
Effect of Using Different Amounts of Multi-Temporal Data on the Accuracy: A Case of Land Cover Mapping of Parts of Africa Using FengYun-3C Data



Abstract
:1. Introduction
2. Materials and Methods
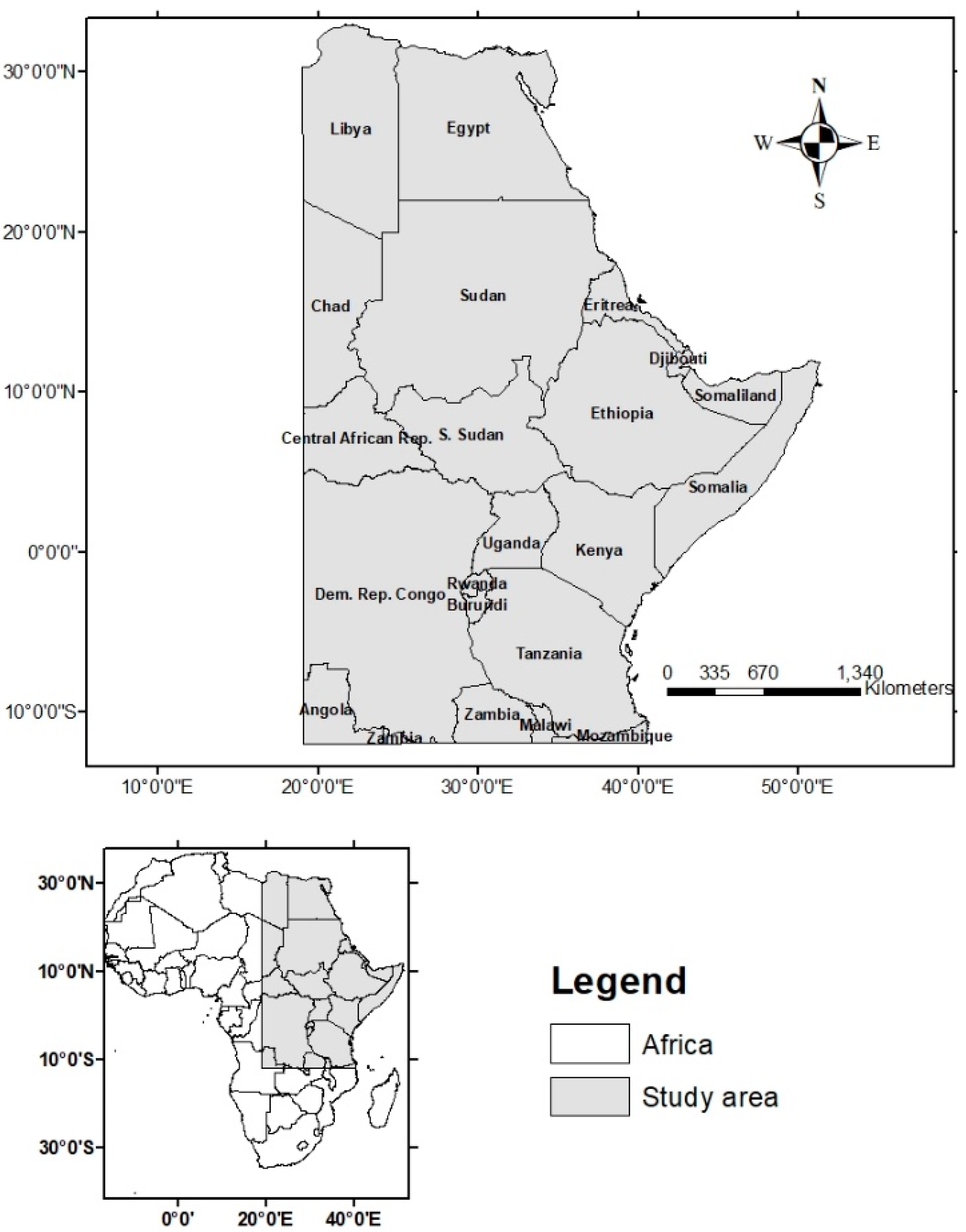
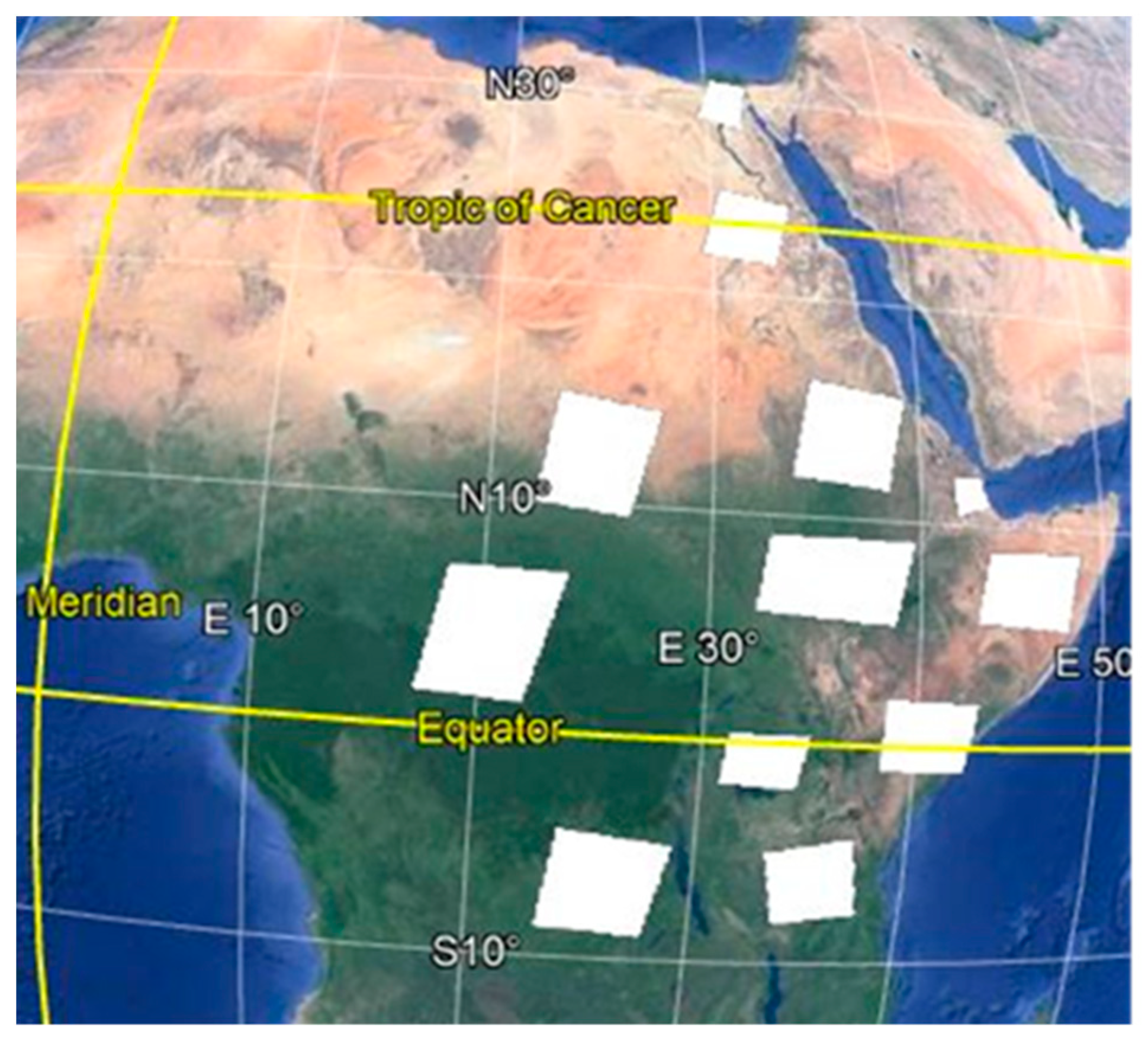
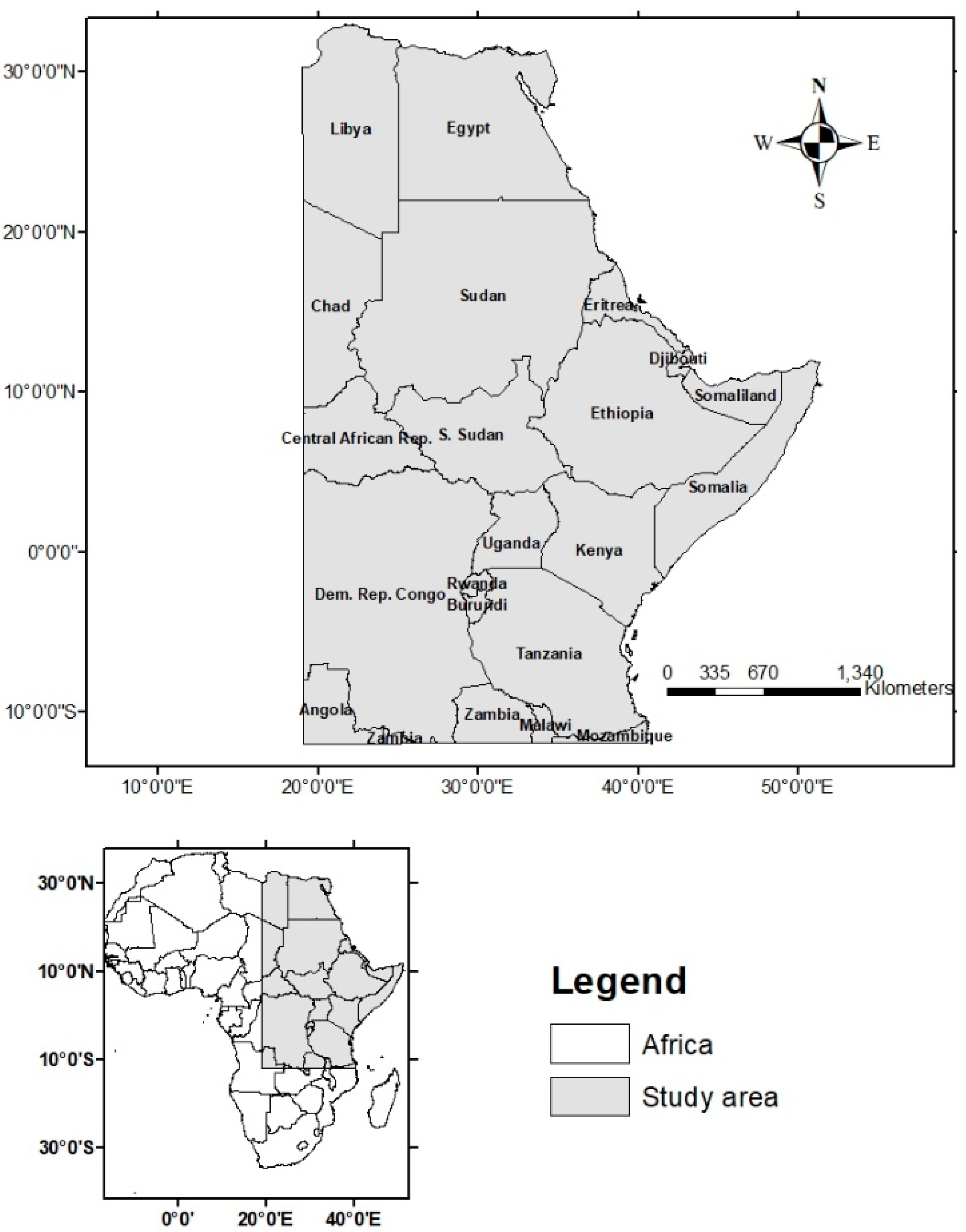
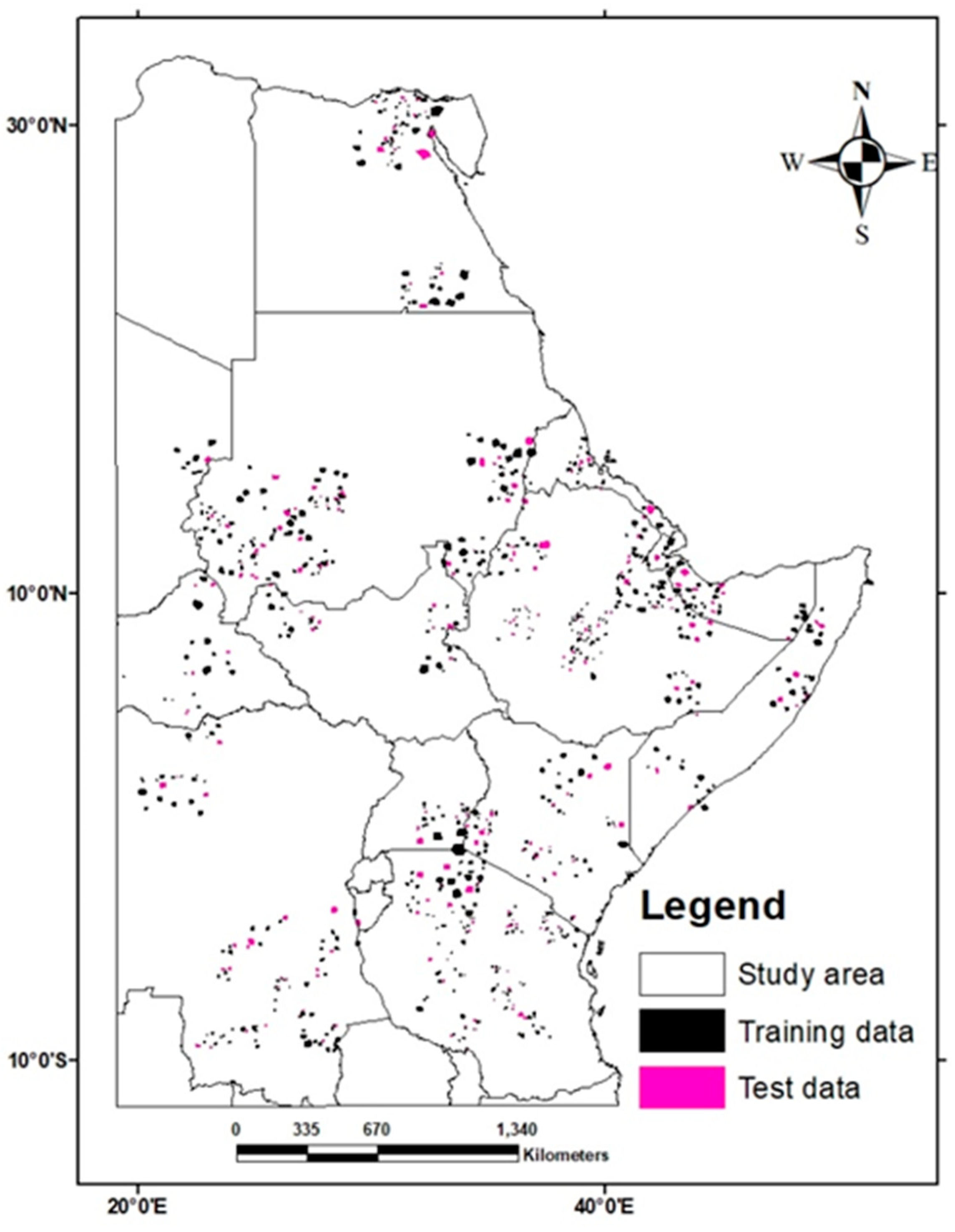
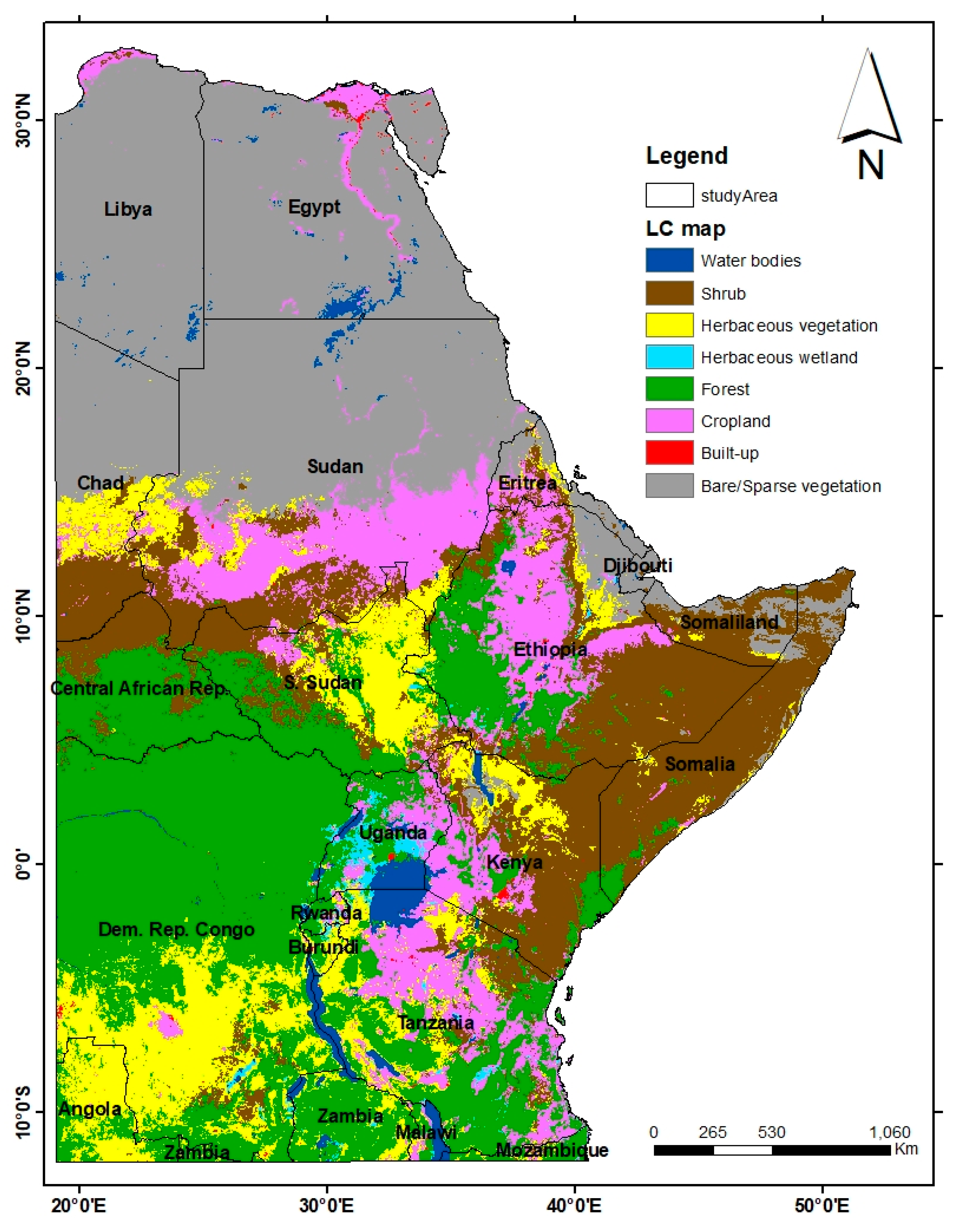
2.1. Study Area
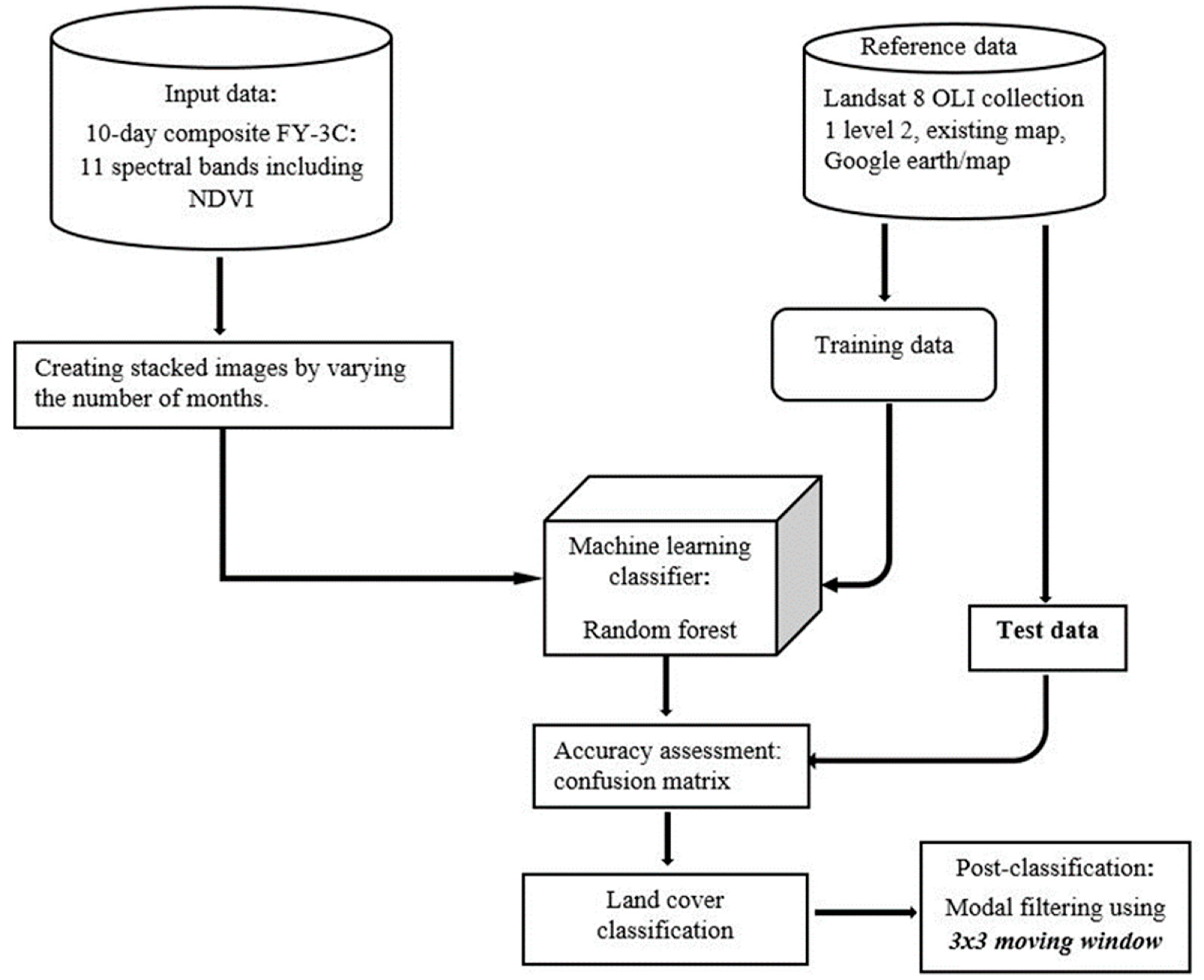
2.2. Technical Workflow
2.3. Materials and/or Resources
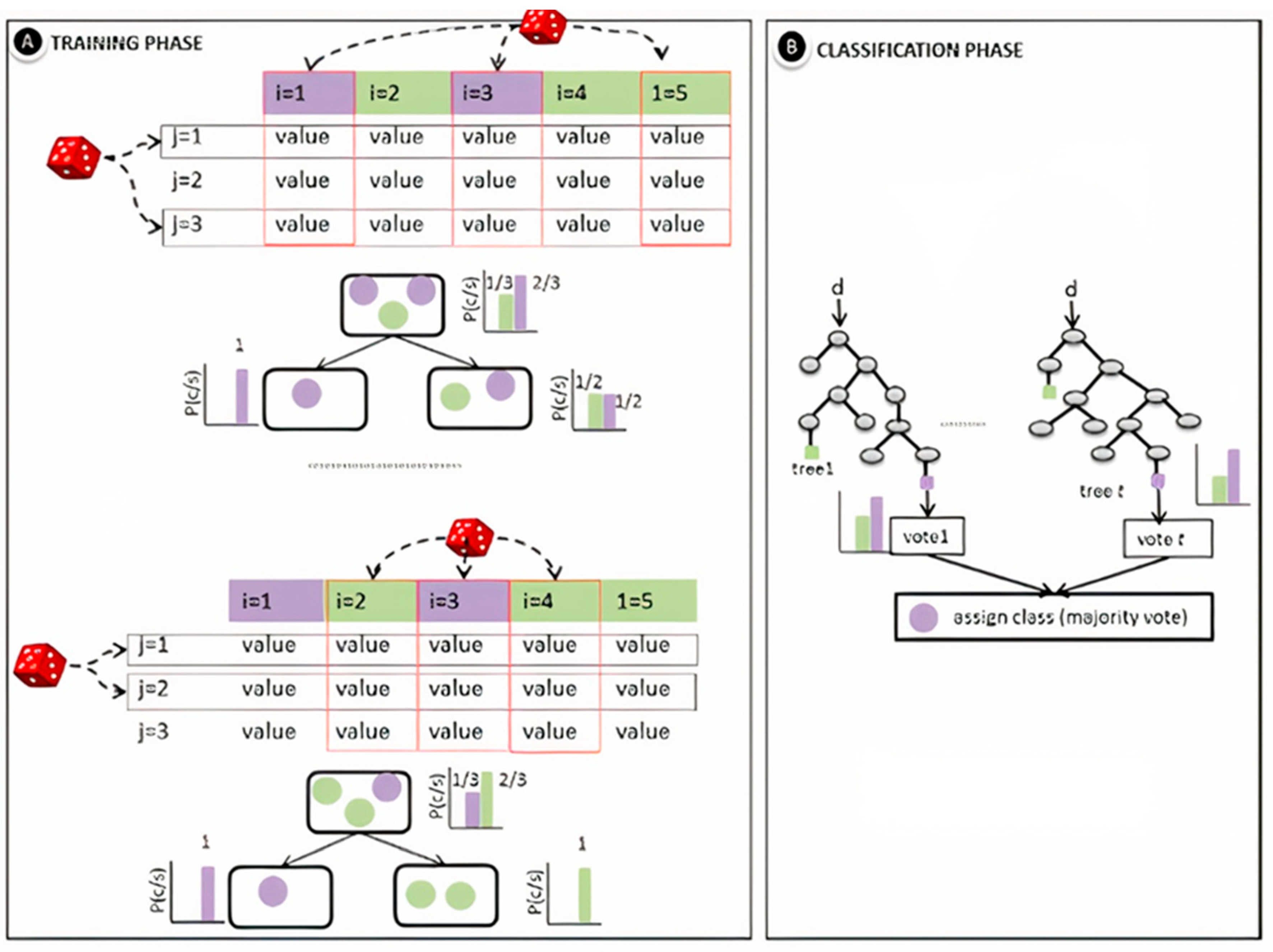
2.4. Random Forest Classifier
2.5. Selecting Reference Data Location and Landsat Data Acquisition
2.6. Naming of Classes
2.7. Reference Data/ROI Collection
- Interpretations of the images by applying image interpretation elements such as texture, pattern, association, color, tone, and others.
- Crosschecking the underlying previous land cover map, i.e., Copernicus global land cover map (100 m) if the class is homogenous for at least the minimum mapping unit (1 km × 1 km, i.e., 40 × 40 Landsat pixels) of the input data.
- Finally, further cross-checking/consolation was done on higher resolution imageries, Google Earth Pro, and Google Maps.
- One-month stacked image (OMSI): this is created from 10-day composite images of a single month (April 2019), it consists of three composite images where each of the images is composed of 10-day scenes. As a result, one month stacked image has a total of 33-bands/features which resulted from the multiplication of three variables as follow:3-Images per month × 1-month × 11-bands = 33 bands/features
- Three months stacked image (TMSI): a stacked image made up of 3-month (Apr, May, and June 2019) composite images, and comprises a total of 99-band images.
- Six months stacked image (SMSI): a stacked composite image of six-month (Apr, May, June, July, August, September 2019) with 198-feature/band.
- Nine months stacked image (NMSI): it is a stacked scene of 9-month (Apr, May, Jun, Jul, August, September, October, November, December 2019) and has a total of 297-bands/features.
- One-year stacked image (OYSI): contains the maximum features/bands, 396, as it is made of one-year, 1 April 2019 to 1 April 2020, composite images.
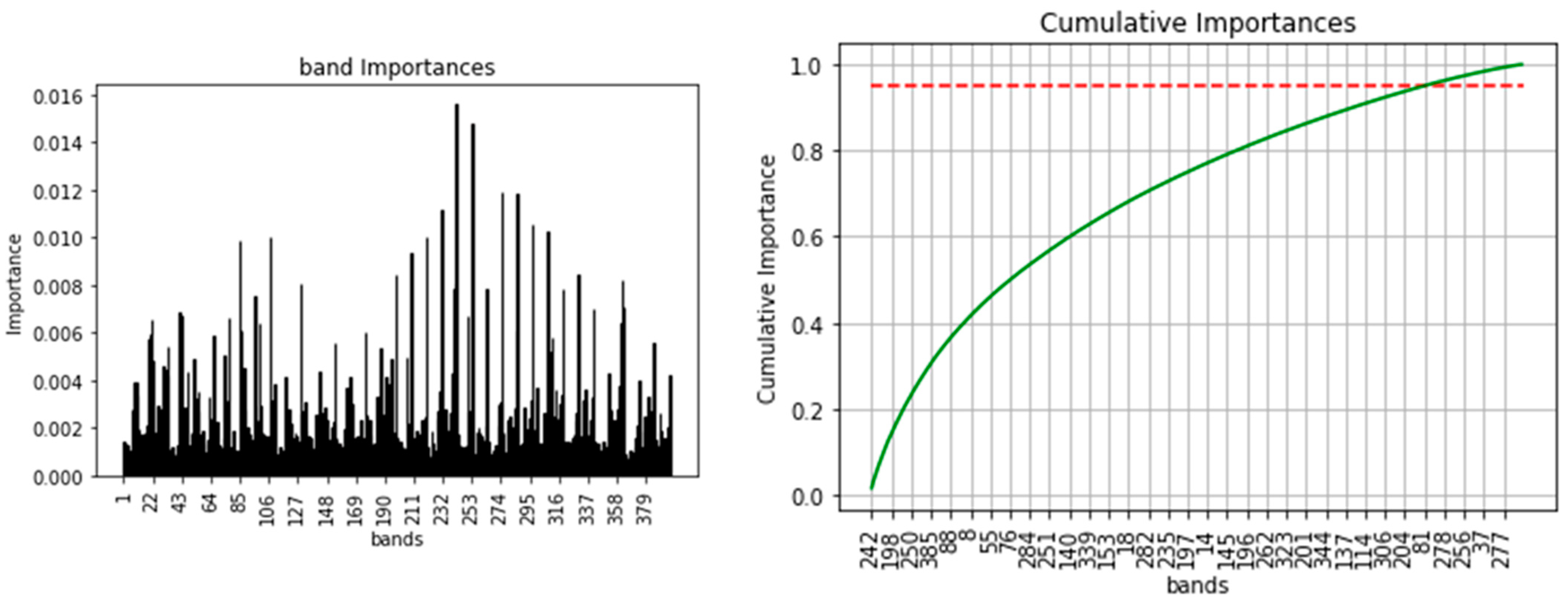
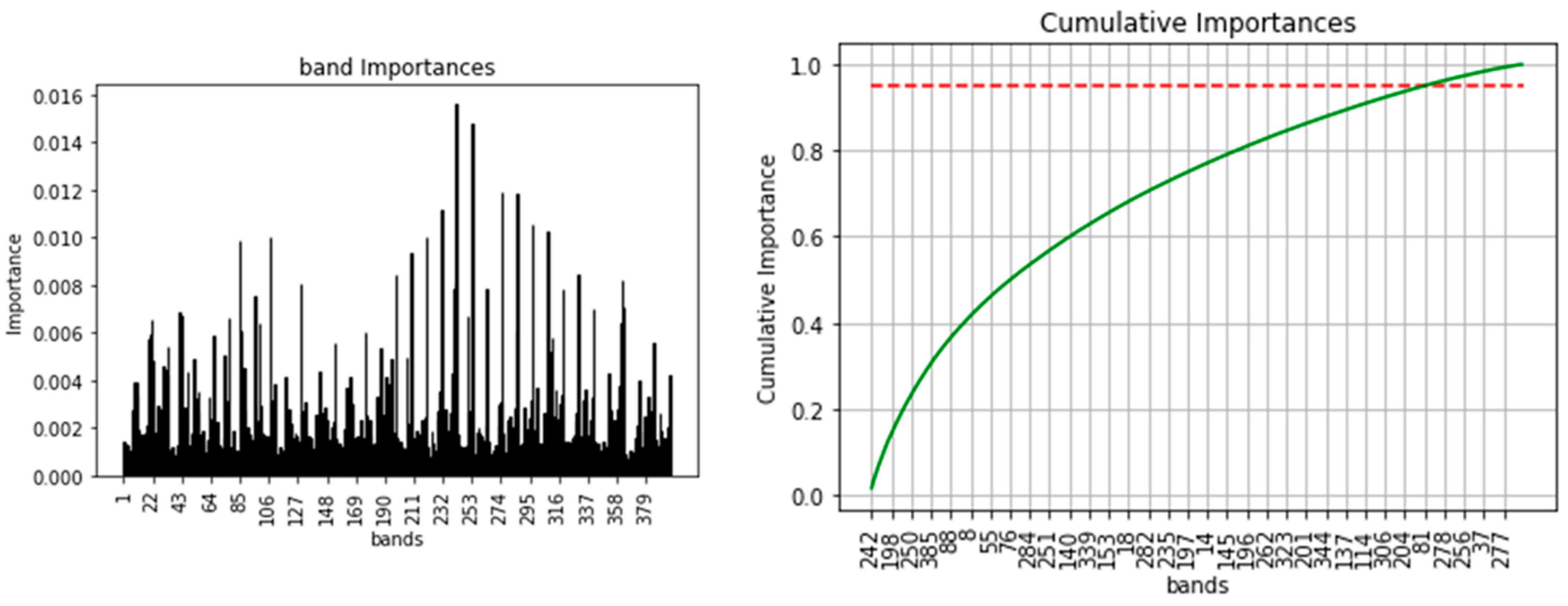
- Selected data from one-year stacked image (SDFOYSI): as the name implies the data are generated by feature selection/reduction methods using variable importance of random forest classifier. One of the advantages of using a random forest classifier is its feature/variable importance algorithm, built-in functionality that helps to select the most important variables and remove the least significant ones. Using the algorithm and by setting 95% cumulative importance, 337 features/bands were selected out of 396 features/bands of OYSI (see Figure 6). Implying the rest 59 bands are the least important features and have an insignificant effect on the overall result.
- Selected nine months stacked image (SNMSI): a stacked image consisting of selected 9-month imageries (April, May, June, July, August, September 2019; and January, Februry, and March 2020) that are created based on the result obtained by processing SMSI and NMSI. That is, it is formed from the one-year data by removing three months (October, November, December 2019) data as there is no variation in accuracy observed by processing SMSI and NMSI where the latter comprises the excluded months. In other words, it is data derived by a systematic feature selection technique.
2.8. Model Training
2.9. Accuracy Assessment
3. Results
4. Discussion
4.1. Effect of Feature Selection/Reduction
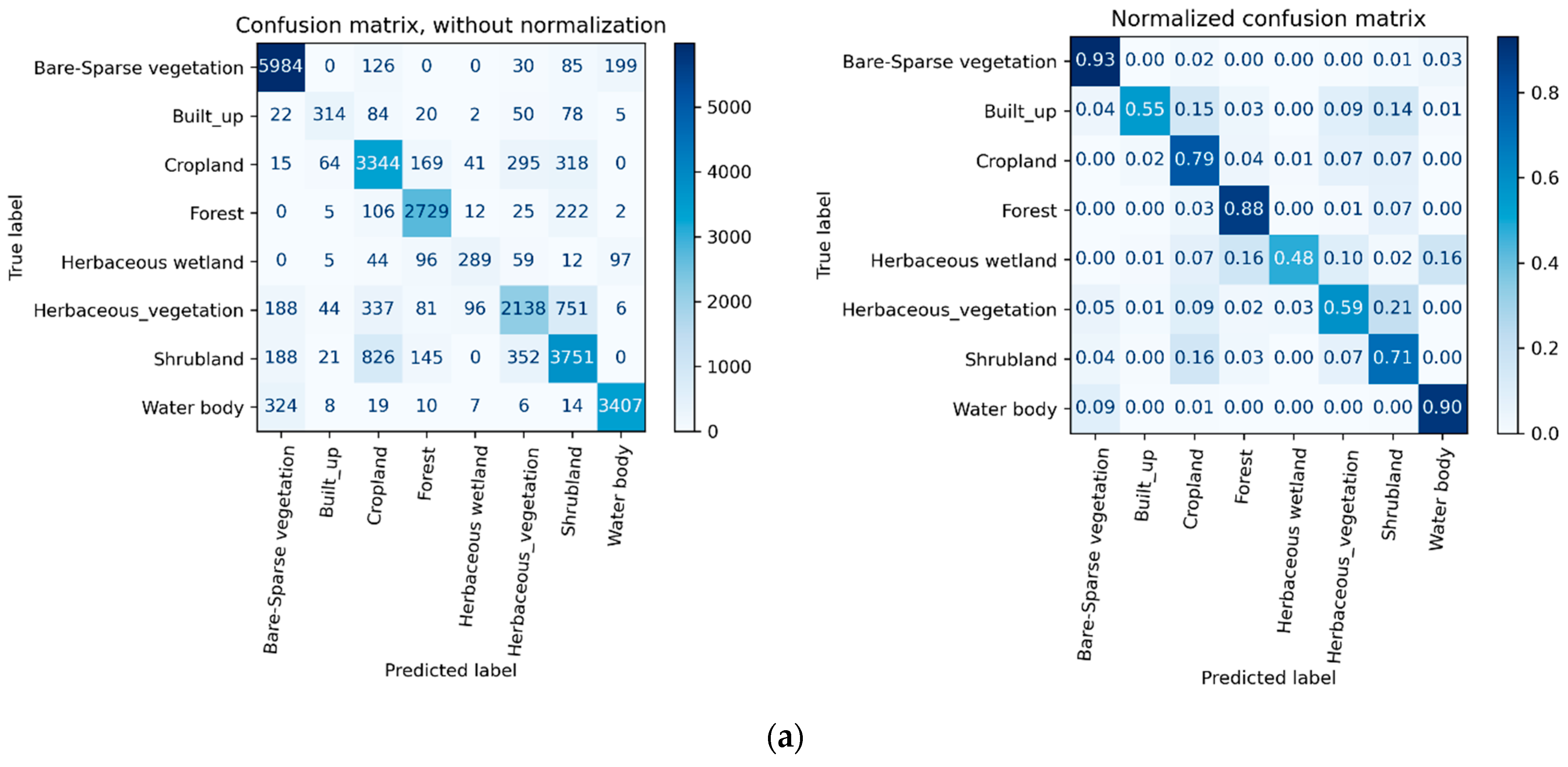
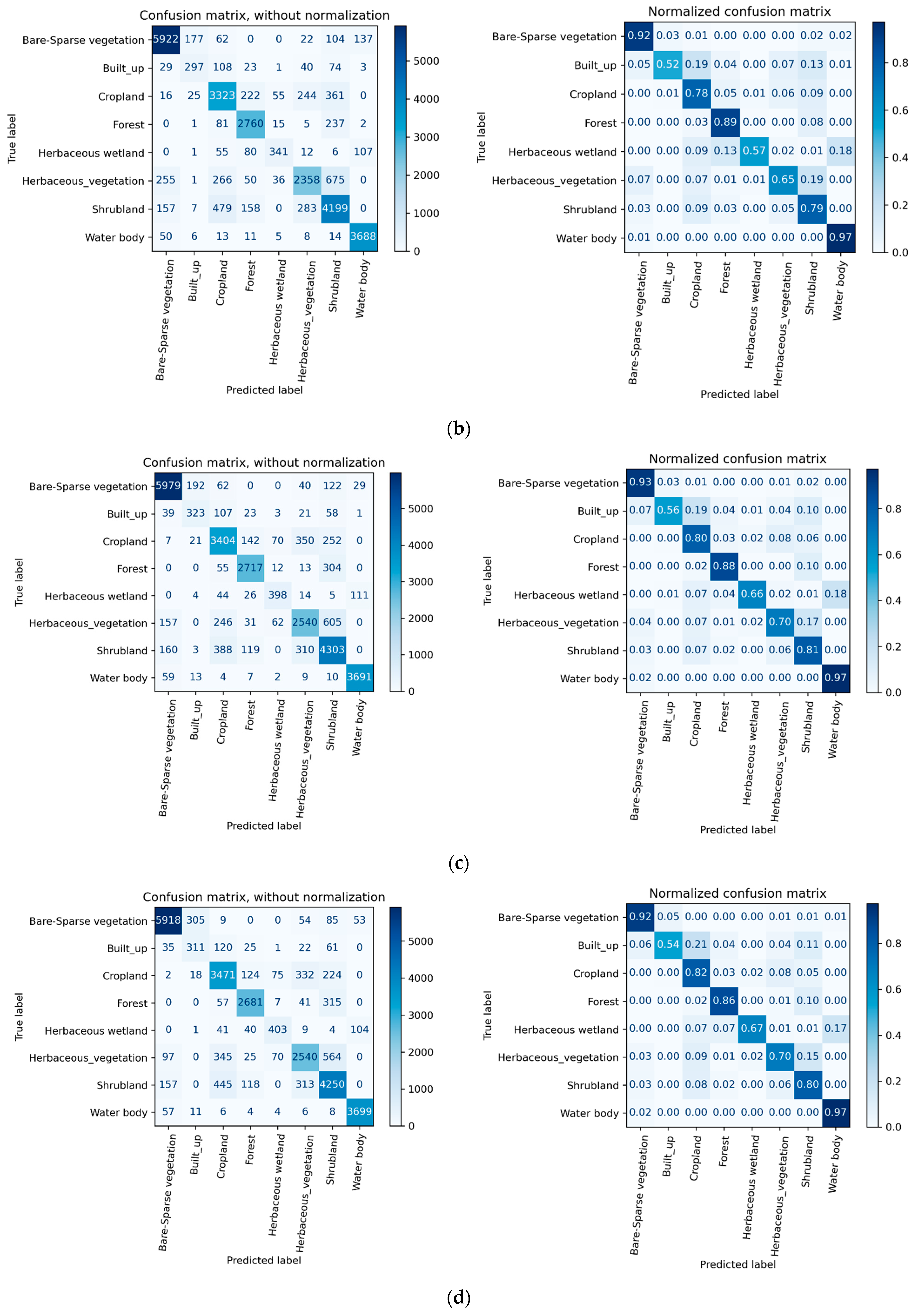
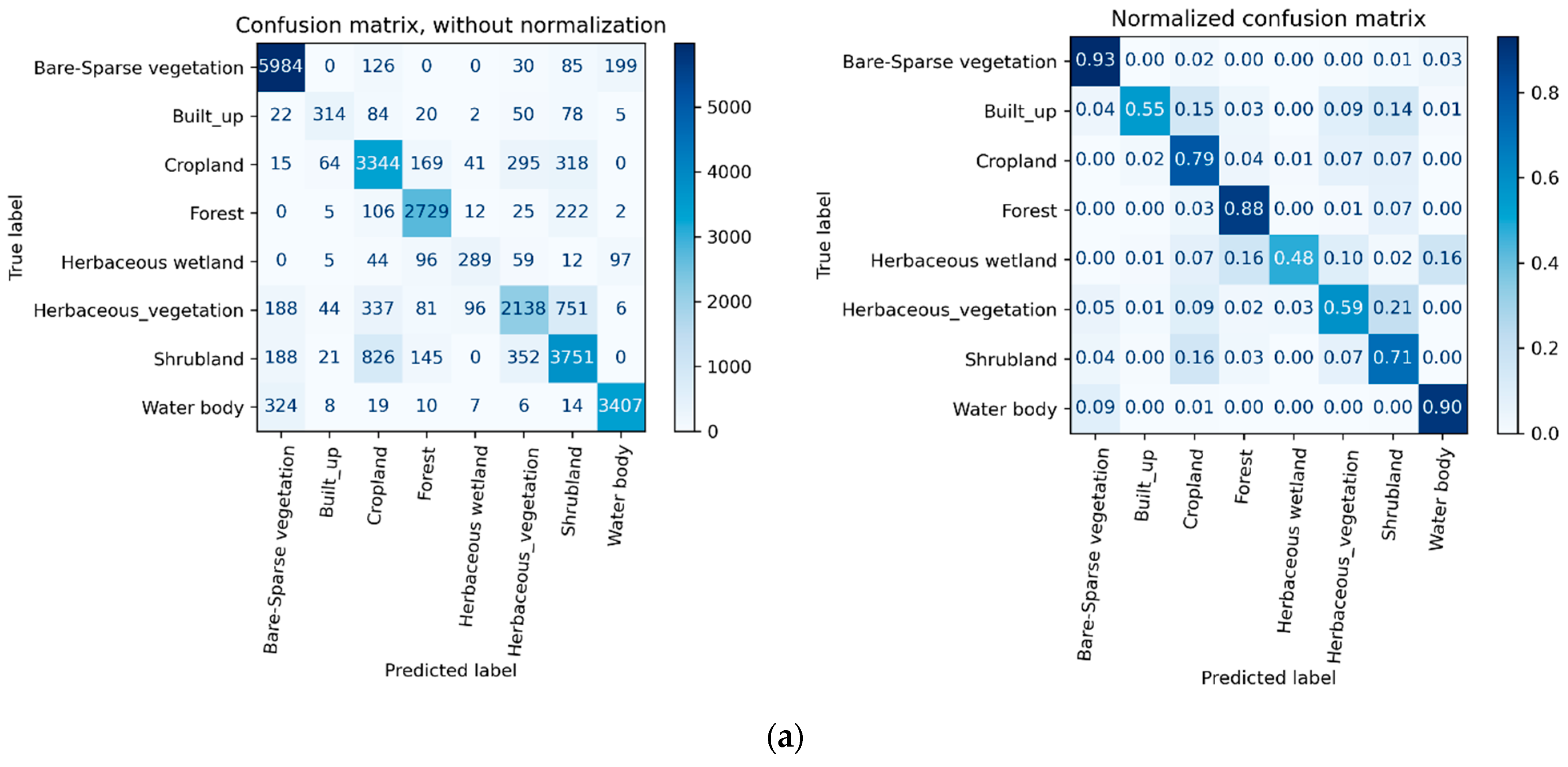
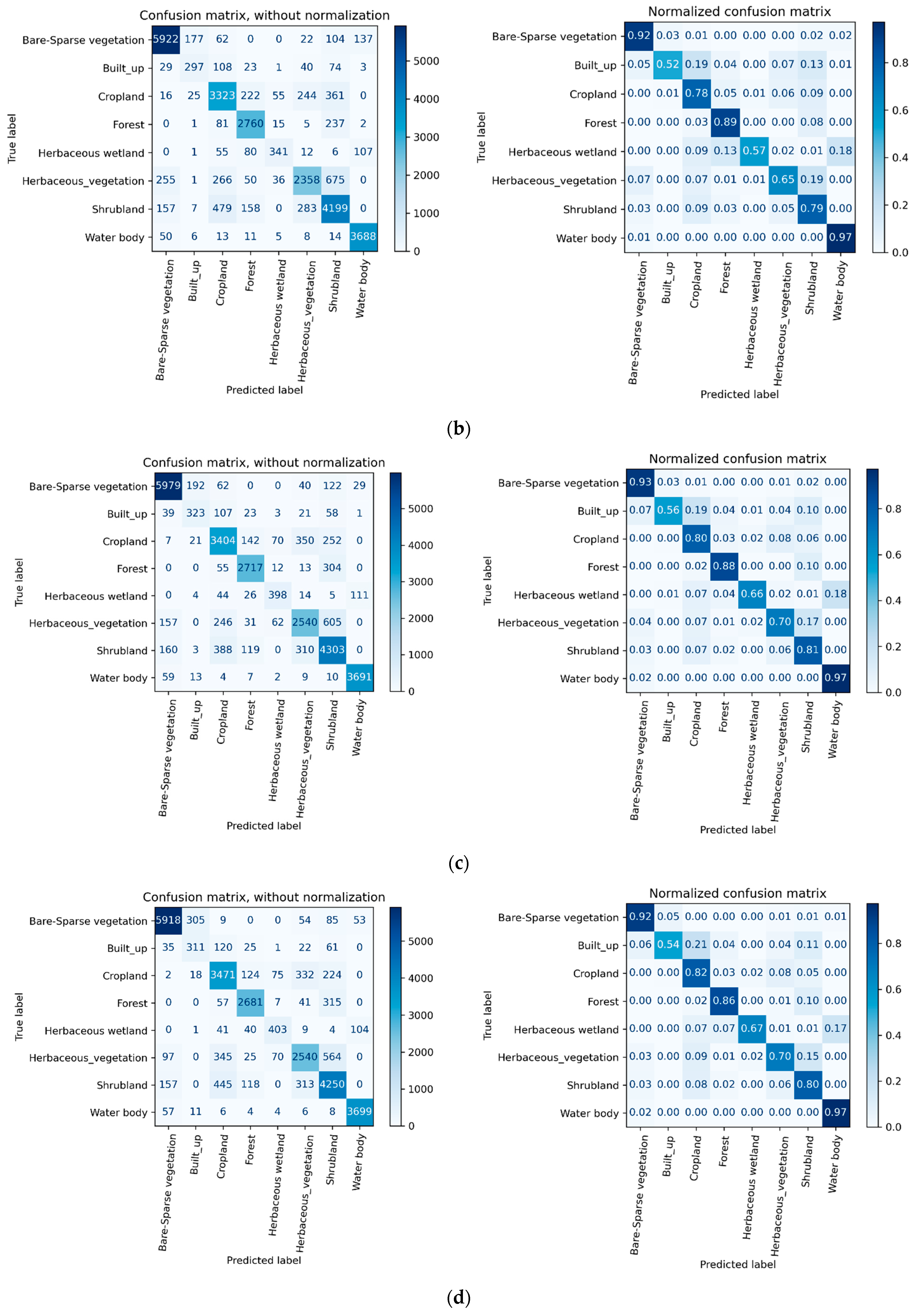
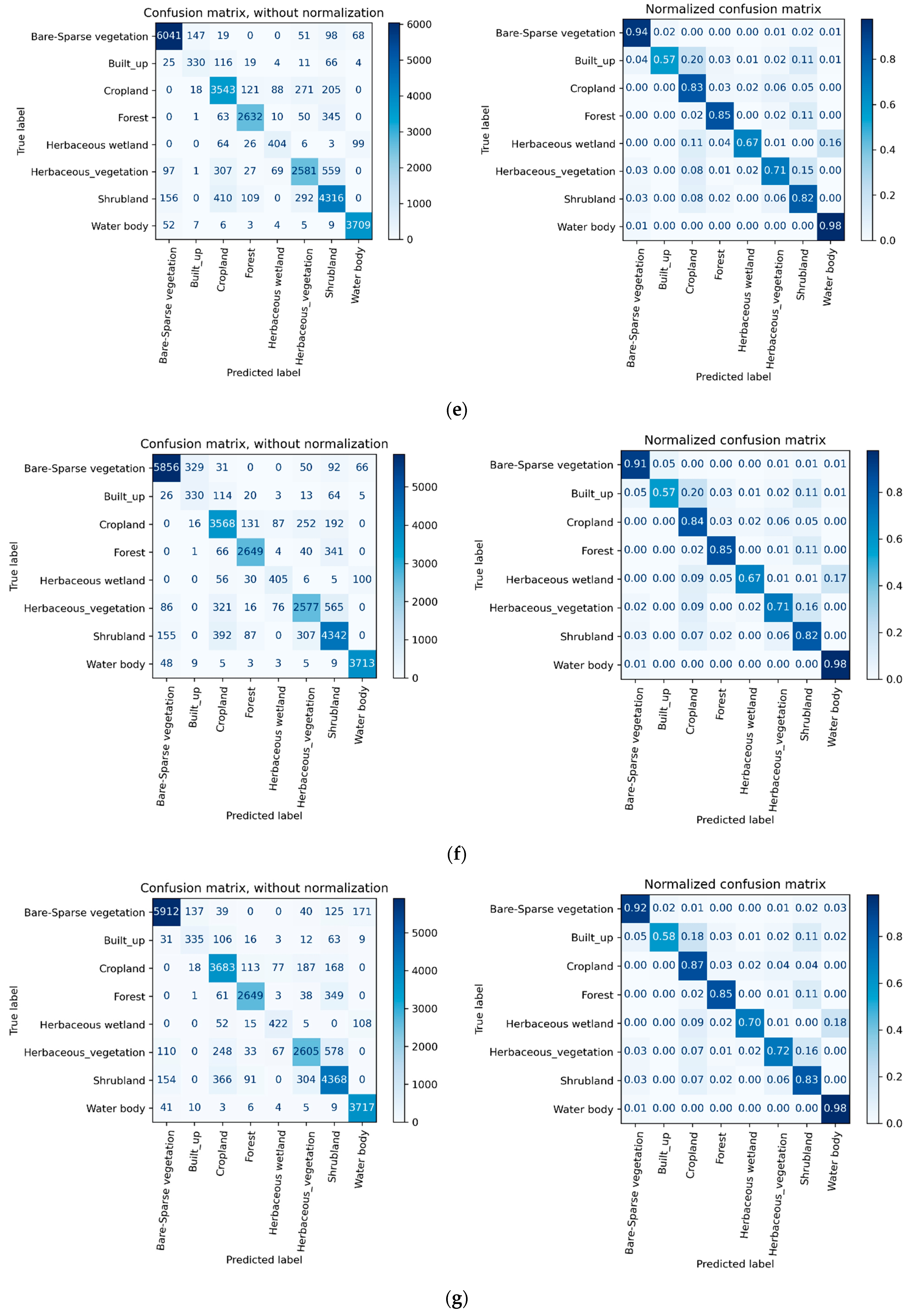
4.2. Error Matrix
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tchuenté, A.T.K.; Roujean, J.-L.; De Jong, S. Comparison and relative quality assessment of the GLC2000, GLOBCOVER, MODIS and ECOCLIMAP land cover data sets at the African continental scale. Int. J. Appl. Earth Obs. Geoinf. 2011, 13, 207–219. [Google Scholar] [CrossRef]
- Cihlar, J. Land Cover Mapping of Large Areas from Satellites: Status and Research Priorities. Int. J. Remote Sens. 2000, 21, 1093–1114. [Google Scholar] [CrossRef]
- Beaubien, J.; Cihlar, J.; Simard, G.; Latifovic, R. Land cover from multiple thematic mapper scenes using a new enhancement-classification methodology. J. Geophys. Res. Atmos. 1999, 104, 27909–27920. [Google Scholar] [CrossRef]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Latifovic, R.; Olthof, I. Accuracy assessment using sub-pixel fractional error matrices of global land cover products derived from satellite data. Remote. Sens. Environ. 2004, 90, 153–165. [Google Scholar] [CrossRef]
- Friedl, M.; McIver, D.; Hodges, J.; Zhang, X.; Muchoney, D.; Strahler, A.; Woodcock, C.; Gopal, S.; Schneider, A.; Cooper, A.; et al. Global land cover mapping from MODIS: Algorithms and early results. Remote Sens. Environ. 2002, 83, 287–302. [Google Scholar] [CrossRef]
- Smets, B.; Buchhorn, M.; Lesiv, M.; Tsendbazar, N.-E. Copernicus Global Land Operations “Vegetation and Energy”; Copernicus: Brussels, Belgium, 2017; Volume 1. [Google Scholar]
- Cihlar, J.; Ly, H.; Xiao, Q. Land cover classification with AVHRR multichannel composites in northern environments. Remote Sens. Environ. 1996, 58, 36–51. [Google Scholar] [CrossRef]
- Campbell, M.; Congalton, R.G.; Hartter, J.; Ducey, M. Optimal Land Cover Mapping and Change Analysis in Northeastern Oregon Using Landsat Imagery. Photogramm. Eng. Remote. Sens. 2015, 81, 37–47. [Google Scholar] [CrossRef] [Green Version]
- Loveland, T.R.; Belward, A.S. The IGBP-DIS global 1km land cover data set, DISCover: First results. Int. J. Remote Sens. 1997, 18, 3289–3295. [Google Scholar] [CrossRef]
- Tang, Y.Q.; Zhang, J.S.; Wang, J.S. FY-3 meteorological satellites and the applications. China J. Space Sci. 2014, 34, 703–709. [Google Scholar]
- Yang, Z.; Zhang, P.; Gu, S.; Hu, X.; Tang, S.; Yang, L.; Xu, N.; Zhen, Z.; Wang, L.; Wu, Q.; et al. Capability of Fengyun-3D Satellite in Earth System Observation. J. Meteorol. Res. 2019, 33, 1113–1130. [Google Scholar] [CrossRef]
- Xu, N.; Niu, X.; Hu, X.; Wang, X.; Wu, R.; Chen, S.; Chen, L.; Sun, L.; Ding, L.; Yang, Z.; et al. Prelaunch Calibration and Radiometric Performance of the Advanced MERSI II on FengYun-3D. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4866–4875. [Google Scholar] [CrossRef]
- Yang, Z.; Lu, N.; Shi, J.; Zhang, P.; Dong, C.; Yang, J. Overview of FY-3 Payload and Ground Application System. IEEE Trans. Geosci. Remote. Sens. 2012, 50, 4846–4853. [Google Scholar] [CrossRef]
- Han, X.; Yang, J.; Tang, S.; Han, Y. Vegetation Products Derived from Fengyun-3D Medium Resolution Spectral Imager-II. J. Meteorol. Res. 2020, 34, 775–785. [Google Scholar] [CrossRef]
- USGS. Available online: https://earthexplorer.usgs.gov/ (accessed on 29 April 2021).
- Pal, M.; Mather, P.M. Support vector machines for classification in remote sensing. Int. J. Remote. Sens. 2005, 26, 1007–1011. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2010, 66, 247–259. [Google Scholar] [CrossRef]
- Belgiu, M.; Drǎgut, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Wulder, M.A.; Coops, N.C.; Roy, D.P.; White, J.C.; Hermosilla, T. Land cover 2.0. Int. J. Remote Sens. 2018, 39, 4254–4284. [Google Scholar] [CrossRef] [Green Version]
- Friedl, M.A.; Brodley, C.E. Decision tree classification of land cover from remotely sensed data. Remote Sens. Environ. 1997, 61, 399–409. [Google Scholar] [CrossRef]
- Hansen, M.C.; Reed, B.W. A comparison of the IGBP DISCover and University of Maryland 1 km global land cover products. Int. J. Remote Sens. 2000, 21, 1365–1373. [Google Scholar] [CrossRef]
- Huang, C.; Davis, L.S.; Townshend, J.R.G. An assessment of support vector machines for land cover classification. Int. J. Remote Sens. 2002, 23, 725–749. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Ghimire, B.; Rogan, J.; Rodriguez-Galiano, V.F.; Panday, P.; Neeti, N. An Evaluation of Bagging, Boosting, and Random Forests for Land-Cover Classification in Cape Cod, Massachusetts, USA. GISci. Remote Sens. 2012, 49, 623–643. [Google Scholar] [CrossRef]
- Otukei, J.R.; Blaschke, T. Land cover change assessment using decision trees, support vector machines and maximum likelihood classification algorithms. Int. J. Appl. Earth Obs. Geoinf. 2010, 12S, S27–S31. [Google Scholar] [CrossRef]
- Breiman, L. RandomForests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Tso, B.; Mather, P. Classification Methods for Remotely Sensed Data; CRC Press: Boca Raton, FL, USA, 2009; p. 367. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Ghosh, A.; Fassnacht, F.E.; Joshi, P.K.; Koch, B. A framework for mapping tree species combining hyperspectral and LiDAR data: Role of selected classifiers and sensor across three spatial scales. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 49–63. [Google Scholar] [CrossRef]
- Kulkarni, V.Y.; Sinha, P.K. Pruning of random forest classifiers: A survey and future directions. In Proceedings of the 2012 International Conference on Data Science & Engineering (ICDSE), Kerala, India, 18–20 July 2012. [Google Scholar]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random Forests for land cover classification. Pattern Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Guan, H.; Li, J.; Chapman, M.; Deng, F.; Ji, Z.; Yang, X. Integration of orthoimagery and lidar data for object-based urban thematic mapping using random forests. Int. J. Remote Sens. 2013, 34, 5166–5186. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Olmo, M.C.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Noi, P.T.; Kappas, M. Comparison of Random Forest, k-Nearest Neighbor, and Support Vector Machine Classifiers for Land Cover Classification Using Sentinel-2 Imagery. Sensors 2018, 18, 18. [Google Scholar]
- Jensen, J.R.; Lulla, K. Introductory digital image processing: A remote sensing perspective. Geocarto Int. 1987, 2, 65. [Google Scholar] [CrossRef]
- Colditz, R.R. An Evaluation of Different Training Sample Allocation Schemes for Discrete and Continuous Land Cover Classification Using Decision Tree-Based Algorithms. Remote Sens. 2015, 7, 9655–9681. [Google Scholar] [CrossRef] [Green Version]
- Campbell, J.B.; Wynne, R.H. Introduction to Remote Sensing, 5th ed.; The Guilford Press: New York, NY, USA, 2011; p. 718. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Band No. | Name of Bands | Wavelength Range in Microm |
|---|---|---|
| Band 1 | FY-3C_VIRR_Day_EV_RefSB | 0.58–0.68 |
| Band 2 | FY-3C_VIRR_Day_EV_RefSB | 0.84–0.89 |
| Band 3 | FY-3C_VIRR_Day_EV_RefSB | 1.55–1.64 |
| Band 4 | FY-3C_VIRR_Day_EV_RefSB | 0.43–0.48 |
| Band 5 | FY-3C_VIRR_Day_EV_RefSB | 0.48–0.53 |
| Band 6 | FY-3C_VIRR_Day_EV_RefSB | 0.53–0.58 |
| Band 7 | FY-3C_VIRR_Day_EV_RefSB | 1.325–1.395 |
| Band 8 | FY-3C_VIRR_Day_EV_Emissive | 3.55–3.93 |
| Band 9 | FY-3C_VIRR_Day_EV_Emissive | 10.3–11.3 |
| Band 10 | FY-3C_VIRR_Day_EV_Emissive | 11.5–12.5 |
| Band 11 | MVC value of NDVI | - |
| Land Cover Class | Class Definition Based on UN LCCS |
|---|---|
| 1. Bare/Sparse vegetation | Bare surface or land with vegetation cover no higher than 10% any time of the year |
| 2. Built-up | Land surface covered by buildings and other man-made structures |
| 3. Cropland | Lands that are covered with intermittent crops, harvested, and then left barren (e.g., single and multiple cropping systems). Perennial woody crops will be categorized as a forest or shrub based on the definition. |
| 4. Forest | Lands covered by woody plants, with a percent cover of more than 15% and a height of more than 5 m. Exceptions: a woody plant having a distinct physiognomic feature of a tree can be categorized as a tree even if its height is less than 5 m but greater than 3 m. |
| 5. Herbaceous wetland | Land covered by a persistent mixture of having water and herbaceous or woody plants. Vegetation may be found in salt, brackish, or freshwater. |
| 6. Herbaceous vegetation | Plants that lack a distinct solid structure and have no persistent stems or shoots above the surface. It may consist of up to 10% trees and shrubs. |
| 7. Shrubs | These are woody perennial plants, with persistent and woody stems, that are less than 5 m tall and lack a distinct main stem. The leaves of the shrub can be either evergreen or deciduous. |
| 8. Water bodies | These include lakes, reservoirs, and rivers. The water could be fresh or salty. |
| Class (Name) | Training Data | Test Data |
|---|---|---|
| Number of Pixels per Class | ||
| Class 1 (Bare/Sparse vegetation) | 20585 | 6424 |
| Class 2 (Built-up) | 1620 | 575 |
| Class 3 (Cropland) | 15472 | 4246 |
| Class 4 (Forest) | 11378 | 3101 |
| Class 5 (Herbaceous wetland) | 1686 | 602 |
| Class 6 (Herbaceous vegetation) | 12394 | 3641 |
| Class 7 (Shrubs) | 18956 | 5283 |
| Class 8 (Water bodies) | 9116 | 3795 |
| Total number pixel | 91207 | 27667 |
| Input Data | Class Name | Bare/Sparse Vegetation | Built-up | Cropland | Forest | Herbaceous Wetland | Herbaceous Vegetation | Shrub | Water Bodies |
|---|---|---|---|---|---|---|---|---|---|
| Class ID | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| No. of Pixels | 6424 | 575 | 4246 | 3101 | 602 | 3641 | 5283 | 3795 | |
| (a) OMSI | precision | 0.89 | 0.68 | 0.68 | 0.84 | 0.65 | 0.72 | 0.72 | 0.92 |
| recall | 0.93 | 0.55 | 0.79 | 0.88 | 0.48 | 0.59 | 0.71 | 0.90 | |
| f1-score | 0.91 | 0.61 | 0.73 | 0.86 | 0.55 | 0.65 | 0.71 | 0.91 | |
| accuracy | 0.79 | ||||||||
| kappa_score | 0.75 | ||||||||
| (b) TMSI | precision | 0.92 | 0.58 | 0.76 | 0.84 | 0.75 | 0.79 | 0.74 | 0.94 |
| recall | 0.92 | 0.52 | 0.78 | 0.89 | 0.57 | 0.65 | 0.79 | 0.97 | |
| f1-score | 0.92 | 0.54 | 0.77 | 0.86 | 0.65 | 0.71 | 0.77 | 0.95 | |
| accuracy | 0.83 | ||||||||
| kappa_score | 0.79 | ||||||||
| (c) SMSI | precision | 0.93 | 0.58 | 0.79 | 0.89 | 0.73 | 0.77 | 0.76 | 0.96 |
| recall | 0.93 | 0.56 | 0.80 | 0.88 | 0.66 | 0.70 | 0.81 | 0.97 | |
| f1-score | 0.93 | 0.57 | 0.80 | 0.88 | 0.69 | 0.73 | 0.79 | 0.97 | |
| accuracy | 0.84 | ||||||||
| kappa_score | 0.81 | ||||||||
| (d) NMSI | precision | 0.94 | 0.48 | 0.77 | 0.89 | 0.72 | 0.77 | 0.77 | 0.96 |
| recall | 0.92 | 0.54 | 0.82 | 0.86 | 0.67 | 0.70 | 0.80 | 0.97 | |
| f1-score | 0.93 | 0.51 | 0.79 | 0.88 | 0.69 | 0.73 | 0.79 | 0.97 | |
| accuracy | 0.84 | ||||||||
| kappa_score | 0.81 | ||||||||
| (e) OYSI | precision | 0.95 | 0.65 | 0.78 | 0.90 | 0.70 | 0.79 | 0.77 | 0.96 |
| recall | 0.94 | 0.57 | 0.83 | 0.85 | 0.67 | 0.71 | 0.82 | 0.98 | |
| f1-score | 0.94 | 0.61 | 0.81 | 0.87 | 0.68 | 0.75 | 0.79 | 0.97 | |
| accuracy | 0.85 | ||||||||
| kappa_score | 0.82 | ||||||||
| (f) SDFOYSI | precision | 0.95 | 0.48 | 0.78 | 0.90 | 0.70 | 0.79 | 0.77 | 0.96 |
| recall | 0.91 | 0.57 | 0.84 | 0.85 | 0.67 | 0.71 | 0.82 | 0.98 | |
| f1-score | 0.93 | 0.52 | 0.81 | 0.88 | 0.69 | 0.75 | 0.80 | 0.97 | |
| accuracy | 0.85 | ||||||||
| kappa_score | 0.82 | ||||||||
| (g) SNMSI | precision | 0.95 | 0.67 | 0.81 | 0.91 | 0.73 | 0.82 | 0.77 | 0.93 |
| recall | 0.92 | 0.58 | 0.87 | 0.85 | 0.70 | 0.72 | 0.83 | 0.98 | |
| f1-score | 0.93 | 0.62 | 0.84 | 0.88 | 0.72 | 0.76 | 0.80 | 0.95 | |
| accuracy | 0.86 | ||||||||
| kappa_score | 0.83 | ||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adugna, T.; Xu, W.; Fan, J. Effect of Using Different Amounts of Multi-Temporal Data on the Accuracy: A Case of Land Cover Mapping of Parts of Africa Using FengYun-3C Data. Remote Sens. 2021, 13, 4461. https://doi.org/10.3390/rs13214461
Adugna T, Xu W, Fan J. Effect of Using Different Amounts of Multi-Temporal Data on the Accuracy: A Case of Land Cover Mapping of Parts of Africa Using FengYun-3C Data. Remote Sensing. 2021; 13(21):4461. https://doi.org/10.3390/rs13214461
Chicago/Turabian StyleAdugna, Tesfaye, Wenbo Xu, and Jinlong Fan. 2021. "Effect of Using Different Amounts of Multi-Temporal Data on the Accuracy: A Case of Land Cover Mapping of Parts of Africa Using FengYun-3C Data" Remote Sensing 13, no. 21: 4461. https://doi.org/10.3390/rs13214461
APA StyleAdugna, T., Xu, W., & Fan, J. (2021). Effect of Using Different Amounts of Multi-Temporal Data on the Accuracy: A Case of Land Cover Mapping of Parts of Africa Using FengYun-3C Data. Remote Sensing, 13(21), 4461. https://doi.org/10.3390/rs13214461