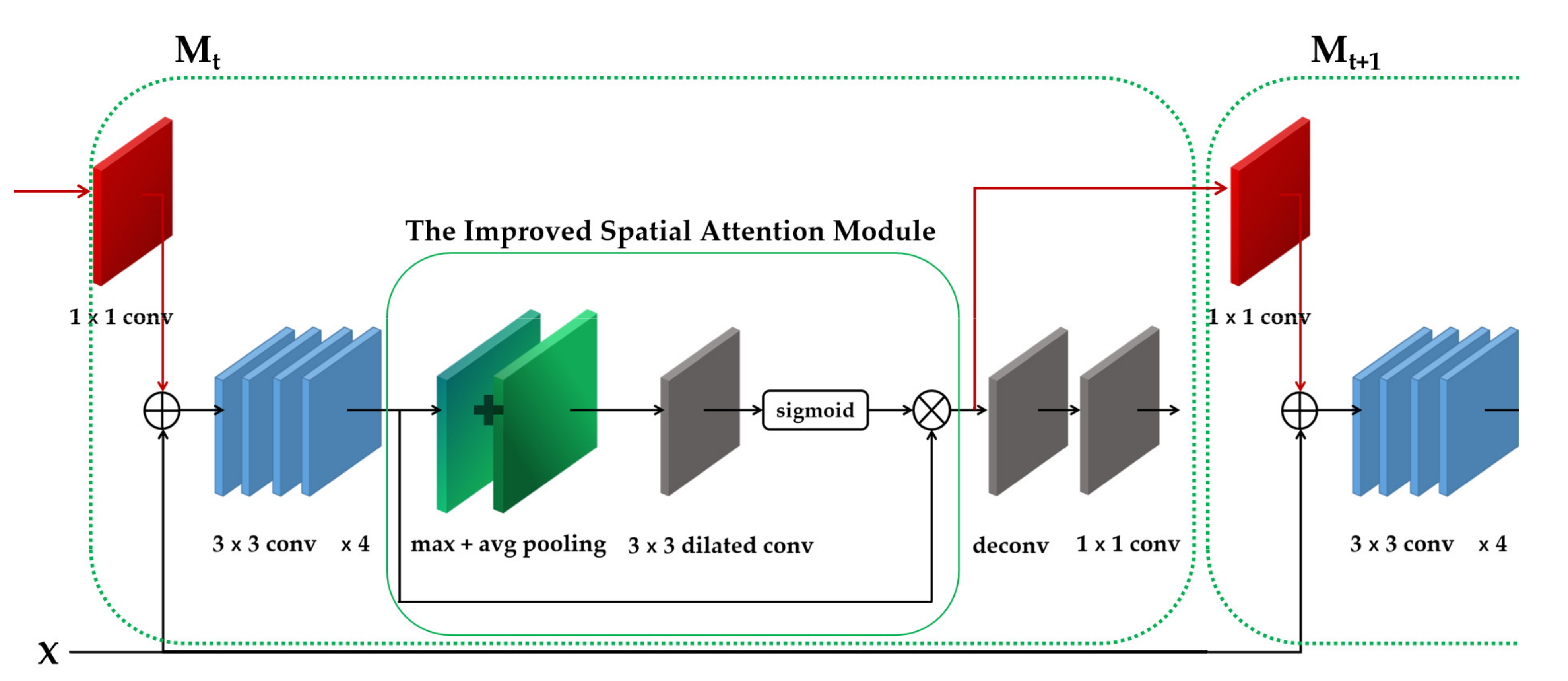
3.2. Spatial Attention Interleaved Execution Cascade (SAIEC)
3.2.1. Interleaved Execution and Mask Information Flow
3.2.2. Spatial Attention Mask Head
4. Results
4.1. Dataset
4.2. Experiments and Analysis
4.3. Ablation Experiment
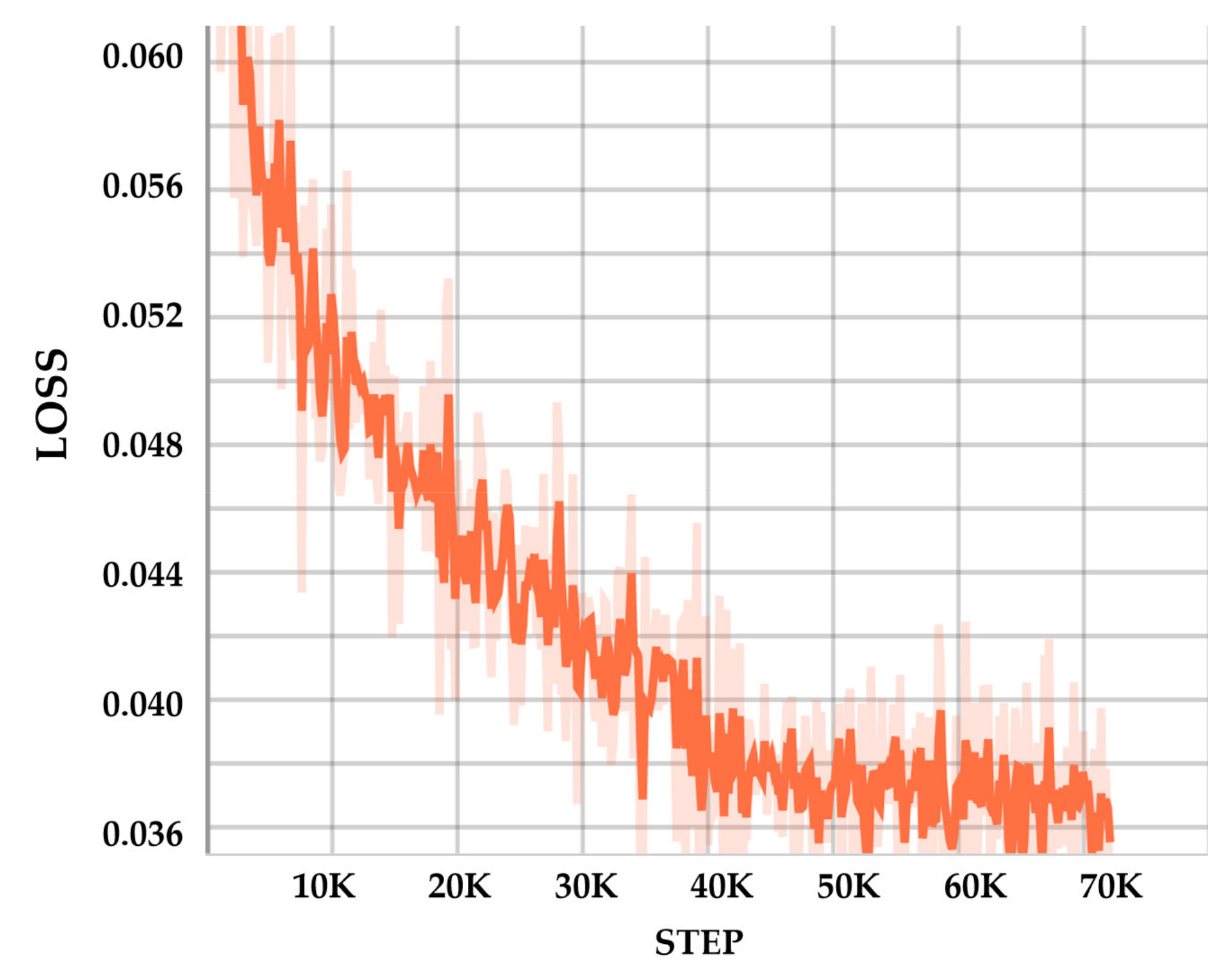
4.3.1. Study for Optimizer and Initial Learning Rate
4.3.2. Experiment for the Swin Transformer and LPST Backbone
4.3.3. Experience for SAIEC and the New Network Model
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cao, C.; Wang, B.; Zhang, W.; Zeng, X.; Yan, X.; Feng, Z.; Liu, Y.; Wu, Z. An Improved Faster R-CNN for Small Object Detection. IEEE Access 2019, 7, 1. [Google Scholar] [CrossRef]
- Zhu, W.T.; Xie, B.R.; Wang, Y.; Shen, J.; Zhu, H.W. Survey on Aircraft Detection in Optical Remote Sensing Images. Comput. Sci. 2020, 47, 1–8. [Google Scholar]
- Wu, J.; Cao, C.; Zhou, Y.; Zeng, X.; Feng, Z.; Wu, Q.; Huang, Z. Multiple Ship Tracking in Remote Sensing Images Using Deep Learning. Remote Sens. 2021, 13, 3601. [Google Scholar] [CrossRef]
- Li, X.Y. Object Detection in Remote Sensing Images Based on Deep Learning. Master’s Thesis, Department Computer Application Technology, University of Science and Technology of China, Hefei, China, 2019. [Google Scholar]
- Hermosilla, T.; Palomar, J.; Balaguer, Á.; Balsa, J.; Ruiz, L.A. Using street based metrics to characterize urban typologies. Comput. Environ. Urban Syst. 2014, 44, 68–79. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE ICCV, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018, IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2018; pp. 8759–8768. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask Scoring R-CNN. In Proceedings of the IEEE/CVF CVPR, Long Beach, CA, USA, 16–20 June 2019; pp. 6409–6418. [Google Scholar]
- Dai, J.F.; He, K.M.; Sun, J. Instance-aware semantic segmentation via multi-task network cascades. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, X.; Kong, T.; Shen, C.; Jiang, Y.; Li, L. Solo: Segmenting objects by locations. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 649–665. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA; 2017; pp. 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the 9th International Conference on Learning Representations (ICLR 2021), Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Nicolas, C.; Francisco, M.; Gabriel, S.; Nicolas, U.; Alexander, K.; Sergey, Z. End-to-End Object Detection with Transformers. In Proceedings of the 16th ECCV, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the 38th ICML, Virtual Event, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.S.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 6881–6890. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.Q.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv 2021, arXiv:2103.14030. Available online: https://arxiv.org/abs/2103.14030 (accessed on 19 October 2021).
- Chen, K.; Pang, J.M.; Wang, J.Q.; Xiong, Y.; Li, X.X.; Sun, S.Y.; Feng, W.F.; Liu, Z.W.; Shi, J.P.; Wangli, O.Y.; et al. Hybrid Task Cascade for Instance Segmentation. In Proceedings of the IEEE CVPR, Long Beach, CA, USA, 15–21 June 2019; pp. 4974–4983. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the IEEE ECCV, Amsterdam, Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HA, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liang, X.; Lin, L.; Wei, Y.C.; Shen, X.H.; Yang, J.C.; Yan, S.C. Proposal-Free Network for Instance-Level Object Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2978–2991. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.L.; Zhang, R.F.; Kong, T.; Li, L.; Shen, C.H. SOLOv2: Dynamic and Fast Instance Segmentation. arXiv 2020, arXiv:2003.10152. Available online: https://arxiv.org/abs/2003.10152v3 (accessed on 19 October 2021).
- Lee, Y.; Park, J. Centermaslc: Real-Time Anchor-Free Instance Segmentation. In Proceedings of the the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13906–13915. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully Convolutional One-Stage Object Detection. In Proceedings of the the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Zhou, X.Z.; Su, W.J.; Lu, L.W.; Li, B.; Wang, X.G.; Dai, J.F. Deformable DETR: Deformable Transformers for End-to-End Object Detection. In Proceedings of the 9th International Conference on Learning Representations (ICLR), Virtual Event, Austria, 3–7 May 2020. [Google Scholar]
- Zheng, M.H.; Gao, P.; Wang, X.G.; Li, H.S.; Dong, H. End-to-End Object Detection with Adaptive Clustering Transformer. arXiv 2020, arXiv:2011.09315. Available online: https://arxiv.org/abs/2011.09315 (accessed on 19 October 2021).
- Wang, Y.Q.; Xu, Z.L.; Wang, X.L.; Shen, C.H.; Cheng, B.S.; Shen, H.; Xia, H.X. End-to-End Video Instance Segmentation with Transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 8741–8750. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. In Proceedings of the 4th International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhu, X.Z.; Cheng, D.Z.; Zhang, Z.; Lin, S.; Dai, J.F. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the ICCV, Seoul, Korea, 27 October–2 November 2019; pp. 6687–6696. [Google Scholar]
- Li, K.; Wang, G.; Cheng, G.; Meng, L.Q.; Han, J.W. Object Detection in Optical Remote Sensing Images: A Survey and A New Benchmark. arXiv 2019, arXiv:1909.00133. Available online: https://arxiv.org/abs/1909.00133v2 (accessed on 19 October 2021). [CrossRef]
- Zhang, Y.L.; Yuan, Y.; Feng, Y.C.; Lu, X.Q. Hierarchical and Robust Convolutional Neural Network for Very High-Resolution Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5535–5548. [Google Scholar] [CrossRef]
- Gong, C.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 12, 7405–7415. [Google Scholar]
- Sun, P.Z.; Zhang, R.F.; Jiang, Y.; Kong, T.; Xu, C.F.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.H.; Wang, C.H.; et al. Sparse R-CNN: End-to-End Object Detection with Learnable Proposals. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 14454–14463. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. In Proceedings of the 7th International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Versaci, M.; Calcagno, S.; Morabito, F.C. Fuzzy Geometrical Approach Based on Unit Hyper-Cubes for Image Contrast Enhancement. In Proceedings of the 2015 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuala Lumpur, Malaysia, 19–21 October 2015; pp. 488–493. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Dior | Hrrsd | Nwpu Vhr-10 | Statistics |
|---|---|---|---|---|
| Number | 403 | 1093 | 304 | 1800 |
| Class | Plane | Ship | Storage tank | |
| Number | 674 | 687 | 557 |
| Method | Optimizer | Learning Rate | ||
|---|---|---|---|---|
| Swin-T | SGD | 1 × 10−4 | 60.1 | 33.9 |
| 1 × 10−5 | 69.2 | 52.1 | ||
| 1 × 10−6 | 53.6 | 41.5 | ||
| AdamW | 1 × 10−4 | 73.9 | 58.0 | |
| 1 × 10−5 | 77.2 | 60.7 | ||
| 1 × 10−6 | 75.0 | 58.4 |
| Various Frameworks | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | Backbone | ARS | FPS | ||||||||
| Mask R-CNN | R-50 Swin-T LPST | 69.0 75.5 75.8 | 91.5 92.8 93.1 | 83.3 88.1 88.0 | 31.6 44.6 46.6 | 57.2 60.9 60.4 | 90.5 91.7 92.1 | 58.9 66.6 65.8 | 25.0 34.1 36.2 | 44.1 47.2 49.2 | 11.5 8.6 8.1 |
| Cascade Mask R-CNN | R-50 Swin-T LPST | 72.1 77.2 77.4 | 91.0 92.7 93.0 | 83.3 87.6 88.0 | 31.3 41.5 46.7 | 56.6 60.7 61.3 | 90.3 91.4 91.7 | 57.7 66.3 68.3 | 32.9 31.7 36.8 | 38.5 45.5 50.0 | 8.4 5.4 5.1 |
| Mask Scoring | R-50 | 71.9 | 91.5 | 84.5 | 40.3 | 60.7 | 90.4 | 67.4 | 32.4 | 43.5 | 11.4 |
| Sparse R-CNN | R-50 | 73.9 | 91.0 | 83.8 | 35.4 | 39.4 | 13.4 | ||||
| PANet | R-50 | 71.6 | 91.8 | 84.5 | 35.3 | 38.3 | 12.1 | ||||
| DETR | R-50 | 65.3 | 86.7 | 74.3 | 21.4 | 29.7 | 15.1 | ||||
| Method | ARS | FPS | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Cascade Mask R-CNN (Swin-T) baseline | 77.2 | 92.7 | 87.6 | 41.5 | 60.7 | 91.4 | 66.3 | 31.7 | 45.5 | 5.4 |
| Cascade Mask R-CNN (LPSW) | 77.4 | 93.0 | 88.0 | 46.7 (+5.2) | 61.3 | 91.7 | 68.3 | 36.8 (+5.1) | 50.0 | 5.1 |
| HTC (Swin-S [18]) | 77.8 | 93.3 | 88.1 | 46.6 | 61.9 | 92.4 | 68.8 | 35.9 | 51.8 | 4.6 |
| HTC (Swin-T) | 77.4 | 92.7 | 88.2 | 41.7 | 61.6 | 91.9 | 69.7 | 31.4 | 49.6 | 5.4 |
| SAIEC (Swin-T) | 77.8 | 93.2 | 88.7 | 43.4 | 62.3 | 92.0 | 69.4 | 33.7 | 50.0 | 5.5 |
| SAIEC (LPSW)(ours) | 78.3 (+1.1) | 93.0 | 88.7 | 46.1 (+4.6) | 62.4 (+1.7) | 92.3 | 70.3 (+4.0) | 35.3 (+3.6) | 53.2 (+7.7) | 5.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Feng, Z.; Cao, C.; Li, M.; Wu, J.; Wu, Z.; Shang, Y.; Ye, S. An Improved Swin Transformer-Based Model for Remote Sensing Object Detection and Instance Segmentation. Remote Sens. 2021, 13, 4779. https://doi.org/10.3390/rs13234779
Xu X, Feng Z, Cao C, Li M, Wu J, Wu Z, Shang Y, Ye S. An Improved Swin Transformer-Based Model for Remote Sensing Object Detection and Instance Segmentation. Remote Sensing. 2021; 13(23):4779. https://doi.org/10.3390/rs13234779
Chicago/Turabian StyleXu, Xiangkai, Zhejun Feng, Changqing Cao, Mengyuan Li, Jin Wu, Zengyan Wu, Yajie Shang, and Shubing Ye. 2021. "An Improved Swin Transformer-Based Model for Remote Sensing Object Detection and Instance Segmentation" Remote Sensing 13, no. 23: 4779. https://doi.org/10.3390/rs13234779
APA StyleXu, X., Feng, Z., Cao, C., Li, M., Wu, J., Wu, Z., Shang, Y., & Ye, S. (2021). An Improved Swin Transformer-Based Model for Remote Sensing Object Detection and Instance Segmentation. Remote Sensing, 13(23), 4779. https://doi.org/10.3390/rs13234779