4.1. Implementation Details
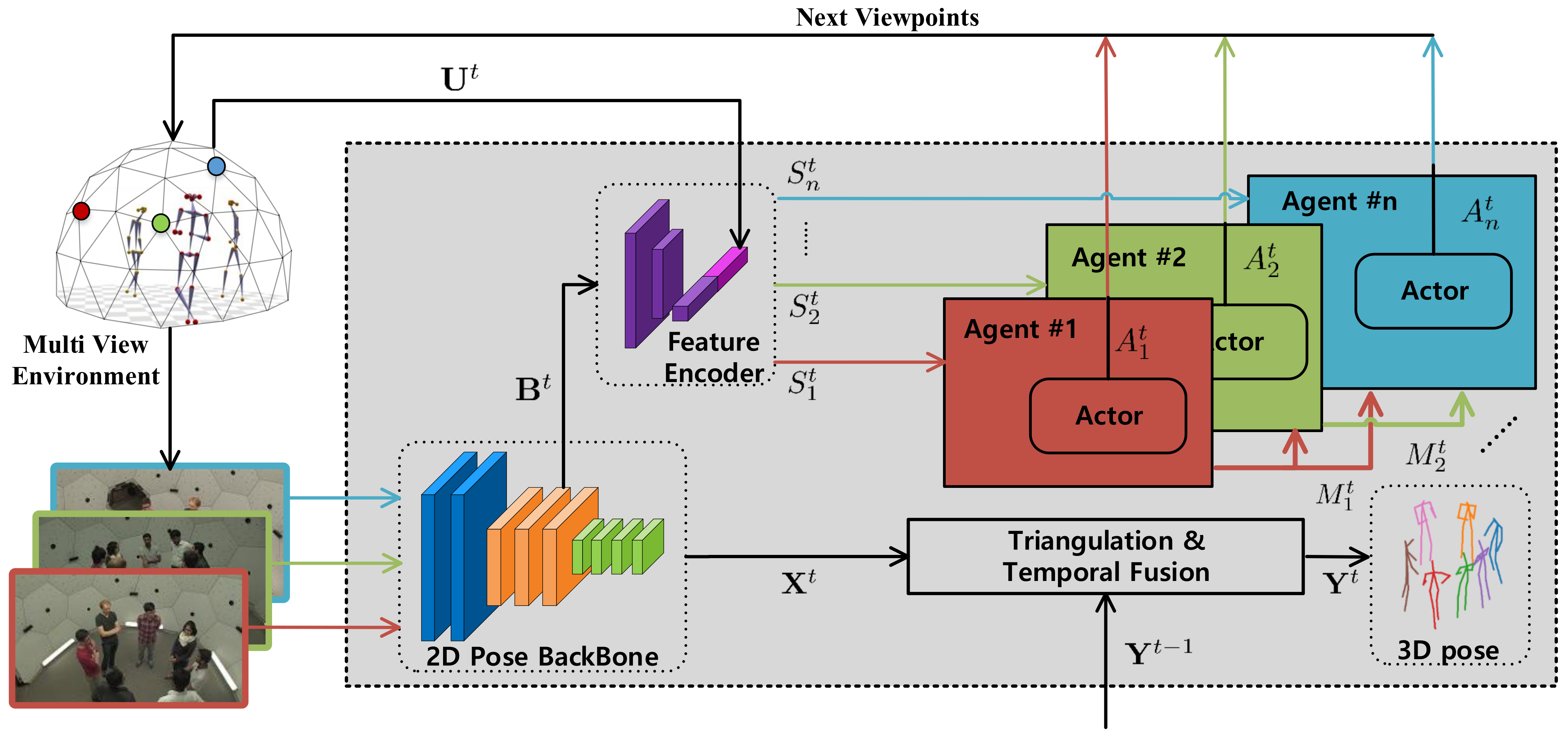
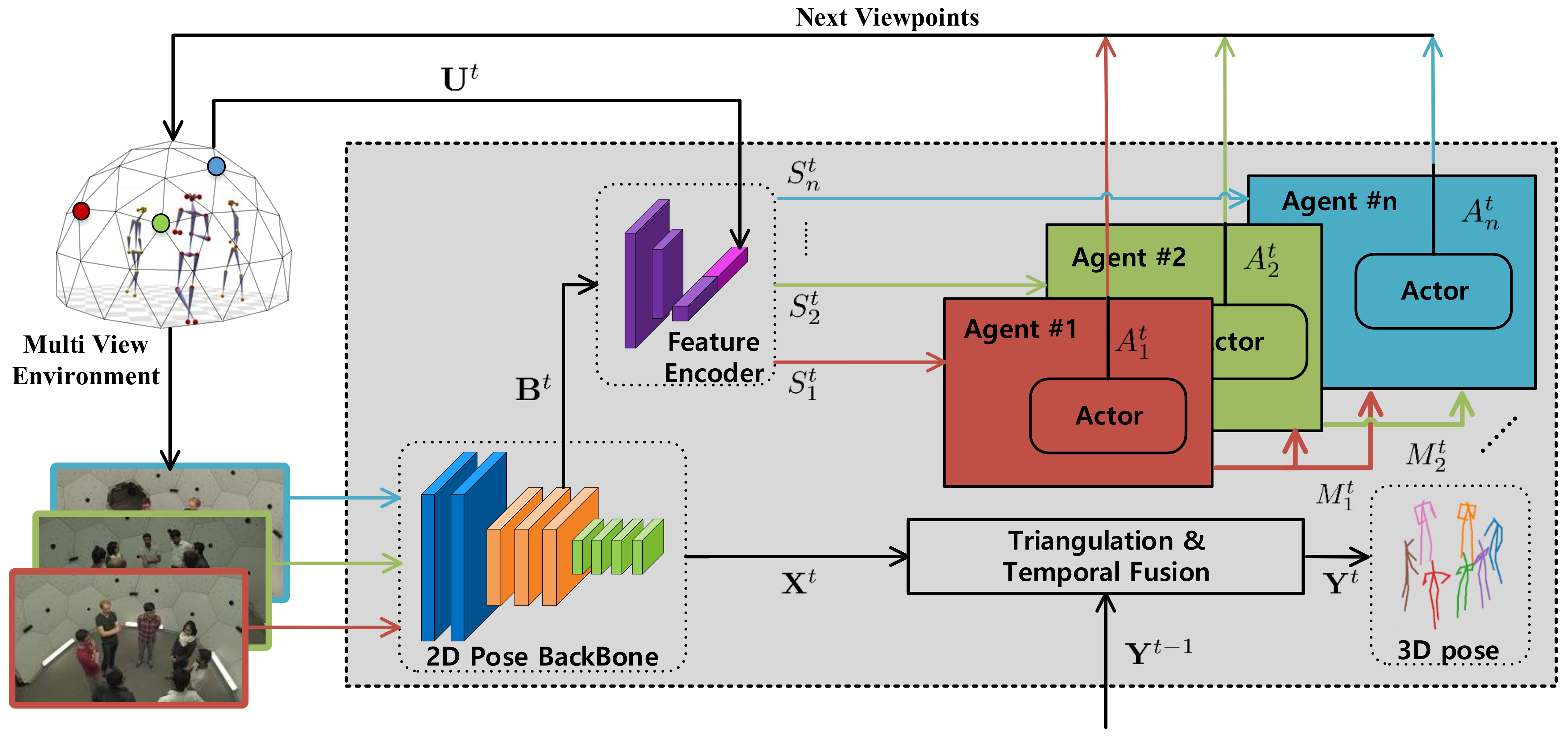
MAO-Pose is implemented on top of an optimized version of Lightweight OpenPose [
35]. Theoretically, our framework can be easily adapted to any 2D pose estimator with feature backbones. The 3D pose estimation is achieved by triangulating each pair of estimated 2D poses via multi-view geometry and taking the median of all 3D candidates. For temporal fusion, we used One Euro Filter [
39], a speed-based low-pass filter to refine estimated poses. The missing joints on the current frame are inferred from previous frames, if available. In case there is no valid previous estimation, we set the reconstruction error a high value (500 mm) to avoid NaN values.
4.1.1. Dataset
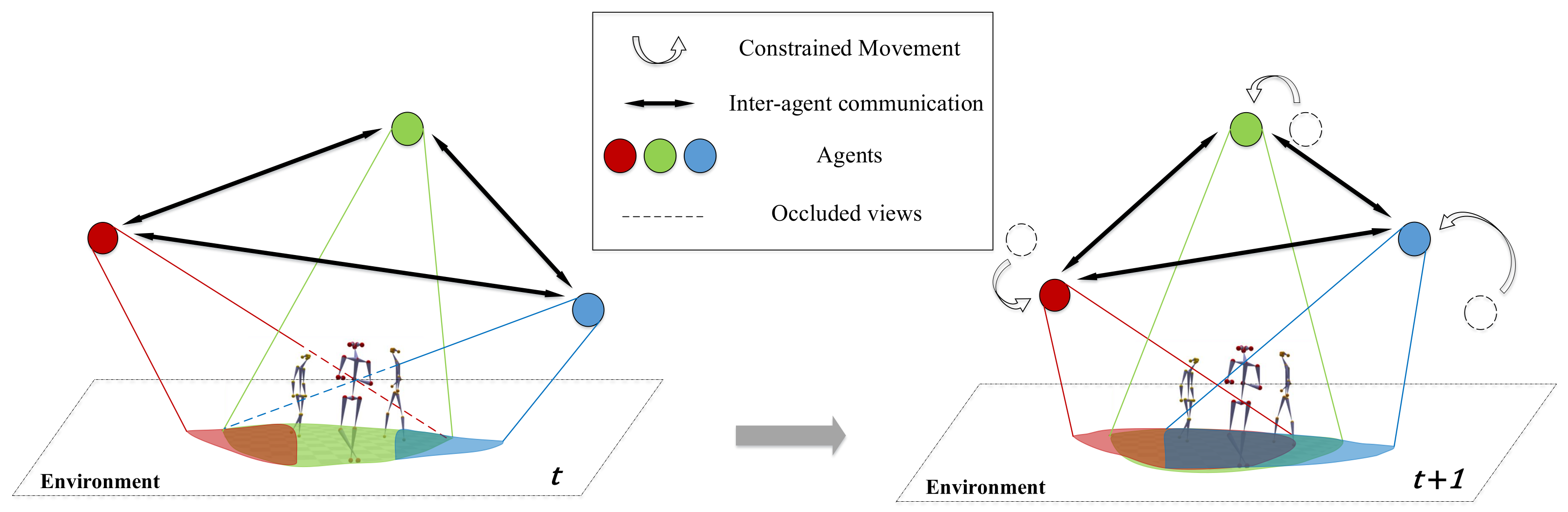
We consider multi-people scenes (
Mafia,
Ultimatum and
Haggling in the Panoptic dataset), where occlusions occur frequently, posing a challenge for the agents to reconstruct the 3D pose. The Panoptic dataset consists of 30 FPS time-synchronized multi-view videos. To ensure the convenient extraction of single frames and agree with maximum control frequency 10 Hz, we convert them to JPEG images and temporally downsample frame rate to 10 FPS beforehand. We only use HD cameras, the number of which is about 31 per scene, since they provide better image quality and their locations are not too sparse to hinder the decision process of agents. We randomly chose 10 scenes out of
Mafia for training, 6 and 21 scenes from all scenes for validation and test, respectively. The splits have no overlap between each other. We trained on limited scenes but tested on all three kinds to force agents to learn a fairly generalized policy.
Table 1 shows the size of the train, validation and test splits. The
Haggling scene is completely invisible during training (with validation sets for early stopping).
4.1.2. Evaluation Metrics
We used two metrics to evaluate the performance. Mean per joint position error (MPJPE) indicates the pose reconstruction error w.r.t. the ground truth. Camera distance (CamDist), defined as the geodesic distance between camera positions in consecutive frames on the dome-like spherical surface of the Panoptic dataset, denotes the moving cost of cameras.
4.1.3. Baselines
We implemented four baselines to compare with our agents. All methods utilized completely identical 2D pose estimator, temporal fusion, matching, triangulation method and multi-agent environments for fairness. The baselines are as follows: (i)
Random: randomly selects
N cameras in a given frame; (ii)
AngleSpread: spreads cameras by choosing cameras that have
of azimuth difference. At each azimuth angle, a random elevation angle is sampled; (iii)
Greedy: greedily choose unvisited cameras that minimize pose reconstruction error most. This exhaustive search method is impractically slow compared with other baselines, yet it exhibits the nearly optimal lower bounds of reconstruction error; (iv)
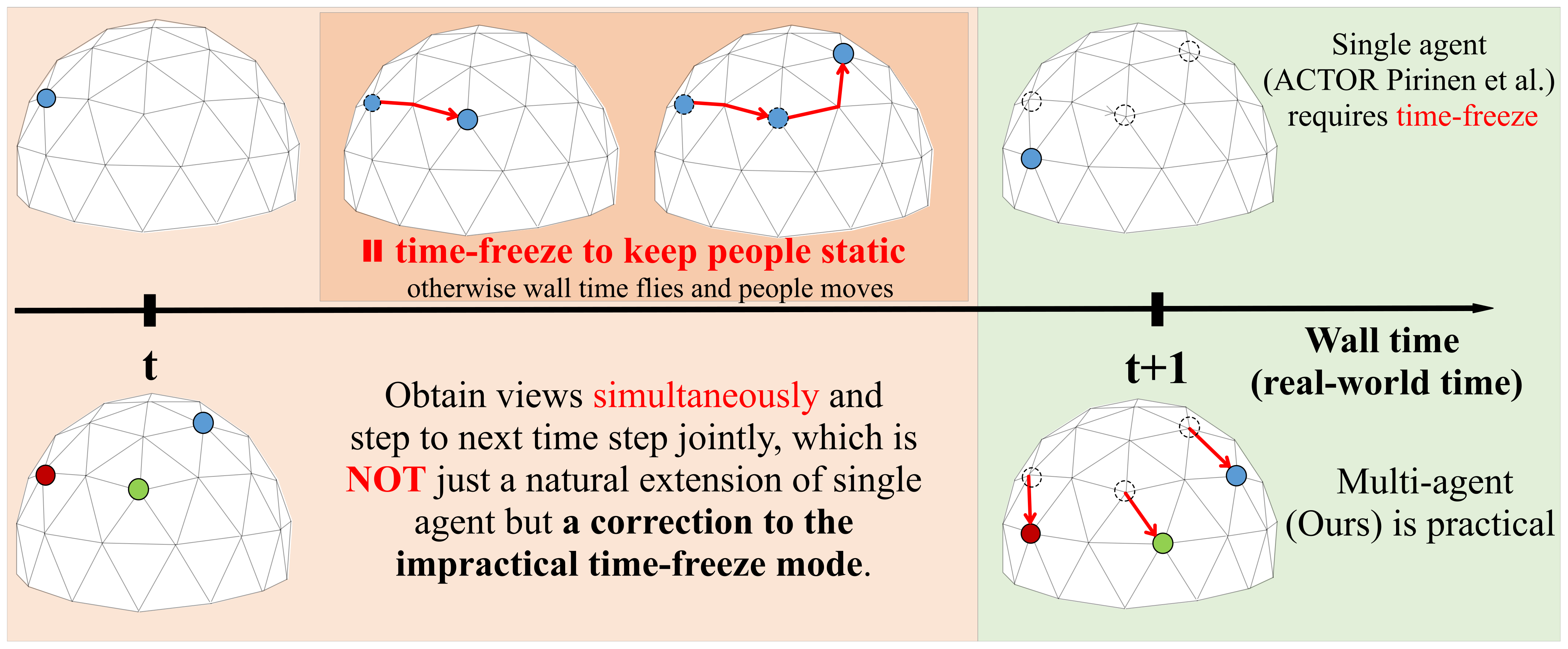
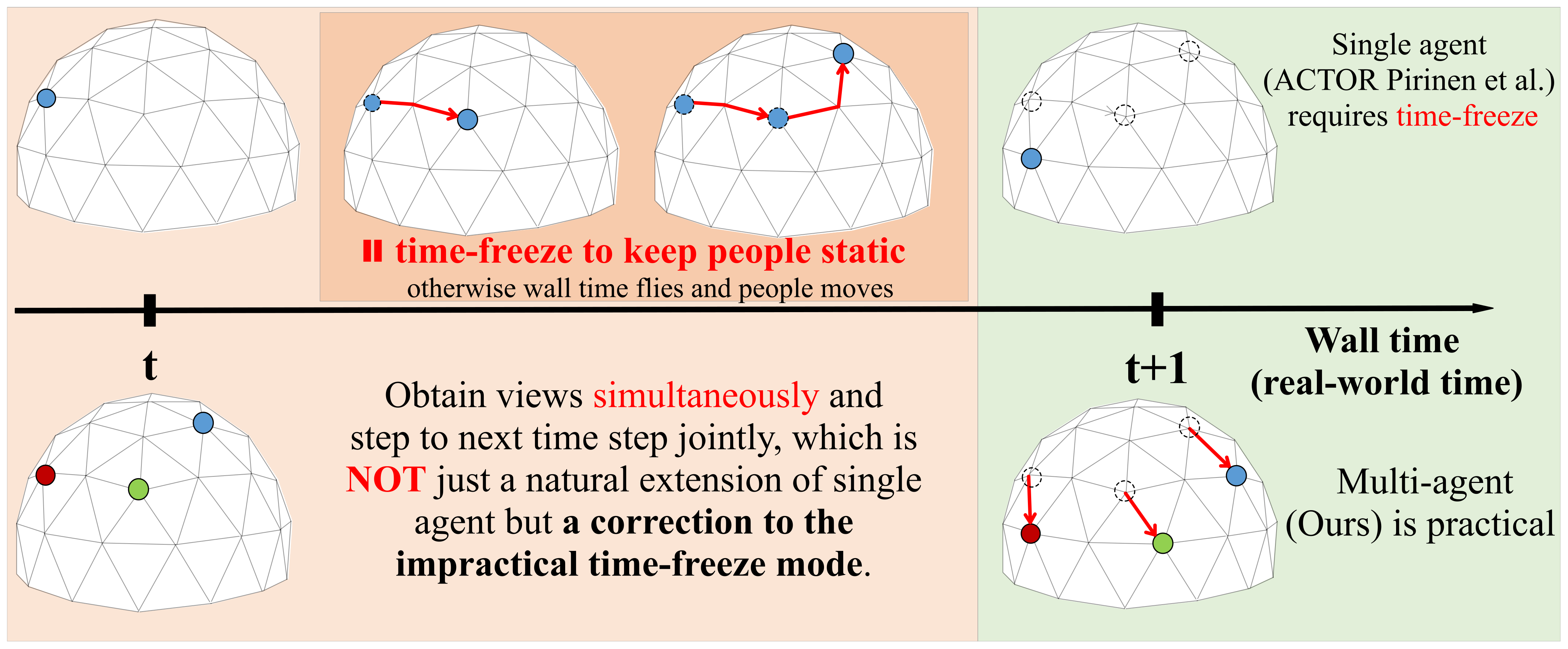
ACTOR: a deep-RL architecture we implemented according to [
7]. Note that as a single-agent paradigm,
ACTOR requires multiple time steps to select multiple views, which must
pause the wall time before it selects enough cameras.
For all the baselines, since they do not model different views as individual agents, we used the Hungarian algorithm to match the cameras selected in the current and previous frame to greedily minimize the camera distance between frames and simulate the behavior of multiple agents. However, this matching mechanism is disabled for MAO-Pose agents, as they are not fungible in our context.
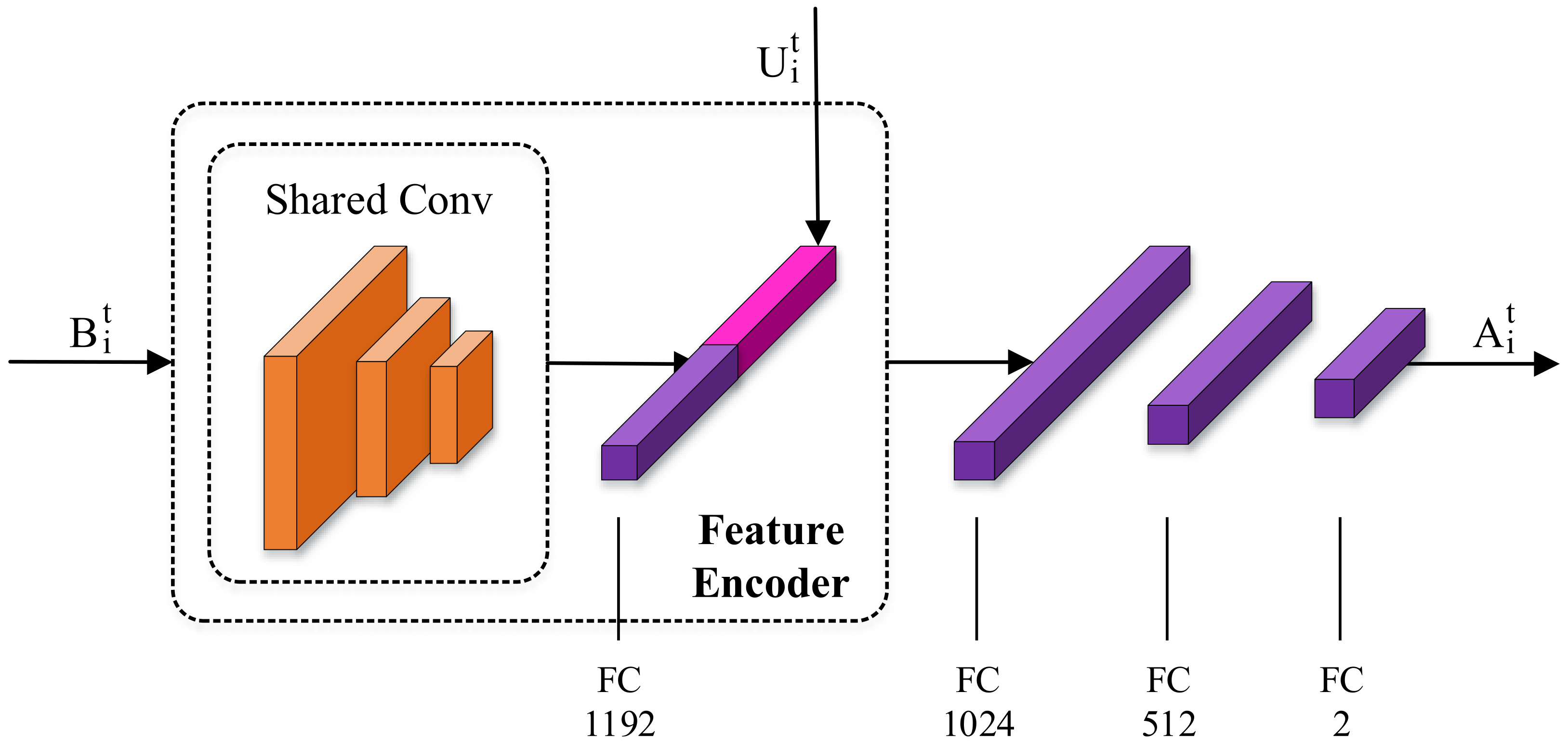
4.1.4. Training
We used sampled returns to approximate value function, with discount factor
for future rewards. Each agent receives the rewards individually and normalizes the discounted rewards during each training step to reduce variance and increase stability. The objectives are optimized via the Adam optimizer with a fixed learning rate
. We trained the agents together for 80 k episodes, annealing the concentration parameters
of Von Mises distribution linearly with rate
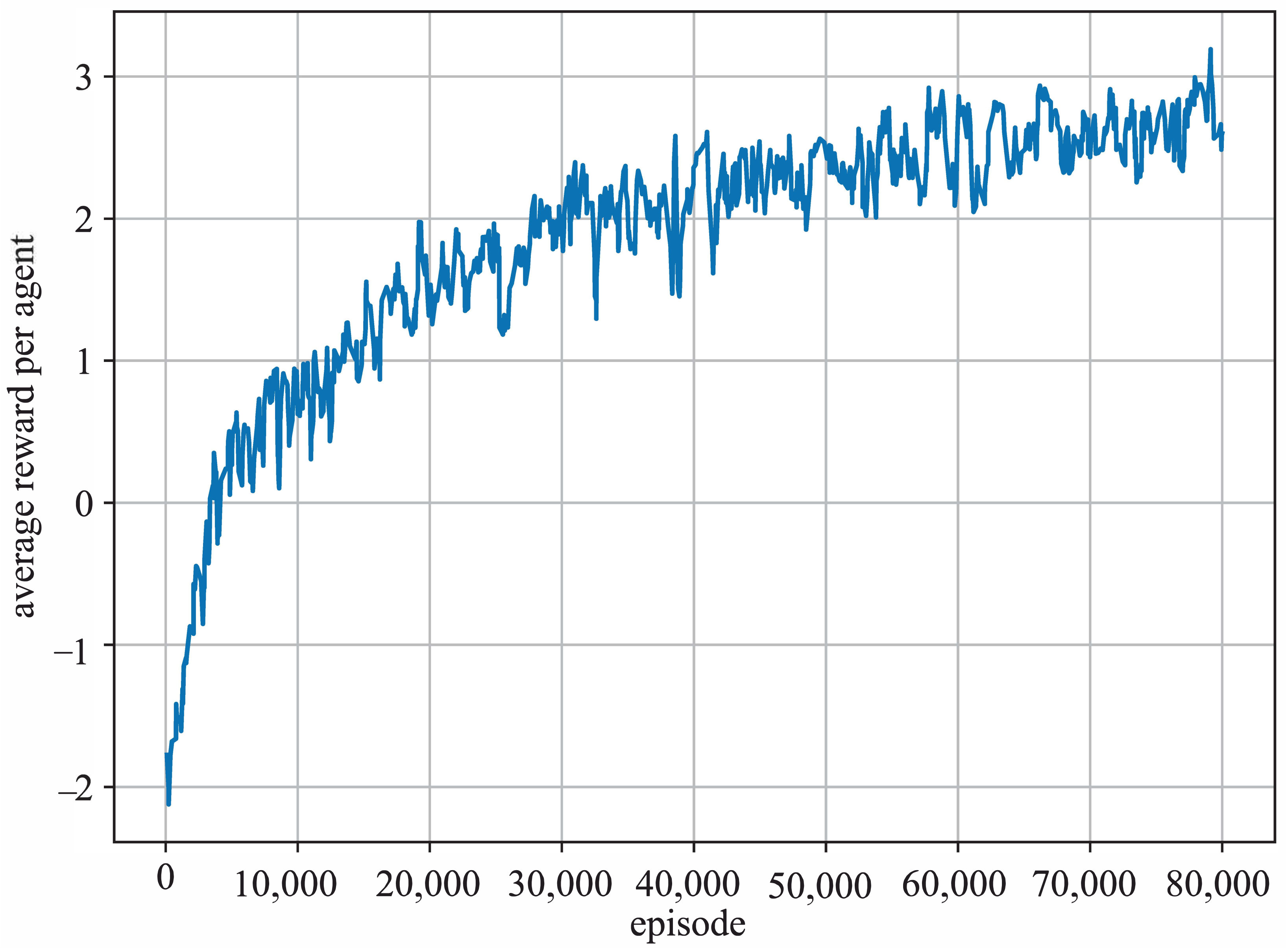
, which ensures adequate exploration at first and then becomes more deterministic as the agents grow more sophisticated. We utilized validation sets during training to perform early stops when necessary. The average reward each agent receives during the training process is shown in
Figure 5.
4.2. Main Results
Our MAO-Pose is trained with 5 agents in total, Consensus enabled and FPS set to 10 and is compared with four baselines on the Panoptic test dataset. In Tables 3 and 4, we report the numerical values of MPJPE and CamDist for MAO-Pose. The results are averaged across the union of three scenes (Mafia, Ultimatum and Haggling) and 5 random seeds, with standard deviation in the bracket. In terms of MPJPE, our model significantly outperforms other methods and is very close to Greedy, which is nearly a theoretically optimal solution. In terms of CamDist, our model with movement constraints (MAO-Pose-Cons) achieves the lowest moving cost.
Since
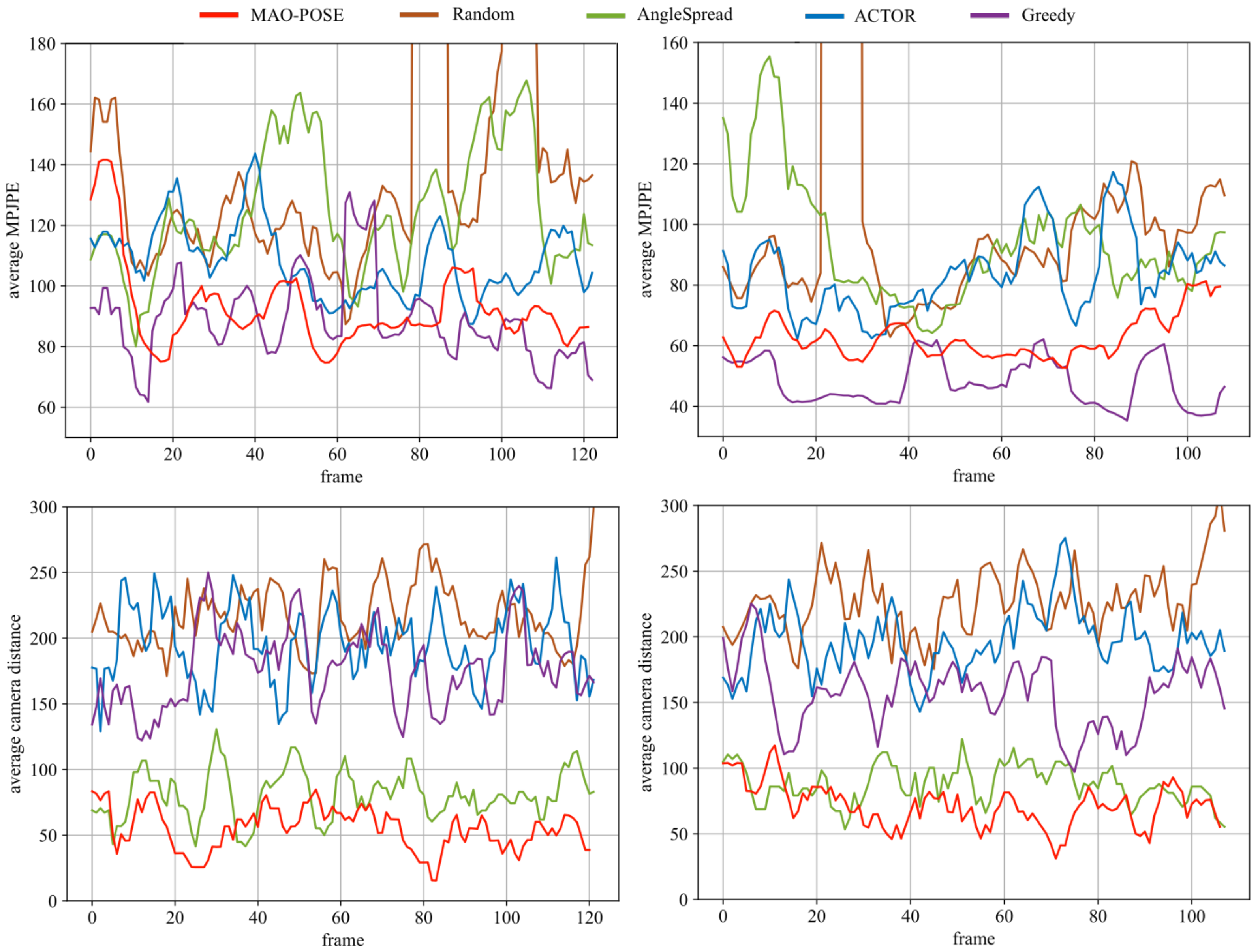
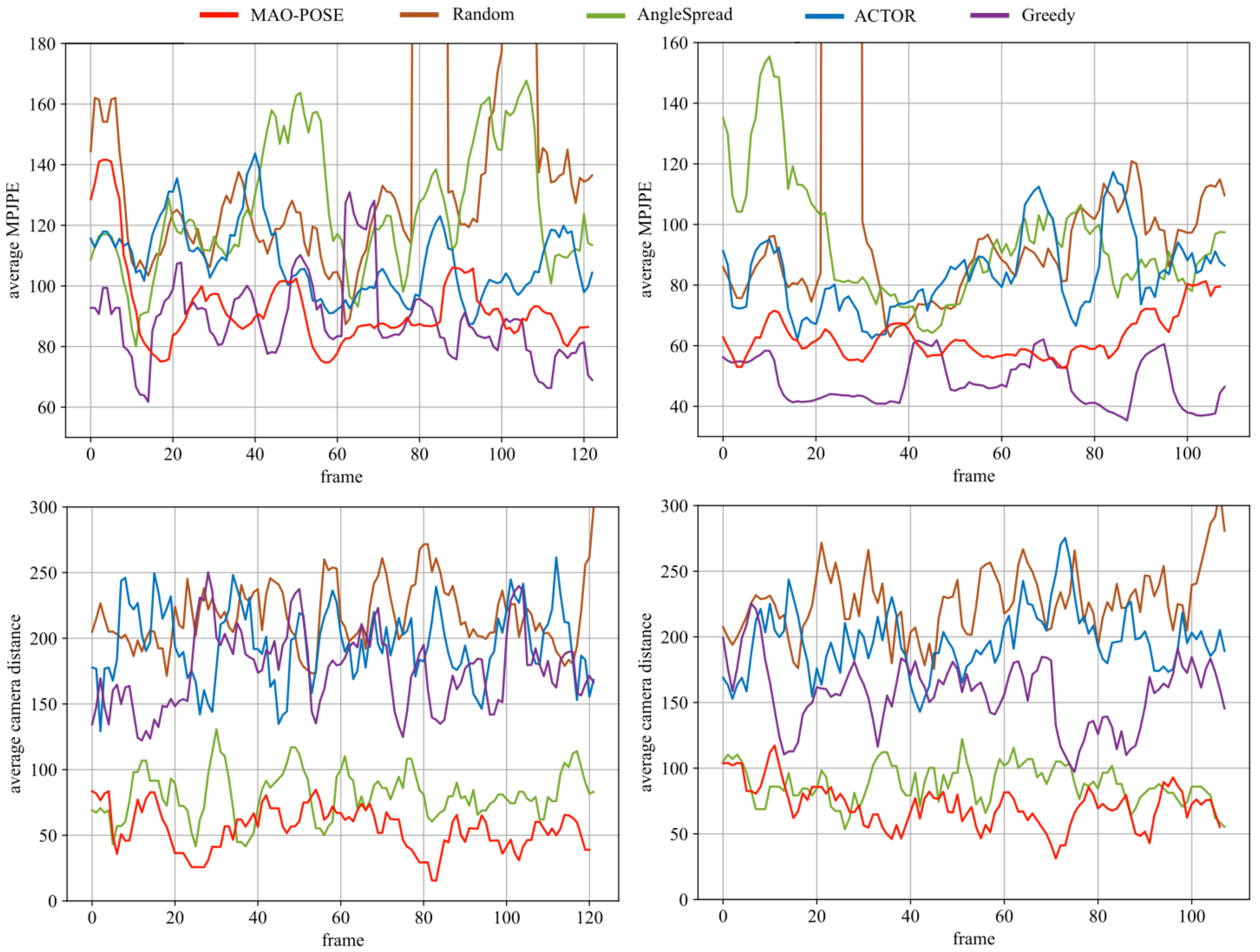
MAO-Pose operates on frame sequences, we want to evaluate its performance temporally.
Figure 6 illustrates MPJPE and camera distance on
Mafia (7 people) and
Haggling (3 people) scenes, to compare the performance in environments with different human densities.
MAO-Pose exhibits more stability during the entire sequence without large peak values while keeping both metrics low enough to outperform all other baselines. Here, we visualized the estimated 3D poses and their reprojected 2D poses in each view the agents have selected. Please refer to
Figure 7 for detail.
4.3. Ablation Studies
The number of agents: As the results showed in Table 3, with an increasing number of views, MAO-Pose achieves lower estimation error, since more valid views are used for reconstruction. However, in Table 4 CamDist increases slightly, especially for MAO-Pose-Cons. This is because, with more cameras in the system, the collision probability is higher. The cameras may move a larger distance to avoid collision.
Consensus: Without the Consensus module, all the agents take action independently without knowing the action of other agents. The result is shown in Tables 3 and 4 as MAO-Pose-noComm. Both MPJPE and CamDist metrics decrease significantly without Consensus module, which proves that our Consensus module enables the agents to work together collaboratively with more information shared in between.
Movement constraints: Since our agents operate on temporal sequences, it would be beneficial to take inter-frame continuity into account. It is desirable if camera movements between two consecutive frames are not too large. To encourage the agent to move with lower cost, a piece-wise linear function
can be added to the penalty term
in Equation (
1), which is based on moving constraints to punish large camera movements between two frames:
where weighting factor
, and
x is the geodesic distance of camera position between time step
t and
on the spherical dome in the Panoptic dataset.
are predefined parameters of sensitivity and
r is the radius of the dome.
is a scaling factor typically larger than 1. We set
(smaller than the minimum distance of cameras in the dataset) to encourage local exploration, within which agents will not be penalized.
and
to enforce high penalty for large camera distances.
is set according to the experiments in
Table 2. It is worth noting that camera distance and reconstruction error are partially adversarial. Constraining camera distance can result in a limited search area and thus deter the accuracy. We chose
since its error is close to that of
, with a much lower camera distance, which is an acceptable trade-off between the two metrics.
As shown in
Table 3 and
Table 4, this movement constraint term sacrifices a little accuracy (mostly within 2) while yielding much better continuity, with consistent decrease in CamDist.
Supervision signal in reward design: In Equation (
1) we associate the quality term
with minimum joint visibility
, which is a self-supervised signal as it does not leverage dataset annotation during training. We can replace this term with a supervised signal
where
is the pose reconstruction error of the
k-th person, which needs ground truth pose label to calculate. The scaling factor
E is set to 200. The supervised signal helps agents to achieve higher accuracy in pose estimation when the number of views is more than 5, without movement constraints in
Table 3. In other cases, its performance is close to that of self-supervised signal designed in Equation (
1). When movement constraints come into play, supervision signal boosts CamDist as shown in
Table 4.
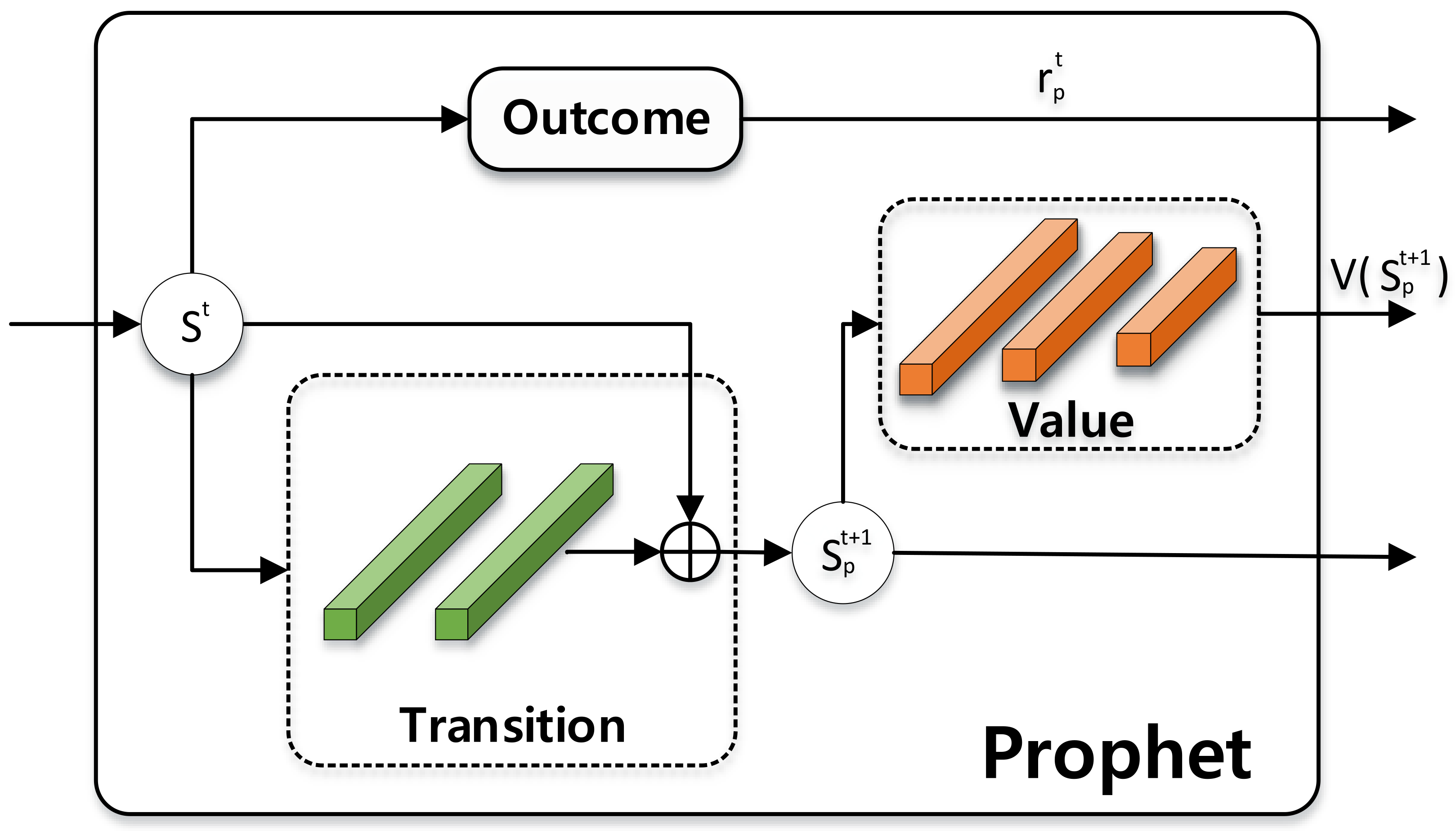
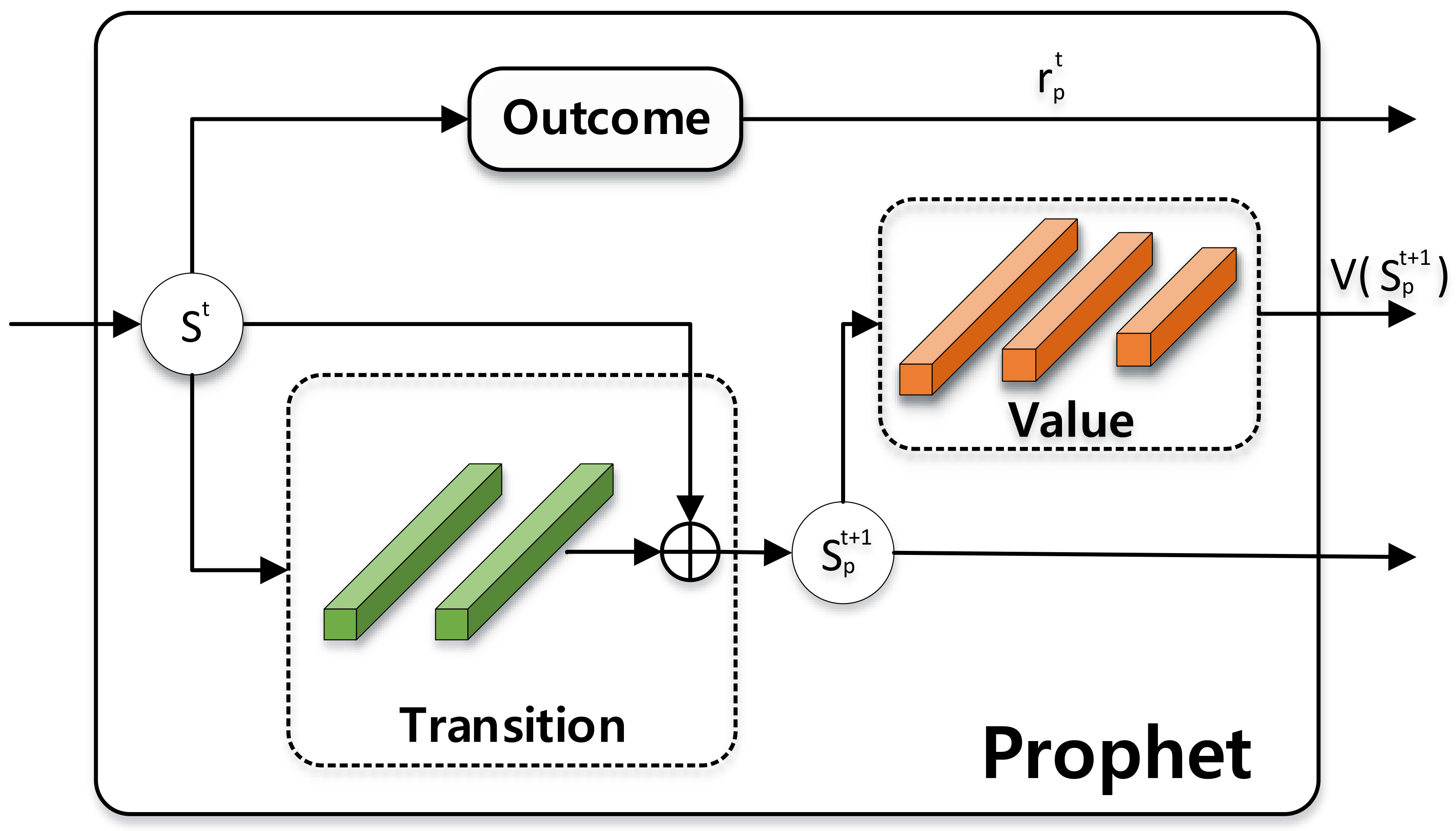
Prophet When agents need to work on wilder and more dynamic environments, where movements between frames can be remarkable, the performance can thus be hampered. We change the FPS of our scenes to simulate this scenario, and compare
MAO-Pose with or without
Prophet module. The results are provided in
Table 5.
4.5. Proof of Concept
Our
MAO-Pose can be easily modified for a multi-drone capture hardware system. A typical application scenario is that people are walking outdoors, and we need to track those moving targets and reconstruct the 3D pose as well. Due to the lack of datasets for 3D pose estimation in the wild, we built up a simulation environment (
Figure 8) based on the virtual dataset,
JTA Dataset [
20], which contains massive body poses with full 3D annotations. The
JTA consists of many full-HD videos that are each 30 s long, recorded at 30 FPS and 1080P resolution with a locked camera. We randomly chose 5 urban scenes, 4 scenes for training and 1 scene for evaluation. Like the training process of
Panoptic, the scenes are split into parts with no overlap between each other.
In this simulation, each camera is mounted on a flying drone with 6DoF and minimizes the limitation of the dome localization in the Panoptic dataset. The view optimization is proceeded in a virtual dome containing discrete viewpoints similar to Panoptic. We insert a tracking action to move the cameras after the view optimization to keep the target people in the center of the virtual dome.
It is worth noting that there are a limited number of views in the dataset (with only 6 views for each scene). As a consequence, it is hard to extract feature as the input of policy network of MAO-Pose given a view of the agent. Therefore, we manage to generate a quasi feature based on 3D annotations to solve the dilemma. Note that, in the simulation environment, our system is still in an annotation-free manner while we only use 3D annotations to simulate features of arbitrary views owing to the limits of the dataset.
Given the pose of the i-th drone , where indicates the rotation and indicates the translation to the world coordinate. Given camera intrinsic and 3D poses , we can get access to the 2D poses in the view of the i-th drone by , where is a scale factor and m is the number of people in current view.
Then, we used the depth of joints as the grayscale value of pixels given the 2D position of joints and skeletons, which aims to encode the spatial information of human bodies. Meanwhile, we computed the occlusion in the current view according to a simple human model, adding noise to the 2D position of occluded joints to encode the occlusions in the quasi feature. In this simulation, the view optimization has proceeded in a virtual dome containing discrete viewpoints similar to the Panoptic dataset. Moreover, we insert a tracking action to move the cameras after the view optimization to keep the target people in the center of the virtual dome, which is applicable in an outdoor scenario. As shown in
Figure 8, the virtual dome is drawn in gray lines and each vertex represents the possible camera position. The selected views are displayed in yellow, blue, purple and light green rays.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}