
Retrieval of Total Phosphorus Concentration in the Surface Water of Miyun Reservoir Based on Remote Sensing Data and Machine Learning Algorithms


Abstract
:1. Introduction
2. Materials and Methods
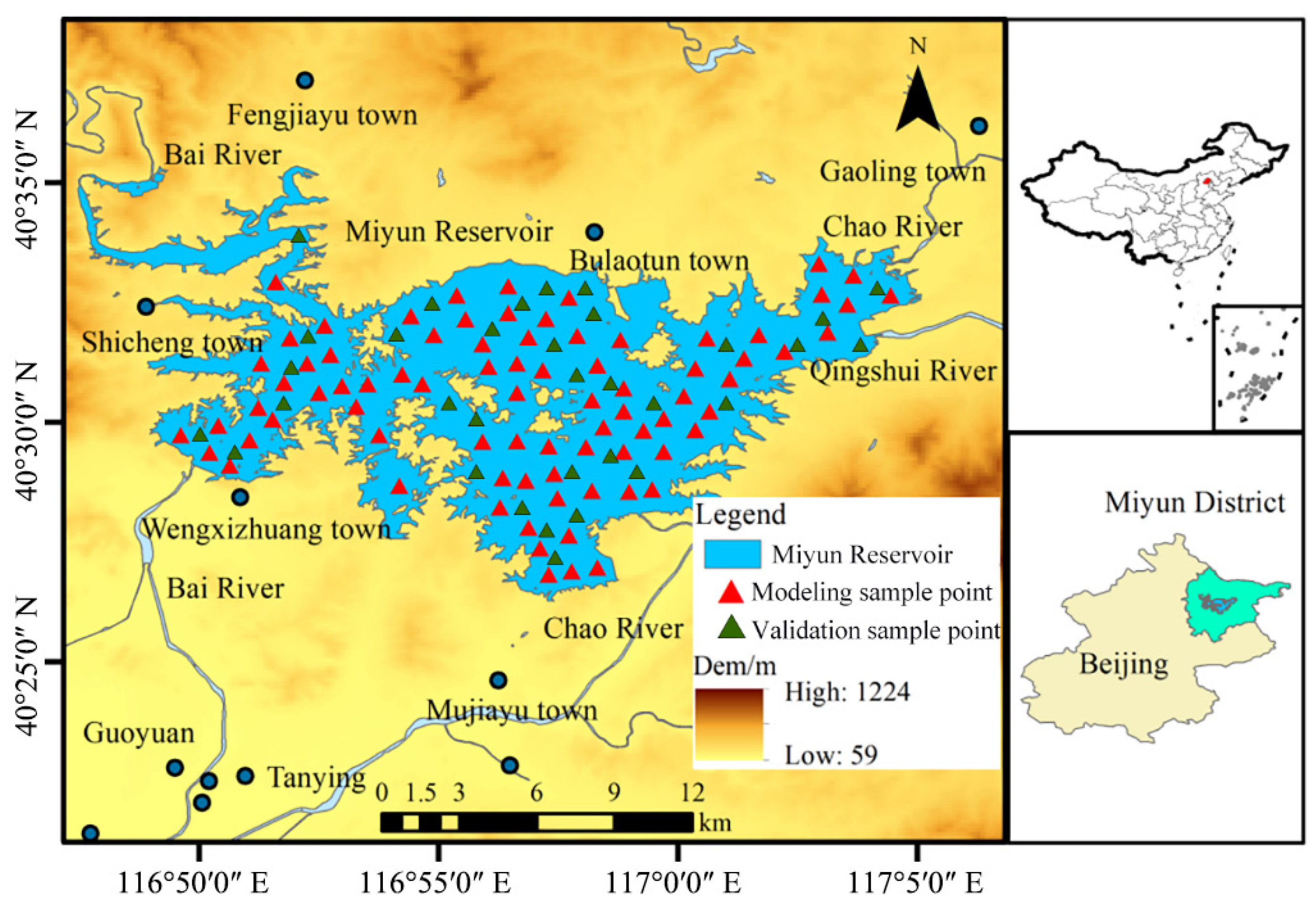
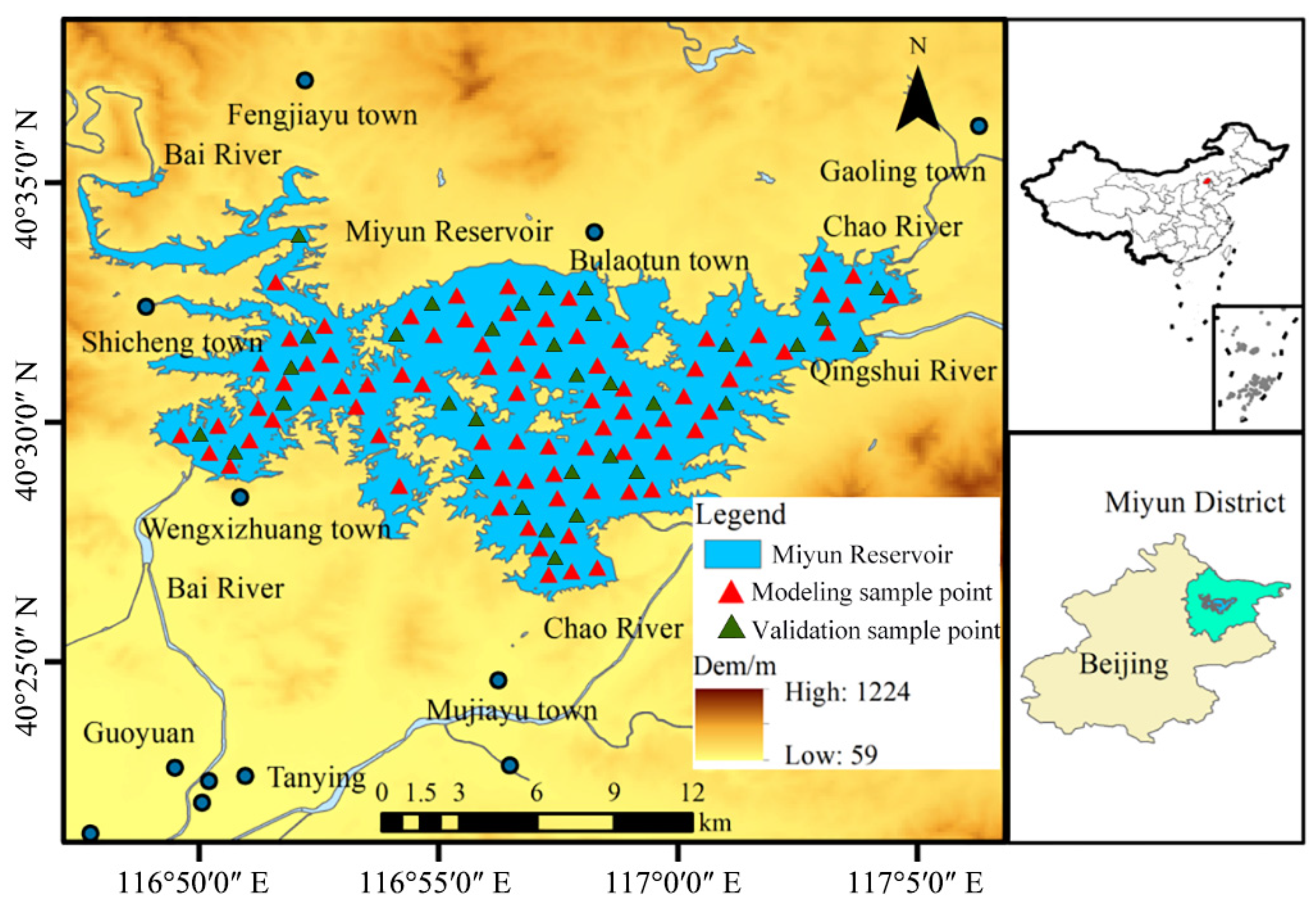
2.1. Study Area
2.2. Data Sources and Processing
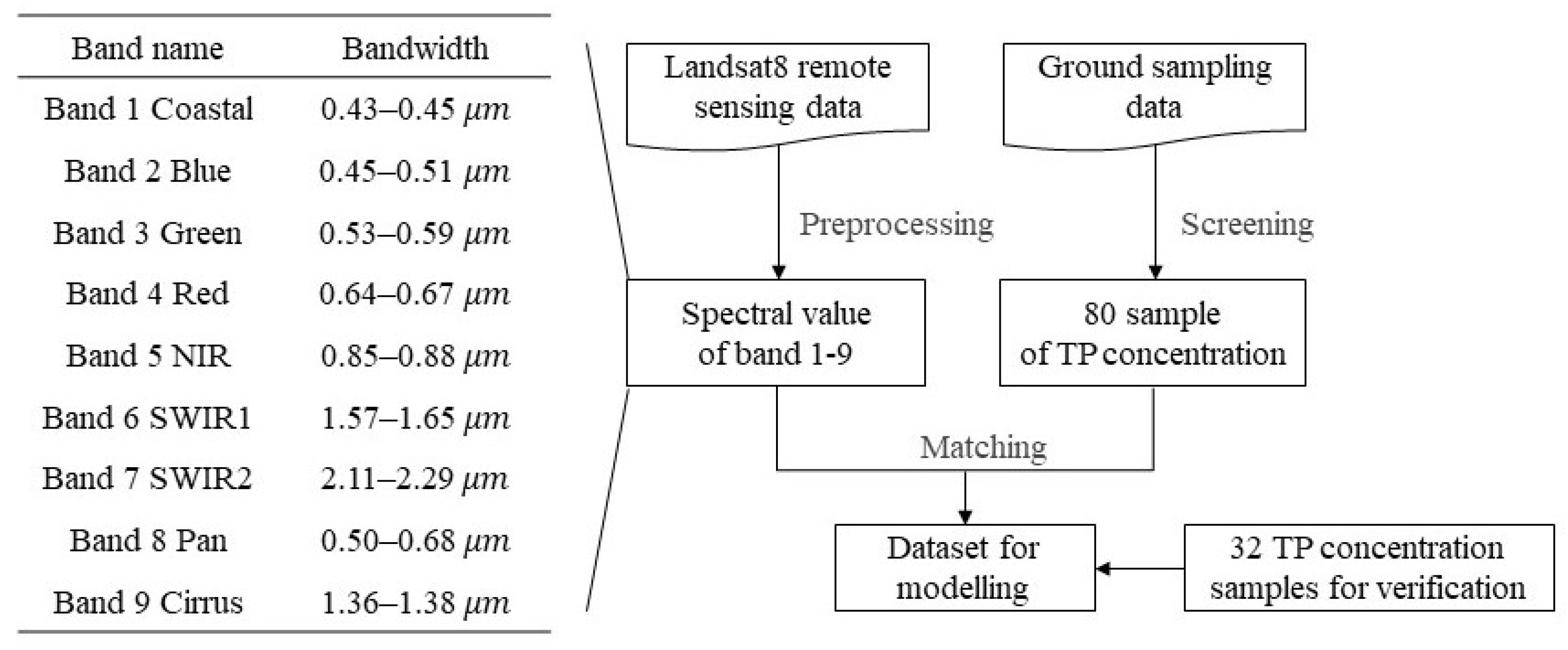
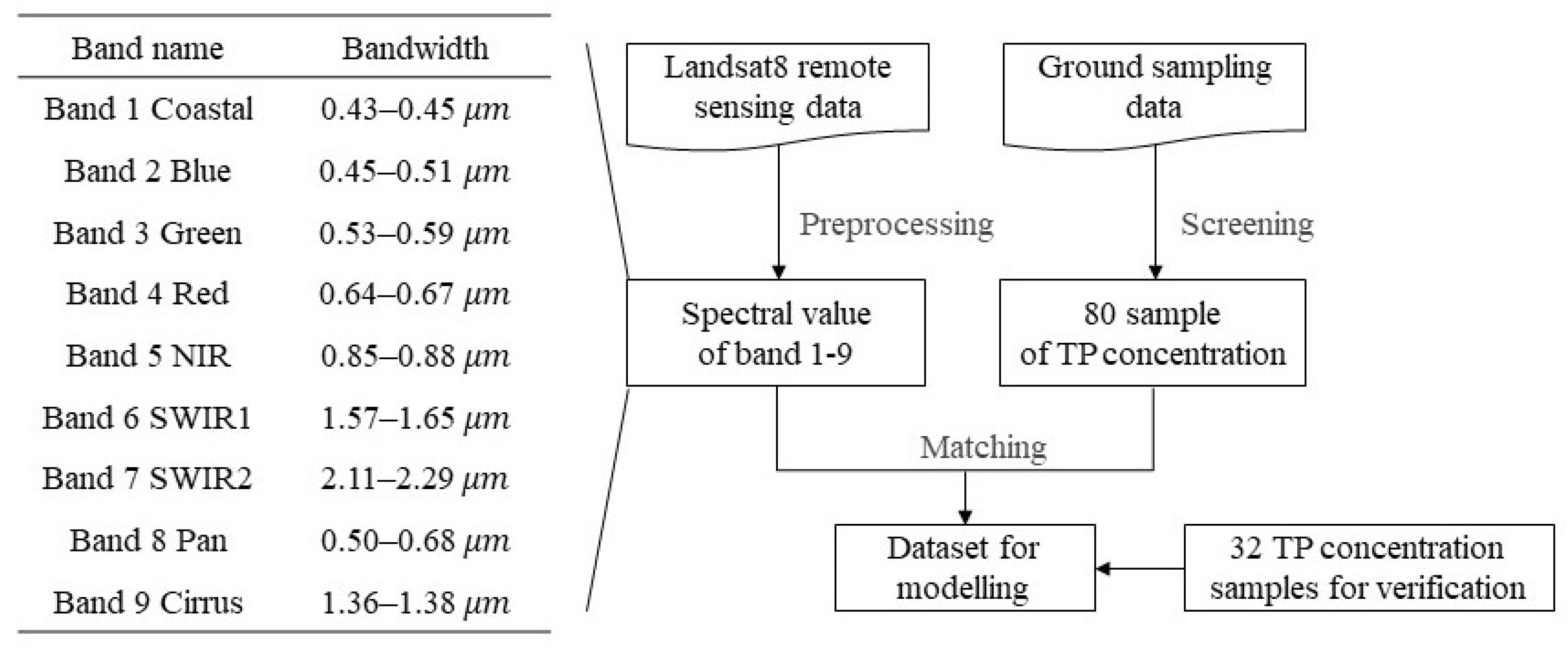
2.2.1. Remote Sensing Data
2.2.2. Ground Monitoring Data
2.2.3. Data Set for Modeling
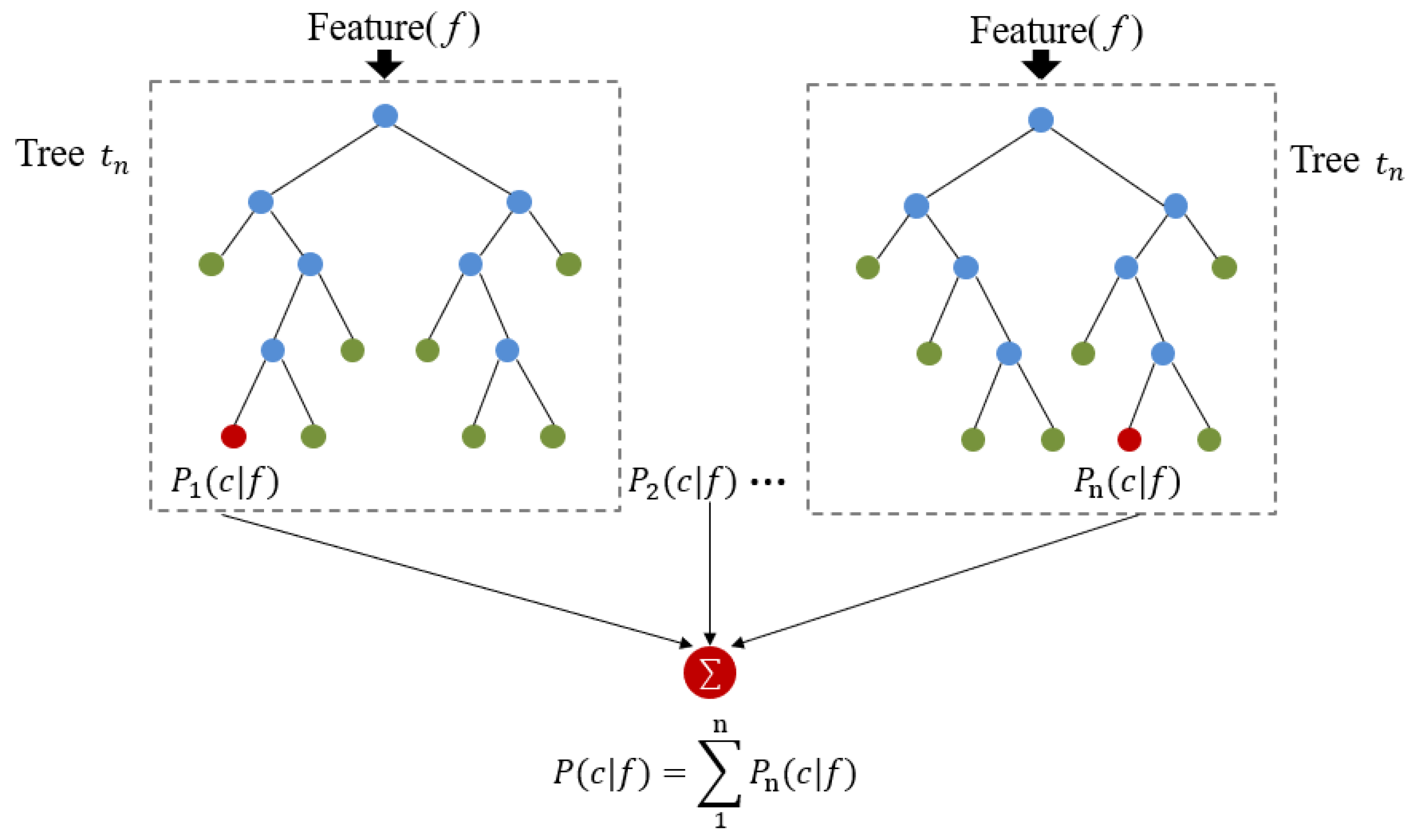
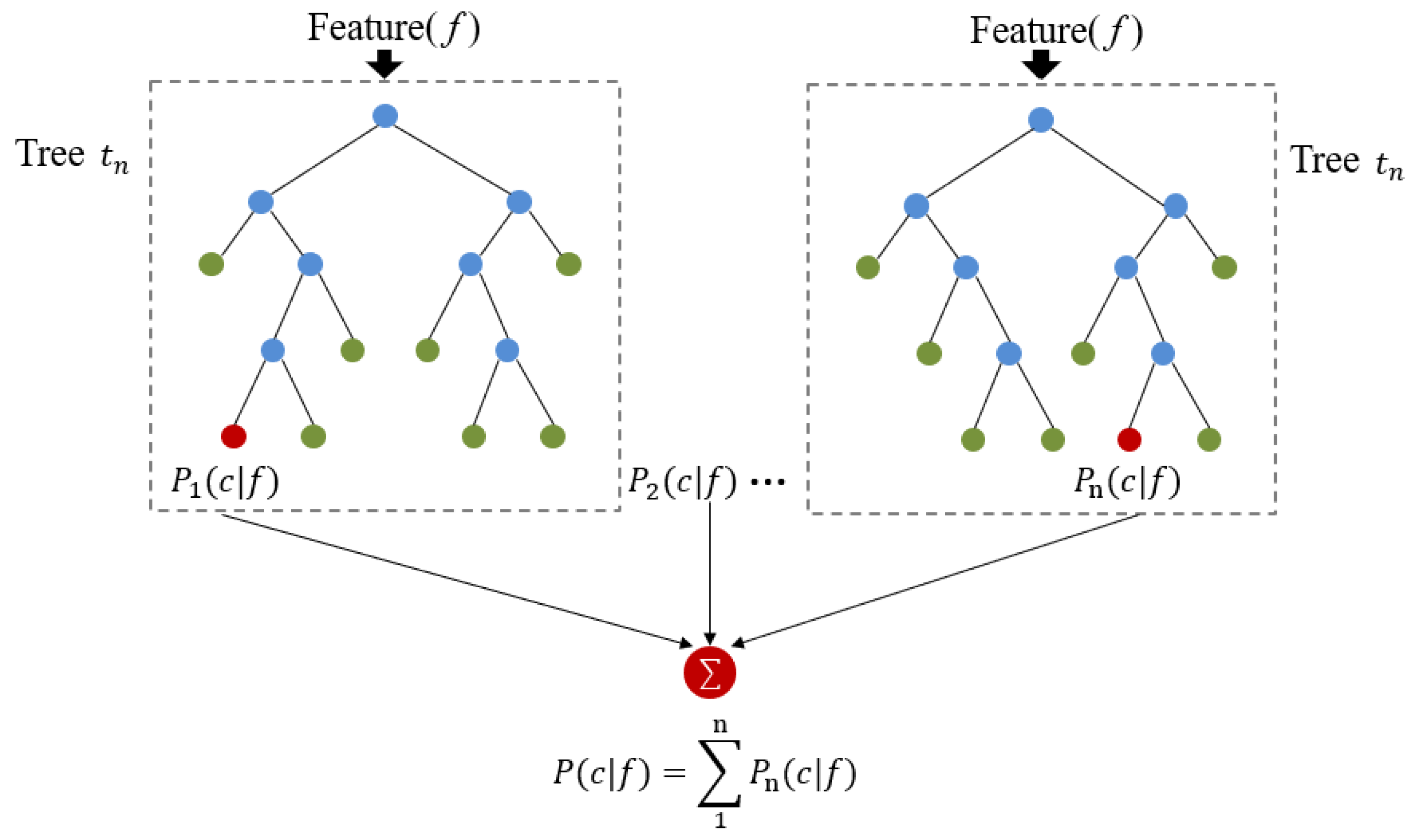
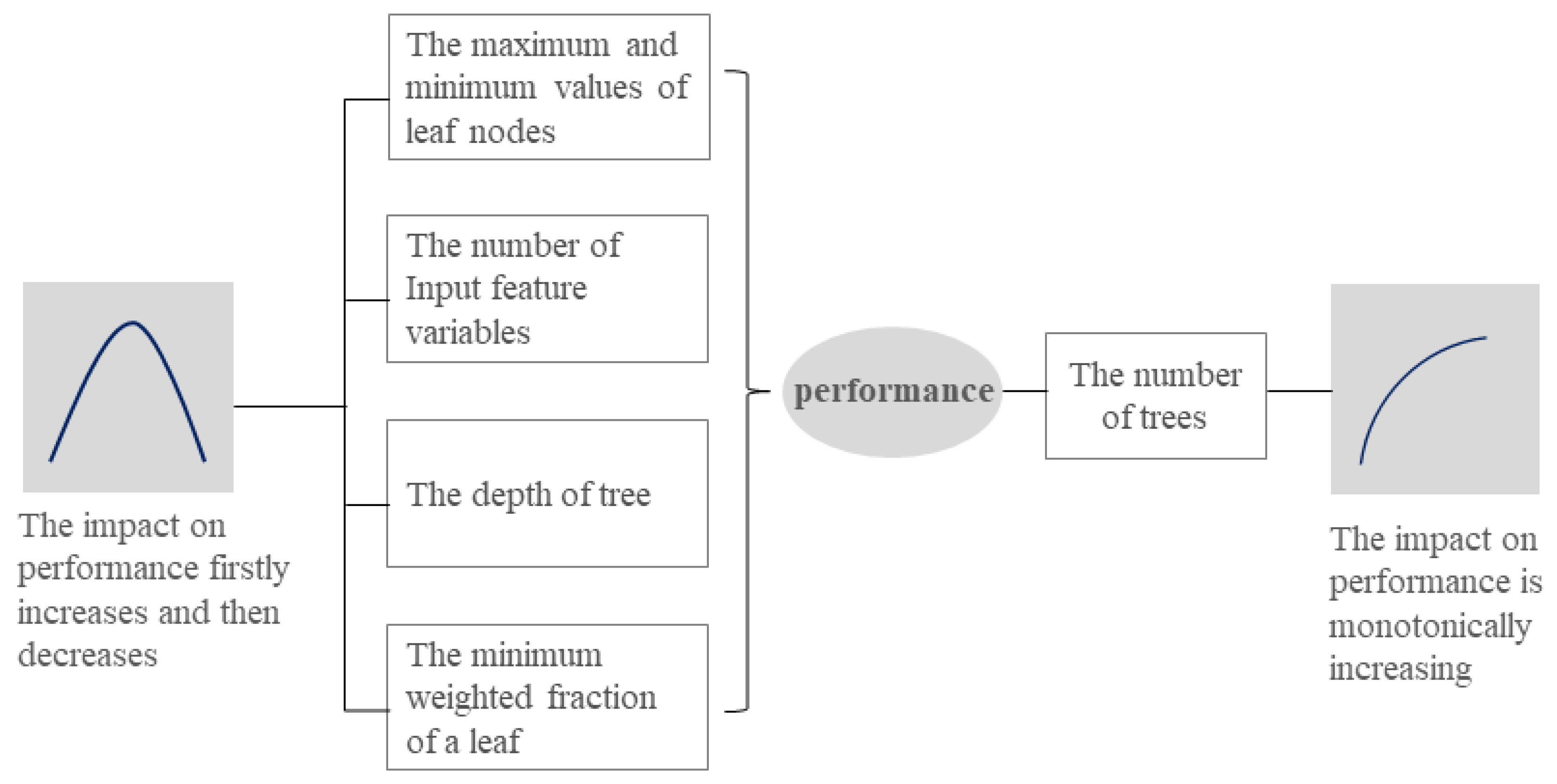
2.3. Methods
3. Results
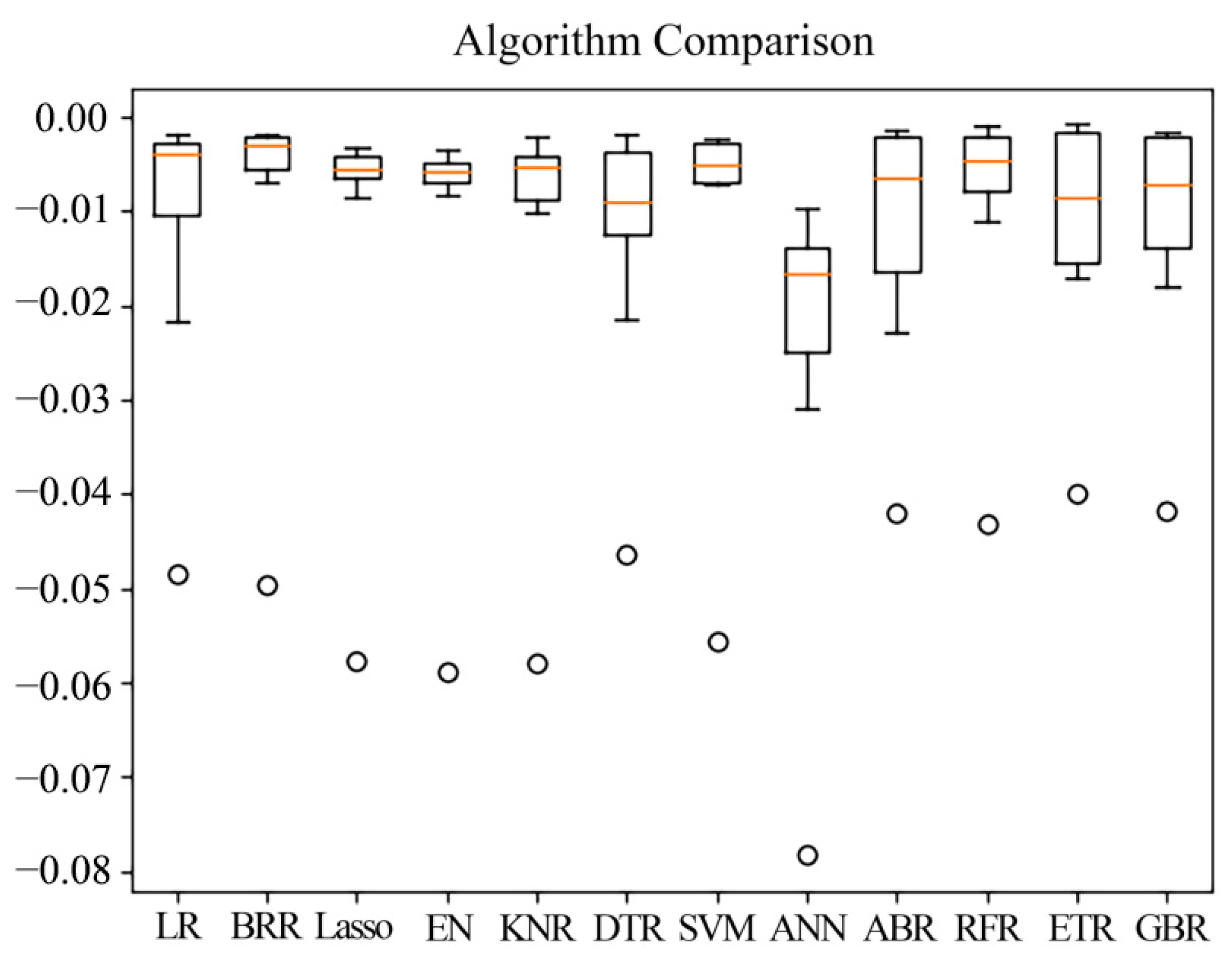
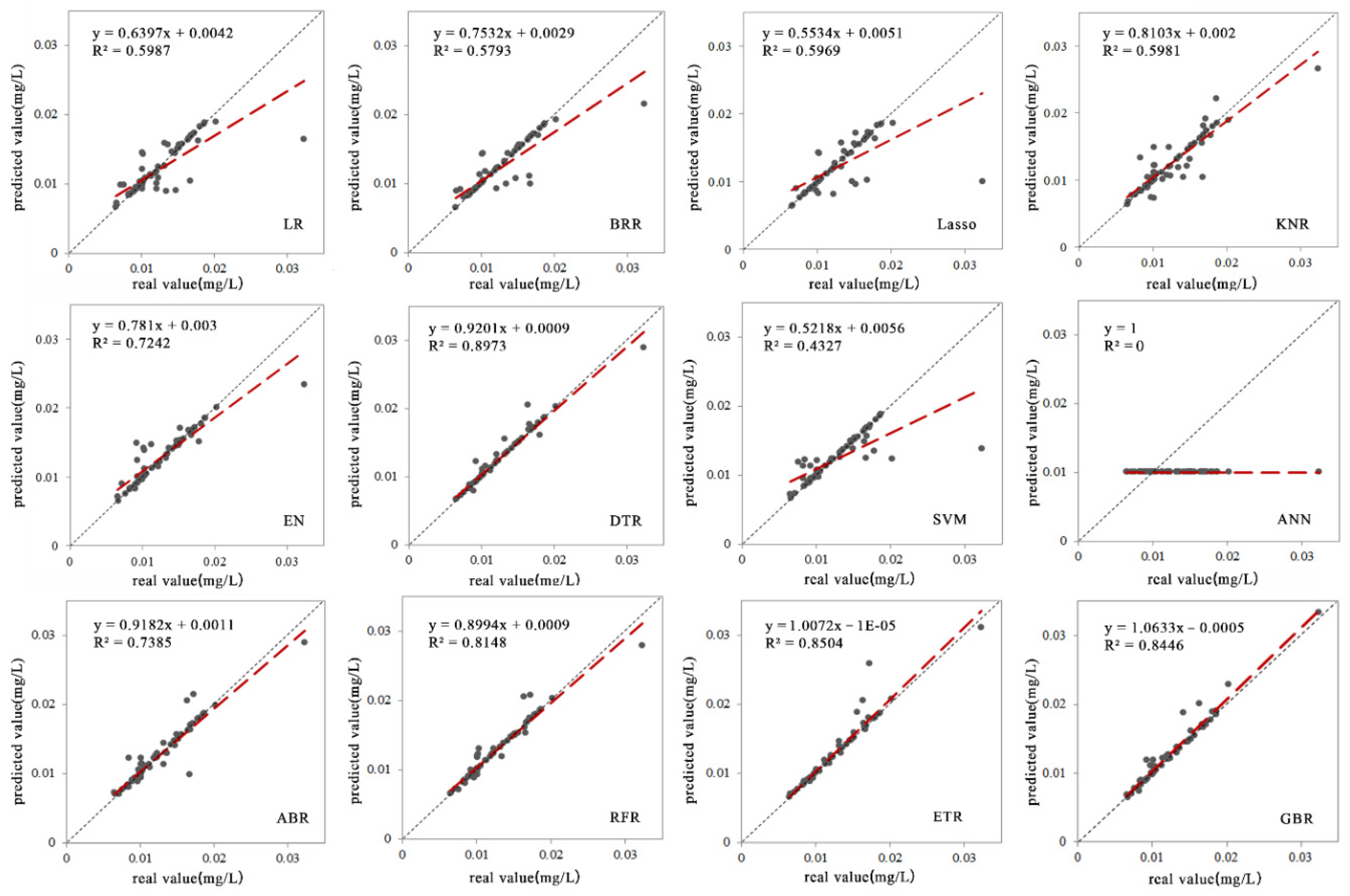
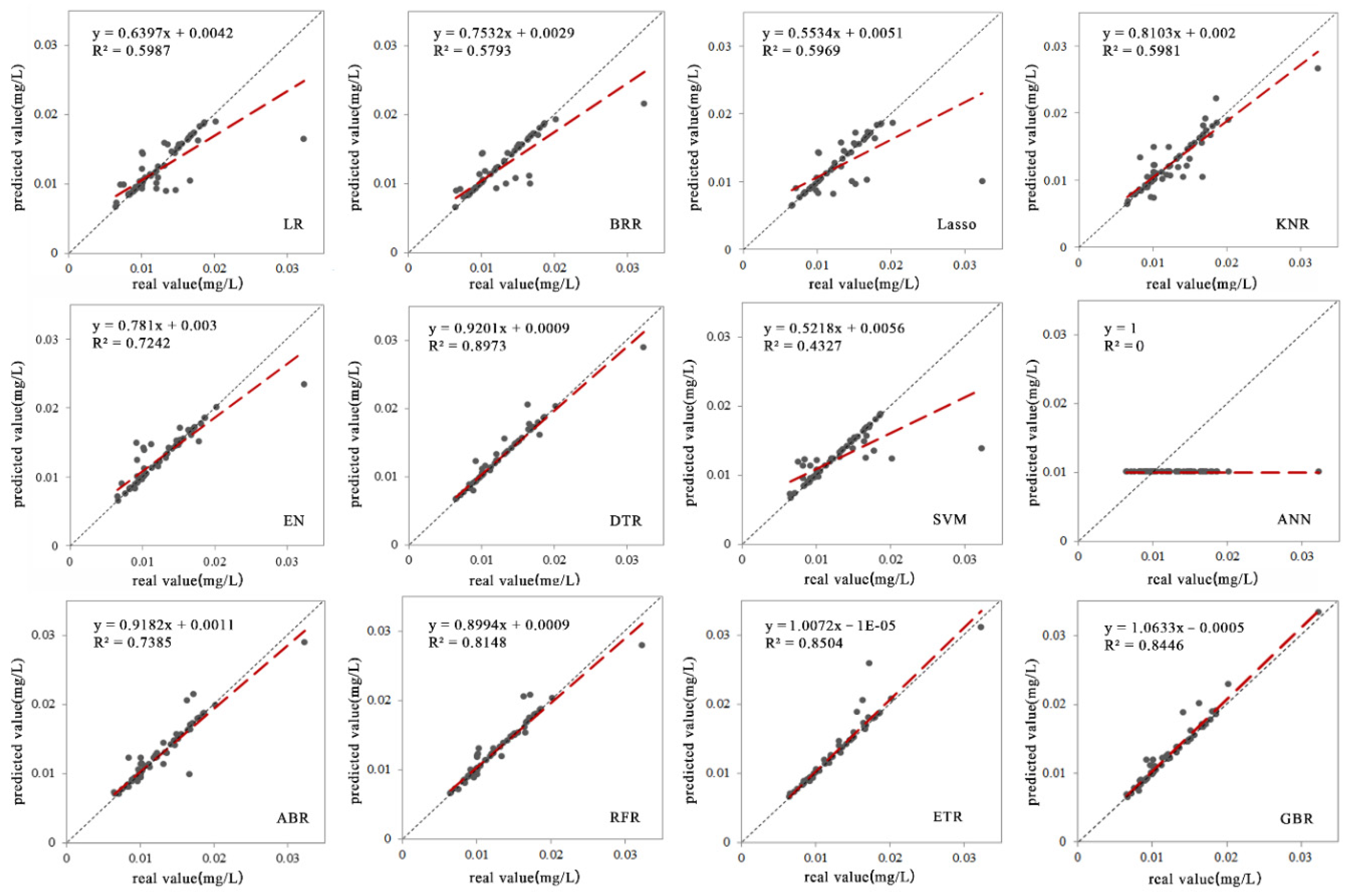
3.1. Retrieval Modeling and Validation for the TP Concentration
3.2. Retrieval Results of the TP Concentration and Its Water Quality Evaluation in Miyun Reservoir
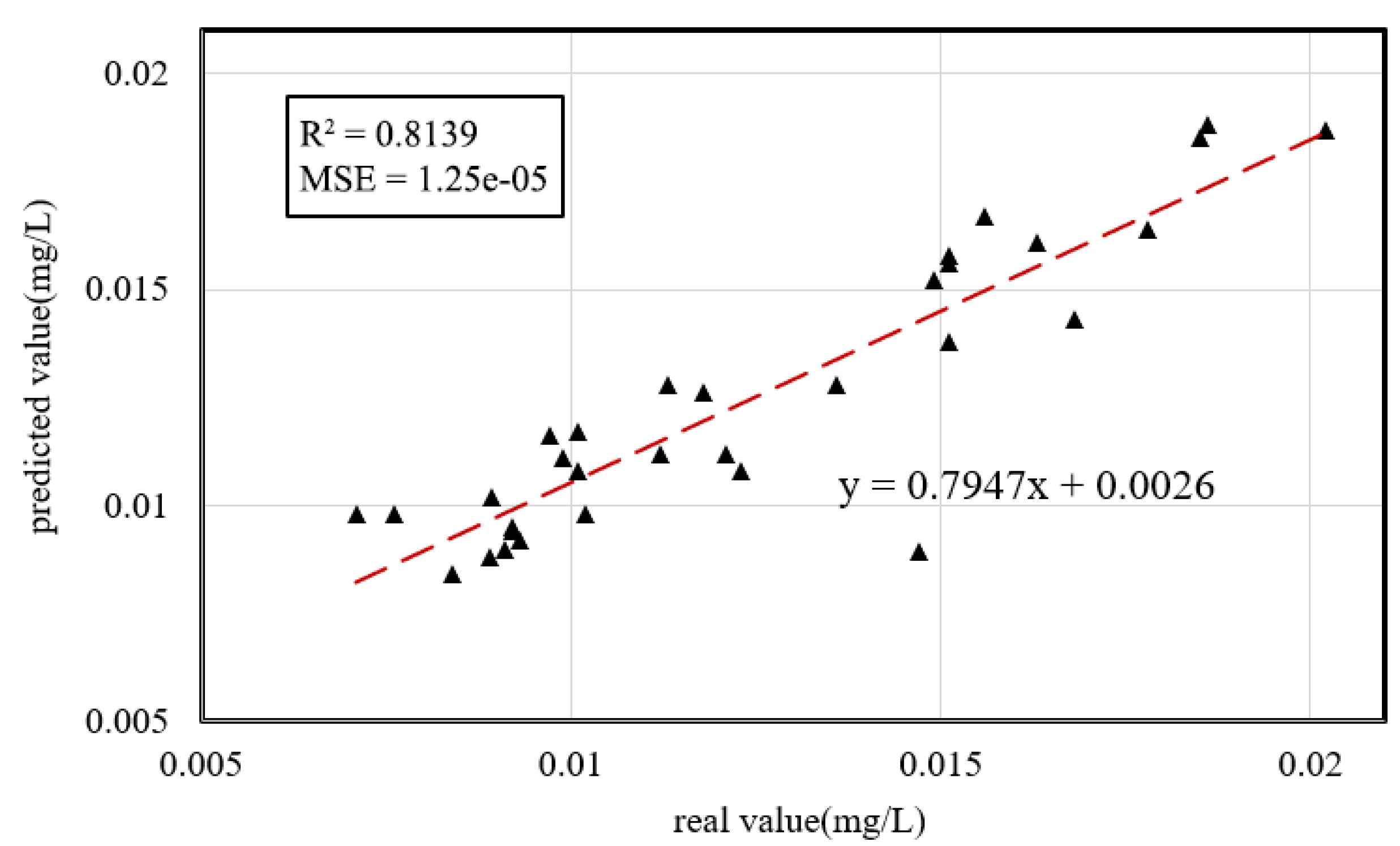
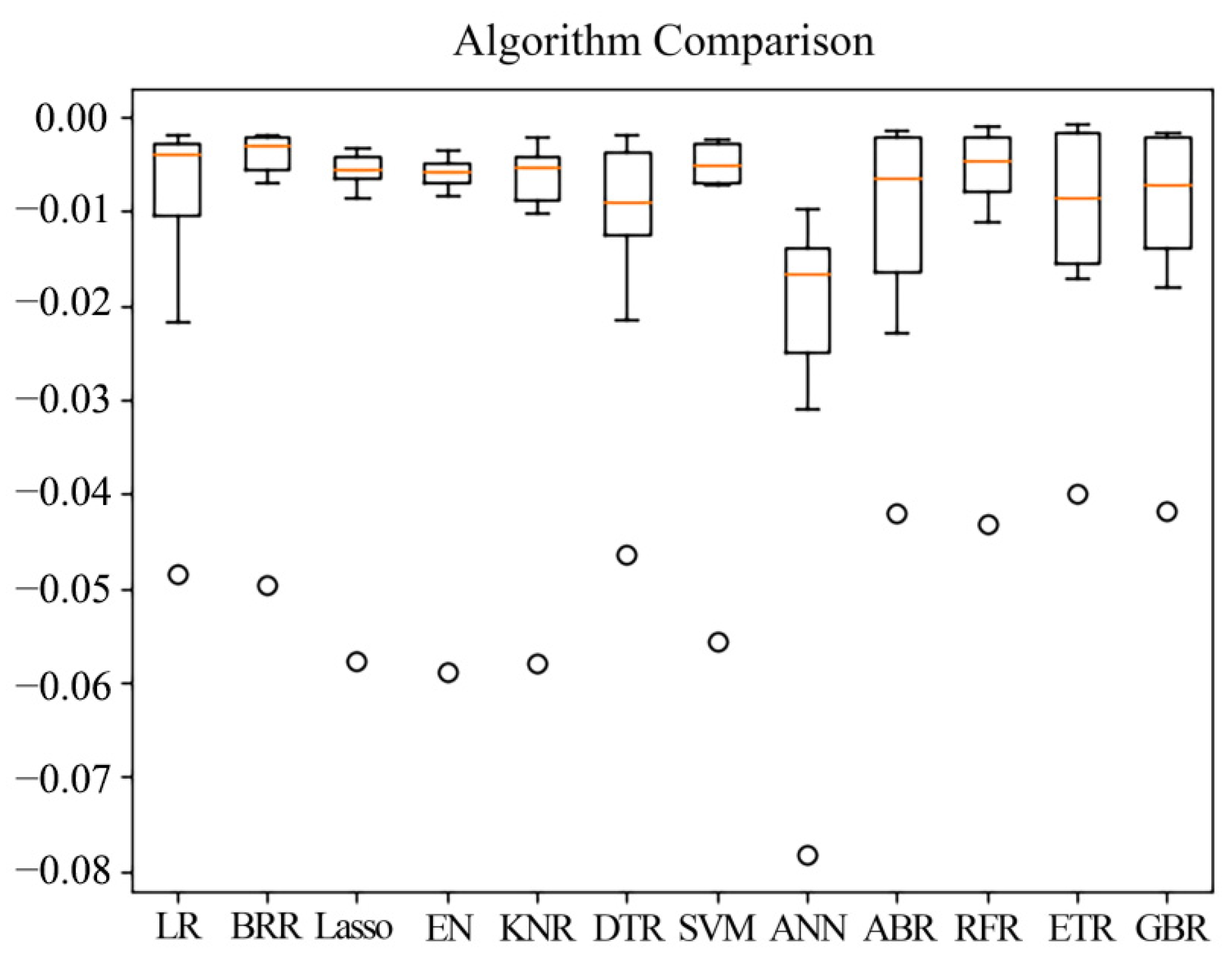
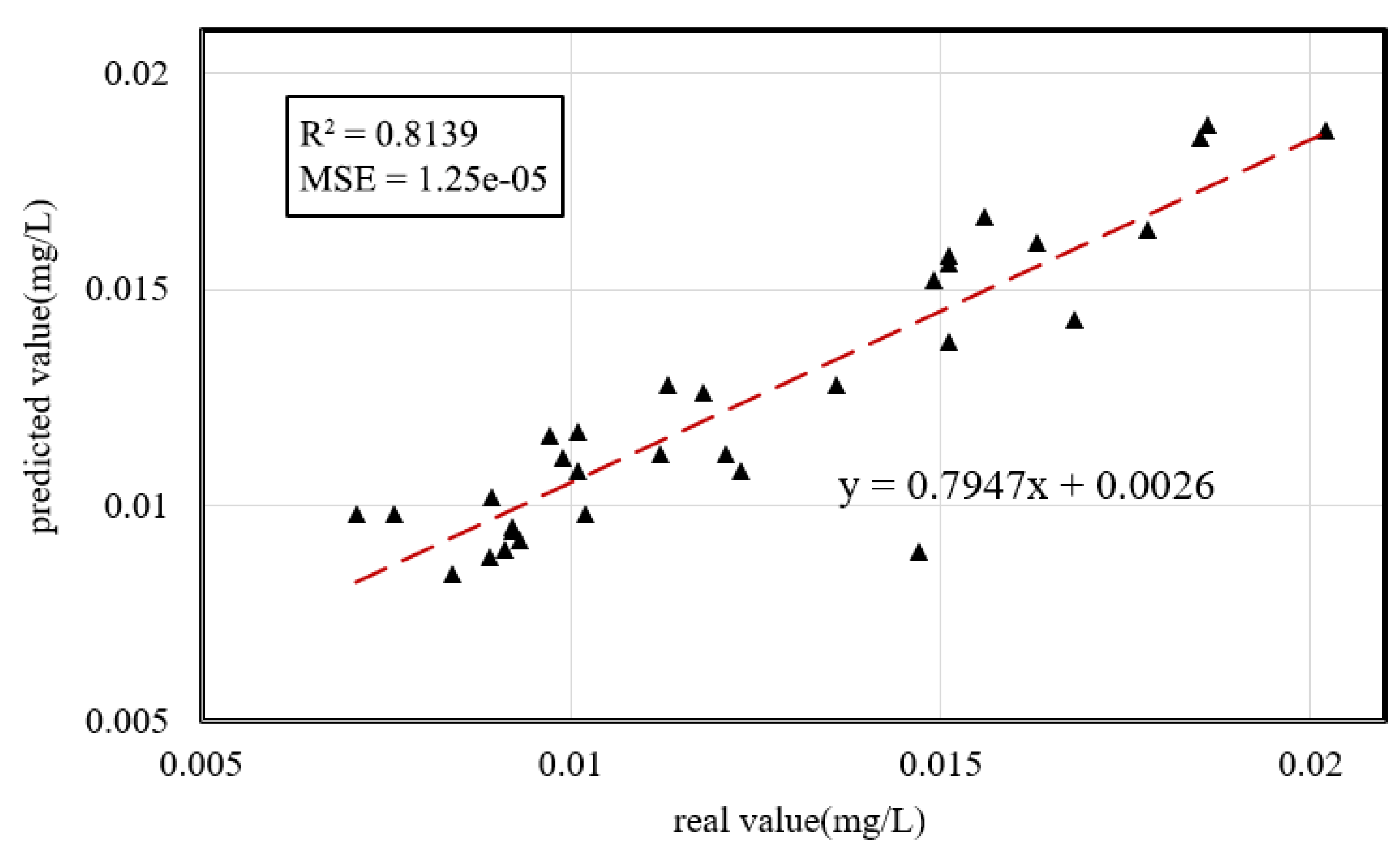
3.2.1. Accuracy Verification of the Retrieval Model
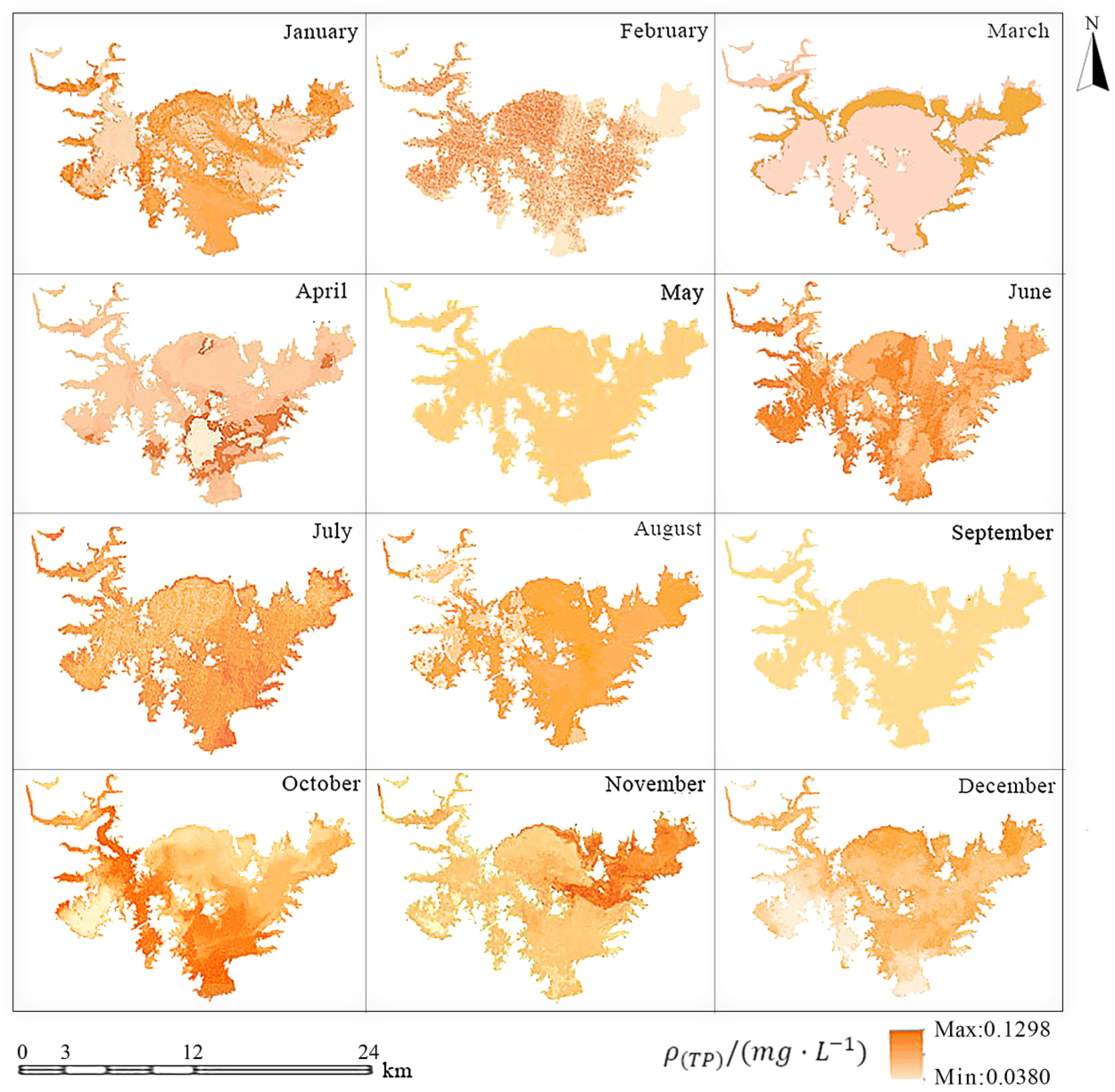
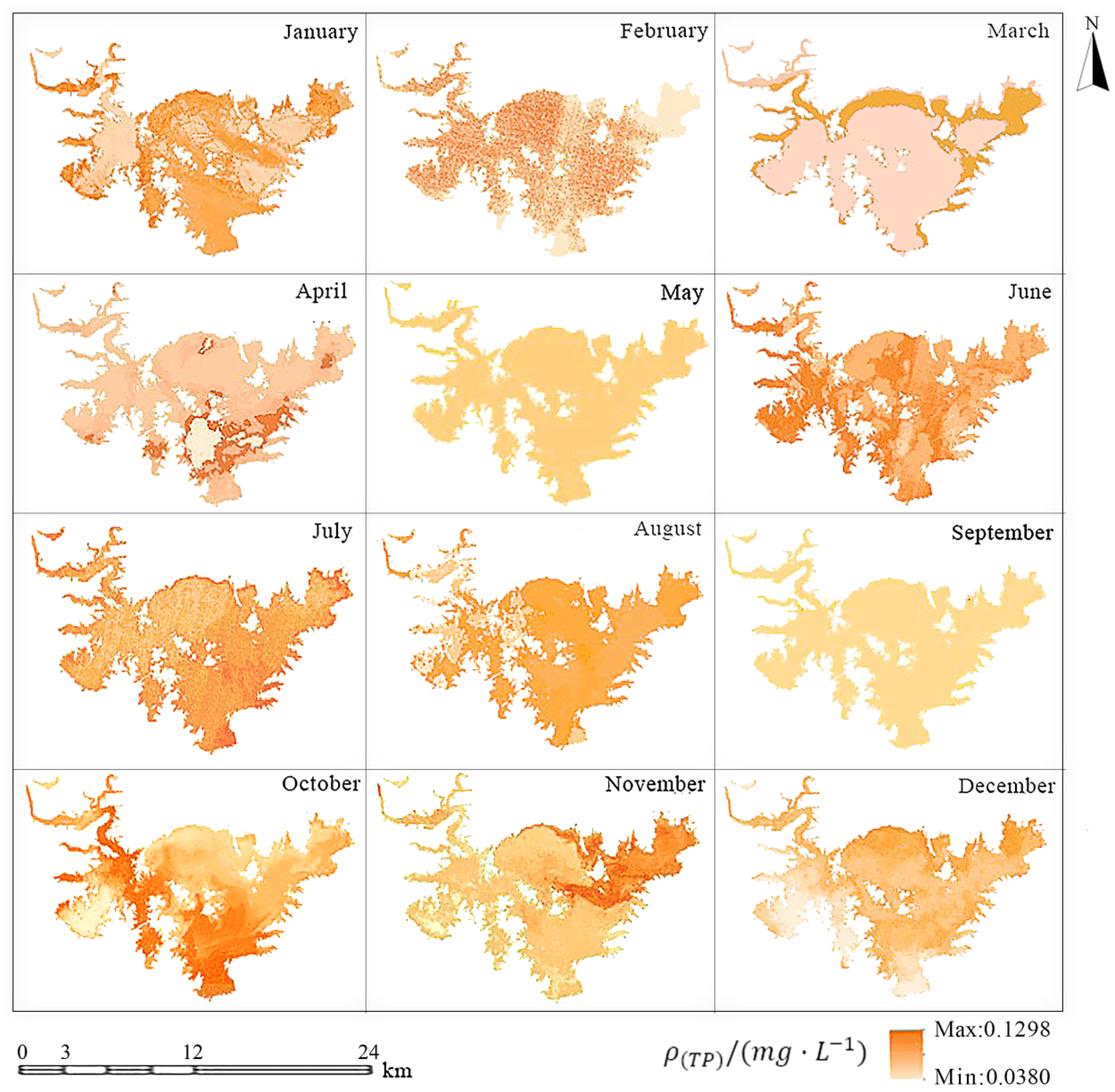
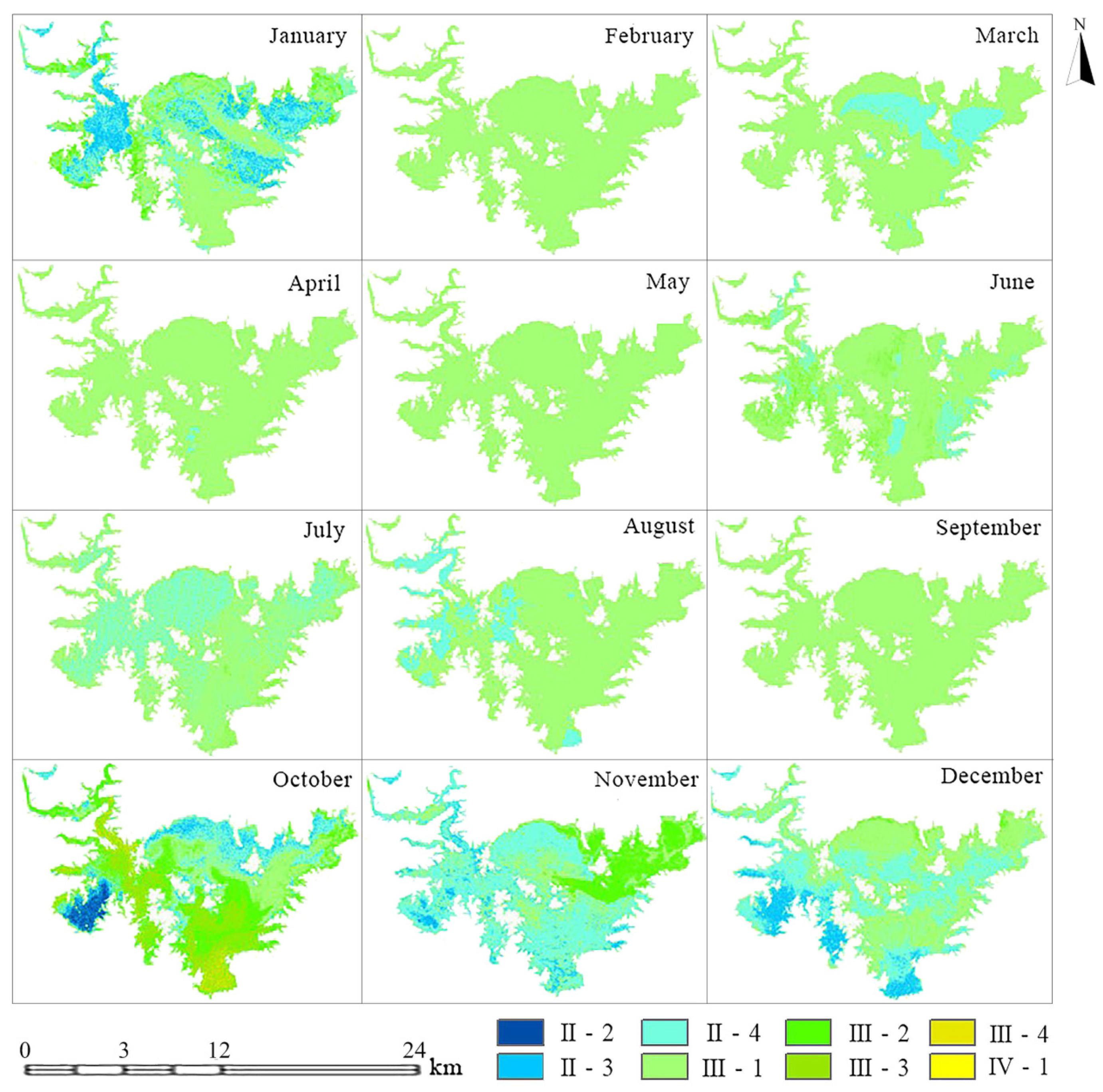
3.2.2. Spatio-Temporal Evolution of the TP Concentration in Miyun Reservoir
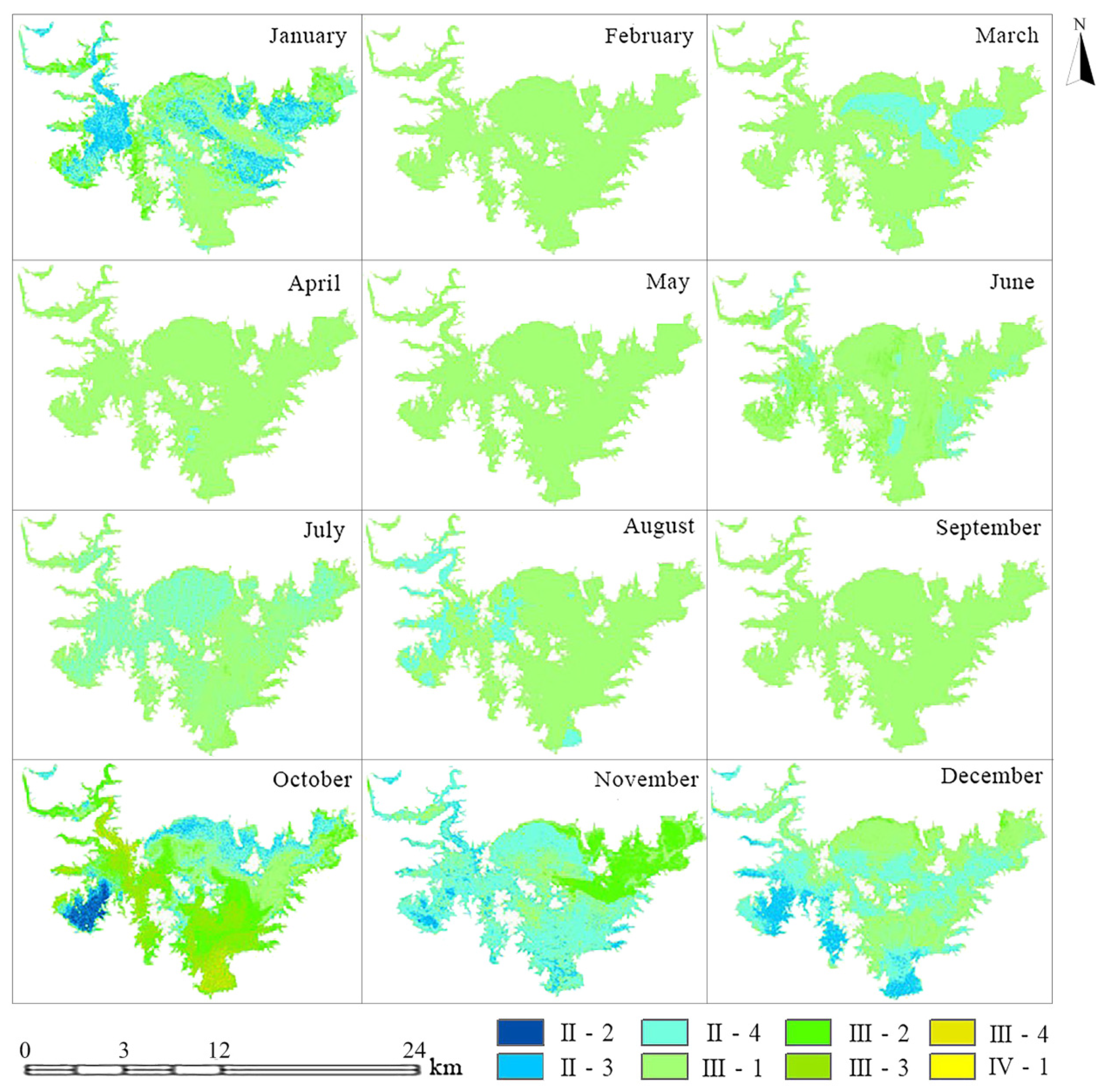
3.2.3. Water Quality Assessment Based on Surface Water Environmental Standards
4. Discussion
4.1. Water Quality Evaluation Base on the Retrieval Model of TP Concentration
4.2. Limitation in the TP Concentration Retrieval Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Al-Jawad, J.Y.; Alsaffar, H.M.; Bertram, D.; Kalin, R.M. A comprehensive optimum integrated water resources management approach for multidisciplinary water resources management problems. J. Environ. Manag. 2019, 239, 211–224. [Google Scholar] [CrossRef]
- Yu, Q.; Jiang, Q.; Yang, D.; Yue, D.; Ma, H.; Huang, Y.; Zhang, Q.; Fang, M. Incorporating Temporal and Spatial Variations of Groundwater into the Construction of a Water-Based Ecological Network: A Case Study in Denko County. Water 2017, 9, 864. [Google Scholar] [CrossRef] [Green Version]
- Kumar, P.; Liu, W.; Chu, X.; Zhang, Y.; Li, Z. Integrated water resources management for an inland river basin in China. Watershed Ecol. Environ. 2019, 1, 33–38. [Google Scholar] [CrossRef]
- Venkatesh, A.; Roopa, D. Assessment of Ground Water Quality in Thuraiyur Taluk Namakkal District. Int. J. Civ. Eng. 2020, 7, 30–34. [Google Scholar] [CrossRef]
- De Vitry, M.M.; Kramer, S.; Wegner, J.D.; Leitão, J.P. Scalable flood level trend monitoring with surveillance cameras using a deep convolutional neural network. Hydrol. Earth Syst. Sci. 2019, 23, 4621–4634. [Google Scholar] [CrossRef] [Green Version]
- Haghiabi, A.H.; Nasrolahi, A.H.; Parsaie, A. Water quality prediction using machine learning methods. Water Qual. Res. J. Can. 2018, 25, 23–28. [Google Scholar] [CrossRef]
- Rozpondek, K.; Rozpondek, R.; Pachura, P. Characteristics of spatial distribution of phosphorus and nitrogen in the bottom sediments of the water reservoir. J. Ecol. Eng. 2017, 18, 178–184. [Google Scholar] [CrossRef]
- Huang, C.; Zhang, Y.; Huang, T.; Yang, H.; Li, Y.; Zhang, Z.; He, M.; Hu, Z.; Song, T.; Zhu, A.-X. Long-term variation of phytoplankton biomass and physiology in Taihu lake as observed via MODIS satellite. Water Res. 2019, 153, 187–199. [Google Scholar] [CrossRef] [PubMed]
- Chapman, D.V.; Bradley, C.; Gettel, G.M.; Hatvani, I.G.; Hein, T.; Kovács, J.; Liska, I.; Oliver, D.M.; Tanos, P.; Trásy, B.; et al. Developments in water quality monitoring and management in large river catchments using the Danube River as an example. Environ. Sci. Policy 2016, 64, 141–154. [Google Scholar] [CrossRef] [Green Version]
- Wimmer, A.; Markus, A.A.; Schuster, M. Silver Nanoparticle Levels in River Water: Real Environmental Measurements and Modeling Approaches—A Comparative Study. Environ. Sci. Technol. Lett. 2019, 11, 32–38. [Google Scholar] [CrossRef]
- Ryberg, K.R.; Blomquist, J.D.; Sprague, L.A.; Sekellick, A.J.; Keisman, J. Modeling drivers of phosphorus loads in Chesapeake Bay tributaries and inferences about long-term change. Sci. Total Environ. 2017, 1423, 616–617. [Google Scholar] [CrossRef]
- Lai, Y.; Zhang, J.; Song, Y.; Gong, Z. Retrieval and Evaluation of Chlorophyll-a Concentration in Reservoirs with Main Water Supply Function in Beijing, China, Based on Landsat Satellite Images. Int. J. Environ. Res. Public Health 2021, 18, 4419. [Google Scholar] [CrossRef]
- Wang, Y.; Jiang, Y.; Liao, W.; Gao, P.; Huang, X.; Wang, H.; Song, X.; Lei, X. 3-D hydro-environmental simulation of Miyun reservoir, Beijin. HydroResearch 2014, 8, 383–395. [Google Scholar] [CrossRef]
- Neil, C.; Spyrakos, E.; Hunter, P.; Tyler, A. A global approach for chlorophyll-a retrieval across optically complex inland waters based on optical water types. Remote Sens. Environ. 2019, 229, 159–178. [Google Scholar] [CrossRef]
- Sayers, M.J.; Bosse, K.R.; Shuchman, R.A.; Ruberg, S.A.; Fahnenstiel, G.L.; Leshkevich, G.A.; Stuart, D.G.; Johengen, T.H.; Burtner, A.M.; Palladino, D. Spatial and temporal variability of inherent and apparent optical properties in western Lake Erie: Implications for water quality remote sensing. J. Great Lakes Res. 2019, 45, 490–507. [Google Scholar] [CrossRef]
- Wang, X.; Xiao, C.; Xue, Z.Y.; Pu, Q.C.; Jiang, T.; Zhao, J.H.; Wang, S.M. Application of Remote Sensing Technology to Monitor NH3N Distribution in the Danjiangkou Reservoir. J. Water Resour. Res. 2019, 8, 436–444. [Google Scholar] [CrossRef]
- Yao, J.; Meng, D.; Zhao, Q.; Cao, W.; Xu, Z. Nonconvex-Sparsity and Nonlocal-Smoothness-Based Blind Hyperspectral Unmixing. IEEE Trans. Image Process. 2019, 28, 2991–3006. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yao, J.; Zhang, B.; Plaza, A.; Chanussot, J. Graph Convolutional Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5966–5978. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, Y.; Yuan, D.; Song, X. Empirical Estimation of Total Nitrogen and Total Phosphorus Concentration of Urban Water Bodies in China Using High Resolution IKONOS Multispectral Imagery. Water 2015, 7, 6551–6573. [Google Scholar] [CrossRef] [Green Version]
- Chidammodzi, C.L.; Muhandiki, V.S. Water resources management and Integrated Water Resources Management implementation in Malawi: Status and implications for lake basin management. Lakes Reserv. Res. Manag. 2017, 22, 12–19. [Google Scholar] [CrossRef]
- Nour, M.H.; Smith, D.W.; El-Din, M.G.; Prepas, E.E. Effect of watershed subdivision on water-phase phosphorus modelling: An artificial neural network modelling application. J. Environ. Eng. Sci. 2008, 7, 95–108. [Google Scholar] [CrossRef]
- Sun, D.; Qiu, Z.; Li, Y.; Shi, K.; Gong, S. Detection of Total Phosphorus Concentrations of Turbid Inland Waters Using a Remote Sensing Method. Water Air Soil Pollut. 2014, 225, 1–17. [Google Scholar] [CrossRef]
- Gao, Y.; Gao, J.; Yin, H.; Liu, C.; Xia, T.; Wang, J.; Huang, Q. Remote sensing estimation of the total phosphorus concentration in a large lake using band combinations and regional multivariate statistical modeling techniques. J. Environ. Manag. 2015, 151, 33–43. [Google Scholar] [CrossRef] [PubMed]
- Ding, C.; Pu, F.; Li, C.; Xu, X.; Zou, T.; Li, X. Combining Artificial Neural Networks with Causal Inference for Total Phosphorus Concentration Estimation and Sensitive Spectral Bands Exploration Using MODIS. Water 2020, 12, 2372. [Google Scholar] [CrossRef]
- Du, C.G.; Li, Y.M.; Wang, Q.; Zhu, L.; Lv, H. Inversion model and daily variation of total phosphorus concentrations in Taihu Lake based on GOCI Data. Environ. Sci. 2016, 37, 862–872. [Google Scholar] [CrossRef]
- Wang, Y.X.; Yang, G.F.; Lin, M.S.; Yang, S.T. Calculating total phosphorus in reservoirs using the satellite Landsat data. J. Irrig. Drain. Eng. 2017, 36, 105–109. [Google Scholar] [CrossRef]
- Hao, W.; Ge-Ping, L.; Wei-Sheng, W.; Konstantin, P.; Yao-Ming, L.; Hong-Wei, Z.; Wei-Jie, H. Inversion of soil moisture content in the farmland in middle and lower reaches of Syr Darya River Basin based on multi-source remotely sensed data. J. Nat. Resour. 2019, 34, 2717–2731. [Google Scholar] [CrossRef]
- Ingles, J.; Louw, T.; Booysen, M. Water quality assessment using a portable UV optical absorbance nitrate sensor with a scintillator and smartphone camera. Water SA 2021, 47, 135–140. [Google Scholar] [CrossRef]
- Sahoo, S.; Russo, T.A.; Elliott, J.; Foster, I. Machine learning algorithms for modeling groundwater level changes in agricultural regions of the U.S. Water Resour. Res. 2017, 53, 3878–3895. [Google Scholar] [CrossRef]
- Huang, L.M.; Chen, B.; Tian, Y.; Huang, N.; Li, N. Coupling relationship optimization of landscape structure and conservation function of lake and reservoir drinking water sources in Nanning, China. Acta Ecol. Sin. 2019, 39, 3494–3506. [Google Scholar] [CrossRef]
- Fezzi, C.; Harwood, A.R.; Lovett, A.A.; Bateman, I.J. Erratum: The environmental impact of climate change adaptation on land use and water quality. Nat. Clim. Chang. 2018, 5, 385. [Google Scholar] [CrossRef] [Green Version]
- Bai, J.; Shen, Z.; Yan, T.; Qiu, J.; Li, Y. Predicting fecal coliform using the interval-to-interval approach and SWAT in the Miyun watershed, China. Environ. Sci. Pollut. Res. 2017, 24, 15462–15470. [Google Scholar] [CrossRef]
- Qiu, J.; Shen, Z.; Chen, L.; Hou, X. Quantifying effects of conservation practices on non-point source pollution in Miyun Reservoir Watershed, China. Environ. Monit. Assess. 2019, 191, 1–21. [Google Scholar] [CrossRef]
- Sun, C.; Chen, L.; Zhai, L.; Liu, H.; Jiang, Y.; Wang, K.; Jiao, C.; Shen, Z. National assessment of spatiotemporal loss in agricultural pesticides and related potential exposure risks to water quality in China. Sci. Total Environ. 2019, 677, 98–107. [Google Scholar] [CrossRef]
- Li, C.L. Under the background of big data review of machine learning algorithms. Inf. Rec. Mater. 2018, 19, 4–5. [Google Scholar] [CrossRef]
- Feng, L.; Li, J.; Gong, W.; Zhao, X.; Chen, X.; Pang, X. Radiometric cross-calibration of Gaofen-1 WFV cameras using Landsat-8 OLI images: A solution for large view angle associated problems. Remote Sens. Environ. 2016, 174, 56–68. [Google Scholar] [CrossRef]
- Qun’Ou, J.; Lidan, X.; Siyang, S.; Meilin, W.; Huijie, X. Retrieval model for total nitrogen concentration based on UAV hyper spectral remote sensing data and machine learning algorithms – A case study in the Miyun Reservoir, China. Ecol. Indic. 2021, 124, 107356. [Google Scholar] [CrossRef]
- Gao, J.; Meng, B.; Liang, T.; Feng, Q.; Ge, J.; Yin, J.; Wu, C.; Cui, X.; Hou, M.; Liu, J.; et al. Modeling alpine grassland forage phosphorus based on hyperspectral remote sensing and a multi-factor machine learning algorithm in the east of Tibetan Plateau, China. ISPRS J. Photogramm. Remote Sens. 2019, 147, 104–117. [Google Scholar] [CrossRef]
- Abedini, M.; Ghasemian, B.; Shirzadi, A.; Bui, D.T. A comparative study of support vector machine and logistic model tree classifiers for shallow landslide susceptibility modeling. Environ. Earth Sci. 2019, 78, 1–15. [Google Scholar] [CrossRef]
- Mojid, M.; Hossain, A.; Ashraf, M. Artificial neural network model to predict transport parameters of reactive solutes from basic soil properties. Environ. Pollut. 2019, 255, 113355. [Google Scholar] [CrossRef] [PubMed]
- Qaderi, F.; Babanezhad, E. Prediction of the groundwater remediation costs for drinking use based on quality of water resource, using artificial neural network. J. Clean. Prod. 2017, 161, 840–849. [Google Scholar] [CrossRef]
- Pyo, J.; Duan, H.; Baek, S.; Kim, M.S.; Jeon, T.; Kwon, Y.S.; Lee, H.; Cho, K.H. A convolutional neural network regression for quantifying cyanobacteria using hyperspectral imagery. Remote Sens. Environ. 2019, 233, 1–11. [Google Scholar] [CrossRef]
- Balokas, G.; Czichon, S.; Rolfes, R. Neural network assisted multiscale analysis for the elastic properties prediction of 3D braided composites under uncertainty. Compos. Struct. 2018, 183, 550–562. [Google Scholar] [CrossRef]
- Assaf, A.G.; Tsionas, M.; Tasiopoulos, A. Diagnosing and correcting the effects of multicollinearity: Bayesian implications of ridge regression. Tour. Manag. 2019, 71, 1–8. [Google Scholar] [CrossRef]
- Zhang, Y.; Ma, F.; Wang, Y. Forecasting crude oil prices with a large set of predictors: Can LASSO select powerful predictors? J. Empir. Financ. 2019, 54, 97–117. [Google Scholar] [CrossRef]
- Liu, J.; Liang, G.; Siegmund, K.D.; Lewinger, J.P. Data integration by multi-tuning parameter elastic net regression. BMC Bioinform. 2018, 19, 369. [Google Scholar] [CrossRef]
- Lv, H.Y.; Feng, Q. A review of random forests algorithm. J. Hebei Acad. Sci. 2019, 36, 37–41. [Google Scholar] [CrossRef]
- Fernández-Martínez, S.; Barán, B.; Pinto-Roa, D.P. Spectrum defragmentation algorithms in elastic optical networks. Opt. Switch. Netw. 2019, 34, 10–22. [Google Scholar] [CrossRef]
- Nystrom, E.; Sharp, J.L.; Bridges, W.C. The Impact of Correlated and/or Interacting Predictor Omission on Estimated Regression Coefficients in Linear Regression. J. Stat. Theory Pract. 2019, 13, 56. [Google Scholar] [CrossRef]
- Li, J.; Wang, Z.; Lai, C.; Zhang, Z. Tree-ring-width based streamflow reconstruction based on the random forest algorithm for the source region of the Yangtze River, China. CATENA 2019, 183, 104216. [Google Scholar] [CrossRef]
- Sempere, J.M. Modeling of Decision Trees Through P Systems. New Gener. Comput. 2019, 37, 325–337. [Google Scholar] [CrossRef]
- Holloway, J.; Helmstedt, K.J.; Mengersen, K.; Schmidt, M. A Decision Tree Approach for Spatially Interpolating Missing Land Cover Data and Classifying Satellite Images. Remote Sens. 2019, 11, 1796. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Li, H.; Wei, K. Automatic fast double KNN classification algorithm based on ACC and hierarchical clustering for big data. Int. J. Commun. Syst. 2018, 31, e3488. [Google Scholar] [CrossRef]
- Lu, D.J.; Cuan, K.X.; Zhang, W.F. Research on Spectral Reflectance Estimation Using Locally Weighted Linear Regression within k-Nearest Neighbors. Spectrosc. Spect. Anal. 2018, 12, 3708–3712. [Google Scholar] [CrossRef]
- Pham, T.M.; Doan, D.C.; Hitzer, E. Feature Extraction Using Conformal Geometric Algebra for AdaBoost Algorithm Based In-plane Rotated Face Detection. Adv. Appl. Clifford Algebras 2019, 29, 61. [Google Scholar] [CrossRef]
- Ghatkar, J.G.; Singh, R.K.; Shanmugam, P. Classification of algal bloom species from remote sensing data using an extreme gradient boosted decision tree model. Int. J. Remote Sens. 2019, 40, 9412–9438. [Google Scholar] [CrossRef]
- Ling, H.; Qian, C.X.; Kang, W.C.; Liang, C.Y.; Chen, H.C. Machine and K-Fold cross validation to predict compressive strength of concrete in marine environment. Constr. Build. Mater. 2019, 206, 355–363. [Google Scholar] [CrossRef]
- Chen, C.; Chen, Z.; Li, M.; Liu, Y.; Cheng, L.; Ren, Y. Parallel relative radiometric normalisation for remote sensing image mosaics. Comput. Geosci. 2014, 73, 28–36. [Google Scholar] [CrossRef]
- Ho, J.Y.; Afan, H.A.; El-Shafie, A.H.; Koting, S.B.; Mohd, N.S.; Jaafar, W.Z.B.; Sai, H.L.; Malek, M.A.; Ahmed, A.N.; Mohtar, W.H.M.W.; et al. Towards a time and cost effective approach to water quality index class prediction. J. Hydrol. 2019, 575, 148–165. [Google Scholar] [CrossRef]
- Bruegge, C.J.; Diner, D.J.; Kahn, R.A.; Chrien, N.; Helmlinger, M.C.; Gaitley, B.J.; Abdou, W.A. The MISR radiometric calibration process. Remote Sens. Environ. 2007, 107, 2–11. [Google Scholar] [CrossRef]
- Nistane, V.; Harsha, S. Performance evaluation of bearing degradation based on stationary wavelet decomposition and extra trees regression. World J. Eng. 2018, 15, 646–658. [Google Scholar] [CrossRef]
- Chang, V.; Li, T.; Zeng, Z. Towards an improved Adaboost algorithmic method for computational financial analysis. J. Parallel Distrib. Comput. 2019, 134, 1–14. [Google Scholar] [CrossRef]
- Xu, E.Q.; Zhang, H.Q. Relationship between land use and nutrients in surface runoff in upper catchment of Miyun Reservior, China. Chinese J. Appl. Ecol. 2018, 29, 2869–2878. [Google Scholar] [CrossRef]
- Zhang, M.; Li, L.J.; Zhao, W.H.; Xu, J.H.; Zhao, W.J. Spatial heterogeneity and cause analysis of water quality in the upper streams of Miyun Reservoir. Acta Sci. Circum. 2019, 39, 1852–1859. [Google Scholar] [CrossRef]
- Qin, L.H.; Zeng, Q.H.; Li, X.Y.; Cheng, P. The distribution characteristics of P forms in Miyun Reservoir sediments. Chinese J. Ecol. 2017, 36, 774–781. [Google Scholar] [CrossRef]
- Gang, D.C.; Qi, W.X.; Liu, H.J.; Qu, J.H. Impact of south-to-north water diversion project on phosphorus release from water level fluctuating zone at Miyun reservoir. Acta Sci. Circum. 2017, 37, 3813–3822. [Google Scholar] [CrossRef]
- Wu, Z.; Cai, Y.; Liu, X.; Xu, C.P.; Chen, Y.; Zhang, L. Temporal and spatial variability of phytoplankton in Lake Poyang: The largest freshwater lake in China. J. Great Lakes Res. 2013, 39, 476–483. [Google Scholar] [CrossRef]
- Cao, Z.; Duan, H.; Feng, L.; Ma, R.; Xue, K. Climate- and human-induced changes in suspended particulate matter over Lake Hongze on short and long timescales. Remote Sens. Environ. 2017, 192, 98–113. [Google Scholar] [CrossRef]
- Feng, L.; Hu, C.; Han, X.; Chen, X.; Qi, L. Long-Term Distribution Patterns of Chlorophyll-a Concentration in China’s Largest Freshwater Lake: MERIS Full-Resolution Observations with a Practical Approach. Remote Sens. 2015, 7, 275–299. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Fell, F.; Liu, Z.; Preusker, R.; Fischer, J.; He, M. Evaluating the performance of artificial neural network techniques for pigment retrieval from ocean color in Case I waters. J. Geophys. Res. Space Phys. 2003, 108, 3286–3298. [Google Scholar] [CrossRef]
- Kishino, M.; Tanaka, A.; Ishizaka, J. Retrieval of Chlorophyll a, suspended solids, and colored dissolved organic matter in Tokyo Bay using ASTER data. Remote Sens. Environ. 2005, 99, 66–74. [Google Scholar] [CrossRef]
- Vilas, L.G.; Spyrakos, E.; Palenzuela, J.M.T. Neural network estimation of chlorophyll a from MERIS full resolution data for the coastal waters of Galician rias (NW Spain). Remote Sens. Environ. 2011, 115, 524–535. [Google Scholar] [CrossRef]
- Zhan, H.; Shi, P.; Chen, C. Retrieval of oceanic chlorophyll concentration using support vector machines. IEEE Trans. Geosci. Remote Sens. 2003, 41, 2947–2951. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Gómez-Chova, L.; Richter, K.; Calpe-Maravilla, J. Biophysical Parameter Estimation with a Semisupervised Support Vector Machine. IEEE Geosci. Remote Sens. Lett. 2009, 6, 248–252. [Google Scholar] [CrossRef]
- Leondes, C.T. Neural network systems techniques and applications. Radiol. Nucl. Med. 1998, 25, 412–419. [Google Scholar] [CrossRef]
- State Environmental Protection Administration (SEPA). Environmental Quality Standard for Surface Water. GB3838-2002. 2002. Available online: https://www.mee.gov.cn/ywgz/fgbz/bz/bzwb/shjbh/shjzlbz/200206/t20020601_66497.shtml (accessed on 18 September 2021).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Parameters | Complexity |
|---|---|---|
| Linear Regression | Estimated coefficient α = 0.1 | O(np2) |
| Bayesian Ridge Regression | Prior parameters (α, λ) = 10–6 | |
| Lasso Regression | Estimated coefficient (α) = 0.1 | |
| K Neighbor Regressor | K = 5 | |
| Elastic Net | Estimated coefficient (α) = default | |
| Decision Tree Regressor | Number of nodes(min) = 20, Tree depth(max) = 30 | O(m∗n∗log(n)) |
| Support Vector Machine | Penalty (C) = 1, Accuracy (ε) = 0.5, Nuclear (γ) = 1 | O(m2∗n2) |
| Artificial Neural Network | Number of nodes = 15, Hidden layers = 2 | O(n·m·hk·o·i) |
| AdaBoost Regressor | Tree number = 125 | O(t∗n∗log(n)) |
| Random Forest Regressor | Tree number = 125 | |
| ExtraTrees Regressor | Tree number = 125, Depth = 25 | |
| Gradient Boosting Regressor | Tree number = 125, Depth = 25 |
| Algorithm | Mean Absolute Error (mg/L) | Mean Square Error (mg/L) | Explained Variance Score | R2 |
|---|---|---|---|---|
| Linear Regression | 0.001747 | 0.000007 | 0.598713 | 0.598713 |
| Bayesian Ridge Regression | 0.001608 | 0.000008 | 0.579374 | 0.579374 |
| Lasso Regression | 0.001723 | 0.000007 | 0.596967 | 0.596967 |
| K Neighbor Regressor | 0.001735 | 0.000007 | 0.598132 | 0.598132 |
| Elastic Net | 0.001447 | 0.000005 | 0.724383 | 0.724263 |
| Decision Tree Regressor | 0.000421 | 0.000003 | 0.850468 | 0.897365 |
| Support Vector Machine | 0.001953 | 0.00001 | 0.44061 | 0.432786 |
| Artificial Neural Network | 0.003344 | 0.000022 | 0 | 0 |
| AdaBoost Regressor | 0.001415 | 0.000005 | 0.739572 | 0.738588 |
| Random Forest Regressor | 0.000935 | 0.000003 | 0.814934 | 0.814851 |
| Extra Trees Regressor | 0.000433 | 0.000003 | 0.850468 | 0.850468 |
| Gradient Boosting Regressor | 0.000636 | 0.000003 | 0.844646 | 0.844646 |
| Level | I | II | III | IV | V | |
|---|---|---|---|---|---|---|
| TP concentration (mg/L) | Standard limit value≤ | 0.01 | 0.025 | 0.05 | 0.1 | 0.2 |
| Range of the retrieval results∈ | Min = 0.014 | Max = 0.051 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiao, Z.; Sun, S.; Jiang, Q.; Xiao, L.; Wang, Y.; Yan, H. Retrieval of Total Phosphorus Concentration in the Surface Water of Miyun Reservoir Based on Remote Sensing Data and Machine Learning Algorithms. Remote Sens. 2021, 13, 4662. https://doi.org/10.3390/rs13224662
Qiao Z, Sun S, Jiang Q, Xiao L, Wang Y, Yan H. Retrieval of Total Phosphorus Concentration in the Surface Water of Miyun Reservoir Based on Remote Sensing Data and Machine Learning Algorithms. Remote Sensing. 2021; 13(22):4662. https://doi.org/10.3390/rs13224662
Chicago/Turabian StyleQiao, Zhi, Siyang Sun, Qun’ou Jiang, Ling Xiao, Yunqi Wang, and Haiming Yan. 2021. "Retrieval of Total Phosphorus Concentration in the Surface Water of Miyun Reservoir Based on Remote Sensing Data and Machine Learning Algorithms" Remote Sensing 13, no. 22: 4662. https://doi.org/10.3390/rs13224662
APA StyleQiao, Z., Sun, S., Jiang, Q., Xiao, L., Wang, Y., & Yan, H. (2021). Retrieval of Total Phosphorus Concentration in the Surface Water of Miyun Reservoir Based on Remote Sensing Data and Machine Learning Algorithms. Remote Sensing, 13(22), 4662. https://doi.org/10.3390/rs13224662